Expected SARSA算法详解:python 从零实现
🧠 向所有学习者致敬!
“学习不是装满一桶水,而是点燃一把火。” —— 叶芝
我的博客主页: https://lizheng.blog.csdn.net
🌐 欢迎点击加入AI人工智能社区!
🚀 让我们一起努力,共创AI未来! 🚀
Expected SARSA 是啥玩意儿?
Expected SARSA 是一种在线策略(on-policy)的时序差分(Temporal Difference,TD)控制算法,属于强化学习领域,它是标准 SARSA 算法的升级版。SARSA 更新当前 Q 值时,用的是策略选择的具体下一个状态-动作对((Q(s’, a’)))的 Q 值,而 Expected SARSA 则用的是根据当前策略,所有可能的下一个动作的 Q 值的期望值。
这种期望值的运用,通常能让更新的方差比 SARSA 更小,因为它不依赖于单独采样的下一个动作,那个动作可能只是探索性的或者次优的。这在某些环境中,能带来更快更稳定的收敛。
Expected SARSA 在哪儿用、怎么用
Expected SARSA 和 SARSA、Q-learning 有很多相似的应用场景,不过在减少更新方差能带来好处的地方,它可能更有优势:
- 随机环境:动作的结果或者奖励有噪声的时候,对所有可能的下一个动作取平均,能让学习过程更平滑。
- 机器人和控制领域:和 SARSA 一样,能用来学习安全的策略,而且由于方差更小,收敛速度可能更快。
- 任何 SARSA 适用但更新方差高的场景。
Expected SARSA 和 SARSA 适用的条件差不多:
- 状态和动作空间是离散的(在表格形式下)。
- 想要采用在线策略的学习方法。
- 环境状态是完全可观测的。
Expected SARSA 的数学基础
原始复杂版本
Expected SARSA 算法用下面这个更新规则来更新 Q 值:
Q ( s t , a t ) ← Q ( s t , a t ) + α [ r t + γ E π [ Q ( s t + 1 , A ′ ) ] − Q ( s t , a t ) ] Q(s_t, a_t) \leftarrow Q(s_t, a_t) + \alpha \left[r_t + \gamma \mathbb{E}_{\pi}[Q(s_{t+1}, A')] - Q(s_t, a_t)\right] Q(st,at)←Q(st,at)+α[rt+γEπ[Q(st+1,A′)]−Q(st,at)]
展开就是:
Q ( s t , a t ) ← Q ( s t , a t ) + α [ r t + γ ∑ a ′ π ( a ′ ∣ s t + 1 ) Q ( s t + 1 , a ′ ) − Q ( s t , a t ) ] Q(s_t, a_t) \leftarrow Q(s_t, a_t) + \alpha \left[r_t + \gamma \sum_{a'} \pi(a'|s_{t+1}) Q(s_{t+1}, a') - Q(s_t, a_t)\right] Q(st,at)←Q(st,at)+α[rt+γa′∑π(a′∣st+1)Q(st+1,a′)−Q(st,at)]
其中:
- (Q(s_t, a_t)) 是状态 (s_t) 和动作 (a_t) 的 Q 值。
- (\alpha) 是学习率(0 < (\alpha) ≤ 1)。
- (r_t) 是在状态 (s_t) 下采取动作 (a_t) 后收到的奖励。
- (\gamma) 是折扣因子(0 ≤ (\gamma) ≤ 1)。
- (s_{t+1}) 是采取动作 (a_t) 后观察到的下一个状态。
- (\sum_{a’} \pi(a’|s_{t+1}) Q(s_{t+1}, a’)) 是在下一个状态 (s_{t+1}) 下的期望 Q 值。它是所有可能的下一个动作 (a’) 的 Q 值的加权和,权重是根据当前策略 (\pi) 在状态 (s_{t+1}) 下采取每个动作 (a’) 的概率。
- 括号里的项是时序差分误差,基于当前策略下下一个状态的期望值。
如果策略 (\pi) 是关于当前 Q 值的 (\epsilon)-贪婪策略:
- 设 (a^*{s’} = \arg\max{a’‘} Q(s’, a’‘)) 是状态 (s’) 下的贪婪动作。
- 选择贪婪动作的概率是 (\pi(a^*_{s’}|s’) = 1 - \epsilon + \frac{\epsilon}{|\mathcal{A}|})。
- 选择任何非贪婪动作 (a’ \neq a^*_{s’}) 的概率是 (\pi(a’|s’) = \frac{\epsilon}{|\mathcal{A}|})。
- 其中 (|\mathcal{A}|) 是状态 (s’) 下可用的动作数量。
期望值项就变成了:
E π [ Q ( s ′ , A ′ ) ] = ( 1 − ϵ + ϵ ∣ A ∣ ) Q ( s ′ , a s ′ ∗ ) + ∑ a ′ ≠ a s ′ ∗ ϵ ∣ A ∣ Q ( s ′ , a ′ ) \mathbb{E}_{\pi}[Q(s', A')] = (1 - \epsilon + \frac{\epsilon}{|\mathcal{A}|}) Q(s', a^*_{s'}) + \sum_{a' \neq a^*_{s'}} \frac{\epsilon}{|\mathcal{A}|} Q(s', a') Eπ[Q(s′,A′)]=(1−ϵ+∣A∣ϵ)Q(s′,as′∗)+a′=as′∗∑∣A∣ϵQ(s′,a′)
= ( 1 − ϵ ) Q ( s ′ , a s ′ ∗ ) + ϵ ∣ A ∣ ∑ a ′ Q ( s ′ , a ′ ) = (1 - \epsilon) Q(s', a^*_{s'}) + \frac{\epsilon}{|\mathcal{A}|} \sum_{a'} Q(s', a') =(1−ϵ)Q(s′,as′∗)+∣A∣ϵa′∑Q(s′,a′)
简化版
简单来说就是:
Q new = Q old + α [ R + γ E [ Q next ] − Q old ] Q_{\text{new}} = Q_{\text{old}} + \alpha \left[ R + \gamma E[Q_{\text{next}}] - Q_{\text{old}} \right] Qnew=Qold+α[R+γE[Qnext]−Qold]
其中 (E[Q_{\text{next}}]) 是下一个状态的期望 Q 值,通过按照策略的概率对所有可能的动作求平均来计算。
或者:
Q new = Q old + α [ Target − Q old ] Q_{\text{new}} = Q_{\text{old}} + \alpha \left[ \text{Target} - Q_{\text{old}} \right] Qnew=Qold+α[Target−Qold]
其中 “Target” 是 (R + \gamma E[Q_{\text{next}}])。
Expected SARSA 的步骤解析
- 初始化 Q 表:为所有状态 (s) 和动作 (a) 创建一个 Q 表,通常用零初始化。
- 每个剧集循环:
a. 初始化状态 (s)。
b. 剧集每一步循环:
i. 使用基于 Q 的策略(例如 (\epsilon)-贪婪)从状态 (s) 选择动作 (a)。
ii. 执行动作 (a),观察奖励 (r) 和下一个状态 (s’)。
iii. 计算 (s’) 的期望 Q 值:计算 (E[Q(s’, A’)] = \sum_{a’} \pi(a’|s’) Q(s’, a’))。
iv. 更新 Q 值:应用 Expected SARSA 更新规则:
(Q(s, a) \leftarrow Q(s, a) + \alpha [r + \gamma E[Q(s’, A’)] - Q(s, a)])
v. 更新状态:(s \leftarrow s’)。
vi. 如果 (s) 是终止状态,结束剧集。 - 重复:继续运行剧集,直到 Q 值收敛或者达到最大剧集数量。
注意:和 SARSA 不一样,从状态 (s’) 选择的动作(在 SARSA 中是 (a’))不会直接用于更新 (Q(s, a))。更新用的是从 (s’) 出发的所有动作的期望值。动作 (a’) 仍然会被选择,以确定下一步的状态转移。
Expected SARSA 的关键组成部分
Q 表
和 Q-Learning、SARSA 一样,用来存储状态-动作值。
探索与利用(策略)
Expected SARSA 是在线策略算法,也就是说,用于更新的策略和用于生成行为的策略是同一个。(\epsilon)-贪婪策略是常用的。计算期望值的时候,会明确地使用 (\epsilon) 值和 Q 值来确定每个动作的概率。
学习率((\alpha))
控制 Q 值更新的步长。和 Q-Learning/SARSA 里的作用一样。
折扣因子((\gamma))
决定未来奖励的现值。和 Q-Learning/SARSA 里的作用一样。
Expected SARSA vs. SARSA vs. Q-Learning
| 特性 | Q-Learning | SARSA | Expected SARSA |
|---|---|---|---|
| 类型 | 离线策略(Off-Policy) | 在线策略(On-Policy) | 在线策略(On-Policy) |
| 更新目标 | (r + \gamma \max_{a’} Q(s’, a’)) | (r + \gamma Q(s’, a’)) | (r + \gamma \sum_{a’} \pi(a’\mid s’) Q(s’, a’)) |
| 基础 | 学习最优价值函数 | 学习当前策略的价值函数 | 学习当前策略的价值函数 |
| 探索 | 学习最优路径,不受探索选择的影响 | 更新依赖于探索性的动作 (a’) | 更新会对探索取平均,减少 (a’) 的选择带来的方差 |
| 方差 | 可能有高方差(最大值操作) | 方差高(依赖于单独采样的 (a’)) | 比 SARSA 方差小(使用期望值) |
| 偏差 | 可能存在最大化偏差 | 比 Q-learning 偏差小 | 比 Q-learning 偏差小 |
| 行为 | 可能更激进/更优 | 通常更保守/更安全 | 通常比 SARSA 学习更稳定/更平滑,行为和 SARSA 类似 |
设置环境
导入必要的库,包括用于数值运算的 NumPy 和用于可视化的 Matplotlib。
# 导入必要的库
import numpy as np # 用于数值运算
import matplotlib.pyplot as plt # 用于可视化# 导入类型提示
from typing import List, Tuple, Dict, Optional# 设置随机种子以保证可重复性
np.random.seed(42)# 为 Jupyter Notebook 启用内联绘图
%matplotlib inline
创建一个简单环境
为了给 Expected SARSA 算法创建一个简单环境,我们来定义一个 4×4 的 GridWorld。这个 GridWorld 有以下属性:
- 4 行 4 列
- 可能的动作:‘up’(上)、‘down’(下)、‘left’(左)、‘right’(右)
- 特定的终止状态和奖励。
- 在后面的 Cliff Walking 示例中会有悬崖状态。
# 定义 GridWorld 环境创建函数
def create_gridworld(rows: int,cols: int,terminal_states: List[Tuple[int, int]],rewards: Dict[Tuple[int, int], int]
) -> Tuple[np.ndarray, List[Tuple[int, int]], List[str]]:"""创建一个简单的 GridWorld 环境。参数:- rows (int): 网格的行数。- cols (int): 网格的列数。- terminal_states (List[Tuple[int, int]]): 终止状态列表,以 (行, 列) 元组形式表示。- rewards (Dict[Tuple[int, int], int]): 字典,将 (行, 列) 映射到奖励值。返回值:- grid (np.ndarray): 一个 2D 数组,表示带有奖励的网格(仅用于参考,不被代理使用)。- state_space (List[Tuple[int, int]]): 网格中所有可能状态的列表。- action_space (List[str]): 可能动作的列表('up'、'down'、'left'、'right')。"""# 初始化网格为零(用于可视化/参考)grid = np.zeros((rows, cols))# 为指定状态分配奖励for (row, col), reward in rewards.items():grid[row, col] = reward# 定义状态空间为所有可能的 (行, 列) 组合state_space = [(row, col)for row in range(rows)for col in range(cols)]# 定义动作空间为四个可能的移动方向action_space = ['up', 'down', 'left', 'right']return grid, state_space, action_space
接下来我们需要状态转移函数,它以当前状态和动作为输入,返回下一个状态。可以理解为代理根据采取的动作在网格中移动。在这个例子中,环境是确定性的。
# 定义状态转移函数
def state_transition(state: Tuple[int, int], action: str, rows: int, cols: int) -> Tuple[int, int]:"""根据当前状态和动作计算下一个状态。处理边界情况。参数:- state (Tuple[int, int]): 当前状态,以 (行, 列) 表示。- action (str): 要采取的动作('up'、'down'、'left'、'right')。- rows (int): 网格的行数。- cols (int): 网格的列数。返回值:- Tuple[int, int]: 采取动作后得到的新状态(行, 列)。"""# 将当前状态拆分为行和列row, col = statenext_row, next_col = row, col# 根据动作更新行或列,同时确保边界被遵守if action == 'up' and row > 0: # 如果不在最上面一行,就向上移动next_row -= 1elif action == 'down' and row < rows - 1: # 如果不在最下面一行,就向下移动next_row += 1elif action == 'left' and col > 0: # 如果不在最左边一列,就向左移动next_col -= 1elif action == 'right' and col < cols - 1: # 如果不在最右边一列,就向右移动next_col += 1# 如果动作会导致离开网格,就保持在同一个状态(行和列保持不变)# 返回新状态,以元组形式return (next_row, next_col)
现在代理可以和环境互动了,我们需要定义奖励函数。这个函数会返回到达某个状态的奖励,用于在训练过程中更新 Q 值。
# 定义奖励函数
def get_reward(state: Tuple[int, int], rewards: Dict[Tuple[int, int], int]) -> int:"""获取给定状态的奖励。参数:- state (Tuple[int, int]): 当前状态,以 (行, 列) 表示。- rewards (Dict[Tuple[int, int], int]): 字典,将状态 (行, 列) 映射到奖励值。返回值:- int: 给定状态的奖励。如果状态不在奖励字典中,返回 0。"""# 使用奖励字典获取给定状态的奖励。# 如果状态不存在,返回默认奖励 0。return rewards.get(state, 0)
现在我们已经定义了 GridWorld 环境和必要的辅助函数,让我们用一个简单例子来测试它们。我们创建一个 4×4 的网格,有两个终止状态在 (0, 0) 和 (3, 3),奖励分别是 1 和 10。然后我们通过从状态 (2, 2) 向上移动来测试状态转移和奖励函数。
# 示例:使用 GridWorld 环境# 定义网格尺寸(4×4)、终止状态和奖励
rows, cols = 4, 4 # 网格的行数和列数
terminal_states = [(0, 0), (3, 3)] # 终止状态
rewards = {(0, 0): 1, (3, 3): 10} # 终止状态的奖励(其他状态的奖励为 0)# 创建 GridWorld 环境
grid, state_space, action_space = create_gridworld(rows, cols, terminal_states, rewards)# 测试状态转移和奖励函数
current_state = (2, 2) # 起始状态
action = 'up' # 要采取的动作
next_state = state_transition(current_state, action, rows, cols) # 计算下一个状态
reward = get_reward(next_state, rewards) # 获取下一个状态的奖励# 打印结果
print("GridWorld(奖励视图):") # 显示带有奖励的网格
print(grid)
print(f"当前状态:{current_state}") # 显示当前状态
print(f"采取的动作:{action}") # 显示采取的动作
print(f"下一个状态:{next_state}") # 显示得到的下一个状态
print(f"下一个状态的奖励:{reward}") # 显示下一个状态的奖励
GridWorld(奖励视图):
[[ 1. 0. 0. 0.][ 0. 0. 0. 0.][ 0. 0. 0. 0.][ 0. 0. 0. 10.]]
当前状态:(2, 2)
采取的动作:up
下一个状态:(1, 2)
下一个状态的奖励:0
可以看到,GridWorld 环境按照指定的尺寸、终止状态和奖励创建好了。我们选择了起始状态 (2, 2) 和动作(‘up’)。计算得到的下一个状态是 (1, 2),到达状态 (1, 2) 的奖励是 0,因为它不是指定的奖励状态。
实现 Expected SARSA 算法
我们已经成功实现了 GridWorld 环境。现在我们来实现核心部分:Q 表初始化、(\epsilon)-贪婪策略和具体的 Expected SARSA 更新规则。
# 初始化 Q 表
def initialize_q_table(state_space: List[Tuple[int, int]], action_space: List[str]) -> Dict[Tuple[Tuple[int, int], str], float]:"""用零初始化所有状态-动作对的 Q 表。使用单个字典,以 (状态, 动作) 元组作为键。参数:- state_space (List[Tuple[int, int]]): 所有可能状态的列表。- action_space (List[str]): 所有可能动作的列表。返回值:- q_table (Dict[Tuple[Tuple[int, int], str], float]): 一个字典,将 (状态, 动作) 对映射到 Q 值,初始化为 0.0。"""q_table: Dict[Tuple[Tuple[int, int], str], float] = {}for state in state_space:for action in action_space:# 初始化 (状态, 动作) 对的 Q 值为 0.0q_table[(state, action)] = 0.0return q_table
# --- 替代 Q 表结构(嵌套字典) ---
# 为了便于比较和重用。run_sarsa_episode 函数会相应调整。
def initialize_q_table_nested(state_space: List[Tuple[int, int]], action_space: List[str]) -> Dict[Tuple[int, int], Dict[str, float]]:"""用零初始化 Q 表,采用嵌套字典结构。参数:- state_space (List[Tuple[int, int]]): 所有可能状态的列表。- action_space (List[str]): 所有可能动作的列表。返回值:- q_table (Dict[Tuple[int, int], Dict[str, float]]): 一个嵌套字典,其中 q_table[状态][动作] 给出 Q 值。"""q_table: Dict[Tuple[int, int], Dict[str, float]] = {}for state in state_space:# 对于终止状态,Q 值应该保持为 0,因为无法从这些状态采取动作。# 不过,为了便于在更新前查找,还是初始化所有状态。q_table[state] = {action: 0.0 for action in action_space}return q_table
接下来,我们实现用于动作选择的 (\epsilon)-贪婪策略。这个策略通过平衡探索和利用,以概率 (\epsilon) 选择随机动作,以概率 (1 - \epsilon) 选择 Q 值最高的动作(最优动作)。
# 使用 \(\epsilon\)-贪婪策略选择动作
def epsilon_greedy_policy(state: Tuple[int, int], # 当前状态,以元组 (行, 列) 表示q_table: Dict[Tuple[int, int], Dict[str, float]], # Q 表,一个嵌套字典action_space: List[str], # 可能动作的列表epsilon: float # 探索率(选择随机动作的概率)
) -> str:"""使用 \(\epsilon\)-贪婪策略选择动作。参数:- state (Tuple[int, int]): 当前状态。- q_table (Dict[Tuple[int, int], Dict[str, float]]): Q 表。- action_space (List[str]): 可能动作的列表。- epsilon (float): 探索率(0 <= epsilon <= 1)。返回值:- str: 选择的动作。"""# 如果状态不在 Q 表中,选择随机动作if state not in q_table:return np.random.choice(action_space)# 以概率 epsilon 选择随机动作(探索)if np.random.rand() < epsilon:return np.random.choice(action_space)else:# 否则,选择 Q 值最高的动作(利用)if q_table[state]: # 确保状态有有效的 Q 值# 找到当前状态的最大 Q 值max_q = max(q_table[state].values())# 找到所有 Q 值最大的动作(处理平局)best_actions = [action for action, q in q_table[state].items() if q == max_q]# 如果有平局,随机选择一个最佳动作return np.random.choice(best_actions)else:# 如果状态没有有效的 Q 值,选择随机动作return np.random.choice(action_space)
接下来,我们来编写代理如何使用 Expected SARSA 算法更新 Q 值的逻辑。它会利用 Q 表计算下一个状态的期望值,这个期望值是根据当前策略((\epsilon)-贪婪)计算的。Q 值的更新将基于收到的奖励和下一个状态的期望值,同时受到学习率((\alpha))和折扣因子((\gamma))的影响。
# 使用 Expected SARSA 规则更新 Q 值
def update_expected_sarsa_value(q_table: Dict[Tuple[int, int], Dict[str, float]], # Q 表state: Tuple[int, int], # 当前状态,以元组 (行, 列) 表示action: str, # 在当前状态采取的动作reward: int, # 采取动作后收到的奖励next_state: Tuple[int, int], # 采取动作后到达的下一个状态alpha: float, # 学习率(步长)gamma: float, # 折扣因子(未来奖励的重要性)epsilon: float, # 探索率(用于计算策略概率)action_space: List[str], # 可能动作的列表terminal_states: List[Tuple[int, int]] # 终止状态列表
) -> None:"""使用 Expected SARSA 规则更新给定状态-动作对的 Q 值。参数:- q_table: 存储所有状态-动作对 Q 值的 Q 表。- state: 当前状态。- action: 在当前状态采取的动作。- reward: 采取动作后收到的奖励。- next_state: 采取动作后到达的下一个状态。- alpha: 学习率(0 < alpha <= 1)。- gamma: 折扣因子(0 <= gamma <= 1)。- epsilon: 探索率(0 <= epsilon <= 1)。- action_space: 可能动作的列表。- terminal_states: 环境中的终止状态列表。返回值:- None: 直接在 Q 表中更新 Q 值。"""# 确保当前状态和动作在 Q 表中if state not in q_table or action not in q_table[state]:return# 初始化下一个状态的期望 Q 值expected_q_next: float = 0.0# 如果下一个状态不是终止状态,计算期望 Q 值if next_state not in terminal_states and next_state in q_table and q_table[next_state]:# 获取下一个状态的所有动作的 Q 值q_values_next_state: Dict[str, float] = q_table[next_state]# 找到下一个状态的最大 Q 值max_q_next: float = max(q_values_next_state.values())# 找到所有 Q 值最大的动作(贪婪动作)greedy_actions: List[str] = [a for a, q in q_values_next_state.items() if q == max_q_next]# 计算贪婪动作和非贪婪动作的概率num_actions: int = len(action_space)num_greedy_actions: int = len(greedy_actions)prob_greedy: float = (1.0 - epsilon) / num_greedy_actions + epsilon / num_actionsprob_non_greedy: float = epsilon / num_actions# 计算下一个状态的期望 Q 值for a_prime in action_space:q_s_prime_a_prime: float = q_values_next_state.get(a_prime, 0.0)if a_prime in greedy_actions:expected_q_next += prob_greedy * q_s_prime_a_primeelse:expected_q_next += prob_non_greedy * q_s_prime_a_prime# 如果下一个状态是终止状态,expected_q_next 保持为 0.0# 计算时序差分(TD)目标和误差# TD 目标:td_target = reward + gamma * expected_q_next# TD 误差:td_error = td_target - q_table[state][action]td_target: float = reward + gamma * expected_q_nexttd_error: float = td_target - q_table[state][action]# 更新当前状态-动作对的 Q 值# Q(s, a) <- Q(s, a) + alpha * td_errorq_table[state][action] += alpha * td_error
到目前为止,我们已经定义了环境和核心的 Expected SARSA Q 值更新逻辑。现在,我们将这些组合到一个函数中,用于运行一个使用 Expected SARSA 更新逻辑的单个剧集。
# 运行一个 Expected SARSA 剧集
def run_expected_sarsa_episode(q_table: Dict[Tuple[int, int], Dict[str, float]], # Q 表state_space: List[Tuple[int, int]], # 环境中所有可能状态的列表action_space: List[str], # 可能动作的列表rewards: Dict[Tuple[int, int], int], # 状态到奖励的字典terminal_states: List[Tuple[int, int]], # 环境中的终止状态列表rows: int, # 网格的行数cols: int, # 网格的列数alpha: float, # 学习率(0 < alpha <= 1)gamma: float, # 折扣因子(0 <= gamma <= 1)epsilon: float, # 探索率(0 <= epsilon <= 1)max_steps: int # 每个剧集的最大步数
) -> Tuple[int, int]:"""使用 Expected SARSA 更新规则运行一个剧集。参数:- q_table: 存储所有状态-动作对 Q 值的 Q 表。- state_space: 环境中所有可能状态的列表。- action_space: 可能动作的列表。- rewards: 状态到奖励的字典。- terminal_states: 环境中的终止状态列表。- rows: 网格的行数。- cols: 网格的列数。- alpha: 学习率(0 < alpha <= 1)。- gamma: 折扣因子(0 <= gamma <= 1)。- epsilon: 探索率(0 <= epsilon <= 1)。- max_steps: 每个剧集的最大步数。返回值:- Tuple[int, int]: 本剧集中累积的总奖励和采取的步数。"""# 随机初始化起始状态,确保它不是终止状态state: Tuple[int, int] = state_space[np.random.choice(len(state_space))]while state in terminal_states:state = state_space[np.random.choice(len(state_space))]total_reward: int = 0 # 累积本剧集的总奖励steps: int = 0 # 记录本剧集采取的步数for _ in range(max_steps):# 使用 \(\epsilon\)-贪婪策略选择动作action: str = epsilon_greedy_policy(state, q_table, action_space, epsilon)# 采取选择的动作,观察下一个状态和奖励next_state: Tuple[int, int] = state_transition(state, action, rows, cols)reward: int = get_reward(next_state, rewards)total_reward += reward # 更新总奖励# 使用 Expected SARSA 规则更新当前状态-动作对的 Q 值update_expected_sarsa_value(q_table, state, action, reward, next_state, alpha, gamma, epsilon, action_space, terminal_states)# 转移到下一个状态state = next_statesteps += 1 # 增加步数计数器# 如果到达终止状态,结束剧集if state in terminal_states:breakreturn total_reward, steps
探索与利用策略
为了在探索和利用之间取得适当的平衡,我们使用前面定义的 (\epsilon)-贪婪策略,并实现动态 (\epsilon) 调整。(\epsilon) 从高值开始(更多探索),然后逐渐衰减,鼓励随着学习的进行更多地进行利用。
# 定义动态 \(\epsilon\) 调整函数(与 Q-Learning/sarsa 参考中的相同)
def adjust_epsilon(initial_epsilon: float,min_epsilon: float,decay_rate: float,episode: int
) -> float:"""使用指数衰减动态调整 \(\epsilon\)。参数:- initial_epsilon (float): 初始探索率。- min_epsilon (float): 最小探索率。- decay_rate (float): \(\epsilon\) 的衰减率。- episode (int): 当前剧集编号。返回值:- float: 当前剧集的调整后探索率。"""# 计算衰减后的 \(\epsilon\) 值,确保不低于最小 \(\epsilon\)return max(min_epsilon, initial_epsilon * np.exp(-decay_rate * episode))
接下来,我们跟踪并绘制 (\epsilon) 在计划剧集中的衰减情况,以可视化探索策略。
# 示例:动态 \(\epsilon\) 调整和绘制衰减曲线# 定义 \(\epsilon\) 参数
initial_epsilon: float = 1.0 # 初始时全探索
min_epsilon: float = 0.1 # 最小探索率
decay_rate: float = 0.01 # \(\epsilon\) 的衰减率
episodes: int = 500 # 训练的总剧集数# 跟踪各剧集的 \(\epsilon\) 值
epsilon_values: List[float] = []
for episode in range(episodes):# 调整当前剧集的 \(\epsilon\)current_epsilon = adjust_epsilon(initial_epsilon, min_epsilon, decay_rate, episode)epsilon_values.append(current_epsilon)# 绘制 \(\epsilon\) 衰减曲线
plt.figure(figsize=(20, 3)) # 稍微调整了图像大小
plt.plot(epsilon_values)
plt.xlabel('剧集') # x 轴标签
plt.ylabel('\(\epsilon\)') # y 轴标签
plt.title('\(\epsilon\) 随剧集衰减曲线') # 图表标题
plt.grid(True) # 添加网格以便更好地阅读
plt.show() # 显示图表

从图中可以看到,(\epsilon) 从 1.0(纯探索)开始,呈指数衰减,逐渐趋向于最小值 0.1(大部分时间进行利用,但仍有 10% 的探索)。这种逐渐的转变让代理能够在初期探索环境,然后根据学到的知识来优化策略。
运行 Expected SARSA 算法
现在我们多次运行 Expected SARSA 算法,在 GridWorld 环境中进行训练,同时使用动态 (\epsilon) 调整。我们将跟踪每个剧集的总奖励和剧集长度。
# 运行 Expected SARSA 的函数
def run_expected_sarsa(state_space: List[Tuple[int, int]], # 环境中所有可能状态的列表action_space: List[str], # 可能动作的列表rewards: Dict[Tuple[int, int], int], # 状态到奖励的字典terminal_states: List[Tuple[int, int]], # 环境中的终止状态列表rows: int, # 网格的行数cols: int, # 网格的列数alpha: float, # 学习率(0 < alpha <= 1)gamma: float, # 折扣因子(0 <= gamma <= 1)initial_epsilon: float, # 初始探索率(0 <= epsilon <= 1)min_epsilon: float, # 最小探索率decay_rate: float, # \(\epsilon\) 的衰减率episodes: int, # 训练的剧集数max_steps: int # 每个剧集的最大步数
) -> Tuple[Dict[Tuple[int, int], Dict[str, float]], List[int], List[int]]:"""在多个剧集中运行 Expected SARSA 算法。参数:- state_space: 环境中所有可能状态的列表。- action_space: 可能动作的列表。- rewards: 状态到奖励的字典。- terminal_states: 环境中的终止状态列表。- rows: 网格的行数。- cols: 网格的列数。- alpha: 学习率(0 < alpha <= 1)。- gamma: 折扣因子(0 <= gamma <= 1)。- initial_epsilon: 初始探索率(0 <= epsilon <= 1)。- min_epsilon: 最小探索率。- decay_rate: \(\epsilon\) 的衰减率。- episodes: 训练的剧集数。- max_steps: 每个剧集的最大步数。返回值:- Tuple 包含:- q_table: 一个嵌套字典,将状态映射到动作及其 Q 值。- rewards_per_episode: 每个剧集累积的总奖励的列表。- episode_lengths: 每个剧集采取的步数的列表。"""# 用零初始化所有状态-动作对的 Q 表q_table: Dict[Tuple[int, int], Dict[str, float]] = initialize_q_table_nested(state_space, action_space)# 列表,用于存储每个剧集的奖励和剧集长度rewards_per_episode: List[int] = []episode_lengths: List[int] = []# 遍历每个剧集for episode in range(episodes):# 为当前剧集动态调整 \(\epsilon\)epsilon: float = adjust_epsilon(initial_epsilon, min_epsilon, decay_rate, episode)# 运行一个 Expected SARSA 剧集total_reward, steps = run_expected_sarsa_episode(q_table, state_space, action_space, rewards, terminal_states,rows, cols, alpha, gamma, epsilon, max_steps)# 存储总奖励和剧集长度rewards_per_episode.append(total_reward)episode_lengths.append(steps)# 返回 Q 表、每个剧集的奖励和剧集长度return q_table, rewards_per_episode, episode_lengths
设置超参数并运行 SARSA 训练过程。
# --- 运行 Expected SARSA ---
# 定义 Expected SARSA 的超参数
alpha_es = 0.1 # 学习率:控制 Q 值更新的步长
gamma_es = 0.9 # 折扣因子:决定未来奖励的重要性
initial_epsilon_es = 1.0 # 初始探索率:选择随机动作的概率
min_epsilon_es = 0.1 # 最小探索率:\(\epsilon\) 的下限
decay_rate_es = 0.01 # \(\epsilon\) 衰减率:控制 \(\epsilon\) 下降的速度
episodes_es = 500 # 训练代理的剧集数
max_steps_es = 100 # 每个剧集允许的最大步数# 打印一条消息,表明训练开始
print("正在运行 Expected SARSA...")# 使用指定的超参数运行 Expected SARSA 算法
es_q_table, es_rewards_per_episode, es_episode_lengths = run_expected_sarsa(state_space, action_space, rewards, terminal_states, rows, cols, alpha_es, gamma_es,initial_epsilon_es, min_epsilon_es, decay_rate_es, episodes_es, max_steps_es
)# 打印一条消息,表明训练完成
print("Expected SARSA 训练完成。")
正在运行 Expected SARSA...
Expected SARSA 训练完成。
可视化学习过程
接下来,我们通过绘制每个剧集的总奖励和剧集长度来可视化训练进度。
# 绘制 Expected SARSA 的结果
plt.figure(figsize=(20, 3))# 奖励
plt.subplot(1, 2, 1)
plt.plot(es_rewards_per_episode)
plt.xlabel('剧集')
plt.ylabel('总奖励')
plt.title('Expected SARSA:剧集奖励')
plt.grid(True)# 剧集长度
plt.subplot(1, 2, 2)
plt.plot(es_episode_lengths)
plt.xlabel('剧集')
plt.ylabel('剧集长度')
plt.title('Expected SARSA:剧集长度')
plt.grid(True)plt.tight_layout()
plt.show()

Expected SARSA 学习曲线分析
奖励曲线(左侧)
- 奖励曲线在整个剧集中高度波动,表明代理的性能经常起伏不定。
- 与平滑收敛不同,奖励在低值和高值之间振荡,表明代理偶尔会遵循次优路径或进行大量探索。
- 这种不稳定性可能是由于高探索率、学习率调整不当或环境本身的变异性引起的。
- 与标准 SARSA 相比,期望值更新似乎并没有显著平滑波动。
剧集长度曲线(右侧)
- 最初,剧集长度较长,证实代理最初采用的策略效率较低。
- 随着时间的推移,剧集长度减少并稳定在较低值,表明代理正在学习更优的路径。
- 总体趋势是下降的,表明学习取得了成功,但后期剧集仍有一些变化。
- 与奖励曲线相比,此图更清晰地显示了学习进展,因为较短的剧集长度对应于更高效的目标达成行为。
分析 Q 值和最优策略
现在,我们可视化 Expected SARSA 算法学习到的 Q 值和由此得出的策略。我们使用热图表示每个动作的 Q 值,并在网格上用箭头表示策略。
# 绘制 Q 值热图的函数
def plot_q_values_heatmap(q_table: Dict[Tuple[int, int], Dict[str, float]], rows: int, cols: int, action_space: List[str], fig: plt.Figure, axes: np.ndarray) -> None:"""在提供的轴上为每个动作绘制 Q 值热图。参数:- q_table: 将状态映射到动作及其 Q 值的嵌套字典。- rows: 网格的行数。- cols: 网格的列数。- action_space: 可能动作的列表(例如,['up', 'down', 'left', 'right'])。- fig: Matplotlib 图形对象。- axes: 用于绘制热图的 Matplotlib 轴数组。"""for i, action in enumerate(action_space):# 初始化一个网格,对于不在 Q 表中的状态用 -inf 填充q_values = np.full((rows, cols), -np.inf)for (row, col), actions in q_table.items():if action in actions:q_values[row, col] = actions[action] # 分配动作的 Q 值# 绘制当前动作的热图ax = axes[i]cax = ax.matshow(q_values, cmap='viridis') # 使用 'viridis' 色彩映射fig.colorbar(cax, ax=ax) # 为热图添加颜色条ax.set_title(f"Expected SARSA Q 值:{action}") # 热图标题# 添加网格线以便更好地可视化ax.set_xticks(np.arange(-.5, cols, 1), minor=True)ax.set_yticks(np.arange(-.5, rows, 1), minor=True)ax.grid(which='minor', color='w', linestyle='-', linewidth=1)# 移除刻度标签以获得更干净的外观ax.set_xticks(np.arange(cols))ax.set_yticks(np.arange(rows))ax.tick_params(axis='both', which='both', length=0)ax.set_xticklabels([])ax.set_yticklabels([])# 绘制学习到的策略的函数
def plot_policy_grid(q_table: Dict[Tuple[int, int], Dict[str, float]], rows: int, cols: int, terminal_states: List[Tuple[int, int]], ax: plt.Axes) -> None:"""在提供的轴上以箭头形式在网格上绘制学习到的策略。参数:- q_table: 将状态映射到动作及其 Q 值的嵌套字典。- rows: 网格的行数。- cols: 网格的列数。- terminal_states: 网格中的终止状态列表。- ax: Matplotlib 轴,用于绘制策略网格。"""# 初始化一个网格来存储策略符号policy_grid = np.empty((rows, cols), dtype=str)action_symbols = {'up': '↑', 'down': '↓', 'left': '←', 'right': '→', '': ''}for r in range(rows):for c in range(cols):state = (r, c)if state in terminal_states:# 用 'T' 标记终止状态policy_grid[r, c] = 'T'continueif state in q_table and q_table[state]:# 找到 Q 值最高的动作max_q = -np.infbest_actions = []for action, q_val in q_table[state].items():if q_val > max_q:max_q = q_valbest_actions = [action]elif q_val == max_q:best_actions.append(action)# 如果有平局,选择第一个动作if best_actions:best_action = best_actions[0]policy_grid[r, c] = action_symbols[best_action]else:# 标记没有有效动作的状态policy_grid[r, c] = '.'else:# 标记未访问或没有 Q 值的状态policy_grid[r, c] = '.'# 绘制策略网格ax.matshow(np.zeros((rows, cols)), cmap='Greys', alpha=0.1) # 背景网格for r in range(rows):for c in range(cols):# 在每个单元格中添加策略符号ax.text(c, r, policy_grid[r, c], ha='center', va='center', fontsize=14, color='black' if policy_grid[r, c] != 'T' else 'red')# 添加网格线和标题ax.set_title("Expected SARSA 学习到的策略")ax.set_xticks(np.arange(-.5, cols, 1), minor=True)ax.set_yticks(np.arange(-.5, rows, 1), minor=True)ax.grid(which='minor', color='black', linestyle='-', linewidth=1)ax.set_xticks([])ax.set_yticks([])
# 可视化 Expected SARSA 的 Q 值和策略
fig_es, axes_es = plt.subplots(1, len(action_space) + 1, figsize=(20, 4))plot_q_values_heatmap(es_q_table, rows, cols, action_space, fig_es, axes_es[:-1])
axes_es[0].set_title(f"Exp. SARSA Q 值:{action_space[0]}") # 调整标题
axes_es[1].set_title(f"Exp. SARSA Q 值:{action_space[1]}")
axes_es[2].set_title(f"Exp. SARSA Q 值:{action_space[2]}")
axes_es[3].set_title(f"Exp. SARSA Q 值:{action_space[3]}")plot_policy_grid(es_q_table, rows, cols, terminal_states, axes_es[-1])
axes_es[-1].set_title("Expected SARSA 学习到的策略")plt.tight_layout()
plt.show()
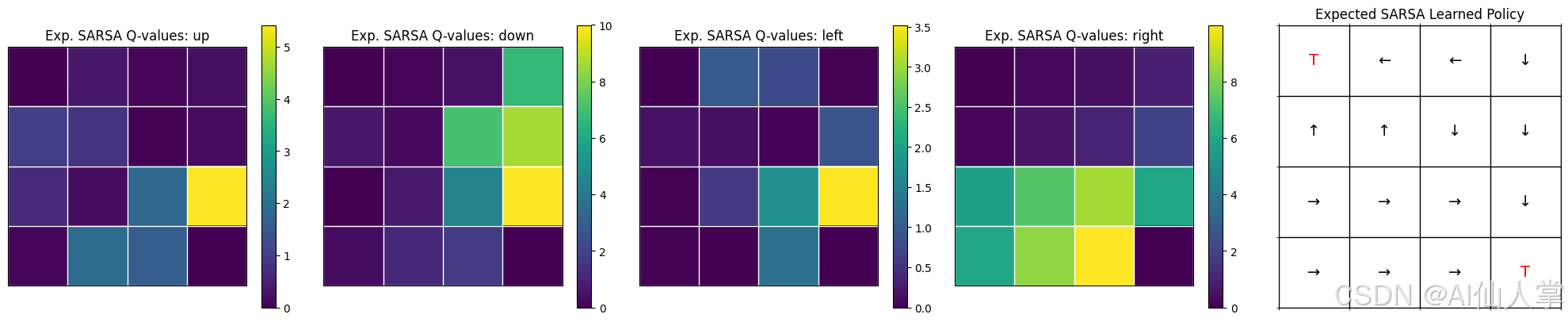
Expected SARSA Q 值和策略分析
Q 值热图(前四个图)
- 这些热图展示了每个动作(上、下、左、右)在所有网格状态下的学习到的 Q 值。
- 较亮的颜色(黄色/绿色)表示较高的 Q 值,意味着这些动作在某些状态下更有利。
- “下”和“右”动作在大多数状态下具有最高的 Q 值,这与引导代理走向目标的最优策略一致。
- 值的传播是可见的,尤其是在靠近终止状态的地方,奖励影响了相邻状态。
学习到的策略(最右图)
- 从 Q 值得出的最优策略以箭头形式可视化,指示每个状态下最佳动作的方向。
- 策略主要遵循向右(→)和向下(↓)的运动模式,引导代理高效地走向右下角的目标状态。
- 在某些状态下出现了向上(↑)和向左(←)的动作,可能是由于早期探索的影响或存在替代但次优的路径。
- 终止状态(‘T’)被正确学习,如红色所示。
总体解读:
- 代理成功地学习到了稳定的策略,从Q 值和方向箭头的清晰结构可以看出。
- Expected SARSA 有效地从目标状态向后传播奖励,创建了最优路径。
- 与 Q-learning 相比,后者遵循更确定性的更新规则,Expected SARSA 的更新受到代理策略的影响,可能导致更平滑的学习过程。
- 最终 Q 值中几乎没有噪声或不稳定性,表明收敛良好。
分析 Q 值和最优策略
让我们以表格形式检查 SARSA 学习到的最优策略,显示每个状态下每个动作的 Q 值以及对应的最优动作。
# --- 表格视图 ---
# 创建一个列表,用于存储每个状态的 Q 值和最优动作
es_q_policy_data = []# 遍历网格的每一行和每一列
for r in range(rows):for c in range(cols):state = (r, c) # 定义当前状态为一个元组 (行, 列)# 检查状态是否在 Q 表中if state in es_q_table:actions = es_q_table[state] # 获取当前状态下所有动作的 Q 值# 如果状态有有效的 Q 值if actions:# 确定最优动作(Q 值最高的动作)# 如果状态是终止状态,将最优动作标记为 'Terminal'best_action = max(actions, key=actions.get) if state not in terminal_states else 'Terminal'# 将状态、Q 值和最优动作添加到数据列表中es_q_policy_data.append({'State': state,'up': actions.get('up', 0.0), # 'up' 动作的 Q 值(如果不存在则默认为 0.0)'down': actions.get('down', 0.0), # 'down' 动作的 Q 值'left': actions.get('left', 0.0), # 'left' 动作的 Q 值'right': actions.get('right', 0.0), # 'right' 动作的 Q 值'Optimal Action': best_action # 当前状态的最优动作})else:# 如果状态没有有效的 Q 值,添加默认值es_q_policy_data.append({'State': state,'up': 0.0,'down': 0.0,'left': 0.0,'right': 0.0,'Optimal Action': 'N/A' # 没有有效动作,标记为 'N/A'})else:# 如果状态不在 Q 表中,添加默认值es_q_policy_data.append({'State': state,'up': 0.0,'down': 0.0,'left': 0.0,'right': 0.0,'Optimal Action': 'N/A' # 缺失状态,标记为 'N/A'})# 按状态对数据进行排序以便于阅读
es_q_policy_data.sort(key=lambda x: x['State'])# 定义表格的标题
header = ['State', 'up', 'down', 'left', 'right', 'Optimal Action']# 打印标题
print(f"{header[0]:<10} {header[1]:<10} {header[2]:<10} {header[3]:<10} {header[4]:<10} {header[5]:<15}")
print("-" * 65) # 打印分隔线# 打印每行 Q 值和最优动作
for row_data in es_q_policy_data:print(f"{row_data['State']!s:<10} {row_data['up']:<10.2f} {row_data['down']:<10.2f} {row_data['left']:<10.2f} {row_data['right']:<10.2f} {row_data['Optimal Action']:<15}")
State up down left right Optimal Action
-----------------------------------------------------------------
(0, 0) 0.00 0.00 0.00 0.00 Terminal
(0, 1) 0.34 0.17 1.00 0.20 left
(0, 2) 0.09 0.46 0.79 0.42 left
(0, 3) 0.21 6.67 0.02 0.88 down
(1, 0) 1.00 0.65 0.17 0.13 up
(1, 1) 0.83 0.25 0.15 0.53 up
(1, 2) 0.04 7.10 0.04 0.95 down
(1, 3) 0.16 8.63 0.91 1.93 down
(2, 0) 0.64 0.01 0.02 5.69 right
(2, 1) 0.18 0.74 0.60 7.32 right
(2, 2) 1.80 4.46 1.77 8.64 right
(2, 3) 5.42 10.00 3.52 5.88 down
(3, 0) 0.10 0.33 0.02 5.90 right
(3, 1) 1.91 1.11 0.00 8.34 right
(3, 2) 1.62 1.73 1.31 10.00 right
(3, 3) 0.00 0.00 0.00 0.00 Terminal
表格形式的 Expected SARSA Q 值和策略分析
关键观察点:
1. Q 值趋势和值传播:
- 靠近目标的状态具有较高的 Q 值,表明代理已有效地学习估算长期奖励。
- 例如,状态 (3,2) 的右移动作具有较高的 Q 值,因为它直接通向目标。
- Q 值从目标向外传播,随着状态离目标越来越远而逐渐降低。
2. 最优动作选择和策略结构:
- “最优动作”列确认代理遵循一条通往目标的合理轨迹。
- “右移 (→)”和“下移 (↓)”动作在大多数状态下占主导地位,与通往目标的高效路径一致。
- 偶尔出现的“上移 (↑)”和“左移 (←)”选择,出现在替代路径被探索的地方,反映了 在线策略学习(SARSA 的 (\epsilon)-贪婪行为)的影响。
3. 终止状态和学习行为:
- 终止状态,包括 目标状态 (3,3),被正确识别,防止进一步的动作选择。
- 终止状态的 Q 值保持为零,因为它们对未来的奖励没有贡献。
4. 风险意识行为和悬崖规避:
- 靠近危险区域(如悬崖或障碍物)的状态具有不同的 Q 值,表明代理已学会权衡不同动作的风险。
- SARSA 的 在线策略学习 方法导致了一种更 谨慎的策略,避免了危险状态,因为奖励可能会丢失。
- 这种风险规避倾向是 与 Q-learning 的关键区别,后者可能会学习到更具侵略性的策略,专注于最高预期回报。
- 这种差异在 悬崖相邻的状态 中尤为明显,SARSA 更为谨慎。
5. 与热图可视化的对齐:
- 表格 Q 值与热图可视化相匹配,验证了策略结构的一致性。
- 在多个动作具有相似 Q 值时,动作选择的微小差异 可以归因于平局时的随机选择。
与 Q-learning 的比较:
- SARSA 的 在线策略更新 优先考虑安全性,避免了悬崖附近的危险动作。
- Q-learning(离线策略)可能会得出一个更具侵略性的策略,只关注最高预期回报。
- 这种差异在 悬崖相邻的状态 中尤为明显,SARSA 更为谨慎。
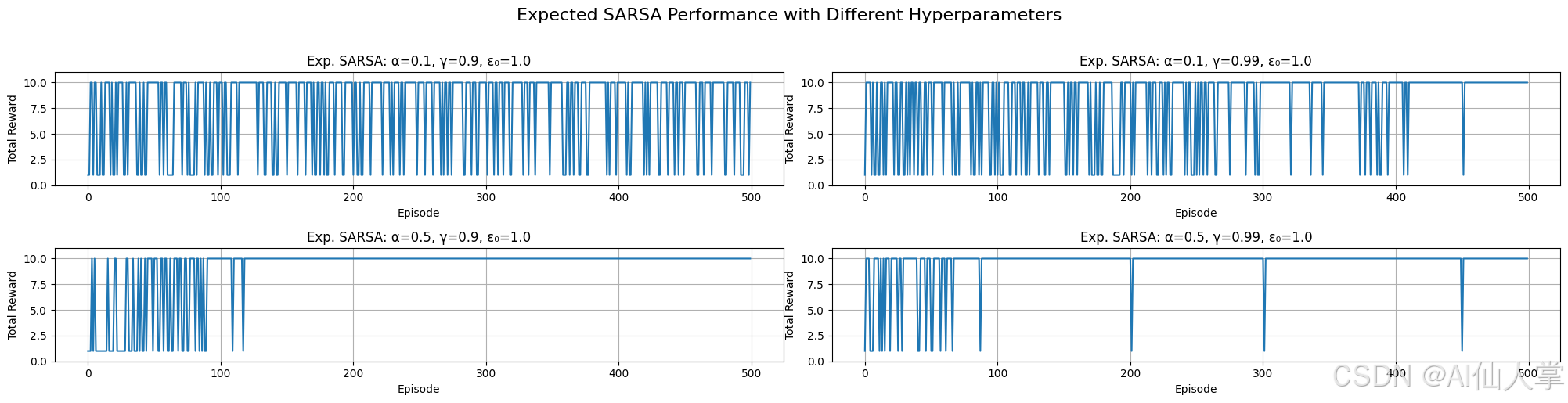
使用不同超参数进行测试(可选)
尝试不同的学习率((\alpha))、折扣因子((\gamma))和初始探索率((\epsilon_0))的值,以观察它们对 Expected SARSA 的学习速度和收敛的影响。
# --- 运行 Expected SARSA 超参数实验 ---# 定义实验的超参数范围
learning_rates_es_exp = [0.1, 0.5] # 要测试的不同学习率(\(\alpha\))
discount_factors_es_exp = [0.9, 0.99] # 要测试的不同折扣因子(\(\gamma\))
exploration_rates_es_exp = [1.0] # 固定初始探索率用于此比较# 列表,用于存储实验结果
es_results_exp = []# 打印消息,表明实验开始
print("正在运行 Expected SARSA 超参数实验...")# 遍历所有学习率、折扣因子和探索率的组合
for alpha in learning_rates_es_exp:for gamma in discount_factors_es_exp:for initial_epsilon in exploration_rates_es_exp:# 打印当前正在测试的超参数组合print(f" 使用 alpha={alpha}, gamma={gamma}, epsilon_init={initial_epsilon} 进行 ES 训练")# 运行 Expected SARSA,使用当前的超参数组合q_table, rewards_per_episode, episode_lengths = run_expected_sarsa(state_space, action_space, rewards, terminal_states, rows, cols, alpha, gamma,initial_epsilon, min_epsilon_es, decay_rate_es, episodes_es, max_steps_es # 使用之前的最小值/衰减率)# 存储当前组合的结果es_results_exp.append({'alpha': alpha, # 学习率'gamma': gamma, # 折扣因子'initial_epsilon': initial_epsilon, # 初始探索率'rewards_per_episode': rewards_per_episode, # 每个剧集的奖励'episode_lengths': episode_lengths # 剧集长度})# 打印消息,表明实验完成
print("实验完成。")# --- 可视化 ---# 确定可视化所需的子图数量
num_results_es = len(es_results_exp) # 实验总数
plot_rows_es = int(np.ceil(np.sqrt(num_results_es))) # 子图网格的行数
plot_cols_es = int(np.ceil(num_results_es / plot_rows_es)) # 子图网格的列数# 创建一个较大的图形来可视化所有超参数组合
plt.figure(figsize=(20, 5))# 遍历结果并绘制每个实验的奖励
for i, result in enumerate(es_results_exp):plt.subplot(plot_rows_es, plot_cols_es, i + 1) # 为当前实验创建子图plt.plot(result['rewards_per_episode']) # 绘制每个剧集的奖励plt.title(f"Exp. SARSA: α={result['alpha']}, γ={result['gamma']}, ε₀={result['initial_epsilon']}") # 标题包含超参数plt.xlabel('剧集') # x 轴标签plt.ylabel('总奖励') # y 轴标签plt.grid(True) # 添加网格以便更好地阅读# 根据所有实验中的最小和最大奖励设置 y 轴范围plt.ylim(min(min(r['rewards_per_episode']) for r in es_results_exp) - 1,max(max(r['rewards_per_episode']) for r in es_results_exp) + 1)# 为整个图形添加超级标题
plt.suptitle("不同超参数下的 Expected SARSA 性能", fontsize=16, y=1.02)# 调整布局以防止重叠并显示图形
plt.tight_layout()
plt.show()
正在运行 Expected SARSA 超参数实验...使用 alpha=0.1, gamma=0.9, epsilon_init=1.0 进行 ES 训练使用 alpha=0.1, gamma=0.99, epsilon_init=1.0 进行 ES 训练使用 alpha=0.5, gamma=0.9, epsilon_init=1.0 进行 ES 训练使用 alpha=0.5, gamma=0.99, epsilon_init=1.0 进行 ES 训练
实验完成。
将 Expected SARSA 应用于不同环境(悬崖行走)
现在,将 Expected SARSA 应用于悬崖行走环境,并比较其行为。我们期望它也可能像 SARSA 一样学习到一条更安全的路径,而且奖励的改善可能更平滑。
# 重新使用 SARSA 悬崖实验的超参数进行比较
alpha_cliff_es = 0.1
gamma_cliff_es = 0.99 # 使用更高的 \(\gamma\)
initial_epsilon_cliff_es = 0.2 # 从较低的探索率开始,以便更快地找到安全路径
min_epsilon_cliff_es = 0.01
decay_rate_cliff_es = 0.005
episodes_cliff_es = 500
max_steps_cliff_es = 200# 定义环境参数
cliff_rows, cliff_cols = 4, 12
cliff_start_state = (3, 0)
cliff_terminal_state = (3, 11)
cliff_states = [(3, c) for c in range(1, 11)]
cliff_action_space = ['up', 'down', 'left', 'right']
# 定义奖励:正常步骤为 -1,掉入悬崖为 -100,达到目标为 +10(目标的隐式奖励由更新处理)
# SARSA/Q-learning 通常使用进入状态的奖励。
# 我们可以稍微调整奖励/转移逻辑以适应这种常见设置。# 修改的悬崖状态转移和奖励
def cliff_state_transition_reward(state: Tuple[int, int],action: str,rows: int,cols: int,cliff_states: List[Tuple[int, int]],start_state: Tuple[int, int]
) -> Tuple[Tuple[int, int], int]:"""计算悬崖行走的下一个状态和奖励。正常步骤的奖励为 -1,掉入悬崖的奖励为 -100。掉入悬崖会重置状态为起始状态。"""row, col = statenext_row, next_col = row, col# 计算潜在的下一个位置if action == 'up' and row > 0:next_row -= 1elif action == 'down' and row < rows - 1:next_row += 1elif action == 'left' and col > 0:next_col -= 1elif action == 'right' and col < cols - 1:next_col += 1next_state = (next_row, next_col)# 确定奖励if next_state in cliff_states:reward = -100next_state = start_state # 掉入悬崖后重置为起始状态elif next_state == cliff_terminal_state:reward = 0 # 标准设置通常在到达目标时给予 0 奖励,-1 的转移成本由步骤奖励处理# 替代方案:在这里给予 +10 或其他正奖励。让我们坚持 -1 的步骤成本结构。目标状态本身在到达时不给予奖励/惩罚。reward = -1 # 应用步骤成本,即使到达目标也一样?不,目标转移是特殊的。# 让我们使用常见的 -1 步骤成本结构。目标状态本身在到达时不给予奖励/惩罚。reward = -1else:reward = -1 # 标准步骤成本return next_state, reward
# 定义一个专门用于悬崖行走环境的 Expected SARSA 运行函数
def run_expected_sarsa_cliff_episode(q_table: Dict[Tuple[int, int], Dict[str, float]], # Q 表action_space: List[str], # 可能动作的列表terminal_state: Tuple[int, int], # 环境中的终止状态cliff_states: List[Tuple[int, int]], # 环境中的悬崖状态列表start_state: Tuple[int, int], # 每个剧集的起始状态rows: int, # 网格的行数cols: int, # 网格的列数alpha: float, # 学习率 (0 < alpha <= 1)gamma: float, # 折扣因子 (0 <= gamma <= 1)epsilon: float, # 探索率 (0 <= epsilon <= 1)max_steps: int # 每个剧集允许的最大步数
) -> Tuple[int, int]:"""运行悬崖行走环境的一个 Expected SARSA 剧集。参数:- q_table: 存储所有状态-动作对 Q 值的 Q 表。- action_space: 所有可能动作的列表。- terminal_state: 环境中的终止状态。- cliff_states: 环境中的悬崖状态列表。- start_state: 每个剧集的起始状态。- rows: 网格的行数。- cols: 网格的列数。- alpha: 学习率 (0 < alpha <= 1)。- gamma: 折扣因子 (0 <= gamma <= 1)。- epsilon: 探索率 (0 <= epsilon <= 1)。- max_steps: 每个剧集允许的最大步数。返回值:- Tuple 包含:- total_reward: 本剧集累积的总奖励。- steps: 本剧集采取的步数。"""# 初始化起始状态state: Tuple[int, int] = start_statetotal_reward: int = 0 # 累积本剧集的总奖励steps: int = 0 # 记录本剧集采取的步数# 循环最多 max_steps 步for _ in range(max_steps):# 使用 \(\epsilon\)-贪婪策略选择动作action: str = epsilon_greedy_policy(state, q_table, action_space, epsilon)# 采取选择的动作并观察下一个状态和奖励next_state, reward = cliff_state_transition_reward(state, action, rows, cols, cliff_states, start_state)total_reward += reward # 更新总奖励# 使用 Expected SARSA 规则更新当前状态-动作对的 Q 值# 将终止状态作为列表传递给更新函数update_expected_sarsa_value(q_table, state, action, reward, next_state, alpha, gamma, epsilon, action_space, [terminal_state])# 转移到下一个状态state = next_statesteps += 1 # 增加步数计数器# 如果到达终止状态,结束剧集if state == terminal_state:breakreturn total_reward, steps
def run_expected_sarsa_cliff(action_space: List[str], # 可能动作的列表(例如,['up', 'down', 'left', 'right'])terminal_state: Tuple[int, int], # 环境中的终止状态cliff_states: List[Tuple[int, int]], # 环境中的悬崖状态列表start_state: Tuple[int, int], # 每个剧集的起始状态rows: int, # 网格的行数cols: int, # 网格的列数alpha: float, # 学习率 (0 < alpha <= 1)gamma: float, # 折扣因子 (0 <= gamma <= 1)initial_epsilon: float, # 初始探索率 (0 <= epsilon <= 1)min_epsilon: float, # 最小探索率decay_rate: float, # 探索率的衰减率episodes: int, # 训练的剧集数max_steps: int # 每个剧集允许的最大步数
) -> Tuple[Dict[Tuple[int, int], Dict[str, float]], List[int], List[int]]:"""在悬崖行走环境中运行 Expected SARSA 算法。参数:- action_space (List[str]): 所有可能动作的列表。- terminal_state (Tuple[int, int]): 环境中的终止状态。- cliff_states (List[Tuple[int, int]]): 环境中的悬崖状态列表。- start_state (Tuple[int, int]): 每个剧集的起始状态。- rows (int): 网格的行数。- cols (int): 网格的列数。- alpha (float): 学习率 (0 < alpha <= 1)。- gamma (float): 折扣因子 (0 <= gamma <= 1)。- initial_epsilon (float): 初始探索率 (0 <= epsilon <= 1)。- min_epsilon (float): 最小探索率。- decay_rate (float): 探索率的衰减率。- episodes (int): 训练的剧集数。- max_steps (int): 每个剧集允许的最大步数。返回值:- Tuple 包含:- q_table (Dict[Tuple[int, int], Dict[str, float]]): 存储所有状态-动作对 Q 值的 Q 表。- rewards_per_episode (List[int]): 每个剧集累积的总奖励的列表。- episode_lengths (List[int]): 每个剧集采取的步数的列表。"""# 生成状态空间,包含所有可能的 (行, 列) 组合state_space: List[Tuple[int, int]] = [(r, c) for r in range(rows) for c in range(cols)]# 用零初始化所有状态-动作对的 Q 表q_table: Dict[Tuple[int, int], Dict[str, float]] = initialize_q_table_nested(state_space, action_space)# 列表,用于存储每个剧集的奖励和剧集长度rewards_per_episode: List[int] = []episode_lengths: List[int] = []# 遍历每个剧集for episode in range(episodes):# 为当前剧集动态调整探索率epsilon: float = adjust_epsilon(initial_epsilon, min_epsilon, decay_rate, episode)# 运行悬崖行走环境的一个 Expected SARSA 剧集total_reward, steps = run_expected_sarsa_cliff_episode(q_table, action_space, terminal_state, cliff_states, start_state,rows, cols, alpha, gamma, epsilon, max_steps)# 存储总奖励和剧集长度rewards_per_episode.append(total_reward)episode_lengths.append(steps)# 返回 Q 表、每个剧集的奖励和剧集长度return q_table, rewards_per_episode, episode_lengths
让我们运行 Expected SARSA 的悬崖行走实验。
# 重新使用 SARSA 悬崖实验的超参数进行比较
alpha_cliff_es = 0.1 # 学习率:控制 Q 值更新的步长
gamma_cliff_es = 0.99 # 折扣因子:决定未来奖励的重要性
initial_epsilon_cliff_es = 0.2 # 初始探索率:选择随机动作的概率
min_epsilon_cliff_es = 0.01 # 最小探索率:\(\epsilon\) 的下限
decay_rate_cliff_es = 0.005 # 探索率的衰减率:控制 \(\epsilon\) 下降的速度
episodes_cliff_es = 500 # 训练代理的剧集数
max_steps_cliff_es = 200 # 每个剧集允许的最大步数# 打印一条消息,表明开始训练
print("正在悬崖行走环境中运行 Expected SARSA...")# 定义悬崖行走环境的参数
cliff_rows, cliff_cols = 4, 12 # 网格尺寸(4 行 × 12 列)
cliff_start_state = (3, 0) # 每个剧集的起始状态
cliff_terminal_state = (3, 11) # 终止状态(目标状态)
cliff_states = [(3, c) for c in range(1, 11)] # 悬崖状态(危险状态,需要避免)
cliff_action_space = ['up', 'down', 'left', 'right'] # 环境中可能的动作# 在悬崖行走环境中运行 Expected SARSA 训练
cliff_q_table_es, cliff_rewards_es, cliff_lengths_es = run_expected_sarsa_cliff(cliff_action_space, # 可能的动作列表cliff_terminal_state, # 终止状态cliff_states, # 悬崖状态列表cliff_start_state, # 每个剧集的起始状态cliff_rows, # 网格的行数cliff_cols, # 网格的列数alpha_cliff_es, # 学习率gamma_cliff_es, # 折扣因子initial_epsilon_cliff_es, # 初始探索率min_epsilon_cliff_es, # 最小探索率decay_rate_cliff_es, # 探索率的衰减率episodes_cliff_es, # 训练的剧集数max_steps_cliff_es # 每个剧集允许的最大步数
)# 打印一条消息,表明训练完成
print("悬崖行走环境中的 Expected SARSA 训练完成。")
正在悬崖行走环境中运行 Expected SARSA...
悬崖行走环境中的 Expected SARSA 训练完成。
接下来,我们可以绘制奖励,如下所示。
# 绘制奖励的函数
def plot_rewards(rewards_per_episode: List[int], ax: plt.Axes = None) -> plt.Axes:"""绘制每个剧集累积的总奖励。参数:- rewards_per_episode (List[int]): 每个剧集累积的总奖励的列表。- ax (plt.Axes, 可选):Matplotlib 轴,用于绘图。如果为 None,则创建一个新的图形和轴。返回值:- plt.Axes: 包含绘图的 Matplotlib 轴。"""# 如果未提供轴,则创建一个新的图形和轴if ax is None:fig, ax = plt.subplots(figsize=(8, 6))# 绘制奖励随剧集的变化ax.plot(rewards_per_episode)ax.set_xlabel('剧集') # x 轴标签ax.set_ylabel('总奖励') # y 轴标签ax.set_title('每个剧集的奖励') # 图表标题# 返回轴,以便需要时进行进一步自定义return ax
为了可视化结果,我们可以像之前一样绘制奖励和剧集长度。我们还可以绘制悬崖行走环境中学习到的策略。
# --- 悬崖行走(Expected SARSA)的可视化 ---
fig_cliff_es, axs_cliff_es = plt.subplots(2, 2, figsize=(18, 8))# 奖励
plot_rewards(cliff_rewards_es, ax=axs_cliff_es[0, 0])
axs_cliff_es[0, 0].set_title("Exp. SARSA: 悬崖行走奖励")
axs_cliff_es[0, 0].grid(True)# 剧集长度
axs_cliff_es[0, 1].plot(cliff_lengths_es)
axs_cliff_es[0, 1].set_xlabel('剧集')
axs_cliff_es[0, 1].set_ylabel('剧集长度')
axs_cliff_es[0, 1].set_title('Exp. SARSA: 悬崖行走剧集长度')
axs_cliff_es[0, 1].grid(True)# 绘制最大 Q 值(热图) - 需要一个函数,该函数接受悬崖环境的参数
def plot_q_values_cliff(q_table, rows, cols, ax):q_values = np.zeros((rows, cols))for r in range(rows):for c in range(cols):state = (r, c)if state in q_table and q_table[state]:q_values[r, c] = max(q_table[state].values())else:q_values[r,c] = -np.inf # 标记未访问/终止状态# 为了更好的可视化,屏蔽悬崖状态q_values_masked = np.ma.masked_where(q_values <= -100, q_values) # 隐藏悬崖的极端负值im = ax.imshow(q_values_masked, cmap='viridis')plt.colorbar(im, ax=ax, label='最大 Q 值')ax.set_title('Expected SARSA: 最大 Q 值(悬崖)')ax.set_xticks(np.arange(cols))ax.set_yticks(np.arange(rows))ax.set_xticklabels([])ax.set_yticklabels([])ax.grid(which='major', color='w', linestyle='-', linewidth=1)# 最大 Q 值
plot_q_values_cliff(cliff_q_table_es, cliff_rows, cliff_cols, ax=axs_cliff_es[1, 0])
axs_cliff_es[1, 0].set_title('Exp. SARSA: 最大 Q 值(悬崖)')# 策略
plot_policy_grid(cliff_q_table_es, cliff_rows, cliff_cols, [cliff_terminal_state], ax=axs_cliff_es[1, 1])
axs_cliff_es[1, 1].set_title("Exp. SARSA: 学习到的策略(悬崖)")plt.tight_layout()
plt.show()
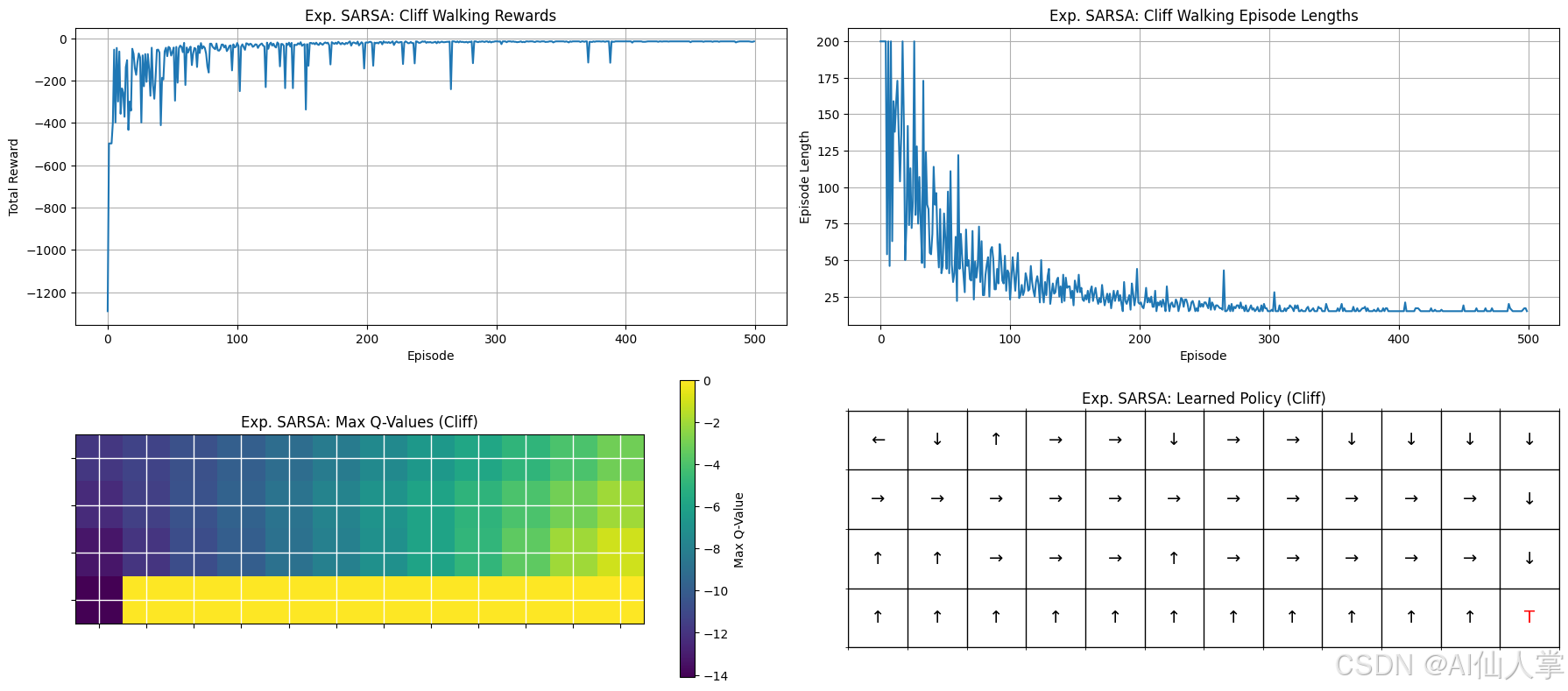
悬崖行走(Expected SARSA)的更新分析:
1. 奖励和剧集长度(上一行):
- 总奖励图 显示初期有明显的下降,这是由于代理在早期剧集中频繁掉入悬崖,导致奖励大幅减少。
- 随着时间的推移,奖励逐渐改善并稳定下来,因为代理学会了避免悬崖并找到更安全的路径。
- 剧集长度持续减少,表明代理越来越高效地到达目标,步数越来越少。
- 更平滑的收敛模式 表明 Expected SARSA 的期望值更新提供了更稳定的学习过程,减少了波动。
2. 最大 Q 值和策略(下一行):
- Q 值热图 进一步证实了学习过程,悬崖附近的 Q 值较低(较暗区域),突出了掉入悬崖的高惩罚性。
- 较高的 Q 值(较亮区域)集中在更安全的路径上,表明代理更倾向于选择这些动作。
- 学习到的策略图 显示代理最初会向上移动以避开悬崖的直接威胁,然后沿着上边沿向右移动,最后向下移动到达目标。
- 这种保守的路径确保了代理最小化了掉入悬崖区域的风险,突出了 Expected SARSA 的风险规避特性。
悬崖行走环境中的 Expected SARSA 结论:
Expected SARSA 成功地学习到了一种稳定且谨慎的策略,更倾向于选择安全的路径,而不是冒险但更短的路径。
与标准 SARSA 相比:
- 它的收敛过程更平滑,因为它的期望值更新减少了方差。
- 最终策略保持了在线策略学习的特性,避免了悬崖,同时保持了效率。
- Expected SARSA 在需要稳定性和风险最小化的环境中表现出色。
常见挑战及解决方案
(从 SARSA 中重用,因为挑战是相似的)
挑战:学习缓慢或陷入困境
- 解决方案:调整超参数((\alpha)、(\gamma)、(\epsilon) 衰减)。增加初始探索或采用更复杂的探索策略。对于较大的状态空间,使用函数近似。
挑战:平衡探索与利用
- 解决方案:使用调整良好的 (\epsilon) 衰减计划。
挑战:选择合适的超参数
- 解决方案:进行实验。从常见的值开始((\alpha)≈0.1,(\gamma)≈0.9-0.99,(\epsilon) 从 1.0 衰减到 0.1/0.01)。
挑战:期望的计算成本
- 解决方案:在表格情况下,动作空间较小时,求和计算成本较低。对于大型/连续动作空间,计算精确期望是不可行的,需要采用不同的技术(例如,采样、为策略使用函数近似)。
Expected SARSA 与其他强化学习算法的比较
Expected SARSA 的优势
- 在线策略:学习当前策略的价值。
- 方差较低:通常比 SARSA 的更新方差小,因为它对所有可能的下一个动作取平均,而不是依赖于单个样本。这可能导致更稳定的学习。
- 更稳定/保守:继承了 SARSA 在危险环境中学习更安全策略的倾向。
- 在标准条件下保证收敛。
Expected SARSA 的局限性
- 可能比 Q-learning 慢:仍然根据当前策略进行学习,可能会探索次优动作,与离线策略的 Q-learning 相比,收敛到真正最优策略的速度可能会更慢。
- 计算成本:需要对下一个状态的所有动作进行迭代以计算期望值,如果动作空间较大(在表格情况下),这可能比 SARSA 或 Q-learning 的每次更新稍微增加一些计算成本。如果动作空间是连续的,则无法直接应用,需要进行修改。
- 在表格形式下,难以处理较大的状态空间。
相关算法
- SARSA:Expected SARSA 所基于的在线策略 TD 算法。
- Q-learning:离线策略 TD 算法,直接学习最优策略。
- SARSA( λ \lambda λ) / Expected SARSA( λ \lambda λ):使用符合资格迹的版本,以便更快地进行信用分配。
- 演员-评论家方法:同时学习策略和价值函数。
结论
Expected SARSA 是一种有效的在线策略时序差分控制算法,通过减少 SARSA 的更新方差而改进。它通过使用当前策略的期望 Q 值(而不是依赖于单个采样的下一个动作)来实现这一点。
这通常可以带来更平滑、有时更快的收敛,同时保留了 SARSA 的在线策略特性,使其非常适合在危险环境中评估当前策略并学习更安全的行为,例如悬崖行走。尽管在表格情况下,每次更新的计算成本略高于 SARSA,但其更稳定的特性使其成为一种强大的在线策略学习方法。
相关文章:

Expected SARSA算法详解:python 从零实现
🧠 向所有学习者致敬! “学习不是装满一桶水,而是点燃一把火。” —— 叶芝 我的博客主页: https://lizheng.blog.csdn.net 🌐 欢迎点击加入AI人工智能社区! 🚀 让我们一起努力,共创…...

SALOME源码分析: JobManager
本文分析SALOME中的JobManager模块。 注1:限于研究水平,分析难免不当,欢迎批评指正。注2:文章内容会不定期更新。 一、核心组件 二、关键流程 三、FAQs 网络资料 Introduction: What is the JOBMANAGER ?...

冯·诺依曼体系:现代计算机的底层逻辑与百年传承
在智能手机流畅运行复杂游戏、超级计算机模拟气候变化的今天,很少有人会想到,驱动这些神奇机器运转的核心架构,依然遵循着70多年前提出的设计理念。这就是由匈牙利裔美国科学家约翰冯诺依曼(John von Neumann)奠定的冯…...

10 种微服务设计模式
微服务的优势与挑战 在详细介绍设计模式之前,我觉得有必要先重申下微服务的概念以及它带来的挑战。 微服务是大型应用程序的一个小型、可独立部署的组件,专注于特定功能。每个微服务都运行自己的进程,通常通过 API 与其他服务进行通信&…...

深入拆解 MinerU 解析处理流程
概述 MinerU更新频率也相当频繁,在短短一个月内,更新了10个小版本。 本文结合最新版本v1.3.10,深入拆解下它进行文档解析时的内部操作细节。 MinerU仓库地址:https://github.com/opendatalab/MinerU 环境准备 在之前的文章中,已经安装了magic-pdf(MinerU的解析包名),…...
)
Nginx部署Vue+ElementPlus应用案例(基于腾讯云)
案例代码链接:https://download.csdn.net/download/ly1h1/90735035 1.参考链接: 基于以下两个链接的参考,创建项目 1.1.基于Vue3前端项目创建-CSDN博客 1.2.基于Vue3引入ElementPlus_vue如何引入elementplus-CSDN博客 2.修改main.js&#…...
门面模式)
设计模式简述(十六)门面模式
门面模式 描述基本组件 描述 门面模式是一种概念相对简单的设计模式。 其核心思想就是:封装内部子系统的复杂调用,提供一个门面对象供外部调用。 基本组件 定义子系统对象(这里做了简化,没有声明抽象) public clas…...

云原生后端:构建高效、可扩展的现代后端架构
📝个人主页🌹:一ge科研小菜鸡-CSDN博客 🌹🌹期待您的关注 🌹🌹 随着云计算技术的迅猛发展,云原生(Cloud Native)架构已经成为现代软件开发的核心趋势。云原生后端指的是在云环境中构建和部署的后端系统,这些系统具有弹性、可扩展性、自动化运维等特性,能够更…...

基于bert的情感分析程序
文章目录 任务介绍数据概览注意事项数据处理代码准备模型构建与训练模型类构建数据集构建数据批处理模型参数查看模型训练结果推理与评估模型推理准确率评估附录任务介绍 在当今信息爆炸的时代,互联网上充斥着海量的文本数据,如社交媒体评论、产品评价、新闻报道等。这些文本…...

情境领导理论——AI与思维模型【89】
一、定义 情境领导理论思维模型是一种强调领导者应根据下属的成熟度(包括工作能力和工作意愿两个方面)来调整领导风格,以实现有效领导的动态理论。该模型认为,没有一种放之四海而皆准的领导方式,领导者的行为要与下属…...

WPF之ProgressBar控件详解
文章目录 1. ProgressBar控件简介2. ProgressBar的基本属性和用法2.1 基本属性2.2 基本用法2.3 代码中修改进度 3. 确定与不确定模式3.1 确定模式(Determinate)3.2 不确定模式(Indeterminate) 4. 在多线程环境中更新ProgressBar4.…...

计算机网络01-网站数据传输过程
局域网: 覆盖范围小,自己花钱买设备,宽带固定,自己维护,,一般长度不超过100米,,,带宽也比较固定,,,10M,,&…...

泰迪杯特等奖案例学习资料:基于边缘计算与多模态融合的温室传感器故障自诊断系统设计
(第十四届泰迪杯数据挖掘挑战赛A题特等奖案例解析) 一、案例背景与核心挑战 1.1 应用场景与行业痛点 在现代智能温室中,传感器网络是环境调控的核心依据,但其长期运行面临以下挑战: 数据异常频发: 传感器老化:温湿度传感器SHT35的精度在连续使用2年后可能漂移1℃。 环…...

力扣面试150题--分隔链表
day 39 题目描述 思路 遍历链表,每一个点与值比较,比值小就继续,比值大就放到链表尾部即可 /*** Definition for singly-linked list.* public class ListNode {* int val;* ListNode next;* ListNode() {}* ListNode(int…...

Shell 脚本基础
一、Shell 简介 1.Shell 的定义与作用 Shell,通常被称为命令行解释器 (Command Line Interpreter),是用户 👤 与 Linux/Unix 操作系统内核进行交互 ↔️ 的“桥梁” 🌉。它扮演着翻译官 🗣️ 的角色: 接…...

【AI面试准备】元宇宙测试:AI+低代码构建虚拟场景压力测试
介绍元宇宙测试:AI低代码构建虚拟场景压力测试(如数字孪生工厂)。如何快速掌握,以及在实际工作中如何运用。 目录 **元宇宙测试:AI低代码构建虚拟场景压力测试****一、元宇宙测试的核心挑战与需求**1. **元宇宙测试的独…...

【网络层】之IP协议
网络层之IP协议 网络层的作用IP地址不足的问题私网IP和公网IP网段划分传统的网段划分的方法CIDR网段划分路由器的角色理解运营商的角色子网划分的过程 路由表IP协议介绍报文如何分离、交付 网络层的作用 IP协议是网络层的一种典型协议,只要弄清楚了IP协议的作用&…...

AI编译器对比:TVM vs MLIR vs Triton在大模型部署中的工程选择
引言:大模型部署的编译器博弈 随着千亿参数大模型成为常态,推理延迟优化成为系统工程的核心挑战。本文基于NVIDIA A100与Google TPUv4平台,通过BERT-base(110M)和GPT-2(1.5B)的实测数据&#x…...

【dify—10】工作流实战——文生图工具
目录 一、创建工作流 应用 二、安装硅基流动 三、配置硅基流动 四、API测试 (1)进入API文档 (2)复制curl代码 (3)Postman测试API 五、 建立文生图工作流 (1)建立http请求 &…...

企业级分布式 MCP 方案
飞书原文档链接地址:https://ik3te1knhq.feishu.cn/wiki/D8kSwC9tFi61CMkRdd8cMxNTnpg 企业级分布式 MCP 方案 [!TIP] 背景:现阶段 MCP Client 和 MCP Server 是一对一的连接方式,若当前 MCP Server 挂掉了,那么 MCP Client 便不…...
:基本概念)
玩转Docker(一):基本概念
容器技术是继大数据和云计算之后又一炙手可热的技术,而且未来相当一段时间内都会非常流行。 本文将对其基本概念和基本使用做出介绍。包括容器生态系统、容器的原理、怎样运行第一个容器、容器技术的概念与实践、Docker镜像等等 目录 一. 鸟瞰容器生态系统 1. 容器…...

Linux系统安装方式+适合初学者的发行版本
Linux系统安装方式适合初学者发行版—目录 一、Linux系统的安装方式1. 物理机直接安装2. 虚拟机安装3. 双系统安装4. Live USB试用5. 云服务器安装 二、适合初学者的Linux发行版1. Ubuntu2. Linux Mint3. Zorin OS4. Pop!_OS5. Elementary OS6. Fedora7. Manjaro 三、选择建议场…...

开启 Spring AI 之旅:从入门到实战
开启 Spring AI 之旅:从入门到实战 引言 在当今人工智能飞速发展的时代,Spring AI 为开发者们提供了一个强大而便捷的工具,用于在 Spring 生态系统中构建 AI 应用程序。本文将为你提供如何开始使用 Spring AI 的详细指南,帮助你…...
:Pandas 数据变形与重塑)
python数据分析(七):Pandas 数据变形与重塑
Pandas 数据变形与重塑全面指南 1. 引言 在数据分析过程中,我们经常需要将数据从一种结构转换为另一种结构,以适应不同的分析需求。Pandas 提供了丰富的数据变形与重塑功能,包括旋转(pivot)、堆叠(stack)、融合(melt)等多种操作。本文将详细…...

SX24C01.UG-PXI程控电阻桥板卡
PXI程控电阻桥板卡 概述 简介 程控电阻桥板卡采用4 个可程控精密调节的电阻臂组成桥式电路,通过计算机PXI总线控制继电器通断进行电阻调节;可根据具体情况,方便地选择不同桥路的连接;程控电阻桥板卡支持“1/4 桥”、“半桥”和…...

Python项目源码69:一键解析+csv保存通达信日线数据3.0
Python项目源码39:学生积分管理系统1.0(命令行界面Json) Python项目源码38:模拟炒股系统2.0(tkinterJson) Python项目源码35:音乐播放器2.0(Tkintermutagen) Python项…...

Conda 与 Spyder 环境管理
前言 作为 Python 科学计算领域的黄金搭档,Anaconda 和 Spyder 为研究人员和数据分析师提供了强大的工作环境。本文将详细介绍如何使用 Conda 管理 Python 环境,并在 Spyder IDE 中灵活切换这些环境,助你打造高效的 Python 开发工作流。 一…...

头皮理疗预约小程序开发实战指南
生活服务类小程序开发正成为互联网创业的热点领域,头皮理疗预约小程序作为其中的细分品类,具有广阔的市场前景和用户需求。基于微信小程序原生开发或uniapp框架,结合Java后端和MySQL数据库,可构建一个功能完善、性能稳定且易于维护的头皮理疗预约平台。本文将从零开始,详细…...

cPanel 的 Let’s Encrypt™ 插件
在 cPanel & WHM 中,推出了一个名为 AutoSSL 的功能。可能有些朋友还不了解 AutoSSL,它是一个能够自动为您的网站申请和安装免费 SSL 证书的工具,这些证书由 Comodo 签发,保证网站的安全性。 AutoSSL 与 Let’s Encrypt Let’…...
)
《Android 应用开发基础教程》——第十一章:Android 中的图片加载与缓存(Glide 使用详解)
目录 第十一章:Android 中的图片加载与缓存(Glide 使用详解) 🔹 11.1 Glide 简介 🔸 11.2 添加 Glide 依赖 🔸 11.3 基本用法 ✦ 加载网络图片到 ImageView: ✦ 加载本地资源 / 文件 / UR…...
)
MySQL 中的游标(Cursor)
一、游标的作用 逐行处理数据:当需要对查询结果集中的每一行进行特定操作(如计算、条件判断、调用其他过程)时使用。替代集合操作:在无法通过单一 SQL 语句完成复杂逻辑时,游标提供逐行处理的能力。…...

【嵌入式Linux】基于ARM-Linux的zero2平台的智慧楼宇管理系统项目
目录 1. 需求及项目准备(此项目对于虚拟机和香橙派的配置基于上一个垃圾分类项目,如初次开发,两个平台的环境变量,阿里云接入,摄像头配置可参考垃圾分类项目)1.1 系统框图1.2 硬件接线1.3 语音模块配置1.4 …...

记忆翻牌游戏:认知科学与状态机的交响曲
目录 记忆翻牌游戏:认知科学与状态机的交响曲引言第一章 网格空间拓扑学1.1 自适应网格算法1.2 卡片排布原理 第二章 状态机设计2.1 状态跃迁矩阵2.2 时空关联模型 第三章 记忆强化机制3.1 认知衰减曲线3.2 注意力热力图 第四章 动画引擎设计4.1 翻牌运动方程4.2 粒…...

【业务领域】InfiniBand协议总结
InfiniBand协议总结 InfiniBand协议是什么?Infiniband产生的原因Mellanox公司介绍及其新闻基于TCP/IP的网络与IB网络的比较IB标准的优势什么是InfiniBand网络什么是InfiniBand架构Mellanox IB卡介绍InfiniBand速率发展介绍InfiniBand网络主要上层协议InfiniBand管理…...

使用Java正则表达式检查字符串是否匹配
在Java开发中,正则表达式(Regular Expression,简称Regex)是处理字符串的强大工具,广泛应用于模式匹配、数据验证和文本处理。Java通过java.util.regex包提供了对正则表达式的支持,包含Pattern和Matcher两个…...

个人健康中枢的多元化AI硬件革新与精准健康路径探析
在医疗信息化领域,个人健康中枢正经历着一场由硬件技术革新驱动的深刻变革。随着可穿戴设备、传感器技术和人工智能算法的快速发展,新一代健康监测硬件能够采集前所未有的多维度生物数据,并通过智能分析提供精准的健康建议。本文将深入探讨构成个人健康中枢的最新硬件技术,…...

Android基础控件用法介绍
Android基础控件用法详解 Android应用开发中,基础控件是构建用户界面的核心元素。本文将详细介绍Android中最常用的基础控件及其用法。 一、TextView(文本显示控件) TextView用于在界面上显示文本信息。 基本用法 <TextViewandroid:id="@+id/textView"andr…...
是Web3隐私的圣杯?)
iO(不可区分混淆)是Web3隐私的圣杯?
1. 引言 iO 是区块链隐私的圣杯吗?本文将探讨: 不可区分混淆(indistinguishability obfuscation, iO)的局限性iO可能带来的变革iO为何重要?iO是否能真正成为可信硬件的替代方案? 区块链隐私面临的最大挑…...

文章三《机器学习基础概念与框架实践》
文章3:机器学习基础概念与框架实践 ——从理论到代码,用Scikit-learn构建你的第一个分类模型 一、机器学习基础理论:三大核心类型 机器学习是人工智能的核心,通过数据让计算机自动学习规律并做出预测或决策。根据学习方式&#…...

中小企业MES系统概要设计
版本:V1.0 日期:2025年5月2日 一、系统架构设计 1.1 整体架构模式 采用分层微服务架构,实现模块解耦与灵活扩展,支持混合云部署: #mermaid-svg-drxS3XaKEg8H8rAJ {font-family:"trebuchet ms",verdana,ari…...

自动化测试项目1 --- 唠嗑星球 [软件测试实战 Java 篇]
目录 项目介绍 项目源码库地址 项目功能测试 1.自动化实施步骤 1.1 编写测试用例 1.2 自动化测试脚本开发 1.2.1 配置相关环境, 添加相关依赖 1.2.2 相关代码编写 2. 自动化功能测试总结 2.1 弹窗的解决相关问题 2.2 断言的使用和说明 2.3 重新登录问题 项目性能…...

c语言 关键字--目录
1.c语言 关键字 2.typedef 关键字 3.volatile 关键字 4.register 关键字 5.const关键字用法 6.extern关键字...

C语言与指针3——基本数据类型
误区补充 char 的 表示范围0-127 signed char 127 unsigned char 0-255enum不常用,但是常见,这里记录一下。 enum Day {Monday 1,//范围是IntTuesday 2,Wednesday 3 }; enum Day d Monday; switch (d) {case Monday:{printf("%d",Monday);…...

[更新完毕]2025五一杯C题五一杯数学建模思路代码文章教学:社交媒体平台用户分析问题
完整内容请看文章最下面的推广群 社交媒体平台用户分析问题 在问题一中为解决博主在特定日期新增关注数的预测问题,本文构建了基于用户历史行为的二分类模型。首先,从用户对博主的观看、点赞、评论、关注等交互行为中提取统计与时序特征,形成…...

使用Vite创建vue3项目
什么是vite Vite 是新一代构建工具,由 Vue 核心团队开发,提供极快的开发体验。 它利用浏览器原生ES模块导入功能,提供了极快的热模块更新(HMR)和开发服务器启动速度。 官网:https://vitejs.cn/vite3-cn/…...

Linux管道识
深入理解管道 (Pipes):连接命令的瑞士军刀 在 Linux 和类 Unix 系统(包括 macOS)的命令行世界里,管道(Pipe)是一个极其强大且基础的概念。它允许你将一个命令的输出直接作为另一个命令的输入,像…...

LabVIEW 中VI Server导出 VI 配置
该 LabVIEW VI 展示了在 VI Server 中配置和执行 Exported VIs 的过程,实现对服务器端导出 VI 的远程调用与操作。 具体过程及模块说明 前期配置:需确保在 LabVIEW 的 “Tools> Options > VI Server > Protocols” 路径下,启用 …...
:)
map和set的遗留 + AVL树(1):
在讲解新的东西之前,我们把上节遗留的问题说一下: 遗留问题: 首先,我们的最上面的代码是一个隐式类型转换,我们插入了一对数据。 我们说了,我们的方括号的底层是insert,当我们调用operator的[…...

Java学习手册:Spring Security 安全框架
一、Spring Security 简介 Spring Security 是一个功能强大且高度可定制的身份验证和访问控制框架,用于保护 Java 应用程序,尤其是基于 Spring 的应用。它构建在 Spring 框架之上,能够轻松地集成到基于 Spring 的应用程序中,包括…...

pip 常用命令及配置
一、python -m pip install 和 pip install 的区别 在讲解 pip 的命令之前,我们有必要了解一下 python -m pip install 和 pip install 的区别,以便于我们在不同的场景使用不同的方式。 python -m pip install 命令使用 python 可执行文件将 pip 模块作…...