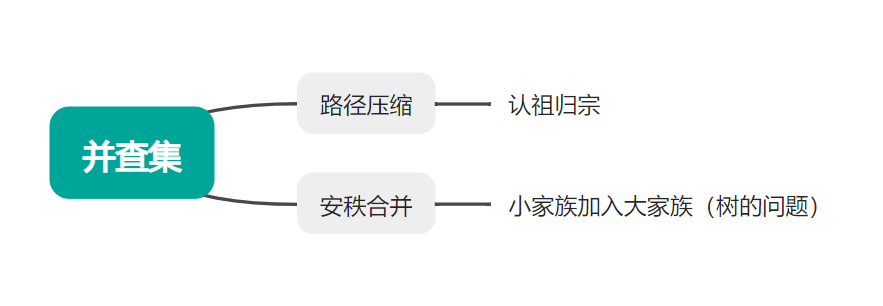
图论算法体系:并查集、生成树、排序与路径搜索全解析

从图论的基础理论入门,到深搜广搜搭建起图论的骨架。
从并查集到最小生成树,从拓扑排序到最短路径。
....
群星璀璨😉

- 并查集
- 最小生成树
- Prim算法
- Kruskal算法
- 拓扑排序(kahn算法)
- ·最短路径
- Dijkstra算法
- Dijkstra朴素
- Dijkstra堆优化
- Bellman_ford算法
- Bellman_ford朴素
- SPFA
- Bellman_ford之判断负权回路
- Bellman_ford之单源有限最短路
- Floyed算法
- 启发式搜索A*算法
- Dijkstra算法
一、并查集
作用:
- 连通性判断(两个节点是否连通)
- 检测环(在无项图中,添加两个节点是否属于同一父节点)
- 最小生成树(KrusKal)
模版:
基础应用
简单例子;
无向图,有1~5这5个节点
1 2
2 3
3 4
求解,2与4是否连通。2与5呢?
加入1-4
是否会成环?
按照模板给出讲解顺序
// 这只是无向图中的应用,是最基础的
// 有向图会麻烦一点点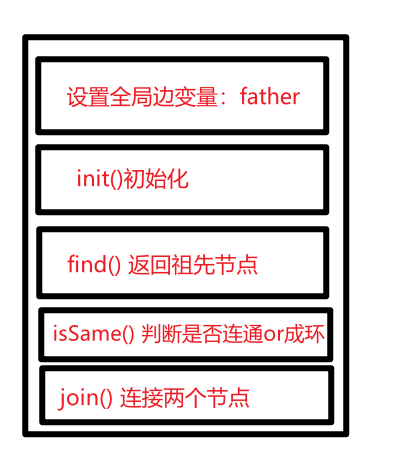
压缩路径:
(最基础、最常用)
int n = 1005; // n根据题目中节点数量而定,一般比节点数量大一点就好
vector<int> father = vector<int> (n, 0); // C++里的一种数组结构// 并查集初始化
void init() {for (int i = 0; i < n; ++i) {father[i] = i;}
}
// 并查集里寻根的过程
int find(int u) {return u == father[u] ? u : father[u] = find(father[u]); // 路径压缩
}// 判断 u 和 v是否找到同一个根
bool isSame(int u, int v) {u = find(u);v = find(v);return u == v;
}// 将v->u 这条边加入并查集
void join(int u, int v) {u = find(u); // 寻找u的根v = find(v); // 寻找v的根if (u == v) return ; // 如果发现根相同,则说明在一个集合,不用两个节点相连直接返回father[v] = u;
}按秩合并:
(大规模场景,需要性能优化时,会用到这个)(我没遇到,不知道)
int n = 1005; // n根据题目中节点数量而定,一般比节点数量大一点就好
vector<int> father = vector<int> (n, 0); // C++里的一种数组结构
vector<int> rank = vector<int> (n, 1); // 初始每棵树的高度都为1// 并查集初始化
void init() {for (int i = 0; i < n; ++i) {father[i] = i;rank[i] = 1; // 也可以不写}
}
// 并查集里寻根的过程
int find(int u) {return u == father[u] ? u : find(father[u]);// 注意这里不做路径压缩
}// 判断 u 和 v是否找到同一个根
bool isSame(int u, int v) {u = find(u);v = find(v);return u == v;
}// 将v->u 这条边加入并查集
void join(int u, int v) {u = find(u); // 寻找u的根v = find(v); // 寻找v的根if (rank[u] <= rank[v]) father[u] = v; // rank小的树合入到rank大的树else father[v] = u;if (rank[u] == rank[v] && u != v) rank[v]++; // 如果两棵树高度相同,则v的高度+1,因为上面 if (rank[u] <= rank[v]) father[u] = v; 注意是 <=
}二、最小生成树
基础定义:
给一个无向连通图,找到一个子图,满足:
- 包含所有顶点(N个顶点)
- 有N-1条边
- 边权值最小
(举例详细解释一下)
prime是以点为基础,所以更适合稠密图(O(N^2))
Kruskal以边为基础,更适合稀疏图 (O(nlogn))
(一般题目会这样出题:有多个城市之间埔公路(A、B、C、D),求如何才能用最少的原材料,让所有城市之间连通?)
Prim算法:
核心思想:
从顶点出发的贪心思想,
每次循环都会连接一个 距离生成树 距离最近 的节点。
基础应用
模板:
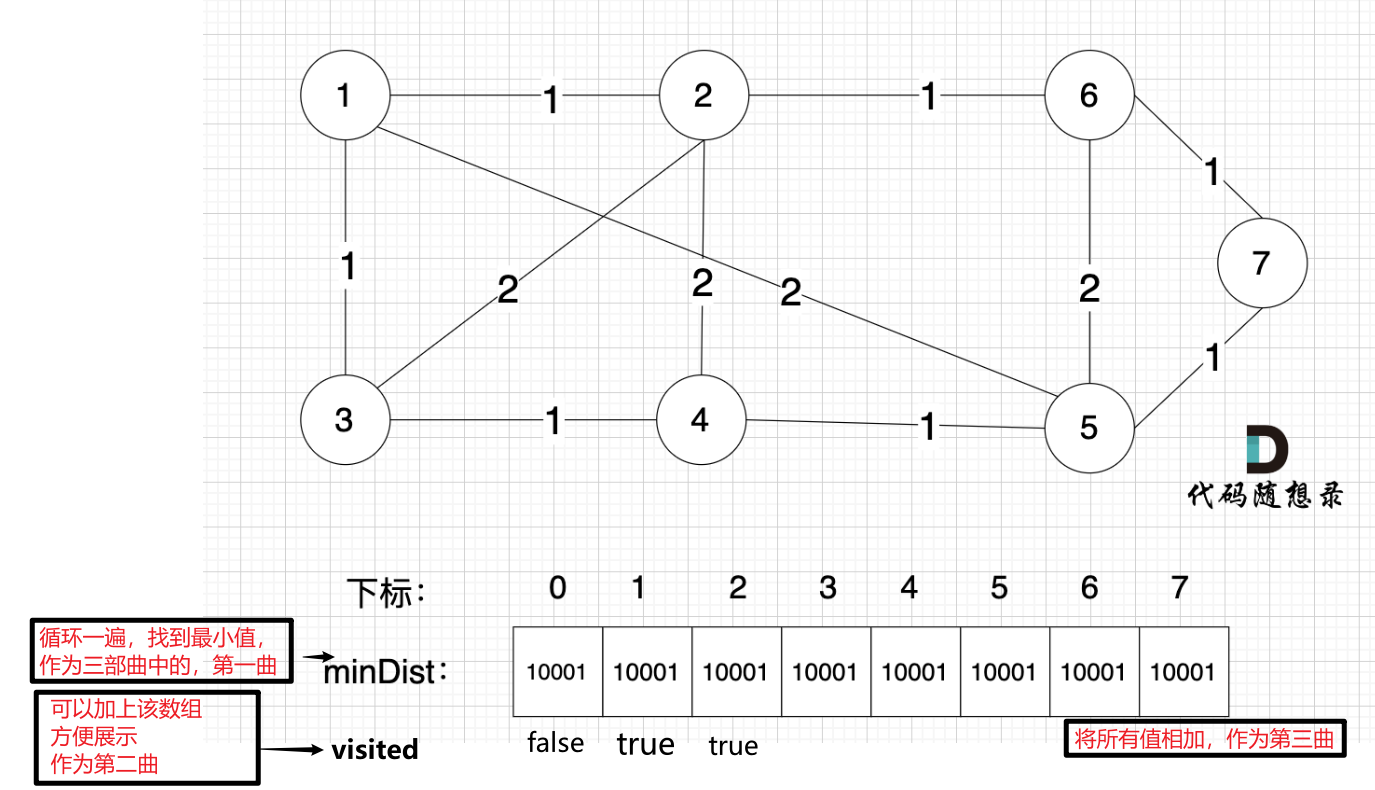
三步走:
- 找出距离已得到生成树最近的节点。
- 更新去重数组
- 更新未加入生成树节点,到达生成树的最小距离。(用新加入的节点表示)

#include<iostream>
#include<vector>
#include <climits>using namespace std;
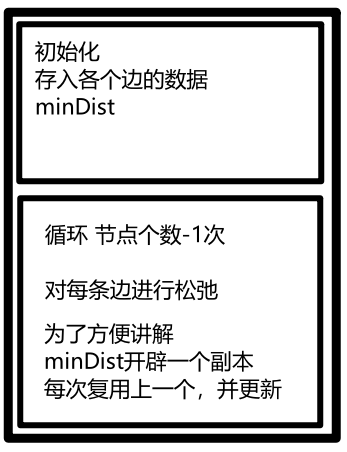
int main() {int v, e;int x, y, k;cin >> v >> e;// 填一个默认最大值,题目描述val最大为10000vector<vector<int>> grid(v + 1, vector<int>(v + 1, 10001));while (e--) {cin >> x >> y >> k;// 因为是双向图,所以两个方向都要填上grid[x][y] = k;grid[y][x] = k;}// 所有节点到最小生成树的最小距离vector<int> minDist(v + 1, 10001);// 这个节点是否在树里vector<bool> isInTree(v + 1, false);// 我们只需要循环 n-1次,建立 n - 1条边,就可以把n个节点的图连在一起for (int i = 1; i < v; i++) {// 1、prim三部曲,第一步:选距离生成树最近节点int cur = -1; // 选中哪个节点 加入最小生成树int minVal = INT_MAX;for (int j = 1; j <= v; j++) { // 1 - v,顶点编号,这里下标从1开始// 选取最小生成树节点的条件:// (1)不在最小生成树里// (2)距离最小生成树最近的节点if (!isInTree[j] && minDist[j] < minVal) {minVal = minDist[j];cur = j;}}// 2、prim三部曲,第二步:最近节点(cur)加入生成树isInTree[cur] = true;// 3、prim三部曲,第三步:更新非生成树节点到生成树的距离(即更新minDist数组)// cur节点加入之后, 最小生成树加入了新的节点,那么所有节点到 最小生成树的距离(即minDist数组)需要更新一下// 由于cur节点是新加入到最小生成树,那么只需要关心与 cur 相连的 非生成树节点 的距离 是否比 原来 非生成树节点到生成树节点的距离更小了呢for (int j = 1; j <= v; j++) {// 更新的条件:// (1)节点是 非生成树里的节点// (2)与cur相连的某节点的权值 比 该某节点距离最小生成树的距离小// 很多录友看到自己 就想不明白什么意思,其实就是 cur 是新加入 最小生成树的节点,那么 所有非生成树的节点距离生成树节点的最近距离 由于 cur的新加入,需要更新一下数据了if (!isInTree[j] && grid[cur][j] < minDist[j]) {minDist[j] = grid[cur][j];}}}// 统计结果int result = 0;for (int i = 2; i <= v; i++) { // 不计第一个顶点,因为统计的是边的权值,v个节点有 v-1条边result += minDist[i];}cout << result << endl;}Kruskal算法:
(克鲁斯卡尔算法)
核心思想:
从 “边” 开始的,贪心思想。
基础应用:
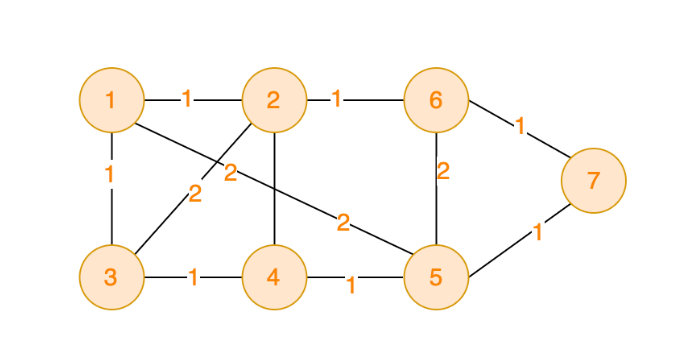
初始数据
7 11 // 7个节点、11条边
1 2 1 // 顶点1与顶点2相连、权值为1
1 3 1
1 5 2
2 6 1
2 4 2
2 3 2
3 4 1
4 5 1
5 6 2
5 7 1
6 7 1
求解最小生成树,权值最小为多少。可以转化为:
(有多个城市之间埔公路,求如何才能用最少的原材料,让所有城市之间连通?)
// 排序过后的
1 2 1
1 3 1
2 6 1
3 4 1
4 5 1
6 7 1
5 7 1
2 3 2
1 5 2
2 4 2
5 6 2模板:

重点步骤:
- 储存每条边,并按照权值大小按照升序排序,放在edges数组中
- 建立并查集模板
- 通过edges数组,建立最小生成树
#include <iostream>
#include <vector>
#include <algorithm>using namespace std;// l,r为 边两边的节点,val为边的数值
struct Edge {int l, r, val;
};// 节点数量
int n = 10001;
// 并查集标记节点关系的数组
vector<int> father(n, -1); // 节点编号是从1开始的,n要大一些// 并查集初始化
void init() {for (int i = 0; i < n; ++i) {father[i] = i;}
}// 并查集的查找操作
int find(int u) {return u == father[u] ? u : father[u] = find(father[u]); // 路径压缩
}// 并查集的加入集合
void join(int u, int v) {u = find(u); // 寻找u的根v = find(v); // 寻找v的根if (u == v) return ; // 如果发现根相同,则说明在一个集合,不用两个节点相连直接返回father[v] = u;
}int main() {int v, e;int v1, v2, val;vector<Edge> edges;int result_val = 0;cin >> v >> e;while (e--) {cin >> v1 >> v2 >> val;edges.push_back({v1, v2, val});}// 执行Kruskal算法// 按边的权值对边进行从小到大排序sort(edges.begin(), edges.end(), [](const Edge& a, const Edge& b) {return a.val < b.val;});// 并查集初始化init();// 从头开始遍历边for (Edge edge : edges) {// 并查集,搜出两个节点的祖先int x = find(edge.l);int y = find(edge.r);// 如果祖先不同,则不在同一个集合if (x != y) {result_val += edge.val; // 这条边可以作为生成树的边join(x, y); // 两个节点加入到同一个集合}}cout << result_val << endl;return 0;
}三、拓扑排序:
作用:
拓扑排序是将,有向图转化为线性关系。
(先上A课,才能上B课,上了A课才能上C课,先上C课才能上B课,上了B课才能上D课)
求上课顺序应该如何排序(有多种排序方式)
最常用的方式是卡恩算法(BFS)(另一种是DFS回溯法)
Kahn算法
两步走:
- 找到入度为0的节点,并加入结果集
- 减去与该节点相连的入度(将该节点从图中移除)
模板

#include <iostream>
#include <vector>
#include <queue>
#include <unordered_map>
using namespace std;
int main() {int m, n, s, t;cin >> n >> m;vector<int> inDegree(n, 0); // 记录每个文件的入度unordered_map<int, vector<int>> umap;// 记录文件依赖关系vector<int> result; // 记录结果while (m--) {// s->t,先有s才能有tcin >> s >> t;inDegree[t]++; // t的入度加一umap[s].push_back(t); // 记录s指向哪些文件}queue<int> que;for (int i = 0; i < n; i++) {// 入度为0的文件,可以作为开头,先加入队列if (inDegree[i] == 0) que.push(i);//cout << inDegree[i] << endl;}// int count = 0;while (que.size()) {int cur = que.front(); // 当前选中的文件que.pop();//count++;result.push_back(cur);vector<int> files = umap[cur]; //获取该文件指向的文件if (files.size()) { // cur有后续文件for (int i = 0; i < files.size(); i++) {inDegree[files[i]] --; // cur的指向的文件入度-1if(inDegree[files[i]] == 0) que.push(files[i]);}}}if (result.size() == n) {for (int i = 0; i < n - 1; i++) cout << result[i] << " ";cout << result[n - 1];} else cout << -1 << endl;}四、最短路径算法
基础定义:
从起点到终点的最短路径。
举一个形象一点的例子:导航地图,你到目的地的推荐路径。
Dijkstra
(迪杰斯特拉算法)--同样是以 “点” 为起始的贪心思想,方法与prim大同小异。
基础应用:
举例:从1到各个节点之间最短距离。(所有权值,必须是正值)
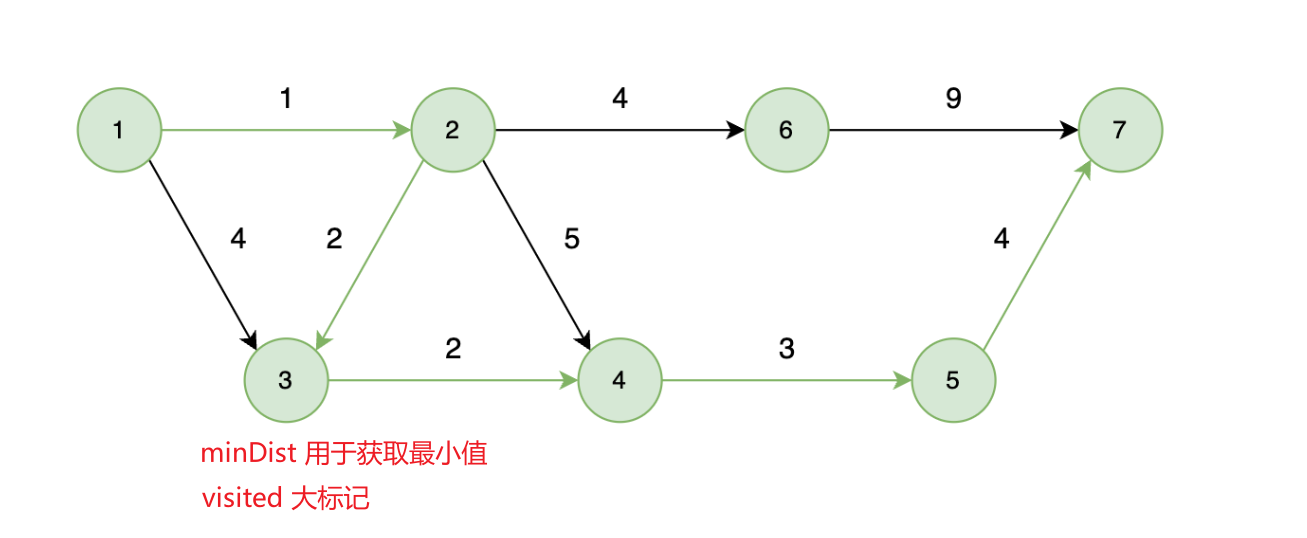
dijkstra朴素版:
模板:
三部走:
- 选源点到那个节点近,且该节点未被访问过
- 标记该节点为已访问过
- 更新非访问节点,到源点的距离

#include <iostream>
#include <vector>
#include <climits>
using namespace std;
int main() {int n, m, p1, p2, val;cin >> n >> m;vector<vector<int>> grid(n + 1, vector<int>(n + 1, INT_MAX));for(int i = 0; i < m; i++){cin >> p1 >> p2 >> val;grid[p1][p2] = val;}int start = 1;int end = n;// 存储从源点到每个节点的最短距离std::vector<int> minDist(n + 1, INT_MAX);// 记录顶点是否被访问过std::vector<bool> visited(n + 1, false);minDist[start] = 0; // 起始点到自身的距离为0for (int i = 1; i <= n; i++) { // 遍历所有节点int minVal = INT_MAX;int cur = 1;// 1、选距离源点最近且未访问过的节点for (int v = 1; v <= n; ++v) {if (!visited[v] && minDist[v] < minVal) {minVal = minDist[v];cur = v;}}visited[cur] = true; // 2、标记该节点已被访问// 3、第三步,更新非访问节点到源点的距离(即更新minDist数组)for (int v = 1; v <= n; v++) {if (!visited[v] && grid[cur][v] != INT_MAX && minDist[cur] + grid[cur][v] < minDist[v]) {minDist[v] = minDist[cur] + grid[cur][v];}}}if (minDist[end] == INT_MAX) cout << -1 << endl; // 不能到达终点else cout << minDist[end] << endl; // 到达终点最短路径}dijkstra堆优化法:
模板:
堆优化法,其实挺好实现的,跟Kruskal挺像,就是以边为中心的贪心思想。

#include <iostream>
#include <vector>
#include <list>
#include <queue>
#include <climits>
using namespace std;
// 小顶堆
class mycomparison {
public:bool operator()(const pair<int, int>& lhs, const pair<int, int>& rhs) {return lhs.second > rhs.second;}
};
// 定义一个结构体来表示带权重的边
struct Edge {int to; // 邻接顶点int val; // 边的权重Edge(int t, int w): to(t), val(w) {} // 构造函数
};int main() {int n, m, p1, p2, val;cin >> n >> m;vector<list<Edge>> grid(n + 1);for(int i = 0; i < m; i++){cin >> p1 >> p2 >> val; // p1 指向 p2,权值为 valgrid[p1].push_back(Edge(p2, val));}int start = 1; // 起点int end = n; // 终点// 存储从源点到每个节点的最短距离std::vector<int> minDist(n + 1, INT_MAX);// 记录顶点是否被访问过std::vector<bool> visited(n + 1, false); // 优先队列中存放 pair<节点,源点到该节点的权值>priority_queue<pair<int, int>, vector<pair<int, int>>, mycomparison> pq;// 初始化队列,源点到源点的距离为0,所以初始为0pq.push(pair<int, int>(start, 0)); minDist[start] = 0; // 起始点到自身的距离为0while (!pq.empty()) {// 1. 第一步,选源点到哪个节点近且该节点未被访问过 (通过优先级队列来实现)// <节点, 源点到该节点的距离>pair<int, int> cur = pq.top(); pq.pop();if (visited[cur.first]) continue;// 2. 第二步,该最近节点被标记访问过visited[cur.first] = true;// 3. 第三步,更新非访问节点到源点的距离(即更新minDist数组)for (Edge edge : grid[cur.first]) { // 遍历 cur指向的节点,cur指向的节点为 edge// cur指向的节点edge.to,这条边的权值为 edge.valif (!visited[edge.to] && minDist[cur.first] + edge.val < minDist[edge.to]) { // 更新minDistminDist[edge.to] = minDist[cur.first] + edge.val;pq.push(pair<int, int>(edge.to, minDist[edge.to]));}}}if (minDist[end] == INT_MAX) cout << -1 << endl; // 不能到达终点else cout << minDist[end] << endl; // 到达终点最短路径
}
为什么不能有负值:
可以自己模拟一遍
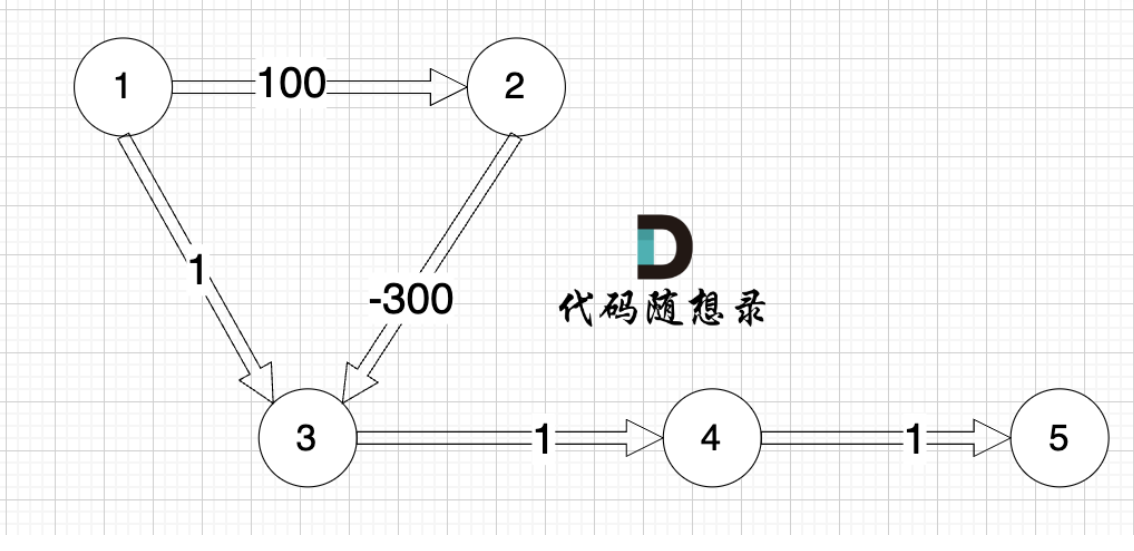
Bellman ford算法
(贝尔曼-福特算法)- 解决权值为负的问题
核心思想:
贝尔曼-福特算法,的核心是松弛操作。
尝试通过中间节点缩短路径的,就是松弛操作。
如:点之间的最短距离,点A到点B的最短距离是3,点B到点C的最短距离是-2,点A到点C之间的最短距离是2;
点A->点C的最短距离(A先到B,再到C)(3+(-2))=1;减半减半的呢
Bellman_ford
基础应用:
A → B:3(花费为 3)
A → C:5(花费为 5)
B → C:-1(花费 -1,相当于补贴了钱)
B → D:3(花费为 3)
C → D:4(花费为 4)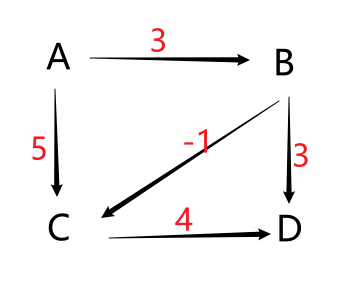
模板:
#include <iostream>
#include <vector>
#include <list>
#include <climits>
using namespace std;int main() {int n, m, p1, p2, val;cin >> n >> m;vector<vector<int>> grid;// 将所有边保存起来for(int i = 0; i < m; i++){cin >> p1 >> p2 >> val;// p1 指向 p2,权值为 valgrid.push_back({p1, p2, val});}int start = 1; // 起点int end = n; // 终点vector<int> minDist(n + 1 , INT_MAX);minDist[start] = 0;for (int i = 1; i < n; i++) { // 对所有边 松弛 n-1 次for (vector<int> &side : grid) { // 每一次松弛,都是对所有边进行松弛int from = side[0]; // 边的出发点int to = side[1]; // 边的到达点int price = side[2]; // 边的权值// 松弛操作 // minDist[from] != INT_MAX 防止从未计算过的节点出发if (minDist[from] != INT_MAX && minDist[to] > minDist[from] + price) { minDist[to] = minDist[from] + price; }}}if (minDist[end] == INT_MAX) cout << "unconnected" << endl; // 不能到达终点else cout << minDist[end] << endl; // 到达终点最短路径}Bellman_ford优先队列(SPFA)
其实,SPFA就是对应kruskal算法。以“边”为起始的贪心算法
基础应用:
A → B:3(花费为 3)
A → C:5(花费为 5)
B → C:-1(花费 -1,相当于补贴了钱)
B → D:3(花费为 3)
C → D:4(花费为 4)
模板:

#include <iostream>
#include <vector>
#include <queue>
#include <list>
#include <climits>
using namespace std;struct Edge { //邻接表int to; // 链接的节点int val; // 边的权重Edge(int t, int w): to(t), val(w) {} // 构造函数
};int main() {int n, m, p1, p2, val;cin >> n >> m;vector<list<Edge>> grid(n + 1); vector<bool> isInQueue(n + 1); // 加入优化,已经在队里里的元素不用重复添加// 将所有边保存起来for(int i = 0; i < m; i++){cin >> p1 >> p2 >> val;// p1 指向 p2,权值为 valgrid[p1].push_back(Edge(p2, val));}int start = 1; // 起点int end = n; // 终点vector<int> minDist(n + 1 , INT_MAX);minDist[start] = 0;queue<int> que;que.push(start); while (!que.empty()) {int node = que.front(); que.pop();isInQueue[node] = false; // 从队列里取出的时候,要取消标记,我们只保证已经在队列里的元素不用重复加入for (Edge edge : grid[node]) {int from = node;int to = edge.to;int value = edge.val;if (minDist[to] > minDist[from] + value) { // 开始松弛minDist[to] = minDist[from] + value; if (isInQueue[to] == false) { // 已经在队列里的元素不用重复添加que.push(to);isInQueue[to] = true;}}}}if (minDist[end] == INT_MAX) cout << "unconnected" << endl; // 不能到达终点else cout << minDist[end] << endl; // 到达终点最短路径
}
Bellman_ford判断负权回路
基础应用:
图中,存在回路,并且回路的值为负值
模板:
1、朴素版
朴素版,其实是最好理解的!
没有负权回路时会循环n-1次,之后n、n+1、n+2...结果都不会在变。
若出现负权回路!不论循环多少次,内容一直会改变。
#include <iostream>
#include <vector>
#include <list>
#include <climits>
using namespace std;int main() {int n, m, p1, p2, val;cin >> n >> m;vector<vector<int>> grid;for(int i = 0; i < m; i++){cin >> p1 >> p2 >> val;// p1 指向 p2,权值为 valgrid.push_back({p1, p2, val});}int start = 1; // 起点int end = n; // 终点vector<int> minDist(n + 1 , INT_MAX);minDist[start] = 0;bool flag = false;for (int i = 1; i <= n; i++) { // 这里我们松弛n次,最后一次判断负权回路for (vector<int> &side : grid) {int from = side[0];int to = side[1];int price = side[2];if (i < n) {if (minDist[from] != INT_MAX && minDist[to] > minDist[from] + price) minDist[to] = minDist[from] + price;} else { // 多加一次松弛判断负权回路if (minDist[from] != INT_MAX && minDist[to] > minDist[from] + price) flag = true;}}}if (flag) cout << "circle" << endl;else if (minDist[end] == INT_MAX) {cout << "unconnected" << endl;} else {cout << minDist[end] << endl;}
}2、SPFA
若要用优先队列解决的话,可以根据他的一个性质,每个节点最多被松弛n-1次。
(也就是做n-1次,中间节点)
一点超过n-1次,就会说明出现了负权回路。
#include <iostream>
#include <vector>
#include <queue>
#include <list>
#include <climits>
using namespace std;struct Edge { //邻接表int to; // 链接的节点int val; // 边的权重Edge(int t, int w): to(t), val(w) {} // 构造函数
};int main() {int n, m, p1, p2, val;cin >> n >> m;vector<list<Edge>> grid(n + 1); // 邻接表// 将所有边保存起来for(int i = 0; i < m; i++){cin >> p1 >> p2 >> val;// p1 指向 p2,权值为 valgrid[p1].push_back(Edge(p2, val));}int start = 1; // 起点int end = n; // 终点vector<int> minDist(n + 1 , INT_MAX);minDist[start] = 0;queue<int> que;que.push(start); // 队列里放入起点 vector<int> count(n+1, 0); // 记录节点加入队列几次count[start]++;bool flag = false;while (!que.empty()) {int node = que.front(); que.pop();for (Edge edge : grid[node]) {int from = node;int to = edge.to;int value = edge.val;if (minDist[to] > minDist[from] + value) { // 开始松弛minDist[to] = minDist[from] + value;que.push(to);count[to]++; if (count[to] == n) {// 如果加入队列次数超过 n-1次 就说明该图与负权回路flag = true;while (!que.empty()) que.pop();break;}}}}if (flag) cout << "circle" << endl;else if (minDist[end] == INT_MAX) {cout << "unconnected" << endl;} else {cout << minDist[end] << endl;}}Bellman_ford之单源最短路
基础应用:
共有1~n各城市,要求城市1->城市n,最多经历k个城市。
模板:
其实挺容易理解的,只要创建两个minDist,复用上一个minDist就行。
在这个前提下,只需要k次,就能求出所有(1~k)的城市。
1、朴素版:
// 版本二
#include <iostream>
#include <vector>
#include <list>
#include <climits>
using namespace std;int main() {int src, dst,k ,p1, p2, val ,m , n;cin >> n >> m;vector<vector<int>> grid;for(int i = 0; i < m; i++){cin >> p1 >> p2 >> val;grid.push_back({p1, p2, val});}cin >> src >> dst >> k;vector<int> minDist(n + 1 , INT_MAX);minDist[src] = 0;vector<int> minDist_copy(n + 1); // 用来记录上一次遍历的结果for (int i = 1; i <= k + 1; i++) {minDist_copy = minDist; // 获取上一次计算的结果for (vector<int> &side : grid) {int from = side[0];int to = side[1];int price = side[2];// 注意使用 minDist_copy 来计算 minDist if (minDist_copy[from] != INT_MAX && minDist[to] > minDist_copy[from] + price) { minDist[to] = minDist_copy[from] + price;}}}if (minDist[dst] == INT_MAX) cout << "unreachable" << endl; // 不能到达终点else cout << minDist[dst] << endl; // 到达终点最短路径}
2、SPFA:
// 将所有边保存起来for(int i = 0; i < m; i++){cin >> p1 >> p2 >> val;// p1 指向 p2,权值为 valgrid[p1].push_back(Edge(p2, val));}int start, end, k;cin >> start >> end >> k;k++;vector<int> minDist(n + 1 , INT_MAX);vector<int> minDist_copy(n + 1); // 用来记录每一次遍历的结果minDist[start] = 0;queue<int> que;que.push(start); // 队列里放入起点int que_size;while (k-- && !que.empty()) {minDist_copy = minDist; // 获取上一次计算的结果que_size = que.size(); // 记录上次入队列的节点个数while (que_size--) { // 上一轮松弛入队列的节点,这次对应的边都要做松弛int node = que.front(); que.pop();for (Edge edge : grid[node]) {int from = node;int to = edge.to;int price = edge.val;if (minDist[to] > minDist_copy[from] + price) {minDist[to] = minDist_copy[from] + price;que.push(to);}}}}if (minDist[end] == INT_MAX) cout << "unreachable" << endl;else cout << minDist[end] << endl;}Floyed算法
基础应用:
假设你有一张包含多个城市的交通图,想一次性知道 任意两个城市之间的最短路线(比如全国城市间的多对多导航)。Floyd 算法专门解决这类 全源最短路径 问题,即求出图中所有点对之间的最短路径。
核心思想:
尝试让每个节点做为一个 “中转节点” 。看能不能缩短两点之间的距离。
适合求多元最短路径,n<200最佳(O(n^3))
模板:

#include <iostream>
#include <vector>
using namespace std;int main() {int n, m, p1, p2, val;cin >> n >> m;vector<vector<int>> grid(n + 1, vector<int>(n + 1, 10005)); // 因为边的最大距离是10^4for(int i = 0; i < m; i++){cin >> p1 >> p2 >> val;grid[p1][p2] = val;grid[p2][p1] = val; // 注意这里是双向图}// 开始 floydfor (int k = 1; k <= n; k++) {for (int i = 1; i <= n; i++) {for (int j = 1; j <= n; j++) {grid[i][j] = min(grid[i][j], grid[i][k] + grid[k][j]);}}}// 输出结果int z, start, end;cin >> z;while (z--) {cin >> start >> end;if (grid[start][end] == 10005) cout << -1 << endl;else cout << grid[start][end] << endl;}
}
A*算法
Astar的核心,在于 启发式函数。
他是建立在BFS广搜的基础之上。
用以下这道题目举例子:

模板:
#include <iostream>
#include <queue>
#include <cstring>
using namespace std;// 本题有好几个地方需要注意
// 第一,创建结构体,并与优先队列相结合
// 第二,创建二维数组用于去重,并记录走了多少步
// 第三,启发式搜索的权值,用欧拉函数计算,且欧拉函数
//(起点到该点经过的距离)+(该点的距离到终点的距离)
// 其中从起点到该点的距离,容易被用错。是依次经过的距离,不是直线距离。int a1,a2,b1,b2;
struct knight{int m1,m2;int g,h,f;bool operator<(const knight& k)const{ // 调节为小根堆return f>k.f;}
};
int visited[1005][1005];
int dir[8][2]={-2,-1,-2,1,-1,2,1,2,2,1,2,-1,1,-2,-1,-2};int get_squeeze(int m1,int m2,int b1,int b2){return (b1-m1)*(b1-m1)+(b2-m2)*(b2-m2);
}void astar(knight k){priority_queue<knight> pq;pq.push(k);knight node,cur;while(!pq.empty()){node = pq.top(); pq.pop();if(node.m1==b1&&node.m2==b2){cout<<visited[node.m1][node.m2]<<endl;break;}for(int i=0; i<8; ++i){cur = node;cur.m1+=dir[i][0];cur.m2+=dir[i][1];if(cur.m1<1||cur.m1>1000||cur.m2<1||cur.m2>1000) continue;if(visited[cur.m1][cur.m2]) continue;visited[cur.m1][cur.m2]=visited[node.m1][node.m2]+1; // 需要在原来的基础上进行操作cur.g=node.g+5; // 1*1+2*2=5cur.h=get_squeeze(cur.m1,cur.m2,b1,b2);cur.f=cur.h+cur.g;pq.push(cur);}}
}int main(){int t;cin>>t;while(t--){cin>>a1>>a2>>b1>>b2;if(a1==b1&&a2==b2){ // 直接排除意外情况cout<<0<<endl;continue;}memset(visited,0,sizeof visited);knight k;k.m1 = a1;k.m2 = a2;k.g = 0;k.h = get_squeeze(k.m1,k.m2,b1,b2);astar(k);}return 0;
}借鉴博客:
1、图论总结篇
相关文章:

图论算法体系:并查集、生成树、排序与路径搜索全解析
从图论的基础理论入门,到深搜广搜搭建起图论的骨架。 从并查集到最小生成树,从拓扑排序到最短路径。 .... 群星璀璨😉 并查集最小生成树 Prim算法Kruskal算法 拓扑排序(kahn算法)最短路径 Dijkstra算法 Dijkstra朴素Di…...

OpenAI为何觊觎Chrome?AI时代浏览器争夺战背后的深层逻辑
目录 引言:一场蓄谋已久的"蛇吞象"计划 一、Chrome:数字世界的"黄金入口" 1.1 用户规模对比:ChatGPT与Chrome的悬殊差距 1.2 Chrome的生态价值远超浏览器本身 二、OpenAI的"入口焦虑"与战略布局 2.1 AI时…...
)
DrissionPage 请求一次换一个代理(不重启chrome)
实现原理:通过插件实现 # !/usr/bin/python3 # -*- coding:utf-8 -*- """ author: JHC000abcgmail.com file: switch_ip.py time: 2025/4/23 22:05 desc:"""R""" 1. chrome s商店下载Proxy SwitchyOmega 3 (ZeroOme…...

JBoltAI 赋能金融文档:基于 RAG 的基金招募说明书视觉增强方案
在金融领域,基金招募说明书是投资者了解基金产品关键信息的重要文件。然而,这类文件通常以 PDF 格式呈现,内容繁杂、文本枯燥,对于普通投资者而言,理解起来存在一定难度。而如何利用 AI 技术对这类枯燥文本进行视觉增强…...

【玩转全栈】—— Django+vue3+讯飞星火API 实现前端页面实时AI答复
技术栈:vue3 element-plus axios pinia router Django5 websocket 讯飞星火API 本文将实现一个 AI 聊天对话功能,将前端用户输入问题以及之前对话发送给后端,通过 api 访问大模型,返回前端实时对话数据。 调用 讯飞星火API…...
)
1.1 java开发的准备工作(入门)
准备工作 一.JDK 开始写java程序之前需要安装jdk jdk是java开发工具,包含着JRE和里面的JVM(虚拟机,可以使得不同环境下都能运行Java程序),和开发工具。 二.了解写程序的三大步骤步骤 java成功运行主要需要经过代码编写,编译&a…...

socket编程基础
上一篇 --- 网络基础概念(下)https://blog.csdn.net/Small_entreprene/article/details/147320155?fromshareblogdetail&sharetypeblogdetail&sharerId147320155&sharereferPC&sharesourceSmall_entreprene&sharefromfrom_link 理…...

根据定义给出json_schema:
根据您提供的智能体定义,以下是符合JSON Schema Draft-07规范的完整架构描述(包含中文注释说明): {"$schema": ""title": "智能体架构规范","type": "object","req…...

深入微服务核心:从架构设计到规模化
作者:腾讯云开发者 原文:深入微服务核心:从架构设计到规模化 01 微服务 什么是微服务? 微服务就是一些协同工作的小而自治的服务。我们在一个单体系统中,通常会采用一些抽象层或者模块来保证代码的内聚性,…...
)
linux与c语言基础知识(未全部完成)
文章很多处理论,没办法写出来,(linux的一些理论问题,我有时间后,会逐个解决) 文章大多数的理论来字这个链接, C语言快速入门-C语言基础知识-CSDN博客 一. linux(Ubuntu) …...
:)
【专题刷题】滑动窗口(四):
📝前言说明: 本专栏主要记录本人的基础算法学习以及LeetCode刷题记录,按专题划分每题主要记录:(1)本人解法 本人屎山代码;(2)优质解法 优质代码;ÿ…...

小白自学python第一天
学习python的第一天 一、常用的值类型(先来粗略认识一下~) 类型说明数字(number)包含整型(int)、浮点型(float)、复数(complex)、布尔(boolean&…...

Redis 服务自动开启、设置密码和闪退问题
一、Redis 服务自动开启 1、以管理员身份运行命令提示符 右键点击“命令提示符”图标,选择“以管理员身份运行”。 2、注册为 Windows 服务 redis-server --service-install 3、启动服务 redis-server --service-start 4、测试 Redis 连接 redis-cli ping …...
)
2025年渗透测试面试题总结-拷打题库14(题目+回答)
网络安全领域各种资源,学习文档,以及工具分享、前沿信息分享、POC、EXP分享。不定期分享各种好玩的项目及好用的工具,欢迎关注。 目录 2025年渗透测试面试题总结-拷打题库14 1. WAF存在的意义 2. 威胁感知能力衡量指标 3. 感知规则有效性…...
--双列集合:MapHashMapTreeMap)
java后端开发day35--集合进阶(四)--双列集合:MapHashMapTreeMap
(以下内容全部来自上述课程) 1.双列集合 1.1 特点 双列集合一次需要存一对数据,分别为键和值键不能重复,值可以重复键和值是一一对应的,每一个键只能找到自己对应的值键值这个整体,我们称之为“键值对”…...
中变量值在控制台输出,查看?)
进行网页开发时,怎样把function()中变量值在控制台输出,查看?
在网页开发过程中,为了及时了解JavaScript中的function函数中的变量值,可以用控制台命令console.log()把变量的值在控制台输出,方便调试时对函数变量值进行了解。 看下面的一段示例: <!DOCTYPE html> <html> &l…...

【计算机网络】现代网络技术核心架构与实战解析
目录 前言技术背景与价值当前技术痛点解决方案概述目标读者说明 一、技术原理剖析核心概念图解核心作用讲解关键技术模块说明技术选型对比 二、实战演示环境配置要求核心代码实现案例1:TCP服务端/客户端通信案例2:Wireshark抓包分析 三、性能对比测试方法…...
)
Python内置函数---bool()
用于将任意对象转换为布尔值(True或False) 1. 基本语法与参数 bool(x) - 参数:x为可选参数,可以是任意Python对象(如数值、字符串、列表、自定义对象等)。 - 返回值:根据x的真值性返回True或Fa…...

Vue 3中如何封装API请求:提升开发效率的最佳实践
在现代前端开发中,API请求是不可避免的一部分,尤其是与后端交互时。随着Vue 3的广泛应用,如何高效地封装API请求,既能提升代码的可维护性,又能确保代码的高复用性,成为了很多开发者关注的话题。 在本文中&…...

【Redis】redis主从哨兵
Redis 主从复制 在访问量极高的场景下,单台 Redis 已难以承载所有请求,且单点故障风险高。通过主从复制,可以实现读写分离、数据备份与高可用。 概念 主节点(Master):负责写操作,将数据变更同…...

16.第二阶段x64游戏实战-分析二叉树结构
免责声明:内容仅供学习参考,请合法利用知识,禁止进行违法犯罪活动! 本次游戏没法给 内容参考于:微尘网络安全 上一个内容:15.第二阶段x64游戏实战-分析怪物血量(遍历周围) 首先通…...

vue | 不同 vue 版本对复杂泛型的支持情况 · vue3.2 VS vue3.5
省流总结:defineProps 的泛型能力,来直接推导第三方组件的 props 类型 引入第三方库的类型,并直接在 <script setup> 中作为 props 使用。这种类型一般是复杂泛型(包含联合类型、可选属性、交叉类型、条件类型等࿰…...
)
OpenGL学习笔记(Blinn-Phong、伽马矫正、阴影)
目录 Blinn-PhongGamma矫正GammaGamma矫正实现方法sRGB纹理衰减 阴影shadow mapping渲染阴影改进阴影贴图PCF GitHub主页:https://github.com/sdpyy1 OpenGL学习仓库:https://github.com/sdpyy1/CppLearn/tree/main/OpenGLtree/main/OpenGL):https://github.com/sdp…...
)
GPLT-2025年第十届团体程序设计天梯赛总决赛题解(2025天梯赛题解,266分)
今天偶然发现天梯赛的代码还保存着,于是决定写下这篇题解,也算是复盘一下了 L1本来是打算写的稳妥点,最后在L1-6又想省时间,又忘记了insert,replace这些方法怎么用,也不想花时间写一个文件测试,…...

day4 pandas学习
%pip install openxyxl 找一个自己觉得有意思的文件。我找的是成绩单来玩。 这节学的比较耗时了,大概用了60分钟。 import pandas as pd data2 pd.read_csv(rD:\python代码区\代码随想录挑战-调试区\python训练营\1_计算类专业分流学生成绩排名.csv) #print(data)…...

【Java学习笔记】循环结构
循环结构 一、for循环 for循环结构 for(循环变量初始化;循环条件;循环变量迭代){循环操作(可以多条语句) }for循环写死循环 for(;;){语句 }注意点:循环变量的初始化在for语句内,属于是局部变量,在全局中会出现未定义…...

URP-UGUI交互功能实现
一、非代码层面实现交互(SetActive) Button :在OnClick()中添加SetActive方法(但是此时只首次有效) Toggle :在OnClick()中添加动态的SetActive方法 &#…...

08-IDEA企业开发工具-集成AI插件通义灵码
需要登陆才可使用!!! 1. 安装AI编程插件 找到插件: 在IDEA的设置中,找到插件(Plugins)部分。安装插件: 搜索“通义灵码”,找到后点击安装(Install),接受条款…...
;)
解决报错:this[kHandle] = new _Hash(algorithm, xofLen);
前端项目编译报错: node:internal/crypto/hash:68this[kHandle] new _Hash(algorithm, xofLen);^Error: error:0308010C:digital envelope routines::unsupportedat new Hash (node:internal/crypto/hash:68:19)at Object.createHash (node:crypto:138:10)at modu…...

使用 Streamlit 打造一个简单的照片墙应用
在现代 web 开发中,快速构建交互式应用是一项重要的技能。Streamlit 是一个强大的 Python 库,允许开发者以最小的代码量创建美观且功能丰富的 web 应用。今天,我们将通过分析一段简单的 Streamlit 代码,展示如何构建一个照片墙应用…...

深度学习优化器和调度器的选择和推荐
一、常用优化器对比 1. 随机梯度下降(SGD) 原理:每次迭代使用小批量数据计算梯度并更新参数。优点:实现简单,适合大规模数据集。缺点:收敛速度慢,容易陷入局部最优或鞍点。适用场景࿱…...
)
“时间”,在数据处理中的真身——弼马温一般『无所不能』(DeepSeek)
电子表格时间处理真理:数值存储最瘦身,真身闯关通四海。 笔记模板由python脚本于2025-04-23 22:25:59创建,本篇笔记适合喜欢在电子表格中探求时间格式的coder翻阅。 【学习的细节是欢悦的历程】 博客的核心价值:在于输出思考与经验…...

为什么Spring中@Bean注解默认创建单例Bean
在Spring框架中,使用Bean注解定义的对象默认确实是单例的,这是由Spring容器的设计哲学和实际需求决定的。下面我从多个角度解释这一设计选择的原因和机制。 1. Spring Bean作用域基础 Spring定义了多种Bean作用域,其中默认是单例(Singleton…...
)
GPLT-2025年第十届团体程序设计天梯赛总决赛题解(2025天梯赛题解,共计266分)
今天偶然发现天梯赛的代码还保存着,于是决定写下这篇题解,也算是复盘一下了 L1本来是打算写的稳妥点,最后在L1-6又想省时间,又忘记了insert,replace这些方法怎么用,也不想花时间写一个文件测试,…...
安装笔记)
JDK(Ubuntu 18.04.6 LTS)安装笔记
一、前言 本文与【MySQL 8(Ubuntu 18.04.6 LTS)安装笔记】同批次:先搭建数据库,再安装JDK,后面肯定就是部署Web应用:典型的单机部署。“麻雀虽小五脏俱全”,善始善终,还是记下来吧。…...

Java 拦截器完全指南:原理、实战与最佳实践
一、引言 拦截器的基本概念 在现代 Java Web 开发中,拦截器(Interceptor)是一种用于在请求处理前后插入自定义逻辑的机制。简单来说,它是一种“横切逻辑处理器”,可以用来对请求进行预处理、后处理,甚至终…...

2025.04.23华为机考第二题-200分
📌 点击直达笔试专栏 👉《大厂笔试突围》 💻 春秋招笔试突围在线OJ 👉 笔试突围OJ 02. 魔法彩灯森林 问题描述 在卢小姐的魔法花园中,有一棵神奇的彩灯树。这棵树的每个节点都装有一盏魔法灯,灯有三种颜色状态:红色(用数字1表示)、绿色(用数字2表示)和蓝色(…...

【Leetcode 每日一题】1399. 统计最大组的数目
问题背景 给你一个整数 n n n。请你先求出从 1 1 1 到 n n n 的每个整数 10 10 10 进制表示下的数位和(每一位上的数字相加),然后把数位和相等的数字放到同一个组中。 请你统计每个组中的数字数目,并返回数字数目并列最多的组…...

系统重装——联想sharkbay主板电脑
上周给一台老电脑重装系统系统,型号是lenovo sharkbay主板的电脑,趁着最近固态便宜,入手了两块长城的固态,装上以后插上启动U盘,死活进不去boot系统。提示 bootmgr 缺失,上网查了许久,终于解决了…...
)
Python数据清洗笔记(上)
一、数据清洗概述 数据清洗是数据分析过程中至关重要的一步,约占整个数据分析过程的60%-80%的时间。主要包括处理缺失值、异常值、重复值、格式不一致等问题。 二、常用工具 主要使用Python的Pandas库进行数据清洗: import pandas as pd import nump…...

三、Python编程基础03
目录 一、debug 调试的使用1. 打断点2. 右键 Debug 运行代码3. 单步执行代码,查看过程 二、字符串1、定义与下标引用2、切片3、查找4、去除空白字符5、转换大小写与拆分6、其他方法-替换、连接、是否为纯数字7、登录案例优化 三、列表 list1、列表基础操作2、案例: …...
电机及专栏介绍)
西门子S7-200SMART 控制Profinet闭环步进MD-4250-PN (1)电机及专栏介绍
一、前言 本系列是我继 《西门子S7-1200PLC 控制步进电机 MD-4240-PN》系列专栏后,新开的一篇专栏。 系列的主题围绕 S7-200SMART Profinet闭环步进(MD-4250-PN) 触摸屏的硬件,预计作四篇文章,分别为:专栏介绍、硬件介绍、PLC…...

NoSQL 简单讲解
目录 1. NoSQL 的背景与意义 1.1 数据库的演变 1.2 NoSQL 的兴起 2. NoSQL 数据库的分类 2.1 键值存储(Key-Value Stores) 2.2 文档数据库(Document Stores) 2.3 列族存储(Column-Family Stores) 2.…...

TCP 协议:原理、机制与应用
一、引言 在当今数字化的时代,网络通信无处不在,而 TCP(Transmission Control Protocol,传输控制协议)作为互联网协议栈中的核心协议之一,扮演着至关重要的角色。无论是浏览网页、发送电子邮件还是进行文件…...
)
C++23 新特性:令声明顺序决定非静态类数据成员的布局 (P1847R4)
文章目录 引言背景知识非静态类数据成员类的内存布局 P1847R4提案内容示例代码 影响和优势提高代码的可预测性与其他语言和库的交互更加方便简化代码调试和优化 编译器支持情况实际应用场景嵌入式系统开发跨语言编程内存优化 总结 引言 在C的发展历程中,每一个新版…...
)
Java 环境配置详解(Windows、macOS、Linux)
Java 环境配置是学习和开发 Java 程序的第一步,也是至关重要的一步。一个正确配置的 Java 环境能够保证你的 Java 程序能够顺利编译、运行和调试。本文将详细介绍在 Windows、macOS 和 Linux 三种主流操作系统上配置 Java 环境的步骤,力求详尽、易懂&…...

ChatBEV:一种理解 BEV 地图的可视化语言模型
25年3月来自上海交大、上海AI实验室、同济大学和MAGIC的论文“ChatBEV: A Visual Language Model that Understands BEV Maps”。 交通场景理解对于智能交通系统和自动驾驶至关重要,可确保车辆安全高效地运行。虽然 VLM 的最新进展已显示出整体场景理解的前景&…...

利用Python爬虫实现百度图片搜索的PNG图片下载
在图像识别、训练数据集构建等场景中,我们经常需要从互联网上批量下载图片素材。百度图片是中文搜索中最常用的来源之一。本文将介绍如何使用Python构建一个稳定、可扩展的百度图片爬虫,专门用于下载并保存高清PNG格式图片。 一、项目目标 本项目的目标…...

自主可控鸿道Intewell工业实时操作系统
鸿道Intewell工业实时操作系统是东土科技旗下科东软件自主研发的新一代智能工业操作系统,以下是相关介绍: 系统架构 -Intewell-C全实时构型:设备上只运行自研RTOS的全实时系统,适用于有功能安全认证需求的实时控制场景…...

【数据结构入门训练DAY-21】信息学奥赛一本通T1334-围圈报数
文章目录 前言一、题目二、解题思路结语 前言 本次训练内容 STL库中队列的使用练习。训练解题思维 一、题目 有n个人依次围成一圈,从第1个人开始报数,数到第m个人出列,然后从出列的下一个人开始报数&am…...