【数据结构】·励志大厂版(复习+刷题):二叉树


前引:哈喽小伙伴们!经过几个月的间隔,还是逃脱不了再次复习的命运!!!本篇文章没有冗杂的闲话,全是干货教学,带你横扫二叉树的几种遍历,怎么前序、、中序、后续?如何识别?二叉树其实难得就是它的递归,代码量其实并不多,插入与遍历打印都是递归,但是本篇文章完全就是buuff加身,看完还不会二叉树的欢迎在评论区留言,小编接受检讨!~~正文开始
目录
知识点速览
树的名词解释
二叉树的四种遍历
二叉树性质:
满二叉树:
完全二叉树:
练习题(1)
练习题(2)
练习题(3)
练习总结
二叉树实现
定义结构体
初始化
新增节点
前序遍历
中序遍历
后序遍历
二叉树OJ(1)
二叉树OJ(2)
二叉树OJ(3)
二叉树OJ(4)
知识点速览
在学二叉树之前我们需要作为补充了解树的几个名词概念
树的名词解释
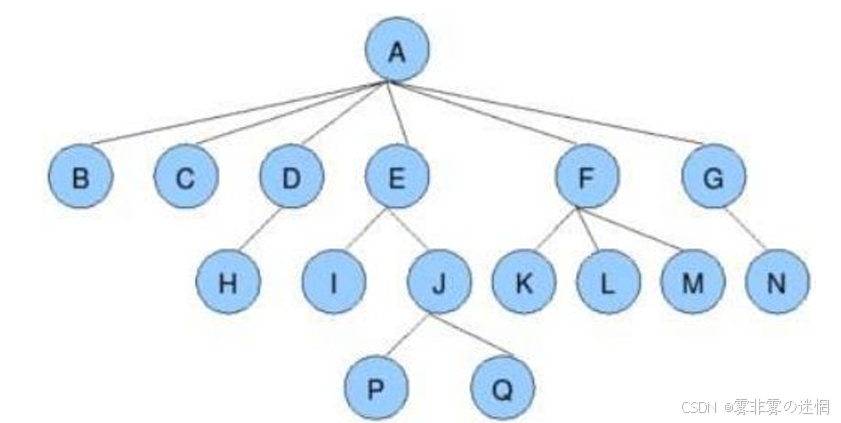
节点的度:一个节点含有子节点的个数。例如A的度:为6
叶节点或终端节点:度为0的节点。例如:B、C、H、P、Q、N都为叶节点
分支节点或非终端节点:度不为0的节点。例如:D、A、G、J都为分支节点
双亲节点或父节点:若一个节点有度(即有子节点),该节点为父节点。例如:A、D、E为父节点
孩子节点或子节点:也就是拥有度的这些节点的下一层节点。例如:B、C、D都为子节点
兄弟节点:拥有相同父节点的子节点。例如:I、J是兄弟节点,K、L、M是兄弟节点
树的度:孩子节点最多的度。例如:这棵树中孩子节点最多的是A节点,那么这颗树的度为6
节点的层次:从根节点开始从1开始算。例如:J的层次为3,Q的层次为4
树的高度或者深度:树中节点的最大层次。例如:这棵树节点层次最大的是P与Q,树最大层次为4
节点的祖先:从根节点到该分支的所有节点。例如:A是所有节点的祖先。G不是L的祖先
子孙:以某节点为根的子树中的任意节点。例如:所有节点是A的子孙。Q不是D的子孙
森林:由 m (m>0)棵互不相交的多棵树的集合称为森林
二叉树的四种遍历
这四种遍历其实并不难,下面小编带大家深刻理解这四种遍历!
首先前、中、后三种遍历中的的这三个关键字“前”“中”“后”都是根据根节点而言的,左子树永远在右子树前面,(大家注意观察根节点与遍历方式的位置!)它的遍历都是将一个子树对应位置遍历完之后再遍历又一个子树,理解:每次不断分成不同大小的树,然后递归到末尾,再原路返回。小编以中序遍历为列,仔细讲解一下!最好的理解方式就是动手画到不出错为止!
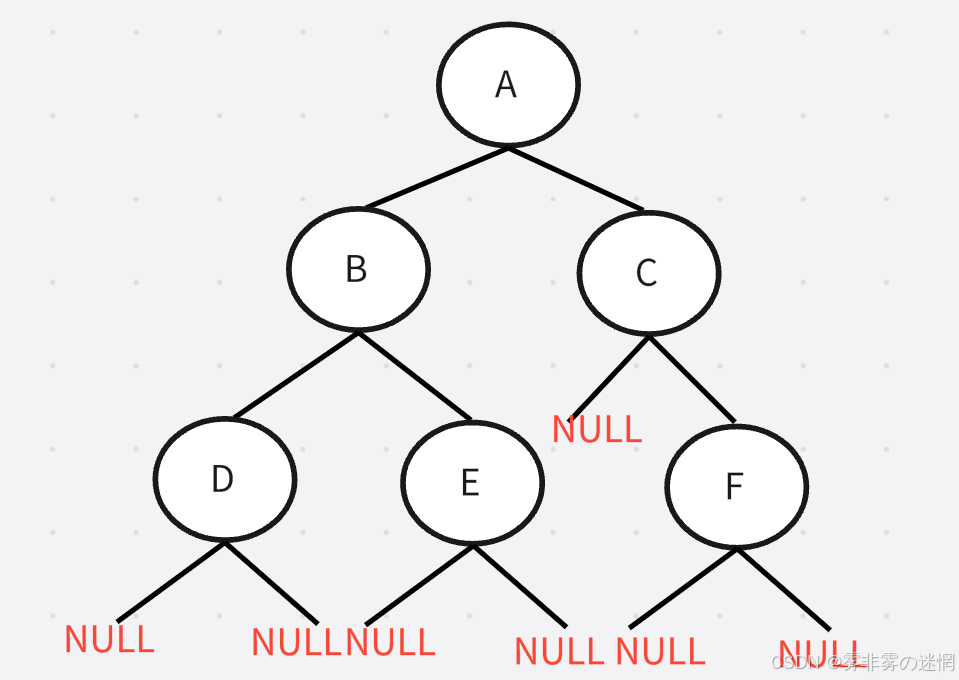
前序遍历:根节点、左子树、右子树
遍历顺序:A->B->D->NULL->NULL->E->NULL->NULL->C->NULL->F->NULL->NILL
中序遍历:左子树、根节点、右子树
以A为根节点,先访问左子树,也就是这部分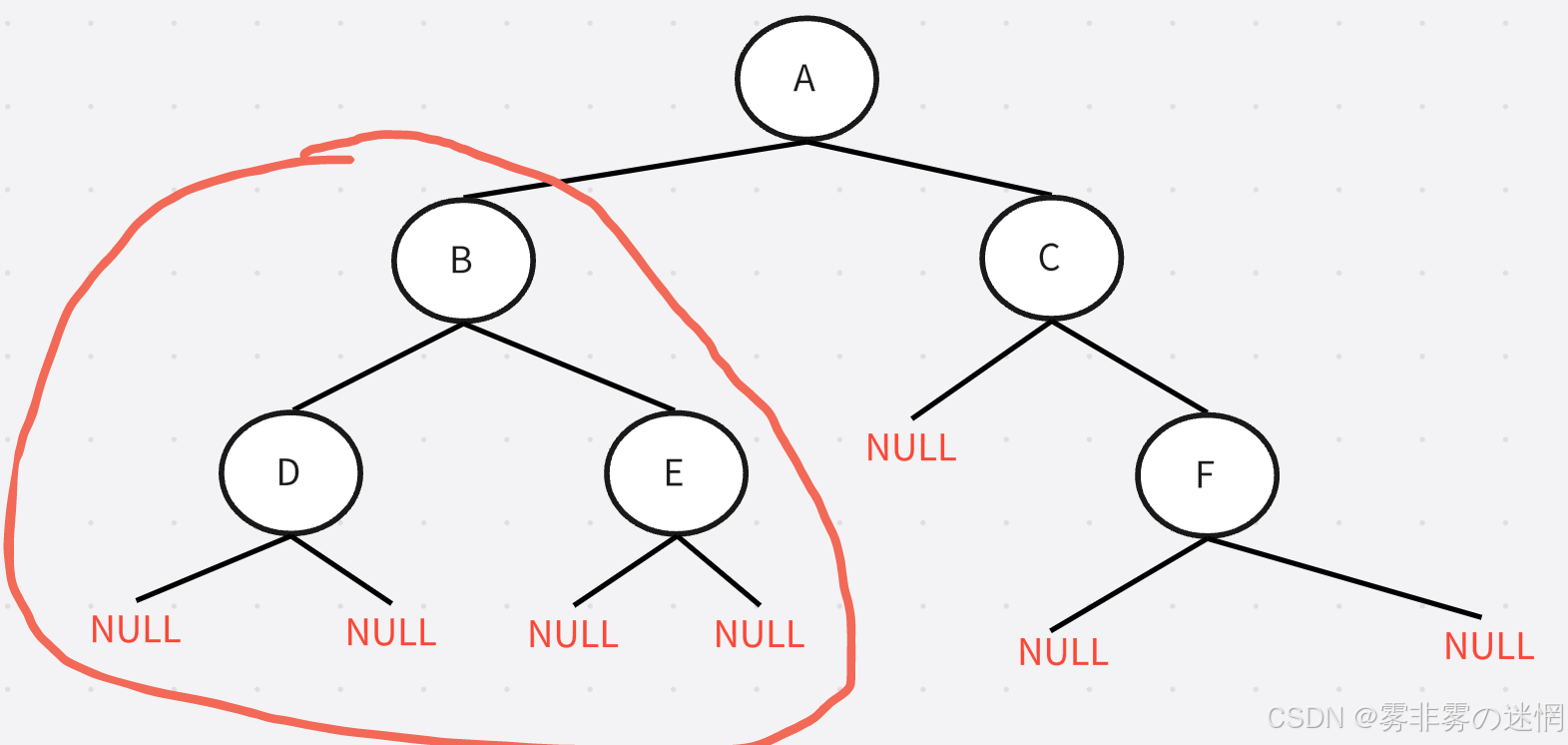
再以B为根节点,再访问左子树,也就是这部分 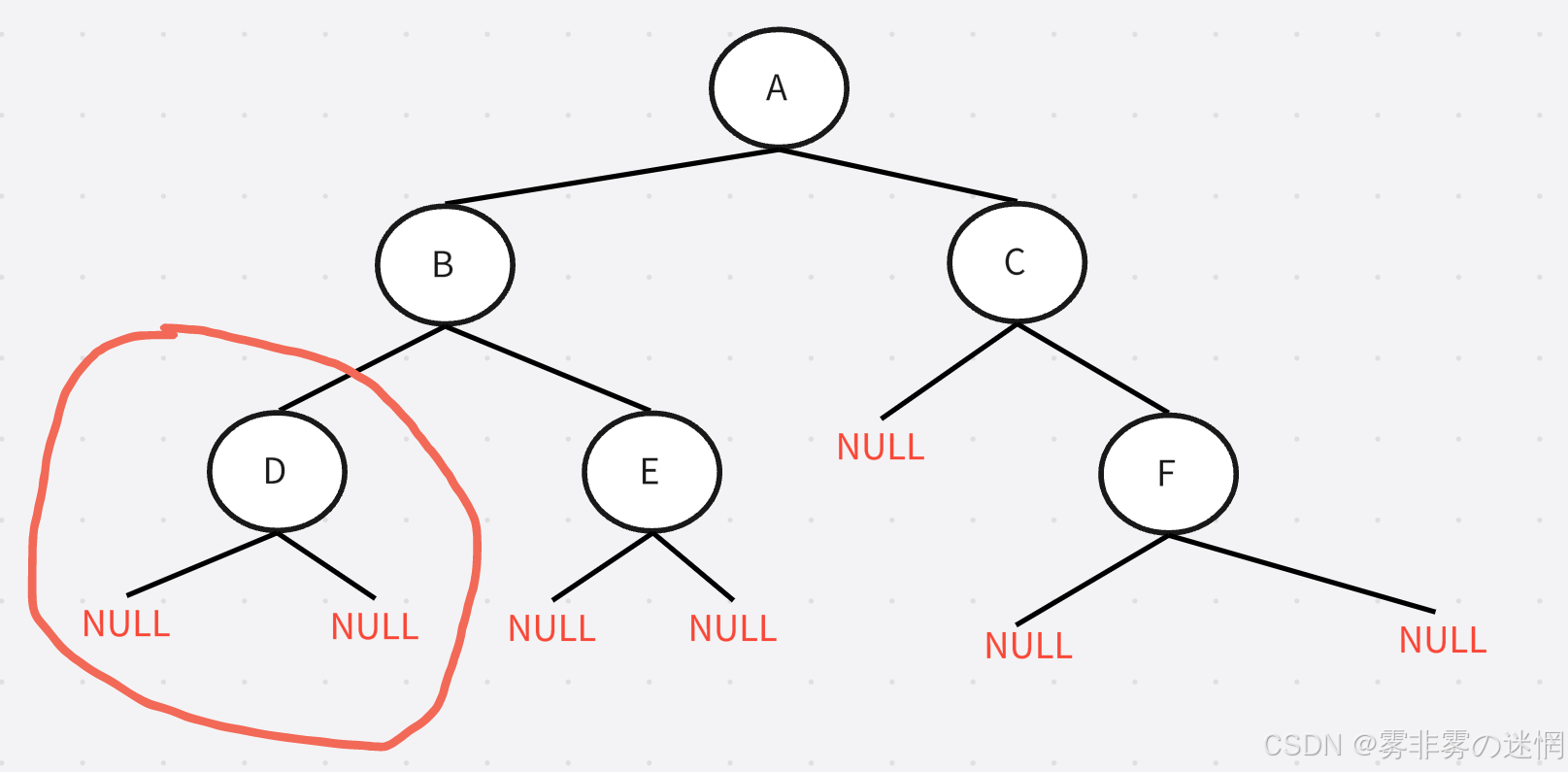
再以D为根节点,访问其左子树,已经是这部分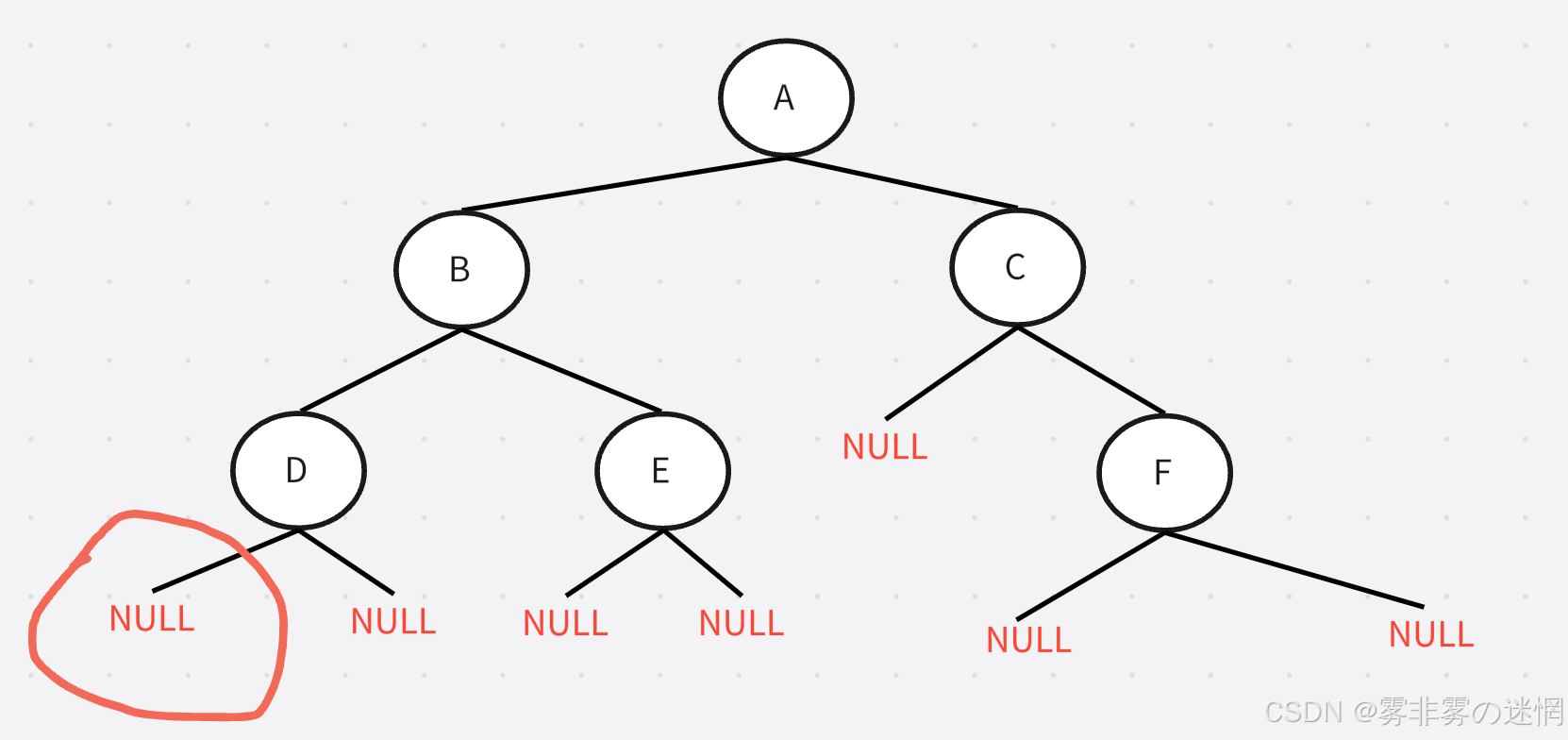
此时已经到底了无法再分,访问“NULL”,然后访问根节点“D”,再访问D的右子树 “NULL”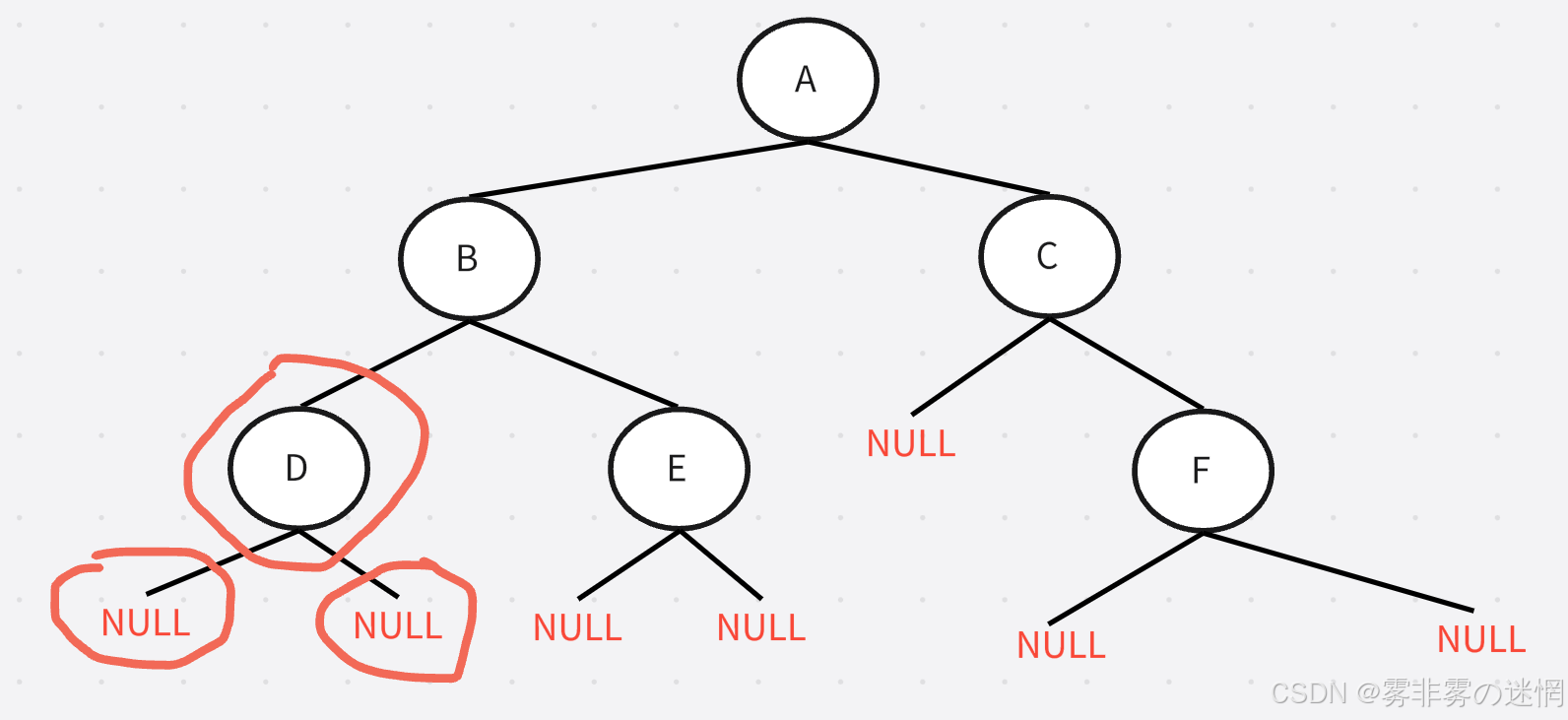
以此类推,直到不能分为止,这里是利用了递归到NULL就返回的原理。
遍历顺序:NULL->D->NULL->B->NULL->E->NULL->A->NULL->C->NULL->F->NULL
后序遍历:左子树、右子树、根节点
遍历顺序:NULL->NULL->D->NULL->NULL->E->B->NULL->NULL->NULL->F->C->A
层序遍历:一层一层访问
遍历顺序:A->B->C->D->E->NULL->F->NULL->NULL->NULL->NULL->NULL->NULL
二叉树性质:
满二叉树:
概念:每个父节点除最后一层的叶子节点外都有两个子节(满二叉树是一种特殊的完全二叉树)
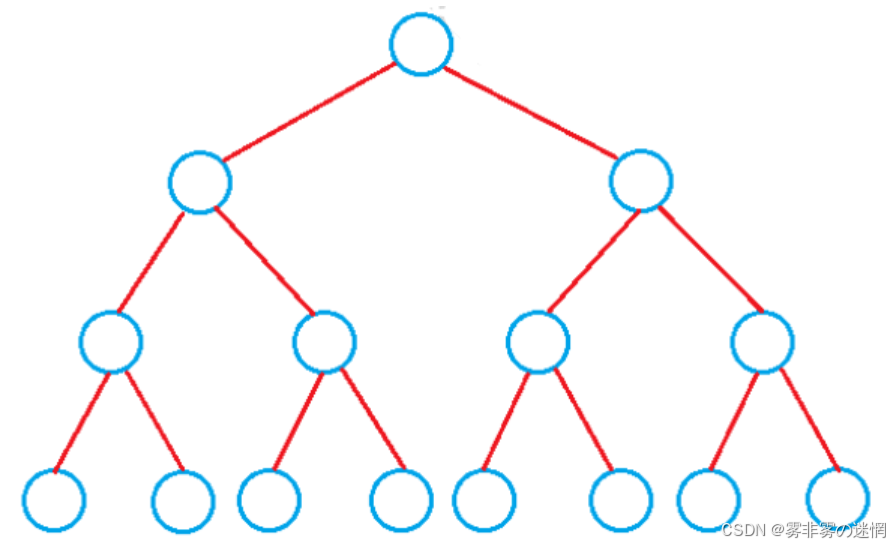
性质(1): 假设根节点层数为0,树层数为K,那么它的节点个数N为 2^K-1,高度为 logN
推论:第一层有1个节点(2^0),第二层有2个节点(2^1),第三层有4个节点(2^2),以此类 推,得到节点数 N = 2^0 + 2^1 + 2^2 + 2^3 + ...... = 2^K -1 . 此时 K = log(N+1)
性质(2):假设根节点层数为0,二叉树第 K 层的节点数最多为 2^K 个
性质(3):任意一棵二叉树,假设度为 0 的节点数为 n0 ,度为 2 的节点数为 n2 ,满足以下关系
满足 n0 = n2+1(只记结论)
例如:假设现在有这样一棵树,度为0的节点数有5个,度为2的节点数有4个,满足 5=4+1
完全二叉树:
概念:只有最后一层不满,且最后一层从左到右是连续的
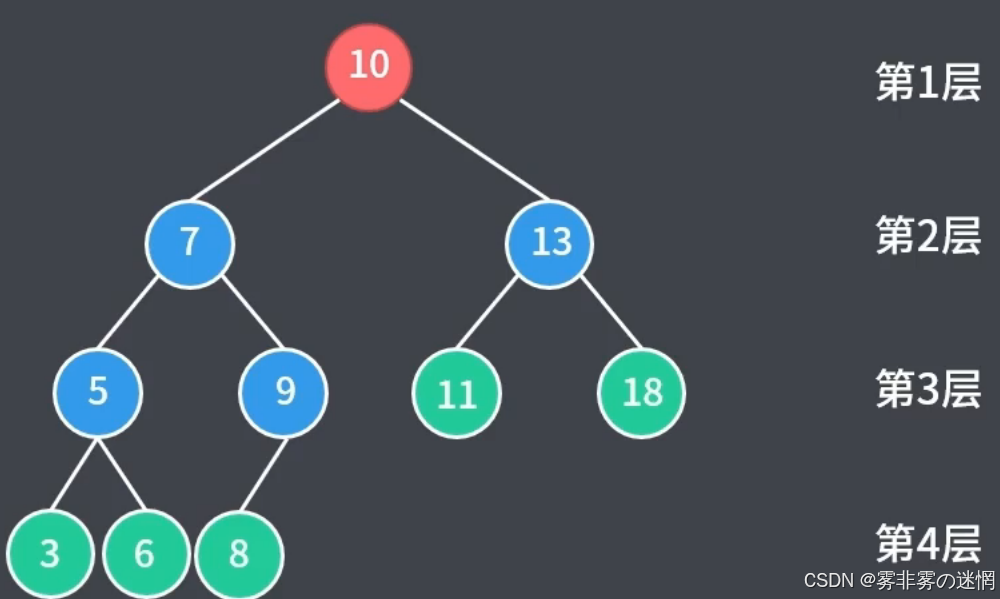
性质:节点总数 N 满足 N < 2^K-1 ,高度 K =log(N+1)
推论:我们无法确定完全二叉树具体的节点个数,只能通过满二叉树进行推理![]() ,其它树亦如此
,其它树亦如此
练习题(1)

套用公式:度为0的节点数(叶子节点)= 度为2的节点数 + 1 ,得到最终答案 200
练习题(2)

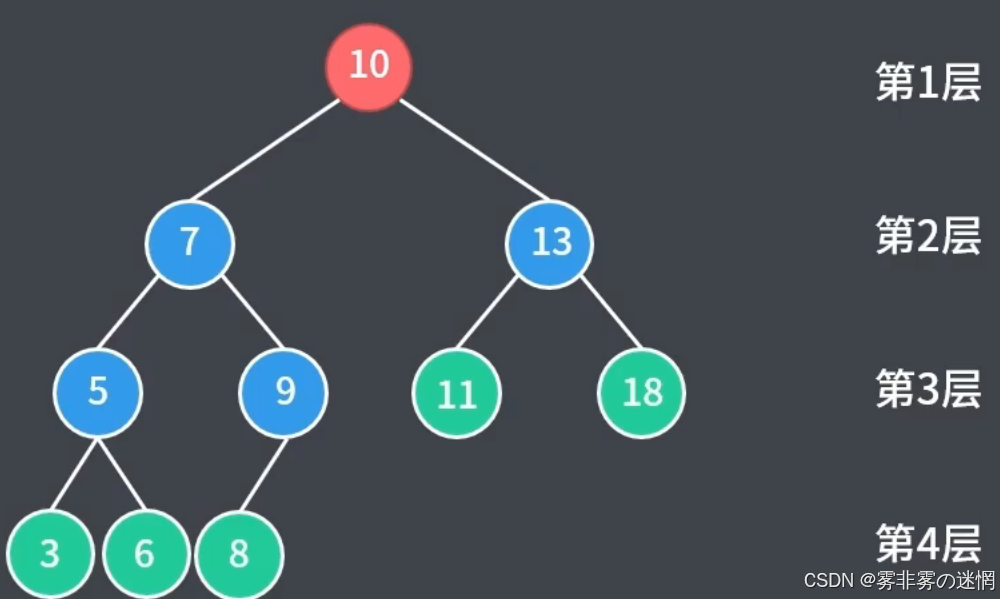
这是一棵完全二叉树,它的节点组成是度为0的、度为1的、度为2的总和,也就是:
x0 + x1 + x2 =2n ,同时套用公式 x0 = x2 + 1,两个结合得到:2 * x0 + x1 - 1 = 2n
我们观察图,发现完全二叉树度为1的节点只有一个,因此 x1 = 1,那么算出来得到 x0 = n
练习题(3)

我们假设高度为 h ,最后一层缺了 x 个,同时知道满二叉树是特殊的完全二叉树
那么满足: 2^h-1 - x = 531. 同时 x 的范围应该在 【0,2 ^ h-1】,x 的范围如下图所示:
直接一个都不缺,为0个
最多缺一个,x为2 ^ h-1个 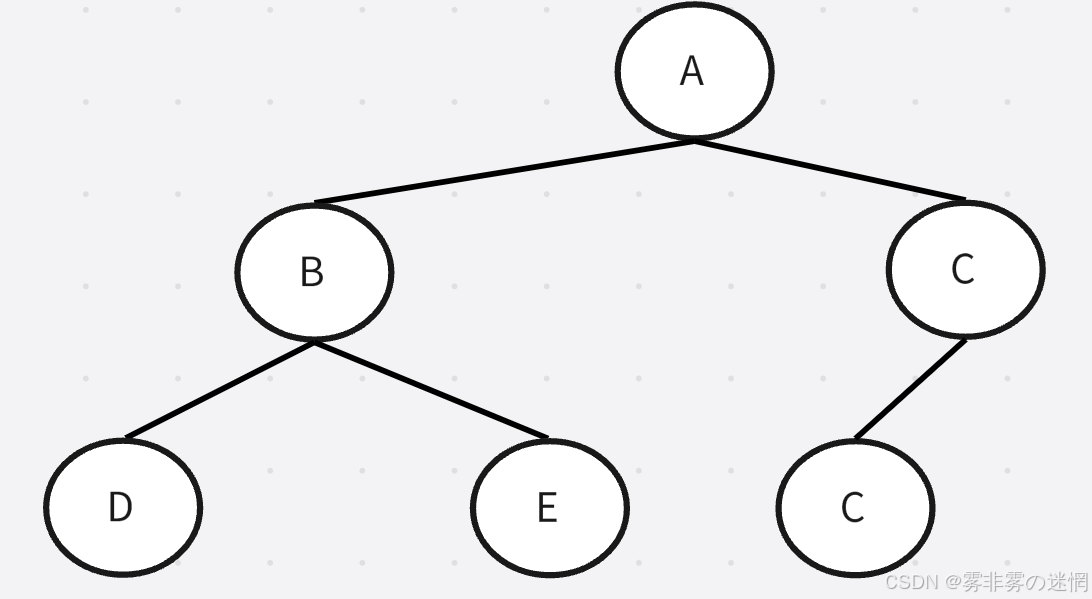
结合这两个关系式,去套,最后得出只有当高度为10时满足 (注意这里的层数从0开始)
练习总结
除了直接套用公式的题,如果出现节点总数求某个变量的值,似乎都要去通过建立方程表示节点总数,表示方式一般有两种:(1)不同度的节点数之和(2)通过节点总数满二叉树计算公式去计算
二叉树实现
定义结构体
咱们按照二叉树的结构,定义一个左子节点、右子节点、一个数据域就行了,这是最简单的定义
//重定义类型
typedef int Datatype;typedef struct Tree
{//左孩子节点struct Tree* left;//右孩子节点struct Tree* right;//数据域Datatype data;
}Tree;初始化
初始化我们开辟一个根节点返回就行了,以后将其作为参数再去连接左右节点
//初始化树
Tree* Perliminary(Datatype data)
{//开辟根节点Tree* newnode = (Tree*)malloc(sizeof(Tree));//判断有效性if (newnode == NULL){printf("节点开辟失败\n");return NULL;}//初始化指针newnode->data = data;newnode->left = NULL;newnode->right = NULL;return newnode;
}新增节点
首先我们初始化了一个根节点,新增的节点值与根节点的值进行比较
如果小于根节点的值,递归左子树;如果大于根节点的值,递归右子树;
随着递归的不断调用,它的根节点会不断改变,如果为空,就返回新增的节点
最后回到最初的根节点
//新增节点
Tree* Capacity(Tree* TreeNode, Datatype data)
{//如果是空节点就插入if (TreeNode == NULL){return Perliminary(data);}//如果是非空节点就继续递归//较小就插入到左子节点if (data < TreeNode->data){TreeNode->left = Capacity(TreeNode->left, data);}elseTreeNode->right = Capacity(TreeNode->right, data);//回到原初的根节点return TreeNode;
}前序遍历
首先递归到子树的极端,遇到空就开始返回,再调整打印顺序
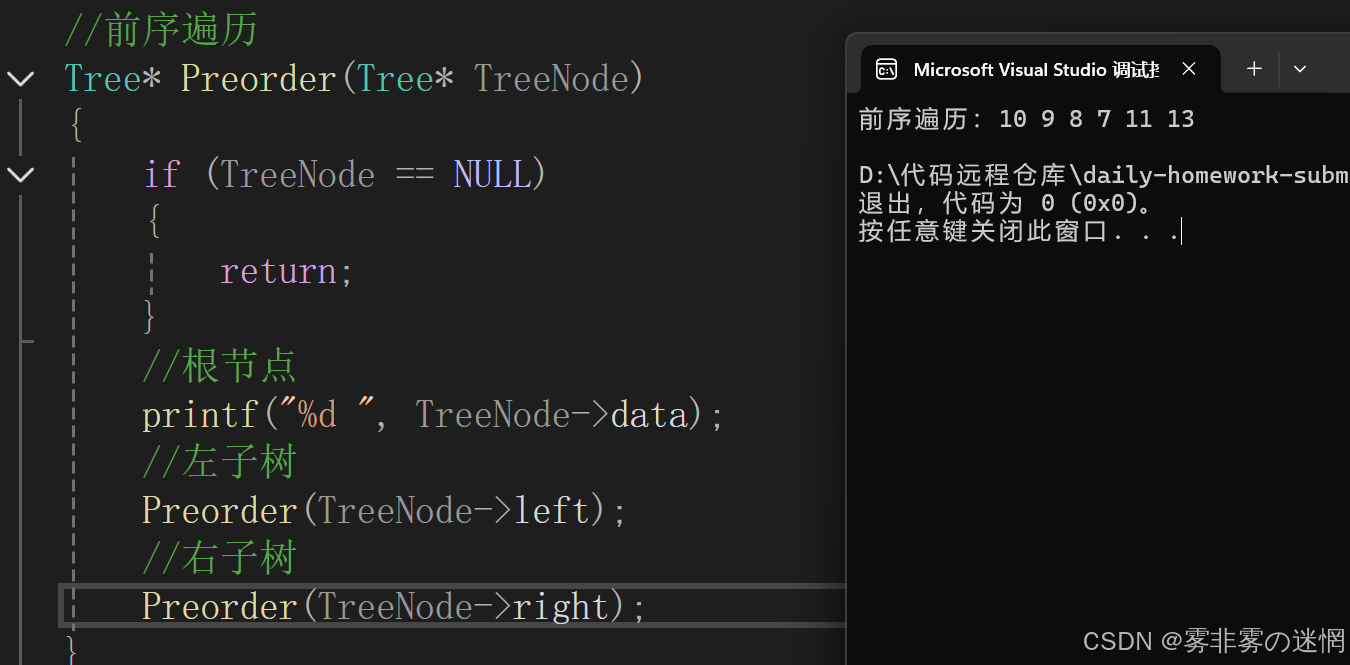
//前序遍历
Tree* Preorder(Tree* TreeNode)
{if (TreeNode == NULL){return;}//根节点printf("%d ", TreeNode->data);//左子树Preorder(TreeNode->left);//右子树Preorder(TreeNode->right);
}中序遍历
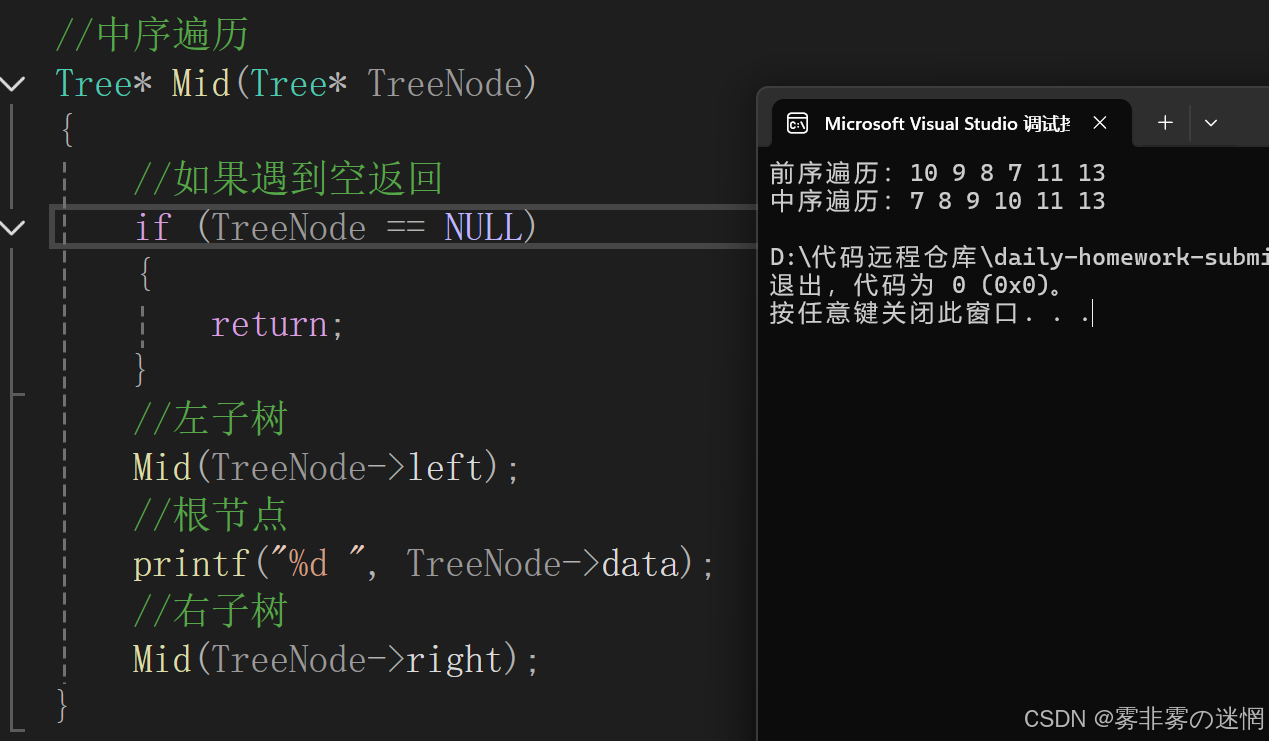
//中序遍历
Tree* Mid(Tree* TreeNode)
{//如果遇到空返回if (TreeNode == NULL){return;}//左子树Mid(TreeNode->left);//根节点printf("%d ", TreeNode->data);//右子树Mid(TreeNode->right);
}后序遍历
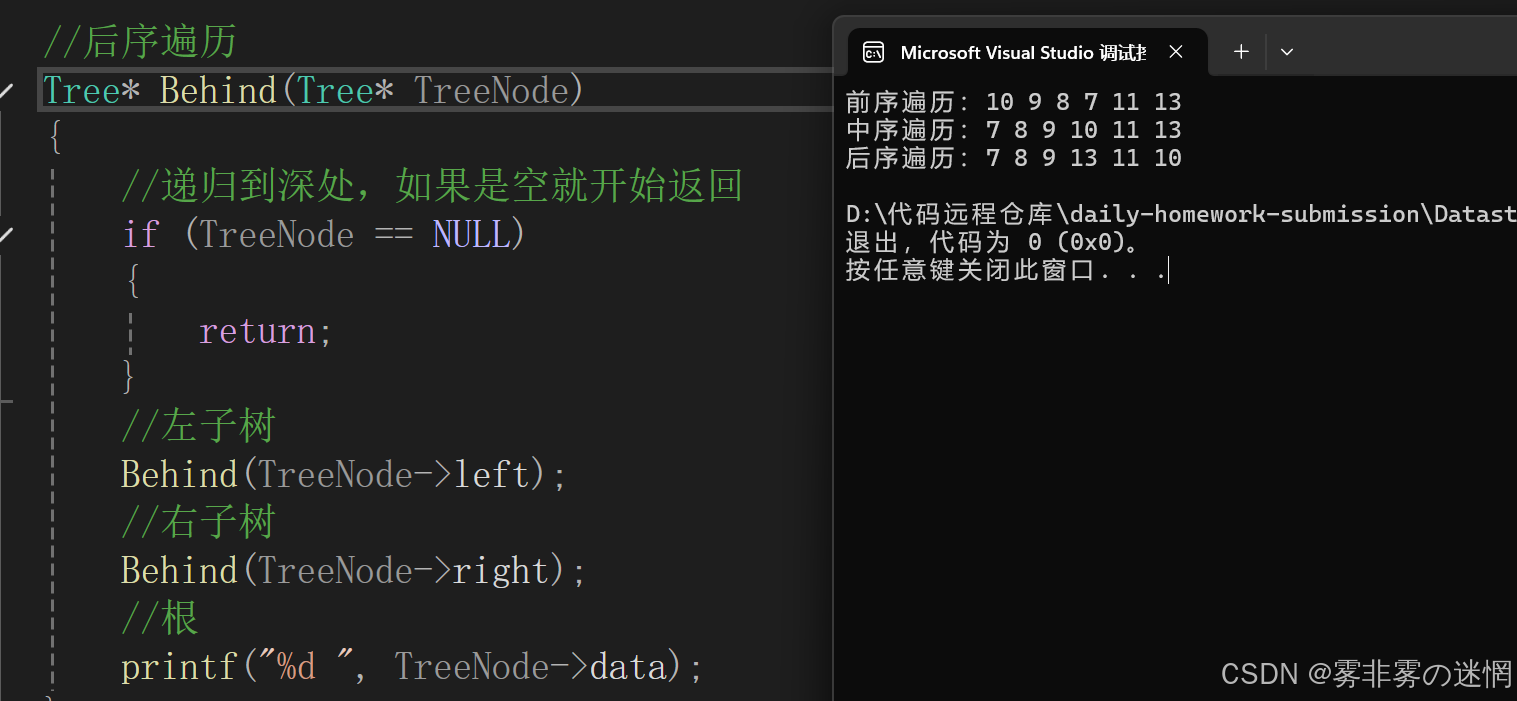
//后序遍历
Tree* Behind(Tree* TreeNode)
{//递归到深处,如果是空就开始返回if (TreeNode == NULL){return;}//左子树Behind(TreeNode->left);//右子树Behind(TreeNode->right);//根printf("%d ", TreeNode->data);
}二叉树OJ(1)

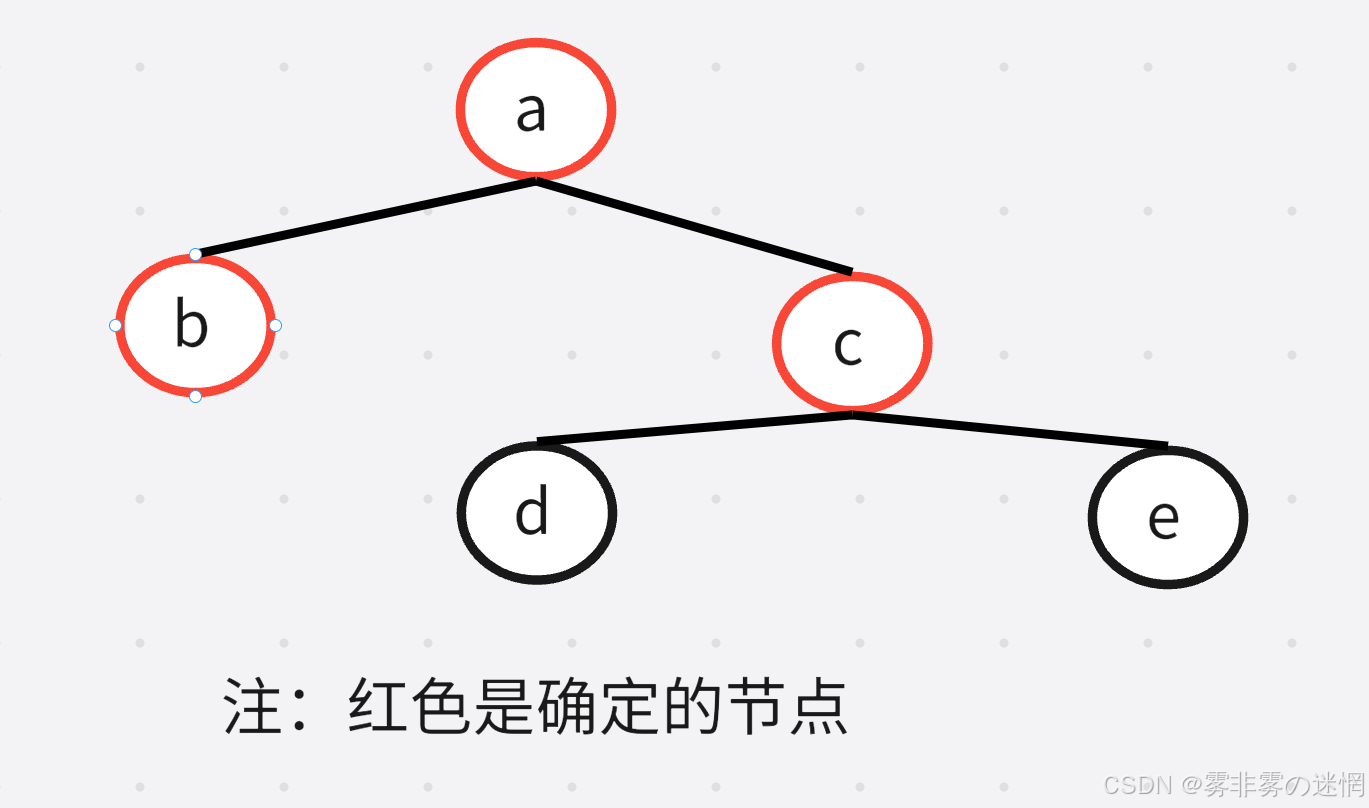
假设现在有这样一棵树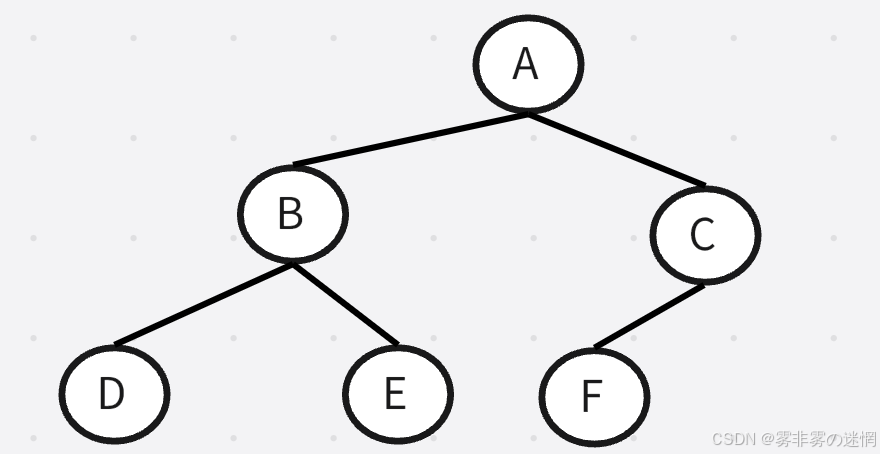
它的中序遍历结果为:D->B->E->A->F->C 后序遍历结果为:D->E->B->F->C->A
按照中序顺序,我们去推得到 b 应该在最左边;按照后序顺序,我们得到 a 应该是根节点
所以 a 是在根节点,再根据中序顺序,得到 a 的左边是 b ,同时 c 是 a 的右子树,这样就能推出
二叉树OJ(2)

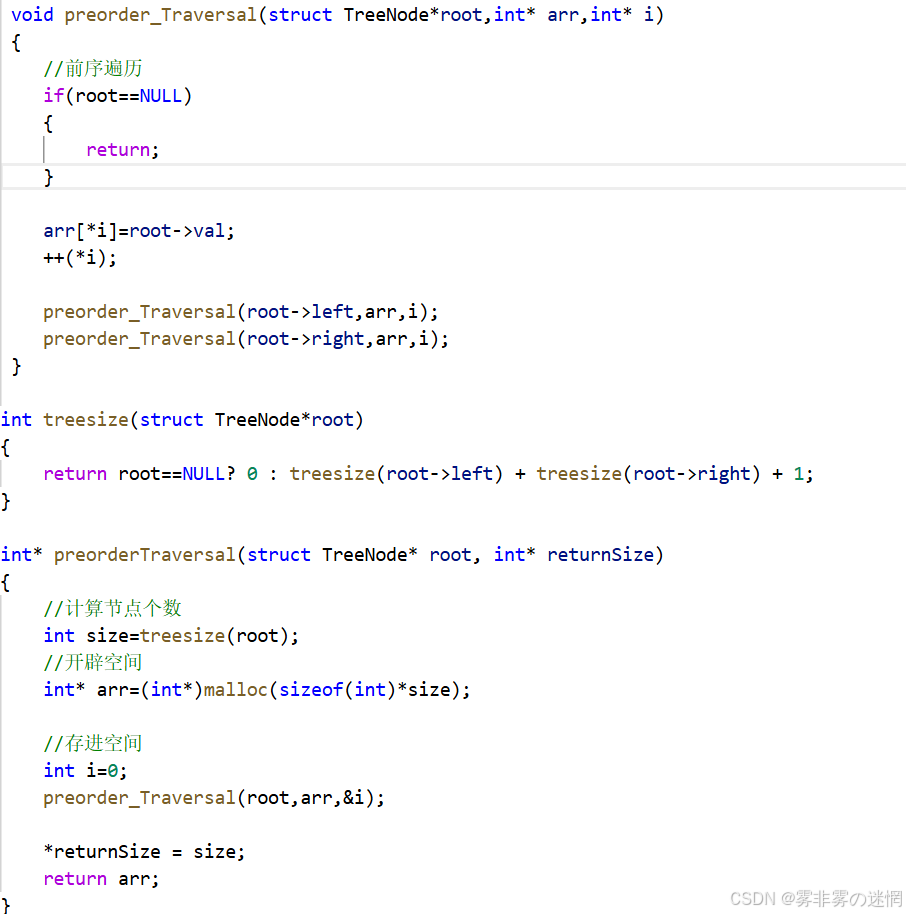
题目链接:https://leetcode.cn/problems/binary-tree-preorder-traversal
题目是要我们将前序遍历的节点结果返回
思维讲解:
流程:用一个空间将每次遍历的值存储起来,然后返回
(1)首先我们开辟数组,数组的空间大小最好是由节点个数决定,因此先遍历二叉树计算节点
return root==NULL? 0 : treesize(root->left) + treesize(root->right) + 1;
(2)然后开辟对应大小的数组空间
//计算节点个数int size=treesize(root);//开辟空间int* arr=(int*)malloc(sizeof(int)*size);(3)接下来就是递归遍历储存节点,但是要考虑一个问题,如果在这个函数里面去递归,那么每次调用都要去开辟空间,所以我们选择再开一个来进行递归遍历,参数是根节点、空间指针、计数
注意:计数的 i 应该取地址,因为递归会开辟多个函数,不然每次 i 都只是一次拷贝而已
//存进空间int i=0;preorder_Traversal(root,arr,&i);(4)然后将之前的前序遍历的打印换成储存即可
//前序遍历if(root==NULL){return;}arr[*i]=root->val;++(*i);preorder_Traversal(root->left,arr,i);preorder_Traversal(root->right,arr,i);(5)最后:这是整型指针空间,返回的只是一个元素,所以按照题目要求,还有设置元素个数
*returnSize = size;return arr;二叉树OJ(3)

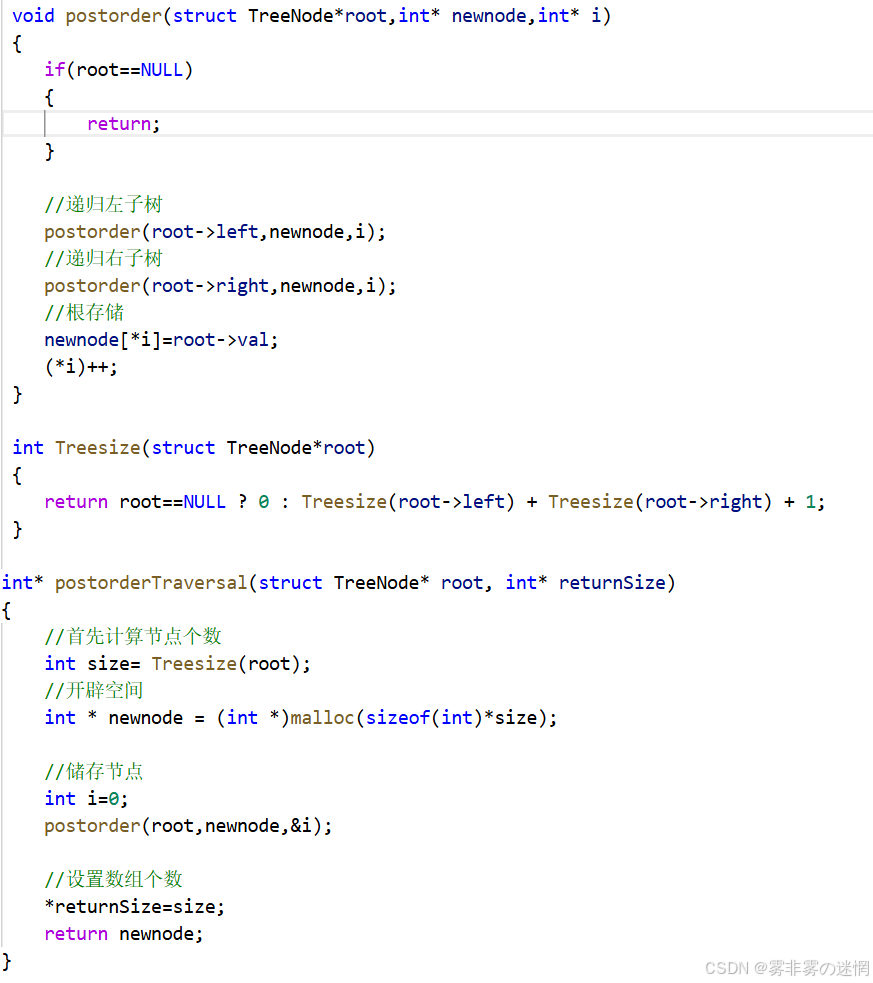
题目链接:https://leetcode.cn/problems/binary-tree-postorder-traversal
此题和上面这题几乎一模一样,就作为思维训练巩固给大家了!记得独立完成哦!
二叉树OJ(4)

题目链接:https://leetcode.cn/problems/maximum-depth-of-binary-tree
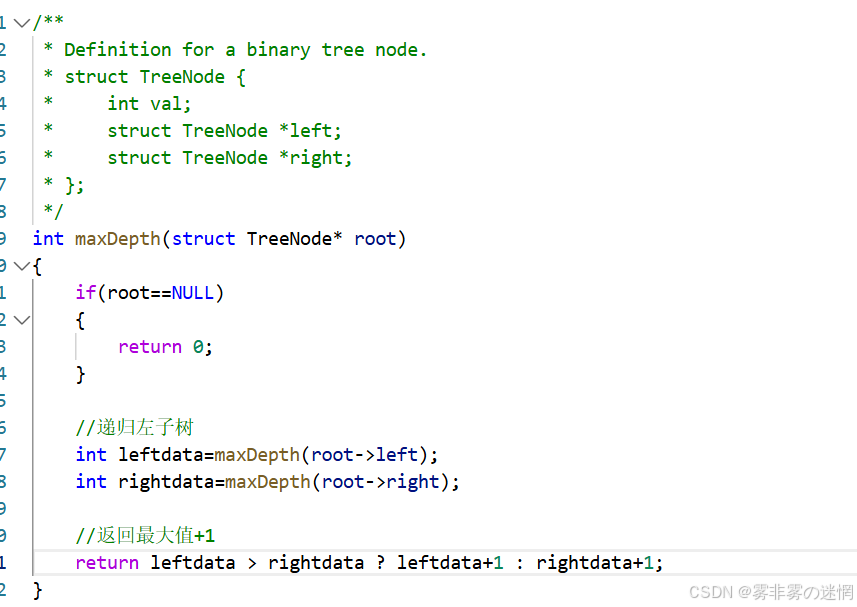
思维讲解:此题是求二叉树的最大深度,二叉树最大深度就是最大层数
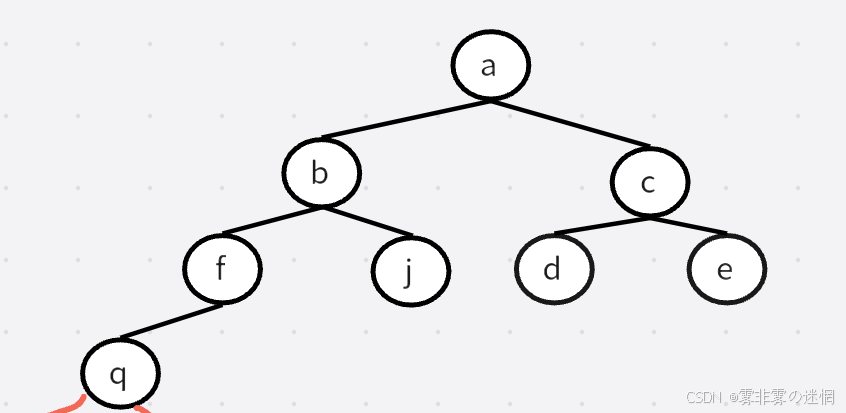
(1)假设有一棵树如上图,它的深度是3。这里采用分治思想,先求左子树的深度为3,再求右子 树的深度为2,再对比找最大值,然后返回 最大值+1(因为一个节点层次为1)
(2)下面我们来实现,先递归左子树,再递归右子树,那么它是如何计算子树深度的呢?
假设递归到左子树的末尾,q 的左子树右子树都为空,返回0,此时0>0为假,返回0+1
那么q拿到的就是1
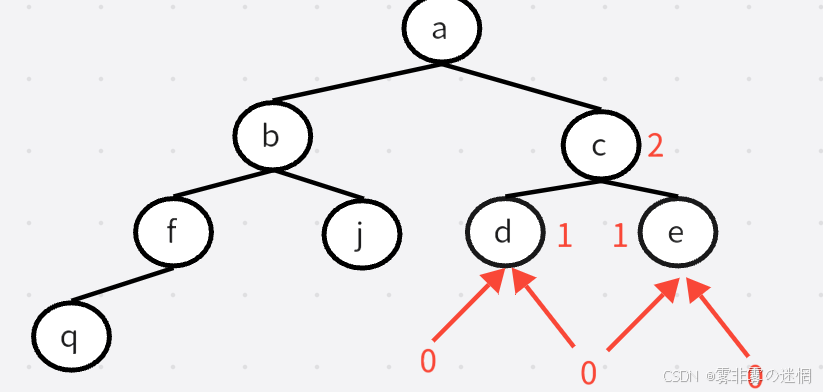
假设递归到 c ,c的左右子树都不为空,继续递归,此时d的左右子树都为空返回,0>0为假d拿到1
同理,e拿到1;1>1为假,c拿到的就是1+1。其它节点类推即可
小编期待与你的下次相遇 !

相关文章:
:二叉树)
【数据结构】·励志大厂版(复习+刷题):二叉树
前引:哈喽小伙伴们!经过几个月的间隔,还是逃脱不了再次复习的命运!!!本篇文章没有冗杂的闲话,全是干货教学,带你横扫二叉树的几种遍历,怎么前序、、中序、后续࿱…...

Spark-Streaming2
一.有状态转化操作 1. UpdateStateByKey UpdateStateByKey 原语用于记录历史记录,有时,我们需要在 DStream 中跨批次维护状态(例如流计算中累加 wordcount)。针对这种情况,updateStateByKey()为我们提供了对一个状态变量的访问&…...

《深入浅出Git:从版本控制原理到高效协作实战》
Git的原理和使用 1、Git初识与安装2、Git基本操作2.1、创建Git本地仓库2.2、配置Git2.3、认识工作区、暂存区、版本库2.4、修改文件2.5、版本回退2.6、撤销修改2.7、删除文件 3、Git分支管理3.1、理解分支3.2、创建、切换、合并分支3.3、删除分支3.4、合并冲突3.5、合并模式3.6…...

内耗型选手如何能做到不内耗?
以下是针对「内耗型选手」的系统性解决方案,结合认知神经科学、行为心理学和效能管理理论,提供可落地的策略框架: 一、建立「内耗熵值」监测系统 1. 绘制内耗热力图 用时间轴记录每日内耗触发点: 时间段内耗场景能量损耗值&…...

pyspark将hive数据写入Excel文件中
不多解释直接上代码,少python包的自己直接下载 #!/usr/bin/env python # -*- encoding: utf-8 -*- from pyspark.sql import SparkSession import pandas as pd import os# 初始化 SparkSession 并启用 Hive 支持 spark SparkSession.builder \.appName("sel…...

Java大师成长计划之第5天:Java中的集合框架
📢 友情提示: 本文由银河易创AI(https://ai.eaigx.com)平台gpt-4o-mini模型辅助创作完成,旨在提供灵感参考与技术分享,文中关键数据、代码与结论建议通过官方渠道验证。 在 Java 编程中,集合框架…...

rt-linux下的D状态的堆栈抓取及TASK_RTLOCK_WAIT状态
一、背景 在之前的博客 缺页异常导致的iowait打印出相关文件的绝对路径-CSDN博客 里的 2.1 一节里的代码,我们已经有了一个比较强大的抓取D状态和等IO状态超过阈值的waker和wakee的堆栈状态的内核模块。在之前的博客 增加等IO状态的唤醒堆栈打印及缺页异常导致iowa…...

数据结构【堆和链式结构】
堆和链式结构 1.堆的概念和定义1.1堆1.2二叉树的性质 2.堆的实现3.实现链式二叉树3.1链式二叉树的概念3.2前中后遍历3.3遍历(举例) 1.堆的概念和定义 1.1堆 定义:是特殊的二叉树 #mermaid-svg-vWPNPMGSLe0nGNcd {font-family:"trebuch…...

聊一聊自动化测试
目录 一、自动化测试的定义与核心价值 (一)什么是自动化测试 (二)核心价值:从人工到智能的跨越 二、自动化测试的发展阶段 (一)萌芽阶段(早期) (二&…...

vue2 开发一个实习管理系统电脑端-前端静态网站练习
为了快速的掌握vue2的所学习到的知识点,最近又使用vue2和element-ui 做了一个实习管理系统来巩固自己的前端技术,我觉得对于新手来说,多写代码,多找一些项目练习,是提供自己编程能力的一个很好的办法,这也是…...

【Hive入门】Hive基础操作与SQL语法:DML操作全面解析
目录 1 Hive DML操作概述 2 数据加载操作 2.1 LOAD DATA语句 2.2 INSERT语句 3 数据导出操作 3.1 INSERT OVERWRITE DIRECTORY 3.2 使用HDFS命令导出 4 数据更新与删除 4.1 UPDATE语句 4.2 DELETE语句 5 MERGE操作(Hive 2.2) 6 性能优化建议…...
)
C++类和对象(上)
目录 类的定义类定义格式访问限定符类域 实例化实例化概念对象大小 this指针C和C语言实现Stack对比 类的定义 类定义格式 在下面的代码中,class为定义类的关键字,Stack为类的名字,{}中为类的主体, 注意类定义结束时后面分号不能省…...

LS2K0300龙芯开发板——智能车竞赛
开启 LS2K0300 调车之旅(自己写的自己慢慢更,可能写的不好欢迎指教) 欢迎大家一起讨论共同进步!逐飞科技针对 LS2K0300 MCU 开发的开源库,涵盖多种实用功能,助力竞赛与产品开发。以下是快速上手指南&#…...
)
电子病历高质量语料库构建方法与架构项目(智能质控体系建设篇)
引言 随着人工智能技术的迅猛发展,医疗信息化建设正经历着前所未有的变革。电子病历作为医疗机构的核心数据资产,其质量直接关系到临床决策的准确性和医疗安全。传统的病历质控工作主要依赖人工审核,存在效率低下、主观性强、覆盖面有限等问题。近年来,基于人工智能技术的…...
超级创新思路:基于CBAM-Transformer的强化学习时间序列预测模型(Python\matlab实现)
首先声明,该模型为原创!原创!原创!且该思路还未有成果发表,感兴趣的小伙伴可以借鉴!需要完整代码可私信或评论! 本方案可用于医疗、金融、交通、零售、光伏功率预测、估计预测、天气预测、流量预测、故障检测等领域! 目录 首先声明,该模型为原创!原创!原创!且该思…...

JVM——垃圾收集策略
GC的基本问题 什么是GC? GC 是 garbage collection 的缩写,意思是垃圾回收——把内存(特别是堆内存)中不再使用的空间释放掉;清理不再使用的对象。 为什么要GC? 堆内存是各个线程共享的空间,…...

从基础到实战的量化交易全流程学习:1.3 数学与统计学基础——概率与统计基础 | 数字特征
从基础到实战的量化交易全流程学习:1.3 数学与统计学基础——概率与统计基础 | 数字特征 第一部分:概率与统计基础 第2节:数字特征:期望值、方差、协方差与相关系数 一、期望值(Expected Value):…...

【MySQL】数据类型和表的操作
目录 一. 常用的数据类型 1.数值类型 1.1 整形类型 1.2 浮点型类型 2.字符串类型 char和varchar的区别 如何选择char和varchar 3.日期类型 4.二进制类型 二. 表的操作 1.查看所有表 2.表的创建 3.查看表的结构 4.表的修改 4.1 添加新的列 4.2 修改表中现有的列 4…...

Tauri打包时出现WixTools以及NSIS报错
前言 Tauri构建时会通过github下载Wix和NSIS,由于国内网络限制,所以这个过程基本都会失败,而且你无法使用挂代理的方式解决此问题,唯一的办法就是先下载对于的库,然后把库丢到对应的文件夹内来解决此问题。。。 文章目…...

Linux操作系统学习---进程地址空间
前言: 在学习c,c这些偏底层的语言时,我们常常会对一个变量取地址,一遍对他进行一系列的操作 . 可是 , 这真的是真实的物理地址吗 ? 其实并非如此 , 通过了解进程地址空间,我们就能解开这个困惑. 一、虚拟地址空间的概念: 同地址,不同值的代码示例: 下面通过创建子进程来看一个…...

docker compose -p的踩坑经验
刚才启动ragflow解析了几百个文件,再次启动登录时报错 没有这个账户,心疼token几秒。。。 再次回顾之前的启动方式和当前的启动方式,才发现有出入。 问题: 第一次启动sudo docker compose up -d 第二次启动sudo docker compose -…...

深入理解 Linux 用户管理:从基础到实践
在 Linux 操作系统中,用户管理是确保系统安全、合理分配资源的核心环节。无论是个人开发者搭建本地开发环境,还是运维人员管理企业级服务器集群,熟练掌握 Linux 用户管理都是一项必备技能。本文将从用户管理的基础概念出发,结合实…...

Go语言之路————指针、结构体、方法
Go语言之路————指针、结构体、方法 前言指针结构体声明初始化使用组合引用结构体和指针结构体的标签 方法例子结合结构体总结 前言 我是一名多年Java开发人员,因为工作需要现在要学习go语言,Go语言之路是一个系列,记录着我从0开始接触Go…...
)
【漫话机器学习系列】227.信息检索与数据挖掘中的常用加权技术(TF-IDF)
在自然语言处理(NLP)、信息检索(IR)和数据挖掘(DM)领域中,TF-IDF 是一种非常经典且常用的加权技术。 无论是搜索引擎排序、文本挖掘,还是特征工程,TF-IDF都扮演着重要角色…...

【音视频】FFmpeg过滤器框架分析
ffmpeg的filter⽤起来是和Gstreamer的plugin是⼀样的概念,通过avfilter_link,将各个创建好的filter按⾃⼰想要的次序链接到⼀起,然后avfilter_graph_config之后,就可以正常使⽤。 ⽐较常⽤的滤镜有:scale、trim、over…...

硬盘损坏数据恢复后对python程序的影响
最近硬盘突然间坏掉了,让数据商恢复了2个月今天终于拿到了恢复后的数据。 但是一测试问题就来了: PS E:\geosystem> python manage.py runserver 0.0.0.0:5000 Unhandled exception in thread started by <function check_errors.<locals>.…...

Azure Devops - 尝试一下在Pipeline中使用Self-hosted Windows agent
1.简单介绍 Azure Devops是微软提供的辅助软件的开发,测试,部署以及计划和进度跟踪的平台,通过Azure Devops可以使开发者,项目经理,运维人员在软件的整个生命周期中更紧密地合作,同时借助Continuous Integ…...
分区管理、交换分区,创建逻辑卷与调整逻辑卷的大小)
Linux红帽:RHCSA认证知识讲解(十 四)分区管理、交换分区,创建逻辑卷与调整逻辑卷的大小
Linux红帽:RHCSA认证知识讲解(十 四)分区管理、交换分区,创建逻辑卷与调整逻辑卷的大小 前言一、分区管理,使用fdisk管理分区1.1 找到硬盘1.2 使用fdisk分区1.3 格式化分区1.4 挂载分区 二、创建逻辑卷,调整…...
)
详解 Unreal Engine(虚幻引擎)
详解 Unreal Engine(虚幻引擎) Unreal Engine(简称 UE)是由 Epic Games 开发的一款全球领先的实时渲染引擎,自 1998 年随首款游戏《Unreal》问世以来,已发展成为覆盖 游戏开发、影视制作、建筑可视化、汽车…...

【Linux网络】Http服务优化 - 增加请求后缀、状态码描述、重定向、自动跳转及注册多功能服务
📢博客主页:https://blog.csdn.net/2301_779549673 📢博客仓库:https://gitee.com/JohnKingW/linux_test/tree/master/lesson 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正! &…...
)
Docker compose 部署微服务项目(从0-1出发纯享版无废话)
目录 一.Docker安装 (1)安装依赖 (2)安装Docker (3)启动Docker服务 (4)系统配置 (5)镜像加速配置 (6)验证安装 二.编写Docke…...

C#学习第19天:多线程
什么是多线程? 定义:多线程允许一个程序分成多个独立的执行路径来进行并发操作。用途:提高程序的执行效率,特别是在I/O操作、计算密集型任务和用户交互中。 多线程核心概念 1. 创建和管理线程 使用 Thread 类 using System; u…...

day7 python针对心脏病数据集预处理
在数据科学与机器学习领域,数据预处理与可视化是挖掘数据价值的关键前置步骤。本文以 heart1.csv 心脑血管疾病数据集为例,借助 Python 中的 pandas、matplotlib、seaborn 以及 scikit-learn 库,详细演示数据加载、缺失值处理、特征相关性分析…...

树莓派学习专题<9>:使用V4L2驱动获取摄像头数据--设定分辨率和帧率
树莓派学习专题<9>:使用V4L2驱动获取摄像头数据--设定分辨率和帧率 1. 设定分辨率2. 设定帧率3. 设定分辨率代码解析4. 获取与设定帧率代码解析5. 实测 1. 设定分辨率 使用如下代码设定摄像头的分辨率: #define CAMERA_RESOLUTI…...

模态链:利用视觉-语言模型从多模态人类视频中学习操作程序
25年4月来自谷歌 DeepMind 和斯坦福大学的论文“Chain-of-Modality: Learning Manipulation Programs from Multimodal Human Videos with Vision-Language-Models”。 从人类视频中学习执行操作任务,是一种很有前景的机器人教学方法。然而,许多操作任务…...

JAVAEE初阶01
个人主页 JavaSE专栏 JAVAEE初阶01 操作系统 1.对下(硬件)管理各种计算机设备 2.对上(软件)为各种软件提供一个稳定的运行环境 线程 运行的程序在操作系统中以进程的形式存在 进程是系统分配资源的最小单位 进程与线程的关…...

【网络安全】用 Linux 命令行 CLI 日志文件处理指南
Linux 命令行 CLI 神技回忆录:日志文件处理指南(以 Zeek Logs 为例) 1. CLI简介2. 基础操作3. 文件读取4. 查找与筛选5. 进阶操作6. Zeek 日志骚操作7. 结语 1. CLI简介 在数据分析的世界里,图形界面(GUI)…...

[C++] 高精度乘法
目录 引入: 大整数比较比较方法例题1-青蛙计数题目描述 输入描述输出描述输入输出样例AC代码 高精度乘法模版高精度运算小合集(这集乘法上集加法) 注意: 若还没有学过高精度运算的话先去看高精度加法 引入: 大整数比较 比较方法 大整数比较可以使用此方法比较(注释有讲解): …...

反事实——AI与思维模型【82】
一、定义 反事实思维模型是一种心理认知模型,它指的是人们在头脑中对已经发生的事件进行否定,然后构建出一种可能性假设的思维活动。简单来说,就是思考“如果当时……,那么就会……”的情景。这种思维方式让我们能够超越现实的限制,设想不同的可能性和结果,从而对过去的…...

Java学习手册:Java开发常用的内置工具类包
以下是常用 Java 内置工具包。 • 日期时间处理工具包 • java.time包(JSR 310):这是 Java 8 引入的一套全新的日期时间 API,旨在替代陈旧的java.util.Date和java.util.Calendar类。其中的LocalDate用于表示不带时区的日期&…...
)
JAVA多线程(8.0)
目录 线程池 为什么使用线程池 线程池的使用 工厂类Executors(工厂模式) submit 实现一个线程池 线程池 为什么使用线程池 在前面我们都是通过new Thread() 来创建线程的,虽然在java中对线程的创建、中断、销毁、等值等功能提供了支持…...

通过门店销售明细表用Python Pandas得到每月每个门店的销冠和按月的同比环比数据
假设我在本地有Excel销售表,包含ID主键、门店ID、日期、销售员姓名和销售额,需要用Pandas统计出每个月所有门店和各门店销售额最高的人,不一定是一个人,以及他所在的门店ID和月总销售额。 步骤1:导入数据并处理日期 …...

详解最新链路追踪skywalking框架介绍、架构、环境本地部署配置、整合微服务springcloudalibaba 、日志收集、自定义链路追踪、告警等
1.skywalking介绍 多种监控手段,可以通过语言探针和service mesh 获得监控数据支持多种语言自动探针,包含java/net/nodejs轻量高效,无需大数据平台和大量的服务器资源模块化,UI、存储、集群管理都有多种机制可选支持告警优秀的可…...

【OSG学习笔记】Day 11: 文件格式与数据交换
OSG 常用文件格式简介 在开始转换前,先了解 OSG 生态中常见的文件格式: .osg:OSG 标准二进制格式,存储场景图数据,体积小、加载快,适合实时渲染。 .ive:OSG 标准文本格式,可读性强,便于手动编辑或调试场景图结构(本质是 XML 格式的文本描述)。 .osgb:OSG 二进制格…...

2025.04.26-美团春招笔试题-第二题
📌 点击直达笔试专栏 👉《大厂笔试突围》 💻 春秋招笔试突围在线OJ 👉 笔试突围OJ 02. 曼哈顿距离探测器 问题描述 K小姐正在研发一种城市交通探测器,该探测器能够检测城市中任意两个位置之间的曼哈顿距离是否恰好为特定值。曼哈顿距离是在直角坐标系中,两点之间…...

搭建基于火灾风险预测与防范的消防安全科普小程序
基于微信小程序的消防安全科普互动平台的设计与实现,是关于微信小程序的,知识课程学习,包括学习后答题。 技术栈主要采用微信小程序云开发,有下面的模块: 1.课程学习模块 2.资讯模块 3.答题模块 4.我的模块 还需…...
的详细安装)
05--Altium Designer(AD)的详细安装
一、软件的下载 Altium Designer官网下载 1、临近五一的假期,想着搞个项目,且这个项目与PCB有关系,所以就下这个软件来玩玩。下面保姆级教大家安装。 2、选择适合自己的版本下载(我安装的是24的) 3、软件安装 1.下…...

药监平台上传数据报资源码不存在
问题:电子监管码上传药监平台提示“导入的资源码不存在” 现象:从生产系统导出的关联关系数据包上传到药监平台时显示: 原因:上传数据包的通道的资源码与数据包的资源码不匹配。 解决方法:检查药监平台和生产系统的药…...

DeepSeek预训练追求极致的训练效率的做法
DeepSeek在预训练阶段通过多种技术手段实现了极致的训练效率,其中包括采用FP8混合精度训练框架以降低计算和内存需求 ,创新性地引入Multi-head Latent Attention(MLA)压缩KV缓存以提升推理效率,以及基于Mixture-of-Experts(MoE)的稀疏计算架构以在保证性能的同时显著降低…...

Windows11系统中GIT下载
Windows11系统中GIT下载 0、GIT背景介绍0.0 GIT概述0.1 GIT诞生背景0.2 Linus Torvalds 的设计目标0.3 Git 的诞生(2005 年)0.4 Git 的后续发展0.5 为什么 Git 能成功? 1、资源下载地址1.1 官网资源1.2 站内资源 2、安装指导3、验证是否下载完…...