【深度学习—李宏毅教程笔记】Transformer
目录
一、序列到序列(Seq2Seq)模型
1、Seq2Seq基本原理
2、Seq2Seq模型的应用
3、Seq2Seq模型还能做什么?
二、Encoder
三、Decoder
1、Decoder 的输入与输出
2、Decoder 的结构
3、Non-autoregressive Decoder
四、Encoder 和 Decoder 之间的配合
1、Encoder 和 Decoder 之间信息的传递
2、Encoder 和 Decoder 是如何训练的?
五、Transformer 的一些 Tips
1、Copy Mechanism
2、Guided Attention
3、Beam Search
4、Optimizing Evaluation Metrics
5、训练过程和测试过程的一个 mismatch
一、序列到序列(Seq2Seq)模型
Transformer 是一个 Sequence-to-sequence 的模型。
Sequence-to-sequence (Seq2seq)模型,输入一个序列,输出一个序列,输出的长度由模型决定。
1、Seq2Seq基本原理
Seq2Seq模型用于将输入序列映射到输出序列,广泛应用于机器翻译、语音识别、语音合成、对话系统等任务。其基本结构由编码器(Encoder)和解码器(Decoder)组成:
-
编码器(Encoder):负责接收输入序列,将其转化为一个上下文向量(或一系列上下文向量),为解码器提供信息。
-
解码器(Decoder):基于编码器的输出生成目标序列。
Seq2Seq通过训练使得编码器和解码器之间的映射关系能够最优化,进而实现输入和输出之间的映射。
2、Seq2Seq模型的应用
Seq2Seq模型广泛应用于以下几个领域:
-
机器翻译:输入源语言,输出目标语言。输入和输出序列长度可不同。
-
语音识别:将语音信号转换为文本。
-
语音合成(TTS):根据文本生成自然语音。
-
对话系统:自动生成与用户输入相应的回答。
-
问答系统:根据输入的上下文和问题,生成相应的答案
3、Seq2Seq模型还能做什么?
下面的的任务虽然能用Seq2Seq来完成,但Seq2Seq并不是最好的,对于不同的任务,刻制化不同的模型,效果会更好。
(1)语法分析
语法分析:对一个句子进行语法分析,如下图:
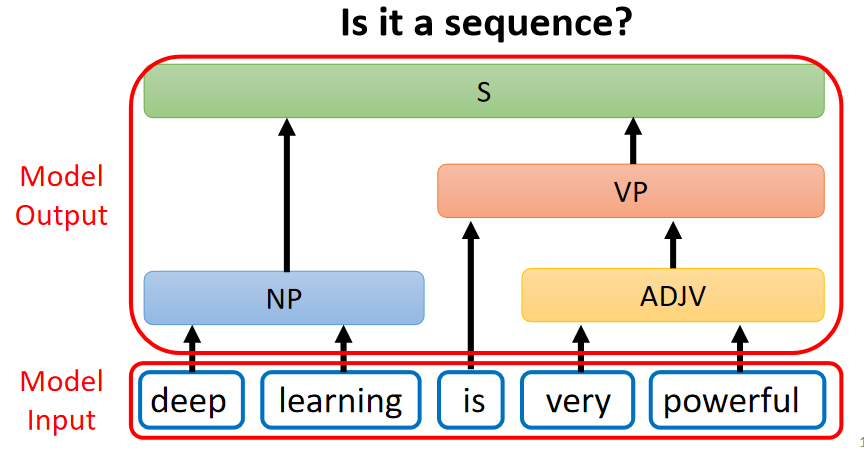
输入是一个句子,输出是一个句子结构的框图,这个结构框图是序列吗?可以把它写成如下序列的形式:
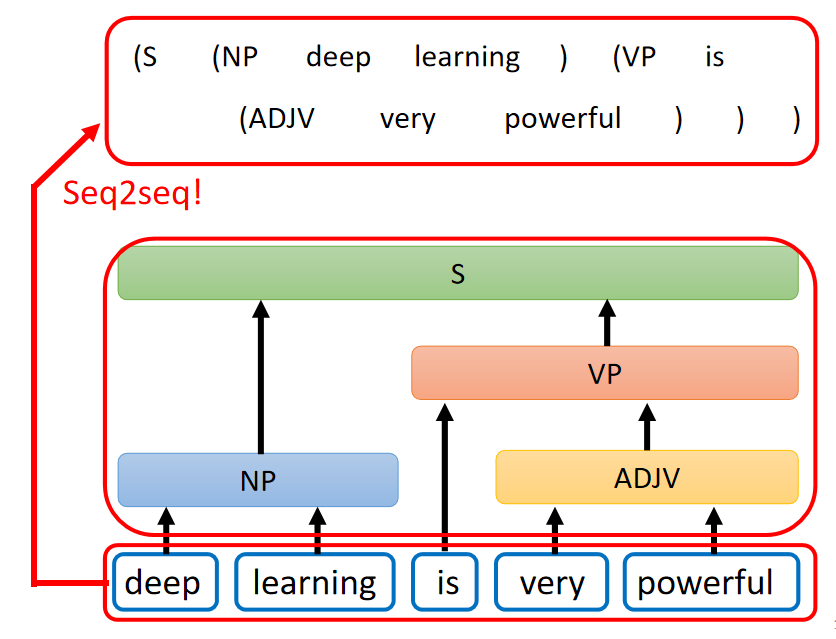
序列中的 “( ” 和 “ )” 都是序列的一部分,通过模型输出。
相关的研究论文:[1412.7449] Grammar as a Foreign Language
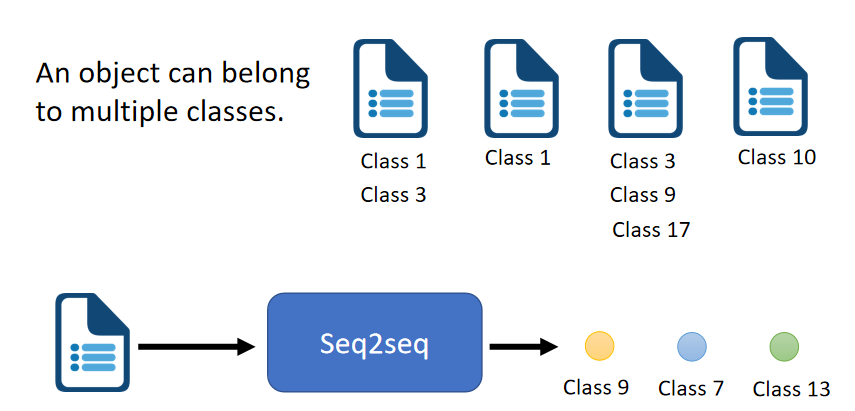
(2)多类别分类
分类任务的类别数不确定,不同的输入可能有不同数量的输出:
相关研究:
[1909.03434] Order-free Learning Alleviating Exposure Bias in Multi-label Classification
[1707.05495] Order-Free RNN with Visual Attention for Multi-Label Classification
(3)物品识别
Seq2Seq还能用在图像中物品的识别,描述图像等
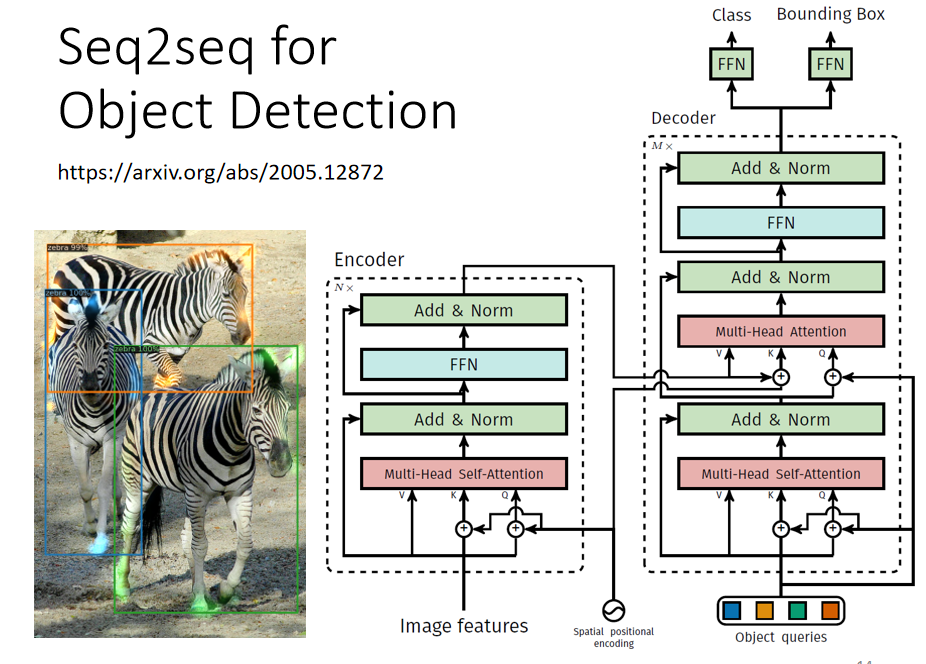
相关研究:[2005.12872] End-to-End Object Detection with Transformers
二、Encoder
功能:给一排向量,输出一排向量。
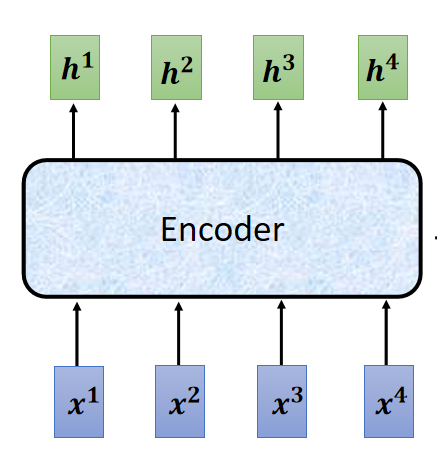
看 Encoder 内部结构如下:
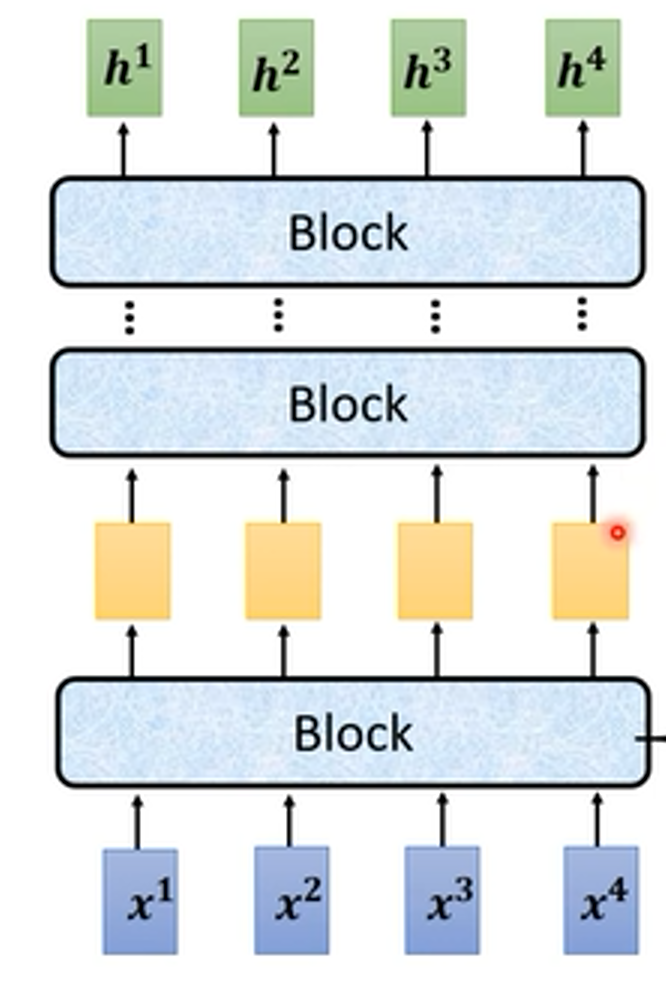
一个 Block 并不是一个 Layer ,他可能是很多层,如下图:是一个 Self-attention 层 + 一个 FC(前馈网络 feedforward Connect)层。
在原来的 Transformer 中,一个Block做的是更复杂的,如下图:
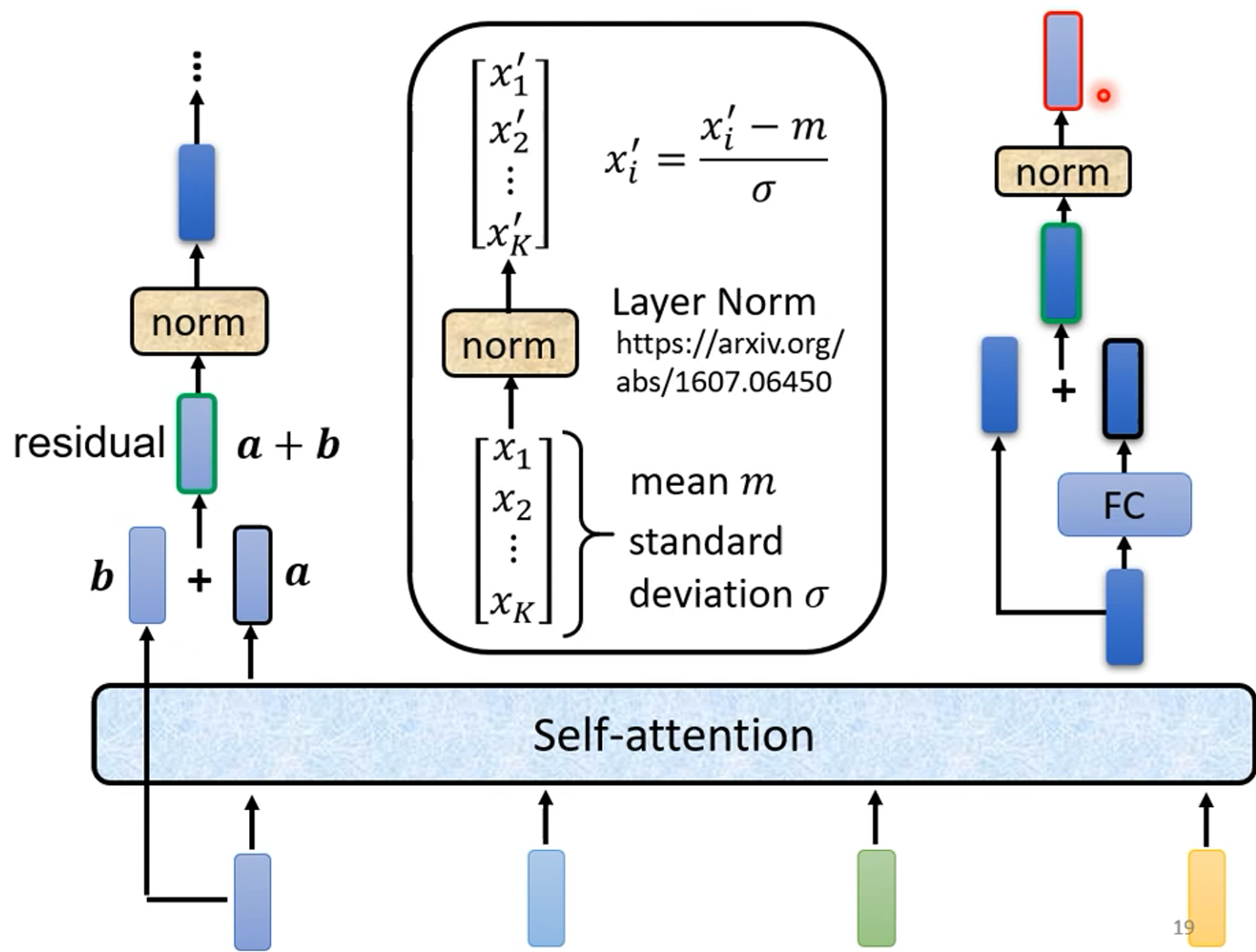
即在 Self-attention 层和 FC 层之间加入一些东西,将 Self-attention 层的输出再加上原来的输入,这样的架构被称为 residual connection。随后呢,再将加和的结果输入一个 Layer normalization 层,随后再输入 FC 层,而这里的 FC 层也用 residual connection 架构,FC 的输出再经过一个 Layer normalization 层,最终它的输出才是一个 Block 的输出。
所以说,整个 Encoder 层如下:
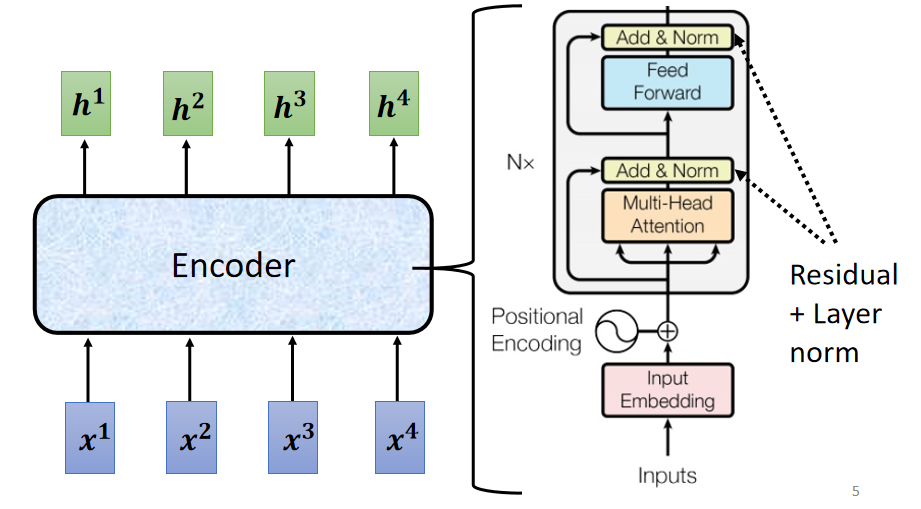
在第一个Block 之前,要加上 位置编码,而且 Block 的 Self-attention 是 Multi-head Self-attention 。上图中的右侧的结构并不是整个 Encoder ,而是只是 Encoder 中的一个 Block 。
至此上面的介绍就是原始论文 transformer 的 Encoder,在 BERT 中的其实就是 transformer 的 Encoder。
下面是一些对原始 Encoder 的改进:
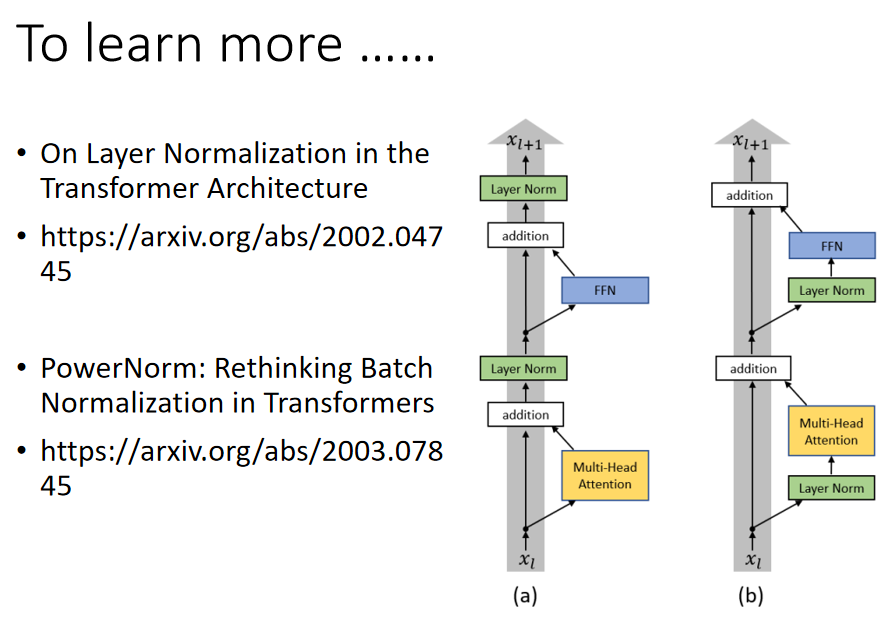
第一篇论文(这里)是对 Layer normalization 放的位置进行了改变,第二篇论文(这里)是将 Layer normalization 改为了 Batch Normalization
三、Decoder
1、Decoder 的输入与输出
这里所讲的 Decoder 是 Autoregressive - Decoder, 即自回归解码器。Autoregressive的缩写为:AT
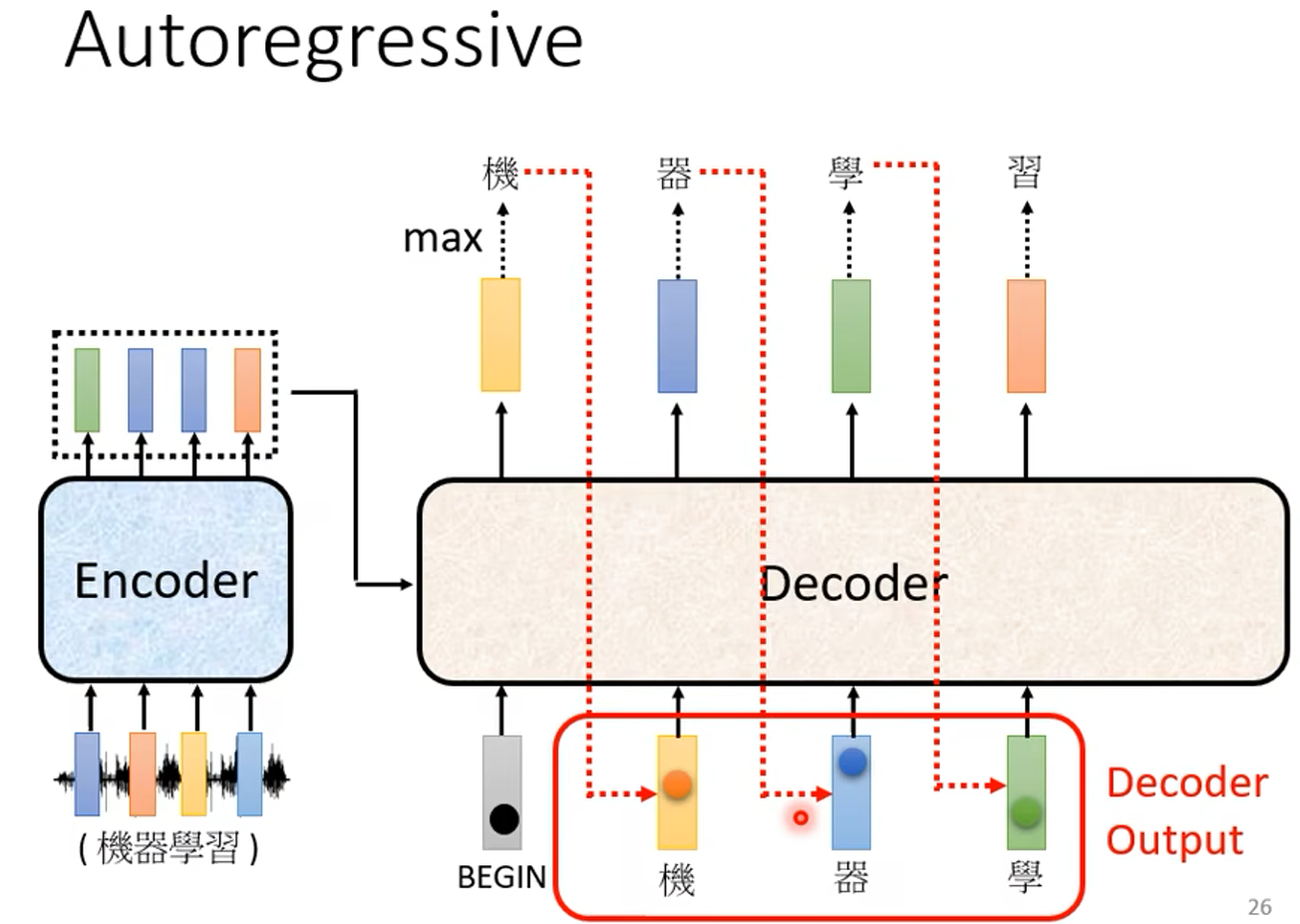
Decoder 接受 Encoder 的输出作为输入,还有就是它在输出序列的第一个元素时接受一个 Begin
的向量作为输入,得到第一个输出后,再将第一个输出作为输入,取代原来 Begin 向量的位置,最后输出序列的第二个元素,依次进行,得到输出的全序列。注意:这里的第一个元素输出是一个字(以汉字为例),但 Decoder 的输出是一个向量,由这个向量再根据原来对所有字的 one-hot 编码,找到输出的是哪一个字,这里的输出并不是一个 one-hot 编码,这个输出的向量的每个元素代表的是每个字的概率,在 one-hot 编码表中找到最大可能的字作为输出的字,但第一个输出作为输入时(为得到第二个输出),输入的是 one-hot 编码,即一个元素是 1 ,其他都是 0 。
这个地方还不确定对不对 ?
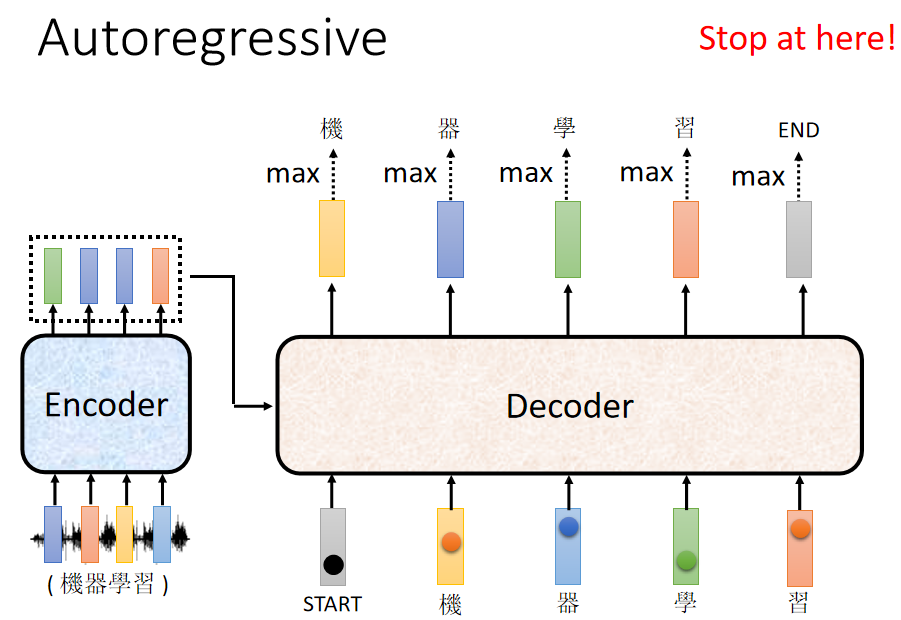
如何知道什么时候结束输出呢?
解决方式如下,在给所有字 one-hot 编码时,给定一个特殊的字,假如说是 “断”,当这个字输出时,就断掉输出。在训练过程中也给训练资料加入这个 “断” ,这样的话模型就可以自已学习到什么时候结束输出了,即什么时候结束输出是由模型决定的。(有的地方这个 序列开始的符号和序列结束的符号用的是同一个),
我们希望上面的模型应该在合适的时候断掉输出,如下图:
2、Decoder 的结构
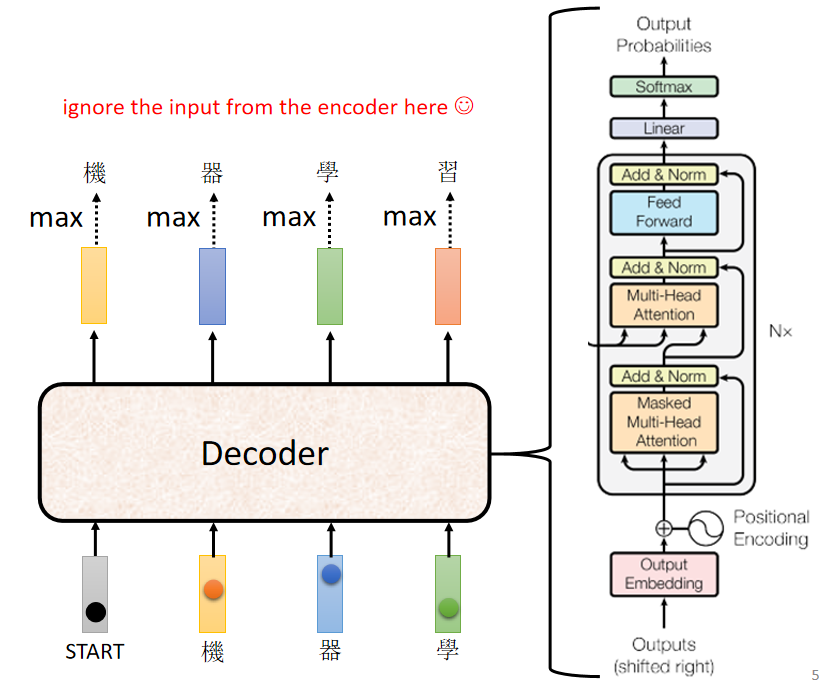
对比 Encoder 和 Decoder 的结构,如下图:
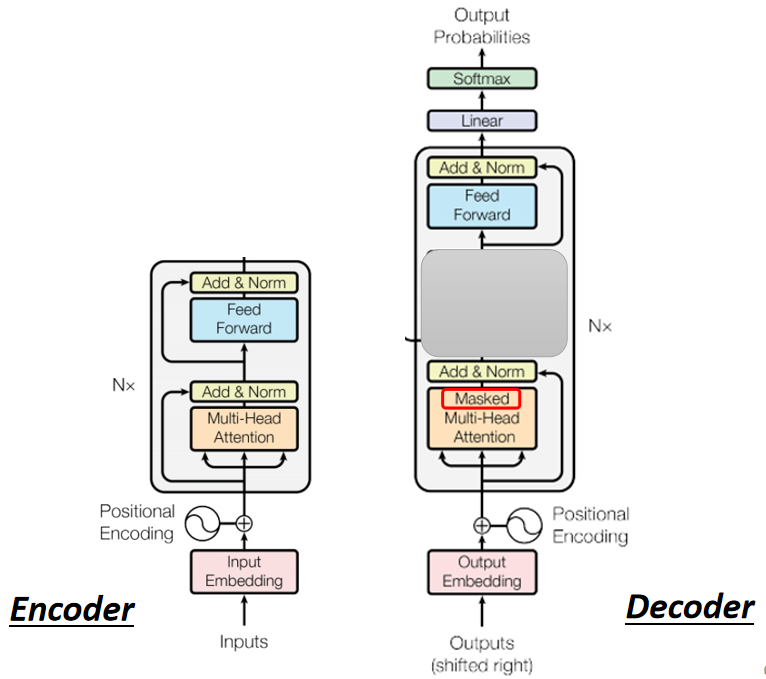
可见,当 Decoder 挡住中间的 一块 “接受 Encoder 输出作为输入的块” 后,它的结构与 Encoder 几乎一样。
挡住后还不一样的地方:
第一个地方就是 Decoder 在最后多加了 Linear 和 Softmax 层,是为了得到输出各个元素的概率信息。
第二个地方就是 Decoder 的注意力机制部分使用了 Masked ,这是由于 Decoder 的输入并不是一次全部并行输入的,它的输入是一个一个加的,所以说在计算 注意力机制层 的输出时不能看到后边的信息(训练的时候即使有后边的信息也不能看),即:
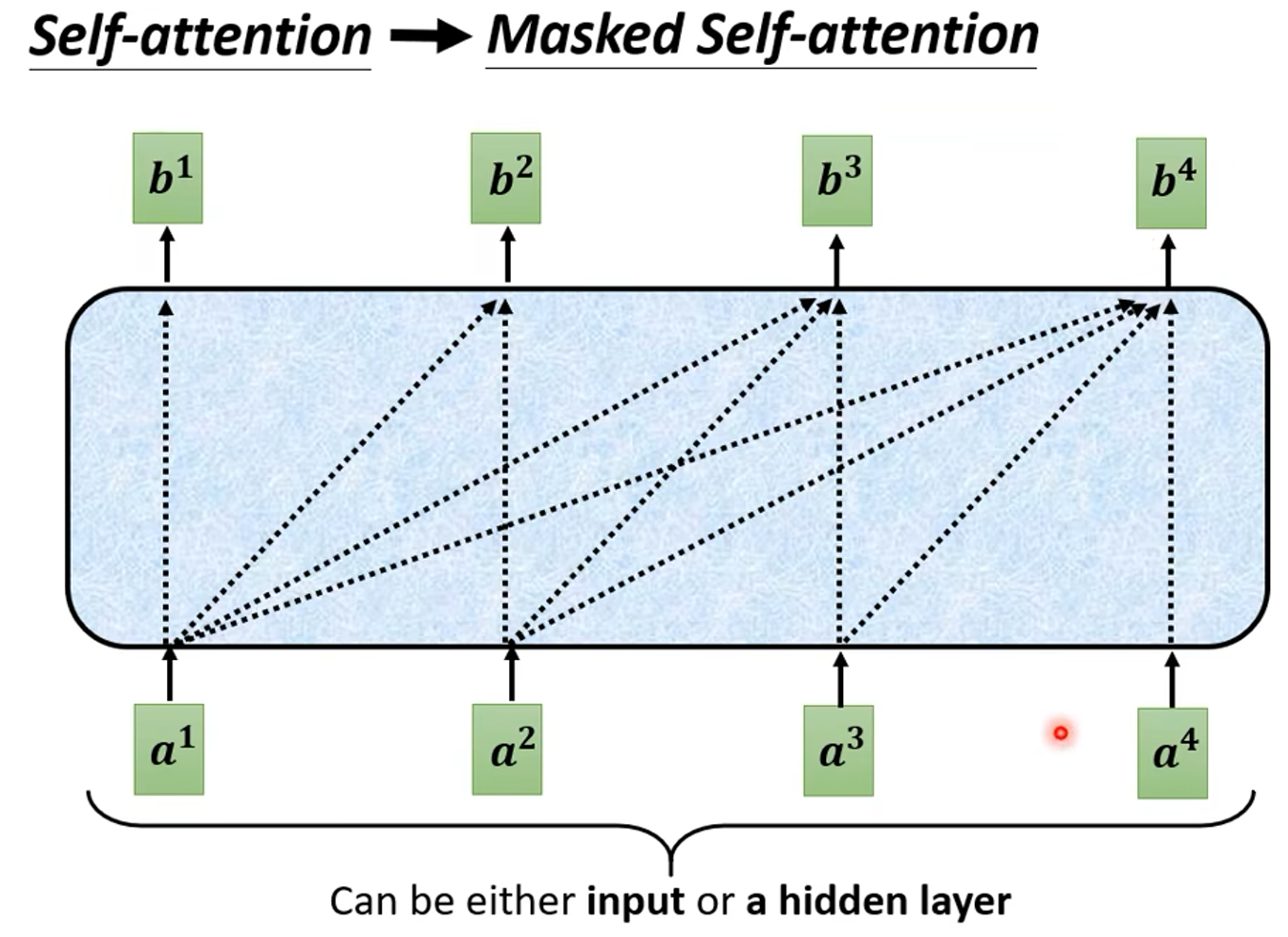
也就是说:
在计算 时,只能考虑
;
在计算 时,只能考虑
、
在计算 时,只能考虑
、
、
在计算 时,只能考虑
、
、
、
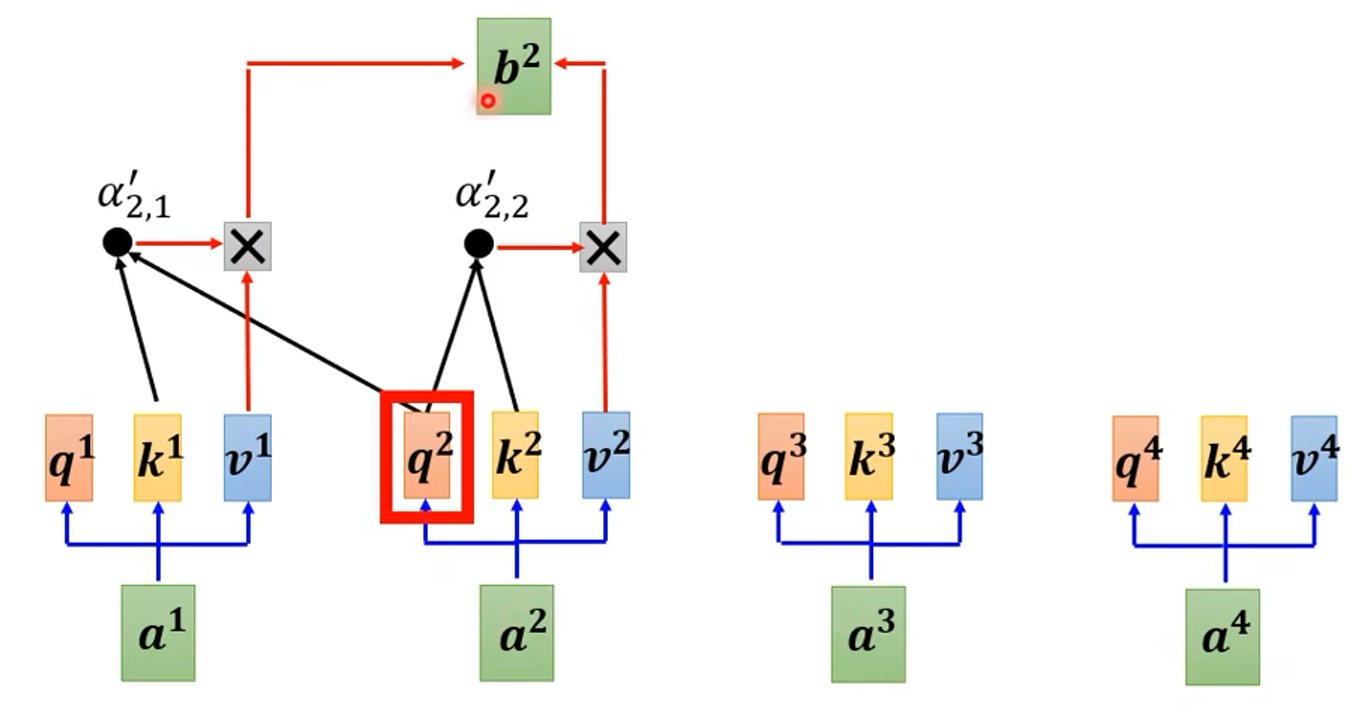
更具体的计算过程,如下图:
3、Non-autoregressive Decoder
Non-autoregressive(非自回归),缩写为:NAT
AT Decoder 是一个一个输出的,而 NAT Decoder 是一下输出序列的全部。

即 NAT Decoder 一次接受很多个 开始符号 Begin,一次输出所有的元素。
在 AT Decoder 中,模型可以通过输出结束标识符来决定什么时候结束输出,那么 NAT Decoder 如何知道什么是结束输出呢?
有两种解决方法:
- 第一种:另外做一个单独的分类器,这个分类器以 Encoder 的输出作为输入,以 NAT Decoder 模型输出序列的长度 n 作为输出,从而决定 NAT Decoder 什么时候能结束输出。即在 NAT Decoder 输入 n 个Begin 。
- 第二种:同样有一个结束标识符,但设置 NAT Decoder 输出非常长的序列,输出的序列中如果有 结束标识符,则标识符后面的截断不要。
NAT Decoder 的优点:
- 它是并行化,在速度上比 AT Decoder 快,
- 如果是另外做一个单独的分类器来决定输出的长度,则可以灵活地决定输出的长度,比如说对于声音输出模型,对输出长度减半(即将 决定模型输出序列长度的分类器的输出除以2 )那么输出的声音长度就为原来的一半,声音就倍速了。
NAT Decoder 的缺点:
NAT 通常是比 AT 的输出性能要差,(为什么呢?因为 Multi-modality(意思是多模态))
更多的 NAT Decoder 相关的知识:https://youtu.be/jvyKmU4OM3c
四、Encoder 和 Decoder 之间的配合
1、Encoder 和 Decoder 之间信息的传递
这部分内容就是上面比较 Encoder 和 Decoder 时遮住的一块。
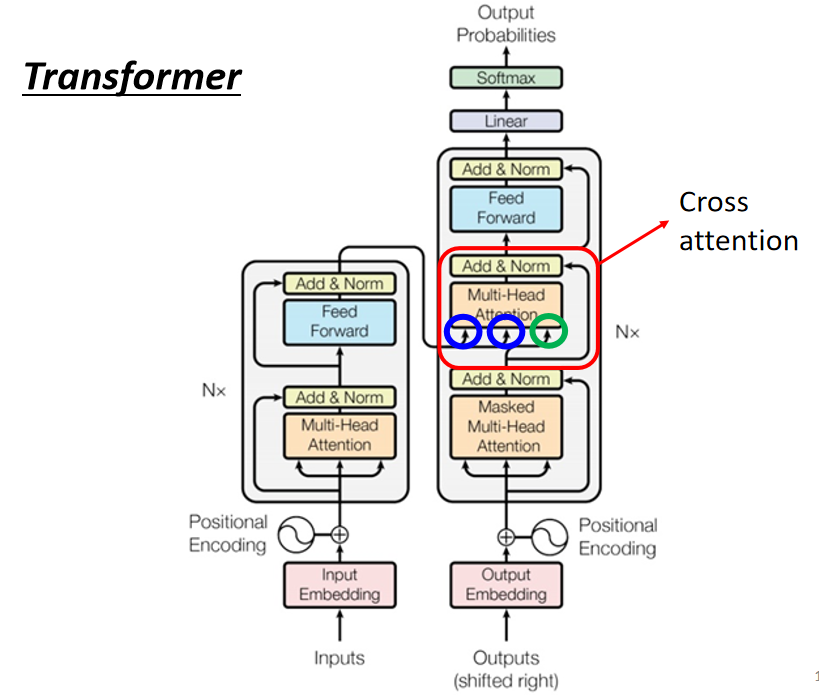
Cross attention 是什么呢?
在计算 注意力 时 使用 Decoder 的 q 值(Query)和 Encoder 的 k、v 值(Key、Value)来计算注意力
的值(代表相关程度)。如下图:
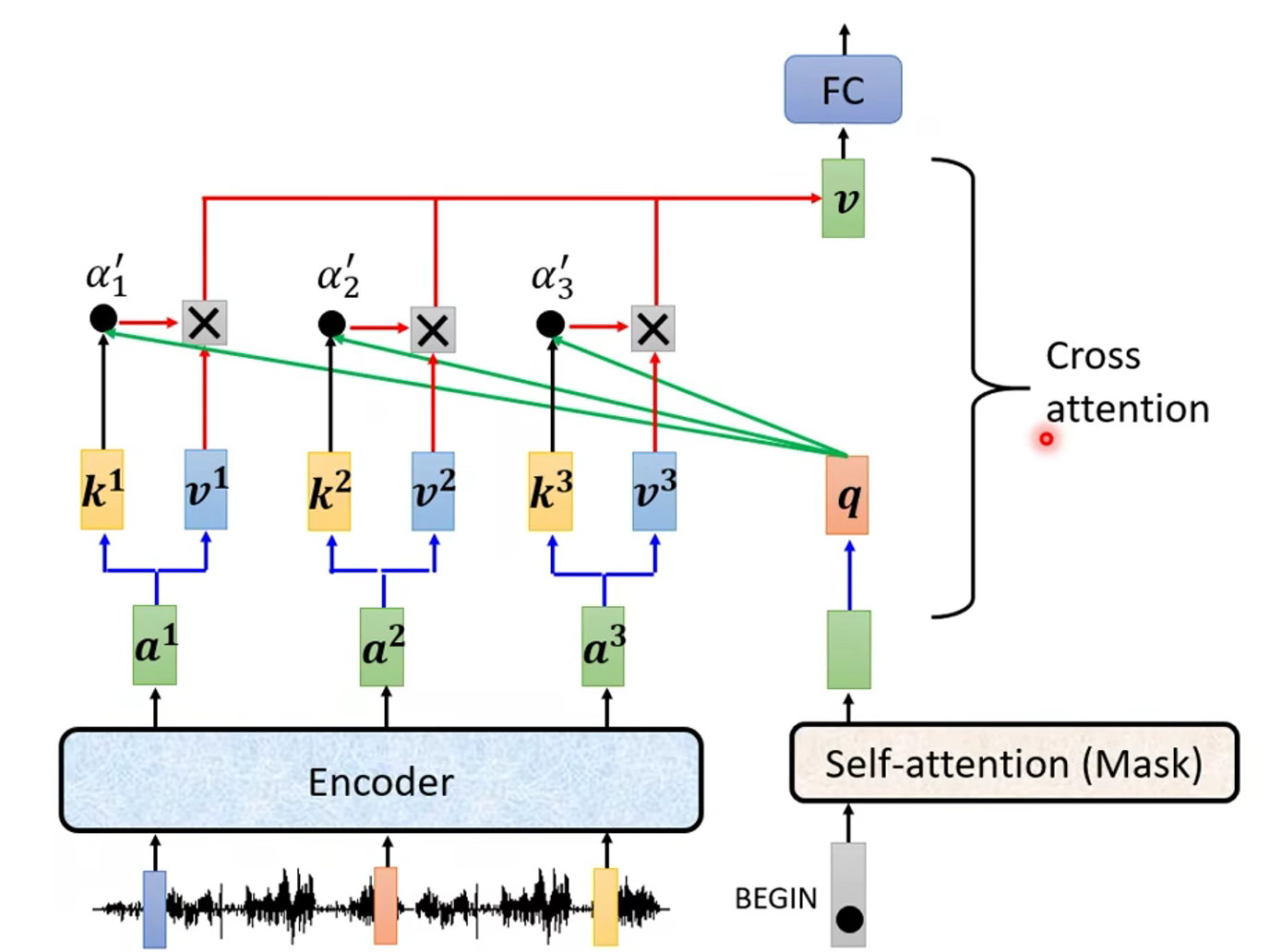
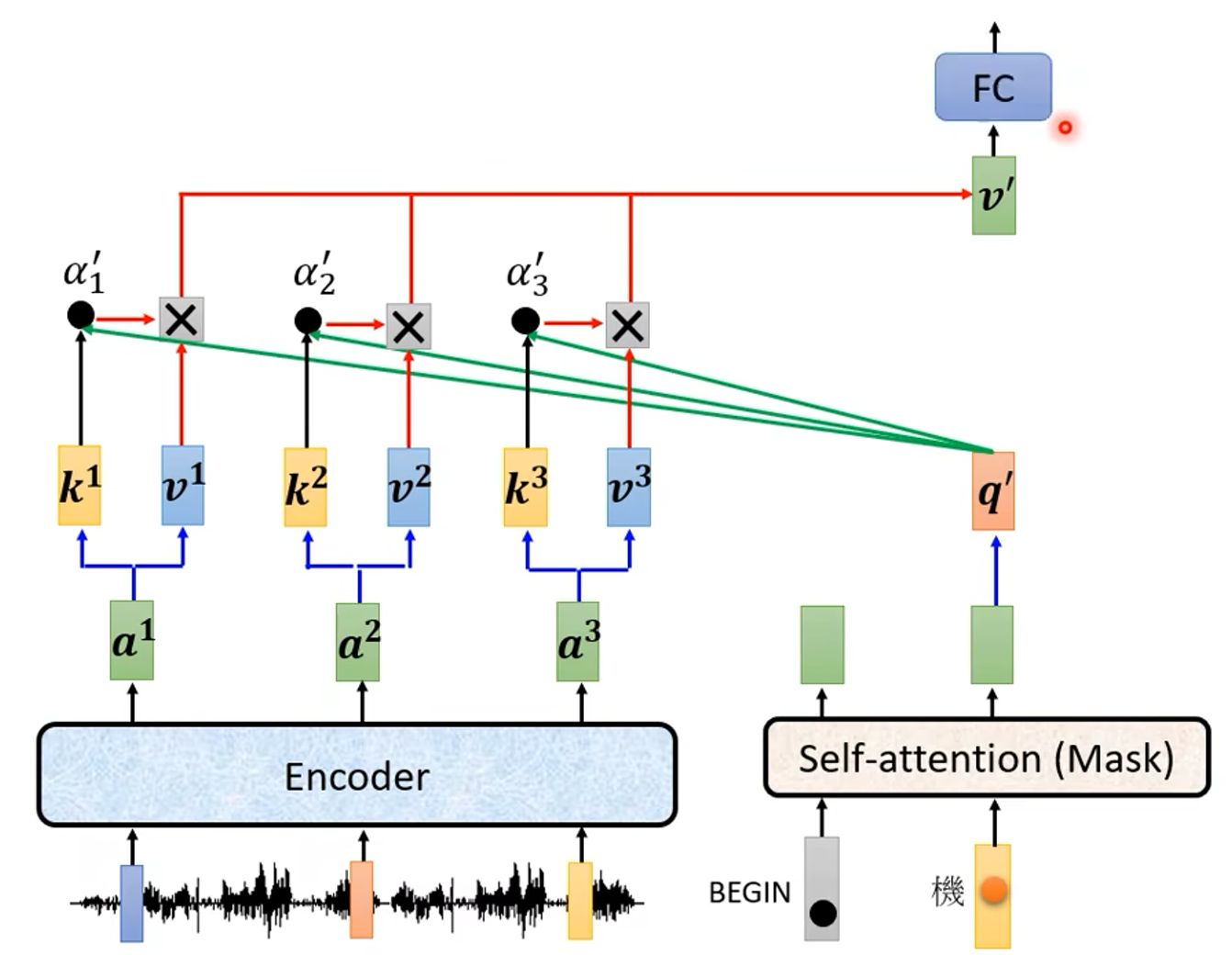
Encoder 和 Decoder 都有很多层,那么从 Encoder 到 Decoder 传递的信息是怎么样的呢?
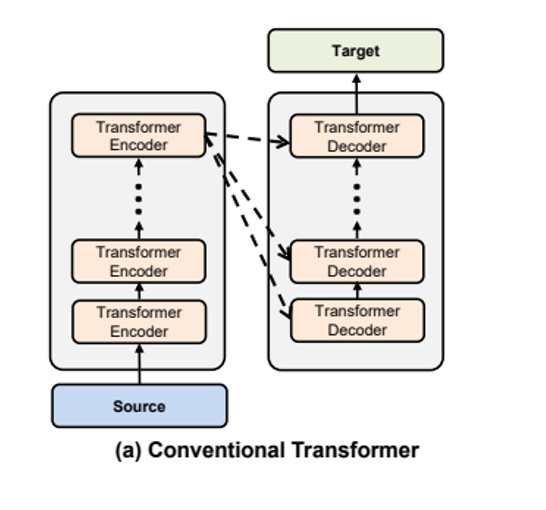
在原始论文中,都是 Encoder 的最后一层向 Decoder 的各个层进信息传递(通过 Cross attention 进行)。如下图:
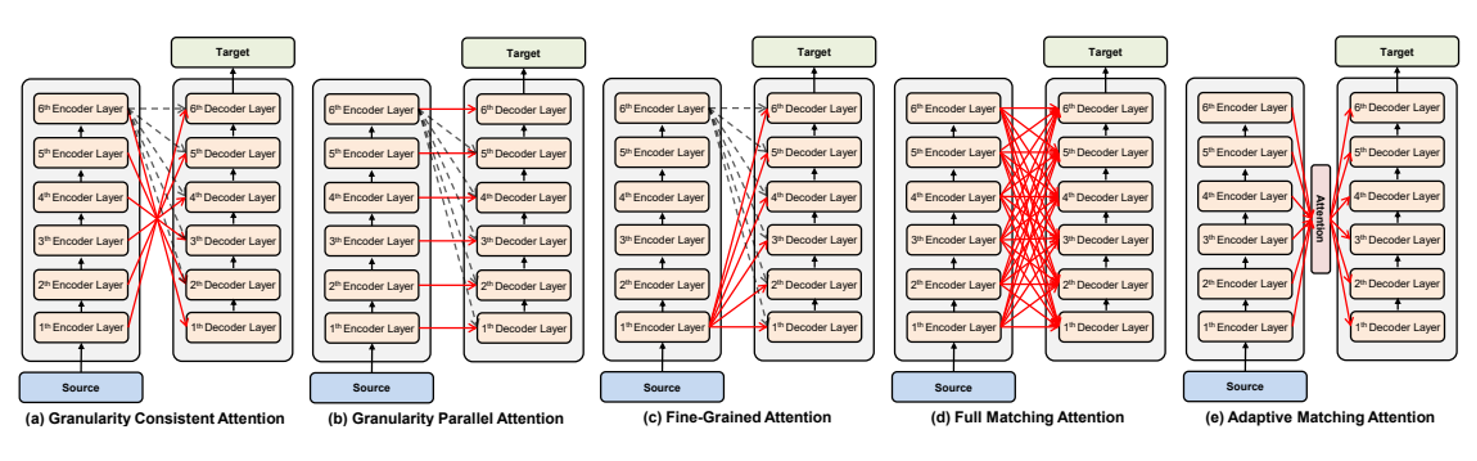
也有一些人尝试不同的信息传递方式,如下图:相关论文(这里)
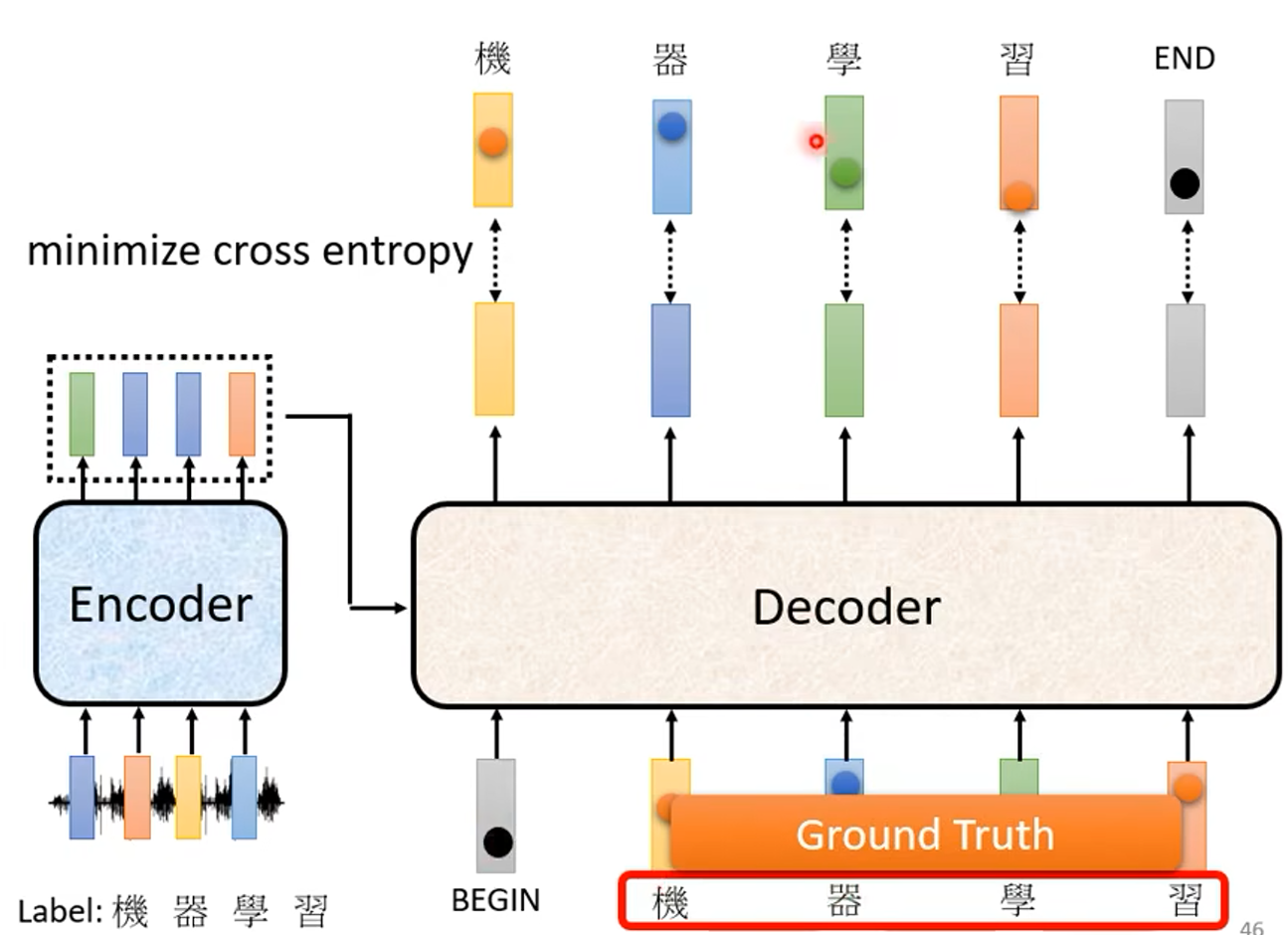
2、Encoder 和 Decoder 是如何训练的?
首先准备好 带标签序列的序列,(这里以声音信号转为文字为例),准备好声音信号和它对应的文字序列。
声音信号传入 Encoder 进行编码,再将信息通过 Cross attention 传递到 Decoder ,传入 Decoder Begin 标识符开始输出第一个元素,但和模型使用时不同,这里并不一定要把输出的第一个元素再次输入到 Decoder ,而是使用真实标签序列的第一个元素输入 Decoder 来得到第二个输出,一次下去,每次输入 Decoder 的都是真实标签,在序列输出完毕后,最后一个元素应该是 “断” 标识符。如下图:
五、Transformer 的一些 Tips
1、Copy Mechanism
Copy Mechanism(复制机制) 是一种在自然语言处理(NLP)和其他序列生成任务中使用的技术,旨在解决模型生成文本时可能面临的重复性或信息遗漏问题,特别是在任务中需要精确复制某些输入内容的情况下。
更详细的:
讲解:Pointer Network : (这里)
论文:Incorporating Copying Mechanism in Sequence-to-Sequence Learning (这里)
2、Guided Attention
Guided Attention(引导注意力) 是一种在神经网络中使用的技术,旨在通过某种方式增强或引导模型的注意力机制,使其专注于对任务更为重要的信息。这种技术在深度学习中尤为重要,尤其是在处理复杂任务时,如图像描述生成、机器翻译、视觉问答等。通过引导模型的注意力,可以有效提高模型的性能和效率。
3、Beam Search
Beam Search(束搜索) 是一种启发式搜索算法,常用于序列生成任务中,特别是在自然语言处理(NLP)任务中,如机器翻译、文本生成、语音识别等。它是一种改进的贪心算法,旨在平衡搜索空间的大小和结果的质量,避免传统贪心搜索可能遇到的局部最优问题。
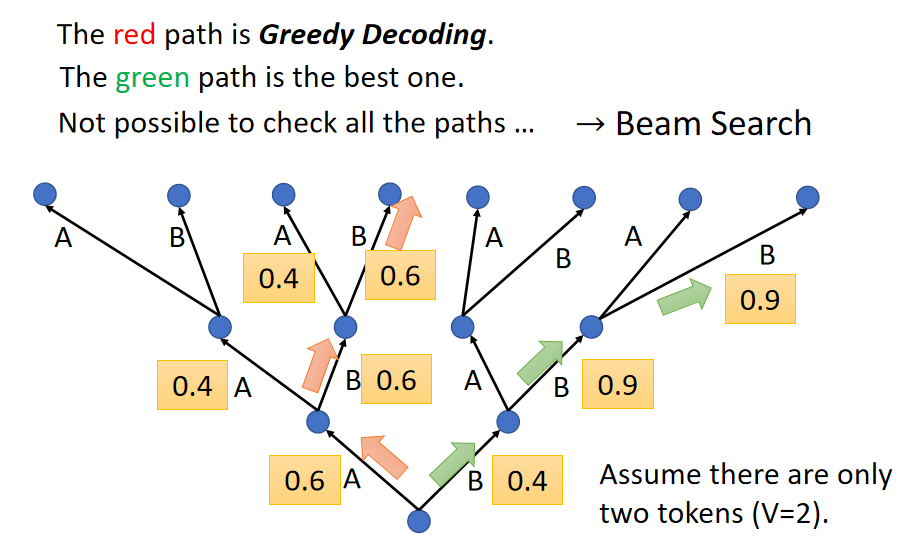
使用 Beam Search 实际情况下并不一定就更好。
4、Optimizing Evaluation Metrics
在模型评估时,使用的 Evaluation Metrics(评估方法)是 BLEU score ,这种方法是比较两个序列之间的区别,由于序列之间的元素是有联系的,这种方法是整体评估两个序列的差别。
但在训练过程中,模型输出序列的每个元素是分开的,是一个一个输出的,而且在每个元素输出前给到 Decoder 的输入都是正是标签序列的相应前一个元素,所以说计算 loss 时使用的评估方法的依据是单个元素之间的差别(交叉熵损失)。为什么在训练时不用 BLEU score 呢?因为 BLEU score 很复杂不容易微分,一般不用。
但像这样不容易计算的问题,有一种万能的方法来解决,就是李宏毅老师教程中所说的 “硬 Train 一发”,即在这个梯度不容易计算的问题中,直接把他当作 Reinforcement Learning(强化学习)的问题,硬做。用另一个额外的模型预测这个 loss 。
相关研究:When you don’t know how to optimize, just use reinforcement learning (RL)!
(这里)
5、训练过程和测试过程的一个 mismatch
在训练过程中,由于有真实的标签,每次 Decoder 输出的前一个的输出都不受真正的前一个的输出,而是真实的标签。但在 test 时(即训练好的模型使用时),并没有真实的标签,每次 Decoder 的输入都是前一个真正的输出,可能会出现 “ 一步错,步步错 ”,要怎么解决呢?
一个解决方法是在训练过程中就给一些错误的信息,即 训练过程中,就给 Decoder 输入一些错误的信息,并不一定要是真实标签。这一招叫做:Scheduled Sampling 。
相关研究:
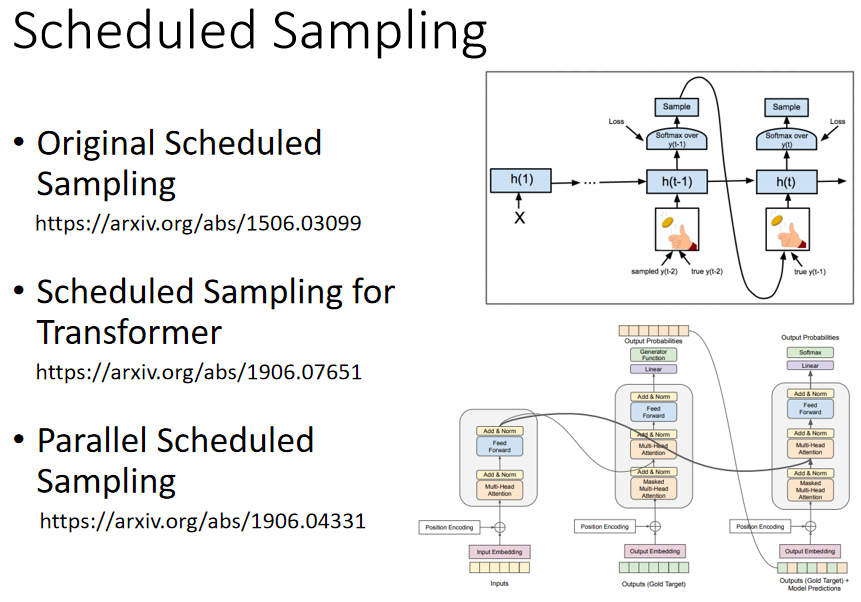
Original Scheduled Sampling:(这里)
Scheduled Sampling for Transformer:(这里)
Parallel Scheduled Sampling:(这里)
相关文章:
【深度学习—李宏毅教程笔记】Transformer
目录 一、序列到序列(Seq2Seq)模型 1、Seq2Seq基本原理 2、Seq2Seq模型的应用 3、Seq2Seq模型还能做什么? 二、Encoder 三、Decoder 1、Decoder 的输入与输出 2、Decoder 的结构 3、Non-autoregressive Decoder 四、Encoder 和 De…...

关于UE5的抗锯齿和TAA
关于闪烁和不稳定现象的详细解释 当您关闭抗锯齿技术时,场景中会出现严重的闪烁和不稳定现象,尤其在有细节纹理和小物体的场景中。这种现象的技术原因如下: 像素采样问题 在3D渲染中,每个像素只能表示一个颜色值,但…...

交换网络基础
学习目标 掌握交换机的基本工作原理 掌握交换机的基本配置 交换机的基本工作原理 交换机是局域网(LAN)中实现数据高效转发的核心设备,工作在 数据链路层(OSI 模型第二层),其基本工作原理可概括为 “学习…...

AUTOSAR图解==>AUTOSAR_SWS_EFXLibrary
AUTOSAR 扩展定点数学函数库(EFX)分析 1. 概述 AUTOSAR (AUTomotive Open System ARchitecture) 是汽车电子控制单元(ECU)软件架构的开放标准。在AUTOSAR架构中,扩展定点数学函数库(Extended Fixed-point library, EFX)提供了一组优化的定点数学运算函数ÿ…...
的坐标)
六边形棋盘格(Hexagonal Grids)的坐标
1. 二位坐标转六边形棋盘的方式 1-1这是“波动式”的 这种就是把【方格子坐标】“左右各错开半个格子”做到的 具体来说有如下几种情况 具体到庙算平台上,是很巧妙的用一个4位整数,前两位为x、后两位为y来进行表示 附上计算距离的代码 def get_hex_di…...
李宏毅NLP-5-RNNTNeural TransducerMoChA
RNN Transducer(RNN-T) 循环神经对齐器(RNA,Recurrent Neural Aligner)对CTC解码器的改进,具体内容如下: “RNA”,全称 “Recurrent Neural Aligner”,引用来自 [Sak, et al., INTERSPEECH’17…...

GPT-SoVITS 使用指南
一、简介 TTS(Text-to-Speech,文本转语音):是一种将文字转换为自然语音的技术,通过算法生成人类可听的语音输出,广泛应用于语音助手、无障碍服务、导航系统等场景。类似的还有SVC(歌声转换&…...

洛谷的几道题
P1000 超级玛丽游戏 # P1000 超级玛丽游戏 ## 题目背景 本题是洛谷的试机题目,可以帮助了解洛谷的使用。 建议完成本题目后继续尝试 [P1001](/problem/P1001)、[P1008](/problem/P1008)。 另外强烈推荐[新用户必读帖](/discuss/show/241461)。 ## 题目描述 …...

利用yakit充实渗透字典
前言 在渗透侧测试结束,在我们的历史记录中会保存过程中的数据包。在其中有些特征,比如API、参数,可以活用于下次的渗透。 比如 fuzz变量,fuzz隐藏API…… 但是我们一个一个提取很麻烦,可以使用yakit的插件…...
:开启数据驱动的创业之旅)
精益数据分析(4/126):开启数据驱动的创业之旅
精益数据分析(4/126):开启数据驱动的创业之旅 在创业的浪潮中,我们都怀揣着梦想,渴望找到那条通往成功的道路。作为一名在创业和数据分析领域摸爬滚打多年的“老兵”,我深知其中的艰辛与挑战。今天&#x…...

机器学习误差图绘
机器学习误差图绘制 绘图类 # Define the ModelComparisonPlot class class ModelComparisonPlot:def __init__(self, model_name):self.model_name model_namedef plot_comparison(self, y_val, y_pred, mse, mae, r2):# Create a figure with two subplotsfig, axes plt.…...

企业级RAG选择难题:数据方案的关键博弈
企业级RAG选择难题:数据方案的关键博弈 向量数据库:高效但易失语境图数据库与知识图谱:关系网络的力量企业级RAG数据方案的最佳实践 智能时代,企业数据每日剧增。员工寻找答案的效率直接影响工作流程,StackOverflow调查…...

JNI 学习
1. JNI 不属于 C,而是 JDK 的 日志失效,可以 adb kill-server adb kill-serveradb start-server 使用 jni final和 private变量都能修改...

PyTorch :优化的张量库
PyTorch 是一个基于 Python 的开源机器学习框架,由 Facebook 的 AI 研究团队(现 Meta AI)于 2016 年推出。它专为深度学习设计,但也可用于传统的机器学习任务。PyTorch 的核心优势在于灵活性、动态计算图和易…...

DevOps 进阶指南:如何让工作流更丝滑?
DevOps 进阶指南:如何让工作流更丝滑? 引言 在 DevOps 世界里,我们追求的是高效、稳定、自动化。但现实总是充满挑战:代码部署失败、CI/CD 过程卡顿、环境不一致……这些痛点让开发和运维团队疲惫不堪。今天,我就来聊聊如何优化 DevOps 工作流,通过实战案例和代码示例,…...

BT-Basic函数之首字母XY
BT-Basic函数之首字母XY 文章目录 BT-Basic函数之首字母XYXxd__ commands Yyes X xd__ commands 当使用外部设备时,开发人员需要在测试计划中添加适当的命令来控制这些设备。下表显示了一个典型的命令序列。 典型的命令序列 NO命令描述1xdload将DLL加载到内存中…...

6. 话题通信 ---- 使用自定义msg,发布方和订阅方cpp,python文件编写
1)在功能包下新建msg目录,在msg目录下新建Person.msg,在Person.msg文件写入: string name uint16 age float64 height 2)修改配置文件 2.1) 功能包下package.xml文件修改 <build_depend>message_generation</build_depend><exec_depend…...

Fastdata极数:全球AR/VR行业发展趋势报告2025
科技的快速发展孕育了一个新的数字前沿领域,那就是虚拟宇宙,也就是我们谈论的元宇宙(Metaverse),虚拟宇宙最初构思于尼尔斯蒂芬森的科幻小说《雪崩》中,小说中虚拟宇宙由虚拟人物居住,并以数字方…...

背包 DP 详解
文章目录 背包DP01 背包完全背包多重背包二进制优化单调队列优化 小结 背包DP 背包 DP,说白了就是往一个背包里扔东西,求最后的最大价值是多少,一般分为了三种:01 背包、完全背包和多重背包。而 01 背包则是一切的基础。 01 背包…...

深入剖析 HashMap:内部结构与性能优化
深入剖析 HashMap:内部结构与性能优化 引言 HashMap 是 Java 集合框架中的核心类,广泛应用于数据存储和检索场景。本文将深入剖析其内部结构,包括数组、链表和红黑树的转换机制,帮助读者理解其工作原理和性能优化策略。 1. Hash…...

数据从辅存调入主存,页表中一定存在
在虚拟内存系统中,数据从辅存调入主存时,页表中一定存在对应的页表项,但页表项的「存在状态」会发生变化。以下是详细分析: 关键逻辑 页表的作用 页表是虚拟内存的核心数据结构,记录了虚拟地址到物理地址的映射关系…...

藏品馆管理系统
藏品馆管理系统 项目简介 这是一个基于 PHP 开发的藏品馆管理系统,实现了藏品管理、用户管理等功能。 藏品馆管理系统 系统架构 开发语言:PHP数据库:MySQL前端框架:BootstrapJavaScript 库:jQuery 目录结构 book/…...
)
力扣算法ing(60 / 100)
4.19 回溯合集—93复原ip地址 有效 IP 地址 正好由四个整数(每个整数位于 0 到 255 之间组成,且不能含有前导 0),整数之间用 . 分隔。 例如:"0.1.2.201" 和 "192.168.1.1" 是 有效 IP 地址&…...

时态--06--现在完成時
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 现在完成時1.语法1.肯定句2.否定句3.疑问句4.have been/gone to5.现在分词 practice 现在完成時 1.语法 1.肯定句 2.否定句 3.疑问句 4.have been/gone to 5.现在分…...

Java中常见的锁synchronized、ReentrantLock、ReentrantReadWriteLock、StampedLock
在Java中,锁是实现多线程同步的核心机制。不同的锁适用于不同的场景,理解其实现原理和使用方法对优化性能和避免并发问题至关重要。 一、隐式锁:synchronized 关键字 实现原理 基于对象监视器(Monitor):每…...

【教程】DVWA靶场渗透
【教程】DVWA靶场渗透 备注一、环境搭建二、弱口令(Brute Force)三、命令注入(Command Injection)四、CSRF(Cross Site Request Forgery)五、文件包含(File Inclusion)六、文件上传&…...
)
23种设计模式-创建型模式之原型模式(Java版本)
Java 原型模式(Prototype Pattern)详解 🧬 什么是原型模式? 原型模式用于通过复制已有对象的方式创建新对象,而不是通过 new 关键字重新创建。 核心是:通过克隆(clone)已有对象&a…...

【深度学习】【目标检测】【Ultralytics-YOLO系列】YOLOV3核心文件common.py解读
【深度学习】【目标检测】【Ultralytics-YOLO系列】YOLOV3核心文件common.py解读 文章目录 【深度学习】【目标检测】【Ultralytics-YOLO系列】YOLOV3核心文件common.py解读前言autopad函数Conv类__init__成员函数forward成员函数forward_fuse成员函数 Bottleneck类__init__成员…...

PDF转excel+json ,vue3+SpringBoot在线演示+附带源码
在线演示地址:Vite Vuehttp://www.xpclm.online/pdf-h5 源码gitee前后端地址: javapdfexcel: javaPDF转excelhttps://gitee.com/gaiya001/javapdfexcel.git 盖亚/vuepdfhttps://gitee.com/gaiya001/vuepdf.git 后续会推出 前端版本跟nestjs版本 识别复…...
(动态规划))
LeetCode 热题 100_乘积最大子数组(88_152_中等_C++)(动态规划)
LeetCode 热题 100_乘积最大子数组(88_152) 题目描述:输入输出样例:题解:解题思路:思路一(暴力破解法(双重循环)):思路二(动态规划): …...

Nvidia显卡架构演进
1 简介 显示卡(英语:Display Card)简称显卡,也称图形卡(Graphics Card),是个人电脑上以图形处理器(GPU)为核心的扩展卡,用途是提供中央处理器以外的微处理器帮…...

TCP/IP、UDP、HTTP、HTTPS、WebSocket 一文讲解
在当今互联网世界中,数据通信是所有应用运行的基础。无论是打开网页、发送消息还是视频通话,背后都依赖于各种网络协议的协同工作。其中,TCP/IP、UDP、HTTP、HTTPS 和 WebSocket 是最为核心的几种协议。本文将围绕它们的概念、特性和适用场景…...

[密码学基础]密码学发展简史:从古典艺术到量子安全的演进
密码学发展简史:从古典艺术到量子安全的演进 密码学作为信息安全的基石,其发展贯穿人类文明史,从最初的文字游戏到量子时代的数学博弈,每一次变革都深刻影响着政治、军事、科技乃至日常生活。本文将以技术演进为主线,…...

包含物体obj与相机camera的 代数几何代码解释
反余弦函数的值域在 [0, pi] 斜体样式 cam_pose self._cameras[hand_realsense].camera.get_model_matrix() # cam2world# 物体到相机的向量 obj_tcp_vec cam_pose[:3, 3] - self.obj_pose.p dist np.linalg.norm(obj_tcp_vec) # 物体位姿的旋转矩阵 obj_rot_mat self.ob…...

【C++算法】65.栈_删除字符中的所有相邻重复项
文章目录 题目链接:题目描述:解法C 算法代码: 题目链接: 1047. 删除字符串中的所有相邻重复项 题目描述: 解法 利用string模拟栈 元素依次进栈,当进栈元素和栈顶元素一样的时候,就弹出栈顶字符…...

【java实现+4种变体完整例子】排序算法中【插入排序】的详细解析,包含基础实现、常见变体的完整代码示例,以及各变体的对比表格
以下是插入排序的详细解析,包含基础实现、常见变体的完整代码示例,以及各变体的对比表格: 一、插入排序基础实现 原理 将元素逐个插入到已排序序列的合适位置,逐步构建有序序列。 代码示例 public class InsertionSort {void…...

神经网络的数学之旅:从输入到反向传播
目录 神经网络简介神经元激活函数神经网络 神经网络的工作过程前向传播(forward)反向传播(backward)训练神经网络 神经网络简介 神经元 在深度学习中,必须要说的就是神经⽹络,或者说是⼈⼯神经⽹络&#…...

软件测试的页面交互标准:怎样有效提高易用性
当用户遇到"反人类"设计时 "这个按钮怎么点不了?"、"错误提示完全看不懂"、"我输入的内容去哪了?"——这些用户抱怨背后,都指向同一个问题:页面交互的易用性缺陷。作为软件测试工程师&a…...

Linux419 三次握手四次挥手抓包 wireshark
还是Notfound 没连接 可能我在/home 准备配置静态IP vim ctrlr 撤销 u撤销 配置成功 准备关闭防火墙 准备配置 YUM源 df -h 未看到sr0文件 准备排查 准备挂载 还是没连接 计划重启 有了 不重启了 挂载准备 修改配置文件准备 准备清理缓存 ok 重新修改配…...

玩转Docker | 使用Docker部署tududi任务管理工具
玩转Docker | 使用Docker部署tududi任务管理工具 前言一、tududi介绍Tududi简介核心功能特点二、系统要求环境要求环境检查Docker版本检查检查操作系统版本三、部署tududi服务下载镜像创建容器创建容器检查容器状态检查服务端口安全设置四、访问tududi服务访问tududi首页登录tu…...

ueditorplus编辑器已增加AI智能
之前功能请参考:https://www.geh3408.top/blog/76 下载:https://gitee.com/mo3408/ueditorplus 注意:key值需要单独获取,默认为DeepSeek,默认key有限制,请更换为自己的。 演示地址:https://www.geh3408.top/ueditorplus/dist 更多体验:ueditorplus编辑器已增加AI智…...

深度学习数据预处理:Dataset类的全面解析与实战指南
前言 在深度学习项目中,数据预处理是模型训练前至关重要的一环。一个高效、灵活的数据预处理流程不仅能提升模型性能,还能大大加快开发效率。本文将深入探讨PyTorch中的Dataset类,介绍数据预处理的常见技巧,并通过实战示例展示如何…...

【机器学习-周总结】-第4周
以下是本周学习内容的整理总结,从技术学习、实战应用到科研辅助技能三个方面归纳: 文章目录 📘 一、技术学习模块:TCN 基础知识与结构理解🔹 博客1:【时序预测05】– TCN(Temporal Convolutiona…...

高可靠 ZIP 压缩方案兼容 Office、PDF、TXT 和图片的二阶段回退机制
一、引言 在企业级应用中,经常需要将多种类型的文件(如 Office 文档、PDF、纯文本、图片等)打包成 ZIP 并提供给用户下载。但由于文件路径过长、特殊字符或权限等问题,Go 标准库的 archive/zip 有时会出现“压缩成功却实际未写入…...

【HDFS入门】HDFS数据冗余与容错机制解析:如何保障大数据高可靠存储?
目录 1 HDFS冗余机制设计哲学 1.1 多副本存储策略的工程权衡 1.2 机架感知的智能拓扑算法 2 容错机制实现原理 2.1 故障检测的三重保障 2.2 数据恢复的智能调度 3 关键场景容错分析 3.1 数据中心级故障应对 3.2 数据损坏的校验机制 4 进阶优化方案 4.1 纠删码技术实…...

06-libVLC的视频播放器:推流RTMP
创建媒体对象 libvlc_media_t* m = libvlc_media_new_path(m_pInstance, inputPath.toStdString().c_str()); if (!m) return -1; // 创建失败返回错误 libvlc_media_new_path:根据文件路径创建媒体对象。注意:toStdString().c_str() 在Qt中可能存在临时字符串析构问题,建议…...

【DT】USB通讯失败记录
项目场景: DT小板 USB通讯失败 问题描述 V1.1 板子含有降压电路、电容充电电路、姿态传感电路,语音电路、电弧电路、TF卡电路 焊接完成:功能正常 V1.2 为方便数传模块拔插,把座子缩小并做在了背面,下载口反向方便狭…...

【笔记】网路安全管理-实操
一、系统安全防护-Windows 开始-》管理工具-》本地安全策略-》账户策略-》密码策略-》 1.密码必须符合复杂性要求。双击打开-》勾选已启用-》单击:应用-》单击:确定 2.密码长度最小值。双击打开-》设置密码长度最小值为:?个字符 3.密码最短使用期限。双击打开-》设置密码…...
)
FFMPEG-视频解码-支持rtsp|rtmp|音视频文件(低延迟)
本人亲测解码显示对比延迟达到7到20毫秒之间浮动兼容播放音视频文件、拉流RTSP、RTMP等网络流 基于 Qt 和 FFmpeg 的视频解码播放器类,继承自 QThread,实现了视频流的解码、播放控制、帧同步和错误恢复等功能 工作流程初始化阶段: 用户设置URL和显示尺寸 调用play()启动线程解…...

LDR、MOV和STR指令详解
文章目录 前言 一、LDR指令详解 1.基本语法 2.寻址方式 3.伪指令形式 二、MOV指令详解 1.基本语法 2.常见用法 3.特殊变体 三、STR指令详解 1.基本语法 2.寻址方式 四、三者区别与联系 1.基本语法 2.操作效率 3.大数值处理 总结 前言 ARM汇编中的LDR、MOV和STR是三个最基础也最…...