Qwen多模态系列论文
From:https://www.big-yellow-j.top/posts/2025/04/28/QwenVL.html
本文主要介绍Qwen-vl系列模型包括:Qwen2-vl、Qwen2.5-vl
Qwen2-vl
http://arxiv.org/abs/2409.12191
模型结构:
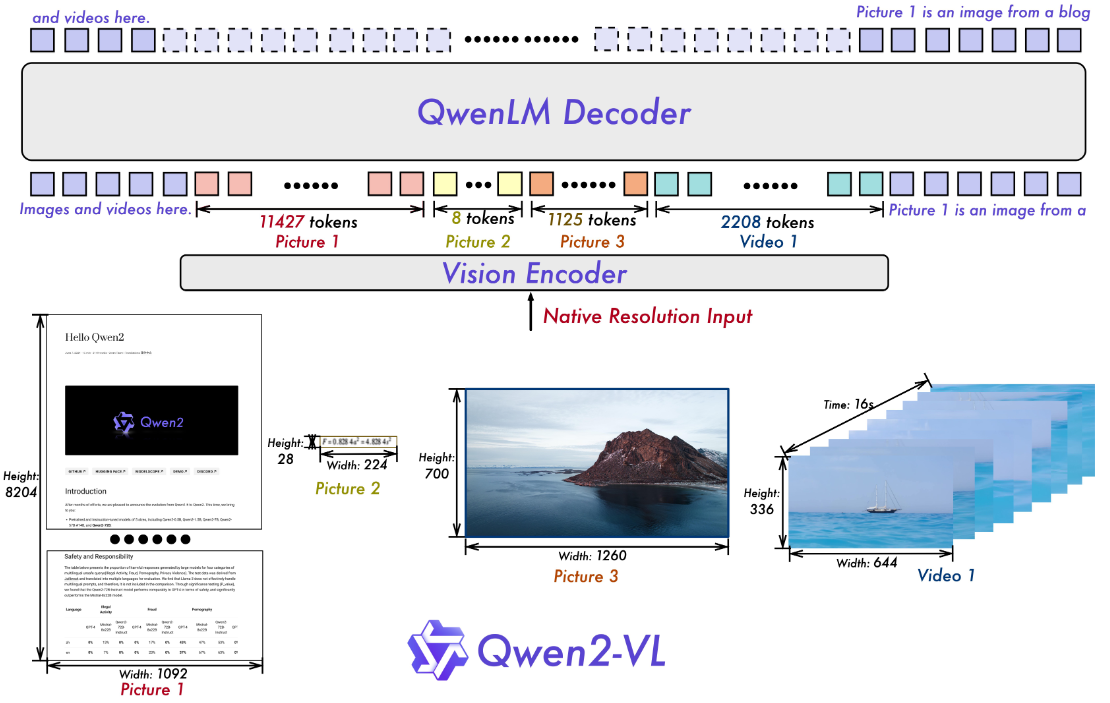
Qwen2-vl主要的改进点在于:1、使用动态分辨率(也就是说输入图像不需要再去改变图像尺寸到一个固定值),于此同时为了减少 visual-token数量,将2x2的的相邻的token进行拼接到一个token而后通过MLP层进行处理。2、使用多模态的旋转位置编码(M-RoPE),也就是将原来位置编码所携带的信息处理为:时序(temporal)、高度(height)、宽度(width)。比如下图中对于文本处理直接初始化为: ( i , i , i ) (i,i,i) (i,i,i)。但是对于图片而言就是: ( i , x , y ) (i,x,y) (i,x,y) 其中 i i i 是恒定的,而对于视频就会将 i i i 换成视频中图像的顺序

Qwen2.5-vl
http://arxiv.org/abs/2502.13923
模型结构:
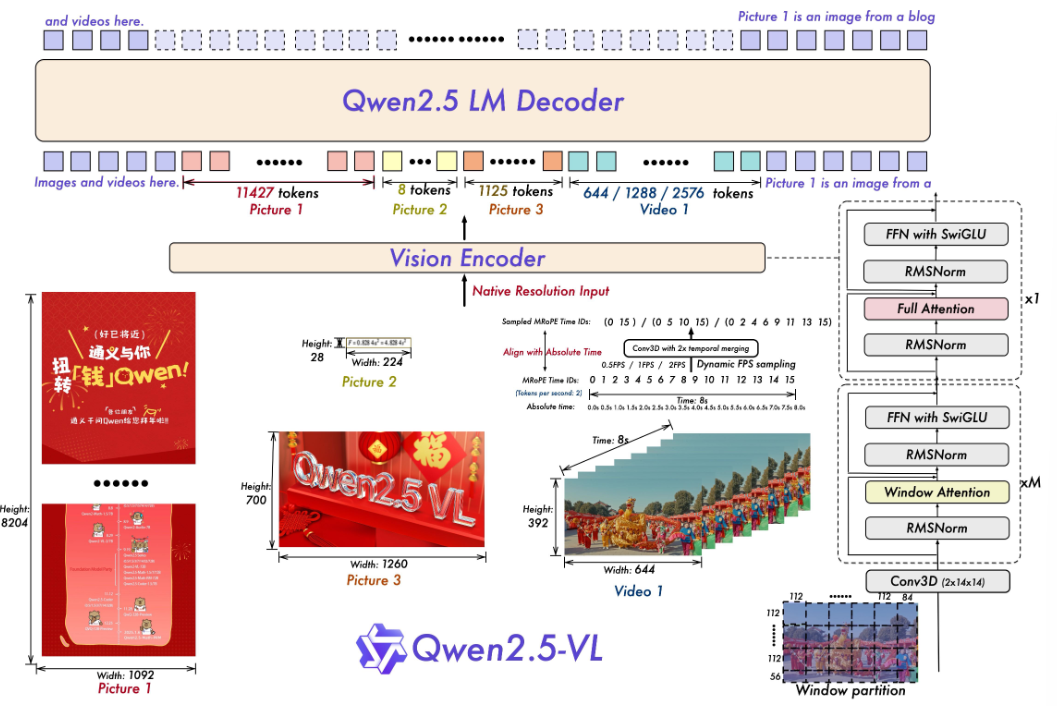
从模型结构上而言在 Qwen2.5-vl 中主要改进点在于:
- 视觉编码器上
1、改进的ViT模型(window-attention+ full-attention);2、2D-RoPE
- MLP处理
通过ViT得到所有的patch之后,直接将这些patch解析分组(4个一组)然后继续拼接在输入到两层MLP中进行处理
补充1:window-attention
https://arxiv.org/abs/2004.05150v2
前面有介绍在Kimi和DeepSeek中如何处理稀疏注意力的(🔗),他们都是通过额外的网络结构来处理注意力计算问题,而在上面提到的注意力计算则是直接通过规则范式计算注意力。
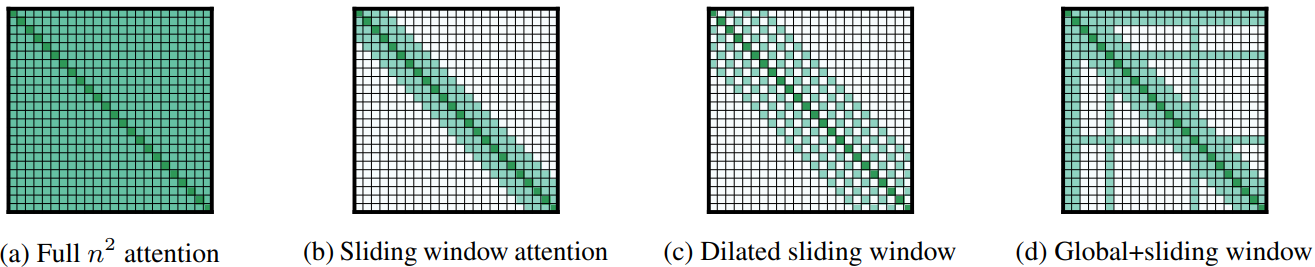
上面 window-attention 处理范式就和卷积操作类似,直接通过移动“步长”然后对“采集”得到的内容进行计算注意力。代码:⚙。代码核心点就在于划分,而后对划分结果计算注意力:
q_window = q[:, :, t:window_end, :] # (B, num_heads, window_size, head_dim)
k_window = k[:, :, t:window_end, :]
v_window = v[:, :, t:window_end, :]
介绍完这部分有必要了解一下他是如何处理数据的(毕竟说实在话,模型(无论为LLM还是MLLM在结构上创新远不如数据集重要)都是数据驱动的)以及他是如何训练模型的。
- 1、模型预训练
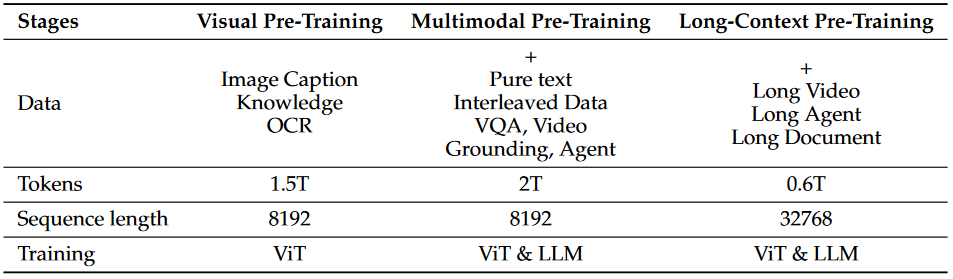
从论文里面作者提到如下几种数据以及处理范式如下:
1、Image-Text Data(图片-文本匹配数据集):保留较高评分匹配对(这里也就是说文本对于图片描述要丰富)、信息互补(图像和文本各自提供独特信息)、信息密度平衡
2、Video Data(视频数据):首先是通过动态采用方式获取视频帧;
3、图像坐标分辨率处理:直接将原始图像进行输入不去修改分辨率(固定每个patch为112x112对于不足的不去做填补,总共8x8个patches),对于里面的坐标直接使用Grounding DINO 或者SAM进行获取。
4、Omni-Parsing Data:对于文档数据集直接解析为html格式
-
3、模型后训练
-
1、监督微调 (SFT)
SFT阶段用到的instruction data包含约 200 万条数据,50% 为纯文本数据,50% 为多模态数据(图文和视频文本)。在数据过滤流程中,先使用 Qwen2-VL-Instag (一个基于Qwen2-VL的分类模型)将 QA 对分层分类为 8 个主要领域和 30 个细粒度子类别,然后对于这些细分类别,使用领域定制过滤,结合基于规则和基于模型的过滤方法。
基于规则的过滤: 删除重复模式、不完整或格式错误的条目,以及不相关或可能导致有害输出的查询和答案。
基于模型的过滤: 使用 Qwen2.5-VL 系列训练的奖励模型评估多模态 QA 对。
此外,在训练中还使用拒绝采样 (Rejection Sampling)技术,增强模型的推理能力。使用一个中间版本的 Qwen2.5-VL 模型,对带有标注(ground truth)的数据集生成响应,将模型生成的响应与标注的正确答案进行比较,只保留模型输出与正确答案匹配的样本,丢弃不匹配的样本。此外还进一步过滤掉不理想的输出,例如:代码切换 (code-switching)、过长 (excessive length)、重复模式 (repetitive patterns)等。通过这种方式,确保数据集中只包含高质量、准确的示例。
这里会不会因此丢弃掉一些好的困难样本?报告中并没有提及,似乎对于SFT阶段,正确性的要求压倒难度,并不指望通过这一阶段获得更强的能力。
- 2、直接偏好优化 (DPO)
报告中基本一笔带过。仅使用图文和纯文本数据,不使用视频数据,利用偏好数据将模型与人类偏好对齐。没有使用GRPO和基于规则的强化学习。对于数学、代码以外的任务,似乎没有特别好的规则定义方法,还是要回到基于奖励模型或者偏好数据的方法。
代码对比
两个模型在代码上差异:
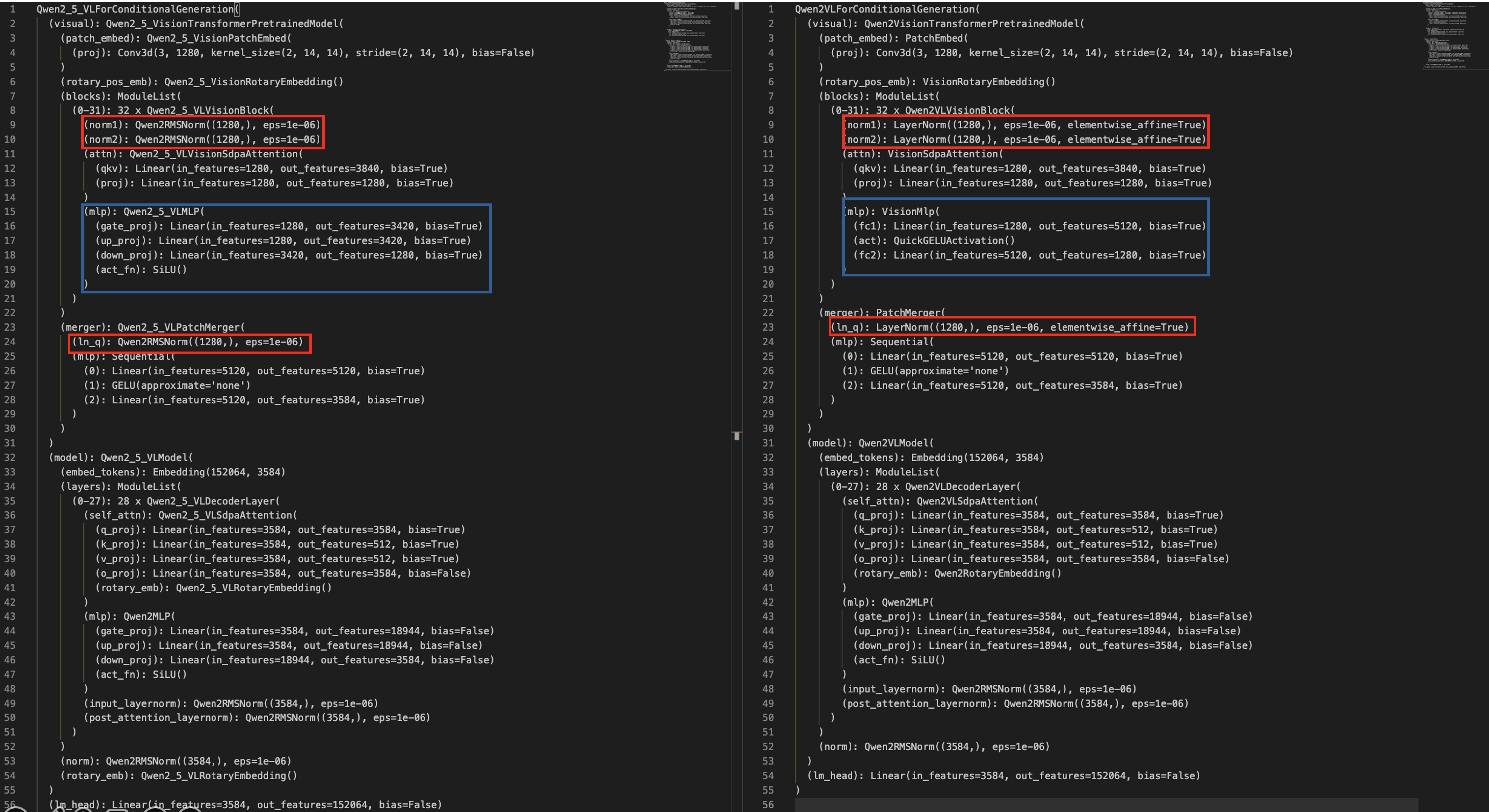
1、ViT代码
值得注意的在 Qwen2-vl中使用了拼接方式,在 Qwen2.5-vl依旧使用了这种方式来将Vit得到的token进行减少进而减小计算量。通过 Qwen2.5-vl来理解模型(Qwen2.5-vl中vit操作,代码),官方代码中划分窗口设置:
def get_window_index(self, grid_thw):window_index: list = []cu_window_seqlens: list = [0]window_index_id = 0vit_merger_window_size = self.window_size // self.spatial_merge_size // self.patch_sizefor grid_t, grid_h, grid_w in grid_thw:#(1)因为位置编码结构是t、h、w(具体描述见Qwen2-vl描述)llm_grid_h, llm_grid_w = (grid_h // self.spatial_merge_size, # spatial_merge_size:空间合并的尺寸grid_w // self.spatial_merge_size,)index = torch.arange(grid_t * llm_grid_h * llm_grid_w).reshape(grid_t, llm_grid_h, llm_grid_w)#(2)计算需要的paddingpad_h = vit_merger_window_size - llm_grid_h % vit_merger_window_sizepad_w = vit_merger_window_size - llm_grid_w % vit_merger_window_size#(3)计算padding后的窗口数量,并且用 -100 进行填补num_windows_h = (llm_grid_h + pad_h) // vit_merger_window_sizenum_windows_w = (llm_grid_w + pad_w) // vit_merger_window_sizeindex_padded = F.pad(index, (0, pad_w, 0, pad_h), "constant", -100)#(4)重塑索引为窗口形式index_padded = index_padded.reshape(grid_t,num_windows_h,vit_merger_window_size,num_windows_w,vit_merger_window_size,)index_padded = index_padded.permute(0, 1, 3, 2, 4).reshape(grid_t,num_windows_h * num_windows_w,vit_merger_window_size,vit_merger_window_size,)#(5)计算每个窗口中有效元素的数量seqlens = (index_padded != -100).sum([2, 3]).reshape(-1)index_padded = index_padded.reshape(-1)index_new = index_padded[index_padded != -100]window_index.append(index_new + window_index_id)cu_seqlens_tmp = seqlens.cumsum(0) * self.spatial_merge_unit + cu_window_seqlens[-1]# self.spatial_merge_unit = self.spatial_merge_size * self.spatial_merge_sizecu_window_seqlens.extend(cu_seqlens_tmp.tolist())window_index_id += (grid_t * llm_grid_h * llm_grid_w).item()# 合并所有的窗口索引window_index = torch.cat(window_index, dim=0)# window_index: 窗口索引;# cu_window_seqlens:每个窗口的间隔return window_index, cu_window_seqlens
争对上面代码,比如输入数据形状以及参数为:
1、grid_thw:[2,8,8];2、self.window_size = 8;3、self.spatial_merge_size=self.patch_size=2。那么每一步得到结果为:
(1)index结果为(因为要进行2x2进行合并操作):
index: tensor([[[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11],[12, 13, 14, 15]],[[16, 17, 18, 19],[20, 21, 22, 23],[24, 25, 26, 27],[28, 29, 30, 31]]])
(3)得到index_padded为:
index_padded: tensor([[[ 0, 1, 2, 3, -100, -100],[ 4, 5, 6, 7, -100, -100],[ 8, 9, 10, 11, -100, -100],[ 12, 13, 14, 15, -100, -100],[-100, -100, -100, -100, -100, -100],[-100, -100, -100, -100, -100, -100]],[[ 16, 17, 18, 19, -100, -100],[ 20, 21, 22, 23, -100, -100],[ 24, 25, 26, 27, -100, -100],[ 28, 29, 30, 31, -100, -100],[-100, -100, -100, -100, -100, -100],[-100, -100, -100, -100, -100, -100]]])
(5)window_size合并得到结果为:
window_index:tensor([ 0, 1, 4, 5, 2, 3, 6, 7, 8, 9, 12, 13, 10, 11, 14, 15, 16, 17,20, 21, 18, 19, 22, 23, 24, 25, 28, 29, 26, 27, 30, 31])
cu_window_seqlens:[0, 16, 32, 32, 48, 64, 64, 64, 64, 64, 80, 96, 96, 112, 128, 128, 128, 128, 128]
# 这里有重复数值,后面计算会通过 torch.unique_consecutive 去除得到:[ 0, 16, 32, 48, 64, 80, 96, 112, 128]
理解上面计算结果(处理思路和卷积神经网络很像):window_index:因为输入是 [ 2 , 8 , 8 ] [2,8,8] [2,8,8] 然后划分大小为2(self.spatial_merge_size=self.patch_size=2)就像是“卷积核”一样。因此得到序列长度就是:32(也就是0-31),其中每一个索引代表图像中的“一块”,比如说:0代表左上角2x2的区域,1:代表0右边2x2区域;cu_window_seqlens:知道每块区域索引之后还需要知道“步长”, 0 , 16 0,16 0,16 代表第一块和第二块之间间隔为16那么就可以确定有4块( 4 × 2 × 2 4\times2\times2 4×2×2 )
得到window_size之后在forward计算中:
def forward(self, hidden_states, grid_thw):hidden_states = self.patch_embed(hidden_states)...window_index, cu_window_seqlens = self.get_window_index(grid_thw)...cu_window_seqlens = torch.unique_consecutive(cu_window_seqlens)#(1)重塑窗口化特征seq_len, _ = hidden_states.size()hidden_states = hidden_states.reshape(seq_len // self.spatial_merge_unit, self.spatial_merge_unit, -1)# 按照window_size进行排序hidden_states = hidden_states[window_index, :, :]hidden_states = hidden_states.reshape(seq_len, -1)#(2)重塑位置编码rotary_pos_emb = rotary_pos_emb.reshape(seq_len // self.spatial_merge_unit, self.spatial_merge_unit, -1)rotary_pos_emb = rotary_pos_emb[window_index, :, :]rotary_pos_emb = rotary_pos_emb.reshape(seq_len, -1)emb = torch.cat((rotary_pos_emb, rotary_pos_emb), dim=-1)position_embeddings = (emb.cos(), emb.sin())#(3)计算序列长度cu_seqlens = torch.repeat_interleave(grid_thw[:, 1] * grid_thw[:, 2], grid_thw[:, 0]).cumsum(dim=0,dtype=grid_thw.dtype if torch.jit.is_tracing() else torch.int32,)cu_seqlens = F.pad(cu_seqlens, (1, 0), value=0)#(4)遍历而后计算注意力for layer_num, blk in enumerate(self.blocks):if layer_num in self.fullatt_block_indexes:cu_seqlens_now = cu_seqlenselse:cu_seqlens_now = cu_window_seqlens# 计算注意力if self.gradient_checkpointing and self.training:hidden_states = self._gradient_checkpointing_func(blk.__call__, hidden_states, cu_seqlens_now, None, position_embeddings)else:hidden_states = blk(hidden_states, cu_seqlens=cu_seqlens_now, position_embeddings=position_embeddings)hidden_states =hidden_states = self.merger(hidden_states)reverse_indices = torch.argsort(window_index)hidden_states = hidden_states[reverse_indices, :]return hidden_states
其中self.merger为:
class Qwen2_5_VLPatchMerger(nn.Module):def __init__(self, dim: int, context_dim: int, spatial_merge_size: int = 2) -> None:super().__init__()self.hidden_size = context_dim * (spatial_merge_size**2)self.ln_q = Qwen2RMSNorm(context_dim, eps=1e-6)self.mlp = nn.Sequential(nn.Linear(self.hidden_size, self.hidden_size),nn.GELU(),nn.Linear(self.hidden_size, dim),)def forward(self, x: torch.Tensor) -> torch.Tensor:x = self.mlp(self.ln_q(x).view(-1, self.hidden_size))return x
总结上面代码过程如下:首先是将图像划分为不同patch(这里操作和常规的Vit操作没有区别)得到特征 hidden_states,而后去划分不同窗口,而这个窗口就是直接去对最开始图像所进行的(比如说图像为:2x8x8,2代表时间帧),首先计算需要合并的块的索引,而后将 hidden_states 根据这个索引进行排序,排序之后就需要对这些排序内容计算注意力即可(很像卷积操作:分块就是我们的卷积核,而cu_window_seqlens就是我们的步长)
grid_thw:[2,8,8];2、self.window_size = 8;3、self.spatial_merge_size=self.patch_size=2
2、位置编码
在Qwen2-VL中,时间方向每帧之间固定间隔 1 ,没有考虑到视频的采样率,例如四秒的视频每秒采样两帧和一秒的视频每秒采样八帧,这样总的帧数都是8,在原来这种编码方式中时间维度的编码都是1->8没有任何区别。Qwen-2.5VL在时间维度上引入了动态 FPS (每秒帧数)训练和绝对时间编码,将 mRoPE id 直接与时间流速对齐。描述原理见:https://spaces.ac.cn/archives/10040
参考
1、https://arxiv.org/abs/2004.05150v2
2、http://arxiv.org/abs/2309.16609
3、http://arxiv.org/abs/2409.12191
4、http://arxiv.org/abs/2502.13923
5、https://zhuanlan.zhihu.com/p/24986805514
6、https://qwenlm.github.io/zh/blog/qwen2.5-vl/
相关文章:

Qwen多模态系列论文
From:https://www.big-yellow-j.top/posts/2025/04/28/QwenVL.html 本文主要介绍Qwen-vl系列模型包括:Qwen2-vl、Qwen2.5-vl Qwen2-vl http://arxiv.org/abs/2409.12191 模型结构: Qwen2-vl主要的改进点在于:1、使用动态分辨率(…...

Astro大屏中关于数据流转的数据接入与数据中心之间的逻辑关系梳理
在 Astro 大屏中,「数据接入」与「数据中心」是紧密关联的一对模块,分别承担“数据从哪来”和“数据怎么管”的职责。为了更形象地帮助初学者理解,我可以用“自来水系统”的比喻来解释整个原理与操作逻辑: 🏠 形象比喻…...
 / 不相邻取数(多状态dp) / 空调遥控(排序+二分/滑动窗口))
【今日三题】小红的ABC(找规律) / 不相邻取数(多状态dp) / 空调遥控(排序+二分/滑动窗口)
⭐️个人主页:小羊 ⭐️所属专栏:每日两三题 很荣幸您能阅读我的文章,诚请评论指点,欢迎欢迎 ~ 目录 小红的ABC(找规律)不相邻取数(多状态dp)空调遥控(排序二分/滑动窗口) 小红的ABC(找规律) 小红的ABC 找最短回文串ÿ…...
)
双重差分模型学习笔记(理论)
【DID最全总结】90分钟带你速通双重差分!_哔哩哔哩_bilibili 一、DID的基本原理 (一) 单重差分 1. Cross-Section Comparison 截面数据 只有某个时间点事件发生后的数据 D1 事件发生后 D0 事件发生前 2. Befor-After Vomparison 时间序列…...

企业级私有化部署,内部聊天软件
如何在激烈的市场竞争中脱颖而出,提升工作效率、降低运营成本,同时保障信息安全,成为众多企业管理者亟待解决的问题。而BeeWorks 企业级私有化部署的内部聊天软件,无疑是为这一难题提供了一把金钥匙。 BeeWorks覆盖即时通讯&#…...

HCIA-Datacom 高阶:VLAN、VLANIF 与静态路由综合实验
拓扑图解读 从拓扑图中可以看到,存在三层交换机 LSW3、普通交换机 LSW4、路由器 R2 以及 PC1 - PC4。LSW4 连接了三个不同 VLAN 的 PC(PC1 属于 VLAN 10、PC2 属于 VLAN 20、PC3 属于 VLAN 30 ),并通过 Ethernet 0/0/1 端口以 tr…...

Android ndk 编译opencv后部分接口std::__ndk1与项目std::__1不匹配
1、opencv-4.11预编译命令(在opencv4.5.0之后兼容免费features2d做特征匹配),NDK版本选用的android-ndk-r23c-linux.zip cmake -G Ninja \ -DCMAKE_TOOLCHAIN_FILE/home/who/Downloads/NDK/android-ndk-r23c/build/cmake/android.toolchain.…...

SQL命令一:SQL 基础操作与建表约束
目录 引言 一、SQL 基础命令 (一)数据库相关操作 (二)表格相关操作 (三)MySQL 常用数据类型 二、增删改查(CRUD)操作 (一)增加数据 (二&a…...

颜色分类,不靠“调色盘”:双指针 VS 计数排序的正面PK
颜色分类,不靠“调色盘”:双指针 VS 计数排序的正面PK 在算法圈混得久了,总有一些题目是面试官的心头好,刷题人绕不过的“鬼门关”。“颜色分类”(LeetCode 75)就是其中之一,看似小儿科…...

Shopify网上商店GraphQL Admin接口查询实战
目录 一、Shopify网上商店 二、个人商店配置接口权限 三、PostMan调用接口测试 四、通过Java服务调用接口 一、Shopify网上商店 Shopify是由Tobi Ltke创办的加拿大电子商务软件开发商,总部位于加拿大首都渥太华,已从一家在咖啡店办公的 5人团队&…...

Laravel基础
Laravel 基础 01.Laravel入门和安装 Composer安装Laravel步骤 要使用 Composer 安装 Laravel,请按照以下步骤操作: 确保已经安装了 Composer。如果还没有安装,请访问 https://getcomposer.org/download/ 下载并安装。 打开命令行或终端。…...

【Leetcode 每日一题 - 补卡】2302. 统计得分小于 K 的子数组数目
问题背景 一个数组的 分数 定义为数组之和 乘以 数组的长度。 比方说, [ 1 , 2 , 3 , 4 , 5 ] [1, 2, 3, 4, 5] [1,2,3,4,5] 的分数为 ( 1 2 3 4 5 ) 5 75 (1 2 3 4 5) \times 5 75 (12345)575。 给你一个正整数数组 n u m s nums nums 和一个整数 k…...

力扣——206.反转链表倒序输出链表
206. 反转链表 - 力扣(LeetCode) 思路(迭代) 设三个指针,前后两个指针都为空,当前指针为输入的头指针 开始循环——判断条件为当前节点不为空 先给下一个节点赋值为——当前节点的下一个 改变当前节点的…...

Arthas在Java程序监控和分析中的应用
Arthas在Java程序监控和分析中的应用 在互联网大厂Java求职者的面试中,经常会被问到关于使用Arthas来监控和分析Java程序的相关问题。本文通过一个故事场景来展示这些问题的实际解决方案。 第一轮提问 面试官:马架构,欢迎来到我们公司的面…...

第13讲:图形尺寸与分辨率设置——适配论文版面,打造专业图稿!
目录 📌 为什么这一讲重要? 🎯 一、先认识几个关键词 ✍️ 二、ggsave() 是导出图的标准方法 📐 三、尺寸设置技巧:对齐目标期刊 🔍 找到目标期刊的图形栏宽 📦 四、多个图组合导出(与 patchwork 搭配) 🧪 五、使用 Cairo / ragg 导出高质量图 🎁 六…...

Docker与Vmware网络模式的对别
前言 在使用了很久的VMware和Docker后,分别独立配置过他们的网络,但是每次配置一方时,总感觉和另一方有点不一样,但是也没有来得及总结。刚好最近有时间可以总结一下。 重点: 1、VMware的桥接模式和Docker的桥接模式完…...

大模型在肾癌诊疗全流程中的应用研究报告
目录 一、引言 1.1 研究背景与意义 1.2 研究目的与方法 1.3 国内外研究现状 二、大模型预测肾癌术前情况 2.1 基于影像组学的肾癌良恶性及分级预测 2.1.1 MRI 影像组学模型预测肾透明细胞癌分级 2.1.2 CT 影像深度学习模型鉴别肾肿物良恶性及侵袭性 2.2 大模型对手术风…...

Springboot使用登录拦截器LoginInteceptor来做登录认证
创建拦截器LoginInteceptor类 interceptors/LoginInteceptor.java package org.example.interceptors;import jakarta.servlet.http.HttpServletRequest; import jakarta.servlet.http.HttpServletResponse; import org.example.utils.JwtUtil; import org.springframework.s…...
---java版)
2025年- H13-Lc120-189.轮转数组(普通数组)---java版
1.题目描述 2.思路 import java.util.Arrays;public class H189 {public static void main(String[] args) {int[] newArr {1, 2, 3, 4, 5};int[] nums new int[5];System.arraycopy(newArr,0,nums,0,4);System.out.println(Arrays.toString(nums)); } }补充2: 3.…...

Android Framework常见问题
以下是不同难度级别的 Android Framework 面试题,包含答案要点,可帮助你为面试做好准备。 初级难度 1. 请简要解释 Android Framework 是什么。 答案要点:Android Framework 是 Android 系统的核心组成部分,它为开发者提供了一…...

【AI】图片处理的AI工具
博主最近需要给客户展示一下做的一些设备和仪器,随手拍了一些照片,觉的背景不是很好看,于是在网上寻找AI图片处理工具。后来随手用了一下豆包AI,发现很好用,这里把一点使用的心得体会记录一下,并和大家分享…...

Python列表全面解析:从基础到高阶操作
一、为什么需要列表? 在Python中,列表是可变有序序列,用于存储多个元素的容器。相较于单一变量存储独立值,列表能更高效地管理批量数据,其特点包括: 引用存储:列表元素存储的是对象的引用…...

C++调用C动态库编译时报undefined reference to “funcxxx“错误
问题描述:Linux平台上C调用C库进行make编译时报undefined reference to "funcxxx"错误,错误实例如下: /usr/bin/ld: CMakeFiles/dialog.dir/widgets/widget.cpp.o: in function Widget::loadVerificationModule(): /home/zhangxia…...
)
基于Spring Boot+Vue 网上书城管理系统设计与实现(源码+文档+部署讲解)
技术范围:SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文编写和辅导、论文…...

C++ 中自主内存管理 new/delete 与 malloc/free 完全详解
C 中 new/delete 与 malloc/free 完全详解 一、new/delete 与 malloc/free 的区别 特性new/deletemalloc/free属于C语言C语言申请的内存区堆(Heap)堆(Heap)返回类型指向对象类型的指针(自动转换)void*&…...

Maven中的依赖管理
目录 什么是依赖范围 什么是依赖传递 依赖范围对依赖传递的影响 依赖冲突 什么是依赖冲突 依赖冲突的解决方案 版本锁定 短路径优先 编辑 声明优先 特殊优先(后来者居上) 可选依赖 排除依赖 可选依赖和排除依赖的区别 刷新依赖的8种方式…...

生态修复项目管理软件
在“双碳”目标与生态文明建设的双重驱动下,生态修复项目正成为全球环境治理的核心战场。然而,矿山复绿、湿地修复、水土保持等工程往往面临跨地域、多主体、长周期的管理难题——从数据分散到进度失控,从成本超支到风险频发,传统…...

深度剖析 RocketMQ 5.0 之架构解析:云原生架构如何支撑多元化场景?
拓展学习:🔍「RocketMQ 中文社区」 持续更新,提供 RocketMQ 领域专家模型的 AI 答疑 作者 | 隆基 简介: 了解 RocketMQ 5.0 的核心概念和架构概览;然后我们会从集群角度出发,从宏观视角学习 RocketMQ 的管…...
)
Spring中bean的生命周期(笔记)
bean的生命周期,按照最重要五步 第一步:实例化bean,调用无参构造方法(通过BeanDefinition利用反射实例化Bean对象(无参数构造方法) 并通过推断构造方法...并放入三级缓存中..) 第二步:给bean属性赋值(调用…...
transform-实现Encoder 编码器模块
Encoder 论文地址 https://arxiv.org/pdf/1706.03762 Encoder结构介绍 Transformer Encoder是Transformer模型的核心组件,负责对输入序列进行特征提取和语义编码。通过堆叠多层结构相同的编码层(Encoder Layer),每层包含自注意力机…...

LVGL -窗口操作
1 窗口背景介绍 在 LVGL 中,screen 是一个顶层对象,代表你设备上当前显示的整个画面。它相当于一个“全屏容器”,你可以在上面添加按钮、标签、图像、容器等各种界面控件。它的本质就是一个特殊的 lv_obj_t,但它没有父对象&#…...

ollama运行qwen3
环境 windows server GPU 32G 内存 40G 升级ollama 需要版本 0.6.6以上 ollama --version拉取模型 ollama pull qwen3:32b时间比较长,耐心等待 运行模型 ollama run qwen3:32b运行起来之后发现GPU是可以跑起来的,发个你好看看 默认是深度思考的,不…...

如何查看和验证AWS CloudFront的托管区域ID
在使用AWS Route 53设置DNS记录时,正确识别CloudFront分发的托管区域ID是至关重要的。本文将详细介绍几种查看和验证CloudFront托管区域ID的方法,特别关注中国区CloudFront的特殊情况。 为什么托管区域ID很重要? 托管区域ID是AWS服务中的一个关键标识符。在创建指向CloudF…...

yum 安装 ncurses-devel 报错 baseurl 的解决方法
解决 yum 安装 ncurses-devel 报错(baseurl 问题) 出现 yum install ncurses-devel 报错 Cannot find a valid baseurl for repo: centos-sclo-rh/x86_64 的原因,很可能是因为 CentOS 7 的 SCL 源在 2024 年 6 月 30 日停止维护了。以下是解…...

《Vue3学习手记7》
组件通信(续) $attrs 组件通信:$attrs 适用于祖传孙或孙传祖 (需要通过中间组件) 传递给后代的数据,但未被接收,都保存在attrs中 1.祖传孙 父组件: <template><div cl…...

算法备案类型解析:如何判断你的算法属于哪种类型?
根据《互联网信息服务算法推荐管理规定》政策,算法备案已经成为了强制性备案。但对于企业而言,如何准确判断自身算法所属的备案类型往往存在困惑,今天我们就来详细盘一盘算法备案的类型,教你如何判断自己的算法属于哪一类 一、算…...

Javascript 中作用域的理解?
一、作用域的类型 1. 全局作用域(公司大门外) 范围:整个 JavaScript 文件变量:像贴在公告栏上的信息,所有人可见例子:const companyName "阿里"; // 全局变量,任何地方都能访问 fu…...

Qt入门——什么是Qt?
Qt背景介绍 什么是Qt? Qt 是⼀个 跨平台的 C 图形用户界面应用程序框架 。它为应用程序开发者提供了建立艺术级图形界面所需的所有功能。它是 完全面向对象 的,很容易扩展。Qt 为开发者提供了 ⼀种基于组件的开发模式 ,开发者可以通过简单的拖拽和组合…...

Snap7西门子PLC通信协议
S7协议,作为西门子的专有协议,广泛应用于多种通讯服务中,如PG通讯、OP通讯以及S7基本通讯等。它独立于西门子的各种通讯总线,能够在MP、PROFIBUS、Ethernet以及PROFINET等多种网络上运行。S7协议实质上是一个由多种应用层协议构成…...

GTC Taipei 2025 医疗域前瞻:从AI代理到医疗生态,解码医疗健康与生命科学的未来图景
引言 2025年,全球医疗健康领域正经历一场由人工智能、机器人技术与分布式计算驱动的范式转移。随着NVIDIA及其生态伙伴在GTC Taipei 2025大会上的深度布局,医疗行业的核心趋势愈发清晰:AI代理程序(Digital AI Agents)赋能临床协作、医疗大数据与精准医学加速落地、医学影…...
 与 push_back() 的区别)
C++的vector中emplace_back() 与 push_back() 的区别
C 中 vector 的 emplace_back() 和 push_back() 均用于向容器末尾添加元素,但二者在实现和效率上有显著区别: 1. 参数传递方式 push_back():接受一个已构造的对象(左值或右值),将其拷贝或移动到容器中。 s…...

LangChain4j +DeepSeek大模型应用开发——5 持久化聊天记忆 Persistence
默认情况下,聊天记忆存储在内存中。如果需要持久化存储,可以实现一个自定义的聊天记忆存储类,以便将聊天消息存储在你选择的任何持久化存储介质中。 1. 存储介质的选择 大模型中聊天记忆的存储选择哪种数据库,需要综合考虑数据特…...

C++核心编程 1.2 程序运行后
1.2 程序运行后 栈区: 由编译器自动分配释放, 存放函数的参数值,局部变量等 注意事项:不要返回局部变量的地址,栈区开辟的数据由编译器自动释放 int * func() {int a 10;return &a; }int main() {int *p func();cout << *p <…...
)
小市值策略复现(A股选股框架回测系统)
相关config配置 https://quantkt.com/forumDetail?id201043 很早就知道了小市值模型,正好量化选股回测框架出来了,把最裸的小市值复现下,顺便验证下框架逻辑。 科普: 小市值策略基于 “小市值效应”,即从历史数据来看…...
—函数递归)
C语言(6)—函数递归
文章目录 一、递归的基本概念1.1 什么是递归1.2 递归的核心思想1.3 递归的必要条件 二、递归的经典应用2.1 阶乘计算 三、递归与迭代的比较3.1 递归的优缺点3.2 迭代的优缺点 四、递归的底层机制4.1 函数调用栈4.2 栈溢出风险 五、递归优化技巧5.1 记忆化(Memoizati…...

【网络】HTTP报文首部字段
目录 一. 预备知识 1.1.代理、网关和隧道 1.1.1.代理 1.1.2.网关 1.1.3.隧道 1.2.保存资源的缓存 1.2.1.缓存的有效期限 1.2.2.客户端的缓存 1.3.用单台虚拟主机实现多个域名 二. HTTP首部字段 2.1.HTTP 首部字段格式 2.2.四种 HTTP 首部字段类型 三. HTTP通用首部…...

【Fifty Project - D20】
今日完成记录 TimePlan完成情况7:30 - 11:30收拾行李闪现广州 & 《挪威的森林》√10:00 - 11:00Leetcode√16:00 - 17:00健身√ Leetcode 每日一题 每日一题来到了滑动窗口系列,今天是越…...

【Linux系统】systemV共享内存
system V共享内存 在Linux系统中,共享内存是一种高效的进程间通信(IPC)机制,它允许两个或者多个进程共享同一块物理内存区域,这些进程可以将这块区域映射到自己的虚拟地址空间中。 共享内存区是最快的IPC形式。一旦这…...

【计算机网络】DHCP——动态配置ip地址
DHCP 是什么? DHCP(Dynamic Host Configuration Protocol,动态主机配置协议) 是一种网络协议,用于自动分配 IP 地址和其他网络配置参数(如子网掩码、默认网关、DNS 服务器等)给网络中的设备&…...

TDengine 订阅不到数据问题排查
简介 TDengine 在实际生产应用中,经常会遇到订阅程序订阅不到数据的问题,总结大部分都为使用不当或状态不正确等问题,需手工解决。 查看服务端状态 通过 sql 命令查看有问题的 topic 和consumer_group 组订阅是否正常。 select * from inf…...