Linux文件操作
在C语言中,我们已经学习了文件相关的知识,那么在Linux中我们为什么还要再来学习文件呢?这是因为C语言中和Linux中,"文件"是2个不同的概念。所以我们要来学习Linux中对文件的操作。
在学习之前,我们先来回顾一下C语言中文件的一些知识。
C语言中的文件IO
我们复习一些重要的接口
fopen
fopen用来打开文件,在打开⽂件的同时,都会返回⼀个FILE*的指针变量指向该⽂件,也相当于建⽴了指针和⽂件的关系。头文件是<stdio.h>。fclose用来关闭文件。
它们的原型如下:
//打开⽂件
FILE * fopen ( const char * pathname, const char * mode );//关闭⽂件
int fclose ( FILE * stream );
- pathname:打开文件的路径
- mode:表⽰⽂件的打开模式,最常用的模式是
r,w,a
r:只读。打开一个已经存在的文件,如果文件不存在,就会报错
w:只写。打开一个文件,如果文件不存在,则会建立一个新的文件。在写入之前,会对文件进行清空处理。
a:只写。向文本文件尾添加数据,如果文件不存在,则会建立一个新的文件。
我们发现w和a都是写入,而w是对文件重新写入,而a是在文本末尾进行写入。接下来,我们将学习一下这2个方式。
我们先来验证一下w方式。
我们创建一个myfile.c文件,写入以下代码:
#include<stdio.h>
#include <string.h>
#include <unistd.h>
#include <sys/types.h>int main()
{printf("PID = %d\n",getpid());FILE* f = fopen("log.txt","w");if(f == NULL){perror("file\n");return 1;}const char* message = "abcde"; fwrite(message,strlen(message),1,f); fprintf(stdout,"%s\n",message);fclose(f);return 0;
}
运行程序,得到结果:

其中fwrite接口的意思是向f中写入message中的内容。它的原型是:
size_t fwrite(const void* ptr, size_t size, size_t nmemb, FILE *stream);
ptr:是一个指向要写入文件的数据的指针。该指针指向的内存区域中的数据将被写入文件。size:表示要写入的每个数据项的大小(以字节为单位)nmemb:表示要写入的数据项的数量。stream:这是一个指向FILE结构体的指针,代表要写入数据的文件流。通过fopen函数打开文件后,会返回一个指向FILE结构体的指针,这个指针就可以作为stream参数传递给fwrite函数。
下面我们向log.txt文件中写hello linux,再来运行这个程序,看看会发生什么。
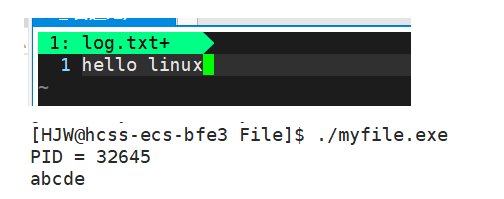
可以看到,写入之前会把文件内容先清空,再进行写入。
接着我们来验证a方式。多运行几次之后,然后再看log.txt。
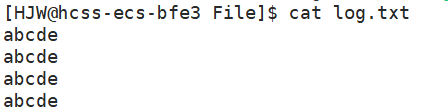
在C语言程序启动的时候,会默认打开3个流:
- stdin:标准输入流,绝大多数场景下是从键盘中获取。
- stdout:标准输出流,绝大多数场景下会将内容输出到显示器上。
- stderr:标准错误流绝大多数场景下会将内容输出到显示器上。
这3个流我们会在后面继续了解。
Linux中的文件IO
在C语言中,所有文件都是通过FILE*指针来进行操作,而在Linux中,我们是通过fd来进行操作。
其中fd叫做“文件描述符”。
open接口(2号手册)
open接口使用的头文件是<sys/types.h>,<sys/stat.h>,<fcntl.h>,它用于打开一个文件。它的返回值是一个int类型,这个就是文件描述符fd,在C语言中我们通过FILE*来控制文件,而在Linux中,我们用fd来操作。它的接口原型如下:
int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);
pathname:文件路径名称。flags:文件打开方式。mode:文件权限。
一般带有2个参数的open接口,我们通常要用在一个已经存在的文件;而3个参数的open接口用于不存在的文件,如果文件不存在,可以创建一个文件。
打开方式
| 方式 | 功能 |
|---|---|
| O_RDONLY | 以只读方式打开 |
| O_WRONLY | 以只写方式打开 |
| O_RDWR | 以读写方式打开 |
| O_CREAT | 如果文件不存在,则新建一个文件 |
下面,我们通过2个参数的ope接口来实验。先把log.txt文件删除,运行以下代码
#include <stdio.h>
#include <unistd.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <fcntl.h>
int main()
{int fd = open("log.txt", O_WRONLY);if(fd < 0){perror("open fail!");}return 0;
}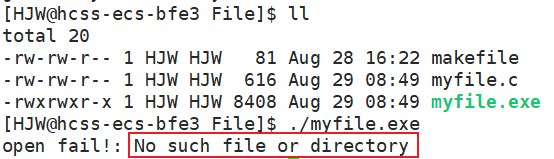
可以看到,文件创建失败。以此就可以看出在Linux文件中,通过以只写方式打开文件的话,文件不存在的话,不会创建一个文件。
而如果想新建一个文件,就需要用到第二个open接口函数。
int fd = open("log.txt",O_WRONLY | O_CREAT);
这个代码的意思是:通过只读方式打开文件,如果文件不存在则创建文件。
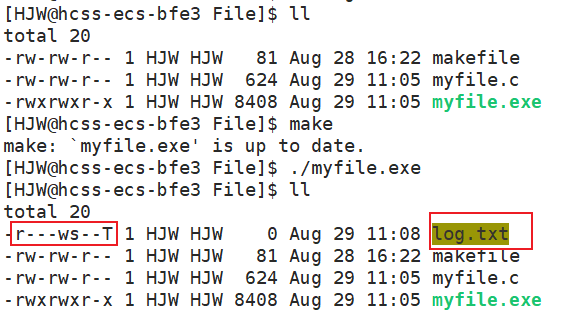
那么为什么要通过这样的方式来进行创建文件呢?这就需要了解open接口的实现方式,是通过位图方式来进行传参的,把所需的选项按照按位或即可。可以用一个简单的程序验证一下。
#define ONE (1<<0) // 1
#define TWO (1<<1) // 2
#define THREE (1<<2) // 4
#define FOUR (1<<3) // 8void show(int flags)
{if(flags&ONE) printf("hello function1\n");if(flags&TWO) printf("hello function2\n");if(flags&THREE) printf("hello function3\n");if(flags&FOUR) printf("hello function4\n");
}
int main()
{printf("-----------------------------\n");show(ONE);printf("-----------------------------\n");show(TWO);printf("-----------------------------\n");show(ONE|TWO);printf("-----------------------------\n");show(ONE|TWO|THREE);printf("-----------------------------\n");show(ONE|THREE);printf("-----------------------------\n");show(THREE|FOUR);printf("-----------------------------\n");return 0;
}
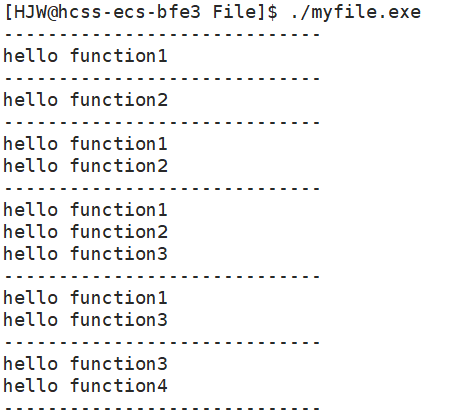
可以看到你想让哪个程序运行起来,就将它们按位或即可。
当我们运行完./myfile.exe之后,可以看到文件的权限是乱码,如果删掉该文件之后,文件权限还可能跟上次的不一样。所以我们需要第三个参数mode来控制文件的初始权限。
int fd = open("log.txt",O_WRONLY | O_CREAT,0666);这段代码可以把文件的权限初始化成0666。运行代码之后看看结果。
#include<stdio.h>
#include <string.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>int main()
{// umask(0);int fd = open("log.txt",O_WRONLY|O_CREAT,0666);if(fd < 0){perror("open fail!");return -1;} return 0;
}
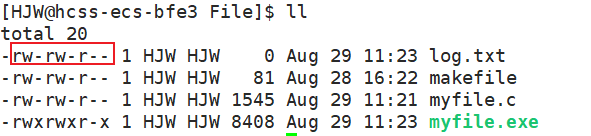
可以看到新建文件的权限是“0664”,这是因为文件的权限还要通过umask来决定,我的umask权限默认是0002。所以想让权限是0666还要在代码中加入umask(0)才可以(放在fd之前)。
close接口
用于关闭文件,头文件是<unistd.h>,原型是int close(int fd);
当使用的时候,直接传入对应文件的接口即可。
write接口(2号手册)
用于向文件中写入,需要的头文件是<unistd.h>,原型是:
ssize_t write(int fd, const void *buf, size_t count);
- fd:被写入的文件
- buf:被写入的字符串。
- count:写入字符的个数
我们执行以下代码
#include<stdio.h>
#include <string.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>int main()
{umask(0);int fd = open("log.txt",O_WRONLY|O_CREAT,0666);const char* buf = "Hello Linux!\n";write(fd,buf,6);close(fd);return 0;
}

可以看到,输出的结果就是6个字符Hello L。接着我们数组改成const char* buf = "xxx";,然后把write的第三个参数改成3,看看结果是什么。

为此我们可以知道一个事情,就是通过O_WRONLY进行写入时,不会把文件的内容进行清空,而是重头开始覆盖写。所以xxx会把原来的Hello L的前三个字符进行覆盖。
如果想要对文件的内容先情况,再进行写入的话,需要知道下面2个选项。
| 选项 | 功能 |
|---|---|
| O_TRUNC | 打开文件时情况文件内容 |
| O_APPEND | 以追加的方式进行写入 |
使用方法还是和上面的一样,这里就不再进行演示了。
O_WRONLY|O_CREAT|O_TRUNC:以写的方式对文件进行写入,如果文件不存在则新建一个文件,打开文件时对文件内容进行清空。O_WRONLY|O_CREAT|O_APPEND:以写的方式对文件进行写入,如果文件不存在则新建一个文件,打开文件时在文件的末尾进行写入。
由上面的例子可以看出,C语言中的文件接口都是经过封装的,是库函数,方便用户使用。
例如:
C语言中的FILE* fp = fopen("log.txt","w"); 等价于 Linux中的int fd = open("log.txt",O_WRONLY|O_CREAT|O_TRUNC,0666);
而C语言中的"a"其实就是O_WRONLY|O_CREAT|O_APPEND
由此说明,fopen是用户操作接口,而open是系统操作接口。fopen就是对open进行了封装。
read接口(2号手册)
用于读取文件,头文件是<unistd.h>,原型是ssize_t read(int fd,void *buf,size_t count)
参数功能和write一样。返回值有3个。
- ·
<0:表示读取失败。 =0:表示读取到文件末尾>0:表示读取成功,返回读取到的字符个数。
先往log.txt文件中写入xxxxxxxxxxxxxxx(15个字符),然后运行以下程序:
#include <stdio.h>
#include <unistd.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <fcntl.h>
#include <string.h>int main()
{int fd = open("log.txt", O_RDONLY);char buf[1024];ssize_t ret1 = read(fd, buf, 1024);printf("ret1 = %d\n", ret1);printf("%s", buf);ssize_t ret2 = read(fd, buf, 1024);printf("ret2 = %d\n", ret2);close(fd);return 0;
}

这个程序开始时先用open打开文件,然后通过read将log.txt中的内容读取到buf数组中,随后将返回值给ret1,接着输出ret1和buf;再接着第二次读取文件内容,并把返回值给ret2。
在输出结果中,为什么第二次通过read读取时会是0呢?这是因为第一次读取的时候已经读到文件末尾了,所以第二次会返回0。
如果我们把第一次的read的参数改为5,那么结果又是什么呢?

第一次会读取5个字符,如果第二个read的参数大于字符个数的话,则会读取到文件结束,即第二次的返回值是剩下的字符个数,小于剩余的字符个数的话,会返回该读取的个数。
访问文件的本质
在Linux中,一切皆文件,而想要管理这些文件,就需要一个方式来整齐的进行管理,防止出现文件访问错误或者失败。所以在Linux中,有一个专门管理文件的结构体,叫做struct file。视图如下:
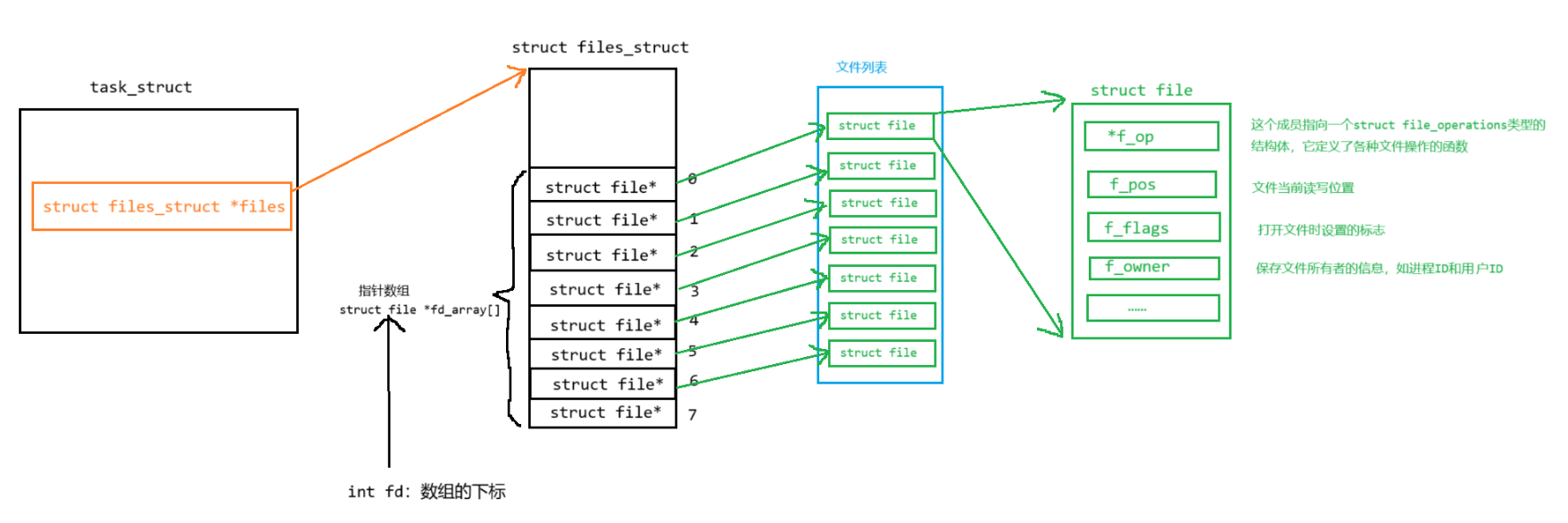
每个数组的元素都是一个指向struct file的指针,struct file对应一个打开的文件。而操作系统有一个全局的struct file_struct,用于统一管理所有进程打开的文件。
当我们打开文件时,操作系统在内存中要创建相应的数据结构来描述目标文件。于是就有了file结构体。表示一个已经打开的文件对象。而进程执行open系统调用,所以必须让进程和文件关联起来。每个进程都有一个指针*files, 指向一张表files_struct,该表最重要的部分就是包涵一个指针数组,每个元素都是一个指向打开文件的指针!所以,本质上,文件描述符就是该数组的下标。所以,只要拿着文件描述符,就可以找到对应的文件
文件描述符fd
通过对open函数的学习,我们知道了文件描述符就是一个小整数。在上面的图中已经写出文件描述符就是fd_array[]数组的下标。
我们可以多创建几个文件来看看,它们对应的下标,运行下面程序:
#include <stdio.h>
#include <unistd.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <fcntl.h>int main()
{umask(0);int fd1 = open("log1.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);int fd2 = open("log2.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);int fd3 = open("log3.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);int fd4 = open("log4.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);if(fd1 < 0){perror("open fail!\n");}printf("fd1 = %d\n", fd1);printf("fd2 = %d\n", fd2);printf("fd3 = %d\n", fd3);printf("fd4 = %d\n", fd4);return 0;
}
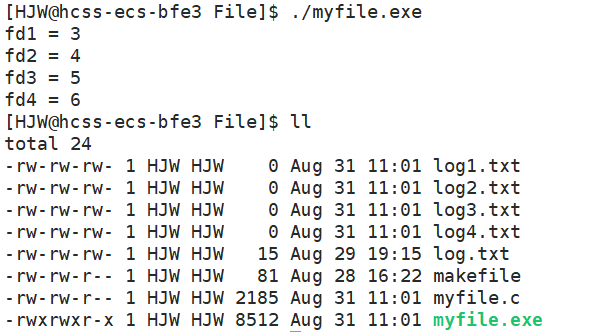
可以看到,文件创建成功,但是fd为什么是从3开始依次排列的,数组下标不是从0开始的吗?
原因是Linux进程默认情况下会有3个缺省打开的文件描述符,分别是标准输入stdin:0, 标准输出stdout:1, 标准错误stderr:2。这3个是默认打开的。
0,1,2对应的物理设备一般是:键盘,显示器,显示器。我们来看看这三个的编号是否是0,1,2。
运行程序:
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>int main()
{printf("stdin->fd: %d\n", stdin->_fileno);printf("stdout->fd: %d\n", stdout->_fileno);printf("stderr->fd: %d\n", stderr->_fileno);return 0;
}
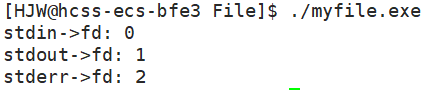
OK,这就很好的证明了stdin,stdout,stderr占用了0 1 2为编号的fd。
缓冲区
我们多多少少都听过缓冲区这个概念,但是我们还是不理解它的作用是什么,可以用来干什么。
简单来说:缓冲区是一块存储区域,用于暂时存放数据,以协调不同速度的设备之间的数据传输,或者在数据处理过程中起到暂存数据的作用,避免数据的丢失或处理不及时。
它的作用主要是用来进行数据暂存和提高效率的。
比如说你要给你的朋友寄个快递,你在西安,而你的朋友在新疆,如果你自己送的话需要花费财力和精力,在这期间不能干任何事;而如果你把快递交给快递公司的话,你就可以干其它的事情,只需要等几天你的朋友就能收到快递了,但是快递公司并不是收到一个快递就发一次,而是要等到把若干个快递收集起来,统一进行发送。这样就能提高效率了。
所以在上面我们了解到C语言的文件接口,是封装了底层的系统调用接口,如果用户频繁的调用fwrite,那么也会多次调用系统接口。于是C语言的设计者认为,反正数据都要被保存到内存当中,这个过程需要调用系统接口,所以就把fwrite写入的数据先保存到一个内存当中,等到合适的时候,再通过write接口,把这块内存当中的数据一次性的写入到磁盘当中。现在我们就知道这块区域叫做“缓冲区”。
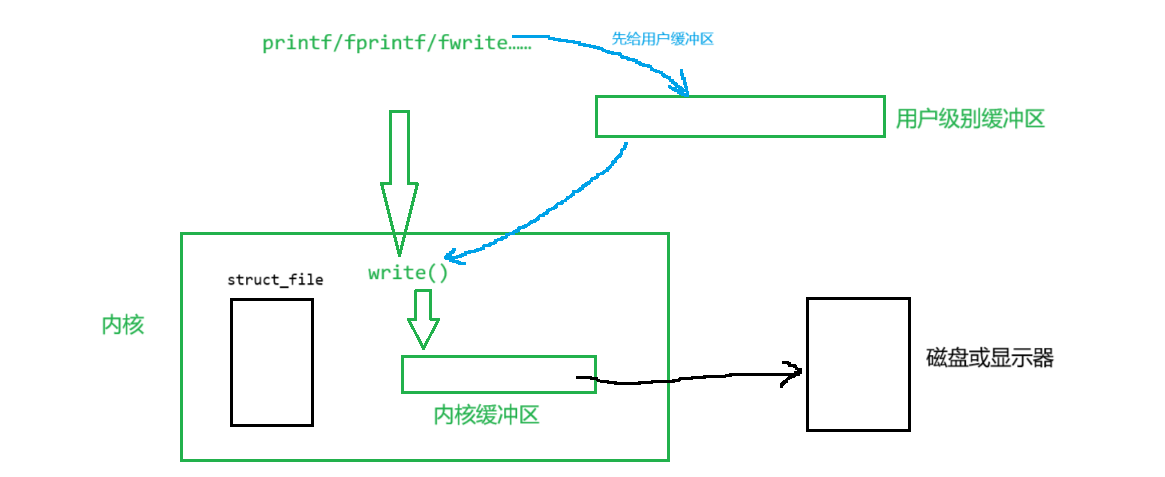
不过我们平时所说的“缓冲区”叫做“用户级缓冲区”,是C语言提供给我们的。用户所使用的C语言文件接口,都会先写入到“缓冲区”当中,调用write接口时,会把之前所有的数据写入到操作系统当中,这个过程叫做“刷新缓冲区”。当然操作系统系统也有自己的“缓冲区”,叫做“内核缓冲区”,这个是由操作系统自己进行管理,用户无法干涉。我们这次只学习“用户级缓冲区”,而“内核缓冲区”等到后面的时候再进行学习。
用户级缓冲区刷新策略
刷新策略有3种:
- 无缓冲:直接刷新
- 行缓冲:只有当碰到
\n才会进行刷新。(向显示器显示数据的时候采用这种方式) - 全缓冲:当缓冲区满了的时候,才会进行刷新。(普通文件进行写入时采用这种方式)
当然,遇到程序结束时和用户使用fflush进行刷新时,必须马上刷新缓冲区里的数据。
证明缓冲区存在
说了这么多,我们如何证明缓冲区是存在的呢?下面我将通过程序来进行证明。
#include<stdio.h>
#include <string.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>//文件缓冲区
int main()
{const char *fstr = "hello fwrite\n";const char *str = "hello write\n"; printf("hello printf\n");fprintf(stdout,"hello fprintf\n");fwrite(fstr,strlen(fstr),1,stdout);write(1,str,strlen(str));fork();return 0;
}
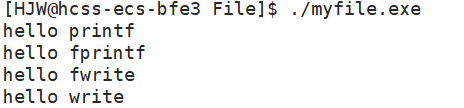
这段代码分别使用系统接口write和用户接口printf/fprintf/fwrite接口来向显示器写入数据。输出的结果也符合预期。
现在我们在最后加上fork()语句,并且把输出结果重定向到log.txt文件当中。
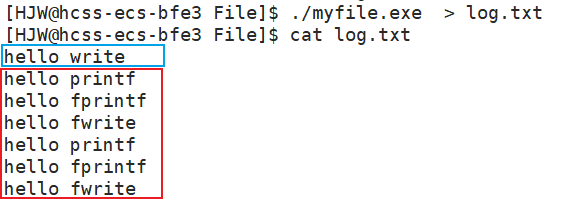
这时我们会发现用户文件接口输出了2次,而系统接口只输出了一次。而且输出顺序与代码顺序不一样,这是为什么呢?
上面我们讲到过,向显示器中打印采用的是行刷新策略,而向普通文件中写入是全刷新策略。
所以在向显示器打印的时候,到最后进行fork()时,所有的数据都已经刷新完成了,此时fork()函数没有作用。
而将结果重定向到文件中时,\n不起作用,直到缓冲区满时才会刷新,而这些数据肯定不会将缓冲区占满,所以只有程序结束时才会刷新。父进程会执行fork()之前的操作,可能已经将部分数据写入了C语言标准输出的缓冲区中,但不一定立即显示在终端上。所以当fork()的时候,会创建一个子进程,子进程会继承父进程的代码和数据,子进程开始执行时,它也会有自己独立的缓冲区副本(对于 C 标准库的缓冲区而言)。当父子进程执行到return语句时,即要刷新缓冲区的时候,发生写时拷贝,这个时候就会调write接口,这时数据才会进入到系统级别的缓冲区,这样就产生了2份数据,分别向文件中进行输出。所以用户接口就输出了2次,而系统接口输出了一次。
输出结果的顺序是由于父子进程并发执行,并且输出操作涉及缓冲区和共享的文件描述符,所以最终在终端上的输出顺序是不确定的。
通过以上解释我们可以确定一个事,那就是缓冲区一定不是由操作系统提供的,而是由C语言标准库提供的。
下面,我们在fork()上面添加fflush(stdout)这段代码,并重定向输出到log.txt文件中,看看结果会有什么变化。
int main()
{const char *fstr = "hello fwrite\n";const char *str = "hello write\n"; printf("hello printf\n");fprintf(stdout,"hello fprintf\n");fwrite(fstr,strlen(fstr),1,stdout);write(1,str,strlen(str));fflush(stdout);fork();return 0;
}
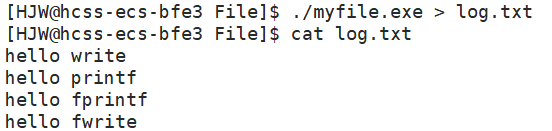
此时,结果只输出了一次。因为父进程执行fflush(stdout)后,此前通过printf、fprintf和fwrite输出到标准输出的内容会立即被输出到终端。接着执行fork()创建子进程。此时,父进程继续执行后续代码,但由于前面已经刷新了缓冲区,所以不会再有这些输出函数残留的未输出内容。write函数不使用 C 标准库的缓冲区,其输出仍然会相对直接地显示在终端上。
子进程是父进程的副本,它也会执行相同的代码逻辑。但是由于在父进程中已经刷新了标准输出的缓冲区,所以子进程开始执行时,标准输出缓冲区中没有来自父进程在执行fflush(stdout)之前的未输出内容。
我们来看一下源码中FILE结构体
struct _IO_FILE {int _flags; /* High-order word is _IO_MAGIC; rest is flags. */#define _IO_file_flags _flags//缓冲区相关/* The following pointers correspond to the C++ streambuf protocol. *//* Note: Tk uses the _IO_read_ptr and _IO_read_end fields directly. */char* _IO_read_ptr; /* Current read pointer */char* _IO_read_end; /* End of get area. */char* _IO_read_base; /* Start of putback+get area. */char* _IO_write_base; /* Start of put area. */char* _IO_write_ptr; /* Current put pointer. */char* _IO_write_end; /* End of put area. */char* _IO_buf_base; /* Start of reserve area. */char* _IO_buf_end; /* End of reserve area. *//* The following fields are used to support backing up and undo. */char *_IO_save_base; /* Pointer to start of non-current get area. */char *_IO_backup_base; /* Pointer to first valid character of backup area */char *_IO_save_end; /* Pointer to end of non-current get area. */struct _IO_marker *_markers;struct _IO_FILE *_chain;int _fileno; //封装的文件描述符#if 0int _blksize;#elseint _flags2;#endif_IO_off_t _old_offset; /* This used to be _offset but it's too small. */#define __HAVE_COLUMN /* temporary *//* 1+column number of pbase(); 0 is unknown. */unsigned short _cur_column;signed char _vtable_offset;char _shortbuf[1];/* char* _save_gptr; char* _save_egptr; */_IO_lock_t *_lock;#ifdef _IO_USE_OLD_IO_FILE
};
由此可得C语言缓冲区是在FILE结构体当中。另外内核缓冲区和用户缓冲区2个互不影响。
模拟实现用户层缓冲区
通过源码我们知道,缓冲区是在FILE结构体当中,所以我们需要创建一个结构体来存储这些数据。把代码创建到Mystdio.h文件当中。
// Mystdio.h
#ifndef __MYSTDIO_H__
#define __MYSTDIO_H__
#include <string.h>
#define SIZE 1024 //缓冲区的大小#define FLUSH_NOW 1 //无刷新
#define FLUSH_LINE 2 //行刷新
#define FLUSH_ALL 4 //全刷新typedef struct IO_FILE{int fileno;int flag; //char inbuffer[SIZE];//int in_pos;char outbuffer[SIZE]; //缓冲区int out_pos; //当前缓冲区的位置
}_FILE;_FILE * _fopen(const char*filename, const char *flag);
int _fwrite(_FILE *fp, const char *s, int len);
void _fclose(_FILE *fp);
#endif下面我们在Mystdio.c文件是中实现4个接口分别是fopen()/fwrite/fflush()/fclose()。
先来实现fopen()接口。
思路:我们实现三种打开方式,分别是w,r,a,这三种的实现方式都是类似的。我们知道C接口都是封装了系统调用接口,所以我们先调用open()接口,然后传入参数。完成之后,返回fd,如果fd大于0,说明文件打开成功,然后此时用malloc函数为FILE结构体开辟空间并进行初始化。
#define FILE_MODE 0666 //文件初始权限
// "w", "a", "r"
_FILE * _fopen(const char*filename, const char *flag)
{assert(filename);assert(flag);int f = 0;int fd = -1;if(strcmp(flag, "w") == 0) {f = (O_CREAT|O_WRONLY|O_TRUNC);fd = open(filename, f, FILE_MODE);}else if(strcmp(flag, "a") == 0) {f = (O_CREAT|O_WRONLY|O_APPEND);fd = open(filename, f, FILE_MODE);}else if(strcmp(flag, "r") == 0) {f = O_RDONLY;fd = open(filename, f);}else return NULL;if(fd == -1) return NULL;_FILE *fp = (_FILE*)malloc(sizeof(_FILE));if(fp == NULL) return NULL;fp->fileno = fd; // 文件描述符//fp->flag = FLUSH_LINE;fp->flag = FLUSH_ALL; //刷新方式fp->out_pos = 0; // 缓冲区位置return fp;
}
fwrite()接口。
思路:将输入的字符串
s复制到文件流的输出缓冲区outbuffer中,从当前的写入位置out_pos开始,写入长度为len的内容。然后更新写入位置out_pos += len。然后判断是用哪种刷新方式进行刷新。
直接刷新:此时会调用write(fp->fileno, fp->outbuffer, fp->out_pos)将缓冲区中的内容写入底层文件描述符(fileno),然后将写入位置重置为 0,即fp->out_pos = 0。
行刷新:检查缓冲区中最后一个写入的字符是否为换行符(fp->outbuffer[fp->out_pos - 1] == '\n'),如果是,则将缓冲区内容写入底层文件并重置写入位置。(这里不考虑中间会不会出现\n)
全刷新:只有当缓冲区满时才会刷新。检查写入位置是否等于缓冲区大小(fp->out_pos == SIZE),如果是,则将缓冲区内容写入底层文件并重置写入位置。
最后函数返回写入的长度len,表示成功写入的字节数。
int _fwrite(_FILE *fp, const char *s, int len)
{// "abcd\n"memcpy(&fp->outbuffer[fp->out_pos], s, len); // 没有做异常处理, 也不考虑局部问题fp->out_pos += len;if(fp->flag&FLUSH_NOW){write(fp->fileno, fp->outbuffer, fp->out_pos);fp->out_pos = 0;}else if(fp->flag&FLUSH_LINE){if(fp->outbuffer[fp->out_pos-1] == '\n'){ // 不考虑其他情况write(fp->fileno, fp->outbuffer, fp->out_pos);fp->out_pos = 0;}}else if(fp->flag & FLUSH_ALL){if(fp->out_pos == SIZE){write(fp->fileno, fp->outbuffer, fp->out_pos);fp->out_pos = 0;}}return len;
}
fflush()接口
void _fflush(_FILE *fp)
{if(fp->out_pos > 0){ //大于0说明缓冲区中有数据write(fp->fileno, fp->outbuffer, fp->out_pos);fp->out_pos = 0;}
}
fclose()接口
void _fclose(_FILE *fp)
{if(fp == NULL) return;_fflush(fp); //刷新缓冲区close(fp->fileno); //关闭文件描述符free(fp);
}
Mystdio.c需要的头文件
#include "Mystdio.h"
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdlib.h>
#include <unistd.h>
#include <assert.h>
至此我们实现的模拟用户缓冲区的代码就完成了
相关文章:

Linux文件操作
在C语言中,我们已经学习了文件相关的知识,那么在Linux中我们为什么还要再来学习文件呢?这是因为C语言中和Linux中,"文件"是2个不同的概念。所以我们要来学习Linux中对文件的操作。 在学习之前,我们先来回顾一…...

PostSwigger Web 安全学习:CSRF漏洞3
CSRF 漏洞学习网站:What is CSRF (Cross-site request forgery)? Tutorial & Examples | Web Security Academy CSRF Token 基本原理 CSRF Token 是服务端生成的唯一、随机且不可预测的字符串,用于验证客户端合法校验。 作用:防止攻击…...
级弹幕后端服务)
【Node.js 】在Windows 下搭建适配 DPlayer 的轻量(简陋)级弹幕后端服务
一、引言 DPlayer官网:DPlayer 官方弹幕后端服务:DPlayer-node MoePlayer/DPlayer-node:使用 Docker for DPlayer Node.js 后端(https://github.com/DIYgod/DPlayer) 本来想直接使用官网提供的DPlayer-node直接搭建…...

淘宝tb.cn短链接生成
淘宝短链接简介 1. 一键在线生成淘宝短链接tb.cn,m.tb.cn等 2. 支持淘宝优惠券短链接等淘宝系的所有网址 3. 生成的淘宝短链接是官方的,安全稳定有保证 4.适合多种场景下使用,如:网站推广,短信推广 量大提供api接口࿰…...
)
在web应用后端接入内容审核——以腾讯云音频审核为例(Go语言示例)
腾讯云对象存储数据万象(Cloud Infinite,CI)为用户提供图片、视频、语音、文本等文件的内容安全智能审核服务,帮助用户有效识别涉黄、违法违规和广告审核,规避运营风险。本文以音频审核为例给出go语言示例代码与相应结…...

优化无头浏览器流量:使用Puppeteer进行高效数据抓取的成本降低策略
概述 使用 Puppeteer 进行数据抓取时,流量消耗是一个重要考虑因素。特别是在使用代理服务时,流量成本可能显著增加。为了优化流量使用,我们可以采用以下策略: 资源拦截:通过拦截不必要的资源请求来减少流量消耗。请求…...

【C语言】fprintf与perror对比,两种报错提示的方法
它们的主要区别在于 信息来源 和 自动包含的系统错误详情。 1. fprintf(stderr, "自定义错误信息\n"); 功能: 这是标准库中的一个通用格式化输出函数。你可以用它向任何文件流(包括 stdout 标准输出, stderr 标准错误, 或任何用 fopen 打开的文件&#x…...

C语言复习笔记--内存函数
在复习完字符函数和字符串函数之后,今天让我们复习一下内存函数吧.这一块的东西不太多,并且与之前的字符串函数有一些地方很相似,所以这里应该会比较轻松. memcpy使用和模拟实现 老规矩,先看函数原型 void * memcpy ( void * destination, const void * source, size_t num );…...

前端面试高频算法
前端面试高频算法 1 排序算法;1.1 如何分析一个排序算法1.1.1 执行效率3.1.2 内存消耗1.1.3 稳定性 1.2 冒泡排序(Bubble Sort)1.3 插入排序(Insertion Sort)1.4 选择排序(Selection Sort)1.5 归…...
)
云原生--核心组件-容器篇-4-认识Dockerfile文件(镜像创建的基础文件和指令介绍)
1、Dockerfile的定义与作用 定义: Dockerfile是一个文本文件,包含一系列Docker指令,用于自动化构建Docker镜像。Docker 在构建镜像时会按照Dockerfile中的指令逐步执行,每一行指令都会生成一个新的镜像层(layer&#x…...

13.组合模式:思考与解读
原文地址:组合模式:思考与解读 更多内容请关注:7.深入思考与解读设计模式 引言 在软件开发中,是否曾经遇到过这样一种情况:你有一个对象,它本身很简单,但是它包含了其他类似的对象。随着系统变得越来越复…...
生成器)
Pycharm(十七)生成器
一、生成器介绍 1.1 概述 生成器指的是Generator对象,它不再像以往一样,一次性生成所有的数据,而是用一个,再生成一个,基于用户写的规则(条件)来生成数据,如果条件不成立ÿ…...

盛元广通实验材料管理系统-实验室管理系统-LIMS
一、引言 在当下科学研究及各类实验日益频繁的背景下,实验材料管理成为实验室高效运作的核心环节。从“人工低效”到“智能自动化”,盛元广通可覆盖实验材料的采购、存储、使用、追踪等全流程,从功能适配性、技术性能、成本效益、供应商服务…...

检查 NetCDF Fortran的版本
执行 nf-config --all命令后,它会输出一堆信息,大致像这样: This netCDF-Fortran version: 4.6.0 netCDF-Fortran installation dir: /usr/local/netcdf4 Fortran compiler: gfortran Fortran compiler flags: -g -O2 Fortran preprocesso…...

MySQL 存储引擎与服务体系深度解析
一、存储引擎核心概念 基本定义 存储引擎:MySQL服务的核心组件,负责数据的存储、检索和管理版本演进: MySQL 5.0/5.1 默认使用MyISAM引擎MySQL 5.5/5.6+ 默认采用InnoDB引擎关键特性 不同存储引擎采用不同的数据存储结构和处理机制直接影响表的CRUD操作性能和数据安全特性作…...

乐企数电发票分布式发票号码生成重复的问题修复思路分享
文章目录 1.前言2.解决思路2.1错误姿势2.2歪打正着2.3正确姿势 3.总结 1.前言 由于之前接了乐企数电开票,服务上线之后,使用的公司少没有啥问题,后面切换了两家日开票量大的公司上线之后,就发现发票号码生成重复了,后面…...

多级缓存架构设计与实践经验
多级缓存架构设计与实践经验 在互联网大厂Java求职者的面试中,经常会被问到关于多级缓存的架构设计和实践经验。本文通过一个故事场景来展示这些问题的实际解决方案。 第一轮提问 面试官:马架构,欢迎来到我们公司的面试现场。请问您对多级…...
)
LCD1602液晶显示屏详解(STM32)
目录 一、介绍 二、传感器原理 1.原理图编辑 2.接口说明 三、程序设计 main文件 lcd1602.h文件 lcd1602.c文件 四、实验效果 五、资料获取 项目分享 一、介绍 LCD1602A字符型液晶显示模块是专门用于显示字母、数字元、符号等的点阵型液晶显示模块。分4位和8位数据…...

Golang | 集合求交
文章目录 bitmap求交集2个有序链表多个有序链表跳表 bitmap求交集 2个有序链表 多个有序链表 为什么非最大的所有都要往后移动呢?因为现在已经知道交集即使有,也最小都是这个目前最大的了,其他不是最大的不可能是交集,所有除了最大…...

手机充电进入“秒充“时代:泡面刚下锅,电量已满格
现代人的生活节奏越来越快,手机充电技术也在飞速发展。从最初的"充电一整晚"到如今的"秒充"时代,充电效率的提升正在悄然改变着我们的生活习惯。最新数据显示,目前最快的手机充电技术仅需4分30秒就能充满一部手机的电量&…...

网站字体文件过大 导致字体从默认变成指定字体的时间过长
1.选择字体中只用到的字符集较小的包 只用到了数字,所以使用了 xx-sans.ttf的版本(86kb) 2.转换ttf格式为woff2 转换后26kb 3.使用字体 // 定义字体 font-face {font-family: "myFont";src: url(/assets/fonts/myFont.woff2) format(woff2);font-weigh…...

WPF常用技巧汇总 - Part 2
WPF常用技巧汇总-CSDN博客 主要用于记录工作中发现的一些问题和常见的解决方法。 目录 WPF常用技巧汇总-CSDN博客 1. DataGrid Tooltip - Multiple 2. DataGrid Tooltip - Cell值和ToolTip值一样 3. DataGrid Tooltip - Cell值和ToolTip值不一样 4. DataGrid - Ctrl A /…...

C++中析构函数
析构函数 析构函数(Destructor)是类的一种特殊成员函数,用于在对象的生命周期结束时执行清理操作,他的主要作用是释放对象占用资源,例如动态分配的内存,文件句柄或网络连接等。 特点 名称与类名称相同 单…...
如何在树莓派上编译树莓派内核)
树莓派超全系列教程文档--(44)如何在树莓派上编译树莓派内核
如何在树莓派上编译树莓派内核 构建内核下载内核源代码 本地构建内核构建配置使用 LOCALVERSION 自定义内核版本构建安装内核 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 构建内核 操作系统预装的默认编译器和链接器被配置为构建在该操作系统…...

flask返回文件的同时返回其他参数
参考:flask实现上传文件与下载文件_flask 文件上传和下载-CSDN博客 在 Flask 中,返回文件的同时附加额外参数(如处理时间)可以通过 自定义 HTTP 响应头 或 返回 JSON 数据与文件结合 的方式实现。以下是具体方法和示例: 方法 1:通过 HTTP 响应头 附加参数(推荐) 将参…...
)
C++23 std::move_only_function:一种仅可移动的可调用包装器 (P0288R9)
文章目录 一、定义与基本概念1.1 定义1.2 基本概念 二、特点2.1 仅可移动性2.2 支持多种限定符2.3 无target_type和target访问器2.4 强前置条件 三、使用场景3.1 处理不可复制的可调用对象3.2 性能优化3.3 资源管理 四、与其他可调用包装器的对比4.1 与std::function的对比4.2 …...

Zookeeper实现分布式锁实战应用
Zookeeper实现分布式锁实战应用示例 1. 分布式锁概述 在分布式系统中,当多个进程或服务需要互斥地访问共享资源时,就需要分布式锁来协调。Zookeeper因其强一致性和临时节点特性,非常适合实现分布式锁。 2. Zookeeper实现分布式锁的核心原理…...

使用 Playwright 构建高效爬虫:原理、实战与最佳实践
随着网站前端技术日益复杂,传统的基于请求解析(如 requests、BeautifulSoup)的爬虫在处理 JavaScript 渲染的网站时变得力不从心。Playwright,作为微软推出的一款强大的自动化浏览器控制框架,不仅适用于自动化测试,也成为了处理现代网站爬取任务的利器。 本篇文章将带你…...

ComfyUI for Windwos与 Stable Diffusion WebUI 模型共享修复
#工作记录 虽然在安装ComfyUI for Windwos时已经配置过extra_model_paths.yaml 文件,但升级ComfyUI for Windwos到最新版本后发现原先的模型配置失效了,排查后发现,原来是 extra_model_paths.yaml 文件在新版本中被移动到了C盘目录下&#x…...
)
【RabbitMQ消息队列】详解(一)
初识RabbitMQ RabbitMQ 是一个开源的消息代理软件,也被称为消息队列中间件,它遵循 AMQP(高级消息队列协议),并且支持多种其他消息协议。 核心概念 生产者(Producer):创建消息并将其…...

【MySQL数据库入门到精通-08 约束】
文章目录 4、约束4.1 概述4.2 约束演示1. 根据需求,完成表的创建2. SQL数据库3. 结果 4.3 外键约束4.3.1 介绍1. 根据需求,完成表的创建2. SQL数据库3. 结果4.3.2 外键约束建立1. 语法2. SQL语句3. 现象4.3.3 外键删除更新行为1. 知识点2.SQL3.结果 4、约…...
)
C++笔记-模板进阶和继承(上)
一.模板进阶 1.1非模板类型参数 那之前学过的stack举例,在这之前我们如果要用N,就要用宏来定义,但是宏毕竟有局限性: 如果我要用到两个stack,一个要求10个空间,另一个要求100空间呢? 这时候…...

云计算赋能质检LIMS的价值 质检LIMS系统在云计算企业的创新应用
在云计算技术高速发展的背景下,实验室信息化管理正经历深刻变革。质检LIMS(实验室信息管理系统)作为实验室数字化转型的核心工具,通过与云计算深度融合,为企业提供了高弹性、高安全性的解决方案。本文将探讨质检LIMS在…...
与面向对象架构风格)
2025系统架构师---数据抽象(Data Abstraction)与面向对象架构风格
引言 在软件系统复杂度与规模不断攀升的今天,如何设计出可扩展、易维护且能快速响应需求变化的架构,是每一位系统架构师面临的挑战。数据抽象(Data Abstraction)与面向对象架构风格(Object-Oriented Architectu…...

[python] 基于WatchDog库实现文件系统监控
Watchdog库是Python中一个用于监控文件系统变化的第三方库。它能够实时监测文件或目录的创建、修改、删除等操作,并在这些事件发生时触发相应的处理逻辑,因此也被称为文件看门狗。 Watchdog库的官方仓库见:watchdog,Watchdog库的官…...

缺省处理、容错处理
布尔判定 假:false 0 null undefined NaN 可选符.?和?? let obj {name: jim,data: {money: 0,age: 18,fn(a){return a}} }1、如果左侧的值为null或者undefined,则使用右侧值。需要使用"??" obj?.data?.a…...

Taro on Harmony :助力业务高效开发纯血鸿蒙应用
背景 纯血鸿蒙逐渐成为全球第三大操作系统,业界也掀起了适配鸿蒙原生的浪潮,用户迁移趋势明显,京东作为国民应用,为鸿蒙用户提供完整的购物体验至关重要。   去年 9 月,京东 AP…...

Java基础——排序算法
排序算法不管是考试、面试、还是日常开发中都是一个特别高频的点。下面对八种排序算法做简单的介绍。 1. 冒泡排序(Bubble Sort) 原理:相邻元素比较,每一轮将最大元素“冒泡”到末尾。 示例数组:[5, 3, 8, 1, 2] pub…...

【操作系统原理07】输入/输出系统
文章目录 零.大纲一.I/O设备的概念和分类0.大纲1.什么是I/O设备2.I/O分类 二.I/O控制器0.大纲1.I/O设备的电子部件(I/O控制器)2.IO控制器组成3.内存映像I/O VS 寄存器独立编址 三.I/O控制方式0.大纲与总结1.程序直接控制方式(1) 操…...

IM云端搜索全面升级,独家能力拓展更多“社交连接”玩法
在这个数字时代,网络让信息传递前所未有的便捷,但同时,海量数据堆积也让内容检索变得像大海捞针。尤其是在我们日常工作生活中最常用的即时通信软件中,信息的快速查找和精准定位正变得越来越重要。 但传统的本地搜索功能受限于设…...

汽车产业链主表及类别表设计
(提前设计,备用) 一、汽车产业链类别表(industry_chain_category) 设计要点 1、核心字段:定义产业链分类(如零部件、整车制造、销售服务等) 2、主键约束:自增ID作为唯一标…...

有效的字母异位词
recorded:用于统计或抵消字符出现次数。 class Solution { public:bool isAnagram(string s, string t) {int record[26]{0};for(int i0;i<s.size();i){record[s[i]-a];}for(int i0;i<t.size();i){record[t[i]-a]--;}for(int i0;i<26;i){if(record[i]!0){…...

汽车网络安全 -- 理解暴露面、攻击面和攻击向量
1.暴露面是攻击面的子集 举个例子,房子都有门、窗户,这些窗户、门不管是否打开,都可能被小偷利用进入到房内,因此这些门窗可能是潜在的漏洞,所以称之为攻击面(Attack Surface)。 小偷经过长期观察,发现家…...

C++异步利器:全面理解 std::packaged_task
在现代 C(C11及以后)中,并发与异步编程是不可回避的重要技能。我们常常希望把某些计算任务扔给后台线程去处理,同时又能优雅地获取任务结果。 这时候,std::packaged_task 就是一个非常强大的工具。 本文将带你深入理解…...
)
Animate 中HTMLCanvas 画布下的鼠标事件列表(DOM 鼠标)
在 JavaScript 和 Adobe Animate(CreateJS) 中,常用的鼠标交互事件可分为两大类:基础 DOM 事件 和 CreateJS 扩展事件12。以下是完整分类: 一、基础 DOM 鼠标事件 事件名触发场景冒泡特性click鼠标左键单…...

RagFlow文档切块提升
1.RagFlow切块介绍 2.复现优化 2.1 General 通用分块 def parser_text(self, txt, blockSize512, overlapSize0, delimiter"\n!?;。;!?"):文本分割sentences self.split_text_by_period_qh(txt, delimiter, blockSizeblockSize)…...

音频转base64
<!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>音频转Base64</title><style>.containe…...

蓝桥杯 11. 打印大X
打印大X 原题目链接 题目描述 小明希望用星号拼凑,打印出一个大 X,他要求能够控制笔画的宽度和整个字的高度。 为了便于比对空格,所有的空白位置都以句点符 . 来代替。 输入描述 输入两个整数 m 和 n,表示笔画的宽度和 X 的高…...

页面需要重加载才能显示的问题修改
1.问题描述:跳转页面后,只有点击重新加载后才会显示内容 经过测试后: / 跳转详情 const goToDetail (bookId) > { router.push({ path: /classic-detail, query: { book_id: bookId } }) } 执行完以上代码后,页面从classics…...

On the Biology of a Large Language Model——Claude团队的模型理解文章【论文阅读笔记】其二——数学计算部分
这篇内容的源博文是 On the Biology of a Large Language Model 这是Anthropic,也就是Claude的团队的一遍技术博客。他的主要内容是用一种改良版的稀疏编码器来解释LLM在inference过程中内部语义特征的激活模式。因为原文太长,我把原文分成了几份来写阅读…...