Transformer系列(二):自注意力机制框架
自注意力机制框架
- 一、K-Q-V的自注意力机制
- 二、位置表征
- 1. 通过学习嵌入来进行位置表征
- 2. 通过直接改变 α \alpha α来进行位置表征
- 三、逐元素非线性变换
- 四、未来掩码(future mask)
- 五、总结
上篇博客:NLP中放弃使用循环神经网络架构讲解了循环神经网络在处理更长的序列或句子时存在很多问题,于是学者们开发了注意力机制来解决该问题。
广义上,注意力机制是一种处理查询的方法,它通过选取与查询最为相似的键所对应的值,来在键值存储中柔和地查找信息。这里所说的“选取”和“最为相似”,指的是对所有值进行加权平均,对于那些与查询更为相似的键所对应的值赋予更大的权重。在自注意力机制中,我们指的是使用与定义键和值相同的元素来帮助我们定义查询。
在本节中,我们将讨论如何使用一些方法来开发上下文表示,在这些方法中,实现上下文关联的主要机制不是循环,而是注意力机制。
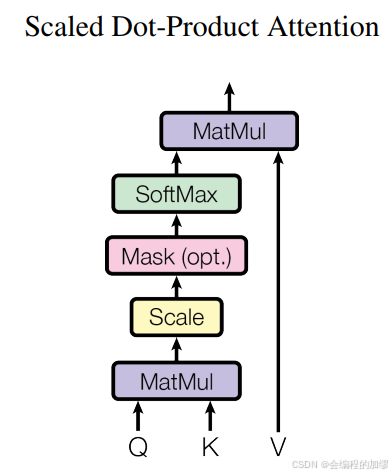
一、K-Q-V的自注意力机制
自注意力机制有多种形式;我们在此要讨论的这种形式目前是最受欢迎的。它被称为键-查询-值自注意力机制(key-query-value)。
考虑序列 x 1 : n x_{1:n} x1:n中的一个词元 x i x_{i} xi。基于它,对于矩阵 Q ∈ R d × d Q\in\mathbb{R}^{d\times d} Q∈Rd×d,我们定义一个查询 q i = Q x i q_{i} = Qx_{i} qi=Qxi。然后,对于序列中的每个词元 x j ∈ { x 1 , … , x n } x_{j}\in\{x_{1},\ldots,x_{n}\} xj∈{x1,…,xn},我们使用另外两个权重矩阵以类似的方式分别定义一个键和一个值:对于 K ∈ R d × d K\in\mathbb{R}^{d\times d} K∈Rd×d和 V ∈ R d × d V\in\mathbb{R}^{d\times d} V∈Rd×d,有 k j = K x j k_{j}=Kx_{j} kj=Kxj以及 v j = V x j v_{j}=Vx_{j} vj=Vxj 。
我们对词元 x i x_{i} xi的上下文表示 h i h_{i} hi是该序列中各个值的线性组合(也就是加权和):
h i = ∑ j = 1 n α i j v j ( 1 ) h_{i}=\sum_{j=1}^n\alpha_{ij}v_{j} \quad (1) hi=j=1∑nαijvj(1)
其中,权重 α i j \alpha_{ij} αij控制着每一个值 v j v_{j} vj的贡献程度。这一点可以从下图中看出,对making贡献较多的词是more和difficult
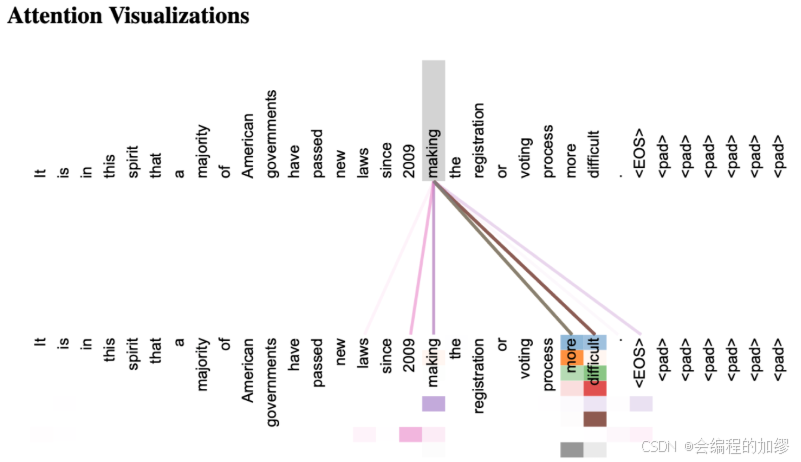
图片来源:Understanding and Coding the Self-Attention Mechanism of Large Language Models From Scratch
回到我们关于键值存储的类比, α i j \alpha_{ij} αij 以一种柔和的方式选择要查找的数据。我们通过计算键与查询之间的亲和度 q i ⊤ k j q_{i}^{\top}k_{j} qi⊤kj来定义这些权重,然后在整个序列上计算 softmax 函数:
α i j = exp ( q i T k j ) ∑ j ′ = 1 n exp ( q i T k ′ ) (2) \alpha_{ij}=\frac{\exp(q_{i}^Tk_{j})}{\sum _{j'=1}^n\exp(q_{i}^Tk')} \tag{2} αij=∑j′=1nexp(qiTk′)exp(qiTkj)(2)
⭐ 所以每个值的权重其实是键和查询的softmax函数,softmax得到的便是一个概率向量(也可以理解为权重向量)
直观上看,该操作通过选取元素 x i x_{i} xi,并在 x i x_{i} xi所在的序列 x 1 : n x_{1:n} x1:n中查找,以确定应该使用来自其他哪些词元的哪些信息,来在上下文中表示 x i x_{i} xi。 从直观上看,矩阵 K K K、 Q Q Q和 V V V的使用,让我们能够针对键、查询和值这三种不同的角色,对词元 x i x_{i} xi采用不同的 “视角” 来进行处理。我们执行这样的操作,从而为所有属于集合 { 1 , … , n } \{1, \ldots, n\} {1,…,n} 的 i i i(即序列中的每一个位置)构建对应的上下文表示 h i h_{i} hi。
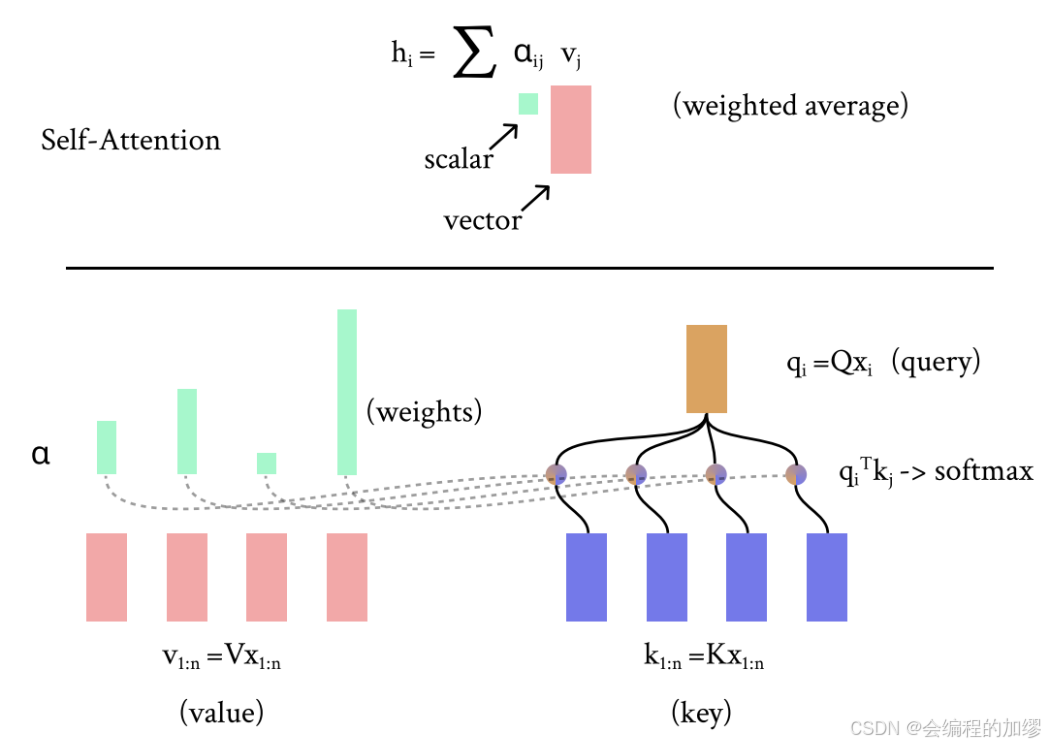
所以 q i T k j q_{i}^Tk_{j} qiTkj是为了得到value的权重,来计算出 x i x_i xi的上下文表征 (所对应的隐向量表征 h i h_{i} hi)
二、位置表征
以“the oven cooked the bread so”(烤箱烤了面包,就这样)这个序列为例。正如你可能猜到的,这与“the bread cooked the oven so”(面包烤了烤箱,就这样)是不同的序列。前一个句子表达的是我们做出了美味的面包,而后者我们可能会理解为面包不知怎么把烤箱弄坏了。
在循环神经网络中,序列的顺序决定了展开的顺序,所以这两个序列有不同的表示。而在自注意力操作中,并没有内置的顺序概念。
⭐ 自注意力操作没有内置的序列顺序概念。
为了理解这一点,让我们来看一下对这个序列进行的自注意力操作。对于“the oven cooked the bread so”这个序列,我们有一组向量 x 1 : n x_{1:n} x1:n,可以将其写为: x 1 : n = [ x t h e ; x o v e n ; x c o o k e d ; x t h e ; x b e ; x s o ] ∈ R 5 × d ( 3 ) x_{1:n} = [x_{the}; x_{oven}; x_{cooked}; x_{the}; x_{be}; x_{so}] \in \mathbb{R}^{5×d} \quad (3) x1:n=[xthe;xoven;xcooked;xthe;xbe;xso]∈R5×d(3)
因此,权重 α s o , 0 \alpha_{so, 0} αso,0(即我们查找第一个单词的权重,通过写出softmax公式可得)为: α s o , 0 = exp ( q s o ⊤ k t h e ) exp ( q s o ⊤ k t h e ) + ⋯ + exp ( q s o ⊤ k b r e a d ) ( 4 ) \alpha_{so, 0}=\frac{\exp(q_{so}^{\top}k_{the})}{\exp(q_{so}^{\top}k_{the}) + \cdots + \exp(q_{so}^{\top}k_{bread})} \quad(4) αso,0=exp(qso⊤kthe)+⋯+exp(qso⊤kbread)exp(qso⊤kthe)(4)
计算第一个单词的权重 softmax(qk)
所以, α ∈ R 5 \alpha\in\mathbb{R}^{5} α∈R5是我们的权重,我们用这些权重按照公式7计算加权平均值,从而得到 h s o h_{so} hso
h s o = α s o , 0 v t h e + α s o , 1 v o v e n + α s o , 2 v c o o k e d + α s o , 3 v t h e + α s o , 4 v b e + α s o , 5 v s o h_{so}=\alpha_{so,0}v_{the}+\alpha_{so,1}v_{oven}+\alpha_{so,2}v_{cooked}+\alpha_{so,3}v_{the}+\alpha_{so,4}v_{be}+\alpha_{so,5}v_{so} hso=αso,0vthe+αso,1voven+αso,2vcooked+αso,3vthe+αso,4vbe+αso,5vso
对于重新排序后的句子“the bread cooked the oven”,注意 α s o , 0 \alpha_{so, 0} αso,0是相同的。分子没有变化,分母也没有变化;我们只是重新排列了求和中的项。同样地,对于 α s o , b r e a d \alpha_{so,bread } αso,bread和 α s o , o v e n \alpha_{so,oven } αso,oven,你可以计算得出,它们也与序列的顺序无关,是相同的。这一切都归结于两个事实:
- x x x的表示与位置无关,对于任何单词 w w w,它都只是 E w Ew Ew;
- 自注意力操作与位置无关。
⭐ 非上下文嵌入词 x i = E w i x_{i}=Ew_{i} xi=Ewi与词在序列 w 1 : n w_{1:n} w1:n中的位置无关,仅取决于词汇表 V V V中该词的身份。
1. 通过学习嵌入来进行位置表征
为了在自注意力机制中表示位置信息,可以:
(1)使用本身就依赖于位置的向量作为输入;
(2)改变自注意力操作本身。
一种常见的解决方案是对(1)的简单实现。我们设定一个新的参数矩阵 P ∈ R N × d P \in \mathbb{R}^{N ×d} P∈RN×d,其中 N N N是你的模型能够处理的任何序列的最大长度。
然后,我们只需将一个单词位置的嵌入表示添加到其词嵌入中:
x ~ i = P i + x i (5) \tilde{x}_{i}=P_{i}+x_{i} \tag{5} x~i=Pi+xi(5)
并像往常一样执行自注意力操作(即位置嵌入是在输入之前就已经嵌入了的)。现在,自注意力操作可以利用嵌入 P i P_{i} Pi,将处于位置 i i i的单词与处于其他位置的同一个单词区别看待。例如,在BERT论文[Devlin等人,2019]中就是这样做的.
2. 通过直接改变 α \alpha α来进行位置表征
除了改变输入表示之外,我们还可以改变自注意力的形式,使其内置位置概念。一种直观的想法是,在其他条件相同的情况下,自注意力应该更多地关注 “附近 ”的词,而不是 “远处 ”的词。带线性偏差的注意力机制(Press等人,2022年)就是这一想法的一种实现方式。其一种实现方式如下:
α i = softmax ( k 1 : n q i + [ − i , . . . , − 1 , 0 , − 1 , . . . , − ( n − i ) ] ) (6) \alpha_{i} = \text{softmax}(k_{1:n}q_{i} + [-i, ..., -1, 0, -1, ..., -(n - i)]) \tag{6} αi=softmax(k1:nqi+[−i,...,−1,0,−1,...,−(n−i)])(6)
其中, k 1 : n q i ∈ R n k_{1:n}q_{i} \in \mathbb{R}^{n} k1:nqi∈Rn是原始的注意力分数,在其他条件相同的情况下,我们添加的偏差使注意力更多地集中在附近的词上,而不是远处的词上。从某种意义上说,这种方法能奏效很奇怪,但也很有趣!
三、逐元素非线性变换
想象一下,如果我们堆叠自注意力层,这是否足以替代堆叠的长短期记忆网络(LSTM)层呢?直观来看,缺少了标准深度学习架构中常见的逐元素非线性变换。实际上,如果我们堆叠两个自注意力层,得到的结果很像单个自注意力层:
o i = ∑ j = 1 n α i j V ( 2 ) ( ∑ k = 1 n α j k V ( 1 ) x k ) = ∑ k = 1 n ( α j k ∑ j = 1 n α i j ) V ( 2 ) V ( 1 ) x k = ∑ k = 1 n α i j ∗ V ∗ x k \begin{align*} o_{i} & =\sum_{j = 1}^{n} \alpha_{ij} V^{(2)}(\sum_{k = 1}^{n} \alpha_{jk} V^{(1)} x_{k})\\ & =\sum_{k = 1}^{n}(\alpha_{jk} \sum_{j = 1}^{n} \alpha_{ij}) V^{(2)} V^{(1)} x_{k}\\ & =\sum_{k = 1}^{n} \alpha_{ij}^{*} V^{*} x_{k} \end{align*} oi=j=1∑nαijV(2)(k=1∑nαjkV(1)xk)=k=1∑n(αjkj=1∑nαij)V(2)V(1)xk=k=1∑nαij∗V∗xk
其中 α i j ∗ = ( α j k ∑ j = 1 n α i j ) \alpha_{ij}^{*}=(\alpha_{jk} \sum_{j = 1}^{n} \alpha_{ij}) αij∗=(αjk∑j=1nαij),且 V ∗ = V ( 2 ) V ( 1 ) V^{*}=V^{(2)} V^{(1)} V∗=V(2)V(1)。所以,这只是对输入进行线性变换后的线性组合,和单层自注意力层很相似!这样就足够了吗?
💡和MLP中加激活函数不同,这里直接加了一个前馈网络。所以,每个注意力块后面都跟一个前馈网络。 |
在实践中,在自注意力层之后,通常会对每个词的表示独立应用前馈网络:
h F F = W 2 ReLU ( W 1 h self - attention + b 1 ) + b 2 (7) h_{FF}=W_{2} \text{ReLU}(W_{1} h_{\text{self - attention}} + b_{1}) + b_{2} \tag{7} hFF=W2ReLU(W1hself - attention+b1)+b2(7)
通常, W 1 ∈ R 5 d × d W_{1} \in \mathbb{R}^{5d ×d} W1∈R5d×d, W 2 ∈ R d × 5 d W_{2} \in \mathbb{R}^{d ×5d} W2∈Rd×5d。也就是说,前馈网络的隐藏层维度远大于整个网络的隐藏层维度 d d d,这样做是因为矩阵乘法是可以高效并行化的操作,因此是进行大量计算和设置参数的有效部分。
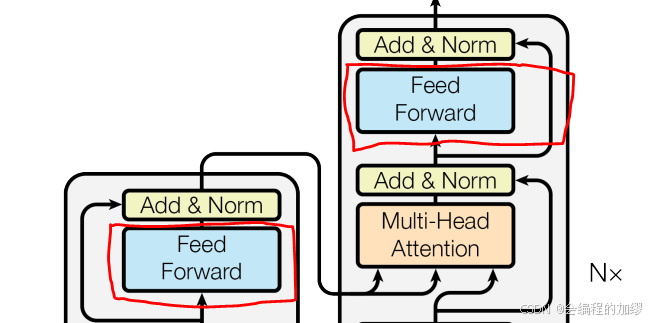
四、未来掩码(future mask)
在进行自回归语言建模时,我们根据目前已有的所有单词来预测下一个单词:
w t ∼ softmax ( f ( w 1 : t − 1 ) ) (18) w_{t} \sim \text{softmax}(f(w_{1:t - 1})) \tag{18} wt∼softmax(f(w1:t−1))(18)
其中 f f f是一个将序列映射到 R ∣ V ∣ \mathbb{R}^{|V|} R∣V∣向量的函数。
这个过程的一个关键方面是,在预测时我们不能查看未来的单词,否则这个问题就变得毫无意义。单向循环神经网络(RNN)中就内置了这个概念。如果我们想用RNN来实现函数 f f f,可以使用单词 w t − 1 w_{t - 1} wt−1的隐藏状态:
w t ∼ softmax ( h t − 1 E ) (19) w_{t} \sim \text{softmax}(h_{t - 1}E) \tag{19} wt∼softmax(ht−1E)(19)
h t − 1 = σ ( W h t − 2 + U x t − 1 ) (20) h_{t - 1}=\sigma(Wh_{t - 2}+Ux_{t - 1}) \tag{20} ht−1=σ(Wht−2+Uxt−1)(20)
通过RNN的展开过程可知,我们不会查看未来的单词(在这种情况下,未来的单词指的是 w t , . . . , w n w_{t}, ..., w_{n} wt,...,wn)。
在Transformer中,自注意力权重 α \alpha α并没有明确限制在表示第 i i i个词元时不能查看索引 j > i j>i j>i的词元。 在实际应用中,我们通过在softmax的输入中添加一个很大的负常数(或者等效地,当 j > i j>i j>i时将 α i j \alpha_{ij} αij设置为 0 0 0 )来强制实施这个约束。
α i j , masked = { α i j j ≤ i 0 否则 \alpha_{ij,\text{masked}} = \begin{cases} \alpha_{ij} & j \leq i \\ 0 & \text{否则} \end{cases} αij,masked={αij0j≤i否则
💡 似乎应该使用负无穷(-∞)作为常数,以“切实”确保无法看到未来的信息。然而,实际并非如此,人们会使用一个即使在“float16”编码的浮点范围内也算适中的常数,比如 -105。使用无穷大可能会导致非数字(NaNs),而且各个库对于无穷大输入的处理方式也不明确,所以我们倾向于避免使用它。由于精度有限,一个足够大的负常数仍然会将注意力权重精确设置为零。 |
从图中看,它就像图3所示。
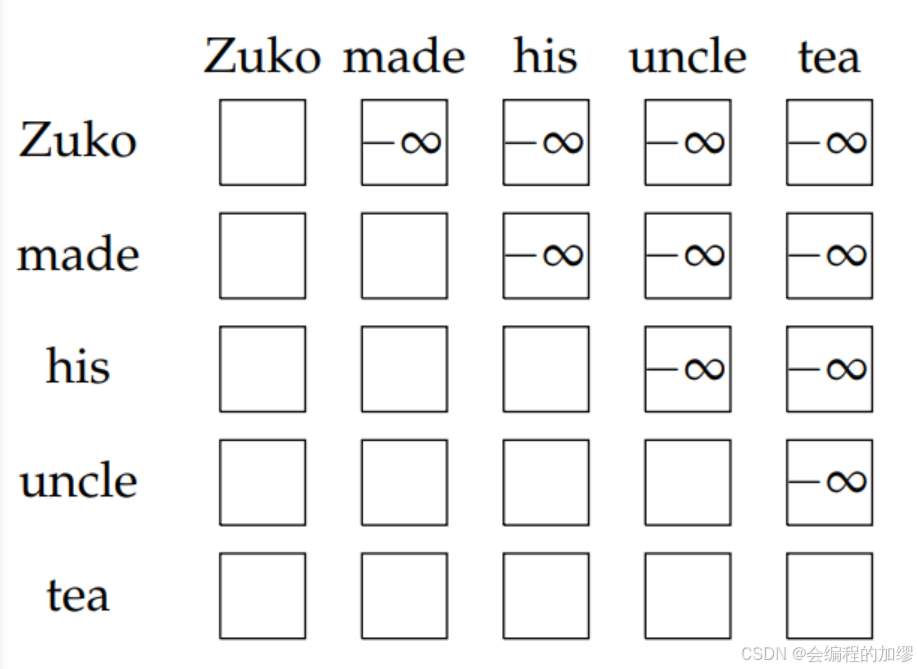
📔 图3:自注意力中自回归未来掩码示意图。每行中的单词都对未来的单词进行了掩码处理(例如,“Zuko”只能关注“Zuko”,而“made”可以关注“Zuko”和“made”)。
五、总结
我们的最简单自注意力架构包含:
(1)自注意力操作;
(2)位置表示;
(3)逐元素非线性变换;
(4)(在语言建模场景下的)未来掩码机制。
直观地说,这些是需要理解的主要部分。然而,截至2023年,自然语言处理中使用最广泛的架构是Transformer,它由[Vaswani等人,2017年]提出,包含许多非常重要的组件。所以现在我们将深入探讨该架构的细节。
相关文章:
Transformer系列(二):自注意力机制框架
自注意力机制框架 一、K-Q-V的自注意力机制二、位置表征1. 通过学习嵌入来进行位置表征2. 通过直接改变 α \alpha α来进行位置表征 三、逐元素非线性变换四、未来掩码(future mask)五、总结 上篇博客:NLP中放弃使用循环神经网络架构讲解了循环神经网络…...

安全技术和防火墙
传输层4.7层防火墙 传输层(4)四层防火墙:ip地址 mac地址 协议 端口号来控制数据流量 应用层防火(7)墙/代理服务器: ip地址 mac地址 协议 端口号来控制数据流量 真实传输的数据(把前面的ip地址…...

深度可分离卷积与普通卷积的区别及原理
1. 普通卷积 普通卷积使用一个滤波器在输入特征图的所有通道上滑动,同时对所有通道进行加权求和,生成一个输出通道。如果有多个滤波器,则生成多个输出通道。假设上一层的特征图有 n 个通道,每个通道是一个二维的图像(…...

STM32时钟树
1、认识时钟树 H:high 高 L:low 低 S:speed 速度 I:internal 内部 E:external 外部 HSE就是高速外部时钟源 HSI就是告诉内部时钟源 外部时钟一般需要接一个时钟源,也就是晶振,这个需要外接&…...

致迈协创C1pro考勤系统简介
1.应用背景 该套件的“数据映射引擎”技术,完成了OA系统与考勤机硬件设备的无缝联接。V5具有良好交互特性和B/S的程序架构,使得客户管理层和HR相关管理人员通过V5能实时查询统计人员的考勤情况,从而及时有效的完成人员考勤的监控与管理&#…...

pivot_root:原理、用途及最简单 Demo
什么是 pivot_root pivot_root 是 Linux 系统中的一个系统调用(和对应的命令行工具),用于更改进程的根文件系统。与 chroot 类似,pivot_root 将一个指定目录设置为进程的新根目录(/),但它比 ch…...
)
【小沐杂货铺】基于Three.JS绘制卫星轨迹Satellite(GIS 、WebGL、vue、react,提供全部源代码)
🍺三维数字地球系列相关文章如下🍺:1【小沐学GIS】基于C绘制三维数字地球Earth(OpenGL、glfw、glut)第一期2【小沐学GIS】基于C绘制三维数字地球Earth(OpenGL、glfw、glut)第二期3【小沐学GIS】…...

MySQL -数据类型
博客主页:【夜泉_ly】 本文专栏:【暂无】 欢迎点赞👍收藏⭐关注❤️ 目录 前言数值类型intbitfloat 字符串charvarcharenum set 日期和时间类型 前言 在之前的操作篇, 我们用到的大多是DDL(数据定义语言)。 在建表时,…...

数据通信学习笔记之OSPF的邻居角色
邻居与邻接 OSPF 使用 Hello 报文发现和建立邻居关系 在以太网链路上,缺省时,OSPF 采用组播的形式发送 Hello 报文 (目的地址 224.0.0.5) OSPF Hello 报文中包含了路由器的 RouterID、邻居列表等信息。 邻居状态: 邻居:2-way 邻…...
)
2025第十六届蓝桥杯python B组满分题解(详细)
目录 前言 A: 攻击次数 解题思路: 代码: B: 最长字符串 解题思路: 代码: C: LQ图形 解题思路: 代码: D: 最多次数 解题思路: 代码: E: A * B Problem 解题思路&…...
——4.2定点加减运算)
计算机组成原理笔记(十七)——4.2定点加减运算
定点数的加减运算包括原码、补码和反码3种带符号数的加减运算,其中补码加减运算实现起来最方便。 4.2.1原码加减运算 原码加减运算详解 原码是计算机中表示数值的基本方式之一,其特点为最高位为符号位(0表正,1表负)…...

javase 学习
一、Java 三大版本 javaSE 标准版 (桌面程序; 控制台开发) javaME 嵌入式开发(手机、小家电)基本不用,已经淘汰了 javaEE E业级发开(web端、 服务器开发) 二、Jdk ,jre jvm 三…...

成品检验工程师心得总结
岗位:成品检验助理工程师 成品检验工程师——————>OQC工程师 何为成品? 简单来说,就是已经完成了产品的开发,测试,满足客户所有需求开发的产品。 成品检验工程师对应的是哪一个角色? 客户&…...

操作系统:进程是一个非常重要的抽象概念
在操作系统中,进程是一个非常重要的抽象概念,它是程序在计算机上的执行实例,是系统进行资源分配和调度的基本单位。 一、进程的定义 从动态角度来说,进程是程序的一次执行过程。例如,当你在计算机上打开一个文本编辑…...

QML 字符串格式化
在 QML 中,处理字符串格式化有多种方法,以下是常用的字符串格式化函数和技巧: 1. 基本字符串连接 qml var str "Hello, " "QML!"; // 简单连接 var name "Alice"; var greeting Hello, ${name}; // 模…...

堆排序的C++相关实现
大根堆的实现 #include <iostream> #include <vector> using namespace std;// 调整堆,确保以i根节点的子树满足大根堆 void heapify(vector<int>& vec, int n , int i) {int largest i;int left 2 * i 1;int right 2 * i 2;if (left &…...
)
c++类与对象(一)
前言: 什么是面向对象编程?什么是类与对象?为啥要搞类与对象啊?凭什么c能支持面向对象编程啊? 每次学东西前问自己几个问题会挺爽的,因为你越是懵逼,你就越想知道答案是什么。希望我的这几篇文章…...
mac中Grafana监控Linux上的MySQL(Mysqld_exporter))
(二)mac中Grafana监控Linux上的MySQL(Mysqld_exporter)
框架:GrafanaPrometheusMysqld_exporter 一、监控查看端安装 Grafana安装-CSDN博客 普罗米修斯Prometheus监控安装(mac)-CSDN博客 1.启动Grafana服务 brew services start grafana 打开浏览器输入http://localhost:3000进入grafana登录…...

认知升级:把握人工智能教育化转型的历史机遇
认知升级:把握人工智能教育化转型的历史机遇 ----灌南县第四中学 孟祥帅 2025年4月17日至19日,我有幸参加了教育部主办的“全国人工智能校长局长专题培训班”。此次大会以“人工智能赋能教育现代化”为主题,汇聚了全国各地的教育局局长、校…...

人形机器人马拉松:北京何以孕育“领跑者”?
“机器人每跑一小步,都是人类科技的一大步”,这句对阿姆斯特朗登月名言的仿写,恰如其分地诠释了全球首场人形机器人半程马拉松赛事的里程碑意义。 2025年4月19日,北京亦庄半程马拉松暨人形机器人半程马拉松圆满结束。在总长21.09…...

HBuilder X:前端开发的终极生产力工具
一、极速下载与部署指南 官方下载地址:HBuilderX-高效极客技巧 HBuilder X 提供轻量化绿色发行包(仅 10 余 MB),支持 Windows、macOS、Linux 全平台。 安装流程: Windows 用户: 下载.zip压缩包后解压至非系…...

对于校园网如何进行用户识别——captive portal的原理学习总结
一、技术名称总结 这一技术的核心称为 Captive Portal(强制门户),中文常译为“认证门户”或“强制门户”。它是通过拦截未认证用户的网络流量,强制跳转到指定登录页面的技术。 二、技术提供方与部署逻辑 Captive Portal的实现主…...

肖特基二极管详解:原理、作用、应用与选型要点
一、肖特基二极管的基本定义 肖特基二极管(Schottky Diode) 是一种基于金属-半导体结(肖特基势垒)的二极管,其核心特性是低正向压降(Vf≈0.3V)和超快开关速度。 结构特点:阳极采用金…...
)
6.数据手册解读—运算放大器(三)
7、应用和实现 7.1应用信息 TLV916x 系列提供了出色的直流精度和交流性能。 这些器件的工作电压高达 16V, 并提供真正的轨到轨输入/输出、 低失调电压、失调电压漂移以及 11MHz 带宽和高输出驱动。TLV916x适用于16V工业应用。 7.2 典型应用 7.2.1 低边电流测量 下…...

关于隔离1
1.隔离的目的: 在隔离电源设计中,输入与输出之间没有直接电气连接,提供绝缘高阻态,防止电流回路。这意味着输入与输出之间呈现为绝缘的高阻态,从而确保了无电流回路的形成。 隔离与可靠保护有关。电隔离是一种电路设…...

大语言模型推理能力的强化学习现状理解GRPO与近期推理模型研究的新见解
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...

【NLP 60、实践 ⑭ 使用bpe构建词表】
目录 一、BPE(Byte Pair Encoding)算法详解 1.基本概念 2.核心思想 3.算法步骤详解 Ⅰ、预处理 Ⅱ、统计字符对频率 Ⅲ、合并高频字符对 Ⅳ、编码与解码 ① 编码(文本→子词序列) ② 解码(子词序列→文本) …...

String +memset字符串类题型【C++】
tips: 1、寻找最大公共子串时,如果字符串可以旋转但是不能反转,考虑在每个字符串后重复一次自身,如 "abcd" 变为 "abcdabcd",这样在用dp就可以了。 如何变环拆环为链: cin>>n&…...

06 GE Modifier
看看这个 问题。怪!究竟下一个modifier能不能访问到上一个?刚才还可以啊现在怎么不行了。 这里捕获了Owner的属性,Source不知道在哪捕获的 CalculationType: 1.使用计算后的值 2.使用基础值 3.使用计算后的值-基础值。 BackingAttributes Sou…...

30元一公斤的樱桃甜不甜
2025年4月20日,13~27℃,还好 待办: 综合教研室——会议记录3份(截止年4月18日) 备课冶金《物理》 备课理工《高数》 备课理工《物理》 教学技能大赛教案(2025年4月24日,校赛,小组合作…...

App-Controller - 通过自然语言操控应用程序的智能框架
本文翻译整理自:https://github.com/alibaba/app-controller 一、关于 App-Controller App-Controller 是基于大语言模型(LLMs)和智能体(Agents)构建的创新性API编排框架,旨在利用LLMs的高级推理能力来集成和同步各类应用程序提供的API。 上图展示了App…...

Deepseek输出的内容如何直接转化为word文件?
我们有时候会直接利用deepseek翻译别人的文章或者想将deepseek输出的内容直接复制到word文档里。但是文本格式和word是不对应的。这时候需要输入如下命令: 以上翻译内容的格式和排版要求如下: 1、一级标题 字体为黑体(三号)&…...

深入剖析 Java Web 项目序列化:方案选型与最佳实践
在 Java Web 开发中,“序列化”是一个你无法绕过的概念。无论是缓存数据、共享 Session,还是进行远程过程调用(RPC)或消息传递,序列化都扮演着底层数据搬运工的角色。它负责将内存中的 Java 对象转换成可传输或可存储的…...
)
第36讲:作物生长预测中的时间序列建模(LSTM等)
目录 🧠 为什么用时间序列模型来预测作物生长? ⛓️ 什么是 LSTM? 📊 示例案例:预测小麦NDVI变化趋势 1️⃣ 模拟数据构建(或使用真实遥感数据) 2️⃣ 构建 LSTM 所需数据格式 3️⃣ 构建并训练 LSTM 模型 4️⃣ 模型预测与效果可视化 🧠 除了 LSTM,还有哪…...

LeetCode 每日一题 2563. 统计公平数对的数目
2563. 统计公平数对的数目 给你一个下标从 0 开始、长度为 n 的整数数组 nums ,和两个整数 lower 和 upper ,返回 公平数对的数目 。 如果 (i, j) 数对满足以下情况,则认为它是一个 公平数对 : 0 < i < j < n,…...

Redis 哨兵与集群脑裂问题详解及解决方案
Redis 哨兵与集群脑裂问题详解及解决方案 本文将深入探讨Redis在哨兵模式和集群模式下可能出现的脑裂问题,包括其发生场景、原因以及有效的解决策略。同时,我们还将提供相应的代码示例和配置方案来帮助读者理解和实施。 一、脑裂问题概述 脑裂&#x…...

Laravel-vite+vue开发前端模板
开始这篇文章的时候,你已经安装了laravel!你已经安装了laravel!你已经安装了laravel! 然后你的laravel服务器环境已经搭建好,应用可以正常访问 laravel vite plugin 官方原文 laravel默认已经集成vitejs,单纯使用vi…...

springboot+vue3+mysql+websocket实现的即时通讯软件
项目演示 即时通讯软件项目演示 业务架构 技术栈 后端 选用编程语言 Javaweb框架SpringBootdb MySQL 持久存储nosql 缓存 Redis全双工通信框架 WebSocket 前端 前端框架Vue3TypescriptUI样式 Css、ElementPlus网页路由 vue-router全双工通信框架Websocket 功能完成情况 已实…...

HTMLCSS实现网页轮播图
网页中轮播图区域的实现与解析 在现代网页设计中,轮播图是一种常见且实用的元素,能够在有限的空间内展示多个内容,吸引用户的注意力。下面将对上述代码中轮播图区域的实现方式进行详细介绍。 一、HTML 结构 <div class"carousel-c…...

HTML表单与数据验证设计
HTML 表单与数据验证设计:构建可靠的用户数据采集系统 引言 互联网的核心是数据交互,而HTML表单是这一交互的主要入口。作为前端工程师,设计高质量的表单不仅关乎用户体验,更直接影响数据收集的准确性和系统安全。 在我的学习实…...

[Windows] 星光桌面精灵 V0.5
[Windows] 星光桌面精灵 链接:https://pan.xunlei.com/s/VOOI9NCNDB0iBONt5gz7zUb9A1?pwdgxa6# [Windows] 星光桌面精灵 V0.5 这款桌面精灵是动态的,而且还可以做快捷启动...

Java 网络编程性能优化:高吞吐量的实现方法
Java 网络编程性能优化:高吞吐量的实现方法 在当今的互联网时代,网络应用的性能优化是开发人员面临的重要挑战之一。Java 作为一门广泛使用的编程语言,提供了强大的网络编程支持,但如何通过优化实现高吞吐量,是每个 J…...
)
【去哪儿网】登录滑块逆向算法AES加密分析(逆天滑块轨迹)
目标:aHR0cHM6Ly91c2VyLnF1bmFyLmNvbS9wYXNzcG9ydC9sb2dpbi5qc3A 验证接口: https://vercode.qunar.com/inner/captcha/snapshot 可以发现是encryption方法生成,进入encryption里面,发现是AES加密的轨迹 track就是轨迹 直接…...

Redis ④-通用命令
Redis 是一个 客户端-服务器 结构的程序,这与 MySQL 是类似的,这点需要牢记!!! Redis 固然好,但也不是任何场景都适合使用 Redis,一定要根据当前的业务需求来选择是否使用 Redis Redis 通用命令…...

机制的作用
“机制”是一个广泛使用的概念,其含义和应用范围因领域而异。在不同的学科和实际应用中,机制有着不同的定义和功能。以下从几个主要领域对“机制”进行详细解释: 一、自然科学中的机制 (一)物理学 定义 在物理学中&…...

Pandas:数据处理与分析的核心操作
Pandas:数据处理与分析的核心操作 Pandas 是 Python 数据分析的核心库,它提供了高性能、易用的数据结构和数据分析工具。本文将详细介绍 Pandas 的核心操作,帮助你高效进行数据处理和分析。 1. Pandas 基础数据结构 Pandas 有两个主要的数…...

Kotlin实现Android应用保活方案
Kotlin实现Android应用保活优化方案 以下的Android应用保活实现方案,更加符合现代Android开发规范,同时平衡系统限制和用户体验。 1. 前台服务方案 class OptimizedForegroundService : Service() {private val notificationId 1private val channel…...
-过温保护器件ksd9700温控开关)
硬件电路(25)-过温保护器件ksd9700温控开关
一、概述 KSD9700系列温控开关是一种双金属作为感温元件的温控器,具有动作迅速、控温精确、控制电流大、使用寿命长的特点,被广泛应用于各类微型电机、电磁炉、空调电机、小家电等做温度保护控制。 二、应用 KSD9700系列产品是一种双金属作为感温元件的…...

vuex实现同一页面radio-group点击不同按钮显示不同表单
本文实现的是点击单一规格和多规格两个按钮会在页面显示不同的表单 方法一 <!-- 单规格和多规格的切换 --> <el-form label-width"80px" class"text-align-left"><el-form-item label"商品规格"><!-- 监听skus_type的改…...

代码随想录训练营第36天 ||1049. 最后一块石头的重量 II 494. 目标和 474. 一和零
1049. 最后一块石头的重量 II 讲解:代码随想录 思路: 01背包问题:题意说要求粉碎石头后留下的最小石头重量,石头粉碎的规则是两个石头如果重量相等,同时粉碎,如果重量不相等,粉碎后的重量是大…...