R7打卡——糖尿病预测模型优化探索
🍨 本文为🔗365天深度学习训练营中的学习记录博客
- 🍖 原作者:K同学啊
1.检查GPU
import torch.nn as nn
import torch.nn.functional as F
import torchvision,torch# 设置硬件设备,如果有GPU则使用,没有则使用cpu
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device
2.查看数据
import numpy as np
import pandas as pd
import seaborn as sns
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
plt.rcParams['savefig.dpi'] = 500 #图片像素
plt.rcParams['figure.dpi'] = 500 #分辨率plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签import warnings
warnings.filterwarnings("ignore")DataFrame=pd.read_excel('data/dia.xls')
DataFrame.head()# 查看数据是否有缺失值
print('数据缺失值---------------------------------')
print(DataFrame.isnull().sum())feature_map = {'年龄': '年龄','高密度脂蛋白胆固醇': '高密度脂蛋白胆固醇','低密度脂蛋白胆固醇': '低密度脂蛋白胆固醇','极低密度脂蛋白胆固醇': '极低密度脂蛋白胆固醇','甘油三酯': '甘油三酯','总胆固醇': '总胆固醇','脉搏': '脉搏','舒张压':'舒张压','高血压史':'高血压史','尿素氮':'尿素氮','尿酸':'尿酸','肌酐':'肌酐','体重检查结果':'体重检查结果'
}
plt.figure(figsize=(15, 10))import matplotlib.pyplot as plt
import seaborn as sns# 删除列 '卡号'
DataFrame.drop(columns=['卡号'], inplace=True)# 计算各列之间的相关系数
df_corr = DataFrame.corr()# 相关矩阵生成函数
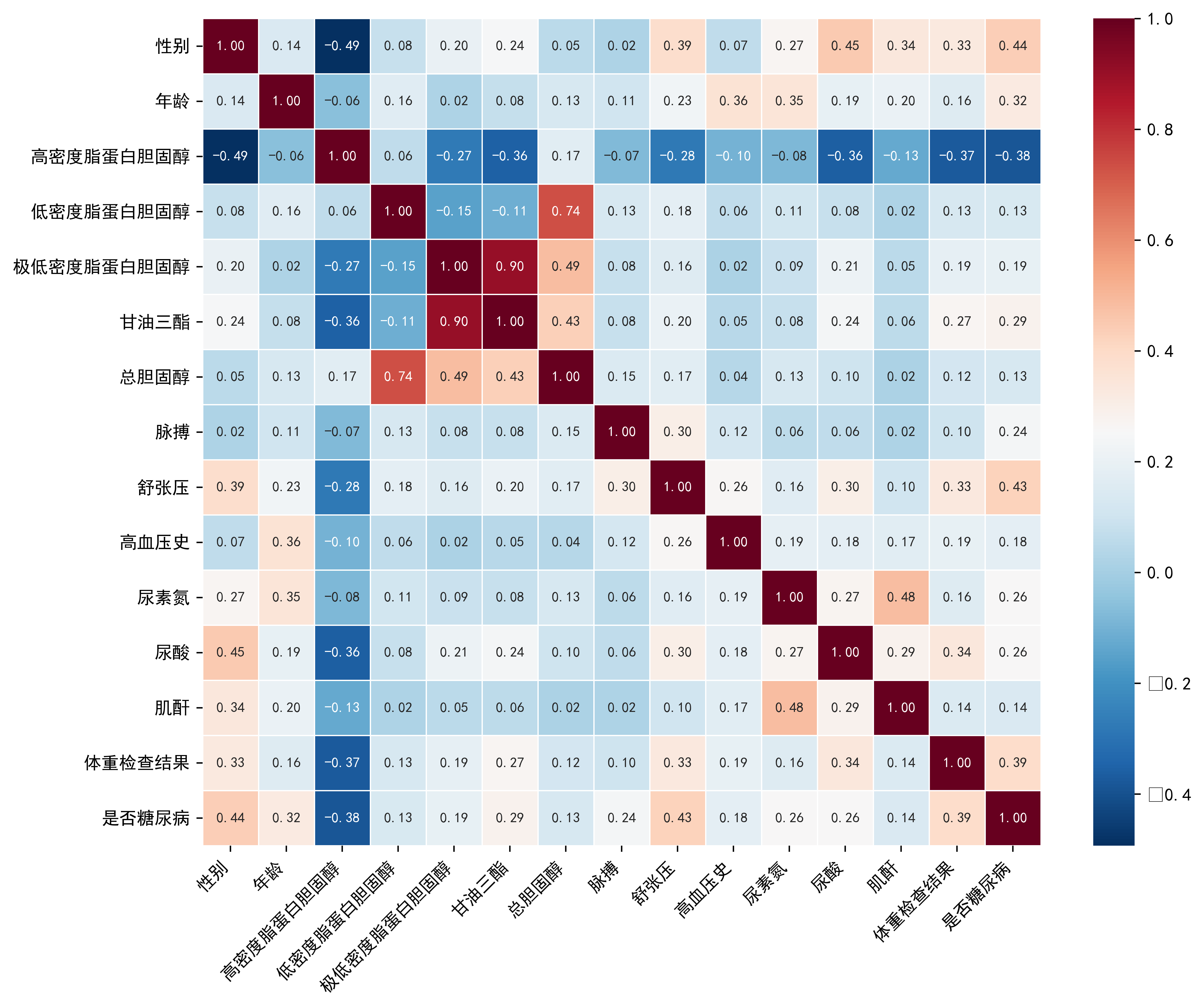
def corr_generate(df):plt.figure(figsize=(10, 8))sns.heatmap(df, annot=True, # 显示数值fmt=".2f", # 保留两位小数cmap='RdBu_r', # 使用相同颜色方案annot_kws={"size": 8}, # 调整注释字号linewidths=0.5) # 单元格间线 宽plt.xticks(rotation=45, ha='right') # 调整x轴标签角度plt.yticks(rotation=0) # 保持y轴标签水平plt.tight_layout() # 自动调整布局plt.show()# 生成相关矩阵
corr_generate(df_corr)for i, (col, col_name) in enumerate(feature_map.items(), 1):plt.subplot(3, 5, i)sns.boxplot(x=DataFrame['是否糖尿病'], y=DataFrame[col])plt.title(f'{col_name}的箱线图', fontsize=14)plt.ylabel('数值', fontsize=12)plt.grid(axis='y', linestyle='--', alpha=0.7)plt.tight_layout()
plt.show()

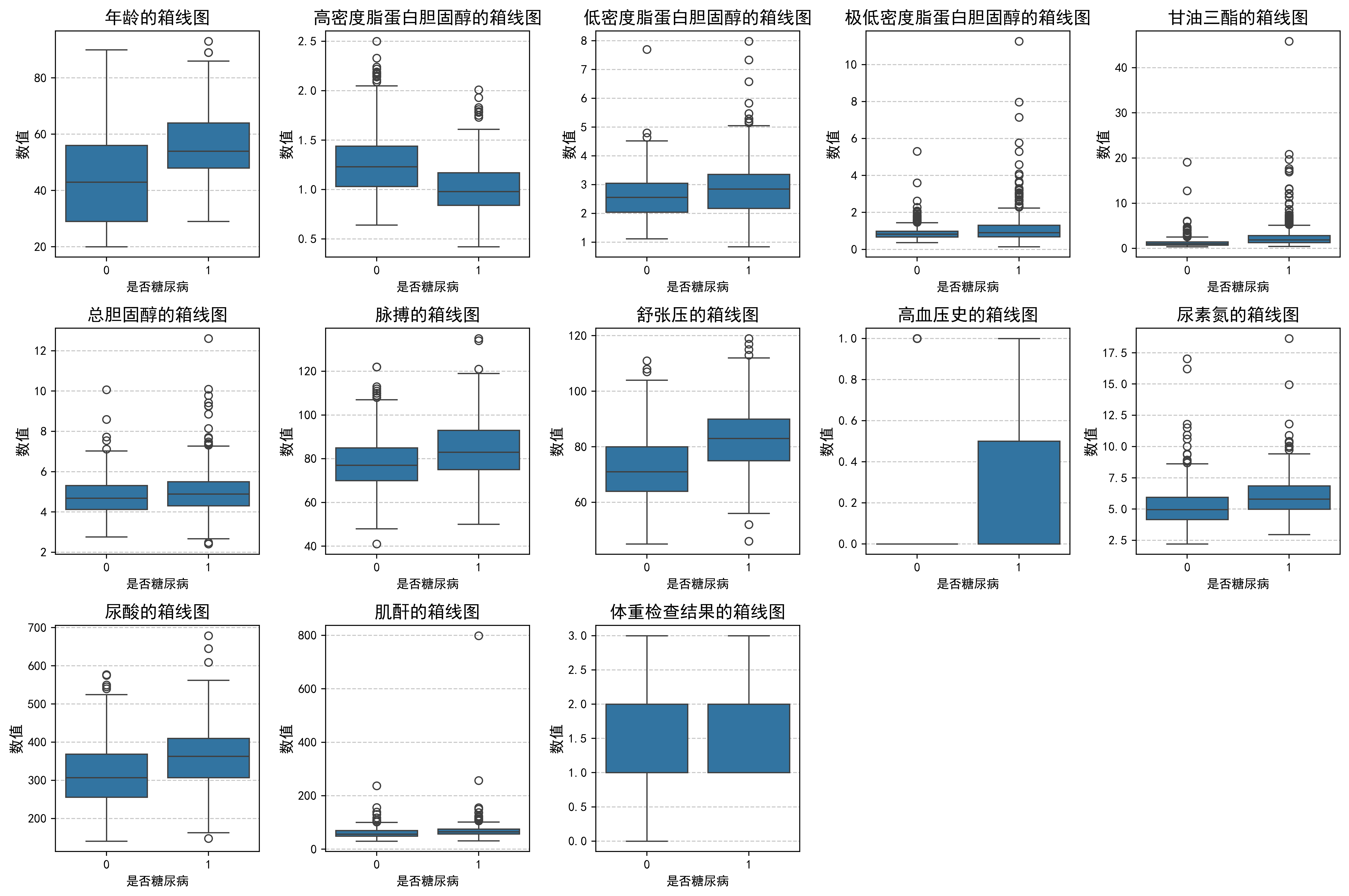
3.划分数据集
from sklearn.preprocessing import StandardScaler
X = DataFrame.drop(['是否糖尿病','高密度脂蛋白胆固醇'],axis=1)
y = DataFrame['是否糖尿病']# 数据集标准化处理
sc_X = StandardScaler()
X = sc_X.fit_transform(X)
X = torch.tensor(np.array(X), dtype=torch.float32)
y = torch.tensor(np.array(y), dtype=torch.int64)
train_X, test_X, train_y, test_y = train_test_split(X, y,test_size=0.2,random_state=1)
# 维度扩增使其符合LSTM模型可接受shape
train_X = train_X.unsqueeze(1)
test_X = test_X.unsqueeze(1)
train_X.shape, train_y.shapefrom torch.utils.data import TensorDataset, DataLoadertrain_dl = DataLoader(TensorDataset(train_X, train_y),
batch_size=64,
shuffle=False)test_dl = DataLoader(TensorDataset(test_X, test_y),
batch_size=64,
shuffle=False)
4.创建模型与编译训练
class model_lstm(nn.Module):def __init__(self):super(model_lstm, self).__init__()self.lstm0 = nn.LSTM(input_size=13 ,hidden_size=200, num_layers=1, batch_first=True)self.lstm1 = nn.LSTM(input_size=200 ,hidden_size=200, num_layers=1, batch_first=True)self.fc0 = nn.Linear(200, 2)def forward(self, x):out, hidden1 = self.lstm0(x) out, _ = self.lstm1(out, hidden1) out = out[:, -1, :] # 只取最后一个时间步的输出out = self.fc0(out) return out model = model_lstm().to(device)
model
5.编译及训练模型
# 训练循环
def train(dataloader, model, loss_fn, optimizer):size = len(dataloader.dataset) # 训练集的大小num_batches = len(dataloader) # 批次数目, (size/batch_size,向上取整)train_loss, train_acc = 0, 0 # 初始化训练损失和正确率for X, y in dataloader: # 获取图片及其标签X, y = X.to(device), y.to(device)# 计算预测误差pred = model(X) # 网络输出loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距,targets为真实值,计算二者差值即为损失# 反向传播optimizer.zero_grad() # grad属性归零loss.backward() # 反向传播optimizer.step() # 每一步自动更新# 记录acc与losstrain_acc += (pred.argmax(1) == y).type(torch.float).sum().item()train_loss += loss.item()train_acc /= sizetrain_loss /= num_batchesreturn train_acc, train_lossdef test (dataloader, model, loss_fn):size = len(dataloader.dataset) # 测试集的大小num_batches = len(dataloader) # 批次数目, (size/batch_size,向上取整)test_loss, test_acc = 0, 0# 当不进行训练时,停止梯度更新,节省计算内存消耗with torch.no_grad():for imgs, target in dataloader:imgs, target = imgs.to(device), target.to(device)# 计算losstarget_pred = model(imgs)loss = loss_fn(target_pred, target)test_loss += loss.item()test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()test_acc /= sizetest_loss /= num_batchesreturn test_acc, test_lossloss_fn = nn.CrossEntropyLoss() # 创建损失函数
learn_rate = 1e-4 # 学习率
opt = torch.optim.Adam(model.parameters(),lr=learn_rate)
epochs = 30train_loss = []
train_acc = []
test_loss = []
test_acc = []for epoch in range(epochs):model.train()epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt)model.eval()epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)train_acc.append(epoch_train_acc)train_loss.append(epoch_train_loss)test_acc.append(epoch_test_acc)test_loss.append(epoch_test_loss)# 获取当前的学习率lr = opt.state_dict()['param_groups'][0]['lr']template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%, Test_loss:{:.3f}, Lr:{:.2E}')print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss, epoch_test_acc*100, epoch_test_loss, lr))
print("="*20, 'Done', "="*20)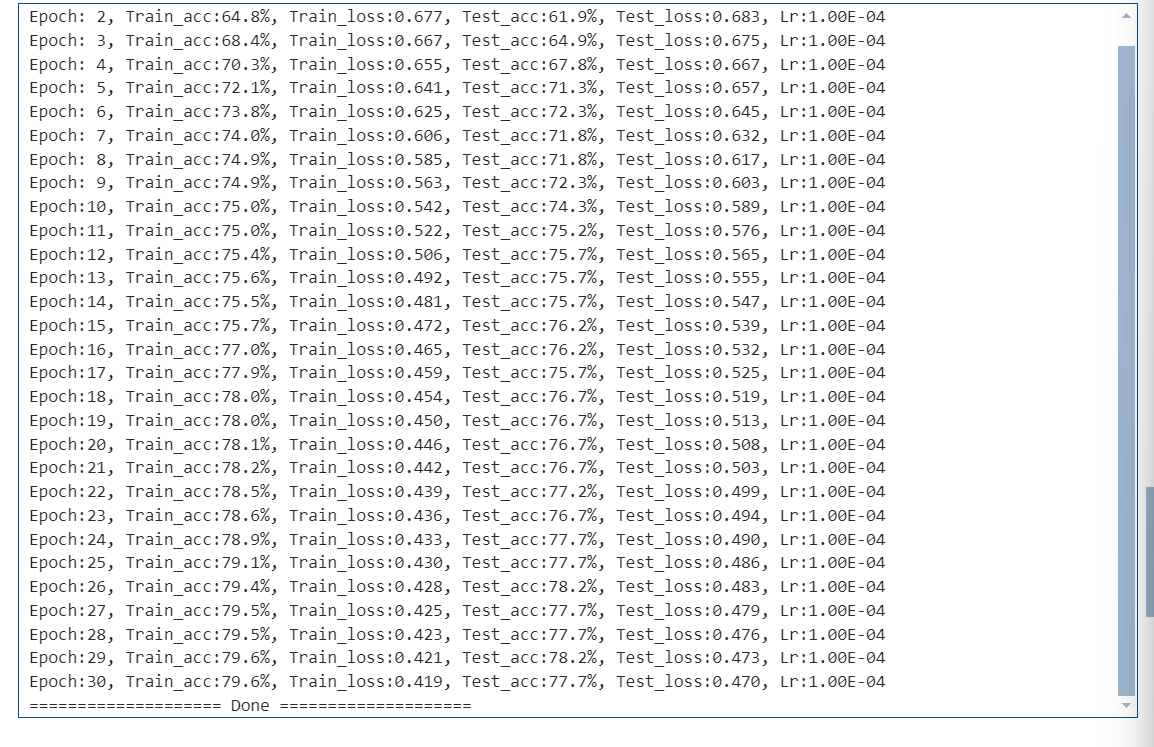
6.结果可视化
import matplotlib.pyplot as plt
#隐藏警告
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 #分辨率from datetime import datetime
current_time = datetime.now() # 获取当前时间epochs_range = range(epochs)plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.xlabel(current_time) # 打卡请带上时间戳,否则代码截图无效plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()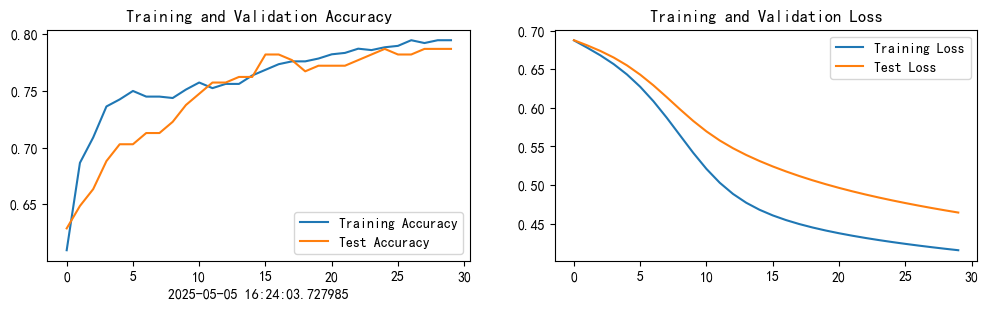
总结:
这段代码是一个完整的 糖尿病预测模型训练流程,基于 PyTorch 框架使用 LSTM 神经网络模型进行二分类任务。以下是对其各个部分的总结和分析:
🔍 一、整体流程概述
这是一个典型的深度学习项目结构,主要包括以下几个阶段:
- 环境与硬件准备(GPU检查)
- 数据加载与预处理
- 数据可视化分析(缺失值、相关性、箱线图等)
- 数据集划分与标准化
- LSTM模型定义与训练
- 模型评估与结果可视化
🧠 二、详细模块说明
1️⃣ GPU设备设置
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")- 自动检测是否有可用的GPU资源,优先使用GPU加速训练。
2️⃣ 数据加载与探索性数据分析(EDA)
✅ 加载Excel数据
DataFrame = pd.read_excel('data/dia.xls')✅ 删除无关列
DataFrame.drop(columns=['卡号'], inplace=True)✅ 缺失值检查
print(DataFrame.isnull().sum())✅ 特征相关性热力图
sns.heatmap(DataFrame.corr(), annot=True, cmap='RdBu_r')✅ 各特征与目标变量的箱线图对比
sns.boxplot(x=DataFrame['是否糖尿病'], y=DataFrame[col])3️⃣ 数据预处理与划分
✅ 特征选择与标签提取
X = DataFrame.drop(['是否糖尿病','高密度脂蛋白胆固醇'],axis=1)
y = DataFrame['是否糖尿病']✅ 标准化处理
sc_X = StandardScaler()
X = sc_X.fit_transform(X)✅ 转换为Tensor并划分训练集/测试集
train_X, test_X, train_y, test_y = train_test_split(...)
train_X = train_X.unsqueeze(1) # 扩展维度以适应LSTM输入✅ 使用DataLoader构建批数据加载器
train_dl = DataLoader(TensorDataset(train_X, train_y), batch_size=64)4️⃣ 模型构建:双层LSTM + 全连接层
class model_lstm(nn.Module):def __init__(self):self.lstm0 = nn.LSTM(input_size=13 ,hidden_size=200, num_layers=1, batch_first=True)self.lstm1 = nn.LSTM(input_size=200 ,hidden_size=200, num_layers=1, batch_first=True)self.fc0 = nn.Linear(200, 2)def forward(self, x):out, hidden1 = self.lstm0(x) out, _ = self.lstm1(out, hidden1) out = out[:, -1, :] # 取最后一个时间步输出out = self.fc0(out) return out- 输入特征维度:13(除去“是否糖尿病”和“高密度脂蛋白胆固醇”)
- 使用了两个堆叠的LSTM层,每个有200个隐藏单元
- 最后一个时间步输出送入全连接层,输出2类(糖尿病 / 非糖尿病)
5️⃣ 训练与评估函数
✅ 损失函数 & 优化器
loss_fn = nn.CrossEntropyLoss()
opt = torch.optim.Adam(model.parameters(), lr=1e-4)✅ 自定义训练循环 train() 和验证循环 test()
- 支持自动计算准确率和损失
- 支持GPU训练
✅ 进行多轮训练(共30轮)
for epoch in range(epochs):model.train()...model.eval()...6️⃣ 结果可视化
plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')- 绘制了训练集与测试集的准确率和损失曲线
- 设置中文显示支持
- 显示当前训练的时间戳
相关文章:

R7打卡——糖尿病预测模型优化探索
🍨 本文为🔗365天深度学习训练营中的学习记录博客 🍖 原作者:K同学啊 1.检查GPU import torch.nn as nn import torch.nn.functional as F import torchvision,torch# 设置硬件设备,如果有GPU则使用,没有…...
)
win10开了移动热点,手机无法连接,解决办法(chatgpt版)
提问: win10连着网线上网,有无线网卡intel Wireless-AC 9560网卡 可以用电脑开移动热点给手机连接吗?如何设置?我现在可以开热点,但是手机连不上,显示正在获取ip地址后就连不上了 chatgpt回答:…...

下载core5compat 模块时,被禁止,显示 - servese replied: Forbbidden. -->换镜像源
怎么解决? --->换镜像源 方法 1:使用命令行参数指定镜像源 在运行 Qt 安装器时,通过 --mirror 参数指定镜像源: # Windows qt-unified-windows-x64-online.exe --mirror https://mirrors.ustc.edu.cn/qtproject# Linux/macO…...

《MATLAB实战训练营:从入门到工业级应用》高阶挑战篇-《用无人机仿真玩转PID控制:MATLAB四旋翼仿真建模全攻略》
《MATLAB实战训练营:从入门到工业级应用》高阶挑战篇-✈️ 用无人机仿真玩转PID控制:MATLAB四旋翼仿真建模全攻略 🚁 欢迎来到这篇超级详细的MATLAB四旋翼无人机仿真教程!无论你是控制理论爱好者、无人机发烧友,还是M…...
))
GESP2024年3月认证C++八级( 第二部分判断题(1-5))
孙子定理参考程序: #include <iostream> #include <vector> using namespace std;// 扩展欧几里得算法:用于求逆元 int extendedGCD(int a, int b, int &x, int &y) {if (b 0) {x 1; y 0;return a;}int x1, y1;int gcd extende…...

PHP的现代复兴:从脚本语言到企业级服务端引擎的演进之路-优雅草卓伊凡
PHP的现代复兴:从脚本语言到企业级服务端引擎的演进之路-优雅草卓伊凡 一、PHP的历史误解与现实真相 1.1 被固化的陈旧认知 当卓伊凡浏览知乎上关于PHP的讨论时,发现大量回答仍然停留在十年前的刻板印象中。这些误解包括但不限于: “PHP只…...

手表功能RunModeTasks
RunModeTasks 功能解释 “RunModeTasks 执行特定于当前模式的功能 根据模式控制作行为”这句话是指 OV-Watch 智能手表项目中的一组任务,这些任务负责管理设备的运行模式并根据不同模式控制设备的行为。 主要组成部分 RunModeTasks 主要由以下三个部分组成&#…...

Qt6.8中进行PDF文件读取和编辑
1.环境配置 在 .pro 文件中添加 PDF 模块依赖: QT core gui pdf # 添加 pdf 模块 注意:独立 pdf 模块的起始版本是Qt 5.15,建议需要 PDF 功能的开发者优先选择此版本或更高版本 2.读取PDF 文件 核心类:QPdfDocument…...

Barrett Reduction算法优化:更紧的界限消除冗余的减法
1. 引言 Barrett Reduction 是一种被广泛使用的模 m m m 运算算法。在zkSecurity 受NEAR团队所委托的(针对RustCrypto: NIST P-256 (secp256r1) elliptic curve——https://github.com/RustCrypto/elliptic-curves/tree/master/p256)进行的 Rust p256 …...

Node.js 是什么?
Node.js 是什么? Node.js 是一个基于 Chrome V8 JavaScript 引擎 的 跨平台 JavaScript 运行时环境,用于在服务器端运行 JavaScript 代码。它使开发者能够使用 JavaScript 编写后端(服务端)程序,而不仅仅局限于浏览器端(前端)。 1. Node.js 的核心特点 (1) 基于 Chrom…...

数据结构中 数组、链表、图的概念
数据结构是计算机存储、组织数据的方式,数组、链表和图是三种常见的数据结构,下面为你详细介绍它们的概念: 数组 数组是一种线性数据结构,它由一组相同类型的元素组成,这些元素存储在连续的内存位置上。每个元素都可…...

基于PPO的自动驾驶小车绕圈任务
1.任务介绍 任务来源: DQN: Deep Q Learning |自动驾驶入门(?) |算法与实现 任务原始代码: self-driving car 在上一篇使用了DDPG算法完成自动驾驶小车绕圈任务之后,继续学习了PPO算法&…...
)
Three.js + React 实战系列 - 客户评价区细解教程 Clients 组件✨(回答式评价 + 评分星级)
对个人主页设计和实现感兴趣的朋友可以订阅我的专栏哦!!谢谢大家!!! 在这篇博客中,我们将实现一个简洁的 Hear from My Clients 客户评价区域。这个区块在个人主页中可以突显用户体验和专业度,帮…...
)
2048游戏(含Python源码)
前言 相关参考游戏: 像素飞机大战(含Python源码)-CSDN博客https://blog.csdn.net/weixin_64066303/article/details/147693018?spm1001.2014.3001.5501使用DeepSeek定制Python小游戏——以“俄罗斯方块”为例-CSDN博客https://blog.csdn.n…...

百度golang开发一面
讲一下数据库的事务机制?acid特性是靠什么实现的? 持久性 redo log 原子性 undo log 隔离性 MVCC或next-lock锁 四个隔离级别是什么,分别解决什么问题? 可串行化实现原理 mysql锁机制?介绍锁的类型,以及原理…...

【Springboot知识】Springboot计划任务Schedule详解
文章目录 Spring Boot 定时任务从原理到实现详解一、核心原理分析1. 架构分层2. 核心组件3. 线程模型 二、基础实现步骤1. 添加依赖2. 主类配置3. 定时任务类 三、高级配置技巧1. 自定义线程池2. 动态配置参数3. 分布式锁集成(Redis示例) 四、异常处理机…...

大模型推理--从零搭建大模型推理服务器:硬件选购、Ubuntu双系统安装与环境配置
自从大模型火了之后就一直想自己组装一台机器去深入研究一下大模型,奈何囊中羞涩,迟迟也没有行动。在下了很大的勇气之后,终于花了接近4万块钱组装了一台台式机,下面给大家详细介绍一下我的装机过程。 1.硬件配置 研究了一周&am…...

如何使用QWidgets设计一个类似于Web Toast的控件?
如何使用QWidgets设计一个类似于Web Toast的控件? 前言 笔者这段时间沉迷于给我的下位机I.MX6ULL做桌面,这里抽空更新一下QT的东西。这篇文章是跟随CCMoveWidget一样的文章,尝试分享自己如何书写这份代码的思考的过程,和笔者…...

博图V20编译报错:备不受支持,无法编译。请更改为受支持的设备。
使用高版本博图打开低版本博图的工程文件时,hmi编译报错不通过,报错提示:备不受支持,无法编译。请更改为受支持的设备。 原因:当前版本的博图软件没有或不支持该组态设备的固件版本。 解决办法:1、安装报错…...
)
凸性(Convexity)
凸性(Convexity)是一个跨学科的重要概念,广泛应用于数学、优化理论、金融等领域。其核心含义是描述某种结构(如函数、集合)在特定条件下的“无凹陷”性质。 1. 数学中的凸性 1.1 凸函数与凹函数 在数学分析中&#…...

Vuex使用指南:状态管理
一、什么是状态管理?为什么需要 Vuex? 1. 状态管理的基本概念 在 Vue 应用中,状态指的是应用中的数据。例如: 用户登录状态购物车中的商品文章列表的分页信息 状态管理就是对这些数据的创建、读取、更新和删除进行有效管理。 …...

kotlin中枚举带参数和不带参数的区别
一 ✅ 代码对比总结 第一段(带参数 工具方法) enum class SeatPosition(val position: Int) {DRIVER_LEFT(0),DRIVER_RIGHT(1),SECOND_LEFT(2),SECOND_RIGHT(3);companion object {fun fromPosition(position: Int): SeatPosition? {return SeatPosi…...

【Python】Python好玩的第三方库之二维码生成,操作xlsx文件,以及音频控制器
前言 🌟🌟本期讲解关于python的三种第三方库的使用介绍~~~ 🌈感兴趣的小伙伴看一看小编主页:GGBondlctrl-CSDN博客 🔥 你的点赞就是小编不断更新的最大动力 🎆那么…...

VTK 交互类介绍
基本概念 交互器(Interactor): 处理用户输入事件的基础类 交互样式(InteractorStyle): 定义具体的交互行为 Widgets: 可交互的UI组件,如滑块、按钮等 Picker: 用于选择场景中的对象 常用交互类 类名功能描述vtkRenderWindowInteractor渲染窗口交互器vtkInteractorStyle交互样式…...

在Window10 和 Ubuntu 24.04LTS 上 Ollama 在线或离线安装部署
Ollama 是一个开源的大型语言模型(LLM)服务框架,旨在通过轻量化、跨平台的设计,简化大模型在本地环境中的部署与应用。其基于 Go 语言开发,通过 Docker 容器化技术封装模型运行环境,提供类似命令行工具的交…...

语音合成之十一 提升TTS语音合成效果:低质量数据清洗、增强与数据扩增
低质量数据清洗、增强与数据扩增 1. 引言:TTS的基石——数据质量2. 基础:TTS数据准备工作流2.1 规划:定义蓝图2.2 执行:从原始数据到训练就绪格式2.3 最佳实践与可复现性 3. 攻克缺陷:低质量语音数据的清洗与增强3.2 手…...

RGB三原色
本文来源 : 腾讯元宝 RGB三原色(红绿蓝)详解 RGB(Red, Green, Blue)是光学的三原色,通过不同比例的混合可以产生人眼可见的绝大多数颜色。它是现代显示技术(如屏幕、投影仪)…...
 1)
BUUCTF 大流量分析(一) 1
BUUCTF:https://buuoj.cn/challenges 文章目录 题目描述:密文:解题思路:flag: 相关阅读 CTF Wiki BUUCTF:大流量分析(一) 题目描述: 某黑客对A公司发动了攻击,以下是一段时间内我们…...

虚幻引擎5-Unreal Engine笔记之显卡环境设置使开发流畅
虚幻引擎5-Unreal Engine笔记之显卡环境设置使开发流畅 code review! 文章目录 虚幻引擎5-Unreal Engine笔记之显卡环境设置使开发流畅1.电源管理2.显卡优先设置3.拯救者支持FnQ性能模式切换,建议开发前切至“野兽模式”或高性能模式。4.NVIDIA 驱动设置5.VS2022中…...
)
suna工具调用可视化界面实现原理分析(一)
这是一个基于React构建的工具调用侧边面板组件,主要用于展示和管理自动化工具调用流程。以下是代码功能解析及关键组件分析: 一、核心功能模块 多工具视图切换系统 • 动态视图加载:通过getToolView函数根据工具名称(如execute-c…...

【将你的IDAPython插件迁移到IDA 9.x:核心API变更与升级指南】
文章目录 将你的 IDAPython 插件迁移到 IDA 9.x:核心 API 变更与升级指南为什么 API 会变化?关键不兼容性一:数据库信息访问 (inf_structure)关键不兼容性二:窗口/视图类型判断 (BWN_* 和 form_type)其他可能的 API 变更迁移策略建…...

《Python星球日记》第31天:Django 框架入门
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 专栏:《Python星球日记》,限时特价订阅中ing 目录 一、Django…...

读《人生道路的选择》有感
读完戴维坎贝尔的《人生道路的选择》,深有感触,虽然只有短短的108也,但作者强调了在复杂的生活环境之中“选择”的重要性。这也是我想要探讨的话题,选择到底会对我们人生产生怎样的影响。 在我们人生当中,确实有许多的…...

opencv+opencv_contrib+cuda和VS2022编译
本文介绍使用OpenCV和OpenCV_Contrib源码及Cuda进行编译的过程,编译过程中会用到OpenCV、OpenCV_Contrib、Toolkit、Cmake、VS2022等工具,最终编译OpenCV的Cuda版本。 一、OpenCV下载地址 OpenCV官网下载地址:https://opencv.org/releases/#࿰…...

STC单片机与淘晶驰串口屏通讯例程之01【新建HDMI工程】
大家好,我是『芯知识学堂』的SingleYork,今天笔者给大家一起学习这款“SYK-0806-A2S1”控制板与淘晶驰串口屏通讯的例程,本例使用的是淘晶驰的4.3寸电阻触摸屏TJC4827T143_011R_I_P20,分辨率为480272,详细参数大家可以查看这个屏的手册。 先来看下本例程整体的效果: 那么…...
)
PE文件结构(导出表)
导出表 什么是导出表? 导出表是PE文件中记录动态链接库(DLL)对外提供的函数或数据的列表,包含函数名称、序号和内存地址等信息,供其他程序调用 我们写一个dll来查看一下导出函数 int exportFunc1(int a, int b) {ret…...

网络安全自动化:精准把握自动化边界,筑牢企业安全防
在当今数字化时代,网络攻击的威胁日益严峻,企业网络安全的重要性不言而喻。随着海量资产与复杂架构的出现,网络安全自动化成为了众多企业关注的焦点。网络安全维护看似简单的修补系统、删除旧账户、更新软件,在大型企业中却极易变…...

实战设计模式之中介者模式
概述 中介者模式是一种强大且灵活的设计模式,适用于需要优化对象间通信的场景。中介者模式通过引入一个中介对象,来封装一系列对象之间的交互。在没有中介者的情况下,这些对象之间可能会直接相互引用,导致系统中的类紧密耦合&…...

价格识别策略思路
该策略是一种基于价格形态和市场条件的交易算法,旨在通过识别特定的价格模式来生成买入和卖出信号。 价格形态识别 策略的核心在于识别价格的高点和低点形态。通过比较当前周期及其前几个周期的最高价和最低价, 策略定义了一系列条件来判断价格是否形成了…...
)
Kotlin带接收者的Lambda介绍和应用(封装DialogFragment)
先来看一个具体应用:假设我们有一个App,App中有一个退出应用的按钮,点击该按钮后并不是立即退出,而是先弹出一个对话框,询问用户是否确定要退出,用户点了确定再退出,点取消则不退出,…...
)
【NLP】32. Transformers (HuggingFace Pipelines 实战)
🤖 Transformers (HuggingFace Pipelines 实战) 本教程基于 Hugging Face 的 transformers 库,展示如何使用预训练模型完成以下任务: 情感分析(Sentiment Analysis)文本生成(Text …...

[ 设计模式 ] | 单例模式
单例模式是什么?哪两种模式? 单例模式就是一个类型的对象,只有一个,比如说搜索引擎中的索引部分,360安全卫士的桌面悬浮球。 饿汉模式和懒汉模式:饿汉模式是线程安全的,懒汉模式不是线程安全的…...

用网页显示工控仪表
一.起因 现在工控也越来越多的使用web页面来显示电压,电流,温度,转速等物理量.本例使用js控制网页显示速度仪表. 二.代码 <html> <head><script type"text/javascript">var ctx;var px0;var movePoint{x0:0,x1:0};function init(){drawFace();m…...

Spring项目改造Solon版,使用体验,对比
概述 对于Solon有些人可能并不了解,在官方概述中,称其是新一代Java企业级应用开发框架,从零开始构建,有自主的标准规范与开放生态。近16万行代码。 并有更快、更小、更简单的特点 什么样的Java项目用Solon好? 按正常…...

2.CFD 计算过程概述:Fluent在散热计算中的优势
1.主流散热软件 2.电子产品热设计的基本要求 3.失效率与温度之间的关系 4.电子产品热设计的基本要求 5.电子产品必须要做散热设计 6.主动散热与被动散热 7.高效山热方案 8.热交换模型 9.Fluent中传热模型...
)
【Java ee初阶】多线程(6)
一、阻塞队列 队列的原则:“先进先出”,队列分为普通队列,优先级队列等等。在数据结构中,堆是特殊的完全二叉树,一定不要把堆和二叉搜索树混淆。 阻塞队列是一种特殊的队列,也遵循“先进先出”的原则。 …...
)
Unity:Surface Effector 2D(表面效应器 2D)
目录 什么是表面效应器 2D? 🎯 它是做什么的? 🧪 从第一性原理解释它是怎么工作的 📦 重要参数解释 为什么不直接用 Rigidbody(刚体)来控制运动 ? 所以什么时候该用哪个&#…...

Spring 框架的底层原理
Spring 框架的底层原理主要包括以下几个方面: 核心容器(IoC 容器) IoC(控制反转)原理 : 依赖注入(DI) :这是 IoC 的实现方式之一。在传统的程序开发中,程序组…...

【Unity】AssetBundle热更新
1.新建两个预制体: Cube1:GameObject Material1:Material Cube1使用了Material1材质 之后设置打包配置 Cube1的打包配置为custom.ab Material1的打包配置为mat.ab 2.在Asset文件夹下创建Editor文件夹,并在Editor下创建BuildBundle…...
:背包dp)
【算法笔记】动态规划基础(二):背包dp
目录 01背包例题状态表示状态计算初始化AC代码 完全背包例题状态表示状态计算初始化TLE代码 多重背包例题状态表示状态计算初始化AC代码 分组背包例题状态表示状态计算初始化AC代码 二维费用背包例题状态表示状态计算初始化AC代码 混合背包问题例题状态表示状态计算初始化TLE代…...