用 Python 从零开始创建神经网络(十四):L1 和 L2 正则化(L1 and L2 Regularization)
L1 和 L2 正则化(L1 and L2 Regularization)
- 引言
- 1. Forward Pass
- 2. Backward pass
- 到此为止的全部代码:
引言
正则化方法旨在降低泛化误差。我们首先讨论的正则化形式是L1正则化和L2正则化。L1和L2正则化用于计算一个数值(称为惩罚项),将其添加到损失值中,以惩罚模型中权重和偏置过大的情况。过大的权重可能表明某个神经元试图记忆数据元素;一般认为,让多个神经元共同对模型输出做出贡献要比依赖少数几个神经元更好。
1. Forward Pass
L1正则化的惩罚项是所有权重和偏置绝对值的总和。这是一种线性惩罚,因为这种正则化函数返回的损失值与参数值成正比。而L2正则化的惩罚项是所有权重和偏置平方值的总和。这种非线性方法因为使用平方函数来计算结果,对较大的权重和偏置施加了比小权重和偏置更大的惩罚。换句话说,L2正则化通常被使用,因为它对小参数值的影响不大,并通过对相对较大的值施加较重的惩罚,防止模型权重增长过大。而L1正则化由于其线性性质,对小权重的惩罚比L2正则化更大,从而使得模型对小输入值的响应逐渐不敏感,仅对较大的输入值敏感。因此,L1正则化很少单独使用,通常是在需要时与L2正则化结合使用。
这类正则化函数会推动权重和参数总和接近0,这在处理梯度爆炸(模型不稳定性导致权重变为非常大的值)时也有帮助。此外,我们还需要控制这种正则化惩罚的影响程度。我们在方程中引入一个被称为lambda的值,较大的lambda值意味着更大的惩罚。
L1权重正则化公式:
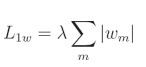
L1偏置正则化公式:
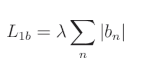
L2权重正则化公式:
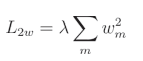
L2偏置正则化公式:
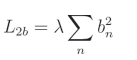
总体损失:
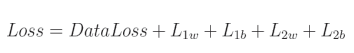
使用代码符号:
l1w = lambda_l1w * sum(abs(weights))
l1b = lambda_l1b * sum(abs(biases))
l2w = lambda_l2w * sum(weights**2)
l2b = lambda_l2b * sum(biases**2)
loss = data_loss + l1w + l1b + l2w + l2b
正则化损失是单独计算的,然后与数据损失相加,形成总体损失。参数 m m m 是遍历模型中所有权重的任意迭代器,参数 n n n 是遍历偏置的等效迭代器, w m w_m wm 是给定的权重, b n b_n bn 是给定的偏置。
为了在神经网络代码中实现正则化,我们将从 Dense 层类的 __init__ 方法开始,该方法将包含正则化强度超参数 λ \lambda λ,因为这些参数可以为每一层单独设置:
# Layer initialization
def __init__(self, inputs, neurons,weight_regularizer_l1=0, weight_regularizer_l2=0,bias_regularizer_l1=0, bias_regularizer_l2=0):# Initialize weights and biasesself.weights = 0.01 * np.random.randn(inputs, neurons)self.biases = np.zeros((1, neurons))# Set regularization strengthself.weight_regularizer_l1 = weight_regularizer_l1self.weight_regularizer_l2 = weight_regularizer_l2self.bias_regularizer_l1 = bias_regularizer_l1self.bias_regularizer_l2 = bias_regularizer_l2
该方法设置了 λ \lambda λ 超参数。现在我们更新损失类,以包括附加的惩罚项(如果我们选择在层的初始化中为任何正则化器设置 λ \lambda λ 超参数)。我们将在 Loss 类中实现此代码,因为它通常适用于隐藏层。此外,正则化计算是相同的,无论使用何种类型的损失函数。正则化仅仅是一个与数据损失值相加的惩罚项,从而得到最终的总体损失值。因此,我们将在通用损失类中添加一个新方法,该类由我们所有具体的损失函数(例如现有的 Loss_CategoricalCrossentropy)继承。
对于该方法的代码,我们将创建层的正则化损失变量。如果对应的 λ \lambda λ 值大于 0,我们会将每个原子正则化损失添加到该变量中。为了执行这些计算,我们将从传入的层对象中读取 λ \lambda λ 超参数、权重和偏置。对于我们的通用损失类:
# Regularization loss calculation
def regularization_loss(self, layer):# 0 by defaultregularization_loss = 0# L1 regularization - weights# calculate only when factor greater than 0if layer.weight_regularizer_l1 > 0:regularization_loss += layer.weight_regularizer_l1 * np.sum(np.abs(layer.weights))# L2 regularization - weightsif layer.weight_regularizer_l2 > 0:regularization_loss += layer.weight_regularizer_l2 * np.sum(layer.weights * layer.weights)# L1 regularization - biases# calculate only when factor greater than 0if layer.bias_regularizer_l1 > 0:regularization_loss += layer.bias_regularizer_l1 * np.sum(np.abs(layer.biases))# L2 regularization - biasesif layer.bias_regularizer_l2 > 0:regularization_loss += layer.bias_regularizer_l2 * np.sum(layer.biases * layer.biases)return regularization_loss然后,我们将计算正则化损失,并将其添加到训练循环中计算出的损失中:
# Calculate loss from output of activation2 so softmax activation
data_loss = loss_function.forward(activation2.output, y)# Calculate regularization penalty
regularization_loss = loss_function.regularization_loss(dense1) + loss_function.regularization_loss(dense2)# Calculate overall loss
loss = data_loss + regularization_loss
我们创建了一个新的变量 regularization_loss,并将所有层的正则化损失添加到了该变量中。这完成了正则化的前向传播部分,但这也意味着我们的总体损失发生了变化,因为计算的一部分可能包括正则化,这在反向传播梯度时必须加以考虑。因此,我们接下来将介绍 L 1 L1 L1 和 L 2 L2 L2 正则化的偏导数。
2. Backward pass
L2 正则化的导数相对简单:
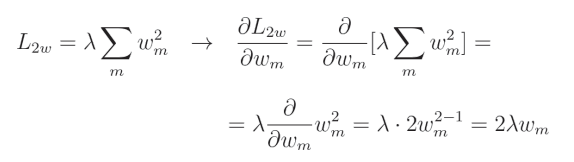
这看起来可能很复杂,但实际上是本书中需要推导的较为简单的导数之一。由于 λ \lambda λ 是常数,因此我们可以将其移出导数项之外。我们可以去掉求和符号,因为我们仅计算针对给定参数的偏导数,而单个元素的求和等于其自身。因此,我们只需要计算 w 2 w^2 w2 的导数,我们知道其导数为 2 w 2w 2w。从编码的角度看,我们只需将所有权重乘以 2 λ 2\lambda 2λ。我们将直接使用 NumPy 来实现这一点,因为这仅是一个简单的乘法操作。
另一方面, L 1 L1 L1 正则化的导数需要更多的解释。在 L 1 L1 L1 正则化的情况下,我们必须分段计算绝对值函数的导数,这实际上是将值乘以 − 1 -1 −1(如果值小于 0),否则乘以 1 1 1。这是因为绝对值函数对于正值是线性的,而我们知道线性函数的导数为:
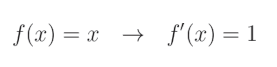
对于负值,它会将值的符号取反以使其变为正值。换句话说,它将值乘以 − 1 -1 −1:
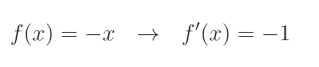
当我们把这些结合起来:
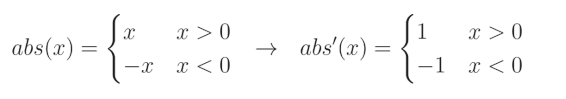
以及 L 1 L1 L1 正则化关于给定权重的完全偏导数:
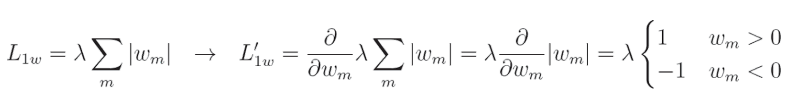
像 L 2 L2 L2正则化一样, λ \lambda λ是一个常数,我们计算该正则化相对于特定输入的偏导数。在这种情况下,偏导数等于1或 − 1 -1 −1,具体取决于 w m w_m wm(权重)的值。
我们正在对权重计算这个偏导数,并将得到的梯度用于更新权重。这个梯度与权重的形状相同。用纯Python代码表达如下:
weights = [0.2, 0.8, -0.5] # weights of one neuron
dL1 = [] # array of partial derivatives of L1 regularization
for weight in weights:if weight >= 0:dL1.append(1)else:dL1.append(-1)
print(dL1)
>>>
[1, 1, -1]
你可能注意到,我们在代码中使用的是 ≥ 0 \geq 0 ≥0,而上面的公式显然描述的是 > 0 > 0 >0。如果我们观察np.abs函数,它的图像是一条向下的直线,在值为 0 0 0的位置“反弹”,类似锯齿的形状。在尖端(即值为 0 0 0的位置),np.abs函数的导数是未定义的,但我们无法以这种方式编码,因此我们需要处理这种情况,并稍微违反一下规则。
现在,让我们尝试修改这个 L 1 L1 L1,导数,使其可以处理一个层中的多个神经元:
weights = [[0.2, 0.8, -0.5, 1], # now we have 3 sets of weights[0.5, -0.91, 0.26, -0.5],[-0.26, -0.27, 0.17, 0.87]]
dL1 = [] # array of partial derivatives of L1 regularization
for neuron in weights:neuron_dL1 = [] # derivatives related to one neuronfor weight in neuron:if weight >= 0:neuron_dL1.append(1)else:neuron_dL1.append(-1)dL1.append(neuron_dL1)
print(dL1)
>>>
[[1, 1, -1, 1], [1, -1, 1, -1], [-1, -1, 1, 1]]
这是原生Python版本的实现,现在使用NumPy实现。借助NumPy,我们将使用条件和二进制掩码来实现。我们将创建一个梯度数组,其值全部为1,并且形状与权重相同,使用np.ones_like(weights)。接着,条件weights < 0将返回一个与dL1形状相同的数组,其中条件为假时值为0,为真时值为1。我们将其作为dL1的二进制掩码,仅在条件为真时(权重值小于0)将值设置为-1:
import numpy as npweights = np.array([[0.2, 0.8, -0.5, 1],[0.5, -0.91, 0.26, -0.5],[-0.26, -0.27, 0.17, 0.87]])dL1 = np.ones_like(weights)dL1[weights < 0] = -1print(dL1)
>>>
[[ 1. 1. -1. 1.][ 1. -1. 1. -1.][-1. -1. 1. 1.]]
这段代码返回了一个与原始权重形状相同的数组,包含值1和-1——这是对np.abs函数的偏导数梯度(我们仍然需要将其乘以lambda超参数)。现在,我们可以使用这些值来更新密集层对象的反向传播方法。对于L1正则化,我们将上述代码乘以权重的 λ \lambda λ,并对偏置执行相同的操作。对于L2正则化,如本章开头所述,我们需要做的只是将权重/偏置乘以 2 λ 2\lambda 2λ,然后将这个结果加到梯度中:
# Dense layer
class Layer_Dense: ...# Backward passdef backward(self, dvalues):# Gradients on parametersself.dweights = np.dot(self.inputs.T, dvalues)self.dbiases = np.sum(dvalues, axis=0, keepdims=True)# Gradients on regularization# L1 on weightsif self.weight_regularizer_l1 > 0:dL1 = np.ones_like(self.weights)dL1[self.weights < 0] = -1self.dweights += self.weight_regularizer_l1 * dL1# L2 on weightsif self.weight_regularizer_l2 > 0:self.dweights += 2 * self.weight_regularizer_l2 * self.weights# L1 on biasesif self.bias_regularizer_l1 > 0:dL1 = np.ones_like(self.biases)dL1[self.biases < 0] = -1self.dbiases += self.bias_regularizer_l1 * dL1# L2 on biasesif self.bias_regularizer_l2 > 0:self.dbiases += 2 * self.bias_regularizer_l2 * self.biases# Gradient on valuesself.dinputs = np.dot(dvalues, self.weights.T)
这样,我们就可以更新我们的印刷品,加入新的信息–正则化损失和总体损失:
print(f'epoch: {epoch}, ' +f'acc: {accuracy:.3f}, ' +f'loss: {loss:.3f} (' +f'data_loss: {data_loss:.3f}, ' +f'reg_loss: {regularization_loss:.3f}), ' +f'lr: {optimizer.current_learning_rate}')
然后,我们可以在定义图层时添加权重和偏置正则参数:
# Create Dense layer with 2 input features and 3 output values
dense1 = Layer_Dense(2, 64, weight_regularizer_l2=5e-4, bias_regularizer_l2=5e-4)
我们通常只对隐藏层添加正则化项。即使我们也对输出层调用了正则化方法,如果我们没有将lambda超参数设置为非零值,正则化方法也不会修改梯度。
到此为止的全部代码:
import numpy as np
import nnfs
from nnfs.datasets import spiral_datannfs.init()# Dense layer
class Layer_Dense:# Layer initializationdef __init__(self, n_inputs, n_neurons,weight_regularizer_l1=0, weight_regularizer_l2=0,bias_regularizer_l1=0, bias_regularizer_l2=0):# Initialize weights and biasesself.weights = 0.01 * np.random.randn(n_inputs, n_neurons)self.biases = np.zeros((1, n_neurons))# Set regularization strengthself.weight_regularizer_l1 = weight_regularizer_l1self.weight_regularizer_l2 = weight_regularizer_l2self.bias_regularizer_l1 = bias_regularizer_l1self.bias_regularizer_l2 = bias_regularizer_l2# Forward passdef forward(self, inputs):# Remember input valuesself.inputs = inputs# Calculate output values from inputs, weights and biasesself.output = np.dot(inputs, self.weights) + self.biases# Backward passdef backward(self, dvalues):# Gradients on parametersself.dweights = np.dot(self.inputs.T, dvalues)self.dbiases = np.sum(dvalues, axis=0, keepdims=True)# Gradients on regularization# L1 on weightsif self.weight_regularizer_l1 > 0:dL1 = np.ones_like(self.weights)dL1[self.weights < 0] = -1self.dweights += self.weight_regularizer_l1 * dL1# L2 on weightsif self.weight_regularizer_l2 > 0:self.dweights += 2 * self.weight_regularizer_l2 * self.weights# L1 on biasesif self.bias_regularizer_l1 > 0:dL1 = np.ones_like(self.biases)dL1[self.biases < 0] = -1self.dbiases += self.bias_regularizer_l1 * dL1# L2 on biasesif self.bias_regularizer_l2 > 0:self.dbiases += 2 * self.bias_regularizer_l2 * self.biases# Gradient on valuesself.dinputs = np.dot(dvalues, self.weights.T)# ReLU activation
class Activation_ReLU: # Forward passdef forward(self, inputs):# Remember input valuesself.inputs = inputs# Calculate output values from inputsself.output = np.maximum(0, inputs)# Backward passdef backward(self, dvalues):# Since we need to modify original variable,# let's make a copy of values firstself.dinputs = dvalues.copy()# Zero gradient where input values were negativeself.dinputs[self.inputs <= 0] = 0# Softmax activation
class Activation_Softmax: # Forward passdef forward(self, inputs):# Remember input valuesself.inputs = inputs# Get unnormalized probabilitiesexp_values = np.exp(inputs - np.max(inputs, axis=1, keepdims=True))# Normalize them for each sampleprobabilities = exp_values / np.sum(exp_values, axis=1, keepdims=True)self.output = probabilities# Backward passdef backward(self, dvalues):# Create uninitialized arrayself.dinputs = np.empty_like(dvalues)# Enumerate outputs and gradientsfor index, (single_output, single_dvalues) in enumerate(zip(self.output, dvalues)):# Flatten output arraysingle_output = single_output.reshape(-1, 1)# Calculate Jacobian matrix of the output andjacobian_matrix = np.diagflat(single_output) - np.dot(single_output, single_output.T)# Calculate sample-wise gradient# and add it to the array of sample gradientsself.dinputs[index] = np.dot(jacobian_matrix, single_dvalues)# SGD optimizer
class Optimizer_SGD:# Initialize optimizer - set settings,# learning rate of 1. is default for this optimizerdef __init__(self, learning_rate=1., decay=0., momentum=0.):self.learning_rate = learning_rateself.current_learning_rate = learning_rateself.decay = decayself.iterations = 0self.momentum = momentum # Call once before any parameter updatesdef pre_update_params(self):if self.decay:self.current_learning_rate = self.learning_rate * (1. / (1. + self.decay * self.iterations))# Update parametersdef update_params(self, layer): # If we use momentumif self.momentum:# If layer does not contain momentum arrays, create them# filled with zerosif not hasattr(layer, 'weight_momentums'):layer.weight_momentums = np.zeros_like(layer.weights)# If there is no momentum array for weights# The array doesn't exist for biases yet either.layer.bias_momentums = np.zeros_like(layer.biases)# Build weight updates with momentum - take previous# updates multiplied by retain factor and update with# current gradientsweight_updates = self.momentum * layer.weight_momentums - self.current_learning_rate * layer.dweightslayer.weight_momentums = weight_updates# Build bias updatesbias_updates = self.momentum * layer.bias_momentums - self.current_learning_rate * layer.dbiaseslayer.bias_momentums = bias_updates# Vanilla SGD updates (as before momentum update)else:weight_updates = -self.current_learning_rate * layer.dweightsbias_updates = -self.current_learning_rate * layer.dbiases# Update weights and biases using either# vanilla or momentum updateslayer.weights += weight_updateslayer.biases += bias_updates# Call once after any parameter updatesdef post_update_params(self):self.iterations += 1# Adagrad optimizer
class Optimizer_Adagrad:# Initialize optimizer - set settingsdef __init__(self, learning_rate=1., decay=0., epsilon=1e-7):self.learning_rate = learning_rateself.current_learning_rate = learning_rateself.decay = decayself.iterations = 0self.epsilon = epsilon # Call once before any parameter updatesdef pre_update_params(self):if self.decay:self.current_learning_rate = self.learning_rate * (1. / (1. + self.decay * self.iterations))# Update parametersdef update_params(self, layer):# If layer does not contain cache arrays,# create them filled with zerosif not hasattr(layer, 'weight_cache'):layer.weight_cache = np.zeros_like(layer.weights)layer.bias_cache = np.zeros_like(layer.biases)# Update cache with squared current gradientslayer.weight_cache += layer.dweights**2layer.bias_cache += layer.dbiases**2# Vanilla SGD parameter update + normalization# with square rooted cachelayer.weights += -self.current_learning_rate * layer.dweights / (np.sqrt(layer.weight_cache) + self.epsilon)layer.biases += -self.current_learning_rate * layer.dbiases / (np.sqrt(layer.bias_cache) + self.epsilon) # Call once after any parameter updatesdef post_update_params(self):self.iterations += 1 # RMSprop optimizer
class Optimizer_RMSprop: # Initialize optimizer - set settingsdef __init__(self, learning_rate=0.001, decay=0., epsilon=1e-7, rho=0.9):self.learning_rate = learning_rateself.current_learning_rate = learning_rateself.decay = decayself.iterations = 0self.epsilon = epsilonself.rho = rho # Call once before any parameter updatesdef pre_update_params(self):if self.decay:self.current_learning_rate = self.learning_rate * (1. / (1. + self.decay * self.iterations))# Update parametersdef update_params(self, layer):# If layer does not contain cache arrays,# create them filled with zerosif not hasattr(layer, 'weight_cache'):layer.weight_cache = np.zeros_like(layer.weights)layer.bias_cache = np.zeros_like(layer.biases)# Update cache with squared current gradientslayer.weight_cache = self.rho * layer.weight_cache + (1 - self.rho) * layer.dweights**2layer.bias_cache = self.rho * layer.bias_cache + (1 - self.rho) * layer.dbiases**2# Vanilla SGD parameter update + normalization# with square rooted cachelayer.weights += -self.current_learning_rate * layer.dweights / (np.sqrt(layer.weight_cache) + self.epsilon)layer.biases += -self.current_learning_rate * layer.dbiases / (np.sqrt(layer.bias_cache) + self.epsilon)# Call once after any parameter updatesdef post_update_params(self):self.iterations += 1# Adam optimizer
class Optimizer_Adam:# Initialize optimizer - set settingsdef __init__(self, learning_rate=0.001, decay=0., epsilon=1e-7, beta_1=0.9, beta_2=0.999):self.learning_rate = learning_rateself.current_learning_rate = learning_rateself.decay = decayself.iterations = 0self.epsilon = epsilonself.beta_1 = beta_1self.beta_2 = beta_2 # Call once before any parameter updatesdef pre_update_params(self):if self.decay:self.current_learning_rate = self.learning_rate * (1. / (1. + self.decay * self.iterations))# Update parametersdef update_params(self, layer):# If layer does not contain cache arrays,# create them filled with zerosif not hasattr(layer, 'weight_cache'):layer.weight_momentums = np.zeros_like(layer.weights)layer.weight_cache = np.zeros_like(layer.weights)layer.bias_momentums = np.zeros_like(layer.biases)layer.bias_cache = np.zeros_like(layer.biases)# Update momentum with current gradientslayer.weight_momentums = self.beta_1 * layer.weight_momentums + (1 - self.beta_1) * layer.dweightslayer.bias_momentums = self.beta_1 * layer.bias_momentums + (1 - self.beta_1) * layer.dbiases# Get corrected momentum# self.iteration is 0 at first pass# and we need to start with 1 hereweight_momentums_corrected = layer.weight_momentums / (1 - self.beta_1 ** (self.iterations + 1))bias_momentums_corrected = layer.bias_momentums / (1 - self.beta_1 ** (self.iterations + 1))# Update cache with squared current gradientslayer.weight_cache = self.beta_2 * layer.weight_cache + (1 - self.beta_2) * layer.dweights**2layer.bias_cache = self.beta_2 * layer.bias_cache + (1 - self.beta_2) * layer.dbiases**2# Get corrected cacheweight_cache_corrected = layer.weight_cache / (1 - self.beta_2 ** (self.iterations + 1))bias_cache_corrected = layer.bias_cache / (1 - self.beta_2 ** (self.iterations + 1))# Vanilla SGD parameter update + normalization# with square rooted cachelayer.weights += -self.current_learning_rate * weight_momentums_corrected / (np.sqrt(weight_cache_corrected) + self.epsilon)layer.biases += -self.current_learning_rate * bias_momentums_corrected / (np.sqrt(bias_cache_corrected) + self.epsilon)# Call once after any parameter updatesdef post_update_params(self):self.iterations += 1# Common loss class
class Loss: # Regularization loss calculationdef regularization_loss(self, layer):# 0 by defaultregularization_loss = 0# L1 regularization - weights# calculate only when factor greater than 0if layer.weight_regularizer_l1 > 0:regularization_loss += layer.weight_regularizer_l1 * np.sum(np.abs(layer.weights))# L2 regularization - weightsif layer.weight_regularizer_l2 > 0:regularization_loss += layer.weight_regularizer_l2 * np.sum(layer.weights * layer.weights)# L1 regularization - biases# calculate only when factor greater than 0if layer.bias_regularizer_l1 > 0:regularization_loss += layer.bias_regularizer_l1 * np.sum(np.abs(layer.biases))# L2 regularization - biasesif layer.bias_regularizer_l2 > 0:regularization_loss += layer.bias_regularizer_l2 * np.sum(layer.biases * layer.biases)return regularization_loss# Calculates the data and regularization losses# given model output and ground truth valuesdef calculate(self, output, y):# Calculate sample lossessample_losses = self.forward(output, y)# Calculate mean lossdata_loss = np.mean(sample_losses)# Return lossreturn data_loss# Cross-entropy loss
class Loss_CategoricalCrossentropy(Loss):# Forward passdef forward(self, y_pred, y_true):# Number of samples in a batchsamples = len(y_pred)# Clip data to prevent division by 0# Clip both sides to not drag mean towards any valuey_pred_clipped = np.clip(y_pred, 1e-7, 1 - 1e-7)# Probabilities for target values -# only if categorical labelsif len(y_true.shape) == 1:correct_confidences = y_pred_clipped[range(samples), y_true] # Mask values - only for one-hot encoded labelselif len(y_true.shape) == 2:correct_confidences = np.sum(y_pred_clipped * y_true, axis=1)# Lossesnegative_log_likelihoods = -np.log(correct_confidences)return negative_log_likelihoods# Backward passdef backward(self, dvalues, y_true):# Number of samplessamples = len(dvalues)# Number of labels in every sample# We'll use the first sample to count themlabels = len(dvalues[0])# If labels are sparse, turn them into one-hot vectorif len(y_true.shape) == 1:y_true = np.eye(labels)[y_true]# Calculate gradientself.dinputs = -y_true / dvalues# Normalize gradientself.dinputs = self.dinputs / samples# Softmax classifier - combined Softmax activation
# and cross-entropy loss for faster backward step
class Activation_Softmax_Loss_CategoricalCrossentropy():# Creates activation and loss function objectsdef __init__(self):self.activation = Activation_Softmax()self.loss = Loss_CategoricalCrossentropy()# Forward passdef forward(self, inputs, y_true):# Output layer's activation functionself.activation.forward(inputs)# Set the outputself.output = self.activation.output# Calculate and return loss valuereturn self.loss.calculate(self.output, y_true) # Backward passdef backward(self, dvalues, y_true):# Number of samplessamples = len(dvalues)# If labels are one-hot encoded,# turn them into discrete valuesif len(y_true.shape) == 2:y_true = np.argmax(y_true, axis=1)# Copy so we can safely modifyself.dinputs = dvalues.copy()# Calculate gradientself.dinputs[range(samples), y_true] -= 1# Normalize gradientself.dinputs = self.dinputs / samples# Create dataset
X, y = spiral_data(samples=100, classes=3)# Create Dense layer with 2 input features and 64 output values
dense1 = Layer_Dense(2, 64, weight_regularizer_l2=5e-4, bias_regularizer_l2=5e-4) # Create ReLU activation (to be used with Dense layer):
activation1 = Activation_ReLU()# Create second Dense layer with 64 input features (as we take output
# of previous layer here) and 3 output values (output values)
dense2 = Layer_Dense(64, 3)# Create Softmax classifier's combined loss and activation
loss_activation = Activation_Softmax_Loss_CategoricalCrossentropy()# Create optimizer
optimizer = Optimizer_Adam(learning_rate=0.02, decay=5e-7) # Train in loop
for epoch in range(10001):# Perform a forward pass of our training data through this layerdense1.forward(X)# Perform a forward pass through activation function# takes the output of first dense layer hereactivation1.forward(dense1.output) # Perform a forward pass through second Dense layer# takes outputs of activation function of first layer as inputsdense2.forward(activation1.output)# Perform a forward pass through the activation/loss function# takes the output of second dense layer here and returns lossdata_loss = loss_activation.forward(dense2.output, y)# Calculate regularization penaltyregularization_loss = loss_activation.loss.regularization_loss(dense1) + loss_activation.loss.regularization_loss(dense2)# Calculate overall lossloss = data_loss + regularization_loss# Calculate accuracy from output of activation2 and targets# calculate values along first axispredictions = np.argmax(loss_activation.output, axis=1)if len(y.shape) == 2:y = np.argmax(y, axis=1)accuracy = np.mean(predictions==y)if not epoch % 100:print(f'epoch: {epoch}, ' +f'acc: {accuracy:.3f}, ' +f'loss: {loss:.3f} (' +f'data_loss: {data_loss:.3f}, ' +f'reg_loss: {regularization_loss:.3f}), ' +f'lr: {optimizer.current_learning_rate}')# Backward passloss_activation.backward(loss_activation.output, y)dense2.backward(loss_activation.dinputs)activation1.backward(dense2.dinputs)dense1.backward(activation1.dinputs)# Update weights and biasesoptimizer.pre_update_params()optimizer.update_params(dense1)optimizer.update_params(dense2)optimizer.post_update_params()# Validate the model
# Create test dataset
X_test, y_test = spiral_data(samples=100, classes=3)# Perform a forward pass of our testing data through this layer
dense1.forward(X_test)# Perform a forward pass through activation function
# takes the output of first dense layer here
activation1.forward(dense1.output)# Perform a forward pass through second Dense layer
# takes outputs of activation function of first layer as inputs
dense2.forward(activation1.output)# Perform a forward pass through the activation/loss function
# takes the output of second dense layer here and returns loss
loss = loss_activation.forward(dense2.output, y_test)# Calculate accuracy from output of activation2 and targets
# calculate values along first axis
predictions = np.argmax(loss_activation.output, axis=1)
if len(y_test.shape) == 2:y_test = np.argmax(y_test, axis=1)
accuracy = np.mean(predictions==y_test)print(f'validation, acc: {accuracy:.3f}, loss: {loss:.3f}')
>>>
epoch: 10000, acc: 0.950, loss: 0.226 (data_loss: 0.165, reg_loss: 0.062), lr: 0.019900507413187767
validation, acc: 0.840, loss: 0.525

代码可视化:https://nnfs.io/abc
此动画展示了背景中的训练数据(暗淡的点)和前景中的验证数据。在向隐藏层添加L2正则化项后,我们实现了更低的验证损失(添加正则化前为0.858,现在为0.435)以及更高的准确率(添加正则化前为0.803,现在为0.830)。我们还可以花点时间举例说明简单增加训练数据量如何带来巨大差异。如果我们将样本量从100增加到1000:
# Create dataset
X, y = spiral_data(samples=1000, classes=3)
然后再次运行代码:
>>>
epoch: 10000, acc: 0.906, loss: 0.331 (data_loss: 0.273, reg_loss: 0.058), lr: 0.019900507413187767
validation, acc: 0.880, loss: 0.339

代码可视化:https://nnfs.io/bcd
我们可以看到,仅此更改也对整体验证准确率以及验证和训练准确率之间的差异产生了显著影响——较低的准确率和较高的训练损失表明模型的容量可能太低。之前较大的差异现在变小了,这表明模型之前很可能存在过拟合现象。从理论上讲,这种正则化允许我们创建更大的模型而不必担心过拟合(或记忆化)。我们可以通过增加每层的神经元数量来测试这一点。将每层神经元数量增加到128或256有助于提高训练准确率,但对验证准确率的提升并不显著:
# Create Dense layer with 2 input features and 256 output values
dense1 = Layer_Dense(2, 256, weight_regularizer_l2=5e-4, bias_regularizer_l2=5e-4)# Create ReLU activation (to be used with Dense layer):
activation1 = Activation_ReLU()# Create second Dense layer with 256 input features (as we take output
# of previous layer here) and 3 output values (output values)
dense2 = Layer_Dense(256, 3)
>>>
epoch: 10000, acc: 0.917, loss: 0.255 (data_loss: 0.215, reg_loss: 0.040), lr: 0.019900507413187767
validation, acc: 0.893, loss: 0.331
这并没有对结果产生多大影响,但将这一数字再次提高到 512 确实也提高了验证的准确性和损失:
# Create Dense layer with 2 input features and 256 output values
dense1 = Layer_Dense(2, 512, weight_regularizer_l2=5e-4, bias_regularizer_l2=5e-4)# Create ReLU activation (to be used with Dense layer):
activation1 = Activation_ReLU()# Create second Dense layer with 256 input features (as we take output
# of previous layer here) and 3 output values (output values)
dense2 = Layer_Dense(512, 3)
>>>
epoch: 10000, acc: 0.921, loss: 0.263 (data_loss: 0.214, reg_loss: 0.049), lr: 0.019900507413187767
validation, acc: 0.913, loss: 0.279

代码可视化:https://nnfs.io/cde
在这种情况下,我们可以看到样本内数据和样本外数据的准确率和损失几乎相同。从这里开始,我们可以添加更多的层和神经元,或者两者兼有。可以随意尝试调整,以进一步改进模型。接下来,我们将介绍另一种正则化方法:Dropout(随机失活)。
本章的章节代码、更多资源和勘误表:https://nnfs.io/ch14
相关文章:
:L1 和 L2 正则化(L1 and L2 Regularization))
用 Python 从零开始创建神经网络(十四):L1 和 L2 正则化(L1 and L2 Regularization)
L1 和 L2 正则化(L1 and L2 Regularization) 引言1. Forward Pass2. Backward pass到此为止的全部代码: 引言 正则化方法旨在降低泛化误差。我们首先讨论的正则化形式是L1正则化和L2正则化。L1和L2正则化用于计算一个数值(称为惩…...

特殊的数学性质
一个数模9的结果等于它的每一位数相加和模9...

最长递增子序列&什么是继承性?C++中如何实现继承?继承的好处和注意事项有哪些?
最长递增子序列 方法一:暴力二维dp,初始状态:每个元素至少和自己构成一个上升序列,大小为1,状态转移:找到前面结尾数字小于当前数组元素的最长序列,当前位置的长度就是lenpre1. class Solutio…...
:架构QML App Architecture Best Practices)
汽车IVI中控开发入门及进阶(三十五):架构QML App Architecture Best Practices
在Qt/QML工程的架构中,架构很重要,虽然本身它有分层,比如QML调用资源文件(图片等)显示GUI界面,后面的CPP文件实现界面逻辑,但是这个分类还有点粗。在实际开发中,界面逻辑也就是基于类cpp的实现,也开始使用各种面向对象的设计模式,实现更加优秀的开发架构,这点尤其在…...
)
面试题整理(二)
芯冰乐知识星球入口:芯冰乐...

编码及其代码
编码 形成文字所需bit点------有相应代号(编码---有好多种8/16/24/32)都已提前形成好,放哪哪就会形成那个文字 同一个文字在不同编码存的码不一样 用一种编码存的话,如果用另一种编码解析就会出现乱码 Windows默认编码为ANSI …...
+chromedriver最新版 定位爬取嵌套shadow-root(open)中内容)
python selenium(4+)+chromedriver最新版 定位爬取嵌套shadow-root(open)中内容
废话不多说,直接开始 本文以无界作为本文测试案例,抓取shadow-root(open)下的内容 shadow Dom in selenium: 首先先讲一下shadow Dom in selenium 版本的区别,链接指向这里 在Selenium 4版本 以及 chrom…...

AutoClass加载预训练实例
AutoClass 由于 Transformer 架构种类繁多,AtuoClass可以创建一个你想要的做模型架构。作为 🤗 Transformer 核心理念的一部分,使库易于使用、简单且灵活,可以AutoClass从给定的检查点自动推断和加载正确的架构。该from_pretrain…...

在 CentOS 上安装 NFS 服务器
文章目录 1. 在 CentOS 上安装 NFS 服务器1.1 安装 NFS 服务器软件包1.2 配置 NFS 共享目录1.3 配置 NFS 导出文件1.4 启动并启用 NFS 服务1.5 导出共享目录1.6 配置防火墙1.7 检查 NFS 状态 2. 在 CentOS 上安装 NFS 客户端2.1 安装 NFS 客户端软件包2.2 挂载 NFS 共享2.3 配置…...

utf8mb4_unicode_ci、utf8mb4_general_ci、utf8mb4_0900_ai_ci; Mysql 排序字符集的优缺点和选择
标题内容 Mysql的排序字符集真让人头疼,如果两个表的排序字符集不一致,还会导致在进行字段比较的时候直接报错。下面分析几个常用的字符集的优劣和选择。 utf8mb4_unicode_ci 特点 Unicode 标准兼容性高:它是基于 Unicode 标准的排序规则&a…...

星宸SSC8836Q/SSC8836Q-H
SSC8836Q产品是高度集成的多媒体片上系统(SoC)产品,适用于汽车和运动/运动相机等高分辨率智能视频录制和播放应用。 该芯片包括64位双核RISC处理器,先进的图像信号处理器(ISP),高性能的H.265/H。264/MJPEG视频编解码器,智能处理单…...

rk3576 , android14 , 编译, 卡死,android.bp , ninja
问题:我在 编译 android14 的时候, 卡死再 analysing android.bp 这里 ,卡了 3,4 个小时。肯定是有问题的。 如图&…...

3、.Net UI库:MaterialSkin - 开源项目研究文章
MaterialSkin 是一个开源的 WinForms 第三方库,提供了许多仿谷歌设计风格的组件,使得 WinForms 窗体程序更加美观。以下是 MaterialSkin 的一些关键特点和使用方法: 主要特点: 仿谷歌设计风格:MaterialSkin 提供了大量…...

2024年构建PHP应用开发环境
文章目录 前言选择合适的PHP版本安装与配置PHP环境Windows平台Linux平台macOS平台 集成Web服务器数据库连接与管理使用Composer进行依赖管理调试工具的选择代码质量管理部署与持续集成安全性考虑参考资料结语 前言 随着互联网的发展,PHP作为一门成熟的服务器端编程…...

苹果手机iPad投屏到安卓电视,不只有AirPlay一种方法,还可以无线远程投屏!
苹果品牌的设备一般都可以使用airplay功能,将一个屏幕投射到另一个屏幕上。如果是跨品牌或跨系统投屏,airplay就未必能够适应。 提供无线投屏和airplay投屏两种方式的AirDroid Cast已经推出TV版本。苹果手机或iPad可以选择无线(远程ÿ…...

什么是内网什么是外网?区别是什么
内网和外网是计算机网络中的两个基本概念,它们在定义、特点和使用场景上有显著的区别。虎观代理小二将带大家详细了解内网与外网的定义以及它们之间的主要差异,帮助读者更好地理解和应用这两种网络。 内网(局域网,LAN࿰…...

基于Springboot+Vue的在线答题闯关系统
基于SpringbootVue的在线答题闯关系统 前言:随着在线教育的快速发展,传统的教育模式逐渐向互联网教育模式转型。在线答题系统作为其中的一个重要组成部分,能够帮助用户通过互动式的学习方式提升知识掌握度。本文基于Spring Boot和Vue.js框架&…...

html css 图片背景透明
html css图标背景透明 css属性: background-color:transparent; mix-blend-mode: multiply; 完整HTML代码: <html><head><title>Test</title></head><body><div id"test" style"background-col…...

Servlet
一 Servlet Servlet (server applet) 是运行在服务端(tomcat)的Java小程序,是sun公司提供一套定义动态资源规范; 从代码层面上来讲Servlet就是一个接口 用来接收、处理客户端请求、响应给浏览器的动态资源。在整个Web应用中,Servlet主要负责接收处理请求…...

MySQL用法---MySQL Workbench创建数据库和表
1. 连接数据库 打开软件,点击左下角卡片,输入设置的数据库密码,勾选单选框 2. 了解主页面的组成部分 3. 创建数据库 先点击工具栏的创建按钮 再输入数据库名称 点击 Apply 创建 4. 创建数据表 展开数据库,在Tables上右键&…...
)
WordPress Elementor Page Builde 任意文件读取漏洞复现(CVE-2024-9935)
0x01 产品描述: WordPress Elementor Page Builder 是一款 WordPress 插件,它允许用户以可视化方式创建和编辑网页。0x02 漏洞描述: WordPress 的 Elementor Page Builder 插件的 PDF 生成器插件在 1.7.5 之前的所有版本中都容易受到路径遍历的攻击,包括 1.7.5 rtw_pgaepb_…...

静态链接和动态链接的特点
静态链接 链接方式:在编译时,所有依赖的库代码被直接打包到生成的可执行文件中。这意味着在程序运行时,不需要再加载任何外部库文件。 优点: 独立性强:生成的可执行文件可以在没有依赖库的系统上直接运行&am…...
)
内核流对象(Kernel Streaming Objects)
内核流对象(Kernel Streaming Objects)是 Windows 系统中用于处理音频、视频等流媒体数据的重要机制。让我详细解释其作用和主要组件: 1. 主要作用: c // 内核流的核心功能 - 音频/视频数据的实时处理 - 多媒体设备驱动开发 - 硬件与软件之间的数据流传…...

Java 在Json对象字符串中查找和提取特定的数据
1、在处理JSON数据时,需要提出个别字段的值,通过正则表达式提取特定的数据 public static void main(String[] args) {//定义多个JSON对象字符串类型,假设每个对象有a,b,c 字段String strJson "{\"a\":1.23,\"b\"…...

21、结构体成员分布
结构体中的成员并不是紧挨着分布的,内存分布遵循字节对齐的原则。 按照成员定义的顺序,遵循字节对齐的原则存储。 字节对齐的原则: 找成员中占据字节数最大的成员,以它为单位进行空间空配 --- 遇到数组看元素的类型 每一个成员距离…...

【深度学习】四大图像分类网络之ResNet
ResNet网络是在2015年由微软实验室中的何凯明等几位提出,在CVPR 2016发表影响深远的网络模型,由何凯明团队提出来,在ImageNet的分类比赛上将网络深度直接提高到了152层,前一年夺冠的VGG只有19层。斩获当年ImageNet竞赛中分类任务第…...

zookeeper学习
解决什么问题? 首先来分析下业务对象,才能对解决的问题进行归纳和总结。它解决的事分布式应用的问题,那么分布式应用会存在哪里问题是由它的业务特性来决定的,这些问题已是为了解决业务的问题。分布式的业务特征有哪些࿱…...

Monkey结合appium模拟操作特定界面
目录 1. 使用 Monkey 操作特定界面(通过UI标识来限制) 2. 结合 uiautomator 或 appium 定位特定元素 步骤: 3. 使用 Monkey Appium 控制特定界面点击 4. 如何结合 Appium 与 Monkey 5. 限制 Monkey 只点击固定界面上的元素 使用 --pc…...

智能指针【C++11】
文章目录 智能指针std::auto_ptr std::unique_ptrstd::shared_ptrstd::shared_ptr的线程安全问题std::weak_ptr 智能指针 std::auto_ptr 管理权转移 auto_ptr是C98中引入的智能指针,auto_ptr通过管理权转移的方式解决智能指针的拷贝问题,保证一个资源…...

plsql 执行存储过程 SYS_REFCURSOR
关键字:plsql 执行存储过程 SYS_REFCURSOR 在PL/SQL中,SYS_REFCURSOR是一种特殊的数据类型,用于表示引用游标,可以用来返回查询结果或者操作数据库中的结果集。 以下是一个使用SYS_REFCURSOR执行存储过程的例子: CR…...
)
git修改某次commit(白痴版)
第一步 在bash窗口运行 git rebase --interactive commitId^ 比如要改的commitId是 abcedf git rebase --interactive abcedf^键盘 按 i 或者 ins 进入编辑状态 进入insert 编辑状态 在bash窗口手动把对应commit前面的pick改为e或edit 按 esc 进入退出程序 输入 :wq 保存退出…...

设计模式:19、桥接模式
目录 0、定义 1、桥接模式的四种角色 2、桥接模式的UML类图 3、示例代码 0、定义 将抽象部门与实现部分分离,使它们都可以独立地变化。 1、桥接模式的四种角色 抽象(Abstraction):一个抽象类,包含实现者…...

闭包函数的基础知识
上期文章 1. 函数装饰器 2.闭包 2.1变量作用域 python有3种变量作用域 模块全局作用域:在类或函数外部分配定义的。函数局部作用域:通过参数或者在函数主体中定义的。第3种作用域:闭包中的变量环境 2.2全局变量和局部变量 def fun(a):print(a)print(b)fun(10)10---------…...

python3D圣诞树
import pygame import math from pygame.locals import *# 初始化Pygame pygame.init()# 设置屏幕尺寸和标题 width, height 800, 600 screen pygame.display.set_mode((width, height)) pygame.display.set_caption(3D 圣诞树)# 设置颜色 GREEN (34, 139, 34) BROWN (139,…...
背景需求分析与核心技术实现)
博物馆导览系统方案(一)背景需求分析与核心技术实现
维小帮提供多个场所的室内外导航导览方案,如需获取博物馆导览系统解决方案可前往文章最下方获取,如有项目合作及技术交流欢迎私信我们哦~撒花! 一、博物馆导览系统的背景与市场需求 在数字化转型的浪潮中,博物馆作为文化传承和知…...

[代码随想录09]字符串2的总结
前言 处理字符串主要是有思路,同时总结方法。 题目链接 151. 反转字符串中的单词 - 力扣(LeetCode) 55. 右旋字符串(第八期模拟笔试) 一、翻转字符串里的单词 这个题目的主要思路,代码采用从后往前遍历字…...

C语言程序设计P5-3【应用函数进行程序设计 | 第三节】——知识要点:函数的嵌套调用和递归调用
知识要点:函数的嵌套调用和递归调用 视频 目录 一、任务分析 二、必备知识与理论 三、任务实施 一、任务分析 本任务要求用递归法求 n!。 我们知道n!n(n-1)(n-2)……1n(n-1)!递归公式为: 1.上面公式分解为n!n(n-1)!,即将求n!的问题变为…...

【Java】protobuf-maven-plugin主动下载protoc编译proto文件
背景: 我们hadoop的代码里,配置的是3.7.1的protocol buffer,但是编译环境上安装的是2.5.0。 能成功编译,且没有什么兼容性问题。这里非常好奇发生了什么,于是研究了一下protobuf-maven-plugin插件, 发现是他去下载的 在使用protobuf-maven-plugin插件时,我们一般会这么…...

Go学习:变量
目录 1. 变量的命名 2. 变量的声明 3. 变量声明时注意事项 4. 变量的初始化 5. 简单例子 变量主要用来存储数据信息,变量的值可以通过变量名进行访问。 1. 变量的命名 在Go语言中,变量名的命名规则 与其他编程语言一样,都是由字母、数…...

AllegroHand 四指灵巧手:机器人领域的创新力量
Allegro Hand 作为一款高性价比且适应性强的机器人四指灵巧手,凭借其四根手指和十六个独立的电流控制接头,成为机器人复杂抓握、柔性操作以及触觉传感器等研究领域的理想之选。 Allegrohand 四指灵巧手技术特点 机械结构 Allegro Hand的机械结构设计高…...
)
蓝桥杯准备训练(lesson3 ,c++)
变量与常量 4.1 变量的创建4.2 变量初始化4.3 变量的分类4.4 常量4.4.1 字⾯常量4.4.2 #define定义常量4.4.3 const定义常量4.5 练习练习1:买票练习2:AB问题练习3:鸡兔同笼 4.1 变量的创建 了解清楚了类型,我们使⽤类型做什么呢&…...

Conda + JuiceFS :增强 AI 开发环境共享能力
Conda 是当前 AI 应用开发领域中非常流行的环境和包管理系统,因其能够简单便捷地创建与系统资源相隔离的虚拟环境广受欢迎。 Conda 支持在不同的操作系统上重建相同的工作环境,但在环境共享复用方面仍存在一些挑战。比如,在不同机器上复用相…...
)
小红薯x-s算法最新补环境教程12-06更新(下)
在上一篇文章中已经讲了如何去定位x-s生成的位置,本篇文章就直接开始撸代码吧 如果没看过的话可以看:小红薯最新x-s算法分析12-06(x-s 56)(上)-CSDN博客 1、获取加密块代码 首先来到参数生成的位置&…...

强化ASPICE合规与认可度:关键策略与实践路径
确保ASPICE(Automotive SPICE)标准的合规性和认可度,是一个涉及多方面努力和持续改进的过程。以下是一些关键步骤和建议,以帮助企业实现这一目标: 一、熟悉ASPICE标准 深入阅读和理解:首先,需要…...

没有合理使用线程池,引发的生产环境BUG
引言 随着多线程和并发处理需求的增加,线程池成为了提升系统性能的重要工具。Java 提供了强大的 ThreadPoolExecutor 类,能够高效地管理线程池,减少线程创建和销毁的开销。然而,当线程池达到其最大容量时,如何优雅地处…...

异步处理与后台任务管理:在 FastAPI 中实现高级特性
异步处理与后台任务管理:在 FastAPI 中实现高级特性 目录 ⚡ 背景任务与异步处理概述🛠️ 使用 BackgroundTasks 执行后台任务🚀 异步视图函数:使用 async 和 await🔄 处理并发任务:提升应用性能与响应能…...

ceph存储池
1、存储池 1、存储池的概念 存储池就是ceph的逻辑分区,专门用来存储对象的 特点 将文件切片成对象,通过hash算法,找到存储池中的pg,池中的pg根据crush算法找到osd节点 存储中的PG数量对性能有重要的影响,过多和过少…...

STM32基于HAL库的串口接收中断触发机制和适用场景
1. HAL_UART_Receive_DMA函数 基本功能 作用:启动一个固定长度的 DMA 数据接收。特点: 需要预先指定接收数据的长度(Size 参数)。DMA 会一直工作直到接收到指定数量的数据,接收完成后触发 HAL_UART_RxCpltCallback 回…...

如何查看电脑的屏幕刷新率?
1、按一下键盘的 win i 键,打开如下界面,选择【系统】: 2、选择【屏幕】-【高级显示设置】 如下位置,显示屏幕的刷新率:60Hz 如果可以更改,则选择更高的刷新率,有助于电脑使用起来界面更加流…...

Q3收入回退,盈利与商业化落地步履艰难,文远知行亟待背水一战
撰稿|行星 来源|贝多财经 12月2日,全球商业杂志《Fortune》(财富)揭晓了2024年“未来50强”(The Future 50)企业榜单,上市不久的全球Rbotaxi第一股文远知行(NASDAQ:WRD)位列第26名…...