Spring Data Elasticsearch
简介说明
spring-data-elasticsearch是比较好用的一个elasticsearch客户端,本文介绍如何使用它来操作ES。本文使用spring-boot-starter-data-elasticsearch,它内部会引入spring-data-elasticsearch。
Spring Data ElasticSearch有下边这几种方法操作ElasticSearch:
ElasticsearchRepository(传统的方法,可以使用)
ElasticsearchRestTemplate(推荐使用。基于RestHighLevelClient)
ElasticsearchTemplate(ES7中废弃,不建议使用。基于TransportClient)
RestHighLevelClient(推荐度低于ElasticsearchRestTemplate,因为API不够高级)
TransportClient(ES7中废弃,不建议使用)
版本改动
spring-data-elasticsearch:4.0的比较重大的修改:4.0对应支持ES版本为7.6.2,并且弃用了对TransportClient的使用(默认使用High Level REST Client)。
ES从7.x版本开始弃用了对TransportClient的使用,并将会在8.0版本开始完全删除TransportClient。
TransportClient:使用9300端口通过TCP与ES连接,不好用,且有高并发的问题。
High Level REST Client:使用9200端口通过HTTP与ES连接,很好用,性能高。
版本对应
Elasticsearch 对于版本的兼容性要求很高,大版本之间是不兼容的。
spring-data-elasticsearch与ES、SpringBoot的对应关系如下:
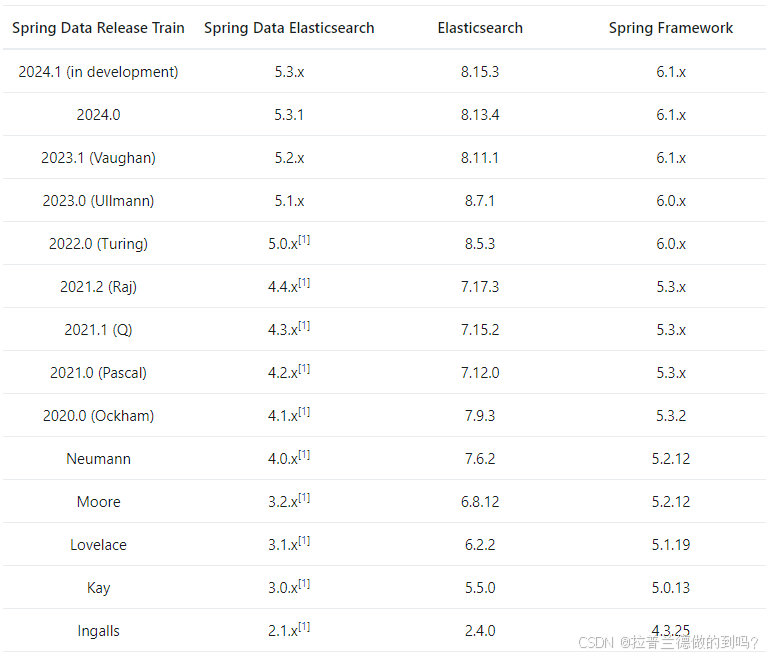
依赖及配置
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>配置(application.yml )
spring:elasticsearch:rest:uris: http://127.0.0.1:9200# username: xxx# password: yyy# connection-timeout: 1# read-timeout: 30
实例索引结构:
{"settings": {"number_of_shards": 5,"number_of_replicas": 1},"mappings": {"properties": {"id":{"type":"long"},"title": {"type": "text"},"content": {"type": "text"},"author":{"type": "text"},"category":{"type": "keyword"},"createTime": {"type": "date","format":"yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd'T'HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss||epoch_millis"},"updateTime": {"type": "date","format":"yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd'T'HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss||epoch_millis"},"status":{"type":"integer"},"serialNum": {"type": "keyword"}}}
}Entity
package com.example.demo.entity;import com.fasterxml.jackson.annotation.JsonFormat;
import lombok.Data;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.DateFormat;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;import java.util.Date;@Data
@Document(indexName = "blog", shards = 1, replicas = 1)
public class Blog {//此项作为id,不会写到_source里边。@Idprivate Long blogId;@Field(type = FieldType.Text)private String title;@Field(type = FieldType.Text)private String content;@Field(type = FieldType.Text)private String author;//博客所属分类。@Field(type = FieldType.Keyword)private String category;//0: 未发布(草稿) 1:已发布 2:已删除@Field(type = FieldType.Integer)private int status;//序列号,用于给外部展示的id@Field(type = FieldType.Keyword)private String serialNum;@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss.SSS")@Field(type= FieldType.Date, format= DateFormat.custom, pattern="yyyy-MM-dd HH:mm:ss.SSS")private Date createTime;@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss.SSS")@Field(type=FieldType.Date, format=DateFormat.custom, pattern="yyyy-MM-dd HH:mm:ss.SSS")private Date updateTime;
}@Document
用于定义一个类为 Elasticsearch 文档的映射。
-
indexName
-
作用:指定文档的索引名称。
-
示例:
@Document(indexName = "product") -
说明:索引名称在 Elasticsearch 中是唯一的,用于存储和检索文档。
-
-
type
-
作用:指定文档的类型。
-
示例:
@Document(type = "product") -
说明:类型在 Elasticsearch 中用于对文档进行分类。在 Elasticsearch 7.x 及更高版本中,类型已被弃用,建议使用单类型索引。
-
-
shards
-
作用:指定索引的分片数。
-
示例:
@Document(shards = 5) -
说明:分片是 Elasticsearch 分布式存储的基本单位,分片数决定了索引的分布和性能。
-
-
replicas
-
作用:指定索引的副本数。
-
示例:
@Document(replicas = 1) -
说明:副本是分片的备份,用于提高数据的可用性和查询性能。
-
-
createIndex
-
作用:指定是否在启动时自动创建索引。
-
示例:
@Document(createIndex = true) -
说明:如果设置为
true,Spring Data Elasticsearch 会在应用启动时自动创建索引。
-
-
refreshInterval
-
作用:指定索引的刷新间隔。
-
示例:
@Document(refreshInterval = "1s") -
说明:刷新间隔决定了索引数据何时对搜索可见。
-
-
versionType
-
作用:指定文档的版本类型。
-
示例:
@Document(versionType = VersionType.EXTERNAL) -
说明:版本类型用于控制文档的版本管理,支持
INTERNAL和EXTERNAL两种类型。
-
-
useServerConfiguration
-
作用:指定是否使用服务器的配置。
-
示例:
@Document(useServerConfiguration = true) -
说明:如果设置为
true,Spring Data Elasticsearch 会使用 Elasticsearch 服务器的配置,而不是应用中的配置。
-
@Id
@Id 是 Spring Data Elasticsearch 中的一个注解,用于标识实体类中的主键字段。在 Elasticsearch 中,每个文档都有一个唯一的标识符(ID),@Id 注解用于指定这个标识符字段。
@Field
-
name
-
作用:指定 Elasticsearch 文档中的字段名称。
-
示例:
@Field(name = "product_name") -
说明:如果未指定
name,则使用 Java 字段名作为 Elasticsearch 字段名。
-
-
type
-
作用:指定字段的类型。
-
示例:
@Field(type = FieldType.Text) -
说明:支持多种类型,如
Text、Keyword、Integer、Double、Date等。
-
-
index
-
作用:指定字段是否索引。
-
示例:
@Field(index = true) -
说明:如果设置为
true,字段将被索引,可以用于搜索;如果设置为false,字段将不会被索引。
-
-
store
-
作用:指定字段是否存储。
-
示例:
@Field(store = true) -
说明:如果设置为
true,字段值将被存储在 Elasticsearch 中,可以直接获取;如果设置为false,字段值不会被存储。
-
-
analyzer
-
作用:指定字段的分析器。
-
示例:
@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart") -
说明:分析器用于对文本字段进行分词和处理。
-
-
searchAnalyzer
-
作用:指定搜索时使用的分析器。
-
示例:
@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart") -
说明:搜索分析器用于在搜索时对查询文本进行分词和处理。
-
-
format
-
作用:指定日期字段的格式。
-
示例:
@Field(type = FieldType.Date,format= DateFormat.custom, pattern="yyyy-MM-dd HH:mm:ss.SSS") -
说明:DateFormat.custom表示使用自定义时间格式
-
-
ignoreFields
-
作用:指定忽略的字段。
-
示例:
@Field(ignoreFields = {"field1", "field2"}) -
说明:用于忽略某些字段,不将其映射到 Elasticsearch 文档中。
-
如果你在 @Field 注解中不指定任何值,Spring Data Elasticsearch 会使用默认值来处理字段。以下是各个属性的默认行为:
默认值
-
name:
-
默认值:Java 字段名。
-
说明:如果不指定
name,Elasticsearch 字段名将与 Java 字段名相同。
-
-
type:
-
默认值:根据 Java 字段类型自动推断。
-
说明:Spring Data Elasticsearch 会根据 Java 字段的类型自动推断 Elasticsearch 字段类型。例如,
String类型会映射为Text,Integer类型会映射为Integer,Date类型会映射为Date等。
-
-
index:
-
默认值:
true。 -
说明:默认情况下,字段会被索引,可以用于搜索。
-
-
store:
-
默认值:
false。 -
说明:默认情况下,字段值不会被存储在 Elasticsearch 中,查询时需要从原始文档中提取。
-
-
analyzer:
-
默认值:
standard。 -
说明:默认使用
standard分析器进行分词和处理。
-
-
searchAnalyzer:
-
默认值:与
analyzer相同。 -
说明:默认情况下,搜索时使用的分析器与索引时使用的分析器相同。
-
-
format:
-
默认值:
strict_date_optional_time||epoch_millis。 -
说明:默认情况下,日期字段支持
strict_date_optional_time和epoch_millis两种格式。
-
@Mapping
用于定义索引的映射信息。通过 @Mapping 注解,你可以指定一个 JSON 文件路径,该文件包含了索引的详细映射配置。这使得你可以在实体类中直接定义复杂的映射规则,而不需要在代码中硬编码这些配置。
例:
entity
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Mapping;@Document(indexName = "product")
@Mapping(mappingPath = "product-mapping.json")
public class Product {@Idprivate String id;private String name;private double price;}json
{"properties": {"id": {"type": "keyword"},"name": {"type": "text","analyzer": "standard","fields": {"english": {"type": "text","analyzer": "english"}}},"price": {"type": "double"}}
}@Setting
用于定义索引的映射信息。通过 @Mapping 注解,你可以指定一个 JSON 文件路径,该文件包含了索引的详细映射配置。这使得你可以在实体类中直接定义复杂的映射规则,而不需要在代码中硬编码这些配置。
例:
{"index": {"number_of_shards": 3,"number_of_replicas": 2,"refresh_interval": "1s","analysis": {"analyzer": {"ik_max_word": {"type": "custom","tokenizer": "ik_max_word"},"ik_smart": {"type": "custom","tokenizer": "ik_smart"}}}}
}-
number_of_shards:-
作用:指定索引的分片数。
-
示例:
"number_of_shards": 3 -
说明:索引将分为 3 个分片。
-
-
number_of_replicas:-
作用:指定索引的副本数。
-
示例:
"number_of_replicas": 2 -
说明:每个分片将有 2 个副本。
-
-
refresh_interval:-
作用:指定索引的刷新间隔。
-
示例:
"refresh_interval": "1s" -
说明:索引数据每 1 秒刷新一次,使其对搜索可见。
-
-
analysis:-
作用:定义自定义分析器。
-
示例:
{"index": {"number_of_shards": 3,"number_of_replicas": 2,"refresh_interval": "1s","analysis": {"analyzer": {"ik_max_word": {"type": "custom","tokenizer": "ik_max_word"},"ik_smart": {"type": "custom","tokenizer": "ik_smart"}}}} }自定义分词器,需要在mapping映射中指定自定义的分词器才会生效。
-
@Score
用于在查询结果中包含评分信息。评分信息表示查询结果的相关性分数,通常用于排序和过滤查询结果。
例:
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
import org.springframework.data.elasticsearch.annotations.Score;@Document(indexName = "product")
public class Product {@Idprivate String id;@Field(type = FieldType.Text)private String name;@Field(type = FieldType.Double)private double price;@Scoreprivate Float score;}@ScriptedField
用于定义脚本字段(Scripted Field)。脚本字段是通过在查询时执行脚本来动态计算的字段,而不是直接从索引中获取的字段。脚本字段可以用于在查询结果中包含动态计算的值,例如根据其他字段的值进行计算。
@GeoPoint
用于定义地理位置字段。地理位置字段用于存储和查询地理位置信息,支持地理空间查询,如距离查询、范围查询等。
@MultiField
用于定义多字段映射。多字段映射允许你为一个字段定义多个子字段,每个子字段可以有不同的分析器和字段类型。这使得你可以根据不同的需求对同一个字段进行不同的处理和查询。
@CompletionField
用于定义自动补全字段(Completion Field)。自动补全字段用于实现搜索建议(Search Suggestions)功能,即在用户输入搜索关键词时,自动补全功能会根据已有的数据提供可能的搜索建议。
@JoinField
用于定义父子文档关系(Parent-Child Relationship)。父子文档关系允许你在同一个索引中存储具有层次结构的数据,并且可以在查询时根据父子关系进行关联查询。
Dao
package com.example.demo.dao;import com.example.demo.entity.Blog;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;public interface BlogRepository extends ElasticsearchRepository<Blog, Long> {}简介
接口的继承

文档的crud

package com.example.demo.controller;import com.example.demo.dao.BlogRepository;
import com.example.demo.entity.Blog;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;import java.util.ArrayList;
import java.util.Date;
import java.util.List;@Api(tags = "增删改查(文档)")
@RestController
@RequestMapping("crud")
public class CrudController {@Autowiredprivate BlogRepository blogRepository;@ApiOperation("添加单个文档")@PostMapping("addDocument")public Blog addDocument() {Long id = 1L;Blog blog = new Blog();blog.setBlogId(id);blog.setTitle("Spring Data ElasticSearch学习教程" + id);blog.setContent("这是添加单个文档的实例" + id);blog.setAuthor("Tony");blog.setCategory("ElasticSearch");blog.setCreateTime(new Date());blog.setStatus(1);blog.setSerialNum(id.toString());return blogRepository.save(blog);}@ApiOperation("添加多个文档")@PostMapping("addDocuments")public Object addDocuments(Integer count) {List<Blog> blogs = new ArrayList<>();for (int i = 1; i <= count; i++) {Long id = (long)i;Blog blog = new Blog();blog.setBlogId(id);blog.setTitle("Spring Data ElasticSearch学习教程" + id);blog.setContent("这是添加单个文档的实例" + id);blog.setAuthor("Tony");blog.setCategory("ElasticSearch");blog.setCreateTime(new Date());blog.setStatus(1);blog.setSerialNum(id.toString());blogs.add(blog);}return blogRepository.saveAll(blogs);}/*** 跟新增是同一个方法。若id已存在,则修改。* 无法只修改某个字段,只能覆盖所有字段。若某个字段没有值,则会写入null。* @return 成功写入的数据*/@ApiOperation("修改单个文档")@PostMapping("editDocument")public Blog editDocument() {Long id = 1L;Blog blog = new Blog();blog.setBlogId(id);blog.setTitle("Spring Data ElasticSearch学习教程" + id);blog.setContent("这是修改单个文档的实例" + id);// blog.setAuthor("Tony");// blog.setCategory("ElasticSearch");// blog.setCreateTime(new Date());// blog.setStatus(1);// blog.setSerialNum(id.toString());return blogRepository.save(blog);}@ApiOperation("查找单个文档")@GetMapping("findById")public Blog findById(Long id) {return blogRepository.findById(id).get();}@ApiOperation("删除单个文档")@PostMapping("deleteDocument")public String deleteDocument(Long id) {blogRepository.deleteById(id);return "success";}@ApiOperation("删除所有文档")@PostMapping("deleteDocumentAll")public String deleteDocumentAll() {blogRepository.deleteAll();return "success";}
}查询操作
查询的方法
Query接口有一个抽象实现和三个实现:

本处我使用NativeSearchQuery。因为它更贴近ES,语法更偏向于ES原来的命令。
构建Query
可通过new NativeSearchQueryBuilder()来构建NativeSearchQuery对象NativeSearchQuery中有众多的方法来为我们实现复杂的查询与筛选等操作。其中的build()返回NativeSearchQuery。

withSort(SortBuilder<?> sortBuilder)
用于设置查询结果的排序条件。SortBuilder 是 Elasticsearch 提供的排序构建器,可以用于构建各种排序条件,如按字段排序、按地理位置排序等。
例:
假设我们有一个 Product 实体类,我们希望根据 price 字段进行升序排序,并且根据 createdAt 字段进行降序排序。
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;import java.util.Date;@Document(indexName = "products")
public class Product {@Idprivate String id;@Field(type = FieldType.Text)private String name;@Field(type = FieldType.Double)private Double price;@Field(type = FieldType.Date)private Date createdAt;// getters and setters
}import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.sort.SortBuilders;
import org.elasticsearch.search.sort.SortOrder;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.elasticsearch.core.ElasticsearchOperations;
import org.springframework.data.elasticsearch.core.SearchHits;
import org.springframework.data.elasticsearch.core.query.NativeSearchQuery;
import org.springframework.data.elasticsearch.core.query.NativeSearchQueryBuilder;
import org.springframework.stereotype.Service;@Service
public class ProductService {@Autowiredprivate ElasticsearchOperations elasticsearchOperations;public void searchAndSortProducts() {NativeSearchQuery query = new NativeSearchQueryBuilder().withQuery(QueryBuilders.matchAllQuery()) // 匹配所有文档.withSort(SortBuilders.fieldSort("price").order(SortOrder.ASC)) // 按 price 升序排序.withSort(SortBuilders.fieldSort("createdAt").order(SortOrder.DESC)) // 按 createdAt 降序排序.build();SearchHits<Product> searchHits = elasticsearchOperations.search(query, Product.class);// 处理查询结果searchHits.forEach(hit -> {System.out.println(hit.getContent());});}
} SortBuilders.fieldSort(String fieldName).order(SortOrder sortOrder)fieldSort 用于按字段值进行排序。fieldName 是要排序的字段名。order 方法用于设置排序顺序。SortOrder 是一个枚举类型,有两个值:ASC(升序)和 DESC(降序)。
其他排序条件
-
SortBuilders.geoDistanceSort(String fieldName, GeoPoint... points):
按地理位置距离排序。 -
SortBuilders.scriptSort(Script script, String type):
按脚本排序。
withPageable(Pageable pageable)
用于设置分页条件。Pageable 是 Spring Data 提供的分页接口,用于指定查询结果的分页参数,如页码和每页大小。
假设我们有一个 Product 实体类,我们希望查询所有产品,并进行分页处理,每页显示 10 条记录,查询第 2 页的数据。
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;@Document(indexName = "products")
public class Product {@Idprivate String id;@Field(type = FieldType.Text)private String name;@Field(type = FieldType.Double)private Double price;// getters and setters
}import org.elasticsearch.index.query.QueryBuilders;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.elasticsearch.core.ElasticsearchOperations;
import org.springframework.data.elasticsearch.core.SearchHits;
import org.springframework.data.elasticsearch.core.query.NativeSearchQuery;
import org.springframework.data.elasticsearch.core.query.NativeSearchQueryBuilder;
import org.springframework.stereotype.Service;@Service
public class ProductService {@Autowiredprivate ElasticsearchOperations elasticsearchOperations;public void searchProductsWithPagination() {// 创建分页条件,查询第 2 页,每页 10 条记录PageRequest pageRequest = PageRequest.of(1, 10);NativeSearchQuery query = new NativeSearchQueryBuilder().withQuery(QueryBuilders.matchAllQuery()) // 匹配所有文档.withPageable(pageRequest) // 设置分页条件.build();SearchHits<Product> searchHits = elasticsearchOperations.search(query, Product.class);// 处理查询结果searchHits.forEach(hit -> {System.out.println(hit.getContent());});}
} PageRequest.of(int page, int size):PageRequest 是 Spring Data 提供的分页请求类,用于创建分页条件。page 参数表示页码(从 0 开始),size 参数表示每页的记录数。
withFields(String... fields)
用于指定查询结果中需要返回的字段。通过使用 withFields 方法,你可以减少返回的字段数量,从而提高查询性能和减少网络传输的数据量。默认情况下,Elasticsearch 查询会返回文档的所有字段。
假设我们有一个 Product 实体类,我们希望查询所有产品,但只返回 name 和 price 字段。
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;@Document(indexName = "products")
public class Product {@Idprivate String id;@Field(type = FieldType.Text)private String name;@Field(type = FieldType.Double)private Double price;@Field(type = FieldType.Text)private String description;// getters and setters
}import org.elasticsearch.index.query.QueryBuilders;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.elasticsearch.core.ElasticsearchOperations;
import org.springframework.data.elasticsearch.core.SearchHits;
import org.springframework.data.elasticsearch.core.query.NativeSearchQuery;
import org.springframework.data.elasticsearch.core.query.NativeSearchQueryBuilder;
import org.springframework.stereotype.Service;@Service
public class ProductService {@Autowiredprivate ElasticsearchOperations elasticsearchOperations;public void searchProductsWithSelectedFields() {NativeSearchQuery query = new NativeSearchQueryBuilder().withQuery(QueryBuilders.matchAllQuery()) // 匹配所有文档.withFields("name", "price") // 只返回 name 和 price 字段.build();SearchHits<Product> searchHits = elasticsearchOperations.search(query, Product.class);// 处理查询结果searchHits.forEach(hit -> {Product product = hit.getContent();System.out.println("Name: " + product.getName() + ", Price: " + product.getPrice());});}
}withHighlightFields(HighlightBuilder.Field... highlightFields)
用于设置高亮字段。高亮字段用于在查询结果中突出显示匹配的文本片段,通常用于搜索结果的展示,以便用户更容易看到匹配的内容。
假设我们有一个 Note 实体类,我们希望在查询结果中高亮显示 content 字段中匹配的文本片段。
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;@Document(indexName = "notes")
public class Note {@Idprivate String id;@Field(type = FieldType.Text)private String title;@Field(type = FieldType.Text)private String content;// getters and setters
}import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.elasticsearch.core.ElasticsearchOperations;
import org.springframework.data.elasticsearch.core.SearchHits;
import org.springframework.data.elasticsearch.core.query.NativeSearchQuery;
import org.springframework.data.elasticsearch.core.query.NativeSearchQueryBuilder;
import org.springframework.stereotype.Service;@Service
public class NoteService {@Autowiredprivate ElasticsearchOperations elasticsearchOperations;public void searchNotesWithHighlighting() {// 创建高亮字段HighlightBuilder.Field highlightContent = new HighlightBuilder.Field("content").preTags("<strong>").postTags("</strong>");NativeSearchQuery query = new NativeSearchQueryBuilder().withQuery(QueryBuilders.matchQuery("content", "Elasticsearch")) // 匹配 content 字段.withHighlightFields(highlightContent) // 设置高亮字段.build();SearchHits<Note> searchHits = elasticsearchOperations.search(query, Note.class);// 处理查询结果searchHits.forEach(hit -> {Note note = hit.getContent();System.out.println("Title: " + note.getTitle());hit.getHighlightFields().forEach((field, fragments) -> {System.out.println("Highlighted " + field + ": " + fragments);});});}
}-
HighlightBuilder.Field用于定义高亮字段。你可以通过preTags和postTags方法设置高亮标签,例如<strong>和</strong>。 -
withHighlightFields(HighlightBuilder.Field... highlightFields):withHighlightFields方法用于将高亮字段添加到查询中。你可以传递多个HighlightBuilder.Field对象。
withQuery(QueryBuilder queryBuilder)
用于设置查询条件。QueryBuilder 是 Elasticsearch 提供的查询构建器,用于构建各种类型的查询。
假设我们有一个 Product 实体类,我们希望查询所有 name 字段中包含 "phone" 的产品。
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;@Document(indexName = "products")
public class Product {@Idprivate String id;@Field(type = FieldType.Text)private String name;@Field(type = FieldType.Double)private Double price;@Field(type = FieldType.Keyword)private String status;// getters and setters
}import org.elasticsearch.index.query.QueryBuilders;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.elasticsearch.core.ElasticsearchOperations;
import org.springframework.data.elasticsearch.core.SearchHits;
import org.springframework.data.elasticsearch.core.query.NativeSearchQuery;
import org.springframework.data.elasticsearch.core.query.NativeSearchQueryBuilder;
import org.springframework.stereotype.Service;@Service
public class ProductService {@Autowiredprivate ElasticsearchOperations elasticsearchOperations;public void searchProductsByName() {NativeSearchQuery query = new NativeSearchQueryBuilder().withQuery(QueryBuilders.matchQuery("name", "phone")) // 匹配 name 字段中包含 "phone" 的文档.build();SearchHits<Product> searchHits = elasticsearchOperations.search(query, Product.class);// 处理查询结果searchHits.forEach(hit -> {System.out.println(hit.getContent());});}
}withFilter(QueryBuilder filterBuilder)
用于设置过滤条件。过滤条件通常用于排除不符合特定条件的文档,但不会影响文档的评分。过滤条件在查询性能上有一定的优势,因为它们可以利用 Elasticsearch 的缓存机制。
假设我们有一个 Product 实体类,我们希望查询所有 status 为 active 的产品,并且这些产品的 price 在 100 到 200 之间。
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;@Document(indexName = "products")
public class Product {@Idprivate String id;@Field(type = FieldType.Text)private String name;@Field(type = FieldType.Double)private Double price;@Field(type = FieldType.Keyword)private String status;// getters and setters
}import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.elasticsearch.core.ElasticsearchOperations;
import org.springframework.data.elasticsearch.core.SearchHits;
import org.springframework.data.elasticsearch.core.query.NativeSearchQuery;
import org.springframework.data.elasticsearch.core.query.NativeSearchQueryBuilder;
import org.springframework.stereotype.Service;@Service
public class ProductService {@Autowiredprivate ElasticsearchOperations elasticsearchOperations;public void searchActiveProductsInPriceRange() {// 创建过滤条件BoolQueryBuilder filterBuilder = QueryBuilders.boolQuery().must(QueryBuilders.termQuery("status", "active")).must(QueryBuilders.rangeQuery("price").gte(100).lte(200));NativeSearchQuery query = new NativeSearchQueryBuilder().withQuery(QueryBuilders.matchAllQuery()) // 匹配所有文档.withFilter(filterBuilder) // 应用过滤条件.build();SearchHits<Product> searchHits = elasticsearchOperations.search(query, Product.class);// 处理查询结果searchHits.forEach(hit -> {System.out.println(hit.getContent());});}
}QueryBuilders
Elasticsearch 提供的用于构建查询条件的工具类。它包含了许多静态方法,用于创建各种类型的查询构建器(QueryBuilder)。
QueryBuilders构造复杂查询条件
NativeSearchQueryBuilder中接收QueryBuilder
withQuery(QueryBuilder queryBuilder)
withFilter(QueryBuilder filterBuilder)
可以用QueryBuilders构造QueryBuilder对象

常用 QueryBuilder 类型
1.MatchQueryBuilder:
用于全文搜索,匹配字段中包含指定值的文档。
QueryBuilder matchQuery = QueryBuilders.matchQuery("content", "Elasticsearch");2.TermQueryBuilder:
用于精确匹配字段值。
QueryBuilder termQuery = QueryBuilders.termQuery("status", "active");3.RangeQueryBuilder:
用于范围查询。
QueryBuilder rangeQuery = QueryBuilders.rangeQuery("price").gte(100).lte(200);4.BoolQueryBuilder:
Elasticsearch 提供的用于构建布尔查询的类。布尔查询允许你组合多个查询条件,使用逻辑运算符(如 must、should、must_not 和 filter)来构建复杂的查询。
(1)must(QueryBuilder queryBuilder):
必须满足的条件,类似于逻辑与(AND)。
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery().must(QueryBuilders.termQuery("status", "active")).must(QueryBuilders.rangeQuery("price").gte(100).lte(200));(2)should(QueryBuilder queryBuilder):
满足任意一个条件即可,类似于逻辑或(OR)。
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery().should(QueryBuilders.termQuery("status", "active")).should(QueryBuilders.termQuery("status", "pending"));(3)mustNot(QueryBuilder queryBuilder):
必须不满足的条件,类似于逻辑非(NOT)。
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery().mustNot(QueryBuilders.termQuery("status", "inactive"));(4)filter(QueryBuilder queryBuilder):
过滤条件,不会影响文档的评分,通常用于提高查询性能。
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery().filter(QueryBuilders.termQuery("status", "active")).filter(QueryBuilders.rangeQuery("price").gte(100).lte(200));5.WildcardQueryBuilder:
用于通配符查询。
QueryBuilder wildcardQuery = QueryBuilders.wildcardQuery("name", "el*search");6.FuzzyQueryBuilder:
用于模糊查询。
QueryBuilder fuzzyQuery = QueryBuilders.fuzzyQuery("name", "elasticserch");7.PrefixQueryBuilder:
用于前缀查询。
QueryBuilder prefixQuery = QueryBuilders.prefixQuery("name", "el");8.MatchAllQueryBuilder:
匹配所有文档。
QueryBuilder matchAllQuery = QueryBuilders.matchAllQuery();9.MultiMatchQueryBuilder:
用于多字段匹配查询。
QueryBuilder multiMatchQuery = QueryBuilders.multiMatchQuery("searchTerm", "title", "content");10.GeoDistanceQueryBuilder:
用于地理位置距离查询。
QueryBuilder geoDistanceQuery = QueryBuilders.geoDistanceQuery("location").point(40.7128, -74.0060).distance(10, DistanceUnit.KILOMETERS);相关文章:

Spring Data Elasticsearch
简介说明 spring-data-elasticsearch是比较好用的一个elasticsearch客户端,本文介绍如何使用它来操作ES。本文使用spring-boot-starter-data-elasticsearch,它内部会引入spring-data-elasticsearch。 Spring Data ElasticSearch有下边这几种方法操作El…...

汇编语言简要记录-1
汇编语言与汇编指令 汇编语言的主题是汇编指令 汇编指令与机器指令的差别在于指令的表示方法上 1、汇编指令是机器机器指令便于记忆的书写格式 2、汇编指令是机器指令的助记符 ag:机器指令 1000100111011000操作:将寄存器BX的值送到AX中汇编指令 MOV …...
)
Java程序猿搬砖笔记(十七)
文章目录 MySQL触发器ElasticSearch按日期分组查询每天的文档数量MySQL中order by排序将null排在最前或者最后面swagger3.0默认访问路径swagger3.0模块化配置MySQL中要少用UNION,多用UNION ALLElasticSearch Bucket & Metric聚合分析及嵌套聚合Mysql case when做…...

代码设计:设计模式:观察者模式
文章目录 定义类结构应用总结 定义 实现响应式编程的代码设计,即触发事件或数据变化时,将数据从被观察者类通过观察器传递给观察者处理,即被观察者类间接调用观察者类的方法处理事件或数据 类结构 被观察者类、观察器类、观察者类 被观察…...

第32天:安全开发-JavaEE应用Servlet路由技术JDBCMybatis数据库生命周期
时间轴: 32天主要学习内容: 1、JavaEE-HTTP-Servlet技术 2、JavaEE-数据库-JDBC&Mybatis java技术使用历史(2023 ): JavaEE-HTTP-Servlet&路由&周期: java学习范围: 3、Java: 功能:数据…...

如何使用Apache HttpClient来执行GET、POST、PUT和DELETE请求
Apache HttpClient 是一个功能强大且灵活的库,用于在Java中处理HTTP请求。 它支持多种HTTP方法,包括GET、POST、PUT和DELETE等。 本教程将演示如何使用Apache HttpClient来执行GET、POST、PUT和DELETE请求。 Maven依赖 要使用Apache HttpClient&…...

Next.js 系统性教学:加载界面、重定向与路由分组
更多有关Next.js教程,请查阅: 【目录】Next.js 独立开发系列教程-CSDN博客 目录 1. 加载界面与流式渲染 1.1 加载界面 (loading.js) 1.2 流式渲染 2. 路由重定向 2.1 基于服务器的重定向 2.2 动态重定向 2.3 中间件中的重定向 3. 路由分组 3.1…...

哪款云手机适合多开?常用云手机功能对比
在全球化和数字化时代,云手机以其独特的灵活性和高效性,成为多账号运营和数字营销的热门工具。云手机能够解决传统设备管理的诸多痛点,例如账号关联、硬件成本高等问题。本文将为您推荐多款优质云手机品牌,帮助您选择最适合的工具…...

基于openzeppelin插件的智能合约升级
一、作用以及优点 部署可升级合约,插件自动部署proxy和proxyAdmin合约,帮助管理合约升级和交互;升级已部署合约,通过插件快速升级合约,脚本开发方便快捷;管理代理管理员的权限,只有proxyAdmin的…...

WGAN生成对抗网络数据生成
数据生成 | WGAN生成对抗网络数据生成 目录 数据生成 | WGAN生成对抗网络数据生成生成效果基本描述程序设计参考资料 生成效果 基本描述 1.WGAN生成对抗网络,数据生成,样本生成程序,MATLAB程序; 2.适用于MATLAB 2020版及以上版本&…...

SQL面试题——拼多多SQL面试题 求连续段的起始位置和结束位置
拼多多SQL面试题 求连续段的起始位置和结束位置 今天的题目来自拼多多,我们先看一下题目描述 有一张表ids记录了id,id不重复,但是会存在间断,求出连续段的开始位置和结束位置 +---+ | id| +---+ | 1| | 2| | 3| | 5| | 6| | 8| | 10| | 12| | 13| | 14| | 15| +--…...

Contextual Affinity Distillation for Image Anomaly Detection
Contextual Affinity Distillation for Image Anomaly Detection 日本东北大学 摘要 先前对无监督工业异常检测的研究主要通过匹配或学习局部特征表示来关注“结构”类型的异常,例如裂纹和颜色污染。虽然在这种异常上实现了显着的高检测性能,但他们面…...
)
如何在HTML中修改光标的位置(全面版)
如何在HTML中修改光标的位置(全面版) 在Web开发中,控制光标位置是一个重要的技巧,尤其是在表单处理、富文本编辑器开发或格式化输入的场景中。HTML中的光标位置操作不仅适用于表单元素(如<input>和<textarea…...
)
Spring Cloud Alibaba(六)
目录: 分布式链路追踪-SkyWalking为什么需要链路追踪什么是SkyWalkingSkyWalking核心概念什么是探针Java AgentJava探针日志监控实现之环境搭建Java探针日志监控实现之探针实现编写探针类TestAgent搭建 ElasticsearchSkyWalking服务环境搭建搭建微服务微服务接入Sky…...

Http请求系列---【http的几个请求时间分别代表什么?以及如何设置?】
在HTTP客户端编程中,通常涉及以下几种关键的超时设置: 连接超时 (connectTimeout): 定义:在与服务器建立连接时等待的最大时间。这包括DNS解析时间、连接建立时间等。作用:如果在指定的时间内无法建立连接,…...

如何将CSDN博客下载为PDF文件
1.打开CSDN文章内容 2.按键盘上的f12键(或者右键—审查元素)进入浏览器调试模式,点击控制台(Console)进入控制台 3.在控制台输入以下代码,回车 4.在弹出的打印页面中将布局设置成横向,纵向会…...

关于IDEA 2024.2.1 Java EE 无框架配置Tomcat环境以及servlet使用教程
前言 这里的IDEA使用的是专业版,大学生认证后即可使用,社区版没有接触过暂不提,如果你是社区版,那么很可惜,本博客并不适用。本博客适用于java web刚入门的朋友学习使用,并不适用于高级部署。注意…...

【23种设计模式】七种设计原则:理论与 Java 实践
文章目录 23 种设计模式之七种设计原则:理论与 Java 实践一、单一职责原则(SRP - Single Responsibility Principle)(一)理论介绍(二)Java 实现示例(三)关键步骤…...

数据库与数据库管理系统概述
title: 数据库与数据库管理系统概述 date: 2024/12/7 updated: 2024/12/7 author: cmdragon excerpt: 在信息化迅速发展的时代,数据已成为企业和组织的重要资产。数据库与数据库管理系统(DBMS)是高效存储、管理和利用数据的核心工具。本文首先定义了数据库的基本概念和特…...
---常见的GAN)
42_GAN网络详解(2)---常见的GAN
DCGAN CGAN 条件生成对抗网络(Conditional Generative Adversarial Networks, CGAN)是生成对抗网络(Generative Adversarial Networks, GAN)的一种变体,由Mehdi Mirza和Simon Osindero在2014年提出。CGAN的主要改进在…...

目前国内【齿轮检测仪】行业整体较为分散,行业竞争日趋激烈
摘要 根据 HengCe (恒策咨询)的统计及预测,2023年全球齿轮检测仪市场销售额达到了6.2亿美元,预计2030年将达到9.4亿美元,年复合增长率(CAGR)为6.0%(2024-2030)。地区层面来看&#…...

【学习路线】Java
Java基础 基础 基础语法 面向对象 集合框架 JCF 进阶 并发编程 JVM 企业级开发 框架 Spring Boot Spring Cloud 分布式 高性能 高可用 安全 基建 Docker 实战 数据库 MySQL Redis 计算机基础 计算机组成原理 操作系统 计算机网络 数据结构与算法 设计模式 参考:…...

一文说清flink从编码到部署上线
引言:目前flink的文章比较多、杂,很少有一个文章,从一个简单的例子入手,说清楚从编码、构建、部署全流程是怎么样的。所以编写本文,自己做个记录备查同时跟大家分享一下。本文以简单的mysql cdc为例展开说明。 环境说明…...

dolphinScheduler 任务调度
#Using docker-compose to Start Server #下载:https://dlcdn.apache.org/dolphinscheduler/3.1.9/apache-dolphinscheduler-3.1.9-src.tar.gz $ DOLPHINSCHEDULER_VERSION3.1.9 $ tar -zxf apache-dolphinscheduler-"${DOLPHINSCHEDULER_VERSION}"-src.t…...

【opencv入门教程】14. 矩阵乘除运算
文章选自: 一、函数multiply、divide //乘法 CV_EXPORTS_W void multiply(InputArray src1, InputArray src2,OutputArray dst, double scale 1, int dtype -1); brief 计算两个数组的每个元素的按比例缩放乘积 note 当输出数组的深度为 CV_32S 时,…...

SpEL
SPEL(Spring Expression Language)是一个强大的 支持查询和操作对象的表达式语言 Spring:https://docs.spring.io/spring-framework/docs/3.2.x/spring-framework-reference/html/expressions.html#expressions 表达式语言支持以下功能 文本…...

【SpringMVC】参数传递 重定向与转发 REST风格
文章目录 参数传递重定向与转发REST风格 参数传递 ModelAndView:包含视图信息和模型数据信息 public ModelAndView index1(){// 返回页面ModelAndView modelAndView new ModelAndView("视图名");// 或// ModelAndView modelAndView new ModelAndView(…...

OD B卷【考勤信息】
题目 公司用一个字符串来表示员工的出勤信息: absent: 缺勤;late: 迟到;leaveearly: 早退;present: 正常上班 现在根据员工出勤信息,判断本次能否获得出勤奖,能获得出勤奖的条件如下:缺勤不超…...

CTF学习24.11.19[音频隐写]
MISC07[音频隐写] 隐写术 隐写术是一门关于信息隐藏的技巧与科学,所谓信息隐藏指的是不让除预期的接收者之外的任何人知晓信息的传递事件或者信息的内容。隐写术的英文叫做Steganography,来源于特里特米乌斯的一本讲述密码学与隐写术的著作Steganograp…...

万字长文解读深度学习——VQ-VAE和VQ-VAE-2
🌺历史文章列表🌺 深度学习——优化算法、激活函数、归一化、正则化 深度学习——权重初始化、评估指标、梯度消失和梯度爆炸 深度学习——前向传播与反向传播、神经网络(前馈神经网络与反馈神经网络)、常见算法概要汇总 万字长…...

电脑投屏到电脑:Windows,macOS及Linux系统可以相互投屏!
本篇其实是电脑远程投屏到另一台电脑的操作介绍。本篇文章的方法可用于Windows,macOS及Linux系统的相互投屏。 为了避免介绍过程中出现“这台电脑”投屏到“那台电脑”的混乱表述,假定当前屏幕投出端是Windows系统电脑,屏幕接收端是Linux系统…...

【JuMP.jl】埃尔米特矩阵半定规划
考虑一个埃尔米特矩阵的半定规划问题: 给定矩阵 P [ 1 i i − 1 ] P\left[\begin{matrix} 1 & i\\ i & -1 \end{matrix}\right] P[1ii−1] 计算 min X ⪰ 0 R e ( t r ( P H X ) ) \begin{aligned} \min_{X\succeq 0} Re(tr(P^HX)) \end{aligned}…...
)
MyCat(mysql的中间件)
文章目录 1 1...

Spring AI入门到精通:气象天气预测技术详解
引言 在全球气候变化的背景下,气象天气的准确预测对于农业、交通、能源等多个领域具有极其重要的意义。随着人工智能(AI)技术的飞速发展,特别是生成式AI和深度学习技术的突破,气象天气预测迎来了新的机遇。Spring AI&…...

ollama的本地部署内含推荐模型!
下载ollama 1.从官网(https://ollama.com/)下载ollama软件并且安装 注意软件是默认安装在C盘 打开cmd后输入:查看命令ollama --version 查看模型仓库:ollama list 显示模型信息: ollama show 在cmd中去拉模型: ollama pull 模…...

要使用 OpenResty 创建一个接口,返回客户端的 IP 地址,并以 JSON 格式输出
要使用 OpenResty 创建一个接口,返回客户端的 IP 地址,并以 JSON 格式输出 要使用 OpenResty 创建一个接口,返回客户端的 IP 地址,并以 JSON 格式输出方案一解决方案(openresty使用cjson)说明:使…...

排序的事
排序的事 C语言实现C实现Java实现Python实现 💐The Begin💐点点关注,收藏不迷路💐 输入n个不相同的正整数,每个数都不超过n。现在需要你把这些整数进行升序排序,每次可以交换两个数的位置,最少需…...

基于Matlab扩展卡尔曼滤波的GPS与DME组合无人机导航系统设计与实现
随着无人机(UAV)在农业监测、环境保护、物流运输、灾害救援等各个领域的广泛应用,精准且可靠的导航系统已成为提升无人机性能和任务执行能力的关键因素。传统的导航方法依赖于单一传感器,往往难以在复杂和动态的环境中提供足够的定…...

GEOBench-VLM:专为地理空间任务设计的视觉-语言模型基准测试数据集
2024-11-29 ,由穆罕默德本扎耶德人工智能大学等机构创建了GEOBench-VLM数据集,目的评估视觉-语言模型(VLM)在地理空间任务中的表现。该数据集的推出填补了现有基准测试在地理空间应用中的空白,提供了超过10,000个经过人工验证的指…...

重邮+数字信号处理实验三:z变换及离散LTI系统的z域分析
实验目的: ( 1 )学会运用 Matlab 求离散时间信号的有理函数 z 变换的部分分式展开; ( 2 )学会运用 Matlab 分析离散时间系统的系统函数的零极点; ( 3 )学会运用 …...

跟 Synchronized 相比,可重入锁 ReentrantLock 其实现原理有什么不同?
与Synchronized相比,可重入锁ReentrantLock在实现原理上存在显著差异。以下是对两者实现原理的详细比较: 一、基本机制 Synchronized: 是JVM基于监视器(Monitor)的实现,提供的内置锁。每个对象都有一个监…...

如何在 Cursor-AI 中配置 Conda 虚拟环境
如何在 CursorAI 中配置 Conda 虚拟环境并使用快捷键 引言 在数据科学和机器学习的开发过程中,使用虚拟环境来管理项目的依赖库是非常重要的。Conda 是一个常用的环境管理工具,它可以帮助我们创建和管理虚拟环境。在这篇博客中,我将介绍如何…...

carsim2020安装记录
step1:双击carsim安装包,进行正常安装, 参考连接:carsim安装流程 这里注意如何破解,踩了一晚上坑 step2:破解d 大体步骤为: 将param目录以及生成MSCLIC_SSQ.lic文件以及MADLIC_SSQ.lic文件,将这两个文件…...

前端开发底层逻辑全解析
前端开发就像是构建一座数字大厦的外表装饰与交互系统,而理解其底层逻辑则是打好坚实基础的关键。今天,我们就来深入剖析前端开发的底层逻辑。 一、浏览器的工作机制:幕后的魔法手 当我们在浏览器中打开一个网页时,一系列复杂的操…...

WSL2下如何部署CosyVoice并开启API服务
环境: WSL2 英伟达4070ti 12G Win10 Ubuntu22.04 问题描述: WSL下如何部署CosyVoice并开启API服务 解决方案: CosyVoice 下载不顺的时候,最好提前开科学 一、部署 1.拉取源码 git clone –recursive https://github.com/FunAudioLLM/CosyVoice.gitwsl下拉取 gi…...

操作系统Lesson8 - 同步互斥机制和编程方法
文章目录 忙等互斥与睡眠唤醒如何解决设立临界区 忙等互斥屏蔽中断可行性对单核处理系统上,最简单 锁变量严格轮询法Peterson算法问题代码:两个人互相谦让,造成死锁。解决方案 TSL指令 忙等互斥与睡眠唤醒 为了解决多个进程之间的操作不会相…...

OSGeo4W64和qtcreator环境配置
OSGeo4W64 release 64位,放在哪个盘都行 随便找个msvc64编译器 完整demo:OSGeo4W64和qtcreator 分享文件:osg4w64和qt.7z 链接:https://pan.xunlei.com/s/VODV85IkEKqQO88_QWNO_Be0A1# 提取码:8k8f 复制这段内容后打开…...

Ubuntu22部署MySQL5.7详细教程
Ubuntu22部署MySQL5.7详细教程 一、下载MySQL安装包二、安装MySQL三、启动MySQL 检查状态登录MySQL 四、开启远程访问功能 1、允许其他主机通过root访问数据库2、修改配置文件,允许其他IP通过自定义端口访问 五、使用Navicat连接数据库 默认情况下,Ubun…...

http和https分别是什么?区别是什么?
HTTP和HTTPS是两种常见的网络协议,用于在Web上进行数据传输。以下是它们的简要解释和主要区别: HTTP(Hypertext Transfer Protocol) HTTP是一种应用层协议,用于在Web上传输数据。它是互联网上应用最为广泛的一种网络…...

文件IO——01
1. 认识文件 1)文件概念 “文件”是一个广义的概念,可以代表很多东西 操作系统里,会把很多的硬件设备和软件资源抽象成“文件”,统一管理 但是大部分情况下的文件,都是指硬盘的文件(文件相当于是对“硬…...