使用 LangGraph 和 Elasticsearch 构建强大的 RAG 工作流
作者:来自 Elastic Neha Saini

在这篇博客中,我们将向你展示如何配置和自定义 LangGraph Retrieval Agent 模板与 Elasticsearch,以构建一个强大的 RAG 工作流,实现高效的数据检索和由 AI 驱动的响应。
Elasticsearch 原生集成了行业领先的生成式 AI 工具和提供商。查看我们关于超越 RAG 基础知识或构建可投入生产的应用程序 Elastic Vector Database 的网络研讨会。
要为你的用例构建最佳搜索解决方案,现在就开始免费云试用,或在本地机器上尝试 Elastic。
LangGraph Retrieval Agent Template 是由 LangChain 开发的入门项目,旨在通过 LangGraph Studio 使用 LangGraph 构建基于检索的问题解答系统。该模板预先配置,可与 Elasticsearch 无缝集成,使开发者能够快速构建能够高效索引和检索文档的智能体。
本博客重点介绍如何使用 LangGraph Studio 和 LangGraph CLI 运行并自定义 LangChain Retrieval Agent Template。该模板为构建检索增强生成(RAG)应用提供了框架,并支持多种检索后端,如 Elasticsearch。
我们将带你逐步完成设置、配置环境,以及如何高效结合 Elastic 执行该模板,并自定义智能体流程。
先决条件
在继续之前,请确保你已安装以下内容:
-
Elasticsearch Cloud 部署或本地 Elasticsearch 部署(也可以在 Elastic Cloud 上创建一个 14 天免费试用)——版本需为 8.0.0 或更高
-
Python 3.9 及以上版本
-
一个 LLM 提供商的访问权限,如 Cohere(本指南使用)、 OpenAI 或 Anthropic / Claude
创建 LangGraph 应用
1. 安装 LangGraph CLI
pip install --upgrade "langgraph-cli[inmem]"2. 从 retrieval-agent-template 创建 LangGraph 应用
mkdir lg-agent-demo
cd lg-agent-demo
langgraph new lg-agent-demo 你会看到一个交互式菜单,可以从中选择可用的模板列表。选择 4 表示 Retrieval Agent,选择 1 表示 Python,如下所示:
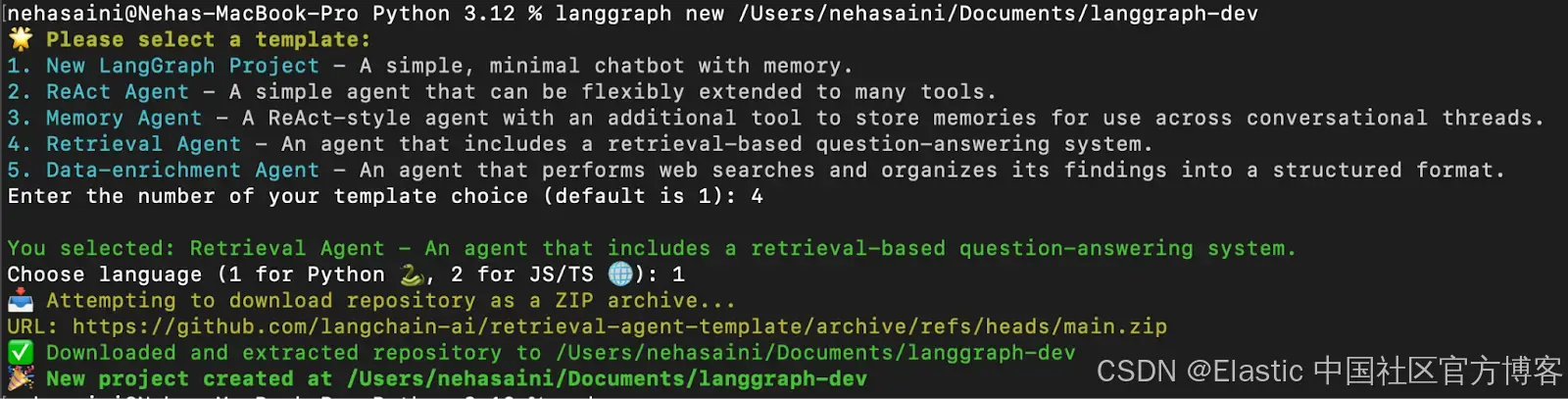
故障排除:如果遇到错误 “urllib.error.URLError: <urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1000)>”
请运行 Python 的安装证书命令来解决此问题,如下所示。

3. 安装依赖项
在新建的 LangGraph 应用根目录下,创建一个虚拟环境并以 edit 模式安装依赖项,这样你的本地更改将被服务器使用:
#For Mac
python3 -m venv lg-demo
source lg-demo/bin/activate
pip install -e .#For Windows
python3 -m venv lg-demo
lg-demo\Scripts\activate
pip install -e .设置环境
1. 创建一个 .env 文件
.env 文件保存 API 密钥和配置,以便应用可以连接到你选择的 LLM 和检索提供者。通过复制示例配置生成一个新的 .env 文件:
cp .env.example .env2. 配置 .env 文件
.env 文件自带一组默认配置。你可以根据你的设置添加必要的 API 密钥和值来更新它。对于与你的使用场景无关的键,可以保持不变或者删除。
# To separate your traces from other applications
LANGSMITH_PROJECT=retrieval-agent# LLM choice (set the API key for your selected provider):
ANTHROPIC_API_KEY=your_anthropic_api_key
FIREWORKS_API_KEY=your_fireworks_api_key
OPENAI_API_KEY=your_openai_api_key# Retrieval provider (configure based on your chosen service):## Elastic Cloud:
ELASTICSEARCH_URL=https://your_elastic_cloud_url
ELASTICSEARCH_API_KEY=your_elastic_api_key## Elastic Local:
ELASTICSEARCH_URL=http://host.docker.internal:9200
ELASTICSEARCH_USER=elastic
ELASTICSEARCH_PASSWORD=changeme## Pinecone:
PINECONE_API_KEY=your_pinecone_api_key
PINECONE_INDEX_NAME=your_pinecone_index_name## MongoDB Atlas:
MONGODB_URI=your_mongodb_connection_string# Cohere API key:
COHERE_API_KEY=your_cohere_api_keyElastic Cloud 和 Cohere 示例 .env 文件
下面是一个示例 .env 配置,使用 Elastic Cloud 作为检索提供者,Cohere 作为 LLM,正如本博客中演示的:
# To separate your traces from other applications
LANGSMITH_PROJECT=retrieval-agent
#Retrieval Provider
# Elasticsearch configuration
ELASTICSEARCH_URL=elastic-url:443
ELASTICSEARCH_API_KEY=elastic_api_key
# Cohere API key
COHERE_API_KEY=cohere_api_key注意:虽然本指南使用 Cohere 进行响应生成和向量生成,但你也可以根据自己的用例选择其他 LLM 提供商,比如 OpenAI、Claude,或者本地的 LLM 模型。请确保你要使用的每个 key 都已经在 .env 文件中正确设置。
3. 更新配置文件 - configuration.py
在 .env 文件中设置好相应的 API key 后,下一步是更新应用程序的默认模型配置。更新配置可以确保系统使用你在 .env 文件中指定的服务和模型。
导航到配置文件:
cd src/retrieval_graphconfiguration.py 文件包含检索代理执行以下三项主要任务时使用的默认模型设置:
-
嵌入模型(Embedding model)—— 将文档转换为向量表示
-
查询模型(Query model)—— 将用户查询处理为向量
-
响应模型(Response model)—— 生成最终回答
默认情况下,代码使用的是 OpenAI(如 openai/text-embedding-3-small)和 Anthropic(如 anthropic/claude-3-5-sonnet-20240620 和 anthropic/claude-3-haiku-20240307)提供的模型。
在本博客中,我们切换为使用 Cohere 模型。如果你已经在使用 OpenAI 或 Anthropic,则无需更改。
使用 Cohere 的示例更改:
打开 configuration.py 并按如下方式修改默认模型设置:
…embedding_model: Annotated[str,{"__template_metadata__": {"kind": "embeddings"}},] = field(default="cohere/embed-english-v3.0",
…
response_model: Annotated[str, {"__template_metadata__": {"kind": "llm"}}] = field(default="cohere/command-r-08-2024",
…
query_model: Annotated[str, {"__template_metadata__": {"kind": "llm"}}] = field(default="cohere/command-r-08-2024",metadata={使用 LangGraph CLI 运行检索代理
1. 启动 LangGraph 服务器
cd lg-agent-demo
langgraph dev这将在本地启动 LangGraph API 服务器。如果运行成功,你应该会看到类似下面的内容:
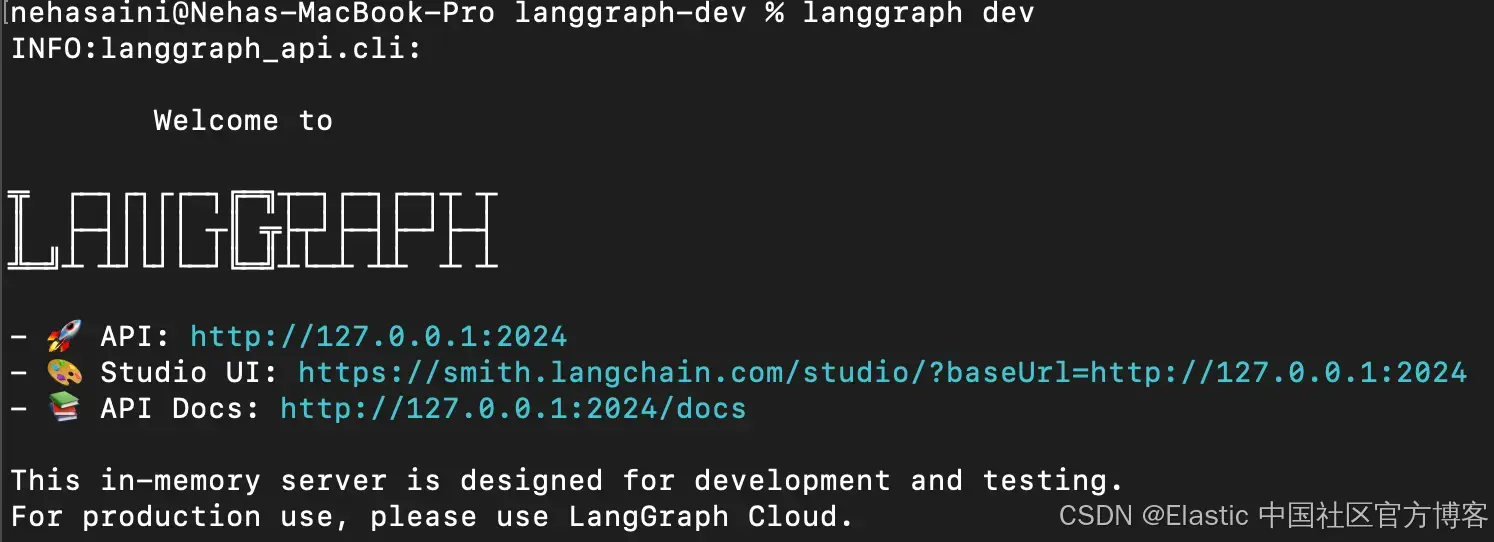
打开 Studio UI 链接。
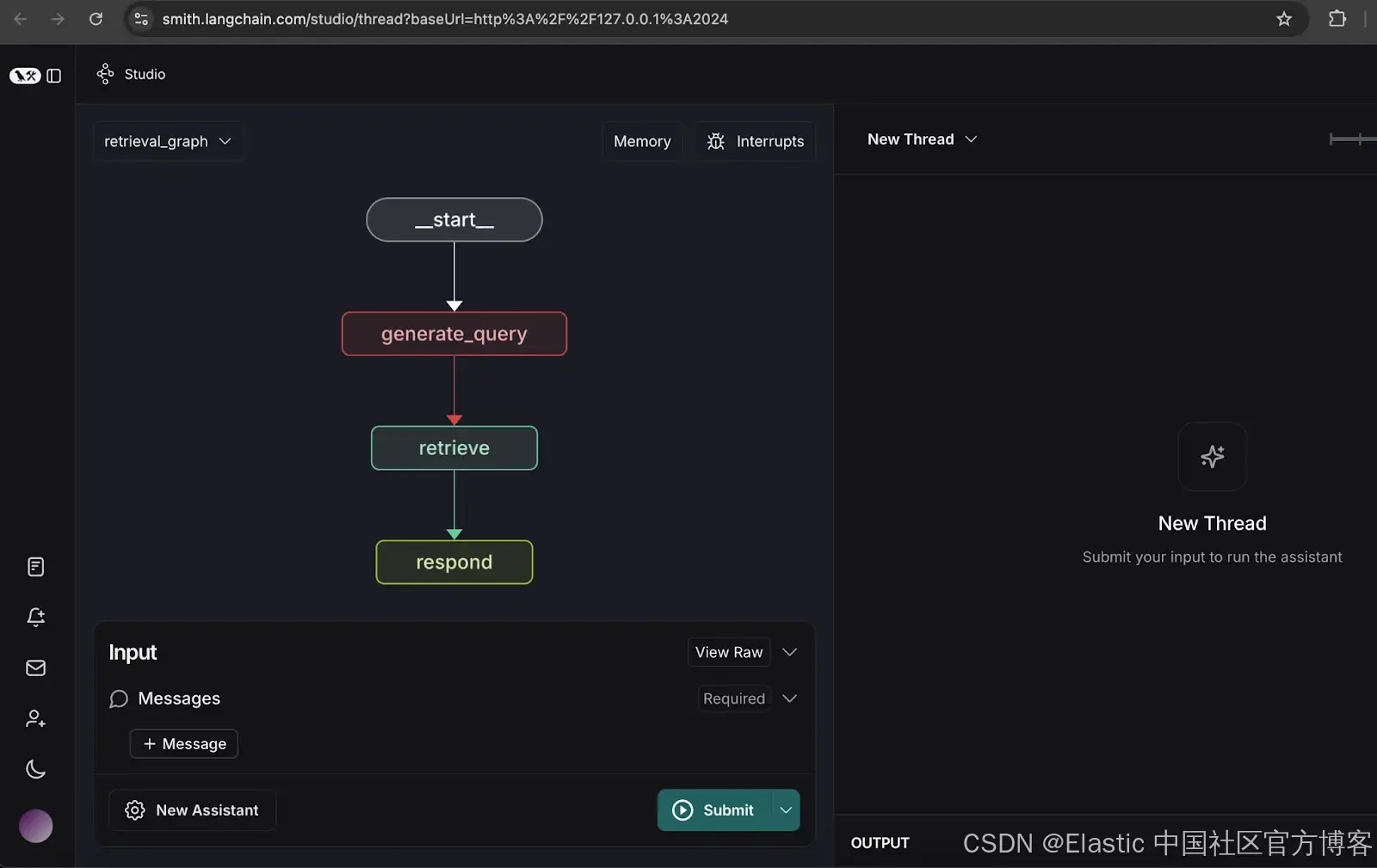
这里有两个可用的图表:
-
Retrieval Graph:从 Elasticsearch 检索数据并使用 LLM 响应查询。
-
Indexer Graph:将文档索引到 Elasticsearch 并使用 LLM 生成向量。
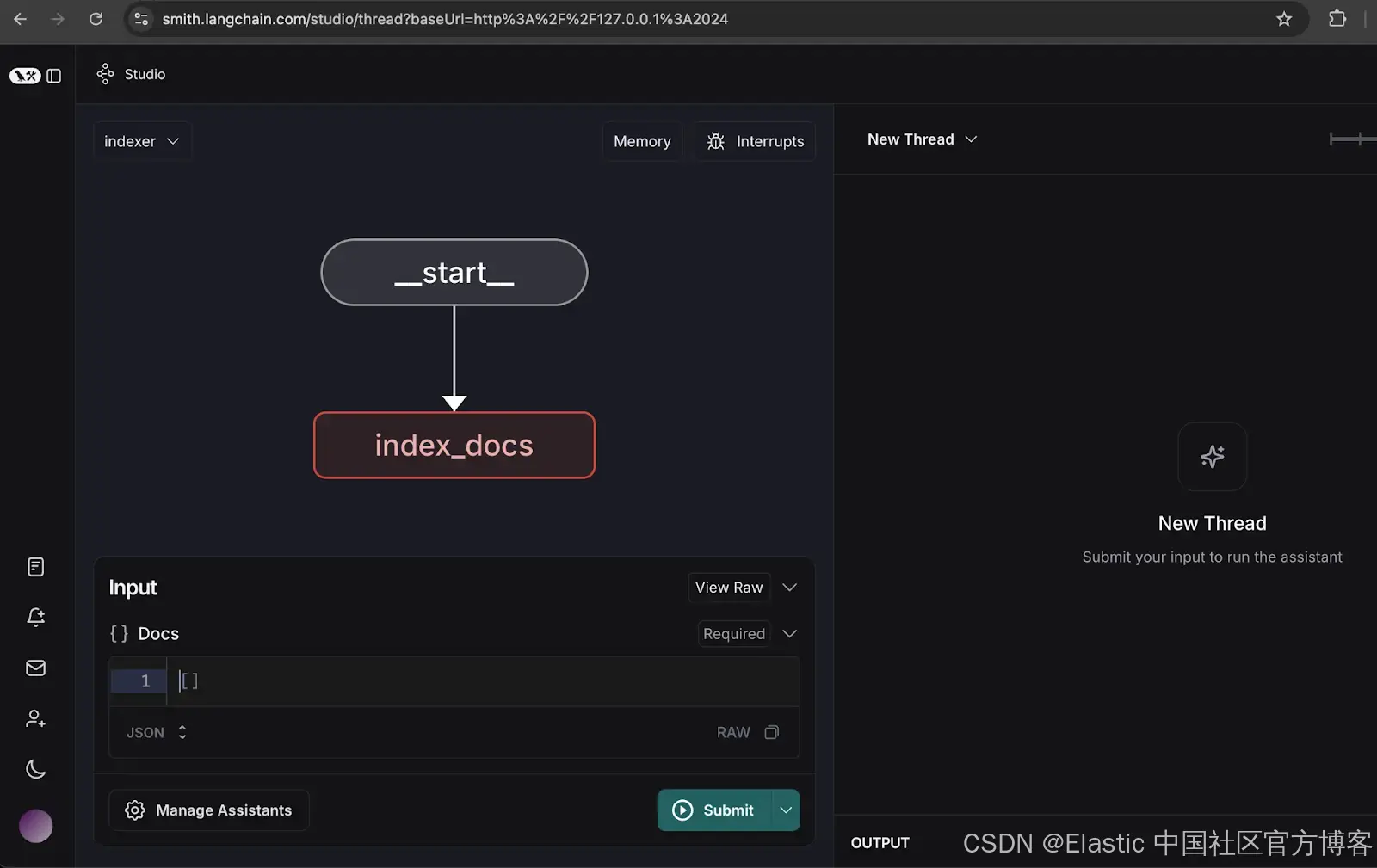
2. 配置 Indexer graph
- 打开 Indexer graph。
- 点击管理助手 (Manage Assistants)。
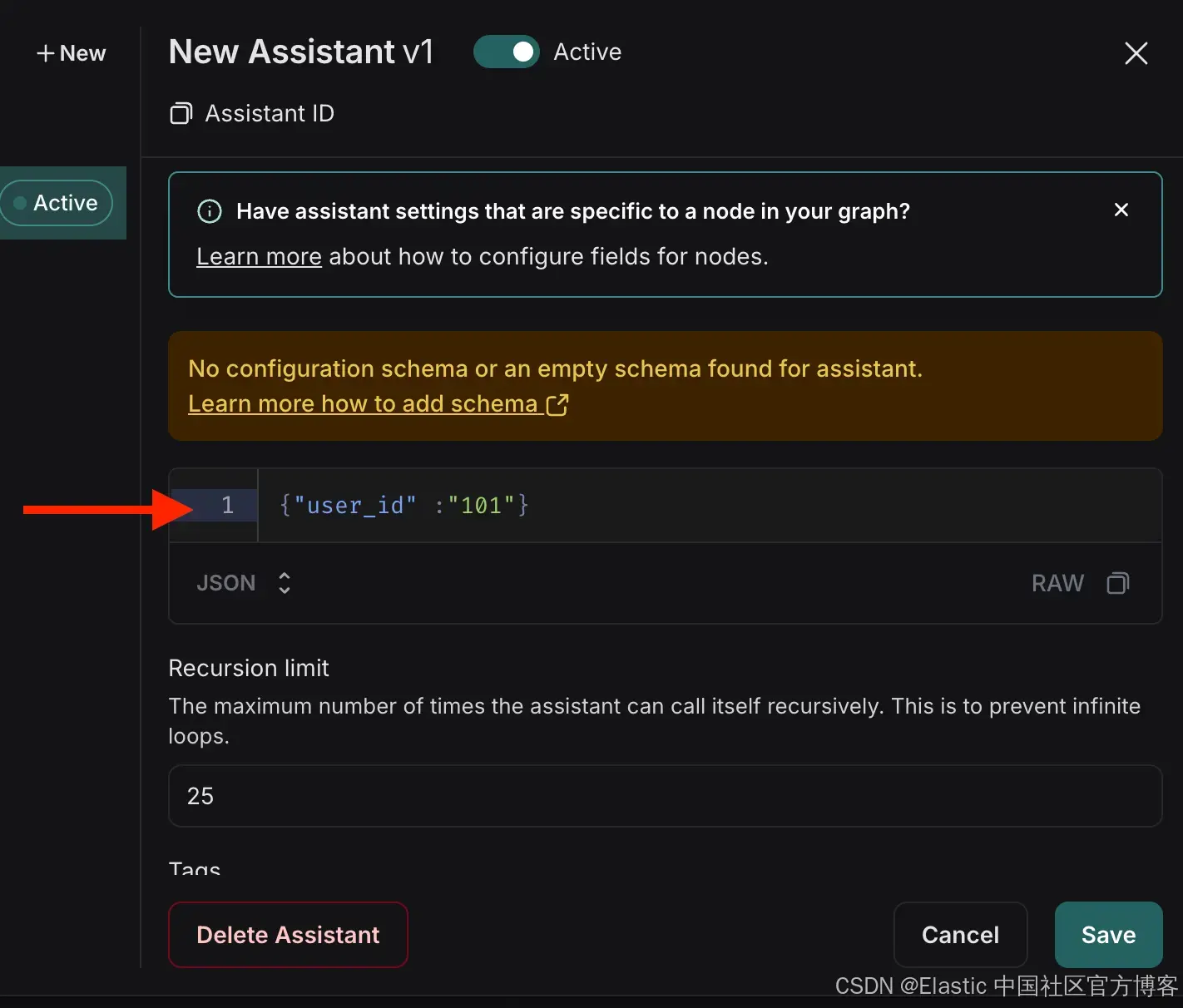
- 点击 “添加新助手” (Add New Assistant),输入指定的用户详情,然后关闭窗口。
{"user_id": "101"}
3. 索引示例文档
索引以下示例文档,这些文档代表组织 NoveTech 的假设季度报告:
[{ "page_content": "NoveTech Solutions Q1 2025 Report - Revenue: $120.5M, Net Profit: $18.2M, EPS: $2.15. Strong AI software launch and $50M government contract secured."},{"page_content": "NoveTech Solutions Business Highlights - AI-driven analytics software gained 15% market share. Expansion into Southeast Asia with two new offices. Cloud security contract secured."},{"page_content": "NoveTech Solutions Financial Overview - Operating expenses at $85.3M, Gross Margin 29.3%. Stock price rose from $72.5 to $78.3. Market Cap reached $5.2B."},{"page_content": "NoveTech Solutions Challenges - Rising supply chain costs impacting hardware production. Regulatory delays slowing European expansion. Competitive pressure in cybersecurity sector."},{"page_content": "NoveTech Solutions Future Outlook - Expected revenue for Q2 2025: $135M. New AI chatbot and blockchain security platform launch planned. Expansion into Latin America."},{"page_content": "NoveTech Solutions Market Performance - Year-over-Year growth at 12.7%. Stock price increase reflects investor confidence. Cybersecurity and AI sectors remain competitive."},{"page_content": "NoveTech Solutions Strategic Moves - Investing in R&D to enhance AI-driven automation. Strengthening partnerships with enterprise cloud providers. Focusing on data privacy solutions."},{"page_content": "NoveTech Solutions CEO Statement - 'NoveTech Solutions continues to innovate in AI and cybersecurity. Our growth strategy remains strong, and we foresee steady expansion in the coming quarters.'"}
]一旦文档被索引,你将在线程中看到一条删除消息,如下所示。
4. 运行检索图(retrieval graph)
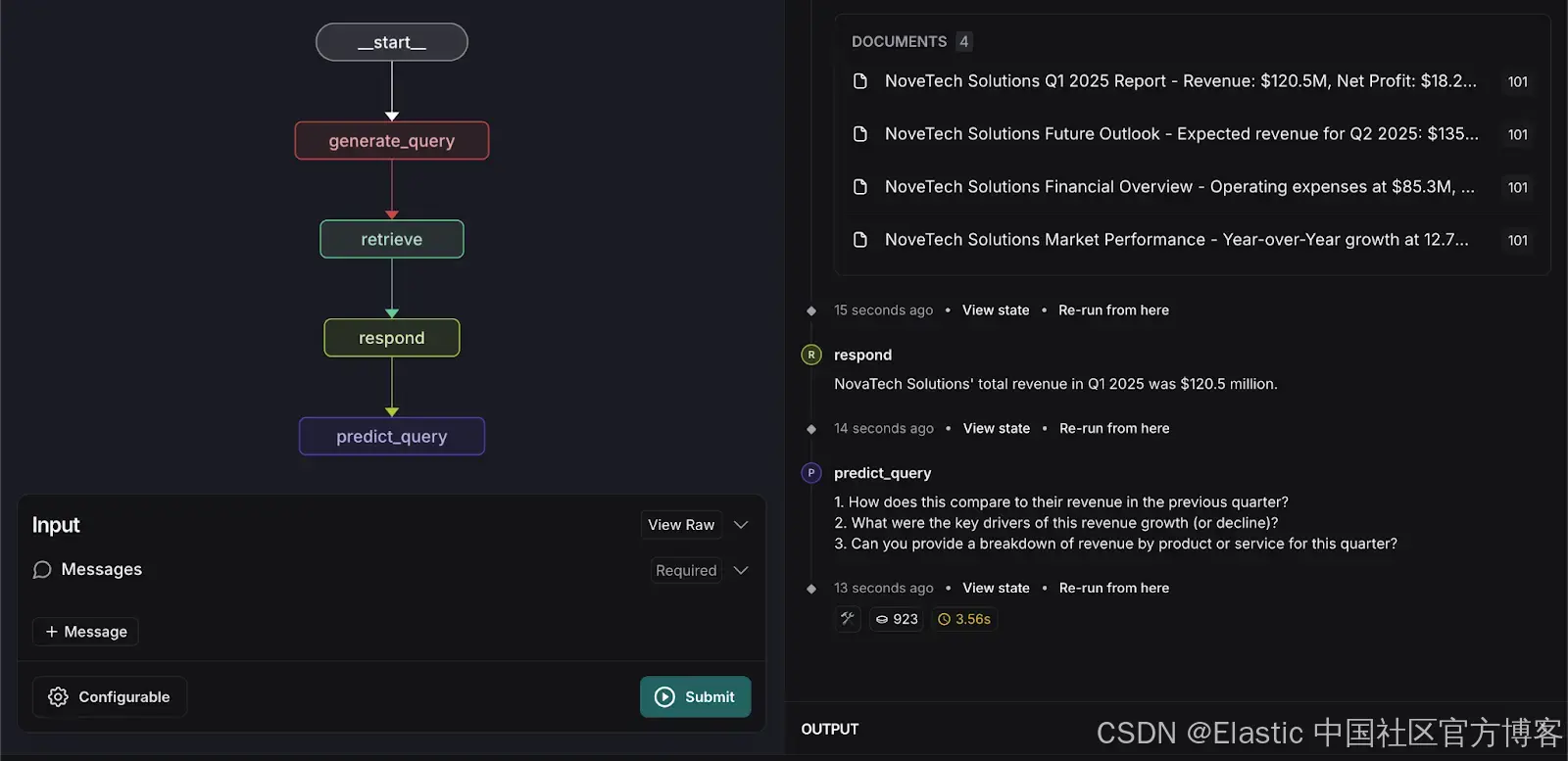
切换到检索图。 输入以下搜索查询:
What was NovaTech Solutions total revenue in Q1 2025?系统将返回相关文档,并根据已索引的数据提供准确的答案。
自定义检索代理
为了增强用户体验,我们在检索图中引入了一个自定义步骤,用于预测用户可能提出的下三个问题。这个预测基于以下内容:
-
从检索到的文档中的上下文
-
之前的用户交互
-
上一个用户查询
实现查询预测功能需要以下代码更改:
1. 更新 graph.py
添加 predict_query 函数:
async def predict_query(state: State, *, config: RunnableConfig
) -> dict[str, list[BaseMessage]]:logger.info(f"predict_query predict_querypredict_query predict_query predict_query predict_query") # Log the queryconfiguration = Configuration.from_runnable_config(config)prompt = ChatPromptTemplate.from_messages([("system", configuration.predict_next_question_prompt),("placeholder", "{messages}"),])model = load_chat_model(configuration.response_model)user_query = state.queries[-1] if state.queries else "No prior query available"logger.info(f"user_query: {user_query}")logger.info(f"statemessage: {state.messages}")#human_messages = [msg for msg in state.message if isinstance(msg, HumanMessage)]message_value = await prompt.ainvoke({"messages": state.messages,"user_query": user_query, # Use the most recent query as primary input"system_time": datetime.now(tz=timezone.utc).isoformat(),},config,)next_question = await model.ainvoke(message_value, config)return {"next_question": [next_question]}修改 respond 函数以返回 response 对象,而不是消息:
async def respond(state: State, *, config: RunnableConfig
) -> dict[str, list[BaseMessage]]:"""Call the LLM powering our "agent"."""configuration = Configuration.from_runnable_config(config)# Feel free to customize the prompt, model, and other logic!prompt = ChatPromptTemplate.from_messages([("system", configuration.response_system_prompt),("placeholder", "{messages}"),])model = load_chat_model(configuration.response_model)retrieved_docs = format_docs(state.retrieved_docs)message_value = await prompt.ainvoke({"messages": state.messages,"retrieved_docs": retrieved_docs,"system_time": datetime.now(tz=timezone.utc).isoformat(),},config,)response = await model.ainvoke(message_value, config)# We return a list, because this will get added to the existing listreturn {"response": [response]}更新图结构以添加新的节点和边用于 predict_query:
builder.add_node(generate_query)
builder.add_node(retrieve)
builder.add_node(respond)
builder.add_node(predict_query)
builder.add_edge("__start__", "generate_query")
builder.add_edge("generate_query", "retrieve")
builder.add_edge("retrieve", "respond")
builder.add_edge("respond", "predict_query")2. 更新 prompts.py
为查询预测(Query Prediction)编写 prompt:
PREDICT_NEXT_QUESTION_PROMPT = """Given the user query and the retrieved documents, suggest the most likely next question the user might ask.**Context:**
- Previous Queries:
{previous_queries}- Latest User Query: {user_query}- Retrieved Documents:
{retrieved_docs}**Guidelines:**
1. Do not suggest a question that has already been asked in previous queries.
2. Consider the retrieved documents when predicting the next logical question.
3. If the user's query is already fully answered, suggest a relevant follow-up question.
4. Keep the suggested question natural and conversational.
5. Suggest at least 3 questionSystem time: {system_time}"""3. 更新 configuration.py
添加 predict_next_question_prompt:
predict_next_question_prompt: str = field(default=prompts.PREDICT_NEXT_QUESTION_PROMPT,metadata={"description": "The system prompt used for generating responses."},)4. 新 state.py
添加以下属性:
response: Annotated[Sequence[AnyMessage], add_messages]
next_question : Annotated[Sequence[AnyMessage], add_messages]5. 重新运行 Retrieval Graph
再次输入以下搜索查询:
What was NovaTech Solutions total revenue in Q1 2025?系统将处理输入并预测用户可能会问的三个相关问题,如下所示。
结论
在 LangGraph Studio 和 CLI 中集成 Retrieval Agent 模板提供了几个关键优势:
- 加速开发:模板和可视化工具简化了检索工作流的创建和调试,减少了开发时间。
- 无缝部署:内置对 API 和自动扩展的支持,确保在不同环境中的顺利部署。
- 简易更新:修改工作流、添加新功能和集成额外节点变得简单,便于扩展和增强检索过程。
- 持久化记忆:系统保留代理的状态和知识,提升一致性和可靠性。
- 灵活的工作流建模:开发人员可以根据特定用例自定义检索逻辑和通信规则。
- 实时交互和调试:能够与运行中的代理进行交互,有效进行测试和问题解决。
通过利用这些功能,组织可以构建强大、高效且可扩展的检索系统,增强数据访问性和用户体验。
该项目的完整源代码可在 GitHub 上找到。
原文:Build a powerful RAG workflow using LangGraph and Elasticsearch - Elasticsearch Labs
相关文章:

使用 LangGraph 和 Elasticsearch 构建强大的 RAG 工作流
作者:来自 Elastic Neha Saini 在这篇博客中,我们将向你展示如何配置和自定义 LangGraph Retrieval Agent 模板与 Elasticsearch,以构建一个强大的 RAG 工作流,实现高效的数据检索和由 AI 驱动的响应。 Elasticsearch 原生集成了…...
)
云原生--核心组件-容器篇-2-认识下Docker(三大核心之镜像,容器,仓库)
1、Docker基本概念 (1)、定义 Docker是一种开源的应用容器引擎,是基于操作系统级虚拟化技术。允许开发者将应用程序及其依赖项打包到一个可移植的容器中,然后发布到任何支持Docker的环境中运行。Docker容器是轻量级、独立且可执…...

智慧园区IOT项目与AI时代下的机遇 - Java架构师面试实战
在互联网大厂的Java求职者面试中,面试官通常会针对实际业务场景提出一系列问题。以下是关于智慧园区IOT项目及AI时代下的机遇的面试模拟对话。 第一轮提问 面试官:马架构,请简要介绍下智慧园区IOT项目的整体架构设计。 马架构:…...

Unity中文件上传以及下载,获取下载文件大小的解决方案
首先现在Unity插件那么的广泛的情况下,很多东西都不需要自己实现,直接使用第三方插件就可以了,但为什么这里需要自己写,接下来说明原因。 在Unity商城中有很多关于关于网络接口调用的插件,其中有一款叫BestHTTP这款使用比较广泛的插件,不知道朋友们是不是都知道,是不是…...

Word/WPS 删除最后一页空白页,且保持前面布局样式不变
如题,试了多种方法,都不行。主要是可能的原因太多了,没有通解,这只是适用于我的情况。 解决方案: 首先光标放在倒数第二页(即想保留的最后一页),点击页面右下角这个小箭头ÿ…...

MySQL长事务的隐患:深入剖析与解决方案
MySQL长事务的隐患:深入剖析与解决方案 一、什么是长事务? 在数据库系统中,长事务(Long Transaction)通常指执行时间超过预期或系统设定阈值的事务。对于MySQL而言,虽然没有严格的时间定义,但一般认为执行时间超过数…...

【Tauri】桌面程序exe开发 - Tauri+Vue开发Windows应用 - 比Electron更轻量!8MB!
效果图 Tauri的二进制文件体积显著小于Electron,安装包通常缩小80%以上。应用启动更快,内存占用更低,尤其在老旧设备上体验更流畅。 写在前面 Tauri官网 https://tauri.app/zh-cn/支持语言:js、ts、rust、.net编译出来的exe文件&…...

2025春季NC:3.1TheTrapeziumRule
3.1TheTrapeziumRule 📐 The Idea Instead of finding the exact area under a curve y = f ( x ) y = f(x) y=...

【摩尔定律】
一、摩尔定律的核心定义 原始表述(1965年) “集成电路上可容纳的晶体管数量,每隔约 18-24个月 便会增加一倍,同时性能提升一倍,而成本下降一半。” 简化理解 芯片的 晶体管密度 和…...

Maven 依赖冲突调解与版本控制
🧑 博主简介:CSDN博客专家,历代文学网(PC端可以访问:https://literature.sinhy.com/#/?__c1000,移动端可微信小程序搜索“历代文学”)总架构师,15年工作经验,精通Java编…...

《Python Web部署应知应会》Flask网站隐藏或改变浏览器URL:从Nginx反向代理到URL重写技术
Flask网站隐藏或改变浏览器显示URL地址的实现方案:从Nginx反向代理到URL重写技术 引言 在Web应用开发中,URL路径的安全性往往被忽视,这可能导致网站结构和后端逻辑被攻击者轻易推断。对于Flask框架开发的网站,如何隐藏或改变浏览…...

6.2 内容生成与营销:个性化内容创作与营销策略优化
随着消费者对个性化体验的需求日益增长,传统的内容创作与营销方式已难以满足市场竞争的需要。基于大语言模型(LLM)与智能代理(Agent)的技术为企业提供了全新的解决方案,能够实现高效、精准、规模化的内容生…...
)
平面连杆机构(上)
1、平面四杆机构的类型与演化 1)平面四杆机构的类型 a、铰链四杆机构:曲柄摇杆机构、双曲柄机构、双摇杆机构 b、其他四杆机构:曲柄滑块机构、导杆机构、滑块机构、双滑块机构、偏心轮四杆机构...... 2)平面四杆机构的演化 a、…...

【数据结构刷题】顺序表与ArrayList
【数据结构刷题】顺序表与ArrayList 1. 杨辉三角2. 合并两个有序数组 1. 杨辉三角 LC链接:杨辉三角 //杨辉三角import java.util.ArrayList; import java.util.List;public class Demo1 {public List<List<Integer>> generate(int numRows) {List<…...

顶点着色器和片元着色器染色+表面体着色器染色
顶点/片元着色器染色 创建材质球及Shader同名文件VFColor //Update NOTE:replaced mul(UNITY_MATRIX_MVP,*) with UnityObjectToClipPos(*) Shader "CreateTest/VFColor" {Properties{_Color("颜色",Color)(1,1,1,1)}SubShader{Pass{//顶点片…...

240426 leetcode exercises
240426 leetcode exercises jarringslee 文章目录 240426 leetcode exercises[1669. 合并两个链表](https://leetcode.cn/problems/merge-in-between-linked-lists/?envTypeproblem-list-v2&envIdlinked-list)🔁基础版 保存断点,先拼再补…...

代码随想录算法训练营Day35
卡码网46.携带研究材料 力扣494.目标和【meidum】 力扣416.分割等和子集【medium】 一、卡码网46.携带研究材料 题目链接:卡码网46.携带研究材料 视频链接:代码随想录 题解链接:代码随想录 1、思路 dp[i][j] 表示从下标为 [0-i] 的物品里任意…...

C++17 折叠表达式
C17 引入的折叠表达式(Fold Expressions) 是处理可变参数模板(Variadic Templates)的革命性特性。它通过简洁的语法,使得对参数包(Parameter Pack)的操作更加直观和高效,避免了传统的…...

Ubuntu编译opencv源码
准备 Ubuntu版本:22.04opencv版本:4.9.0没下载Ubuntu镜像的可以在清华镜像下载 本文以4.9.0版本演示,可根据自身情况选择 安装JDK和依赖项 本次编译主要为了获取java在linux环境下的动态库,所以需要在虚拟机上下载jdk # 安装…...

一种滑窗像素自差值的深度学习损失函数
公司项目,已申请专利。 深度学习作为新兴技术在图像领域蓬勃发展,因其自主学习图像数据特征避免了人工设计算法的繁琐,精准的检测性能、高效的检测效率以及对各种不同类型的图像任务都有比较好的泛化性能,使得深度学习技术在图像领…...

【Typecho】给Joe主题后台添加custom自定义功能!
大家好,今天来添加一下自定义功能! 😂 温馨提示:站长已经通过本地环境测试custom自定义功能,功能正常可以使用,按照我的操作来一定成功! 大纲 创建custom.php粘贴代码到custom.php文件引入cus…...

一些常见的资源池管理、分布式管理和负载均衡的监控工具
资源池管理监控工具 Prometheus 是一款开源的系统监控和警报工具。它可以通过收集各种指标数据,如CPU使用率、内存使用量、磁盘I/O等,来监控资源池中的服务器、容器等资源。Prometheus具有强大的查询语言和可视化功能,能够帮助管理员快速了解资源的使用情况,并及时发现潜在…...

WPF程序使用Sugar操作数据库
WPF 程序使用 Sugar ORM 操作数据库 一、引言 在 WPF(Windows Presentation Foundation)应用程序中,数据库操作是不可或缺的一部分。Sugar ORM(对象关系映射)是一种轻量级的 ORM 框架,它简化了数据库操作,使得开发者能够以面向对象的方式与数据库进行交互。本文将详细…...

【Castle-X机器人】四、智能机械臂安装与调试
持续更新。。。。。。。。。。。。。。。 【Castle-X机器人】智能机械臂安装与调试 四、智能机械臂安装与调试2.1 安装2.2 调试2.2.1 2D摄像头测试 四、智能机械臂安装与调试 2.1 安装 使用相应工具将机械臂固定在Castle-X机器人底盘 2.2 调试 2.2.1 2D摄像头测试 内容地址 链…...

goweb-signup注册功能实现
注册功能 route.go package routerimport ("bluebell/controller""github.com/gin-gonic/gin" )func SetupRouter(mode string) *gin.Engine {r : gin.Default()r.POST("/signup", controller.SignupHandler)return r }UserController.go pac…...

Linux: 如何在VMware上安装Ubuntu操作系统
在VMware上安装Ubuntu操作系统是一个相对简单的过程,以下是详细的步骤: 一、准备工作 安装VMware软件 确保你已经在电脑上安装了VMware Workstation(适用于Windows)或VMware Fusion(适用于Mac)。如果没有安…...

详解 Network.framework:iOS 网络开发的新基石
详解 Network.framework:iOS 网络开发的新基石 引言 自 iOS 12 和 macOS 10.14 起,Apple 推出了一个新的网络开发框架 —— Network.framework。它被定位为下一代网络连接的基础设施,让开发者可以以更安全、更高效的方式,管理 T…...

Java—— 五道算法水题
第一题 需求: 包装类:键盘录入一些1~100之间的整数,并添加到集合中。直到集合中所有数据和超过200为止 代码实现: import java.util.ArrayList; import java.util.Scanner;public class Test1 {public static void main(String[]…...

将服务器接到路由器上访问
应用场景: 实验室网卡更换了,新网卡没有报备到校园网,暂时无法通过外部链接连到服务器. 除了跳板机之外,可以使用以下方法将服务器接入到路由器访问. 将服务器接到交换机上,将交换机接到路由器上本地电脑 连接路由器wifi登录http://192.168.0.1/,访问路…...

MyBatis缓存配置的完整示例,包含一级缓存、二级缓存、自定义缓存策略等核心场景,并附详细注释和总结表格
以下是MyBatis缓存配置的完整示例,包含一级缓存、二级缓存、自定义缓存策略等核心场景,并附详细注释和总结表格: 1. 一级缓存(默认开启) // 使用同一SqlSession执行两次查询,自动命中一级缓存 try (SqlSe…...
)
我爱学算法之—— 二分查找(上)
了解二分算法 二分查找,想必多多少少有一点了解了,我们了解的二分查找算法: 当一个数组有序的时候,我们可以使用二分算法来查找一个值; 直接比较mid((left right)/2)和我们要查找的值target;如果nums[mid]…...

Tauri快速入门1 - 搭设开发环境
前言 Tauri框架结合了 Web 技术的优势,开发者能用熟悉的 HTML、CSS 和 JavaScript 进行开发,像开发网页应用一样便捷高效。 其次,该框架有着出色的性能表现,相比一些传统框架,其资源占用相对较低。在安全性方面&#x…...

tigase源码学习杂记-IO处理的线程模型
前言 tigase是一个高性能的服务器,其实个人认为作为即时通讯的服务器,高性能主要体现在他对IO复用,和多线程的使用上,今天来学习一下他的IO的线程处理模型的源码,并记录一下他优秀的设计。 概述 tigase是使用的NIO作…...

电商秒杀系统技术栈与难点解析 - Java架构师面试实战
电商秒杀系统技术栈与难点解析 - Java架构师面试实战 第一轮提问 面试官:马架构,欢迎参加我们公司的面试。首先,请您简单介绍一下自己。 马架构:您好,我叫马架构,拥有十年的Java研发经验和架构设计经验&…...

ASP.NET MVC 入门指南三
16. 安全性 16.1 身份验证和授权 身份验证:确认用户的身份。ASP.NET MVC 支持多种身份验证方式,如表单身份验证、Windows 身份验证和 OAuth 等。 表单身份验证:用户通过输入用户名和密码登录,服务器验证后颁发一个身份验证票证&…...

导览项目KD-Tree最近地点搜索优化
背景描述 我在做一个校园导览的小程序的时候,涉及到最近地点搜索的业务功能,根据当前位置搜索最近的校园地点,比如教学楼,图书馆,自习室,办事地点等等。 我最初想到的办法就是获取用户当前位置的经纬度后&…...

【Pandas】pandas DataFrame rmul
Pandas2.2 DataFrame Binary operator functions 方法描述DataFrame.add(other)用于执行 DataFrame 与另一个对象(如 DataFrame、Series 或标量)的逐元素加法操作DataFrame.add(other[, axis, level, fill_value])用于执行 DataFrame 与另一个对象&…...
手机怎么开启开发者模式(简单明了版))
苹果(IOS)手机怎么开启开发者模式(简单明了版)
苹果手机怎么开启开发者模式(简单明了版) iOS 16 以后,苹果新增了「开发者模式」。如果你要在 iPhone 上运行自己开发的 App,比如通过 Xcode 或其它工具安装测试包,必须先开启这个模式。 下面是开启方法👇…...

Agent2Agent
rag系列文章目录 文章目录 rag系列文章目录前言一、协议设计原则与技术基础二、通信机制与消息格式三、身份验证与安全设计四、能力发现与任务协作总结 前言 谷歌于2025年4月推出了A2A(Agent2Agent)协议,旨在解决当前AI智能体生态中的互操作…...

【MCP】了解远程MCP调用背后使用的SSE协议
本文介绍了远程MCP使用的SSE协议,通过wireshark抓包的方式了解MCP客户端和服务端之间通过SSE协议交互涉及到的请求与响应。 1. 什么是SSE协议? 参考:https://zhuanlan.zhihu.com/p/1894024642395619635和https://blog.csdn.net/aerror/artic…...

Log4j Properties 配置项详细说明
Log4j Properties 配置项详细说明 1. 核心配置项说明 根日志记录器:定义全局日志级别和输出目标 log4j.rootLogger [级别], appender1, appender2,...Appender 定义:指定日志输出目标(控制台、文件等) log4j.appender.[名称].[属…...

哪些物联网框架支持多协议接入?选型指南与核心能力解析
在物联网(IoT)领域,设备通信协议的多样性(如MQTT、CoAP、Modbus、Zigbee等)是开发者面临的核心挑战之一。选择支持多协议接入的物联网框架,可以显著降低异构设备连接的复杂度,提升系统的兼容性和…...

第三方测试机构如何保障软件质量并节省企业成本?
在软件行业,第三方测试机构扮演着极其重要的角色。他们提供独立且专业的测试服务,目的是为了保障软件的质量以及提升用户的使用体验。 专业独立 测试机构拥有经验丰富的测试员和严谨的测试流程。他们会对软件各项功能进行细致检验,力求不放…...

Eigen迭代求解器类
1. 迭代求解器核心类概览 Eigen 提供多种迭代法求解稀疏线性方程组 AxbAxb,适用于大规模稀疏矩阵: 求解器类适用矩阵类型算法关键特性ConjugateGradient对称正定(SPD)共轭梯度法(CG)高精度,内…...

AI 与高性能计算的深度融合:开启科技新纪元
在当今科技迅猛发展的时代,人工智能(AI)与高性能计算(HPC)正以前所未有的态势深度融合,这种融合宛如一场强大的风暴,席卷并重塑着众多领域的格局。从科学研究的突破到商业应用的革新,…...

写入cache时数据格式错误产生的ERRO导致整个测试框架无法运行
背景 在yaml文件里面提取request放入缓存时,request是form-data,错用jsonpath提取并写入缓存,导致后面的所有运行都异常 原因 起因是我想引用请求体的Uid,提取方式用错了,所以可以看到最后一段current_request_set_…...

3:QT联合HALCON编程—海康相机SDK二次程序开发
思路: 1.定义带UI界面的主函数类 1.1在主函数中包含其它所有类头文件,进行声明和实例化;使用相机时,是用公共相机的接口在某一个具体函数中去实例化具体的海康相机对象。 1.2设计界面:连接相机,单次采集&a…...
)
图论---LCA(倍增法)
预处理 O( n logn ),查询O( log n ) #include<bits/stdc.h> using namespace std; typedef pair<int,int> pii; const int N40010,M2*N;//是无向边,边需要见两边int n,m; vector<int> g[N]; //2的幂次范围 0~15 int depth[N],fa[N][1…...

Bento4的安装和简单转码
1.下载Bento4 2解压复制到安装位置 3配置环境变量 在path下配置 5.视频转码为Dash 视频分片化 mp4fragment --track video --fragment-duration 4000 C:\Users\zcc\Downloads\Video\gg.mp4 C:\Users\zcc\Downloads\Video\out3\input_fragmented.mp4分片化的视频转码为dash…...

用python写一个相机选型的简易程序
最近有点忙,上来写的时间不多。 今天就把之前写的一个选型的简易程序,供大家参考。 代码: import sys from PyQt5.QtWidgets import (QApplication, QMainWindow, QWidget, QVBoxLayout, QHBoxLayout,QLabel, QLineEdit, QPushButton, QGro…...