C++--入门基础
C++入门基础
1. C++的第一个程序
C++继承C语言许多大多数的语法,所以以C语言实现的hello world也可以运行,C++中需要把文件定义为.cpp,vs编译器看是.cpp就会调用C++编译器编译,linux下要用g++编译,不再是gcc。
// test.cpp
#include <stdio.h>int main()
{printf("hello world\n");return 0;
}
当然C++有一套自己的输入输出,严格说C++版本的hello world应该是这样写的。
// test.cpp
// 这里的std cout等我们都看不懂,没关系,下面我们会依次讲解
#include <iostream>
using namespace std;int main()
{cout << "hello world\n" << endl;return 0;
}
因为C++是在C语言基础上进行完善和在发展,所以二者的结构是十分相似的。比较上述两个程序,将下面的C++程序与熟悉的C语言程序类比可知:
iostream是程序的头文件,根据释义可知其包含输入输出函数的头文件。cout是输出函数。
然而其中using namespace std;可能无法理解,若要理解这条语句需要继续学习命名空间的知识。
2. 命名空间
2.1 namespace的价值
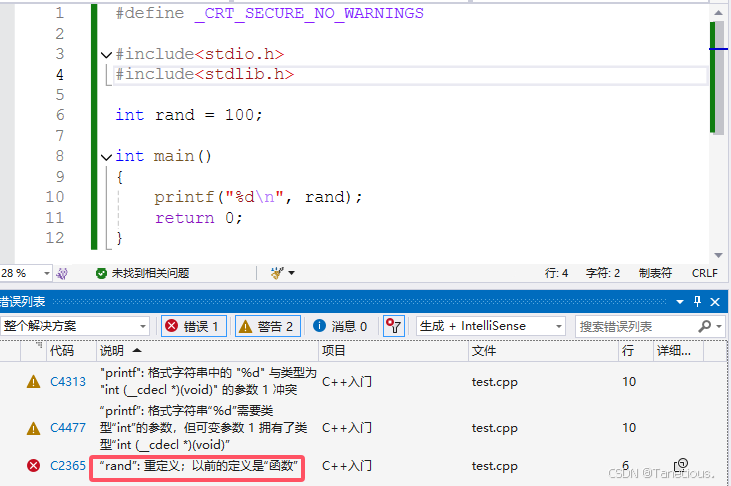
在下面的程序中,程序中包含了 <stdlib.h> 头文件,该头文件中含有 rand 函数,如果再用 rand 作为变量名定义变量,就会造成重定义。
#include <stdio.h>
#include <stdlib.h>// 其中定义了函数rand(),若不包含此头文件,则程序可以正常编译运行int rand = 10;int main()
{printf("%d\n", rand);return 0;
}
// 编译报错: error C2365: “rand”: 重定义;以前的定义是“函数”
在C/C++中,变量、函数和面向对象的类都是大量存在的,在编写大型项目的时候这些变量、函数和类的名称都在全局作用域内冲突,可能会导致很多命名冲突。使用命名空间的目的是对标准符的名称进行本地化,以避免命名冲突或者符号污染,其中定义命名空间的关键字是 namespace。
2.2 命名空间的定义
定义命名空间,需要使用到namespace关键字,后面跟命名空间的名字,然后接一对{}即可,{}中即为命名空间内的变量/函数/类等。
- 命名空间中可以定义变量/函数/类等。
- namespace只能定义在全局,当然还可以嵌套定义。
- namespace后面的空间名不受限制,可以随机取,一般取项目名称作为空间名。
命名空间的定义:
//定义命名空间
namespace N1
{//定义变量int rand = 100;//定义函数int Add(int a, int b){return a + b;}//定义类型(结构体)typedef struct SLNode{int data;SLNode* next;}SLNode;
}
命名空间的嵌套定义:
//定义命名空间
namespace N1//定义一个名为N1的命名空间
{//定义变量int a = 100;namespace N2 //嵌套定义另一个名为N2的命名空间{int b = 200;}
}//嵌套定义的访问
int main()
{printf("%d\n", N1::N2::b);
}
多文件命名空间的定义
- 项目工程中多个文件中定义的同名namespace会认为是一个namespace,编译器最后会将其成员合成在同一个命名空间中,不会冲突。
- 所以不能在相同名称的命名空间中定义两个相同名称的成员。
- 注意:一个命名空间就定义了一个新的作用域,命名空间中所有内容都局限于该命名空间中。
2.2.1 命名空间的本质解释
2.2.1.1 namespace
- namespace本质是定义一个区域,这个区域跟区域各自独立,不同的区域可以定义不同变量。
- 上面那个C语言的程序之所以会报错是因为主函数中定义的变量
rand和stdilb.h这个头文件中的rand函数都是被定义在全局域中,所以会产生命名冲突。在使用了namespace使用了命名空间这个概念之后就相当于形成了一个新的域,此时的rand因为在不同的域中则下面程序中rand不在冲突了。 - 既然已经创建了两个域,那么如何分别调用这不同域中的数据呢?这里就需要使用域作用限定符
::,未加::默认访问全局域,加上了::则默认访问此域中的信息。
代码示例:
#include<stdio.h>
#include<stdlib.h>namespace N2
{int rand = 100;
}int main()
{// 这里默认是访问的是全局的rand函数指针printf("%p\n", rand);//这里指定访问N2命名空间中的rand//::域作用限定符printf("%d\n", N2::rand);return 0;
}
运行结果:
这样即可分别调用不同域中的同一个名称为rand的信息了。
2.2.1.2 域
-
C++中域有函数局部域、全局域、命名空间域、类域;区域影响的是编译时查找一个变量/函数/类型出现的位置(声明或定义),所有有了域隔离,名字冲突就解决了。
-
局部域和全局域除了不会影响编译查找逻辑,是会影响变量的生命周期的,命名空间域和类域不影响变量生命周期。
- 在namespace中的定义的变量,其生命周期都是全局的,命名空间域只是起到隔离的作用,没有影响变量生命周期。
- 局部域中的变量只能在当前局部内访问。
-
不同的域中可以用同名变量,同一个域中不可以用同名变量。
示例代码:
#include <stdio.h>//全局域
int x = 0;//局部域
void func()
{int x = 1;
}
//命名空间域
namespace N1
{int x = 2;
}int main()
{//局部域int x = 3;//打印局部域--打印3printf("%d\n", x);//打印命名空间域--打印2printf("%d\n", N1::x);//打印全局域--打印0printf("%d\n", ::x);
}
//这里的打印是在main函数中进行的,所以打印的就是当前局部域中的变量x,而不是func这个局部域中的局部变量
2.2.2 C++标准库
- C++标准库都放在一个叫std(standard)的命名空间中。
这也就解释了开头using namespace std;中namespace std;的含义,其表示要调用C++标准库中的定义的变量和函数。
2.3 命名空间的使用
编译查找一个变量的声明/定义时,默认只会在局部或全局查找,不会主动到命名空间里面去查找。所以下面程序会编译报错。
#include <stdio.h>
namespace N1 {int a = 0;int b = 1;
}int main()
{// 编译报错: error C2065: “a”: 未声明的标识符printf("%d\n", a);return 0;
}
可以使用命名空间中的变量/函数,有三种方式:
- **法一:**指定命名空间访问:项目中推荐这样方式。
- **法二:**using 将命名空间中的某些成员展开,项目中经常访问的不在冲突的成员推荐这样方式。
- 法三:展开命名空间中全部成员,项目不推荐,冲突风险很大,日常小练习程序为了方便推荐使用。
//法一:指定命名空间访问
int main()
{printf("%d\n", N1::a);return 0;
}//法二:using 将命名空间中某个成员展开
using N::b;
int main()
{printf("%d\n", N1::a);printf("%d\n", b);return 0;
}//法三:展开命名空间中全部成员
using namespace N1
int main()
{ptintf("%d\n", a);printf("%d\n", b);return 0;
}
这里再次回归到上面那个第一个C++代码中,就可以看懂这句using namespace std;了,他表示的是利用展开命名空间全部成员的方式展开std(C++标准库)。
3. C++ 输入与输出
这里再次引入,第一个C++代码:
#include <iostream>
using namespace std;int main()
{cout << "hello world\n" << endl;return 0;
}
在C语言中有标准输入输出函数scanf和printf,而在C++中有**cin标准输入和cout标准输出**。在C语言中使用scanf和printf函数,需要包含头文件stdio.h。在C++中使用cin和cout,需要包含头文件iostream以及std标准命名空间(如果不写则需要完整表示std::cout或者std::cin)。
- 是 Input Output Stream 的缩写,是标准的输入、输出流库,定义了标准的输入、输出对象。
3.1 输入输出函数
3.1.1 cin函数和 cout函数
-
std::cin 是 istream 类的对象,它主要面向窄字符(narrow characters of type char) 的标准输入流。
-
std::cout 是 ostream 类的对象,它主要面向窄字符的标准输出流。
补充知识:
cin和cout中的c是什么意思?c的含义是窄字符,其本质思想是将内存中的各种数据类型或者原反补码等数据都转化成字符流。cin就相当于将输入的字符流解析成内存中的各种数据,cout就相当于将内存中的各种数据转化成字符流输出。
只有在内存中才会有整型、浮点型各种类型和原反补码等概念,因为CPU需要对这些二进制数据进行一系列运算;但是在其他环境中比如文件、网络、终端控制台中只有字符的概念。所以当内存中的一个整型数据想要在控制台或者文件中来回传递都需要先经过字符流进行转化。
3.1.2 endl函数
-
std::endl 是一个函数,流输出时,相当于插入一个换行字符加刷新区。
-
endl其实是end line的缩写。
3.2 运算符
<<是流插入运算符- 这个符号用于数据的输出,可以想象运算符右边的数据流进cout,然后输出。
>>是流提取运算符- 这个符号用于数据的输入,可以想象运算符右边的数据流入cin,然后输入。
- 这两个运算符是对C语言中的进行复用,C语言还用这两个运算符做位运算符左右移/右移。
3.3 输入输出示例
使用C++输入输出更方便,不需要像printf/scanf输入输出时那样,需要手动指定格式,C++的输入输出可以自动识别变量类型(本质是通过函数模板重载实现的),这个以后会学到,其实最重要的是C++的流能够更好地支持自定义类型对象的输入输出。
#include<iostream>
#include<stdio.h>int main()
{//打印字符串std::cout << "hello world\n";//打印整型int i = 10;std::cout << i << '\n' << "\n";//打印浮点型double d = 1.1;std::cout << d << std::endl;//输入一个整型,一个浮点型并打印出来//C++和C语言可以混合使用并不干扰std::cin >> i >> d;scanf("%d%lf", &i, &d);std::cout << i << " " << d << std::endl;printf("%d %.2lf", i, d);
}
详细讲解
- 利用语句
std::cout进行输出或者std::cin进行数据输入的时候,不再需要像C语言中的printf一样先输入其类型的占位符再输出,cout不需要指定其输出内容是什么类型可以自动识别变量的类型。 cout和cin支持连续的字符流的输出和插入,就像第8行代码,可以在i输出之后继续在后面执行换行的命令,直接对流进行插入即可。- 最推荐的输出换行方式就是利用函数
endl进行换行操作,因为在不同的操作系统下可能有不同的换行符,但是使用这个函数只要程序使用C++的代码编写都可以执行换行的命令。 - 在C++代码中是可以进行和C语言进行混合使用的,并且有些目标的实现利用C语言的函数实现得更加简单。如这里对于浮点数小数位数的控制则推荐使用
printf,C++内置的控制函数过于复杂。 - 这里没有包含
<stdio.h>,也可以使用printf和scanf,在包含头文件时,vs系列编译器是这样子的,其他编译器可能会报错。
3.4 补充知识
- IO流涉及类和对象,运算符重载,继承等很多面向对象的知识,这些知识还办法进行阐释,所以这里只能简单认识一下C++ IO流的用法,后面会有专门的一个部分来细讲IO流库。
cout/cin/end等都属于C++标准库,C++标准库都放在一个叫std(standard)的命名空间中,所以要通过命名空间的使用方式去调用它们。
- 因为C++中的
cout和cin的效率不高,至于为什么效率会不高也会在后面对IO流做细致讲解的时候有介绍,如果IO需求较高则采用下面的方式。
#include <iostream>
using namespace std;int main()
{// 在io需求比较高的地方,如部分大量输入的竞赛题中,加上以下3行代码// 可以提高C++IO效率ios_base::sync_with_stdio(false);cin.tie(nullptr);cout.tie(nullptr);return 0;
}
4. 缺省参数
4.1 缺省参数的概念
缺省参数是声明或定义函数时为函数的参数指定一个缺省值。在调用该函数时,如果没有指定实参,则采用该形参的缺省值,否则使用指定的实参,缺省参数为全缺省和半缺省参数。(有些地方把缺省参数也叫默认参数)
代码示例:
#include <iostream>
#include <cassert>
using namespace std;void Func(int a = 0)
{cout << a << endl;
}int main()
{Func(); // 没有传参数时,使用参数的默认值Func(10); // 传参数时,使用指定的实参return 0;
}
运行结果:
0
10
4.2 缺省参数的分类
4.2.1 全缺省参数
全缺省就是全部形参给缺省值。
void Func(int a = 10, int b = 20, int c = 30)
{cout << "a = " << a << endl;cout << "b = " << b << endl;cout << "c = " << c << endl;
}
4.2.2 半缺省参数
半缺省就是部分形参给缺省值。
C++规定半缺省参数必须从左至右次序连续缺省,不能间隔跳跃缺省参数。
void Func(int a, int b = 10, int c = 20)
{cout << "a = " << a << endl;cout << "b = " << b << endl;cout << "c = " << c << endl;
}
4.2.3 注意事项
- 带缺省参数的函数调用,C++规定必须从左到右依次给实参,不能跳跃给实参。
- 函数声明和定义分离时,缺省参数不能在函数声明和定义中同时出现,规定必须函数声明给缺省值。
缺省参数在实际代码中的应用:
// Stack.h
#include <iostream>
#include <cassert>
using namespace std;typedef int STDataType;
typedef struct Stack
{STDataType* a;int top;int capacity;
}ST;void STInit(ST* ps, int n = 4);//半缺省,给的默认空间为4个类型大小的空间// Stack.cpp
#include "Stack.h"void STInit(ST* ps, int n)
{assert(ps && n > 0);ps->a = (STDataType*)malloc(n * sizeof(STDataType));ps->top = 0;ps->capacity = n;
}// test.cpp
#include "Stack.h"
int main()
{ST s1;STInit(&s1);//可以在初始化的时候,不指定空间大小,因为缺省参数,会自动把空间设置为4// 如果确定知道要插入1000个数据,初始化时把容量设置大,避免扩容,影响效率ST s2;STInit(&s2, 1000);//由此可以看出缺省参数十分灵活、好用return 0;
}
5. 函数重载
5.1 函数重载的概念
C++支持在同一作用域中出现同名函数,但是要求这些同名函数的形参不同,可以是参数个数不同或者参数类型不同。这样C++函数调用表现出了多态行为,使用更灵活。C语言是不支持同一作用域中出现同名函数的。
#include <iostream>
using namespace std;// 1、参数类型不同
int Add(int left, int right)
{cout << "int Add(int left, int right)" << endl;return left + right;
}double Add(double left, double right)
{cout <<"double Add(int left, int right)" << endl;return left + right;
}//2、参数个数不同
void f()
{cout << "f()" << endl;
}void f(int a)
{cout << "f(int a)" << endl;
}//3、参数顺序不同(本质还是类型不同)
void f(int a, char b)
{cout << "f(int a, char b)" << endl;
}void f(char b, int a)
{cout << "f(char b, int a)" << endl;
}int main()
{Add(10, 20);//打印int Add(int left, int right),并计算10+20的结果返回Add(10.1, 20.2);//打印double Add(int left, int right)并计算10.1+20.2的结果返回f();//打印f()f(10);//打印f(int a)f(10, 'a');//打印f(int a, char b)f('a', 10);//打印f(char b, int a)return 0;
}
补充知识:
- 返回值不同不能作为重载条件,因为调用时也无法区分。(因为参数不同可以区分函数,但是返回值不同无法区分函数)
void f1()
{}int f1()
{return 0;
}
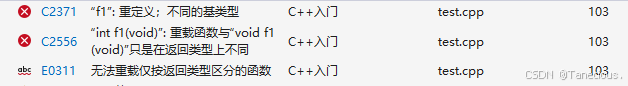
- 构成重载的函数也有可能报错,下面代码两个重载函数语法正确,但是会发生调用不明确的问题。
//下面两个函数构成重载(参数不同)
//f() 但是调用时,会报错,存在歧义,编译器不知道调用哪个
void f1()
{cout << "f()" << endl;
}void f1(int a = 10)
{cout << "f(int a)" << endl;
}

6. 引用
6.1 引用的概念和定义
引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空间,它和它引用的变量共享同一块内存空间。例如:水浒传中李逵,宋江叫"铁牛",江湖上人称"黑旋风"; 林冲,外号豹子头;
语法:类型& 引用别名 = 引用对象;
C++中为了避免引用太多的运算符,会复用C语言的一些符号,比如前面的<<和>>,这里引用也和取址使用了同一个符号&,注意用法角度区分就可以。
这里和C语言中的typedef不一样,typedef是给类型取别名,这里的引用是给变量取别名。
#include <iostream>
using namespace std;int main()
{int a = 0;// 引用:b和c是a的别名int& b = a;int& c = a;// 也可以给别名b取别名,d相当于a的别名int& d = b;++d;// 这里取地址看到是一样的,d++他们都++cout << &a << endl;cout << &b << endl;cout << &c << endl;cout << &d << endl;return 0;
}
实际的底层情况如下:也就是一块空间有多个名字。

6.2 引用的特性
-
引用在定义时必须初始化
int a = 10; int& b = a;//引用在定义时必须初始化 -
一个变量可以有多个引用
int a = 10; int& b = a; int& c = a; //给别名起别名 int& d = b; -
引用一旦引用一个实体,就不可以再引用其他实体
这个特性也也就决定了别名是没有办法替代指针的。
在链表这一个数据结构中,数据与数据之间利用指针相互连接,当删除中间的一个数据的时候,需要将其前一个数据的指针地址由原来的指向此时删除的数据改为指向现在删除的这个数据的后一个数据,这样的行为引用是没有办法做到的,因为引用的实体没有办法改变,也就无法实现将链表的删除操作,所以其无法替代指针。
int a = 10; int& b = a; int c = 20; b = c; //想法:让b转而引用c,但是实际操作的是把c中的20赋值给了a
6.3 引用的使用
引用在实践中主要是用于引用传参和引用返回值中减少拷贝(利用别名达到不开辟新空间的目的)提高效率和改变引用对象时改变被引用对象。
6.3.1 引用传参
示例一:
引用传参跟指针传参功能是类似的,引用传参更方便一些。

- 上面代码体现了引用特性的功能2:改变引用对象时改变被引用对象。
- 这里使用引用的方式,将a作为rx的引用,e作为ry的引用;同样可以起到传址调用的效果。
- 其实本质是让形参作为实参的别名,让形参的改变也会影响实参。
示例二:
struct A
{int arr[1000];
};void func(A aa)
{}int main()
{A aa1;func(aa1);return 0;
}
上述代码中利用别名代替形参的方式,避免了再次创建四千个字节的情况,避免了空间的浪费。
6.3.2 引用作返回值
引用返回值的场景相对比较复杂,在这里只简单讲了一下场景,还有一些内容后续类和对象章节中会继续深入讲解。
#include<iostream>
int& Add(int a, int b)
{static int c = a + b;return c;
}int main()
{int a = 10, b = 20;Add(a, b)++;std::cout << Add(a, b) << std::endl;return 0;
}//运行结果:31
上述代码就是引用作为返回值的应用,函数Add的返回值是c的别名,并在主函数中对对其++,最后打印结果,运行成功。
这里使用引用作为返回值是因为,函数的返回值的本质和形参的本质一样也是将返回值的数值拷贝到一块临时空间,所以如果这里的返回值单纯的使用int表示,编译器则会报错:

注意:也并不是所有函数都可以使用别名作为返回值
函数返回的数据不能是函数内部创建的普通局部变量,因为在函数内部定义的普通的局部变量会随着函数调用的结束而被销毁。函数返回的数据必须是被static修饰或者是动态开辟的或者是全局变量等不会随着函数调用的结束而被销毁的数据,才可以使用引用将其返回。
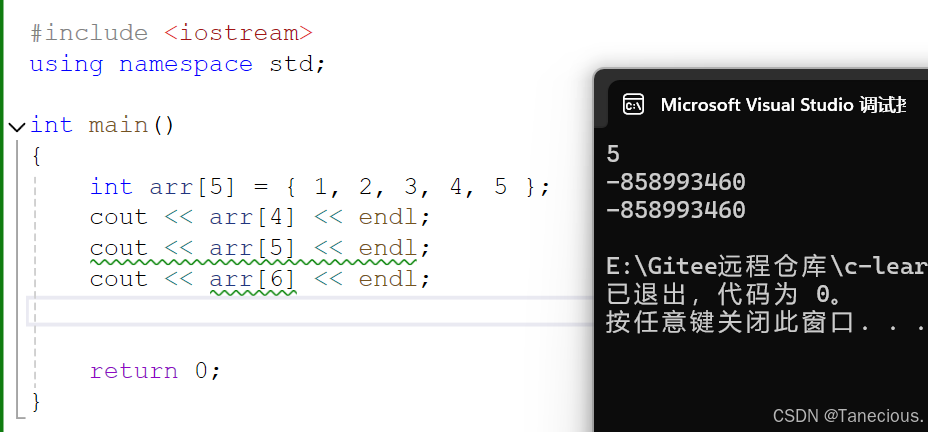
补充:越界不一定报错
-
越界读一定不报错
-
越界写不一定报错
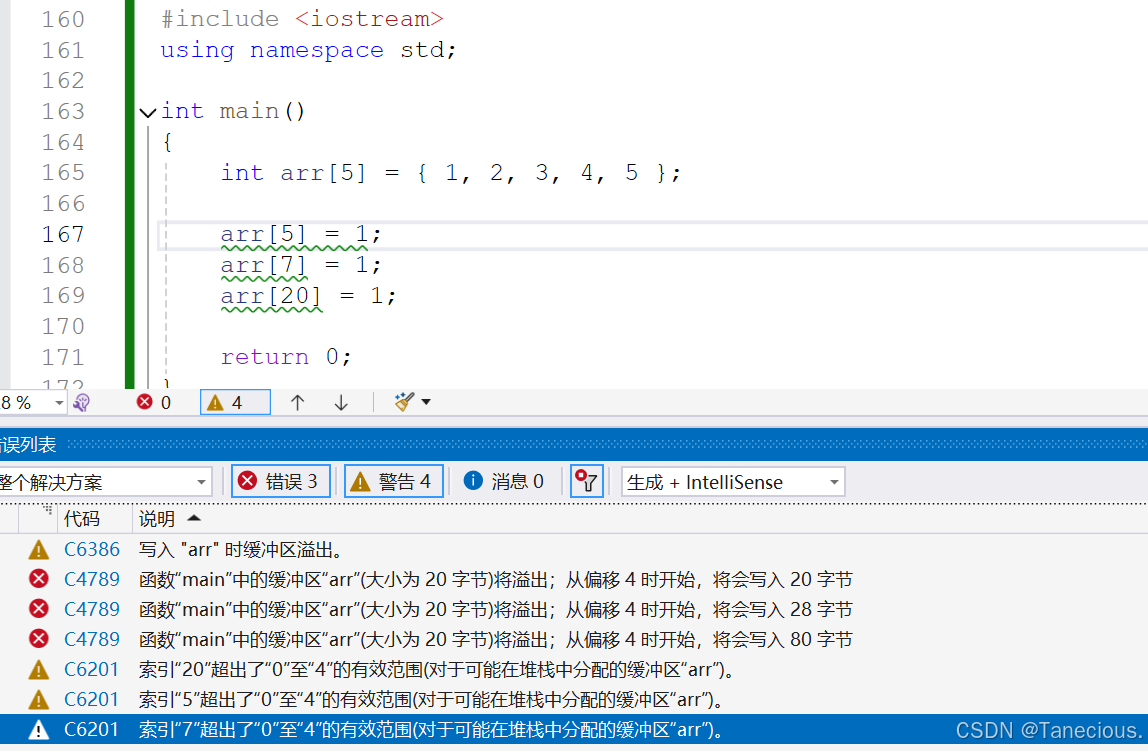
这是因为编译器对于越界的检查是抽查,在这里会在数组后面的几个字节中固定写入某个值,在程序运行中会去检查这几个字节位置的数据有没有被更改,如果有则报错,说明一定越界了。但是有时修改数据的位置可能不在抽查位置,这个时候程序就可以正常运行,不会报错。
6.4 const引用
6.4.1 权限
- 可以引用一个
const对象,但是必须用const引用。const引用也可以引用普通对象,因为对象的访问权限在引用过程中可以缩小或者平移,但是不能放大。
//const中的权限问题
int main()
{//访问权限的放大const int a = 10;int& ra = a;// 编译报错: error C2440: “初始化”: 无法从“const int”转换为“int &”// 权限可以缩小int b = 1;const int& rb = b;rb++;b++;//正常编译运行//访问权限的平移const int a = 10;const int& ra = a;//正常编译运行//const的使用const int& ra = a;ra++;//const修饰的ra,所以就不能对ra进行修改// 编译报错: error C3892: “ra”: 不能给常量赋值//空间访问权限和空间拷贝的辨析const int x = 0;int y = x;//这里的y仅仅是对x中的值进行拷贝,不涉及权限问题return 0;
}
//指针中的权限问题
int main()
{// 权限不能放大const int a = 10;const int* p1 = &a;int* p2 = p1;//报错// 权限可以缩小int b = 20;int* p3 = &b;const int* p4 = p3;//正常编译运行// 不存在权限放大,因为const修饰的是p5本身不是指向的内容int* const p5 = &b;int* p6 = p5;return 0;
}
6.4.2 临时对象的常性
- 需要注意的是类似
int& rb = a*3; double d = 12.34; int& rd = d;这样一些场景下,表达式a*3的结果保存在一个临时对象中,int& rd = d也是类似,在类型转换中会产生临时对象储存中间值,也就是此时rb和rd引用的都是临时对象,而C++规定临时对象具有常性(相当于被const修饰),所以这里就触发了引用限制,必须要用常引用才可以。 - 所调用临时对象就是编译器需要一个空间暂时存储表达式的求值结果时临时创建的一个未命名的对象,C++中把这个未命名对象做临时对象。
- 临时对象一般用于存放表达式的结果或者是类型转换时的中间值。
#include <iostream>
using namespace std;int main()
{int a = 10;int& rb = a * 3;// 报错,原因是这里的a*3被保存在临时对象中,相当于这里的指向a*3的这块空间被const修饰了,现在用"int&"去修饰本质也是权限的放大//应该改为const int& rb = a * 3;即可double d = 12.34;int& rd = d;// 编译报错: “初始化”: 无法从“double”转换为“int &”//在类型转换的时候也会产生临时空间存在d,临时空间因为有常性,所以就相当于指向d的这块空间被const修饰,所以现在用"int&"去修饰本质也是权限的放大//改为const int& rd = d;即可return 0;
}
6.4.3 const引用的使用场景
void f1(const int& rx)
{}int main()
{int a = 10;double b = 12.34;f1(a);f1(a * 3);f1(d);
}
在函数f1的形参使用const进行修饰,可以在调用此函数的对于形参的填写形式更加宽泛,其实本质都是因为加上了const权限变得更小了,所以正常的各种参数都可以作为形参传过去。
使用const可以引用const对象、普通对象和临时对象,引用对象十分宽泛。
**注意:(非常重要!!!)**当然其实上述代码,将形参改为int rx也可以,也是可以正常传参的,虽然传入的是实参的临时拷贝,这样其实也是可以的。这是因为现在使用的数据类型都是一些简单数据类型类似int、float等,但是如果这里的数据类型是A(一个极大地数据类型),这里使用传值传参就会拷贝这个极大的数据,这样的代价就会很大,所以还是推荐引用传参,使用引用传参能接收更多类型的对象,并且要保证引用内容不被更改,所以使用const int& XX的方式作为函数的形参。这是后期C++学习常见的形参格式。
6.5 指针和引用的关系
C++中指针和引用就像两个性格迥异的亲兄弟,指针是哥哥,引用是弟弟,在实践中它们相辅相成,功能能有重叠性,但是各有自己的特点,互相不可替代。
-
语法概念上引用是一个变量的取别名不开辟新空间,指针是存储一个变量地址,要开空间。
-
从底层汇编语言来看,引用也是利用指针实现的,也需要开辟空间。

-
-
引用在定义时必须初始化,指针建议初始化,也不是必须的。
-
引用在初始化时引用一个对象后,就不能再引用其他对象;而指针可以不断地改变指向对象。
-
引用可以直接访问指向对象,指针需要解引用才能访问指向对象。
-
sizeof中含义不同,引用结果为引用类型的大小,但指针始终是地址空间所占字节个数(32位平台下占4个字节,64位下是8个字节)
-
指针很容易出现空指针和野指针的问题,引用很少出现,引用使用起来相对更安全一些。
7. 内联函数
7.1 内联函数的定义
用inline修饰的函数叫做内联函数,编译时C++编译器会在调用的地方展开内联函数,这样调用内联函数就不需要建立栈帧了,就可以提高效率。
#include <iostream>
using namespace std;inline int Add(int x, int y)
{int ret = x + y;ret += 1;ret += 1;ret += 1;return ret;
}int main()
{// 可以通过汇编程序是否展开// 有call Add语句就没有展开,没有就是展开了int ret = Add(1, 2);return 0;
}
下图左是以上代码的汇编代码,下图右是函数Add加上inline后的汇编代码:

7.2 inline与宏函数
7.2.1 回忆宏函数
C语言实现宏函数也会在预处理时替换展开,但是宏函数实现很容易出错的,而且不方便调试。
// 正确的宏实现
#define ADD(a, b) ((a) + (b))
// 为什么不能分号?
// 为什么要加外面的括号?
// 为什么要加里面的括号?
//重点:宏函数虽然坑很多,但是因为替换机制让其调用的时候不同开辟栈帧,提高程序运行效率int main()
{int ret = ADD(1, 2);//不加;的原因cout << ADD(1, 2) << endl;//加外面括号的原因cout << ADD(1, 2) * 5 << endl;//加里面括号的原因int x = 1, y = 2;//位运算符优先级较低,会先执行+-操作ADD(x & y, x | y); // -> (x & y + x | y)return 0;
}
7.2.2 inline
为了弥补C语言中宏函数的各种坑,C++设计了inline的目的是替代C的宏函数。
7.2.2.1 inline的底层逻辑
inline对于编译器而言只是一个建议,也就是说,加了inline编译器也可以选择在调用的地方不展开,不同编译器关于inline什么情况展开各不相同,因为C++标准没有规定这个。inline适用于频繁调用的小函数,对于递归函数,代码相对多一些的函数,加上inline也会被编译器忽略。
-
vs编译器debug版本下面默认是不展开inline的,这样方便调试,debug版本想展开需要设置一下以下两个地方。
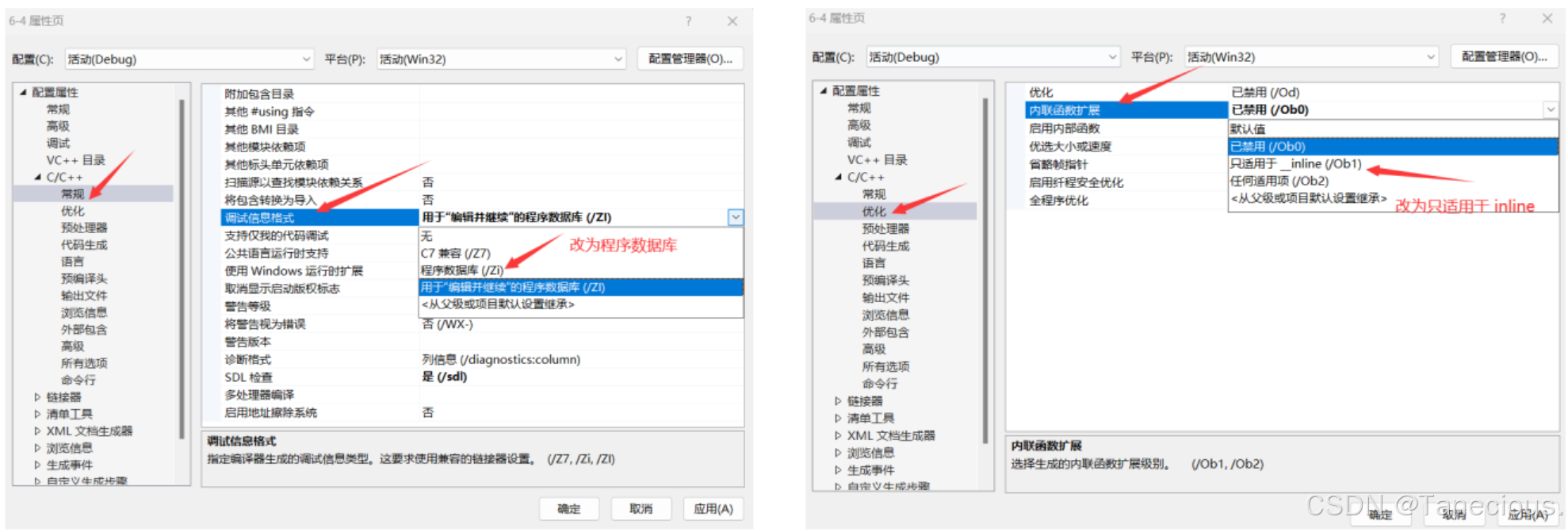
下图右边是未展开内联函数,在底层汇编中还是用了指令call创建了函数栈帧。左图这是已经展开了内联函数,可以看到并没有调用指令call而是直接执行ADD函数的逻辑。
在这里插入图片描述
但是当内联函数行数过长(这里判断过长函数一般是由编译器决定的,比如这里的VS一般是10行以上)编译器就不会将内联函数展开。
补充:为什么将inline设置为对编译器的建议,而不是将决定权交给程序员?
eg:现在有一个100行指令的ADD函数,在1000个位置调用这个函数。
比较:所需要的指令(这里的指令不是内存空间,不要弄混淆)
inline展开,占多少指令:10000*100
inline不展开,占多少指令:10000*1+100(call调用指令每个函数占一次)
要想理解其底层原理,需要对程序运行的本质有一个了解。
在计算机中编写的所有程序都是一个个文件,在这些文件编译之后会形成一个.exe(以windows为例)的可执行文件,这个文件中就是实际的指令,计算机会生成一个进程去分配内存去将这个可执行文件的指令加载到内存中。
有了以上铺垫和上面的比较可以看出当内联函数过长,会导致其所占的指令会很多,也就导致指令膨胀,就会导致可执行文件变大,所以将其加载到进程中所占据的内存就会变大,就会造成很多影响。
inline设计的本质思路是一种以空间换时间的做法,省去了调用函数的额外开销。而将是否将内联函数展开的决定权交给编译器,这样的设计本质是一种防御策略,害怕遇到那些不靠谱的程序员。
7.2.2.2 inline的注意事项
- inline不建议声明和定义分别到两个文件,分离会导致链接错误。因为inline被展开,就没有函数地址,链接时会出报错。
- 在使用inline定义内联函数的时候不需要声明,直接定义到头文件中即可。
//F.h
#include <iostream>
using namespace std;inline void f(int i);// F.cpp
#include "F.h"
void f(int i)
{cout << i << endl;
}// main.cpp
#include "F.h"
int main()
{// 链接错误:无法解析的外部符号 "void __cdecl f(int)" (?f@YAXH@Z)f(10);return 0;
}
8. nullptr
NULL 实际上是一个宏,在传统的 C 头文件(stddef.h)中,可以看到如下代码:
#ifndef NULL#ifdef __cplusplus#define NULL 0#else#define NULL ((void*)0)#endif
#endif
C++中 NULL 可能被定义为整数 0,或者 C 中被定义为无类型指针 (void*) 的常量。不论取何种定义,在使用空值的指针时,都不可避免的会遇到一些麻烦。
#include <iostream>
using namespace std;void f(int x)
{cout << "f(int x)" << endl;
}void f(int* ptr)
{cout << "f(int* ptr)" << endl;
}int main()
{f(0);// 本想通过f(NULL)调用指针版本的f(int*)函数,但是由于NULL被定义成0,调用了f(int x)f(NULL);f((int*)NULL);return 0;
}
本想通过 f(NULL) 调用指针版本的 f(int*) 函数,但是由于 NULL 被定义成 0,调用了 f(int x),因此与程序的初衷相悖。f((void*)NULL) 调用会报错。
C++11中引入了 nullptr,nullptr 是一个特殊的关键字,nullptr 是一种特殊类型的字面量,它可以转换成任何其他类型的指针类型。使用 nullptr 定义空指针可以避免类型转换的问题,因为 nullptr 只能被隐式地转换为指针类型,而不能被转换为整型类型。
#include <iostream>
using namespace std;void f(int x)
{cout << "f(int x)" << endl;
}void f(int* ptr)
{cout << "f(int* ptr)" << endl;
}int main()
{f(0);f(nullptr);//正常运行不会报错return 0;
}
相关文章:

C++--入门基础
C入门基础 1. C的第一个程序 C继承C语言许多大多数的语法,所以以C语言实现的hello world也可以运行,C中需要把文件定义为.cpp,vs编译器看是.cpp就会调用C编译器编译,linux下要用g编译,不再是gcc。 // test.cpp #inc…...

Ubuntu环境下如何管理系统中的用户:创建用户、删除用户、修改密码、切换用户、用户组管理
管理用户的操作需要root权限,在执行命令时需要加sudo,关于sudo命令可以看这篇:Linux_sudo命令的使用与机制 1、添加用户 使用命令: adduser 用户名,主要是按提示输入密码和用户信息(可直接回车使用默认配置…...

广告事件聚合系统设计
需求背景 广告事件需要进行统计,计费,分析等。所以我们需要由数据接入,数据处理,数据存储,数据查询等多个服务模块去支持我们的广告系统 规模上 10000 0000个点击(10000 00000 / 100k 1wQPS) …...

PDF智能解析与知识挖掘:基于pdfminer.six的全栈实现
前言 在数字化信息爆炸的时代,PDF(便携式文档格式)作为一种通用的电子文档标准,承载着海量的结构化与非结构化知识。然而,PDF格式的设计初衷是用于展示而非数据提取,这使得从PDF中挖掘有价值的信息成为数据…...

VGG网络模型
VGG网络模型 诞生背景 VGGNet是牛津大学计算机视觉组核谷歌DeepMind一起研究出来的深度卷积神经网络。VGG是一种被广泛使用的卷积神经网络结构,其在2014年的ImageNet大规模视觉识别挑战中获得亚军。 通常所说的VGG是指VGG-16(13层卷积层3层全连接层)。具有规律的…...
vs 接口类不变,原实现类可变)
开闭原则与依赖倒置原则区别:原类不变,新增类(功能)vs 接口类不变,原实现类可变
好,我来用最通俗的方式,用角色扮演 场景对话,不讲术语,让你彻底明白「依赖倒置原则」和「开闭原则」的区别。 🎭 场景:你是老板(高层),你要雇人做事 一、【依赖倒置原则…...

【AI面试准备】Azure DevOps沙箱实验全流程详解
介绍动手实验:通过 Azure DevOps 沙箱环境实操,体验从代码提交到测试筛选的全流程。如何快速掌握,以及在实际工作中如何运用。 通过 Azure DevOps 沙箱环境进行动手实验,是快速掌握 DevOps 全流程(从代码提交到测试筛选…...

大数据面试问答-数据湖
1. 概念 数据湖(Data Lake): 以原始格式(如Parquet、JSON等)存储海量原始数据的存储库,支持结构化、半结构化和非结构化数据(如文本、图像)。采用Schema-on-Read模式,数…...
显示模式设置)
驱动开发系列56 - Linux Graphics QXL显卡驱动代码分析(三)显示模式设置
一:概述 如之前介绍,在qxl_pci_probe 中会调用 qxl_modeset_init 来初始化屏幕分辨率和刷新率,本文详细看下 qxl_modeset_init 的实现过程。即QXL设备的显示模式设置,是如何配置CRTC,Encoder,Connector 的以及创建和更新帧缓冲区的。 二:qxl_modeset_init 分析 in…...

沥青路面裂缝的目标检测与图像分类任务
文章题目是《A grid‐based classification and box‐based detection fusion model for asphalt pavement crack》 于2023年发表在《Computer‐Aided Civil and Infrastructure Engineering》 论文采用了一种基于网格分类和基于框的检测(GCBD)ÿ…...

单片机-STM32部分:0、学习资料汇总
飞书文档https://x509p6c8to.feishu.cn/wiki/Kv7VwjDD8idFWKkMj4acZA3lneZ 一、软件部分 STM32F1系列资料官网下载地址 https://www.stmcu.com.cn/Designresource/list/STM32F1/document/document STM32官方数据手册 有哪些版本,哪些资源,对应哪些IO…...
题解)
杭电oj(1180、1181)题解
目录 1180 题目 思路 问题概述 代码思路分析 1. 数据结构与全局变量 2. BFS 函数 bfs 3. 主函数 main 总结 代码 1181 题目 思路 1. 全局变量的定义 2. 深度优先搜索函数 dfs 3. 主函数 main 总结 代码 1180 题目 思路 注:当走的方向和楼梯方向一…...
:匿名内部类)
内部类(3):匿名内部类
1 匿名类 请看下面这个例子: public class Parcel7 {public Contents contents() {return new Contents() {private int i 11;public int value() {return i;}};}public static void main(String[] args) {Parcel7 p new Parcel7();Contents c p.contents();} }…...

组件通信-$attrs
概述:$attrs用于实现当前组件的父组件,向当前组件的子组件通信(爷→孙)。 具体说明:$attrs是一个对象,包含所有父组件传入的标签属性。 注意:$attrs会自动排除props中声明的属性(可以认为声明过…...

Laravel Octane 项目加速与静态资源优化指南
Laravel Octane 项目加速与静态资源优化指南 一、Octane 核心加速配置 扩展安装与环境配置 composer require laravel/octane # 安装核心扩展php artisan octane:install # 生成配置文件(选择 Swoole/RoadRunner 等服务器)服务器参数调优 …...

【Linux】Petalinux U-Boot
描述 部分图片和经验来源于网络,若有侵权麻烦联系我删除,主要是做笔记的时候忘记写来源了,做完笔记很久才写博客。 专栏目录:记录自己的嵌入式学习之路-CSDN博客 目录 0 引导流程示例 1 进入U-Boot 2 常用U-Boot操作命…...

【KWDB 创作者计划】技术解读:多模架构、高效时序数据处理与分布式实现
技术解读:多模架构、高效时序数据处理与分布式实现 一、多模架构1.1 架构概述1.2 源码分析1.3 实现流程 二、高效时序数据处理2.1 处理能力概述2.2 源码分析2.3 实现流程 三、分布式实现3.1 分布式特性概述3.2 源码分析3.3 实现流程 四、总结 在当今数据爆炸的时代&…...
——使用PyTorch构建模型)
深度学习框架PyTorch——从入门到精通(YouTube系列 - 4)——使用PyTorch构建模型
这部分是 PyTorch介绍——YouTube系列的内容,每一节都对应一个youtube视频。(可能跟之前的有一定的重复) torch.nn.Module(PyTorch神经网络模块)和torch.nn.Parameter(PyTorch神经网络参数)常见…...

通过组策略使能长路径
打开组策略编辑器,依次展开: 计算机配置 > 管理模板然后双击 所有设置 右侧就会出现列表。接着在列表中找到 启用 win32 长路径 ,双击 改成 已启用 ,然后点击确定。最后重启计算机。...
如何设计一个支持多协议的Dubbo服务?)
Dubbo(90)如何设计一个支持多协议的Dubbo服务?
设计一个支持多协议的Dubbo服务需要考虑以下几个方面: 服务接口设计:确保服务接口的定义可以被不同协议实现。多协议配置:配置不同的协议,例如 Dubbo、HTTP、gRPC 等。服务注册与发现:确保服务能够在多个协议下注册和…...

JavaScript常规解密技术解析指南
第一章:密码学基础铺垫 逆向思维提示框 逆向思维在密码学中至关重要。当面对加密数据时,不要局限于常规的加密过程,而是要从解密的角度去思考。例如,在看到Base64编码的数据时,要立刻联想到它是如何从原始数据转换而…...

字符串的相关方法
1. equals方法的作用 方法介绍 public boolean equals(String s) 比较两个字符串内容是否相同、区分大小写 示例代码 public class StringDemo02 {public static void main(String[] args) {//构造方法的方式得到对象char[] chs {a, b, c};String s1 new String(chs);…...

云原生后端架构的实践与挑战:探索现代后端开发的未来
📝个人主页🌹:一ge科研小菜鸡-CSDN博客 🌹🌹期待您的关注 🌹🌹 随着云计算的普及,云原生架构已经逐渐成为现代软件开发的主流方式。云原生后端架构通过容器化、微服务、自动化运维等技术,帮助企业构建具有高度可扩展性和可靠性的系统。在本文中,我们将深入探讨…...
)
MySQL基础关键_005_DQL(四)
目 录 一、分组函数 1.说明 2.max/min 3.sum/avg/count 二、分组查询 1.说明 2.实例 (1)查询岗位和平均薪资 (2)查询每个部门编号的不同岗位的最低薪资 3.having (1)说明 (2ÿ…...
——实时语音识别技术)
Gradio全解20——Streaming:流式传输的多媒体应用(3)——实时语音识别技术
Gradio全解20——Streaming:流式传输的多媒体应用(3)——实时语音识别技术 本篇摘要20. Streaming:流式传输的多媒体应用20.3 实时语音识别技术20.3.1 环境准备和开发步骤1. 环境准备2. ASR应用开发步骤(基于Transform…...

[android]MT6835 Android 关闭selinux方法
Selinux SELinux is an optional feature of the Linux kernel that provides support to enforce access control security policies to enforce MAC. It is based on the LSM framework. Working with SELinux on Android – LineageOS Android 关闭selinux MT6835 Android…...
)
GitHub 趋势日报 (2025年05月01日)
本日报由 TrendForge 系统生成 https://trendforge.devlive.org/ 📈 今日整体趋势 Top 10 排名项目名称项目描述今日获星总星数语言1hacksider/Deep-Live-Camreal time face swap and one-click video deepfake with only a single image⭐ 1311⭐ 56231Python2day…...
Python实现——密码学基础(Python出现No module named “Crypto” 解决方案))
对称加密算法(AES、ChaCha20和SM4)Python实现——密码学基础(Python出现No module named “Crypto” 解决方案)
文章目录 一、对称加密算法基础1.1 对称加密算法的基本原理1.2 对称加密的主要工作模式 二、AES加密算法详解2.1 AES基本介绍2.2 AES加密过程2.3 Python中实现AES加密Python出现No module named “Crypto” 解决方案 2.4 AES的安全考量 三、ChaCha20加密算法3.1 ChaCha20基本介…...

n8n 键盘快捷键和控制键
n8n 键盘快捷键和控制键 工作流控制键画布操作移动画布画布缩放画布上的节点操作选中一个或多个节点时的快捷键 节点面板操作节点面板分类操作 节点内部操作 n8n 为部分操作提供了键盘快捷键。 工作流控制键 Ctrl Alt n:创建新工作流Ctrl o:打开工作…...
再战Superset)
部署Superset BI(二)再战Superset
上次安装没有成功,这次把superset的安装说明好好看了一下。 rootNocobase:/usr# cd superset rootNocobase:/usr/superset# git clone https://github.com/apache/superset.git Cloning into superset... remote: Enumerating objects: 425644, done. remote: Count…...

生日快乐祝福网页制作教程
原文:https://www.w3cschool.cn/article/88229685.html (本文非我原创,请标记为付费文章,也请勿将我标记为原创) 一、引言 生日是每个人一年中最特别的日子之一。在这个特别的日子里,我们都希望能够给亲…...

Spring MVC @RequestHeader 注解怎么用?
我们来详细解释一下 Spring MVC 中的 RequestHeader 注解。 RequestHeader 注解的作用 RequestHeader 注解用于将 HTTP 请求中的**请求头(Request Headers)**的值绑定到 Controller 方法的参数上。 请求头是 HTTP 请求的一部分,包含了关于…...

【Linux深入浅出】之全连接队列及抓包介绍
【Linux深入浅出】之全连接队列及抓包介绍 理解listen系统调用函数的第二个参数简单实验实验目的实验设备实验代码实验现象 全连接队列简单理解什么是全连接队列全连接队列的大小 从Linux内核的角度理解虚拟文件、sock、网络三方的关系回顾虚拟文件部分的知识struct socket结构…...

Linux C++ JNI封装、打包成jar包供Java调用详细介绍
在前面 Android专栏 中详细介绍了如何在Android Studio中调用通过jni封装的c库。 在Android使用 opencv c代码,需要准备opencv4android,也就是c的任何代码,是使用Android NDK编译的,相当于在windows/mac上使用Android stdido交叉…...
)
CPO-BP+NSGA,豪冠猪优化BP神经网络+多目标遗传算法!(Matlab完整源码和数据)
目录 效果一览基本介绍程序设计参考资料 效果一览 基本介绍 1.CPO-BPNSGA,豪冠猪优化BP神经网络多目标遗传算法!(Matlab完整源码和数据),豪冠猪算法优化BP神经网络的权值和阈值,运行环境Matlab2020b及以上…...

组件通信-v-model
概述:实现 父↔子 之间相互通信。 前序知识 —— v-model的本质 <!-- 使用v-model指令 --> <input type"text" v-model"userName"><!-- v-model的本质是下面这行代码 --> <input type"text" :value"use…...

使用PyMongo连接MongoDB的基本操作
MongoDB是由C语言编写的非关系型数据库,是一个基于分布式文件存储的开源数据库系统,其内容存储形式类似JSON对象,它的字段值可以包含其他文档、数组及文档数组。在这一节中,我们就来回顾Python 3下MongoDB的存储操作。 常用命令:…...

010302-oss_反向代理_负载均衡-web扩展2-基础入门-网络安全
文章目录 1 OSS1.1 什么是 OSS 存储?1.2 OSS 核心功能1.3 OSS 的优势1.4 典型使用场景1.5 如何接入 OSS?1.6 注意事项1.7 cloudreve实战演示1.7.1 配置cloudreve连接阿里云oss1.7.2 常见错误1.7.3 安全测试影响 2 反向代理2.1 正向代理和反向代理2.2 演示…...

PyQt 或 PySide6 进行 GUI 开发文档与教程
一、官网文档 Qt 官方文档:Porting to Qt 6 | Qt 6.9Qt 维基:Qt WikiQt for Python (PySide6) :Qt for Python - Qt WikiPySide6 快速上手指南:Getting Started - Qt for Python PyS…...

【东枫科技】AMD / Xilinx Alveo™ V80计算加速器卡
AMD / Xilinx Alveo™ V80计算加速器卡 AMD/Xilinx Alveo ™ V80计算加速器卡是一款功能强大的计算加速器,基于7nm Versal™ 自适应SoC架构而打造。 AMD/Xilinx Alveo V80卡设计用于内存密集型任务。 这些任务包括HPC、数据分析、网络安全、传感器处理、计算存储和…...

C++ 动态内存管理
operator new和operator delete函数是两个全局函数,编译器在编译new和delete时会调用这两个函数,其底层分别是封装malloc和free 1.new new 内置类型 内置类型没有构造函数,所以使用new就是调operator new函数开空间,如果要初始化…...
Vue-Router路由的详细使用)
(11)Vue-Router路由的详细使用
本系列教程目录:Vue3Element Plus全套学习笔记-目录大纲 文章目录 第2章 路由 Vue-Router2.1 Vue路由快速入门2.1.1 创建项目2.1.2 路由运行流程 2.2 传递参数-useRoute2.2.1 路径参数-params1)普通传参2)传递多个参数3)对象方式传…...

RISCV的smstateen-ssstateen扩展
RISC-V 的 Smstateen / Ssstateen 扩展是为了解决安全性和资源隔离性问题而设计的,尤其是针对在多个上下文(如用户线程、多个虚拟机)之间 潜在的隐蔽信道(covert channel) 风险。 🌐 背景:隐蔽信道与上下文切换问题 当…...

C++ 与 Lua 联合编程
在软件开发的广阔天地里,不同编程语言各有所长。C 以其卓越的性能、强大的功能和对硬件的直接操控能力,在系统开发、游戏引擎、服务器等底层领域占据重要地位,但c编写的程序需要编译,这往往是一个耗时操作,特别对于大型…...

瑞萨 EZ-CUBE2 调试器
瑞萨 EZ-CUBE2 调试器 本文介绍了瑞萨 EZ-CUBE2 调试器的基本信息、调试方式、环境搭建、硬件连接、软件测试等。 包装展示 调试器展示 开关选项 详见:EZ-CUBE2 | Renesas 瑞萨电子 . 环境搭建 使用 Renesas 公司的 e2 studio 开发工具,下载 并安装该…...

MATLAB滤波工具箱演示——自定义维度、滤波方法的例程演示与绘图、数据输出
使用 M A T L A B MATLAB MATLAB的界面做了一个 M A T L A B MATLAB MATLAB滤波工具箱 d e m o demo demo,本文章给出演示:自定义维度、滤波方法的例程演示与绘图、数据输出 文章目录 编辑界面使用方法优势待改进点部分代码 编辑界面 使用 M A T L A B …...

数据库索引优化实战: 如何设计高效的数据库索引
数据库索引优化实战: 如何设计高效的数据库索引 一、理解数据库索引的核心原理 1.1 B树索引的结构特性 数据库索引(Database Index)的本质是通过特定数据结构加速数据检索。现代关系型数据库普遍采用B树(B Tree)作为默认索引结构&…...

TS 安装
TS较JS优势 1 TS静态类型编程语言。编译时发现错误 2 类型系统 强化变量类型概念 3 支持新语法 4 类型推断机制 可以和React框架中的各种hook配合 5 任何地方都有代码提示 tsc 命令 将TS转为JS 1 tsc 文件.ts 生成 js文件 2 执行JS代码...

CMake separate_arguments用法详解
separate_arguments 是 CMake 中用于将字符串分割成参数列表的命令,适用于处理包含空格的参数或复杂命令行参数。以下是其用法详解: 基本语法 separate_arguments(<variable> [UNIX|WINDOWS_COMMAND] [PROGRAM <program>] [ARGS <args&…...

【AI科技】AMD ROCm 6.4 新功能:突破性推理、即插即用容器和模块化部署,可在 AMD Instinct GPU 上实现可扩展 AI
AMD ROCm 6.4 新功能:突破性推理、即插即用容器和模块化部署,可在 AMD Instinct GPU 上实现可扩展 AI 现代 AI 工作负载的规模和复杂性不断增长,而人们对性能和部署便捷性的期望也日益提升。对于在 AMD Instinct™ GPU 上构建 AI 和 HPC 未来…...