通过规范化模型自训练增强医学图像分割中的无监督域自适应|文献速递-深度学习医疗AI最新文献
Title
题目
Enhancing source-free domain adaptation in Medical Image Segmentationvia regulated model self-training
通过规范化模型自训练增强医学图像分割中的无监督域自适应
01
文献速递介绍
深度卷积神经网络对训练数据分布(源域)和测试数据分布(目标域)之间的偏移极为敏感(庄等人,2020)。为解决这一问题,人们提出了大量域自适应方法,这些方法试图将源域和目标域的特征空间对齐到一个共同的潜在嵌入空间,以便在源域上学习的模型能够很好地适应目标域(苏尔卡,2017)。考虑到医学领域标注数据稀缺,众多研究致力于无监督域自适应(UDA)设定,旨在不产生目标域标注成本的情况下追求令人满意的自适应性能(加宁和伦皮茨基,2015;陈等人,2019;王等人,2019)。随着对无监督域自适应研究的推进,当代研究频繁指出无监督域自适应在处理严重域偏移时存在局限性(如跨不同成像模态),并提出了无监督域自适应(SFDA)设定(陈等人,2021;徐等人,2022;李等人,2022;胡等人,2022;沈等人,2022)。在无监督域自适应设定下,研究人员将未标注的目标样本输入到在源域训练好的模型中,并将生成的预测结果作为伪标签,以引导模型针对目标域进行自我适应。在此基础上,人们提出了各种去噪策略,通过进行不确定性估计(陈等人,2021)、自适应阈值设定(徐等人,2022)、熵最小化(VS等人,2022)等方法,来消除因域偏移导致的伪标签中易出错的区域。大多数情况下,当遇到较小的域差异(如由不同成像设备供应商导致的偏移)时,上述方法能产生令人满意的自适应性能。因为从原始源模型输出估计的初始伪标签可以达到较高的准确率(例如,在跨供应商分割视盘和视杯的任务中,骰子系数(Dice)约为80% (王等人,2019;陈等人,2021)),通过去噪策略进一步优化这些伪标签,能为模型训练提供更可靠的监督。 然而,当涉及到更具挑战性的场景,比如在两种完全不同的成像模态之间进行自适应时,源自伪标签的监督会因严重的域差异而急剧恶化。以将心脏分割模型从CT图像适配到MR图像为例,初始伪标签包含大量误报预测,导致骰子系数(Dice)的准确率约为20% (陈等人,2019)。即使当代去噪策略能够去除伪标签中所有误导性的指导信息,剩余的指导信息可能也不足以在目标域上产生理想的自适应性能。由于多模态数据在临床诊断流程中普遍使用(庄和沈,2016),人们迫切需要一种具有广泛适用性的无监督域自适应模型,即不仅适用于不同供应商(如西门子、飞利浦)之间较小的域偏移,也适用于不同成像模态(如CT、MR)之间严重的域偏移。 为实现这一目标,我们深入研究源模型中已获取的知识,并探究无监督域自适应过程中一个重要但尚未充分探索的问题,即源模型参数的哪一部分捕获了源域和目标域通用的先验知识,而哪一部分利用了源域独特的、对目标域可迁移性或兼容性较差的特征。先前优化伪标签的无监督域自适应方法一直忽视了这个问题(见图1)。它们简单地将源模型视为自我训练的理想起点,并在后续优化中完全覆盖其所有参数(甚至包括域不变参数)。然而,正如最近的研究(昆杜等人,2021;赵等人,2020;李等人,2020a)所指出的,集中于共同共享表示(如形状先验)的域不变参数与域变化无关,因此通常具有较高的可迁移性,可用于未来的自适应。保持这些参数的良好功能非常有价值,尤其是在遇到显著域差异时,保护它们不被不可靠的指导信息污染。这样,当源自当前伪标签的监督不足时,我们可以依赖早期获取的先验知识来支持模型进行令人满意的自我适应。对于专注于给定域独特特征的域特定参数,现有的特征嵌入已针对源域特征进行了定制,因此应该主动将其更新为目标特定的特征嵌入。 在本文中,我们提出了一种规范化模型自训练(RMST)方法,以应对无监督域自适应的广泛应用场景,即在较小的域偏移(跨供应商)和严重的域偏移(跨模态)情况下都能表现良好。首先,我们分析了源模型每个参数的可迁移性,并将源模型参数分为高可迁移参数(如获取了域不变先验知识的参数)和低可迁移参数(如学习了域特定特征的参数)。对于每类参数,我们采用定制策略来调控其自训练过程,以充分利用从源域早期获取的知识。对于域不变参数,我们限制其自训练过程中的大幅更新,以保护域共享知识在伪标签质量较差时不被污染。通过这种方式,域不变知识可以保持在可用状态,持续助力目标域自适应。同时,对于域特定参数,我们主动将其嵌入从源特定更新为目标特定。我们进行选择性特征白化,以引导模型专注于获取主要的目标特定特征,从而提高模型效率。在自训练结束时,模型将具备令人满意地处理目标域数据的能力。 我们在多个域自适应场景下全面评估了我们的框架,包括涉及三维跨模态心脏分割任务的严重域偏移场景,以及涉及二维跨供应商眼底分割任务的较小域偏移场景。在这两种场景下,我们的方法都大幅优于其他对比方法。我们的主要贡献总结如下: - 我们提出根据参数级别的可迁移性来规范模型自训练,以增强模型在具有严重域偏移的挑战性域自适应场景中的能力。 - 对于域不变参数,我们限制其大幅更新,以复用源模型中现有的域不变先验知识,并使其持续助力目标域自适应。 - 对于域特定参数,我们主动将其特征嵌入从源特定更新为目标特定,尤其是主要的特征嵌入。 - 我们在较小和严重域偏移场景下都验证了我们的方法,并且我们的方法相比其他竞争方法表现更优。
Abatract
摘要
Source-free domain adaptation (SFDA) has drawn increasing attention lately in the medical field. It aims toadapt a model well trained on source domain to target domains without accessing source domain data norrequiring target domain labels, to enable privacy-protecting and annotation-efficient domain adaptation. MostSFDA approaches initialize the target model with source model weights, and guide model self-training withthe pseudo-labels generated from the source model. However, when source and target domains have hugediscrepancies (e.g., different modalities), the obtained pseudo-labels would be of poor quality. Different fromprior works that overcome it by refining pseudo-labels to better quality, in this work, we try to explore itfrom the perspective of knowledge transfer. We recycle the beneficial domain-invariant prior knowledge inthe source model, and refresh its domain-specific knowledge from source-specific to target-specific, to help themodel satisfyingly tackle target domains even when facing severe domain shifts. To achieve it, we proposeda regulated model self-training framework. For high-transferable domain-invariant parameters, we constraintheir update magnitude from large changes, to secure the domain-shared priors from going stray and letit continuously facilitate target domain adaptation. For the low-transferable domain-specific parameters, weactively update them to let the domain-specific embedding become target-specific. Regulating them together,the model would develop better capability for target data even under severe domain shifts. Importantly,the proposed approach could seamlessly collaborate with existing pseudo-label refinement approaches tobring more performance gains. We have extensively validated our framework under significant domainshifts in 3D cross-modality cardiac segmentation, and under minor domain shifts in 2D cross-vendor fundussegmentation, respectively. Our approach consistently outperformed the competing methods and achievedsuperior performance
无监督域自适应(SFDA)最近在医学领域受到了越来越多的关注。它旨在使在源域上训练良好的模型适应目标域,且无需访问源域数据,也不需要目标域的标签,从而实现保护隐私且标注高效的域自适应。大多数无监督域自适应方法使用源模型的权重来初始化目标模型,并利用源模型生成的伪标签来引导模型进行自训练。 然而,当源域和目标域存在巨大差异时(例如,不同的成像模态),所得到的伪标签质量会很差。与之前通过优化伪标签以提高其质量来解决该问题的研究不同,在这项工作中,我们尝试从知识迁移的角度来探索这一问题。我们回收源模型中有益的域不变先验知识,并将其特定于源域的知识更新为特定于目标域的知识,以便即使在面临严重的域偏移时,模型也能令人满意地处理目标域。 为了实现这一目标,我们提出了一个规范化模型自训练框架。对于具有高迁移性的域不变参数,我们限制它们的更新幅度,避免出现大幅变化,以确保域共享的先验知识不会偏离正轨,并让它持续助力目标域的自适应。对于低迁移性的域特定参数,我们主动更新它们,使域特定的嵌入变为目标特定的嵌入。通过共同调控这些参数,即使在严重的域偏移情况下,模型也能对目标数据形成更强的处理能力。 重要的是,所提出的方法可以与现有的伪标签优化方法无缝协作,带来更多的性能提升。我们分别在三维跨模态心脏分割的显著域偏移场景以及二维跨厂商眼底分割的微小域偏移场景下,对我们的框架进行了广泛验证。我们的方法始终优于其他竞争方法,并取得了卓越的性能。
Method
方法
In the problem setting of source-free domain adaptation, we aregiven a model 𝐌𝑠* that is previously trained by a set of samples ofthe source domain 𝑠 = {(𝑥 𝑖 𝑠 , 𝑦𝑖 𝑠 )}𝑁 𝑖=1 𝑠 and a set of unlabeled targetdomain data 𝑡 = {𝑥 𝑖 𝑡 } 𝑁 𝑖=1 𝑡 . Different from previous unsupervised domainadaptation settings, the source domain dataset 𝑠 is not available touse due to data transmission regulations and safety concerns. The goalis to exploit the source-trained model 𝐌𝑠 and unlabeled target dataset{𝑥 𝑖 𝑡 } 𝑁 𝑖=1 𝑡 , to obtain a model 𝐌𝑡 that could satisfyingly deal with targetdomain data.
Fig. 2 illustrates our regulated model self-training approach. As astarter, we measure the parameter-level transferability of the sourcetrained model to identify the high-transferable domain-invariant parameters and the low-transferable domain-specific parameters. Then,we regulate the update magnitude of domain-invariant parameters fromlarge changes, to sustain the domain-shared prior knowledge and makeit continually facilitate the target domain. Meanwhile, we discoverthe domain-specific embeddings that are highly responsive to domainchanges and actively update them to become target-specific, to help themodel tackle target domain data.
在无监督域自适应的问题设定中,我们有一个模型(\mathbf{M}^s),该模型先前是由源域(\mathcal{D}s = {(\mathbf{x}i^s, \mathbf{y}i^s)}{i = 1}^{N_s})的一组样本训练得到的,同时还有一组未标注的目标域数据(\mathcal{D}t = {\mathbf{x}i^t}{i = 1}^{N_t})。与以往的无监督域自适应设定不同,由于数据传输规定和安全方面的考虑,源域数据集(\mathcal{D}_s)无法使用。我们的目标是利用在源域上训练好的模型(\mathbf{M}^s)以及未标注的目标域数据集({\mathbf{x}i^t}{i = 1}^{N_t}),得到一个能够令人满意地处理目标域数据的模型(\mathbf{M}^*t)。 图2展示了我们的规范化模型自训练方法。首先,我们对在源域训练好的模型进行参数级可迁移性评估,以识别出高可迁移的域不变参数和低可迁移的域特定参数。然后,我们限制域不变参数的更新幅度,避免其出现大幅变化,从而维持域共享的先验知识,并使其能持续助力目标域的自适应。同时,我们找出对域变化高度敏感的域特定嵌入,并主动将它们更新为目标特定的嵌入,以帮助模型处理目标域的数据。
Conclusion
结论
We presented a regulated model self-training framework to supportsource-free domain adaptation under both minor and major domain discrepancies. Rather than wildly overriding all source-trained model parameters, we proposed to investigate their parameter-wise transferability and present customized training strategies for the high-transferabledomain-invariant parameters and low-transferable domain-specific parameters, to finely regulate model self-training for satisfying targetdomain adaptation. Since the domain-invariant parameters are enriched with domain-shared prior knowledge, we regulate their updatemagnitude from large changes to secure these representations andlet them further benefit the adaptation on the target domain. In themeantime, we actively refresh the embedding of domain-specific parameters from source-specific to target-specific. We perform selectivefeature whitening to regulate them focusing on acquiring the principaltarget-specific features for improved adaptation performance. We haveextensively evaluated our approach in the scenarios when encounteringminor domain shifts (e.g., cross vendors) and severe domain shifts(e.g., cross modalities). Our approach consistently outperformed othercomparison methods and showed superior segmentation performanceon target domains.
我们提出了一个规范化模型自训练框架,以支持在较小和较大的域差异情况下进行无监督域自适应。我们没有盲目地覆盖所有在源域上训练的模型参数,而是建议研究这些参数在参数层面的可迁移性,并针对高可迁移的域不变参数和低可迁移的域特定参数提出定制化的训练策略,从而精细地规范模型的自训练过程,以实现令人满意的目标域自适应。 由于域不变参数蕴含着丰富的域共享先验知识,我们限制它们的更新幅度,避免出现大幅变化,以确保这些表征得以保留,并让它们进一步助力目标域的自适应。同时,我们主动将域特定参数的嵌入从源特定更新为目标特定。我们进行选择性的特征白化处理,引导这些参数专注于获取主要的目标特定特征,从而提高自适应性能。 我们在遇到较小域偏移(例如,跨不同厂商)和严重域偏移(例如,跨不同模态)的场景中对我们的方法进行了广泛评估。我们的方法始终优于其他对比方法,并且在目标域上展现出了卓越的分割性能。
Figure
图
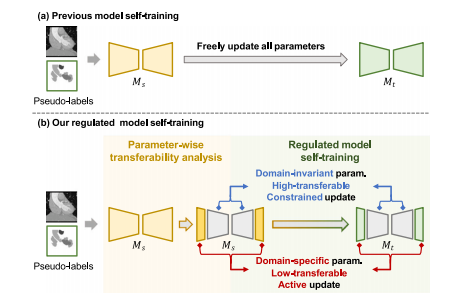
Fig. 1. Illustration of our main idea. (a) The model self-training in previous source-freedomain adaptation approaches allows any parameter updates instructed by pseudolabels. When poor-quality pseudo-labels occur due to large domain shifts, unconstrainedmodel self-training will make the target model easily misguided and contaminated,leading to unsatisfactory adaptation performance on target data. (b) To address it, weproposed to regulate model self-training. We constrain the domain-invariant parametersfrom large updates to secure the beneficial domain-shared prior knowledge from beingmisguided by inferior pseudo-labels. By doing so, even when confronting severe domaindiscrepancies, the domain-invariant embedding transferred from the source model 𝐌𝑠 tothe target model 𝐌𝑡 would be maintained at a well-functional stage. In the meantime,we actively update the domain-specific embedding to refresh it from source-specific totarget-specific. Regulating them together, the model would gain better competence fordiverse domain adaptation scenarios, including those having huge domain shifts (e.g.,across different imaging modalities).
图1. 主要思路说明。(a)以往无监督域自适应方法中的模型自训练允许由伪标签引导的任何参数更新。当由于较大的域偏移导致伪标签质量较差时,无约束的模型自训练会使目标模型容易受到误导和污染,从而导致在目标数据上的自适应性能不佳。(b)为解决该问题,我们提议对模型自训练进行调控。我们限制域不变参数的大幅更新,以确保有益的域共享先验知识不会被劣质伪标签误导。这样一来,即使面对严重的域差异,从源模型$\mathbf{M}^_s$迁移到目标模型$\mathbf{M}^_t$的域不变嵌入也能保持在良好的功能状态。同时,我们主动更新域特定嵌入,将其从源特定更新为目标特定。通过对二者共同调控,模型将在包括存在巨大域偏移(如跨不同成像模态)等各种域自适应场景中获得更强的适应能力。
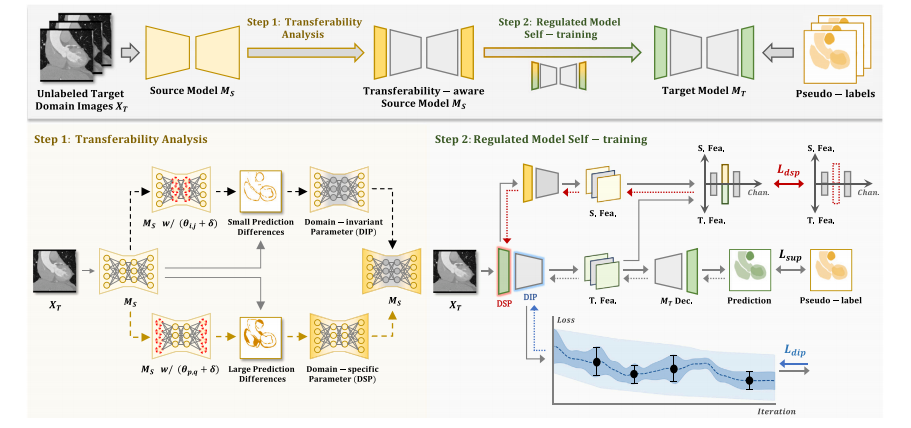
Fig. 2. Overview of our source-free domain adaptation framework. We proposed to regulate model self-training at a finer level according to the parameter-wise transferabilityfrom source to target domain. (a) In Step 1, we analyzed the transferability of each source model parameter by observing how the predicted outputs react to small perturbationsin that parameter, when taking target domain images as inputs. Small prediction differences would indicate this parameter remains stable and converged when dealing withtarget data, suggesting it is high-transferable and domain-invariant, i.e., the domain-invariant parameters. While large prediction differences would indicate this parameter is highlyresponsive to the potential gradient updates and requires further optimization to reach convergence, suggesting it is low transferable for the target domain and optimal specificallyto the source domain, i.e., the domain-specific parameters. (b) In Step 2, we regulated model self-training according to each parameter’s transferability to make the best use of theexisting weights in the source model. We constrain the domain-invariant parameters from large updates via 𝑑𝑖𝑝 to protect the domain-shared prior knowledge from going stray andmake it continuously facilitate target domain adaptation. Meanwhile, we identify the domain-specific embeddings that are highly sensitive to domain changes and actively updatethem from being source-specific to target-specific via 𝑑𝑠𝑝. As a result, our model would satisfyingly tackle a broad range of domain adaptation scenarios, even the challengingcross-modality adaptation cases.
图2. 我们的无监督域自适应框架概述。我们提议根据从源域到目标域的参数级可迁移性,在更精细的层面上规范模型的自训练过程。(a)在步骤1中,当以目标域图像作为输入时,我们通过观察预测输出对每个源模型参数的微小扰动的反应来分析其可迁移性。较小的预测差异表明,在处理目标数据时,该参数保持稳定且已收敛,这意味着它具有高可迁移性且是域不变的,即域不变参数。而较大的预测差异则表明,该参数对潜在的梯度更新高度敏感,并且需要进一步优化才能达到收敛状态,这意味着它对目标域的可迁移性较低,且是专门针对源域优化的,即域特定参数。(b)在步骤2中,我们根据每个参数的可迁移性来规范模型的自训练,以便充分利用源模型中现有的权重。我们通过(L{dip})限制域不变参数的大幅更新,以保护域共享的先验知识不偏离正轨,并使其持续助力目标域的自适应。同时,我们识别出对域变化高度敏感的域特定嵌入,并通过(L{dsp})主动将它们从源特定更新为目标特定。因此,我们的模型能够令人满意地处理广泛的域自适应场景,甚至是具有挑战性的跨模态自适应情况。
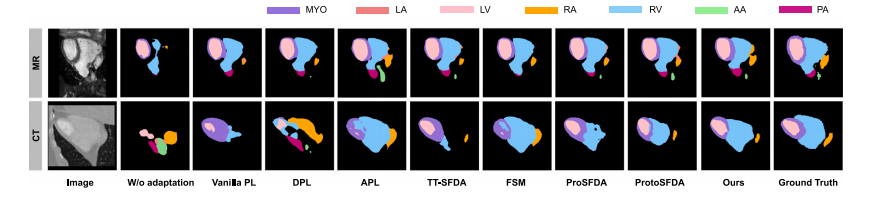
Fig. 3. Visual comparisons for 3D cross-modality cardiac segmentation. Here we highlighted different structures in different colors.
图3. 三维跨模态心脏分割的可视化对比。在此,我们用不同颜色突出显示了不同的结构。
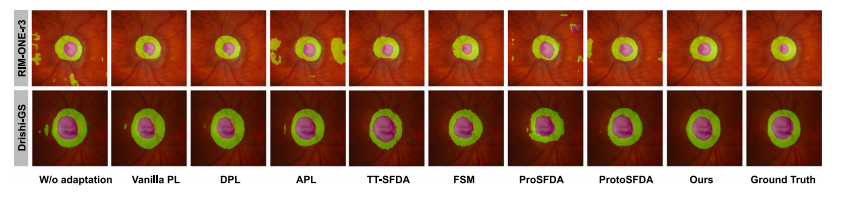
Fig. 4. Visual comparison for 2D cross-vendor fundus segmentation, where we highlighted optic disc in green and optic cup in pink.
图4:二维跨厂商眼底分割的可视化对比,我们用绿色突出显示了视盘,用粉色突出显示了视杯。
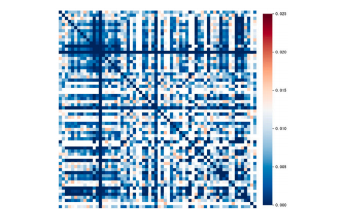
Fig. 5. The variance matrix of feature covariance in layer 1(The white color denotesthose in the high-variance group)
图5:第一层特征协方差的方差矩阵(白色表示属于高方差组的部分)
Table
表
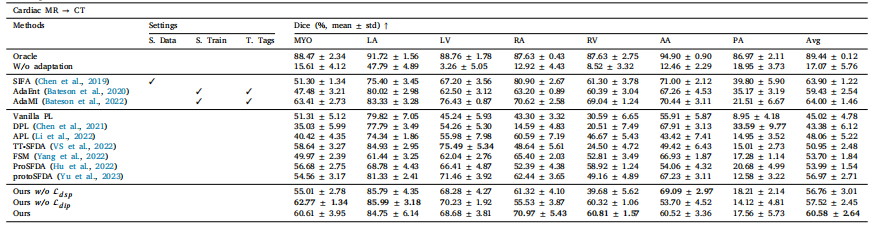
Table 1Performance comparison under major domain shifts on the task of 3D cross-modality cardiac segmentation evaluated by dice. Here, we take MR as the source domain and CT asthe target domain. The best SFDA results are marked in bold.
表1:在三维跨模态心脏分割任务中,基于骰子系数(Dice)评估的严重域偏移情况下的性能比较。在此,我们以磁共振成像(MR)作为源域,计算机断层扫描(CT)作为目标域。最佳的无监督域自适应(SFDA)结果以粗体标出。
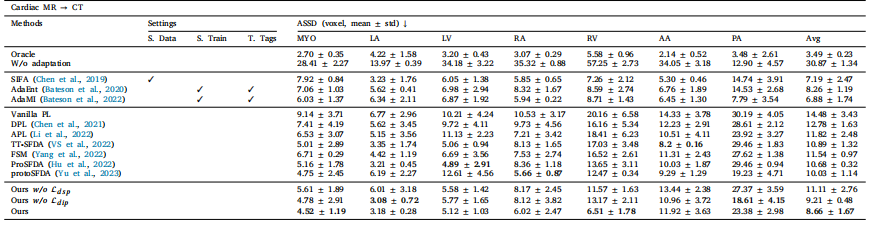
Table 2Performance comparison under major domain shifts on the task of 3D cross-modality cardiac segmentation evaluated by ASSD. Here, we take MR as the source domain and CTas the target domain. The best SFDA results are marked in bold
表2:在三维跨模态心脏分割任务中,依据平均对称表面距离(ASSD)进行评估的、在较大域偏移情况下的性能对比。在此,我们把磁共振成像(MR)当作源域,把计算机断层扫描(CT)当作目标域。表现最佳的无监督域自适应(SFDA)结果以粗体标注。
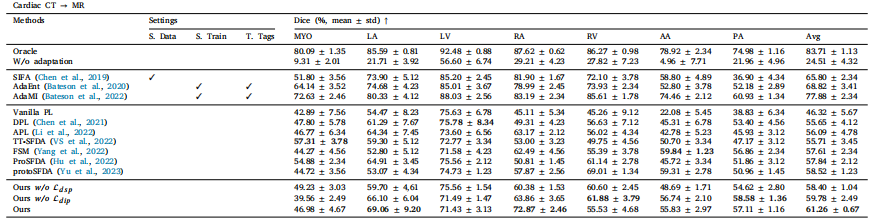
Table 3Performance comparison under major domain shifts on the task of 3D cross-modality cardiac segmentation evaluated by dice. Here, we take CT as the source domain and MR asthe target domain. The best SFDA results are marked in bold
表3:在三维跨模态心脏分割任务中,基于骰子系数(Dice)评估的严重域偏移情况下的性能比较。在此,我们将计算机断层扫描(CT)作为源域,将磁共振成像(MR)作为目标域。最佳的无监督域自适应(SFDA)结果以粗体标出。
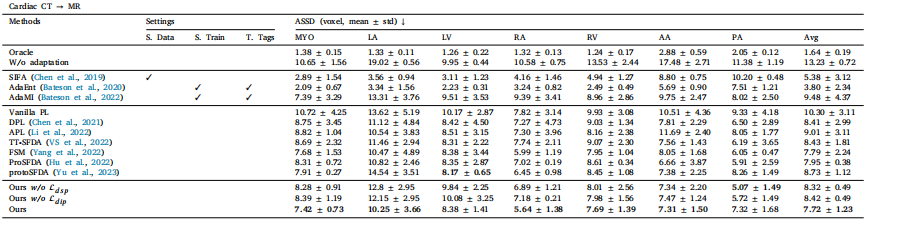
Table 4Performance comparison under major domain shifts on the task of 3D cross-modality cardiac segmentation evaluated by ASSD. Here, we take CT as the source domain and MRas the target domain. The best SFDA results are marked in bold.
表4:在三维跨模态心脏分割任务中,基于平均对称表面距离(ASSD)评估的严重域偏移情况下的性能比较。在此,我们将计算机断层扫描(CT)作为源域,将磁共振成像(MR)作为目标域。最佳的无监督域自适应(SFDA)结果以粗体标出。
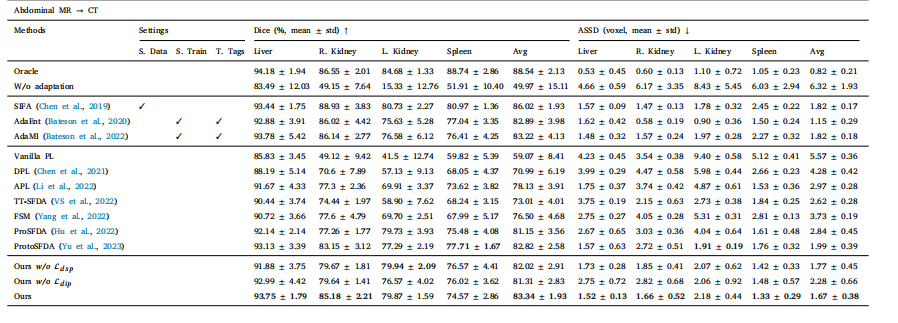
Table 5Performance comparison under major domain shifts on the task of 3D cross-modality abdominal multi-organ segmentation evaluated by Dice and ASSD. Here, we take MR as thesource domain and CT as the target domain. The best SFDA results are marked in bold.
表5:在三维跨模态腹部多器官分割任务中,基于骰子系数(Dice)和平均对称表面距离(ASSD)来评估的在较大域偏移情况下的性能对比。在此处,我们将磁共振成像(MR)作为源域,将计算机断层扫描(CT)作为目标域。最佳的无监督域自适应(SFDA)结果以粗体标出。
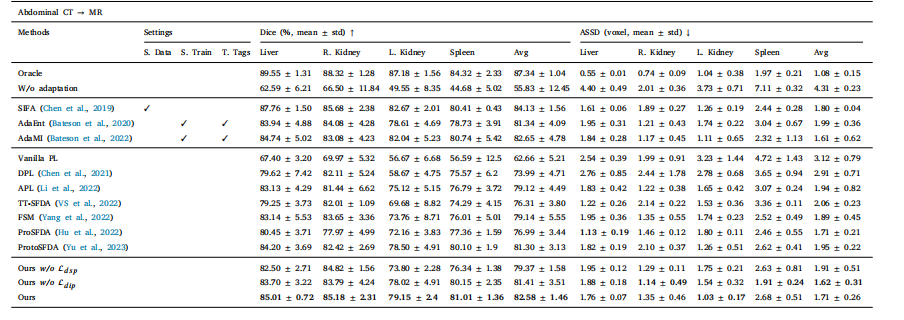
Table 6Performance comparison under major domain shifts on the task of 3D cross-modality abdominal multi-organ segmentation evaluated by Dice and ASSD. Here, we take CT as thesource domain and MR as the target domain. The best SFDA results are marked in bold
表6:在三维跨模态腹部多器官分割任务中,基于骰子系数(Dice)和平均对称表面距离(ASSD)评估的严重域偏移情况下的性能比较。在此,我们将计算机断层扫描(CT)作为源域,将磁共振成像(MR)作为目标域。最佳的无监督域自适应(SFDA)结果以粗体标出。
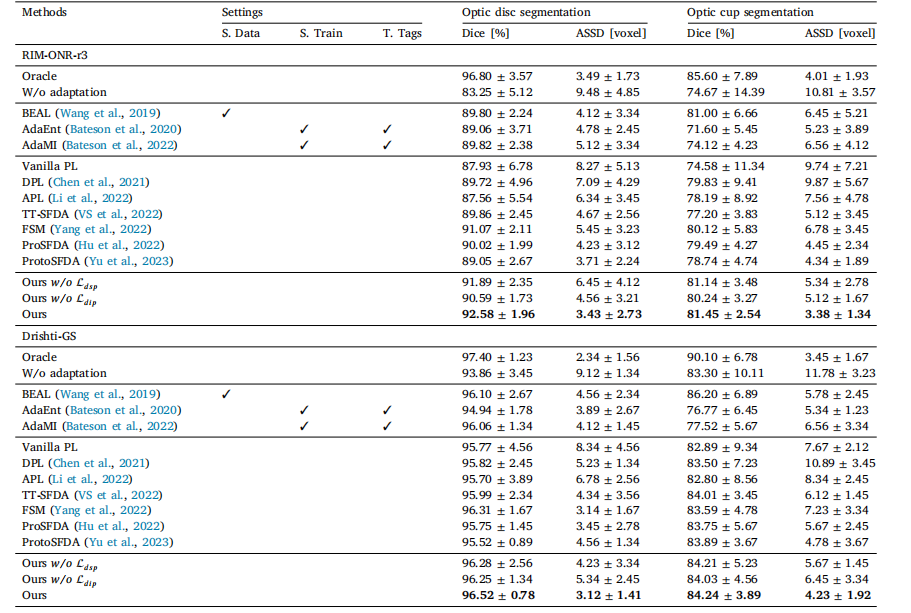
Table 7Performance comparison under minor domain shifts on the task of 2D cross-vendor fundus segmentation(mean ± standard deviation). We evaluated the performance of optic disc(OD) and optic cup (OC) by Dice. Here, we have marked the best SFDA results in bold
表7:在二维跨厂商眼底分割任务中,较小域偏移情况下的性能比较(均值±标准差)。我们通过骰子系数(Dice)评估了视盘(OD)和视杯(OC)的分割性能。在此,我们将最佳的无监督域自适应(SFDA)结果用粗体标出。
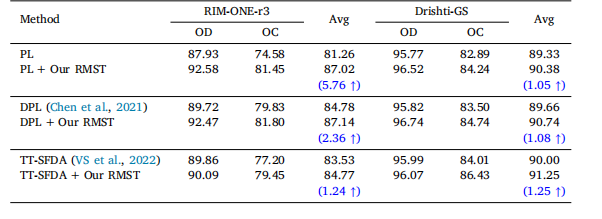
Table 8Performance comparison before and after applying our proposed RMST approach for the existing pseudo-label basedmethods. We have highlighted the Dice improvements in blue.
表8:在应用我们提出的规范化模型自训练(RMST)方法前后,基于现有伪标签方法的性能比较。我们用蓝色突出显示了骰子系数(Dice)的提升情况。
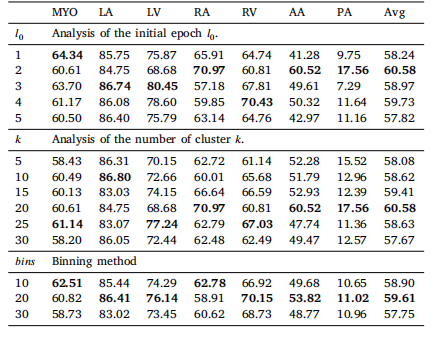
Table 9Hyperparameter analysis of 𝑙0 , 𝑘, and 𝑏𝑖𝑛𝑠 number
表9:$l_0$、$k$和$bins$数量的超参数分析
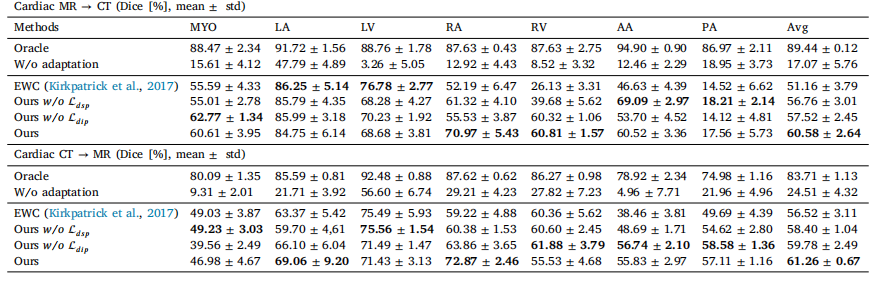
Table 10Performance comparison with ours and EWC under major domain shifts on the task of 3D cross-modality cardiac segmentation evaluated by dice. The best results are marked inbold
表10:在三维跨模态心脏分割任务中,基于骰子系数(Dice)评估的严重域偏移情况下,我们的方法与弹性权重巩固(EWC)方法的性能比较。最佳结果以粗体标出。
相关文章:

通过规范化模型自训练增强医学图像分割中的无监督域自适应|文献速递-深度学习医疗AI最新文献
Title 题目 Enhancing source-free domain adaptation in Medical Image Segmentationvia regulated model self-training 通过规范化模型自训练增强医学图像分割中的无监督域自适应 01 文献速递介绍 深度卷积神经网络对训练数据分布(源域)和测试数…...
)
Linux常见指令介绍中(入门级)
1. man 在Linux中,man命令是用于查看命令手册页的工具,它可以帮助用户了解各种命令、函数、系统调用等的详细使用方法和相关信息。 用法:在终端中输入man加上要查询的命令或工具名称,例如man ls,就会显示ls命令的手册…...

一文详解卷积神经网络中的卷积层和池化层原理 !!
文章目录 前言 一、卷积核大小(Kernel Size) 1. 卷积核大小的作用 2. 常见的卷积核大小 3. 选择卷积核大小的原则 二、步长(Stride) 1. Stride的作用 三、填充(Padding) 1. 填充的作用 四、通道数ÿ…...

神经网络直接逆控制:神经网络与控制的结合入门级结合
目录 1. 前言 2. 什么是直接逆控制? 2.1 直接逆控制的优点 2.2 直接逆控制的局限性 3. 直接逆控制的实现步骤 3.1 数据准备 3.2 神经网络设计 3.3 训练神经网络 3.4 控制实现 4. 使用 PyTorch 实现直接逆控制 4.1 问题描述 4.2 数据生成 4.3 神经网络设…...

使用tabs组件搭建UI框架
本节任务 使用tabs组件搭建ui框架 包含页签:首页、动态、发布,会员购、我的。 涉及内容: Tabs、TabContent组件Builder装饰器属性模型封装,包括:接口、枚举、常量 界面原型 1 Tabs布局 在MainPage(如果…...

jmeter跟踪重定向和自动重定向有什么区别?
在 JMeter 中,跟踪重定向和自动重定向有以下区别: 概念 跟踪重定向:指的是 JMeter 会按照服务器返回的重定向信息,继续发送请求到重定向的目标地址,并记录下整个重定向的过程,包括重定向的地址、响应信息…...

unity3d实现物体闪烁
unity3d实现物体闪烁,代码如下: using UnityEngine;public class Test : MonoBehaviour {//创建一个常量,用来接收时间的变化值private float shake;//通过控制物体的MeshRenderer组件的开关来实现物体闪烁的效果private MeshRenderer BoxColliderClick…...
安卓开发中的MVP模式详解)
(三十)安卓开发中的MVP模式详解
在安卓开发中,MVP(Model-View-Presenter) 是一种常见的软件架构模式,它通过将应用程序的逻辑与用户界面分离,使得代码更加模块化、易于维护和测试。本文将详细讲解MVP模式的组成部分、工作流程、优点,并结合…...

独立ADC和MCU中ADC模块的区别
以图中两种方案为例: 使用独立ADC和使用MCU的内部ADC来实现模数转换,有什么性能、技术上的区别吗? 集成和独立芯片各有优劣势: 1、集成的节约了板子空间,减少了外围设计。工艺也不一样,集成的工艺相对高一…...

微软Entra新安全功能引发大规模账户锁定事件
误报触发大规模锁定 多家机构的Windows管理员报告称,微软Entra ID新推出的"MACE"(泄露凭证检测应用)功能在部署过程中产生大量误报,导致用户账户被大规模锁定。这些警报和锁定始于昨夜,部分管理员认为属于误…...
与 Ray Casting(光线投射))
Ray Tracing(光线追踪)与 Ray Casting(光线投射)
Ray Casting(光线投射) 定义:一种从观察点(如摄像机)向场景中每个像素投射单条光线,找到最近可见物体的渲染技术。 核心任务:确定像素对应的物体表面颜色,通常仅计算直接光照&#…...

Shell脚本-变量的分类
在Shell脚本编程中,变量是存储数据的基本单位。它们可以用来保存字符串、数字甚至是命令的输出结果。正确地定义和使用变量能够极大地提高脚本的灵活性与可维护性。本文将详细介绍Shell脚本中变量的不同分类及其应用场景,帮助你编写更高效、简洁的Shell脚…...

go for 闭环问题【踩坑记录】
Go 中的for 循环闭包问题,是每个 Go 程序员几乎都踩过的坑,也是面试和实际开发中非常容易出错和引起 bug 的地方。这里我会通过原理、示例、修正方法、背后机制等角度详细为你讲解。 一、问题描述 当你在 for 循环里写匿名函数(闭包…...

【分布式理论17】分布式调度3:分布式架构-从中央式调度到共享状态调度
文章目录 一、中央式调度器1. 核心思想2. 工作流程3. 优缺点4. **典型案例:Google Borg** 二、两级调度器1. **核心思想**2. **工作流程**3. 优缺点4. **典型案例:Hadoop YARN** 三、共享状态调度器1. **核心思想**2. **工作流程**3. 优缺点4. **典型案例…...

Java高频面试之并发编程-04
hello啊,各位观众姥爷们!!!本baby今天来报道了!哈哈哈哈哈嗝🐶 面试官:调用 start()方法时会执行 run()方法,那为什么不直接调用 run()方法? 多线程中调用 start() 方法…...
)
2025Java面试指南(附答案)
Java全家桶 Java基础 1. Java为什么被称为平台无关性语言? 2. 解释下什么是面向对象?面向对象和面向过程的区别 3. 面向对象的三大特性?分别解释下? 4. Java 中的参数传递时传值呢?还是传引用? 5. JD…...

springboot对接阿里云大模型
阿里云百炼文档地址: 百炼控制台 设置账号 首先跟着文档设置账号,新建一个api key 文档地址: 百炼控制台 对接会话API 你可以使用sdk来对接,但没有必要,因为所有接口对接都是http形式的,直接使用http库来对接就行了ÿ…...

理性决策与情绪偏差
“在愤怒中做决策,你会在懊悔中收拾残局。”—本杰明富兰克林 在情绪激动时,我们往往容易做出冲动的决定。但等情绪平复,回过头来看,常常会发现这些决定并不如我们当初所想的那样明智。诺贝尔经济学奖得主在其行为经济学研究中提…...

基于LLM的响应式流式处理实践:提升用户体验的关键技术
基于LLM的响应式流式处理实践:提升用户体验的关键技术 前言:当AI生成遇到用户等待焦虑 在人工智能应用井喷式发展的今天,大语言模型(LLM)的文本生成延迟问题始终是开发者需要直面的挑战。想象这样一个场景࿱…...
)
2025年渗透测试面试题总结-拷打题库09(题目+回答)
网络安全领域各种资源,学习文档,以及工具分享、前沿信息分享、POC、EXP分享。不定期分享各种好玩的项目及好用的工具,欢迎关注。 目录 2025年渗透测试面试题总结-拷打题库09 1. Linux系统加固降权思路 2. 系统后门检测工具 3. 绕过CDN获…...

批量替换多个 Word 文档中的指定图片
在 Word 文档中,我们可以插入各种各样的图片,比如插入 logo、插入设计图、施工图等等。在某些情况下,我们也会碰到需要将 Word 文档中某张图片替换成其它图片的场景,比如将旧的 Logo 替换成新的 Logo。当我们有大量的 Word 文档需…...

海外版高端Apple科技汽车共享投资理财系统
这一款PHP海外版高端Apple、科技汽车、共享投资理财系统phplaravel框架。...

【Unity iOS打包】报错解决记录
打包报错1: Invalid Bundle. The bundle at ProductName.app/Frameworks/UnityFramework.framework contains disallowed file Frameworks. (ID: 87a95518-52e2-4ce0-983d-aab8d8006f11) 解决: Target > UnityFramework > Build Settings > Bu…...

新能源汽车零部件功率级测试方案搭建研究
摘要:本文旨在针对新能源汽车核心零部件功率级测试需求,提出基于Python与PyVISA的自动化测试方案。通过集成主流设备(如Keysight 34980A、功率分析仪等),构建多协议兼容(CAN、RS485等)的测试平台…...

DeepSeek与WPS的动态数据可视化图表构建
摘要 在数据驱动决策的时代,动态数据可视化对于信息的高效传递与分析至关重要。本文聚焦于利用DeepSeek和WPS实现近百种动态数据可视化图表的技术应用,详细阐述其操作流程、技术原理及潜在价值。通过深入剖析这一技术组合的应用场景与实践意义࿰…...
)
XCTF-web(五)
Web_php_unserialize 当通过KaTeX parse error: Expected group after _ at position 42: …erialize,触发魔术方法_̲_wakeup和__destr…this->file)输出文件内容,若KaTeX parse error: Expected group after _ at position 17: …ile可控࿰…...
)
数字ic后端设计从入门到精通2(含fusion compiler, tcl教学)
上篇回顾 上一篇文章需要讨论了net,pin的基础用法,让我们来看一下高级一点的用法 instance current_instance current_instance 是 Synopsys 工具(如 Fusion Compiler 或 Design Compiler)中用于在设计层次结构中导航的关键命令。它允许用…...

Vue2集成ElementUI实现左侧菜单导航
文章目录 简介静态导航安装element-ui,vue-router,vuex编写router/index.jsmain.js中引入elementui,router编写左侧导航返回的菜单数据 动态导航编写router/index.js左侧菜单通过for循环生成通过for循环递归生成 store/index.jsmain.js中引入store登录页面代码菜单返回数据 总结…...

Flask API 项目 Swagger 版本打架不兼容
Flask API 项目 Swagger 版本打架不兼容 1. 问题背景 在使用 Flask 3.0.0 时遇到以下问题: 安装 flask_restful_swagger 时,它强制将 Flask 降级到 1.1.4,并导致其他依赖(如 flask-sqlalchemy、flask-apispec)出现版…...

spark和Hadoop的区别和联系
区别 计算模型 Hadoop:主要基于 MapReduce 计算模型,将任务分为 Map 和 Reduce 两个阶段,适合处理大规模的批处理数据,但在处理迭代式计算和交互式查询时性能相对较差。Spark:基于内存的分布式计算框架,采…...
接入方式)
Unity接入安卓SDK(2)接入方式
1 方式一:SDK打成aar形式放入Unity 把SDK编译成aar,然后把aar文件、manifest文件放入Unity工程的Assets/Plugins/Android目录下,以及libs下,没有的文件夹就自己新建. SDK的aar包也可以放入Assets/Plugins/Android目录中 其中一…...

【HDFS入门】深入解析DistCp:Hadoop分布式拷贝工具的原理与实践
目录 1 DistCp概述与应用场景 2 DistCp架构设计解析 2.1 系统架构图 2.2 执行流程图 3 DistCp核心技术原理 3.1 并行拷贝机制 3.2 断点续传实现原理 4 DistCp实战指南 4.1 常用命令示例 4.2 性能优化策略 5 异常处理与监控 5.1 常见错误处理流程 5.2 监控指标建议…...

电力MOSFET漏源过电压与窄脉冲自保护驱动电路
1 电力MOSFET的漏源过电压 2 窄脉冲自保护驱动电路说明 3 脉冲变压器设计说明 1 电力MOSFET的漏源过电压 如果器件接有感性负载,则当器件关断时,漏极电流的突变(di/dt)会产生比外部电源高的多的漏极尖峰电压,导致器件的击穿。电力MOSFET关断得越快,产生的过电压越高…...

【scikit-learn基础】--『监督学习』之 均值聚类
聚类算法属于无监督学习,其中最常见的是均值聚类,scikit-learn中,有两种常用的均值聚类算法: 一种是有名的K-means(也就是K-均值)聚类算法,这个算法几乎是学习聚类必会提到的算法; 另一个是均值偏移聚类,它与K-means各有千秋,只是针对的应用场景不太一样,但是知名度…...

Android 15强制edge-to-edge全面屏体验
一、背景 Edge-to-edge 全面屏体验并非 Android 15 才有的新功能,早在 Android 15 之前系统就已支持。然而,该功能推出多年来,众多应用程序依旧未针对全面屏体验进行适配。因此,在 Android 15 的更新中,Google 终于决…...
)
广州可信数据空间上线:1个城市枢纽+N个产业专区+高质量数据集(附28个数据集清单)
广州数据要素市场今日迎来历史性突破!全国首个城市可信数据空间正式上线,首批28个高质量数据集同步出台,覆盖生物医药、智能装备、绿色低碳等12大产业领域,激活37个高价值场景。 一、广州城市可信数据空间:1个城市枢纽…...

AgentGPT开源程序可以在浏览器中组装、配置和部署自主人工智能代理
一、软件介绍 文末提供程序和源码下载学习 AgentGPT开源程序可以允许您配置和部署自主 AI 代理。命名您自己的定制 AI 并让它开始实现任何可想象的目标。它将通过思考要执行的任务、执行它们并从结果中学习来尝试达到目标。 二、开始使用 AgentGPT 入门最简单的方式是使用项目…...

前端笔记-Axios
Axios学习目标 Axios与API交互1、Axios配置与使用2、请求/响应拦截器3、API设计模式(了解RESTful风格即可) 学习参考:起步 | Axios中文文档 | Axios中文网 什么是Axios Axios 是一个基于 Promise 的现代化 HTTP 客户端库,专…...

【EasyPan】MySQL主键与索引核心作用解析
【EasyPan】项目常见问题解答(自用&持续更新中…)汇总版 MySQL主键与索引核心作用解析 一、主键(PRIMARY KEY)核心作用 1. 数据唯一标识 -- 创建表时定义主键 CREATE TABLE users (id INT AUTO_INCREMENT PRIMARY KEY,use…...
概述)
基于RK3588+FPGA+AI YOLO的无人船目标检测系统(一)概述
无人船在海洋监测、资源勘测、海上安全和科学研究等领域扮演着关键角色, 提升了海上任务的执行效率和安全性。在这一过程中,环境感知技术和目标检测 技术相辅相成,共同构建了系统的核心功能。随着人工智能行业的迅速发展,各 种…...
)
无人船 | 图解基于PID控制的路径跟踪算法(以全驱动无人艇WAMV为例)
目录 1 PID控制基本原理2 基于全驱动运动学的PID控制3 跟踪效果分析 1 PID控制基本原理 PID控制是一种常用的经典控制算法,其应用背景广泛,例如 工业自动化控制:温度控制、压力控制、流量控制、液位控制等过程控制系统多采用PID闭环&#x…...

为什么RPN经过的候选框处理后,要使用rcnn来进行候选框的分类和回归操作?
一句大白话总结:RPN是广撒网捕鱼,RCNN是细化鱼的分类和具体尺寸 在目标检测任务中,RPN(区域提议网络) 生成的候选框需要经过 RCNN(如 Fast R-CNN、Faster R-CNN) 进行分类和回归,这…...

代码实战保险花销预测
文章目录 摘要项目地址实战代码(初级版)实战代码(进阶版) 摘要 本文介绍了一个完整的机器学习流程项目,重点涵盖了多元线性回归的建模与评估方法。项目详细讲解了特征工程中的多项实用技巧,包括࿱…...

8.1 线性变换的思想
一、线性变换的概念 当一个矩阵 A A A 乘一个向量 v \boldsymbol v v 时,它将 v \boldsymbol v v “变换” 成另一个向量 A v A\boldsymbol v Av. 输入 v \boldsymbol v v,输出 T ( v ) A v T(\boldsymbol v)A\boldsymbol v T(v)Av. 变换 T T T…...

PythonWeb
参考:如何安装 Django |Django 文档 |姜戈 一、框架搭建 1、安装Django框架 pip3 install django 2、查看是否安装成功 pip3 show django 这样显示就是成功了 3、初始化项目 你想在哪个路径就 cd到哪个路径下输入一下命令就可以 django-admin startproject my…...

【大模型ChatGPT +DeepSeeK+python】最新AI赋能Python长时序植被遥感动态分析、物候提取、时空变异归因及RSEI生态评估
在遥感技术与人工智能深度融合的2025年,AI大模型正重塑长时序植被遥感数据分析范式。从Landsat/Sentinel卫星数据的智能化去云处理,到MODIS植被产品的AI辅助质量控制,以ChatGPT 、DeepSeeK为代表的大模型技术已成为提升遥感数据处理效率与精度…...
:辨别虚荣指标,挖掘数据真价值)
精益数据分析(11/126):辨别虚荣指标,挖掘数据真价值
精益数据分析(11/126):辨别虚荣指标,挖掘数据真价值 大家好!在创业和数据分析的学习道路上,我一直希望能和大家携手前行、共同进步。今天,咱们接着深入研读《精益数据分析》,这次聚…...

Time to event :Kaplan-Meier曲线、Log Rank检验与Shiny R
代码: # 创建数据框 data_a <- data.frame( usubjid = c(1- 1, 1- 2, 1- 3, 1- 4, 1- 5, 1- 6, 1- 7, 1- 8, 1- 9, 1-10, 2- 1, 2- 2, 2- 3, 2- 4, 2- 5, 2- 6, 2- 7, 2- 8, 2- 9, 2-10), cnsr = c(0,1,0,1,0,1,0,0,0,1,…...

线上救急-AWS限频
线上救急-AWS限频 问题 在一个天气炎热的下午,我正喝着可口可乐,悠闲地看着Cursor生成代码,忽然各大群聊中出现了加急➕全体的消息,当时就心里一咯噔,点开一看,果然,线上服务出问题࿰…...

JavaWeb学习打卡-Day1-分层解耦、Spring IOC、DI
三层架构 Controller(控制层):接收前端发送的请求,对请求进行处理,并响应数据。Service(业务逻辑层):处理具体的业务逻辑。DAO(数据访问层/持久层)ÿ…...