第十五章:预训练大语言模型
目录
15.1 数据准备
15.1.1 数据预处理
15.1.2 数据调度
15.2 模型架构
15.2.1 主流架构
一、编码器架构(Encoder-only,以 BERT 为代表)
核心特点:
代表模型:BERT、RoBERTa、ALBERT
典型应用:
二、解码器架构(Decoder-only,以 GPT 为代表)
核心特点:
代表模型:GPT-1/2/3/4、PaLM、Llama
典型应用:
三、编码器 - 解码器架构(Encoder-Decoder,以 T5 为代表)
核心特点:
代表模型:T5、BART、Whisper、ERNIE-GEN
典型应用:
四、核心差异对比
五、为什么需要不同架构?
15.2.2 长上下文模型
15.3 模型预训练
15.3.1 预训练任务
15.3.2 优化参数设置
15.3.3 可扩展的训练技术
15.4 小结
参考
如14.2节大语言模型的构建过程所述,大语言模型的构建过程可以分为预训练和微调两个阶段。通过在大规模语料上进行预训练,大语言模型可以获得通用的语言理解与生成能力,并且学习到较为广泛的世界知识。
本章将按顺序依次介绍预训练中的各个步骤,包含原始数据的收集、数据预处理、分词、以及预训练过程中的数据调度方法。
15.1 数据准备
现有的大语言模型主要将各种公开的文本数据进行混合作为预训练语料,如图 15-1 所示。预训练数据可以分为通用文本数据和专用文本数据,其中通用文本数据规模较大,涵盖了网页、书籍和对话等内容,用以增强模型的语言建模能力;专用文本数据则是为了进一步提升大语言模型在特定任务上的表现,如多语数据、科学数据和代码数据等。
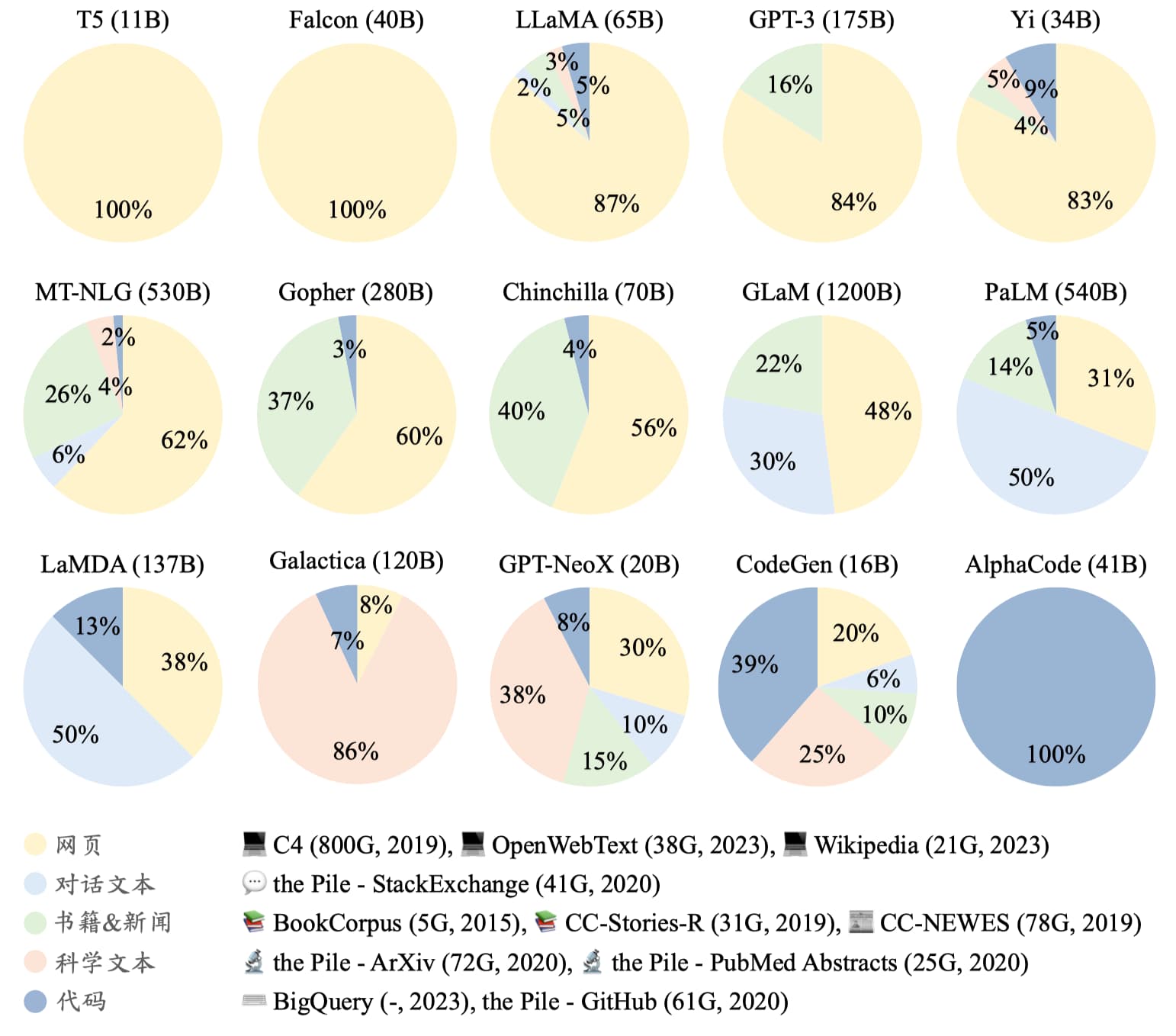
常用的专用文本数据分为三种:
- 多语文本:多语文本数据可以帮助模型更好地建立多语言间的语义关联,增强模型的多语理解与生成能力,为跨语言理解与对话任务提供支持。此外,多语言数据还能有效增加数据的多样性,从而有助于提升模型的综合性能。
- 科学文本:科学文本数据可以增强大语言模型对科学知识的理解,从而提高科学问答与推理等任务的性能。常用方法是收集 arXiv 论文、科学教材、数学网页等。但是由于科学文本数据中包含数学公式、蛋白质序列等特殊符号,通常需要采用特定的分词和预处理技术将数据转化为大语言模型能够处理的统一格式。
- 代码:代码语料可以提高其模型生成的程序质量,其来源主要是 Stack Exchange 等编程问答社区的数据以及 GitHub 等开源项目仓库。由于代码主要以结构化的编程语言形式呈现,在代码数据上训练能够提升模型的结构化语义理解与逻辑推理能力。同时,代码中的函数调用关系还有助于增强模型的工具使用与学习能力。将推理任务格式化为代码通常可以得到更准确的结果。
15.1.1 数据预处理
在收集了丰富的文本数据之后,就需要对数据进行预处理,消除低质量、冗余、无关甚可能有害的数据。一般来说,需要构建并使用系统化的数据处理框架,例如开源库 Data-Juicer。典型的数据预处理流程如图 15-2 所示,包括质量过滤、敏感内容过滤、数据去重等步骤。

步骤一:质量过滤
在质量过滤方面,目前主要使用以下两种数据清洗方法:
-
基于启发式规则的方法:通过精心设计的规则有针对性地识别和剔除低质量数据。例如(1)为了训练特定目标语言的模型可以过滤掉其他语言的文本。(2)使用单词比率等统计特征来衡量文本质量。还可以利用困惑度(Perplexity)等文本生成评估指标来检测和删除表达不自然的句子,以及训练 FastText 分类器来检测有毒或仇恨言论。(3)制定精准的清洗规则,结合关键词集合进行过滤。
延伸
常用的统计指标过滤规则有:对于网页数据,过滤任何具有超过 100 个重复单词或句子的文档,以及过滤符号和词元比大于 0.1 的文档;对于论坛数据,过滤掉任何点赞数少于 3 的用户评论。
常用的关键词过滤规则有:对于维基百科数据,过滤掉任何拥有少于 25 个 UTF-8 单词的页面;对于网页数据,过滤掉 HTML 标签,以及过滤掉任何不含有 the, be, to, of, and, that, have, with 词汇的文档;对于所有数据,过滤掉电话号码,邮箱地址、IP 地址等隐私信息。
-
基于分类器的方法:训练判别数据质量的文本分类器进行数据清洗。具体来说,可以选取部分代表性的数据进行质量标注以训练分类器,例如将维基百科等高质量数据作为正样本、将筛选出含有不良内容或低质量数据的样本作为负样本。文本过滤的粒度可以是文档级别也可以是句子级别。为了减少误筛,可以使用多个分类器进行联合过滤或召回,还可以针对不同的评估维度训练不同的分类器。
目前常用方法包括轻量级模型(如 FastText)、可微调的预训练模型(如 BERT)以及闭源大语言模型 API(如 GPT-4)。轻量级模型效率较高,但是分类的准确率和精度受限于模型能力;预训练模型可以针对性微调, 但是通用性和泛化性具有限制;闭源大语言模型的能力较强, 但是无法灵活针对任务进行适配而且成本较高。
延伸
过滤效率也是预处理需要考虑的核心要素。基于启发式的方法效率较高,能够迅速过滤 10M 乃至 100M 级别的庞大文档集,而基于分类器的方法虽然精度更高,但是效率较低。因此可以结合多种策略平衡效率与准确性,例如首先利用启发式规则进行初步筛选,然后再采用分类器方法进行精细过滤。此外,还可以同时应用多种分类器,例如使用更为有效但是资源消耗更高的分类器在轻量级分类器粗滤后的数据上再次进行选择。
步骤二:敏感内容过滤
在敏感内容过滤方面,目前主要关注对有毒内容和隐私信息的过滤方法。为了精确过滤含有有毒内容的文本,通常采用基于分类器的过滤方法,例如基于 Jigsaw 评论数据集训练分类器。而过滤隐私内容则主要使用启发式方法(如关键字识别),例如 Dolma 采用规则方法来过滤邮箱地址、IP 地址以及电话号码,如果文档中的隐私信息少于五条则使用使用特定的词元进行替换(如“[EMAIL_ADDRESS]”),如果隐私信息达到六条则直接删除整个文档。
步骤三:数据去重
数据去重同样是一个重要步骤。由于大语言模型具有较强的数据拟合与记忆能力,很容易习得训练数据中的重复模式,可能导致对这些模式的过度学习。研究发现,预训练语料中出现的重复低质量数据可能诱导模型在生成时频繁输出类似数据。此外,这些数据也可能导致训练过程不稳定(训练损失震荡)甚至导致训练崩溃。目前数据去重主要关注计算粒度以及匹配方法两个方面:
-
计算粒度:去重可以在句子、文档等多种粒度上进行。在句子级别上,可以删除包含重复单词和短语的句子;在文档级别上,可以依靠单词或 n 元词组的重叠等表层特征来衡量文档的重叠比率;数据集级别往往采用多阶段、多粒度的方式来进行。一般首先在数据集和文档级别进行去重(去除高度相似甚至完全一致文档),然后在句子级别实现更为精细的去重,例如当两个句子公共子串的长度过长时直接删除某一个句子。
-
匹配方法:在去重过程中,可以使用精确匹配算法(即每个字符完全相同)或近似匹配算法(基于相似度)。对于精确匹配,通常使用后缀数组来匹配最小长度的完全相同子串;对于近似匹配,可以采用局部敏感哈希(Locality-Sensitive Hashing, LSH)算法,如最小哈希(MinHash) 来实现。为了平衡去重效率和效果,实际操作通常会结合多种匹配方法,例如在文档层面采用近似匹配而在句子层面采用精确匹配。
延伸
MinHash 是一种估计两个集合之间相似度的技术,可以迅速判断文档间的相似性。其核心思想是通过哈希处理集合元素,并选择最小的哈希值作为集合表示,然后通过比较两个集合的最小哈希值估算相似度。 为了提升估计精确度还可以采用不同的哈希函数为每个集合生成多个 MinHash 值。
MinHash 技术只需比较那些更为简洁、易于对比的哈希值,可以避免对集合中所有元素进行逐一比较,使得其在处理超大型集合时具有较好的计算效率。
现有的研究证明,预训练数据的数量和质量都对训练效果具有重大影响。
如14.1节大语言模型技术概览中介绍的那样,早期的研究工作认为增加模型参数更为重要,而最近的研究表明扩展训练数据量对于提升大语言模型的性能同样非常关键,整体上语言模型的性能会随着训练数据量的增加而提升。
在获取充足的预训练数据后,数据质量直接决定了模型的实际性能。通过提升数据质量,语言模型就能展现出与更大规模模型相匹敌甚至更为优异的性能。相反,使用大量低质量数据会导致模型训练过程不稳定,容易造成模型训练不收敛等问题。而且如果模型在包含事实性错误的、过时的数据上进行训练,那么它在处理相关主题时就可能会产生不准确或虚假的信息,这种现象被称为“幻觉”(Hallucination)。
此外,已有研究普遍认为重复数据对于模型训练及最终性能会带来不良影响,例如导致模型训练损失出现“双下降”现象(先下降然后升高再下降)。而且重复数据可能会降低模型利用上下文信息的能力,从而削弱模型在上下文学习中的泛化能力。因此通常的建议是对于预训练数据进行精细的去重操作。
最后,数据中包含有偏、有毒、隐私的内容将会对于模型造成严重的不良影响。例如如果训练数据中包含有毒内容,模型就可能会产生侮辱性、攻击性或其他有害的输出;而在含有隐私内容的数据上训练可能会导致模型在输出中泄露或利用个人数据。
步骤四:分词
分词(Tokenization)步骤负责将原始文本分割成模型可识别和建模的词元序列,作为大语言模型的输入数据。如5.2.1节分词策略中介绍的那样,当前基于 Transformer 的语言模型大多采用子词分词器(Subword Tokenizer)进行分词,常见方法有 BPE 分词、WordPiece 分词和 Unigram 分词三种。
虽然直接使用已有的分词器较为方便(例如 GPT-3 模型使用了 GPT-2 的分词器),但是使用为语料专门设计的分词器会更加有效,尤其对于混合了多领域、多语言和多种格式的语料。最近的工作通常使用 SentencePiece 代码库定制化分词器。
15.1.2 数据调度
完成数据预处理之后,需要设计合适的调度策略来安排这些多来源的数据。数据调度(Data Scheduling)主要关注两个方面:各个数据源的混合比例以及各数据源用于训练的顺序(称为数据课程,Data Curriculum),具体的数据调度流程如图 15-3 所示。
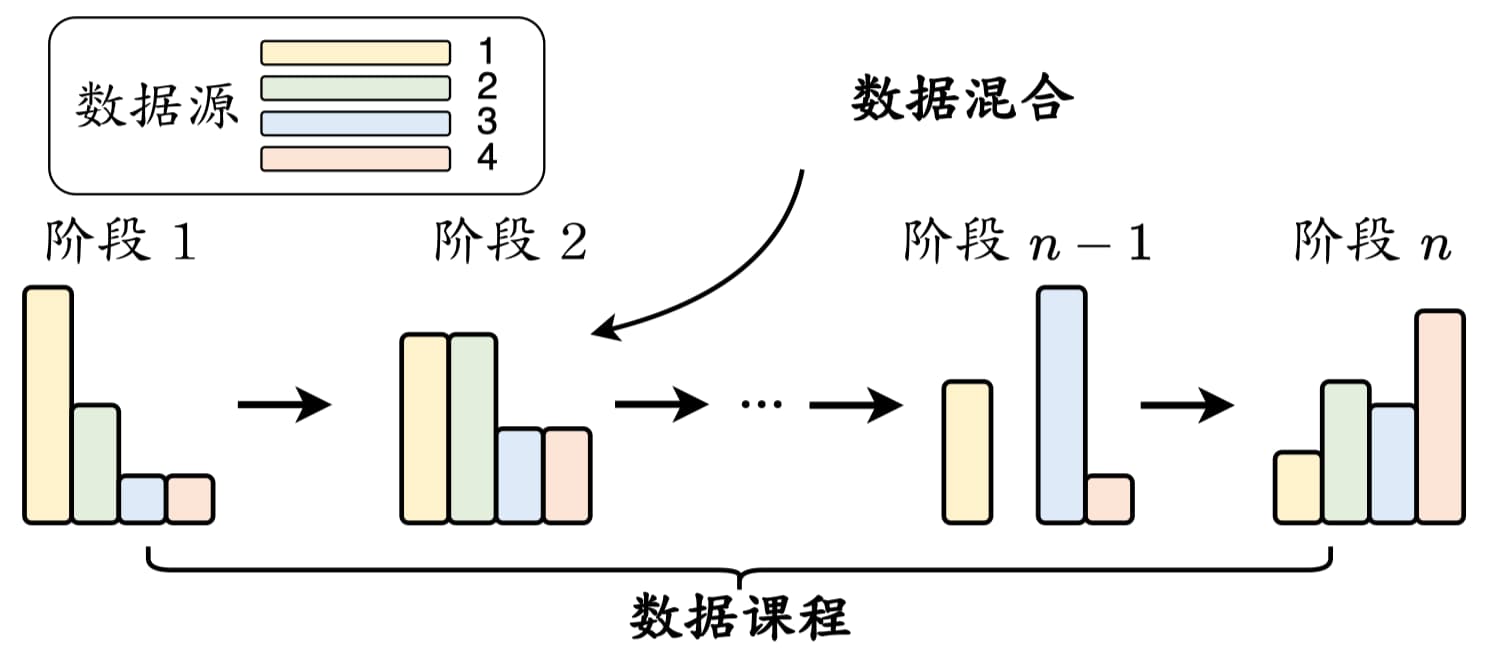
数据混合
由于数据源与大语言模型某些特定能力的学习具有紧密的联系,因此设置合适的数据混合比例非常重要。
数据混合通常设置的是预训练数据的整体分布,在预训练期间,将根据混合比例从不同数据源中采样数据,也可以在不同训练阶段采用 不同的混合比例。如图 15-1 所示,代表性大语言模型 LLaMA 的预训练数据主要包括超过 80% 的网页数据、来自 GitHub 和 StackExchange 的 6.5% 代码密集型数据、4.5% 的书籍数据,以及来自 arXiv 的 2.5% 科学数据,这个数据配比可以作为训练大语言模型的一个重要参考。
注意
即使是训练专业模型(例如代码模型 CodeGen)时,依然需要混合一定比例的网页数据来提供或者保留通用的语义知识。
在实践中,数据混合通常是根据经验确定的,下面汇总了几种常见的数据混合策略。
- 增加数据源的多样性:多样化的数据(如网页、书籍、代码等)能够改进大语言模型在下游任务中的综合表现。
- 优化数据混合:除了手动设置数据混合配比外,还可以使用可学习的方法来优化数据组成。实践中通常采用不同的数据混合从头开始训练几个小型语言模型(例如 1.3B 规模),然后选择获得最理想性能的数据混合配比。但是这个方法假设以类似方式训练出的小模型与大模型会表现出相似的模型能力或行为,在实际中并不总是成立。
- 优化特定能力:可以通过增加特定数据源的比例来增强某些对应的模型能力,例如使用更多的数学和代码数据可以增强大语言模型的数学推理和编程能力。常见做法是采用多阶段训练方法,例如在连续的两个阶段分别安排通用数据和任务特定数据,这种在多个阶段使用不同数据源混合配比进行训练的方法被称为“数据课程”。
数据课程
除了设置数据混合配比,在训练过程中对数据顺序进行合适的安排也很重要。一种实用方法是基于专门构建的评测基准监控大语言模型关键能力的学习过程,然后在预训练期间动态调整数据的混合配比。
由于预训练阶段需要耗费大量的计算资源,目前针对数据课程的研究工作主要集中在继续预训练(Continual Pre-training)。研究表明,为了学习某些特定的技能,按照技能依赖顺序编排对应数据集的学习方法(例如从基本技能到目标技能)比直接在相关语料上学习效果更好。
下面将以三种常见能力为例,介绍具体的数据课程在继续预训练中的应用。
- 代码能力: 为了提高模型的代码生成能力,研究人员基于 LLaMA-2 开发了 CodeLLaMA,采用的数据课程为:2T 通用词元 → 500B 代码密集型词元。CodeLLaMA 还提供了一个面向 Python 语言的特定代码大模型 CodeLLaMA-Python,采用的数据课程为:2T 通用词元 → 500B 代码相关词元 → 100B Python 代码相关词元。
- 数学能力: Llemma 选择 CodeLLaMA 作为基座,进一步在包含论文、数学和代码的混合数据集合上进行继续预训练,采用的数据课程为:2T 通用词元 → 500B 代码相关词元 → 50∼200B 数学相关词元。特别地,Llemma 在继续预训练数据中还包含 5%的通用领域数据,这可以看做一种模型能力的“正则化”技术,加强对于基座模型通用能力的保持。
- 长文本能力: 很多工作通过继续预训练有效扩展了大语言模型的上下文窗口,主要是针对 RoPE 中的位置嵌入编码进行修改。例如 CodeLLaMA 将 LLaMA-2 的上下文窗口从 4K 扩展到了 100K,采用的数据课程为:4K 上下文窗口的 2.5T 词元 → 16K 上下文窗口的 20B 词元。
15.2 模型架构
15.2.1 主流架构
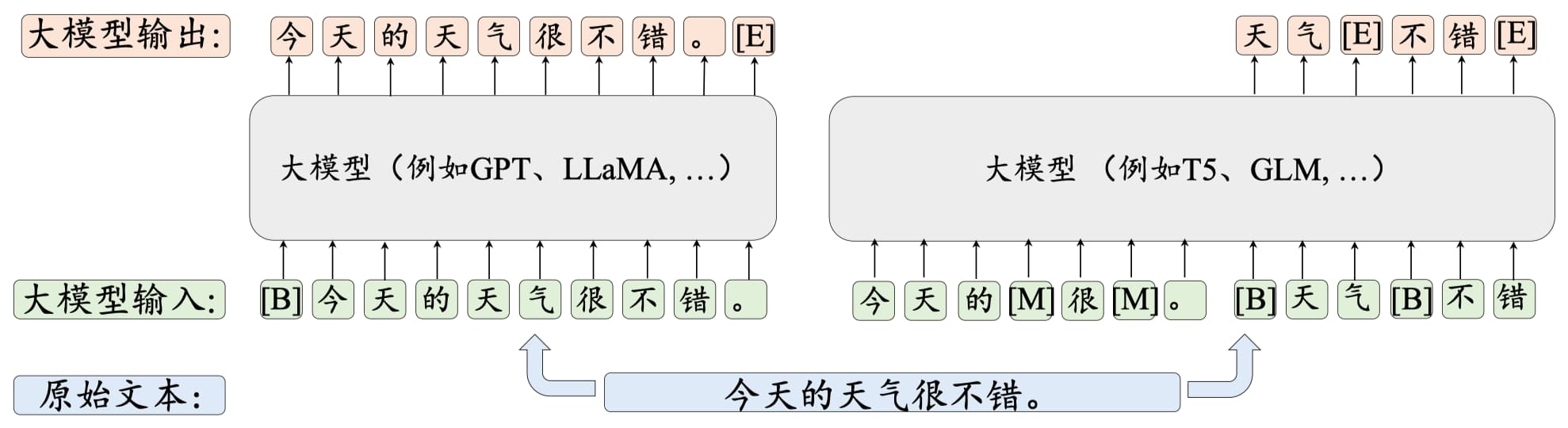
如 2.4 节 Transformer 家族中介绍的那样,语言模型大致可以分为三种架构:以 BERT 为代表的编码器(Encoder-only)架构、以 GPT 为代表的解码 器(Decoder-only)架构和以 T5 为代表的编码器-解码器(Encoder-decoder)架构。近年来,随着 GPT 系列模型取得重大成功,解码器架构已经成为了大语言模型的主流架构。特别地,解码器架构还可以细分为因果解码器(Causal Decoder)和前缀解码器(Prefix Decoder),默认情况下指的就是因果解码器架构。
这几种架构的对比如图 15-4 所示,其中蓝色、绿色、黄色和灰色矩形分别表示前缀词元之间的注意力、前缀词元和目标词元之间的注意力、目标词元之间的注意力以及掩码注意力。
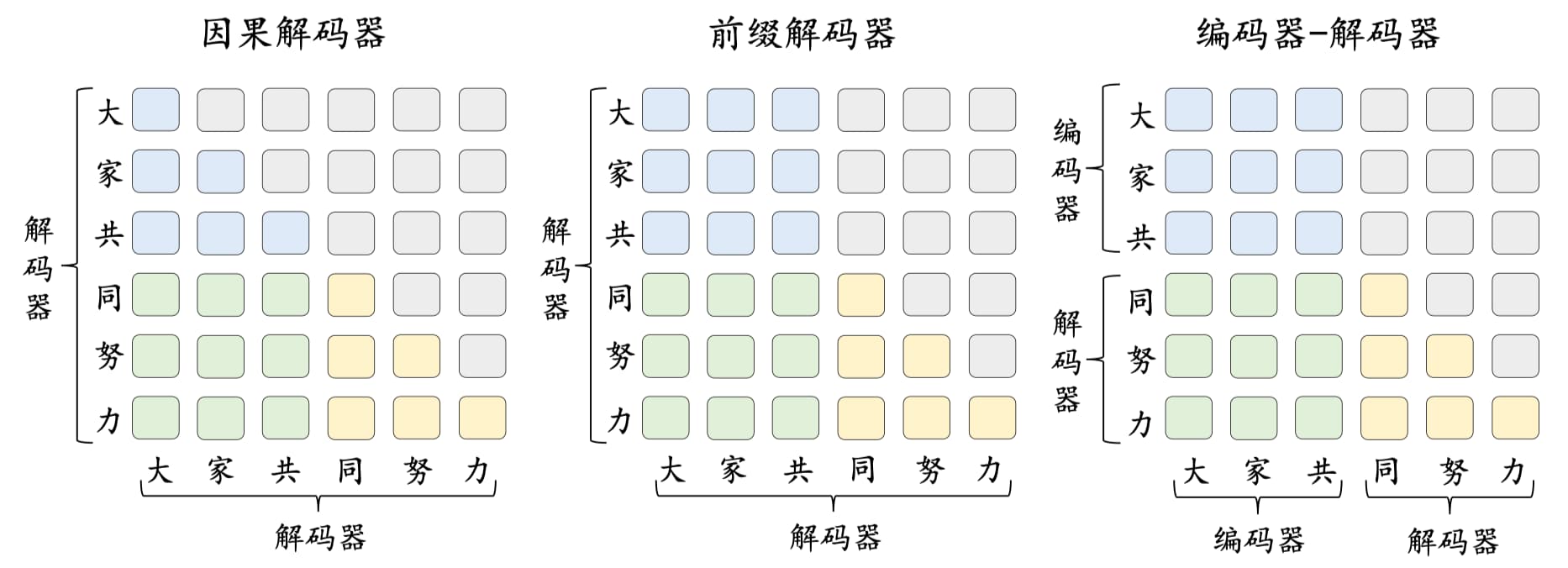
编码器-解码器架构是一种经典的模型结构。如图 15-4 所示,该架构在编码器端采用了双向自注意力机制对输入信息进行编码,而在解码器端则使用了交叉注意力与掩码自注意力机制,进而通过自回归的方式对输出进行生成。目前只有如 Flan-T5 等少数大语言模型是基于编码器-解码器架构构建的。
因果解码器架构没有显式地区分输入和输出部分。如图 15-4 所示,该架构采用单向掩码注意力机制,使得每个输入的词元只关注序列中位于它前面的词元和它本身,进而自回归地预测输出的词元。目前绝大部分大语言模型都采用因果解码器架构,最具有代表性的模型就是 OpenAI 推出的 GPT 系列模型。
前缀解码器架构参考了编码器-解码器的设计。如图 5.6 所示,该架构对于输入(前缀)部分使用双向注意力进行编码,对于输出部分利用单向的掩码注意力利用该词元本身和前面的词元进行自回归地预测。当前基于前缀解码器架构的代表性大语言模型包括 GLM-130B 和 U-PaLM。
补充:
语言模型的三种主流架构(编码器、解码器、编码器 - 解码器)是基于 Transformer 结构的不同设计,核心区别在于对 “语义理解” 和 “文本生成” 功能的侧重不同。以下从技术原理、代表模型和应用场景三方面具体解析:
一、编码器架构(Encoder-only,以 BERT 为代表)
核心特点:
- 双向语义理解:仅使用 Transformer 的编码器层,每个词的表示通过双向自注意力(同时关注前后文)计算,能捕捉完整上下文依赖(如 “苹果” 在 “吃苹果” 和 “苹果公司” 中的不同含义)。
- 不生成文本:输出是固定长度的语义向量(编码结果),用于描述输入文本的整体语义,不直接生成新文本。
代表模型:BERT、RoBERTa、ALBERT
典型应用:
- 文本理解任务:如文本分类(判断情感)、命名实体识别(标注实体类型)、问答(基于上下文找答案)。
例如:BERT 处理 “猫坐在垫子上” 时,会同时分析 “猫” 和 “垫子” 的关系,生成包含完整语义的向量。二、解码器架构(Decoder-only,以 GPT 为代表)
核心特点:
- 单向生成:仅使用 Transformer 的解码器层,通过掩码自注意力(只能看到当前词左边的内容),按 “从左到右” 顺序逐词预测下一个词,模拟人类语言生成过程。
- 专注文本生成:输入是已生成的前缀(如 “今天天气”),输出是续写内容(如 “很好,适合散步”),适合开放式生成任务。
代表模型:GPT-1/2/3/4、PaLM、Llama
典型应用:
- 文本生成任务:如对话(聊天机器人)、写作(文章生成)、代码补全、翻译(作为生成端)。
例如:GPT 输入 “从前有座山”,会逐步预测后续内容,每次只依赖已生成的前文。三、编码器 - 解码器架构(Encoder-Decoder,以 T5 为代表)
T5(Text-to-Text Transfer Transformer)是 2020 年由 Google 团队提出的一种编码器 - 解码器架构的预训练语言模型,其核心思想是将所有自然语言处理(NLP)任务统一为 “文本到文本” 的生成问题 —— 无论任务是翻译、问答、摘要还是文本生成,都转化为 “输入一段文本,输出一段目标文本” 的形式。T5 的核心设计:用 “文本” 统一所有任务。
核心特点:
- 两段式处理:
- 编码器:先对输入文本(如源语言句子、问题)进行双向编码,提取深层语义(类似 Encoder-only)。
- 解码器:基于编码器输出的语义向量,通过掩码自注意力单向生成目标文本(类似 Decoder-only)。
- 灵活适配多种任务:将所有任务(如翻译、问答、摘要)统一为 “文本到文本” 生成问题(输入和输出都是文本)。
代表模型:T5、BART、Whisper、ERNIE-GEN
典型应用:
- 跨模态或复杂生成任务:
- 机器翻译(编码器处理源语言,解码器生成目标语言);
- 文本摘要(编码器理解长文本,解码器生成短摘要);
- 语音识别(Whisper 的编码器处理音频特征,解码器生成文字)。
例如:T5 处理 “将‘Hello’翻译成中文” 时,编码器先理解输入指令,解码器再生成 “你好”。四、核心差异对比
维度 编码器(BERT) 解码器(GPT) 编码器 - 解码器(T5) 自注意力 双向(无掩码) 单向(左到右掩码) 编码器双向,解码器单向 核心功能 语义理解(编码) 文本生成(解码) 先理解后生成(编解码) 输入输出 输入文本→语义向量 前缀文本→续写文本 输入文本→目标文本 典型任务 分类、问答、匹配 续写、对话、创作 翻译、摘要、跨模态生成 五、为什么需要不同架构?
- 任务需求驱动:
- 若只需 “理解” 文本(如判断情感),编码器的双向语义足够,无需生成能力;
- 若需 “创造” 文本(如写故事),解码器的单向生成更高效,避免双向信息干扰预测;
- 若需 “先理解再创造”(如翻译),编码器 - 解码器的分工更合理,兼顾理解深度和生成灵活性。
这三种架构覆盖了 NLP 的核心场景:从基础的语义分析到复杂的生成任务,形成了当前大语言模型的技术基石。
15.2.2 长上下文模型
实际应用中,大语言模型对于长文本的处理需求日益凸显。为此,多家机构已推出了具有超长上下文窗口的大语言模型或 API,例如支持 128K 上下文窗口的 GPT-4 Turbo、具有 200K 上下文窗口的 Claude-2.1等。目前,增强大语言模型长文本建模能力的研究主要集中在扩展位置编码和调整上下文窗口两个方向。
扩展位置编码
大语言模型的上下文建模能力通常受到训练集中文本数据长度分布的限制。一旦超出这个分布范围,模型的位置编码往往无法得到充分训练而导致模型处理长文本的性能下降。因此,需要对于位置编码进行扩展。
目前主流的位置编码方法 RoPE 在未经特殊修改的情况下并不具备良好的外推能力。因此,很多研究工作在 RoPE 的基础上进行了重要改进,旨在提升其在不经过训练或继续训练的情况下对于长文本的建模能力,例如通过位置内插、位置截断等方式修改位置索引来调整所有子空间的旋转角度,从而保证其不超过原始上下文窗口所允许的最大值。
延伸
某些特定的位置编码在超出原始上下文窗口的文本上也能表现出较好的建模能力,这种能力被称为外推(Extrapolation),例如 T5 偏置、ALiBi 以及 xPos 等方法都展现出了不同程度的外推能力。
尽管外推能力使得模型在长文本上继续生成流畅的文本,但模型对长文本本身的理解能力可能无法达到与短文本相同的水平。为了真正增强长文本建模能力,通常还需要在更长的文本上进行一定训练。
调整上下文窗口
除了使用扩展位置编码来拓宽上下文窗口外,另一种行之有效的策略是采用受限的注意力机制来调整原始的上下文窗口,从而实现对更长文本的有效建模。常见的三种方法为并行上下文窗口、Λ 形上下文窗口和词元选择,如图 15-5 所示,其中白色表示被掩盖的词元、蓝色表示进行注意力计算的词元,块上面的数字表示位置编码的相对位置。
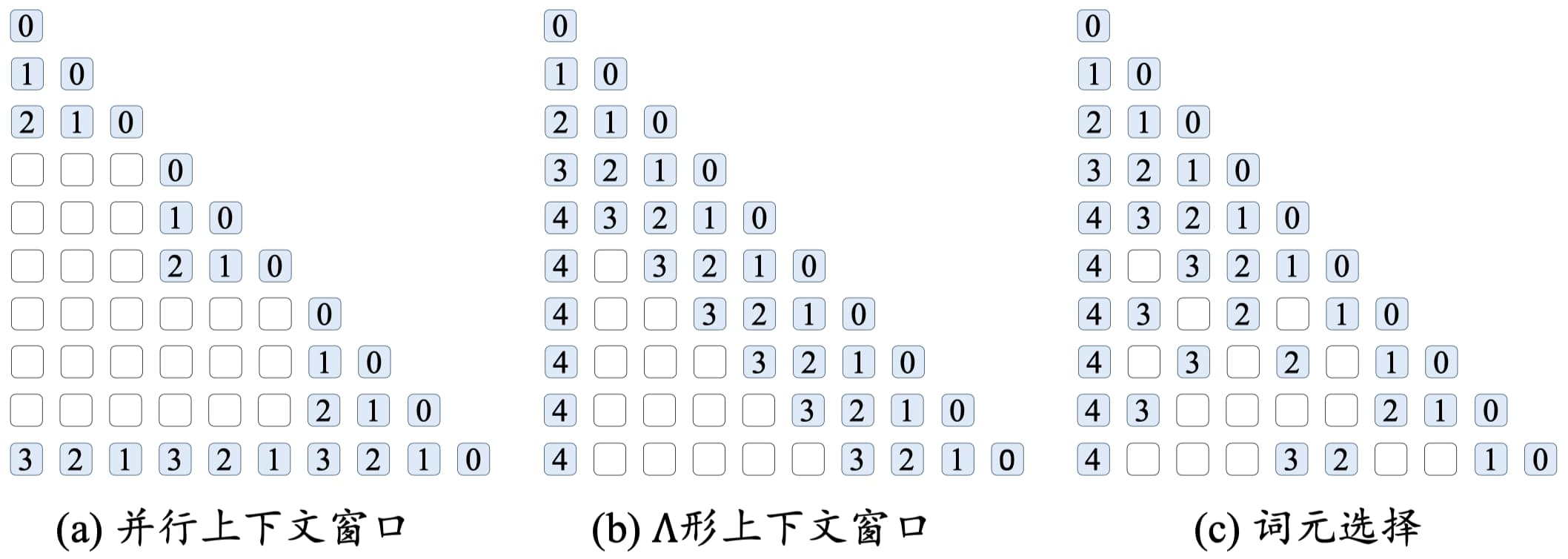
图 15-5 三种调整上下文窗口方法的示意图
- 并行上下文窗口:将输入文本划分为若干个片段,每个片段都进行独立的编码处理,并共享相同的位置编码信息。在生成阶段,通过调整注意力掩码,使得后续生成的词元能够访问到前序的所有词元。然而,该方法无法有效地区分不同段落之间的顺序关系,在某些特定任务上可能表现不佳。
- Λ 形上下文窗口:有选择性地关注每个查询的邻近词元以及序列起始的词元,同时忽略超出这一范围的其他词元。然而,由于无法有效利用被忽略的词元信息,这种方法无法充分利用所有的上下文信息。
- 词元选择:挑选出最重要的 k 个词元,以实现对于完整注意力的有效拟合。词元选择方法可以通过查询与词元的相似度和查询词元所在分块的相似度实现。其中(1)查询与词元相似度方法根据位置索引和上下文窗口,将词元划分为窗口内的近距离词元和窗口外的远距离词元。对于上下文窗口外的远距离词元,利用外部存储保存它们的键值对,并采用 k 近邻搜索方法来获取当前生成所需的最相关词元;(2)查询与分块相似度方法将序列划分为不同的长度固定的分块,并从分块序列中选择出最相关的部分分块。
15.3 模型预训练
15.3.1 预训练任务
目前,大语言模型常用的预训练任务可以分为三类:语言建模(Language Modeling, LM)、去噪自编码(Denoising Autoencoding, DAE)以及混合去噪器(Mixture-of-Denoisers, MoD),如图 15-6 所示。
语言建模(Language Modeling, LM)

可以发现,语言建模任务与人类生成语言数据(如口语表达、书面写作等)的方式十分相似,都是基于前序内容生成(或预测)后续的内容。尽管这种方式形式简单,但当预训练数据足够丰富时,大语言模型便能够学习到自然语言的生成规律与表达模式。
此外,语言建模任务还可以看作是一种多任务学习过程。例如,在预测前缀“这部电影剧情饱满,演员表演得也很棒,非常”中的“好看”时,模型实际上在进行情感分析任务;而预测句子前缀“小明有三块糖,给了小红两块糖,还剩下”中的“一块糖”时,则是在进行数学算术任务。

但是,由于前缀语言建模任务并未将所有词元的损失都纳入计算,当使用相同规模的数据集进行训练时,采用前缀语言建模训练的模型在性能上通常会稍逊于使用标准语言建模任务训练的模型。

中间填充任务经常被用于训练代码预训练模型以提升模型在代码补全等实际应用场景中的表现。
去噪自编码(Denoising Autoencoding, DAE)

与语言建模相比,去噪自编码任务的实现更为复杂,需要设定额外的优化策略,如词元替换策略、替换片段长度、替换词元比例等。这些策略的选择会直接影响模型的训练效果。目前使用去噪自编码进行预训练的大语言模型较为有限,代表性模型包括 Flan-T5。
混合去噪器(Mixture-of-Denoisers, MoD)
混合去噪器,又称 UL2 损失,通过将语言建模和去噪自编码的目标均视为不同类型的去噪任务,对预训练任务进行了统一建模。具体来说,混合去噪器定义了三种去噪器:S-去噪器、R-去噪器和 X-去噪器。
S-去噪器与前缀语言建模的目标相同(如式 15.2 所示),旨在学习基于给定前缀信息生成合理后缀文本的能力。而 R-去噪器和 X-去噪器 与去噪自编码任务的优化目标更为相似(如式 15.4 所示),二者仅在被掩盖片段的跨度和损坏比例上有所区别。混合去噪器被应用于训练 UL2 和 PaLM-2 等大语言模型。
15.3.2 优化参数设置
与传统神经网络的优化类似,大语言模型通常使用批次梯度下降算法来进行模型参数的调优。同时,通过调整学习率以及优化器中的梯度修正策略,可以进一步提升训练的稳定性。为了防止模型对数据产生过度拟合,训练中还需要引入一系列正则化方法。
基于批次数据的训练
在大语言模型预训练中,通常将批次大小(Batch Size)设置为较大的数值,例如 1M 到 4M 个词元以提高训练的稳定性和吞吐量。现在很多工作都采用了动态批次调整策略,即在训练过程中逐渐增加批次大小,最终达到百万级别。例如,GPT-3 的批次大小从 32K 个词元逐渐增加到 3.2M 个词元。研究表明,动态调整批次大小的策略可以有效地稳定大语言模型的训练过程。
学习率
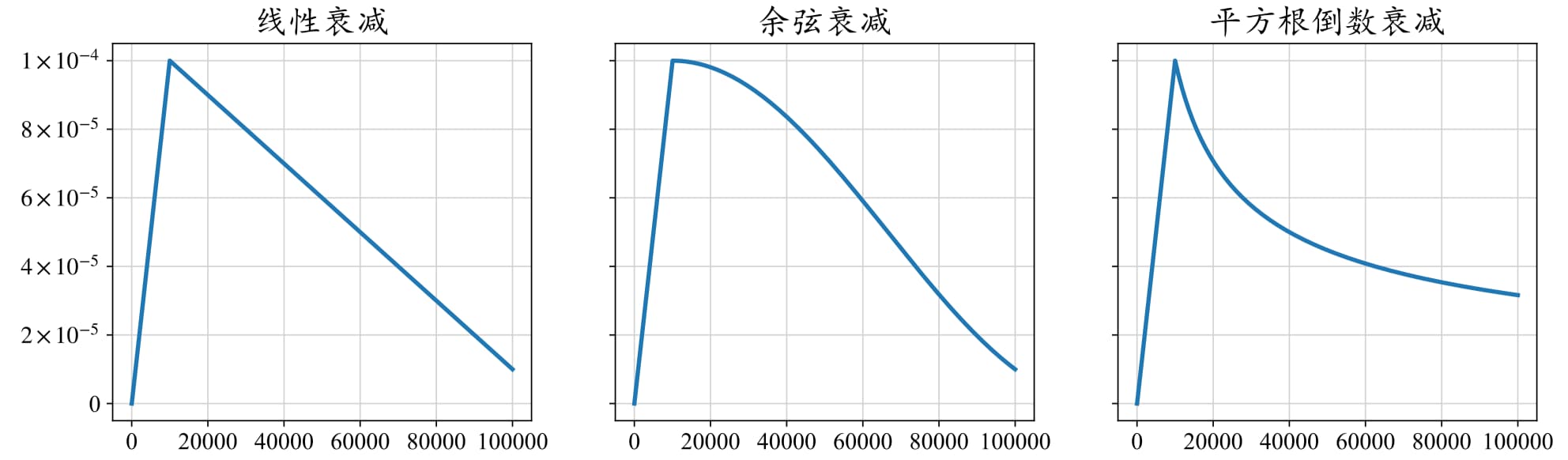
现有的大语言模型在预训练阶段通常采用相似的学习率调整策略,包括预热阶段和衰减阶段。预热阶段一般占整个训练步骤的 0.1% 至 0.5%,然后学习率便开始进行衰减。

学习率达到最大阈值之后就会开始逐渐衰减,以避免在较优点附近来回震荡,最后一般会衰减到最大阈值的 10%。常见的衰减策略有线性衰减、余弦衰减、平方根倒数衰减,它们的学习率变化如图 15-7 所示。
优化器
已有大语言模型通常采用 Adam 及其变种 AdamW 作为优化器。Adam 在优化中引入了三个超参数,在大模型训练中通常采用以下设置:β1= 0.9,β2= 0.95 和 ϵ = 10−8。此外,谷歌公司提出了 Adafactor 优化器,引入了特殊设计可以在训练过程中节省显存,被用于 PaLM 和 Flan-T5 等大语言模型的训练。Adafactor 常见的超参数设置如下:β1 = 0.9,β2 = 1.0−k−0.8,其中 k 表示训练步数。
稳定优化技术
在大语言模型的训练过程中,经常会遇到训练不稳定的问题,可以使用下面几种稳定训练技术:
- 梯度裁剪:训练中一种常见的现象是损失的突增。为了解决这一问题,可以采取梯度裁剪(Gradient Clipping),把梯度限制在一个较小的区间内。当梯度的模长超过给定的阈值后,便按照这个阈值进行截断。在大语言模型训练中,这个阈值通常设置为 1.0。
- 训练恢复:为了避免训练过程的异常情况,一种常用的策略是每隔固定的步数设置一些模型存档点。当模型发生了训练异常时,便可以选择前一个存档点重启训练过程。
- 权重衰减:引入正则化技术来稳定训练过程以提高模型的泛化能力。AdamW 优化器中采用了权重衰减(Weight Decay)方法,在每次更新模型参数的时候引入衰减系数,这个系数通常设置为 0.1。
15.3.3 可扩展的训练技术
大语言模型的训练主要面临着两个技术问题:一是如何提高训练效率;二是如何将庞大的模型有效地加载到不同的处理器中。常见的高效训练技术包括 3D 并行训练、零冗余优化器和混合精度训练,如图 15-8 所示。
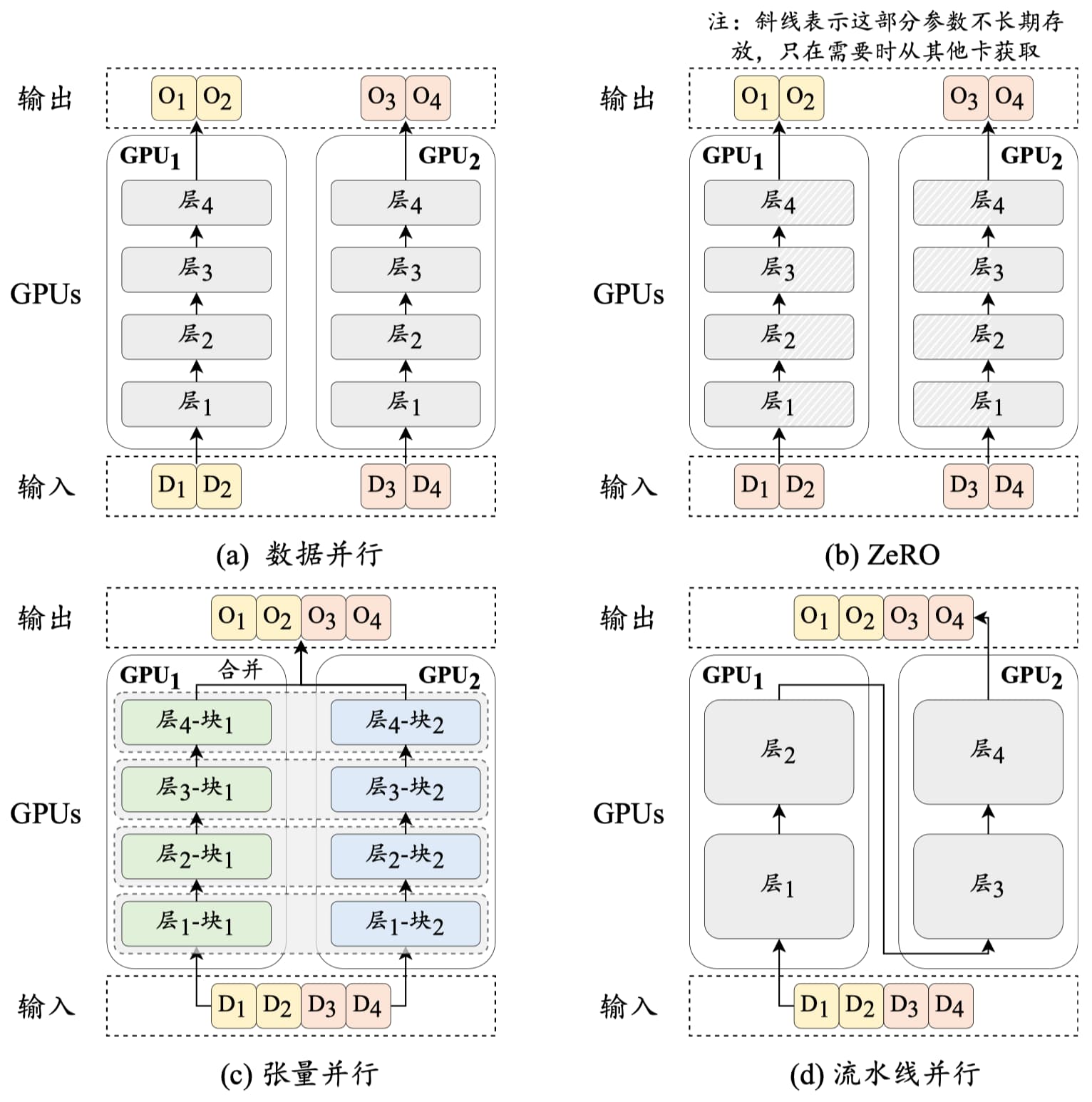
3D 并行训练
3D 并行策略是三种并行训练技术的组合,即数据并行(Data Parallelism)、流水线并行(Pipeline Parallelism)和张量并行(Tensor Parallelism)。
-
数据并行:将模型参数和优化器状态复制到多个 GPU 上,然后将训练数据平均分配给这些 GPU,当所有 GPU 都执行前向传播和反向传播以获取梯度后,再将不同 GPU 的梯度进行平均,以得到整体的梯度来统一更新所有 GPU 上的模型参数。如图 15-8 (a) 所示,四条数据被分成两份, 由两张卡分别计算,这样便等效于执行了批次为 4 的梯度更新。
由于梯度在不同 GPU 上是独立计算的,数据并行机制展现出高度的可扩展性,可以通过增加 GPU 数量来提高训练效率。数据并行技术的实现相对简便,目前 TensorFlow、PyTorch 等深度学习库均已内置了对数据并行策略的支持。
-
流水线并行:将大语言模型不同层的参数分配到不同的 GPU 上。如图 15-8 (d) 中,Transformer 的第 1-2 层部署在 GPU1,将 3-4 层部署在 GPU2。但是 GPU1 在前向传播后需要等待 GPU2 反向传播的结果才能进行梯度传播,即整个流程是“GPU1 前向,GPU2 前向,GPU2 反向,GPU1 反向”,并不能达到真正的并行效果。因此流水线并行通常需要配合梯度累积技术进行优化,例如 GPU1 前向传播完第一个批次后,可以不用等待,继续传播第二个和后续的批次。
延伸
梯度累积(Gradient Accumulation)的主要思想是在计算一个批次的梯度后不立刻更新模型参数,而是累积几个批次后再更新,这样便可以在不增加显存消耗的情况下模拟更大的批次。
-

目前张量并行已经在多个开源库中得到支持,例如 Megatron-LM 支持对参数矩阵按行按列分块进行张量并行。
-
零冗余优化器
零冗余优化器(Zero Redundancy Optimizer, ZeRO)技术由 DeepSpeed 代码库提出,用于解决数据并行中的模型冗余问题。从图 15-8 (a) 中可以看到,每个 GPU 都需要存储大语言模型的相同副本,包括模型参数和优化器参数等。但是对于每个 GPU,在模型传播到某一层时,其他层的模型和优化器参数并不参与计算,这导致了严重的显存冗余现象。
ZeRO 技术仅在每个 GPU 上保留部分模型参数和优化器参数,当需要时再从其它 GPU 中读取。如图 15-8 (b) 所示,模型被均分在两张 GPU 上,当需要使用第一层计算时,两张卡分别从对方获取相应的模型参数进行计算,使用完之后便可以释放相应显存。
延伸
PyTorch 中也实现了与 ZeRO 相似的技术,称为完全分片数据并行(Fully Sharded Data Parallel, FSDP)。
混合精度训练
早期的预训练语言模型(例如 BERT)主要使用单精度浮点数(FP32)表示模型参数并进行优化计算。近年来,为了训练超大规模参数的语言模型,研发人员提出了混合精度训练(Mixed Precision Training)技术,通过同时使用半精度浮点数(2 个字节)和单精度浮点数(4 个字节)进行运算,以实现显存开销减半、训练效率翻倍的效果。
具体来说,为了保证表示精度,需要保留原始 32 位模型的参数副本。但在训练过程中,会先将这些 32 位参数转换为 16 位参数,随后以 16 位精度执行前向传播和反向传播等操作,最后在参数更新时再对 32 位模型进行优化。由于前向传播和反向传播占用了绝大部分的优化时间,混合精度训练能够显著提升模型的训练效率。
常见的半精度浮点数表示方式为 FP16,其包含 1 位符号位、5 位指数位和 10 位尾数位,表示范围为 −65504 到 65504。谷歌后来提出了新的半精度浮点数表示 BF16,其包含 1 位符 号位、8 位指数位和 7 位尾数位,表示范围可达 1038 数量级。
目前较为主流的 GPU(例如 Nvidia A100)都支持 16 位计算单元运算,因此混合精度训练能够被硬件很好地支持。
15.4 小结
本节简要介绍了预训练大语言模型的步骤以及涉及的关键技术,包括数据准备阶段、模型架构以及实际的预训练操作。
在下一章中,本教程将对大语言模型构建过程的第二个关键环节——微调进行详细介绍。
参考
[1] 赵鑫等.2024.大语言模型
相关文章:

第十五章:预训练大语言模型
目录 15.1 数据准备 15.1.1 数据预处理 15.1.2 数据调度 15.2 模型架构 15.2.1 主流架构 一、编码器架构(Encoder-only,以 BERT 为代表) 核心特点: 代表模型:BERT、RoBERTa、ALBERT 典型应用: 二…...

万象生鲜配送系统代码2025年4月29日更新日志
亲爱的用户:万象生鲜配送系统始终致力于为您提供更优质、高效的服务体验。经过我们技术团队的不懈努力,万象生鲜配送系统在 2025 年 4 月迎来了一次重大更新。本次更新涵盖了多个方面,包括功能新增、性能优化以及问题修复,旨在进一…...

Mac 创建QT按钮以及一些操作
在创建QT项目好 后我们打开mainwindow.cpp,下面所示的代码都是在这个cpp文件里面因为它是窗口的入口函数 #include "mainwindow.h" #include "ui_mainwindow.h" #include<QPushButton>//按钮的头文件MainWindow::MainWindow(QWidget *pa…...

C++学习之shell高级和正则表达式
目录 1.正则表达式 2.C中使用正则 3.复习 4.sort命令 5.uniq命令 6.wc命令 7.grep命令 8.find命令 9.xargs命令 10.sed命令 11.awk命令 12.crontab 1.正则表达式 1 管道 使用| 将多个命令拼接在一起 原理,就是将前一个命令的标准输出作为后一个…...
)
SpringBoot获取用户信息常见问题(密码屏蔽、驼峰命名和下划线命名的自动转换)
文章目录 一、不返回password字段二、返回的createTime和updateTime为空原因解决:开启驼峰命名和下划线命名的自动转换 一、不返回password字段 在字段上面添加JsonIgnore注解即可 JsonIgnore // 在把对象序列化成json字符串时,忽略该字段 private Str…...
 – 运用U-Turn Via设计破解阻抗匹配困境,改善信号完整性)
优化PCB Via Stub系列(2) – 运用U-Turn Via设计破解阻抗匹配困境,改善信号完整性
在PCB设计中,往往透过制程改善如背钻、盲孔或埋孔,来消除不必要的Via stub,可是多出来的制造成本会压低产品的毛利,可是又有什么办法可以不透过制程改善以缩小Via stub带来的SI困扰呢? 本周我们来讲从Layout布局的角度…...

飞鸟游戏模拟器 1.0.3 | 完全免费无广告,内置大量经典童年游戏,重温美好回忆
飞鸟游戏模拟器是一款专为安卓用户设计的免费游戏模拟器,内置了大量经典的童年游戏。该模拟器拥有丰富的游戏资源,目前已有约20,000款游戏,包括多种类型如冒险、动作、角色扮演等。用户可以直接搜索查找想要玩的游戏进行下载并启动。游戏库中…...

钓鱼网页散播银狐木马,远控后门威胁终端安全
在当今网络环境下,许多人都有通过搜索引擎下载应用程序的习惯,虽然这种方式简单又迅速,但这也可能被不法分子所利用,通过设置钓鱼网站来欺骗用户。这些钓鱼网站可能会通过各种方式吸引用户点击,从而进行病毒的传播&…...

一文读懂 JavaScript 中的深浅拷贝
在 JavaScript 编程里,深浅拷贝是处理数据时极为关键的概念。理解它们的差异,能帮我们规避许多数据操作上的 “陷阱”。今天,咱们就借助简单的 “abc” 相关示例,深入探索深浅拷贝的奥秘,并且通过在浏览器控制台输出结…...

5G技术在工业4.0中的应用:连接未来,驱动智能制造
5G技术在工业4.0中的应用:连接未来,驱动智能制造 引言 工业4.0,作为第四次工业革命的核心,已经在全球范围内掀起了智能制造的浪潮。它不仅包括了自动化生产、智能物流、云计算和大数据的应用,更是融合了互联网、物联网…...
:从设备树到驱动——深入理解Linux时钟子系统的实战链路)
驱动开发硬核特训 · Day 25 (附加篇):从设备树到驱动——深入理解Linux时钟子系统的实战链路
一、前言 在嵌入式Linux开发中,无论是CPU、外设控制器,还是简单的GPIO扩展器,大多数硬件模块都离不开时钟信号的支撑。 时钟子系统(Clock Subsystem),作为Linux内核中基础设施的一部分,为设备…...

数据结构---单链表的增删查改
前言: 经过了几个月的漫长岁月,回头时年迈的小编发现,数据结构的内容还没有写博客,于是小编赶紧停下手头的活动,补上博客以洗清身上的罪孽 目录 前言 概念: 单链表的结构 我们设定一个哨兵位头节点给链…...

【codeforces 2104D,E】欧拉筛,字符串上dp
【codeforces 2104D,E】欧拉筛,字符串上dp Problem - D - Codeforces 题意: 给定一个长度为 n n n的数组 a 1 , a 2 , . . . , a n a_1, a_2, ... , a_n a1,a2,...,an,其中 2 ≤ a i ≤ 1 0 9 2 \leq a_i \leq 10^9 2≤…...

UEC++第15天|番茄插件、实现跳跃、实现背景运动
这是flyBird的第二天,做了一些简单的功能,明天继续更新 vs的番茄插件 在visual stdudio里使用可以帮助代码补全,这一篇博客写的不错,大家可以参考一下。VS2019 安装番茄助手(Visual Assist x 插件)攻略_vs…...
的多变量桥式起重机自适应安全制动与距离预测)
论文笔记-基于多层感知器(MLP)的多变量桥式起重机自适应安全制动与距离预测
《IET Cyber-Systems and Robotics》出版山东大学 Tenglong Zhang 和 Guoliang Liu 团队的研究成果,文章题为“Adaptive Safe Braking and Distance Prediction for Overhead Cranes With Multivariation Using MLP”。 摘要 桥式起重机的紧急制动及其制动距离预测是…...

[论文阅读]Adversarial Semantic Collisions
Adversarial Semantic Collisions Adversarial Semantic Collisions - ACL Anthology Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) 对抗样本是相似的输入但是产生不同的模型输出,而语义冲突是对抗样本的逆…...

Redis Sentinel 和 Redis Cluster 各自的原理、优缺点及适用场景是什么?
我们来详细分析下 Redis Sentinel (哨兵) 和 Redis Cluster (集群) 这两种方案的原理和使用场景。 Redis Sentinel (哨兵) 原理: Sentinel 本身是一个或一组独立于 Redis 数据节点的进程。它的核心职责是监控一个 Redis 主从复制 (Master-Slave) 架构。多个 Sentinel 进程协同…...

面向人工智能、量子科技、人形机器人等产业,山东启动制造业创新中心培育认定
从山东省工业和信息化厅了解到,2025年山东省制造业创新中心培育和认定已启动,重点面向全省传统优势产业、新兴产业及未来产业等领域,鼓励具备条件的龙头企业牵头创建省制造业创新中心。 今年,山东重点面向全省冶金、化工、轻工、…...

无锡哲讯科技:SAP财务系统——赋能企业智慧财务管理
数字化时代,财务管理的新挑战 在全球化竞争和数字经济快速发展的背景下,企业财务管理正面临前所未有的挑战。传统的财务核算方式效率低下、数据孤岛严重、决策滞后,难以满足现代企业高效运营的需求。如何实现财务数据的实时整合࿱…...
)
Linux命令使用记录(自用)
阿里开源镜像站:https://developer.aliyun.com/mirror/?spma2c6h.13651102.0.0.6c2a1b11I9pmUD&serviceTypemirror&tag top命令 top [选项] -p 只显示某个进程的信息 -d 设置刷新时间,默认是5s -c 显示产生进程的完整命令,默认是进程…...

Spring Security 的 CSRF 防护机制
CSRF:跨站请求伪造(Cross-Site Request Forgery) Spring Security 中的 .csrf() 是用来开启或配置这种保护机制,防止恶意网站“冒充用户”向你的网站发起请求。 一、CSRF 攻击原理简要 CSRF 的典型攻击场景如下: 用…...

跨平台项目部署全攻略:Windows后端+Mac前端在服务器的协同实战
当你的后端(Flask+MySQL,Windows开发)与前端(Vue,Mac开发)需要统一部署到服务器并实现交互时,完全可以通过「跨平台适配+反向代理」方案实现。本文将分步骤讲解如何在 Linux服务器(推荐)或 Windows服务器 上部署,并解决跨平台兼容性、跨域请求等核心问题。 一、技术…...

第八章 磁盘管理未完待续
1.磁盘管理 磁盘简介 名词:磁盘/硬盘/disk 存储设备类型从工作原理区分 机械 机械硬盘即是传统普通硬盘,主要由:盘片,磁头,盘片转轴及 控制电机,磁头控制器,数据转换器,接口&…...

杰理AC79-WiFi 的 AP、STA 和 Monitor 模式
WiFi 的 AP、STA 和 Monitor 模式是无线网卡的不同工作模式,它们的区别如下: AP 模式(Access Point 模式,接入点模式) 功能:将有线网络转换为无线网络,允许其他无线设备连接到该网络ÿ…...

MAC安装unar并解压.rar文件
MAC上默认解压.zip文件,对.rar文件进行解压需要安装专门对软件。本文记录如何在命令行安装unar并对.rar文件进行解压。 命令行安装 brew install unar打印如下log则安装成功 使用brew list unar检查是否安装成功 brew list unar使用unar解压 unar 文件名.rar...

`nmi_watchdog` 与 `softlockup_panic` 的区别与关系
1. 功能区别 参数作用触发条件影响nmi_watchdog启用 NMI(不可屏蔽中断)看门狗检测 CPU 是否长时间不执行调度(软死锁)仅记录警告(默认),需配合 softlockup_panic 才会触发 panicsoftlockup_pan…...

【Bash】可以请您解释性地说明一下“2>1”这个语法吗?
Qwen3-235B 当然可以!我们一步步拆解 2>&1 的含义,用生活化的例子来理解它: 🧠 前提知识:三个“水流通道” 在 Linux/Unix 系统中,程序运行时有三种默认的“水流通道”: 标准输入&…...

打造美观 API 文档:Spring Boot + Swagger 实战指南
目录 打造美观 API 文档:Spring Boot Swagger 实战指南导语一、Swagger 简介二、Spring Boot 2 集成 Swagger1. 添加依赖2. 配置 Swagger3. 访问 Swagger UI 三、Spring Boot 3 集成 Swagger1. 添加依赖2. 配置 Swagger3. 访问 Swagger UI 四、多种接口文档风格展示…...

如何在 Android 上恢复已删除的照片?:简短指南
没有什么比不小心从 Android 智能手机中删除所有照片更糟糕的了。这样,除非您在重置之前已经备份了数据,否则您的所有照片都会消失。如果您忘记备份照片,您仍然可以按照一些简单的技术在 Android 设备上恢复已删除的照片。 如何在 Android 上…...

第十六届蓝桥杯大赛网安组--几道简单题的WP
目录 1. ezEvtx 2.flowzip 3.Enigma 4.星际XML解析器 1. ezEvtx 题目内容 EVTX文件是Windows操作系统生成的事件日志文件,用于记录系统、应用程序和安全事件。(本题需要选手找出攻击者访问成功的一个敏感文件,提交格式为flag{文件名},其中…...

Element:Cheack多选勾选效果逻辑判断
效果展示 取消子级勾选,父级的勾选效果 代码合集 (1)组件代码 fromlist.cheackType 类型,permissio表示是权限. fromlist:[{id:1,children:[{...}]},...]传递的数据大致结构 <!-- 操作权限 --><template v-if"…...

从摄像头到 RAW 数据:MJPEG 捕获与验证
从摄像头捕获 MJPEG 原始数据:完整指南与验证方法 🔍 引言 MJPEG(Motion JPEG)是一种常见的视频压缩格式,广泛应用于摄像头、监控系统和嵌入式设备。在某些场景下,我们需要直接从摄像头获取 MJPEG 原始数据…...

【展位预告】正也科技将携营销精细化管理解决方案出席中睿营销论坛
在医药行业面临政策深化、技术迭代、全球化竞争的多重挑战下,第二届中睿医药健康生态生长力峰会暨第三十五届中睿医药营销论坛将于广州盛大启幕。5月19-20日本次峰会以“聚焦政策变革、把握产业趋势、构建生态共赢”为核心,旨在通过全产业链资源整合与创…...

记录 Flink jdbc、mysql-cdc 连接 mysql8 碰到的适配问题
前言 记录 Flink jdbc、mysql-cdc 连接 mysql8 碰到的小问题 版本 Flink 1.15.3mysql-cdc 2.3.0MySQL 8.0.27 cdc_mysql2mysql MySQL5 之前主要用 MySQL5 ,下面是 MySQL5 的 sql ,具体见 Flink MySQL CDC 使用总结 set yarn.application.namecdc_mysql2mysql;…...

TCP概念+模拟tcp服务器及客户端
目录 一、TCP基本概念 二、ser服务器代码 三、cil客户端代码 一、TCP基本概念 TCP(Transmission Control Protocol,传输控制协议)是一种面向连接的、可靠的、基于字节流的传输层协议。以下是TCP的一些基本概念: 面向连接&…...

高翔《视觉SLAM十四讲》第七章视觉里程计3d-2d位姿估计代码详解与理论解析
高翔《视觉SLAM十四讲》第七章代码详解与理论解析 一、三维空间位姿估计核心算法实现 在视觉SLAM领域,3D - 2D位姿估计是确定相机在三维空间中位置和姿态的关键技术。本部分将详细解析其工程实现框架,同时说明代码模块的划分逻辑。 代码整体结构清晰,各模块分工明确,主要…...

Elasticsearch 内存使用指南
作者:来自 Elastic Valentin Crettaz 探索 Elasticsearch 的内存需求以及不同类型的内存统计信息。 Elasticsearch 拥有丰富的新功能,帮助你为你的使用场景构建最佳搜索解决方案。浏览我们的示例笔记本了解更多信息,开始免费云试用࿰…...

【Stable Diffusion】原理详解:从噪声到艺术的AI魔法
引言 Stable Diffusion是 stability.ai 开源的图像生成模型,是近年来AI生成内容(AIGC)领域最具突破性的技术之一。它通过将文本描述转化为高分辨率图像,实现了从“文字到视觉”的创造性跨越。其开源特性与高效的生成能力ÿ…...
:消息传递(Message Passing))
并发设计模式实战系列(9):消息传递(Message Passing)
🌟 大家好,我是摘星! 🌟 今天为大家带来的是并发设计模式实战系列,第九章消息传递(Message Passing),废话不多说直接开始~ 目录 一、核心原理深度拆解 1. 消息传递架构 2. 并发…...
:MCP 安全体系建设)
【MCP Node.js SDK 全栈进阶指南】高级篇(3):MCP 安全体系建设
背景 随着MCP协议在企业和个人应用中的广泛采用,安全性已成为MCP系统设计和开发中不可忽视的核心要素。一个健壮的MCP安全体系不仅能保护敏感数据和用户隐私,还能确保AI模型与外部工具交互的可靠性和完整性。本文将深入探讨MCP TypeScript-SDK的安全体系建设,帮助开发者构建…...

C++智能指针
智能指针是C中用于自动管理动态分配内存的类模板,它们通过在适当的时机自动释放内存来帮助防止内存泄漏。C11引入了以下几种主要的智能指针: 1. std::unique_ptr 独占所有权的智能指针,同一时间只能有一个unique_ptr指向特定对象。 #inclu…...

基于STM32、HAL库的ATECC608B安全验证及加密芯片驱动程序设计
一、简介: ATECC608B是Microchip公司生产的一款安全加密芯片,提供以下主要特性: 基于硬件的高安全性加密算法 ECC P-256加密引擎 SHA-256哈希算法 AES-128加密 真随机数生成器(TRNG) 16KB安全存储空间 IC接口(最高1MHz) 低功耗设计,适合物联网应用 二、硬件接口: ATECC60…...

【安全扫描器原理】ICMP扫描
【安全扫描器原理】ICMP扫描 1.ICMP协议概述2.ping命令3.tracert命令4.ICMP通信实例5.ICMP协议内容6.ICMP扫描的安全性7.ICMP扫描器的原理及优化策略1.ICMP协议概述 ICMP是TCP/IP协议族中的一个重要协议,主要用于在IP主机之间、主机和路由器之间传递控制消息,这些控制消息包…...

前端 AI 开发实战:基于自定义工具类的大语言模型与语音识别调用指南
在人工智能技术快速发展的今天,将大语言模型(LLM)和语音识别(ASR)功能集成到前端应用中,已经成为提升用户体验、打造智能化应用的重要手段。本文将结合一段实际的 AI 工具类代码,详细讲解如何在…...

组件轮播与样式结构重用实验
任务一:使用“Swiper 轮播组件”对自行选择的图片和文本素材分别进行轮播,且调整对应的“loop”、“autoPlay”“interval”、“vertical”属性,实现不同的轮播效果,使用Swiper 样式自定义,修改默认小圆点和被选中小圆…...
洛谷 P8386 PA2021 Od deski do deski/P10375 AHOI2024 计数 题解)
(计数)洛谷 P8386 PA2021 Od deski do deski/P10375 AHOI2024 计数 题解
题意 给定 n n n, m m m,求满足以下限制的长度为 n n n 的序列数目: 每个元素在 [ 1 , m ] [1,m] [1,m] 之间;一次操作定义为删除一个长度至少为 2 2 2 且区间两端相等的区间,该序列需要在若干次操作内被删空。 …...

基于C++数据结构双向循环链表实现的贪吃蛇
大二上数据结构I-课程设计 1.设计思路 建模:程序界面是一个二维平面图蛇:蛇的身体可以看作是链表的节点,当蛇吃到食物时,就增加一节链表节点食物:相应地在边界内随机生成蛇的移动:取得上下左右键的ASCII码…...

H3C ER3208G3路由实现内网机器通过公网固定IP访问内网服务器
内网机器可以通过内网访问服务器;公网机器可以通过公网固定IP访问服务器;但内网机器无法通过公网固定IP访问内网服务器;想实现内网机器通过公网固定IP访问内网服务器 WEB登录管理后台,网络设置->NAT配置,选“高级配…...

Vue3+Three JS高德地图自定义经纬度实现围栏
Vue3实现代码 index.html需要引入three.js <script src"https://cdn.jsdelivr.net/npm/three0.142/build/three.js"></script> 围栏组件 <template><div id"mapContainer" ref"mapContainer"></div> </templ…...

远程访问你的家庭NAS服务器:OpenMediaVault内网穿透配置教程
文章目录 前言1. OMV安装Cpolar工具2. 配置OMV远程访问地址3. 远程访问OMV管理界面4. 固定远程访问地址 前言 在这个数据爆炸的时代,无论是管理家人的照片和视频,还是企业老板处理财务报表和技术文档,高效的数据管理和便捷的文件共享已经变得…...