二、机器学习中Python变量基础
二、Python变量基础
像C语言和Matlab一样,变量名由字母、数字、下划线组成(但不能以数字开头,字母区分大小写)变量名不能与内置的函数同名。
根据变量是否可以充当容器,将变量类型分为基本类型和高级类型。
基本变量类型:字符串、数字。布尔型
高级变量类型:集合、元组。列表、字典。
2.1 常见变量类型
七种变量类型
# 字符串(str)
str_v = "a real man"# 数字(int或float)
num_v = 415411#布尔型(bool)
bool_v = True# 集合(set)
set_v = {1,2,3,1}# 元组(tuple)
tuple_v = (1,2,3)#列表(list)
list_v = [1,2,3]# 字典(dict)
dict_v = {'a':1,'b':2,'c':3}Python语言的标准输出方法是:print(变量名)
2.2 常用运算符
数字有两种数据类型,分别是整数(int)和浮点数(float)
常见的数字运算符
| 运算符 | 含义 | 输入 | 输出 |
| +、-、*、/ | 加、减、乘、除 | 1*2+3/4 | 2.75 |
| ** | 幂 | 2**4 | 16 |
| () | 修正运算次序 | 1*(2+3)/4 | 1.25 |
| // | 取整 | 28//5 | 5 |
| % | 取余 | 28%5 | 3 |
2.3 基于基本变量类型生成
对字符串作比较,使用等于号==与不等号!=;
对数字作比较,使用大于>、大于等于>=、等于==、小于<、小于等于<=。
# 字符串——检查某字符串的值
str_v = 'cxk'
print(str_v == 'chicken')
print(str_v != 'chicken') #False
#True
# 数字——检查某数字是否在某范围
num_v = 3
print(num_v > 5)
print(num_v == 5)
print(num_v < 5)#False
#False
#True
2.4 基于高级变量类型生成
# 集合——检查某变量是否在该集合中
set_v = {1, 2, 3}
print(2 in set_v)
print(2 not in set_v)

# 元组——检查某变量是否在该元组中
tuple_v = (1, 2, 3)
print(2 in tuple_v)
print(2 not in tuple_v) 
2.5 同时检查多个条件
and 的规则是,两边全为True则为True,其它情况均为False;
or 的规则是,两边有一个是True则为True,其他情况为False。
2.6 判断语句
bool 值通常作为if判断的条件,if判断的语法规则为
核心语句
if 条件1:# 条件1为 True 时执行的代码
elif 条件2:# 条件1为 False,但条件2为 True 时执行的代码
else:# 所有条件均为 False 时执行的代码"""1.条件表达式必须返回布尔值(True 或 False)"""
# 比较运算(返回布尔值)
age = 18
if age >= 18:print("成年人")# 逻辑运算(返回布尔值)
x = 5
if x > 0 and x < 10:print("x在0到10之间")"""2.缩进定义代码块:Python 通过缩进(通常4个空格)标识代码归属。"""
if True:print("执行代码块1") # 缩进属于ifprint("执行代码块2") # 缩进属于if
print("始终执行") # 无缩进,不属于if"""3.简单判断"""
num = 10
if num > 0:print("正数")
elif num < 0:print("负数")
else:print("零")# 输出: 正数"""4.多条件组合"""
username = "admin"
password = "123456"if username == "admin" and password == "123456":print("登录成功")
else:print("用户名或密码错误")# 输出: 登录成功"""5.嵌套判断"""
score = 85
if score >= 60:if score >= 90:print("优秀")elif score >= 80:print("良好")else:print("及格")
else:print("不及格")# 输出: 良好"""6.检查数据存在性"""
names = ["Alice", "Bob", "Charlie"]
name = "Bob"if name in names:print(f"{name} 在名单中")
else:print(f"{name} 不在名单中")# 输出: Bob 在名单中# 比较运算:==, !=, >, <, >=, <=
print(3 > 5) # False# 逻辑运算:and, or, not
print(not (False or True)) # False# 成员检测:in, not in
print("a" in ["a", "b"]) # True# 对象存在性:空对象(如空列表、空字符串)视为 False,非空视为 True
if []:print("非空") # 不会执行
else:print("空列表") # 输出: 空列表输出结果

2.7 基本变量间的转换
字符串、整数、浮点数、布尔型四者之间可以无缝切换。
转换为字符串使用str函数;
转换为整数型数字使用int函数;
转换为浮点型数字使用float函数;
转换为布尔型使用bool函数。
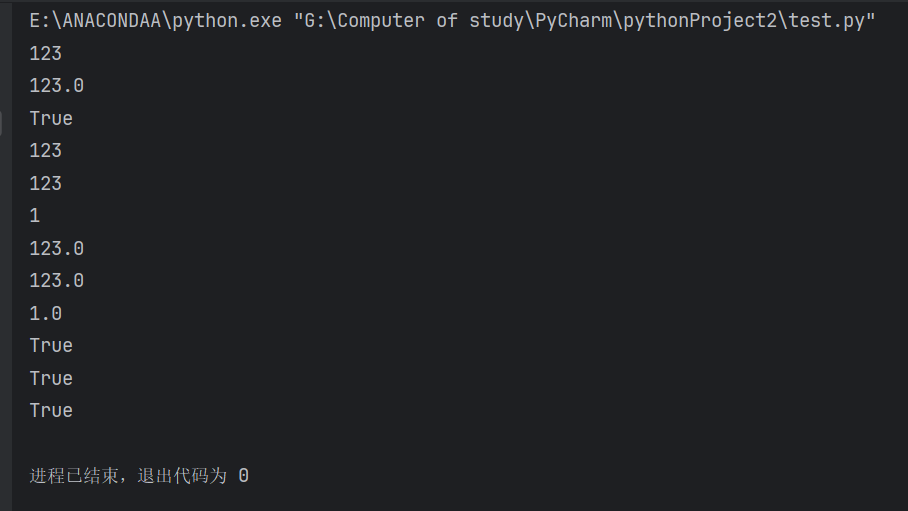
# 定义变量
str_v = '123'
int_v = 123
float_v = 123.0
bool_v = True
# 转化为字符串
print(str(int_v))
print(str(float_v))
print(str(bool_v))# 转化为整数型变量
print(int(str_v))
print(int(float_v))
print(int(bool_v))# 转化为浮点型变量
print(float(str_v))
print(float(float_v))
print(float(bool_v))# 转化为布尔型变量
print(bool(str_v))
print(bool(int_v))
print(bool(float_v))
2.8 高级变量类型(集合、元组、列表和字典)
高级变量类型,主要是集合、元组、列表和字典,它们具有随意容纳任意变量特点
(1)集合
集合是无序的、不可重复的元素的组合。集合内元素存储没有顺序,不支持索引访问,元素不可重复,自动去重;可动态增删元素(但元素本身必须是不可变类型,如数字、字符串、元组)。
集合运算:支持并集(|)、交集(&)、差集(-)等数学运算。
创建方式:使用大括号 {1, 2, 3} 或 set() 函数(空集合必须用 set())
# 元组拆分法——只要前两个答案
values = 98, 99, 94, 94, 90, 92
a, b, *rest = values
print(a,b,rest)
"""(1)数据去重(唯一性)集合自动去除重复元素,适用于快速清理重复数据。"""
# 从列表去重
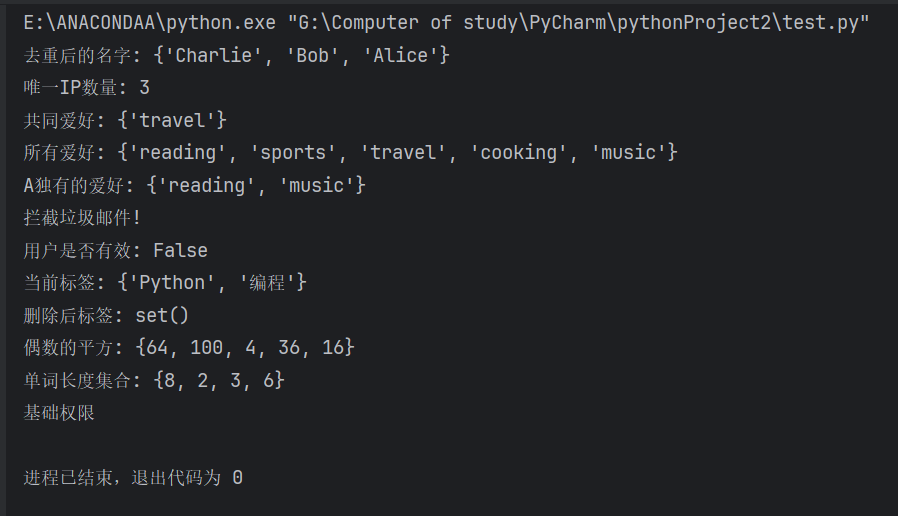
names = ["Alice", "Bob", "Alice", "Charlie", "Bob"]
unique_names = set(names)
print("去重后的名字:", unique_names) # 输出: {'Alice', 'Bob', 'Charlie'}# 统计唯一IP访问量
ip_list = ["192.168.1.1", "10.0.0.1", "192.168.1.1", "10.0.0.2"]
unique_ips = set(ip_list)
print("唯一IP数量:", len(unique_ips)) # 输出: 3"""(2)集合运算(并集、交集、差集)集合支持数学运算,适合处理分组数据的关系分析。"""# 定义两组用户的爱好
hobbies_a = {"reading", "music", "travel"}
hobbies_b = {"travel", "sports", "cooking"}# 共同爱好(交集)
common_hobbies = hobbies_a & hobbies_b
print("共同爱好:", common_hobbies) # 输出: {'travel'}# 所有爱好(并集)
all_hobbies = hobbies_a | hobbies_b
print("所有爱好:", all_hobbies) # 输出: {'reading', 'music', 'travel', 'sports', 'cooking'}# A有但B没有的爱好(差集)
unique_to_a = hobbies_a - hobbies_b
print("A独有的爱好:", unique_to_a) # 输出: {'reading', 'music'}"""(3)成员快速检测(高效查找)集合的成员检测时间复杂度为 O(1),适合高频查询。"""# 黑名单过滤(快速判断是否在集合中)
blacklist = {"spam@example.com", "phishing@bad.com", "malware@virus.org"}
email = "spam@example.com"if email in blacklist:print("拦截垃圾邮件!") # 输出: 拦截垃圾邮件!
else:print("允许通过")# 白名单验证
valid_users = {"admin", "user1", "guest"}
username = "hacker"
print("用户是否有效:", username in valid_users) # 输出: False"""(4)动态增删元素(可变性)
集合支持动态添加或删除元素,但元素本身必须是不可变类型。"""# 初始化一个空集合
tags = set()# 添加标签
tags.add("Python")
tags.add("编程")
tags.add("Python") # 重复添加会被忽略
print("当前标签:", tags) # 输出: {'Python', '编程'}# 删除标签
tags.discard("编程") # 安全删除(元素不存在时不报错)
tags.remove("Python") # 强制删除(元素不存在时报错)
print("删除后标签:", tags) # 输出: set()"""(5)集合推导式(Set Comprehension)
类似列表推导式,生成集合时自动去重。"""
# 生成1~10中偶数的平方的集合
squares = {x**2 for x in range(1, 11) if x % 2 == 0}
print("偶数的平方:", squares) # 输出: {64, 4, 36, 16, 100}# 统计句子中不同单词的长度
sentence = "Python is simple but powerful"
word_lengths = {len(word) for word in sentence.split()}
print("单词长度集合:", word_lengths) # 输出: {2, 4, 6, 8}"""(6)不可变集合(frozenset)
使用 frozenset 创建不可变集合,可作为字典的键。"""
# 创建不可变集合
allowed_operations = frozenset(["read", "execute"])# 作为字典的键
permissions = {allowed_operations: "基础权限",frozenset(["read", "write", "execute"]): "高级权限"
}print(permissions[allowed_operations]) # 输出: 基础权限输出结果
常应用于数据去重、成员快速检测、数字集合运算等。
(2)元组
元组具有有序性和不可变型。元组内插入顺序存储,可通过索引(如 t[0])访问;一旦创建,元素不可修改、增删。元组可以包含任意元素类型(如混合数字、字符串、列表等)。若元素均为不可变类型,元组可作为字典的键。
创建方式:
使用圆括号 (1, 'a') 或 tuple() 函数。
应用场景:存储不可变数据(如配置项)、作为字典的键、保证数据不被修改。
案例 1:存储不可变数据(如坐标、配置项)
元组常用于存储不可修改的固定数据,例如坐标点、配置参数等。
# 定义坐标点 (x, y)
point = (3, 5)
print(f"坐标点: {point}") # 输出: (3, 5)# 定义应用配置项 (host, port, debug_mode)
config = ("localhost", 8080, False)
print(f"服务器配置: {config}") # 输出: ('localhost', 8080, False)# 尝试修改元组(会报错)
try:point[0] = 10 # 触发 TypeError
except TypeError as e:print(f"错误: {e}") # 输出: 'tuple' object does not support item assignment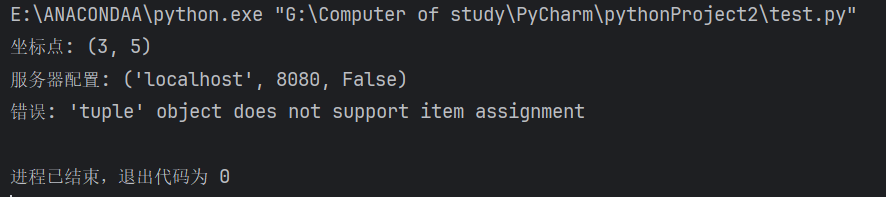
案例 2:作为字典的键(键必须不可变)
元组可以作为字典的键(而列表不行),因为它不可变。
# 定义坐标到颜色的映射
color_map = {(255, 0, 0): "红色",(0, 255, 0): "绿色",(0, 0, 255): "蓝色"
}# 查询颜色
rgb = (255, 0, 0)
print(f"{rgb} 对应的颜色是: {color_map[rgb]}") # 输出: 红色# 尝试用列表作为键(会报错)
try:bad_key = [1, 2, 3]color_map[bad_key] = "黑色"
except TypeError as e:print(f"错误: {e}") # 输出: unhashable type: 'list'输出结果

案例 3:函数返回多个值
元组常用于函数返回多个值,避免使用临时对象。
def calculate_stats(numbers):"""返回总和和平均值"""total = sum(numbers)average = total / len(numbers)return (total, average) # 返回元组# 调用函数并解包结果
data = [10, 20, 30, 40]
sum_result, avg_result = calculate_stats(data)
print(f"总和: {sum_result}, 平均值: {avg_result}") # 输出: 总和: 100, 平均值: 25.0
案例 4:保护数据不被修改
当需要传递数据并防止被意外修改时,使用元组替代列表。
# 敏感数据(如权限列表)
read_only_permissions = ("read", "execute") # 使用元组确保不可变def check_permission(permission):if permission in read_only_permissions:print(f"权限 {permission} 有效")else:print(f"权限 {permission} 无效")check_permission("write") # 输出: 权限 write 无效
check_permission("read") # 输出: 权限 read 有效输出结果

案例 5:结合解包操作
元组支持解包(Unpacking),简化代码逻辑。
# 元组解包
dimensions = (1920, 1080)
width, height = dimensions
print(f"分辨率: {width}x{height}") # 输出: 分辨率: 1920x1080# 交换变量值
a, b = 5, 10
a, b = b, a # 通过元组解包交换
print(f"交换后: a={a}, b={b}") # 输出: 交换后: a=10, b=5

案例 6:命名元组(增强可读性)
使用 collections.namedtuple 创建带字段名的元组(类似轻量级类)。
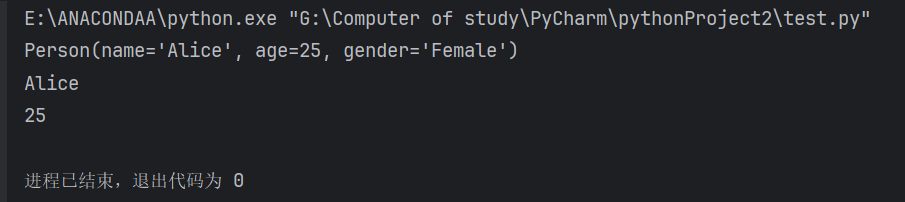
from collections import namedtuple# 定义命名元组类型 "Person"
Person = namedtuple("Person", ["name", "age", "gender"])# 创建实例
alice = Person("Alice", 25, "Female")
print(alice) # 输出: Person(name='Alice', age=25, gender='Female')
print(alice.name) # 输出: Alice
print(alice[1]) # 输出: 25(仍支持索引访问)输出结果
(3)列表
列表具有有序性和可变性,元素按插入顺序存储,支持索引和切片操作。可动态增删改元素(如append()、pop() 等方法),还提供排序sort()、反转 reverse() 等。
元素类型支持任意类型元素,包括嵌套列表
创建方式:
使用方括号 [1, 2, 3] 或 list() 函数。
应用场景:需要频繁修改的动态数据集合(如日志记录、数据批量处理)。
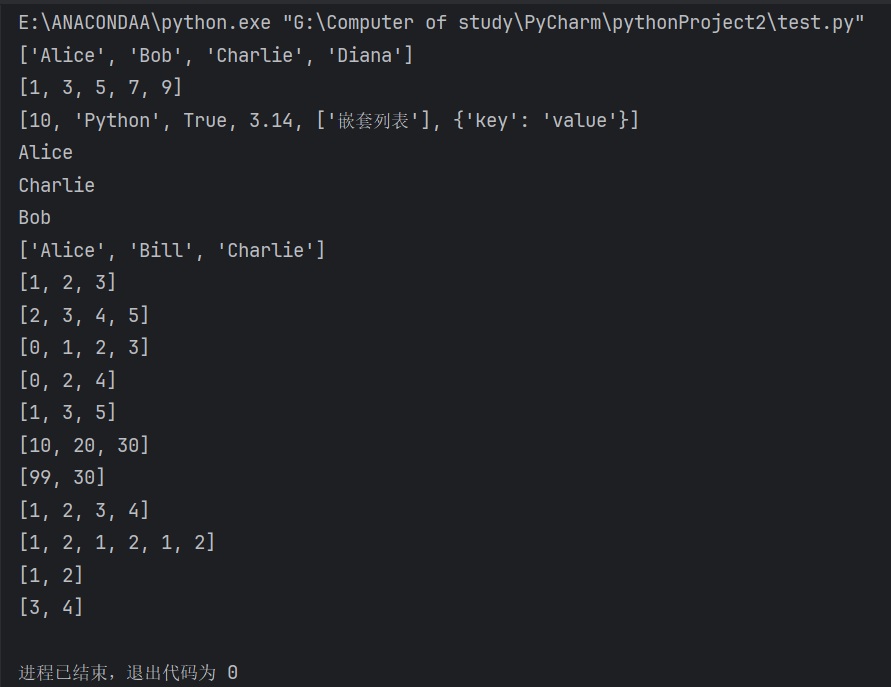
"""(1)创建列表"""
# a. 全是字符串的列表
names = ["Alice", "Bob", "Charlie", "Diana"]
print(names) # 输出: ['Alice', 'Bob', 'Charlie', 'Diana']# b. 全是数字的列表
numbers = [1, 3, 5, 7, 9]
print(numbers) # 输出: [1, 3, 5, 7, 9]# c. 混合类型的“释放自我”列表,允许包含任意数据类型(甚至嵌套列表、字典等):
mixed = [10, "Python", True, 3.14, ["嵌套列表"], {"key": "value"}]
print(mixed) # 输出: [10, 'Python', True, 3.14, ['嵌套列表'], {'key': 'value'}]"""(2)访问与修改元素"""
# a. 访问元素(索引从 0 开始)
names = ["Alice", "Bob", "Charlie"]
print(names[0]) # 输出第一个元素: Alice
print(names[-1]) # 输出倒数第一个元素: Charlie
print(names[-2]) # 输出倒数第二个元素: Bob# b. 修改元素
names[1] = "Bill" # 修改索引1的元素
print(names) # 输出: ['Alice', 'Bill', 'Charlie']"""(3)切片——访问部分元素"""
# 切片语法:list[start:end:step](含头不含尾,step 为步长)
# 切片后生成新列表,与原列表独立。
# a. 从第 x 个元素切到第 y 个元素
numbers = [0, 1, 2, 3, 4, 5]
subset = numbers[1:4] # 索引1到3(元素1, 2, 3)
print(subset) # 输出: [1, 2, 3]# b. 切除开头或结尾
# 切除前2个元素
print(numbers[2:]) # 输出: [2, 3, 4, 5]# 切除后2个元素
print(numbers[:-2]) # 输出: [0, 1, 2, 3]# c. 每隔 n 个元素采样一次
# 每隔2个元素取一次(步长=2)
print(numbers[::2]) # 输出: [0, 2, 4]# 从索引1开始,每隔1个取到末尾
print(numbers[1::2]) # 输出: [1, 3, 5]# d. 切片与原列表独立
original = [10, 20, 30]
sliced = original[1:] # 切片得到新列表 [20, 30]
sliced[0] = 99print(original) # 原列表不变: [10, 20, 30]
print(sliced) # 切片后的列表: [99, 30]"""(4)列表元素的添加(+ 和 * 操作)"""
# a. + 合并列表(生成新列表)
list1 = [1, 2]
list2 = [3, 4]
combined = list1 + list2
print(combined) # 输出: [1, 2, 3, 4]# b. * 重复列表元素(生成新列表)
repeated = list1 * 3
print(repeated) # 输出: [1, 2, 1, 2, 1, 2]# c. 注意:+ 和 * 不修改原列表
print(list1) # 原列表不变: [1, 2]
print(list2) # 原列表不变: [3, 4]
输出结果
(4)字典
字典具有键值对结构、无序性、高效查找和可变性
存储 {键: 值} 对,键唯一且必须为不可变类型(如字符串、数字、元组),值可为任意类型。Python 3.7+ 后按插入顺序保存,但设计上仍视为“无序”。基于哈希表实现,键的查找速度极快(时间复杂度接近 O(1))。可动态增删改键值对。
创建方式:
使用大括号 {'name': 'Alice', 'age': 25} 或 dict() 函数。
"""以下是关于 Python字典(Dict) 的案例详解,涵盖创建、修改、添加和删除操作"""
"""(1)创建字典
a. 字典与列表的对比,字典可以理解为“升级版的列表”——列表的索引是固定数字(0,1,2...),
而字典的索引(键)可以自定义为字符串、数字等不可变类型,且键值对结构更灵活。"""
"""b. 创建与列表等效的特殊字典
用数字作为键模拟列表索引:"""
# 列表方式
list_data = ["数学", "物理", "化学"]# 字典方式(等效)
dict_data = {0: "数学", 1: "物理", 2: "化学"}print(dict_data[1]) # 输出: 物理(等效于 list_data[1])"""c. 常规字典(键为字符串)
以学科名称为键,学科实力为值:"""
# 键为学科名称(字符串),值为学科实力(任意类型)
subjects = {"数学": 95, # 值可以是数字"物理": "A+", # 值可以是字符串"化学": ["实验强", "理论弱"], # 值可以是列表"计算机": {"排名": 1, "实验室": "国家级"} # 值可以是字典
}print(subjects["化学"]) # 输出: ['实验强', '理论弱']"""(2)字典元素的修改、添加与删除
以学科名称为键,学科实力为值,演示动态操作:a. 修改元素
直接通过键修改对应的值:"""
# 修改数学的学科实力
subjects["数学"] = 98
print(subjects["数学"]) # 输出: 98"""b. 添加新元素
通过新键赋值即可添加新键值对:"""
# 添加新学科 "生物"
subjects["生物"] = "B+"
print(subjects["生物"]) # 输出: B+"""c. 删除元素
使用 del 或 pop() 删除键值对:"""
# 删除 "化学" 学科
del subjects["化学"]
print(subjects) # 输出中不再包含 "化学"# 使用 pop() 删除并返回被删值
physics_rank = subjects.pop("物理")
print(physics_rank) # 输出: A+
print(subjects) # 输出中不再包含 "物理"

应用场景
存储关联数据(如JSON结构)、快速键值查询、配置映射。
| 特性 | 集合(Set) | 元组(Tuple) | 列表(List) | 字典(Dict) |
| 有序性 | 无序 | 有序 | 有序 | 无序(Python3.7+ 按插入顺序) |
| 可变性 | 可变(元素不可变) | 不可变 | 可变 | 可变 |
| 元素唯一性 | 唯一 | 允许重复 | 允许重复 | 键唯一,值可重复 |
| 元素类型 | 不可变元素 | 任意类型 | 任意类型 | 键不可变,值任意 |
| 典型操作 | 集合运算 | 索引访问 | 增删改、切片 | 键值查询与更新 |
| 内存效率 | 较高(去重优化) | 较高(不可变) | 较低(动态扩展) | 中等(哈希表开销) |
# ------------------------------
# 功能:管理学生信息、课程和成绩
# 使用四种数据结构:
# - 列表(动态操作学生信息)
# - 元组(存储不可变课程信息)
# - 集合(去重选修课程)
# - 字典(存储学生成绩,快速查询)
# ------------------------------# 1. 元组(Tuple): 存储固定课程信息(课程名, 学分)
courses = (("Math", 4),("Python", 3),("Physics", 4),("Chemistry", 3)
)# 2. 列表(List): 动态管理学生姓名(可增删改)
students = ["Alice", "Bob", "Charlie"]# 3. 集合(Set): 存储学生选修的课程(自动去重)
selected_courses = {"Math", "Python", "Physics"}# 4. 字典(Dict): 存储学生成绩 {学生: {课程: 分数}}
scores = {"Alice": {"Math": 90, "Python": 85},"Bob": {"Math": 78, "Physics": 92},"Charlie": {"Python": 88, "Chemistry": 76}
}# ------------------------------
# 功能函数实现
# ------------------------------def add_student(name: str):"""添加学生(列表的增操作)"""students.append(name)print(f"添加学生: {name}")def remove_course(course: str):"""删除选修课程(集合的删操作)"""if course in selected_courses:selected_courses.remove(course)print(f"移除课程: {course}")else:print(f"课程 {course} 不存在")def update_score(student: str, course: str, score: int):"""更新成绩(字典的改操作)"""if student in scores and course in scores[student]:scores[student][course] = scoreprint(f"更新 {student} 的 {course} 成绩为 {score}")else:print("学生或课程不存在")def check_course_credit(course_name: str):"""通过课程名查询学分(元组的查操作)"""for course in courses:if course[0] == course_name:return course[1]return None# ------------------------------
# 演示操作
# ------------------------------if __name__ == "__main__":# 初始状态print("\n----- 初始数据 -----")print("学生名单:", students)print("选修课程:", selected_courses)print("Alice的成绩:", scores["Alice"])# 动态操作数据add_student("David") # 列表追加remove_course("Physics") # 集合删除update_score("Bob", "Math", 85) # 字典修改# 查询操作credit = check_course_credit("Python")print(f"\nPython课程的学分: {credit}")# 最终状态print("\n----- 更新后数据 -----")print("学生名单:", students)print("选修课程:", selected_courses)print("Bob的成绩:", scores["Bob"])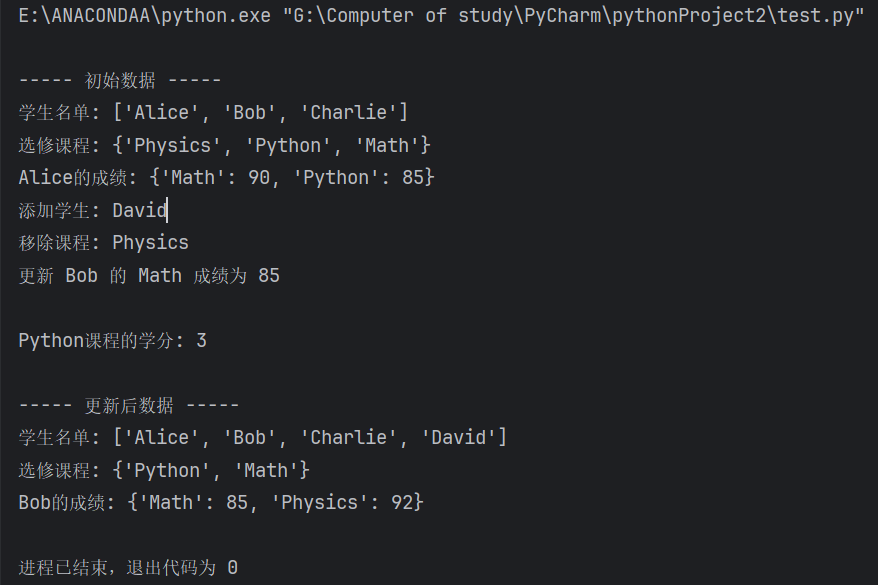
相关文章:

二、机器学习中Python变量基础
二、Python变量基础 像C语言和Matlab一样,变量名由字母、数字、下划线组成(但不能以数字开头,字母区分大小写)变量名不能与内置的函数同名。 根据变量是否可以充当容器,将变量类型分为基本类型和高级类型。 基本变量…...

有机玻璃材质数据采集活性炭吸附气体中二氧化硫实验装置
JGQ112Ⅱ有机玻璃材质数据采集活性炭吸附气体中二氧化硫实验装置 一.实验目的 1.熟悉活性炭吸附剂的特性和在SO2气体净化方面的应用。 2.掌握活性炭吸附法的流程和实验过程中各参数的控制方法。 3.了解主要参数变化对吸附效率的影响。 4.掌握吸附等温线概念和测定方法。 二.技术…...

Javase 基础入门 —— 07 接口
本系列为笔者学习Javase的课堂笔记,视频资源为B站黑马程序员出品的《黑马程序员JavaAI智能辅助编程全套视频教程,java零基础入门到大牛一套通关》,章节分布参考视频教程,为同样学习Javase系列课程的同学们提供参考。 01 概述 接…...

LangChain:重构大语言模型应用开发的范式革命
2022年10月22日,Harrison Chase在GitHub上提交了名为LangChain的开源项目的第一个代码版本。这个看似普通的代码提交,却悄然开启了一场重塑大语言模型(LLM)应用开发范式的技术革命。彼时,距离ChatGPT引爆全球人工智能浪…...

【现代深度学习技术】现代循环神经网络04:双向循环神经网络
【作者主页】Francek Chen 【专栏介绍】 ⌈ ⌈ ⌈PyTorch深度学习 ⌋ ⌋ ⌋ 深度学习 (DL, Deep Learning) 特指基于深层神经网络模型和方法的机器学习。它是在统计机器学习、人工神经网络等算法模型基础上,结合当代大数据和大算力的发展而发展出来的。深度学习最重…...

重塑数学边界:人工智能如何引领数学研究的新纪元
目录 一、人工智能如何重新定义数学研究的边界 (一)数学与AI的关系:从基础理论到创新思维的回馈 (二)AI的创造力:突破传统推理的局限 (三)AI对数学研究的潜在贡献:创…...

链表的回文结构题解
首先阅读题目: 1.要保证是回文结构 2.他的时间复杂度为O(n)、空间复杂度为O(1) 给出思路: 1.首先利用一个函数找到中间节点 2.利用一个函数逆置中间节点往后的所有节点 3.现在有两个链表,第一个链表取头节点一直到中间节点、第二个链表取头结点到尾…...

xLua笔记
Generate Code干了什么 肉眼可见的,在Asset文件夹生成了XLua/Gen文件夹,里面有一些脚本。然后对加了[CSharpCallLua]的变量寻找引用,发现它被XLua/Gen/DelegatesGensBridge引用了。也可以在这里查哪些类型加了[CSharpCallLua]。 public over…...

【Hive入门】Hive与Spark SQL深度集成:通过Spark ThriftServer高效查询Hive表
目录 引言 1 Spark ThriftServer架构解析 1.1 核心组件与工作原理 1.2 与传统HiveServer2的对比 2 Spark ThriftServer部署指南 2.1 环境准备与启动流程 2.1.1 前置条件检查 2.1.2 服务启动流程 2.2 高可用部署方案 2.2.1 基于ZooKeeper的HA架构 3 性能优化实战 3.…...

快速掌握--cursor
Cursor - The AI Code Editor 官网下载安装 详细教程:cursor 下载安装使用(保姆教程)_cursor下载-CSDN博客 不知道为啥,第一次给我用的是繁体回答 然后改了一下询问方式 codebase就是告诉ai可以从整个项目中找答案࿰…...
)
Linux之基础开发工具(yum,vim,gcc,g++)
目录 一、软件包管理器 1.1、什么是软件包 1.2、yum具体操作 1.2.1、查看软件包 1.2.2、安装软件 1.2.3、卸载软件 1.2.4、安装源 二、编辑器vim 2.1、vim的基本概念 2.2、vim的基本操作 2.3、vim正常模式命令集 2.4、vim末行模式命令集 2.5、替换模式 2.6、视图…...

【计算机视觉】三维重建: OpenMVS:工业级多视图立体视觉重建框架
深度解析OpenMVS:工业级多视图立体视觉重建框架 技术架构与核心算法1. 系统架构设计2. 核心算法解析稠密点云重建表面重建网格优化 实战全流程指南环境配置硬件要求编译安装(Ubuntu) 数据处理流程输入准备(OpenMVG输出)…...

C++负载均衡远程调用学习之异步消息任务功能与连接属性
目录 1.LarV0.11-异步消息机制的event_loop增添属性分析 2.LARS 3.LarV0.11异步消息发送机制的实现及测试 4.LarV0.11异步消息任务机制bug修复和效果演示 5.LarV0.12链接参数属性的绑定 1.LarV0.11-异步消息机制的event_loop增添属性分析 ## 4) 事件触发event_loop …...

内存性能测试方法
写于 2022 年 6 月 24 日 内存性能测试方法 - Wesley’s Blog dd方法测试 cat proc/meminfo console:/ # cat proc/meminfo MemTotal: 3858576 kB MemFree: 675328 kB MemAvailable: 1142452 kB Buffers: 65280 kB Cached: 992252 …...

游戏引擎学习第256天:XBox 控制器卡顿和修复 GL Blit 伽玛问题
回顾并为今天定下基调 今天的主要任务是让我们的性能分析工具正常工作,因为昨天已经完成了结构性工作。现在,剩下的工作大部分应该是调试和美化。性能分析工具现在应该已经基本可用了。昨天我们在这个方面取得了很大的进展。 接下来,我们将…...

4.29-4.30 Maven+单元测试
单元测试: BeforeAll在所有的单元测试方法运行之前,运行一次。 AfterAll在所有单元测试方法运行之后,运行一次。 BeforeEach在每个单元测试方法运行之前,都会运行一次 AfterEach在每个单元测试方法运行之后,都会运行…...

Android 端如何监控 ANR、Crash、OOM 等严重问题
在移动互联网时代,Android 应用已经成为我们生活中不可或缺的一部分。从社交聊天到在线购物,从娱乐消遣到办公学习,几乎每个人的手机里都装满了各式各样的应用。然而,作为开发者,咱们得面对一个残酷的现实:…...

Spring Boot 微服务打包为 Docker 镜像并部署到镜像仓库实战案例
案例项目素材可以拉取我github上的: https://github.com/AcademicTECHNERD/SpringCoudEurekaDemo 下面的案例将把我的product-service(也就是提供者)打包为镜像 执行maven命令: mvn clean package -DskipTests在根目录加一个dock…...

springAop代理责任链模式源码解析
目录 两次匹配 Bean 后置处理器中的匹配 方法调用时的匹配 Bean后置处理器中Advisor匹配流程 方法调用时的匹配 Jdk cglib 小小总结 Advisor 收集与排序 责任链执行过程 两次匹配 Bean 后置处理器中的匹配 在 Bean 初始化过程中,Spring 会通过 Bean 后置…...
:Object、Nested、Flattened类型)
ElasticSearch深入解析(九):Object、Nested、Flattened类型
文章目录 一、Object 类型:默认的嵌套对象处理方式核心原理典型场景关键限制 二、Nested 类型:解决嵌套数组的关联查询核心原理典型场景使用示例注意事项 三、Join 类型:跨文档的父子关联核心原理典型场景使用示例注意事项 四、Flattened 类型…...

list的迭代器详讲
1.list的迭代器就是封装了节点指针的类 2.迭代器失效 迭代器失效即迭代器封装的节点指针无效 。因为 list 的底层结构为带头结点的双向循环链表 ,因此 在 list 中进行插入时是不会导致 list 的迭代 器失效的,只有在删除时才会失效,并且失效的…...

动态规划之多状态问题1
题目解析: 也就是给一个预约数组,选择一些数字,让其总和最大,但不能选择相邻的两个数字 算法原理: 依旧可以根据经验题目 以dp[i]位置结尾时,巴拉巴拉 根据题目要求补充完整,dp[i]ÿ…...

音视频开源项目列表
音视频开源项目列表 一、多媒体处理框架 通用音视频处理 FFmpeg - https://github.com/FFmpeg/FFmpeg 最强大的音视频处理工具库支持几乎所有格式的编解码提供命令行工具和开发库 GStreamer - https://gitlab.freedesktop.org/gstreamer/gstreamer 跨平台多媒体框架基于管道…...

论微服务架构及其应用
试题四 论微服务架构及其应用 微服务提倡将单一应用程序划分成一组小的服务,服务之间互相协调、互相配合,为用户提供最终价值。每个服务运行在其独立的进程中,服务与服务间采用轻量级的通信机制互相沟通。在微服务架构中,每个服务…...

Spring Cloud与Service Mesh集成:Istio服务网格实践
文章目录 引言一、Spring Cloud与Service Mesh概述二、Istio服务网格架构三、Spring Cloud与Istio集成的基础设施准备四、服务发现与负载均衡五、流量管理与弹性模式六、安全通信与认证授权七、可观测性集成八、配置管理集成总结 引言 微服务架构已成为现代分布式系统的主流设…...

Day109 | 灵神 | 148.排序链表 | 归并排序
Day109 | 灵神 | 148.排序链表 | 归并排序 148. 排序链表 - 力扣(LeetCode) 以下是灵神的题解,笔者认为这题只要可以看懂就好了 两种方法:分治和迭代 文章目录 Day109 | 灵神 | 148.排序链表 | 归并排序前置题目方法一&#x…...

[更新完毕]2025东三省C题深圳杯C题数学建模挑战赛数模思路代码文章教学: 分布式能源接入配电网的风险分析
完整内容请看文章最下面的推广群 分布式能源接入配电网的风险分析 摘要 随着可再生能源渗透率的不断提升,分布式光伏发电在配电网中的大规模接入给传统电力系统运行带来了新的挑战。光伏发电固有的间歇性和波动性特征,加之配电网拓扑结构的复杂性&…...
)
ActiveMQ 集群搭建与高可用方案设计(二)
五、高可用方案设计与优化 (一)Zookeeper 在 ActiveMQ 集群中的应用 作用:在 ActiveMQ 集群中,Zookeeper 扮演着至关重要的角色。它主要用于选举 Master 节点,通过其内部的选举机制,从众多的 ActiveMQ Br…...
多协议 Tracker 系统架构与传感融合实战 第六章 多传感器时钟同步与数据对齐
第六章 多传感器时钟同步与数据对齐 摘要 本章围绕多源传感融合系统中——尤其是 IMU 与 UWB——的时钟同步与数据对齐问题展开,系统介绍: 硬件时钟源类型及漂移特性 软件校准策略:NTP/PTP 与自定义心跳同步 多源时钟同步算法:两阶段对齐与漂移补偿 数据缓冲与双队列对齐架…...

【算法基础】插入排序算法 - JAVA
一、算法基础 1.1 什么是插入排序 插入排序是一种简单直观的排序算法,它的工作原理类似于我们打牌时整理手牌的过程。插入排序的核心思想是将数组分为已排序和未排序两部分,每次从未排序部分取出一个元素,插入到已排序部分的适当位置。 1.…...

#Paper Reading# DeepSeek-R1
论文题目: DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning 论文地址: https://arxiv.org/pdf/2501.12948 论文发表于: arXiv 2025年1月 论文所属单位: DeepSeek 论文大体内容 本文提出DeepSeek-R1模型,主要是以DeepSeek-V3[…...

HTML与CSS实现风车旋转图形的代码技术详解
在前端开发中,HTML和CSS是构建网页的基础技术。通过巧妙运用HTML的结构搭建和CSS的样式控制,我们能够实现各种精美的视觉效果。本文将对一段实现旋转图形效果的HTML和CSS代码进行详细解读,剖析其中的技术要点。 一、运行效果 HTML与CSS实现风…...

AWS在跨境电商中的全场景实践与未来生态构建
AWS在跨境电商中的全场景实践与未来生态构建 一、核心应用场景与技术赋能 1. AI驱动运营效率革命 • 智能选品与市场分析:通过Amazon SageMaker机器学习平台,跨境电商企业可构建精准选品模型。陕西自贸试验区案例显示,AI对亚马逊等平台销…...

AWS云服务深度技术解析:架构设计与最佳实践
作为全球市场份额占比32%的云服务提供商(Synergy Research 2023数据),AWS的技术体系已成为企业级应用架构的标杆。本文将深入剖析AWS核心技术组件的实现原理,并附可落地的架构设计范式。 AWS云服务器:中国企业出海的“…...

130. 被围绕的区域
题目链接:130. 被围绕的区域 思路:使用两遍dfs,第一遍找到可以被替换区域的可进入点并记录,第二遍就从所有的可进入点入手遍历区域内所有点并替换。 这是我的思路,感觉还是挺新颖的(应该很少有人这样想我…...

【Linux】进程优先级与进程切换理解
🌟🌟作者主页:ephemerals__ 🌟🌟所属专栏:Linux 目录 前言 一、进程优先级 1. 什么是进程优先级 2. 为什么有进程优先级 3. 进程优先级的作用 4. Linux进程优先级的本质 5. 修改进程优先级 二、进…...

数据分析与可视化实战:从鸢尾花到乳腺癌数据集
数据分析是现代数据科学中不可或缺的一部分,它帮助我们理解数据、发现模式并做出明智的决策。本文将分享两个实战案例:鸢尾花数据集分析和乳腺癌数据集预处理,展示如何使用Python进行数据探索和可视化。 鸢尾花数据集分析 数据加载与基本统…...

怎样提升社交机器人闲聊能力
怎样提升社交机器人闲聊能力 本文聚焦社交机器人闲聊能力,指出闲聊在社交中意义重大,当前大语言模型(LLMs)驱动社交机器人闲聊存在不足。通过实验评估ChatGPT-3.5、Gemini Pro和LLaMA-2等LLMs闲聊表现,发现其与人类闲聊存在差异。 为此提出基于观察者模型的反馈重定向方…...

图论之幻想迷宫
题目描述: 幻象迷宫可以认为是无限大的,不过它由若干个 NM 的矩阵重复组成。矩阵中有的地方是道路,用 . 表示;有的地方是墙,用 # 表示。LHX 和 WD 所在的位置用 S 表示。也就是对于迷宫中的一个点(x,y),如…...

数学实验Matlab
一、Matlab语言环境和线性代数实验 1.Matlab语言环境 Matlab简介 Matlab:Matrix Laboratry 矩阵实验室 Matlab 提供了强大的科学计算、灵活的程序设计流程、高质量的图形可视化与界面设计等功能,被广泛应用于科学计算、控制系统、信息处理等领域的分…...

AI日报 · 2025年5月03日|Perplexity 集成 WhatsApp,苹果传与 Anthropic 合作开发 Xcode
1、Perplexity AI 功能更新:新增 WhatsApp 集成与多项优化 Perplexity 于 5 月 2 日发布其每周更新摘要,重点包括新增 WhatsApp 集成,用户现可直接在 WhatsApp 内与 Perplexity AI 交互,显著提升了信息获取的便捷性 [1]。此次更新…...

Maven 实现多模块项目依赖管理
🧑 博主简介:CSDN博客专家,历代文学网(PC端可以访问:https://literature.sinhy.com/#/?__c1000,移动端可微信小程序搜索“历代文学”)总架构师,15年工作经验,精通Java编…...

【JavaScript-Day 2】开启 JS 之旅:从浏览器控制台到 `<script>` 标签的 Hello World 实践
Langchain系列文章目录 01-玩转LangChain:从模型调用到Prompt模板与输出解析的完整指南 02-玩转 LangChain Memory 模块:四种记忆类型详解及应用场景全覆盖 03-全面掌握 LangChain:从核心链条构建到动态任务分配的实战指南 04-玩转 LangChai…...

Windows 中使用dockers创建指定java web 为镜像和运行容器
以下是在 Windows 中使用 Docker 创建 Java Web 应用镜像并运行容器的分步指南: 步骤 1:安装 Docker 下载并安装 Docker Desktop for Windows启动 Docker Desktop,确保使用 WSL 2 后端(推荐)或 Hyper-V。 步骤 2&…...

机器人--MCU
MCU MCU(Microcontroller Unit,微控制器) 是机器人的“神经末梢”,负责 实时控制、传感器接口、低层通信 等关键任务。 作用 MCU的核心作用 功能具体任务示例实时控制电机PWM生成、PID调节、紧急制动机械臂关节控制、无人机电调…...
)
从融智学视域快速回顾世界历史和主要语言文字最初历史证据(列表对照分析比较)
融智学视域下世界历史与语言文字起源对照分析表 以下从融智学五个基本范畴(物、意、文、道、理义法),梳理主要古代文明的文字起源,及其历史证据,并进行跨文明比较: 文明/文字 物(载体…...
:缓存策略与离线优化)
JavaScript性能优化实战(8):缓存策略与离线优化
前言 在Web应用中,性能优化不仅仅是关于代码执行速度,还与资源获取和数据持久化密切相关。合理的缓存策略可以显著减少网络请求,提升应用响应速度,同时有效降低服务器负载和用户流量消耗。离线优化则进一步解决了网络不稳定或断网场景下的用户体验问题,为Web应用提供类似…...

quantization-大模型权重量化简介
原文地址 https://towardsdatascience.com/introduction-to-weight-quantization-2494701b9c0c/ https://towardsdatascience.com/4-bit-quantization-with-gptq-36b0f4f02c34/ 权重量化简介 大型语言模型(LLM) 以其庞大的计算需求而闻名。通常,模型的大小是通过将参…...

unity ScriptObject的使用
1.先定义一个类数据类型 [Serializable] public class FoodItemData { public int foodID; // 食物唯一ID public string foodName; // 食物名称 [TextArea(3, 10)] // 多行文本输入 public string description; // 食物描述 pu…...

广义线性模型三剑客:线性回归、逻辑回归与Softmax分类的统一视角
文章目录 广义线性模型三剑客:线性回归、逻辑回归与Softmax分类的统一视角引言:机器学习中的"家族相似性"广义线性模型(GLMs)基础三位家族成员的统一视角1. 线性回归(Linear Regression)2. 逻辑回归(Logistic Regression)3. Softmax分类(Softm…...