Flink+Paimon实时数据湖仓实践分享

随着 Paimon 近两年的推广普及,使用 Flink+Paimon 构建数据湖仓的实践也越来越多。在 Flink 实时数据开发中,对于依赖大量状态 state 的场景,如长周期的累加指标计算、回撤长历史数据并更新等,使用实时数仓作为中间存储来代替 Flink 的内部状态 state 是非常有必要的。
本文主要分享了使用 Paimon 作为实时状态存储,并在 Flink 中通过 Lookup 维表 Join 的方式进行状态查询和更新的应用实践。

简介
▐ 是什么
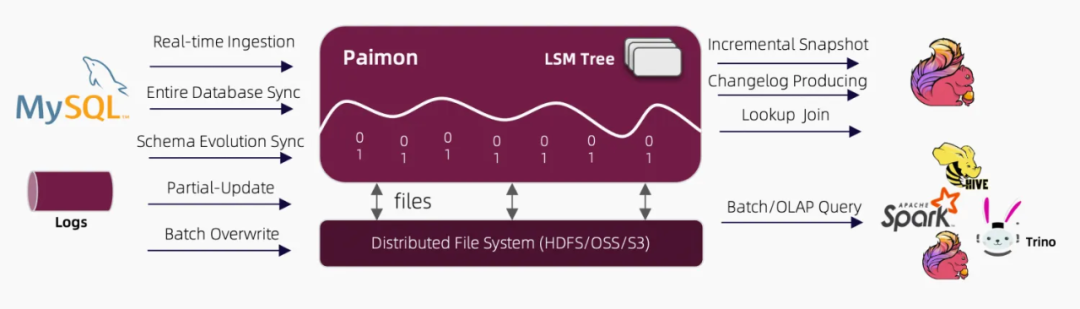
Apache Paimon是一种流批统一的数据湖存储格式,结合 Flink 可以构建流批处理的实时湖仓一体架构。Paimon 具有实时更新的能力(可应用于对时效性要求不太高的场景,如 1-5 分钟),其主键表支持大规模更新写入,具有非常高的更新性能,同时也支持定义合并引擎,按照自定义的方式更新记录。
Paimon 底层使用 OSS/HDFS 等作为存储,同时数据文件以 LSMtree 的格式进行组织,具有更优的实时数据更新能力和完整的流处理能力。
图片来源于 paimon 官网
▐ 为什么
1. 低成本、可扩展性:实时数仓产品也可以作为 flink 的中间存储,比如 hologres,但是 Paimon 的存储成本约为其的 1/9(通过查询官网,OSS 的存储为 0.12 元/GB/月,Hologres 为 1 元/GB/月)。同时数据湖相比于数据仓库可以与更多的大数据引擎(Hive/Spark/Trino 等等)兼容,解决数据孤岛和数据冗余存储的问题。
2. 实时性能:相比于其他的数据湖产品,Paimon 是天然面向 Flink 设计而诞生的,相比于 hudi(面向 Spark 批处理设计)、Iceberg 等,Paimon在与 Flink 结合具有更优的处理大批量数据的 upsert 能力,同时数据更新时效性最短可支持到 1 分钟,且性能稳定。
应用案例▐ 1. 排除逆向退款的用户下单标签
需求背景
目前奥格运营平台提供的下单相关的实时标签(如用户最近一次实物购买时间等),都是基于实时下单流来加工的,即不考虑用户后续的逆向退款情况。然而,运营同学需要实时圈选出近一段时间未成功购买(未下单或下单后退款)的人群,制定运营策略及发放权益,提高复购率。因此,该需求可以明确为:构建手淘用户排除逆向退款后的最近一次下单时间的实时标签。
问题分析
用户的下单行为和退款行为是有时序性的,因此当用户在下单后发生逆向退款行为时,需要回撤之前的订单结果,并回溯最近一次支付成功且未退款的订单信息。由于下单流和退款流是两条独立的流,因此我们首先考虑到使用双流 join 的方法将他们关联起来,但是会有如下两个限制:
1. 时效性限制:由于用户的两个行为发生的时间间隔是无法确定的(用户可能下单后立刻退款,也可能隔几个月后再申请退款),interval join 和 window join 对窗口的间隔长度有较大的限制,而 regular join 会受到状态存储大小的限制,无法将间隔时间很长的两条流关联在一起。
2. 状态依赖限制:这些方法都是完全依赖状态,任务一旦无状态重启,状态会丢失,导致数据不准确。
解决方法
为了突破上述限制,考虑采用 Paimon 表作为中间存储表,存储用户在某商家的历史订单的下单时间,当退款流来的时候,可以去进行 lookupjoin 维表关联,获取该用户在该商家的历史订单信息,并排除掉所有退款成功的订单后,输出最近一次未退款的订单时间。
整体方案设计
方案优势:
不依赖状态,可以节省大量内存,且任务可以随时无状态启动。
突破业务行为时间上的限制,即使用户在下单后 1 年退款成功,依然可以实现回撤。
方案不足:
Paimon 表固有的数据时效性限制。
存储在 Paimon 表中的历史订单数限制,不可能无限存储某用户 x 商家维度近一年的所有订单,通过和业务沟通,确定只需要存储近 10 单,即在极端情况下,如果用户近 10 单全部退款,则无法再回溯。
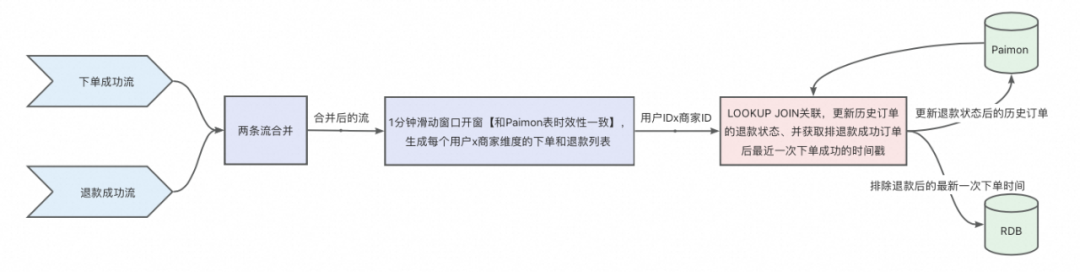
Paimon 维表设计
CREATE TABLE `paimon-catalog`.`paimon-db`.test_dws_pay_refund (test_buyer_id VARCHAR,test_seller_id VARCHAR,test_order_dict VARCHAR, -- 历史订单字典,格式见下文说明PRIMARY KEY (test_buyer_id, test_seller_id) NOT ENFORCED
) WITH ('merge-engine' = 'deduplicate', -- 使用预聚合数据合并机制产生聚合表'changelog-producer' = 'none','bucket' = '1000','bucket-key' = 'test_buyer_id,test_seller_id','delete-file.thread-num' = '32'
);说明:
1. 非分区表:该维表主要是用于存储用户的历史订单信息,与日期没有直接关系,因此直接设置为非分区表。
2. 主键表:主键设置为买家 ID+商家 ID,合并引擎采用 deduplicate,即保留同一主键下最新一条数据。
3. 分桶数量:因为要进行维表 join,为了能够采用 shuffle 策略,设置固定分桶,提前探查历史数据后,预估维表大小在 TB 级别,遵循每个桶的数据量大小在 2GB 左右的官方建议,设置分桶数量为 1000。
4. 不产生 changelog:由于该表只作为维表使用,为了节省资源,可以不产生 changelog。
5. 字段含义:对于非主键字段,test_order_dict 用于存储用的历史订单信息,格式为:${order_id}:${pay_timestamp}_${is_refund_flag},其中 order_id 表示订单号,pay_timestamp 表示下单时间,is_refund_flag 表示是否退款。
开发经验分享
1. 分桶数量设置不合理
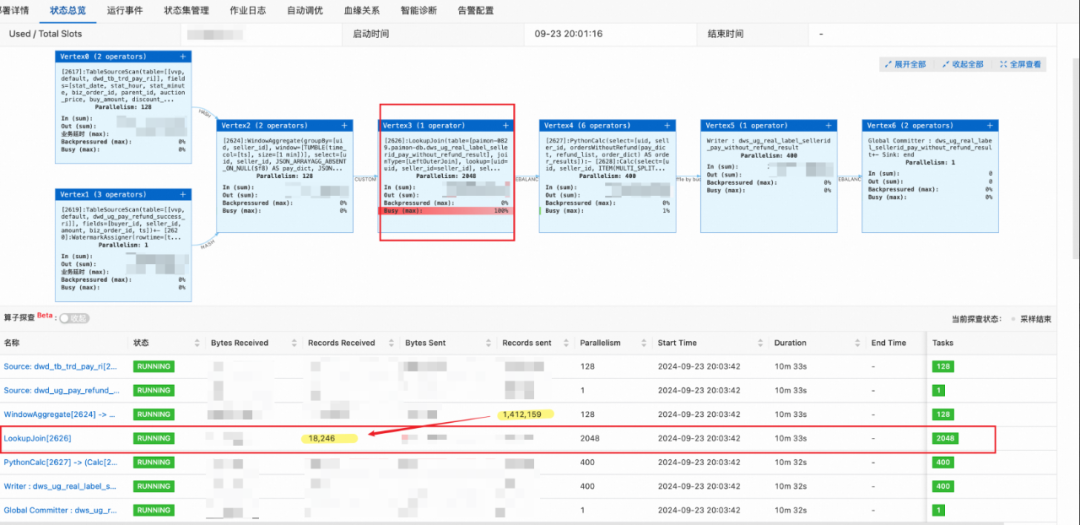
问题描述:初始化 Paimon 表后的大小为 TB 级别,一开始设置的分桶数为 400,即每个桶的数据量在 5-10GB 范围内,启动任务后,发现数据总是卡在 LookupJoin 这一节点,一直增大并发至 2048,也一直堵塞,如下图所示:
原因分析:
通过日志发现主要是在读取 Paimon 表的 OSS 存储时,出现了阻塞,原因是单个桶的文件量太大,且传输速率已达到带宽上线,因此依然需要长时间的同步。
对于 shuffle join,会对 join key(必须要包含所有的 bucket key)基于 bucket 的数量进行 shuffle,然后分配到各个并发上,当算子的并发=分桶数时,每个并发刚好只需要加载一个桶的文件到内存,如果并发数小于分桶数,则某些并发可能需要加载多个桶的文件数据,可能会出现倾斜的情况。
解决方法:按照官方文档的推荐,单个桶的数据量不要超过 5G,因此增大桶的数量到 1000,启动任务时,LookupJoin 算子各并发加载 Paimon 维表的时间明显缩短,3 分钟左右即可加载完成并正常处理数据。
2. 写 Paimon 表出现Heartbeat of TaskManager timed out
问题描述:初始化 Paimon 维表时,需要将 ODPS 计算好的历史数据批量写入到 Paimon 表中,在 vvp 中提交批任务,但是在 writer 算子阶段部分 TM 会出现Heartbeat of TaskManager timed out 大的报错导致频繁失败重启。
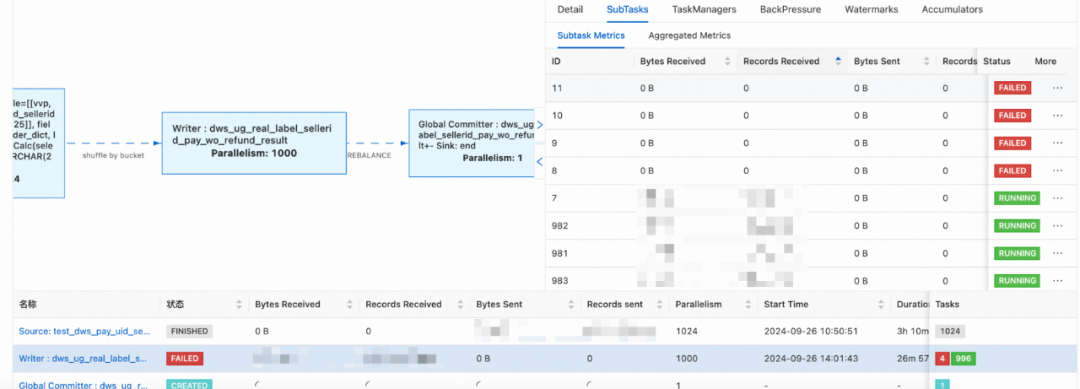
原因分析:通过查看官方文档,writer 算子出现此类情况通常是因为 TM 的堆内存不足导致的,paimon 表使用堆内存只要是以下 3 种方式:
Paimon 主键表 writer 算子的每个并发都有一个内存 buffer 用于排序。该 buffer 的大小受
write-buffer-size表参数控制,默认值为 256 mb。Paimon 默认使用 orc 文件格式,因此还需要一个内存 buffer 将内存里的数据分批转为列存格式。该 buffer 的大小受
orc.write.batch-size表参数控制,默认值为 1024,即默认保存 1024 行数据。每个被修改的分桶都有一个专用的 writer 对象处理该分桶的写入数据。
解决方法:
批任务配置时,增大 TM 的内存从 4GB 到 8GB
设置如下参数:如果 Flink 作业不依赖于状态,可以避免使用托管内存,从而增加对内存的使用。
taskmanager.memory.managed.size=1m3. 非分区表数据清除策略
问题描述:对于非分区主键表,无法向分区表一样设置分区定期清除策略,这样会导致表的数据量越来越大,影响后续该表的读写性能。
尝试方法:Paimon 官网中有对记录级别过期清除的参数,如下:
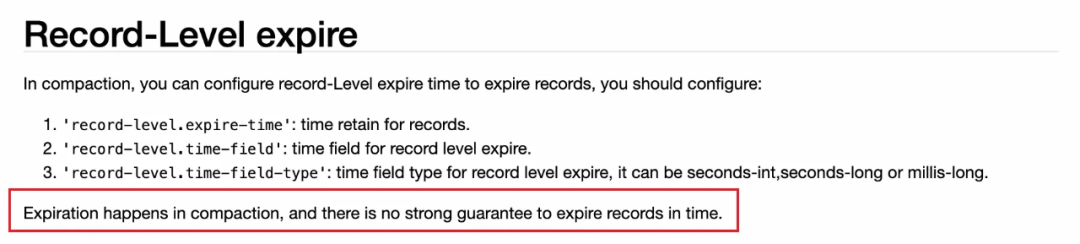
但在实际应用的过程中,发现这种方法只是在新记录写入时,会根据时间字段去判断该记录是否过期,若过期,则不会写入这条新记录,对于 Paimon 表中已有的历史记录,无法生效。
解决方法:
将 Paimon 表改为只写入不压缩模式

alter table `paimon-catalog`.`paimon-db`.test_dws_pay_refund set ('write-only' = 'true');通过 delete 语句清除过期数据【批处理】
待清除完成后,恢复压缩参数,设置为 write-only = 'false'
说明:如果直接启动批作业执行 delete 语句,在提交阶段任务会直接失败,因为当多个 writer 同时写入同一个分桶数据时,由于多个 writer 标记了同一条数据为‘deleted',,在压缩过程中会发生冲突,导致任务失败重启,但是批作业无法进行重启。
▐ 累加类实时标签开发
需求背景
目前平台提供的下单类实时标签大都为:某段时间是否下单的二元标签,为了丰富实时标签的多元性,考虑新增某段时间下单数量、下单金额等累计类的实时标签。
问题分析
对于长周期可累加型指标的问题,通常有以下几种思路:
1. 开窗聚合,这种方法的缺点是长时间的开窗会受到状态大小的限制,因此不适用于长周期指标的累加。
2. 离线 T-2 结果+实时结果关联汇总,这种方法需要:
离线任务必须在当天产出,在大促期间需要强保障;
实时任务依然需要进行长达 2 天的开窗,任务一旦无状态重启,就需要从 2 天前的点位重新计算。
解决方法
对于上述问题,中间存储是一定需要的,但是我们考虑使用 Paimon 表来代替方法 2 中的离线结果表,这样既可以摆脱对离线任务的强依赖,同时也可以随时进行无状态重启。
整体方案设计
1. 累计日期的选择:累计周期 N 的取值可以让用户自定义选择,这要求我们提前算好不同 N 天的结果并存储在数据库中, 因此 Paimon 维表必须存储天粒度的累加数据,方便不同时间段指标结果的累加。针对该方案,累加周期 N 的选择不建议太长,因为这样会增大 Paimon 表的存储成本和维表关联时的计算成本,因此我们这里选择 N 的最大取值为 7,也可以根据业务的需要,适当增加。
2. DAU 刷新数据:如果某个用户今日没有下单,那么存储在 Tair 中的近 N 天结果是不会被更新的,这就导致结果的不准确,因此需要使用 DAU 流驱动近 N 天累加结果的更新。
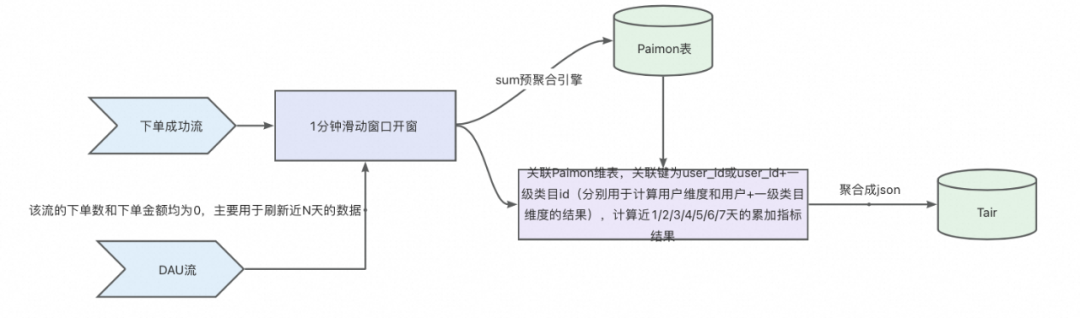
Paimon 维表设计
CREATE TABLE `paimon-catalog`.`paimon-db`.`test_dws_pay_cate1_result` (`test_buyer_id` BIGINT NOT NULL, `test_cate1_id` STRING NOT NULL, -- 一级类目ID`ds` STRING NOT NULL,`test_order_cnt` BIGINT, -- 下单数`test_gmv` DOUBLE, -- GMVPRIMARY KEY (test_buyer_id, test_cate1_id, ds) NOT ENFORCED
)
COMMENT ''
WITH ('bucket' = '40','bucket-key' = 'test_buyer_id','changelog-producer' = 'lookup','fields.test_order_cnt.aggregate-function' = 'sum','fields.test_gmv.aggregate-function' = 'sum','merge-engine' = 'aggregation','partition.expiration-time' = '7d','partition.timestamp-formatter' = 'yyyyMMdd','partition.timestamp-pattern' = '$ds'
)说明:
1. 分区表:分区粒度为天分区,存储每天每个用户 x 一级类目的成交单数和金额,设置分区过期日期为 7 天
2. 主键表:主键设置为用户 ID+一级类目 ID +分区字段
3. 分桶数量:分桶键设置为用户 ID(具体原因可在下文会详述),分桶数量根据维表大小(GB 级别)设置为 40
4. 聚合引擎:使用 Paimon 主键表的 aggregation 预聚合引擎,分别对字段 test_order_cnt(下单数)和 test_gmv(下单金额)采用 sum 累加的方式预聚合。
5. changelog 产生方式:设置为 lookup,其实我们下游并不需要实时消费 paimon 维表,但是对于使用 aggregation 引擎的表,必须设置该参数。
开发经验分享
由于分桶键设置不合理导致的 LookupJoin 算子报错
问题描述:在设计 Paimon 维表的时候,一开始会自然得把分桶键设置为主键,即 test_buyer_id 和test_cate1_id两个字段,但是在LookupJoin 的时候,发现如果 joinkey 只是 test_buyer_id,即 bucket key 的一部分,对应算子就会长时间处于初始化中,最后报错。
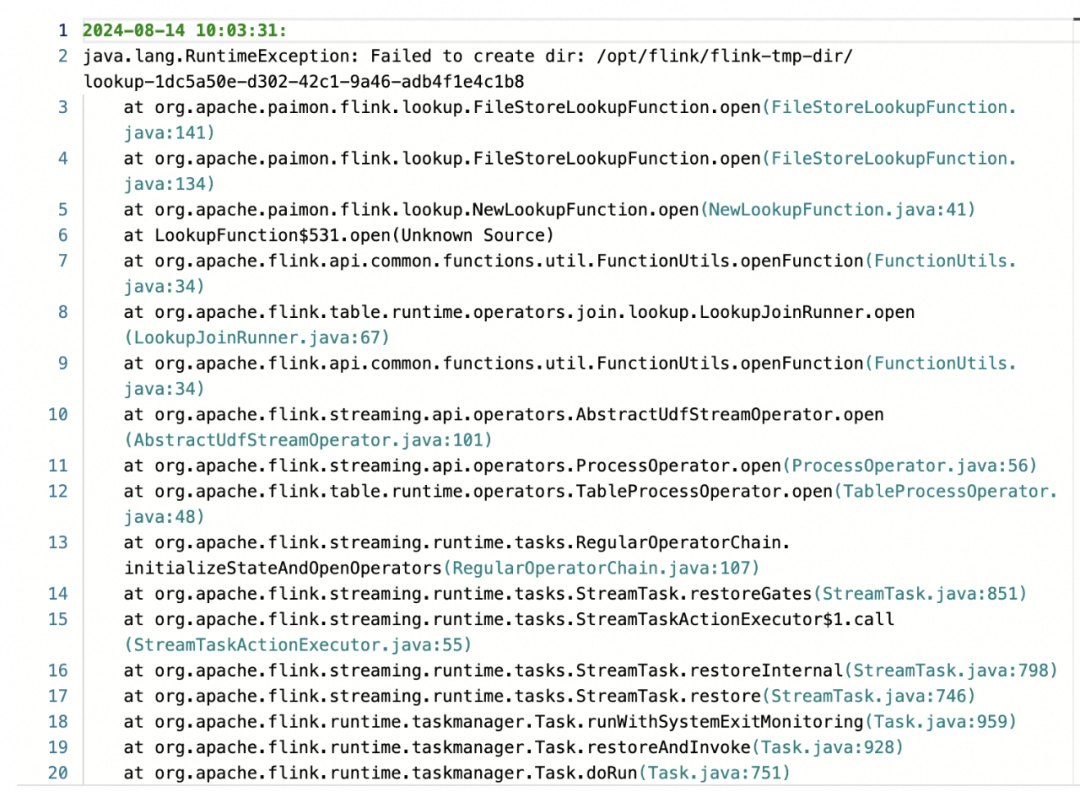
原因分析:如果 joinkey 只是 bucket key 的一部分,就会导致在 join 的时候,无法通过 joinkey 快速定位到目标维表数据所在分桶及目标数据的位置,导致查询效率低下。
解决方法:需要保证 joinkey 完全包括 bucket key,这样才可以通过 joinkey 快速定位到维表数据所在的分桶,从而定位快速读取维表数据。因此,将 bucket key 设置为 test_buyer_id。
衍生问题:采用上述解决方法后启动任务,会发现 LookupJoin 算子会有 5-10 分钟的初始化过程,这是因为我们在 join 的时候没有指定 ds 分区字段的值,导致 join 的时候会读取多个分区,而不同分区的数据是存在不同的分桶中的,因此 vvp 在加载维表数据的时候,不会通过 shuffle 策略将维表数据加载到对应内存中,而是将维表的全量数据加载到每个 TM 的 rocksdb 中,然后再去从 TM 本地根据 joinkey 查询数据,因此加载需要较长的时间。
经验总结通过上述两个案例,我们成功实践了 Paimon +Flink 的实时湖仓架构用于需要大量实时状态存储的场景。使用 Paimon 作为中间存储进行维表 JOIN,可以解决 Flink 内部状态 state 成本高、不可重启、存储周期短等限制,从而满足复杂实时场景的数据开发需求,同时这些中间存储结果也可以通过流/批的形式被 ODPS/Hologres 等大数据引擎消费,实现数据统一,这也是我们后续会进一步探索和应用的场景。

参考资料
Writer 算子堆内存的使用:
https://paimon.apache.org/docs/master/maintenance/write-performance/#write-memory
Flink 维表 Join:
https://help.aliyun.com/zh/flink/developer-reference/join-statements-for-dimension-tables#section-syw-j1p-cgb
Paimon dedicated compaction:
https://paimon.apache.org/docs/0.9/maintenance/dedicated-compaction/
记录级别过期策略:
https://paimon.apache.org/docs/0.9/primary-key-table/compaction/
数据湖产品对比:
https://www.cnblogs.com/johnnyzen/p/18189005

团队介绍
淘天业务技术用户运营平台技术团队是一支懂用户,技术驱动的年轻队伍,以用户为中心,通过技术创新提升用户全生命周期体验,持续为用户创造价值。团队立足体系化打造业界领先的用户增长基础设施,以媒体外投平台、ABTest平台、用户运营平台为代表的基础设施赋能阿里集团用户增长,日均处理数据量千亿规模、调用QPS千万级。
¤ 拓展阅读 ¤
3DXR技术 | 终端技术 | 音视频技术
服务端技术 | 技术质量 | 数据算法
相关文章:

Flink+Paimon实时数据湖仓实践分享
随着 Paimon 近两年的推广普及,使用 FlinkPaimon 构建数据湖仓的实践也越来越多。在 Flink 实时数据开发中,对于依赖大量状态 state 的场景,如长周期的累加指标计算、回撤长历史数据并更新等,使用实时数仓作为中间存储来代替 Flin…...

全面解析DApp开发中的智能合约设计
在DApp的开发过程中,智能合约的设计起到了至关重要的作用。智能合约是运行在区块链上的程序,负责处理和执行DApp中的逻辑、交易和数据存储。下面我们将深入探讨智能合约的设计原则、挑战和优化方法,帮助开发者掌握如何设计高效、安全的智能合…...

强化学习新突破:情节记忆与奖励机制引领多智能体协作
简介 本推文介绍了韩国科学技术院发表在人工智能顶会ICLR 2024上的论文《Efficient Episodic Memory Utilization of Cooperative Multi-Agent Reinforcement Learning》。该论文提出创新性高效情节记忆利用(Efficient Episodic Memory Utilization,EMU…...

VUE3学习二
教程视频 【尚硅谷Vue3入门到实战,最新版vue3TypeScript前端开发教程】https://www.bilibili.com/video/BV1Za4y1r7KE?p67&vd_sourcef1bd3b5218c30adf0a002c8c937e0a27 零 环境搭建 学习环境 windows10node 18vue3 创建项目 npm create vuelatest 选项中…...

MySQL Group Replication
参考文档: https://dev.mysql.com/doc/refman/8.4/en/group-replication-configuring-instances.html MySQL版本: mysql> select version(); ----------- | version() | ----------- | 8.4.3 | ----------- 1 row in set (0.00 sec)mysql> …...

设计模式学习思路二
设计模式的学习思路_设计模式必须按顺序进行吗-CSDN博客 以下是一些方法和思路可以帮助你更清晰地识别使用了哪种设计模式。 1. 确定模式时的思考步骤 以下是分析代码时,你可以遵循的一些思路和步骤,帮助你识别可能使用的设计模式: a. 识别…...

MySql 笔记
drop database if exists school; create database school default charset utf8; -- 切换到数据库school use school; -- 创建学生表 drop table if exists tb_student; create table tb_student ( stuid int not null comment 学号, stuname varchar(20) not null comment 姓…...

【Qt】QTableView选中行发生变化时触发的信号
问题 QTableView选中的行发生变化时,使用的信号是QTableView的selectionModel()里的currentChanged信号,界面点击行来回切换,发现怎么也触发不了? 原因 信号槽连接放在了QTableView数据初始化前面,这时候QTableView…...

qt图像合成模式分析
文章目录 定义含义示例分析CompositionMode_ClearCompositionMode_SourceCompositionMode_DestinationCompositionMode_SourceOverCompositionMode_DestinationOverCompositionMode_SourceInCompositionMode_DestinationInCompositionMode_SourceOutCompositionMode_Destinatio…...

http与https的区别
加密方式: 加密技术是对信息进行编码和解码的技术,编码是把原来可读信息(又称明文)译成代码形式(又称密文),其逆过程就是解码(解密),加密技术的要点是加密算…...

Pyside6 --Qt Designer--Qt设计师--了解+运行ui_demo_1.py
目录 一、打开Qt设计师1.1 Terminal终端1.2 打开env,GUI虚拟环境下的scripts文件1.3 不常用文件介绍(Scripts下面) 二、了解Qt设计师的各个控件作用2.1 点击widget看看效果!2.2 点击Main Window看看效果 三、编写一个简易的UI代码…...

11.17【大数据】Hadoop【DEBUG】
列出hdfs文件系统所有的目录和文件 主节点上 子结点 是一样的 *为什么能登进 slave 02 的主机,但是 master 当中依然显示 slave 02 为 DeadNode?* hadoop坏死节点的重启_hadoop3 子节点重启-CSDN博客 注意hadoop-daemon.sh 实际上位于 Hadoop 的 sbin 目录中,而不…...

MQ:kafka-消费者的三种语义
文章目录 前言(一) 创建topic(二) 生产者(三)消费者1. At-most-once Kafka Consumer2. At-least-once kafka consumer3. 使用subscribe实现Exactly-once4. 使用assign实现Exactly-once 前言 本文主要是以kafka 09的client为例子,详解kafka c…...

QT 线程锁
在 Qt 中,线程锁是用来同步多线程访问共享资源的机制,防止数据竞争和线程安全问题。Qt 提供了几种线程锁和同步工具,主要包括以下几种: 1. QMutex 功能:QMutex 是 Qt 中最常用的互斥锁(mutex)…...

C++中protobuf Message与JSON的互相转换
C中protobuf Message与JSON的互相转换 环境: protobuf: v27.3(2024-08-01) abseil: 20240722.0文章目录 C中protobuf Message与JSON的互相转换前言1. 编写通讯录addressbook.proto2. 编译3. C中测试protobuf与json的转换4. 结果 前言 PB转JSON:Protoc…...

Milvus向量数据库03-搜索理论
Milvus向量数据库03-搜索理论 1-ANN搜索 通过 k-最近邻(kNN)搜索可以找到一个查询向量的 k 个最近向量。kNN 算法将查询向量与向量空间中的每个向量进行比较,直到出现 k 个完全匹配的结果。尽管 kNN 搜索可以确保准确性,但十分耗…...

qt QCryptographicHash详解
1、概述 QCryptographicHash是Qt框架中提供的一个类,用于实现加密散列函数,即哈希函数。哈希函数能够将任意长度的数据转换为固定长度的哈希值,也称为散列值或数据指纹。这个哈希值通常用于数据的完整性校验、密码存储等场景。QCryptographi…...
综述:连接数字与物理世界的桥梁)
【论文阅读】具身人工智能(Embodied AI)综述:连接数字与物理世界的桥梁
摘要 具身人工智能(Embodied AI)对于实现通用人工智能(AGI)至关重要,是连接数字世界与物理世界的各类应用的基础。近年来,多模态大模型(MLMs)和世界模型(WMs)…...

使用el-row和el-col混合table设计栅格化,实现表头自适应宽度,表格高度占位
演示效果: 如上图,由于地址信息很长,需要占多个格子,所以需要错开,若想实现这种混合效果,可以这样搭建: 页面效果: 代码分析: 上面使用el-row和el-col搭建表单显示 第一排三个8,第二排8和16 下面混合table实现,并使用border来自适应宽度…...

MQ的基本概念
1 MQ的基本概念 RabbitMQ是一个开源的消息代理和队列服务器,它使用Erlang语言编写并运行在多种操作系统上,如Linux、Windows等。RabbitMQ可以接收、存储和转发消息(也称为“事件”)到连接的客户端。它适用于多种场景,…...

基于协同过滤的图书推荐系统 爬虫分析可视化【源码+文档】
【1】系统介绍 研究背景 随着互联网的普及和电子商务的发展,用户可以在线获取大量的图书资源。然而,面对海量的信息,用户往往难以找到自己真正感兴趣的书籍。同时,对于在线书店或图书馆等提供图书服务的平台来说,如何…...

Kruskal 算法在特定边权重条件下的性能分析及其实现
引言 Kruskal 算法是一种用于求解最小生成树(Minimum Spanning Tree, MST)的经典算法。它通过逐步添加权重最小的边来构建最小生成树,同时确保不会形成环路。在本文中,我们将探讨在特定边权重条件下 Kruskal 算法的性能,并分别给出伪代码和 C 语言实现。特别是,我们将分…...

【Pandas】pandas from_dummies
Pandas2.2 General Data manipulations 方法描述melt(frame[, id_vars, value_vars, var_name, …])将多个列的值转换为行形式pivot(data, *, columns[, index, values])将长格式的数据转化为宽格式pivot_table(data[, values, index, columns, …])用于创建数据透视表&#…...

【信息系统项目管理师】第8章:项目整合管理过程详解
文章目录 一、制定项目章程1、输入2、工具和技术3、输出 二、制订项目管理计划1、输入2、工具和技术3、输出 三、指导与管理项目工作1、输入2、工具和技术3、输出 四、管理项目知识1、输入2、工具和技术3、输出 五、监控项目工作1、输入2、工具和技术3、输出 六、实施整体变更控…...

从变更到通知:使用Python和MongoDB Change Streams实现即时事件监听
MongoDB提供了一种强大的功能,称为Change Streams,它允许应用程序监听数据库中的变更事件,并在数据发生变化时立即做出响应。这在mysql数据库是不具备没有这个功能的。又如:我们在支付环节想一直监听支付回调的状态,就…...

vue3+elementPlus封装的数据过滤区
目录结构 源码 index.vue <template><el-form class"mb-5" :rules"rules" :model"queryForm" ref"queryDOM" label-width"80"><el-row :gutter"20"><slot></slot><el-col cla…...

PHP RabbitMQ连接超时问题
问题背景 Error: The connection timed out after 3 sec while awaiting incoming data 看到这个报错,我不以为意,认为是我设置的超时时间不够导致的,那就设置长一点 Error: The connection timed out after 300 sec while awaiting incom…...
)
SpringMvc完整知识点二(完结)
SpringMVC获取请求参数 环境准备工作等均省略,可详见快速入门,此处只写非共有部分代码 该部分示例项目SpringMvcThree已上传至Gitee,可自行下载 客户端请求参数的格式为:namevalue&passwordvalue... ... 服务端想要获取请求…...

WebSocket 通信说明与基于 ESP-IDF 的 WebSocket 使用
一、 WebSocket 出现的背景 最开始 客户端(Client) 和 服务器(Server) 通信使用的是 HTTP 协议,HTTP 协议有一个的缺陷为:通信只能由客户端(Client)发起。 在一些场景下࿰…...

UE5 Compile Plugins | Rebuild from Source Manually | Unreal Engine | Tutorial
Step 1 Open Engine Folder H:\UE5\UE_5.3\Engine\Build\BatchFiles Step 2 Hold "Shift""Mouse Right Click"in Empty Area Step 3 Select "Open PowerShell window here .\RunUAT.bat BuildPlugin -plugin"H:\projects\MetaHuman光照2\plu…...
)
深度解析 Ansible:核心组件、配置、Playbook 全流程与 YAML 奥秘(下)
文章目录 六、playbook运行playbook方式Playbook VS ShellScripts忽略错误 ignore_errorshandlers和notify结合使用触发条件playbook中tags的使用playbook中变量的使用invertory参数模板templates迭代与条件判断迭代:with_items迭代嵌套子变量roles 六、playbook 运…...

langchain chroma 与 chromadb笔记
chromadb可独立使用也可搭配langchain 框架使用。 环境: python 3.9 langchain0.2.16 chromadb0.5.3 chromadb 使用示例 import chromadb from chromadb.config import Settings from chromadb.utils import embedding_functions# 加载embedding模型 en_embeddin…...

04 创建一个属于爬虫的主虚拟环境
文章目录 回顾conda常用指令创建一个爬虫虚拟主环境Win R 调出终端查看当前conda的虚拟环境创建 spider_base 的虚拟环境安装完成查看环境是否存在 为 pycharm 配置创建的爬虫主虚拟环境选一个盘符来存储之后学习所写的爬虫文件用 pycharm 打开创建的文件夹pycharm 配置解释器…...

xcode开发相关英语单词
创建项目: otheraudio unit extension app音频单元扩展应用程序generic kernel extension通用内核扩展installer plug-in安装程序插件instruments package仪器包iokit driveriokit驱动程序presence pane状态窗格screen saver屏幕保护程序...
-STM)
etcd-v3.5release-(2)-STM
a.b.c表示a文件里的b类的方法c,注意a不一定是包名,因为文件名不一定等于包名 !!!!etcd在put的过程中使用的batchTxBuffered,这个事务是写bbolt数据库使用的事务,是对bbolt.Tx的一个…...

多系统萎缩锻炼如何好起来?
多系统萎缩(Multiple System Atrophy, MSA)是一种复杂的神经系统退行性疾病,影响着患者的自主神经系统、运动系统和平衡功能等多个方面。面对这一挑战,科学、合理的锻炼对于缓解症状、提高生活质量至关重要。本文将详细介绍多系统…...
)
非对称任意进制转换器(安卓)
除了正常进制转换,还可以输入、输出使用不同的数字符号,达成对数值进行加密的效果 点我下载APK安装包提取码:h4nw 使用unity开发。新建一个c#代码文件,把代码覆盖进去,再把代码文件添加给main camera即可。 using Sy…...

MySQL数据库安全与管理
1、创建两个新用户U_student1和U_student2,密码分别为1234和5678 create user U_student1@localhost identified by 1234, U_student2@localhost identified by 5678; 2、创建两个新用户的详细信息保存在MySQL数据库的user表中 use mysql; select user, host, authentication…...

python使用PyPDF2 和 pdfplumber操作PDF文件
文章目录 一、第三方库介绍二、基本使用1、拆分pdf2、合并pdf3、提取文字内容4、提取表格内容5、PDF加密6、PDF解密 一、第三方库介绍 Python 操作 PDF 会用到两个库,分别是:PyPDF2 和 pdfplumber。 PyPDF2 可以更好的读取、写入、分割、合并PDF文件&a…...
效果)
【vue2自定义指令】v-disabled 实现el-switch,el-button等elementUI禁用(disabled)效果
如果你搜过类似的功能,肯定看到过千篇一律的 // 实现按钮禁用el.disabled true// 增加 elementUI 的禁用样式类el.classList.add(is-disabled)但是这个方案明显对el-switch,不起作用,所以我这边直接把方案贴出来,不想了解具体原理…...

从容面对大规模作业:利用PMI提升作业启用和结束效率
1.进程管理瓶颈 随着集群规模的不断扩大和处理器性能的不断提升,高性能计算HPC(High Performance Computing)系统性能已经进入百亿亿次时代,进程管理是高性能计算的一个重要组成部分,传统进程管理已经不能满足海量处理器的管理需求ÿ…...
云中的海盐解题全过程文档及程序)
2024年认证杯SPSSPRO杯数学建模C题(第一阶段)云中的海盐解题全过程文档及程序
2024年认证杯SPSSPRO杯数学建模 C题 云中的海盐 原题再现: 巴黎气候协定提出的目标是:在2100年前,把全球平均气温相对于工业革命以前的气温升幅控制在不超过2摄氏度的水平,并为1.5摄氏度而努力。但事实上,许多之前的…...
暴力破解与验证码识别绕过)
burp(6)暴力破解与验证码识别绕过
声明! 学习视频来自B站up主 **泷羽sec** 有兴趣的师傅可以关注一下,如涉及侵权马上删除文章,笔记只是方便各位师傅的学习和探讨,文章所提到的网站以及内容,只做学习交流,其他均与本人以及泷羽sec团队无关&a…...

不同系统查看软件占用端口的方式
Windows 使用命令提示符(CMD) 打开命令提示符: 按 Win R 键打开“运行”对话框,输入 cmd 并按回车。为了执行某些命令,您可能需要以管理员身份运行命令提示符。可以通过右键点击“开始”按钮并选择“命令提示符(管理…...

【已解决】黑马点评项目中-实战篇11-状态登录刷新章节设置RefreshTokenInterceptor拦截器后登录异常的问题
黑马点评项目中-实战篇11-状态登录刷新章节设置RefreshTokenInterceptor拦截器后登录异常的问题 在 MvcConfig 文件中添加好RefreshTokenInterceptor拦截器 出现异常情况 按照验证码登录后,进入主页面,再点击“我的”,又跳入登录界面 原因…...

Artec Leo 3D扫描仪 革新家具行业的数字化展示【沪敖3D】
随着科技的飞速进步,三维扫描技术已被广泛应用于包括家居行业在内的多个行业。面对现代消费者对家居产品日益增长的个性化和多样化需求,传统的家居设计和展示方法已难以满足市场需求。三维扫描技术的出现,为家居行业带来了新的发展机遇&#…...
-UIStyler-选取点)
UG NX二次开发(Python)-UIStyler-选取点
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 1、前言2、设计一个UI界面3、创建长方体的代码4、需要引入的库5、测试验证1、前言 采用Python语言进行UG NX二次开发的资料比较少,我本来不是很认可采用Python进行二次开发的,但是近期有读者咨询…...

Linux网络编程之---组播和广播
一.组播 1.概述 单播地址标识单个IP 接口,广播地址标识某个子网的所有IP 接口, 多播地址标识一组IP 接口。单播和广播是寻址方案的两个极端(要么单个要么全部), 多播则意在两者之间提供一种折中方案。多播数据报只应该由对它感兴趣的接口接收…...

[计算机网络] HTTP/HTTPS
一. HTTP/HTTPS简介 1.1 HTTP HTTP(超文本传输协议,Hypertext Transfer Protocol)是一种用于从网络传输超文本到本地浏览器的传输协议。它定义了客户端与服务器之间请求和响应的格式。HTTP 工作在 TCP/IP 模型之上,通常使用端口 …...

运动模糊效果
1、运动模糊效果 运动模糊效果,是一种用于 模拟真实世界中快速移动物体产生的模糊现象 的图像处理技术,当一个物体以较高速度移动时,由于人眼或摄像机的曝光时间过长,该物体会在图像中留下模糊的运动轨迹。这种效果游戏、动画、电…...