深度学习每周学习总结J8(Inception V1 算法实战与解析 - 猴痘识别)
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊 | 接辅导、项目定制
目录
- 0. 总结
- Inception V1 简介
- 1. 设置GPU
- 2. 导入数据及处理部分
- 3. 划分数据集
- 4. 模型构建部分
- 5. 设置超参数:定义损失函数,学习率,以及根据学习率定义优化器等
- 6. 训练函数
- 7. 测试函数
- 8. 正式训练
- 9. 结果可视化
- 10. 模型的保存
- 11.使用训练好的模型进行预测
0. 总结
数据导入及处理部分:本次数据导入没有使用torchvision自带的数据集,需要将原始数据进行处理包括数据导入,查看数据分类情况,定义transforms,进行数据类型转换等操作。
划分数据集:划定训练集测试集后,再使用torch.utils.data中的DataLoader()分别加载上一步处理好的训练及测试数据,查看批处理维度.
模型构建部分:Inception V1
设置超参数:在这之前需要定义损失函数,学习率(动态学习率),以及根据学习率定义优化器(例如SGD随机梯度下降),用来在训练中更新参数,最小化损失函数。
定义训练函数:函数的传入的参数有四个,分别是设置好的DataLoader(),定义好的模型,损失函数,优化器。函数内部初始化损失准确率为0,接着开始循环,使用DataLoader()获取一个批次的数据,对这个批次的数据带入模型得到预测值,然后使用损失函数计算得到损失值。接下来就是进行反向传播以及使用优化器优化参数,梯度清零放在反向传播之前或者是使用优化器优化之后都是可以的,一般是默认放在反向传播之前。
定义测试函数:函数传入的参数相比训练函数少了优化器,只需传入设置好的DataLoader(),定义好的模型,损失函数。此外除了处理批次数据时无需再设置梯度清零、返向传播以及优化器优化参数,其余部分均和训练函数保持一致。
训练过程:定义训练次数,有几次就使用整个数据集进行几次训练,初始化四个空list分别存储每次训练及测试的准确率及损失。使用model.train()开启训练模式,调用训练函数得到准确率及损失。使用model.eval()将模型设置为评估模式,调用测试函数得到准确率及损失。接着就是将得到的训练及测试的准确率及损失存储到相应list中并合并打印出来,得到每一次整体训练后的准确率及损失。
结果可视化
模型的保存,调取及使用。在PyTorch中,通常使用 torch.save(model.state_dict(), ‘model.pth’) 保存模型的参数,使用 model.load_state_dict(torch.load(‘model.pth’)) 加载参数。
需要改进优化的地方:确保模型和数据的一致性,都存到GPU或者CPU;注意numclasses不要直接用默认的1000,需要根据实际数据集改进;实例化模型也要注意numclasses这个参数;此外注意测试模型需要用(3,224,224)3表示通道数,这和tensorflow定义的顺序是不用的(224,224,3),做代码转换时需要注意。
关于调优(十分重要):本次将测试集准确率提升到了96.03%(随机种子设置为42)
1:使用多卡不一定比单卡效果好,需要继续调优
2:本次微调参数主要调整了两点一是初始学习率从1e-4 增大为了3e-4;其次是原来图片预处理只加入了随机水平翻转,本次加入了小角度的随机翻转,随机缩放剪裁,光照变化等,发现有更好的效果。测试集准确率有了很大的提升。从训练后的准确率图像也可以看到,训练准确率和测试准确率很接近甚至能够超过。之前没有做这个改进之前,都是训练准确率远大于测试准确率。
关键代码示例:
import torchvision.transforms as transforms# 定义猴痘识别的 transforms
train_transforms = transforms.Compose([transforms.Resize([224, 224]), # 统一图片尺寸transforms.RandomHorizontalFlip(p=0.5), # 随机水平翻转transforms.RandomRotation(degrees=15), # 小角度随机旋转transforms.RandomResizedCrop(size=224, scale=(0.8, 1.2)), # 随机缩放裁剪transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.1), # 光照变化transforms.ToTensor(), # 转换为 Tensor 格式transforms.Normalize( # 标准化mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225])
])
Inception V1 简介
什么是Inception V1?
Inception V1,也被称为GoogLeNet,是Google在2014年ILSVRC比赛中提出的一种卷积神经网络(CNN)架构,并且在比赛中获得了冠军。与当时流行的VGGNet相比,Inception V1在保持相似性能的同时,显著减少了参数数量,从而提高了计算效率。
Inception Module的核心思想
Inception V1的核心是Inception Module,它通过并行的卷积操作在同一层提取不同尺度的特征。这种设计不仅增加了网络的深度,还有效地捕捉了多种特征信息。
具体来说,一个Inception Module通常包含以下几个分支:
- 1x1卷积分支:用于降低输入特征图的通道数,减少计算量。
- 1x1卷积后接3x3卷积分支:先用1x1卷积降维,再进行3x3卷积提取特征。
- 1x1卷积后接5x5卷积分支:类似于3x3分支,但使用更大的卷积核以捕捉更大范围的特征。
- 3x3最大池化后接1x1卷积分支:先进行池化操作,再用1x1卷积进行特征整合。
通过将这些分支的输出在通道维度上拼接,Inception Module能够在同一层次上整合多种尺度的信息,提升模型的表达能力。
1x1卷积的作用
1x1卷积主要用于降维,即减少特征图的通道数。这不仅降低了网络的参数量和计算量,还间接增加了网络的深度,有助于提升模型性能。例如:
- 原始输入:100x100x128
- 经过1x1卷积降维到32通道,再进行5x5卷积,输出仍为100x100x256
- 参数量由原来的约8.192×10⁹降低到2.048×10⁹
辅助分类器
Inception V1还引入了辅助分类器,主要有两个作用:
- 缓解梯度消失:通过在中间层添加分类器,帮助梯度更好地传播。
- 模型融合:将中间层的输出用于分类,增强模型的泛化能力。
不过,在实际应用中,这些辅助分类器通常在训练过程中使用,推理时会被去掉。
import torch
import torch.nn as nn
import torchvision
from torchvision import datasets,transforms
from torch.utils.data import DataLoader
import torchvision.models as models
import torch.nn.functional as F
from collections import OrderedDict import os,PIL,pathlib
import matplotlib.pyplot as plt
import warningswarnings.filterwarnings('ignore') # 忽略警告信息plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 # 分辨率
1. 设置GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device
device(type='cuda')
2. 导入数据及处理部分
# 获取数据分布情况
path_dir = './data/mpox_recognize/'
path_dir = pathlib.Path(path_dir)paths = list(path_dir.glob('*'))
# classNames = [str(path).split("\\")[-1] for path in paths] # ['Bananaquit', 'Black Skimmer', 'Black Throated Bushtiti', 'Cockatoo']
classNames = [path.parts[-1] for path in paths]
classNames
['Monkeypox', 'Others']
# 定义transforms 并处理数据
# train_transforms = transforms.Compose([
# transforms.Resize([224,224]), # 将输入图片resize成统一尺寸
# transforms.RandomHorizontalFlip(), # 随机水平翻转
# transforms.ToTensor(), # 将PIL Image 或 numpy.ndarray 装换为tensor,并归一化到[0,1]之间
# transforms.Normalize( # 标准化处理 --> 转换为标准正太分布(高斯分布),使模型更容易收敛
# mean = [0.485,0.456,0.406], # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
# std = [0.229,0.224,0.225]
# )
# ])# 定义猴痘识别的 transforms 并处理数据
train_transforms = transforms.Compose([transforms.Resize([224, 224]), # 统一图片尺寸transforms.RandomHorizontalFlip(p=0.5), # 随机水平翻转transforms.RandomRotation(degrees=15), # 小角度随机旋转transforms.RandomResizedCrop(size=224, scale=(0.8, 1.2)), # 随机缩放裁剪transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.1), # 光照变化transforms.ToTensor(), # 转换为 Tensor 格式transforms.Normalize( # 标准化mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225])
])test_transforms = transforms.Compose([transforms.Resize([224,224]),transforms.ToTensor(),transforms.Normalize(mean = [0.485,0.456,0.406],std = [0.229,0.224,0.225])
])
total_data = datasets.ImageFolder('./data/mpox_recognize/',transform = train_transforms)
total_data
Dataset ImageFolderNumber of datapoints: 2142Root location: ./data/mpox_recognize/StandardTransform
Transform: Compose(Resize(size=[224, 224], interpolation=bilinear, max_size=None, antialias=True)RandomHorizontalFlip(p=0.5)RandomRotation(degrees=[-15.0, 15.0], interpolation=nearest, expand=False, fill=0)RandomResizedCrop(size=(224, 224), scale=(0.8, 1.2), ratio=(0.75, 1.3333), interpolation=bilinear, antialias=True)ColorJitter(brightness=(0.8, 1.2), contrast=(0.8, 1.2), saturation=(0.9, 1.1), hue=None)ToTensor()Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]))
3. 划分数据集
# 设置随机种子
torch.manual_seed(42)# 划分数据集
train_size = int(len(total_data) * 0.8)
test_size = len(total_data) - train_sizetrain_dataset,test_dataset = torch.utils.data.random_split(total_data,[train_size,test_size])
train_dataset,test_dataset
(<torch.utils.data.dataset.Subset at 0x1b854727580>,<torch.utils.data.dataset.Subset at 0x1b854727c40>)
# 定义DataLoader用于数据集的加载batch_size = 32 # 如使用多显卡,请确保 batch_size 是显卡数量的倍数。train_dl = torch.utils.data.DataLoader(train_dataset,batch_size = batch_size,shuffle = True,num_workers = 1
)
test_dl = torch.utils.data.DataLoader(test_dataset,batch_size = batch_size,shuffle = True,num_workers = 1
)# 观察数据维度
for X,y in test_dl:print("Shape of X [N,C,H,W]: ",X.shape)print("Shape of y: ", y.shape,y.dtype)breakShape of X [N,C,H,W]: torch.Size([32, 3, 224, 224])
Shape of y: torch.Size([32]) torch.int64
4. 模型构建部分
import torch
import torch.nn as nn
import torch.nn.functional as Fclass inception_block(nn.Module):def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5, pool_proj):super(inception_block, self).__init__()# 1x1 conv branchself.branch1 = nn.Sequential(nn.Conv2d(in_channels, ch1x1, kernel_size=1),nn.BatchNorm2d(ch1x1),nn.ReLU(inplace=True))# 1x1 conv -> 3x3 conv branchself.branch2 = nn.Sequential(nn.Conv2d(in_channels, ch3x3red, kernel_size=1),nn.BatchNorm2d(ch3x3red),nn.ReLU(inplace=True),nn.Conv2d(ch3x3red, ch3x3, kernel_size=3, padding=1),nn.BatchNorm2d(ch3x3),nn.ReLU(inplace=True))# 1x1 conv -> 5x5 conv branchself.branch3 = nn.Sequential(nn.Conv2d(in_channels, ch5x5red, kernel_size=1),nn.BatchNorm2d(ch5x5red),nn.ReLU(inplace=True),nn.Conv2d(ch5x5red, ch5x5, kernel_size=5, padding=2),nn.BatchNorm2d(ch5x5),nn.ReLU(inplace=True))# 3x3 max pooling -> 1x1 conv branchself.branch4 = nn.Sequential(nn.MaxPool2d(kernel_size=3, stride=1, padding=1),nn.Conv2d(in_channels, pool_proj, kernel_size=1),nn.BatchNorm2d(pool_proj),nn.ReLU(inplace=True))def forward(self, x):# Compute forward pass through all branches and concatenate the output feature mapsbranch1_output = self.branch1(x)branch2_output = self.branch2(x)branch3_output = self.branch3(x)branch4_output = self.branch4(x)outputs = [branch1_output, branch2_output, branch3_output, branch4_output]return torch.cat(outputs, 1)class InceptionV1(nn.Module):def __init__(self, num_classes=1000):super(InceptionV1, self).__init__()self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3)self.maxpool1 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)self.conv2 = nn.Conv2d(64, 64, kernel_size=1, stride=1, padding=0)self.conv3 = nn.Conv2d(64, 192, kernel_size=3, stride=1, padding=1)self.maxpool2 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)self.inception3a = inception_block(192, 64, 96, 128, 16, 32, 32)self.inception3b = inception_block(256, 128, 128, 192, 32, 96, 64)self.maxpool3 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)self.inception4a = inception_block(480, 192, 96, 208, 16, 48, 64)self.inception4b = inception_block(512, 160, 112, 224, 24, 64, 64)self.inception4c = inception_block(512, 128, 128, 256, 24, 64, 64)self.inception4d = inception_block(512, 112, 144, 288, 32, 64, 64)self.inception4e = inception_block(528, 256, 160, 320, 32, 128, 128)self.maxpool4 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)self.inception5a = inception_block(832, 256, 160, 320, 32, 128, 128)self.inception5b=nn.Sequential(inception_block(832, 384, 192, 384, 48, 128, 128),nn.AvgPool2d(kernel_size=7,stride=1,padding=0),nn.Dropout(0.4))# 全连接层前的池化层: 在Inception V1中,最后一个Inception模块后通常会有一个全局平均池化层,# 以减少特征维度。你可以在inception5b后添加:self.avgpool = nn.AdaptiveAvgPool2d((1, 1))# 全连接网络层,用于分类self.classifier = nn.Sequential(nn.Linear(in_features=1024, out_features=1024),nn.ReLU(),nn.Linear(in_features=1024, out_features=num_classes),nn.Softmax(dim=1))def forward(self, x):x = self.conv1(x)x = F.relu(x)x = self.maxpool1(x)x = self.conv2(x)x = F.relu(x)x = self.conv3(x)x = F.relu(x)x = self.maxpool2(x)x = self.inception3a(x)x = self.inception3b(x)x = self.maxpool3(x)x = self.inception4a(x)x = self.inception4b(x)x = self.inception4c(x)x = self.inception4d(x)x = self.inception4e(x)x = self.maxpool4(x)x = self.inception5a(x)x = self.inception5b(x)x = self.avgpool(x) # 全连接层前的池化层x = torch.flatten(x, start_dim=1)x = self.classifier(x)return xmodel = InceptionV1(num_classes=len(classNames)).to(device)
model
InceptionV1((conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3))(maxpool1): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)(conv2): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1))(conv3): Conv2d(64, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(maxpool2): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)(inception3a): inception_block((branch1): Sequential((0): Conv2d(192, 64, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True))(branch2): Sequential((0): Conv2d(192, 96, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(96, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True))(branch3): Sequential((0): Conv2d(192, 16, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(16, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))(4): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True))(branch4): Sequential((0): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=False)(1): Conv2d(192, 32, kernel_size=(1, 1), stride=(1, 1))(2): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(3): ReLU(inplace=True)))(inception3b): inception_block((branch1): Sequential((0): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True))(branch2): Sequential((0): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(128, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(4): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True))(branch3): Sequential((0): Conv2d(256, 32, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(32, 96, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))(4): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True))(branch4): Sequential((0): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=False)(1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1))(2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(3): ReLU(inplace=True)))(maxpool3): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)(inception4a): inception_block((branch1): Sequential((0): Conv2d(480, 192, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True))(branch2): Sequential((0): Conv2d(480, 96, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(96, 208, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(4): BatchNorm2d(208, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True))(branch3): Sequential((0): Conv2d(480, 16, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(16, 48, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))(4): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True))(branch4): Sequential((0): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=False)(1): Conv2d(480, 64, kernel_size=(1, 1), stride=(1, 1))(2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(3): ReLU(inplace=True)))(inception4b): inception_block((branch1): Sequential((0): Conv2d(512, 160, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(160, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True))(branch2): Sequential((0): Conv2d(512, 112, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(112, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(112, 224, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(4): BatchNorm2d(224, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True))(branch3): Sequential((0): Conv2d(512, 24, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(24, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True))(branch4): Sequential((0): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=False)(1): Conv2d(512, 64, kernel_size=(1, 1), stride=(1, 1))(2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(3): ReLU(inplace=True)))(inception4c): inception_block((branch1): Sequential((0): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True))(branch2): Sequential((0): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True))(branch3): Sequential((0): Conv2d(512, 24, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(24, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True))(branch4): Sequential((0): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=False)(1): Conv2d(512, 64, kernel_size=(1, 1), stride=(1, 1))(2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(3): ReLU(inplace=True)))(inception4d): inception_block((branch1): Sequential((0): Conv2d(512, 112, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(112, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True))(branch2): Sequential((0): Conv2d(512, 144, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(144, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(144, 288, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(4): BatchNorm2d(288, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True))(branch3): Sequential((0): Conv2d(512, 32, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True))(branch4): Sequential((0): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=False)(1): Conv2d(512, 64, kernel_size=(1, 1), stride=(1, 1))(2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(3): ReLU(inplace=True)))(inception4e): inception_block((branch1): Sequential((0): Conv2d(528, 256, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True))(branch2): Sequential((0): Conv2d(528, 160, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(160, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(160, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(4): BatchNorm2d(320, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True))(branch3): Sequential((0): Conv2d(528, 32, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(32, 128, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True))(branch4): Sequential((0): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=False)(1): Conv2d(528, 128, kernel_size=(1, 1), stride=(1, 1))(2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(3): ReLU(inplace=True)))(maxpool4): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)(inception5a): inception_block((branch1): Sequential((0): Conv2d(832, 256, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True))(branch2): Sequential((0): Conv2d(832, 160, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(160, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(160, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(4): BatchNorm2d(320, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True))(branch3): Sequential((0): Conv2d(832, 32, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(32, 128, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True))(branch4): Sequential((0): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=False)(1): Conv2d(832, 128, kernel_size=(1, 1), stride=(1, 1))(2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(3): ReLU(inplace=True)))(inception5b): Sequential((0): inception_block((branch1): Sequential((0): Conv2d(832, 384, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(384, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True))(branch2): Sequential((0): Conv2d(832, 192, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(192, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(4): BatchNorm2d(384, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True))(branch3): Sequential((0): Conv2d(832, 48, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(48, 128, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True))(branch4): Sequential((0): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=False)(1): Conv2d(832, 128, kernel_size=(1, 1), stride=(1, 1))(2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(3): ReLU(inplace=True)))(1): AvgPool2d(kernel_size=7, stride=1, padding=0)(2): Dropout(p=0.4, inplace=False))(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))(classifier): Sequential((0): Linear(in_features=1024, out_features=1024, bias=True)(1): ReLU()(2): Linear(in_features=1024, out_features=2, bias=True)(3): Softmax(dim=1))
)
# 查看模型详情
import torchsummary as summary
summary.summary(model,(3,224,224))
----------------------------------------------------------------Layer (type) Output Shape Param #
================================================================Conv2d-1 [-1, 64, 112, 112] 9,472MaxPool2d-2 [-1, 64, 56, 56] 0Conv2d-3 [-1, 64, 56, 56] 4,160Conv2d-4 [-1, 192, 56, 56] 110,784MaxPool2d-5 [-1, 192, 28, 28] 0Conv2d-6 [-1, 64, 28, 28] 12,352BatchNorm2d-7 [-1, 64, 28, 28] 128ReLU-8 [-1, 64, 28, 28] 0Conv2d-9 [-1, 96, 28, 28] 18,528BatchNorm2d-10 [-1, 96, 28, 28] 192ReLU-11 [-1, 96, 28, 28] 0Conv2d-12 [-1, 128, 28, 28] 110,720BatchNorm2d-13 [-1, 128, 28, 28] 256ReLU-14 [-1, 128, 28, 28] 0Conv2d-15 [-1, 16, 28, 28] 3,088BatchNorm2d-16 [-1, 16, 28, 28] 32ReLU-17 [-1, 16, 28, 28] 0Conv2d-18 [-1, 32, 28, 28] 12,832BatchNorm2d-19 [-1, 32, 28, 28] 64ReLU-20 [-1, 32, 28, 28] 0MaxPool2d-21 [-1, 192, 28, 28] 0Conv2d-22 [-1, 32, 28, 28] 6,176BatchNorm2d-23 [-1, 32, 28, 28] 64ReLU-24 [-1, 32, 28, 28] 0inception_block-25 [-1, 256, 28, 28] 0Conv2d-26 [-1, 128, 28, 28] 32,896BatchNorm2d-27 [-1, 128, 28, 28] 256ReLU-28 [-1, 128, 28, 28] 0Conv2d-29 [-1, 128, 28, 28] 32,896BatchNorm2d-30 [-1, 128, 28, 28] 256ReLU-31 [-1, 128, 28, 28] 0Conv2d-32 [-1, 192, 28, 28] 221,376BatchNorm2d-33 [-1, 192, 28, 28] 384ReLU-34 [-1, 192, 28, 28] 0Conv2d-35 [-1, 32, 28, 28] 8,224BatchNorm2d-36 [-1, 32, 28, 28] 64ReLU-37 [-1, 32, 28, 28] 0Conv2d-38 [-1, 96, 28, 28] 76,896BatchNorm2d-39 [-1, 96, 28, 28] 192ReLU-40 [-1, 96, 28, 28] 0MaxPool2d-41 [-1, 256, 28, 28] 0Conv2d-42 [-1, 64, 28, 28] 16,448BatchNorm2d-43 [-1, 64, 28, 28] 128ReLU-44 [-1, 64, 28, 28] 0inception_block-45 [-1, 480, 28, 28] 0MaxPool2d-46 [-1, 480, 14, 14] 0Conv2d-47 [-1, 192, 14, 14] 92,352BatchNorm2d-48 [-1, 192, 14, 14] 384ReLU-49 [-1, 192, 14, 14] 0Conv2d-50 [-1, 96, 14, 14] 46,176BatchNorm2d-51 [-1, 96, 14, 14] 192ReLU-52 [-1, 96, 14, 14] 0Conv2d-53 [-1, 208, 14, 14] 179,920BatchNorm2d-54 [-1, 208, 14, 14] 416ReLU-55 [-1, 208, 14, 14] 0Conv2d-56 [-1, 16, 14, 14] 7,696BatchNorm2d-57 [-1, 16, 14, 14] 32ReLU-58 [-1, 16, 14, 14] 0Conv2d-59 [-1, 48, 14, 14] 19,248BatchNorm2d-60 [-1, 48, 14, 14] 96ReLU-61 [-1, 48, 14, 14] 0MaxPool2d-62 [-1, 480, 14, 14] 0Conv2d-63 [-1, 64, 14, 14] 30,784BatchNorm2d-64 [-1, 64, 14, 14] 128ReLU-65 [-1, 64, 14, 14] 0inception_block-66 [-1, 512, 14, 14] 0Conv2d-67 [-1, 160, 14, 14] 82,080BatchNorm2d-68 [-1, 160, 14, 14] 320ReLU-69 [-1, 160, 14, 14] 0Conv2d-70 [-1, 112, 14, 14] 57,456BatchNorm2d-71 [-1, 112, 14, 14] 224ReLU-72 [-1, 112, 14, 14] 0Conv2d-73 [-1, 224, 14, 14] 226,016BatchNorm2d-74 [-1, 224, 14, 14] 448ReLU-75 [-1, 224, 14, 14] 0Conv2d-76 [-1, 24, 14, 14] 12,312BatchNorm2d-77 [-1, 24, 14, 14] 48ReLU-78 [-1, 24, 14, 14] 0Conv2d-79 [-1, 64, 14, 14] 38,464BatchNorm2d-80 [-1, 64, 14, 14] 128ReLU-81 [-1, 64, 14, 14] 0MaxPool2d-82 [-1, 512, 14, 14] 0Conv2d-83 [-1, 64, 14, 14] 32,832BatchNorm2d-84 [-1, 64, 14, 14] 128ReLU-85 [-1, 64, 14, 14] 0inception_block-86 [-1, 512, 14, 14] 0Conv2d-87 [-1, 128, 14, 14] 65,664BatchNorm2d-88 [-1, 128, 14, 14] 256ReLU-89 [-1, 128, 14, 14] 0Conv2d-90 [-1, 128, 14, 14] 65,664BatchNorm2d-91 [-1, 128, 14, 14] 256ReLU-92 [-1, 128, 14, 14] 0Conv2d-93 [-1, 256, 14, 14] 295,168BatchNorm2d-94 [-1, 256, 14, 14] 512ReLU-95 [-1, 256, 14, 14] 0Conv2d-96 [-1, 24, 14, 14] 12,312BatchNorm2d-97 [-1, 24, 14, 14] 48ReLU-98 [-1, 24, 14, 14] 0Conv2d-99 [-1, 64, 14, 14] 38,464BatchNorm2d-100 [-1, 64, 14, 14] 128ReLU-101 [-1, 64, 14, 14] 0MaxPool2d-102 [-1, 512, 14, 14] 0Conv2d-103 [-1, 64, 14, 14] 32,832BatchNorm2d-104 [-1, 64, 14, 14] 128ReLU-105 [-1, 64, 14, 14] 0inception_block-106 [-1, 512, 14, 14] 0Conv2d-107 [-1, 112, 14, 14] 57,456BatchNorm2d-108 [-1, 112, 14, 14] 224ReLU-109 [-1, 112, 14, 14] 0Conv2d-110 [-1, 144, 14, 14] 73,872BatchNorm2d-111 [-1, 144, 14, 14] 288ReLU-112 [-1, 144, 14, 14] 0Conv2d-113 [-1, 288, 14, 14] 373,536BatchNorm2d-114 [-1, 288, 14, 14] 576ReLU-115 [-1, 288, 14, 14] 0Conv2d-116 [-1, 32, 14, 14] 16,416BatchNorm2d-117 [-1, 32, 14, 14] 64ReLU-118 [-1, 32, 14, 14] 0Conv2d-119 [-1, 64, 14, 14] 51,264BatchNorm2d-120 [-1, 64, 14, 14] 128ReLU-121 [-1, 64, 14, 14] 0MaxPool2d-122 [-1, 512, 14, 14] 0Conv2d-123 [-1, 64, 14, 14] 32,832BatchNorm2d-124 [-1, 64, 14, 14] 128ReLU-125 [-1, 64, 14, 14] 0inception_block-126 [-1, 528, 14, 14] 0Conv2d-127 [-1, 256, 14, 14] 135,424BatchNorm2d-128 [-1, 256, 14, 14] 512ReLU-129 [-1, 256, 14, 14] 0Conv2d-130 [-1, 160, 14, 14] 84,640BatchNorm2d-131 [-1, 160, 14, 14] 320ReLU-132 [-1, 160, 14, 14] 0Conv2d-133 [-1, 320, 14, 14] 461,120BatchNorm2d-134 [-1, 320, 14, 14] 640ReLU-135 [-1, 320, 14, 14] 0Conv2d-136 [-1, 32, 14, 14] 16,928BatchNorm2d-137 [-1, 32, 14, 14] 64ReLU-138 [-1, 32, 14, 14] 0Conv2d-139 [-1, 128, 14, 14] 102,528BatchNorm2d-140 [-1, 128, 14, 14] 256ReLU-141 [-1, 128, 14, 14] 0MaxPool2d-142 [-1, 528, 14, 14] 0Conv2d-143 [-1, 128, 14, 14] 67,712BatchNorm2d-144 [-1, 128, 14, 14] 256ReLU-145 [-1, 128, 14, 14] 0inception_block-146 [-1, 832, 14, 14] 0MaxPool2d-147 [-1, 832, 7, 7] 0Conv2d-148 [-1, 256, 7, 7] 213,248BatchNorm2d-149 [-1, 256, 7, 7] 512ReLU-150 [-1, 256, 7, 7] 0Conv2d-151 [-1, 160, 7, 7] 133,280BatchNorm2d-152 [-1, 160, 7, 7] 320ReLU-153 [-1, 160, 7, 7] 0Conv2d-154 [-1, 320, 7, 7] 461,120BatchNorm2d-155 [-1, 320, 7, 7] 640ReLU-156 [-1, 320, 7, 7] 0Conv2d-157 [-1, 32, 7, 7] 26,656BatchNorm2d-158 [-1, 32, 7, 7] 64ReLU-159 [-1, 32, 7, 7] 0Conv2d-160 [-1, 128, 7, 7] 102,528BatchNorm2d-161 [-1, 128, 7, 7] 256ReLU-162 [-1, 128, 7, 7] 0MaxPool2d-163 [-1, 832, 7, 7] 0Conv2d-164 [-1, 128, 7, 7] 106,624BatchNorm2d-165 [-1, 128, 7, 7] 256ReLU-166 [-1, 128, 7, 7] 0inception_block-167 [-1, 832, 7, 7] 0Conv2d-168 [-1, 384, 7, 7] 319,872BatchNorm2d-169 [-1, 384, 7, 7] 768ReLU-170 [-1, 384, 7, 7] 0Conv2d-171 [-1, 192, 7, 7] 159,936BatchNorm2d-172 [-1, 192, 7, 7] 384ReLU-173 [-1, 192, 7, 7] 0Conv2d-174 [-1, 384, 7, 7] 663,936BatchNorm2d-175 [-1, 384, 7, 7] 768ReLU-176 [-1, 384, 7, 7] 0Conv2d-177 [-1, 48, 7, 7] 39,984BatchNorm2d-178 [-1, 48, 7, 7] 96ReLU-179 [-1, 48, 7, 7] 0Conv2d-180 [-1, 128, 7, 7] 153,728BatchNorm2d-181 [-1, 128, 7, 7] 256ReLU-182 [-1, 128, 7, 7] 0MaxPool2d-183 [-1, 832, 7, 7] 0Conv2d-184 [-1, 128, 7, 7] 106,624BatchNorm2d-185 [-1, 128, 7, 7] 256ReLU-186 [-1, 128, 7, 7] 0inception_block-187 [-1, 1024, 7, 7] 0AvgPool2d-188 [-1, 1024, 1, 1] 0Dropout-189 [-1, 1024, 1, 1] 0
AdaptiveAvgPool2d-190 [-1, 1024, 1, 1] 0Linear-191 [-1, 1024] 1,049,600ReLU-192 [-1, 1024] 0Linear-193 [-1, 2] 2,050Softmax-194 [-1, 2] 0
================================================================
Total params: 7,039,122
Trainable params: 7,039,122
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 69.62
Params size (MB): 26.85
Estimated Total Size (MB): 97.05
----------------------------------------------------------------
5. 设置超参数:定义损失函数,学习率,以及根据学习率定义优化器等
# loss_fn = nn.CrossEntropyLoss() # 创建损失函数# learn_rate = 1e-3 # 初始学习率
# def adjust_learning_rate(optimizer,epoch,start_lr):
# # 每两个epoch 衰减到原来的0.98
# lr = start_lr * (0.92 ** (epoch//2))
# for param_group in optimizer.param_groups:
# param_group['lr'] = lr# optimizer = torch.optim.Adam(model.parameters(),lr=learn_rate)# 调用官方接口示例
loss_fn = nn.CrossEntropyLoss()# learn_rate = 1e-4
learn_rate = 3e-4
lambda1 = lambda epoch:(0.92**(epoch//2))optimizer = torch.optim.Adam(model.parameters(),lr = learn_rate)
scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer,lr_lambda=lambda1) # 选定调整方法6. 训练函数
# 训练函数
def train(dataloader,model,loss_fn,optimizer):size = len(dataloader.dataset) # 训练集大小num_batches = len(dataloader) # 批次数目train_loss,train_acc = 0,0for X,y in dataloader:X,y = X.to(device),y.to(device)# 计算预测误差pred = model(X)loss = loss_fn(pred,y)# 反向传播optimizer.zero_grad()loss.backward()optimizer.step()# 记录acc与losstrain_acc += (pred.argmax(1)==y).type(torch.float).sum().item()train_loss += loss.item()train_acc /= sizetrain_loss /= num_batchesreturn train_acc,train_loss7. 测试函数
# 测试函数
def test(dataloader,model,loss_fn):size = len(dataloader.dataset)num_batches = len(dataloader)test_acc,test_loss = 0,0with torch.no_grad():for X,y in dataloader:X,y = X.to(device),y.to(device)# 计算losspred = model(X)loss = loss_fn(pred,y)test_acc += (pred.argmax(1)==y).type(torch.float).sum().item()test_loss += loss.item()test_acc /= sizetest_loss /= num_batchesreturn test_acc,test_loss8. 正式训练
import copyepochs = 60train_acc = []
train_loss = []
test_acc = []
test_loss = []best_acc = 0.0# 检查 GPU 可用性并打印设备信息
if torch.cuda.is_available():for i in range(torch.cuda.device_count()):print(f"GPU {i}: {torch.cuda.get_device_name(i)}")print(f"Initial Memory Allocated: {torch.cuda.memory_allocated(i)/1024**2:.2f} MB")print(f"Initial Memory Cached: {torch.cuda.memory_reserved(i)/1024**2:.2f} MB")
else:print("No GPU available. Using CPU.")# 多显卡设置 当前使用的是使用 PyTorch 自带的 DataParallel,后续如有需要可以设置为DistributedDataParallel,这是更加高效的方式
# 且多卡不一定比单卡效果就好,需要调整优化
# if torch.cuda.device_count() > 1:
# print(f"Using {torch.cuda.device_count()} GPUs")
# model = nn.DataParallel(model)
# model = model.to('cuda')for epoch in range(epochs):# 更新学习率——使用自定义学习率时使用# adjust_learning_rate(optimizer,epoch,learn_rate)model.train()epoch_train_acc,epoch_train_loss = train(train_dl,model,loss_fn,optimizer)scheduler.step() # 更新学习率——调用官方动态学习率时使用model.eval()epoch_test_acc,epoch_test_loss = test(test_dl,model,loss_fn)# 保存最佳模型到 best_modelif epoch_test_acc > best_acc:best_acc = epoch_test_accbest_model = copy.deepcopy(model)train_acc.append(epoch_train_acc)train_loss.append(epoch_train_loss)test_acc.append(epoch_test_acc)test_loss.append(epoch_test_loss)# 获取当前学习率lr = optimizer.state_dict()['param_groups'][0]['lr']template = ('Epoch:{:2d},Train_acc:{:.1f}%,Train_loss:{:.3f},Test_acc:{:.1f}%,Test_loss:{:.3f},Lr:{:.2E}')print(template.format(epoch+1,epoch_train_acc*100,epoch_train_loss,epoch_test_acc*100,epoch_test_loss,lr))# 实时监控 GPU 状态if torch.cuda.is_available():for i in range(torch.cuda.device_count()):print(f"GPU {i} Usage:")print(f" Memory Allocated: {torch.cuda.memory_allocated(i)/1024**2:.2f} MB")print(f" Memory Cached: {torch.cuda.memory_reserved(i)/1024**2:.2f} MB")print(f" Max Memory Allocated: {torch.cuda.max_memory_allocated(i)/1024**2:.2f} MB")print(f" Max Memory Cached: {torch.cuda.max_memory_reserved(i)/1024**2:.2f} MB")print('Done','best_acc: ',best_acc)
GPU 0: NVIDIA GeForce RTX 4070 Laptop GPU
Initial Memory Allocated: 335.65 MB
Initial Memory Cached: 586.00 MB
Epoch: 1,Train_acc:63.3%,Train_loss:0.645,Test_acc:64.8%,Test_loss:0.634,Lr:3.00E-04
GPU 0 Usage:Memory Allocated: 455.01 MBMemory Cached: 2072.00 MBMax Memory Allocated: 1845.06 MBMax Memory Cached: 2072.00 MB
Epoch: 2,Train_acc:63.6%,Train_loss:0.638,Test_acc:62.5%,Test_loss:0.670,Lr:2.76E-04
GPU 0 Usage:Memory Allocated: 454.59 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1872.34 MBMax Memory Cached: 2086.00 MB
Epoch: 3,Train_acc:67.1%,Train_loss:0.622,Test_acc:62.9%,Test_loss:0.651,Lr:2.76E-04
GPU 0 Usage:Memory Allocated: 454.37 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1874.41 MBMax Memory Cached: 2086.00 MB
Epoch: 4,Train_acc:66.1%,Train_loss:0.627,Test_acc:67.1%,Test_loss:0.621,Lr:2.54E-04
GPU 0 Usage:Memory Allocated: 453.73 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1874.41 MBMax Memory Cached: 2086.00 MB
Epoch: 5,Train_acc:68.6%,Train_loss:0.616,Test_acc:60.8%,Test_loss:0.683,Lr:2.54E-04
GPU 0 Usage:Memory Allocated: 453.00 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1874.41 MBMax Memory Cached: 2086.00 MB
Epoch: 6,Train_acc:68.5%,Train_loss:0.601,Test_acc:69.5%,Test_loss:0.602,Lr:2.34E-04
GPU 0 Usage:Memory Allocated: 454.46 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1874.41 MBMax Memory Cached: 2086.00 MB
Epoch: 7,Train_acc:72.2%,Train_loss:0.583,Test_acc:70.4%,Test_loss:0.601,Lr:2.34E-04
GPU 0 Usage:Memory Allocated: 454.09 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1874.41 MBMax Memory Cached: 2086.00 MB
Epoch: 8,Train_acc:72.6%,Train_loss:0.572,Test_acc:69.9%,Test_loss:0.607,Lr:2.15E-04
GPU 0 Usage:Memory Allocated: 453.72 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1875.13 MBMax Memory Cached: 2086.00 MB
Epoch: 9,Train_acc:75.8%,Train_loss:0.545,Test_acc:73.7%,Test_loss:0.567,Lr:2.15E-04
GPU 0 Usage:Memory Allocated: 454.52 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1875.13 MBMax Memory Cached: 2086.00 MB
Epoch:10,Train_acc:75.8%,Train_loss:0.544,Test_acc:72.0%,Test_loss:0.584,Lr:1.98E-04
GPU 0 Usage:Memory Allocated: 454.52 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1875.13 MBMax Memory Cached: 2086.00 MB
Epoch:11,Train_acc:76.6%,Train_loss:0.539,Test_acc:75.3%,Test_loss:0.542,Lr:1.98E-04
GPU 0 Usage:Memory Allocated: 455.12 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1875.13 MBMax Memory Cached: 2086.00 MB
Epoch:12,Train_acc:78.6%,Train_loss:0.517,Test_acc:72.7%,Test_loss:0.574,Lr:1.82E-04
GPU 0 Usage:Memory Allocated: 455.12 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1875.13 MBMax Memory Cached: 2086.00 MB
Epoch:13,Train_acc:78.2%,Train_loss:0.521,Test_acc:74.1%,Test_loss:0.569,Lr:1.82E-04
GPU 0 Usage:Memory Allocated: 455.12 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1875.13 MBMax Memory Cached: 2086.00 MB
Epoch:14,Train_acc:78.1%,Train_loss:0.525,Test_acc:79.3%,Test_loss:0.509,Lr:1.67E-04
GPU 0 Usage:Memory Allocated: 454.52 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1875.13 MBMax Memory Cached: 2086.00 MB
Epoch:15,Train_acc:83.0%,Train_loss:0.483,Test_acc:72.7%,Test_loss:0.575,Lr:1.67E-04
GPU 0 Usage:Memory Allocated: 454.52 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1875.13 MBMax Memory Cached: 2086.00 MB
Epoch:16,Train_acc:82.6%,Train_loss:0.482,Test_acc:75.3%,Test_loss:0.545,Lr:1.54E-04
GPU 0 Usage:Memory Allocated: 455.53 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1875.22 MBMax Memory Cached: 2086.00 MB
Epoch:17,Train_acc:83.1%,Train_loss:0.476,Test_acc:79.5%,Test_loss:0.506,Lr:1.54E-04
GPU 0 Usage:Memory Allocated: 454.47 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1875.22 MBMax Memory Cached: 2086.00 MB
Epoch:18,Train_acc:84.8%,Train_loss:0.457,Test_acc:83.4%,Test_loss:0.471,Lr:1.42E-04
GPU 0 Usage:Memory Allocated: 454.93 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1875.22 MBMax Memory Cached: 2086.00 MB
Epoch:19,Train_acc:84.5%,Train_loss:0.467,Test_acc:81.8%,Test_loss:0.495,Lr:1.42E-04
GPU 0 Usage:Memory Allocated: 455.60 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1875.26 MBMax Memory Cached: 2086.00 MB
Epoch:20,Train_acc:85.2%,Train_loss:0.457,Test_acc:83.2%,Test_loss:0.467,Lr:1.30E-04
GPU 0 Usage:Memory Allocated: 455.02 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1875.26 MBMax Memory Cached: 2086.00 MB
Epoch:21,Train_acc:86.0%,Train_loss:0.445,Test_acc:79.7%,Test_loss:0.503,Lr:1.30E-04
GPU 0 Usage:Memory Allocated: 455.60 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1875.26 MBMax Memory Cached: 2086.00 MB
Epoch:22,Train_acc:86.2%,Train_loss:0.444,Test_acc:86.0%,Test_loss:0.454,Lr:1.20E-04
GPU 0 Usage:Memory Allocated: 453.39 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1875.26 MBMax Memory Cached: 2086.00 MB
Epoch:23,Train_acc:87.0%,Train_loss:0.437,Test_acc:85.5%,Test_loss:0.452,Lr:1.20E-04
GPU 0 Usage:Memory Allocated: 453.02 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1875.26 MBMax Memory Cached: 2086.00 MB
Epoch:24,Train_acc:87.9%,Train_loss:0.432,Test_acc:88.8%,Test_loss:0.427,Lr:1.10E-04
GPU 0 Usage:Memory Allocated: 454.34 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1875.26 MBMax Memory Cached: 2086.00 MB
Epoch:25,Train_acc:88.5%,Train_loss:0.423,Test_acc:86.2%,Test_loss:0.435,Lr:1.10E-04
GPU 0 Usage:Memory Allocated: 454.33 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1875.26 MBMax Memory Cached: 2086.00 MB
Epoch:26,Train_acc:89.3%,Train_loss:0.421,Test_acc:86.7%,Test_loss:0.436,Lr:1.01E-04
GPU 0 Usage:Memory Allocated: 454.33 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1875.26 MBMax Memory Cached: 2086.00 MB
Epoch:27,Train_acc:90.0%,Train_loss:0.411,Test_acc:87.2%,Test_loss:0.435,Lr:1.01E-04
GPU 0 Usage:Memory Allocated: 454.33 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1875.26 MBMax Memory Cached: 2086.00 MB
Epoch:28,Train_acc:90.4%,Train_loss:0.404,Test_acc:89.3%,Test_loss:0.424,Lr:9.34E-05
GPU 0 Usage:Memory Allocated: 453.29 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1875.26 MBMax Memory Cached: 2086.00 MB
Epoch:29,Train_acc:90.3%,Train_loss:0.405,Test_acc:89.7%,Test_loss:0.411,Lr:9.34E-05
GPU 0 Usage:Memory Allocated: 455.36 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1875.26 MBMax Memory Cached: 2086.00 MB
Epoch:30,Train_acc:89.6%,Train_loss:0.411,Test_acc:89.0%,Test_loss:0.424,Lr:8.59E-05
GPU 0 Usage:Memory Allocated: 455.31 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1875.26 MBMax Memory Cached: 2086.00 MB
Epoch:31,Train_acc:91.9%,Train_loss:0.392,Test_acc:90.7%,Test_loss:0.412,Lr:8.59E-05
GPU 0 Usage:Memory Allocated: 453.24 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1875.26 MBMax Memory Cached: 2086.00 MB
Epoch:32,Train_acc:91.8%,Train_loss:0.392,Test_acc:89.5%,Test_loss:0.420,Lr:7.90E-05
GPU 0 Usage:Memory Allocated: 453.27 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1875.26 MBMax Memory Cached: 2086.00 MB
Epoch:33,Train_acc:91.7%,Train_loss:0.392,Test_acc:91.8%,Test_loss:0.387,Lr:7.90E-05
GPU 0 Usage:Memory Allocated: 455.28 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1875.26 MBMax Memory Cached: 2086.00 MB
Epoch:34,Train_acc:91.0%,Train_loss:0.401,Test_acc:89.7%,Test_loss:0.410,Lr:7.27E-05
GPU 0 Usage:Memory Allocated: 454.91 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1875.26 MBMax Memory Cached: 2086.00 MB
Epoch:35,Train_acc:91.6%,Train_loss:0.392,Test_acc:92.5%,Test_loss:0.389,Lr:7.27E-05
GPU 0 Usage:Memory Allocated: 453.79 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1875.26 MBMax Memory Cached: 2086.00 MB
Epoch:36,Train_acc:92.8%,Train_loss:0.386,Test_acc:92.1%,Test_loss:0.387,Lr:6.69E-05
GPU 0 Usage:Memory Allocated: 453.79 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1875.26 MBMax Memory Cached: 2086.00 MB
Epoch:37,Train_acc:91.9%,Train_loss:0.392,Test_acc:88.8%,Test_loss:0.422,Lr:6.69E-05
GPU 0 Usage:Memory Allocated: 453.79 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1875.26 MBMax Memory Cached: 2086.00 MB
Epoch:38,Train_acc:93.2%,Train_loss:0.382,Test_acc:90.9%,Test_loss:0.405,Lr:6.15E-05
GPU 0 Usage:Memory Allocated: 453.79 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1875.26 MBMax Memory Cached: 2086.00 MB
Epoch:39,Train_acc:93.1%,Train_loss:0.382,Test_acc:93.0%,Test_loss:0.380,Lr:6.15E-05
GPU 0 Usage:Memory Allocated: 455.30 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1875.26 MBMax Memory Cached: 2086.00 MB
Epoch:40,Train_acc:93.1%,Train_loss:0.381,Test_acc:92.8%,Test_loss:0.386,Lr:5.66E-05
GPU 0 Usage:Memory Allocated: 455.30 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1875.26 MBMax Memory Cached: 2086.00 MB
Epoch:41,Train_acc:93.5%,Train_loss:0.377,Test_acc:92.8%,Test_loss:0.387,Lr:5.66E-05
GPU 0 Usage:Memory Allocated: 455.30 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1875.26 MBMax Memory Cached: 2086.00 MB
Epoch:42,Train_acc:93.8%,Train_loss:0.373,Test_acc:93.9%,Test_loss:0.374,Lr:5.21E-05
GPU 0 Usage:Memory Allocated: 453.05 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1875.26 MBMax Memory Cached: 2086.00 MB
Epoch:43,Train_acc:94.3%,Train_loss:0.370,Test_acc:92.8%,Test_loss:0.381,Lr:5.21E-05
GPU 0 Usage:Memory Allocated: 453.05 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1875.26 MBMax Memory Cached: 2086.00 MB
Epoch:44,Train_acc:93.8%,Train_loss:0.373,Test_acc:92.3%,Test_loss:0.394,Lr:4.79E-05
GPU 0 Usage:Memory Allocated: 453.05 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1875.26 MBMax Memory Cached: 2086.00 MB
Epoch:45,Train_acc:94.5%,Train_loss:0.368,Test_acc:93.9%,Test_loss:0.367,Lr:4.79E-05
GPU 0 Usage:Memory Allocated: 453.05 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1875.26 MBMax Memory Cached: 2086.00 MB
Epoch:46,Train_acc:94.3%,Train_loss:0.370,Test_acc:93.0%,Test_loss:0.385,Lr:4.41E-05
GPU 0 Usage:Memory Allocated: 453.05 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1875.26 MBMax Memory Cached: 2086.00 MB
Epoch:47,Train_acc:94.6%,Train_loss:0.364,Test_acc:93.0%,Test_loss:0.378,Lr:4.41E-05
GPU 0 Usage:Memory Allocated: 453.05 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1875.26 MBMax Memory Cached: 2086.00 MB
Epoch:48,Train_acc:93.2%,Train_loss:0.380,Test_acc:93.0%,Test_loss:0.383,Lr:4.06E-05
GPU 0 Usage:Memory Allocated: 453.05 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1875.26 MBMax Memory Cached: 2086.00 MB
Epoch:49,Train_acc:93.9%,Train_loss:0.371,Test_acc:95.1%,Test_loss:0.361,Lr:4.06E-05
GPU 0 Usage:Memory Allocated: 454.08 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1875.26 MBMax Memory Cached: 2086.00 MB
Epoch:50,Train_acc:94.6%,Train_loss:0.368,Test_acc:94.6%,Test_loss:0.367,Lr:3.73E-05
GPU 0 Usage:Memory Allocated: 454.08 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1875.26 MBMax Memory Cached: 2086.00 MB
Epoch:51,Train_acc:94.3%,Train_loss:0.368,Test_acc:94.6%,Test_loss:0.365,Lr:3.73E-05
GPU 0 Usage:Memory Allocated: 454.08 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1875.26 MBMax Memory Cached: 2086.00 MB
Epoch:52,Train_acc:94.9%,Train_loss:0.363,Test_acc:93.2%,Test_loss:0.376,Lr:3.43E-05
GPU 0 Usage:Memory Allocated: 454.08 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1875.26 MBMax Memory Cached: 2086.00 MB
Epoch:53,Train_acc:95.2%,Train_loss:0.362,Test_acc:94.4%,Test_loss:0.362,Lr:3.43E-05
GPU 0 Usage:Memory Allocated: 454.08 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1875.26 MBMax Memory Cached: 2086.00 MB
Epoch:54,Train_acc:96.4%,Train_loss:0.348,Test_acc:94.4%,Test_loss:0.373,Lr:3.16E-05
GPU 0 Usage:Memory Allocated: 454.08 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1875.26 MBMax Memory Cached: 2086.00 MB
Epoch:55,Train_acc:96.5%,Train_loss:0.347,Test_acc:93.7%,Test_loss:0.371,Lr:3.16E-05
GPU 0 Usage:Memory Allocated: 454.08 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1875.26 MBMax Memory Cached: 2086.00 MB
Epoch:56,Train_acc:95.6%,Train_loss:0.355,Test_acc:95.8%,Test_loss:0.355,Lr:2.91E-05
GPU 0 Usage:Memory Allocated: 453.93 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1875.26 MBMax Memory Cached: 2086.00 MB
Epoch:57,Train_acc:95.4%,Train_loss:0.358,Test_acc:94.6%,Test_loss:0.363,Lr:2.91E-05
GPU 0 Usage:Memory Allocated: 453.93 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1875.26 MBMax Memory Cached: 2086.00 MB
Epoch:58,Train_acc:95.6%,Train_loss:0.355,Test_acc:94.4%,Test_loss:0.369,Lr:2.67E-05
GPU 0 Usage:Memory Allocated: 453.93 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1875.26 MBMax Memory Cached: 2086.00 MB
Epoch:59,Train_acc:96.5%,Train_loss:0.348,Test_acc:93.9%,Test_loss:0.372,Lr:2.67E-05
GPU 0 Usage:Memory Allocated: 453.93 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1875.26 MBMax Memory Cached: 2086.00 MB
Epoch:60,Train_acc:96.8%,Train_loss:0.344,Test_acc:96.0%,Test_loss:0.355,Lr:2.46E-05
GPU 0 Usage:Memory Allocated: 453.93 MBMemory Cached: 2086.00 MBMax Memory Allocated: 1875.26 MBMax Memory Cached: 2086.00 MB
Done best_acc: 0.9603729603729604
9. 结果可视化
epochs_range = range(epochs)plt.figure(figsize = (12,3))plt.subplot(1,2,1)
plt.plot(epochs_range,train_acc,label = 'Training Accuracy')
plt.plot(epochs_range,test_acc,label = 'Test Accuracy')
plt.legend(loc = 'lower right')
plt.title('Training and Validation Accuracy')plt.subplot(1,2,2)
plt.plot(epochs_range,train_loss,label = 'Test Accuracy')
plt.plot(epochs_range,test_loss,label = 'Test Loss')
plt.legend(loc = 'lower right')
plt.title('Training and validation Loss')
plt.show()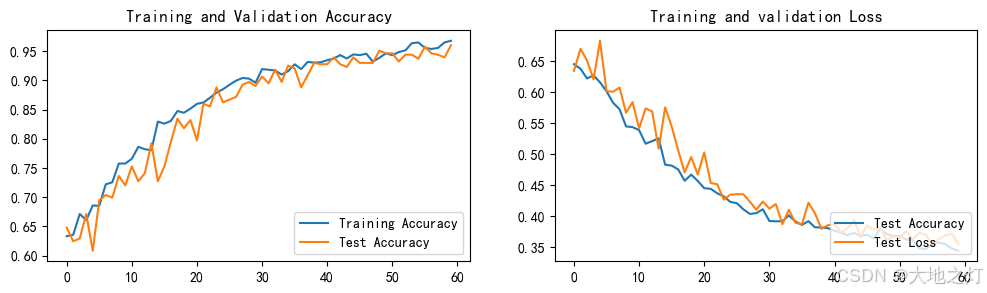
10. 模型的保存
# 自定义模型保存
# 状态字典保存
torch.save(model.state_dict(),'./模型参数/J8_InceptionV1_model_state_dict.pth') # 仅保存状态字典# 定义模型用来加载参数
best_model = InceptionV1(num_classes=len(classNames)).to(device)best_model.load_state_dict(torch.load('./模型参数/J8_InceptionV1_model_state_dict.pth')) # 加载状态字典到模型<All keys matched successfully>
11.使用训练好的模型进行预测
# 指定路径图片预测
from PIL import Image
import torchvision.transforms as transformsclasses = list(total_data.class_to_idx) # classes = list(total_data.class_to_idx)def predict_one_image(image_path,model,transform,classes):test_img = Image.open(image_path).convert('RGB')# plt.imshow(test_img) # 展示待预测的图片test_img = transform(test_img)img = test_img.to(device).unsqueeze(0)model.eval()output = model(img)print(output) # 观察模型预测结果的输出数据_,pred = torch.max(output,1)pred_class = classes[pred]print(f'预测结果是:{pred_class}')# 预测训练集中的某张照片
predict_one_image(image_path='./data/mpox_recognize/Monkeypox/M01_01_04.jpg',model = model,transform = test_transforms,classes = classes)tensor([[0.0015, 0.9985]], device='cuda:0', grad_fn=<SoftmaxBackward0>)
预测结果是:Others
classes
['Monkeypox', 'Others']
相关文章:
)
深度学习每周学习总结J8(Inception V1 算法实战与解析 - 猴痘识别)
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 | 接辅导、项目定制 目录 0. 总结Inception V1 简介1. 设置GPU2. 导入数据及处理部分3. 划分数据集4. 模型构建部分5. 设置超参数:定义损失函数&am…...

Django模板系统
1.常用语法 Django模板中只需要记两种特殊符号: {{ }}和 {% %} {{ }}表示变量,在模板渲染的时候替换成值,{% %}表示逻辑相关的操作。 2.变量 {{ 变量名 }} 变量名由字母数字和下划线组成。 点(.)在模板语言中有…...
)
【JavaWeb后端学习笔记】MySQL的数据操作语言(Data Manipulation Language,DML)
MySQL DML 0、准备表结构1、添加数据1.1 指定字段添加数据(单条)1.2 全部字段添加数据(单条)1.3 指定字段添加数据(批量)1.4 全部字段添加数据(批量) 2、修改数据3、删除数据 MySQL的…...

【SpringBoot】Day10-09 动态SQL-XML文件
动态SQL-XML文件的三点规范 1.XML映射文件的名称与Mapper接口名称保持一致,并且将XML映射文件和Mapper接口放置在相同包下(同包同名)- 在项目开发当中,一般都是一个接口对应一份儿映射配置文件; 2.XML映射文件的namesp…...
 Ubuntu桌面版添加中文拼音输入法)
Linux絮絮叨(三) Ubuntu桌面版添加中文拼音输入法
步骤很详细,直接上教程 一. 配置安装简体拼音输入法 #安装相应的平台支持包 sudo apt install ibus-gtk ibus-gtk3# 安装简体拼音输入法 sudo apt install ibus-pinyin安装完成如果下面的步骤找不到对应输入法可以重启一下,一般不需要 二. 添加简体拼音…...
(VENC))
rockit 学习、开发笔记(六)(VENC)
前言 上节我们讲到了VDEC解码模块,那当然少不了VENC编码模块了,一般有编解码的需求都是为了压缩视频的大小,方便减少传输所占用的带宽。 概述 VENC 模块,即视频编码模块。本模块支持多路实时编码,且每路编码独立&am…...

Python+Django框架山东济南景点数据可视化系统网站作品截图和开题报告参考
博主介绍:黄菊华老师《Vue.js入门与商城开发实战》《微信小程序商城开发》图书作者,CSDN博客专家,在线教育专家,CSDN钻石讲师;专注大学生毕业设计教育、辅导。 所有项目都配有从入门到精通的基础知识视频课程ÿ…...

【C#】键值对的一种常见数据结构Dictionary<TKey, TValue>
在 C# 中,Dictionary<TKey, TValue> 是一个 键值对(key-value)集合,是一种非常常见的数据结构。它允许通过 键(key)来快速查找与之相关的 值(value)。你可以将其类比为一个映射…...
)
SQL Server:调用的目标发生了异常。(mscorlib)
我之前安装的SQL Server是2014版本,SSMS运行也很流畅,有一次有个同事让我链接云服务器SQL地址,直接报上图的错误,把我弄的一愣一愣的。 后面才发现,这是版本太低导致的,但是你如果使用Navicat是没有问题的…...

windows 上ffmpeg编译好的版本选择
1. Gyan.dev Gyan.dev 是一个广受信赖的 FFmpeg 预编译库提供者,提供多种版本的 FFmpeg,包括静态和动态链接版本。 下载链接: https://www.gyan.dev/ffmpeg/builds/ 特点: 提供最新稳定版和开发版。 支持静态和共享(动态&…...
)
前端工程化面试题(一)
如何使用 Docker 部署前端项目? 使用 Docker 部署前端项目通常涉及以下几个步骤: 创建项目:首先,需要在本地创建并配置好前端项目。 准备 Docker 文件: .dockerignore:这个文件用于排除不需要上传到 Dock…...
)
Java设计模式笔记(二)
十四、模版方法模式 1、介绍 1)模板方法模式(Template Method Pattern),又叫模板模式(Template Patern),在一个抽象类公开定义了执行它的方法的模板。它的子类可以按需重写方法实现,但调用将以抽象类中定义的方式进行。 2&…...
安装(ubuntu20.04))
vscode(一)安装(ubuntu20.04)
1、更新软件包列表 sudo apt update2、安装依赖包 sudo apt install software-properties-common apt-transport-https wget3、导入Microsoft GPG密钥 wget -q https://packages.microsoft.com/keys/microsoft.asc -O- | sudo apt-key add -4、向系统添加VSCode存储库 sudo…...
)
C# 命名空间(Namespace)
文章目录 前言一、命名空间的定义与使用基础(一)定义语法与规则(二)调用命名空间内元素 二、using 关键字三、嵌套命名空间 前言 命名空间(Namespace)在于提供一种清晰、高效的方式,将一组名称与…...
)
云计算介绍_3(计算虚拟化——cpu虚拟化、内存虚拟化、io虚拟化、常见集群策略、华为FC)
计算虚拟化 1.计算虚拟化介绍1.1 计算虚拟化 分类(cpu虚拟化、内存虚拟化、IO虚拟化)1.2 cpu虚拟化1.3 内存虚拟化1.4 IO虚拟化1.5 常见的集群的策略1.6 华为FC 1.计算虚拟化介绍 1.1 计算虚拟化 分类(cpu虚拟化、内存虚拟化、IO虚拟化&#…...

Flutter开发App,编译条件下UI没问题,打包后UI出现问题
刚入门Flutter3个月,终于进入项目打包阶段,发现之前编译环境下都正常的UI,忽然有小部分出现异常,不显示UI部分了。查了2个小时都没发现原因。因为编译环境下,Android、iOS端都正常显示。但是进入打包安装后,…...

Python+OpenCV系列:Python和OpenCV的结合和发展
PythonOpenCV系列:Python和OpenCV的结合和发展 **引言****Python语言的发展****1.1 Python的诞生与发展****1.2 Python的核心特性与优势****1.3 Python的应用领域** **OpenCV的发展****2.1 OpenCV的起源与发展****2.2 OpenCV的功能特性****2.3 OpenCV的应用场景** *…...

报错 JSON.parse: expected property name or ‘}‘,JSON数据中对象的key值不为字符串
报错 JSON.parse: expected property name or ‘}’ 原因 多是因为数据转换时出错,可能是存在单引号或者对象key值不为string导致 这里记录下我遇见的问题(后端给的JSON数据里,对象key值不为string) 现在后端转换JSON数据大多…...

Flutter:商品多规格内容总结,响应式数据,高亮切换显示。
如图所示: 代码为练习时写的项目,写的一般,功能实现了,等以后再来优化。 自己模拟的数据结构 var data {id:1,name:精品小米等多种五谷杂粮精品小等多种五谷杂粮,logo:https://cdn.uviewui.com/uview/swiper/1.jpg,price:100.5…...

WPF+LibVLC开发播放器-LibVLC播放控制
接上一篇: LibVLC在C#中的使用 实现LibVLC播放器播放控制 界面 界面上添加一个Button按钮用于控制播放 <ButtonGrid.Row"1"Width"88"Height"24"Margin"10,0,0,0"HorizontalAlignment"Left"VerticalAlignme…...

Mac环境下brew安装LNMP
安装不同版本PHP 在Mac环境下同时运行多个版本的PHP,同Linux环境一样,都是将后台运行的php-fpm设置为不同的端口号,下面将已php7.2 和 php7.4为例 添加 tap 目的:homebrew仅保留最近的php版本,可能没有你需要的版本…...

nodejs后端项目使用pm2部署
nodejs后端项目使用pm2部署 安装pm2 npm install pm2 -g查看版本号 pm2 --version启动项目 pm2 start app.js# 设置别名 pm2 start app.js --name demo停止项目 pm2 stop [AppName] pm2 stop [ID]# 停止所有项目 pm2 stop all重启项目 pm2 restart [AppName] pm2 re…...

【C++】深入理解字符变量取地址的特殊性与内存管理机制详解
博客主页: [小ᶻ☡꙳ᵃⁱᵍᶜ꙳] 本文专栏: C 文章目录 💯前言💯栈内存中的变量分配:谁先谁后?cout 的输出行为:按顺序执行,按地址递增读取代码执行顺序与内存布局的关系编译器优化的影响 &…...

【银河麒麟操作系统真实案例分享】内存黑洞导致服务器卡死分析全过程
了解更多银河麒麟操作系统全新产品,请点击访问 麒麟软件产品专区:https://product.kylinos.cn 开发者专区:https://developer.kylinos.cn 文档中心:https://documentkylinos.cn 现象描述 机房显示器连接服务器后黑屏ÿ…...

蓝桥杯软件赛系列---lesson1
🌈个人主页:羽晨同学 💫个人格言:“成为自己未来的主人~” 我们今天会再开一个系列,那就是蓝桥杯系列,我们会从最基础的开始讲起,大家想要备战明年蓝桥杯的,让我们一起加油。 工具安装 DevC…...

工业异常检测-CVPR2024-新的3D异常数据合成办法和自监督网络IMRNet
论文:https://arxiv.org/pdf/2311.14897v3.pdf 项目:https://github.com/chopper-233/anomaly-shapenet 这篇论文主要关注的是3D异常检测和定位,这是一个在工业质量检查中至关重要的任务。作者们提出了一种新的方法来合成3D异常数据&#x…...

HeidiSQL:MySQL图形化管理工具深度解析
本文还有配套的精品资源,点击获取 简介:HeidiSQL是一款开源的MySQL图形化管理工具,适用于多种数据库系统,如MySQL、MariaDB、SQL Server、PostgreSQL和SQLite。其提供的直观操作界面和丰富的功能简化了数据库操作,包…...

【Redis】深入解析Redis缓存机制:全面掌握缓存更新、穿透、雪崩与击穿的终极指南
文章目录 一、Redis缓存机制概述1.1 Redis缓存的基本原理1.2 常见的Redis缓存应用场景 二、缓存更新机制2.1 缓存更新的策略2.2 示例代码:主动更新缓存 三、缓存穿透3.1 缓存穿透的原因3.2 缓解缓存穿透的方法3.3 示例代码:使用布隆过滤器 四、缓存雪崩4…...
(subprocess))
Flask使用Celery与多进程管理:优雅处理长时间任务与子进程终止技巧(multiprocessing)(subprocess)
在许多任务处理系统中,我们需要使用异步任务队列来处理繁重的计算或长时间运行的任务,如模型训练。Celery是一个广泛使用的分布式任务队列,而在某些任务中,尤其是涉及到调用独立脚本的场景中,我们需要混合使用multipro…...

【PyTorch】torch.distributed.elastic.multiprocessing.errors.ChildFailedError:
报错说明 torch.distributed.elastic.multiprocessing.errors.ChildFailedError: 报错如图所示 报错分析 该报错是 torch 和 CUDA 版本不兼容导致。 (一般N卡自带的CUDA版本与最新的torch版本相差较大) 解决方案 1.查看自己的CUDA版本 # 查看自己的…...
,有通讯的发送和接收消息界面)
使用android studio写一个Android的远程通信软件(APP),有通讯的发送和接收消息界面
以下是使用 Android Studio 基于 Java 语言编写一个简单的 Android APP 实现远程通信(这里以 TCP 通信为例)的代码示例,包含基本的通信界面以及发送和接收消息功能。 1. 创建项目 打开 Android Studio,新建一个 Empty Activity …...

突破空间限制!从2D到3D:北大等开源Lift3D,助力精准具身智能操作!
文章链接:https://arxiv.org/pdf/2411.18623 项目链接:https://lift3d-web.github.io/ 亮点直击 提出了Lift3D,通过系统地提升隐式和显式的3D机器人表示,提升2D基础模型,构建一个3D操作策略。 对于隐式3D机器人表示&a…...

Android KEY的哪些事儿
目录 一、APK应用签名 1、什么是APK应用签名? 1.1 目的和作用? 1.2 长什么样子? 2、APK应用签名使用流程 步骤一:如何生成APK应用签名文件? 步骤二:如何集成APK应用签名文件? 步骤三&am…...

李宏毅深度学习-Pytorch Tutorial2
什么是张量? 张量(Tensor)是深度学习和机器学习中一个非常基础且重要的概念。在数学上,张量可以被看作是向量和矩阵的泛化。简单来说,张量是一种多维数组,它可以表示标量(0维)、向量…...
 创建选择屏幕)
【译】为 SAP 表维护视图 (SM30) 创建选择屏幕
原文标题:Create Selection Screen for SAP Table Maintenance View (SM30) 原文链接: https://www.saphub.com/abap-dictionary/sap-abap-tmg-selection-screen/ 通常,带有单个屏幕的 SAP 表维护视图 (SM30) 会显示表中的所有记录ÿ…...

element Plus中 el-table表头宽度自适应,不换行
在工作中,使用el-table表格进行开发后,遇到了小屏幕显示器上显示表头文字会出现换行展示,比较影响美观,因此需要让表头的宽度变为不换行,且由内容自动撑开。 以下是作为工作记录,用于demo演示教程 先贴个…...

C语言程序设计P5-4【应用函数进行程序设计 | 第四节】——知识要点:数组作函数参数
知识要点:数组作函数参数 视频: 目录 一、任务分析 二、必备知识与理论 三、任务实施 一、任务分析 任务要求用选择法对数组中的 10 个整数按由小到大的顺序排序,前面在讲解数组时讲冒泡法排序曾提到选择法排序的思想。 所谓选择法就是…...

时间序列模型在LSTM中的特征输入
这里写目录标题 前言LSTM的输入组成时间步例子 实际代码解读特征提取处理成dataloader格式(用于输入到模型当中)对应到lstm的模型创建代码 总结 前言 本文章将帮助理解如何将一个时间序列的各种特征(年月日的时间特征,滚动窗口滞…...

Python_Flask02
所有人都不许学Java了,都来学Python! 如果不来学的话请网爆我的老师 连接前的准备 安装pymysql 和 flask_sqlalchemy,安装第三下面两个所需要的包才能连接上数据库 pip install pymysql pip install flask_sqlalchemy pymysql是一个Pyth…...

threejs相机辅助对象cameraHelper
为指定相机创建一个辅助对象,显示这个相机的视锥。 想要在场景里面显示相机的视锥,需要创建两个相机。 举个例子,场景中有个相机A,想要显示相机A的视锥,那么需要一个相机B,把B放在A的后面,两个…...

断点续传+测试方法完整示例
因为看不懂网上的断点续传案例,而且又不能直接复制使用,干脆自己想想写了一个。 上传入参类: import com.fasterxml.jackson.annotation.JsonIgnore; import io.swagger.annotations.ApiModel; import io.swagger.annotations.ApiModelProp…...
)
C#设计模式--状态模式(State Pattern)
状态模式是一种行为设计模式,它允许对象在其内部状态发生变化时改变其行为。这种模式的核心思想是将状态封装在独立的对象中,而不是将状态逻辑散布在整个程序中。 用途 简化复杂的条件逻辑:通过将不同的状态封装在不同的类中,可…...

Excel技巧:如何批量调整excel表格中的图片?
插入到excel表格中的图片大小不一,如何做到每张图片都完美的与单元格大小相同?并且能够根据单元格来改变大小?今天分享,excel表格里的图片如何批量调整大小。 方法如下: 点击表格中的一个图片,然后按住Ct…...

hadoop中导出表与数据的步骤
大家好,我是 V 哥。在Hadoop中导出表与数据,可以通过多种方式实现,包括使用Hive的EXPORT命令、MapReduce作业、Hive查询以及Sqoop工具。下面V 哥将详细介绍这些步骤和一些代码示例,来帮助大家更好理解。 1. 使用Hive的EXPORT命令…...

springBoot中的日志级别在哪里配置
在Spring Boot中,日志级别的配置可以通过多种方式来实现,主要包括在配置文件中设置、使用自定义的logback配置文件,以及在代码中动态配置等。以下是一些具体的配置方法: 一、在配置文件中设置日志级别 Spring Boot默认使用appli…...

17. Threejs案例-Three.js创建多个立方体
17. Threejs案例-Three.js创建多个立方体 实现效果 知识点 WebGLRenderer (WebGL渲染器) WebGLRenderer 是 Three.js 中用于渲染 WebGL 场景的核心类。它负责将场景中的对象渲染到画布上。 构造器 new THREE.WebGLRenderer(parameters) 参数类型描述parametersObject可选…...

数据结构——有序二叉树的删除
在上一篇博客中,我们介绍了有序二叉树的构建、遍历、查找。 数据结构——有序二叉树的构建&遍历&查找-CSDN博客文章浏览阅读707次,点赞18次,收藏6次。因为数据的类型决定数据在内存中的存储形式。left right示意为左右节点其类型也为…...

力扣1401. 圆和矩形是否有重叠
用矢量计算: class Solution { public:bool checkOverlap(int radius, int xCenter, int yCenter, int x1, int y1, int x2, int y2) {//矩形中心float Tx(float)(x1x2)/2;float Ty(float)(y1y2)/2;//强行进行对称操作,只考虑第一象限if(xCenter<Tx)…...

idea连接到docker出现 org.apache.hc.client5.http.ConnectTimeoutException 异常怎么办?
前情提要 我电脑是win11,我安装了centOS7虚拟机,配置linux环境 idea是2024社区免费版本 我就这一步步排查问题,终于发现了是因为我的2375端口没有ipv4开放,只在ipv6开放 踩坑提醒: 对了,一个一个问题排…...

一番赏小程序定制开发,打造全新抽赏体验平台
随着盲盒的热潮来袭,作为传统的潮玩方式一番赏也再次受到了大家的关注,市场热度不断上升! 一番赏能够让玩家百分百中奖,商品种类丰富、收藏价值高,拥有各种IP,从而吸引着各个圈子的粉丝玩家,用…...