大数据产品销售数据分析:基于Python机器学习产品销售数据爬虫可视化分析预测系统设计与实现
文章目录
- 大数据产品销售数据分析:基于Python机器学习产品销售数据爬虫可视化分析预测系统设计与实现
- 一、项目概述
- 二、项目说明
- 三、研究意义
- 四、系统总体架构设计
- 总体框架
- 技术架构
- 数据可视化模块设计图
- 后台管理模块设计
- 数据库设计
- 五、开发技术介绍
- Flask框架
- Python爬虫之Selenium
- AJAX技术介绍
- 数据可视化
- 机器学习
- 六、开发环境介绍
- Pycharm开发工具简介
- Firefox简介
- 七、机器学习多元线性回归模型算法部分模块核心代码
- 八、项目截图
- 九、结语
大数据产品销售数据分析:基于Python机器学习产品销售数据爬虫可视化分析预测系统设计与实现
一、项目概述
本项目旨在设计与实现一个基于Python机器学习的产品销售数据爬虫可视化分析预测系统,结合现代数据技术,提升企业产品销售管理的智能化与数字化水平。该系统主要包括数据管理和后台管理两个核心模块,其中数据管理部分涵盖数据爬取、数据存储、数据分析、数据可视化以及基于多元线性回归的销量预测五大功能模块。
在数据爬取方面,本平台使用Selenium爬虫技术,从相关网站获取销售数据,并借助Pandas进行数据清洗,最后将清洗后的数据存入MySQL数据库。在数据可视化方面,采用Echarts技术展示销售趋势及其他关键指标,使得数据更加直观易懂。平台还利用多元线性回归算法对产品销量进行预测,为管理者提供未来销售趋势的预测信息。
本平台使用Flask框架进行后台管理系统的开发,并结合Lay-UI与Bootstrap框架进行前端设计,确保界面的友好与易操作性。通过黑盒测试验证了系统的功能性与稳定性,确保平台能够高效、精准地进行数据分析与管理。该系统为企业提供了强大的数据分析与决策支持工具,助力企业提高管理效率与市场竞争力。
二、项目说明
本次设计将产品销售和数据分析系统结合,使用数字化加持,简化平台管理,赋能智慧企业的一款数据分析可视化管理系统。本文主要工作为:分析产品销售背景后,对本平台所使用到的相关技术如Selenium、Echarts、Ajax、MySQL和Flask、Lay-UI、Bootstrap框架进行介绍及对比分析,通过产品销售数据平台管理者的基本需求及相关产品销售管理模块的需求分析进行总结,对本平台的设计概要分为数据管理部分及后台管理两大核心模块,数据管理部分囊括了数据爬取、数据存储、数据分析、数据可视化以及基于多元线性回归的数据预测五个板块。本课题的核心内容是以产品销售企业对数据分析平台的基本需求为背景,根据预先设计的思路进行平台的搭建。运用Selenium爬虫技术将数据爬取并用Pandas进行清洗后,将数据导入到MySQL中,使用数据可视化技术对数据进行直观地展示,同时也通过机器学习中的多元线性回归算法对产品销量进行预测,并导入后台在后台管理中查看或使用。最后,本平台运用黑盒测试对数据管理和后台管理进行功能性测试,测试结果均符合预期且平台能够正常运行。
三、研究意义
该本研究的意义在于推动产品销售管理向数字化、智能化转型,提升企业在市场竞争中的决策能力。随着大数据时代的到来,企业面对的数据量日益增多,如何从中提取有效信息进行精准决策成为企业发展的重要课题。本平台结合Python机器学习技术,构建了一个集数据爬取、存储、分析与预测为一体的系统,能够为产品销售管理提供强有力的数据支持。采用Selenium技术进行数据爬取,结合Pandas进行数据清洗与处理,解决了传统人工采集和整理数据的低效问题,极大提高了数据获取和处理的效率。其次,系统运用Echarts等数据可视化技术,将复杂的销售数据以图表形式呈现,使管理者能够直观地了解销售趋势和市场变化,为决策提供依据。更重要的是,通过多元线性回归算法的引入,系统能够对未来的产品销量进行精准预测,帮助企业预测市场需求变化,制定科学的销售策略。
本研究不仅为产品销售企业提供了一个高效、精准的数据分析与管理平台,还通过现代机器学习与数据技术的融合,推动了传统企业的数字化转型和智能化管理,为企业提高市场竞争力和运营效率提供了有力保障。
四、系统总体架构设计
总体框架
通过对数据的爬取、保存、计算分析、可视化展示,构成了产品销售数据分析平台的功能。其中主要包括如下几个层面:
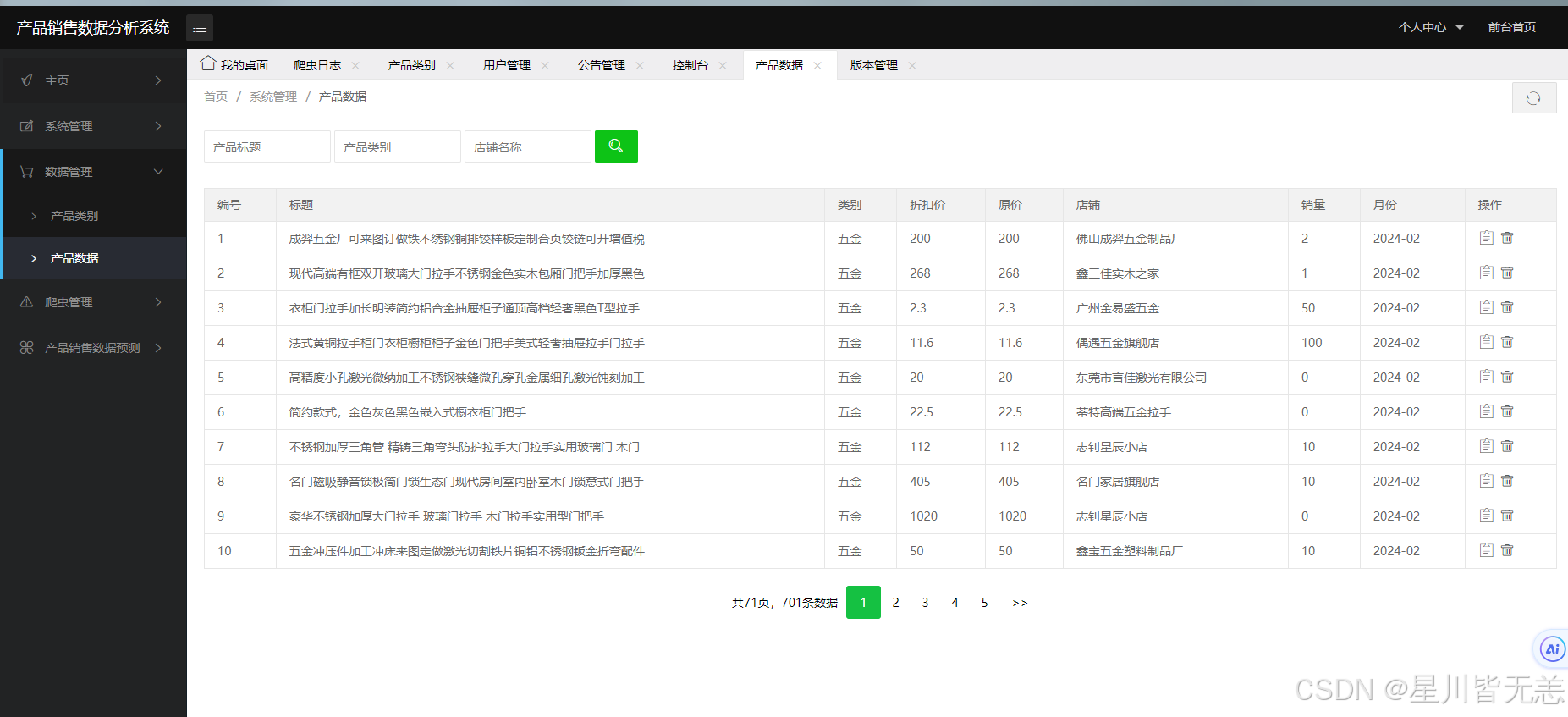
1)产品销售数据爬虫。在本课题中,需要爬取的数据主要包括产品基本信息数据——产品名称、产品原价格、产品折扣价格、店铺名称、产品销量。
2)完整的保存爬取到的数据。在本项目中,由于存在大量的数据,合理有效地存储数据就变得非常重要。而如果使用早前单机时代的数据库,是无法保证高效读写大量数据的,所以必须采用分布式的存储系统。
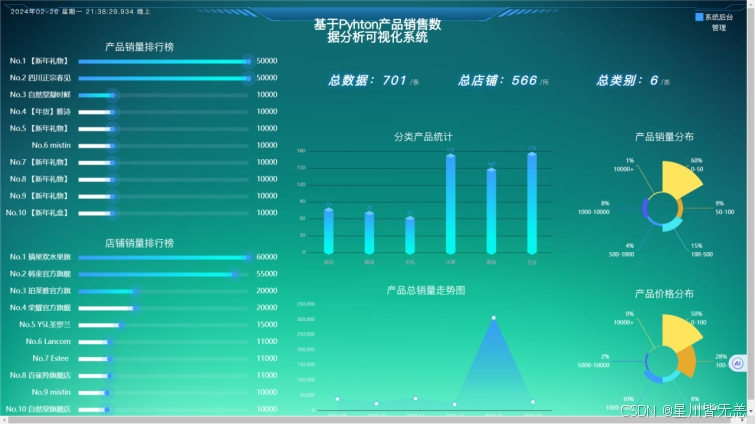
3)多角度的数据分析。基于前面的需求分析,可以从多个角度对产品销售平台的现有数据进行有效的信息挖掘。本课题采用了六种角度:产品销量排行榜,品牌销量排行榜、分类产品统计、总销量走势图、产品销量分布、产品价格分布;然后使用合适的机器学习算法对这些数据加以分析。
4)恰当的数据可视化展示。当计算分析出数据结论之后,会采用合适的方式去展示最终的结果数据。比如可以使用动态排序柱状图、旭日图、面积图等去表明数据的特点。
技术架构
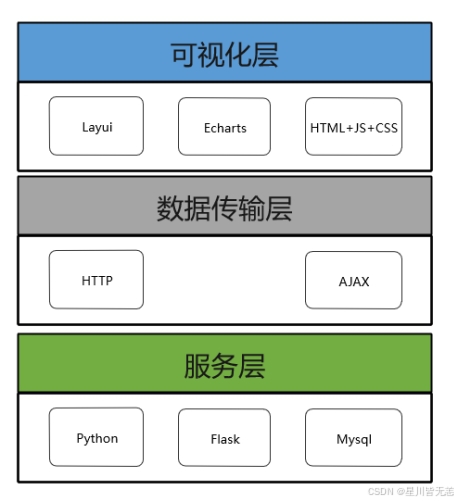
数据可视化模块设计图
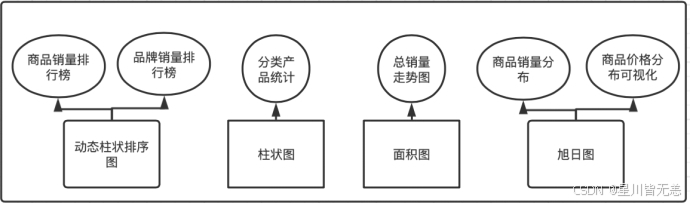
后台管理模块设计
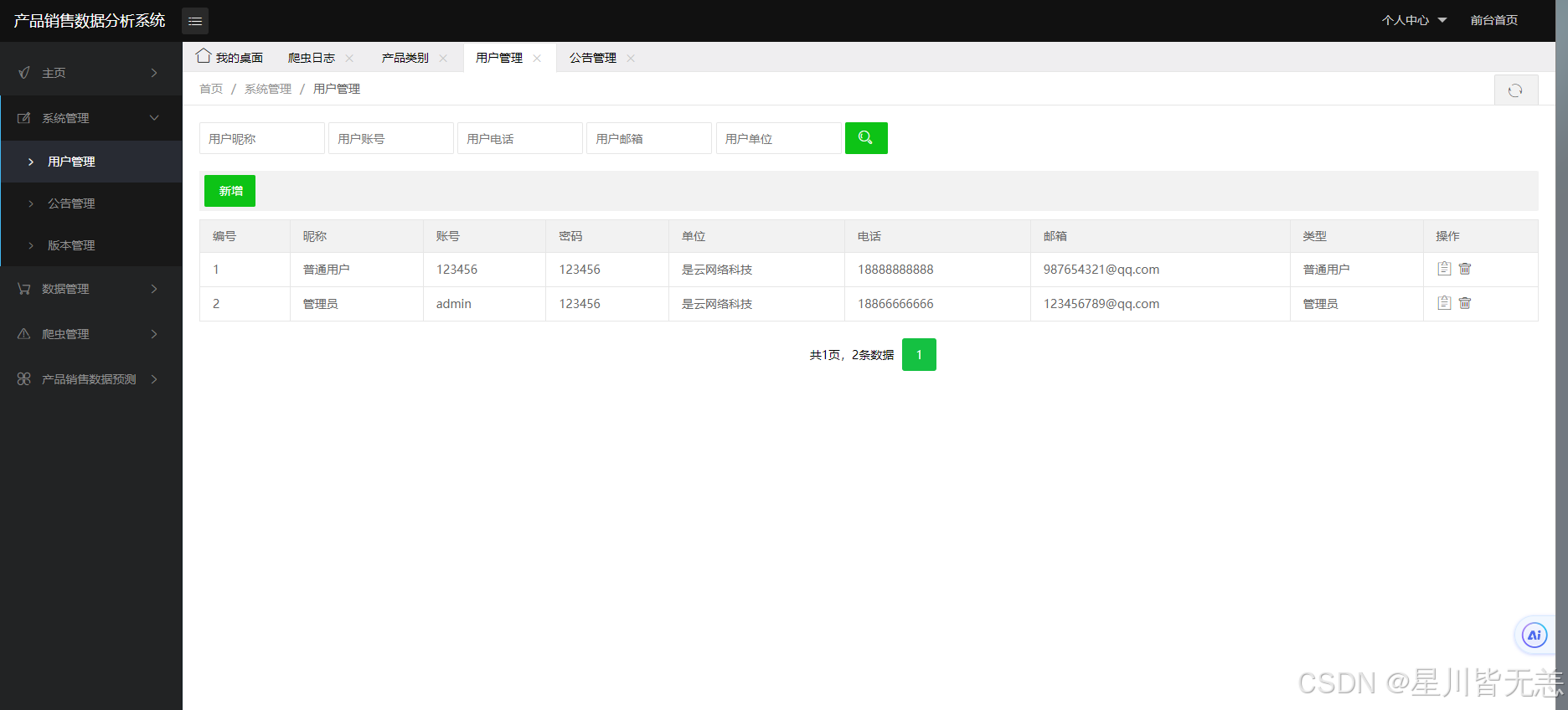
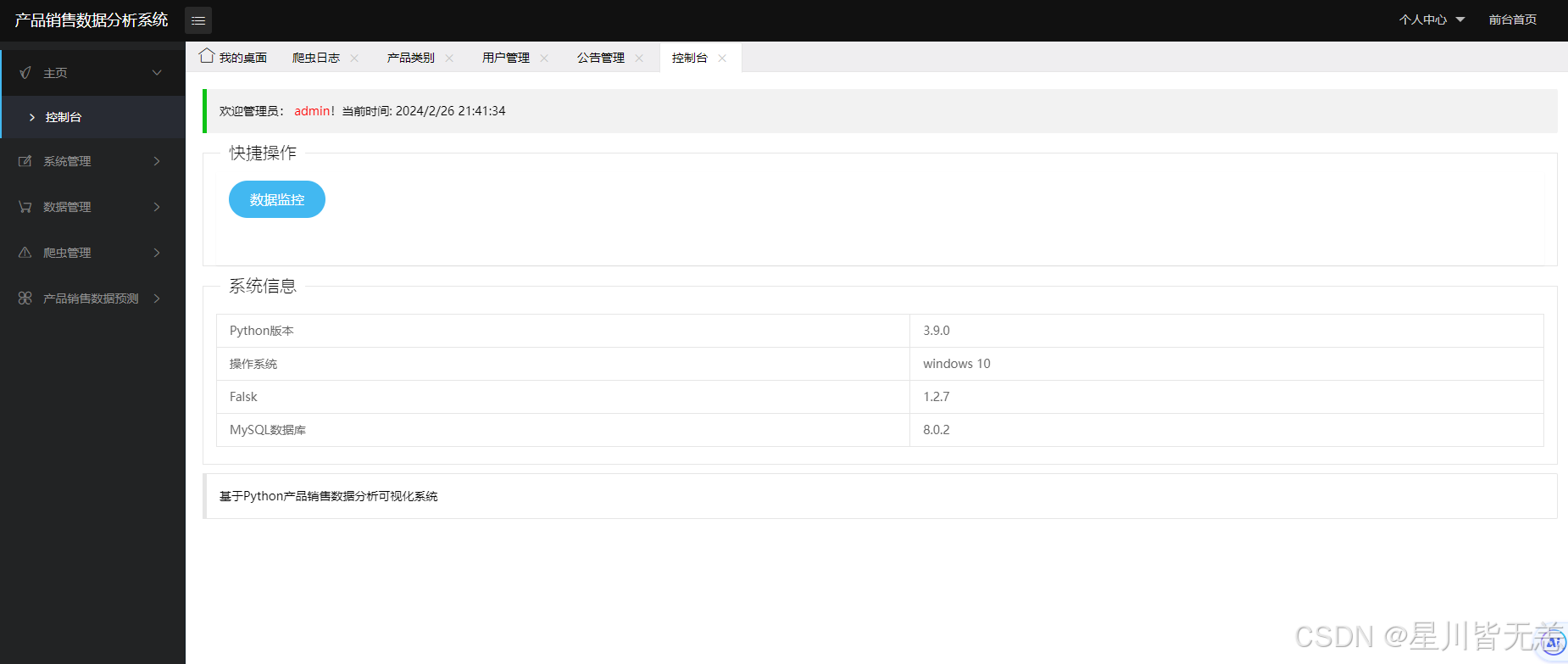
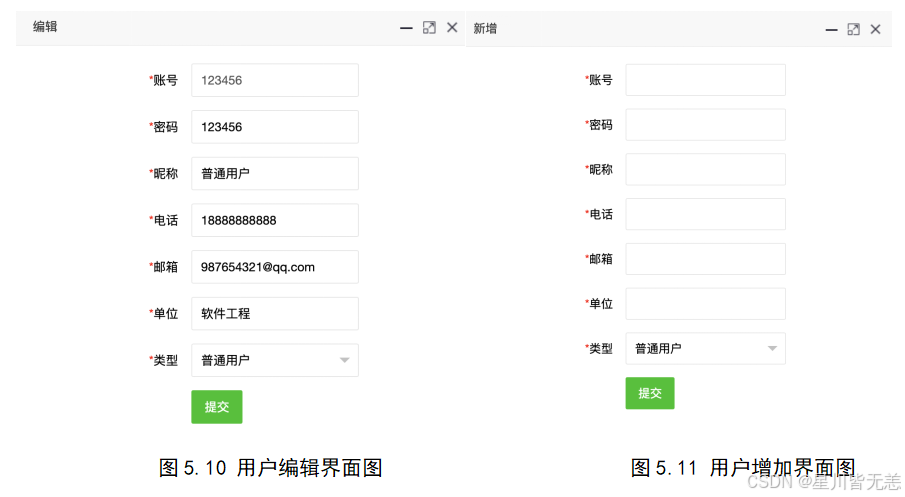
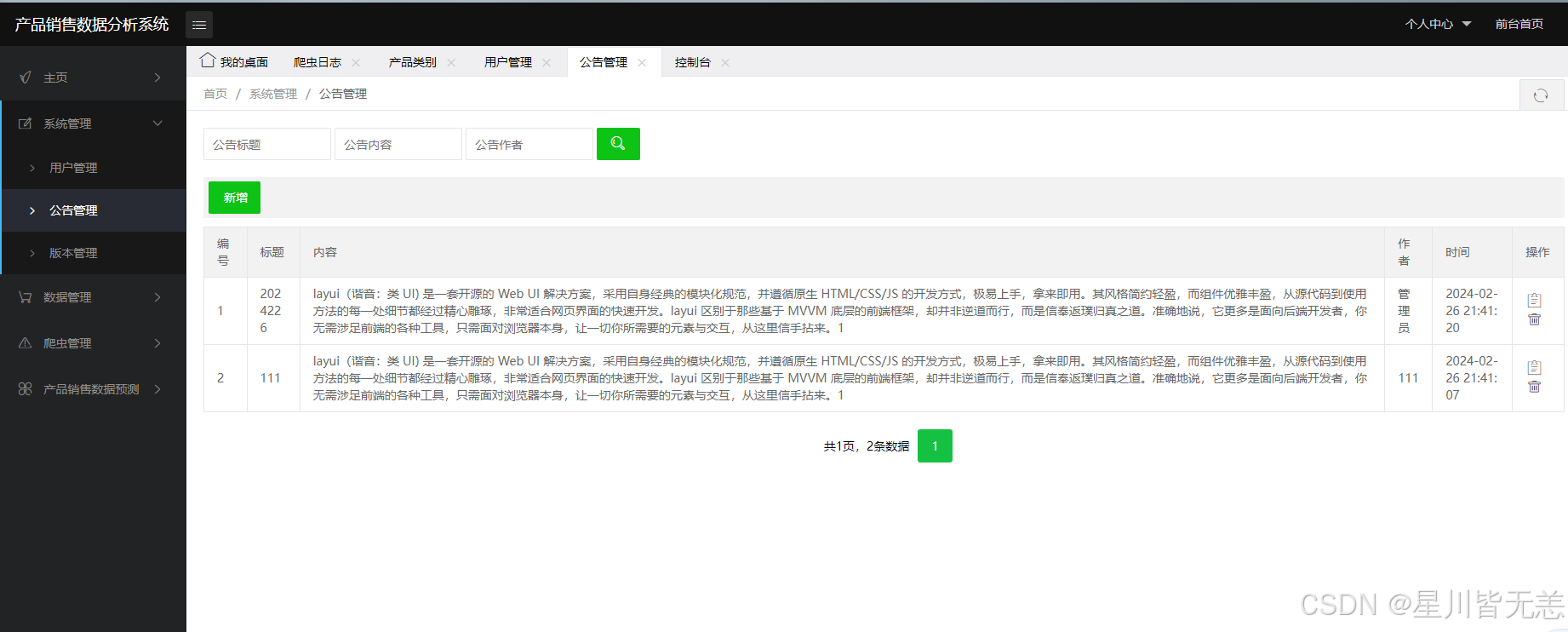
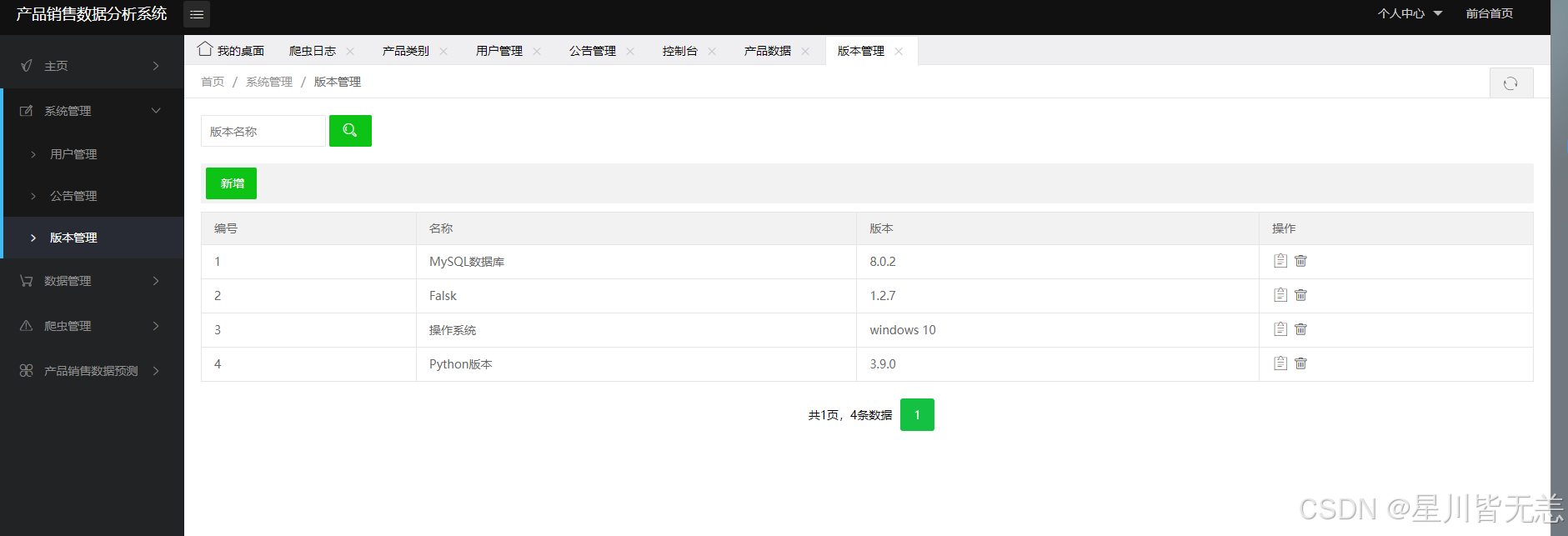
管理员后台管理可以对用户管理、版本管理、公告管理、产品数据管理、产品类别管理、爬虫管理以及数据预测。对用户管理、版本管理、公告管理、产品数据管理、产品类别管理进行基本的查看、修改、增加、删除;在爬虫管理处可以对想要的产品进行爬取,得到一个目标数据的文件,并在爬取后进行统计,最后将此次操作的爬取内容和爬取时间记录进爬虫日志中,方便管理员对数据进行保护。数据预测部分输入索要预测的产品类别,并输入产品折扣价和原价,根据多元线性回归算法获得预测结果,并提示预测成功。
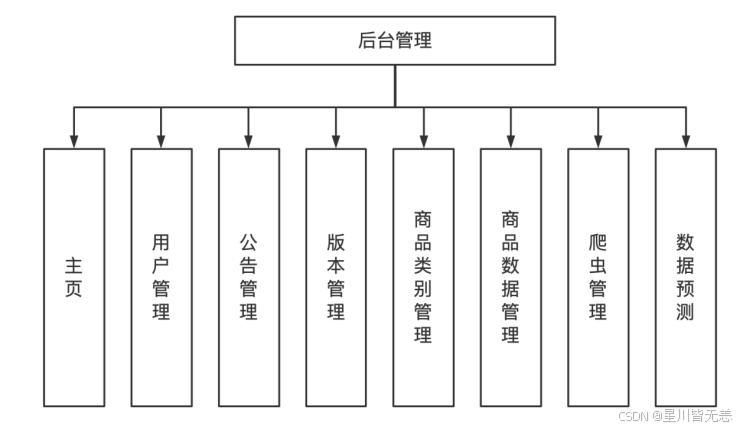
数据库设计
产品实体和产品训练实体是一对一的关系。
用户实体和产品实体之间是一对多的关系。
用户实体和公告实体之间是一对多的关系。
用户实体和版本实体之间是一对多的关系。
用户实体和日志实体之间是一对多的关系。
产品实体和产品类别实体是多对一的关系。
产品训练实体和产品类别实体是多对一的关系。
五、开发技术介绍
Flask框架
Flask 框架是一个轻量级的、便捷的、Python 所提供的 Web 框架,微框架基于Werkzeug(这是WSGI的工具包,即Web服务器网关接口)和Jinja(即Python的模板引擎)的基础。
Flask不仅支持关系数据库,而且还支持非关系数据库(例如MongoDB),由于Flask本身就是相当于一个内核,其结构并不含有数据库抽象层以及表单特征,所以 Flask体积很小。但是Flask具有非常强大的扩展性,用户可以自由选择和组合需要的功能。这也使得Flask变得灵活多变。这些特性让Flask框架一经推出就受到广大用户的喜爱。Flask的工作流程如图3所示,在Flask中每一个URL代表一个是视图函数。当用户访问这些URL时,系统就会调用相对应视图函数,并将函数结果返回给用户。
它更加的灵活、轻便、安全且容易上手,是目前主流的服务器框架。利用 Flask 框架,能实现前后端的数据交互,它可以不用写很多的业务代码,也可以不使用手动设置参数,就可以轻松开发出前端网页接口。Flask可以使程序员在开发时只关注开发业务的本身,而不需要去关注框架怎么设计、结构怎么设计以及框架怎么配置等操作,这样可以大大降低我们开发时所需要付出的精力,增加我们的开发效率。
相对于适合于大型项目的Django,本系统采用性能高于Django且适合高负载的小型且不复杂的Web应用程序的Flask框架。

图2.1 Flask工作原理
Python爬虫之Selenium
Selenium是一个Web应用程序测试的工具,起初是为了网站自动化测试而开发的,作是模拟用户在浏览器上的操作。Selenium自己不带浏览器,不支持浏览器的功能,它需要与第三方浏览器结合在一起才能使用,但Selenium可以直接运行在浏览器上,它支持所有主流的浏览器,包括PhantomJS这些无界面的浏览器,可谓作用之广泛。Selenium可以根据用户的指令,指导浏览器自动加载页面,获取需要的数据,甚至于网页截屏、监听网站动作等等。
由于本数据分析平台选用“淘宝”为产品销售的数据对象,而淘宝的商业数据,它的价值远远高出普通数据。在对网站的页面进行抓包分析后发现,页面中的数据带有加密混淆,所以传统的爬虫思路再次站点行不通。遇到这种情况,一般有两种解决方法第一种是通过使用JavaScript逆向技术找到站点的加密逻辑,并用Python代码将其加密逻辑模拟构造出来。第二种是通过Selenium自动化测试工具来模拟浏览器,直接获取页面源码。
基于以上原因,本系统采用的是第二种方案。首先,需要认为的对爬虫主程序进行初始化信息,需要向爬虫提供一些参数,例如目标数据所在的初始网页地址,需要爬取的页面数、关键词等。然后,设置无头浏览器,Selenium开始工作,在后台默默打开浏览器,输入网址,翻页。每次翻页过后,网页下载器便会获取当前页面的网页源代码,然后提交给网页解析器解析内容。时序图如图2.1所示。在进行元素定位后,需要设置元素等待,不然就会造成获取数据残缺甚至获取不到数据的情况。最后,将网页源代码中的目标数据提取出来,保存到数据库中,便于以后进行更进一步的处理。
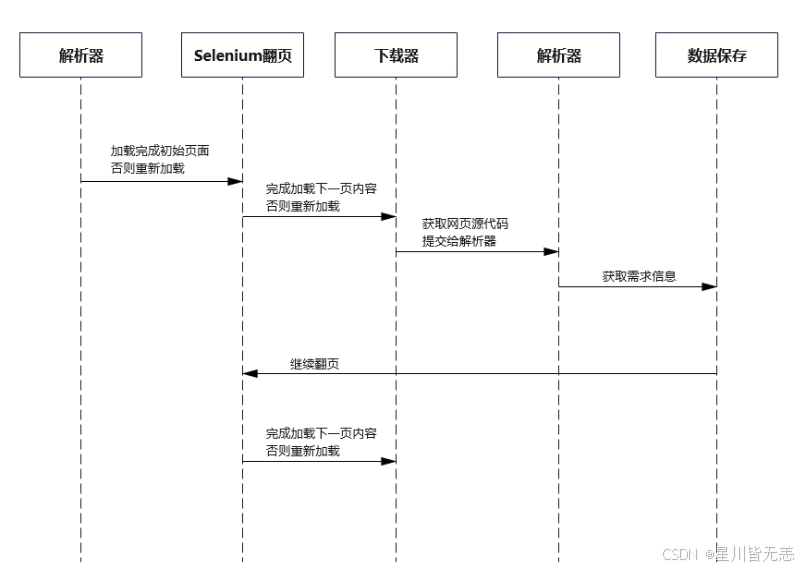
图2.1 爬虫时序图
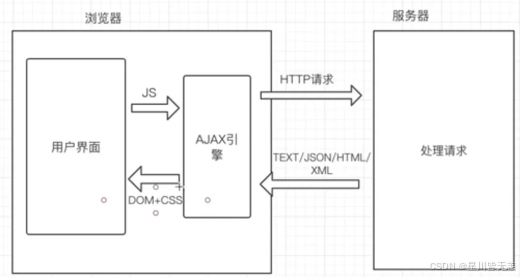
AJAX技术介绍
Ajax是一种在无需重新加载整个网页的情况下,能够更新部分网页的技术。通过在后台与服务器进行少量数据交换,Ajax可以使网页实现异步更新。这意味着可以在不重新加载整个网页的情况下,对网页的某部分进行更新。传统的网页(不使用Ajax)如果需要更新内容,必需重载整个网页面。有很多使用Ajax的应用程序案例:新浪微博、Google 地图、开心网等等。同样他也是一款优秀的前端框架,采用自身模块规范编写的前端UI框架严格遵循HTML/CSS/JS的开发方式,简单易用,可以说是开箱即用,对中小项目具有极高的友好度。虽然目前Lay-UI官网下架,但项目仍然在Github开源。
数据可视化
可视化技术是用来展示数据分析结果的一种大数据技术,它可以直观地表达信息,通常使用柱状图、饼状图、折线图、词云图等图来表达。一般而言,常用到的大数据可视化工具有:Tableau Desktop、QlikView、Microsoft Excel、SAS、IBM SPSS、Echarts等。下面分别来介绍三大可视化技术:
Tableau Desktop:由Tableau公司进行研发的一款智能商业软件,它既可以具有检测数据的功能,也具有良好的分析能力。Tableau将数据计算与图表完美的结合在了一起,通过拖动的方式使人们很方便使用。
QlikView是一款商业分析软件,可以构建强大的应用给研发者以及分析者使用。QlikView的存在使得用户可以用一种高度可视化的方式研究分析业务数据信息。
Echarts是由百度研发的一款图表插件,有着丰富多样的图表功能。它使用Java Script程序编写而成,遵守Apache-2.0的开源协议,供给开发人员免费使用。
本系统选用Echarts作为数据可视化技术。基于淘宝相关产品数据集,利用Python 语言的 Flask框架、ECharts 等技术完成数据的可视化。后端完成数据的提取与封装,利用 Ajax 技术完成前后端的数据交互。ECharts 技术与 Jinja2 模板引擎等技术实现数据可视化。
机器学习
机器学习是人工智能的主要表现形式,其学习形式主要分为:有监督学习、无监督学习、半监督学习等,对于“监督”一词会不明就里,其实你可以把这个词理解为习题的“参考答案”,专业术语叫做“标记”。比如有监督学习就是有参考答案的学习,而无监就是无参考答案。
- 有监督学习
有监督学习(Supervised Learning),需要你事先需要准备好要输入数据(训练样本)与真实的输出结果(参考答案),然后通过计算机的学习得到一个预测模型,再用已知的模型去预测未知的样本,这种方法被称为有监督学习。这也是是最常见的机器学习方法。简单来说,就像你已经知道了试卷的标准答案,然后再去考试,相比没有答案再去考试准确率会更高,也更容易。
- 无监督学习
理解了有监督学习,那么无监督学习理解起来也变的容易。所谓无监督学习(Unsupervised Learning)就是在没有“参考答案”的前提下,计算机仅根据样本的特征或相关性,就能实现从样本数据中训练出相应的预测模型。
由于本次数据分析的数据集数据集(产品类别,产品原价、产品现价,销售量)包含来源于一些淘宝产品,采用多元线性回归算法对产品价格变动后的销量进行预测,其学习形式选定为有监督学习。
六、开发环境介绍
Pycharm开发工具简介
IntelliJ Pycharm,它是为Python语言开发的集成开发环境。目前在业界好评如潮,受广大程序爱好者所青睐,是目前公认的Python最好的开发工具之一。它的特色在于,拥有强大的代码自动补全提示功能、代码重构功能以及对各种第三方插件的高度支持,例如git、svn、代码规范、在线翻译等插件。这些优秀的功能能够大大提高开发效率以及出错概率,同时还有助于养成一个良好的代码习惯。
Firefox简介
Firefox是一款十流行的浏览器。工欲善其事必先利其器,Firefox浏览器就是这这样的利器存在,他提供强大的浏览器插件支持,可以大大提供前端调试效率,其中像Web 前端助手这样的优秀插件了包括 Json格式化、二维码生成与解码、美化、页面取色、Markdown 与 HTML 互转、正则表达式、时间转换工具、编码规范检测、页面性能检测、Ajax 接口调试、网页编码设置等各种功能。
七、机器学习多元线性回归模型算法部分模块核心代码
这里使用机器学习的多元线性回归算法来实现产品销量的预测。首先定义算法模型,喂入数据模型,进行训练,最终得到结果。此外,我们需要对该模型根据损失函数进行评估,这里主要使用预测值和实际值来计算准确率,得到模型的EMS损失值。具体代码如下:
# 分割数据集合
train_data = []
test_data = []
for index, item in enumerate(data):if index % 5 == 0: # 每5条数据,第6条保留为测试集合,也就是训练集:测试集=5:1test_data.append(item)else:train_data.append(item)
train_data, test_data = np.array(train_data), np.array(test_data)X = np.array(train_data[:, 1:3]).astype(float)
Y = np.array(train_data[:, 3]).astype(float)test_X = np.array(test_data[:, 1:3]).astype(float)
text_Y = np.array(test_data[:, 3]).astype(float)# 定义算法模型
model = LinearRegression()
# 喂入模型数据
model.fit(X, Y)
joblib.dump(model, "./goods.joblib")
根据上述代码运行后得到模型的EMS损失值如下:
[INFO] 多元线性回归预测销量-训练开始
[INFO] 模型EMS损失值(模型评分越低越好): 0.0049775877557516335
[INFO] 多元线性回归预测销量-训练完成
八、项目截图
九、结语
需项目源码文档等资料/商业合作/交流探讨等可以添加下面个人名片进行源码文档等获取,后续有时间会持续更新更多优质项目内容,感谢各位的喜欢与支持!
相关文章:

大数据产品销售数据分析:基于Python机器学习产品销售数据爬虫可视化分析预测系统设计与实现
文章目录 大数据产品销售数据分析:基于Python机器学习产品销售数据爬虫可视化分析预测系统设计与实现一、项目概述二、项目说明三、研究意义四、系统总体架构设计总体框架技术架构数据可视化模块设计图后台管理模块设计数据库设计 五、开发技术介绍Flask框架Python爬…...

「Mac畅玩AIGC与多模态21」开发篇17 - 多字段判断与多路径分支工作流示例
一、概述 本篇在结构化输出字段控制流程的基础上,进一步引入多字段联合判断与多路径分支控制。通过综合分析用户输入的情绪类型和紧急程度,实现三分支路径执行逻辑,开发人员将掌握复杂流程中多条件判断节点的配置技巧。 二、环境准备 macO…...

网页截图指南
截取网页截图看似是一项简单的任务,但当你真正动手去做的时候,就会发现事情远没有那么容易。我在尝试截取一篇很长的 Reddit 帖子时就深有体会。一开始我以为只要调用 browser.TakeImage() 就万事大吉,结果却陷入了浏览器视口、动态内容加载、…...

作为主动唤醒的节点,ECU上电如何请求通讯
一个ECU如果作为主动唤醒的节点,ECU上电时可以通过以下方式请求通信 如上图所示,ECU在上电后,在OS起来后,可以通过在BSWM模块中完成NvM_ReadAll和相关BSW 模块初始化以及Rte_Start后,这个时候周期性Task已经可以正常调…...

应用服务器Tomcat
启动两给tomcat apache-tomcat-9.0.60\bin——> 启动tomcat startup.bat (Windows) / startup.sh(Linux) 关闭tomcat shutdown.bat(Windows)/shutdown.sh (Linux) 复制一个Tomcat为2,先启…...

【安全】端口保护技术--端口敲门和单包授权
【安全】端口保护技术--端口敲门和单包授权 备注一、端口保护二、端口敲门三、单包授权 备注 2025/05/06 星期二 最近学习了端口保护技术总结一下 一、端口保护 为了保护联网设备的安全,一般会尽量减小暴露的攻击面,开放的端口就是最常见的攻击面&…...

金升阳科技:配套AC/DC砖类电源的高性能滤波器
金升阳推出的FC-L15HB是为我司AC砖类电源配套使用的EMC辅助器。将FC-L15HB加装在金升阳AC/DC砖类电源的前端,可以提高电源产品IEC/EN61000—4系列及CISPR32/EN55032标准的EMC性能。 01 产品优势 (1)高共差模插入损耗 ①DM&CM࿱…...

浅谈 - GPTQ为啥按列量化
前言 曾在游戏世界挥洒创意,也曾在前端和后端的浪潮间穿梭,如今,而立的我仰望AI的璀璨星空,心潮澎湃,步履不停!愿你我皆乘风破浪,逐梦星辰! 先说结论 GPTQ 按列量化 W,…...

引用第三方自定义组件——微信小程序学习笔记
1. 使用 npm 安装第三方包 1.1 下载安装Node.js 工具 下载地址:Node.js — Download Node.js 1.2 安装 npm 包 在项目空白处右键弹出菜单,选择“在外部终端窗口打开”,打开命令行工具,输入以下指令: 1> 初始化:…...

解决android studio 中gradle 出现task list not built
点击 file 选择settings...

UE5 材质淡入淡出
混合模式选择半透明,灯光照明模式选择Surface TranslucencyVolume...

如何用Java读取PDF
在本文中,我将向您展示如何使用JPedal(一个用于转换、打印、查看PDF文件的Java库)在Java中读取PDF。 如何在Java中读取PDF文件 • 将JPedal添加到您的类或模块路径中(下载试用版jar包)。 • 使用JPedal库中的&q…...
)
tinyrenderer笔记(中)
tinyrenderer个人代码仓库:tinyrenderer个人练习代码 前言 原教程的第 4 课与第 5 课主要介绍了坐标变换的一些知识点,但这一篇文章的内容主要是手动构建 MVP 矩阵,LookAt 矩阵以及原教程涉及到的一些知识点,不是从一个图形学小白…...

人工智能对人类的影响
人工智能对人类的影响 近年来,人工智能(AI)技术以惊人的速度发展,深刻改变了人类社会的方方面面。从医疗、教育到交通、制造业,AI的应用正在重塑我们的生活方式。然而,这一技术革命也带来了机遇与挑战并存…...

LeetCode 220 存在重复元素 III 题解
LeetCode 220 存在重复元素 III 题解 题目描述 给定一个整数数组 nums 和两个整数 k 和 t,请判断数组中是否存在两个不同的索引 i 和 j,使得: abs(nums[i] - nums[j]) < tabs(i - j) < k 方法思路:桶排序 滑动窗口 核…...

0506--01-DA
36. 单选题 在娱乐方式多元化的今天,“ ”是不少人(特别是中青年群体)对待戏曲的态度。这里面固然存在 的偏见、难以静下心来欣赏戏曲之美等因素,却也有另一个无法回避的原因:一些戏曲虽然与观众…...

单应性估计
单应性估计是计算机视觉中的核心技术,主要用于描述同一平面在不同视角下的投影变换关系。以下从定义、数学原理、估计方法及应用场景等方面进行综合解析: 一、单应性的定义与核心特性 单应性(Homography)是射影几何中的概念&…...

Missashe考研日记-day33
Missashe考研日记-day33 1 专业课408 学习时间:2h30min学习内容: 今天开始学习OS最后一章I/O管理的内容,听了第一小节的内容,然后把课后习题也做了。知识点回顾: 1.I/O设备分类:按信息交换单位、按设备传…...

YOLO8之学习指南
一、引言 在计算机视觉领域,目标检测是一项核心任务,其应用范围广泛,涵盖安防监控、自动驾驶、智能医疗等众多领域。YOLO(You Only Look Once)系列算法凭借其高效、快速的特点,在目标检测领域占据重要地位。YOLO8 作为 YOLO 系列的最新版本,进一步提升了检测精度和速度…...

中达瑞和便携式高光谱相机:珠宝鉴定领域的“光谱之眼”
在珠宝行业中,真伪鉴定始终是核心需求。随着合成技术与优化处理手段的日益精进,传统鉴定方法逐渐面临挑战。中达瑞和推出的便携式高光谱相机,凭借其独特的“图谱合一”技术,为珠宝真假鉴定提供了科学、高效且无损的解决方案&#…...

C++自动重连机制设计与实现指南
一、为什么需要自动重连 在网络通信场景中,连接中断是不可避免的常见问题: 网络波动(移动网络切换、WiFi信号不稳) 服务端维护/重启 中间设备故障(路由器、负载均衡器) 操作系统资源限制 长时间空闲断…...

昇腾Atlas 200I DK A2 开发者套件无法上网问题的解决
目录 引言 USB WiFi网卡 USB以太网卡 结语 引言 今年通过华为的智能基座项目得到了三个Atlas 200I DK A2 开发者套件,很不幸其中有一块是坏的,其上网部分不能使用:2个RJ45的口在Linux系统内都无法识别,而USB口虽然能够识别&a…...

私有仓库 Harbor、GitLab
gitlab 部署资料 Harbor...

极狐GitLab 如何将项目共享给群组?
极狐GitLab 是 GitLab 在中国的发行版,关于中文参考文档和资料有: 极狐GitLab 中文文档极狐GitLab 中文论坛极狐GitLab 官网 共享项目和群组 (BASIC ALL) 在极狐GitLab 16.10 中,更改为在成员页面的成员选项卡上显示被邀请群组成员…...

QGIS分割平行四边形
需求:四个点确定的平行四边形的范围,我想把他们均分成20份,然后取质心。 解决方案:找了好几个插件,Polygon Divider、Split Polygon发现不好用,不能满足需求。最终找到了Equalyzer,就是比较麻烦…...
)
NestJS 的核心构建块有哪些?请简要描述它们的作用(例如,Modules, Controllers, Providers)
NestJS 核心构建块解析(Modules、Controllers、Providers) NestJS 是一个基于 TypeScript 的渐进式 Node.js 框架,核心设计借鉴了 Angular 的模块化思想。下面从实际开发角度解析它的三大核心构建块,并附代码示例和避坑指南。 一…...

Nginx 安全防护与Https 部署实战
目录 一、核心安全配置 1. 编译安装 Nginx 2. 隐藏版本号 3. 限制危险请求方法 4. 请求限制(CC 攻击防御) (1)使用 Nginx 的 limit_req 模块限制请求速率 (2)压力测试验证 5. 防盗链 二、高级防护 …...

电商双十一美妆数据分析
1. 数据读取与基础查看 库导入:使用 import numpy as np 和 import pandas as pd 导入常用数据分析库。数据读取: df pd.read_csv(双十一_淘宝美妆数据.csv) 读取数据文件。数据查看:通过 df.head() 查看数据前几行; df.info() 了…...
)
高等数学第六章---定积分(§6.1元素法6.2定积分在几何上的应用1)
本文是关于定积分应用的系列讲解的第一讲,主要介绍元素法的基本思想,并重点讲解如何运用定积分计算平面图形的面积,包括直角坐标系和极坐标系下的情况。 6.1 元素法 曲边梯形的面积回顾 我们首先回顾曲边梯形的面积。设函数 f ( x ) ≥ 0 …...

十分钟了解 @MapperScan
MapperScan 是 MyBatis 和 MyBatis-Plus 提供的一个 Spring Boot 注解,用于自动扫描并注册 Mapper 接口,使其能够被 Spring 容器管理,并与对应的 XML 或注解 SQL 绑定。它的核心作用是简化 MyBatis Mapper 接口的配置,避免手动逐个…...

爬虫程序中如何添加异常处理?
在爬虫程序中添加异常处理是确保程序稳定性和可靠性的关键步骤。异常处理可以帮助你在遇到错误时捕获问题、记录日志,并采取适当的措施,而不是让程序直接崩溃。以下是一些常见的异常处理方法和示例,帮助你在爬虫程序中实现健壮的错误处理机制…...

[250506] Auto-cpufreq 2.6 版本发布:带来增强的 TUI 监控及多项改进
目录 Auto-cpufreq 2.6 版本发布:带来增强的 TUI 监控及多项改进 Auto-cpufreq 2.6 版本发布:带来增强的 TUI 监控及多项改进 Auto-cpufreq,一款适用于 Linux 的免费开源自动 CPU 速度与功耗优化器,已发布其最新版本 2.6。该工具…...

探索Hello Robot开源移动操作机器人Stretch 3的技术亮点与市场定位
Hello Robot 推出的 Stretch 3 机器人凭借其前沿技术和多功能性在众多产品中占据优势。Stretch 3 机器人采用开源设计,为开发者提供了灵活的定制空间,能够满足各种不同的需求。其配备的灵活手腕组件和 Intel Realsense D405 摄像头,显著增强了…...

【Harbor v2.13.0 详细安装步骤 安装证书启用 HTTPS】
Harbor v2.13.0 详细安装步骤(启用 HTTPS) 1. 环境准备 系统要求:至少 4GB 内存,100GB 磁盘空间。 已安装组件: Docker(版本 ≥ 20.10)Docker Compose(版本 ≥ v2.0) 域…...

码蹄集——直角坐标到极坐标的转换、射线、线段
目录 MT1052 直角坐标到极坐标的转换 MT1066 射线 MT1067 线段 MT1052 直角坐标到极坐标的转换 思路: arctan()在c中是atan(),结果是弧度要转换为度,即乘与180/PI 拓展:cos()、sin()在c代码中表示方式不变 #include<bits/…...
 reject() hide())
accept() reject() hide()
1. accept() 用途 确认操作:表示用户完成了对话框的交互并确认了操作(如点击“确定”按钮)。 关闭模态对话框:结束 exec() 的事件循环,返回 QDialog::Accepted 结果码。适用场景 模态对话框(通过 exec()…...

天文探秘学习小结
宇宙 宇宙大爆炸 时间 130亿年前 10-30次方秒内发生大爆炸 发现 20世纪80年代 哈勃发现 通过基于其他星系相对地球的移动速度得出的结论 哈勃发现离地球越远的星系 离开地球的速度越快 得出宇宙加速膨胀的结论 测量造父变星到地球的距离 哈勃测量的是一种恒星 叫造父变星 造…...

游戏引擎学习第261天:切换到静态帧数组
game_debug.cpp: 将ProfileGraph的尺寸初始化为相对较大的值 今天的讨论主要围绕性能分析器(Profiler)以及如何改进它的可用性展开。当前性能分析器已经能够正常工作,但我们希望通过一些改进,使其更易于使用,特别是在…...

利用 Kali Linux 进行信息收集和枚举
重要提示: 在对任何系统进行信息收集和枚举之前,务必获得明确的授权。未经授权的扫描和探测行为是非法的,并可能导致严重的法律后果。本教程仅用于教育和授权测试目的。 Kali Linux 官方链接: 官方网站: https://www…...

深入解析代理服务器:原理、应用与实战配置指南
一、代理服务器的核心原理与工作机制 1.1 网络通信的中介架构 代理服务器(Proxy Server)本质上是位于客户端与目标服务器之间的中间层节点,其核心工作机制遵循OSI模型的会话层与应用层协议。当客户端发起网络请求时&#x…...
)
[蓝桥杯 2025 省 B] 水质检测(暴力 )
暴力暴力 菜鸟第一次写题解,多多包涵!!! 这个题目的数据量很小,所以没必要去使用bfs,直接分情况讨论即可 一共两排数据,我们使用贪心的思想,只需要实现从左往右的过程中每个检测器相互连接即…...

区块链+数据库:技术融合下的应用革新与挑战突围
引言 近年来,区块链技术凭借其去中心化、不可篡改、透明可追溯等特性,逐渐从数字货币领域扩展到更广泛的应用场景,包括供应链管理、医疗健康、政务服务和数字身份等。与此同时,传统数据库系统在应对海量数据、多方协作与安全需求…...
)
油气地震资料信号处理中的NMO(正常时差校正)
油气地震资料信号处理中的NMO(正常时差校正)介绍与应用 NMO基本概念 **正常时差校正(Normal Moveout Correction,NMO)**是地震资料处理中的一项关键技术,主要用于消除由于炮检距(source-recei…...

TDengine 车联网案例
简介 随着科技的迅猛发展和智能设备的广泛普及,车联网技术已逐渐成为现代交通领域的核心要素。在这样的背景下,选择一个合适的车联网时序数据库显得尤为关键。车联网时序数据库不仅仅是数据存储的解决方案,更是一个集车辆信息交互、深度分析…...

探索编程世界:从“爱编程的小黄鸭”B站账号启航
探索编程世界:从“爱编程的小黄鸭”B站账号启航 在编程学习的漫漫长路上,你是否常常为寻找优质、易懂的学习资源而烦恼?今天,我想给大家分享一个宝藏B站账号——“爱编程的小黄鸭”,希望能为大家的编程学习之旅提供一…...

使用 git subtree 方法将六个项目合并到一个仓库并保留提交记录
使用 git subtree 方法将六个项目合并到一个仓库并保留提交记录 步骤 1:初始化主仓库步骤 2:逐个添加子项目2.1 添加子项目远程仓库2.2 将子项目合并到主仓库的指定目录2.3 重复操作其他子项目 步骤 3:验证提交历史步骤 4(可选&am…...

Django缓存框架API
这里写自定义目录标题 访问缓存django.core.cache.cachesdjango.core.cache.cache 基本用法cache.set(key, value, timeoutDEFAULT_TIMEOUT, versionNone)cache.get(key, defaultNone, versionNone)cache.add(key, value, timeoutDEFAULT_TIMEOUT, versionNone)cache.get_or_se…...
)
Linux云计算训练营笔记day02(Linux、计算机网络、进制)
Linux 是一个操作系统 Linux版本 RedHat Rocky Linux CentOS7 Linux Ubuntu Linux Debian Linux Deepin Linux 登录用户 管理员 root a 普通用户 nsd a 打开终端 放大: ctrl shift 缩小: ctrl - 命令行提示符 [rootlocalhost ~]# ~ 家目录 /root 当前登录的用户…...

LIO-Livox
用单台Livox Horizon (含内置IMU) 实现高鲁棒性的激光-惯性里程计,可在各类极端场景下鲁棒运行,并达到高精度的定位和建图效果。(城区拥堵、高速公路、幽暗隧道) 注:该系统主要面向大型室外环境中的汽车平台设计。用户可以使用 Livox Horizo…...

VNP46A3灯光遥感数据全球拼接并重采样
感谢Deepseek帮我写代码,本人在此过程中仅对其进行调试和部分修改: 灯光遥感2024年1月全球拼接结果 代码如下: import os import glob import h5py import numpy as np from osgeo import gdal, osr import rasterio from rasterio.merge im…...