第一章:自然语言处理
目录
1.1 自然语言处理发展史
1.2 统计语言模型发展史
统计语言模型
NNLM 模型
Word2Vec 模型
ELMo 模型
BERT 模型
大语言模型
1.3 小结
自然语言处理(Natural Language Processing,NLP)是一门借助计算机技术研究人类语言的科学。虽然该领域的发展历史不长,但是其发展迅速并且取得了许多令人印象深刻的成果。
在上手实践之前,我想先给大家简单介绍一下自然语言处理的发展历史以及 Transformer 模型的概念,这对于后面理解模型结构会有很大帮助。本章将带大家快速穿越自然语言处理的发展史,了解从统计语言模型到大语言模型的发展历程。
1.1 自然语言处理发展史
自然语言处理的发展大致上可以分为两个阶段:
第一阶段:不懂语法怎么理解语言?
20 世纪 50 年代到 70 年代,人们对自然语言处理的认识都局限在人类学习语言的方式上,用了二十多年时间苦苦探寻让计算机理解语言的方法,最终却一无所获。
当时的学术界普遍认为,要让计算机处理自然语言必须先让其理解语言,因此分析语句和获取语义成为首要任务,而这主要依靠语言学家人工总结文法规则来实现。特别是 20 世纪 60 年代,基于乔姆斯基形式语言(Chomsky Formal languages)的编译器取得了很大进展,更加鼓舞了研究者通过概括语法规则来处理自然语言的信心。

但是与规范严谨的程序语言不同,自然语言复杂又灵活,是一种上下文有关文法(Context-Sensitive Grammars,CSGs),因此仅靠人工编写文法规则根本无法覆盖,而且随着编写的规则数量越来越多、形式越来越复杂,规则与规则之间还可能会存在矛盾。因此这一阶段自然语言处理的研究可以说进入了误区。
第二阶段:只要看的足够多,就能处理语言
正如人类是通过空气动力学而不是简单模仿鸟类造出了飞机,计算机处理自然语言也未必需要理解语言。

20 世纪 70 年代,随着统计语言学的提出,基于数学模型和统计方法的自然语言处理方法开始兴起。当时的代表性方法是“通信系统加隐马尔可夫模型”,其输入和输出都是一维且保持原有次序的符号序列,可以处理语音识别、词性分析等任务,但是这种方法在面对输出为二维树形结构的句法分析以及符号次序有很大变化的机器翻译等任务时就束手无策了。
20 世纪 80 年代以来,随着硬件计算能力的提高以及海量互联网数据的出现,越来越多的统计机器学习方法被应用到自然语言处理领域,例如一些研究者引入基于有向图的统计模型来处理复杂的句法分析任务。2005 年 Google 公司基于统计方法的翻译系统更是全面超过了基于规则的 SysTran 系统。

2006 年,随着辛顿(Hinton)证明深度信念网络(Deep Belief Networks,DBN)可以通过逐层预训练策略有效地进行训练,基于神经网络和反向传播算法(Back Propagation)的深度学习方法开始兴起。许多之前由于缺乏数据、计算能力以及有效优化方法而被忽视的神经网络模型得到了复兴。例如 1997 年就已提出的长短时记忆网络(Long Short Term Memory,LSTM)模型在重新被启用后在许多任务上大放异彩。
延伸
即使在 Transformer 模型几乎“一统江湖”的今天,LSTM 模型依然占有一席之地。2024 年 5 月 8 日,LSTM 提出者和奠基者 Sepp Hochreiter 公布了 LSTM 模型的改良版本——xLSTM,在性能和扩展方面都得到了显著提升。论文的所属机构中还出现了一家叫做 NXAI 的公司,Sepp Hochreiter 表示:“借助 xLSTM,我们缩小了与现有最先进大语言模型的差距。借助 NXAI,我们已开始构建欧洲自己的大语言模型。”
随着越来越多研究者将注意力转向深度学习方法,诸如卷积神经网络(Convolutional Neural Networks,CNN)等模型被广泛地应用到各种自然语言处理任务中。2017 年,Google 公司提出了 Attention 注意力模型,论文中提出的 Transformer 结构更是引领了后续神经网络语言模型的发展。
得益于抛弃了让计算机简单模仿人类的思路,这一阶段自然语言处理研究出现了蓬勃发展。今天可以说已经没有人再会质疑统计方法在自然语言处理上的可行性。
1.2 统计语言模型发展史
要让计算机处理自然语言,首先需要为自然语言建立数学模型,这种模型被称为“统计语言模型”,其核心思想是判断一个文字序列是否构成人类能理解并且有意义的句子。这个问题曾经困扰了学术界很多年。
统计语言模型
20 世纪 70 年代之前,研究者尝试从文字序列是否合乎文法、含义是否正确的角度来建立语言模型。最终,随着人工编写出的规则数量越来越多、形式越来越复杂,对语言模型的研究陷入瓶颈。直到 20 世纪 70 年代中期,IBM 实验室的贾里尼克(Jelinek)为了研究语音识别问题换了一个思路,用一个简单的统计模型就解决了这个问题。

贾里尼克的想法是要判断一个文字序列 w1,w2,…,wn 是否合理,就计算这个句子 S 出现的概率 P(S),出现概率越大句子就越合理:
![]()
其中,词语 wn 出现的概率取决于在句子中出现在它之前的所有词(理论上也可以引入出现在它之后的词语)。但是,随着文本长度的增加,条件概率 ![]() 会变得越来越难以计算,因而在实际计算时会假设每个词语 wi 仅与它前面的 N−1 个词语有关,即:
会变得越来越难以计算,因而在实际计算时会假设每个词语 wi 仅与它前面的 N−1 个词语有关,即:
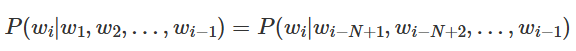
这种假设被称为马尔可夫(Markov)假设,对应的语言模型被称为 N 元(N-gram)模型。例如当 N=2 时,词语 wi 出现的概率只与它前面的词语 wi−1 有关,被称为二元(Bigram)模型;而 N=1 时,模型实际上就是一个上下文无关模型。由于 N 元模型的空间和时间复杂度都几乎是 N 的指数函数,因此实际应用中比较常见的是取 N=3 的三元模型。
延伸
即使是使用三元、四元甚至是更高阶的语言模型,依然无法覆盖所有的语言现象。在自然语言中,上下文之间的关联性可能跨度非常大,例如从一个段落跨到另一个段落,这是马尔可夫假设解决不了的。此时就需要使用 LSTM、Transformer 等模型来捕获词语之间的远距离依赖(Long Distance Dependency)了。
NNLM 模型
2003 年,本吉奥(Bengio)提出了神经网络语言模型(Neural Network Language Model,NNLM)。可惜它生不逢时,由于神经网络在当时并不被人们看好,在之后的十年中 NNLM 模型都没有引起很大关注。

直到 2013 年,随着越来越多的研究者使用深度学习模型来处理自然语言,NNLM 模型才被重新发掘,并成为使用神经网络建模语言的经典范例。NNLM 模型的思路与统计语言模型保持一致,它通过输入词语前面的 N−1 个词语来预测当前词。模型结构如图 1-6 所示。
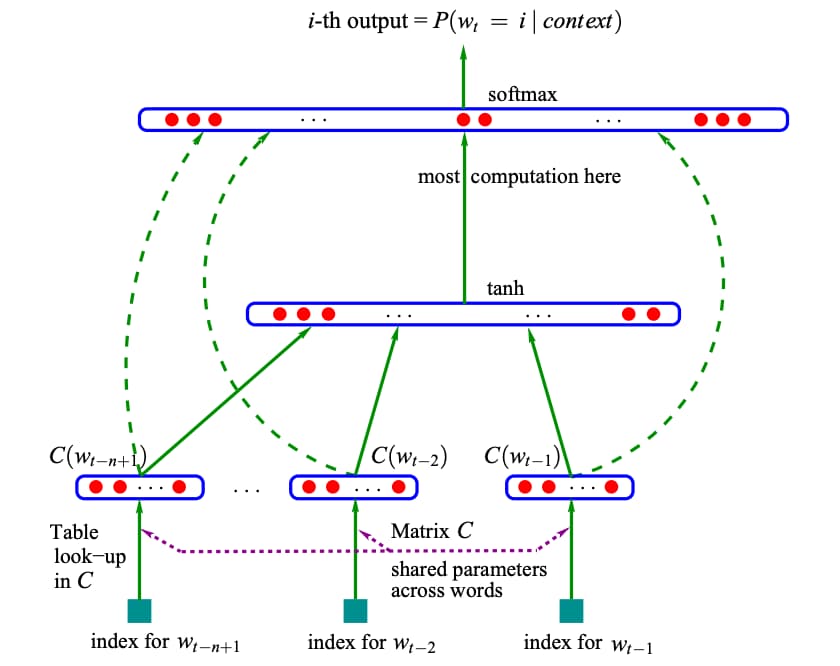
具体来说,NNLM 模型首先从词表 C 中查询得到前面 N−1 个词语对应的词向量 ![]() ,然后将这些词向量拼接后输入到带有激活函数的隐藏层中,通过 Softmax 函数预测当前词语的概率。特别地,包含所有词向量的词表矩阵 C 也是模型的参数,需要通过学习获得。因此 NNLM 模型不仅能够能够根据上文预测当前词语,同时还能够给出所有词语的词向量(Word Embedding)。
,然后将这些词向量拼接后输入到带有激活函数的隐藏层中,通过 Softmax 函数预测当前词语的概率。特别地,包含所有词向量的词表矩阵 C 也是模型的参数,需要通过学习获得。因此 NNLM 模型不仅能够能够根据上文预测当前词语,同时还能够给出所有词语的词向量(Word Embedding)。
Word2Vec 模型
真正将神经网络语言模型发扬光大的是 2013 年 Google 公司提出的 Word2Vec 模型。Word2Vec 模型提供的词向量在很长一段时间里都是自然语言处理方法的标配,即使是后来出现的 Glove 模型也难掩它的光芒。
Word2Vec 的模型结构和 NNLM 基本一致,只是训练方法有所不同,分为 CBOW (Continuous Bag-of-Words) 和 Skip-gram 两种,如图 1-7 所示。
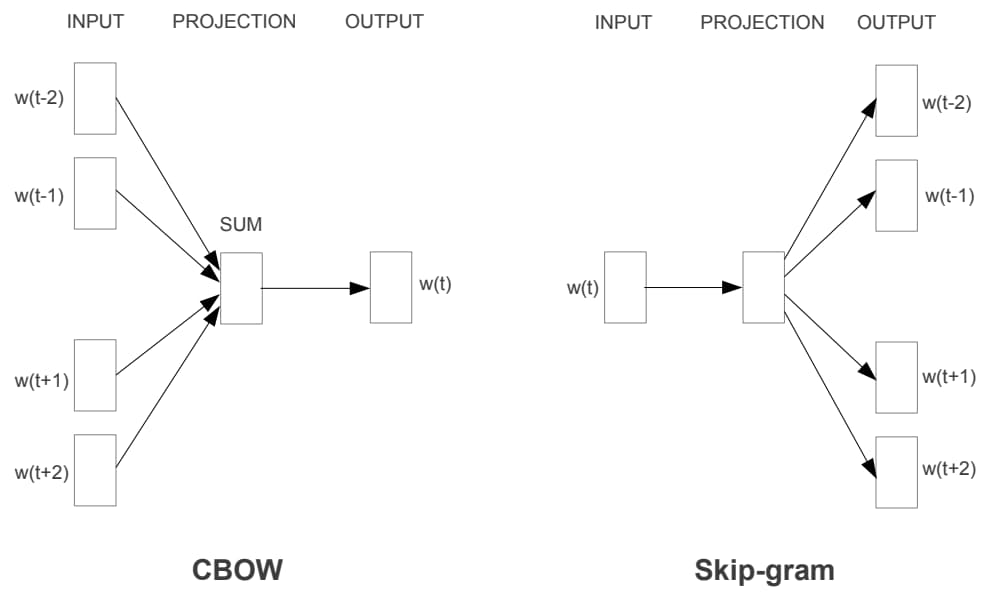
图 1-7 Word2Vec 模型的训练方法
其中 CBOW 使用周围的词语 w(t−2),w(t−1),w(t+1),w(t+2) 来预测当前词 w(t),而 Skip-gram 则正好相反,它使用当前词 w(t) 来预测它的周围词语。
可以看到,与严格按照统计语言模型结构设计的 NNLM 模型不同,Word2Vec 模型在结构上更加自由,训练目标也更多地是为获得词向量服务。特别是同时通过上文和下文来预测当前词语的 CBOW 训练方法打破了语言模型“只通过上文来预测当前词”的固定思维,为后续一系列神经网络语言模型的发展奠定了基础。
然而,有一片乌云一直笼罩在 Word2Vec 模型的上空——多义词问题。一词多义是语言灵活性和高效性的体现,但是 Word2Vec 模型却无法处理多义词,一个词语无论表达何种语义,Word2Vec 模型都只能提供相同的词向量,即将多义词编码到了完全相同的参数空间。实际上在 20 世纪 90 年代初,雅让斯基(Yarowsky)就给出了一个简洁有效的解决方案——运用词语之间的互信息(Mutual Information)。

具体来说,对于多义词,可以使用文本中与其同时出现的互信息最大的词语集合来表示不同的语义。例如对于“苹果”,当表示水果时,周围出现的一般就是“超市”、“香蕉”等词语;而表示“苹果公司”时,周围出现的一般就是“手机”、“平板”等词语,如图 1-9 所示。
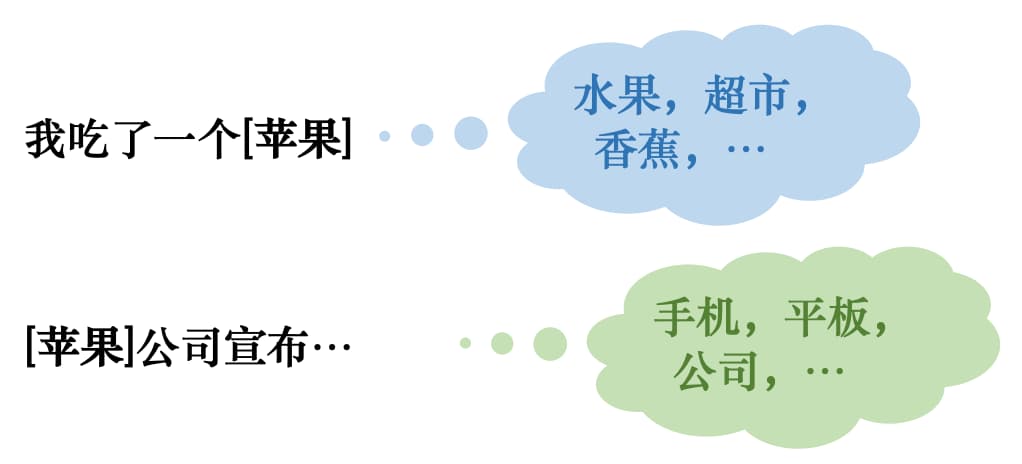
因此,在判断多义词究竟表达何种语义时,只需要查看哪个语义对应集合中的词语在上下文中出现的更多就可以了,即通过上下文来判断语义。
延伸
1948 年,香农(Claude Elwood Shannon)在他著名的论文《通信的数学原理》中提出了“信息熵”(Information Entropy)的概念,解决了信息的度量问题,并且量化出信息的作用。上面提到的互信息就来自于信息论。如果你对此感兴趣,可以阅读《信息的度量和作用:信息论基本概念》。
后来自然语言处理的标准流程就是先将 Word2Vec 模型提供的词向量作为模型的输入,然后通过 LSTM、CNN 等模型结合上下文对句子中的词语重新进行编码,以获得包含上下文信息的词语表示。
ELMo 模型
为了更好地解决多义词问题,2018 年研究者提出了 ELMo 模型(Embeddings from Language Models)。与 Word2Vec 模型只能提供静态词向量不同,ELMo 模型会根据上下文动态地调整词语的词向量。
具体来说,ELMo 模型首先对语言模型进行预训练,使得模型掌握编码文本的能力;然后在实际使用时,对于输入文本中的每一个词语,都提取模型各层中对应的词向量拼接起来作为新的词向量。ELMo 模型采用双层双向 LSTM 作为编码器,如图 1-10 所示,从两个方向编码词语的上下文信息,相当于将编码层直接封装到了语言模型中。
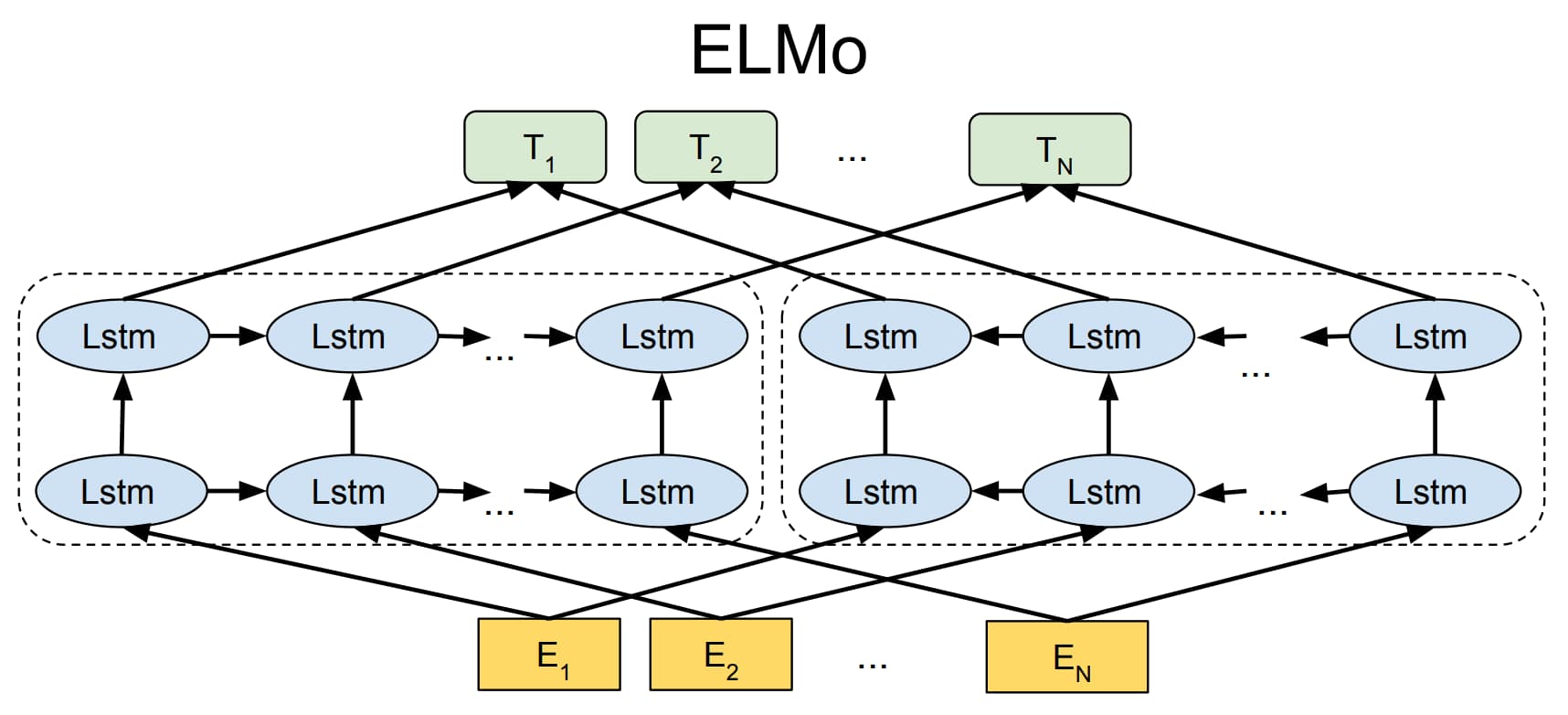
训练完成后 ELMo 模型不仅学习到了词向量,还训练好了一个双层双向的 LSTM 编码器。对于输入文本中的词语,可以从第一层 LSTM 中得到包含句法信息的词向量,从第二层 LSTM 中得到包含语义信息的词向量,最终通过加权求和得到每一个词语最终的词向量。
但是 ELMo 模型存在两个缺陷:首先它使用 LSTM 模型作为编码器,而不是当时已经提出的编码能力更强的 Transformer 模型;其次 ELMo 模型直接通过拼接来融合双向抽取特征的做法也略显粗糙。
不久之后,将 ELMo 模型中的 LSTM 更换为 Transformer 的 GPT 模型就出现了。但是 GPT 模型再次追随了 NNLM 的脚步,只通过词语的上文进行预测,这在很大程度上限制了模型的应用场景。例如对于文本分类、阅读理解等任务,如果不把词语的下文信息也嵌入到词向量中就会白白丢掉很多信息。
BERT 模型
2018 年底随着 BERT 模型(Bidirectional Encoder Representations from Transformers)的出现,这一阶段神经网络语言模型的发展终于出现了一位集大成者,发布时 BERT 模型在 11 个任务上都取得了最好性能。
BERT 模型采用和 GPT 模型类似的两阶段框架,首先对语言模型进行预训练,然后通过微调来完成下游任务。但是,BERT 不仅像 GPT 模型一样采用 Transformer 作为编码器,而且采用了类似 ELMo 模型的双向语言模型结构,如图 1-11 所示。因此 BERT 模型不仅编码能力强大,而且对各种下游任务,BERT 模型都可以通过简单地改造输出部分来完成。
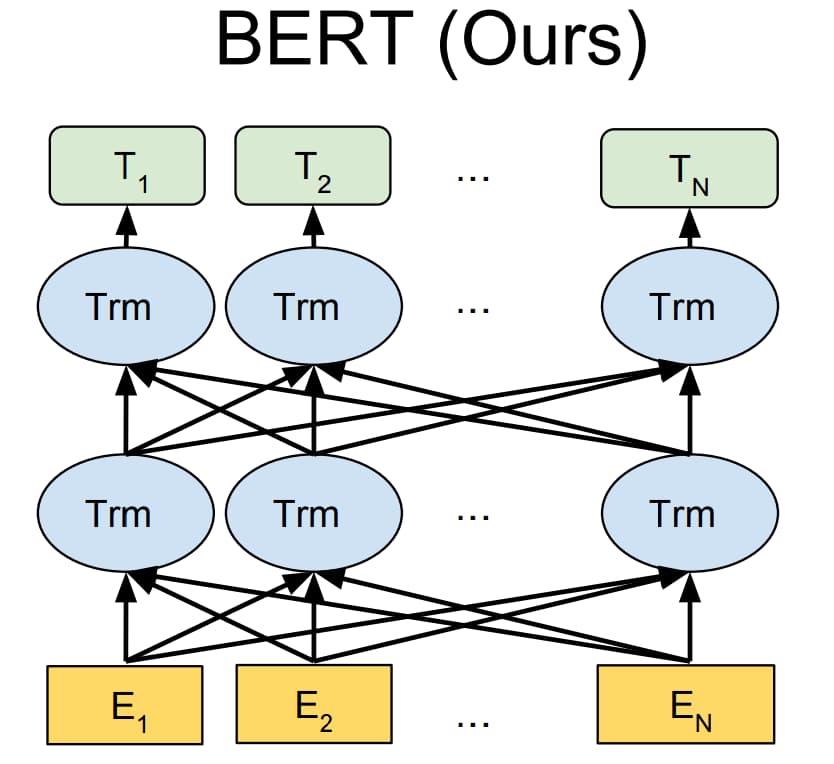
但是 BERT 模型的优点同样也是它的缺陷,由于 BERT 模型采用双向语言模型结构,因而无法直接用于生成文本。
可以看到,从 2003 年 NNLM 模型提出时的无人问津,到 2018 年底 BERT 模型横扫自然语言处理领域,神经网络语言模型的发展也经历了一波三折。在此期间,研究者一直在不断地对前人的工作进行改进,这才取得了 BERT 模型的成功。BERT 模型的出现并非一蹴而就,它不仅借鉴了 ELMo、GPT 等模型的结构与框架,而且延续了 Word2Vec 模型提出的 CBOW 训练方式的思想,可以看作是这一阶段语言模型发展的集大成者。
在 BERT 模型取得成功之后,研究者并没有停下脚步,在 BERT 模型的基础上又提出了诸如 MASS、ALBERT、RoBERTa 等改良模型。其中具有代表性的就是微软提出的 UNILM 模型(UNIfied pretrained Language Model),它把 BERT 模型的 MASK 机制运用到了一个很高的水平,如图 1-12 所示。
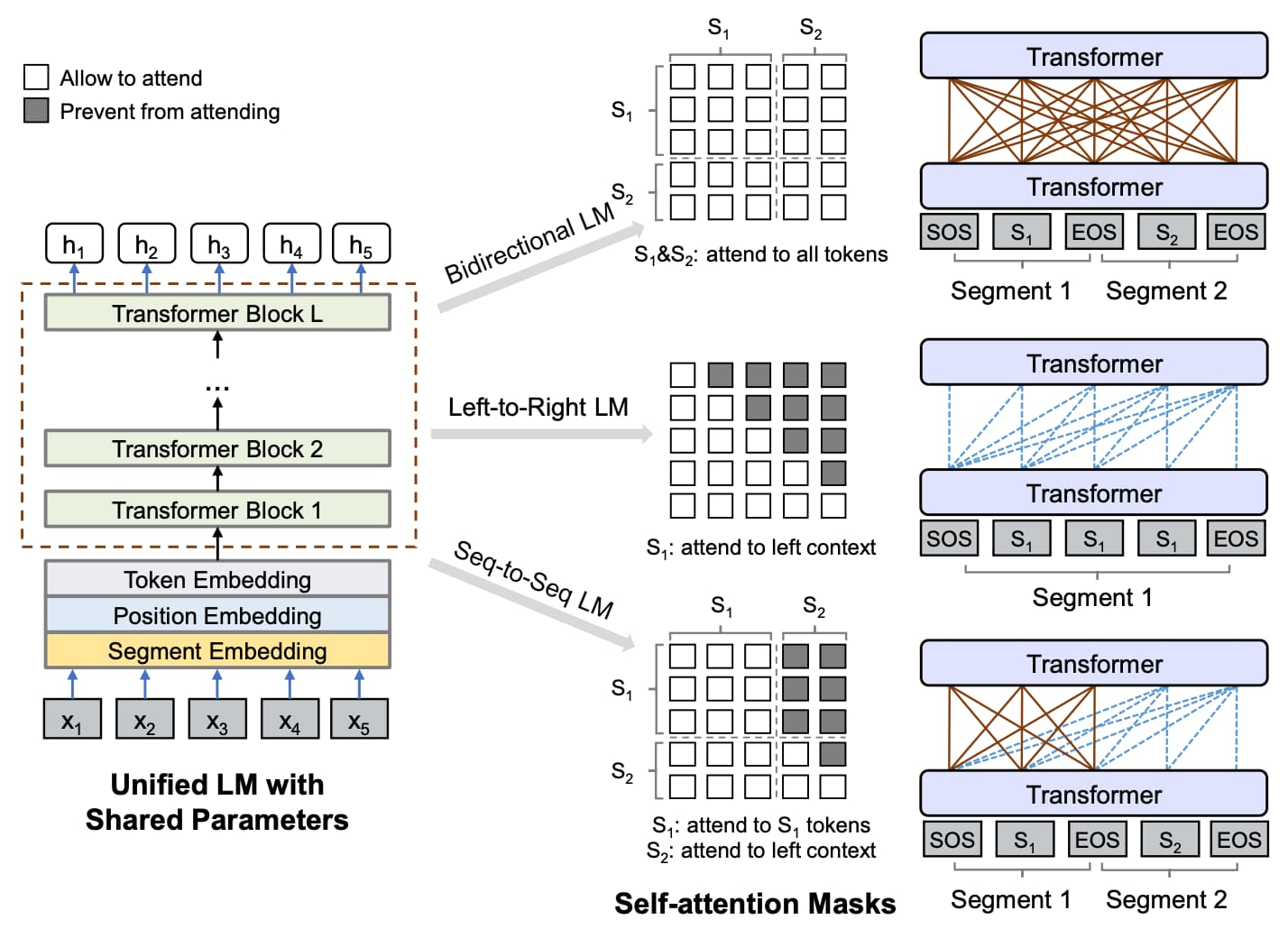
具体来说,UNILM 模型通过给 Transformer 中的 Self-Attention 机制添加不同的 MASK 矩阵,在不改变 BERT 模型结构的基础上同时实现了双向、单向和序列到序列(Sequence-to-Sequence,Seq2Seq)语言模型,是一种对 BERT 模型进行扩展的优雅方案。
大语言模型
除了优化模型结构,研究者发现扩大模型规模也可以提高性能。在保持模型结构以及预训练任务基本不变的情况下,仅仅通过扩大模型规模就可以显著增强模型能力,尤其当规模达到一定程度时,模型甚至展现出了能够解决未见过复杂问题的涌现(Emergent Abilities)能力。例如 175B 规模的 GPT-3 模型只需要在输入中给出几个示例,就能通过上下文学习(In-context Learning)完成各种小样本(Few-Shot)任务,而这是 1.5B 规模的 GPT-2 模型无法做到的。
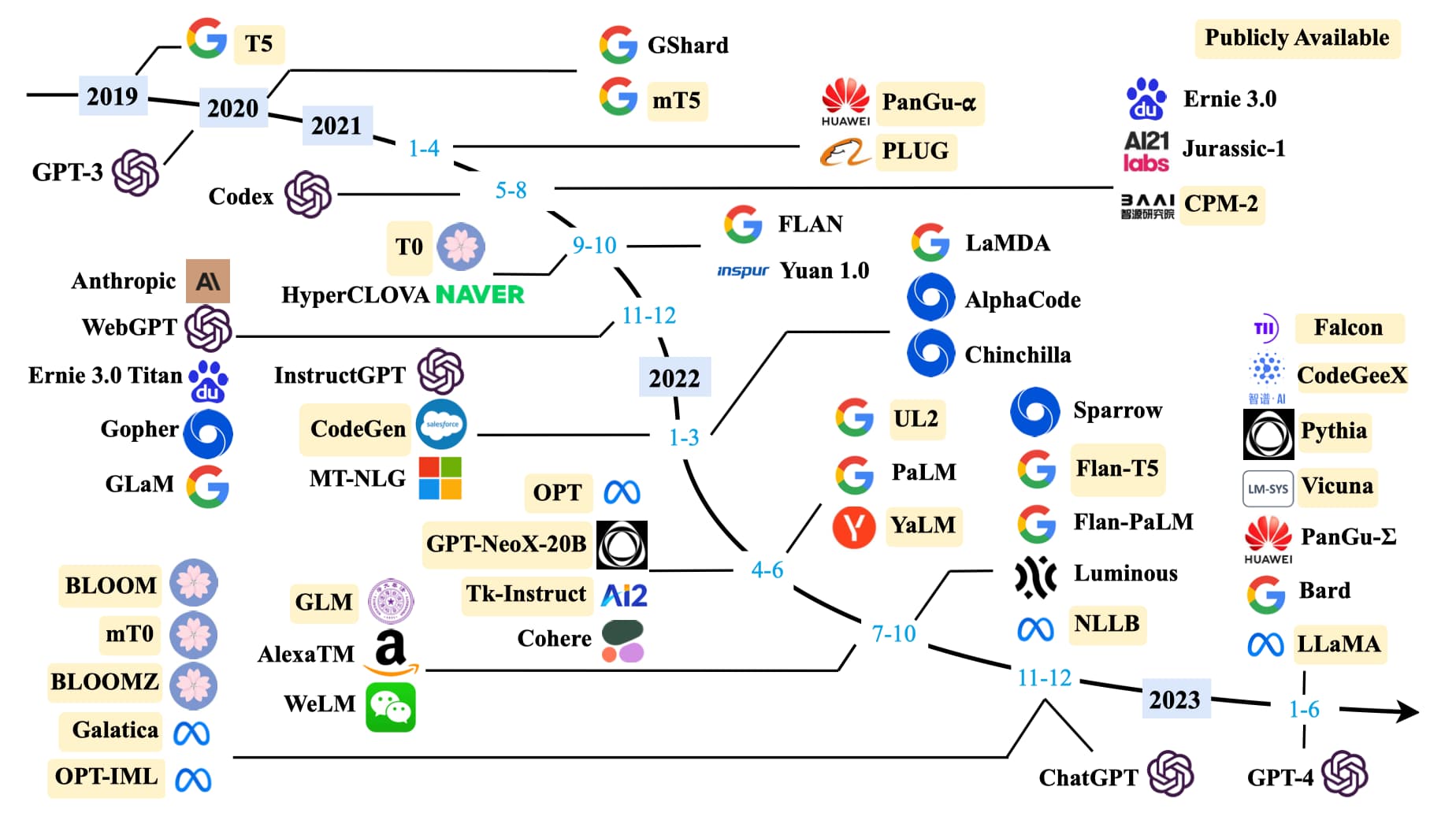
在规模扩展定律(Scaling Laws)被证明对语言模型有效之后,研究者基于 Transformer 结构不断加深模型深度,构建出了许多大语言模型,如图 1-13 所示。
一个标志性的事件是 2022 年 11 月 30 日 OpenAI 公司发布了面向普通消费者的 ChatGPT 模型(Chat Generative Pre-trained Transformer),它能够记住先前的聊天内容真正像人类一样交流,甚至能撰写诗歌、论文、文案、代码等。发布后,ChatGPT 模型引起了巨大轰动,上线短短 5 天注册用户数就超过 100 万。2023 年一月末,ChatGPT 活跃用户数量已经突破 1 亿,成为史上增长最快的消费者应用。
下面本章将按照模型规模介绍一些可供开发者使用的大语言模型。首先是数百亿参数的大语言模型:
- Flan-T5(11B):指令微调(Instruction Tuning)研究领域的代表性模型,通过扩大任务数量、扩大模型规模以及在思维链提示(Chain-of-Thought Prompting)数据上进行微调探索了指令微调技术的应用;
- CodeGen 以及 CodeGen2(11B):为生成代码而设计的自回归(Autoregressive)语言模型,是探索大语言模型代码生成能力的一个代表性模型;
- mT0(13B):多语言(Multilingual)大语言模型的代表,使用多语言提示在多语言任务上进行了微调;
- Baichuan 以及 Baichuan-2(7B):百川智能公司开发的大语言模型,支持中英双语,在多个中英文基准测试上取得优异性能;
- PanGu-α(13B):华为公司开发的中文大语言模型,在零样本(Zero-Shot)和小样本(Few-Shot)设置下展现出了优异的性能;
- Qwen(72B):阿里巴巴公司开源的多语言大模型,在语言理解、推理、数学等方面均展现出了优秀的模型能力,还为代码、数学和多模态设计了专业化版本 Code-Qwen、Math-Qwen、Qwen-VL 等可供用户使用;
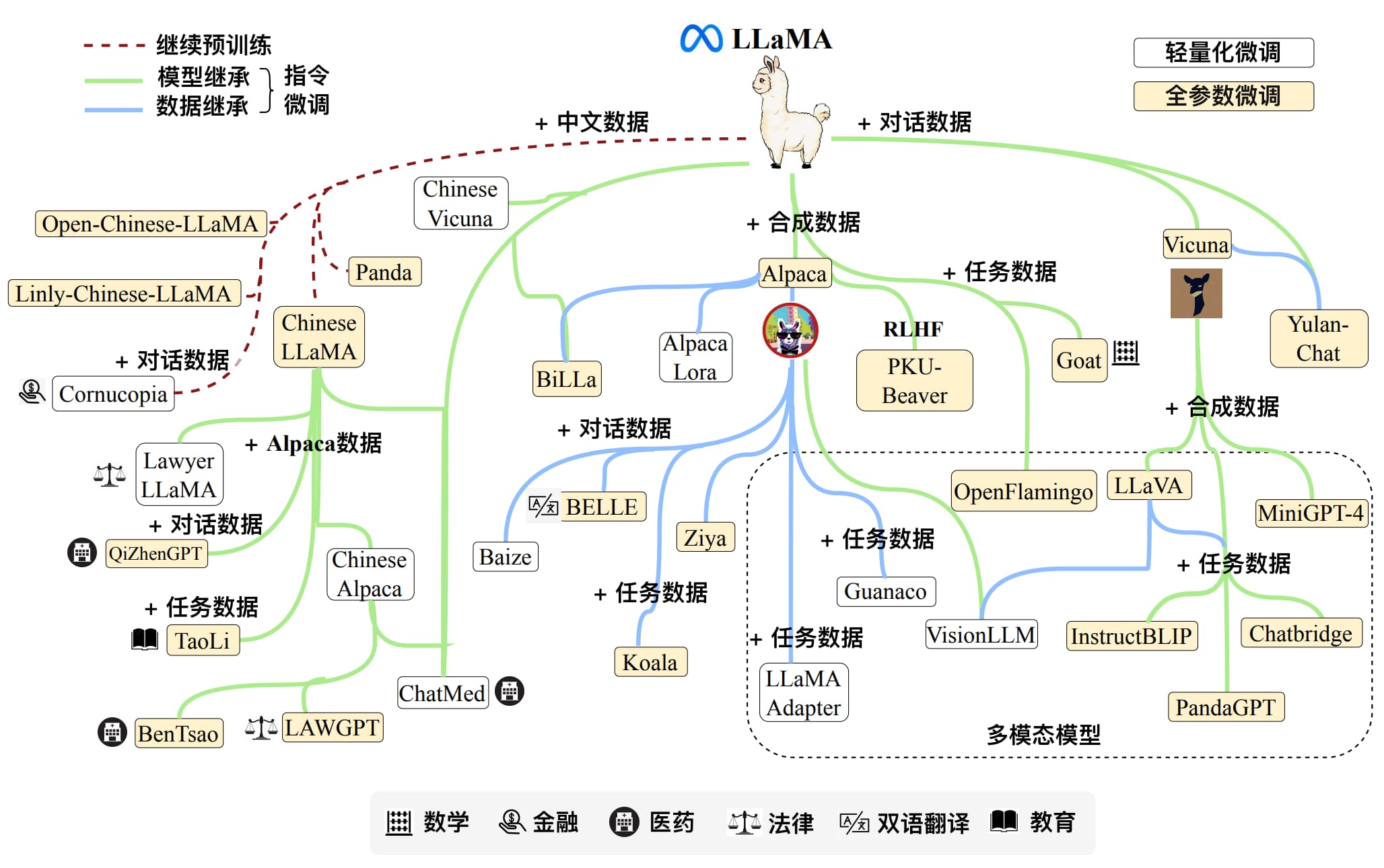
- LLaMA 以及 LLaMA-2(65B):在一系列指令遵循(Instruction Following)任务中展现出卓越性能。由于 LLaMA 模型的开放性和有效性,吸引了许多研究者在其之上指令微调或继续预训练不同的模型版本,例如 Stanford Alpaca 模型、Vicuna 模型等,如图 1-14 所示。
- Mixtral(46.7B):稀疏混合专家模型架构的大语言模型,这也是较早对外公开的 MoE 架构的语言模型,其处理速度和资源消耗与 12.9B 参数的模型相当,在 MT-bench 基准上取得了与 GPT-3.5 相当的性能表现;
然后是数千亿计参数规模的大语言模型:
- OPT(175B)以及指令微调版本 OPT-IML:致力于开放共享,使得研究者可以对大规模模型进行可复现的研究;
- BLOOM 以及 BLOOMZ(176B):跨语言泛化(Cross-Lingual Generalization)研究领域的代表性模型,具有多语言建模的能力;
- GLM:双语大语言模型,其小规模中文聊天版本 ChatGLM2-6B 在中文任务研究中十分流行,在效率和容量方面有许多改进,支持量化(Quantization)、32K 长度的上下文、快速推理等。
相关
如果你对提示(Prompting)、指令微调(Instruction Tuning)等专业术语不熟悉也不用着急,本教程会在第十三章《Prompting 情感分析》以及第十四章《使用大语言模型》中进行详细介绍。
对于普通开发者,一种更简单的方式是直接调用大语言模型接口,这样就不需要在本地搭建环境部署模型。例如通过 OpenAI 公司提供的接口就可以调用 GPT-3.5、GPT-4 等一系列 GPT 模型,其中一些还支持通过接口进行微调。
延伸
如果你对如何通过接口调用 GPT 模型感兴趣,可以阅读《ChatGPT 教程 (Python 调用 OpenAI API)》。
1.3 小结
可以看到,自然语言处理的发展并非一帆风顺,期间也曾走入歧路而停滞不前,正是一代又一代研究者的不懈努力才使得该领域持续向前发展并取得了许多令人印象深刻的成果。如今预训练语言模型、大语言模型在学术界和工业界都获得了广泛的应用,深刻地改变着我们的生活,我们需要明白这些成功并非一蹴而就,而是“站在巨人的肩膀上”。
相关文章:

第一章:自然语言处理
目录 1.1 自然语言处理发展史 1.2 统计语言模型发展史 统计语言模型 NNLM 模型 Word2Vec 模型 ELMo 模型 BERT 模型 大语言模型 1.3 小结 自然语言处理(Natural Language Processing,NLP)是一门借助计算机技术研究人类语言的科学。虽…...

Git 大文件使用 Git-LFS 管理,推送失败
配置了.gitattributes文件后, *.jar filterlfs difflfs mergelfs -text *.so filterlfs difflfs mergelfs -text *.aar filterlfs difflfs mergelfs -text *.bin filterlfs difflfs mergelfs -text *.a filterlfs difflfs mergelfs -text 仍然推送失败 POST git-…...

[c语言日寄]免费文档生成器——Doxygen在c语言程序中的使用
【作者主页】siy2333 【专栏介绍】⌈c语言日寄⌋:这是一个专注于C语言刷题的专栏,精选题目,搭配详细题解、拓展算法。从基础语法到复杂算法,题目涉及的知识点全面覆盖,助力你系统提升。无论你是初学者,还是…...

RK3588上编译opencv 及基于c++实现图像的读入
参考博文: https://blog.csdn.net/qq_47432746/article/details/147203889 一、安装依赖包 sudo apt install build-essential cmake git pkg-config libgtk-3-dev libavcodec-dev libavformat-dev libswscale-dev libv4l-dev libxvidcore-dev libx264-dev libjpe…...

C++ GPU并行计算开发实战:利用CUDA/OpenCL加速粒子系统与流体模拟
🧑 博主简介:CSDN博客专家、CSDN平台优质创作者,高级开发工程师,数学专业,10年以上C/C, C#, Java等多种编程语言开发经验,拥有高级工程师证书;擅长C/C、C#等开发语言,熟悉Java常用开…...

Java 设计模式心法之第3篇 - 总纲:三大流派与导航地图
前两章,我们修炼了 SOLID 这套强大的“内功心法”,为构建高质量软件打下了坚实根基。现在,是时候鸟瞰整个设计模式的“武林”了!本文将为您展开一幅由 GoF 四人帮精心绘制的 23 种经典设计模式的“全景导航地图”。我们将探索这些…...

高级java每日一道面试题-2025年4月19日-微服务篇[Nacos篇]-Nacos未来的发展方向和规划有哪些?
如果有遗漏,评论区告诉我进行补充 面试官: Nacos未来的发展方向和规划有哪些? 我回答: Nacos 作为阿里巴巴开源的服务发现、配置管理和服务治理平台,其未来的发展方向和规划主要体现在以下几个关键领域: 1. 安全性与标准化 API分类精细化…...

跳过reCAPTCHA验证的技术解析与优化实践
Google的reCAPTCHA验证系统已成为保护网站安全的核心工具之一。然而,频繁的验证弹窗可能降低用户体验,甚至导致用户流失。如何在遵守平台规则的前提下,通过技术优化与用户行为管理减少验证触发率,成为我们亟需解决的难题。 但需要…...

idea使用docker插件一键部署项目
一、首先保证我们电脑上已经安装了docker docker -v查看docker版本,如果不能识别,需要先下载docker destop,在官网下载正常安装即可。 安装成功就可以使用docker 命令了 二、idea下载docker插件并配置docker参数 我是通过tcp连接docker服务…...
——表格型方法(蒙特卡洛、时序差分))
强化学习笔记(三)——表格型方法(蒙特卡洛、时序差分)
强化学习笔记(三)——表格型方法(蒙特卡洛、时序差分) 一、马尔可夫决策过程二、Q表格三、免模型预测1. 蒙特卡洛策略评估1) 动态规划方法和蒙特卡洛方法的差异 2. 时序差分2.1 时序差分误差2.2 时序差分方法的推广 3. 自举与采样…...

[SpringMVC]请求响应参数传递
controller前置url解决业务重名 在项目中,常常会碰到不同的业务之间的某个方法同名的情况。例如在一个文档管理系统(有着文档和发布者两个实体)中,两个实体都有着 "add" 业务。如果两个实体相关的业务url都用 "/ad…...

在C++业务类和QML之间创建一个数据桥梁
工作中经常会遇到两种业务直接按无法直接沟通,此时需要建立一个桥梁将两者进行联系起来,假设一个C业务类,有一个QML UI, 如果将BridgeClass 类通过qmlRegisterType 注册到QML中,在C中如何能够调用到BridgeClass 对象吗…...

超详细mac上用nvm安装node环境,配置npm
一、安装NVM 打开终端,运行以下命令来安装NVM: curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.39.5/install.sh | bash 然后就会出现如下代码: > Profile not found. Tried ~/.bashrc, ~/.bash_profile, ~/.zprofile, ~/.…...

MH2103系列coremark1.0跑分数据和优化,及基于arm2d的优化应用
CoreMark 1.0 介绍 CoreMark 是由 EEMBC(Embedded Microprocessor Benchmark Consortium)组织于 2009 年推出的一款用于衡量嵌入式系统 CPU 或 MCU 性能的标准基准测试工具。它旨在替代陈旧的 Dhrystone 标准(Dhrystone 容易受到各种libc不同…...

YOLO11改进 | 特征融合Neck篇之Lowlevel Feature Alignment机制:多尺度检测的革新性突破
## 为什么需要重新设计特征融合机制? 在目标检测领域,YOLO系列模型因其高效的实时性成为工业界和学术界的标杆。然而,随着应用场景的复杂化(如自动驾驶中的多尺度目标、无人机图像中的小物体检测),传统特征融合策略的局限性逐渐暴露:**特征对齐不足导致语义信息错位、多…...

解决方案:远程shell连不上Ubuntu服务器
服务器是可以通过VNC登录,排除了是服务器本身故障 检查服务是否在全网卡监听 sudo ss -tlnp | grep sshd确保有一行类似 LISTEN 0 128 0.0.0.0:22 0.0.0.0:* users:(("sshd",pid...,fd3))返回无结果,表明系统里并没有任…...

Flutter路由模块化管理方案
总结记录一下Flutter路由模块管理: 1、创建路由基类 abstract class BaseRouteConfig {Map<String, WidgetBuilder> get routes; } 2、创建不同模块的路由配置类 // 认证模块路由 class AuthRoutes extends BaseRouteConfig {overrideMap<String, Widg…...
)
Java BIO、NIO、AIO、Netty面试题(已整理全套PDF版本)
什么是IO Java中的I/O(输入/输出)机制基于流(Stream)的概念实现数据的传输。流将数据序列化,即按照特定顺序逐次进行读写操作。简而言之,Java程序通过I/O流与外部设备进行数据交换。 Java类库中的I/O功能十…...

TapData × 梦加速计划 | 与 AI 共舞,TapData 携 AI Ready 实时数据平台亮相加速营,企业数据基础设施现代化
在实时跃动的数据节拍中,TapData 与 AI 共舞,踏出智能未来的新一步。 4月10日,由前海产业发展集团、深圳市前海梦工场、斑马星球科创加速平台等联合发起的「梦加速计划下一位独角兽营」正式启航。 本次加速营以“打造下一位独角兽企业”为目…...

一键部署k8s之EFK日志收集系统
一、部署es 1.下载安装 #下载安装 https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-8.13.2-linux-x86_64.tar.gz #解压 [rootes software]# tar xf elasticsearch-8.13.2-linux-x86_64.tar.gz #创建运行elasticsearch服务用户并修改权限 [rootes softw…...

Python常用的第三方模块【openpyxl库】读写Excel文件
openpyxl库模块是用于处理Microsoft Excel文件的第三方库,可以对Excel文件中的数据进行写入和读取。 weather.pyimport reimport requests#定义函数 def get_html():urlhttps://www.weather.com.cn/weather1d/101210101.shtml #爬虫打开浏览器上的网页resprequests.…...

加油站小程序实战教程12显示会员信息
目录 1 布局搭建1.1 搭建头像1.2 显示会员等级1.3 余额显示 最终效果 我们上一篇介绍了会员注册的功能,会员注册后再次进入页面的时候就可以根据openid加载会员信息,本篇我们介绍一下显示会员的余额 1 布局搭建 我们现在在我的页面显示的是会员未开通…...

iOS中使用AWS上传zip文件到Minio上的oss平台上
1. 集成AWS相关库(千万不要用最新的版本,否则会出现风格化虚拟路径,找不到主机名) pod AWSS3, ~> 2.10.0 pod AWSCore, ~> 2.10.0 2. 编写集成的相关代码 - (void)uploadFileToMinIO {NSString *endPoint "http://…...
)
PaginationInnerInterceptor使用(Mybatis-plus分页)
引言 最近在编写SQL语句时总是想着偷懒,于是在前不久学习黑马点评时学到可以使用PaginationInnerInterceptor,于是现在我也在自己的项目中进行使用了,但是使用也遇到一些问题,如果你和我的问题一样,希望我的解决办法能…...

极狐GitLab CEO 柳钢受邀出席 2025 全球机器学习技术大会
极狐GitLab 是 GitLab 在中国的发行版,关于中文参考文档和资料有: 极狐GitLab 中文文档极狐GitLab 中文论坛极狐GitLab 官网 2025 年 4 月 18 日至 19 日,2025 全球机器学习技术大会(ML-Summit 2025)在上海隆重举行。…...

数据仓库 vs 数据湖:架构、应用场景与技术差异全解析
目录 一、概念对比:结构化 vs 全类型数据 二、技术架构对比 1. 数据仓库架构特点 2. 数据湖架构特点 三、典型应用场景 数据仓库适合: 数据湖适合: 四、数据湖仓一体:趋势还是折中? 五、总结:如何…...
CSMA/CD、二进制指数退避算法、最小帧长计算)
【25软考网工笔记】第三章 局域网(1)CSMA/CD、二进制指数退避算法、最小帧长计算
目录 一、CSMA/CD 1. 局域网架构概述 2. 局域网的拓扑结构 3. CSMA 1)CSMA的三种监听算法 1、1-坚持型监听算法(继续监听,不等待) 2、非坚持型监听算法(后退随机事件) 3、P-坚持型监听算法 2&#…...

Harbor对接非AWS对象存储
背景说明 项目的应用完全运行在一个离线环境中,同时通过K8S的方式进行容器编排。需要自建一个harbor的镜像仓库。并且通过私有云提供的S3服务进行容器镜像的持久化存储。我踩的其中的一个坑就是S3的region名字非AWS的标准名称。运行时抱错如下: 2025-04…...

实训Day-1 漏洞攻击实战
目录 实训任务1 漏洞攻击实战一 实训任务2 漏洞攻击实战二 实训任务3 白云新闻搜索 实训任务4 手速要快 实训任务5 包罗万象 总结 今天的实训目的是为了:了解漏洞攻击的一般步骤;掌握SQL注入的基本原理;掌握XSS攻击的基本原理ÿ…...

Linux-网络基础
一.网络背景 网络的起源与20世纪中期的冷战背景密切相关。美苏争霸期间,美国国防部担心传统集中式通信系统(如电话网络)在核战争中容易被摧毁,因此急需一种去中心化、高容错的通信方式。1969年,美国国防部高级研究计划…...
原理,公式,应用,算法改进研究综述,完整matlab代码)
算法 | 鲸鱼优化算法(WOA)原理,公式,应用,算法改进研究综述,完整matlab代码
===================================================== github:https://github.com/MichaelBeechan CSDN:https://blog.csdn.net/u011344545 ===================================================== 鲸鱼优化算法 一、原理与公式二、应用领域三、算法改进研究四、完整MAT…...

[BJDCTF2020]EzPHP
这一道题里面的知识点实在是太多了,即使这道题是我最喜欢的RCE也有点大脑停转了,所以还是做个笔记,以后方便回忆 直接跳过打点,来到源码 <?php highlight_file(__FILE__); error_reporting(0); $file "1nD3x.php"…...

企业微信-自建应用
1. 创建自建应用 2. 配置小程序/H5入口 3. 准备 : CorpId(企业id)、 AgentID(应用id)、 CorpsecretID(应用Secret) 4. 配置企业可信IP 5. 如H5需要授权登录,那么需要配置网页授…...

[FPGA基础] 时钟篇
Xilinx FPGA 时钟管理详细文档 本文档详细介绍 Xilinx FPGA 中的时钟管理,包括时钟资源、时钟管理模块、设计注意事项以及最佳实践。适用于使用 Xilinx 7 系列、UltraScale 和 UltraScale 系列 FPGA 的开发者。 1. 时钟资源概述 Xilinx FPGA 提供丰富的时钟资源&a…...
转WGS84坐标)
高德火星坐标(GCJ-02)转WGS84坐标
高德火星坐标(GCJ-02)转WGS84坐标 1 转换算法 import mathdef gcj02_to_wgs84(lon, lat):"""高德火星坐标(GCJ-02)转WGS84坐标"""a 6378245.0 # 长半轴ee 0.00669342162296594323 # 扁率def transform_lon(x, y):ret 300.0 x 2.0 * y …...

基于opencv和PaddleOCR识别身份证信息
1、安装组件 pip install --upgrade paddlepaddle paddleocr 2、完整code import cv2 import numpy as np from paddleocr import PaddleOCR# 初始化 PaddleOCR use_angle_clsTrue, lang"ch", det_db_thresh0.1, det_db_box_thresh0.5)def preprocess_image(image…...

Day-1 漏洞攻击实战
实训任务1 漏洞攻击实战一 使用 御剑 得到网站后台地址 数据库登录与日志配置 使用默认密码 root:root 登录phpMyAdmin,执行 SHOW VARIABLES LIKE general% 查看日志状态。 开启日志功能:set global general_log "ON";(配图&…...

穿透数据迷雾:PR 曲线与 ROC 曲线的深度剖析+面试常见问题及解析
一、混淆矩阵与评价指标基础 混淆矩阵核心构成:混淆矩阵是分类模型性能评估的基石,以 22 矩阵形式呈现分类结果。其中,真正例(TP)表示实际为正类且被正确预测的样本;假正例(FP)是实…...

【Linux篇】轻松搭建命名管道通信:客户端与服务器的互动无缝连接
从零开始:基于命名管道实现客户端与服务器的实时通信 一. 命名管道1.1 基本概念1.2 创建命名管道1.2.1 创建方法1.2.2 示例代码:1.2.3 注意事项:1.3 与匿名管道区别 1.4 打开原则1.4.1 管道打开顺序1.4.2 阻塞行为1.4.3 管道的关闭1.4.4 关闭…...

快充协议芯片XSP04D支持使用一个Type-C与电脑传输数据和快充取电功能
快充是由充电器端的充电协议和设备端的取电协议进行握手通讯进行协议识别来完成的,当充电器端的充电协议和设备端的取电协议握手成功后,设备会向充电器发送电压请求,充电器会根据设备的需求发送合适的电压给设备快速供电。 设备如何选择快充…...
)
MySQL的窗口函数(Window Functions)
一、窗口函数核心概念 窗口(Window) 窗口是数据行的集合,由OVER()子句定义。它决定了函数计算的“数据范围”,可以是一个分区的全部行、当前行前后的行,或动态变化的子集。 语法结构 SELECT window_f…...

一个很简单的机器学习任务
一个很简单的机器学习任务 前言 基于线上colab做的一个简单的案例,应用了线性回归算法,预测了大概加州3000多地区的房价中位数 过程 先导入了Pandas,这是一个常见的Python数据处理函数库 用Pandas的read_csv函数把网上一个共享数据集&…...

ORION:通过视觉-语言指令动作生成的一个整体端到端自动驾驶框架
25年3月来自华中科技和小米电动汽车的论文“ORION: A Holistic End-to-End Autonomous Driving Framework by Vision-Language Instructed Action Generation”。 由于因果推理能力有限,端到端 (E2E) 自动驾驶方法仍然难以在交互式闭环评估中做出正确决策。当前的方…...

python全栈-flask
python全栈-flask 文章目录 入门上手hello worldflask运行方式测试路由with app.test_request_context():debug模式配置flask参数动态路由数据类型自定义转换器to_pythonPostMan(API测试查询参数的获取请求体参数上传文件其它参数url_for 函数重定向响应内容自定义响…...

Unity中的数字孪生项目:两种输入方式对观察物体的实现
在数字孪生项目中,精确的相机控制至关重要。相机不仅需要灵活地跟随目标,还要能够平滑地旋转和缩放,以便观察和分析物体的各个细节。今天,我将通过 TouchControlCamera 和 CameraRotate 两个脚本,展示如何实现一个适用…...

ECharts散点图-散点图14,附视频讲解与代码下载
引言: ECharts散点图是一种常见的数据可视化图表类型,它通过在二维坐标系或其它坐标系中绘制散乱的点来展示数据之间的关系。本文将详细介绍如何使用ECharts库实现一个散点图,包括图表效果预览、视频讲解及代码下载,让你轻松掌握…...

【教程】Digispark实现串口通信
转载请注明出处:小锋学长生活大爆炸[xfxuezhagn.cn] 如果本文帮助到了你,欢迎[点赞、收藏、关注]哦~ 没想到这么老,很多代码都不能用,修了好久。。。 TinySoftwareSerial.cpp #include <stdlib.h> #include <stdio.h&g…...

GPT-4.1 开启智能时代新纪元
GPT-4.1 全解析:开启智能时代新纪元(含费用详解) 2025年4月,OpenAI 正式推出全新一代语言模型——GPT-4.1 系列,包括 GPT-4.1、GPT-4.1 Mini 和 GPT-4.1 Nano。相比以往模型,它在代码生成、指令理解、长文本…...

4.21 spark和hadoop的区别与联系
一、Hadoop 1. 定义 Hadoop是一个由Apache基金会开发的分布式系统基础架构。它最初是为了解决大规模数据存储和处理的问题而设计的。Hadoop的核心组件包括HDFS(Hadoop Distributed File System)和MapReduce。 2. HDFS(Hadoop Distributed Fi…...

Nacos 客户端 SDK 的核心功能是什么?是如何与服务端通信的?
Nacos 客户端 SDK 的核心功能 Nacos 客户端 SDK 是应用程序集成 Nacos 能力的桥梁,它封装了与 Nacos 服务端交互的复杂性,为开发者提供了简单易用的 API。其核心功能主要围绕两大方面:服务发现 和 配置管理。 服务发现 (Service Discovery) …...