人工智能与机器学习:Python从零实现逻辑回归模型
🧠 向所有学习者致敬!
“学习不是装满一桶水,而是点燃一把火。” —— 叶芝
我的博客主页: https://lizheng.blog.csdn.net
🌐 欢迎点击加入AI人工智能社区!
🚀 让我们一起努力,共创AI未来! 🚀
嘿,朋友们!今天咱们要来搞个大事情——自己动手实现逻辑回归!为啥要这么干呢?因为有时候,用现成的工具就像吃别人嚼过的糖,没劲!自己动手,那才叫真本事,不仅能搞懂背后的原理,还能在朋友面前炫耀一番:“看我这代码,多牛!”所以,咱们这就开始,一起踏上这个充满挑战和乐趣的旅程吧!🚀
逻辑回归
逻辑回归是一种算法,能帮咱们预测一个变量的两个类别。现实生活里头,这玩意儿能干不少事儿,比如:
- 检测垃圾邮件
- 预测客户会不会流失
- 预测客户会不会拖欠贷款
这些用例有个共同点:它们的结果都只有两种。当然啦,逻辑回归也有能预测多个结果的类型,不过这篇文章就只讲二分类的逻辑。
逻辑回归的假设(二分类)
你会发现逻辑回归模型的假设和线性回归模型很像,因为逻辑回归也是线性的。
- 二元因变量:目标变量必须只有两种可能的结果。
- 没有多重共线性:自变量之间应该没啥相关性,不然模型的效果会大打折扣。
- 自变量与对数几率的线性关系:对数几率是另一种表示概率的方式,形式上就是 log ( p / ( 1 − p ) ) \log(p/(1-p)) log(p/(1−p))。
还有一些对其他模型也很关键的假设,比如没有异常值(如果有,记得处理一下),样本量要足够大。虽然没有明确的样本量阈值,但记住:样本越多越好。
搭建我们的逻辑回归对象
咱们先从创建初始化函数和对象里要用到的属性开始。你会看到初始化函数里有三个属性:学习率(learning_rate)、迭代次数(iterations)和测试集比例(test_size)。
在用梯度下降找到模型最优权重的时候,fit 方法会用到学习率和迭代次数这两个属性。等咱们讲到这一步的时候,还会详细说说。咱们还加了一个训练集和测试集划分的方法,能将特征和目标变量的数据分成训练集和测试集。
自己动手搭建这些对象的时候,我喜欢把能用的功能都塞进去,这样后面写代码的时候就能更省事儿。
大部分属性一看就懂,除了 min_ 和 max_。咱们会在这些属性里存归一化缩放器的信息。对数据进行归一化处理,能让咱们在模型拟合的时候更快地找到解决方案。
import numpy as np
import pandas as pdclass DIYLogisticRegression:def __init__(self, learning_rate=0.01, iterations=1000, test_size=0.2):# 学习率,用于控制梯度下降的步长self.learning_rate = learning_rate# 迭代次数,决定了训练过程的循环次数self.iterations = iterations# 测试集占总数据集的比例self.test_size = test_size# 权重,初始值为 None,稍后会初始化self.W = None# 偏置项,初始值为 None,稍后会初始化self.b = None# 训练集特征数据self.X_train = None# 测试集特征数据self.X_test = None# 训练集目标数据self.y_train = None# 测试集目标数据self.y_test = None# 用于归一化处理的最小值self.min_ = None# 用于归一化处理的最大值self.max_ = None
训练集/测试集划分与归一化
要正确地训练机器学习模型,必须用一个数据集来训练,另一个数据集来验证。机器学习生命周期里的另一个关键步骤是数据清洗,这可能包括归一化处理。咱们会创建一个方法,把特征和目标数据分成训练集和测试集,同时填充相应的属性。这个方法还会用最大最小值归一化方法对训练数据进行缩放,并把同样的逻辑应用到测试数据上。这就是 min_ 和 max_ 属性的用武之地啦。
注意,这些最小值和最大值是从训练集中得到的,然后应用到测试集上。为啥要这么做呢?假设咱们训练好了一个模型,把它放到生产环境中,那咱们根本不知道新数据的上下限是多少,所以只能依赖从训练集中提取出来的逻辑。
def train_test_split_scale(self, X, y):## 训练集和测试集划分n_samples = X.shape[0]test_size = int(n_samples * self.test_size)indices = np.arange(n_samples)np.random.shuffle(indices)test_indices = indices[:test_size]train_indices = indices[test_size:]self.X_train, self.X_test = X.iloc[train_indices], X.iloc[test_indices]self.y_train, self.y_test = y.iloc[train_indices], y.iloc[test_indices]# 最大最小值归一化self.min_ = self.X_train.min()self.max_ = self.X_train.max()self.X_train = (self.X_train - self.min_) / (self.max_ - self.min_)self.X_test = (self.X_test - self.min_) / (self.max_ - self.min_)
Sigmoid 函数
文章前面提到,咱们要搭建的是一个预测二元结果的逻辑回归模型,背后的原理其实是线性模型:
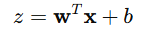
图由作者提供
和线性回归一样,咱们把线性模型设为等于 (z)。这个变量会被代入 Sigmoid 函数。Sigmoid 函数是逻辑回归模型做出预测之前的最后一步。这个函数的关键特性是,它的输出值会被限制在 0 和 1 之间。现在知道为啥逻辑回归要用它了吧?有了 Sigmoid 函数的输出,通常情况下,如果值大于或等于 0.5,咱们就预测二元变量的结果为 1,否则就是 0。当然啦,这个 0.5 的决策边界也可以根据具体需求调整。咱们这就把这个函数作为对象的一个方法加进去。
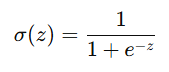
图由作者提供
def sigmoid(self, z):# Sigmoid 函数,将输入值映射到 0 和 1 之间return 1 / (1 + np.exp(-z))
最大似然估计和二元交叉熵损失
要理解逻辑回归,有一个最基本的概念必须得搞清楚,那就是怎么找到特征数据的权重 (W)。这个是通过最大似然估计(MLE)来实现的。MLE 的过程就是找到最能契合咱们数据的权重。一开始我琢磨这个概念的时候,总是在想,找到最优权重是不是就能得到最高的预测准确率呢?其实不是这么回事。最大似然估计函数(咱们要最大化这个函数)的目标是找到最能契合数据内在模式的权重。举个例子,假设咱们有一条观测数据,它的特征并没有明显显示出目标变量是 1 还是 0 的模式。那找到的最优权重和偏置就应该预测这个结果接近 0.5。再假设咱们有另一条观测数据,它的特征明显和预测结果为 1 的模式强相关,那咱们找到的权重和偏置就应该预测这个观测的结果接近 1。
所以,知道最大化 MLE 函数能找到最优权重,但它是怎么做到的呢?这就要通过梯度下降这个迭代过程来实现。梯度下降更适合最小化问题,所以咱们会用 MLE 函数的负值,也就是二元交叉熵损失。
在梯度下降的每一步迭代中,咱们都要计算这个损失函数。接下来的部分,咱们会详细讲讲怎么做到这一点。
先看看计算这个损失函数的方法。你会注意到,咱们在这个损失函数里加了一个额外的步骤,用到了 np.clip() 函数。这个损失函数很容易得到极小值。
一旦出现这种情况,Python 可能会直接四舍五入到 0,那就会出现对数为 0 的情况,这是未定义的。np.clip() 函数会设置一个极小值下限,这样咱们就不会得到 0 了。
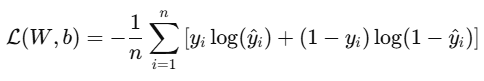
图由作者提供
def compute_loss(self, y, y_hat):# 计算二元交叉熵损失epsilon = 1e-10y_hat = np.clip(y_hat, epsilon, 1 - epsilon)return -np.mean(y * np.log(y_hat) + (1 - y) * np.log(1 - y_hat))
找到最优权重和偏置
这一步就是咱们要把模型拟合到数据上了。正如前面提到的,这是一个叫梯度下降的迭代过程。一开始,咱们会随机初始化权重和偏置的值,然后用它们通过线性函数和 Sigmoid 激活函数来预测每一个 (y) 值。这些预测值就叫 (y_{\text{hat}})。有了 (y_{\text{hat}}) 之后,咱们就能通过二元交叉熵损失函数对权重和偏置进行调整,朝着更优的解靠近。具体来说,咱们要对二元交叉熵损失函数分别对权重和偏置求偏导数。
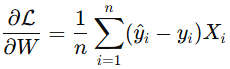
图由作者提供
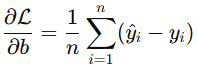
图由作者提供
接下来,咱们把这两个导数值乘以学习率 (\alpha),然后从当前的权重和偏置中减去。这个过程会不断重复,直到损失函数的值不再下降。
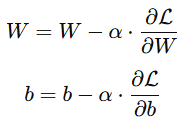
图由作者提供
在咱们的 fit 方法里,每迭代 100 次就输出一次损失函数的值,看看它是不是正确收敛了。如果学习率太高,损失值可能会一直越过最小值,那咱们就永远也“撞”不到最优权重和偏置了。反过来,如果学习率太小,那可能要经过很多次迭代才能“撞”到最小值。
def fit(self):n_samples, n_features = self.X_train.shape# 随机初始化权重self.W = np.random.randn(n_features) * 0.01# 初始化偏置为 0self.b = 0for i in range(self.iterations):linear_model = np.dot(self.X_train, self.W) + self.by_hat = self.sigmoid(linear_model)dW = (1 / n_samples) * np.dot(self.X_train.T, (y_hat - self.y_train))db = (1 / n_samples) * np.sum(y_hat - self.y_train)self.W -= self.learning_rate * dWself.b -= self.learning_rate * dbif i % 100 == 0:loss = self.compute_loss(self.y_train, y_hat)print(f"Iteration {i}, Loss: {loss:.4f}")
预测和评估
重头戏已经搞定了!接下来只要再加几个方法就行啦。一切都已经准备就绪,咱们可以开始添加预测和评估方法了。首先,咱们会创建一个方法,用拟合过程中找到的最优权重,代入线性函数,再通过 Sigmoid 方法,预测结果的概率。这个方法最终会输出一个介于 0 和 1 之间的值,也就是咱们对预测结果的概率估计。
接下来,我会再加一个预测方法,它会根据一个阈值,把概率转换成 1 或者 0。默认的阈值就设为 0.5 吧。
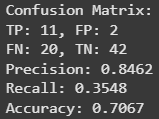
最后,我还会加一个综合评估方法,打印出混淆矩阵、精确率、召回率,还有咱们模型的整体准确率。注意,这些都是基于咱们的测试集来评估模型性能的。
def predict_proba(self, X):"""预测给定输入 X 的概率"""linear_model = np.dot(X, self.W) + self.breturn self.sigmoid(linear_model)def predict(self, X, threshold=0.5):"""根据阈值预测类别标签(0 或 1)"""probabilities = self.predict_proba(X)return (probabilities >= threshold).astype(int)def evaluate(self):"""使用精确率、召回率、准确率和混淆矩阵评估模型"""y_pred = self.predict(self.X_test)tp = np.sum((self.y_test == 1) & (y_pred == 1))fp = np.sum((self.y_test == 0) & (y_pred == 1))fn = np.sum((self.y_test == 1) & (y_pred == 0))tn = np.sum((self.y_test == 0) & (y_pred == 0))precision = tp / (tp + fp) if (tp + fp) > 0 else 0recall = tp / (tp + fn) if (tp + fn) > 0 else 0accuracy = (tp + tn) / (tp + tn + fp + fn)print("混淆矩阵:")print(f"TP: {tp}, FP: {fp}")print(f"FN: {fn}, TN: {tn}\n")print(f"精确率(预测为正的样本中实际为正的比例): {precision:.4f}")print(f"召回率(所有实际为正的样本中预测正确的比例): {recall:.4f}")print(f"准确率(所有样本预测正确的比例): {accuracy:.4f}")
测试我们的对象
咱们来看看这个逻辑回归对象在实际中的表现吧。为了测试它,咱们用的是 Kaggle 上的 心脏病发作预测数据集。这个数据集有 13 列,其中 12 列是特征,最后一列是目标变量 DEATH_EVENT。幸好,咱们的对象已经具备了处理数据、训练模型和评估模型的所有功能。
df = pd.read_csv("heart_failure_clinical_records_dataset.csv") # 加载数据集
X = df.drop('DEATH_EVENT', axis=1)
y = df['DEATH_EVENT']model = DIYLogisticRegression(learning_rate=0.1, iterations=1000, test_size=0.25)
model.train_test_split_scale(X, y)
model.fit()
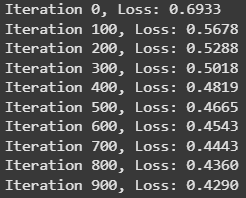
图由作者提供
model.evaluate()

还不错嘛,咱们的模型准确率达到了大约 80%。而且损失函数也收敛得很好,每次迭代的损失值都在下降。咱们来好好聊聊数据和模型吧。这个模型能帮咱们告诉患者他们是否有心脏病发作的风险,所以可别小瞧了它的表现哦。我列出了三个评估指标:精确率、召回率和准确率。你觉得哪个最重要呢?要是咱们告诉某人他有心脏病发作的风险,但实际上他没有,这算不算坏事呢?我觉得不算,但如果咱们没告诉某人他有风险,而他其实有,那可就太糟糕了。所以,咱们应该尽量提高召回率,它能告诉我们所有实际为正的样本中有多少被正确预测了。
和 Sklearn 的逻辑回归对象对比
咱们成功地从零搭建了一个逻辑回归对象,现在来看看它和 sklearn 的逻辑回归类比起来怎么样吧。
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix, accuracy_score, precision_score, recall_scoreX = df.drop('DEATH_EVENT', axis=1)
y = df['DEATH_EVENT']# 训练集和测试集划分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)# 最大最小值归一化
scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)# 初始化并训练逻辑回归模型
model = LogisticRegression()
model.fit(X_train, y_train)# 在测试数据上进行预测
y_pred = model.predict(X_test)# 计算评估指标
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
cm = confusion_matrix(y_test, y_pred)# 显示结果
print("混淆矩阵:")
print(f"TP: {cm[1,1]}, FP: {cm[0,1]}")
print(f"FN: {cm[1,0]}, TN: {cm[0,0]}")
print(f"精确率: {precision:.4f}")
print(f"召回率: {recall:.4f}")
print(f"准确率: {accuracy:.4f}")
总的来说,评估指标都很接近!感谢您阅读这篇文章!希望您通过这篇文章对逻辑回归模型有了更深入的理解。
相关文章:

人工智能与机器学习:Python从零实现逻辑回归模型
🧠 向所有学习者致敬! “学习不是装满一桶水,而是点燃一把火。” —— 叶芝 我的博客主页: https://lizheng.blog.csdn.net 🌐 欢迎点击加入AI人工智能社区! 🚀 让我们一起努力,共创…...

大模型助力嘉兴妇幼:数据分类分级的智能化飞跃
在医疗行业数字化转型进程中,数据已成为驱动服务升级与业务创新的核心要素。作为医疗行业数字化的探索者,嘉兴市妇幼保健院携手美创打造的智能化数据分类分级项目,数据识别率和分类分级率高达99%,分类分级准确率达90%,…...

MyBatisPlus文档
一、MyBatis框架回顾 使用springboot整合Mybatis,实现Mybatis框架的搭建 1、创建示例项目 (1)、创建工程 新建工程 创建空工程 创建模块 创建springboot模块 选择SpringBoot版本 (2)、引入依赖 <dependencies><dependency><groupId>org.springframework.…...

支持Function Call的本地ollama模型对比评测-》开发代理agent
目标是开发支持多个 Function 定义的智能体代理系统 ✅ 第一部分:是否支持多个函数(multi-function calling) 模型名称支持多个函数注册是否支持函数选择(name 匹配)是否能生成结构化参数OpenChat 3.5 / 3.5-0106✅&a…...

Docker拉取镜像代理配置实践与经验分享
Docker拉取镜像代理配置实践与经验分享 一、背景概述 在企业内网环境中,我们部署了多台用于测试与学习的服务器。近期,接到领导安排,需在其中一台服务器上通过Docker安装n8n应用程序。然而在实际操作过程中,遭遇Docker官方镜像库…...

Jinja 的详细介绍和学习方法
Jinja 是一种流行的 模板引擎(Template Engine),主要用于生成动态的文本内容(如 HTML、XML、配置文件等)。它最初是为 Python 的 Web 框架(如 Flask、Django)设计的,但也可以独立使用…...

在 Windows 系统上升级 Node.js
一、查询电脑端已经安装的 Node.js 版本 1、通过【winR】 键,输入 cmd,点击【确定】按钮打开 cmd 窗口 2、命令行界面输入 node -v 查看目前 Node.js 版本 3、命令行界面输入 npm -v 查看目前 npm 版本 二、进入官网地址下载安装包 1、官网地址&#x…...

特斯拉宣布启动自动驾驶网约车测试,无人出租车服务进入最后准备阶段
特斯拉公司于4月24日正式宣布,已在美国得克萨斯州奥斯汀和加利福尼亚州旧金山湾区启动自动驾驶网约车服务的员工内部测试。这项测试将为今年夏季计划推出的完全无人驾驶出租车服务进行最后的验证和准备。 此次测试使用约200辆经过特殊改装的Model 3车型,…...
2025.4.25)
C++面试复习(7)2025.4.25
1,说一说常用的 Linux 命令(NIUKE) 1,cat 查看文件内容 cat filename2,rm 删除 rm filename:删除文件。 rm -r directory:删除目录及其内容。 rm -f filename:强制删除文件(不询问确认&…...
)
使用 uv 工具快速创建 MCP 服务(Trae 配置并调用 MCP 服务)
文章目录 下载Traeuv 工具教程参考我的这篇文章创建 uv 项目main.pyTrae 配置 MCP 服务添加 MCP创建智能体 使用智能体调用 MCP 创建 demo 表查询 demo 表结构信息demo 表插入 2 条测试数据查询 demo 表中的数据 下载Trae https://www.trae.com.cn/ uv 工具教程参考我的这篇…...

07 Python 字符串全解析
文章目录 一. 字符串的定义二. 字符串的基本用法1. 访问字符串中的字符2. 字符串切片3. 字符串拼接4. 字符串重复5.字符串比较6.字符串成员运算 三. 字符串的常用方法1. len() 函数2. upper() 和 lower() 方法3. strip() 方法4. replace() 方法5. split() 方法 四. 字符串的进阶…...

IEEE期刊目录重磅更新!共242本期刊被收录!
🔥 🔥 🔥 🔥 【IEEE期刊目录】 2025年2月,IEEE出版社更新了242本期刊目录,其中: • 完全OA期刊36本:SCI有6本,ESCI有15本; • 混合OA期刊183本&…...

微型计算机原理与接口技术第六版第四章课后习题答案-周荷琴,冯焕清-中国科学技术大学出版社
第六版书籍编排的第3章和第4章,仅这两章习题答案跟第四版的答案是相同的,可以参考第四版的答案 原第四版习题答案,蓝奏云: https://wwss.lanzouq.com/iWXOY1kvk3yf 第六版的第四章的习题我没有单独编辑,它是在上面第四…...

反爬策略应对指南:淘宝 API 商品数据采集的 IP 代理与请求伪装技术
一、引言 在电商数据驱动决策的时代,淘宝平台海量的商品数据极具价值。然而,淘宝为保障平台安全和用户体验,构建了严密的反爬体系。当采集淘宝 API 商品数据时,若不采取有效措施,频繁的请求极易触发反爬机制&#x…...

前端技术Ajax入门
1.1 AJAX 概念和 axios 使用 目标 了解 AJAX 概念并掌握 axios 库基本使用 讲解 1. 什么是 AJAX? 使用浏览器的 XMLHttpRequest 对象与服务器通信。在浏览器网页中,通过 AJAX 技术(XHR 对象)发起获取省份列表数据的请求&…...

【沉浸式求职学习day25】【部分网络编程知识分享】【基础概念以及简单代码】
不知道大家一直高强度学习自己是什么样的感觉,反正我现在逐渐变得麻木了,马上又要实习笔试了,每次笔试都要突击,每次突击都意识到自己有太多不会的,主打一个心累,但是又能怎样呢,自己选的路就是…...

聊聊Spring AI Alibaba的YoutubeDocumentReader
序 本文主要研究一下Spring AI Alibaba的YoutubeDocumentReader YoutubeDocumentReader community/document-readers/spring-ai-alibaba-starter-document-reader-youtube/src/main/java/com/alibaba/cloud/ai/reader/youtube/YoutubeDocumentReader.java public class You…...

常用第三方库:flutter_boost混合开发
常用第三方库:flutter_boost混合开发 前言 在移动应用开发中,混合开发是一个非常重要的话题。特别是对于已有原生应用想要引入Flutter的团队来说,如何实现Flutter页面和原生页面的无缝整合就显得尤为关键。本文将深入介绍flutter_boost这个…...

什么是 JSON?学习JSON有什么用?在springboot项目里如何实现JSON的序列化和反序列化?
作为一个学习Javaweb的新手,理解JSON的序列化和反序列化非常重要,因为它在现代Web开发,特别是Spring Boot中无处不在。 什么是 JSON? 首先,我们简单了解一下JSON (JavaScript Object Notation)。 JSON 是一种轻量级的…...

[mysql]数据类型精讲
目录 数据类型精讲: 整数类型 浮点类型 日期和时间类型 文本字符串类型 数据类型精讲: 精度问题:不能损失数据 性能问题:表的设计,范式的讲解. 表设计的时候需要设置字段,我们现在要把字段类型讲完.,细节点一点点给大家拆解. Float和double是有精度的损失的,这边推荐使用…...

WordPress AI插件能自动写高质量文章吗,如何用AI提升网站流量
WordPress AI插件能自动写高质量文章吗? 最近很多站长都在问,用wordpress AI插件真的能写出搜索引擎喜欢的好文章吗?作为一个用过10款AI写作工具的老站长,今天我就来分享真实使用体验,告诉你哪些插件好用、怎么用才能…...
)
【中级软件设计师】函数调用 —— 传值调用和传地址调用 (附软考真题)
【中级软件设计师】函数调用 —— 传值调用和传地址调用 (附软考真题) 目录 【中级软件设计师】函数调用 —— 传值调用和传地址调用 (附软考真题)一、历年真题二、考点:函数调用 —— 传值调用和传地址调用🔺1、传值调用🔺2、传引用(地址)调…...
:JavaScript 的开端)
ECMAScript 1(ES1):JavaScript 的开端
1. 版本背景与发布 ●发布时间:1997 年 6 月,由 ECMA International 正式发布,标准编号为 ECMA-262。 ●历史意义:ES1 是 JavaScript 的首个标准化版本,结束了 Netscape Navigator 与 Internet Explorer 浏览器间脚本语…...

C++入侵检测与网络攻防之暴力破解
目录 1.nessus扫描任务 2.漏洞信息共享平台 3.nessus扫描结果 4.漏扫报告的查看 5.暴力破解以及hydra的使用 6.crunch命令生成字典 7.其他方式获取字典 8.复习 9.关于暴力破解的防御的讨论 10.pam配置的讲解 11.pam弱密码保护 12.pam锁定账户 13.shadow文件的解析 …...
)
基于ssm的同城上门维修平台管理系统(源码+数据库)
54基于ssm的同城上门维修平台管理系统:前端jsp、jquery、bootstrap,后端 spring、mybatis,集成订单管理、商品管理、商品类型管理、商品浏览、购物车等功能于一体的系统。 ## 功能介绍 ### 用户 - 基本功能:登录、注册、退出、…...
)
力扣-hot100(和为k的子数组)
560. 和为 K 的子数组 中等 给你一个整数数组 nums 和一个整数 k ,请你统计并返回 该数组中和为 k 的子数组的个数 。 子数组是数组中元素的连续非空序列。 示例 1: 输入:nums [1,1,1], k 2 输出:2 示例 2: 输入…...

【计算机视觉】CV实战 - 基于YOLOv5的人脸检测与关键点定位系统深度解析
基于YOLOv5的人脸检测与关键点定位系统深度解析 1. 技术背景与项目意义传统方案的局限性YOLOv5多任务方案的优势 2. 核心算法原理网络架构改进关键点回归分支损失函数设计 3. 实战指南:从环境搭建到模型应用环境配置数据准备数据格式要求数据目录结构 模型训练配置文…...

HTML word属性
介绍 CSS word-spacing 属性,用于指定段字之间的空间,例如: p {word-spacing:30px; }word-spacing属性增加或减少字与字之间的空白。 注意: 负值是允许的。 浏览器支持 表格中的数字表示支持该属性的第一个浏览器版本号。 属…...

Java—ThreadLocal底层实现原理
首先,ThreadLocal 本身并不提供存储数据的功能,当我们操作 ThreadLocal 的时候,实际上操作线程对象的一个名为 threadLocals 成员变量。这个成员变量的类型是 ThreadLocal 的一个内部类 ThreadLocalMap,它是真正用来存储数据的容器…...

GTSRB德国交通标志数据集下载以及训练集划分
GTSRB德国交通标志数据集下载以及训练集划分 一、数据集下载二、数据集划分 一、数据集下载 官网地址:附含数据集说明文档点击下载:训练数据集点击下载:测试数据集 二、数据集划分 在模型训练时,将训练数据集分成训练集和验证集&…...

python 实现客户端软件许可证书签名授权 cryptography
目录 1.需求 2.cryptography介绍 3.实际代码 4.结束语 1.需求 采用pyside6开发了一款客户端软件, 为保护核心算法源码, 采用Nuitka打包python代码,这仅仅保护了核心算法代码,不能限制用户使用软件,因此需要软件许可授权签名证书ÿ…...

明远智睿SD2351核心板:以48元撬动AI视觉产业革命的“硬核引擎”
在人工智能浪潮席卷全球的今天,AI视觉作为连接虚拟与现实的“智慧之眼”,正以惊人的速度重塑着产业格局。从智慧城市中的安防监控到自动驾驶汽车的“视觉神经”,从工业产线的缺陷检测到家庭场景的智能管家,AI视觉技术的每一次突破…...

【C语言】全局变量、静态本地变量
在C语言中,变量是存储数据的基本单元。 不同类型的变量有着不同的特性和用途,其中全局变量和本地变量是比较特殊且重要的两类变量。 一、全部变量 1.1 全局变量的作用域和生存期 全局变量是在函数外部定义的变量,其作用域从定义的位置开始&…...

32.768kHz晶振详解:作用、特性及与其他晶振的区别
一、32.768kHz晶振的核心作用 实时时钟(RTC)驱动: 提供精确的1Hz时钟信号,用于计时功能(如电子表、计算机CMOS时钟)。 分频公式: 1Hz 32.768kHz / 2^15(通过15级二分频实现&#x…...

classfinal 修改过源码,支持jdk17 + spring boot 3.2.8
先贴图 使用 classfinal 修改过源码 支持jdk17 spring boot 3.3.0 使用方式: 1、springboot的jar加密 java -jar classfinal-fatjar-1.2.1.jar -file MySpringBoot.jar -libjars my-common.jar -packages cn.com.cmd -pwd 123456 -Y 得到: MySpri…...

算法训练营 Day1
努力追上那个曾经被寄予厚望的自己 —— 25.4.25 一、LeetCode_26 删除有序数组中的重复项 给你⼀个 升序排列 的数组 nums ,请你 原地 删除重复出现的元素,使每个元素 只出现⼀次 ,返回删除后数组的 新⻓度。元素的 相对顺序 应该保持 ⼀致 …...

4/25 研0学习日志
Python学习 python 4个常用的数据容器 list dict tuple set list 列表中数据类型可以不一样 构造方式 mylist["xxx","xxxx"] 获取数据方式 mylist[1] mylist[:4] mylist[-1:] 添加数据 mylist.append() mylist.extern(["aaa","aaaa&…...

手机打电话时电脑坐席同时收听对方说话并插入IVR预录声音片段
手机打电话时电脑坐席同时收听对方说话并插入IVR预录声音片段 --本地AI电话机器人 前言 书接上一篇,《手机打电话通话时如何向对方播放录制的IVR引导词声音》中介绍了【蓝牙电话SDK示例App】可以实现手机app在电话通话过程中插播预先录制的开场白等语音片段的功能。…...

汽车零配件供应商如何通过EDI与主机厂生产采购流程结合
当前,全球汽车产业正经历深刻的数字化转型,供应链协同模式迎来全新变革。作为产业链核心环节,汽车零部件供应商与主机厂的高效对接已成为企业发展的战略要务。然而,面对主机厂日益严格的数字化采购要求,许多供应商在ED…...

sql server 开启cdc报事务正在执行
今天开启数据库cdc 功能的时候提示:一个dbrole 的存储过程,rolemember cdc db_ower, ,有事务正在进行,执行失败。 执行多次仍然如此,开启cdc的存储过程是sys.sp_cdc_enable_db;查询了一下网络,给出的方…...
)
03实战篇Redis02(优惠卷秒杀、分布式锁)
3、优惠卷秒杀 3.1 -全局唯一ID 每个店铺都可以发布优惠券: 当用户抢购时,就会生成订单并保存到tb_voucher_order这张表中,而订单表如果使用数据库自增ID就存在一些问题: id的规律性太明显 受单表数据量的限制 场景分析&…...

ECharts 地图开发入门
一、准备工作:环境搭建与数据准备 1. 引入 ECharts 库 TypeScript 取消自动换行复制 <!-- 引入 ECharts 核心库 --> <script src"https://cdn.jsdelivr.net/npm/echarts5.4.0/dist/echarts.min.js"></script> <!-…...

机器学习基础 - 回归模型之线性回归
机器学习: 线性回归 文章目录 机器学习: 线性回归1. 线性回归1. 简介2. 线性回归如何训练?1. 损失函数2. 正规方程3. 梯度下降法4. 两种方法的比较2. 岭回归岭回归与线性回归3. Lasso 回归4. ElasticNet 回归LWR - 局部加权回归QA1. 最小二乘法估计2. 最小二乘法的几何解释3…...

《解锁LLMs from scratch:开启大语言模型的探索之旅》
《解锁LLMs from scratch:开启大语言模型的探索之旅》 GitHub - datawhalechina/llms-from-scratch-cn: 仅需Python基础,从0构建大语言模型;从0逐步构建GLM4\Llama3\RWKV6, 深入理解大模型原理 项目首页 - LLMs-from-scratch:从零开始逐步指导开发者构建自己的大型语言模型…...

嵌入式 C 语言面试核心知识点全面解析:基础语法、运算符与实战技巧
在嵌入式面试中,C 语言基础是重中之重。本文针对经典面试题进行详细解析,帮助新手系统掌握知识点,提升面试应对能力。 一、数据结构逻辑分类 题目 在数据结构中,从逻辑上可以把数据结构分为( )。 A、动态…...

pyqt中以鼠标所在位置为锚点缩放图片
在编写涉及到图片缩放的pyqt程序时,如果以鼠标为锚点缩放图片,图片上处于鼠标所在位置的点(通常也是用户关注的图片上的点)不会移动,更不会消失在图片显示区域之外,可以提高用户体验,是一个值得…...

登高架设作业证考试的实操项目有哪些?
登高架设作业证考试的实操项目分为 4 个科目,包括安全防护用品使用、作业现场安全隐患排除、安全操作技术、作业现场应急处置,具体内容如下: 科目一:安全防护用品使用(K1) 考试项目:安全帽、安全…...

闻性与空性:从耳根圆通到究竟解脱的禅修路径
一、闻性之不动:超越动静的觉性本质 在《楞严经》中,佛陀以钟声为喻揭示闻性的奥秘:钟声起时,闻性显现;钟声歇时,闻性不灭。此“不动”并非如磐石般凝固,而是指觉性本身超越生灭、来去的绝对性…...
)
404了怎么办快把路由给我断掉(React配置路由)
路由基础概念 什么是前端路由? 核心作用:管理单页面应用的页面切换主要功能: 根据URL显示对应组件 保持浏览器历史记录 实现页面间导航不刷新 React Router 包含三个主要包: react-router:核心逻辑react-router-d…...

React类组件与React Hooks写法对比
React 类组件 vs Hooks 写法对比 分类类组件(Class Components)函数组件 Hooks组件定义class Component extends React.Componentconst Component () > {}状态管理this.state this.setState()useState()生命周期componentDidMount, componentDidU…...