深入解析MapReduce:大数据处理的经典范式
引言
在大数据时代,如何高效处理海量数据成为技术核心挑战之一。Hadoop生态中的MapReduce框架应运而生,以其“分而治之”的思想解决了大规模数据的并行计算问题。本文将从原理、核心组件到实战案例,带你全面理解这一经典计算模型。
一、MapReduce概述
MapReduce是一种分布式计算框架,核心思想是将任务拆分为两个阶段:
-
Map阶段:将输入数据分割成独立块,并行处理生成中间键值对。
-
Reduce阶段:对中间结果聚合,生成最终输出。
其优势在于:
-
横向扩展性:通过增加节点轻松应对数据量增长。
-
容错机制:自动重试失败任务,保障任务可靠性。
-
数据本地化:优先在存储数据的节点执行计算,减少网络传输。
二、MapReduce工作原理
1. 数据流与核心流程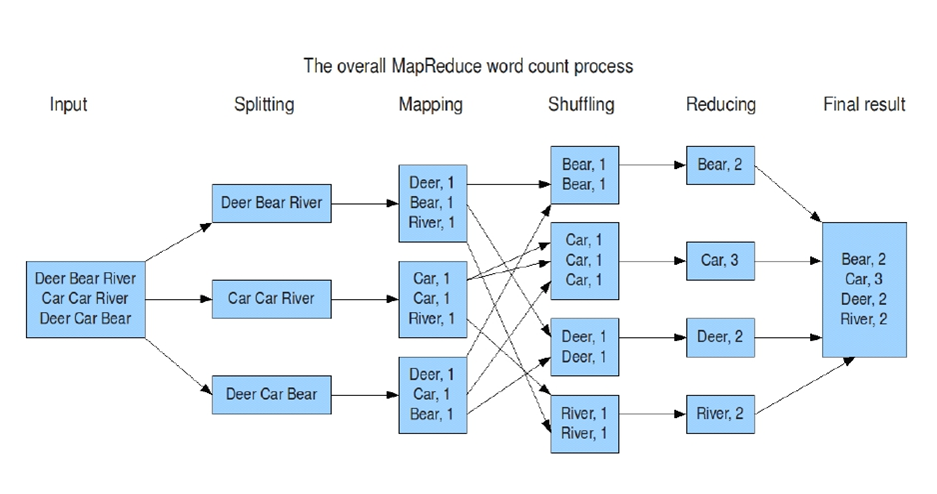
-
Input Split:输入数据被划分为多个分片(Split),每个分片启动一个Map任务。
-
Map阶段:处理分片数据,输出
<key, value>对。 -
Shuffle & Sort:将相同Key的数据分发到同一Reducer,并按Key排序。
-
Reduce阶段:聚合中间结果,输出最终结果。
2. 关键角色
1.Mapper:处理原始数据,生成中间结果。
Mapper类是一个泛型类,包含四个泛型参数,定义了输入输出的键值类型:
public class Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> { // 核心方法
} | 参数 | 描述 | 示例(WordCount) |
|---|---|---|
KEYIN | Map任务的输入键类型 | LongWritable(文件偏移量) |
VALUEIN | Map任务的输入值类型 | Text(一行文本) |
KEYOUT | Map任务的输出键类型(Reducer输入键) | Text(单词) |
VALUEOUT | Map任务的输出值类型(Reducer输入值) | IntWritable(出现次数1) |
2.Reducer:聚合中间结果,输出最终结果。
public class Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT> { // 核心方法
} | 参数 | 描述 | 示例(WordCount) |
|---|---|---|
KEYIN | Reducer 的输入键类型(Mapper 输出键) | Text(单词) |
VALUEIN | Reducer 的输入值类型(Mapper 输出值) | IntWritable(出现次数1) |
KEYOUT | Reducer 的输出键类型 | Text(单词) |
VALUEOUT | Reducer 的输出值类型 | IntWritable(总次数) |
Reducer 的输入并非直接来自 Mapper,而是经过以下处理:
-
Shuffle:框架将 Mapper 输出的中间数据按 Key 分组,并跨节点传输到对应的 Reducer。
-
Sort:数据按 Key 排序(默认升序),确保相同 Key 的值连续排列。
-
Group:将同一 Key 的所有 Value 合并为
Iterable<VALUEIN>供reduce()处理。
3.Combiner(可选):在Map端本地聚合,减少数据传输量。
4.Partitioner:控制中间结果的分区策略,决定数据流向哪个Reducer。
1. 自定义 Partitioner
public class GenderPartitioner extends Partitioner<Text, IntWritable> { @Override public int getPartition(Text key, IntWritable value, int numPartitions) { // 按性别分区,男→0,女→1 return key.toString().equals("男") ? 0 : 1; }
} 2. 配置作业
job.setPartitionerClass(GenderPartitioner.class);
job.setNumReduceTasks(2); // 需与分区数匹配 三、核心组件详解
1. Mapper的生命周期
public class Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> { protected void setup(Context context) { /* 初始化操作 */ } protected void map(KEYIN key, VALUEIN value, Context context) { /* 核心逻辑 */ } protected void cleanup(Context context) { /* 收尾操作 */ }
} -
setup():在Map任务启动时执行一次,用于初始化资源(如连接数据库、加载配置文件)。调用时机:在所有
map()方法调用之前。protected void setup(Context context) { // 初始化计数器或全局变量 Configuration conf = context.getConfiguration(); String param = conf.get("custom.param"); } -
map():处理每条输入记录,生成中间键值对。每条数据调用一次。
protected void map(KEYIN key, VALUEIN value, Context context) { // 示例:WordCount的切分单词逻辑 String line = value.toString(); StringTokenizer tokenizer = new StringTokenizer(line); while (tokenizer.hasMoreTokens()) { word.set(tokenizer.nextToken()); context.write(word, one); // 输出<单词, 1> } } -
cleanup():在Map任务结束时执行一次,用于释放资源(如关闭文件句柄、清理缓存)。调用时机:在所有
map()方法调用之后。protected void cleanup(Context context) { // 关闭数据库连接或写入日志 }
2. Reducer的输入输出
Reducer接收Mapper输出的<key, list<value>>,通过迭代计算生成最终结果。
public class Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT> { protected void reduce(KEYIN key, Iterable<VALUEIN> values, Context context) { // 例如:计算单词总频次 int sum = 0; for (VALUEIN value : values) sum += value.get(); context.write(key, new IntWritable(sum)); }
} 3. Combiner优化
Combiner本质是“本地Reducer”,在Map端预聚合数据。
job.setCombinerClass(IntSumReducer.class); // 直接复用Reducer逻辑 注意事项:
-
Combiner 的输入输出类型必须与 Mapper 的输出类型一致。
-
仅适用于可结合(Associative)和可交换(Commutative)的操作(如求和、最大值)。
适用场景:求和、最大值等可交换与结合的操作。
4. Partitioner自定义分发
默认分区策略是哈希取模,但可通过实现Partitioner接口自定义:
1. 自定义 Partitioner
public class GenderPartitioner extends Partitioner<Text, IntWritable> { @Override public int getPartition(Text key, IntWritable value, int numPartitions) { // 按性别分区,男→0,女→1 return key.toString().equals("男") ? 0 : 1; }
} 2. 配置作业
job.setPartitionerClass(GenderPartitioner.class);
job.setNumReduceTasks(2); // 需与分区数匹配 5.Job 类:作业控制中心
Job 类是 MapReduce 作业的入口,负责定义作业配置、设置任务链并提交到集群执行。
1. 核心方法
// 创建作业实例
Job job = Job.getInstance(Configuration conf, String jobName); // 设置作业的主类(包含main方法)
job.setJarByClass(Class<?> cls); // 配置Mapper和Reducer
job.setMapperClass(Class<? extends Mapper> cls);
job.setReducerClass(Class<? extends Reducer> cls); // 设置输入输出路径
FileInputFormat.addInputPath(Job job, Path path);
FileOutputFormat.setOutputPath(Job job, Path path); // 指定键值类型
job.setMapOutputKeyClass(Class<?> cls);
job.setMapOutputValueClass(Class<?> cls);
job.setOutputKeyClass(Class<?> cls);
job.setOutputValueClass(Class<?> cls); // 设置Combiner和Partitioner
job.setCombinerClass(Class<? extends Reducer> cls);
job.setPartitionerClass(Class<? extends Partitioner> cls); // 提交作业并等待完成
boolean success = job.waitForCompletion(boolean verbose); 2. 示例:WordCount 作业配置
public class WordCount { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf, "WordCount"); job.setJarByClass(WordCount.class); job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); }
} 6.InputFormat 与 OutputFormat
1. InputFormat
定义如何读取输入数据(如文件分片、记录解析)。常用实现类:
-
TextInputFormat:默认格式,按行读取文本文件,键为偏移量,值为行内容。
-
KeyValueTextInputFormat:按分隔符(如Tab)解析键值对。
-
SequenceFileInputFormat:读取Hadoop序列化文件。
自定义示例:
// 设置输入格式为KeyValueTextInputFormat
job.setInputFormatClass(KeyValueTextInputFormat.class); 2. OutputFormat
定义如何写入输出数据。常用实现类:
-
TextOutputFormat:将键值对写入文本文件,格式为
key \t value。 -
SequenceFileOutputFormat:输出为Hadoop序列化文件。
自定义示例:
// 设置输出格式为SequenceFileOutputFormat
job.setOutputFormatClass(SequenceFileOutputFormat.class); 7.Counter:任务级统计
通过 Counter 可收集作业运行时的统计信息(如无效记录数)。
// 在Mapper或Reducer中定义计数器
public class WordCountMapper extends Mapper<...> { enum Counter { INVALID_RECORDS } protected void map(...) { if (line == null) { context.getCounter(Counter.INVALID_RECORDS).increment(1); return; } // 正常处理 }
} 8.Context 对象:任务上下文
Context 对象贯穿 Mapper 和 Reducer 的生命周期,提供以下功能:
-
数据写入:
context.write(key, value) -
配置访问:
Configuration conf = context.getConfiguration() -
进度报告:
context.progress()(防止任务超时)
四、数据类型与序列化
MapReduce要求键值类型实现Writable或WritableComparable接口,确保跨节点序列化。
public interface WritableComparable<T> extends Writable, Comparable<T> {}1. 常用内置类型
| 序号 | Writable类 | 对应的Java类/类型 | 描述 |
|---|---|---|---|
| 1 | BooleanWritable | Boolean | 布尔值变量的封装 |
| 2 | ByteWritable | Byte | Byte的封装 |
| 3 | ShortWritable | Short | Short的封装 |
| 4 | IntWritable | Integer | 整数的封装 |
| 5 | LongWritable | Long | 长整型的封装 |
| 6 | FloatWritable | Float | 单精度浮点数的封装 |
| 7 | DoubleWritable | Double | 双精度浮点数的封装 |
| 8 | Text | String | UTF-8格式字符串的封装 |
| 9 | NullWritable | Null | 无键值的占位符(空类型) |
2. 自定义数据类型
以学生信息为例,需实现WritableComparable接口:
public class Student implements WritableComparable<Student> { private int id; private String name; // 实现序列化与反序列化 public void write(DataOutput out) { /* 序列化字段 */ } public void readFields(DataInput in) { /* 反序列化字段 */ } // 定义排序规则 public int compareTo(Student o) { /* 按ID或性别排序 */ }
} 五、实战案例:WordCount
1. Mapper实现
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); protected void map(LongWritable key, Text value, Context context) { String line = value.toString(); StringTokenizer tokenizer = new StringTokenizer(line); while (tokenizer.hasMoreTokens()) { word.set(tokenizer.nextToken()); context.write(word, one); } }
} 2. Reducer实现
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> { private IntWritable result = new IntWritable(); protected void reduce(Text key, Iterable<IntWritable> values, Context context) { int sum = 0; for (IntWritable val : values) sum += val.get(); result.set(sum); context.write(key, result); }
} 3. 提交作业
Job job = Job.getInstance(conf, "WordCount");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1); 六、优化与挑战
1. 性能瓶颈
-
Shuffle开销:跨节点数据传输可能成为瓶颈,可通过Combiner和压缩中间数据缓解。
-
小文件问题:过多小文件导致Map任务激增,需合并输入或使用SequenceFile。
2. 适用场景
-
批处理任务:ETL、日志分析等。
-
非实时计算:适合对延迟不敏感的场景。
3. 与Spark对比
| 特性 | MapReduce | Spark |
|---|---|---|
| 计算模型 | 批处理 | 批处理+流处理 |
| 内存使用 | 磁盘优先 | 内存优先 |
| 延迟 | 高 | 低 |
七、总结
MapReduce作为大数据处理的基石,其“分而治之”的思想深刻影响了后续计算框架(如Spark、Flink)。尽管在实时性上存在局限,但其高可靠性和成熟生态仍使其在离线计算领域占据重要地位。理解MapReduce不仅是掌握Hadoop的关键,更是构建分布式系统思维的重要一步。
相关文章:

深入解析MapReduce:大数据处理的经典范式
引言 在大数据时代,如何高效处理海量数据成为技术核心挑战之一。Hadoop生态中的MapReduce框架应运而生,以其“分而治之”的思想解决了大规模数据的并行计算问题。本文将从原理、核心组件到实战案例,带你全面理解这一经典计算模型。 一、MapR…...

JVM性能调优的基础知识 | JVM内部优化与运行时优化
目录 JVM内部的优化逻辑 JVM的执行引擎 解释执行器 即时编译器 JVM采用哪种方式? 即时编译器类型 JVM的分层编译5大级别: 分层编译级别: 热点代码: 如何找到热点代码? java两大计数器: OSR 编译…...

云计算-容器云-部署jumpserver 版本2
应用部署:堡垒机部署 # 使用提供的软件包配置Yum源,通过地址将jumpserver.tar.gz软件包下载至Jumpserver节点的/root目录下 [rootjumpserver ~]# tar -zxvf jumpserver.tar.gz -C /opt/ [rootjumpserver ~]# cp /opt/local.repo /etc/yum.repos.d/ [roo…...
)
MSP430G2553驱动0.96英寸OLED(硬件iic)
1.前言 最近需要用MSP430单片机做一个大作业,需要用到OLED模块,在这里记录一下 本篇文章主要讲解MSP430硬件iic的配置和OLED函数的调用,不会详细讲解OLED显示原理(其实就是江科大的OLED模块如何移植到msp430上).OLED显示原理以及底层函数讲解请参考其他…...

同质化的旅游内核
湘西凤凰古城、北京非常有文艺氛围的方家胡同都在被改造翻新为现代的其他城市范式式的样式。 什么意思呢?很多古城的老房子,从外面看,很古老、很漂亮,但是进去以后,完全不是那么回事,整座房子已经被完全掏…...
)
2025年五一数学建模A题【支路车流量推测】原创论文讲解(含完整python代码)
大家好呀,从发布赛题一直到现在,总算完成了2025年五一数学建模A题【支路车流量推测】完整的成品论文。 本论文可以保证原创,保证高质量。绝不是随便引用一大堆模型和代码复制粘贴进来完全没有应用糊弄人的垃圾半成品论文。 A题论文共104页&a…...
与自然语言处理》)
文章六:《循环神经网络(RNN)与自然语言处理》
文章6:循环神经网络(RNN)与自然语言处理——让AI学会"说人话" 引言:你的手机为什么能秒懂你? 当你说"我想看科幻片"时,AI助手能立刻推荐《星际穿越》,这背后是RNN在"…...

Redis总结及设置营业状态案例
Redis简介: rRedis服务开启与停止: 服务开启: 在Redis配置文件中输入cmd进入命令行输入redis-server redis-cli.exe -h -p:连接到redis服务 设置密码:在redis.windows.conf中找到requirepass 密码 服务停止: 在服务开启的界面按ctrlc Redis数据类…...

中科大:LLM几何推理数据生成
📖标题:Enhancing the Geometric Problem-Solving Ability of Multimodal LLMs via Symbolic-Neural Integration 🌐来源:arXiv, 2504.12773 🌟摘要 🔸多模态大语言模型(MLLM)的最…...

AimRT从入门到精通 - 04RPC客户端和服务器
一、ROS中的service通信机制 服务通信也是ROS中一种极其常用的通信模式,服务通信是基于请求响应模式的,是一种应答机制。也即:一个节点A向另一个节点B发送请求,B接收处理请求并产生响应结果返回给A。比如如下场景: 机器…...

【Android】Intent
目录 一、什么是Intent 二、显式Intent 三、隐式Intent 四、复杂数据传递 五、跨应用权限管理 六、常见问题 一、什么是Intent 1. 跨组件通信桥梁 实现组件间通信(Activity/Service/BroadcastReceiver)封装操作指令与数据传输逻辑 目标组件启动…...
)
从0开始建立Github个人博客(hugoPaperMod)
从0开始建立Github个人博客(hugo&PaperMod) github提供给每个用户一个网址,用户可以建立自己的静态网站。 一、Hugo hugo是一个快速搭建网站的工具,由go语言编写。 1.安装hugo 到hugo的github标签页Tags gohugoio/hugo选择一个版本,…...

Python集合全解析:从基础到高阶应用实战
一、集合核心特性与创建方法 1.1 集合的本质特征 Python集合(Set)是一种无序且元素唯一的容器类型,基于哈希表实现,具有以下核心特性: 唯一性:自动过滤重复元素无序性ÿ…...

Matlab自学笔记
一、我下载的是Matlab R2016a软件,打开界面如下: 二、如何调整字体大小,路径为:“主页”->“预设”->“字体”。 三、命令行窗口是直接进行交互式的,如下输入“3 5”,回车,就得到结果“…...

Python爬虫实战:获取好大夫在线各专业全国医院排行榜数据并分析,为患者就医做参考
一、引言 在当今医疗资源丰富但分布不均的背景下,患者在选择合适的心血管内科医院时面临诸多困难。好大夫在线提供的医院排行榜数据包含了医院排名、线上服务得分、患者评价得分等重要信息,对患者选择医院具有重要的参考价值。本研究通过爬取该排行榜数据,并进行深入分析,…...

多模态人工智能研究:视觉语言模型的过去、现在与未来
多模态人工智能研究:视觉语言模型的过去、现在与未来 1. 引言:定义多模态图景 多模态人工智能指的是旨在处理和整合来自多种数据类型或“模态”信息的人工智能系统,这些模态包括文本、图像、音频和视频等。与通常侧重于单一模态(…...

DeepSeek+Excel:解锁办公效率新高度
目录 一、引言:Excel 遇上 DeepSeek二、认识 DeepSeek:大模型中的得力助手2.1 DeepSeek 的技术架构与原理2.2 DeepSeek 在办公场景中的独特优势 三、DeepSeek 与 Excel 结合的准备工作3.1 获取 DeepSeek API Key3.2 配置 Excel 环境 四、DeepSeekExcel 实…...

3033. 修改矩阵
题目来源: leetcode题目:3033. 修改矩阵 - 力扣(LeetCode) 解题思路: 获取每列的最大值后将-1替换即可。 解题代码: #python3 class Solution:def getMaxRow(matrix:List[List[int]])->List[int]:r…...

Android面试总结之jet pack模块化组件篇
一、ViewModel 深入问题 1. ViewModel 如何实现跨 Fragment 共享数据?其作用域是基于 Activity 还是 Fragment? 问题解析: ViewModel 的作用域由 ViewModelStoreOwner 决定。当 Activity 和其内部 Fragment 共享同一个 ViewModelStoreOwner…...

【无需docker】mac本地部署dify
环境安装准备 #安装 postgresql13 brew install postgresql13 #使用zsh的在全局添加postgresql命令集 echo export PATH"/usr/local/opt/postgresql13/bin:$PATH" >> ~/.zshrc # 使得zsh的配置修改生效 source ~/.zshrc # 启动postgresql brew services star…...

清洗数据集
将label在图片上画出来 按照第一行的属性分类 import os import cv2 import multiprocessing as mp from tqdm import tqdm# ---------- 路径配置 ---------- # IMAGE_DIR = r"C:\Users\31919\Desktop\datasets\13k_100drive_raw_with_hand\images\test" LABEL_DIR =…...
详解)
支持向量机(SVM)详解
引言 支持向量机(Support Vector Machine, SVM)是一种强大的监督学习算法,主要用于分类和回归任务。其核心思想是找到一个最优的决策边界(超平面),最大化不同类别之间的间隔(Margin)…...

MIT XV6 - 1.2 Lab: Xv6 and Unix utilities - pingpong
接上文 MIT XV6 - 1.1 Lab: Xv6 and Unix utilities - user/_sleep 是什么?做什么? pingpong 不务正业了那么久(然而并没有,虽然还在探索sleep,但是教材我已经看完了前三章了),让我们赶紧继续下去 在进行本实验之前请务…...

“淘宝闪购”提前4天全量,意味着什么?
4月30日推出,首日上线50个城市,既定5月6日推广至全国的“淘宝闪购”,突然在5月2日早上官宣,提前4天面向全国消费者全量开放。 这一系列节奏,剑指一个字“快”! 是业务发展远超预期的“快”。 4月30日&am…...

Servlet 解决了什么问题?
Servlet 主要解决了以下几个核心问题: 性能问题 (Performance): CGI 的问题: 传统的 CGI 技术为每个Web 请求都启动一个新的进程。进程的创建和销毁涉及大量的系统资源开销(内存分配、CPU 时间、进程上下文切换等)。在高并发场景下…...

Cherry Studio的MCP协议集成与应用实践:从本地工具到云端服务的智能交互
Cherry Studio的MCP协议集成与应用实践:从本地工具到云端服务的智能交互 一、MCP协议与Cherry Studio的技术融合 MCP(Model Context Protocol) 是由Anthropic提出的标准化协议,旨在为AI模型提供与外部工具交互的通用接口。通过M…...
系列)
CPU:AMD的线程撕裂者(Threadripper)系列
AMD的线程撕裂者(Threadripper)系列是AMD面向高性能计算(HPC)、工作站(Workstation)和高端桌面(HEDT)市场推出的顶级处理器产品线。该系列以极高的核心数、强大的多线程性能、丰富的…...
 六十二、(2022) LKA 大核注意力)
(即插即用模块-Attention部分) 六十二、(2022) LKA 大核注意力
文章目录 1、Larger Kernel Attention2、代码实现 paper:Visual Attention Network Code:https://github.com/Visual-Attention-Network 1、Larger Kernel Attention 自注意力机制在 NLP 领域取得了巨大成功,但其应用于计算机视觉任务时存在…...

Spring 分批处理 + 冷热数据分离:历史订单高效迁移与数据清理实战
在实际业务中,随着时间推移,订单量持续增长,若未及时进行数据治理,会造成数据库膨胀、查询缓慢、性能下降等问题。为了实现数据分层管理和系统高性能运行,我们在项目中采用了“冷热数据分离 分批迁移 数据清理”的综…...

Mybatis中的一级二级缓存扫盲
思维导图: MyBatis 提供了一级缓存和二级缓存机制,用于提高数据库查询的性能,减少对数据库的访问次数。(本质上是减少IO次数)。 一级缓存 1. 概念 一级缓存也称为会话缓存,它是基于 SqlSession 的缓存。在同…...

Elasticsearch 常用的 API 接口
文档类 API Index API :创建并建立索引,向指定索引添加文档。例如:PUT /twitter/tweet/1 ,添加一个文档。 Get API :获取文档,通过索引、类型和 ID 获取文档。如GET /twitter/tweet/1。 DELETE API &…...

纯前端专业PDF在线浏览器查看器工具
纯前端专业PDF在线浏览器查看器工具 工具简介 我们最新开发的PDF在线浏览器工具现已发布!这是一个基于Web的轻量级PDF阅读器,无需安装任何软件,直接在浏览器中即可查看和操作PDF文档。 主要功能 ✅ PDF文件浏览 支持本地PDF文件上传流畅的…...

传奇各职业/战士/法师/道士手套/手镯/护腕/神秘腰带爆率及出处产出地/圣战/法神/天尊/祈祷/虹魔/魔血
护腕排行(战士): 名字攻击攻击(均)魔法魔法(均)道术道术(均)防御防御(均)魔御魔御(均)重量要求图标外观产出圣战手镯2-32.50-000-000-10.50-002攻击: 400.02%双头金刚(50级/5000血/不死系)|赤月魔穴(1725,2125)60分钟2只 0.02%双头血魔(55级/5000血/不死系)|赤月魔穴(1725,212…...

觅知解析计费系统重构版在线支付卡密充值多解析接口免授权无后门源码扶风二开
一、源码描述 这是一套视频解析计费源码(扶风二开),可配置多接口和专用特征解析接口,对接在线支付和卡密支付,支持在线充值和卡密充值,支持点数收费模式和包月套餐收费模式,可配置多个视频解析…...

C++11新特性_委托构造函数
格式定义 在 C11 里,委托构造函数的格式为:一个构造函数能够在其成员初始化列表里调用同一个类的其他构造函数。基本语法如下: class ClassName { public:// 被委托的构造函数(目标构造函数)ClassName(参数列表1) : …...

网工_IP协议
2025.02.17:小猿网&网工老姜学习笔记 第19节 IP协议 9.1 IP数据包的格式(首部数据部分)9.1.1 IP协议的首部格式(固定部分可变部分) 9.2 IP数据包分片(找题练)9.3 TTL生存时间的应用9.4 常见…...

C++负载均衡远程调用学习之QPS性能测试
目录 1.昨日回顾 2.QPS_TEST_PROTOBUF协议的集成 3.QPS_TEST_SERVER端实现 4.QPS_TEST_QPS简单介绍 5.QPS_TEST_QPS客户端工具编写和性能测试 1.昨日回顾 2.QPS_TEST_PROTOBUF协议的集成 ## 14) Reactor框架QPS性能测试 接下来我们写一个测试用例来测一下我们…...

C++负载均衡远程调用学习之消息队列与线程池
目录 1.昨日回顾 2.单线程的多路IO服务器模型和多线程模型区别 3.服务器的集中并发模式 4.LARSV0.8-task_msg消息队列任务数据类型 5.LARSV0.8--thread_queue消息队列的发送和接收流 6.LARSV0.8-thread_pool线程池的实现 7.LARSV0.8-thread_pool线程池的实现 8.LARSV0.8…...

Kotlin 基础
Kotlin基础语法详解 Kotlin是一种现代静态类型编程语言,由JetBrains开发,与Java完全互操作。以下是Kotlin的基础语法详解: 1. 基本语法 1.1 变量声明 // 不可变变量(推荐) val name: String = "Kotlin" val age = 25 // 类型推断// 可变变量 var count: In…...

实验数据的转换
最近做实验需要把x轴y轴z轴的数据处理一下,总结一下解决的方法: 源文件为两个txt文档,分别为x轴和y轴,如下: 最终需要达到的效果是如下: 就是需要把各个矩阵的数据整理好放在同一个txt文档里。 步骤① …...

多种尝试解决Pycharm无法粘贴外部文本【本人问题已解决】
#作者:允砸儿 #日期:乙巳青蛇年 四月初五 笔者在写demo的时候遇到一个非常棘手的问题就是pycharm无法复制粘贴,笔者相信有很多的朋友遇到过这种问题,笔者结合搜素到的和自己揣摩出来的方法帮助朋友们解决这种问题。 1、第一种…...

【C++】红黑树迭代版
目录 前言: 一:什么是红黑树? 二:插入什么颜色节点? 三:定义树 四:左单旋和右单旋 1.右单旋 2.左单旋 五:调整树 1.当parent节点为黑色时 2.当parent节点为红色时 2.1 u…...

OSPF路由协议配置
初始环境与准备: 物理连接:按照文件的拓扑连接了 3 台路由器 (R01, R02, R03)、2 台交换机 (Switch0, Switch1) 和 2 台 PC (PC0, PC1)。关键发现:路由器之间的连接实际使用的是以太网线(连接到 FastEthernet 接口),而不是串口线。…...

linux下抓包工具--tcpdump介绍
文章目录 1. 前言2. 命令介绍3. 常见选项3.1. 接口与基本控制3.2 输出控制3.3 文件操作3.4 高级调试 4. 过滤表达式4.1 协议类型4.2 方向与地址4.3 逻辑运算符 5. 典型使用场景5.1 网络故障排查5.2 安全分析与入侵检测5.3 性能分析与优化 linux下抓包工具--tcpdump介绍 1. 前言…...

探索 Disruptor:高性能并发框架的奥秘
在当今的软件开发领域,处理高并发场景是一项极具挑战性的任务。传统的并发解决方案,如基于锁的队列,往往在高负载下表现出性能瓶颈。而 Disruptor 作为一个高性能的并发框架,凭借其独特的设计和先进的技术,在处理海量数…...

smss源代码分析之smss!SmpLoadSubSystemsForMuSession函数分析加载csrss.exe
第一部分: Next SmpSubSystemsToLoad.Flink; while ( Next ! &SmpSubSystemsToLoad ) { p CONTAINING_RECORD( Next, SMP_REGISTRY_VALUE, Entry )…...
)
《AI大模型应知应会100篇》第44篇:大模型API调用最佳实践(附完整代码模板)
第44篇:大模型API调用最佳实践(附完整代码模板) 摘要 当你的应用突然面临每秒1000请求时,如何保证大模型API调用既稳定又经济?本文通过12个实战代码片段、3套生产级架构方案和20优化技巧,带你构建高性能的…...

第5篇:EggJS中间件开发与实战应用
在Web开发中,中间件(Middleware)是处理HTTP请求和响应的核心机制之一。EggJS基于Koa的洋葱模型实现了高效的中间件机制,本文将深入探讨中间件的执行原理、开发实践以及常见问题解决方案。 一、中间件执行机制与洋葱模型 1. 洋葱模…...
(文末有下载方式))
数字智慧方案6187丨智慧应急指挥平台体系建设方案(78页PPT)(文末有下载方式)
数字智慧方案6187丨智慧应急指挥平台体系建设方案 详细资料请看本解读文章的最后内容。 引言 随着社会经济的快速发展,应急管理面临着越来越复杂的挑战。智慧应急指挥平台体系的建设,旨在通过先进的信息技术和智能化手段,提升应急管理的效…...

Linux 常用命令 - tar【归档与压缩】
简介 tar 这个名称来源于 “tape archive”,最初设计用于将文件归档到磁带上。现在,tar 命令已经成为 Linux 系统中最常用的归档工具,它可以将多个文件和目录打包成一个单独的归档文件,并且可以选择使用不同的压缩算法进行压缩&a…...