音视频之H.265/HEVC熵编码
H.265/HEVC系列文章:
1、音视频之H.265/HEVC编码框架及编码视频格式
2、音视频之H.265码流分析及解析
3、音视频之H.265/HEVC预测编码
4、音视频之H.265/HEVC变换编码
5、音视频之H.265/HEVC量化
6、音视频之H.265/HEVC环路后处理
7、音视频之H.265/HEVC熵编码
熵编码是指按信息熵原理进行的无损编码方式,无损编码也是有损视频编码中的一个关键模块,它处于视频压缩系统的末端。编码把一系列用来表示视频序列的元素符号转变为一个用来传输或存储的压缩码流,输入的符号可能包括量化的变换系数、运动矢量信息、预测模式信息等。熵编码可以有效去除这些视频元素符号的统计几余,是保证视频编码压缩效率的重要工具之一。
一、熵编码基本原理:
1、熵:
信息的定义:
人们常说,当今时代是一个信息大爆炸的时代。然而,你真的了解什么是信息吗?很多人错误地把信息等同于消息,认为得到了消息就是得到了信息。然而,信息与消息并不是一回事,不能等同。我们知道,电报、电话、广播、电视、互联网等通信系统中传输的是各种各样的消息,这些消息有着各种不同的形式,如文字、符号、数据、语言、图片和视频等。所有这些不同形式的消息都可以被人们的感觉器官所感知,经过大脑的分析,得到关于某些事物状态的描述信息。
把客观物质运动和主观思维的活动状态表达出来就成为了消息。消息中包含信息,是信息的载体。因此,信息与消息既有区别又有联系的。
得到消息后,从中提取出我们想要了解的事物状态,就是获得信息的过程。实际上,获得信息的过程就是一个消除或部分消除不确定性的过程。因此香农给出信息的定义是:信息是事物运动状态或存在方式的不确定性的描述。
信息的度量:
然而信息是如何度量的呢?信息的多少我们称为信息量。显然,信息量与不确定性消除的程度有关。消除的不确定性大,信息量就大;反之,信息量就小。那么,不确定性的大小又是用什么度量的呢?直观来讲,不确定性的大小可以直观地看成事先猜测某随机事件发生的难易程度,因此,它与事件发生的概率相关,是一个关于事件发生概率的函数。由此可见,不确定性的大小能够度量,更进一步,信息也是可以度量的。


2、变长编码:
对信源输出的消息(一个信源符号或者固定数目的多个信源符号)采用不同长度的码字表示,这种编码方式称为变长编码。为了提高编码效率,需要根据符号出现的概率大小设计码长,即对于大概率符号采用较短的码字表示,小概率符号采用较长的码字表示,以达到平均码长最短的目的。
无失真编码:
值得注意的是,变长码必须是唯一可译码,才能实现无失真编码。那么,如何判断一组码字是不是唯一可译呢?萨德纳斯(A.A.Sardinas)和彼特森(Patterson)于1957年设计出了一种判断唯一可译码的测试方法。根据唯一可译码的定义可知,当且仅当有限长的码符号序列能译成两种不同的码字序列时,此码是非唯一可译变长码。那么一定存在一个码字的尾随后缀是另一个码字的前缀。根据这个原理得出唯一可译码的判断方法是:对于码字集合C={},将C中所有可能的尾随后缀组成一个集合F,当且仅当集合F中没有包含任一码字,可判断此码C为唯一可译变长码。
同一信源的唯一可译码可能有多种,从传输信息的观点来考虑,应该选择由短的码符号组成的码字,即用码长作为选择准则。对于某一信源和某一码符号集来说,若有一个唯一可译码,其平均长度小于所有其他唯一可译码的平均长度,则该码称为最佳码。无失真信源编码的基本问题就是要找到最佳码。现在我们来讨论码长的极限值。


香农第一定理说明:
- 通过对扩展信源进行可变长编码,可以使平均码长无限趋近于极限熵值,但这是以编码复杂性为代价的。
- 无失真信源编码的实质:对离散信源进行适当的变换,使变换后新的符号序列信源尽可能为等概率分布,从而使新信源的每个码符号平均所含的信息量达到最大。
- 香农第一定理仅是一个存在性定理,至于如何构造最佳码,定理并没有直接给出。
哈夫曼编码:
哈夫曼在1952年提出了一种针对已知信源构造最佳变长码的方法,即哈夫曼码,它也是最经典的变长码。其基本思想是为信源输出的大概率符号分配较短的码字,为小概率符号分配较长的码字,使平均码长最短。
尽管哈夫曼编码是一种最佳变长码,但是它也存在一定的不足。首先,解码器需要知道哈夫曼编码树的结构,因而编码器必须为解码器保存或传输编码树,增加了存储空间的要求。其次,传统的哈夫曼解码方式是从码流中一次读入比特,直到在哈夫曼树中搜索找到相应码字,这种做法增加了解码器的计算复杂度。哈夫曼码的不规则结构导致了哈夫曼码快速解码的困难,因此研究者们提出了具有规则结构的变长码来回避哈夫曼码的不足,指数哥伦布码(Exponential Golomb Code)是其中应用比较广泛的。
3、指数哥伦布编码:
指数哥伦布码也是变长码的一种,这种码字有很好的结构性。指数哥伦布码由前缀和后缀两部分构成,前缀和后缀都依赖于指数哥伦布码的阶数k。
指数哥伦布码生成步骤:
用来表示非负整数N的k阶指数哥伦布码可用如下步生成。
- 将数字N以二进制形式写出,去掉最低的k个比特位,之后加1。
- 计算留下的比特数,将此数减一,即是需要增加的前缀零的个数。
- 将步骤①中去掉的最低k个比特位补回比特串尾部。
以数值4的一阶指数哥伦布编码为例:
- 4的二进制表示为100,去掉最低1个比特位0变成10,加1后留下 11。
- 11的比特数为2,因此前缀中0的个数为1。
- 在比特串最低比特位补上步骤①中去掉的0,最终码字为0110。
表 8.1给出了0阶、1阶、2阶和3阶指数哥伦布码的结构,前缀由m个连续的0和一个1构成,后缀由m+k个比特构成,是的二进制表示,即表中的
串,
的范围为[0,m+k-1],每个
的值为0或1。
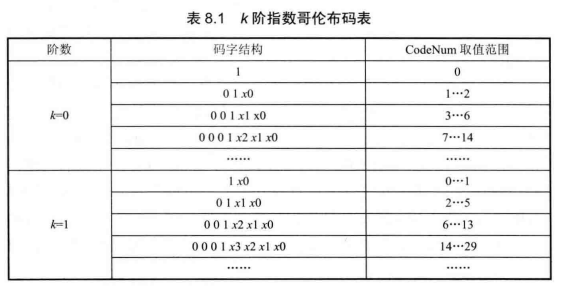
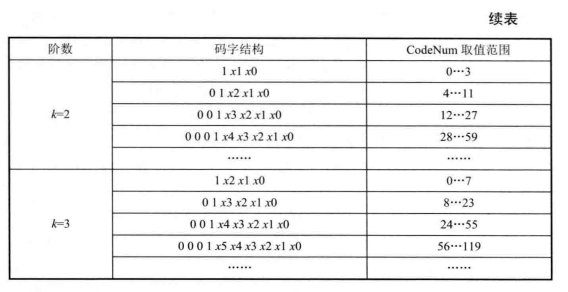
指数哥伦布码解码原理:
解析k阶指数哥伦布码时,首先从比特流的当前位置开始寻找第一个非零比特,并将找到的零比特个数记为,第一个非零比特之后
位二进制比特串的十进制值为 Value,计算解码值 CodeNum。
可见,指数哥伦布码基于这些规则结构,解码器可以很快地判断一个码字的长度,并通过简单计算来解码码字。其他规则结构的码字还包括 Golomb-Rice 码、Hybrid-Golomb码等。这些变长码,对于某些信源其编码效率也是最优的。
变长码与定长码相比,虽然编码效率有一定提升,但是变长码为每个符号指定码字,每个符号需要整数个比特来表示。只有当信源符号的概率质量函数为2的负幂次方时,变长码的平均码长才能达到信源的。将多个符号进行联合编码,可以有效地提高编码效率,但也极大地增加了编码复杂度。
4、算术编码:
与变长码不同,算术编码的本质是为整个输入序列分配一个码字,而不是给每个输入流中的每个字符分别指定码字,因此平均意义上可以为单个字符分配码长小于1的码字,所以算术编码可以给出接近最优的编码结果。
算术编码的基本原理:
根据信源可能发生的不同符号序列的概率,把[0,1)区间划分为互不重叠的子区间,子区间的宽度恰好是各符号序列的概率,这样信源发出的不同符号序列将与各子区间一一对应。因此每个子区间内的任意一个实数都可以用来表示对应的符号序列,这个数就是该符号序列所对应的码字。显然,一串符号序列发生的概率越大,对应的子区间就越宽,要表达它所用的比特数就越少,因而相应的码字就越短。
算术编码用到两个基本的参数:符号的概率和它的编码间隔。信源符号的概率决定编码过程中信源符号的间隔,而这些间隔包含在0到1之间。编码过程中的间隔决定了符号压缩后的输出。
算术编码步骤:
给定事件序列的算术编码步骤如下:
- 编码器在开始时将“当前间隔”[L,H)设置为[0,1)。
- 对每一事件,编码器按步骤a和b进行处理。
a、编码器将“当前间隔”分为子间隔,每一个事件一个。
b、一个子间隔的大小与下一个将出现的事件的概率成比例,编码器选择子间隔与下一个确切发生的事件相对应,并使它成为新的“当前间隔”。
- 最后输出的“当前间隔”的下边界就是该给定事件序列的算术编码。
算数编码的编、解码过程例子:
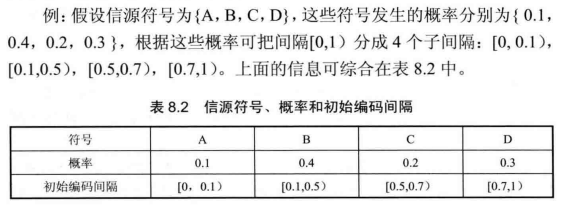
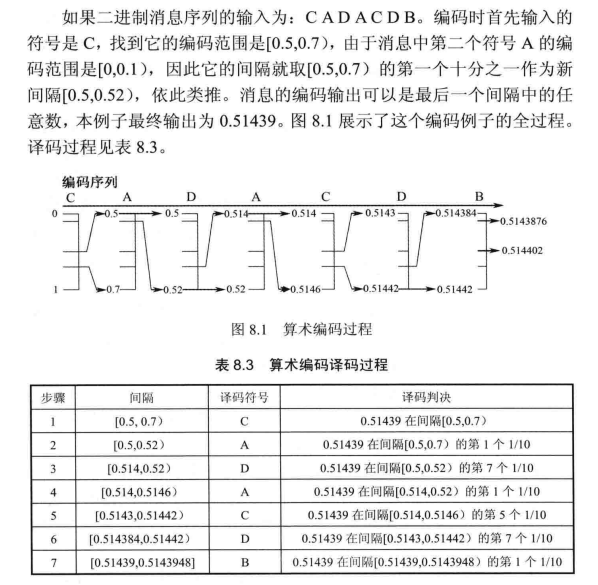
在上面的例子中,我们假定编码器和译码器都知道消息的长度,因此译码器的译码过程不会无限制地运行下去。实际上在译码器中需要添加一个专门的终止符,当译码器看到终止符时就停止译码。
算术编码需注意的问题:
在算术编码中有以下几个问题需要注意:
- 由于实际中计算机的精度不可能无限长,一个明显的问题是运算中出现溢出,但多数计算机都有16、32或者64位的精度,因此这个问题可使用比例缩放方法解决。
- 算术编码器对整个消息只产生一个码字,这个码字是在间隔[0,1)中的一个实数,因此译码器在收到表示这个实数的所有位之前不能进行译码。
- 算术编码也是一种对错误很敏感的编码方法,如果有一位发生错误就会导致整个消息译错。
算术编码可以是静态的或自适应的。在静态算术编码中,信源符号的概率是固定的;在自适应算术编码中,信源符号的概率根据编码时符号出现的频繁程度动态地进行修改。需要开发动态算术编码是因为事先知道精确的信源概率是很难的,而且是不切实际的。在编码期间估算信源符号概率的过程叫作建模。当压缩消息时,我们不能期待一个算术编码器获得最大的效率,所能做的是尽量提高编码过程中符号概率的估算精度,因此动态建模就成为决定编码器压缩效率的关键因素。不可否认,算术编码的编、解码计算复杂度要明显高于变长码。这也是算术编码不如变长码应用广泛的主要原因。
二、零阶指数哥伦布编码及其应用:
指数哥伦布码属于可变长码,其基本原理是用短码表示出现频率较高的信息,而用长码表示出现频率较低的信息。它是一种特殊的可变长码,其码长有规律可循。具体来讲就是如果一个符号x进行Exp-Golomb编码,只要根据码字信息的值就可以计算出编码后的码长。在编码中,很多语法元素都采用指数哥伦布码的形式映射为二进制比特流。其中零阶指数哥伦布编码应用非常广泛。
零阶指数哥伦布编码:
零阶指数哥伦布码是指数哥伦布码家族中的一种,它可以直接根据公式解析码字,无须查表,解码复杂度较低。零阶指数哥伦布码由前缀和后缀串接而成,前缀长度和后缀长度
满足
。前缀具有一元码的形式,即00…001,其中零的个数M为


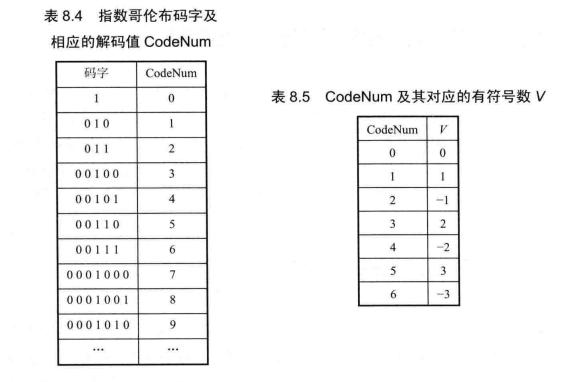
零阶指数哥伦布编解码可以通过简单的计算来实现,在节省存储空间的同时,也省去了码表的设计过程。可以根据信源的概率分布选择是否采用零阶指数哥伦布编码,以便更有效地表示信息。
H.265/HEVC指数哥伦布编码语法元素:
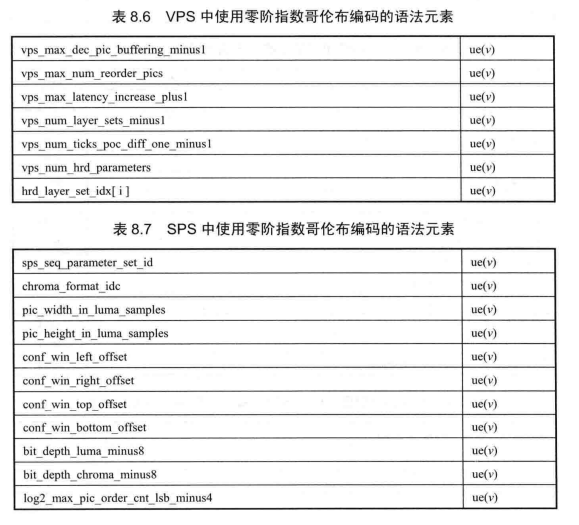
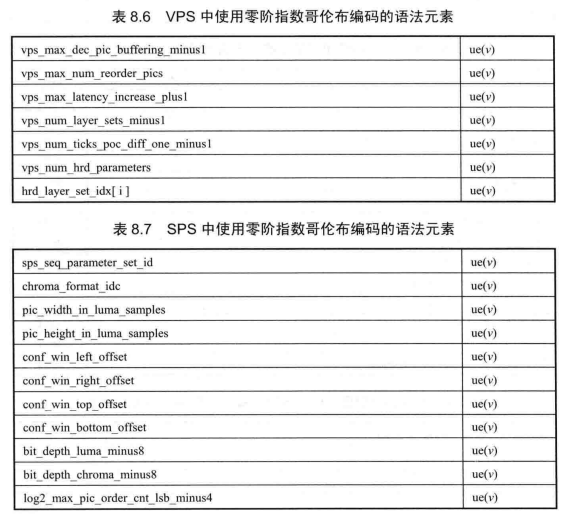
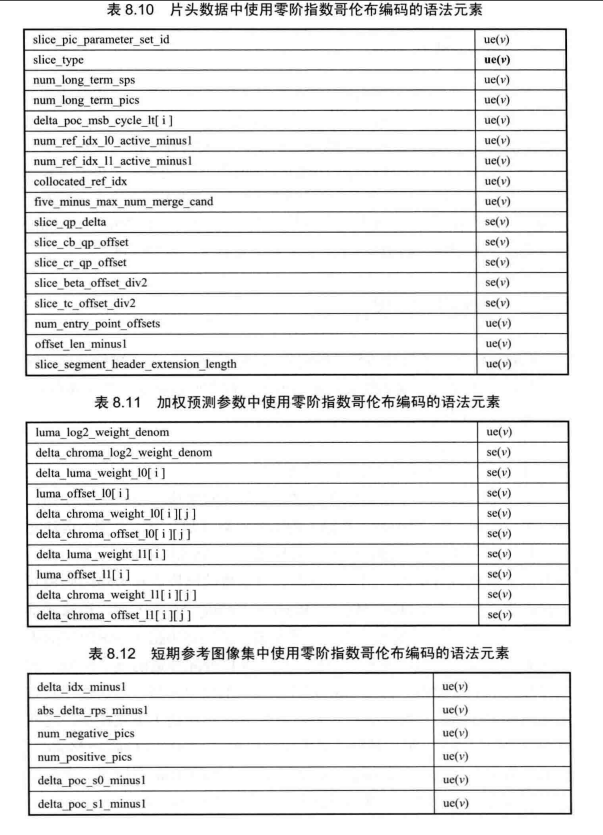
熵编码已成为视频编码中不可或缺的重要组成部分,尽管CABAC(Context-based Adaptive Binary Arithmetic Coding)具有高的压缩效率,并作为 H.265/HEVC 标准的主要编码方法。由于零阶指数哥伦布编解码简单,且对广义高斯信源的压缩效率也较高,在H.265/HEVC中,零阶指数哥伦布编码方法被用于视频参数集(VideoParameterSet,VPS)、序列参数集(Sequence Parameter Set,SPS)、图像参数集(Picture ParameterSet,PPS)和片头信息等所涉及的大部分语法元素中。具体的语法元素以及它所采用的是无符号数的指数哥伦布编码 ue(1)还是有符号数的指数哥伦布编码 se(v),见表 8.6~表 8.12。
三、CABAC:
基于上下文的自适应二进制算术编码(CABAC)是一种将自适应的二进制算术编码与一个设计精良的上下文模型结合起来得到的方法。它很好地利用了语法元素数值之间的高阶信息,使编码效率得到了进一步提高。在编码中,每一个符号的编码都与以前编码的结果有关,根据符号流的统计特性来自适应地为每一个符号分配码字。CABAC允许非整数的码字位数分配给各个符号,尤其适合于出现概率较大的符号。2001年,Marpe首次提出了 CABAC的初步算法,之后又进行了一系列改进。
CABAC原理:
CABAC采用了高效的算术编码思想,同时充分考虑了视频流相关统计特性,大大提高了编码效率。
二进制化是将一个给定的非二进制语法元映射成一个二进制序列,即一个二元流(Bin String)。若输入的语法元素就是一个二进制的语法元素,则二进制化的处理被省略掉,数据通过一条旁路直接送往下一步,即对二元数据进行编码。二元算术编码有常规编码模式和旁路编码模式两种以供选择。在常规编码模式(Regular Coding Mode)中,语法元素的二元位(Bin)顺序地进入上下文模型器。编码器根据先前编码过的语法元素或二元位的值,为每一个输入的二元位分配合适的概率模型,该过程即为上下文建模。将该Bin和分配给它的概率型一起送进二元算术编码器进行编码。此外编码器还要根据Bin值更新上下文模型,这就是编码中的自适应。另一种模式是旁路编码模式(Bypass Coding Mode),它无须为每个二元位分配特定的概率模型,输入的Bin直接用一个简单的旁路编码器进行编码,以加快整个编码以及解码的速度。
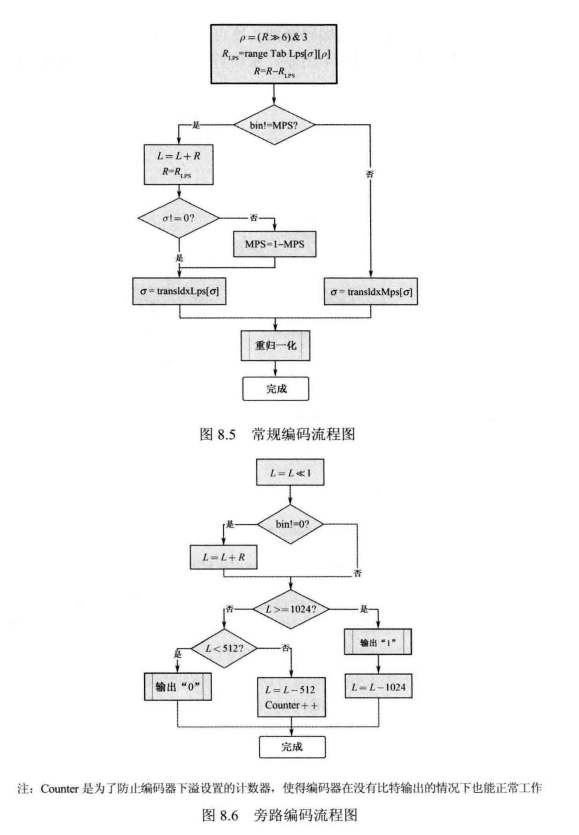
总体流程,如图8.2所示;
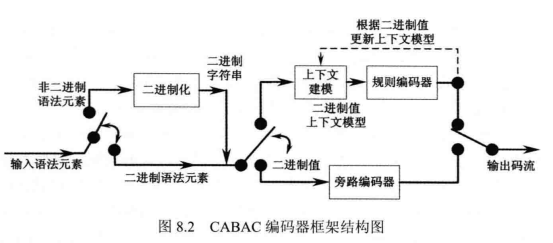
它的编码过程主要包括3个基本步骤:
- 二进制化: 在实际的二元化方法设计过程中,一般采用码字结构比较简单的二元化方法,例如一元码、定长码和指数哥伦布码等二元化方法。
- 上下文建模:一般情况下,不同的语法元素之间并不是完全独立的,且相同语法元素自身也具有一定的记忆性。因此,根据条件熵理论,利用其他已编码的语法元素进行条件编码,相对于独立编码或者无记忆编码能够进一步提高编码性能。这些用来作为条件的已编码符号信息称为上下文。为了利用有限的概率模型资源实现尽可能高的编码性能,上下文模型的应用就要有所针对性。具体表现就是,对于那些高概率发生的对编码性能的影响起主导作用的事件,建立精致的上下文模型,可以增加上下文模型的阶数以达到更为精细的条件估计;而对于低概率发生的对编码性能影响不大的事件,可以建立比较简单的上下文模型,甚至可以存在不同上下文模型,或者视其为等概率时间进行编码。
- 二进制算术编码:根据算术编码器的输入符号取值空间的大小,可以将算术编码分为多元算术编码和二元算术编码两类。二元算术编码相对于多元算术编码来说有很多优点。首先,二元算术编码是一种通用的编码方法,即任何大小的多元符号都能将其简单地转换为二元符号序列来进行二元算术编码。其次二元算术编码更容易实现自适应编码,这是因为它的概率模型非常简单,在自适应编码过程中对其更新时能够避免多元算术编码所存在的烦琐的概率更新操作。另外,算术编码过程本身的运算量非常大,与多元算术编码相比,二元算术编码实现简单,更容易实现无乘法运算的快速算法。因此二元算术编码技术在视频编码中得到了广泛应用。
H.265/HEVC中的CABAC:
基于上下文的自适应二元算术编码技术是H.265/HEVC的主要熵编码方案。
二进制化:
在 H.265/HEVC中,常用的二元化方法有截断莱斯二元化(TR)、K阶指数哥伦布二元化(EGK)和定长二元化(FL)。针对不同的语法元素,根据其不同的概率分布特性来选择不同的二元化方案。其
截断莱斯二进制化:
在已知门限值cMax、莱斯参数R和语法元素值V的情况下,即可获得截断莱斯二元码串。截断莱斯码由前缀和后缀串接而成,前缀值P的计算方法为

定长二进制化:
当语法元素的概率呈均匀分布时,可选用定长编码的二元化方案。假设某一给定语法元素的值为x,且0≤x≤Max,则直接利用十进制数转换为二进制数法则来得到x的定长二值符号串,其长度。
上下文模型:
在编码中,语法元素使用的上下文概率模型都被唯一的上下文索引号标识,每一个
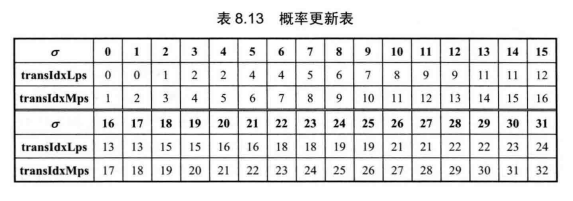
涉及两个概率模型变量:最大概率符号MPS和概率状态索引
。MPS表示待编码的 Bin很有可能出现的符号,取值为1或0:与之对应的,待编码的Bin不可能出现的符号即为最小概率符号LPS。在CABAC中,根据先验知识为LPS的概率设定了64个代表值。概率状态索引
与LPS的概率值一一对应,LPS概率自适应的更新就表现为的变化。
那么在编码第一个二进制符号前,如何为该符号初始化其上下文概率模型。在 H.265/HEVC中,为每一个上下文模型索引分配了一个初始值V,通过V来计算上下文模型的初始变量MPS和。具体计算方法如下:

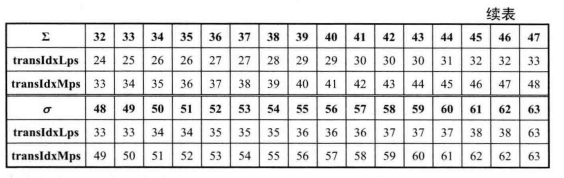
从概率模型更新过程可以看出:若当前编码比特为MPS符号,更新后的概率索引值变大,这表示下一个符号是MPS的概率增大,出现LPS的概率减小;若当前编码比特为LPS,更新后的概率索引值变小,则表示下一个符号是LPS的概率增大,出现MPS的概率减小:当概率模型变量为0时,表示MPS和LPS的概率相同,若再出现LPS符号,MPS和 LPS 必须交换。
二进制算术编码:
二进制算术编码对当前语法元素二进制化后的每一个Bin根据其概率模型参数进行算术编码,得到最后的输出码流。二进制算术编码基于递归区间划分的方式,在递归过程中保存编码区间和区间下限。它包括两种编码方式:常规编码和旁路编码。前者利用自适应的概率模型进行编码,后者以等概率的方式进行编码,其概率状态无须更新。
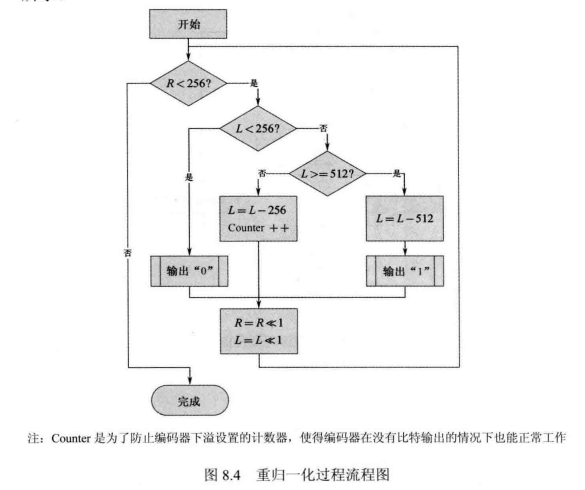
常规编码模式:编码器的输入值是上下文模型变量和待编码的Bin值,编码器的状态是当前编码区间R和区间下限。根据给定的率模型变量对当前区间进行细分。首先计算索引值:


如果当前二进制符号Bin等于MPS,则MPS的编码区间作为下一个二元符号的编码区间R,区间下限不变;如果当前二进制符号Bin 等于 LPS,则 LPS 的区间 Rps作为下一个二元符号的编码区间 R,区间下限L要增加
的长度。随后根据当前Bin值更新上下文模型经过区间划分后得到的新的编码区间长度可能不在
之内,就需要进行重归一化过程,如图8.4所示。最终整个常规编码的流程如图8.5所示。
旁路编码模式无须对概率进行自适应更新,而是采用0和1概率名占1/2的固定概率进行编码,因此该编码较为简单。为了使区间划分操作更加简便,不采用直接对区间长度二等分的方法,而采用保存编码区间长度不变,使区间下限工值加倍的方法来实现区间划分,效果是一样的。随后进行重归一化操作。旁路编码的整个流程如图8.6所示。
CABAC在H.265/HEVC中的应用:
CABAC把一系列用来表示视频序列的语法元素转变为一个用来传输或存储的压缩码流。那么在H.265/HEVC中,知道各个语法元素使用的二元化方式及上下文模型参数初始值,就可以按照CABAC的实现方案来获得最终的码流。
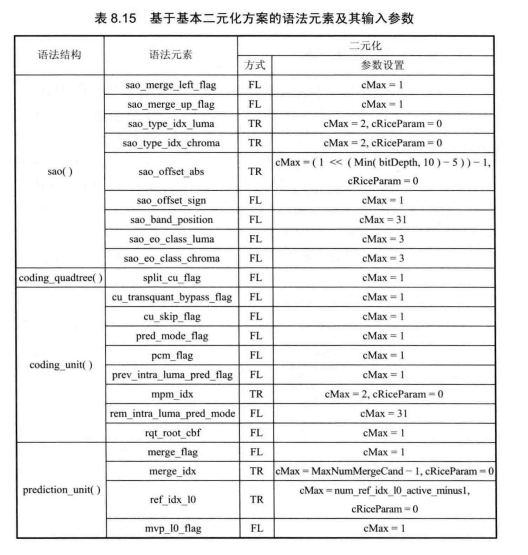
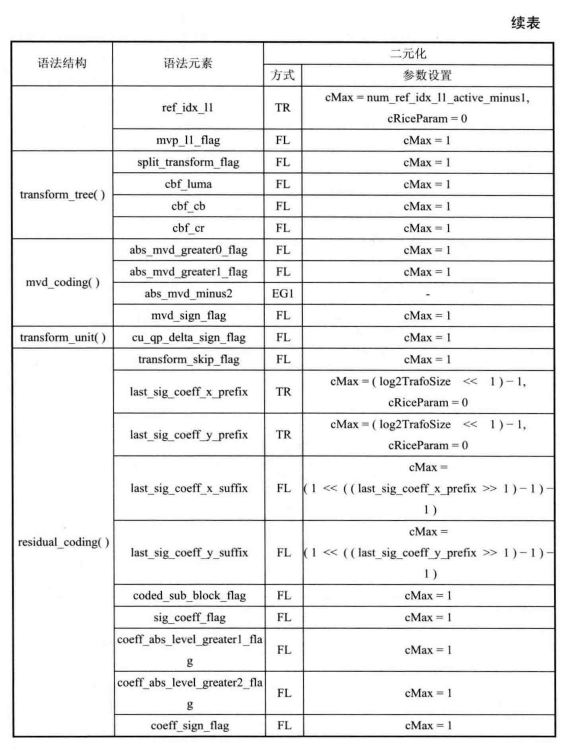
语法元素二元化方案:
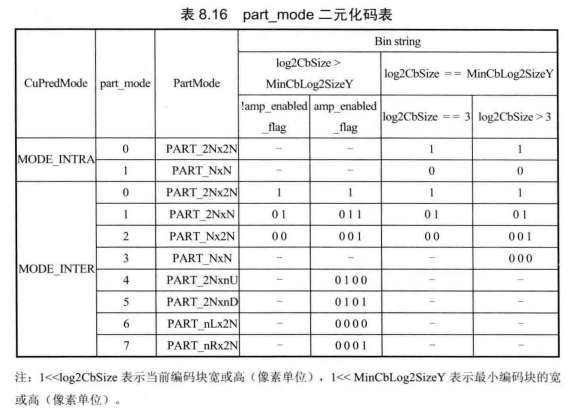
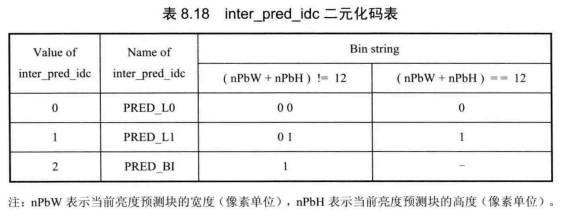
不同语法元素的概率统计分布略有差异,根据各自的特点CABAC采用不同的二元化方法。表8.15给出了采用FL、TR和EG1二元化方法的语法元素及输入参数,包括 SAO、树块分割结构、CU、PU、TU分割结构、运动信息、残差等相关语法元素。还有部分语法元素的二元化码字采用查表的方式来获取,包括part_mode、intra_chroma_pred_mode、inter_pred_idc,见表8.16~表 8.18。此外语法元素cu_qp_delta_abs 和coeff_abs_level_remaining采用基本二元化法联合的方式生成Bin串。
语法元素cu_qp_delta_abs的二元化码字由前缀码和后缀码构成。前缀值为:



语法元素上下文模型初始化:
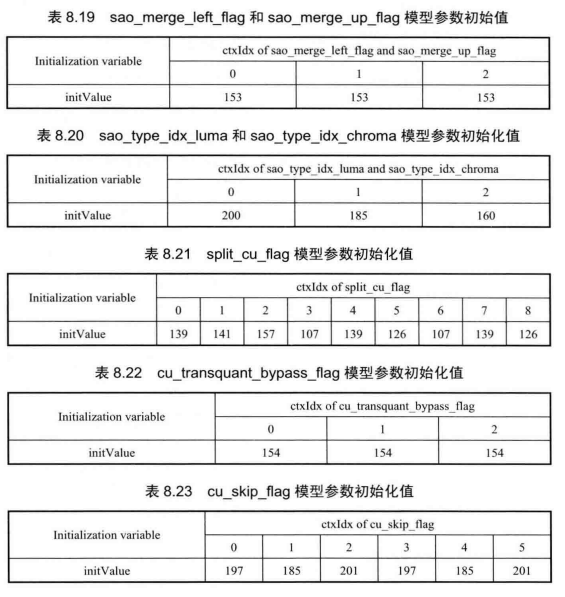
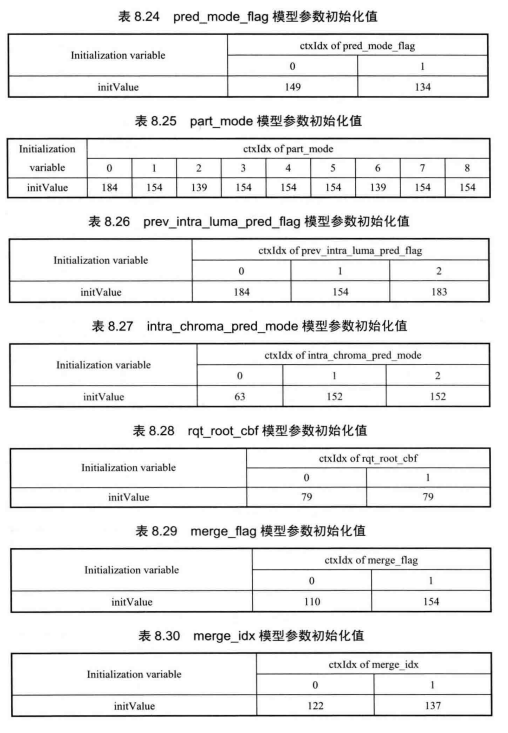
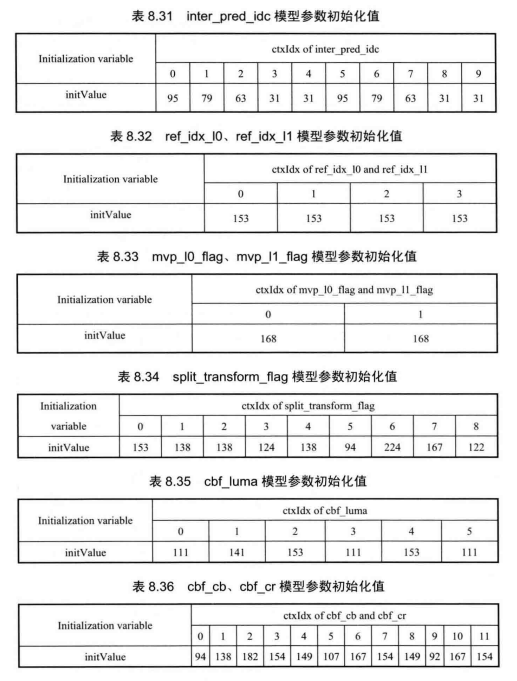
由于每个语法元素的概率分布特性不同,因此其上下文模型参数MPS和a的初始值也应该有所差异。在H.265/HEVC中,采用查表的方式来为每种语法元素进行上下文模型参数初始化。表8.19~表8.45给出了各个语法元素使用的上下文模型索引(ctxIdx)对应的模型参数初始值。在获取语法元素初始值后,计算每个语法元素就可以按照8.3.2节中描述的方法进行逐一编码。
四、变换系数熵编码:
量化后变换系数的熵编码在整个熵编码中占有举足轻重的地位,由于量化后变换系数大多为零值或幅度较小的值,如何有效利用这一特性是熵编码的关键环节。H.265/HEVC 标准中,亮度数据和色度数据均以变换块(Transform Block,TB)为单位,通过编码非零系数的位置信息和非零系数的幅值信息来表示其变换系数。
下面将详细介绍一个NxN变换块的变换系数是如何进行熵编码的。
变换系数扫描:
在对量化后的变换系数进行熵编码前,须先通过扫描技术将二维的变换系数排列成一维变换系数序列。扫描的顺序需要考虑变换系数幅值的分布,一般将幅度相近的系数尽量相近排列,以便于在CABAC中建立更有效的上下文模型,提高编码效率。
在 H.265/HEVC中,变换系数的扫描是基于4x4大小的子块进行的,较大的 TB需要首先被分割为多个4x4子块,子块和子块内部系数按照相同的方式进行递归扫描。图8.7(a)给出了8x8的TB采用对角扫描时变换系数的扫描顺序,8x8的TB被划分为4个4x4的TB,扫描起始于最后一个系数,终止于DC系数,扫描过程包括了子块的扫描和子块内变换系数的扫描!21。子块扫描中 4x4子块从右上角到左下角逐一扫描,子块内变换系数扫描中4x4系数从右上角到左下角逐一扫描。这种基于4x4 子块的扫描技术可以一致性地处理所有大小的TB,有助于编码器模块化。一个 4x4子块内扫描后的16个连续系数称为系数组(Coeffcient Group,CG).
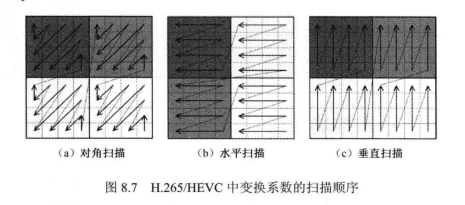
上述的对角扫描与H.264/AVC中zig-zag 扫描方式相似,此外,H.265/HEVC 还采用了另两种新的扫描方式:水平扫描和垂直扫描,具体扫描顺序分别如图8.7(b)、图8.7(c)所示。所有的扫描都起始于TB内最后一个系数,终止于DC系数,以反向的水平或垂直扫描的方式进行。
采用不同预测模式的TB,其系数分布往往具有一定的规律。如一个采用水平预测模式的帧内块,变换后的能量很大程度上集中在前几列,垂直扫描方式对变化系数的熵编码非常有利,垂直预测模式则更适于水平扫描方式。H.265/HEVC详细规定了预测模式与扫描方式的对应关系,这种方法叫模式依赖的系数扫描,因此扫描方式不需要语法元素显式表示。如对于帧内预测的4x4TB和8x8TB,垂直预测模式对应水平扫描方式。对于16x16 TB和32x32 TB的帧内模式以及帧间预测模式都采用对角扫描。
非零系数位置信息编码:
一个TB的变换系数经过扫描后就可得到一组一维的变换系数,该组系数可以根据非零系数位置信息和幅值信息完全表示,H.265/HEVC 标准就是对该组系数中非零系数位置信息和幅值信息进行CABAC编码。
表示非零系数位置信息涉及的语法元素有Iast_sig_coeff_prefix、last_sig_coeff_y_prefix、last_sig_coeff_x_suffix 、last_sig_coeff_y_suffix、CSBF(coded_sub_block_flag)和sig_coeff_flag。前4个语法元素用于标定TB中的最后一个非零系数的位置,即经扫描后的第一个非零系数在TB中的位置。后面两个语法元素用于标定经扫描后除第一个非零系数外的所有非零系数位置。
最后一个非零系数的位置:
对一个 TB的变换系数进行熵编码,首先是编码 TB中的最后一个非零系数的位置。设经过扫描后的最后一个非零系数在TB中的位置坐标为(xy),x和分别表示该系数所在的列号和行号。x使用语法元素last_sig_coeff_x_prefix和last_sig_coeff_x_suffx 表示,y使用语法元素last_sig_coeff_y_prefix和 last_sig_coeff_y_sufix 表示。这4个语法元素值的获取过程为:将TB的行和列划分为N个区间,不同尺寸的变换块对应的N不同,变换块尺寸为4x4、8x8、16x16、32x32时,对应的N分别为 4、6、8、10。每个区间对应一个区间索引,表示该区间内的最小位置坐标,通过x和y值就可以得到它们各自所在的区间索引以及区间内的偏移量,last_significant_coeff x_prefix和last _significant_coey_prefx 就等于x和y各自所在的区间索引值,last_signifcant_coeff_x_sumx和last_signifcant_coeff_y_sux就等于x和y各自所在区间内的偏移量,区间索引值对应的最小位置坐标加上偏移量,即可分别得到x和,最终的位置坐标。表8.46给出了TB为32x32时,x或y所对应的区间索引和区间内的偏移量,以及各自的二元码。
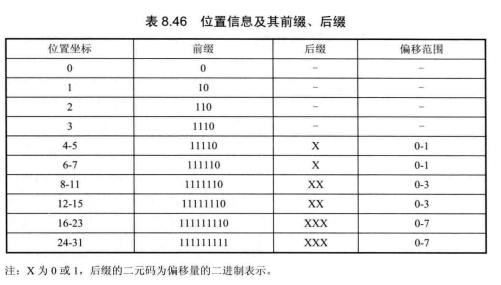
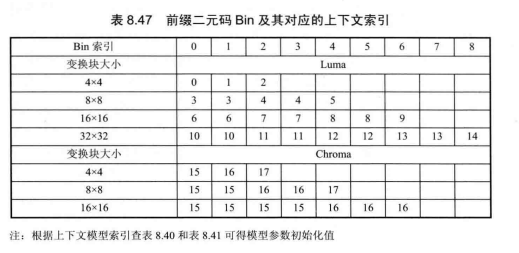
最后一个非零系数位置的熵编码即为对这4个语法元素进行CABAC编码,具体顺序为:首先,编码语法元素ast_sig_coeff_x_prefix和 last_sig_coeff_y_prefix;然后,编码 last_sig_coeffx_sux和last_sig_coeff_y_suffx,last_significant_coeff_x_prefix 和 last_significant_coeff_y_prefix经TR二元化后进行常规编码,采用的上下文模型索引见表8.47,last_signifcant_coeffx_suffx和last_ signifcant_coeff_y_suffx经FL二元化后进行旁路编码。
其余非零系数的位置:
最后一个非零系数位置信息之后,是剩余非零系数的位置信息,其涉及CSBF(coded subblock flag)和 sig coef flag 两个语法元素。CSBF表示当前系数组CG中是否含有非零系数,其值为1,表示CG内至少含有一个非零系数;其值为0,表示CG内无非零系数。sigcoefag表示当前位置上的系数是否为0,其值为1,表示该位置的系数值是非零的:其值为0,表示该位置的系数为0。对于扫描后的一维变换系数,先编码一个CG的CSBF,若CSBF值为0,则编码下一个CG的CSBF;若CSBF为1,则按照扫描顺序逐一编码CG内每一个位置上非零系数标识sig coetf fag,然后再编码所有非零系数的幅值信息。按照这种方式接着编码下一个 CG,直到编码完一个完整 TB。
在CABAC,CSBF和sig_coeff_flag语法元素无须二元化,直接进行常规编码。CSBF上下文模板的选择基于邻近CG的CSBF值,选取当前CG的右相邻和下相邻CG作为邻近参考CG,邻近CG的CSBF均为0时,当前CG的上下文模型索引为0,否则当前CG的上下文模型索引为1。sig_coeff_ flag 的上下文模板的选择取决于 TB 的尺寸,对于 4x4的 TB,sig_coeff_flag 使用的上下文模板由系数的位置决定,对于其他尺寸的 TB,sig_coeff_nag的上下文模板选择不仅与系数所在的位置有关,还与邻近CG的CSBF取值有关。sig_coeff_flag 的上下文模型没有利用相邻系数之间的相关性,在一定程度上牺牲了编码增益,但可以并行地为一个CG内16个 sig_coeff_flag 确定上下文模板。
由于 H.265/HEVC 采用了多种先进的编码工具,使得变换后预测残差的能量集中在少量的变换系数上,然后经量化处理,得到的变换系数大部分为零,其分布呈稀疏性。使用CSBF和sig_coeff_flag两个语法元素来表示剩余非零系数位置信息,能够有效地利用系数分布的稀疏性。
非零系数幅值信息编码:
当一个CG内含有非零系数时,编码完CG内所有非零系数的位置信息后,再对非零系数的幅值信息依次进行编码。非零系数幅值信息涉及
的语法元素:coeff_sign_flag表示非零系数是正值还是负值,coeff_abs_level_greaterl_flag 表示编码的非零系数幅值绝对值是否大于1;coeff_abs_level_greater2_flag 表示非零系数幅值绝对值是否大于2;coeff_abs_level_remaining表示非零系数幅值绝对值的剩余部分,其值为:coeff_abs_level_remaining = absCoeffLevel-baseLevelbaseLevel = sig_coeff_flag+coeff_abs_level_greaterl_flag+coeff_abs_level_greater2_flag其中,absCoeffLevel为非零系数幅值绝对值。
若编码的 coeff_abs_level_greater1_flag等于0,则表示absCoeffLevel等于1,无须编码 coeff_abs_level_greater2_flag 和 coeff_abs_level_remaining。若编码的 coeff_abs_level_greater2_flag等于0,则表示 absCoeffLevel 等于 2,无须编码 coeff_abs_level_ remaining。
非零系数幅值信息编码的步骤是:按照扫描顺序先编码一个G内所有非零系数的幅值信息,然后再编码下一个CG内所有非零系数的幅值信息。一个CG内所有非零系数的幅值信息编码过程如下。
- 按照扫描顺序先逐一编码CG内前8个非零系数各自的语法元素coeff_abs_level_greaterl_flag,后续的非零系数不再进行语法元素coeff_abs_level_greaterl_flag 的编码,默认它们各自的 coeff_abs_level_greaterl_flag为0;
- 编码CG内第一个absCoeffLevel > 1的非零系数的语法元素coeff_abs level_greater2_flag,后续的非零系数不再进行语法元素coeff_abs_level_greater2_flag 的编码,默认它们各自的 coeff abs_level_greater2_flag为0。
- 编码 CG 内所有非零系数的符号 coeff_sign_flag。
- 计算 CG内所有的非零系数的 coeff_abs_level_remaining,按照扫描顺序进行依次编码。
其中,coeff_abs_level_greater1_flag和coeff_abs_level_greater2_flag采用常规编码,采用的上下文模型参数初始化值见表8.44和表8.45,coeff_abs_level_remaining和 coeff_sign_flag 采用旁路编码。
每个非零系数的符号采用语法元素coeff_signa_flag来标识,该语法元素可以通过旁路编码器进行熵编码,其在视频压缩码流中占据了很大的比例(15%~20%)。在H.265/HEVC中,对非零系数符号的编码允许使用一种符号数据隐藏(Sign Data Hiding,SDH)技术,来减少编码符号数据的比特数。
SDH技术为:首先计算CG内所有非零系数幅值绝对值之和;然后对和值进行奇偶判断,若和值为偶数,则最后一个非零系数的符号被判为“+”,若和值为奇数,则最后一个非零系数的符号被判为“-”。使用SDH 技术,解码端直接判断CG中最后一个非零系数的符号,因此编码端可以省略它的语法元素coeff_sign_flag 的熵编码。然而,若 SDH 的最终结果与CG中最后一个非零系数的真实符号不一致,需要对CG中的系数进行调整以使其保持一致,可以采用以下两种方法。
一种方法是编码过程中采用率失真优化量化(RDOQ)的方法,即编码器允许使用SDH技术,通过调整量化系数,来使SDH判决结果与CG中最后一个非零系数的真实符号保持一致。具体哪个系数修改以及怎样修改,则根据率失真代价来决定。这种方法是基于RDOQ进行的,无须增加额外的运算量,因此编码复杂度增加不多。
对于不进行 RDOQ的编码器,引入下面的方法。在一个CG中,计算原始系数值和反量化系数值之间的差值,对差值最大的量化值进行修正:若差值为正,则量化值加1,若差值为负,则量化值减1。由于差值最大的系数最接近其可行量化值,因此这种量化值的调整所产生的影响较小,且复杂度很低。
是否采用SDH技术需要显式标识,图像参数集中的语法元素sign_data_hiding_enabled _flag置为1表示允许编码器应用 SDH 技术。具体使用方法规定:当编码器允许使用SDH技术且当前编码的CG中第一个非零系数和最后一个非零系数之间的间隔大于等于4时,则该CG才能省略最后一个非零系数符号的熵编码。
参考资料:
《新一代高效视频编码 H.265/HEVC 原理、标准与实现》——万帅 杨付正 编著
相关文章:

音视频之H.265/HEVC熵编码
H.265/HEVC系列文章: 1、音视频之H.265/HEVC编码框架及编码视频格式 2、音视频之H.265码流分析及解析 3、音视频之H.265/HEVC预测编码 4、音视频之H.265/HEVC变换编码 5、音视频之H.265/HEVC量化 6、音视频之H.265/HEVC环路后处理 7、音视频之H.265/HEVC熵编…...

【视频生成模型】通义万相Wan2.1模型本地部署和LoRA微调
目录 1 简介2 本地部署2.1 配置环境2.2 下载模型 3 文生视频3.1 运行命令3.2 生成结果 4 图生视频4.1 运行命令4.2 生成结果 5 首尾帧生成视频5.1 运行命令5.2 生成结果 6 提示词扩展7 LoRA微调 1 简介 2 本地部署 2.1 配置环境 将Wan2.1工程克隆到本地: git cl…...

Java高频面试之并发编程-09
hello啊,各位观众姥爷们!!!本baby今天来报道了!哈哈哈哈哈嗝🐶 面试官:详细说说ThreadLocal ThreadLocal 是 Java 中用于实现线程本地变量的工具类,主要解决多线程环境下共享变量的…...
)
[Vulfocus解题系列]Apache HugeGraph JWT Token硬编码导致权限绕过(CVE-2024-43441)
[Vulfocus解题系列]Apache HugeGraph JWT Token硬编码导致权限绕过(CVE-2024-43441) Apache HugeGraph 是一款快速、高度可扩展的图数据库。它提供了完整的图数据库功能,具有出色的性能和企业级的可靠性。 Apache HugeGraph 存在一个 JWT t…...
)
MySQL最新安装、连接、卸载教程(Windows下)
文章目录 MySQL最新安装、连接、卸载教程(Windows下)1.MySQL安装2.MySQL连接2.1 命令行连接2.2 图形化连接(推荐) 3.MySQL卸载参考 MySQL最新安装、连接、卸载教程(Windows下) 1.MySQL安装 MySQL 一共可以…...

Scala 函数柯里化及闭包
一、柯里化 1.1 定义 柯里化是将一个接受多个参数的函数转换为一系列接受单个参数的函数的过程。每个函数返回一个新函数,直到所有参数都被收集完毕,最终返回结果。 1.2 示例 非柯里化函数(普通多参数函数) def add(a: Int, b…...

EasyRTC嵌入式音视频通信SDK助力视频客服,开启智能服务新时代
一、背景 在数字化服务浪潮下,客户对服务体验的要求日益提升,传统语音及文字客服在复杂业务沟通、可视化指导等场景下渐显不足。视频客服虽成为企业服务升级的关键方向,但普遍面临音视频延迟高、画质模糊、多端适配难、功能扩展性差等问题&a…...

OceanBase数据库-学习笔记1-概论
多租户概念 集群和分布式 随着互联网、物联网和大数据技术的发展,数据量呈指数级增长,单机数据库难以存储和处理如此庞大的数据。现代应用通常需要支持大量用户同时访问,单机数据库在高并发场景下容易成为性能瓶颈。单点故障是单机数据库的…...

Android 理清 Gradle、AGP、Groovy 和构建文件之间的关系
在 Android 开发中,我们常常会接触到一系列看似相近却各有分工的名词,比如:Gradle、Groovy、AGP、gradle-wrapper.properties、build.gradle、settings.gradle 等等。 它们彼此之间到底是什么关系?各自又承担了什么角色࿱…...

ubuntu 安装ollama后,如何让外网访问?
官网下载linux版本:https://ollama.com/download/linux 1、一键安装和运行 curl -fsSL https://ollama.com/install.sh | sh 2、下载和启动deepseek-r1大模型 ollama run deepseek-r1 这种方式的ollama是systemd形式的服务,会随即启动。默认开启了 …...

安卓的Launcher 在哪个环节进行启动
安卓Launcher在系统启动过程中的关键环节启动,具体如下: 内核启动:安卓设备开机后,首先由引导加载程序启动Linux内核。内核负责初始化硬件设备、建立内存管理机制、启动系统进程等基础工作,为整个系统的运行提供底层支…...

【银河麒麟高级服务器操作系统】在VMware虚拟机情况下出现软锁处理过程
系统环境及配置 系统环境 物理机/虚拟机/云/容器 VMware虚拟机,宿主机型号是YK SR750 网络环境 外网/私有网络/无网络 私有网络 硬件环境 机型 VMware Virtual Platform 处理器 Intel(R) Xeon(R) Gold 6348 CPU 2.60GHz 内存 64GB 整机类型/架构 x86…...

Ubuntu 22.04.4操作系统初始化详细配置
上一章节,主要讲解了Ubuntu 22.04.4操作系统的安装,但是在实际生产环境中,需要对Ubuntu操作系统初始化,从而提高系统的性能和稳定性。 一、查看Ubuntu系统版本和内核版本 # 查看系统版本 testubuntu:~$ sudo lsb_release -a Rel…...

[ACTF2020 新生赛]Upload
先写一个万能的一句话木马 使用一句话木马 发现这个是有内容过滤的 过滤了 <? 发现这个过滤的很死那就只能使用 不带 ? 的短标签了 使用script 标签 这个的使用只限于对方的php是5版本的 正好是低版本的 所以直接上传 改一下后缀为 phtml 成功上传 但是我们没有…...

Harbor2.0仓库镜像清理策略
背景 在持续集成和持续部署的流程中,频繁的构建和部署会生成大量的镜像版本。这些历史镜像如果不及时清理,会占用大量的存储空间,导致 Harbor 仓库膨胀,影响系统性能。 目前 公司的Harbor存储已经占用1T,好多的repo的…...
——电子制造行业趋势分析案例)
从零开始了解数据采集(二十一)——电子制造行业趋势分析案例
这次分享一个偏行业性的趋势分析案例,在项目中为企业实实在在的提高了良品率。不懂什么是趋势分析的同学,可以翻看前面的文章。 在广东某电子制造厂中,管理层发现最近几个月生产良品率有所波动,但无法明确波动原因,也…...

从零开始开发一个简易的五子棋游戏:使用 HTML、CSS 和 JavaScript 实现双人对战
介绍 五子棋,作为一种经典的棋类游戏,不仅考验玩家的策略与判断力,还能在繁忙的生活中带来一丝轻松。今天,我们将用 HTML、CSS 和 JavaScript 来开发一个简易的五子棋游戏,玩家可以在浏览器中与朋友展开一场刺激的对决…...
)
用Node.js施展文档比对魔法:轻松实现Word文档差异比较小工具,实现Word差异高亮标注(附完整实战代码)
引言:当「找不同」遇上程序员的智慧 你是否经历过这样的场景? 法务同事发来合同第8版修改版,却说不清改了哪里 导师在论文修改稿里标注了十几处调整,需要逐一核对 团队协作文档频繁更新,版本差异让人眼花缭乱 传统…...

计算机基本理论与 ARM 相关概念深度解析
一、计算机基本理论 1. 计算机的组成 计算机硬件系统由五大部件构成: 运算器:负责算术运算(如加减乘除)与逻辑运算(如与、或、非),是数据处理的核心单元。控制器:从存储器中逐条提…...

adb常用的20个命令
ADB(Android Debug Bridge)是Android开发工具中的一个命令行工具,常用于与Android设备进行交互、调试和测试。以下是ADB常用的20个命令: adb devices:列出所有已连接的设备及其状态。adb connect <device_ip…...
进行程序调试保姆级教程(2万字长文))
C++如何使用调试器(如GDB、LLDB)进行程序调试保姆级教程(2万字长文)
C作为一门高性能、接近底层的编程语言,其复杂性和灵活性为开发者提供了强大的能力,同时也带来了更高的调试难度。与一些高级语言不同,C程序往往直接操作内存,涉及指针、引用、多线程等特性,这些都可能成为错误的温床。…...
:你吸收什么,便成为什么)
【计算机哲学故事1-2】输入输出(I/O):你吸收什么,便成为什么
“我最近,是不是废了……”她瘫在沙发上,手机扣在胸口,盯着天花板自言自语。 我坐在一旁,随手翻着桌上的杂志,没接话,等着她把情绪发泄完。 果然,几秒后,她重重地叹了口气…...
: 电源管理体系完整梳理:I2C、Regulator、PMIC与Power-Domain框架)
驱动开发硬核特训 · Day 22(上篇): 电源管理体系完整梳理:I2C、Regulator、PMIC与Power-Domain框架
📘 一、电源子系统总览 在现代Linux内核中,电源管理不仅是系统稳定性的保障,也是实现高效能与低功耗运行的核心机制。 系统中涉及电源管理的关键子系统包括: I2C子系统:硬件通信基础Regulator子系统:电源…...

Linux一个系统程序——进度条
一、回车与换行 \n :回车加换行 \r:换行 观察我们发现以上的两个代码除了缺少/n没有任何区别,但是运行代码之后我们会发现有何大的不同,图一会先在屏幕上打印helloworld在进行休眠2,但是图二会先休眠2在打印helloworld,原因是pr…...

从零到精通:深入剖析GoFrame的gcache模块及其在项目中的实战应用
一、引言 在后端开发的世界里,Go语言凭借其简洁的语法、高效的并发模型和强大的标准库,已成为许多开发者的首选。从Web服务到分布式系统,Go的身影无处不在,而其生态也在不断壮大。作为Go生态中的一颗新星,GoFrame&…...

【Linux系统】静态库与动态库
库制作与原理 1. 什么是库 库是写好的现有的,成熟的,可以复用的代码。现实中每个程序都要依赖很多基础的底层库,不可能每个人的代码都从零开始,因此库的存在意义非同寻常。 本质上来说库是一种可执行代码的二进制形式ÿ…...

从零实现分布式WebSocket组件:设计模式深度实践指南
一、为什么需要WebSocket组件? 实时通信需求 传统HTTP轮询效率低,WebSocket提供全双工通信适用于即时聊天、实时数据监控、协同编辑等场景 分布式系统挑战 多节点部署时需解决会话同步问题跨节点消息广播需借助中间件(Redis/RocketMQ等&…...

使用 OpenCV 和 dlib 进行人脸检测
文章目录 1. 什么是 dlib2. 前期准备介绍2.1 环境准备2.2 dlib 的人脸检测器 3. 代码实现3.1 导入库3.2 加载检测器3.3 读取并调整图像大小3.4 检测人脸3.5 绘制检测框3.6 显示结果 4. 完整代码5. 优化与改进5.1 提高检测率5.2 处理 BGR 与 RGB 问题 6. 总结 人脸检测是计算机视…...

03.使用spring-ai玩转MCP
接着上篇:https://blog.csdn.net/sinat_15906013/article/details/147052013,我们介绍了,什么是MCP?使用cline插件/cherry-studio安装了Mcp Server,本篇我们要借助spring-ai实现MCP Client和Server。 使用spring-ai的…...

LeetCode12_整数转罗马数字
LeetCode12_整数转罗马数字 标签:#哈希表 #数字 #字符串Ⅰ. 题目Ⅱ. 示例 0. 个人方法:模拟官方题解二:硬编码数字 标签:#哈希表 #数字 #字符串 Ⅰ. 题目 七个不同的符号代表罗马数字,其值如下: 符号值I…...

展销编辑器操作难度及优势分析
也许有人会担心,如此强大的展销编辑器,操作起来是否会很复杂?答案是否定的。展销编辑器秉持着 “简单易用” 的设计理念,致力于让每一位用户都能轻松上手,即使是没有任何技术背景的小白,也能在短时间内熟练掌握。 编…...

展销编辑器在未来的发展前景
展销编辑器在展销行业的发展前景极为广阔,有望引领行业迈向更加智能化、个性化、沉浸式的新时代,对行业变革产生深远影响。 随着人工智能、虚拟现实、增强现实等技术的不断发展和融合,展销编辑器将实现更加智能化的功能。例如,借…...

央视两次采访报道爱藏评级,聚焦生肖钞市场升温,评级币成交易安全“定心丸”
CCTV央视财经频道《经济信息联播》《第一时间》两档节目分别对生肖贺岁钞进行了5分钟20秒的专题报道。长期以来,我国一直保持着发行生肖纪念钞和纪念币的传统,生肖纪念钞和纪念币在收藏市场保持着较高的热度。特别是2024年初,央行发行了首张贺…...

登高架设作业指的是什么?有什么安全操作规程?
登高架设作业是指在高处从事脚手架、跨越架架设或拆除的作业。具体包括以下方面: 脚手架作业 搭建各类脚手架,如落地式脚手架、悬挑式脚手架、附着式升降脚手架等,为建筑施工、设备安装、高处维修等作业提供安全稳定的工作平台。对脚手架进行…...

Kaamel白皮书:IoT设备安全隐私评估实践
1. IoT安全与隐私领域的现状与挑战 随着物联网技术的快速发展,IoT设备在全球范围内呈现爆发式增长。然而,IoT设备带来便捷的同时,也引发了严峻的安全与隐私问题。根据NSF(美国国家科学基金会)的研究表明,I…...

uniapp跨平台开发---动态控制底部切换显示
业务需求 不同用户或者应用场景,底部tab展示不同的内容,针对活动用户额外增加底部tab选项 活动用户 非活动用户 实现思路 首先在tabbar list中增加中间活动tab的路径代码,设置visible:false,然后再根据条件信息控制活动tab是否展示 pages.json {"pagePath": "…...

django admin 去掉新增 删除
在Django Admin中,你可以通过自定义Admin类来自定义哪些按钮显示,哪些不显示。如果你想隐藏“新增”和“删除”按钮,可以通过重写change_list_template或使用ModelAdmin的has_add_permission和has_delete_permission属性来实现。 方法1&…...

final static 中是什么final static联合使用呢
final static 联合使用详解 final 和 static 在 Java 中经常一起使用,主要用来定义类级别的常量。这种组合具有两者的特性: 基本用法 public class Constants {// 典型的 final static 常量定义public static final double PI 3.141592653589793;pub…...

【项目管理】知识点复习
项目管理-相关文档,希望互相学习,共同进步 风123456789~-CSDN博客 (一)知识总览 项目管理知识域 知识点: (项目管理概论、立项管理、十大知识域、配置与变更管理、绩效域) 对应:第6章-第19章 第6章 项目管理概论 4分第13章 项目资源管理 3-4分第7章 项目…...

cocos creator使用jenkins打包流程,打包webmobile
windows电脑使用 如果你的电脑作为打包机,一定要锁定自己的ip,如果ip动态获取,可能后续会导致jenkins无法访问,还需要重新配置jenkins和http-server的端口 从jenkins官网下载windows版 Thank you for downloading Windows Stable installer 1.jenkins安…...

颠覆传统微商!开源AI智能名片链动2+1模式S2B2C商城小程序:重构社交电商的“降维打击”革命
摘要:传统微商模式长期依赖暴力刷屏、多层分销与价格战,导致用户信任崩塌、行业合规风险激增,近三年行业淘汰率高达67%。本文创新性提出“开源AI智能名片链动21模式S2B2C商城小程序”技术-商业融合架构,通过AI驱动的智能内容引擎、…...

pycharm无法创建venv虚拟环境
pycharm 2022.2.2在创建新project时,选择Virtualenv environment时,提示“无法创建虚拟环境”。 1.查看 PyCharm 日志 日志文件(路径示例:C:\Users\<用户名>\AppData\Local\JetBrains\PyCharm2022.1\log\idea.logÿ…...

nextjs整合快速整合市面上各种AI进行prompt连调测试
nextjs整合快速整合市面上各种AI进行prompt连调测试。这样写法只是我用来做测试。快速对比各种AI大模理效果. 这里参数通过APIPOST进来 import { OpenAIService } from ./openai.service; import { Controller, Post, Body, Param } from nestjs/common; import { jsonrepair …...
开源GVM容器docker部署和汉化介绍)
Greenbone(绿骨)开源GVM容器docker部署和汉化介绍
文章目录 Greenbone(绿骨)开源GVM容器docker部署和汉化介绍前言用容器部署GVM第一步:安装依赖项第二步:安装 Docker第三步:使用 docker-compose编排文件,完成GVM服务部署第四步:启动Greenbone社…...

PDF嵌入隐藏的文字
所需依赖 <dependency><groupId>com.itextpdf</groupId><artifactId>itext-core</artifactId><version>9.0.0</version><type>pom</type> </dependency>源码 /*** PDF工具*/ public class PdfUtils {/*** 在 PD…...

为什么从Word复制到PPT的格式总是乱掉?
从Word复制到PPT的格式总是乱掉,主要有以下原因: 格式兼容性问题 - 软件版本差异:不同版本的Office或WPS软件,对文档格式的支持和处理方式有所不同。如Office 2021中的新功能“动态网格对齐”,在粘贴到Office 2016的…...

五分钟讲清数据需求怎么梳理!
目录 一、为什么要进行数据需求梳理? 1.确保企业收集到真正有价值的数据 2.有助于提高数据分析的效率和质量 3.促进企业内部各部门之间的沟通与协作 二、数据需求怎么梳理? 1. 与业务部门深度沟通 2. 进行业务流程分析 3. 参考行业最佳实践 4. …...

03_多线程任务失败解决方案
文章目录 问题:多线程并发处理时,其中一个任务失败怎么办?1. 异常捕获2. 线程同步3. 资源清理4. 错误恢复5. 通知其他线程6. 使用并发框架 问题:多线程并发处理时,其中一个任务失败怎么办? 这是一个典型的并发编程问题࿰…...
注册与映射机制:JsonListTypeHandler和JsonListTypeHandler注册时机)
MyBatis 类型处理器(TypeHandler)注册与映射机制:JsonListTypeHandler和JsonListTypeHandler注册时机
下面几种机制会让你的 List<String>/Map<String,?> 能正确读写成 JSON 数组/对象文本: MyBatis-Plus 自动注册 最新版本的 MyBatis-Plus starter 会把类路径下所有带 MappedTypes({List.class})、MappedJdbcTypes(JdbcType.VARCHAR) 这类注…...

Spark SQL开发实战:从IDEA环境搭建到UDF/UDAF自定义函数实现
利用IDEA开发Spark-SQL 1、创建子模块Spark-SQL,并添加依赖 <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.12</artifactId> <version>3.0.0</version> </dependency> 3…...