Segment Anything in Images and Videos
目录
摘要
Abstract
SAM2
模型框架
图像编码器
记忆机制
提示编码器和掩码解码器
实验
代码
总结
摘要
SAM2是基于Meta公司推出的Segment Anything Model升级而来的先进分割模型。它在SAM的基础上,通过引入记忆注意力模块和优化图像编码器等改进,显著提升了图像和视频分割的精度与效率。SAM2解决了SAM在小物体分割、多物体重叠场景处理以及视频分割能力上的不足,能够实时处理视频流并实现细粒度分割。其采用Hiera作为骨干网络,结合Prompt驱动机制,生成高质量的分割掩码。SAM2在大规模数据集上表现出色,构建了目前最大的高清视频分割数据集SA-V,并在医学图像分割等任务中超越了现有先进模型,如在BTCV数据集上达到92.30%的Dice相似系数,超越了nnUNet。此外,SAM2在伪装物体检测、显著性物体检测等多个任务上也展现了卓越性能,标志着实时对象分割技术的重大突破。
Abstract
SAM2 is an advanced segmentation model based on the Segment Anything Model released by Meta. Building on SAM, it significantly enhances the accuracy and efficiency of image and video segmentation through improvements such as the introduction of a memory attention module and optimization of the image encoder. SAM2 addresses SAM's limitations in small object segmentation, handling scenes with multiple overlapping objects, and video segmentation capabilities. It can process video streams in real-time and achieve fine-grained segmentation. Using Hiera as the backbone network and combining a Prompt-driven mechanism, SAM2 generates high-quality segmentation masks. It performs well on large-scale datasets, constructing the largest high-definition video segmentation dataset SA-V to date. In tasks such as medical image segmentation, SAM2 surpasses existing state-of-the-art models, achieving a Dice similarity coefficient of 92.30% on the BTCV dataset, outperforming nnUNet. Additionally, SAM2 demonstrates excellent performance in multiple tasks, including camouflage object detection and salient object detection, marking a significant breakthrough in real-time object segmentation technology.
SAM2
Demo:https://sam2.metademolab.com
项目地址:https://github.com/facebookresearch/sam2
Website:https://ai.meta.com/sam2
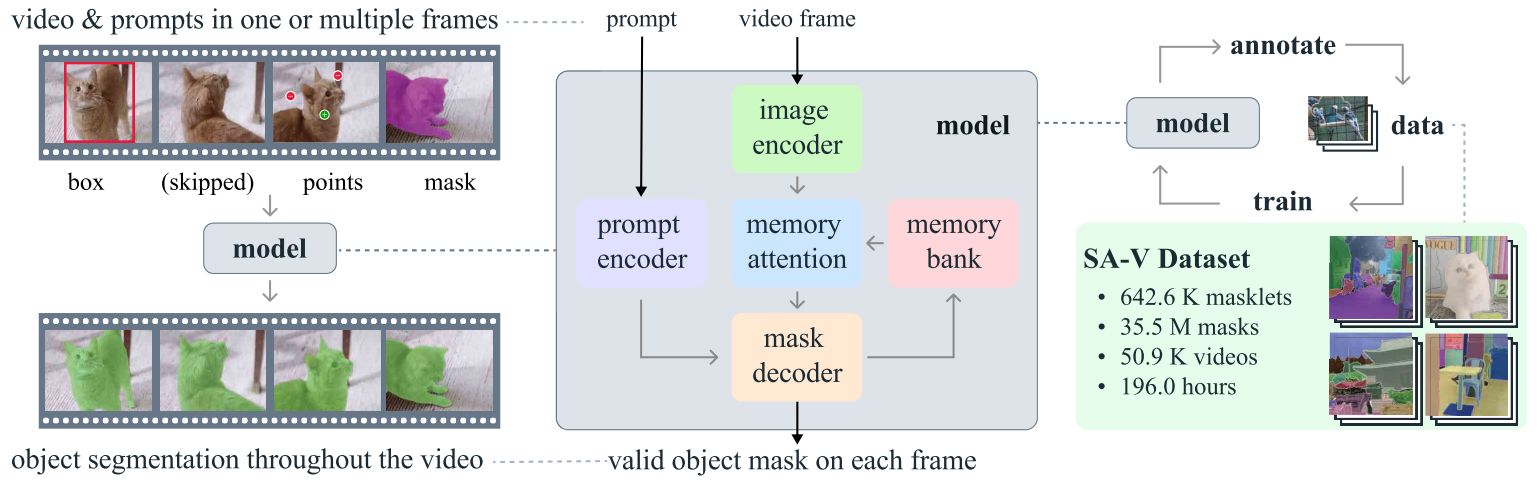
SAM2的核心创新在于其将图像视为"单帧视频"的统一视角,通过扩展原始SAM的架构,引入了专门针对视频处理的记忆机制和流式处理能力。这种设计理念使得SAM2不仅保留了SAM在图像分割上的所有优势,还新增了对视频时序信息的理解与利用能力。模型采用基于Transformer的架构,配合高效的记忆注意力模块,能够实时处理视频流并保持对目标对象的连续跟踪,即使面对遮挡、变形等复杂情况也能表现出色。
SAM2的零样本泛化能力是其另一项突出特性。与需要针对特定类别进行训练的传统分割模型不同,SAM2能够准确分割训练数据中从未出现过的对象类型,这种能力使其可以应用于几乎无限的现实场景而无需额外调整。测试表明,SAM2在17个零样本视频数据集上的交互式分割性能显著优于先前方法,且所需人机交互减少了约3倍。同时,其处理速度达到每秒约44帧,比前代SAM快6倍,真正实现了实时处理能力。
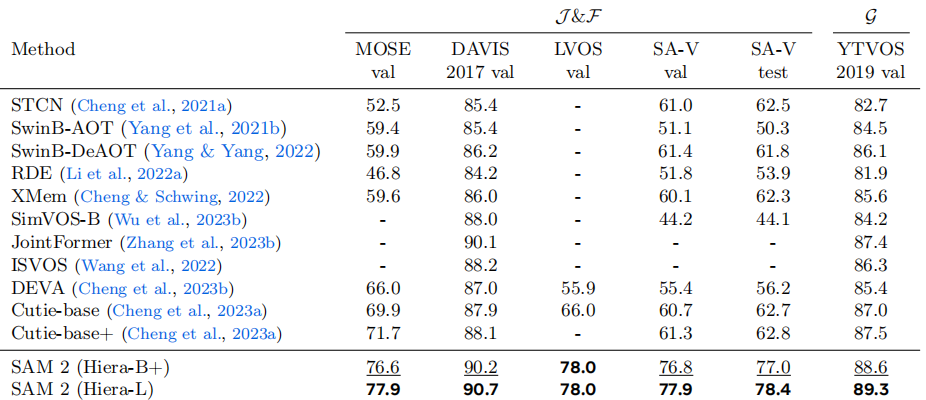
从技术指标来看,SAM2在多个基准测试中创造了新纪录。在DAVIS 2017和YouTube-VOS等主流视频分割基准上,SAM2的J&F分数分别达到82.5和81.2,大幅领先之前的最先进模型。在交互式分割任务中(DAVIS交互数据集),SAM2仅需1.54次点击即可达到90%的精度(AUC为0.872),显示出极高的交互效率。这些性能提升源于Meta团队专门为SAM2开发的大规模SA-V数据集,该数据集包含约51,000个视频和超过600,000个掩码注释,是此前最大视频分割数据集规模的4.5倍。
模型框架
图像编码器
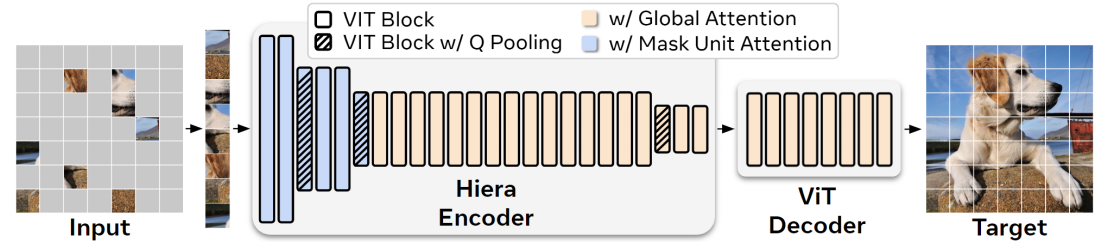
图像编码器在整个交互过程中仅运行一次,其作用是为每一帧提供无条件的特征嵌入。SAM2使用了一个预训练的 MAE Hiera 图像编码器,该编码器是分层的,允许在解码过程中使用多尺度特征。
记忆机制
记忆注意力的作用是将当前帧的特征基于过去的帧特征和预测结果以及任何新的提示进行条件化处理。作者堆叠了 L 个 Transformer 块,第一个块以当前帧的图像编码作为输入。每个块执行自注意力操作,随后进行交叉注意力操作,关注(有提示/无提示)帧的记忆和目标指针,这些内容存储在记忆库中,最后通过一个 MLP。我们使用标准的注意力操作来进行自注意力和交叉注意力,从而能够受益于最近在高效注意力内核方面的进展。
提示编码器和掩码解码器
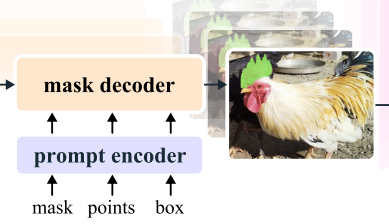
提示编码器与 SAM的完全相同,可以通过点、框或掩码来定义给定帧中对象的范围。稀疏提示通过位置编码与每种提示类型的学习嵌入相加来表示,而掩码则通过卷积嵌入并与帧嵌入相加,SAM2 解码器设计在很大程度上遵循了 SAM 的方法。
堆叠了“双向”Transformer 块,用于更新提示和帧嵌入。与 SAM 一样,对于模糊提示可能存在多个兼容的目标掩码,同时预测多个掩码。这种设计对于确保模型输出有效掩码至关重要。在视频中,模糊性可能会跨越多个视频帧,因此模型会在每一帧上预测多个掩码。如果没有后续提示来解决这种模糊性,模型只会传播当前帧中预测的具有最高 IoU 的掩码。与 SAM 不同,SAM 在给定正向提示的情况下总是有一个有效的对象可以分割,而在 PVS 任务中,某些帧上可能根本不存在有效的对象。为了支持这种新的输出模式,增加了一个额外的头部,用于预测感兴趣的对象是否出现在当前帧上。另一个新特性是从分层图像编码器添加跳跃连接,以引入用于掩码解码的高分辨率嵌入。
实验
对比SAM模型:

与先前工作对比:
代码
SAM2.py
import loggingimport numpy as np
import torch
import torch.distributed
from sam2.modeling.sam2_base import SAM2Base
from sam2.modeling.sam2_utils import (get_1d_sine_pe,get_next_point,sample_box_points,select_closest_cond_frames,
)from sam2.utils.misc import concat_pointsfrom training.utils.data_utils import BatchedVideoDatapointclass SAM2Train(SAM2Base):def __init__(self,image_encoder,memory_attention=None,memory_encoder=None,prob_to_use_pt_input_for_train=0.0,prob_to_use_pt_input_for_eval=0.0,prob_to_use_box_input_for_train=0.0,prob_to_use_box_input_for_eval=0.0,# if it is greater than 1, we interactive point sampling in the 1st frame and other randomly selected framesnum_frames_to_correct_for_train=1, # default: only iteratively sample on first framenum_frames_to_correct_for_eval=1, # default: only iteratively sample on first framerand_frames_to_correct_for_train=False,rand_frames_to_correct_for_eval=False,# how many frames to use as initial conditioning frames (for both point input and mask input; the first frame is always used as an initial conditioning frame)# - if `rand_init_cond_frames` below is True, we randomly sample 1~num_init_cond_frames initial conditioning frames# - otherwise we sample a fixed number of num_init_cond_frames initial conditioning frames# note: for point input, we sample correction points on all such initial conditioning frames, and we require that `num_frames_to_correct` >= `num_init_cond_frames`;# these are initial conditioning frames because as we track the video, more conditioning frames might be added# when a frame receives correction clicks under point input if `add_all_frames_to_correct_as_cond=True`num_init_cond_frames_for_train=1, # default: only use the first frame as initial conditioning framenum_init_cond_frames_for_eval=1, # default: only use the first frame as initial conditioning framerand_init_cond_frames_for_train=True, # default: random 1~num_init_cond_frames_for_train cond frames (to be constent w/ previous TA data loader)rand_init_cond_frames_for_eval=False,# if `add_all_frames_to_correct_as_cond` is True, we also append to the conditioning frame list any frame that receives a later correction click# if `add_all_frames_to_correct_as_cond` is False, we conditioning frame list to only use those initial conditioning framesadd_all_frames_to_correct_as_cond=False,# how many additional correction points to sample (on each frame selected to be corrected)# note that the first frame receives an initial input click (in addition to any correction clicks)num_correction_pt_per_frame=7,# method for point sampling during evaluation# "uniform" (sample uniformly from error region) or "center" (use the point with the largest distance to error region boundary)# default to "center" to be consistent with evaluation in the SAM paperpt_sampling_for_eval="center",# During training, we optionally allow sampling the correction points from GT regions# instead of the prediction error regions with a small probability. This might allow the# model to overfit less to the error regions in training datasetsprob_to_sample_from_gt_for_train=0.0,use_act_ckpt_iterative_pt_sampling=False,# whether to forward image features per frame (as it's being tracked) during evaluation, instead of forwarding image features# of all frames at once. This avoids backbone OOM errors on very long videos in evaluation, but could be slightly slower.forward_backbone_per_frame_for_eval=False,freeze_image_encoder=False,**kwargs,):super().__init__(image_encoder, memory_attention, memory_encoder, **kwargs)self.use_act_ckpt_iterative_pt_sampling = use_act_ckpt_iterative_pt_samplingself.forward_backbone_per_frame_for_eval = forward_backbone_per_frame_for_eval# Point sampler and conditioning framesself.prob_to_use_pt_input_for_train = prob_to_use_pt_input_for_trainself.prob_to_use_box_input_for_train = prob_to_use_box_input_for_trainself.prob_to_use_pt_input_for_eval = prob_to_use_pt_input_for_evalself.prob_to_use_box_input_for_eval = prob_to_use_box_input_for_evalif prob_to_use_pt_input_for_train > 0 or prob_to_use_pt_input_for_eval > 0:logging.info(f"Training with points (sampled from masks) as inputs with p={prob_to_use_pt_input_for_train}")assert num_frames_to_correct_for_train >= num_init_cond_frames_for_trainassert num_frames_to_correct_for_eval >= num_init_cond_frames_for_evalself.num_frames_to_correct_for_train = num_frames_to_correct_for_trainself.num_frames_to_correct_for_eval = num_frames_to_correct_for_evalself.rand_frames_to_correct_for_train = rand_frames_to_correct_for_trainself.rand_frames_to_correct_for_eval = rand_frames_to_correct_for_eval# Initial multi-conditioning framesself.num_init_cond_frames_for_train = num_init_cond_frames_for_trainself.num_init_cond_frames_for_eval = num_init_cond_frames_for_evalself.rand_init_cond_frames_for_train = rand_init_cond_frames_for_trainself.rand_init_cond_frames_for_eval = rand_init_cond_frames_for_evalself.add_all_frames_to_correct_as_cond = add_all_frames_to_correct_as_condself.num_correction_pt_per_frame = num_correction_pt_per_frameself.pt_sampling_for_eval = pt_sampling_for_evalself.prob_to_sample_from_gt_for_train = prob_to_sample_from_gt_for_train# A random number generator with a fixed initial seed across GPUsself.rng = np.random.default_rng(seed=42)if freeze_image_encoder:for p in self.image_encoder.parameters():p.requires_grad = Falsedef forward(self, input: BatchedVideoDatapoint):if self.training or not self.forward_backbone_per_frame_for_eval:# precompute image features on all frames before trackingbackbone_out = self.forward_image(input.flat_img_batch)else:# defer image feature computation on a frame until it's being trackedbackbone_out = {"backbone_fpn": None, "vision_pos_enc": None}backbone_out = self.prepare_prompt_inputs(backbone_out, input)previous_stages_out = self.forward_tracking(backbone_out, input)return previous_stages_outdef _prepare_backbone_features_per_frame(self, img_batch, img_ids):"""Compute the image backbone features on the fly for the given img_ids."""# Only forward backbone on unique image ids to avoid repetitive computation# (if `img_ids` has only one element, it's already unique so we skip this step).if img_ids.numel() > 1:unique_img_ids, inv_ids = torch.unique(img_ids, return_inverse=True)else:unique_img_ids, inv_ids = img_ids, None# Compute the image features on those unique image idsimage = img_batch[unique_img_ids]backbone_out = self.forward_image(image)(_,vision_feats,vision_pos_embeds,feat_sizes,) = self._prepare_backbone_features(backbone_out)# Inverse-map image features for `unique_img_ids` to the final image features# for the original input `img_ids`.if inv_ids is not None:image = image[inv_ids]vision_feats = [x[:, inv_ids] for x in vision_feats]vision_pos_embeds = [x[:, inv_ids] for x in vision_pos_embeds]return image, vision_feats, vision_pos_embeds, feat_sizesdef prepare_prompt_inputs(self, backbone_out, input, start_frame_idx=0):"""Prepare input mask, point or box prompts. Optionally, we allow tracking froma custom `start_frame_idx` to the end of the video (for evaluation purposes)."""# Load the ground-truth masks on all frames (so that we can later# sample correction points from them)# gt_masks_per_frame = {# stage_id: targets.segments.unsqueeze(1) # [B, 1, H_im, W_im]# for stage_id, targets in enumerate(input.find_targets)# }gt_masks_per_frame = {stage_id: masks.unsqueeze(1) # [B, 1, H_im, W_im]for stage_id, masks in enumerate(input.masks)}# gt_masks_per_frame = input.masks.unsqueeze(2) # [T,B,1,H_im,W_im] keep everything in tensor formbackbone_out["gt_masks_per_frame"] = gt_masks_per_framenum_frames = input.num_framesbackbone_out["num_frames"] = num_frames# Randomly decide whether to use point inputs or mask inputsif self.training:prob_to_use_pt_input = self.prob_to_use_pt_input_for_trainprob_to_use_box_input = self.prob_to_use_box_input_for_trainnum_frames_to_correct = self.num_frames_to_correct_for_trainrand_frames_to_correct = self.rand_frames_to_correct_for_trainnum_init_cond_frames = self.num_init_cond_frames_for_trainrand_init_cond_frames = self.rand_init_cond_frames_for_trainelse:prob_to_use_pt_input = self.prob_to_use_pt_input_for_evalprob_to_use_box_input = self.prob_to_use_box_input_for_evalnum_frames_to_correct = self.num_frames_to_correct_for_evalrand_frames_to_correct = self.rand_frames_to_correct_for_evalnum_init_cond_frames = self.num_init_cond_frames_for_evalrand_init_cond_frames = self.rand_init_cond_frames_for_evalif num_frames == 1:# here we handle a special case for mixing video + SAM on image training,# where we force using point input for the SAM task on static imagesprob_to_use_pt_input = 1.0num_frames_to_correct = 1num_init_cond_frames = 1assert num_init_cond_frames >= 1# (here `self.rng.random()` returns value in range 0.0 <= X < 1.0)use_pt_input = self.rng.random() < prob_to_use_pt_inputif rand_init_cond_frames and num_init_cond_frames > 1:# randomly select 1 to `num_init_cond_frames` frames as initial conditioning framesnum_init_cond_frames = self.rng.integers(1, num_init_cond_frames, endpoint=True)if (use_pt_inputand rand_frames_to_correctand num_frames_to_correct > num_init_cond_frames):# randomly select `num_init_cond_frames` to `num_frames_to_correct` frames to sample# correction clicks (only for the case of point input)num_frames_to_correct = self.rng.integers(num_init_cond_frames, num_frames_to_correct, endpoint=True)backbone_out["use_pt_input"] = use_pt_input# Sample initial conditioning framesif num_init_cond_frames == 1:init_cond_frames = [start_frame_idx] # starting frameelse:# starting frame + randomly selected remaining frames (without replacement)init_cond_frames = [start_frame_idx] + self.rng.choice(range(start_frame_idx + 1, num_frames),num_init_cond_frames - 1,replace=False,).tolist()backbone_out["init_cond_frames"] = init_cond_framesbackbone_out["frames_not_in_init_cond"] = [t for t in range(start_frame_idx, num_frames) if t not in init_cond_frames]# Prepare mask or point inputs on initial conditioning framesbackbone_out["mask_inputs_per_frame"] = {} # {frame_idx: <input_masks>}backbone_out["point_inputs_per_frame"] = {} # {frame_idx: <input_points>}for t in init_cond_frames:if not use_pt_input:backbone_out["mask_inputs_per_frame"][t] = gt_masks_per_frame[t]else:# During training # P(box) = prob_to_use_pt_input * prob_to_use_box_inputuse_box_input = self.rng.random() < prob_to_use_box_inputif use_box_input:points, labels = sample_box_points(gt_masks_per_frame[t],)else:# (here we only sample **one initial point** on initial conditioning frames from the# ground-truth mask; we may sample more correction points on the fly)points, labels = get_next_point(gt_masks=gt_masks_per_frame[t],pred_masks=None,method=("uniform" if self.training else self.pt_sampling_for_eval),)point_inputs = {"point_coords": points, "point_labels": labels}backbone_out["point_inputs_per_frame"][t] = point_inputs# Sample frames where we will add correction clicks on the fly# based on the error between prediction and ground-truth masksif not use_pt_input:# no correction points will be sampled when using mask inputsframes_to_add_correction_pt = []elif num_frames_to_correct == num_init_cond_frames:frames_to_add_correction_pt = init_cond_frameselse:assert num_frames_to_correct > num_init_cond_frames# initial cond frame + randomly selected remaining frames (without replacement)extra_num = num_frames_to_correct - num_init_cond_framesframes_to_add_correction_pt = (init_cond_frames+ self.rng.choice(backbone_out["frames_not_in_init_cond"], extra_num, replace=False).tolist())backbone_out["frames_to_add_correction_pt"] = frames_to_add_correction_ptreturn backbone_outdef forward_tracking(self, backbone_out, input: BatchedVideoDatapoint, return_dict=False):"""Forward video tracking on each frame (and sample correction clicks)."""img_feats_already_computed = backbone_out["backbone_fpn"] is not Noneif img_feats_already_computed:# Prepare the backbone features# - vision_feats and vision_pos_embeds are in (HW)BC format(_,vision_feats,vision_pos_embeds,feat_sizes,) = self._prepare_backbone_features(backbone_out)# Starting the stage loopnum_frames = backbone_out["num_frames"]init_cond_frames = backbone_out["init_cond_frames"]frames_to_add_correction_pt = backbone_out["frames_to_add_correction_pt"]# first process all the initial conditioning frames to encode them as memory,# and then conditioning on them to track the remaining framesprocessing_order = init_cond_frames + backbone_out["frames_not_in_init_cond"]output_dict = {"cond_frame_outputs": {}, # dict containing {frame_idx: <out>}"non_cond_frame_outputs": {}, # dict containing {frame_idx: <out>}}for stage_id in processing_order:# Get the image features for the current frames# img_ids = input.find_inputs[stage_id].img_idsimg_ids = input.flat_obj_to_img_idx[stage_id]if img_feats_already_computed:# Retrieve image features according to img_ids (if they are already computed).current_vision_feats = [x[:, img_ids] for x in vision_feats]current_vision_pos_embeds = [x[:, img_ids] for x in vision_pos_embeds]else:# Otherwise, compute the image features on the fly for the given img_ids# (this might be used for evaluation on long videos to avoid backbone OOM).(_,current_vision_feats,current_vision_pos_embeds,feat_sizes,) = self._prepare_backbone_features_per_frame(input.flat_img_batch, img_ids)# Get output masks based on this frame's prompts and previous memorycurrent_out = self.track_step(frame_idx=stage_id,is_init_cond_frame=stage_id in init_cond_frames,current_vision_feats=current_vision_feats,current_vision_pos_embeds=current_vision_pos_embeds,feat_sizes=feat_sizes,point_inputs=backbone_out["point_inputs_per_frame"].get(stage_id, None),mask_inputs=backbone_out["mask_inputs_per_frame"].get(stage_id, None),gt_masks=backbone_out["gt_masks_per_frame"].get(stage_id, None),frames_to_add_correction_pt=frames_to_add_correction_pt,output_dict=output_dict,num_frames=num_frames,)# Append the output, depending on whether it's a conditioning frameadd_output_as_cond_frame = stage_id in init_cond_frames or (self.add_all_frames_to_correct_as_condand stage_id in frames_to_add_correction_pt)if add_output_as_cond_frame:output_dict["cond_frame_outputs"][stage_id] = current_outelse:output_dict["non_cond_frame_outputs"][stage_id] = current_outif return_dict:return output_dict# turn `output_dict` into a list for loss functionall_frame_outputs = {}all_frame_outputs.update(output_dict["cond_frame_outputs"])all_frame_outputs.update(output_dict["non_cond_frame_outputs"])all_frame_outputs = [all_frame_outputs[t] for t in range(num_frames)]# Make DDP happy with activation checkpointing by removing unused keysall_frame_outputs = [{k: v for k, v in d.items() if k != "obj_ptr"} for d in all_frame_outputs]return all_frame_outputsdef track_step(self,frame_idx,is_init_cond_frame,current_vision_feats,current_vision_pos_embeds,feat_sizes,point_inputs,mask_inputs,output_dict,num_frames,track_in_reverse=False, # tracking in reverse time order (for demo usage)run_mem_encoder=True, # Whether to run the memory encoder on the predicted masks.prev_sam_mask_logits=None, # The previously predicted SAM mask logits.frames_to_add_correction_pt=None,gt_masks=None,):if frames_to_add_correction_pt is None:frames_to_add_correction_pt = []current_out, sam_outputs, high_res_features, pix_feat = self._track_step(frame_idx,is_init_cond_frame,current_vision_feats,current_vision_pos_embeds,feat_sizes,point_inputs,mask_inputs,output_dict,num_frames,track_in_reverse,prev_sam_mask_logits,)(low_res_multimasks,high_res_multimasks,ious,low_res_masks,high_res_masks,obj_ptr,object_score_logits,) = sam_outputscurrent_out["multistep_pred_masks"] = low_res_maskscurrent_out["multistep_pred_masks_high_res"] = high_res_maskscurrent_out["multistep_pred_multimasks"] = [low_res_multimasks]current_out["multistep_pred_multimasks_high_res"] = [high_res_multimasks]current_out["multistep_pred_ious"] = [ious]current_out["multistep_point_inputs"] = [point_inputs]current_out["multistep_object_score_logits"] = [object_score_logits]# Optionally, sample correction points iteratively to correct the maskif frame_idx in frames_to_add_correction_pt:point_inputs, final_sam_outputs = self._iter_correct_pt_sampling(is_init_cond_frame,point_inputs,gt_masks,high_res_features,pix_feat,low_res_multimasks,high_res_multimasks,ious,low_res_masks,high_res_masks,object_score_logits,current_out,)(_,_,_,low_res_masks,high_res_masks,obj_ptr,object_score_logits,) = final_sam_outputs# Use the final prediction (after all correction steps for output and eval)current_out["pred_masks"] = low_res_maskscurrent_out["pred_masks_high_res"] = high_res_maskscurrent_out["obj_ptr"] = obj_ptr# Finally run the memory encoder on the predicted mask to encode# it into a new memory feature (that can be used in future frames)self._encode_memory_in_output(current_vision_feats,feat_sizes,point_inputs,run_mem_encoder,high_res_masks,object_score_logits,current_out,)return current_outdef _iter_correct_pt_sampling(self,is_init_cond_frame,point_inputs,gt_masks,high_res_features,pix_feat_with_mem,low_res_multimasks,high_res_multimasks,ious,low_res_masks,high_res_masks,object_score_logits,current_out,):assert gt_masks is not Noneall_pred_masks = [low_res_masks]all_pred_high_res_masks = [high_res_masks]all_pred_multimasks = [low_res_multimasks]all_pred_high_res_multimasks = [high_res_multimasks]all_pred_ious = [ious]all_point_inputs = [point_inputs]all_object_score_logits = [object_score_logits]for _ in range(self.num_correction_pt_per_frame):# sample a new point from the error between prediction and ground-truth# (with a small probability, directly sample from GT masks instead of errors)if self.training and self.prob_to_sample_from_gt_for_train > 0:sample_from_gt = (self.rng.random() < self.prob_to_sample_from_gt_for_train)else:sample_from_gt = False# if `pred_for_new_pt` is None, only GT masks will be used for point samplingpred_for_new_pt = None if sample_from_gt else (high_res_masks > 0)new_points, new_labels = get_next_point(gt_masks=gt_masks,pred_masks=pred_for_new_pt,method="uniform" if self.training else self.pt_sampling_for_eval,)point_inputs = concat_points(point_inputs, new_points, new_labels)# Feed the mask logits of the previous SAM outputs in the next SAM decoder step.# For tracking, this means that when the user adds a correction click, we also feed# the tracking output mask logits along with the click as input to the SAM decoder.mask_inputs = low_res_masksmultimask_output = self._use_multimask(is_init_cond_frame, point_inputs)if self.use_act_ckpt_iterative_pt_sampling and not multimask_output:sam_outputs = torch.utils.checkpoint.checkpoint(self._forward_sam_heads,backbone_features=pix_feat_with_mem,point_inputs=point_inputs,mask_inputs=mask_inputs,high_res_features=high_res_features,multimask_output=multimask_output,use_reentrant=False,)else:sam_outputs = self._forward_sam_heads(backbone_features=pix_feat_with_mem,point_inputs=point_inputs,mask_inputs=mask_inputs,high_res_features=high_res_features,multimask_output=multimask_output,)(low_res_multimasks,high_res_multimasks,ious,low_res_masks,high_res_masks,_,object_score_logits,) = sam_outputsall_pred_masks.append(low_res_masks)all_pred_high_res_masks.append(high_res_masks)all_pred_multimasks.append(low_res_multimasks)all_pred_high_res_multimasks.append(high_res_multimasks)all_pred_ious.append(ious)all_point_inputs.append(point_inputs)all_object_score_logits.append(object_score_logits)# Concatenate the masks along channel (to compute losses on all of them,# using `MultiStepIteractiveMasks`)current_out["multistep_pred_masks"] = torch.cat(all_pred_masks, dim=1)current_out["multistep_pred_masks_high_res"] = torch.cat(all_pred_high_res_masks, dim=1)current_out["multistep_pred_multimasks"] = all_pred_multimaskscurrent_out["multistep_pred_multimasks_high_res"] = all_pred_high_res_multimaskscurrent_out["multistep_pred_ious"] = all_pred_iouscurrent_out["multistep_point_inputs"] = all_point_inputscurrent_out["multistep_object_score_logits"] = all_object_score_logitsreturn point_inputs, sam_outputs输入图片:

分割结果:

总结
SAM2 作为一种先进的图像分割模型,成功解决了通用图像分割、实时性与效率、多模态输入以及零样本学习等关键问题。它在多个标准数据集上取得了接近或超越现有最先进方法的性能,同时保持了较高的推理速度,展现出强大的泛化能力和灵活性。SAM2 的多模态输入支持和零样本学习能力减少了对大量标注数据的依赖,降低了数据准备的成本和时间。其成功为未来的研究和开发提供了重要启发,特别是在进一步提升多模态输入的结合效果、优化实时性和效率、探索跨模态学习以及拓展零样本学习的场景等方面。
相关文章:

Segment Anything in Images and Videos
目录 摘要 Abstract SAM2 模型框架 图像编码器 记忆机制 提示编码器和掩码解码器 实验 代码 总结 摘要 SAM2是基于Meta公司推出的Segment Anything Model升级而来的先进分割模型。它在SAM的基础上,通过引入记忆注意力模块和优化图像编码器等改进…...

C++之异常
目录 一、异常的概念及使用 1.1、异常的概念 1.2、异常的抛出和捕获 1.3、栈展开 1.4、查找匹配的处理代码 1.5、异常重新抛出 1.6、异常安全问题 1.7、异常规范 1.8、C异常的优缺点 二、标准库的异常 一、异常的概念及使用 1.1、异常的概念 异常处理机制允许程序中…...

服务器不能复制粘贴文件的处理方式
1.打开远程的服务器,在服务器的任务栏随便一块空白处右击鼠标,选择“启动任务管理器”。 2.在打开的任务管理器中,我们找到“rdpclip.exe”这个进程,如果没有找到那么如图所示 任务管理器–文件–运行新任务,然后在弹出的对话框内输入rdpclip.exe 如下图࿱…...

Golang | 搜索表达式
// (( A | B | C ) & D ) | E & (( F | G ) & H )import "strings"// 实例化一个搜索表达式 func NewTermQuery(field, keyword string) *TermQuery {return &TermQuery{Keyword: &Keyword{Field: field, Word: keyword},} }func (tq *TermQuery…...
)
【速写】conda安装(linux)
序言 昨天叶凯浩空降(全马241),降维打击,10分24秒断层夺冠。 夏潇阳10分53秒绝杀小崔10分54秒第2,小崔第3,均配都在3’30"以内,即便我是去年巅峰期也很难跑出这种水平。我就知道他去年大…...

linux两个特殊的宏 _RET_IP_ 和_THIS_IP_ 实现
本文探讨了Linux环境下两个特殊的宏,_RET_IP_和_THIS_IP_,它们分别用于获取当前函数的返回地址和当前指令指针的地址。 1、宏定义 我们先看它们的宏定义 include./linux/kernel.h#define _RET_IP_ (unsigned long)__builtin_return_address(0)#define _THIS_IP_ ({ __labe…...

开源|上海AILab:自动驾驶仿真平台LimSim Series,兼容端到端/知识驱动/模块化技术路线
导读 随着自动驾驶技术快速发展,有效的仿真环境成为验证与增强这些系统的关键。来自上海人工智能实验室的研究团队推出了LimSim Series——一个革命性的自动驾驶仿真平台,它巧妙解决了行业面临的三大挑战:仿真精度与持续时间的平衡、功能性与…...

全栈黑暗物质:可观测性之外的非确定性调试
一、量子计算的测不准Bug 1. 经典 vs. 量子系统的错误模式 量子程序崩溃的观测影响: 调试方法崩溃复现率观测干扰度日志打印12%35%断点调试5%78%无侵入跟踪27%9%量子态层析成像63%2% 二、量子调试工具箱 1. 非破坏性观测协议 # 量子程序的无干扰快照 from qiski…...

光耦、继电器
一、光耦 1.什么是光耦? ①图一:Ic受控于Ib,间接受控于Ia ②如果Va和Vb是隔离的两个电压系统该咋控制?可以利用光耦来控制,让两边建立关系 2.光电耦合器的基本原理 ①是以光为媒介来传输电信号的器件,通常把发光器…...
)
使用Three.js搭建自己的3Dweb模型(从0到1无废话版本)
教学视频参考:B站——Three.js教学 教学链接:Three.js中文网 老陈打码 | 麒跃科技 一.什么是Three.js? Three.js 是一个基于 JavaScript 的 3D 图形库,用于在网页浏览器中创建和渲染交互式 3D 内容。它基于 WebGL࿰…...

Redis远程链接应用案例
1.配置文件设置 打开配置文件redis.windows.conf,配置以下内容: 1.bind 0.0.0.0(设置所有IP可访问) 2.requirepass 1234.com(密码设置) 3.protected-mode no(远程可访问) 2.防火…...

STM32 定时器TIM
定时器基础知识 定时器就是用来定时的机器,是存在于STM32单片机中的一个外设。STM32总共有8个定时器,分别是2个高级定时器(TIM1、TIM8),4个通用定时器(TIM2、TIM3、TIM4、TIM5)和2个基本定时器(TIM6、TIM7),如下图所示: STM32F1…...

基于大模型的急性化脓性阑尾炎全程诊疗预测与方案研究
目录 一、引言 1.1 研究背景与意义 1.2 国内外研究现状 1.3 研究目标与方法 二、大模型技术原理与应用基础 2.1 大模型概述 2.2 相关技术原理 2.3 数据收集与预处理 三、术前风险预测与准备 3.1 病情评估指标分析 3.2 大模型预测方法与结果 3.3 术前准备方案 四、…...

第一个 servlet请求
文章目录 前端后端前后端 产生 联系 前端 后端 package com.yanyu;import jakarta.servlet.ServletException; import jakarta.servlet.http.HttpServlet; import jakarta.servlet.http.HttpServletRequest; import jakarta.servlet.http.HttpServletResponse;import java.io.I…...

XLSX.utils.sheet_to_json设置了blankrows:true,但无法获取到开头的空白行
在用sheetJs的XLSX库做导入,遇到一个bug。如果开头行是空白行的话,调用sheet_to_json转数组获得的数据也是没有包含空白行的。这样会导致在设置对应的起始行时,解析数据不生效。 目前是直接跳过了开头的两行空白行 正确应该获得一下数据 问…...

python一款简单的数据库同步dts小实现
一、实现说明 在数据开发与运维场景中,数据库同步是一项基础且高频的需求。无论是开发环境与生产环境的数据镜像,还是多数据库之间的数据分发,都需要可靠的同步工具。本文将基于 Python 和pymysql库,实现一个轻量级数据库同步工具…...
)
误触网络重置,笔记本电脑wifi连接不上解决方法(Win10,Win11通用)
笔记本电脑连接不上网,有人说网络重置按钮可以解决,结果把wifi图标都给搞没了,只剩飞行模式,解决方法(错误码39),罪魁祸首就是这个网络重置,一下连网络都检测不到了 那么没有网络怎…...

markdown-it-katex 安装和配置指南
markdown-it-katex 是一个用于 Markdown-it 的插件,旨在通过 KaTeX 库在 Markdown 文档中添加数学公式支持。KaTeX 是一个快速渲染数学公式的库,相比于 MathJax,它在性能上有显著优势。 步骤 1: 安装 Markdown-it 首先,你需要安装…...

开源财务软件:企业财务数字化转型的有力工具
在当今数字化时代,企业财务数字化转型已成为必然趋势。随着业务的不断拓展和复杂化,企业对财务软件的需求也在日益增长。然而,传统商业财务软件往往伴随着高昂的授权费用和有限的定制化能力,这让许多企业,尤其是中小企…...

大模型——Suna集成浏览器操作与数据分析的智能代理
大模型——Suna集成浏览器操作与数据分析的智能代理 Suna 是 Kortix AI 开发的一个开源通用 AI 代理,托管在 GitHub 上,基于 Apache 2.0 许可证,允许用户免费下载、修改和自托管。它通过自然语言对话帮助用户完成复杂任务,如网页浏览、文件管理、数据抓取和网站部署。Suna…...

QT中的事件及其属性
Qt中的事件是对操作系统提供的事件机制进行封装,Qt中的信号槽就是对事件机制的进一步封装 但是特殊情况下,如对于没有提供信号的用户操作,就需要通过重写事件处理的形式,来手动处理事件的响应逻辑 常见的Qt事件: 常见事…...

flutter 选择图片 用九宫格显示图片,右上角X删除选择图片,点击查看图片放大缩小,在多张图片可以左右滑动查看图片
flutter 选择图片 用九宫格显示图片,右上角X删除选择图片,点击查看图片放大缩小,在多张图片可以左右滑动查看图片 ************ 暂无压缩图片功能 ********* 显示图片 — import dart:io;import package:flutter/material.dart; import pa…...

机器学习day2-seaborn绘图练习
1.使用tips数据集,创建一个展示不同时间段(午餐/晚餐)账单总额分布的箱线图 import seaborn as sns import matplotlib.pyplot as plt import pandas as pd import numpy as np# 设置主题 sns.set_theme(style"darkgrid")# 设置中文 plt.rcParams[font.s…...

如何优雅地解决AI生成内容粘贴到Word排版混乱的问题?
随着AI工具的广泛应用,越来越多人开始使用AI辅助撰写论文、报告或博客。然而,当我们直接将AI生成的文本复制到Word文档中时,常常会遇到排版混乱、格式异常的问题。这是因为大部分AI输出时默认使用了Markdown格式,而Word对Markdown…...

设计一个食品种类表
需求:设计一个食品种类表,注意食品种类有多层,比如面食下面,面条、方便面,面条下有干面、湿面等 一、食品种类表结构设计(food_category) CREATE TABLE food_category (category_id INT IDENT…...

Haply MinVerse触觉3D 鼠标—沉浸式数字操作,助力 3D 设计与仿真
在2025年CES展上,Haply MinVerse触觉3D鼠标凭借创新交互方式引发关注。这款设备为用户与数字环境的互动带来新维度,操作虚拟物体时能感受真实触觉反馈。 三维交互与触觉反馈 MinVerse 突破传统鼠标二维限制,增加第三运动轴,实现真…...

神经网络预测评估机制:损失函数详解
文章目录 一、引言二、损失函数的引入三、回顾预测算法四、损失函数的形式五、成本函数六、损失函数的定义与作用七、损失函数的重要性注释思维导图 一、引言 在上一篇文章中,我们了解到神经网络可通过逻辑回归等算法对输入进行预测。而判断预测结果是否准确至关重要…...

PHP实现 Apple ID 登录的服务端验证指南
在 iOS 应用中启用 “通过 Apple 登录”(Sign In with Apple)后,客户端会获取一个 身份令牌(identity token)。该令牌是一个JWT(JSON Web Token),需要由服务端验证其真实性和完整性&…...

一、linux系统启动过程操作记录
一、linux系统启动过程 经历: 上电–>uboot–>加载内核–>挂载根文件系统–>执行应用程序 uboot等效bootloader,启动过程进行了 跳转到固定的位置执行相应的代码 初始化硬件设备,如:cpu初始化 ,看门狗&a…...

【首款Armv9开源芯片“星睿“O6测评】SVE2指令集介绍与测试
SVE2指令集介绍与测试 一、什么是SVE2 在Neon架构扩展(其指令集向量长度固定为128位)的基础上,Arm设计了可伸缩向量扩展(Scalable vector extension, SVE)。SVE是一种新的单指令多数据(SIMD&am…...

获取电脑mac地址
Windows 系统 方法1:通过命令提示符 1. 按下 `Win + R`,输入 `cmd` 后按回车,打开命令提示符。 2. 输入以下命令并按回车:...

AI核心技术与应用场景的深度解析
AI核心技术与应用场景的深度解析 在互联网大厂Java求职者的面试中,经常会被问到关于AI核心技术与应用场景的问题。本文通过一个故事场景来展示这些问题的实际解决方案。 第一轮提问 面试官:马架构,欢迎来到我们公司的面试现场。请问您对AI…...

练习普通话,声音细柔和
《繁星》 我爱月夜,但我也爱星天。从前在家乡七八月 的夜晚,在庭院里纳凉的时候,我最爱看天上密密 麻麻的繁星。望着星天,我就会忘记一切,仿佛回 到了母亲的怀里似的。 三年前在南京我住的地方,有…...

Linux进程详细解析
1.操作系统 概念 任何计算机系统都包含⼀个基本的程序集合,称为操作系统(OS)。笼统的理解,操作系统包括: • 内核(进程管理,内存管理,文件管理,驱动管理) • 其他程序(…...

Linux执行脚本报错
执行脚本报错:./startup.sh -bash: ./startup.sh: /bin/bash^M: bad interpreter: No such file or directory ./startup.sh -bash: ./startup.sh: /bin/bash^M: bad interpreter: No such file or directory可能的原因: 文件开头格式问题:…...

C++学习:六个月从基础到就业——模板编程:类模板
C学习:六个月从基础到就业——模板编程:类模板 本文是我C学习之旅系列的第三十三篇技术文章,也是第二阶段"C进阶特性"的第十一篇,主要介绍C中的类模板编程。查看完整系列目录了解更多内容。 目录 引言类模板的基本语法…...

Conda 虚拟环境复用
文章目录 一、导出环境配置二、克隆环境配置三、区别小结 一、导出环境配置 导出:将当前虚拟环境导出成一个yml配置文件。conda activate your_env conda env export > your_env.yml导入:基于yml文件创建新环境,会自动按照yml里的配置&am…...

Nacos简介—4.Nacos架构和原理三
大纲 1.Nacos的定位和优势 2.Nacos的整体架构 3.Nacos的配置模型 4.Nacos内核设计之一致性协议 5.Nacos内核设计之自研Distro协议 6.Nacos内核设计之通信通道 7.Nacos内核设计之寻址机制 8.服务注册发现模块的注册中心的设计原理 9.服务注册发现模块的注册中心的服务数…...

4月27日日记
现在想来,可以想到什么就记录下来,这也是网上写日记的一个好处,然后 今天英语课上看到一个有关迷信的视频,就是老师课件里的,感觉画风很不错,但是我贫瘠的语言形容不出来,就想到是不是世界上的…...

CentOS7.9安装OpenSSL 1.1.1t和OpenSSH9.9p1
一、临时开启telnet登录方式,避免升级失败无法登录系统 (注意telnet登录方式存在安全隐患,升级openssh相关服务后要记得关闭) 1.安装telnet服务 yum -y install xinetd telnet* 2.允许root用户通过telnet登陆,编辑…...

单例模式:全局唯一性在软件设计中的艺术实践
引言 在软件架构设计中,单例模式(Singleton Pattern)以其独特的实例控制能力,成为解决资源复用与全局访问矛盾的经典方案。该模式通过私有化构造方法、静态实例存储与全局访问接口三大核心机制,确保系统中特定类仅存在…...
)
Spring 与 ActiveMQ 的深度集成实践(三)
五、实战案例分析 5.1 案例背景与需求 假设我们正在开发一个电商系统,其中订单模块和库存模块是两个独立的子系统 。当用户下单后,订单模块需要通知库存模块进行库存扣减操作 。在传统的同步调用方式下,订单模块需要等待库存模块完成扣减操…...
-第三十天)
30-算法打卡-字符串-重复的子字符串-leetcode(459)-第三十天
1 题目地址 459. 重复的子字符串 - 力扣(LeetCode)459. 重复的子字符串 - 给定一个非空的字符串 s ,检查是否可以通过由它的一个子串重复多次构成。 示例 1:输入: s "abab"输出: true解释: 可由子串 "ab" 重复两次构成…...

rocketmq一些异常记录
rocketmq一些异常记录 Product 设置不重复发送 发送 一次失败,不会在被发送到mq消息队列中,相当于消息丢失。 2、 Consumer 消费失败 重试三次消费 都失败 则消息消费失败,失败后 会放入 死信队列,可以手动处理在mq面板 处理死信队…...

SQLMesh 测试自动化:提升数据工程效率
在现代数据工程中,确保数据模型的准确性和可靠性至关重要。SQLMesh 提供了一套强大的测试工具,用于验证数据模型的输出是否符合预期。本文将深入探讨 SQLMesh 的测试功能,包括如何创建测试、支持的数据格式以及如何运行和调试测试。 SQLMesh …...

WPF使用SQLite与JSON文本文件结合存储体侧平衡数据的设计与实现
✅作者简介:2022年博客新星 第八。热爱国学的Java后端开发者,修心和技术同步精进。 🍎个人主页:Java Fans的博客 🍊个人信条:不迁怒,不贰过。小知识,大智慧。 💞当前专栏…...

关系型数据库PostgreSQL vs MySQL 深度对比:专业术语+白话解析+实战案例
PostgreSQL 与 MySQL 的详细对比 PostgreSQL 和 MySQL 是两种最流行的开源关系型数据库,它们在设计理念、功能特性和适用场景上有显著差异。以下是它们的详细对比: 一、基本架构与设计理念 PostgreSQL:多进程架构,使用共享内存通…...

利用 SSRF 和 Redis 渗透
环境搭建 在本次实验中,我们使用 Docker 环境进行测试。 解压实验包,搭建 docker 环境。 docker环境 web的dockerfile 主要利用代码 : redis服务器 通过 docker-compose up -d 启动相关容器,初次启动失败。 发现 docker 版本问…...

脏读、幻读、可重复读
脏读 定义:一个事务读取了另一个事务尚未提交的数据 。比如事务 A 修改了某条数据但还没提交,此时事务 B 读取了这条被修改但未提交的数据。若事务 A 后续回滚,事务 B 读到的数据就是无效的,相当于读到了 “脏数据”。危害&#…...

第1讲、#PyTorch教学环境搭建与Tensor基础操作详解
引言 PyTorch是当前深度学习领域最流行的框架之一,因其动态计算图和直观的API而备受开发者青睐。本文将从零开始介绍PyTorch的环境搭建与基础操作,适合各种平台的用户和深度学习初学者。 1. 安装和环境搭建 macOS (Apple Silicon) 对于Mac M1/M2/M3用…...