2024-12-6-sklearn学习(4) 支持向量机 吴楚东南坼,乾坤日夜浮。
文章目录
- sklearn学习(4) 支持向量机
- 4.1 分类
- 4.1.1 多元分类
- 4.1.2 得分和概率
- 4.1.3 非均衡问题
- 4.2 回归
- 4.3 密度估计, 异常(novelty)检测
- 4.4 复杂度
- 4.5 使用诀窍(Tips on Practical Use)
- 4.6 核函数
- 4.6.1 自定义核
- 4.6.1.1 使用 python 函数作为内核
- 4.6.1.2 使用 Gram 矩阵
- 4.6.1.3 RBF 内核参数
- 4.7 数学公式
- 4.7.1 SVC
- 4.7.2 NuSVC
- 4.7.3 SVR
- 4.8 实现细节
sklearn学习(4) 支持向量机
文章参考网站:
https://sklearn.apachecn.org/
和
https://scikit-learn.org/stable/
支持向量机 (SVMs) 可用于以下监督学习算法: 分类, 回归 和 异常检测.
支持向量机的优势在于:
- 在高维空间中非常高效.
- 即使在数据维度比样本数量大的情况下仍然有效.
- 在决策函数(称为支持向量)中使用训练集的子集,因此它也是高效利用内存的.
- 通用性: 不同的核函数 核函数 与特定的决策函数一一对应.常见的 kernel 已经提供,也可以指定定制的内核.
支持向量机的缺点包括:
- 如果特征数量比样本数量大得多,在选择核函数 核函数 时要避免过拟合, 而且正则化项是非常重要的.
- 支持向量机不直接提供概率估计,这些都是使用昂贵的五次交叉验算计算的. (详情见 得分和概率).
在 scikit-learn 中,支持向量机提供 dense(numpy.ndarray ,可以通过 numpy.asarray 进行转换) 和 sparse (任何 scipy.sparse) 样例向量作为输出.然而,要使用支持向量机来对 sparse 数据作预测,它必须已经拟合这样的数据.使用行优先存储(C-order)的 numpy.ndarray (dense) 或者带有 dtype=float64 的 scipy.sparse.csr_matrix (sparse) 来优化性能.
4.1 分类
SVC, NuSVC 和 LinearSVC 能在数据集中实现多元分类.
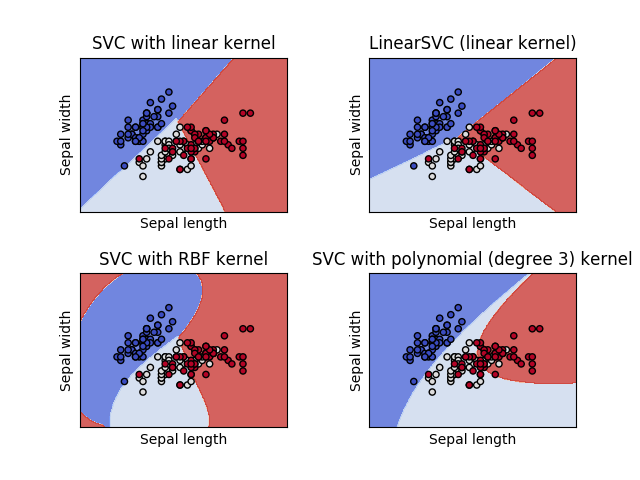
SVC 和 NuSVC 是相似的方法, 但是接受稍许不同的参数设置并且有不同的数学方程(在这部分看 [4.7 数学公式]). 另一方面, LinearSVC 是另一个实现线性核函数的支持向量分类. 记住 LinearSVC 不接受关键词 kernel, 因为它被假设为线性的. 它也缺少一些 SVC 和 NuSVC 的成员(members) 比如 support_ .
和其他分类器一样, SVC, NuSVC 和 LinearSVC 将两个数组作为输入:
[n_samples, n_features] 大小的数组 X 作为训练样本,
[n_samples] 大小的数组 y 作为类别标签(字符串或者整数):
from sklearn import svm
X = [[0, 0], [1, 1]]
y = [0, 1]
clf = svm.SVC(gamma='scale')
clf.fit(X, y)
在拟合后, 这个模型可以用来预测新的值:
clf.predict([[2., 2.]])
SVMs 决策函数取决于训练集的一些子集, 称作支持向量. 这些支持向量的部分特性可以在 support_vectors_, support_ 和 n_support 找到:
>>> # 获得支持向量
>>> clf.support_vectors_
array([[ 0., 0.],[ 1., 1.]])
>>> # 获得支持向量的索引
>>> clf.support_
array([0, 1]...)
>>> # 为每一个类别获得支持向量的数量
>>> clf.n_support_
array([1, 1]...)
4.1.1 多元分类
SVC 和 NuSVC 为多元分类实现了 “one-against-one” 的方法 (Knerr et al., 1990) 如果 n_class 是类别的数量, 那么 n_class * (n_class - 1) / 2 分类器被重构, 而且每一个从两个类别中训练数据. 为了提供与其他分类器一致的接口, decision_function_shape 选项允许聚合 “one-against-one” 分类器的结果成 (n_samples, n_classes) 的大小到决策函数:
>>> X = [[0], [1], [2], [3]]
>>> Y = [0, 1, 2, 3]
>>> clf = svm.SVC(gamma='scale', decision_function_shape='ovo')
>>> clf.fit(X, Y)
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,decision_function_shape='ovo', degree=3, gamma='scale', kernel='rbf',max_iter=-1, probability=False, random_state=None, shrinking=True,tol=0.001, verbose=False)
>>> dec = clf.decision_function([[1]])
>>> dec.shape[1] # 4 classes: 4*3/2 = 6
6
>>> clf.decision_function_shape = "ovr"
>>> dec = clf.decision_function([[1]])
>>> dec.shape[1] # 4 classes
4
另一方面, LinearSVC 实现 “one-vs-the-rest” 多类别策略, 从而训练 n 类别的模型. 如果只有两类, 只训练一个模型.:
>>> lin_clf = svm.LinearSVC()
>>> lin_clf.fit(X, Y)
LinearSVC(C=1.0, class_weight=None, dual=True, fit_intercept=True,intercept_scaling=1, loss='squared_hinge', max_iter=1000,multi_class='ovr', penalty='l2', random_state=None, tol=0.0001,verbose=0)
>>> dec = lin_clf.decision_function([[1]])
>>> dec.shape[1]
4
参见 数学公式 查看决策函数的完整描述.
记住 LinearSVC 也实现了可选择的多类别策略, 通过使用选项 multi_class='crammer_singer', 所谓的多元 SVM 由 Crammer 和 Singer 明确表达. 这个方法是一致的, 对于 one-vs-rest 是不正确的. 实际上, one-vs-rest 分类通常受到青睐, 因为结果大多数是相似的, 但是运行时间却显著减少.
对于 “one-vs-rest” LinearSVC, 属性 coef_ 和 intercept_ 分别具有 [n_class, n_features] 和 [n_class] 尺寸. 系数的每一行符合 n_class 的许多 one-vs-rest 分类器之一, 并且就以这一类的顺序与拦截器(intercepts)相似.
至于 one-vs-one SVC, 属性特征的布局(layout)有少多些复杂. 考虑到有一种线性核函数, coef_ 和 intercept_ 的布局(layout)与上文描述成 LinearSVC 相似, 除了 coef_ 的形状 [n_class * (n_class - 1) / 2, n_features], 与许多二元的分类器相似. 0到n的类别顺序是 “0 vs 1”, “0 vs 2” , … “0 vs n”, “1 vs 2”, “1 vs 3”, “1 vs n”, … “n-1 vs n”.
dual_coef_ 的形状是 [n_class-1, n_SV], 这个结构有些难以理解. 对应于支持向量的列与 n_class * (n_class - 1) / 2 “one-vs-one” 分类器相关. 每一个支持向量用于 n_class - 1 分类器中.对于这些分类器,每一行的 n_class - 1 条目对应于对偶系数(dual coefficients).
通过这个示例更容易说明:
考虑一个三类的问题,类0有三个支持向量 v 0 0 , v 0 1 , v 0 2 v^{0}_0, v^{1}_0, v^{2}_0 v00,v01,v02,而类 1 和 2 分别有 如下两个支持向量 v 1 0 , v 1 1 v^{0}_1, v^{1}_1 v10,v11 和 v 2 0 , v 2 1 v^{0}_2, v^{1}_2 v20,v21.对于每个支持 向量 v i j v^{j}_i vij, 有两个对偶系数.在类别 i i i、 k k k 和 α i , k j \alpha^{j}_{i,k} αi,kj 中, 我们将支持向量的系数记录为 v i j v^{j}_i vij 那么 dual_coef_ 可以表示为:

4.1.2 得分和概率
SVC 方法的 decision_function 给每一个样例每一个类别分值(scores)(或者在一个二元类中每一个样例一个分值). 当构造器(constructor)选项 probability 设置为 True 的时候, 类成员可能性评估开启.(来自 predict_proba 和 predict_log_proba 方法) 在二元分类中,概率使用 Platt scaling 进行标准化: 在 SVM 分数上的逻辑回归,在训练集上用额外的交叉验证来拟合.在多类情况下,这可以扩展为 per Wu et al.(2004)
Platt缩放中涉及的交叉验证对于大型数据集来说是一项昂贵的操作。此外,概率估计可能与分数不一致:
- score 的 “argmax” 可能不是概率的 argmax;
- 在二元分类中,即使
predict_proba的输出小于0.5,样本也可以通过predict标记为属于正类;同样,即使predict_proba的输出大于0.5,它也可以被标记为阴性。
Platt的方法也存在理论问题。如果需要置信度分数,但这些分数不一定是概率,那么建议将概率设置为probability=False,并使用decision_function 而不是 predict_proba 。
参考资料:
- Wu, Lin and Weng,
"Probability estimates for multi-class classification by pairwise coupling(成对耦合的多类分类的概率估计)"_, JMLR 5:975-1005, 2004. - Platt
"Probabilistic outputs for SVMs and comparisons to regularized likelihood methods(SVMs 的概率输出和与规则化似然方法的比较)"_ .
4.1.3 非均衡问题
这个问题期望给予某一类或某个别样例能使用的关键词 class_weight 和 sample_weight 提高权重(importance).
SVC (而不是 NuSVC) 在 fit 方法中生成了一个关键词 class_weight. 它是形如 {class_label : value} 的字典, value 是浮点数大于 0 的值, 把类 class_label 的参数 C 设置为 C * value.
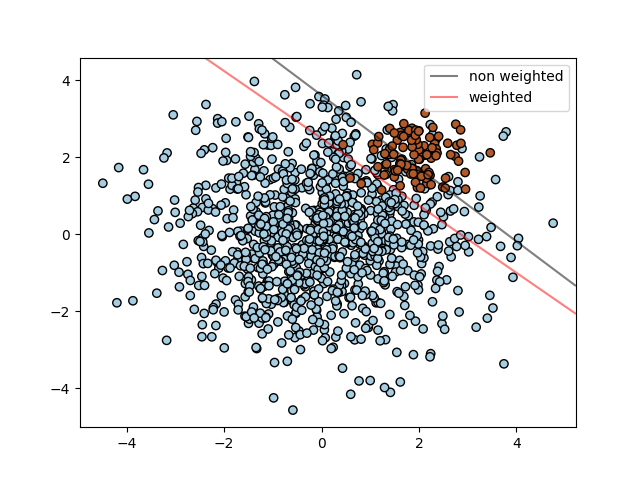
SVC, NuSVC, SVR, NuSVR 和 OneClassSVM 在 fit 方法中通过关键词 sample_weight 为单一样例实现权重weights.与 class_weight 相似, 这些把第i个样例的参数 C 换成 C * sample_weight[i].
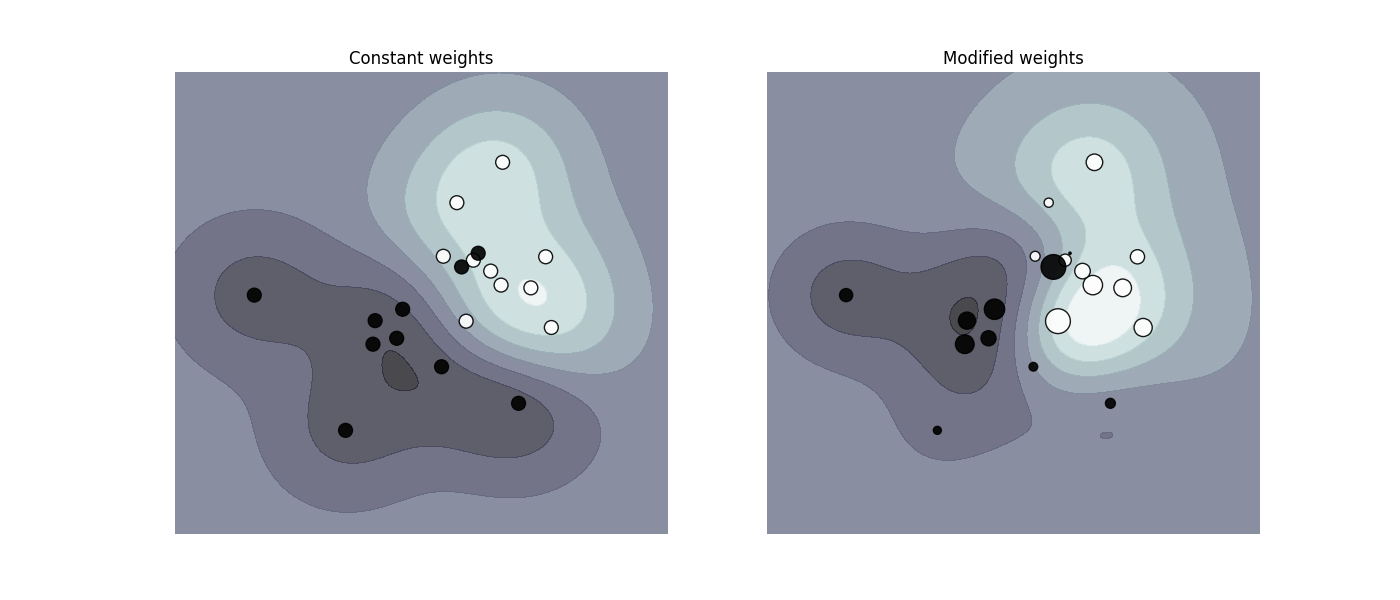
示例:(单独学习!)
- Plot different SVM classifiers in the iris dataset,
- SVM: Maximum margin separating hyperplane,
- SVM: Separating hyperplane for unbalanced classes
- SVM-Anova: SVM with univariate feature selection,
- Non-linear SVM
- SVM: Weighted samples
4.2 回归
支持向量分类的方法可以被扩展用作解决回归问题. 这个方法被称作支持向量回归.
支持向量分类生成的模型(如前描述)只依赖于训练集的子集,因为构建模型的 cost function 不在乎边缘之外的训练点. 类似的,支持向量回归生成的模型只依赖于训练集的子集, 因为构建模型的 cost function 忽略任何接近于模型预测的训练数据.
支持向量回归有三种不同的实现形式: SVR, NuSVR 和 LinearSVR. (区别与分类的:SVC, NuSVC 和 LinearSVC 能在数据集中实现多元分类.)在只考虑线性核的情况下, LinearSVR 比 SVR 提供一个更快的实现形式, 然而比起 SVR 和 LinearSVR, NuSVR 实现一个稍微不同的构思(formulation).细节参见 实现细节.
与分类的类别一样, fit方法会调用参数向量 X, y, 只在 y 是浮点数而不是整数型.:
>>> from sklearn import svm
>>> X = [[0, 0], [2, 2]]
>>> y = [0.5, 2.5]
>>> clf = svm.SVR()
>>> clf.fit(X, y)
SVR(C=1.0, cache_size=200, coef0=0.0, degree=3, epsilon=0.1, gamma='auto_deprecated',kernel='rbf', max_iter=-1, shrinking=True, tol=0.001, verbose=False)
>>> clf.predict([[1, 1]])
array([ 1.5])
示例:(待学习)
- Support Vector Regression (SVR) using linear and non-linear kernels
4.3 密度估计, 异常(novelty)检测
类OneClassSVM实现了一个用于离群点检测的单类SVM。
有关OneClassSVM的描述和使用,请参见新奇和异常值检测.
4.4 复杂度
支持向量机是个强大的工具,不过它的计算和存储空间要求也会随着要训练向量的数目增加而快速增加。 SVM的核心是一个二次规划问题(Quadratic Programming, QP),是将支持向量和训练数据的其余部分分离开来。 在实践中(数据集相关),会根据 libsvm 的缓存有多效,在 O ( n f e a t u r e s × n s a m p l e s 2 ) O(n_{features} \times n_{samples}^2) O(nfeatures×nsamples2) 和 O ( n f e a t u r e s × n s a m p l e s 3 ) O(n_{features} \times n_{samples}^3) O(nfeatures×nsamples3)之间基于 libsvm 的缩放操作才会调用这个 QP 解析器。 如果数据是非常稀疏,那 n f e a t u r e s n_{features} nfeatures 就用样本向量中非零特征的平均数量去替换。
另外请注意,在线性情况下,由 liblinear 操作的 LinearSVC 算法要比由它的 libsvm 对应的 SVC 更为高效,并且它几乎可以线性缩放到数百万样本或者特征。
4.5 使用诀窍(Tips on Practical Use)
-
避免数据复制: 对于
SVC,SVR,NuSVC和NuSVR, 如果数据是通过某些方法而不是用行优先存储(C-order)的双精度,那它会在调用底层的 C 命令前先被复制。 您可以通过检查它的flags属性,来确定给定的 numpy 数组是不是行优先存储(C-order)的。对于
LinearSVC(和LogisticRegression) 的任何输入,都会以 numpy 数组形式,被复制和转换为 用 liblinear 内部稀疏数据去表达(双精度浮点型 float 和非零部分的 int32 索引)。 如果您想要一个适合大规模的线性分类器,又不打算复制一个密集的行优先存储(C-order)双精度 numpy 数组作为输入, 那我们建议您去使用SGDClassifier类作为替代。目标函数可以配置为和LinearSVC模型差不多相同的。 -
内核的缓存大小: 在大规模问题上,对于
SVC,SVR,nuSVC和NuSVR, 内核缓存的大小会特别影响到运行时间。如果您有足够可用的 RAM,不妨把它的缓存大小设得比默认的 200(MB) 要高,例如为 500(MB) 或者 1000(MB)。 -
惩罚系数C的设置:在合理的情况下,
C(4.1.3 非均衡问题中提到) 的默认选择为1。如果您有很多混杂的观察数据, 您应该要去调小它。C越小,就能更好地去正规化估计。当C值较大时,LinearSVC和LinearSVR对C值较不敏感,即当C值大于特定阈值后,模型效果将会停止提升。同时,较大的C值将会导致较长的训练时间,Fan et al.(2008)的论文显示,训练时间的差距有时会达到10倍。 -
支持向量机算法本身不能够很好地支持非标准化的数据,所以 我们强烈建议您将数据标准化。 举个示例,对于输入向量 X, 规整它的每个数值范围为 [0, 1] 或 [-1, +1] ,或者标准化它的为均值为0方差为1的数据分布。请注意, 相同的缩放标准必须要应用到所有的测试向量,从而获得有意义的结果。
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVCclf = make_pipeline(StandardScaler(), SVC())
请参考章节 预处理数据 ,那里会提供到更多关于缩放和规整。 -
关于
shrinking参数,引用[12]:我们发现,如果迭代次数很大,那么收缩可以缩短训练时间。然而,如果我们松散地解决优化问题(例如,通过使用较大的停止容差),不使用收缩的代码可能会快得多。 -
在
NuSVC/OneClassSVM/NuSVR内的参数nu, 近似是训练误差和支持向量的比值。 -
在
SVC, ,如果分类器的数据不均衡(例如,很多正例很少负例),设置class_weight='balanced'与/或尝试不同的惩罚系数C。 -
底层实现的随机性:
SVC和NuSVC的底层实现仅使用随机数生成器来打乱数据顺序进行概率估计(当probability被设置为True时)。这种随机性可以用random_state参数来控制。如果将probability设为False,这些估计器就不是随机的,random_state对结果没有影响。底层的OneClassSVM实现类似于SVC和NuSVC的实现。由于OneClassSVM没有提供概率估计,所以它不是随机的。 底层的LinearSVC实现使用随机数生成器来选择特征,当用双坐标下降(当dual被设置为True)。因此,对于相同的输入数据,结果略有不同并不罕见。如果发生这种情况,尝试使用较小的tol参数。这种随机性也可以通过random_state参数来控制。当dual设置为False时,LinearSVC的底层实现不是随机的,random_state对结果没有影响。 -
使用由
LinearSVC(loss='l2', penalty='l1', dual=False)提供的 L1 惩罚去产生稀疏解,也就是说,特征权重的子集不同于零,这样做有助于决策函数。 随着增加C会产生一个更复杂的模型(有更多的特征被选择)。可以使用l1_min_c去计算C的数值,去产生一个”null” 模型(所有的权重等于零)。
参考资料:
- Fan, Rong-En, et al., “LIBLINEAR: A library for large linear classification.”, Journal of machine learning research 9.Aug (2008): 1871-1874.
4.6 核函数
核函数 可以是以下任何形式::
- 线性: ⟨ x , x ′ ⟩ \langle x, x'\rangle ⟨x,x′⟩.
- 多项式: ( γ ⟨ x , x ′ ⟩ + r ) d (\gamma \langle x, x'\rangle + r)^d (γ⟨x,x′⟩+r)d. d d d 是关键词
degree, r r r 指定coef0。 - rbf: exp ( − γ ∣ x − x ′ ∣ 2 ) \exp(-\gamma |x-x'|^2) exp(−γ∣x−x′∣2) 是关键词
gamma, 必须大于 0。 - sigmoid ( tanh ( γ ⟨ x , x ′ ⟩ + r ) \tanh(\gamma \langle x,x'\rangle + r) tanh(γ⟨x,x′⟩+r)), 其中 r r r 指定
coef0。
初始化时,不同内核由不同的函数名调用:
>>> linear_svc = svm.SVC(kernel='linear')
>>> linear_svc.kernel
'linear'
>>> rbf_svc = svm.SVC(kernel='rbf')
>>> rbf_svc.kernel
'rbf'
4.6.1 自定义核
您可以自定义自己的核,通过使用python函数作为内核或者通过预计算 Gram 矩阵。
自定义内核的分类器和别的分类器一样,除了下面这几点:
- 空间
support_vectors_现在是空的, 只有支持向量的索引被存储在support_ fit()方法的第一个参数的引用(不是副本)将被存储,并作为将来的引用。 如果在fit()和predict()之间有数组发生改变,您将会碰到意料外的结果。
4.6.1.1 使用 python 函数作为内核
在构造时,您同样可以通过一个函数传递到关键词 kernel ,来使用您自己定义的内核。
您的内核必须要以两个矩阵作为参数,大小分别是 (n_samples_1, n_features), (n_samples_2, n_features) 和返回一个内核矩阵,shape 是 (n_samples_1, n_samples_2).
以下代码定义一个线性核,和构造一个使用该内核的分类器示例:
>>> import numpy as np
>>> from sklearn import svm
>>> def my_kernel(X, Y):
... return np.dot(X, Y.T)
...
>>> clf = svm.SVC(kernel=my_kernel)
示例:
- 自定义核的SVM
4.6.1.2 使用 Gram 矩阵
在适应算法中,设置 kernel='precomputed' 和把 X 替换为 Gram 矩阵。 此时,必须要提供在 所有 训练矢量和测试矢量中的内核值。
>>> import numpy as np
>>> from sklearn import svm
>>> X = np.array([[0, 0], [1, 1]])
>>> y = [0, 1]
>>> clf = svm.SVC(kernel='precomputed')
>>> # 线性内核计算
>>> gram = np.dot(X, X.T)
>>> clf.fit(gram, y)
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,decision_function_shape='ovr', degree=3, gamma='auto_deprecated',kernel='precomputed', max_iter=-1, probability=False,random_state=None, shrinking=True, tol=0.001, verbose=False)
>>> # 预测训练样本
>>> clf.predict(gram)
array([0, 1])
4.6.1.3 RBF 内核参数
当用 径向基 (RBF) 内核去训练 SVM,有两个参数必须要去考虑: C 惩罚系数和 gamma 。参数 C , 通用在所有 SVM 内核,与决策表面的简单性相抗衡,可以对训练样本的误分类进行有价转换。 较小的 C 会使决策表面更平滑,同时较高的 C 旨在正确地分类所有训练样本。 Gamma 定义了单一 训练样本能起到多大的影响。较大的 gamma 会更让其他样本受到影响。
选择合适的 C 和 gamma ,对SVM的性能起到很关键的作用。建议一点是 使用 sklearn.model_selection.GridSearchCV 与 C 和 gamma 相隔 成倍差距从而选择到好的数值。
示例:
- RBF SVM parameters
4.7 数学公式
支持向量机在高维度或无穷维度空间中,构建一个超平面或者一系列的超平面,可以用于分类、回归或者别的任务。 直观地看,借助超平面去实现一个好的分割, 能在任意类别中使最为接近的训练数据点具有最大的间隔距离(即所 谓的函数余量),这样做是因为通常更大的余量能有更低的分类器泛化误差。
4.7.1 SVC
在两类中,给定训练向量 x i i = 1 , … , n x_i \, i=1,…, n xii=1,…,n, 和一个向量 y ∈ 1 , − 1 n y \in {1, -1}^n y∈1,−1n , SVC能解决 如下主要问题:
min w , b , ζ 1 2 w T w + C ∑ i = 1 n ζ i subject to y i ( w T ϕ ( x i ) + b ) ≥ 1 − ζ i ζ i ≥ 0 , i = 1 , . . . , n \min_ {w, b, \zeta} \frac{1}{2} w^T w + C \sum_{i=1}^{n} \zeta_i \\ \textrm {subject to} y_i (w^T \phi (x_i) + b) \geq 1 - \zeta_i \\ \zeta_i \geq 0 , i=1, ..., n w,b,ζmin21wTw+Ci=1∑nζisubject toyi(wTϕ(xi)+b)≥1−ζiζi≥0,i=1,...,n
它的对偶是
min α 1 2 α T Q α − e T α subject to y T α = 0 0 ≤ α i ≤ C , i = 1 , . . . , n \min_{\alpha} \frac{1}{2} \alpha^T Q \alpha - e^T \alpha \\ \textrm {subject to } y^T \alpha = 0\ \\ 0 \leq \alpha_i \leq C, i=1, ..., n αmin21αTQα−eTαsubject to yTα=0 0≤αi≤C,i=1,...,n
其中 e e e 是所有的向量, C > 0 C > 0 C>0 是上界, Q Q Q 是一个 n n n 由 n 个半正定矩阵, 而 Q i j ≡ y i y j K ( x i , x j ) Q_{ij} \equiv y_i y_j K(x_i, x_j) Qij≡yiyjK(xi,xj),其中 K ( x i , x j ) = ϕ ( x i ) T ϕ ( x j ) K(x_i, x_j) = \phi (x_i)^T \phi (x_j) K(xi,xj)=ϕ(xi)Tϕ(xj) 是内核。所以训练向量是通过函数 ϕ \phi ϕ,间接反映到一个更高维度的(无穷的)空间。
决策函数是:
sgn ( ∑ i = 1 n y i α i K ( x i , x ) + ρ ) \operatorname{sgn}(\sum_{i=1}^n y_i \alpha_i K(x_i, x) + \rho) sgn(i=1∑nyiαiK(xi,x)+ρ)
注意:
- 虽然这些SVM模型是从 libsvm 和 liblinear 中派生出来,使用了
C作为调整参数,但是大多数的 攻击使用了alpha。两个模型的正则化量之间的精确等价,取决于模型优化的准确目标函数。举 个示例,当使用的估计器是sklearn.linear_model.Ridge做回归时,他们之间的相关性是 C = 1 a l p h a C = \frac{1}{alpha} C=alpha1 。
这些参数能通过成员 dual_coef_、 support_vectors_ 、 intercept_ 去访问,这些成员分别控制了输出 y i α i y_i \alpha_i yiαi 支持向量和无关项 ρ \rho ρ :
参考资料:
- “Automatic Capacity Tuning of Very Large VC-dimension Classifiers”, I. Guyon, B. Boser, V. Vapnik - Advances in neural information processing 1993.
- “Support-vector networks”, C. Cortes, V. Vapnik - Machine Learning, 20, 273-297 (1995).
4.7.2 NuSVC
我们引入一个新的参数 ν \nu ν 来控制支持向量的数量和训练误差。参数 ν \nu ν 是训练误差分数的上限和支持向量分数的下限。
可以看出, ν \nu ν -SVC 公式是 C C C-SVC 的再参数化,所以数学上是等效的。
4.7.3 SVR
给定训练向量 x i ∈ R p , i = 1 , … , n x_i \in \mathbb{R}^p,i=1,…, n xi∈Rp,i=1,…,n ,向量 y ∈ R n y \in \mathbb{R}^n y∈Rn ε \varepsilon ε-SVR 能解决以下的主要问题:
min w , b , ζ , ζ ∗ 1 2 w T w + C ∑ i = 1 n ( ζ i + ζ i ∗ ) subject to y i − w T ϕ ( x i ) − b ≤ ε + ζ i , w T ϕ ( x i ) + b − y i ≤ ε + ζ i ∗ , & ζ i , ζ i ∗ ≥ 0 , i = 1 , . . . , n \min_ {w, b, \zeta, \zeta^*} \frac{1}{2} w^T w + C \sum_{i=1}^{n} (\zeta_i + \zeta_i^*) \\ \textrm {subject to } y_i - w^T \phi (x_i) - b \leq \varepsilon + \zeta_i,\\ w^T \phi (x_i) + b - y_i \leq \varepsilon + \zeta_i^*,\& \zeta_i, \zeta_i^* \geq 0, i=1, ..., n w,b,ζ,ζ∗min21wTw+Ci=1∑n(ζi+ζi∗)subject to yi−wTϕ(xi)−b≤ε+ζi,wTϕ(xi)+b−yi≤ε+ζi∗,&ζi,ζi∗≥0,i=1,...,n
它的对偶是
min α , α ∗ 1 2 ( α − α ∗ ) T Q ( α − α ∗ ) + ε e T ( α + α ∗ ) − y T ( α − α ∗ ) subject to e T ( α − α ∗ ) = 0 0 ≤ α i , α i ∗ ≤ C , i = 1 , . . . , n \min_{\alpha, \alpha^*} \frac{1}{2} (\alpha - \alpha^*)^T Q (\alpha - \alpha^*) + \varepsilon e^T (\alpha + \alpha^*) - y^T (\alpha - \alpha^*) \\ \textrm {subject to } e^T (\alpha - \alpha^*) = 0 \\ 0 \leq \alpha_i, \alpha_i^* \leq C, i=1, ..., n α,α∗min21(α−α∗)TQ(α−α∗)+εeT(α+α∗)−yT(α−α∗)subject to eT(α−α∗)=00≤αi,αi∗≤C,i=1,...,n
其中 e e e 是所有的向量, C > 0 C > 0 C>0 是上界, Q Q Q 是一个 n n n 由 n 个半正定矩阵, 而 Q i j ≡ K ( x i , x j ) = ϕ ( x i ) T ϕ ( x j ) Q_{ij} \equiv K(x_i, x_j) = \phi (x_i)^T \phi (x_j) Qij≡K(xi,xj)=ϕ(xi)Tϕ(xj) 是内核。 所以训练向量是通过函数 ϕ \phi ϕ,间接反映到一个更高维度的(无穷的)空间。
决策函数是:
∑ i = 1 n ( α i − α i ∗ ) K ( x i , x ) + ρ \sum_{i=1}^n (\alpha_i - \alpha_i^*) K(x_i, x) + \rho i=1∑n(αi−αi∗)K(xi,x)+ρ
这些参数能通过成员 dual_coef_、 support_vectors_ 、 intercept_ 去访问,这些 成员分别控制了不同的 α i − α i ∗ \alpha_i - \alpha_i^* αi−αi∗ 、支持向量和无关项 ρ \rho ρ:
参考资料:
- “A Tutorial on Support Vector Regression”, Alex J. Smola, Bernhard Schölkopf - Statistics and Computing archive Volume 14 Issue 3, August 2004, p. 199-222.
4.8 实现细节
在底层里,我们使用 libsvm 和 liblinear 去处理所有的计算。这些库都使用了 C 和 Cython 去包装。
参考资料:
- 有关实现的描述和使用算法的细节,请参考
- LIBSVM: A Library for Support Vector Machines.
- LIBLINEAR – A Library for Large Linear Classification.
相关文章:
 支持向量机 吴楚东南坼,乾坤日夜浮。)
2024-12-6-sklearn学习(4) 支持向量机 吴楚东南坼,乾坤日夜浮。
文章目录 sklearn学习(4) 支持向量机4.1 分类4.1.1 多元分类4.1.2 得分和概率4.1.3 非均衡问题 4.2 回归4.3 密度估计, 异常(novelty)检测4.4 复杂度4.5 使用诀窍(Tips on Practical Use)4.6 核函数4.6.1 自定义核4.6.1.1 使用 python 函数作为内核4.6.1…...

Linux 正确关机方式详解
在Linux系统中,正确地关机是一个重要的操作,它不仅影响到系统的数据完整性,还可能影响到其他用户的工作。本文将详细介绍Linux系统中的各种关机方式,包括它们的使用场景和具体命令。 为什么需要正确关机 在DOS和Windows系统中&a…...

React Portals 有什么用
React Portals是React提供的一种机制,它允许开发者将组件渲染到DOM树中的不同位置,而不受组件层次结构的限制。React Portals的主要用途和优势包括以下几个方面: 用途和优势 处理全局UI元素 React Portals允许将UI元素渲染到应用的根DOM之外…...

光学偏振的基础知识
前言与目录 XXX 目录 一、 二、 三、 一、总结 光的偏振 光具有三个基本特性,即波长、强度和偏振。光的波长很容易理解,以常见的可见光为例,波长范围为380~780nm。光的强度也很容易理解,一束光的强弱可以通过功率的大小来表征…...

小程序 - 计算器
小程序交互练习 - 计算器小程序 目录 计算器 功能描述 准备工作 创建项目 配置导航栏 创建utils目录 math.js文件内容 calc.js文件内容 页面内容 页面样式内容 页面脚本事件 功能截图 总结 计算器 在日常生活中,计算器是人们广泛使用的工具࿰…...

软件架构:从传统单体到现代微服务的技术演变
1.引言 在软件开发中,架构设计不仅仅是程序员的技术任务,它更是一个项目成功的关键。无论是小型应用还是大型分布式系统,软件架构都直接影响着系统的可维护性、可扩展性、性能和稳定性。理解软件架构的必要性,能够帮助开发人员做…...
)
CTF之密码学(rot密码)
ROT加密算法,也被称为Caesar加密,是一种简单的字母替换加密算法。以下是对ROT加密算法的详细介绍: 一、基本原理 ROT加密算法通过将字母表中的每个字母向后(或向前)移动固定的位置来加密文本。选择一个固定的偏移量&…...

linux安装nodejs管理器,并配置node、npm 软链接
一,安装nodejs管理器 注意——不同版本,可能有问题 亲测这个版本,安装后,npm正常使用——v20.10.0 二,配置软链接——快速访问——不要多些空格(会出现invalid option错误) ln -s /www/server…...

Linux 环境下 PostgreSQL 常用命令操作指南
在 Linux 系统中,PostgreSQL 配备了一系列实用命令以进行数据库操作。具体如下: 注意事项:若采用 docker 部署,需预先进入 docker 容器。 进入 docker 容器命令: docker exec -it 容器名 bash 向容器内复制本地文件命…...

Implicit style-content separation using lora
1.Introduction 图像风格化,这个任务涉及根据某些风格参考改编图像的风格,这些参考可以是基于文本或基于图像的,同时保持其内容不变,内容指的是图像的语义信息和结构,而风格通常指的是视觉特征和模式,例如颜色和纹理。这是一个有挑战的任务,因为风格和内容之间的强关联…...
源代码并和eclipse做关联)
网易博客旧文-----如何在WINDOWS下载安卓(android)源代码并和eclipse做关联
如何在WINDOWS下载安卓(android)源代码并和eclipse做关联 2013-02-05 17:27:16| 分类: 安卓开发 | 标签: |举报 |字号大中小 订阅 编写安卓程序时,有时想看看安卓某些类的实现,但默认情况下环境是不带的。…...

Qt入门9——绘图
基本概念 虽然Qt已经内置了很多的控件,但是不能保证现有控件就可以应对所有场景. 很多时候我们需要更强的"DIY"能力; Qt 提供了画图相关的API,可以允许我们在窗口上绘制任意的图形形状,来完成更复杂的界面设计。 绘图api核心类: 类说明QPaint…...

漫画之家系统:Spring Boot框架下的漫画版权保护
摘 要 随着信息技术和网络技术的飞速发展,人类已进入全新信息化时代,传统管理技术已无法高效,便捷地管理信息。为了迎合时代需求,优化管理效率,各种各样的管理系统应运而生,各行各业相继进入信息管理时代&a…...

K8S服务突然中断无法访问:报The node had condition: [DiskPressure]异常
一、背景 程序在运行过程中,突然无法访问,发现后台接口也无法访问;查看kuboard,发现报如下异常:The node had condition: [DiskPressure]. 继续查看磁盘使用率,发现系统盘使用率已经高达93%。问题前后呼应…...

5.11【机器学习】
先是对图像进行划分 划分完后, 顺序读取文件夹,在文件夹里顺序读取图片, 卷积层又称为滤波器,通道是说滤波器的个数,黑白通道数为1,RGB通道个数为3 在输入层,对于输入层而言,滤波…...

JavaWeb开发12
登陆拦截 会话技术 会话:用户打开浏览器,访问web服务器的资源,会话建立,直到有一方断开连接,会话结束。在一次会话中可以包含多次请求和响应 会话跟踪:一种维护浏览器状态的方法,服务器需要识…...

《乌合之众》笔记
1.集体会降智,会互相传染 2.群体是无名氏,因此没必要承担责任。约束个人的责任感消失 3.有意识人格的消失,无意识人格的得势,思想和感情因为暗示和互相传染而转向一个共同的方向,以及立刻把暗示的观念转化为行动的倾…...

[241206] X-CMD 发布 v0.4.15:env 升级,mirror 支持华为/腾讯 npm 镜像,pb-wayland 剪贴板
目录 X-CMD 发布 v0.4.15📃Changelog📦 env|pkg🪞 mirror📑 pb🎨 theme|starship|ohmyposh🤖 chat📝 man✅ 升级指南 X-CMD 发布 v0.4.15 📃Changelog 📦 env|pkg 新增…...

Vue前端开发-路由跳转及带参数跳转
在Vue 3中,由于没有实例化对象this,因此,无法通过this去访问 $route对象,而是通过导入一个名为 useRouter 的方法,执行这个方法后,返回一个路由对象,通过这个路由对象就可以获取到当前路由中的信…...

AI赋能:构建安全可信的智能电子档案库
在档案的政策与法规上,《中华人民共和国档案法》2020年修订新增,对电子档案的合法要件、地位和作用、安全管理要求和信息化系统建设等方面作出了明确规定,保障数字资源的安全保存和有效利用。 日前,国家档案局令第22号公布《电子…...

时间序列绘图1
用到的包 #时间序列预测 library(forecast) #数据可视化 library(ggplot2) #包含《Forecasting: Principles and Practice》第三版中使用的数据集和函数 library(fpp3)时间序列图 #提取1990年及以后的零售贸易职位的数据,并选择月份和就业人数 us_employment |>…...

云计算.运维.面试题
1、计算机能直接识别的语言( C )。 A、汇编语言 B、自然语言 C、机器语言 D、高级语言 2、应用软件是指( D )。 A、所有能够使用的软件 B、能被各应用单位共同使用的某种软件 C、所有计算机上都应使用的基本软件D、专门为某一应用目的而编制的软件 3、计算机的显示器是一…...
Bootstrap5列表组全解析)
Bootstrap-HTML(三)Bootstrap5列表组全解析
Bootstrap-HTML(三)Bootstrap5列表组全解析 前言(一)HTML 列表基础回顾1.无序列表2.有序列表3.定义列表 二、无样式的有序列表和无序列表内联列表 三、Bootstrap5 列表组1.基础的列表组2.设置禁用和活动项3.链接项的列表组4.移除列…...

黑马程序员MybatisPlus/Docker相关内容
Day01 MP相关知识 1. mp配置类: 2.条件构造器: 具体的实现例子: ①QuerryWapper: ②LambdaQueryWrapper: 3.MP的自定义SQL 4.MP的Service层的实现 5.IService下的Lambda查询 原SQL语句的写法: Lambda 查询语句的…...
)
01_Node.js入门 (黑马)
01_Node.js入门 知识点自测 从 index.js 出发,访问到 student/data.json 的相对路径如何写? A:../public/teacher/data.json B:./public/student/data.json C:../student/data.json <details><summary>答案</sum…...
)
在Java中使用Apache POI导入导出Excel(六)
本文将继续介绍POI的使用,上接在Java中使用Apache POI导入导出Excel(五) 使用Apache POI组件操作Excel(六) 43、隐藏和取消隐藏行 使用 Excel,可以通过选择该行(或行)来隐藏工作表…...

黑马微服务开发与实战学习笔记_MybatisPlus_P2核心功能
系列博客目录 文章目录 系列博客目录Part1:条件构造器案例 基于QueryWrapper的查询案例 基于UpdateWrapper的查询条件构造器的用法总结 Part2:自定义SQL案例1案例2解决方案 Part3:IService接口IService接口基本用法实战案例准备工作开始基本用法实战IService的Lambda查询实战 批…...

华为云域名网站修改DNS服务器教程
修改单个域名的DNS服务器 登录域名注册控制台。 进入“域名列表”页面。 在域名列表中,单击“域名”列的待修改DNS服务器的域名。 进入域名信息页面。 图1 域名信息 在域名信息页面,单击“DNS服务器”后的“修改”,进入“修改DNS服务器”页面。 图2 修改DNS服务器 在…...

Redis 基础、Redis 应用
Redis 基础 什么是 Redis? Redis (REmote DIctionary Server)是一个基于 C 语言开发的开源 NoSQL 数据库(BSD 许可)。与传统数据库不同的是,Redis 的数据是保存在内存中的(内存数据库…...

三分钟掌握MySQL-MVCC底层原理
MVCC介绍 mvcc是mysql为了解决脏读、不可重复读等事务之间读写问题而诞生的;它替代了一些场景下的低效锁,在保证隔离性的基础上,提升了读取效率和并发性。 MVCC实现 在mysql中mvcc是基于mysql的undo log和readview来实现的。 undo log 在…...

CSS 快速上手
目录 一. CSS概念 二. CSS语法 1. 基本语法规范 2. CSS的三种引入方式 (1) 行内样式 (2) 内部样式表 (3) 外部样式表 3. CSS选择器 (1) 标签选择器 (2) 类选择器 (3) id选择器 (4) 通配符选择器 (5) 复合选择器 <1> 空格 <2> 没有空格 <3> &q…...

51c视觉~YOLO~合集4
我自己的原文哦~ https://blog.51cto.com/whaosoft/12512597 1、Yolo8 1.1、检测PCB元件 技术世界正在以惊人的速度发展,而这种转变的核心是一个革命性的工具 — 计算机视觉。它最有趣的应用之一是电子印刷电路板 (PCB) 的检测和分析。本文…...

深入浅出:PHP函数的定义与使用
文章目录 前言什么是函数定义函数语法示例 调用函数示例 参数传递按值传递示例按引用传递示例默认参数示例可变数量的参数示例 返回值示例 变量作用域全局作用域示例局部作用域示例静态作用域示例 匿名函数示例闭包示例 递归函数示例 内置函数常见内置函数示例 用户自定义函数示…...

前端调试实践
作者:效能研发部 黄泽平 前言 在日常调试问题中,相信我们很多人都是用console去排查相关的问题,虽然问题也可以排查出来,但是有时它的效率并不高。这篇文章主要讲解关于断点和一些日常调试技巧的内容,方便你在日后调…...

芯科科技突破性超低功耗Wi-Fi 6和低功耗蓝牙5.4模块加速设备部署
致力于以安全、智能无线连接技术,建立更互联世界的全球领导厂商Silicon Labs(亦称“芯科科技”,今日宣布推出SiWx917Y超低功耗Wi-Fi 6和低功耗蓝牙(Bluetooth LE)5.4模块。 作为成功的第二代无线开发平台的新产品&…...

Matlab自学笔记四十三:使用函数拆分日期时间型数据的子信息:年、月、日、时、分、秒
使用函数拆分日期时间型数据的子信息:年、月、日、时、分、秒,函数包括年year,季度quarter,月month,周week,日day,时hour,分minute,秒second,年月日ymd&#…...

【NLP高频面题 - LLM架构篇】大模型使用SwiGLU相对于ReLU有什么好处?
【NLP高频面题 - LLM架构篇】大模型使用SwiGLU相对于ReLU有什么好处? 重要性:★★★ 💯 NLP Github 项目: NLP 项目实践:fasterai/nlp-project-practice 介绍:该仓库围绕着 NLP 任务模型的设计、训练、优化…...

【Python爬虫实战】轻量级爬虫利器:DrissionPage之SessionPage与WebPage模块详解
🌈个人主页:易辰君-CSDN博客 🔥 系列专栏:https://blog.csdn.net/2401_86688088/category_12797772.html 目录 前言 一、SessionPage (一)SessionPage 模块的基本功能 (二)基本使…...

python查找大文件
完整代码,不仅会捕获错误,还会输出大于 1MB 文件的大小(以 MB 为单位),并跳过访问受限或已删除的文件。 代码 import os# 查找当前目录及子目录下大于 1MB 的文件,并输出文件大小 for root, dirs, files in os.walk(.):for name in files:...

秒懂:使用js验证hash, content hash , chunk hash的区别
一、使用js验证hash, content hash , chunk hash的区别 1、计算一般的 Hash(以简单字符串为例) 使用crypto-js库来进行哈希计算,需提前引入npm install crypto-js库。 crypto-js: 是一个JavaScript加密算法库,用于实…...

RabbitMQ消息可靠性保证机制6--可靠性分析
在使用消息中间件的过程中,难免会出现消息错误或者消息丢失等异常情况。这个时候就需要有一个良好的机制来跟踪记录消息的过程(轨迹溯源),帮助我们排查问题。 在RabbitMQ中可以使用Firehose实现消息的跟踪,Firehose可…...
)
【NoSQL数据库】MongoDB数据库——集合和文档的基本操作(创建、删除、更新、查询)
目录 一、MongoDB数据库原理 二、MongoDB数据库和集合基本操作(增删改查) 三、MongoDB数据库的文档基本操作(增删改) 四、学习笔记 往期文章:【NoSQL数据库】MongoDB数据库的安装与卸载-CSDN博客 一、MongoDB数据…...
IDL处理卫星数据)
IDL学习笔记(二)IDL处理卫星数据
IDL处理卫星数据 HDF文件数据集属性通用属性 常用HDF4操作函数常用的HDF5操作函数读取HDF文件的一般步骤 HDF4文件读取-----数据信息查询HDF4文件读取示例-----目标数据TIFF输出提取modis产品中数据,与某一点经纬度最接近的点有效结果,并按每行内容为日期…...

用点云信息来进行监督目标检测
🍑个人主页:Jupiter. 🚀 所属专栏:传知代码 欢迎大家点赞收藏评论😊 目录 概述问题分析Making Lift-splat work well is hard深度不准确深度过拟合不准确的BEV语义 模型总体框架显性深度监督 深度细化模块演示效果核心…...

Python编写api接口读取电商商品详情数据示例
以下是一个使用 Python 的 Flask 框架来编写一个简单的 API 接口,用于读取模拟的电商商品详情数据的示例代码。这里假设商品详情数据是存储在一个简单的字典中模拟数据库存储,实际应用中你需要连接真正的数据库(如 MySQL、MongoDB 等…...

用纯 CSS 实现网格背景
是不是在日常开发中经常遇到实现网格的需求,网格通常对网页中展示的元素能起到很好的定位和对齐作用。 这里介绍如何只通过 CSS 来实现这个需求? 使用背景图 这里我们的背景图使用 SVG 来创建,首先,创建绘出一个正方形ÿ…...

CNN+LSTM+AM研究方向初尝试
CNNLSTMAM研究方向初尝试 简单介绍 CNN CNN 的基本结构 卷积层(Convolutional Layer): 该层通过卷积操作提取输入数据的特征。卷积操作使用多个卷积核(滤波器)对输入图像进行局部感知,从而识别出边缘、纹…...

对比 LiveData 和 Flow 的实现方式
前一段忙完了鸿蒙,现在又开始 Android 开发了。由于之前公司都是都是偏传统开发方式,基本都是 Java 开发 Android 那一套。现在开始学习现代 Android 开发了。 对比 LiveData 和 Flow 的实现方式 在 Android 开发中,LiveData 和 Flow 都可以用来管理异步数据流和实现 UI 的…...

React.memo 和useMemo 的区别
React.memo 和 useMemo 都是 React 中的性能优化工具,但它们的用途和工作原理不同。以下是它们的主要区别: 1. React.memo React.memo 是一个高阶组件(HOC),用于优化组件的渲染,防止不必要的重新渲染。当组…...

视频码率到底是什么?详细说明
视频码率(Video Bitrate)是指在单位时间内(通常是每秒)传输或处理的视频数据量,用比特(bit)表示。它通常用来衡量视频文件的压缩程度和质量,码率越高,视频质量越好&#…...