抖音集团电商流量实时数仓建设实践
摘要:本文整理自抖音集团电商数据工程师姚遥老师在 Flink Forward Asia 2024 分论坛中的分享。内容主要分为五个部分:
1、业务和挑战
2、电商流量建模架构
3、电商流量流批一体
4、大流量任务调优
5、总结和展望
01.业务和挑战
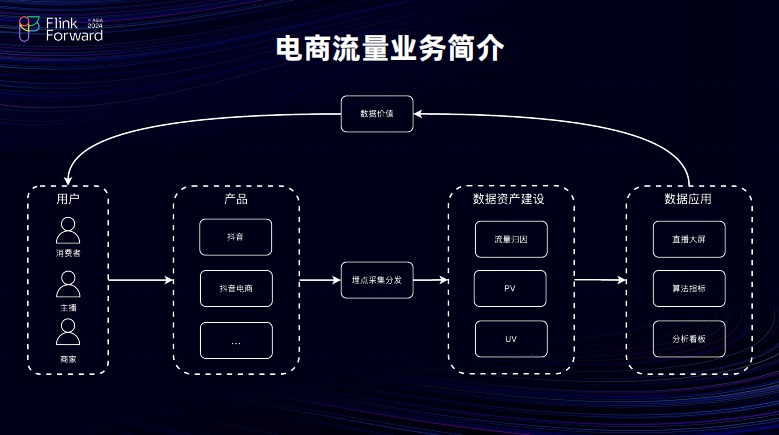
第一部分给大家介绍一下流量到底是什么?流量是用户在各个产品当中进行一系列行为活动的数据集合,其数据载点是的买点,买点经过采集分发到达了数仓的建设,再经过数据的归因以及指标的统计会被分别在应用在各个场景当中,分别为用户、主播以及商家带来各自的数据价值。消费者可以买到更好的产品,主播可以根据其带货的实时数据反馈来调整其带货的策略,商家可以根据主播的带货效果去选择跟对应的主播进行合作。
在建设时遇到了不少的问题与挑战,这些问题与挑战可以主要总结为以下三个方面效率、质量、成本以及稳定性。
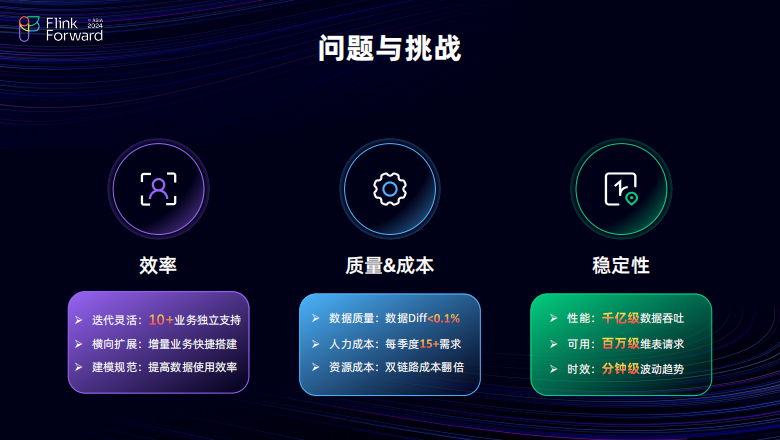
对于效率,需要同时去支持十多个不同的独立业务并且这些业务由于迭代迅速,可能随时会新增。这就要求数据首先建模规范并且具备一定的灵活性且具备横向的扩展能力。对于质量与成本,其实是在有限的人力以及有限的资源下去达成实时和离线,数据递付率可以保持在千分之一以内。对于稳定性,需要每天去吞吐千亿级的数据并产出分钟级的指标波动的指标趋势同时还要避免对于维表百万级的数据请求的压力。
上述问题分别从三个视角来去解决。
02.电商流量建模架构
这张图是目前抖音电商的流量数据架构图。流量的重点建设核心在于流量公共层数据明细层。对于明细层建设思路主要有两个,其中是横向的根据用户动线进行行为建模,在纵向进行职责分层。对于横向的建模,将数据分成内容互动与搜索域、页面域以及商品交易域。这么分的原因是因为通过的内容互动进行吸引用户搜索,搜索之后页面会进行承接并展示商品。当用户进入商品详情页之后,就会最后达成的交易。
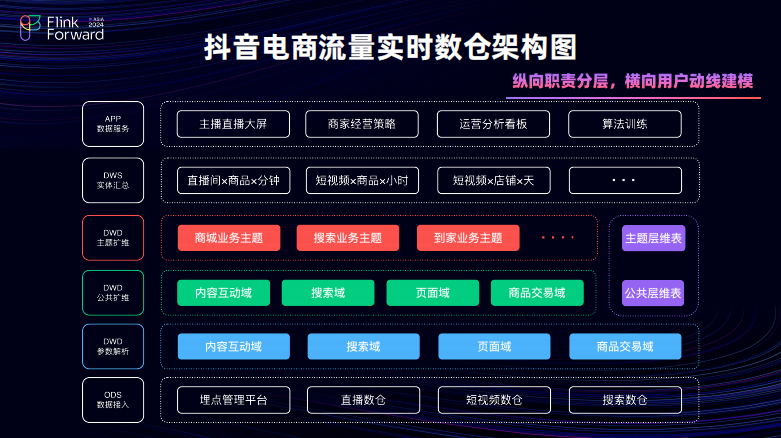
相对来说,数据的建模方式可以让流量数据进行横向解耦避免流量 KPS 过大导致处理的压力,以及同时对应 ODS 数据的各个不同的接入源。
从纵向的视角来看,将数据分层分为了参数解析层、公共扩维层以及主题扩维层。参数解析层主要是负责 ODS 数据的接入以及买点信息的统一规范命名。业务公共扩维层主要负责的是一些公共的逻辑的、维度的信息的扩展以及公共的归因逻辑的实现。对于主题扩维层,更加倾向于将每一个业务主题独立建设。每个业务主题可以独自进行各自的业务扩维以及相应的逻辑运算。一旦出现一个新的业务场景,就可以在业务主题扩维层额外的新增一个主题层,可以敏捷的去支持业务的需求。
上面讲述的建模较为宏观,以商品为例,主要介绍单个数据域里面是怎么建设任务。
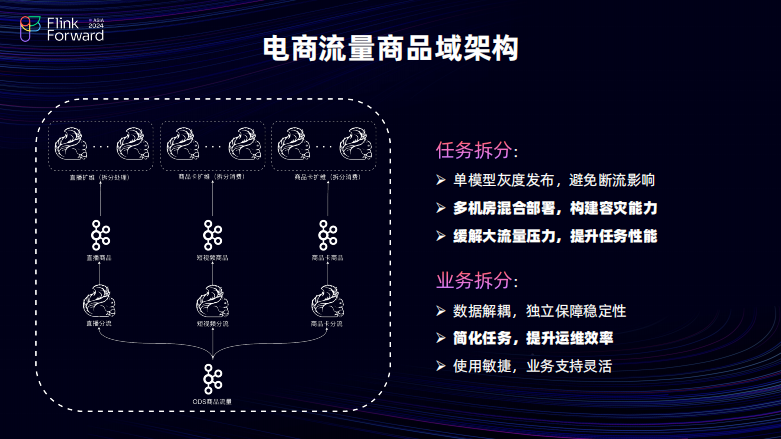
首先进建设思路主要有两点:第一点,按计算进行任务的拆分,按存储进行业务的拆分。对于任务来说,着眼于解决提升任务、提升运维以及容灾止损的一个效率。对于业务拆分,更加专注于让数据进行更加细粒度的解耦并且简化业务的逻辑,进而提升开发的敏捷性以及效率。
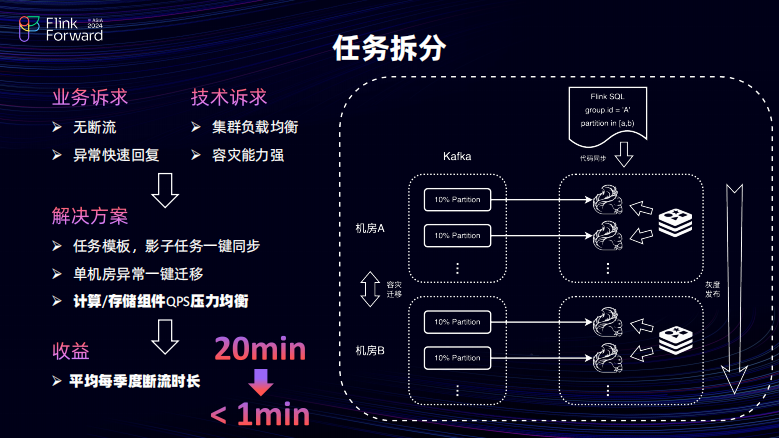
接下来分别展开到底是怎么做的。对于任务财团来说,主要可以有三点。第一,统一运维、机房混布以及灰度发布。统一运维可以理解为是所有的任务都会将一个任务拆分成多个子任务,但是这些子任务都会由交由统一的副任务进行运维,对任务的进行开发以及上下线的一些工作,全部都交由副任务进行操作,然后所有的子任务都会去消费同一个 Kafka 的 Topic。但是,消费使用了相同的 Group ID 每一个任务的消费的分区并不一致,这样的好好处是所有的任务不会出现重复的运维的成本的问题。第二点,对任务这些子任务的进行不同机房的部署,优势是由于任务的 QPS 大概在在百万级以上,会出现如果所有的任务都部署在单个机房会出现严重的机房压力倾斜问题。在对于这些机房进行一个较为均衡的部署之后,可以实现整体的集群的负载均衡,同时会还可以提升一定的容灾能力。当单个机房出现问题时,首先它不会影响到全局的数据产出只会影响到部分。当异常时可以进行通过副任务一键进行数据迁移避免恢复的效率过慢。第三点是灰度发布,针对灰度发布来主要是应用于增量场景,在一些增量业务迭代时,如果在大 QBS 下单个任务启停会造成短期内的数据尖刺。如果灰度发布以此任务为力度逐个发布,可以避免这种数据监测的问题。
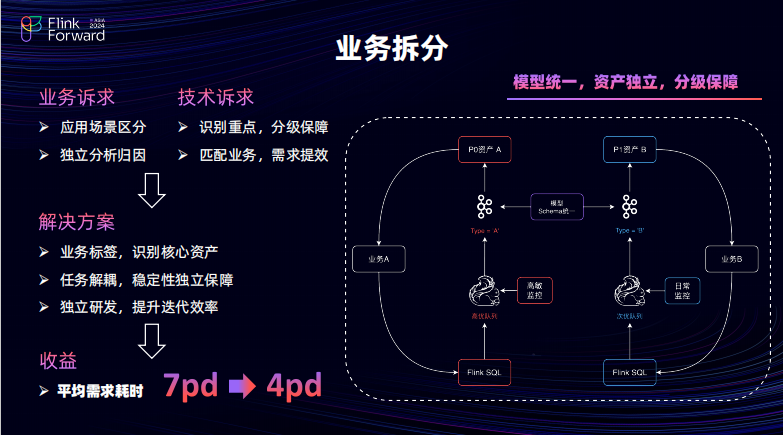
接下来是业务拆分。业务拆分主要是的建设思路是,在数据逻辑上模型是统一的,但是物理存储上会进行隔离。再具体一点来说使用相同的模型的 Schema 的数据由于其应用的场景不同会将其分别存储于不同的 Kafka 的 Topic 当中。根据其应用的稳定保障程度将其进行资产达标。对于核心的场景,会将其相应的任务部署在高优的队列,也会对其进行高敏监控。这样对数据进行更精细化的运维可以大幅的降低运维压力并且它还会有两个优势:可以去简化单个任务的处理逻辑,可以去降低运维成本,并且任务间是独立解耦的可以提升开发的效率。
上述建模解决了效率问题,接下来通过流批体可以去解决实时离线数据统一以及数仓在建设当中的建设成本问题。
03.电商流量流批一体
目前对于流批一体的建设方向主要是包含计算一体以及存储一体,并且其分别可以在物理以及逻辑两个维度进行去探索。综合下来,会有四个主要的方向。
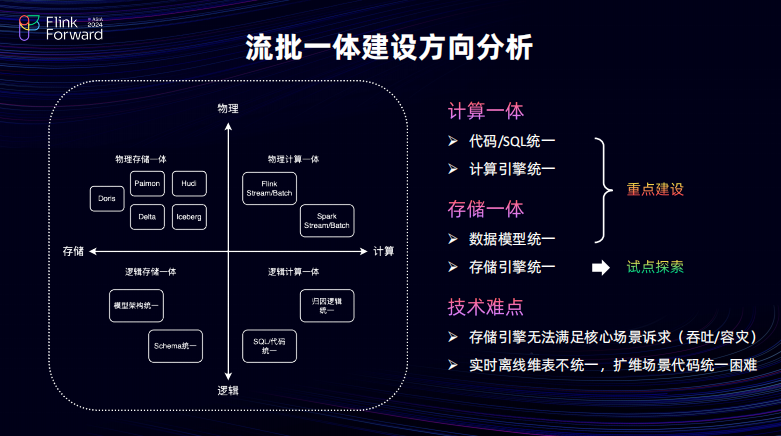
在抖音电商看来主要认为最终的终态包含,代码跟 SQL 的统一,计算引擎的统一以及数据模型的统一,最后存储引擎的统一。分别在这些方向其实都是会有做努力不过受限于存储引擎目前无法满足大流量下的稳定性诉求,所以重点建设了前三者并且近期也在探索存储引擎统一的方向。接下来主要介绍一下流量在流批一体的建设架构当中的情况。
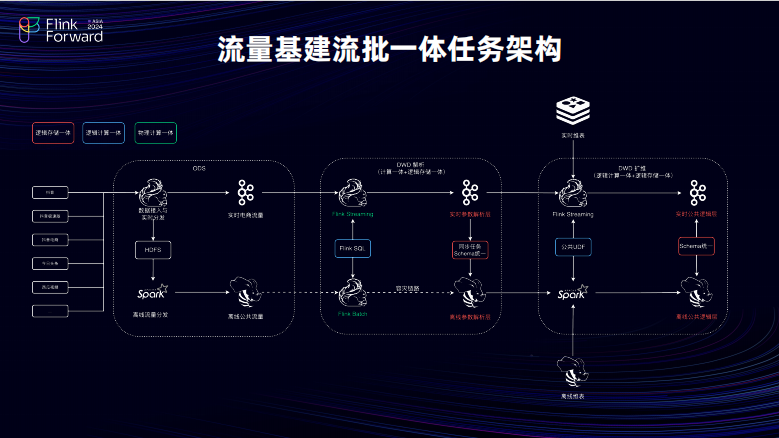
首先对于存储一体,主要致力于实时跟离线的模型上的 Schema 的统一,以及期望能做到并且也做到流量的基建的公共层实时和离线模型一一映射。对于计算统一,受限于实时跟离线的维表的差异,有实时离线,他们会存在时效性差异以及存储引擎的差异在解析层以及扩维层分别做了独立的计算一体的实践。对于解析层,使用 FLINK 以及 Flink SQL 做到计算。物理计算以及逻辑计算的完全一体化并且将产出实时 Kafka 数据进行同步,做到了实时离线数据,在解析层可以做到 0 Deep 的效果。对于扩维层,受限于执行引擎的差异,通过将公共的逻辑注入到公用的实时离线 UDF 做到统一,两者虽然执行引擎存在差异但是最后产出的数据、数据递付率非常低,可以接近保持数据的一致性。接下来将从介绍如何在这两层去实现。
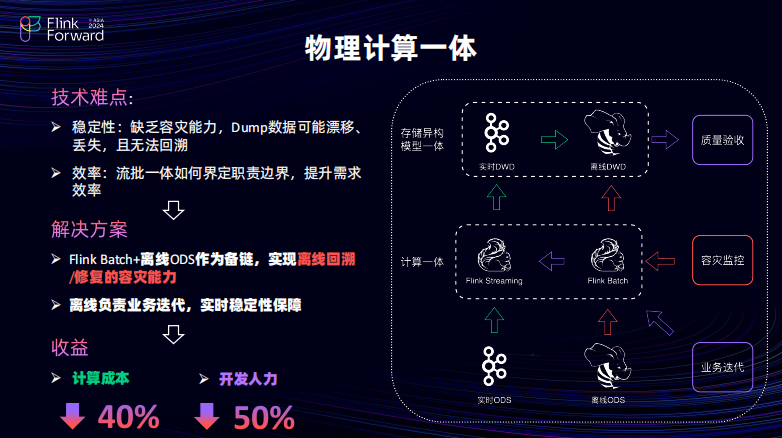
首先在解析层,主要是实现了物理的计算一体。在计算一体,刚才也提到了将实时的数据通过同步任务写给了离线会出现一个问题,在写给离线的时候可能出现漂移,丢失以及如果离线数据口径出现变更它就无法进行一个数据回溯。因此,充分利用 FLINK 的 Batch 的流批作业的能力并且复用了之前离线的 ODS 将其完全搭建成一个数据被列,当出现数据异常的时候,可以使用容灾监控能力将启用 Flink Batch 的背链将离线的 ODS 数据重新回写到离线的 DWD 明细层以避免数据的丢失。以及在一些回溯场景可以直接快速的覆盖历史的分区。同时,离线的迭代效率会比实时快很多,因为当前实时在迭代的时候都需要双跑一个 Flink Streaming 的任务企业需要执行一段时间才能看到效果 Flink Batch 可以快速的经过批任务去验证一些增量场景当中的业务,迭代逻辑变更。只要是在验收完成之后 Flink Batch 的逻辑已经是正确。那只需要做到能通过一键同步,可以让实时也可以执行一个快速上线的能力进而避免刚才提到的在 Flink Streaming 当中的双跑链路的成本。整体下来计算成本可以节约将近 40%,开发人力会节约 50%。
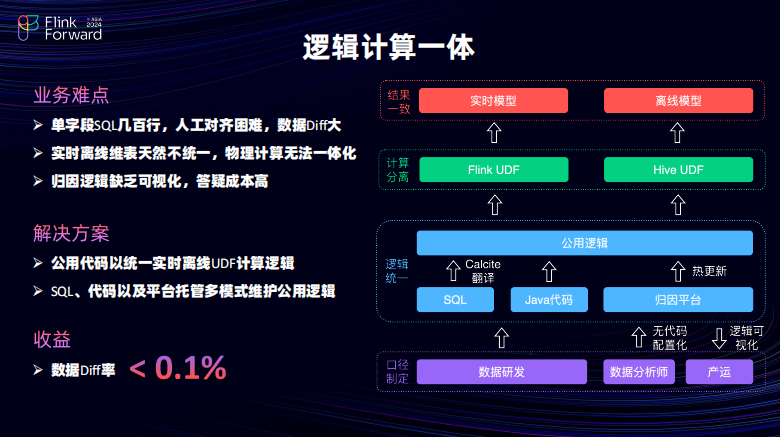
在扩维层受到计算分离的影响其实想要做到逻辑的计算一体。刚才也提到,主要是通过公共逻辑分别注入到 FLINK 的 UDF 以及 Have 的 UDF 当中,然后在执行虽然两者计算分离。但是可以保障最后的数据结果从逻辑上是完全对齐。最后的数据递付其实是可以控制在千分之一以内,并且千分之一是由维表差异引入的,而不是自己的逻辑引入的。是怎么实现的?公用逻辑是有多种形式,可以通过 SQL 以及 Java 代码,还有外置的一个归因平台来实现。对于公对于 SQL 来说主要是复用了 FLINK 的 Kill Set 翻译执行的功能。这样 SQL 可以兼容一些历史上没有做成流批体的逻辑,可以直接做一个水平的迁移。java 代码主要去适用于一些增量的场景,增量简便为了更加敏捷的开发,可以用 java 代码来实现。对于归因平台主要是面向的是一些迭代频繁的归因逻辑,这样迭代,由于迭代频繁,人力有些时候是受限的并且这些迭代频繁的逻辑变更,往往都是比较的具有统一性的将这部分的变更逻辑托管给归因平台。由数据分析师进行无代码可视化的逻辑数配置进而通过归因平台更新到的 UDF 当中。同时产运也可以在归因平台上快速的去查询其想要的这些归因逻辑。也可以大幅的去减少答疑成本。接下来对于大流量任务会面临很多稳定性的一些挑战。由于这些稳定性挑战的问题来源非常的多,因此就对大流量任务分享一些调优的经验。
04.大流量任务调优
首先大流量基建的数据任务特点比较明确,流量的 KPS 比较高。经过的建模优化之后,单个任务可能还会有 100 到 200 万左右的 KPS 并且任务的计算逻辑是十分复杂的。大概会单个任务可能会有一两千行的一个 SQL 的长度,并且由于是公共层基建所以维度扩围也是特别多的.大概会有 20 多张尾表单个任务,并且在基建上是不存在任何聚合动作。基于上述特点按 DAG 进行拆分,将已有的任务,已有的问题主要拆分成了消费层、计算层以及生产层三点,并且在计算层对算子进行了更精细化的拆分。
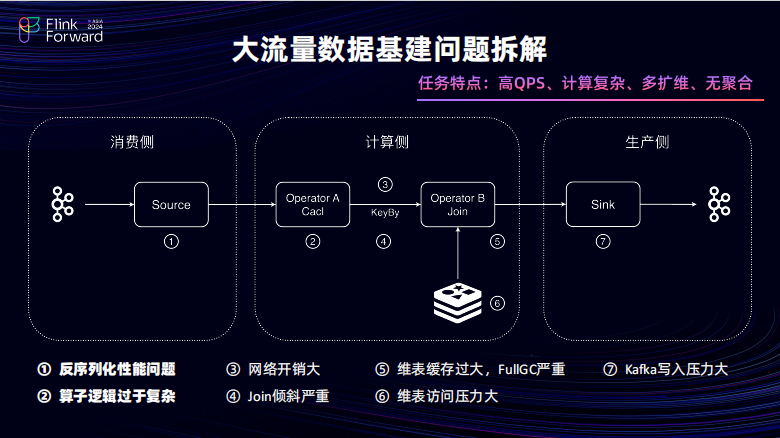
主要是负责计算的 CP 算子以及负责为表扩维的 Join 算子。并且在这些算子间如果开启了 Key By,可能会出现一些算子间通信问题。对这些问题进行了标续,主要有几点,在消费侧的话是在反序列化的性能压力会比较高在生产车的话主要是对类似于 Kafka 以及其他的一些 Sink 组件的压力会比较高。在计算侧,会开个算子引起过多的计算复杂问题。网络间通信会导致任务的 SHUFFER 网络开销比较大并且开启 Key By 之后数据会存在严重倾斜的问题,然后在 Join 算子当中会存在几个。首先由于关联的维表非常的多维表的缓存会被使用满导致了任务频繁的 Full GC 并且维表访问的 QPS 压力也会变得非常大。针对上述问题,按序给了相应的适用场景以及对应的解决方案。这样为了方便大家在会后进行快速快捷的查询。

接下来大家介绍一下对这些任务的问题的优化的思路以及解决方案。首先,针对消费成本高的问题其比较适用的场景是去消费较大的流量在消费当中会存在着不少的无效数据。如何去识别这些无效数据以及如何去避免这些无效数据的反序列化是需要考虑的问题。
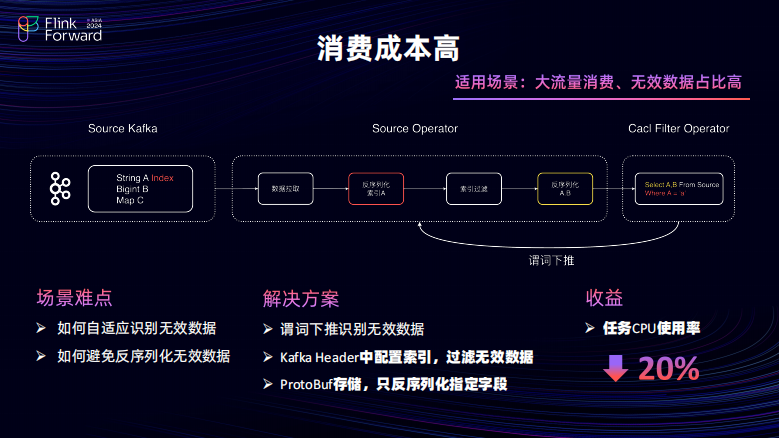
无效的数据的识别,每个任务是并不相同的。可以通过各自任务的 Source 算子下游的 KO 算子当中的 select 以及 VR 条件分别去识别的无效数据以及有效数据当中的这些无效字段并且将其经位置下推下推至 Source 算子以处理,进而去处理避免反序列化的问题。如何实现反序列化?其实针对上述的两种无效数据有独立的处理方案,对于 VR 条件对应的无效字段,无对应的无效数据可以利用 Kafka Header 的性能将需要的外条件当中的字段配置索引并且写入到 Kafka Header,当中的数据在拉取之后优先先反序列化 Header 逻辑并进行根据索引进行过滤,过滤之后再进行相应的反序列化操作,这样可以避免的无效无效的数据进行反序列化。同时,为了避免那些有效数据当中的无效字段,在最后一步会有反序列化的压力。Kafka 采用 PB 的存储格式,并经过位置下推对 PB 的存储文件进行一些逻辑上的裁剪只保留需要的字段。经过上述两点的优化之后,整体的任务的 CPU 使用率可以下降 20%。针对维表访问压力问题,主要在于维表访问压力过大。
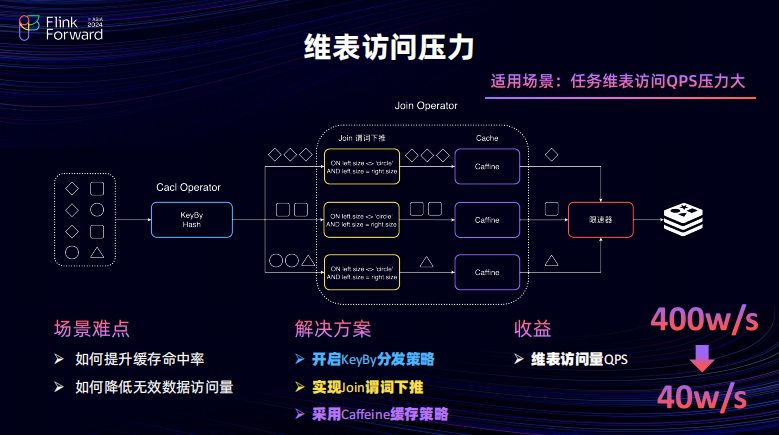
QPS 高主要解决思路其实是在避免无需访问维表的数据然后从进行访问,第二点在于避免已经访问过为表的数据进行重复访问的动作。
因此,相应也会有对应的解决方案,Join 的逻辑当中进行一个对于 Join 算子条件进行位置下推。比如说在图中示例其实是不需要圆形的数据进行一个维表的关联,在关联的条件当中会配置它,它的尺寸不能是圆形。在执行的时候可以在关联之前进行一个维表的一个过滤。
其次,可以去通过提高一些的缓存命中率,提高缓存命中率可以降低相同的数据重复去对维表的访问。主要解决方案是由对在之前对数据按进行 Hash Key By,让数据提升缓存命中率。第二点,比如说 AB、比如说对 H Base 对于 REDIS 的 Connector 当中的缓存组件将其组由谷歌的 Guava 替换成了 Caffeine,Caffeine 有一个更好的一个缓存命中策略经过上述优化之后,单个的任务对于维表的访问,KBS 从 400 万可以降至 40 万。其实 Key By,很好的去解决了缓存命中率的问题但是不可避免的会引起的数据倾斜问题。
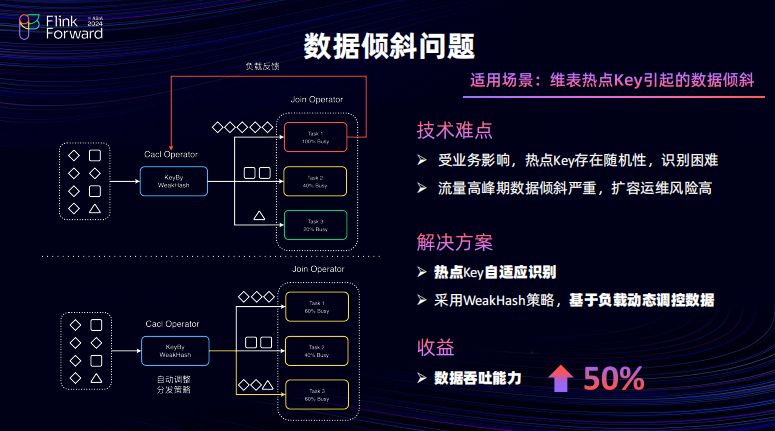
因此,在数据倾斜问题上比较适用的场景采用了 Key By 动作并且由于业务的影响会存在的数据严重倾斜问题。解决思路其实是做到一个 Join 算子负载均衡。因此,对于已有的场景进行数据分析对于上算子的 BA 状态进行分析,如果算子是百分之百 BZ 或者说超过一定阈值之后会对上游算子进行一个负载反馈,让上游算子进行一个 Key By 的 Hash 的策略调整。因此最后提出了一个非完全一致性的 Hash 策略。一旦出现了负载反馈会对负载过高的算子的相应的数据进行调控,进而保障所有的 Join 算子尽可能的做到一个负载均衡。通过上述的能力将在一些严重的数据倾斜场景,数据吞吐能力可以上涨 50%。无论是 Key By 也好,WeakHash 也好,它都无法去避免一个问题,在网络 IO 上会有吞吐,吞吐就不可避免会 SHUFFER 网络通信对外的内存会有压力。同时,在还有一个另外的对外内存问题在写入 Kafka 当中 Kafkaclient 的频繁的访问也会出现压力。针对上述两个问题分别进行了调优,首先对于网络 IO 问题每一个 Sub Task 都是需要为下游的所有并发提供一个单独提供一个缓存的队列,由于并发越多缓存的队列也就越多。
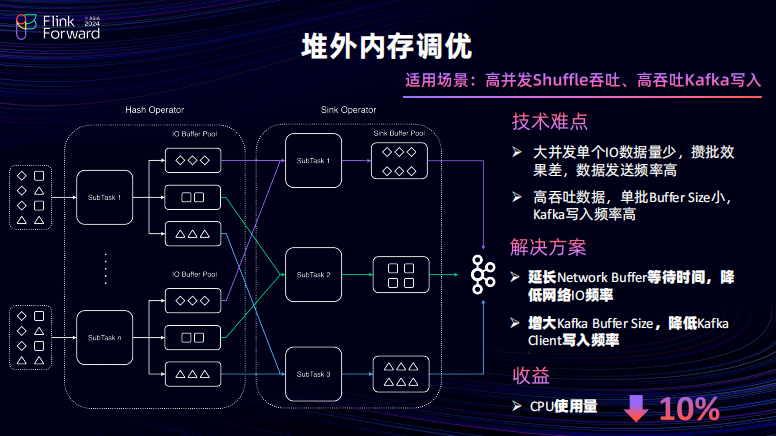
为了更加好的去是执行吞吐这么大的 QPS 或并发程度可能会提升到上千或者说几百在这种情况下,单个缓存的被使用的被用满的可能性就会变低,会立刻达到最大的等待时长然后进行网络 IO 的吞吐。因此的解决思路通过延长 Network Buffer 的等待时间去以降低整个网络 IO 的访问频率,来提升任务的执行效率对于高吞吐的 Kafka 的问题其实是一个相反的动作。所有的数据会快速的去填满的 Kafka 的 Buffer 的缓存池,然后频繁的去访问 Kafka Client。为了解决问题,其实通过调大的 Kafka Buffer 池来降低访问的写入的频率。整体下来 CPU 的使用率可以大概下降 10%左右。
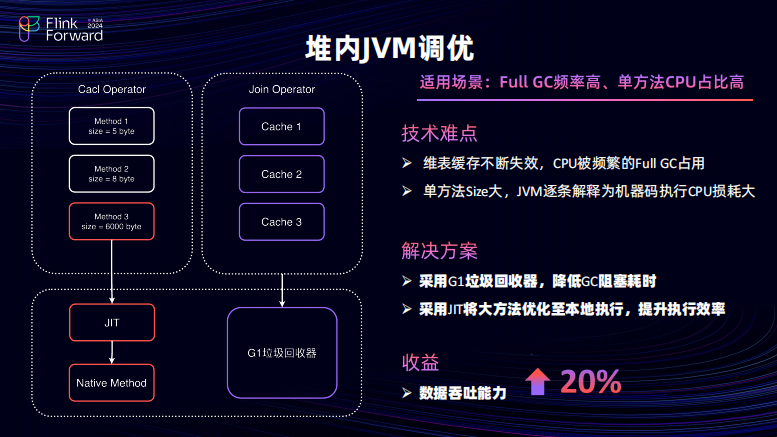
刚才也聊了对外的调优,最后聊一下在堆内的 JVM 的上面的调优。调优主要是有两点,也根算子来拆分。对于 Kimi 算子来说,其实会出现单个方法特别大的情况,由于 Java 是有一定的解释性语言的,需要逐条进行解释整个 CPU 的资源损耗量会极大。但是,Flink 在执行的时候又没有办法对这么大的方法进行 JIT 优化。因此,和字节的引擎团队 Flink 引擎团队协作把这种大的方法进行识别然后识别之后通过 JVM 的 JIT 优化成本地方法,加快了的执行效率。第二点,是在 Join 算子当中会出现 Cash 频繁失效导致不断的有 Full GC 出现并且 JDK8 默认的垃圾回收器是 PARAMM 的垃圾回收器,其 Stop The Word 的时间过长会导致整个任务主要的耗费时间在于去处理的 Full GC,而不是去专注于处理的数据。因此的话,对于该问题,其实是通过升级的 JDK 版本并且去采用更高级的 G One 的垃圾回收器来提升整体的垃圾回收效率以及降低 Stop The Word 的时间进而去提升吞吐的能力。综合下来,通过上述两点的优化,整体的数据吞吐能力可以提升 20%。
05.总结和展望
接下来我将进行一下最后的总结与展望。经过数据的建模,流批一体的建设,以及最后的大流量的任务调优在效率、质量、成本以及稳定性性上都拿到了不错的收益。数据质量和规律达到了 99%以上,然后人效节约 20%消费成本,对人效提升 70%,消费成本节约 20%,以及任务的处理性能综合来看平均提升了 70%。

在接下来的工作当中核心动作是降本以及增效,对在增效方面,期望能把数据建设做得更加自动化、更加配置化,以及做的数据可以做成可视化的动作。
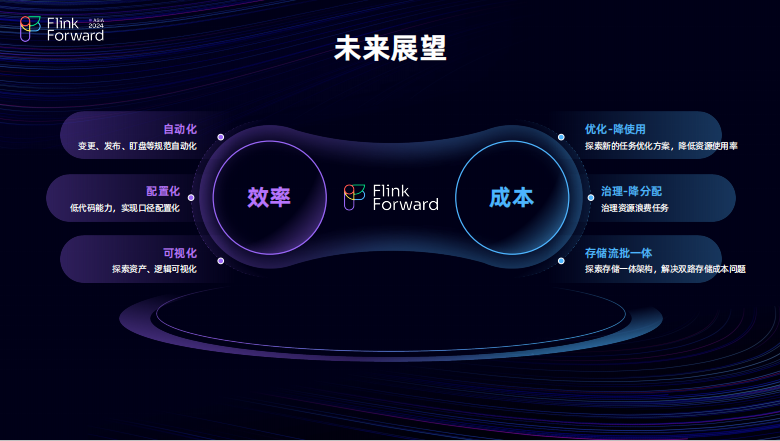
未来,我们希望探索变更、发布、盯盘的一些自动化操作,并在某些配置化场景中实现低代码化,以实现标准化的自动配置。我们希望能够使现有的数据、资产以及归因逻辑更加可视化。在成本优化方面,目标是降低 CPU 和内存的使用。关于降低 CPU 的策略,主要分为两个步骤:首先进行优化,然后进行治理。优化阶段旨在减少任务的 CPU 使用率,通过治理不断调整任务的资源申请量,以降低任务的分配量。在存储方面,我们计划探索流批一体化的解决方案,以解决实时与离线双重存储的压力。
相关文章:

抖音集团电商流量实时数仓建设实践
摘要:本文整理自抖音集团电商数据工程师姚遥老师在 Flink Forward Asia 2024 分论坛中的分享。内容主要分为五个部分: 1、业务和挑战 2、电商流量建模架构 3、电商流量流批一体 4、大流量任务调优 5、总结和展望 01.业务和挑战 第一部分给大家介绍一下流…...

redis客户端库redis++在嵌入式Linux下的交叉编译及使用
在开发过程中,我们经常会遇到需要在嵌入式Linux系统上与Redis进行交互的需求。因此选择一个适合的Redis客户端库就显得尤为重要。下面介绍下c中有名的redis-plus-plus(redis)三方库在嵌入式linux下的交叉编译及使用。该库底层是基于hiredis的…...

5.3 Dify:低代码平台,适用于企业快速部署合规AI应用
Dify作为一款开源低代码平台,已成为企业快速构建和部署合规AI应用的首选工具。Dify通过整合后端即服务(Backend-as-a-Service, BaaS)、大型语言模型操作(LLMOps)以及直观的视觉化界面,显著降低了AI应用开发…...

什么是可重入锁ReentrantLock?
大家好,我是锋哥。今天分享关于【什么是可重入锁ReentrantLock?】面试题。希望对大家有帮助; 什么是可重入锁ReentrantLock? ReentrantLock 是 Java 中的一个锁实现,它是 java.util.concurrent.locks 包中的一部分,主要用于提供…...

【Java学习日记26】:方法的重载
一、方法重载核心概念 方法重载(Overload):指在同一个类中定义多个同名方法,但这些方法的参数列表必须不同。重载的目的是让同一功能的方法能处理不同类型或数量的参数,提高代码复用性。 二、判断是否构成重载的规则 …...

分层设计数据仓库的架构和设计高效数据库系统的方法
结合你所有的知识和技术,设计一套高效的数据仓库的分层架构说明每一层分层的用途以及为什么要这么设计,有什么优势?再从数据建模和其它的角度详细论述如何设计出一个高性能的数据仓库系统? 高效数据仓库分层架构设计 分层架构及…...

铃木一郎女儿是奥运会选手吗·棒球1号位
铃木一朗(Ichiro Suzuki) 铃木一朗职业生涯时间线 1973年出生于日本爱知县名古屋市。1992年以选秀第四顺位加入日本职棒(NPB)欧力士蓝浪队,开启职业棒球生涯。 1994-2000年 连续7年获得NPB太平洋联盟打击王ÿ…...

ORB-SLAM3核心模块、数据结构和线程交互方面解析
ORB-SLAM3作为当前最先进的视觉SLAM系统之一,其代码架构设计体现了高度模块化和多线程协同的特点。以下结合代码实现和系统原理,从核心模块、数据结构和线程交互三个维度展开详细解析: 一、核心架构模块 1. 线程划分 ORB-SLAM3采用多线程架构,主要包含以下核心线程: Tra…...
)
小刚说C语言刷题——1565成绩(score)
1.题目描述 牛牛最近学习了 C 入门课程,这门课程的总成绩计算方法是: 总成绩作业成绩 20% 小测成绩 30% 期末考试成绩 50%。 牛牛想知道,这门课程自己最终能得到多少分。 输入 三个非负整数 A、B、C ,分别表示牛牛的作业成…...

查找函数【C++】
二分查找函数 lower_bound(起始地址, 末尾地址, target):查找第一个大于等于target目标值的位置 upper_bound(起始地址, 末尾地址, target):查找第一个大于target目标值的位置 binary_search(起始地址, 末尾地址, target):查找target是否存在…...

利用车联网中的 V2V 通信技术传播公平的紧急信息
与移动自组织网络 (MANET) 相比,车载自组织网络 (VANET) 的节点移动速度更快。网络连接的节点可以在自身内部或其他基础设施之间交换安全或非安全消息,例如车对车 (V2V) 或车对万物 (V2X)。在车载通信中,紧急消息对于安全至关重要,必须分发给所有节点,以提醒它们注意潜在问…...

Semantic Kernel也能充当MCP Client
背景 笔者之前,分别写过两篇关于Semantic Kernel(下简称SK)相关的博客,最近模型上下文协议(下称MCP)大火,实际上了解过SK的小伙伴,一看到 MCP的一些具体呈现,会发现&…...
)
assertEquals()
assertEquals() 是 JUnit 框架中用于进行断言操作的一个非常常用的方法,其主要目的是验证两个值是否相等。如果两个值不相等,测试就会失败,JUnit 会给出相应的错误信息,提示开发者测试未通过。下面为你详细介绍: 方法…...
 failed 解决方案)
【ESP32S3】 下载时遇到 libusb_open() failed 解决方案
之前写过一篇 《VSCode 开发环境搭建》 的文章,很多小伙伴反馈说在下载固件或者配置的时候会报错,提示大多是 libusb_open() failed ...... : 这其实是由于 USB 驱动不正确导致的,准确来说应该是与 ESP-IDF 中内置的 OpenOCD 需要…...

【Pandas】pandas DataFrame rsub
Pandas2.2 DataFrame Binary operator functions 方法描述DataFrame.add(other)用于执行 DataFrame 与另一个对象(如 DataFrame、Series 或标量)的逐元素加法操作DataFrame.add(other[, axis, level, fill_value])用于执行 DataFrame 与另一个对象&…...
)
[C]基础13.深入理解指针(5)
博客主页:向不悔本篇专栏:[C]您的支持,是我的创作动力。 文章目录 0、总结1、sizeof和strlen的对比1.1 sizeof1.2 strlen1.3 sizeof和strlen的对比 2、数组和指针笔试题解析2.1 一维数组2.2 字符数组2.2.1 代码12.2.2 代码22.2.3 代码32.2.4 …...

巧记英语四级单词 Unit5-上【晓艳老师版】
count 数, counter n.计算器,柜台 a.相反的 数数的东西就是计算器,在哪数,在柜台里面数;你和售货员的关系就是相反的(一个买货,一个卖货account n.账户,账号 一再的数accountant n.会计 一再的…...

Linux系统中命令设定临时IP
1.查看ip ---ifconfig 进入指定的网络接口 ifconfig ens160 建立服务器临时IP ifconfig ens160 ip地址 network 系统进行重启后,临时IP将会消失 ip address add ip地址 dev 服务器 ---添加临时ip ip address delete ip地址 dev 服务器 ---删除临时ip 设置ip&a…...

13.ArkUI Navigation的介绍和使用
ArkUI Navigation 组件介绍与使用指南 什么是 Navigation 组件? Navigation 是 ArkUI 中的导航组件,用于管理页面间的导航和路由。它提供了页面栈管理、导航栏定制、页面切换动画等功能,是构建多页面应用的核心组件。 Navigation 的核心概…...

MYSQL 常用数值函数 和 条件函数 详解
一、数值函数 1、ROUND(num, decimals) 四舍五入到指定小数位。 SELECT ROUND(3.1415, 2); -- 输出 3.142、ABS(num) 取绝对值 SELECT ABS(-10); -- 输出 103、CEIL(num) / FLOOR(num) 向上/向下取整 SELECT CEIL(3.2), FLOOR(3.7); -- 输出 4 和 34、MOD(num1, num2) 取…...
 加速python数据分析脚本)
CuML + Cudf (RAPIDS) 加速python数据分析脚本
如果有人在用Nvidia RAPIDS加速pandas和sklearn等库,请看我这个小示例,可以节省你大量时间。 1. 创建环境 请使用uv,而非conda/mamba。 # install uv if not yetcurl -LsSf https://astral.sh/uv/install.sh | shuv init data_gpucd data_g…...

c#操作excel表格
c#操作excel表格有很多方法,本文介绍的是基于Interop.Excel方式。该方式并不是winform操作excel的最好方法,本文介绍该方法主要是为一些仍有需求的小伙伴。建议有兴趣的小伙伴可以看一下miniexcel,该方法更简洁高效。 一、首先需要下载inter…...

【uniapp】vue2 搜索文字高亮显示
【uniapp】vue2 搜索文字高亮显示 我这里是把方法放在公共组件中使用 props: {// 帖子listpostList: {type: Array,required: true},// 搜索文本字体高亮highLightSearch: {type: String,required: false} }, watch: {// 监听 props 的变化postList: {immediate: true,handle…...
深度解析)
Android ActivityManagerService(AMS)深度解析
目录 一、什么是AMS? 二、AMS 的架构层次 1. 客户端层 2. 服务层 3. 底层驱动 三、AMS 的主要功能 四、核心模块与工作流程 1. 核心模块 2. Activity 启动流程 3. 进程启动流程 4. 广播分发流程 五、AMS 的启动流程 1. S…...

C语言中操作字节的某一位
在C语言中,可以使用位操作来设置或清除一个字节中的特定位。以下是几种常见的方法: 设置某一位为1(置位) // 将字节byte的第n位(从0开始计数)设置为1 byte | (1 << n); 例如,将第3位置…...

【特殊场景应对8】LinkedIn式动态简历的利弊分析:在变革与风险间走钢丝
写在最前 作为一个中古程序猿,我有很多自己想做的事情,比如埋头苦干手搓一个低代码数据库设计平台(目前只针对写java的朋友),比如很喜欢帮身边的朋友看看简历,讲讲面试技巧,毕竟工作这么多年,也做到过高管,有很多面人经历,意见还算有用,大家基本都能拿到想要的offe…...

UOJ 228 基础数据结构练习题 Solution
Description 给定序列 a ( a 1 , a 2 , ⋯ , a n ) a(a_1,a_2,\cdots,a_n) a(a1,a2,⋯,an),有 m m m 个操作分三种: add ( l , r , k ) \operatorname{add}(l,r,k) add(l,r,k):对每个 i ∈ [ l , r ] i\in[l,r] i∈[l,r] 执行 …...

工业相机——镜头篇【机器视觉,图像采集系统,成像原理,光学系统,成像光路,镜头光圈,镜头景深,远心镜头,分辨率,MTF曲线,焦距计算 ,子午弧矢】
文章目录 1 机器视觉,图像采集系统2 相机镜头,属于一种光学系统3 常规镜头 成像光路4 镜头光圈5 镜头的景深6 远心镜头 及 成像原理7 远心镜头种类 及 应用场景8 镜头分辨率10 镜头的对比度11 镜头的MTF曲线12 镜头的焦距 计算13 子午弧矢 图解 反差 工业…...

珍爱网:从降本增效到绿色低碳,数字化新基建价值凸显
2024年12月24日,法大大联合企业绿色发展研究院发布《2024签约减碳与低碳办公白皮书》,深入剖析电子签在推动企业绿色低碳转型中的关键作用,为企业实现环境、社会和治理(ESG)目标提供新思路。近期,法大大将陆…...

Java大师成长计划之第3天:Java中的异常处理机制
📢 友情提示: 本文由银河易创AI(https://ai.eaigx.com)平台gpt-4o-mini模型辅助创作完成,旨在提供灵感参考与技术分享,文中关键数据、代码与结论建议通过官方渠道验证。 在 Java 编程中,异常处理…...

主题模型三大基石:Unigram、LSA、PLSA详解与对比
🌟 主题模型演进图谱 文本建模三阶段: 词袋模型 → 潜在语义 → 概率生成 Unigram → LSA → PLSA → LDA 📦 基础模型:Unigram模型 核心假设 文档中每个词独立生成(词袋假设) 忽略词语顺序和语义关联 …...

【Linux网络】TCP服务中IOService应用与实现
📢博客主页:https://blog.csdn.net/2301_779549673 📢博客仓库:https://gitee.com/JohnKingW/linux_test/tree/master/lesson 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正! &…...

终端运行java出现???
1.检查是否系统区域设置冲突(控制面板 → 区域 → 管理 → 更改系统区域设置 → 勾选 Beta: UTF-8)。 2.修改 Windows 终端编码 方法 1:临时修改(当前窗口) 在终端执行:cmd chcp 65001 …...
)
Mysql8.0 推出的强大功能 窗口函数(Window Functions)
🧠 一、什么是窗口函数? 窗口函数是 SQL 中一种在保留原始行的基础上,对行进行分组排序后执行聚合、排名、累计等计算的方法。 与传统的 GROUP BY 聚合不同的是: 👉 窗口函数不会把多行聚成一行,而是为每…...

opencv--通道,彩色和灰度
图像的灰度值和颜色值的区别 灰度值(Grayscale Value)和颜色值(Color Value)是描述像素信息的两种基本方式,它们的核心区别在于对颜色信息的表示方式和应用场景。 (1) 灰度值(Grayscale Value)…...

cmake 执行命令
在命令行中执行 CMake 的命令主要用于配置、生成和构建项目。以下是一些常用的 CMake 命令及其用法。 1. 配置项目 配置项目是 CMake 的第一步,它会根据 CMakeLists.txt 文件生成相应的构建系统文件(如 Makefile 或 Visual Studio 解决方案文件&#x…...

Shell脚本-for循环语法结构
在Shell脚本编程中,for循环是一种非常常用的流程控制语句。它允许我们对一系列值进行迭代,并为每个值执行特定的命令或代码块。无论是处理文件列表、遍历目录内容还是简单的计数任务,for循环都能提供简洁而强大的解决方案。本文将详细介绍She…...
CDK 构建的全流程实践)
【AI落地应用实战】借助 Amazon Q 实现内容分发网络(CDN)CDK 构建的全流程实践
随着生成式 AI 技术的快速发展,开发者在构建云原生应用时正以前所未有的效率推进项目落地。而 Amazon Q,作为亚马逊云科技推出的专为开发者和 IT 人员设计的生成式 AI 助手,正逐步改变着我们与代码、基础设施以及 亚马逊云科技 服务交互的方式…...

Windows同步技术-使用命名对象
在 Windows 系统下使用命名对象(如互斥体、事件、信号量、文件映射等内核对象)时,需注意以下关键要点: 命名规则 唯一性:名称需全局唯一,避免与其他应用或系统对象冲突,建议使用 GUID 或应用专…...

Python Cookbook-6.8 避免属性读写的冗余代码
任务 你的类会用到某些 property 实例,而 getter 或者 setter 都是一些千篇一律的获取或者设置实例属性的代码。你希望只用指定属性名,而不用写那些非常相似的代码。 解决方案 需要一个工厂函数,用它来处理那些 getter 或 setter 的参数是…...

热带气旋【CH报文数据插值】中央气象台-台风路径数据每小时插值
对CH报文数据进行每小时插值 原始数据文件 数据 三小时一次的报文数据 需求 按小时补齐热带气旋路径信息 插值后数据效果如下: 插值代码 # 对ch文件插值import pandas as pd import datetime import osdef interpolate_ch_one_hour (file_name):new_file_name…...

06-stm32时钟体系
一、时钟体系 1、概念 1.时钟信号:是一种周期性的电信号,例如为方波,正弦波,余弦波等各种波形,用于同步数字电路中的各种操作,它控制着数据的传输以及电路状态的变化。 2、时钟系统在 STM32 的系统中扮演…...

Hbase集群管理与实践
一、HBase集群搭建实战 1.1 环境规划建议 硬件配置基准(以10节点集群为例): 角色CPU内存磁盘网络HMaster4核16GBSSD 200GB(系统盘)10GbpsRegionServer16核64GB124TB HDD(JBOD)25GbpsZooKeepe…...

基于大模型对先天性巨结肠全流程预测及医疗方案研究报告
目录 一、引言 1.1 研究背景与意义 1.2 研究目的与创新点 二、大模型在先天性巨结肠预测中的理论基础 2.1 大模型概述 2.2 大模型预测先天性巨结肠的可行性分析 三、术前预测与准备方案 3.1 大模型对术前病情的预测 3.1.1 疾病确诊预测 3.1.2 病情严重程度评估 3.2 …...

计算机组成原理-408考点-数的表示
常见题型:C语言中的有符号数和无符号数的表示。 【例】有如下C语言程序段: short si-32767;unsigned short usisi;执行上述两条语句后,usi的值为___。short和unsigned short均使用16位二进制数表示。 【分析】考点:同…...

vue滑块组件设计与实现
vue滑块组件设计与实现 设计一个滑块组件的思想主要包括以下几个方面:用户交互、状态管理、样式设计和事件处理。以下是详细的设计思想: 1. 用户交互 滑块组件的核心是用户能够通过拖动滑块来选择一个值。因此,设计时需要考虑以下几点&…...

Linux阻塞与非阻塞I/O:从原理到实践详解
Linux阻塞与非阻塞I/O:从原理到实践详解 1. 阻塞与非阻塞I/O基础概念 1.1 阻塞与非阻塞简介 在Linux系统编程中,I/O操作可以分为两种基本模式:阻塞I/O和非阻塞I/O。这两种模式决定了当设备或资源不可用时,程序的行为方式。 阻…...

form表单提交前设置请求头request header及文件下载
需求:想要在form表单submit之前,设置一下请求头。 除了用Ajax发起请求之外,还可以使用FormData来实现,咱不懂就问。 1 问:FormData什么时间出现的?与ajax什么联系? 2 问:FormData使…...

整合 CountVectorizer 和 TfidfVectorizer 绘制词云图
本文分别整合 CountVectorizer 和 TfidfVectorizer 绘制词云图 ✨ CountVectorizer CountVectorizer 是 scikit-learn 中用于 文本特征提取 的一个工具,它的主要作用是将一组文本(文本集合)转换为词频向量(Bag-of-Words…...

国产AI大模型超深度横评:技术参数全解、商业落地全场景拆解
评测方法论与指标体系 评测框架设计 采用三层评估体系,涵盖技术性能、商业价值、社会效益三大维度,细分为12个二级指标、36个三级指标: 测试环境配置 项目配置详情硬件平台8NVIDIA H100集群,NVLink全互联,3TB内存软…...