海量数据存储与分析:HBase vs ClickHouse vs Doris 三大数据库优劣对比指南
1.引言
在当今大数据时代,数据正以前所未有的速度持续增长。来自各个领域的数据,如互联网行业用户的每一次点击、浏览记录,金融机构的海量交易数据,以及物联网设备源源不断上传的实时监测数据等,其规模呈指数级攀升。据权威机构统计,全球每年产生的数据量从过去的 EB 级迅速迈向 ZB 级。如此庞大的数据量,对数据存储和分析提出了极为严苛的要求。
数据存储不仅要能够容纳海量数据,还需确保数据的安全与高效访问。传统的数据库存储方式在面对如此大规模、高增长的数据时,逐渐显得力不从心。而数据的价值,更多地体现在对其深入分析后所挖掘出的信息。企业期望通过对数据的分析,精准把握市场趋势、优化业务流程、提升客户体验,进而在激烈的市场竞争中占据优势。这就需要强大的分析工具和技术,能够快速、准确地处理复杂的查询和分析任务。
在此背景下,数仓工程师肩负着为企业搭建高效数据仓库的重任,而数据库的选型则是其中最为关键的一环。面对市场上琳琅满目的数据库产品,尤其是 HBase、ClickHouse、Doris 这三款在大数据领域备受瞩目的数据库,数仓工程师往往陷入深深的困惑。HBase 基于 Hadoop 生态,以其出色的海量稀疏数据存储和实时读写性能而闻名;ClickHouse 凭借高性能的向量化执行引擎和强大的分布式架构,在海量数据分析方面表现卓越;Doris 作为国内优秀的开源项目,基于 MPP 架构,在交互式分析和数据仓库构建方面独具优势。
本文旨在通过对 HBase、ClickHouse、Doris 进行全面且深入的对比,从基础概念、技术架构、适用场景、性能表现、扩展性、运维复杂度等多个维度展开分析,为广大数仓工程师拨开数据库选型的迷雾,提供清晰、实用的决策依据,助力企业构建更加高效、稳定的数据仓库系统,充分释放大数据的价值。
2.HBase 介绍
2.1 HBase是什么
HBase 是一种基于 Hadoop 的分布式列式存储数据库。可能这些术语听起来有点复杂,咱们一点点拆开来看。首先,它是基于 Hadoop 的,Hadoop 就像是一个大数据的超级工厂,能够处理海量的数据。HBase 借助 Hadoop 的力量,也具备了强大的大数据处理能力。
再说说 “分布式”,这就好比有很多个小仓库分布在不同地方,一起合作来存储和管理数据。数据不会都挤在一个地方,而是分散在各个 “小仓库” 里,这样就能更高效地工作,而且就算某个 “小仓库” 出了问题,其他的还能继续运作,保证数据不会丢失。
“列式存储” 又是什么意思呢?我们平常接触的表格,可能是一行一行记录数据的,每一行包含很多列的信息。但 HBase 不一样,它是把同一列的数据存放在一起。想象一下,有一个记录学生信息的表格,有姓名、年龄、成绩等列。在 HBase 里,所有学生的姓名会被存放在一起,年龄也会被单独存放在一起,成绩同样如此。这样做有个很大的好处,当我们只需要查询学生成绩的时候,就不用把整行数据都读出来,只读取成绩这一列的数据就行,大大节省了时间和资源。
HBase 的诞生也有一段故事。它起源于 2006 年,当时 Facebook 的工程师 Chad Walters 受到 Google 的 Bigtable 论文启发,开发出了 HBase。当时,随着互联网数据量的急剧膨胀,传统关系型数据库在处理海量数据时面临性能瓶颈,无法满足对数据高并发读写和扩展性的需求。HBase 应运而生,作为 Hadoop 生态系统的重要组成部分,它依托 Hadoop 分布式文件系统(HDFS),致力于解决大规模结构化数据的存储与实时访问问题。
在初始阶段,HBase 的功能相对简单,但凭借其分布式架构和对海量数据的处理能力,逐渐吸引了众多开发者和企业的关注。随着时间推移,HBase 社区不断壮大,来自全球各地的开发者积极贡献代码,持续优化其性能、扩展功能特性。如今,HBase 已经发展成为一个成熟、稳定的分布式列式存储数据库,被广泛应用于互联网、金融、电信等多个行业,支撑着各类对海量数据处理有高要求的业务场景。
2.2 HBase技术架构
HBase 的架构主要由两个重要部分组成,一个是HMaster,另一个是多个RegionServer。
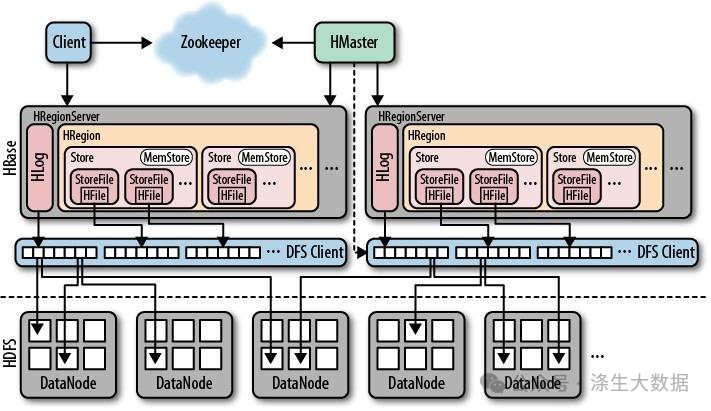
HMaster 就像是一个大管家,负责管理整个 “仓库” 的运作。它要管理 RegionServer 的生命周期,比如说,当有新的 RegionServer 加入进来,HMaster 要负责安排它的工作;要是某个 RegionServer 出故障了,HMaster 也要及时发现并处理。同时,HMaster 还管理着元数据,就像一个仓库的库存清单,记录着数据都存放在哪些地方。它会把数据的存储区域(也就是 Region)分配给合适的 RegionServer,还要处理 Region 的分裂和合并。比如说,当某个 Region 里的数据太多了,HMaster 就会把它分成两个小一点的 Region,让存储和查询更高效。
RegionServer 则是真正干活的 “小工”,负责数据的存储和读写。每个 RegionServer 管理着多个 Region,这些 Region 以 HFile 的形式存储在 Hadoop 分布式文件系统(HDFS)上。当我们要往 HBase 里写入数据,或者从里面读取数据的时候,请求都会先到达 RegionServer。RegionServer 会根据数据的唯一标识(RowKey),快速找到对应的 Region,然后进行读写操作。
为了让读写更快,RegionServer 里面还有两个重要的东西,一个是 MemStore,另一个是 StoreFile(也就是 HFile)。写入的数据会先放在 MemStore 里,MemStore 就像是一个临时的小仓库,数据放在这里读写速度非常快。但是 MemStore 的空间有限,当它存满了(比如说达到 64MB),里面的数据就会被 “搬” 到磁盘上,形成一个新的 HFile,这个过程就叫做 MemStore Flush。而当我们读取数据的时候,RegionServer 会先在 MemStore 里找,如果找到了就直接返回给我们;要是没找到,就会去 HFile 里找。HFile 有自己的索引机制,就像一本书的目录,能帮助 RegionServer 快速找到我们需要的数据。
2.3 HBase 读写流程
对于数仓工程师而言,深入理解 HBase 的数据读写流程,是在实际工作中高效运用 HBase 管理海量数据、优化数据处理性能的关键。HBase 独特的架构设计决定了其读写流程具备高效性与可靠性,以下将详细展开介绍。
1)写入流程
当数仓工程师向 HBase 发起数据写入操作时,整个流程便有条不紊地启动。客户端发送的写入请求会迅速抵达 RegionServer,RegionServer 在 HBase 架构中扮演着数据存储与读写的核心角色。它负责管理多个 Region,每个 Region 对应表中的一段连续 RowKey 范围的数据。
在 RegionServer 内部,数据的写入旅程首先在 MemStore 开启。MemStore 本质上是一块内存缓冲区,它的存在极大提升了写入效率。由于内存读写速度相较于磁盘 I/O 快几个数量级,数据先被暂存于 MemStore,就如同快递先被放在距离收件人更近的临时站点,能够快速响应写入请求。例如,在处理大量实时交易数据写入时,MemStore 可迅速接纳数据,避免因磁盘写入速度慢而导致的写入延迟,保障业务系统的实时性需求。 与此同时,为了确保数据的可靠性,防止在系统故障时数据丢失,写入操作会同步记录到预写日志(WAL,Write - Ahead Log)。WAL 就像是一个严谨的记录员,按照顺序记录每一次写入操作的详细信息。一旦系统发生崩溃或故障,在恢复过程中,HBase 可以依据 WAL 中的记录,重新执行未完成的写入操作,从而保证数据的完整性。例如,若在 MemStore 数据刷写磁盘过程中系统断电,重启后可借助 WAL 恢复未写入磁盘的数据。
随着数据不断写入,当 MemStore 达到特定的阈值大小(通常设定为 64MB)时,便会触发一个关键且自动的操作 ——MemStore Flush。此时,MemStore 中的数据会被异步地刷写到磁盘上,转化为 HFile 格式存储。HFile 是 HBase 在磁盘上存储数据的基本格式,它采用了一系列优化技术,如数据压缩(常用的压缩算法有 Gzip、Snappy 等)和布隆过滤器(Bloom Filter)索引机制。压缩技术有效减少了磁盘空间占用,对于存储海量数据的数仓而言,这能显著降低存储成本;布隆过滤器则加快了数据读取时的查找速度,如同给书籍配备了更精准的目录,能快速定位数据所在位置。例如,在存储数十亿条用户行为数据时,HFile 的压缩与索引机制可大幅提升存储与读取效率。
下面通过一张详细的流程图来直观展示 HBase 的写入流程:
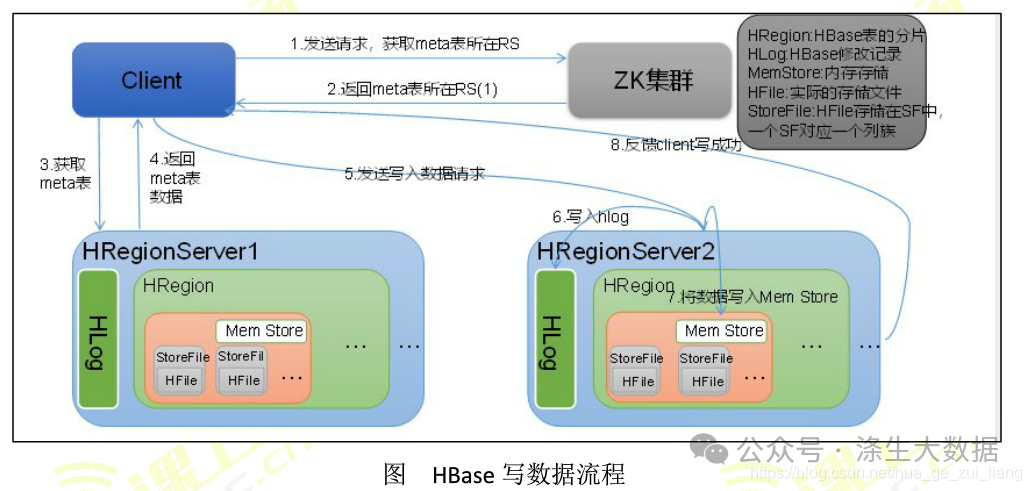
在图中,清晰呈现了客户端的写入请求从发出,到 RegionServer 接收,数据在 MemStore 和 WAL 中的走向,以及最终如何通过 MemStore Flush 生成 HFile 并持久化到磁盘的全过程。这对数仓工程师理解数据在 HBase 中的写入路径、排查写入性能问题等方面具有重要指导意义。
2)读取流程
当数仓工程师需要从 HBase 中读取数据时,HBase 同样遵循一套严谨且高效的流程。客户端发起的读取请求,如同传递的指令,首先被 RegionServer 接收。RegionServer 在接到请求后,会依据自身的缓存策略,优先在 MemStore 中查找所需数据。因为 MemStore 存储的是最新写入的数据,若能在此找到匹配的数据,RegionServer 可直接将数据返回给客户端,这大大缩短了读取的响应时间,满足了数仓中对实时性查询的部分需求。例如,在查询刚刚更新的用户账户余额时,
若数据还在 MemStore 中,就能快速获取最新结果。 若 MemStore 中未找到目标数据,RegionServer 便会根据请求中的 RowKey,在 HFile 的索引块中进行查找。HFile 的索引块构建了一种高效的数据查找结构,类似于图书馆的索引系统,通过它能快速定位到存储目标数据的 Data Block。找到对应的 Data Block 后,RegionServer 从磁盘读取该数据块。需要注意的是,由于 HFile 采用了压缩存储,若读取到的 Data Block 处于压缩状态,RegionServer 还需先执行解压缩操作,将数据还原为原始格式,然后在解压缩后的数据块中查找符合条件的 KeyValue 对,最终将查找到的数据返回给客户端。例如,在查询历史交易记录时,即使数据量庞大且存储在磁盘的 HFile 中,借助 HFile 的索引机制,也能快速定位并读取到所需数据。
以下是 HBase 读取流程的示意图:
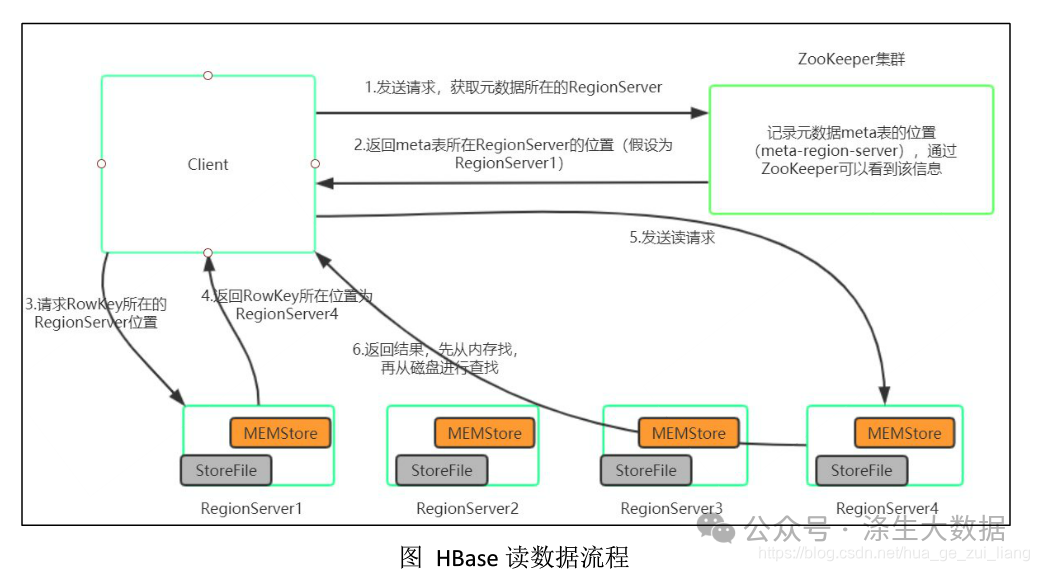
该图清晰展示了读取请求从客户端出发,在 RegionServer 中依次查找 MemStore 和 HFile 的过程,直观地呈现了 HBase 读取数据的路径与方式,帮助数仓工程师理解读取过程中的数据流向,以便在实际工作中优化查询性能,如通过合理设置缓存策略、优化 RowKey 设计等方式提升读取效率。
2.4 适用场景
1)海量用户账户信息管理
互联网金融公司往往拥有庞大的用户群体,每个用户的账户信息涵盖基本资料、资产状况、信用评级等多维度数据。以一家拥有千万级用户的互联网金融平台为例,传统关系型数据库在存储如此海量且不断增长的用户信息时,可能面临性能瓶颈与存储成本剧增的问题。HBase 的分布式架构与列式存储模式则能有效应对。 在用户账户信息存储中,可将用户 ID 设为 RowKey,利用其唯一性确保数据快速定位。不同类型的账户信息,如个人身份信息设为一个列族,资产相关信息设为另一个列族。这种设计下,当需要查询用户的资产数据时,HBase 仅需读取资产列族的数据,避免读取整行数据带来的资源浪费,极大提升查询效率。同时,随着用户数量的持续增长,通过简单添加 RegionServer 即可轻松扩展存储容量,保障系统的稳定运行。
2) 高频交易记录存储与实时查询
互联网金融交易频繁,像股票交易、在线支付等业务场景,每秒可能产生数千甚至上万笔交易记录。这些交易数据不仅要准确、及时地存储,还需满足后续实时查询与分析的需求。HBase 的实时读写特性使其成为理想选择。 交易数据写入时,先快速存入 MemStore,实现毫秒级写入响应,确保交易数据的及时记录,不影响交易流程的顺畅进行。例如在股票高频交易场景中,交易数据能迅速落库,为投资者提供及时的交易反馈。当需要实时查询某笔交易详情时,依据交易 ID(作为 RowKey),HBase 能快速定位到对应 Region,从 MemStore 或 HFile 中读取数据并返回,满足投资者对交易信息的即时查询需求。并且,在面对海量交易数据时,HBase 的分布式存储可轻松应对,保证数据存储与查询性能不受影响。
3)风险管理系统数据
互联网金融公司在开展业务时,风险评估至关重要。为准确评估用户风险,需整合多源数据,如用户的消费行为、还款记录、社交关系等。这些数据规模庞大且具有稀疏性,部分用户可能在某些维度上数据缺失。 HBase 的稀疏表设计能高效存储此类数据,仅存储实际产生的数据值,减少存储空间占用。在构建风险评估模型时,利用 HBase 的分布式计算能力,结合 Hadoop MapReduce 可对海量风险数据进行并行处理。例如,快速计算用户的信用评分、分析不同用户群体的风险特征等。通过高效处理这些数据,互联网金融公司能够更精准地评估风险,制定合理的信贷政策,降低违约风险,保障业务的稳健发展。
4)反欺诈数据存储与分析
防范欺诈是互联网金融的重要任务。欺诈行为往往具有隐蔽性,需要对大量历史交易数据、用户行为数据进行深度分析,挖掘潜在的欺诈模式。 HBase 可将历史交易数据按时间序列存储,以交易时间结合交易 ID 作为 RowKey,方便按时间维度查询与分析。在反欺诈数据挖掘过程中,通过扫描 HBase 表,结合复杂算法识别异常交易行为,如短期内大量资金异常转移、异地登录频繁交易等。其分布式架构能支持大规模数据的并行分析,大大缩短分析时间,快速发现欺诈线索,及时采取措施防范欺诈行为,保护用户资金安全与公司利益。
3.ClickHouse 介绍
3.1 开源背景与发展态势
ClickHouse 起源于俄罗斯的互联网巨头 Yandex,2016 年开源后迅速在大数据分析领域崭露头角。当时,随着互联网业务的多元化发展,企业对海量数据的实时分析需求愈发迫切,传统数据库在应对高并发、大规模数据分析时显得力不从心。Yandex 基于自身在搜索、广告等业务中积累的海量数据处理经验,开发出 ClickHouse 这一高性能分析型数据库。
开源后的 ClickHouse 凭借其卓越的性能和独特的技术架构,吸引了全球众多开发者和企业的关注。社区活跃度极高,大量的贡献者不断为其注入新功能,优化性能。如今,ClickHouse 在全球范围内被广泛应用于各个行业,无论是互联网企业、金融机构,还是电信运营商等,都借助 ClickHouse 来处理 PB 级别的数据,实现高效的数据分析与洞察,其发展态势持续向好,在大数据分析数据库市场中占据了重要的一席之地。
3.2 面向 OLAP 的高性能特质
ClickHouse 专为联机分析处理(OLAP)场景量身定制,在性能方面表现卓越。当面对数十亿条数据的聚合查询任务时,传统数据库往往需要耗费数分钟甚至更长时间,而 ClickHouse 却能在令人惊叹的秒级时间内完成。这一卓越性能主要得益于其先进的向量化执行引擎以及精心优化的数据存储结构。
在数据类型支持上,ClickHouse 表现得极为丰富。它不仅对常见的数值、字符串类型提供常规支持,对于复杂的数据类型,如数组、嵌套数据结构等,也能轻松驾驭。这使得 ClickHouse 在处理多样化的数据时,展现出极高的灵活性。此外,ClickHouse 具备强大的分布式扩展能力,只需简单地添加节点,便能实现集群规模的无缝扩展,满足企业数据量持续增长的需求。尤为关键的是,在扩展过程中,其性能能够保持稳定,不会因集群规模的扩大而出现大幅下滑的情况。
3.3 ClickHouse 技术架构原理
1)分布式架构基石
ClickHouse 的分布式架构堪称其性能强劲的根基。整个集群如同一个有序运转的大型工厂,由众多节点协同发力。这些节点主要分为两类:一类是协调器节点,它如同工厂的调度员,专门负责接收客户端的请求,并统筹规划查询的执行流程;另一类则是存储节点,它们才是实实在在存储数据、执行查询任务的 “主力军”。每个存储节点都具备独立处理部分数据的能力,各个存储节点分工协作,共同承担起海量数据的存储与分析重任。
在数据存储环节,ClickHouse 运用了数据分片机制。这就好比将一个巨大的仓库划分成多个小区域,每个区域存放一部分货物。常见的数据分片规则有按哈希值分片和按范围分片。以按哈希值分片为例,假设我们以用户 ID 作为哈希分片的依据。系统会像一个智能分拣员,根据用户 ID 计算出对应的哈希值,然后依据这个哈希值,将与该用户相关的数据精准地分配到不同的存储节点上。如此一来,数据就能均匀地散布在各个节点,有效避免了某个节点数据堆积如山,而其他节点却 “吃不饱” 的情况,从而实现了负载均衡,大幅提升了整体的存储和查询效率。
2)数据存储奥秘
ClickHouse 的数据存储格式和结构十分独特,它主打列式存储。这与传统的行式存储有着显著区别。打个比方,若有一张记录学生信息的表格,包含姓名、年龄、成绩等列。在行式存储模式下,每个学生的所有信息(姓名、年龄、成绩)会像打包行李一样,被放在一起存储。但在 ClickHouse 的列式存储体系里,所有学生的姓名会被集中放置在一个 “小仓库”,年龄列的数据存放在另一个专属 “小仓库”,成绩列数据同样单独存放。
这种存储方式在数据分析场景中展现出诸多优势。当我们进行只涉及某几列的查询时,比如只查询学生的成绩,ClickHouse 就像一个训练有素的图书管理员,只需径直走向存放成绩数据的 “小仓库”,读取成绩这一列的数据即可,无需将整行学生信息都读取出来,极大地减少了磁盘 I/O 操作,查询速度自然大幅提升。而且,列式存储在数据压缩方面也更具优势。由于同一列的数据类型相同,数据特征相似,就如同将同一种类的物品打包,压缩效果更好。通过压缩,不仅能节省大量的磁盘空间,在读取数据时,由于数据量减少,查询性能也能得到进一步提升。
3)向量化执行引擎的魔法
ClickHouse 的向量化执行引擎堪称其性能卓越的关键 “法宝”。传统数据库在执行查询时,大多像一个慢吞吞的工人,按行处理数据,每次仅能操作一条记录。而 ClickHouse 的向量化执行引擎则截然不同,它如同一个高效的团队,以向量(也就是一批数据)为单位进行处理。
例如,在进行两列数据的加法运算时,传统方式需要像一个一个台阶往上爬一样,依次读取每一行中这两列的数据,然后逐一相加。但向量化执行引擎会把这两列数据分别视为一个整齐的队伍,通过一次指令操作,就能完成整个向量的加法运算。这就好比传统方式是一个人一次搬一块砖,而向量化执行引擎是一个人一次搬一摞砖,效率提升显而易见。向量化执行引擎充分利用了现代 CPU 的 SIMD(单指令多数据)指令集,大大减少了指令执行的次数,提高了 CPU 的利用率。尤其在处理大量数据的聚合、过滤等复杂操作时,性能提升效果惊人,能让查询速度实现数倍甚至数十倍的飞跃。
4)分布式查询执行流程
当客户端向 ClickHouse 集群发起查询请求时,请求首先会像快递包裹一样,被送到协调器节点手中。协调器节点此时就如同一个经验丰富的指挥官,它会仔细解析查询语句,弄清楚到底要查询什么数据,涉及哪些表和字段。然后,根据数据分片信息以及集群中各节点的实时状态,制定出一份详细的作战计划,也就是查询执行计划。
这个执行计划会把整个查询任务像拆解大工程一样,拆分成多个子查询,分别分发给对应的存储节点。每个存储节点接到子查询任务后,就如同接到战斗任务的士兵,立刻在本地存储的数据中展开查询处理。由于数据早已按照分片规则分散在各个节点,每个节点只需专注处理自己负责的那部分数据,这就巧妙地实现了并行处理。各个存储节点完成本地数据查询后,将结果像汇报战果一样,返回给协调器节点。最后,协调器节点把这些来自不同存储节点的结果进行汇总整合,形成最终的查询结果,再像交付成果一样,返回给客户端。这种分布式查询执行流程,极大地提高了查询处理速度,特别是在处理海量数据的复杂查询时,优势尽显,能迅速响应用户的查询请求,满足业务对实时数据分析的迫切需求。
3.5 适用场景
1)海量数据分析场景,如互联网公司用户行为分析案例
在互联网公司中,每天都会产生海量的用户行为数据,如用户的点击、浏览、购买等行为记录。以某大型电商平台为例,每天的用户行为数据量可达数十亿条。ClickHouse 凭借其高性能和分布式处理能力,能够高效地对这些数据进行分析。通过对用户行为数据的分析,互联网公司可以了解用户的兴趣偏好、购买习惯等,从而为用户精准推荐商品、优化网站页面布局。
在实际应用中,该电商平台利用 ClickHouse 构建用户行为分析系统,将用户行为数据实时写入 ClickHouse 集群。当需要分析用户在过去一周内浏览但未购买的商品信息时,ClickHouse 能够在秒级内完成对数十亿条数据的查询和分析,为市场运营团队提供及时、准确的数据支持,助力其制定营销策略,提升业务转化率。
2)复杂查询与高并发查询场景,如电商平台报表生成案例
电商平台需要生成各种复杂的报表,如不同地区、不同时间段、不同商品类别的销售报表,这些报表涉及多表关联、聚合计算等复杂查询操作。同时,在业务高峰期,可能会有大量用户同时请求报表数据,对查询并发性能要求极高。
ClickHouse 能够很好地应对这种复杂查询与高并发查询场景。例如,在生成月度销售报表时,报表需要关联用户表、订单表、商品表等多张表,并进行按地区、按商品类别等多层次的聚合计算。ClickHouse 的分布式架构和向量化执行引擎能够并行处理这些复杂查询任务,快速生成报表数据。在高并发场景下,ClickHouse 通过合理的资源调度和优化的查询缓存机制,能够同时处理大量用户的查询请求,保证响应时间在可接受范围内,为电商平台的运营决策提供及时的数据支持,保障业务的稳定运行。
4.Doris 介绍
在大数据分析的工具阵营中,Doris 正逐渐崭露头角,成为不可忽视的一款数据库产品。它为处理海量数据、满足多样化数据分析需求,提供了一套高效且易用的解决方案。
4.1 开源项目背景
Doris 源自百度,于 2017 年开源。当时,随着大数据时代的全面来临,企业面临着海量数据的存储与分析难题。传统数据库在应对大规模数据的实时查询、复杂分析等场景时,显得力不从心。百度凭借在搜索引擎、信息流等业务中积累的深厚技术实力和大规模数据处理经验,开发出 Doris 这一高性能分析型数据库,并将其开源,希望能为大数据领域贡献一份力量,推动行业的整体发展。
开源之后,Doris 迅速吸引了众多开发者的关注。来自不同行业的技术人员纷纷参与到项目中来,他们积极贡献代码、分享使用经验,不断完善 Doris 的功能,优化其性能。如今,Doris 已经形成了一个活跃的开源社区,社区成员们共同努力,让 Doris 在功能丰富度、性能稳定性等方面都得到了极大提升,应用范围也从最初的百度内部业务,扩展到互联网、金融、电信等多个行业,帮助企业高效地处理和分析海量数据。
4.2 基于 MPP 架构的分析型数据库特性
4.2.1 大规模并行处理能力
Doris 基于大规模并行处理(MPP,Massively Parallel Processing)架构构建。这一架构赋予了 Doris 强大的并行计算能力。在 MPP 架构下,Doris 集群由多个节点组成,每个节点都具备独立的计算和存储能力。当执行查询任务时,Doris 会将查询请求分解成多个子任务,分发给集群中的各个节点并行处理。例如,在处理一个涉及数十亿条数据的复杂查询时,传统单机数据库可能需要依次处理每一条数据,耗时较长。而 Doris 通过 MPP 架构,将数据分片存储在不同节点上,各个节点同时处理自己负责的数据分片,大大缩短了查询响应时间。这种并行处理能力使得 Doris 在面对海量数据时,依然能够保持高效的查询性能,满足企业对实时数据分析的需求。
4.2.2 实时数据导入与查询
Doris 具备出色的实时数据导入能力。在实际业务场景中,数据源源不断地产生,企业希望新产生的数据能够尽快被存储并用于分析。Doris 支持多种数据导入方式,如通过 Kafka 实时消费数据进行导入,或者使用 Sqoop 从关系型数据库中抽取数据实时导入。一旦数据导入 Doris,即可立即用于查询分析,无需复杂的预处理步骤。这一特性对于互联网金融行业的交易数据处理尤为重要。例如,在股票交易过程中,实时产生的交易数据能够快速导入 Doris,分析师可以实时查询和分析这些数据,及时掌握市场动态,为投资决策提供支持。
4.2.3 丰富的数据模型支持
Doris 提供了丰富的数据模型,以适应不同的业务场景。其中包括明细模型、聚合模型和更新模型。明细模型适用于需要保留数据原始细节的场景,例如记录用户的每一次操作行为。聚合模型则在数据聚合分析场景中表现出色,通过预先对数据进行聚合计算,存储聚合结果,当进行查询时,可以直接从聚合结果中获取数据,大大提高查询效率。更新模型允许对已存储的数据进行更新操作,满足一些对数据实时更新有要求的业务场景。例如,在电商平台中,商品的库存数据可能会随着订单的产生而实时更新,Doris 的更新模型可以很好地支持这种场景,确保库存数据的准确性和实时性。
4.2.4 良好的 SQL 兼容性
对于数仓工程师来说,Doris 的一个显著优势是其对标准 SQL 的良好兼容性。Doris 支持几乎所有的标准 SQL 语法,包括复杂的查询语句、多表关联、聚合函数等。这意味着,工程师们无需花费大量时间学习新的查询语言,就可以使用熟悉的 SQL 语句对 Doris 中的数据进行查询和分析。例如,在进行多表关联查询时,Doris 的语法与传统关系型数据库的 SQL 语法相似,工程师可以轻松编写查询语句,从多个表中获取所需数据。这种良好的 SQL 兼容性,极大地降低了学习成本,提高了开发效率,使得 Doris 能够快速融入企业现有的技术体系中。
4.5 适用场景
1) 交互式分析场景,如企业 BI 报表即时查询案例
在企业的商业智能(BI)应用中,数据分析师和业务人员经常需要对数据进行即时查询和分析,以获取业务洞察。例如,某企业的销售部门需要实时了解不同地区、不同产品线的销售情况,以便及时调整销售策略。Doris 的高性能和实时查询能力使其成为这类交互式分析场景的理想选择。通过将企业的销售数据存储在 Doris 中,用户可以在 BI 工具中通过简单的 SQL 查询,即时获取所需的报表数据。无论是复杂的多维度聚合查询,还是对数据进行切片、钻取操作,Doris 都能在秒级甚至亚秒级内返回结果,为企业决策提供及时、准确的数据支持,助力企业快速响应市场变化。
2) 数据仓库构建场景,如数据集市快速搭建案例
数据仓库是企业数据管理和分析的核心基础设施,而数据集市是数据仓库的子集,针对特定的业务领域或部门进行数据存储和分析。在构建数据仓库和数据集市时,Doris 展现出强大的优势。以某金融机构为例,其需要为风险管理部门快速搭建一个数据集市,用于分析客户的信用风险。Doris 的 MPP 架构和高效的数据加载能力,能够快速将来自不同数据源(如客户信息系统、交易系统等)的数据集成到数据集市中。同时,Doris 丰富的数据模型和查询优化能力,能够满足风险管理部门复杂的分析需求,例如对客户信用评分的计算、风险指标的多维分析等。通过使用 Doris,该金融机构成功在短时间内搭建起数据集市,为风险管理提供了有力的数据支持,提升了风险管理的效率和准确性。
5.三者对比
5.1 数据模型对比
| 数据库 | 数据模型特点 | 适用场景举例 |
|---|---|---|
| Hbase | 基于列族的稀疏表模型,每行数据通过行键(Row Key)唯一标识,数据按列族存储,同一列族下的列可以动态添加,适合存储稀疏数据 | 互联网企业记录用户行为日志,很多用户在特定行为维度无记录,HBase 能高效存储,避免大量空值占用空间 |
| Clickhouse | 以列式存储为基础的扁平表结构,数据按列存储在本地磁盘,便于按列进行快速查询与聚合操作 | 互联网广告平台对大规模广告投放数据,按投放渠道、时间等列进行统计分析,ClickHouse 可快速返回聚合结果 |
| Doris | 支持明细模型、聚合模型和更新模型。明细模型保留原始数据细节;聚合模型预先计算并存储聚合结果,加速查询;更新模型便于对数据实时更新 | 电商平台实时更新商品库存、价格等数据,Doris 的更新模型能确保数据及时准确变更,同时聚合模型可快速统计商品销售总额等信息 |
5.2 性能对比
| 数据库 | 查询性能特点 | 适用查询场景 |
|---|---|---|
| Hbase | 基于主键查询速度极快,可在海量数据中迅速定位特定行数据。但非主键列查询性能差,缺乏二级索引(需借助额外组件实现) | 物联网设备管理系统,根据设备 ID 实时查询设备状态等详细信息 |
| Clickhouse | 海量数据分析查询性能卓越,尤其复杂聚合查询和多表关联查询,利用向量化执行引擎和分布式计算能力,秒级甚至毫秒级返回结果 | 金融机构分析多年交易流水,进行复杂的资金流向、收益统计等分析查询 |
| Doris | 支持高吞吐量交互式分析和高并发点查询,对标准 SQL 高度兼容,复杂查询性能出色。在高并发场景下,通过分布式架构和查询优化器合理调度,保障查询效率 | 在线数据可视化平台,大量用户并发查询不同时间段业务数据,Doris 能快速响应 |
5.3 数据更新对比
| 数据库 | 数据更新特点 | 应用场景 |
|---|---|---|
| Hbase | 支持实时写入和更新操作,写入性能较高。数据更新先写入 WAL(预写式日志)确保可靠性,再更新到 MemStore,满足条件后刷写到磁盘 | 互联网日志系统,实时记录用户操作日志,后续可对部分日志信息 |
| Clickhouse | 支持实时写入,但数据更新通常采用覆盖式写入,即重新插入新数据覆盖旧数据,在数据更新频繁场景下效率较低 | 数据仓库中,定期对历史数据进行全量更新,覆盖式写入可保证数据一致性 |
| Doris | 具备实时数据导入与更新能力,支持多种数据导入方式,实现 Merge - on - Write 机制,保证数据一致性同时,提升并发点查询性能 | 电商平台实时更新商品销售数据,Doris 能快速导入新数据并保证查询性能不受影响 |
5.4 扩展性对比
| 数据库 | 扩展性描述 | 实际应用优势 |
|---|---|---|
| Hbase | 借助 Hadoop 生态扩展性,增加 HDFS 节点和 RegionServer 节点,轻松实现水平扩展,应对数据量增长 | 大型互联网公司,随着用户量和业务数据量不断攀升,可灵活扩展 HBase 集群规模 |
| Clickhouse | 线性扩展能力良好,添加节点提升存储和计算能力,节点添加和配置相对简单,不影响业务情况下扩展集群规模 | 新兴互联网企业,业务快速发展阶段,可按需逐步增加 ClickHouse 节点 |
| Doris | 基于 MPP 架构,扩展性强,添加节点提升系统整体性能,对新节点加入有完善管理机制,保障集群稳定性和高效性 | 金融科技公司,数据量和查询负载波动大,通过添加节点可快速适应业务变化 |
5.5 SQL 支持对比
| 数据库 | SQL支持情况 | 对工程师影响 |
|---|---|---|
| Hbase | 原生不支持 SQL 查询,需借助 Phoenix 等第三方工具实现 SQL 接口 | 习惯 SQL 语法的工程师使用 HBase 时,需额外学习第三方工具使用,增加学习成本 |
| Clickhouse | 支持类 SQL 查询语法,但与标准 SQL 有差异,复杂 SQL 功能(如复杂事务处理)支持较弱 | 工程师需熟悉 ClickHouse 特定语法,在复杂业务逻辑实现上,可能无法完全照搬标准 SQL 写法 |
| Doris | 对标准 SQL 兼容性极佳,支持几乎所有标准 SQL 语法,包括复杂查询语句、多表关联、聚合函数等 | 工程师可直接使用熟悉的 SQL 语法操作 Doris,降低学习成本,提高开发效率 |
通过上述多维度对比可知,HBase 在基于主键的快速查询和稀疏数据存储方面优势显著;ClickHouse 擅长海量数据分析查询;Doris 在实时数据处理、高并发查询及对标准 SQL 支持上表现突出。数仓工程师需依据具体业务场景和需求,综合考量各数据库特性,做出最佳选型 。
6.选型建议
6.1 根据数据量选型
1)小数据量场景下三者的适用性分析
| 数据库 | 优势 | 劣势 | 适用场景 |
|---|---|---|---|
| Hbase | 即使数据量小,其架构也能保障稳定读写性能,在处理稀疏数据时优势明显,可按需存储,不浪费空间 | 部署相对复杂,涉及Hadoop 生态组件,对于小数据量场景,运维成本相对较高 | 小型物联网项目,虽设备数量有限,但数据稀疏特性明显,如智能办公区域的少量环境监测设备数据存储 |
| Clickhouse | 查询性能优秀,向量化执行引擎即便处理小数据量也能快速响应,支持丰富的分析函数 | 对于小数据量,其强大的分布式架构优势难以充分发挥,资源可能存在一定浪费 | 初创互联网公司的小规模用户行为分析,数据量暂时不大,但需灵活分析功能 |
| Doris | MPP 架构保证并行处理能力,在小数据量下也能快速执行查询,对 SQL 支持良好,便于开发人员上手 | 数据量小的情况下,集群的部分优势无法体现,可能存在资源闲置 | 小型电商企业,数据量不大,需快速构建报表系统进行销售数据分析 |
2)大数据量场景下的推荐选型
| 数据库 | 优势 | 适用场景示例 |
|---|---|---|
| Hbase | 通过不断添加 RegionServer 可实现水平扩展,能高效存储 PB 级别的海量稀疏数据,实时读写性能稳定 | 大型物联网平台,数亿设备持续产生海量稀疏数据,如智能电网中大量电表的实时数据存储与读取 |
| Clickhouse | 分布式架构下可轻松扩展节点,向量化执行引擎结合分布式查询,能在海量数据下快速完成复杂分析任务 | 超大型互联网公司的用户行为分析,每天数十亿条甚至更多数据的分析处理,如社交媒体平台的用户互动数据挖掘 |
| Doris | 基于 MPP 架构可线性扩展集群,数据导入高效,对海量数据的复杂查询和多表关联查询表现出色 | 大型金融机构的海量交易数据处理,需实时生成各类复杂报表,进行风险评估和业务决策分析 |
6.2 根据业务场景选型
1)实时读写业务优先选择建议
| 数据库 | 实时读写优势 | 适用场景示例 |
|---|---|---|
| Hbase | 数据写入先存 MemStore,能实现毫秒级写入,基于行键的读取可快速定位数据 | 金融交易系统,每秒数千笔交易需实时记录和查询,如股票交易记录的实时存储与查询 |
| Doris | 具备实时数据导入能力,查询响应速度快,可满足对实时性要求高的业务场景 | 电商平台的实时订单处理系统,新订单数据能快速写入并可即时查询订单状态 |
2)复杂分析业务优先选择建议
| 数据库 | 复杂分析优势 | 适用场景示例 |
|---|---|---|
| Clickhouse | 支持复杂数据类型,查询优化器可针对复杂查询生成高效执行计划,分布式架构并行处理能力强 | 互联网广告精准投放分析,需结合多维度数据(用户属性、行为、广告特征等)进行复杂建模与分析 |
| Doris | 多维数据模型便于多维度分析,查询优化器深度优化多表关联等复杂查询 | 企业级数据仓库的深度数据分析,如大型制造企业从生产、销售、供应链等多维度综合分析企业运营状况 |
6.3 根据成本预算选型
1)硬件成本、软件许可成本等方面对比与选型建议
| 数据库 | 硬件成本 | 软件许可成本 | 综合建议 |
|---|---|---|---|
| HBase | 依托 Hadoop 生态,对硬件要求与 Hadoop 相似,可利用普通硬件构建集群,成本相对可控 | 开源免费 | 数据量较大且有实时读写需求,对硬件成本敏感,可考虑 HBase,但其运维成本相对较高 |
| ClickHouse | 对硬件资源有一定要求,尤其是内存和CPU,以发挥向量化执行优势,可能需要配置较高性能硬件 | 开源免费 | 大数据量且复杂分析需求为主,可承受较高硬件成本以获取极致性能,ClickHouse 是不错选择 |
| Doris | 基于 MPP 架构,对硬件要求适中,可根据业务量灵活扩展硬件资源 | 开源免费 | 业务增长较快,需灵活控制成本,同时对运维简便性有要求,Doris 在硬件成本和运维成本上有较好平衡 |
7.结论
HBase、ClickHouse 和 Doris 作为大数据领域各具特色的数据库,各自展现出强大的能力。HBase 基于 Hadoop 生态,以其分布式列式存储和稀疏表数据模型,在海量稀疏数据存储与实时读写场景中表现卓越,能够高效处理如物联网设备监控这类数据量庞大且稀疏的业务场景。ClickHouse 凭借其面向 OLAP 的设计理念、向量化执行引擎以及分布式架构,在海量数据分析和复杂查询处理方面一骑绝尘,尤其适用于互联网公司对用户行为数据的深度挖掘与分析。Doris 则依托 MPP 架构,在交互式分析和数据仓库构建方面优势显著,其多维数据模型以及对 SQL 的良好支持,极大地降低了开发与使用门槛,满足了企业在 BI 报表即时查询和数据集市快速搭建等场景下的需求。 数据库选型并非简单的技术抉择,而是紧密关联企业业务发展与技术战略的关键决策。不同的业务场景对数据库的性能、扩展性、运维复杂度等技术指标有着各异的要求。例如,实时读写业务更侧重于数据库的低延迟写入与快速查询能力;而复杂分析业务则需要强大的查询优化和并行处理能力。企业必须全面考量自身业务需求,精准匹配数据库的技术特性,才能构建高效、稳定且经济的数据存储与分析体系,充分释放数据的价值,为企业决策提供有力支撑。 随着大数据、人工智能、物联网等技术的持续发展,数据量将呈爆发式增长,数据类型也将更加多样化。数据库技术将朝着更高性能、更强扩展性、更智能化以及更便捷运维的方向演进。例如,在性能提升方面,会进一步优化执行引擎,挖掘硬件潜力,实现更高效的数据处理;扩展性上,能够更轻松地应对全球分布式数据中心的部署需求;智能化层面,数据库将具备自动优化查询、自我修复故障等能力;运维便捷性上,将通过更智能的监控与自动化工具,降低运维成本。这些发展趋势将促使数据库在企业数字化转型中发挥更为核心的作用,持续推动各行业的创新与发展。
相关文章:

海量数据存储与分析:HBase vs ClickHouse vs Doris 三大数据库优劣对比指南
1.引言 在当今大数据时代,数据正以前所未有的速度持续增长。来自各个领域的数据,如互联网行业用户的每一次点击、浏览记录,金融机构的海量交易数据,以及物联网设备源源不断上传的实时监测数据等,其规模呈指数级攀升。…...

Redis 挂掉后高并发系统的应对策略:使用 Sentinel 实现限流降级与 SkyWalking 监控优化
前言 在现代分布式系统中,Redis 被广泛用作缓存中间件以提升性能和减轻数据库压力。然而,在高并发场景下,一旦 Redis 出现故障(如宕机、网络中断等),如果没有有效的容错机制,可能会导致大量请求…...

C++11新特性_自动类型推导_decltype
decltype 是 C11 引入的一个关键字,用于在编译时推导表达式的类型。它提供了一种方式,让编译器根据表达式的类型来确定变量的类型,而不需要显式地指定类型。下面为你详细介绍 decltype 的使用方法和应用场景。 基本语法 decltype 的基本语法…...

Scrapy爬虫实战总结:动态与登录爬取的精炼经验
引言 在AI时代,信息和数据往往成就你的速度和高度。。。 这篇文章基于前两篇的实践基础之上的一次小结,通过“爬取动态网页”和“登录网站”两场实战,我用Scrapy+Splash破译JavaScript,用FormRequest敲开权限大门。这篇总结凝练两场冒险的体验,淬炼Scrapy爬虫的通用经验…...
)
windows系统搭建自己的ftp服务器,保姆级教程(用户验证+无验证)
前言 最近在搭建环境时,我发现每次都需要在网上下载依赖包和软件,这不仅耗时,而且有时还会遇到网络不稳定的问题,导致下载速度慢或者中断,实在不太方便。于是,我产生了搭建一个FTP服务器的想法。通过搭建FT…...

PDF本地化开源项目推荐
Stirling-PDF 项目详细总结 1. 项目概述 Stirling-PDF 是一个基于 Docker 的本地化 Web 应用,专注于 PDF 文件的多样化处理。其核心特点是: 完全本地化部署:所有文件处理均在用户设备或服务器内存中进行,任务完成后自动清理临…...

从工厂到生活:算法 × 深度学习,正在改写自动化的底层逻辑
一.背景: 从工业革命时期的机械自动化,到信息时代的智能自动化,人类对自动化技术的追求从未停歇。近年来,随着物联网、大数据、云计算等技术的蓬勃发展,自动化系统的复杂度与智能化程度显著提升。算法与深度学习的深度…...

如何拿奖蓝桥杯
要在蓝桥杯中拿奖,可参考以下方法: 备赛规划方面 - 明确目标与计划:选择自己感兴趣或有基础的组别,了解比赛大纲和历年真题,制定包含基础语法学习、算法入门、真题训练等阶段的合理学习计划。 - 合理安排时间…...
)
【STM32单片机】#12 SPI通信(软件读写)
主要参考学习资料: B站江协科技 STM32入门教程-2023版 细致讲解 中文字幕 开发资料下载链接:https://pan.baidu.com/s/1h_UjuQKDX9IpP-U1Effbsw?pwddspb 单片机套装:STM32F103C8T6开发板单片机C6T6核心板 实验板最小系统板套件科协 目录 SPI…...

从请求到响应:初探spring web
引入: 首先小编想分享下一些开发小知识 2000年——手写servlet/JSP时代 在这个阶段中,那时候写后端代码,可谓是个麻烦事。 毕竟什么都要自己干 发来的请求都要写extends HttpServlet的类,手动在web.xml配置 <servlet>…...

【中间件】bthread_基础_TaskControl
TaskControl 1 Definition2 Introduce**核心职责** 3 成员解析**3.1 数据结构与线程管理****3.2 任务调度与负载均衡****3.3 线程停放与唤醒(ParkingLot)****3.4 统计与监控** 4 **工作流程**5 **设计亮点**6 **使用场景示例**7 **总结**8 学习过程中的疑…...

systemd和OpenSSH
1 systemd 1.1 配置文件 /etc/systemd/system /lib/systemd/system /run/systemd/system /usr/lib/systemd/user 1.2 commands systemctl list-unit-files | grep enable systemctl cat dlt-daemon.service systemctl cat dlt-system.service systemctl show dlt-daemon.ser…...

08 Python集合:数据 “去重神器” 和运算魔法
文章目录 一、Python 中的集合概述1. 集合的特性 二、集合的创建三、元素的遍历四、集合的运算1. 成员运算2. 二元运算3. 比较运算 五、集合的方法六、不可变集合 一、Python 中的集合概述 在 Python 里,集合(Set)是一种无序且元素唯一的数据…...

配置和使用基本存储
配置和使用基本存储 文章目录 配置和使用基本存储[toc]一、什么是卷?二、卷的类型三、使用EmptyDir卷存储数据1.了解EmptyDir卷2.测试EmptyDir卷的使用 四、使用HostPath卷挂载宿主机文件1.了解HostPath卷2.测试HostPath卷的使用 五、使用NFS卷挂载NFS共享目录1.准备…...

win11 终端 安装ffmpeg 使用终端Scoop
1、安装scoop (Windows 包管理器) Set-ExecutionPolicy RemoteSigned -Scope CurrentUser iwr -useb get.scoop.sh | iex 2、使用scoop来安装ffmpeg scoop install ffmpeg 3、测试一下ffmpeg,将Mp3文件转为Wav文件 ffmpeg -i A.mp3 A.wav 然后我们就看到A.wav生成…...
)
navicat中导出数据表结构并在word更改为三线表(适用于navicat导不出doc)
SELECTCOLUMN_NAME 列名,COLUMN_TYPE 数据类型,DATA_TYPE 字段类型,IS_NULLABLE 是否为空,COLUMN_DEFAULT 默认值,COLUMN_COMMENT 备注 FROMINFORMATION_SCHEMA.COLUMNS WHEREtable_schema db_animal(数据库名) AND table_name activity(…...

Azure Monitor 实战指南:全方位监控应用与基础设施
Azure Monitor 是 Azure 云原生的统一监控解决方案,能够实时追踪应用性能、基础设施健康状态及日志数据。本文将通过 实战步骤 演示如何利用 Azure Monitor 监控 GPT-4 服务、虚拟机、存储等资源,并结合自动化告警和日志分析,构建企业级监控体系。 1. Azure Monitor 核心功能…...

【人工智能】释放本地AI潜能:LM Studio用户脚本自动化DeepSeek的实战指南
《Python OpenCV从菜鸟到高手》带你进入图像处理与计算机视觉的大门! 解锁Python编程的无限可能:《奇妙的Python》带你漫游代码世界 随着大型语言模型(LLM)的快速发展,DeepSeek以其高效的性能和开源特性成为开发者关注的焦点。LM Studio作为一款强大的本地AI模型管理工具…...
)
智能体-CyberTask Orchestrator设计概要(V4.1超长版)
智能体-CyberTask Orchestrator设计概要(V4.0超长版) 一、深度演进背景与战略定位(核心篇幅拓展至2187字) (本段新增行业趋势与技术必要性论证) 1.1 全球网络安全威胁态势分析(2023-2025&…...

C# 面向对象实例演示
C# 面向对象编程实例演示 一、基础概念回顾 面向对象编程(OOP)的四大基本特性: 封装 - 将数据和操作数据的方法绑定在一起继承 - 创建新类时重用现有类的属性和方法多态 - 同一操作作用于不同对象产生不同结果抽象 - 简化复杂系…...

软件产品测试报告:如何全面评估及保障软件质量?
软件产品测试报告可以对软件产品质量做全面评估,还能够把评估结果展示出来,它依靠一系列测试手段和数据分析,能为产品的完善以及决策提供重要依据。下面从不同方面展开说明。 测试目的 开展本次软件产品测试,主要目的有三个。一…...

leetcode42-接雨水
leetcode 42 思路 本题使用 单调栈 来计算每个位置能够接住的雨水量 理解问题 题目要求计算一系列柱子之间可以接住的雨水量。输入是一个数组,每个元素代表柱子的高度。输出是一个整数,表示能够接住的水量。 找到边界条件 什么情况下可以接住雨水…...

普通IT的股票交易成长史--20250430晚
声明:本文章的内容只是自己学习的总结,不构成投资建议。文中观点基本来自yt站Andylee,美股Alpha姐,综合自己的观点得出。感谢他们的无私分享。 送给自己的话: 仓位就是生命,绝对不能满仓!&…...

Elastic Security 8.18 和 9.0 中的新功能
作者:来自 Elastic Mark Settle, Tamarian Del Conte, James Spiteri, Tinsae Erkailo, Charles Davison, Raquel Tabuyo, Kseniia Ignatovych, Paul Ewing, Smriti 检测规则的自动迁移、用于 ES|QL 的 Lookup Join、AI 功能增强,以及更多功能。 Elasti…...
)
使用 Vue 开发 VS Code 插件前端页面(上)
本文的方案主要参考了这篇博客: Vscode 的 extension webview 开发示例: Vue 和 React 实现 https://juejin.cn/post/7325132202970136585样例项目地址: github | vscode-webview-with-vuehttps://github.com/HiMeditator/vscode-webview-w…...

Vue Router路由原理
Vue Router 是 Vue.js 官方的路由管理器,它与 Vue.js 核心深度集成,使得构建单页应用(SPA)变得非常容易。Vue Router 的主要功能包括动态路由匹配、嵌套路由、编程式导航、命名路由、路由守卫等 Vue Router 原理 单页应用&#x…...

Tauri v1 与 v2 配置对比
本文档对比 Tauri v1 和 v2 版本的配置结构和内容差异,帮助开发者了解版本变更并进行迁移。 配置结构变化 v1 配置结构 {"package": { ... },"tauri": { "allowlist": { ... },"bundle": { ... },"security":…...

详解 MyBatis-Plus 框架中 QueryWrapper 类
QueryWrapper 一、 QueryWrapper 的概念为什么需要 QueryWrapper? 二、 QueryWrapper 的基本使用1. 创建 QueryWrapper 实例2. 添加查询条件3. 执行查询 三、 QueryWrapper 的常见方法1. 基本条件方法1.1 eq - 等于1.2 ne - 不等于1.3 gt - 大于1.4 ge - 大于等于1.…...

小米MiMo-7B大模型:解锁推理潜力的新传奇!
在大语言模型(LLMs)蓬勃发展的时代,推理能力成为衡量模型优劣的关键指标。今天为大家解读的这篇论文,介绍了小米的MiMo-7B模型,它通过独特的预训练和后训练优化,展现出强大的推理实力,快来一探究…...
)
联邦学习的收敛性分析(全设备参与,不同本地训练轮次)
联邦学习的收敛性分析 在联邦学习中,我们的目标是分析全局模型的收敛性,考虑设备异构性(不同用户的本地训练轮次不同)和数据异质性(用户数据分布不均匀)。以下推导从全局模型更新开始,逐步引入假设并推导期望损失的递减关系,最终给出收敛性结论。 1. 全局模型更新与泰…...
)
硬件工程师面试常见问题(10)
第四十六问:锁存器,触发器,寄存器三者的区别 触发器:能够存储一位二值信号的基本单元电路统称为 "触发器"。(单位) 锁存器:一位触发器只能传送或存储一位数据,而在实际工…...

1295. 统计位数为偶数的数字
题目 解法一 遍历数组挨个判断元素位数并统计(我的第一想法) class Solution { public:int findNumbers(vector<int>& nums) {int result 0;for(int n: nums){if(judge(n)) result;}return result;}bool judge(int a){int sum 1;a a / 10…...

3.1/Q1,Charls最新文章解读
文章题目:Social participation patterns and associations with subsequent cognitive function in older adults with cognitive impairment: a latent class analysis DOI:10.3389/fmed.2025.1493359 中文标题:认知障碍老年人的社会参与模…...

楼宇智能化四章【期末复习】
四、火灾自动报警系统 结构组成:火灾探测器、区域报警器、集中报警器 形式:1. 多线制系统 2.总线制系统 3.集中智能系统 4.分布智能系统 5.网络通信系统 工作原理: 以下是关于火灾自动报警系统及相关灭火系统的详细解答: 1. 火灾自动报警系统有哪几种形式? 区…...

Splunk 使用Role 实现数据隔离
很多人知道 Splunk 有很多自带的Role, 今天我就要说说定制化的Role: 1: 在创建新role 的界面: 2: 在如下的界面,可以定制allow index name: 3: 创建好新Role 后,在SAML 添加新的group 的时候,就可以看到Role 给某个group: 4: 这样一个特定组的人来申请Splunk 权限,就可…...

Learning vtkjs之ImplicitBoolean
隐式函数布尔操作 介绍 vtkImplicitBoolean 允许对隐式函数(如平面、球体、圆柱体和盒子)进行布尔组合。操作包括并集、交集和差集。可以指定多个隐式函数(所有函数都使用相同的操作进行组合)。 支持的操作:‘UNION…...

LabelVision - yolo可视化标注工具
LabelVision是一款可视化图像标注工具,主要用于计算机视觉研究中的各种标注任务。 支持多边形、矩形、圆形等多种标注方式,并且可以输出JSON、COCO等多种数据格式,方便与其他软件和框架进行集成和互操作。 通过它可以很轻易的对图像进行标注,适合Y…...

系统分析师-第十五章
学习目标 通过参加考试,训练学习能力,而非单纯以拿证为目的。 1.在复习过程中,训练快速阅读能力、掌握三遍读书法、运用番茄工作法。 2.从底层逻辑角度理解知识点,避免死记硬背。 3.通过考试验证学习效果。 学习阶段 快速阅读 …...
:KNN原理及应用)
大连理工大学选修课——机器学习笔记(3):KNN原理及应用
KNN原理及应用 机器学习方法的分类 基于概率统计的方法 K-近邻(KNN)贝叶斯模型最小均值距离最大熵模型条件随机场(CRF)隐马尔可夫模型(HMM) 基于判别式的方法 决策树(DT)感知机…...

09 Python字典揭秘:数据的高效存储
文章目录 一.字典是什么1.字典的特点 二.字典的创建和使用三.字典的操作1.访问元素2.修改元素3.删除元素4.遍历字典5.成员运算 四.字典方法1.获取字典中的指定元素2.获取字典中的元素3.字典合并4.删除元素 一.字典是什么 在 Python 中,字典(dict&#x…...

20250430在ubuntu14.04.6系统上完成编译NanoPi NEO开发板的FriendlyCore系统【严重不推荐,属于没苦硬吃】
【开始编译SDK之前需要更新源】 rootrootubuntu:~/friendlywrt-h3$ sudo apt update 【这两个目录你在ubuntu14.04.6系统上貌似git clone异常了】 Y:\friendlywrt-h3\out\wireguard Y:\friendlywrt-h3\kernel\exfat-nofuse 【需要单线程编译文件系统,原因不明】 Y:…...

第五部分:进阶项目实战
在前面的学习中,我们已经掌握了图像和视频的基础操作、增强滤波、特征提取以及一些基础的目标检测方法。现在,我们将综合运用这些知识来构建一些更复杂、更实用的应用项目。 这一部分的项目将结合前面学到的技术,并介绍一些新的概念和工具&a…...

【Linux】记录一个有用PS1
PS1 是用来定义shell提示符的环境变量 下面是一个带有颜色和丰富信息的 Linux PS1 配置示例,包含用户名、主机名、路径、时间、Git 分支和退出状态提示: # 添加到 ~/.bashrc 文件末尾 PS1\[\e[1;32m\]\u\[\e[m\] # 绿色粗体用户名 PS…...
)
【SpringBoot】基于mybatisPlus的博客管理系统(2)
目录 1.实现用户登录 Jwt令牌 1.引入依赖 2.生成令牌(token) Controller Service Mapper 2.实现强制登录 定义拦截器: 配置拦截器: 1.实现用户登录 在之前的项目登录中,我使用的是Session传递用户信息实现校验…...

免费在Colab运行Qwen3-0.6B——轻量高性能实战
Qwen一直在默默地接连推出新模型。 每个模型都配备了如此强大的功能和高度量化的规模,让人无法忽视。 继今年的QvQ、Qwen2.5-VL和Qwen2.5-Omni之后,Qwen团队现在发布了他们最新的模型系列——Qwen3。 这次他们不是发布一个而是发布了八个不同的模型——参数范围从6亿到235…...
:SaaS商业模式关键指标解析)
精益数据分析(35/26):SaaS商业模式关键指标解析
精益数据分析(35/26):SaaS商业模式关键指标解析 在创业与数据分析的征程中,我们持续探索不同商业模式的运营奥秘。今天,我们带着共同进步的期望,深入研读《精益数据分析》,聚焦SaaS商业模式&am…...

【论文速读】《Scaling Scaling Laws with Board Games》
论文链接:https://arxiv.org/pdf/2104.03113 《Scaling Scaling Laws with Board Games》:探索棋盘游戏中的扩展规律 摘要 如今,机器学习领域中规模最大的实验所需的资源,超出了仅有几家机构的预算。幸运的是,最近的…...

C++ 与多技术融合的深度实践:从 AI 到硬件的全栈协同
在数字化技术高速发展的今天,C 凭借其卓越的性能优势和底层控制能力,成为连接上层应用与底层硬件的核心纽带。这种独特定位使其在与 AI 深度学习、Python 生态及硬件加速技术的融合中展现出不可替代的价值,构建起从算法实现到硬件优化的全栈技…...

AdaBoost算法的原理及Python实现
一、概述 AdaBoost(Adaptive Boosting,自适应提升)是一种迭代式的集成学习算法,通过不断调整样本权重,提升弱学习器性能,最终集成为一个强学习器。它继承了 Boosting 的基本思想和关键机制,但在…...

无刷马达驱动芯片算法逐步革新着风扇灯行业--其利天下
风扇灯市场热度持续攀升,根据行业数据,风扇灯市场规模从2010年的100亿元增长至2019年的200亿元,年均复合增长率超10%,预计2025年将达30%,借此其利天下有限公司进一步提升了无刷风扇灯驱动方案。 一、性能参数 电压&a…...