AI Agents系列之构建多智能体系统
🧠 向所有学习者致敬!
“学习不是装满一桶水,而是点燃一把火。” —— 叶芝
我的博客主页: https://lizheng.blog.csdn.net
🌐 欢迎点击加入AI人工智能社区!
🚀 让我们一起努力,共创AI未来! 🚀
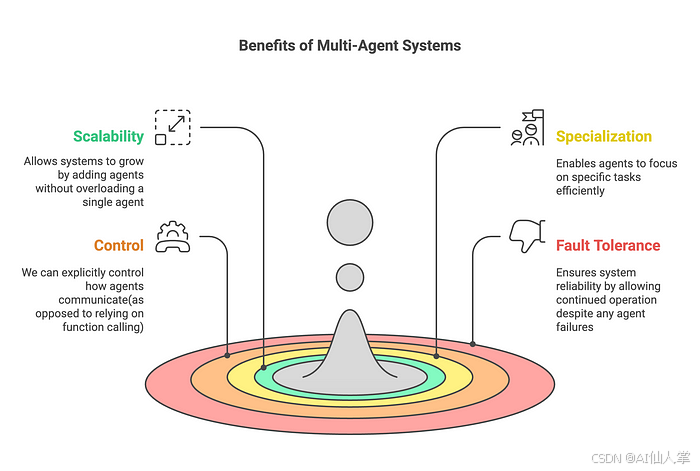
智能体是一个使用大型语言模型(LLM)来决定应用程序控制流程的系统。随着这些系统的开发,它们可能会随着时间的推移变得越来越复杂,从而难以管理和扩展。例如,你可能会遇到以下问题:
- 智能体拥有太多工具,却不知道该调用哪个工具,或者何时调用。
- 上下文变得过于复杂,单个智能体难以跟踪。
- 系统需要多个专业领域(例如规划者、研究者、数学专家等)。
为了解决这些问题,你可以考虑将应用程序拆分为多个较小的独立智能体,并将它们组合成一个多智能体系统。这些独立智能体可以简单到只是一个提示和一个LLM调用,也可以复杂到一个ReAct智能体(以及更多)!
文章目录
- 🧠 向所有学习者致敬!
- 🌐 欢迎[点击加入AI人工智能社区](https://bbs.csdn.net/forums/b8786ecbbd20451bbd20268ed52c0aad?joinKey=bngoppzm57nz-0m89lk4op0-1-315248b33aafff0ea7b)!
- 1.1 单智能体架构与多智能体架构
- 2\. 多智能体架构
- 2.1 多智能体系统中的模式
- **2.1.1 并行**
- **2.1.2 顺序**
- **2.1.3 循环**
- **2.1.4 路由器**
- **2.1.5 聚合器(或合成器)**
- **2.1.6 网络(或水平)**
- **2.1.7 交接**
- **2.1.8 监督者**
- **2.1.9 监督者(工具调用)**
- **2.1.10 层级(或垂直)**
- **2.1.11 自定义多智能体工作流**
- 3\. 智能体之间的通信
- 3.1 图状态与工具调用
- 3.2 不同的状态模式
- 3.3 共享消息列表
- 4\. 结论
随着智能体框架的发展,许多公司开始构建自己的多智能体系统,并寻找一种能够解决所有智能体任务的万能解决方案。两年前,研究人员设计了一个名为 ChatDev的多智能体协作系统。ChatDev就像一家虚拟软件公司,通过各种具有不同角色的智能体(如首席执行官、首席产品官、艺术设计师、编码员、审查员、测试员等)来运营,就像一家普通的软件工程公司一样。

图片来源:ChatDev
所有这些智能体共同努力并相互沟通,成功创建了一款视频游戏,他们的努力取得了成功。在这一成就之后,许多人相信任何软件工程任务都可以通过这种多智能体架构来解决,其中每个AI都有一个独特的角色。然而,现实世界的实验表明,并非每个问题都可以用相同的架构来解决。在某些情况下,更简单的架构可能会提供更有效、更经济的解决方案。
1.1 单智能体架构与多智能体架构
一开始,单智能体方法似乎很有道理(即一个AI智能体能够完成从浏览器导航到文件操作的所有任务)。然而,随着时间的推移,随着任务变得越来越复杂,工具数量不断增加,我们的单智能体方法将开始面临挑战。
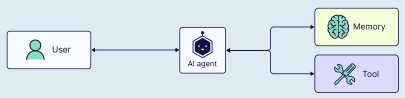
单智能体 | 图片来源:Weaviate
我们会注意到当智能体开始出现异常行为时,这可能是由于以下原因导致的:
- 工具过多:智能体在使用哪些工具以及何时使用方面变得困惑。
- 上下文过于复杂:智能体的上下文窗口越来越大,包含的工具也越来越多。
- 错误过多:由于职责过于广泛,智能体开始产生次优或错误的结果。
当我们开始自动化多个不同的子任务(如数据提取或报告生成)时,可能就是时候开始分离职责了。通过使用多个AI智能体,每个智能体专注于自己的领域和工具集,我们可以提高解决方案的清晰度和质量。这不仅可以让智能体变得更加高效,还能简化智能体本身的开发过程。
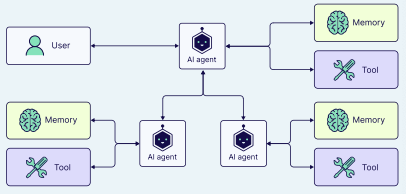
多智能体 | 图片来源:Weaviate
2. 多智能体架构
正如你所看到的,单智能体和多智能体架构都有各自的优缺点。单智能体架构适用于任务简单明了、定义明确且没有特定资源限制的情况。另一方面,多智能体架构在用例复杂且动态、需要更多专业知识和协作,或者有可扩展性和适应性要求时会更有帮助。
2.1 多智能体系统中的模式
在多智能体系统中,有几种连接智能体的方式:
2.1.1 并行
多个智能体同时处理任务的不同部分。
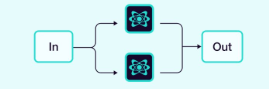
图片来源:Weaviate
示例:我们希望同时使用3个智能体对给定文本进行总结、翻译和情感分析。
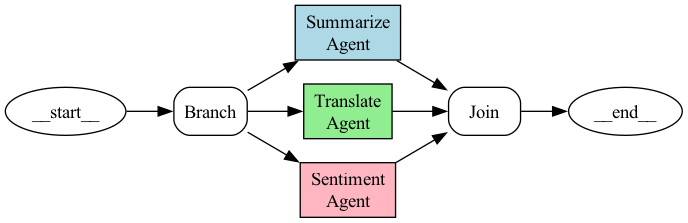
图由作者提供
代码:
from typing import Dict, Any, TypedDict
from langgraph.graph import StateGraph, END
from langchain_core.runnables import RunnableConfig
from textblob import TextBlob
import re
import time# 定义状态
class AgentState(TypedDict):text: strsummary: strtranslation: strsentiment: strsummary_time: floattranslation_time: floatsentiment_time: float# 总结智能体
def summarize_agent(state: AgentState) -> Dict[str, Any]:print("总结智能体:运行中")start_time = time.time()try:text = state["text"]if not text.strip():return {"summary": "未提供用于总结的文本。","summary_time": 0.0}time.sleep(2)sentences = re.split(r'(?<=[.!?]) +', text.strip())scored_sentences = [(s, len(s.split())) for s in sentences if s]top_sentences = [s for s, _ in sorted(scored_sentences, key=lambda x: x[1], reverse=True)[:2]]summary = " ".join(top_sentences) if top_sentences else "文本太短,无法总结。"processing_time = time.time() - start_timeprint(f"总结智能体:完成,耗时 {processing_time:.2f} 秒")return {"summary": summary,"summary_time": processing_time}except Exception as e:return {"summary": f"总结时出错:{str(e)}","summary_time": 0.0}# 翻译智能体
def translate_agent(state: AgentState) -> Dict[str, Any]:print("翻译智能体:运行中")start_time = time.time()try:text = state["text"]if not text.strip():return {"translation": "未提供用于翻译的文本。","translation_time": 0.0}time.sleep(3)translation = ("El nuevo parque en la ciudad es una maravillosa adición. ""Las familias disfrutan de los espacios abiertos, y a los niños les encanta el parque infantil. ""Sin embargo, algunas personas piensan que el área de estacionamiento es demasiado pequeña.")processing_time = time.time() - start_timeprint(f"翻译智能体:完成,耗时 {processing_time:.2f} 秒")return {"translation": translation,"translation_time": processing_time}except Exception as e:return {"translation": f"翻译时出错:{str(e)}","translation_time": 0.0}# 情感分析智能体
def sentiment_agent(state: AgentState) -> Dict[str, Any]:print("情感分析智能体:运行中")start_time = time.time()try:text = state["text"]if not text.strip():return {"sentiment": "未提供用于情感分析的文本。","sentiment_time": 0.0}time.sleep(1.5)blob = TextBlob(text)polarity = blob.sentiment.polaritysubjectivity = blob.sentiment.subjectivitysentiment = "Positive" if polarity > 0 else "Negative" if polarity < 0 else "Neutral"result = f"{sentiment} (Polarity: {polarity:.2f}, Subjectivity: {subjectivity:.2f})"processing_time = time.time() - start_timeprint(f"情感分析智能体:完成,耗时 {processing_time:.2f} 秒")return {"sentiment": result,"sentiment_time": processing_time}except Exception as e:return {"sentiment": f"情感分析时出错:{str(e)}","sentiment_time": 0.0}# 合并并行结果
def join_parallel_results(state: AgentState) -> AgentState:return state# 构建图
def build_parallel_graph() -> StateGraph:workflow = StateGraph(AgentState)# 定义并行分支parallel_branches = {"summarize_node": summarize_agent,"translate_node": translate_agent,"sentiment_node": sentiment_agent}# 添加并行处理节点for name, agent in parallel_branches.items():workflow.add_node(name, agent)# 添加分支和合并节点workflow.add_node("branch", lambda state: state) # 简化的分支函数workflow.add_node("join", join_parallel_results)# 设置入口点workflow.set_entry_point("branch")# 添加并行执行的边for name in parallel_branches:workflow.add_edge("branch", name)workflow.add_edge(name, "join")workflow.add_edge("join", END)return workflow.compile()# 主函数
def main():text = ("The new park in the city is a wonderful addition. Families are enjoying the open spaces, ""and children love the playground. However, some people think the parking area is too small.")initial_state: AgentState = {"text": text,"summary": "","translation": "","sentiment": "","summary_time": 0.0,"translation_time": 0.0,"sentiment_time": 0.0}print("\n构建新图...")app = build_parallel_graph()print("\n开始并行处理...")start_time = time.time()config = RunnableConfig(parallel=True)result = app.invoke(initial_state, config=config)total_time = time.time() - start_timeprint("\n=== 并行任务结果 ===")print(f"输入文本:\n{text}\n")print(f"总结:\n{result['summary']}\n")print(f"翻译(西班牙语):\n{result['translation']}\n")print(f"情感分析:\n{result['sentiment']}\n")print("\n=== 处理时间 ===")processing_times = {"summary": result["summary_time"],"translation": result["translation_time"],"sentiment": result["sentiment_time"]}for agent, time_taken in processing_times.items():print(f"{agent.capitalize()}:{time_taken:.2f} 秒")print(f"\n总墙钟时间:{total_time:.2f} 秒")print(f"各处理时间之和:{sum(processing_times.values()):.2f} 秒")print(f"并行处理节省的时间:{sum(processing_times.values()) - total_time:.2f} 秒")if __name__ == "__main__":main()
输出:
构建新图...开始并行处理...
情感分析智能体:运行中
总结智能体:运行中
翻译智能体:运行中
情感分析智能体:完成,耗时 1.50 秒
总结智能体:完成,耗时 2.00 秒
翻译智能体:完成,耗时 3.00 秒=== 并行任务结果 ===
输入文本:
The new park in the city is a wonderful addition. Families are enjoying the open spaces, and children love the playground. However, some people think the parking area is too small.总结:
Families are enjoying the open spaces, and children love the playground. The new park in the city is a wonderful addition.翻译(西班牙语):
El nuevo parque en la ciudad es una maravillosa adición. Las familias disfrutan de los espacios abiertos, y a los niños les encanta el parque infantil. Sin embargo, algunas personas piensan que el área de estacionamiento es demasiado pequeña.情感分析:
Positive (Polarity: 0.31, Subjectivity: 0.59)=== 处理时间 ===
Summary: 2.00 秒
Translation: 3.00 秒
Sentiment: 1.50 秒总墙钟时间:3.01 秒
各处理时间之和:6.50 秒
并行处理节省的时间:3.50 秒
- 并行性:总结、翻译和情感分析这三个任务同时运行,减少了总处理时间。
- 独立性:每个智能体独立处理输入文本,在执行过程中不需要智能体之间的通信。
- 协调性:队列确保结果被安全收集并按顺序显示。
- 实际用例:总结、翻译和情感分析是常见的自然语言处理任务,从较大的文本中受益于并行处理。
2.1.2 顺序
任务按顺序处理,一个智能体的输出成为下一个智能体的输入。
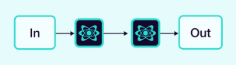
图片来源:Weaviate
示例:多步骤审批。
代码:
from typing import Dict
from langgraph.graph import StateGraph, MessagesState, END
from langchain_core.runnables import RunnableConfig
from langchain_core.messages import HumanMessage, AIMessage
import json# 智能体1:团队负责人
def team_lead_agent(state: MessagesState, config: RunnableConfig) -> Dict:print("智能体(团队负责人):开始审批")messages = state["messages"]proposal = json.loads(messages[0].content)title = proposal.get("title", "")amount = proposal.get("amount", 0.0)if not title or amount <= 0:status = "Rejected"comment = "团队负责人:由于缺少标题或金额无效,提案被拒绝。"goto = ENDelse:status = "Approved by Team Lead"comment = "团队负责人:提案完整且已批准。"goto = "dept_manager"print(f"智能体(团队负责人):审批完成 - {status}")messages.append(AIMessage(content=json.dumps({"status": status, "comment": comment}),additional_kwargs={"agent": "team_lead", "goto": goto}))return {"messages": messages}# 智能体2:部门经理
def dept_manager_agent(state: MessagesState, config: RunnableConfig) -> Dict:print("智能体(部门经理):开始审批")messages = state["messages"]team_lead_msg = next((m for m in messages if m.additional_kwargs.get("agent") == "team_lead"), None)proposal = json.loads(messages[0].content)amount = proposal.get("amount", 0.0)if json.loads(team_lead_msg.content)["status"] != "Approved by Team Lead":status = "Rejected"comment = "部门经理:由于团队负责人拒绝,跳过。"goto = ENDelif amount > 100000:status = "Rejected"comment = "部门经理:预算超出限制。"goto = ENDelse:status = "Approved by Department Manager"comment = "部门经理:预算在限制范围内。"goto = "finance_director"print(f"智能体(部门经理):审批完成 - {status}")messages.append(AIMessage(content=json.dumps({"status": status, "comment": comment}),additional_kwargs={"agent": "dept_manager", "goto": goto}))return {"messages": messages}# 智能体3:财务总监
def finance_director_agent(state: MessagesState, config: RunnableConfig) -> Dict:print("智能体(财务总监):开始审批")messages = state["messages"]dept_msg = next((m for m in messages if m.additional_kwargs.get("agent") == "dept_manager"), None)proposal = json.loads(messages[0].content)amount = proposal.get("amount", 0.0)if json.loads(dept_msg.content)["status"] != "Approved by Department Manager":status = "Rejected"comment = "财务总监:由于部门经理拒绝,跳过。"elif amount > 50000:status = "Rejected"comment = "财务总监:预算不足。"else:status = "Approved"comment = "财务总监:已批准且可行。"print(f"智能体(财务总监):审批完成 - {status}")messages.append(AIMessage(content=json.dumps({"status": status, "comment": comment}),additional_kwargs={"agent": "finance_director", "goto": END}))return {"messages": messages}# 路由函数
def route_step(state: MessagesState) -> str:for msg in reversed(state["messages"]):goto = msg.additional_kwargs.get("goto")if goto:print(f"路由:智能体 {msg.additional_kwargs.get('agent')} 设置 goto 为 {goto}")return gotoreturn END# 构建 LangGraph
builder = StateGraph(MessagesState)
builder.add_node("team_lead", team_lead_agent)
builder.add_node("dept_manager", dept_manager_agent)
builder.add_node("finance_director", finance_director_agent)builder.set_entry_point("team_lead")builder.add_conditional_edges("team_lead", route_step, {"dept_manager": "dept_manager",END: END
})
builder.add_conditional_edges("dept_manager", route_step, {"finance_director": "finance_director",END: END
})
builder.add_conditional_edges("finance_director", route_step, {END: END
})workflow = builder.compile()# 主运行器
def main():initial_state = {"messages": [HumanMessage(content=json.dumps({"title": "New Equipment Purchase","amount": 40000.0,"department": "Engineering"}))]}result = workflow.invoke(initial_state)messages = result["messages"]proposal = json.loads(messages[0].content)print("\n=== 审批结果 ===")print(f"提案标题:{proposal['title']}")final_status = "Unknown"comments = []for msg in messages[1:]:if isinstance(msg, AIMessage):try:data = json.loads(msg.content)if "status" in data:final_status = data["status"]if "comment" in data:comments.append(data["comment"])except Exception:continueprint(f"最终状态:{final_status}")print("评论:")for comment in comments:print(f" - {comment}")if __name__ == "__main__":main()
输出(金额 = $40,000):
智能体(团队负责人):开始审批
智能体(团队负责人):审批完成 - 已由团队负责人批准
路由:智能体 team_lead 设置 goto 为 dept_manager
智能体(部门经理):开始审批
智能体(部门经理):审批完成 - 已由部门经理批准
路由:智能体 dept_manager 设置 goto 为 finance_director
智能体(财务总监):开始审批
智能体(财务总监):审批完成 - 已批准
路由:智能体 finance_director 设置 goto 为 __end__=== 审批结果 ===
提案标题:New Equipment Purchase
最终状态:Approved
评论:- 团队负责人:提案完整且已批准。- 部门经理:预算在限制范围内。- 财务总监:已批准且可行。
- 顺序执行:
- 智能体按顺序运行:团队负责人 → 部门经理 → 财务总监。
- 如果任何智能体拒绝,循环将中断,跳过剩余的智能体。
- 每个智能体修改共享的 Proposal 对象,更新状态和评论。
- 协调性:
- 结果存储在列表中,但 Proposal 对象在智能体之间传递状态。
- 不使用多处理,确保单线程、有序的工作流。
2.1.3 循环
智能体在迭代周期中运行,根据其他智能体的反馈不断改进其输出。
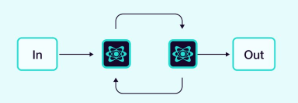
图片来源:Weaviate
示例:评估用例,如代码编写和代码测试。
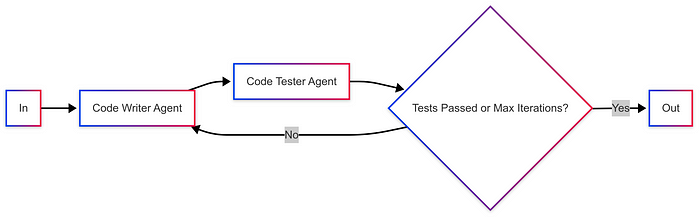
图由作者提供
代码:
from typing import Dict, Any, List
from langgraph.graph import StateGraph, END
from langchain_core.runnables import RunnableConfig
import textwrap# 状态用于跟踪工作流
class EvaluationState(Dict[str, Any]):code: str = ""feedback: str = ""passed: bool = Falseiteration: int = 0max_iterations: int = 3history: List[Dict] = []def __init__(self, *args, **kwargs):super().__init__(*args, **kwargs)self.setdefault("code", "")self.setdefault("feedback", "")self.setdefault("passed", False)self.setdefault("iteration", 0)self.setdefault("max_iterations", 3)self.setdefault("history", [])# 智能体1:代码编写者
def code_writer_agent(state: EvaluationState, config: RunnableConfig) -> Dict[str, Any]:print(f"迭代 {state['iteration'] + 1} - 代码编写者:生成代码")print(f"迭代 {state['iteration'] + 1} - 代码编写者:收到反馈:{state['feedback']}")iteration = state["iteration"] + 1feedback = state["feedback"]if iteration == 1:# 初始尝试:基本阶乘(有漏洞,未处理零或负数)code = textwrap.dedent("""def factorial(n):result = 1for i in range(1, n + 1):result *= ireturn result""")writer_feedback = "初始代码已生成。"elif "factorial(0)" in feedback.lower():# 修复零的情况code = textwrap.dedent("""def factorial(n):if n == 0:return 1result = 1for i in range(1, n + 1):result *= ireturn result""")writer_feedback = "修复了 n=0 的处理。"elif "factorial(-1)" in feedback.lower() or "negative" in feedback.lower():# 修复负数输入code = textwrap.dedent("""def factorial(n):if n < 0:raise ValueError("阶乘对负数未定义")if n == 0:return 1result = 1for i in range(1, n + 1):result *= ireturn result""")writer_feedback = "添加了对负数输入的错误处理。"else:code = state["code"]writer_feedback = "未发现进一步改进。"print(f"迭代 {iteration} - 代码编写者:代码已生成")return {"code": code,"feedback": writer_feedback,"iteration": iteration}# 智能体2:代码测试者
def code_tester_agent(state: EvaluationState, config: RunnableConfig) -> Dict[str, Any]:print(f"迭代 {state['iteration']} - 代码测试者:测试代码")code = state["code"]try:# 定义测试用例test_cases = [(0, 1), # factorial(0) = 1(1, 1), # factorial(1) = 1(5, 120), # factorial(5) = 120(-1, None), # 应该引发 ValueError]# 在安全命名空间中执行代码namespace = {}exec(code, namespace)factorial = namespace.get('factorial')if not callable(factorial):return {"passed": False, "feedback": "未找到阶乘函数。"}feedback_parts = []passed = True# 运行所有测试用例并收集所有失败情况for input_val, expected in test_cases:try:result = factorial(input_val)if expected is None: # 期望出错passed = Falsefeedback_parts.append(f"测试失败:factorial({input_val}) 应该引发错误。")elif result != expected:passed = Falsefeedback_parts.append(f"测试失败:factorial({input_val}) 返回 {result},期望 {expected}。")except ValueError as ve:if expected is not None:passed = Falsefeedback_parts.append(f"测试失败:factorial({input_val}) 意外引发 ValueError:{str(ve)}")except Exception as e:passed = Falsefeedback_parts.append(f"测试失败:factorial({input_val}) 导致错误:{str(e)}")feedback = "所有测试通过!" if passed else "\n".join(feedback_parts)print(f"迭代 {state['iteration']} - 代码测试者:测试完成 - {'通过' if passed else '失败'}")# 在历史记录中记录此次尝试history = state["history"]history.append({"iteration": state["iteration"],"code": code,"feedback": feedback,"passed": passed})return {"passed": passed,"feedback": feedback,"history": history}except Exception as e:print(f"迭代 {state['iteration']} - 代码测试者:失败")return {"passed": False, "feedback": f"测试时出错:{str(e)}"}# 条件边以决定是否继续循环
def should_continue(state: EvaluationState) -> str:if state["passed"] or state["iteration"] >= state["max_iterations"]:print(f"迭代 {state['iteration']} - {'循环停止:测试通过' if state['passed'] else '循环停止:达到最大迭代次数'}")return "end"print(f"迭代 {state['iteration']} - 循环继续:测试失败")return "code_writer"# 构建 LangGraph 工作流
workflow = StateGraph(EvaluationState)# 添加节点
workflow.add_node("code_writer", code_writer_agent)
workflow.add_node("code_tester", code_tester_agent)# 添加边
workflow.set_entry_point("code_writer")
workflow.add_edge("code_writer", "code_tester")
workflow.add_conditional_edges("code_tester",should_continue,{"code_writer": "code_writer","end": END}
)# 编译图
app = workflow.compile()# 运行工作流
def main():initial_state = EvaluationState()result = app.invoke(initial_state)# 显示结果print("\n=== 评估结果 ===")print(f"最终状态:{'通过' if result['passed'] else '失败'},经过 {result['iteration']} 次迭代")print(f"最终代码:\n{result['code']}")print(f"最终反馈:\n{result['feedback']}")print("\n迭代历史:")for attempt in result["history"]:print(f"迭代 {attempt['iteration']}:")print(f" 代码:\n{attempt['code']}")print(f" 反馈:{attempt['feedback']}")print(f" 通过:{attempt['passed']}\n")if __name__ == "__main__":main()
输出:
迭代 1 - 代码编写者:生成代码
迭代 1 - 代码编写者:收到反馈:
迭代 1 - 代码编写者:代码已生成
迭代 1 - 代码测试者:测试代码
迭代 1 - 代码测试者:测试完成 - 失败
迭代 1 - 循环继续:测试失败
迭代 2 - 代码编写者:生成代码
迭代 2 - 代码编写者:收到反馈:测试失败:factorial(-1) 应该引发错误。
迭代 2 - 代码编写者:代码已生成
迭代 2 - 代码测试者:测试代码
迭代 2 - 代码测试者:测试完成 - 通过
迭代 2 - 循环停止:测试通过=== 评估结果 ===
最终状态:通过,经过 2 次迭代
最终代码:def factorial(n):if n < 0:raise ValueError("阶乘对负数未定义")if n == 0:return 1result = 1for i in range(1, n + 1):result *= ireturn result最终反馈:
所有测试通过!迭代历史:
迭代 1:代码:def factorial(n):result = 1for i in range(1, n + 1):result *= ireturn result反馈:测试失败:factorial(-1) 应该引发错误。通过:False迭代 2:代码:def factorial(n):if n < 0:raise ValueError("阶乘对负数未定义")if n == 0:return 1result = 1for i in range(1, n + 1):result *= ireturn result反馈:所有测试通过!通过:True
- 全面反馈:代码测试者现在报告所有测试失败情况,确保代码编写者能够逐步修复问题。
- 正确处理反馈:代码编写者优先修复问题(先处理零的情况,然后是负数输入),确保逐步改进。
- 循环终止:当测试通过时,循环正确退出,而不是不必要地运行所有 3 次迭代。
2.1.4 路由器
一个中央路由器根据任务或输入决定调用哪些智能体。
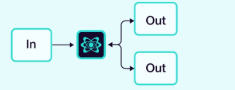
图片来源:Weaviate
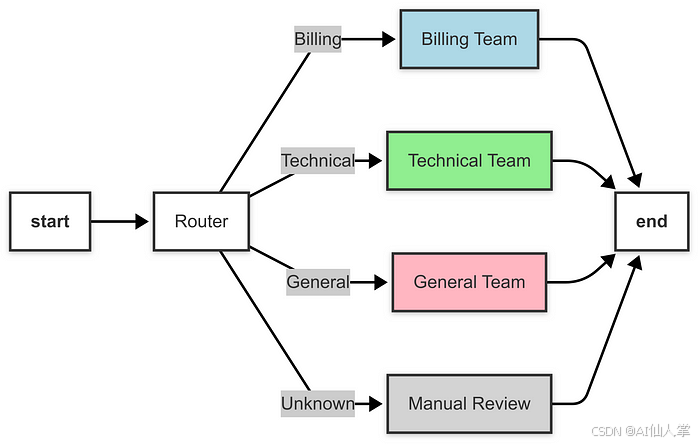
示例:客户支持工单路由
代码:
from typing import Dict, Any, TypedDict, Literal
from langgraph.graph import StateGraph, END
from langchain_core.runnables import RunnableConfig
import re
import time# 第一步:定义状态
# 状态保存工单信息和处理结果
class TicketState(TypedDict):ticket_text: str # 工单内容category: str # 确定的类别(计费、技术、一般或未知)resolution: str # 支持团队提供的解决方案processing_time: float # 处理工单所用时间# 第二步:定义路由器智能体
# 该智能体分析工单并确定其类别
def router_agent(state: TicketState) -> Dict[str, Any]:print("路由器智能体:分析工单...")start_time = time.time()ticket_text = state["ticket_text"].lower()# 简单的基于关键字的分类(可以用 LLM 或 ML 模型替换)if any(keyword in ticket_text for keyword in ["billing", "payment", "invoice", "charge"]):category = "Billing"elif any(keyword in ticket_text for keyword in ["technical", "bug", "error", "crash"]):category = "Technical"elif any(keyword in ticket_text for keyword in ["general", "question", "inquiry", "info"]):category = "General"else:category = "Unknown"processing_time = time.time() - start_timeprint(f"路由器智能体:在 {processing_time:.2f} 秒内将工单分类为 '{category}'")return {"category": category,"processing_time": processing_time}# 第三步:定义支持团队智能体
# 每个智能体处理特定类别的工单# 计费团队智能体
def billing_team_agent(state: TicketState) -> Dict[str, Any]:print("计费团队智能体:处理工单...")start_time = time.time()ticket_text = state["ticket_text"]resolution = f"计费团队:已审阅工单 '{ticket_text}'。请检查您的发票详情,或联系我们的计费部门以获取进一步帮助。"processing_time = time.time() - start_timetime.sleep(1) # 模拟处理时间print(f"计费团队智能体:在 {processing_time:.2f} 秒内完成")return {"resolution": resolution,"processing_time": state["processing_time"] + processing_time}# 技术支持团队智能体
def technical_team_agent(state: TicketState) -> Dict[str, Any]:print("技术支持团队智能体:处理工单...")start_time = time.time()ticket_text = state["ticket_text"]resolution = f"技术支持团队:已审阅工单 '{ticket_text}'。请尝试重新启动您的设备,或提交详细的错误日志以便进一步调查。"processing_time = time.time() - start_timetime.sleep(1.5) # 模拟处理时间print(f"技术支持团队智能体:在 {processing_time:.2f} 秒内完成")return {"resolution": resolution,"processing_time": state["processing_time"] + processing_time}# 一般支持团队智能体
def general_team_agent(state: TicketState) -> Dict[str, Any]:print("一般团队智能体:处理工单...")start_time = time.time()ticket_text = state["ticket_text"]resolution = f"一般团队:已审阅工单 '{ticket_text}'。有关更多信息,请参阅我们的常见问题解答,或通过电子邮件联系我们。"processing_time = time.time() - start_timetime.sleep(0.8) # 模拟处理时间print(f"一般团队智能体:在 {processing_time:.2f} 秒内完成")return {"resolution": resolution,"processing_time": state["processing_time"] + processing_time}# 手动审核智能体(用于未知类别)
def manual_review_agent(state: TicketState) -> Dict[str, Any]:print("手动审核智能体:处理工单...")start_time = time.time()ticket_text = state["ticket_text"]resolution = f"手动审核:工单 '{ticket_text}' 无法分类。标记为人工审核。请手动分配给适当的团队。"processing_time = time.time() - start_timetime.sleep(0.5) # 模拟处理时间print(f"手动审核智能体:在 {processing_time:.2f} 秒内完成")return {"resolution": resolution,"processing_time": state["processing_time"] + processing_time}# 第四步:定义路由器函数
# 该函数根据工单类别确定下一个节点
def route_ticket(state: TicketState) -> Literal["billing_team", "technical_team", "general_team", "manual_review"]:category = state["category"]print(f"路由:工单类别为 '{category}'")if category == "Billing":return "billing_team"elif category == "Technical":return "technical_team"elif category == "General":return "general_team"else:return "manual_review"# 第五步:构建带有路由器模式的图
def build_router_graph() -> StateGraph:workflow = StateGraph(TicketState)# 添加节点workflow.add_node("router", router_agent) # 入口点:对工单进行分类workflow.add_node("billing_team", billing_team_agent) # 处理计费工单workflow.add_node("technical_team", technical_team_agent) # 处理技术工单workflow.add_node("general_team", general_team_agent) # 处理一般咨询workflow.add_node("manual_review", manual_review_agent) # 处理未分类工单# 设置入口点workflow.set_entry_point("router")# 添加条件边以进行路由workflow.add_conditional_edges("router",route_ticket, # 路由器函数,用于确定下一个节点{"billing_team": "billing_team","technical_team": "technical_team","general_team": "general_team","manual_review": "manual_review"})# 从每个团队添加边到 ENDworkflow.add_edge("billing_team", END)workflow.add_edge("technical_team", END)workflow.add_edge("general_team", END)workflow.add_edge("manual_review", END)return workflow.compile()# 第六步:运行工作流
def main():# 不同工单类别的测试用例test_tickets = ["我对我的最后一张发票有计费问题。似乎我被多收费了。","我的应用程序不断出现技术错误。请帮忙!","我对您的服务有一个一般性问题。能否提供更多信息?","我需要帮助解决一个与计费或技术问题无关的问题。"]for ticket_text in test_tickets:# 初始化每个工单的状态initial_state: TicketState = {"ticket_text": ticket_text,"category": "","resolution": "","processing_time": 0.0}print(f"\n=== 正在处理工单:'{ticket_text}' ===")app = build_router_graph()start_time = time.time()result = app.invoke(initial_state, config=RunnableConfig())total_time = time.time() - start_timeprint("\n=== 工单结果 ===")print(f"类别:{result['category']}")print(f"解决方案:{result['resolution']}")print(f"总处理时间:{result['processing_time']:.2f} 秒")print(f"总运行时间:{total_time:.2f} 秒")print("-" * 50)if __name__ == "__main__":main()
输出:
=== 正在处理工单:'我对我的最后一张发票有计费问题。似乎我被多收费了。' ===
路由器智能体:分析工单...
路由器智能体:在 0.00 秒内将工单分类为 'Billing'
路由:工单类别为 'Billing'
计费团队智能体:处理工单...
计费团队智能体:在 0.00 秒内完成=== 工单结果 ===
类别:Billing
解决方案:计费团队:已审阅工单 '我对我的最后一张发票有计费问题。似乎我被多收费了。'。请检查您的发票详情,或联系我们的计费部门以获取进一步帮助。
总处理时间:0.00 秒
总运行时间:1.03 秒
--------------------------------------------------=== 正在处理工单:'我的应用程序不断出现技术错误。请帮忙!' ===
路由器智能体:分析工单...
路由器智能体:在 0.00 秒内将工单分类为 'Technical'
路由:工单类别为 'Technical'
技术支持团队智能体:处理工单...
技术支持团队智能体:在 0.00 秒内完成=== 工单结果 ===
类别:Technical
解决方案:技术支持团队:已审阅工单 '我的应用程序不断出现技术错误。请帮忙!'。请尝试重新启动您的设备,或提交详细的错误日志以便进一步调查。
总处理时间:0.00 秒
总运行时间:1.50 秒
--------------------------------------------------=== 正在处理工单:'我对您的服务有一个一般性问题。能否提供更多信息?' ===
路由器智能体:分析工单...
路由器智能体:在 0.00 秒内将工单分类为 'General'
路由:工单类别为 'General'
一般团队智能体:处理工单...
一般团队智能体:在 0.00 秒内完成=== 工单结果 ===
类别:General
解决方案:一般团队:已审阅工单 '我对您的服务有一个一般性问题。能否提供更多信息?'。有关更多信息,请参阅我们的常见问题解答,或通过电子邮件联系我们。
总处理时间:0.00 秒
总运行时间:0.80 秒
--------------------------------------------------=== 正在处理工单:'我需要帮助解决一个与计费或技术问题无关的问题。' ===
路由器智能体:分析工单...
路由器智能体:在 0.00 秒内将工单分类为 'Billing'
路由:工单类别为 'Billing'
计费团队智能体:处理工单...
计费团队智能体:在 0.00 秒内完成=== 工单结果 ===
类别:Billing
解决方案:计费团队:已审阅工单 '我需要帮助解决一个与计费或技术问题无关的问题。'。请检查您的发票详情,或联系我们的计费部门以获取进一步帮助。
总处理时间:0.00 秒
总运行时间:1.00 秒
--------------------------------------------------
- 动态路由:路由器智能体确定工单类别,route_ticket 函数使用 add_conditional_edges 指导工作流流向适当的节点。
- 基于条件的流程:与并行模式不同(多个节点同时运行),路由器模式仅根据条件(类别)执行一个路径。
- 可扩展性:通过扩展节点并更新 route_ticket 函数以处理新类别,可以轻松添加更多支持团队。
2.1.5 聚合器(或合成器)
智能体贡献输出,这些输出由聚合器智能体收集并合成最终结果。
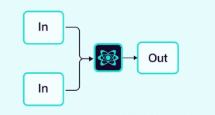
图片来源:Weaviate
示例:社交媒体情感分析聚合器
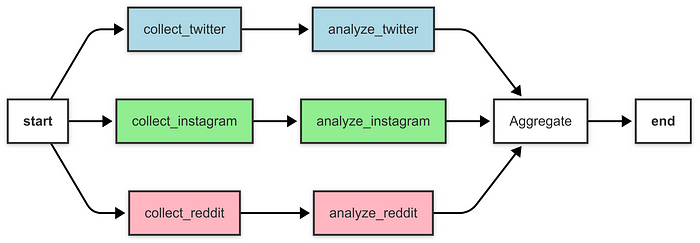
图由作者提供
代码:
from typing import Dict, Any, TypedDict, List
from langgraph.graph import StateGraph, END
from langchain_core.runnables import RunnableConfig
from textblob import TextBlob
import time
from typing_extensions import Annotated
from operator import add# 第一步:定义状态
class SocialMediaState(TypedDict):twitter_posts: List[str]instagram_posts: List[str]reddit_posts: List[str]twitter_sentiment: Dict[str, float]instagram_sentiment: Dict[str, float]reddit_sentiment: Dict[str, float]final_report: strprocessing_time: Annotated[float, add]# 第二步:定义帖子收集智能体
def collect_twitter_posts(state: SocialMediaState) -> Dict[str, Any]:print("推特智能体:收集帖子...")start_time = time.time()posts = ["Loving the new product from this brand! Amazing quality.","Terrible customer service from this brand. Very disappointed."]time.sleep(1) # 模拟处理时间processing_time = time.time() - start_time # 包括 time.sleep 在处理时间中print(f"推特智能体:在 {processing_time:.2f} 秒内完成")return {"twitter_posts": posts,"processing_time": processing_time}def collect_instagram_posts(state: SocialMediaState) -> Dict[str, Any]:print("Instagram 智能体:收集帖子...")start_time = time.time()posts = ["Beautiful design by this brand! #loveit","Not impressed with the latest release. Expected better."]time.sleep(1.2) # 模拟处理时间processing_time = time.time() - start_timeprint(f"Instagram 智能体:在 {processing_time:.2f} 秒内完成")return {"instagram_posts": posts,"processing_time": processing_time}def collect_reddit_posts(state: SocialMediaState) -> Dict[str, Any]:print("Reddit 智能体:收集帖子...")start_time = time.time()posts = ["This brand is awesome! Great value for money.","Had a bad experience with their support team. Not happy."]time.sleep(0.8) # 模拟处理时间processing_time = time.time() - start_timeprint(f"Reddit 智能体:在 {processing_time:.2f} 秒内完成")return {"reddit_posts": posts,"processing_time": processing_time}# 第三步:定义情感分析智能体
def analyze_twitter_sentiment(state: SocialMediaState) -> Dict[str, Any]:print("推特情感分析智能体:分析情感...")start_time = time.time()posts = state["twitter_posts"]polarities = [TextBlob(post).sentiment.polarity for post in posts]avg_polarity = sum(polarities) / len(polarities) if polarities else 0.0time.sleep(0.5) # 模拟处理时间processing_time = time.time() - start_timeprint(f"推特情感分析智能体:在 {processing_time:.2f} 秒内完成")return {"twitter_sentiment": {"average_polarity": avg_polarity, "num_posts": len(posts)},"processing_time": processing_time}def analyze_instagram_sentiment(state: SocialMediaState) -> Dict[str, Any]:print("Instagram 情感分析智能体:分析情感...")start_time = time.time()posts = state["instagram_posts"]polarities = [TextBlob(post).sentiment.polarity for post in posts]avg_polarity = sum(polarities) / len(polarities) if polarities else 0.0time.sleep(0.6) # 模拟处理时间processing_time = time.time() - start_timeprint(f"Instagram 情感分析智能体:在 {processing_time:.2f} 秒内完成")return {"instagram_sentiment": {"average_polarity": avg_polarity, "num_posts": len(posts)},"processing_time": processing_time}def analyze_reddit_sentiment(state: SocialMediaState) -> Dict[str, Any]:print("Reddit 情感分析智能体:分析情感...")start_time = time.time()posts = state["reddit_posts"]polarities = [TextBlob(post).sentiment.polarity for post in posts]avg_polarity = sum(polarities) / len(polarities) if polarities else 0.0time.sleep(0.4) # 模拟处理时间processing_time = time.time() - start_timeprint(f"Reddit 情感分析智能体:在 {processing_time:.2f} 秒内完成")return {"reddit_sentiment": {"average_polarity": avg_polarity, "num_posts": len(posts)},"processing_time": processing_time}# 第四步:定义聚合智能体
def aggregate_results(state: SocialMediaState) -> Dict[str, Any]:print("聚合智能体:生成最终报告...")start_time = time.time()twitter_sentiment = state["twitter_sentiment"]instagram_sentiment = state["instagram_sentiment"]reddit_sentiment = state["reddit_sentiment"]total_posts = (twitter_sentiment["num_posts"] +instagram_sentiment["num_posts"] +reddit_sentiment["num_posts"])weighted_polarity = (twitter_sentiment["average_polarity"] * twitter_sentiment["num_posts"] +instagram_sentiment["average_polarity"] * instagram_sentiment["num_posts"] +reddit_sentiment["average_polarity"] * reddit_sentiment["num_posts"]) / total_posts if total_posts > 0 else 0.0overall_sentiment = ("Positive" if weighted_polarity > 0 else"Negative" if weighted_polarity < 0 else "Neutral")report = (f"Overall Sentiment: {overall_sentiment} (Average Polarity: {weighted_polarity:.2f})\n"f"Twitter Sentiment: {twitter_sentiment['average_polarity']:.2f} (Posts: {twitter_sentiment['num_posts']})\n"f"Instagram Sentiment: {instagram_sentiment['average_polarity']:.2f} (Posts: {instagram_sentiment['num_posts']})\n"f"Reddit Sentiment: {reddit_sentiment['average_polarity']:.2f} (Posts: {reddit_sentiment['num_posts']})")time.sleep(0.3) # 模拟处理时间processing_time = time.time() - start_timeprint(f"聚合智能体:在 {processing_time:.2f} 秒内完成")return {"final_report": report,"processing_time": processing_time}# 第五步:构建带有聚合器模式的图
def build_aggregator_graph() -> StateGraph:workflow = StateGraph(SocialMediaState)# 添加收集帖子的节点workflow.add_node("collect_twitter", collect_twitter_posts)workflow.add_node("collect_instagram", collect_instagram_posts)workflow.add_node("collect_reddit", collect_reddit_posts)# 添加情感分析节点workflow.add_node("analyze_twitter", analyze_twitter_sentiment)workflow.add_node("analyze_instagram", analyze_instagram_sentiment)workflow.add_node("analyze_reddit", analyze_reddit_sentiment)# 添加聚合节点workflow.add_node("aggregate", aggregate_results)# 添加一个分支节点以并行触发所有收集节点workflow.add_node("branch", lambda state: state)# 将入口点设置为分支节点workflow.set_entry_point("branch")# 添加从分支到收集节点的边(并行执行)workflow.add_edge("branch", "collect_twitter")workflow.add_edge("branch", "collect_instagram")workflow.add_edge("branch", "collect_reddit")# 添加从收集到情感分析的边workflow.add_edge("collect_twitter", "analyze_twitter")workflow.add_edge("collect_instagram", "analyze_instagram")workflow.add_edge("collect_reddit", "analyze_reddit")# 添加从情感分析到聚合器的边workflow.add_edge("analyze_twitter", "aggregate")workflow.add_edge("analyze_instagram", "aggregate")workflow.add_edge("analyze_reddit", "aggregate")# 添加从聚合器到 END 的边workflow.add_edge("aggregate", END)return workflow.compile()# 第六步:运行工作流
def main():initial_state: SocialMediaState = {"twitter_posts": [],"instagram_posts": [],"reddit_posts": [],"twitter_sentiment": {"average_polarity": 0.0, "num_posts": 0},"instagram_sentiment": {"average_polarity": 0.0, "num_posts": 0},"reddit_sentiment": {"average_polarity": 0.0, "num_posts": 0},"final_report": "","processing_time": 0.0}print("\n开始社交媒体情感分析...")app = build_aggregator_graph()start_time = time.time()config = RunnableConfig(parallel=True)result = app.invoke(initial_state, config=config)total_time = time.time() - start_timeprint("\n=== 情感分析结果 ===")print(result["final_report"])print(f"\n总处理时间:{result['processing_time']:.2f} 秒")print(f"总运行时间:{total_time:.2f} 秒")if __name__ == "__main__":main()
输出:
开始社交媒体情感分析...
Instagram 智能体:收集帖子...
Reddit 智能体:收集帖子...
推特智能体:收集帖子...
Reddit 智能体:在 0.80 秒内完成
推特智能体:在 1.00 秒内完成
Instagram 智能体:在 1.20 秒内完成
Instagram 情感分析智能体:分析情感...
Reddit 情感分析智能体:分析情感...
推特情感分析智能体:分析情感...
Reddit 情感分析智能体:在 0.40 秒内完成
推特情感分析智能体:在 0.50 秒内完成
Instagram 情感分析智能体:在 0.60 秒内完成
聚合智能体:生成最终报告...
聚合智能体:在 0.30 秒内完成=== 情感分析结果 ===
Overall Sentiment: Positive (Average Polarity: 0.15)
Twitter Sentiment: -0.27 (Posts: 2)
Instagram Sentiment: 0.55 (Posts: 2)
Reddit Sentiment: 0.18 (Posts: 2)总处理时间:4.80 秒
总运行时间:2.13 秒
- 并行执行:收集和分析节点并行运行,减少了总运行时间(2.1 秒),与各个处理时间之和(3.8 秒)相比。
- 聚合:聚合节点将情感分析结果合并为最终报告,计算整体情感,并按平台提供分解。
2.1.6 网络(或水平)
智能体以多对多的方式直接相互通信,形成一个去中心化的网络。
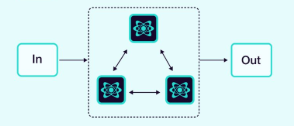
图片来源:Weaviate
这种架构适用于没有明确的智能体层级结构或智能体调用顺序的问题。
from typing import Literal
from langchain_openai import ChatOpenAI
from langgraph.graph import StateGraph, MessagesState, START, END
model = ChatOpenAI()
def agent_1(state: MessagesState) -> Command[Literal["agent_2", "agent_3", END]]:# 你可以将相关部分的状态传递给 LLM(例如,state["messages"])# 以确定要调用的下一个智能体。一种常见模式是调用模型# 并要求其返回一个结构化输出(例如,强制其返回一个包含 "next_agent" 字段的输出)response = model.invoke(...)# 根据 LLM 的决策,路由到其中一个智能体或退出# 如果 LLM 返回 "__end__",图将结束执行return Command(goto=response["next_agent"],update={"messages": [response["content"]]},)
def agent_2(state: MessagesState) -> Command[Literal["agent_1", "agent_3", END]]:response = model.invoke(...)return Command(goto=response["next_agent"],update={"messages": [response["content"]]},)
def agent_3(state: MessagesState) -> Command[Literal["agent_1", "agent_2", END]]:...return Command(goto=response["next_agent"],update={"messages": [response["content"]]},)
builder = StateGraph(MessagesState)
builder.add_node(agent_1)
builder.add_node(agent_2)
builder.add_node(agent_3)
builder.add_edge(START, "agent_1")
network = builder.compile()
API 参考:ChatOpenAI | StateGraph | START | END
优点:分布式协作和群体驱动的决策制定。即使某些智能体失败,系统仍然可以正常运行。
缺点:管理智能体之间的通信可能会变得复杂。更多的通信可能会导致效率低下,并且智能体可能会重复工作。
2.1.7 交接
在多智能体架构中,智能体可以表示为图的节点。每个智能体节点执行其步骤,并决定是结束执行还是路由到另一个智能体,包括可能路由到自身(例如,在循环中运行)。多智能体交互中的一种常见模式是交接,其中一个智能体将控制权移交给另一个智能体。交接允许你指定:
- 目标:目标智能体(例如,要导航到的节点名称)
- 负载:要传递给该智能体的信息(例如,状态更新)
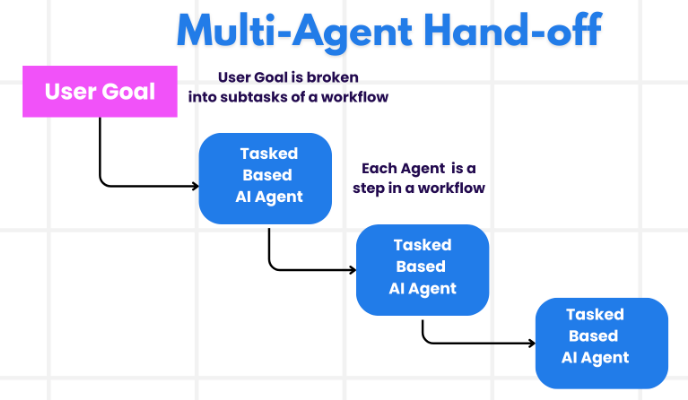
图片来源:aka.ms/ai-agents-beginners
要在 LangGraph 中实现交接,智能体节点可以返回一个 Command 对象,该对象允许你同时控制流程和状态更新:
def agent(state) -> Command[Literal["agent", "another_agent"]]:# 路由/停止的条件可以是任何内容,例如 LLM 工具调用 / 结构化输出等。goto = get_next_agent(...) # 'agent' / 'another_agent'return Command(# 指定要调用的下一个智能体goto=goto,# 更新图状态update={"my_state_key": "my_state_value"})
在一个更复杂的场景中,每个智能体节点本身就是一个图(即,一个子图),一个子图中的节点可能希望导航到另一个智能体。例如,如果你有两个智能体,alice 和 bob(父图中的子图节点),并且 alice 需要导航到 bob,你可以在 Command 对象中设置 graph=Command.PARENT:
def some_node_inside_alice(state)return Command(goto="bob",update={"my_state_key": "my_state_value"},# 指定要导航到的图(默认为当前图)graph=Command.PARENT,)
注意
如果你需要为子图之间的通信使用 Command(graph=Command.PARENT) 提供可视化支持,你需要将它们包装在一个带有 Command 注解的节点函数中,例如,而不是这样:
builder.add_node(alice)
你需要这样做:
def call_alice(state) -> Command[Literal["bob"]]:return alice.invoke(state)builder.add_node("alice", call_alice)
交接作为工具
最常见的智能体类型之一是 ReAct 风格的工具调用智能体。对于这种类型的智能体,一个常见模式是将交接包装在一个工具调用中,例如:
def transfer_to_bob(state):"""移交到 bob。"""return Command(goto="bob",update={"my_state_key": "my_state_value"},graph=Command.PARENT,)
这是从工具中更新图状态的一个特殊情况,除了状态更新外,还包括控制流程。
重要
如果你希望使用返回 Command 的工具,你可以使用预构建的 create_react_agent /ToolNode 组件,或者自己实现一个工具执行节点,该节点收集工具返回的 Command 对象并返回一个列表,例如:
def call_tools(state):...commands = [tools_by_name[tool_call["name"]].invoke(tool_call) for tool_call in tool_calls]return commands
让我们更仔细地看看不同的多智能体架构。
2.1.8 监督者
在这种架构中,我们将智能体定义为节点,并添加一个监督者节点(LLM),该节点决定应该调用哪些智能体节点。我们使用 Command 根据监督者的决策将执行路由到适当的智能体节点。这种架构也非常适合并行运行多个智能体,或者使用Map-Reduce模式。
from typing import Literal
from langchain_openai import ChatOpenAI
from langgraph.graph import StateGraph, MessagesState, START, ENDmodel = ChatOpenAI()def supervisor(state: MessagesState) -> Command[Literal["agent_1", "agent_2", END]]:# 你可以将相关部分的状态传递给 LLM(例如,state["messages"])# 以确定要调用的下一个智能体。一种常见模式是调用模型# 并要求其返回一个结构化输出(例如,强制其返回一个包含 "next_agent" 字段的输出)response = model.invoke(...)# 根据监督者的决策,路由到其中一个智能体或退出# 如果监督者返回 "__end__",图将结束执行return Command(goto=response["next_agent"])def agent_1(state: MessagesState) -> Command[Literal["supervisor"]]:# 你可以将相关部分的状态传递给 LLM(例如,state["messages"])# 并添加任何额外的逻辑(不同的模型、自定义提示、结构化输出等)response = model.invoke(...)return Command(goto="supervisor",update={"messages": [response]},)def agent_2(state: MessagesState) -> Command[Literal["supervisor"]]:response = model.invoke(...)return Command(goto="supervisor",update={"messages": [response]},)builder = StateGraph(MessagesState)
builder.add_node(supervisor)
builder.add_node(agent_1)
builder.add_node(agent_2)builder.add_edge(START, "supervisor")supervisor = builder.compile()
API 参考:ChatOpenAI | StateGraph | START | END
查看这个 教程,了解监督者多智能体架构的示例。
2.1.9 监督者(工具调用)
这是 监督者 架构的一个变体,我们将单独的智能体定义为 工具,并在监督者节点中使用工具调用 LLM。这可以实现为一个 ReAct-风格的智能体图,其中包含两个节点——一个 LLM 节点(监督者)和一个工具调用节点,用于执行工具(在这种情况下是智能体)。
from typing import Annotated
from langchain_openai import ChatOpenAI
from langgraph.prebuilt import InjectedState, create_react_agentmodel = ChatOpenAI()# 这是将被调用为工具的智能体函数
# 注意,你可以通过 InjectedState 注解将状态传递给工具
def agent_1(state: Annotated[dict, InjectedState]):# 你可以将相关部分的状态传递给 LLM(例如,state["messages"])# 并添加任何额外的逻辑(不同的模型、自定义提示、结构化输出等)response = model.invoke(...)# 以字符串形式返回 LLM 响应(预期的工具响应格式)# 这将被预构建的 create_react_agent(监督者)自动转换为 ToolMessagereturn response.contentdef agent_2(state: Annotated[dict, InjectedState]):response = model.invoke(...)return response.contenttools = [agent_1, agent_2]
# 使用预构建的 ReAct 智能体图来构建带有工具调用的监督者
# 该图由一个工具调用 LLM 节点(即监督者)和一个工具执行节点组成
supervisor = create_react_agent(model, tools)
API 参考:ChatOpenAI | InjectedState | create_react_agent
2.1.10 层级(或垂直)
智能体以树状结构组织,高层智能体(监督者智能体)管理低层智能体。
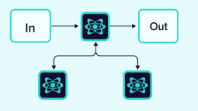
图片来源:Weaviate
随着你向系统中添加更多智能体,监督者可能难以管理所有智能体。监督者可能开始对调用下一个智能体做出错误决策,上下文可能变得过于复杂,以至于单个监督者难以跟踪。换句话说,你最终会遇到最初促使你采用多智能体架构的相同问题。
为了解决这个问题,你可以设计一个分层的系统。例如,你可以创建由单独的监督者管理的独立、专业化的智能体团队,并由一个顶层监督者来管理这些团队。
from typing import Literal
from langchain_openai import ChatOpenAI
from langgraph.graph import StateGraph, MessagesState, START, END
from langgraph.types import Command
model = ChatOpenAI()# 定义团队 1(与上面的单监督者示例相同)def team_1_supervisor(state: MessagesState) -> Command[Literal["team_1_agent_1", "team_1_agent_2", END]]:response = model.invoke(...)return Command(goto=response["next_agent"])def team_1_agent_1(state: MessagesState) -> Command[Literal["team_1_supervisor"]]:response = model.invoke(...)return Command(goto="team_1_supervisor", update={"messages": [response]})def team_1_agent_2(state: MessagesState) -> Command[Literal["team_1_supervisor"]]:response = model.invoke(...)return Command(goto="team_1_supervisor", update={"messages": [response]})team_1_builder = StateGraph(Team1State)
team_1_builder.add_node(team_1_supervisor)
team_1_builder.add_node(team_1_agent_1)
team_1_builder.add_node(team_1_agent_2)
team_1_builder.add_edge(START, "team_1_supervisor")
team_1_graph = team_1_builder.compile()# 定义团队 2(与上面的单监督者示例相同)
class Team2State(MessagesState):next: Literal["team_2_agent_1", "team_2_agent_2", "__end__"]def team_2_supervisor(state: Team2State):...def team_2_agent_1(state: Team2State):...def team_2_agent_2(state: Team2State):...team_2_builder = StateGraph(Team2State)
...
team_2_graph = team_2_builder.compile()# 定义顶层监督者builder = StateGraph(MessagesState)
def top_level_supervisor(state: MessagesState) -> Command[Literal["team_1_graph", "team_2_graph", END]]:# 你可以将相关部分的状态传递给 LLM(例如,state["messages"])# 以确定要调用的下一个团队。一种常见模式是调用模型# 并要求其返回一个结构化输出(例如,强制其返回一个包含 "next_team" 字段的输出)response = model.invoke(...)# 根据监督者的决策,路由到其中一个团队或退出# 如果监督者返回 "__end__",图将结束执行return Command(goto=response["next_team"])builder = StateGraph(MessagesState)
builder.add_node(top_level_supervisor)
builder.add_node("team_1_graph", team_1_graph)
builder.add_node("team_2_graph", team_2_graph)
builder.add_edge(START, "top_level_supervisor")
builder.add_edge("team_1_graph", "top_level_supervisor")
builder.add_edge("team_2_graph", "top_level_supervisor")
graph = builder.compile()
优点:在不同层级的智能体之间有明确的角色和职责划分。通信顺畅。适用于具有结构化决策流程的大型系统。
缺点:上层的失败可能会破坏整个系统。下层智能体的独立性有限。
API 参考:ChatOpenAI | StateGraph | START | END | Command
2.1.11 自定义多智能体工作流
每个智能体仅与部分智能体通信。流程的一部分是确定性的,只有部分智能体可以决定接下来调用哪些智能体。
在这种架构中,我们将各个智能体作为图节点添加,并提前定义智能体被调用的顺序,形成一个自定义工作流。在 LangGraph 中,可以通过以下两种方式定义工作流:
- 显式控制流(普通边):LangGraph 允许你通过普通图边显式定义应用程序的控制流(即智能体之间的通信顺序)。这是上述架构中最确定性的变体 —— 我们可以提前知道下一个将被调用的智能体。
- 动态控制流(Command):在 LangGraph 中,你可以允许 LLM 决定应用程序控制流的一部分。这可以通过使用
Command来实现。一个特殊情况是带有工具调用的监督者架构。在这种情况下,为监督者智能体提供支持的工具调用 LLM 将决定工具(智能体)被调用的顺序。
from langchain_openai import ChatOpenAI
from langgraph.graph import StateGraph, MessagesState, STARTmodel = ChatOpenAI()def agent_1(state: MessagesState):response = model.invoke(...)return {"messages": [response]}def agent_2(state: MessagesState):response = model.invoke(...)return {"messages": [response]}builder = StateGraph(MessagesState)
builder.add_node(agent_1)
builder.add_node(agent_2)
# 显式定义流程
builder.add_edge(START, "agent_1")
builder.add_edge("agent_1", "agent_2")
API 参考:ChatOpenAI | StateGraph | START
3. 智能体之间的通信
构建多智能体系统时,最重要的是弄清楚智能体之间如何通信。有以下几点需要考虑:
3.1 图状态与工具调用
在智能体之间传递的“负载”是什么?在上述讨论的大多数架构中,智能体通过图状态进行通信。在带有工具调用的监督者的情况下,负载是工具调用参数。
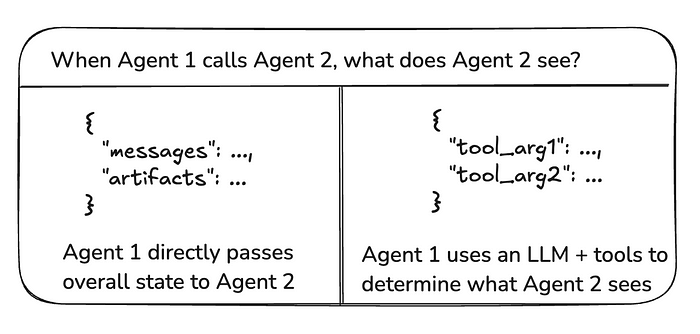
图片来源:Langchain
图状态
为了通过图状态进行通信,各个智能体需要被定义为图节点。这些可以被添加为函数或整个子图。在图执行的每一步中,智能体节点接收当前图状态,执行智能体代码,然后将更新后的状态传递给下一个节点。
通常,智能体节点共享一个单一的状态模式。然而,你可能希望设计具有不同状态模式的智能体节点。
3.2 不同的状态模式
一个智能体可能需要拥有与其他智能体不同的状态模式。例如,一个搜索智能体可能只需要跟踪查询和检索到的文档。在 LangGraph 中,可以通过以下两种方式实现:
- 定义具有独立状态模式的子图智能体。如果子图和父图之间没有共享状态键(通道),则需要添加输入/输出转换,以便父图知道如何与子图通信。
- 定义具有私有输入状态模式的智能体节点函数,该模式与整体图状态模式不同。这允许传递仅用于执行该特定智能体的信息。
3.3 共享消息列表
智能体之间通信的最常见方式是通过共享状态通道,通常是一个消息列表。这假设状态中至少有一个通道(键)被智能体共享。当通过共享消息列表进行通信时,还有一个额外的考虑:智能体是共享完整的对话历史记录,还是只共享最终结果?
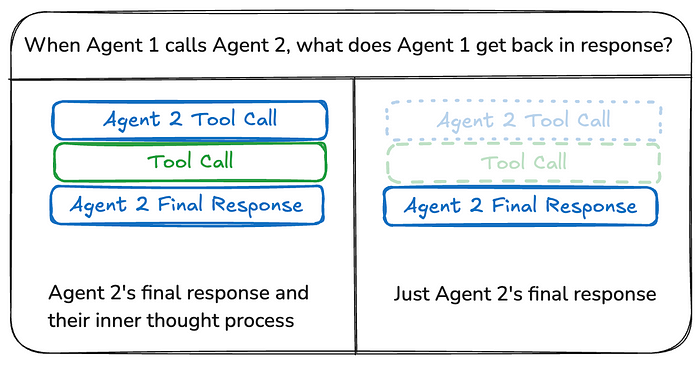
图片来源:Langchain
共享完整历史记录
智能体可以共享完整的思考过程(即“草稿”)与其他所有智能体。这个“草稿”通常看起来像一个消息列表。共享完整思考过程的好处是,它可能有助于其他智能体做出更好的决策,并提高整个系统的推理能力。缺点是,随着智能体数量和复杂性的增加,“草稿”会迅速增长,可能需要额外的内存管理策略。
仅共享最终结果
智能体可以有自己的私有“草稿”,并且只共享最终结果与其余智能体。这种方法可能更适合拥有许多智能体或智能体更复杂的系统。在这种情况下,你需要定义具有不同状态模式的智能体。
对于作为工具被调用的智能体,监督者根据工具模式确定输入。此外,LangGraph 允许在运行时将状态传递给工具,以便从属智能体在需要时可以访问父状态。
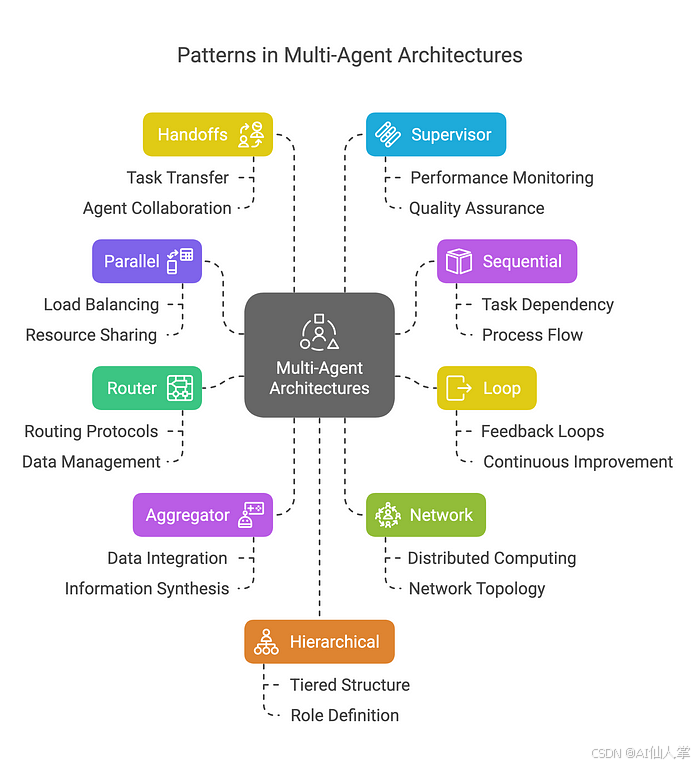
4. 结论
多智能体 LLM 系统提供了一个强大的范式,用于通过利用并行、顺序、路由器和聚合器工作流等多种架构模式来解决复杂任务,正如我们在本博客中所探讨的那样。
通过详细检查共享状态、消息列表和工具调用等通信机制,我们看到了智能体如何协作以实现无缝协调。
原作者:vipra_singh-https://medium.com/@vipra_singh/ai-agents-multi-agent-architectures
相关文章:

AI Agents系列之构建多智能体系统
🧠 向所有学习者致敬! “学习不是装满一桶水,而是点燃一把火。” —— 叶芝 我的博客主页: https://lizheng.blog.csdn.net 🌐 欢迎点击加入AI人工智能社区! 🚀 让我们一起努力,共创…...

FPGA学习——DE2-115开发板上设计波形发生器
1. 实验目的 掌握直接数字频率合成(DDS)技术的基本原理和应用。使用DE2-115开发板实现正弦波和方波的生成。使用SignalTap II嵌入式逻辑分析仪测试输出波形的离散数据。 2. 实验原理 DDS技术:通过相位累加器生成相位信息,结合波…...

51单片机实验二:数码管静态显示
目录 一、实验环境与实验器材 二、实验内容及实验步骤 1.单个数码管显示 2.六个数码管依次从0~F变换显示 3.proteus仿真 一、实验环境与实验器材 环境:Keli,STC-ISP烧写软件,Proteus. 器材:TX-1C单片机(STC89C52RC…...

JavaScript性能优化实战指南
1. 引言 JavaScript作为现代Web开发的核心技术,为网页带来了丰富的交互性和动态功能。然而,随着Web应用日益复杂,JavaScript代码的性能成为影响用户体验的关键因素。性能不佳的JavaScript可能导致页面加载缓慢、交互卡顿、甚至浏览器无响应&…...
)
POSIX 信号量(Semaphore)
一、POSIX 信号量基础 1. 什么是信号量? 信号量 是一种同步机制,用于控制对共享资源的访问。它通过一个整数值表示可用资源的数量,支持两种原子操作: P操作(Wait):尝试减少信号量值࿰…...

深度学习驱动下的字符识别:挑战与创新
一、引言 1.1 研究背景 深度学习在字符识别领域具有至关重要的地位。随着信息技术的飞速发展,对字符识别的准确性和效率要求越来越高。字符识别作为计算机视觉领域的一个重要研究方向,其主要目的是将各种形式的字符转换成计算机可识别的文本信息。近年…...

DOM TreeWalker API 详解
DOM TreeWalker API 详解 TreeWalker API 是 DOM 中一个强大但相对较少使用的功能,它提供了一种有效遍历文档树的方式。它比手动递归或使用简单的节点导航方法更加灵活和高效。 TreeWalker 基本概念 TreeWalker 对象可以让你按照指定的过滤条件,以特定…...
)
深度学习| Deep Snake环境配置+训练+预测评估(超全面)
前言:Deep Snake是一个比较经典结合了轮廓的深度学习分割方法,但是去实际运行Deep Snake项目的时候遇到了很多问题。这篇文章把Deep Snake从环境配置、训练到预测评估,都做了详细的教程,还补充了一些相关的知识点。 Deep Snake配置和运行 Deep Snake信息数据集COCOMask-&g…...

NHANES指标推荐:CMI
文章题目:Association between cardiometabolic index and biological ageing among adults: a population-based study DOI:10.1186/s12889-025-22053-3 中文标题:成年人心脏代谢指数与生物衰老之间的关系:一项基于人群的研究 发…...

非比较排序——计数排序
计数排序 计数排序是非比较排序 void CountSort(int *a,int n) {//找范围int mina[0],maxa[0];for(int i0;i<n;i){if(a[i]<min){mina[i];}if(a[i]>max){mina[i];}}int rangemax-min1;//创建计数用的数组int *count(int *) malloc(range* sizeof(int));//计数数组的元…...

spring cloud gateway前面是否必须要有个nginx
在 **"客户端 → Nginx (前置限流) → Spring Cloud Gateway → 微服务(Sentinel 熔断限流)"** 的架构中,**Spring Cloud Gateway 前面并不强制要求必须有 Nginx**,是否需要取决于具体场景。以下是详细分析: 一、必须使用 Nginx 的…...
)
复现SCI图像增强(Toward fast, flexible, and robust low-light image enhancement.)
运行train.py报错 > File "/home/uriky/桌面/SCI-main/SCI-main/train.py", line 105, in main > train_queue torch.utils.data.DataLoader( File "/home/uriky/anaconda3/envs/AA/lib/python3.8/site-packages/torch/utils/data/dataloader.py&q…...

Linux 进程
文章目录 1. 冯诺依曼体系结构1.1 什么是冯诺依曼体系结构1.2 为什么选择冯诺依曼结构 2. 操作系统2.1 操作系统是什么2.2 操作系统如何对硬件资源进行管理2.3 计算机的层状体系结构 3. 进程3.1 进程是什么3.2 进程的相关属性3.3 在Linux中了解进程3.3.1 查看进程3.3.2 子进程由…...

TVM计算图分割--Collage
1 背景 为满足高效部署的需要,整合大量优化的tensor代数库和运行时做为后端成为必要之举。现在的深度学习后端可以分为两类:1)算子库(operator kernel libraries),为每个DL算子单独提供高效地低阶kernel实现。这些库一般也支持算…...

Liunx知识点
1./dev:是系统设备文件存放位置 /home:是普通用户存放目录 /etc:大部分配置文件的存放目录 /mnt:挂载服务需要的目录 /tmp:存放临时文件 /boot:启动文件 /root:root用户存放目录 /var&am…...

全栈架构设计图
以下是针对Vue前端、服务端、管理后台及数据库的架构图和交互流程设计,采用分层结构和模块化设计思路: 一、系统整体架构图 #mermaid-svg-vAtZ3R6d5Ujm6lYT {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}…...

【SAP ME 42】SAP ME 性能改进
性能问题症状 可观察到以下症状:com.sap.me.production$SfcStartService#startSfc - 此 API 方法具有来自 RESOURCE_TYPE_RESOURCE 表的 SQL 查询的运行速度较慢。 com.sap.me.production$CreateSfcService#createSfc - 对于每个创建的车间作业控制,检查在计划标准配置中是否…...

《GPT-4.1深度解析:AI进化新标杆,如何重塑行业未来?》
一、GPT-4.1:AI 领域的 “全能战士” 降临 1.1 发布背景与战略意义 在 OpenAI 的技术迭代版图中,GPT-4.1 被赋予了 “承前启后” 的关键角色。它不仅是 GPT-4o 的全面升级版,更被视为向 GPT-5 过渡的重要桥梁。2025 年 4 月 15 日的发布会上,OpenAI 宣布 GPT-4.1 系列模型…...

node.js 基础
模块导入和导出 形式1 function get_jenkins(){return "jenkins....." }function test_cc(){return "4444444" }export {get_jenkins,test_cc}// 主函数 import { get_jenkins, test_cc } from ./module.js;console.log(get_jenkins()); console.log(tes…...

数据结构中的宝藏秘籍之广义表
广义表,也被称作列表(Lists),是一种递归的数据结构。它就像一个神秘的盒子,既可以装着单个元素(原子),也可以嵌套着其他的盒子(子列表)。比如广义表 (a (b c)…...

电流模式控制学习
电流模式控制 电流模式控制(CMC)是开关电源中广泛使用的一种控制策略,其核心思想是通过内环电流反馈和外环电压反馈共同调节占空比。相比电压模式控制,CMC具有更快的动态响应和更好的稳定性,但也存在一些固有缺点。 …...

汽车免拆诊断案例 | 2011款雪铁龙世嘉车刮水器偶尔自动工作
故障现象 一辆2011款雪铁龙世嘉车,搭载1.6 L 发动机,累计行驶里程约为19.8万km。车主反映,该车刮水器偶尔会自动工作,且前照灯偶尔会自动点亮。 故障诊断 接车后试车发现,除了上述故障现象以外,当用遥控器…...

#去除知乎中“盐选”付费故事
添加油猴脚本,去除知乎中“盐选”付费故事 // UserScript // name 盐选内容隐藏脚本 // namespace http://tampermonkey.net/ // version 0.2 // description 自动隐藏含有“盐选专栏”或“盐选”文字的回答卡片 // author YourName // mat…...

github 项目迁移到 gitee
1. 查看远程仓库地址 git remote -v 2. 修改远程仓库地址 确保 origin 指向你的 Gitee 仓库,如果不是,修改远程地址。 git remote set-url origin https://gitee.com/***/project.git 3. 查看本地分支 git branch 4. 推送所有本地分支 git p…...
等级考试试卷(五级)答案 + 解析)
2025年03月中国电子学会青少年软件编程(Python)等级考试试卷(五级)答案 + 解析
青少年软件编程(Python)等级考试试卷(五级) 分数:100 题数:38 一、单选题(共25题,共50分) 1. 以下哪个选项不是Python中的推导式?( ) A. 列表推导式 B. 字典推导式 C. 集合推导式 D. 元组推导式 正确答案:D 答案解析:Python中的推导式包括列表推导式、字典推导式…...

[Unity]-[UI]-[Prefab] 关于UGUI UI Prefab的制作技巧
从上到下,从外到里,多用空物体套壳 这个意思就是说在使用ugui时制作prefab时,要遵循“从上到下,从外到里,多用空物体套壳”的原则,好处就是后面好修改,并且可以复用不同的prefab子模块。且在布…...
Favorite Articles from 2025 March)
【Reading Notes】(8.3)Favorite Articles from 2025 March
【March】 雷军一度登顶中国首富,太厉害了(2025年03月02日) 早盘,小米港股一路高歌猛进,暴涨4%,股价直接飙到52港元的历史新高。这一波猛如虎的操作,直接把雷军的身家拉到了2980亿元,…...

2021-11-09 C++倍数11各位和为13
缘由c函数题找数字的-编程语言-CSDN问答 void 倍数11各位和为13(int n, int& b, int* h) {//缘由https://ask.csdn.net/questions/7559803?spm1005.2025.3001.5141b !(n % 11);while(n)*h n % 10, n / 10; }int a 1, b 1, c 0, d 0;while (a < 100){倍数11各位和…...
等级考试试卷(六级)真题)
2025年03月中国电子学会青少年软件编程(Python)等级考试试卷(六级)真题
青少年软件编程(Python)等级考试试卷(六级) 分数:100 题数:38 答案解析:https://blog.csdn.net/qq_33897084/article/details/147341458 一、单选题(共25题,共50分) 1. 在tkinter的…...

Linux简介
一、Linux 简介 Linux 内核最初只是由芬兰人林纳斯托瓦兹(Linus Torvalds)在赫尔辛基大学上学时出于个人爱好而编写的。 Linux 是一套免费使用和自由传播的类 Unix 操作系统,是一个基于 POSIX 和 UNIX 的多用户、多任务、支持多线程和多 CP…...
:pwd)
每天学一个 Linux 命令(22):pwd
可访问网站查看,视觉品味拉满: http://www.616vip.cn/22/index.html pwd 命令用于打印当前工作目录(Print Working Directory)的绝对路径,帮助用户快速确认自己在文件系统中的位置。虽然简单,但它是终端操作中不可或缺的基础命令,尤其在处理相对路径或脚本编写时尤为…...

Windows 11设置开机自动运行 .jar 文件
Windows 11设置开机自动运行 .jar 文件 打开启动文件夹: 按下 Win R,输入 shell:startup,回车。 此路径为当前用户的启动文件夹: C:\Users\<用户名>\AppData\Roaming\Microsoft\Windows\Start Menu\Programs\Startup创…...

西门子 博途 软件 崩溃
西门子 博途 软件 编译/仿真 崩溃 是因为项目中OPC UA的接口问题 解决拌饭见 https://support.industry.siemens.com/cs/document/109971630/tia-portal-%E5%9C%A8%E7%BC%96%E8%AF%91-plc-%E6%97%B6%E5%B4%A9%E6%BA%83?dti0&dlzh&lcen-WW...

12芯束装光纤不同包层线颜色之间的排列顺序
为什么光纤线必须按照以下颜色顺序进行排序?这其实是为了防止光污染的问题,不同颜色在传递光时从包层表皮漏光传感到梳妆的其它纤芯上,会有光污染的问题,而为了减少并防止光污染的现象,所以在光通信之中,需…...

数据驱动、精准协同:高端装备制造业三位一体生产管控体系构建
开篇引入 鉴于集团全面推行生产运营体建设以及对二级单位生产过程管控力度逐步加强,某高端装备制造企业生产部长王总正在开展新的一年企业生产管控规划工作,为了能够更好地进行体系规划与建设应用,特邀请智能制造专家小智来进行讨论交流。 王…...

HAL详解
一、直通式HAL 这里使用一个案例来介绍直通式HAL,选择MTK的NFC HIDL 1.0为例,因为比较简单,代码量也比较小,其源码路径:vendor/hardware/interfaces/nfc/1.0/ 1、NFC HAL的定义 1)NFC HAL数据类型 通常定…...

RAG知识库中引入MCP
MCP(Memory, Context, Planning)是一种增强AI系统认知能力的框架。将MCP引入RAG知识库可以显著提升系统的性能和用户体验。下面我将详细介绍如何实现这一整合。 MCP框架概述 MCP框架包含三个核心组件: Memory(记忆):存储和管理历史交互和知识Context(上下文):理解当…...
再读bert(Bidirectional Encoder Representations from Transformers)
再读 BERT,仿佛在数字丛林中邂逅一位古老而智慧的先知。初次相见时,惊叹于它以 Transformer 架构为罗盘,在预训练与微调的星河中精准导航,打破 NLP 领域长久以来的迷雾。而如今,书页间跃动的不再仅是 Attention 机制精…...

C# 单例模式
创建一个类 在类中定义方法 internal class Config {// 实现单利模式private static Config instance null;private Config() { }private static object Locker new object(); // 定义lock锁// 通过公有的方法 返回实力public static Config GetInstance(){// 空的自己构造…...

mainwidget.cpp:1741:21: error: use of undeclared identifier ‘mainTab‘
这个错误表明在你的代码中,mainTab 这个变量没有被正确声明或定义。这通常是因为以下原因之一: 变量未声明:mainTab 可能没有在类的成员变量中声明。 变量未初始化:mainTab 可能没有在构造函数中正确初始化。 作用域问题&#x…...

OpenCV day6
函数内容接上文:OpenCV day4-CSDN博客 , OpenCV day5-CSDN博客 目录 平滑(模糊) 25.cv2.blur(): 26.cv2.boxFilter(): 27.cv2.GaussianBlur(): 28.cv2.medianBlur(): 29.cv2.bilateralFilter(): 锐…...

MySQL:Join连接的原理
连接查询的执行过程: 确定第一个需要查询的表【驱动表】 选取代价最小的访问方法去执行单表查询语句 从驱动表每获取到一条记录,都需要到t2表中查找匹配的记录 两表连接查询需要查询一次t1表,两次t2表,在两表的连接查询中&…...
)
Linux MySQL版本升级(rpm安装方式)
一、背景 近期生产环境扫描发现MySQL的多个安全漏洞。目前厂商已经发布了升级补丁以修复此安全问题,补丁获取链接:https://www.oracle.com/security-alerts/cpuoct2024.html 二、升级注意事项 备份数据:升级前务必备份数据库。检查兼容性&…...
)
数字图像处理(膨胀与腐蚀)
腐蚀 核心原理:结构元四肢运算结果全为1,则结构元中心为1,否则为0。 怎么计算是否为1还是为0 结构元的值与前景的值进行与运算,如果结构元四肢的与运算结果全为1,则结构元中心为1,否则为0。 假设下图为结构…...
)
J值即正义——Policy Gradient思想、REINFORCE算法,以及贪吃蛇小游戏(三)
文章目录 前情提要谁的J值大呢?那么 ∇ θ J ( θ ) \nabla_\theta J(\theta) ∇θJ(θ)要怎么求呢?构建loss函数**代码实现示例**(PyTorch伪代码):前情提要 上回咱说道,对于强化学习而言,J值即正义。 比如,你当了老板,你手下的两个高管,分别都为公司的发展提出了…...

pdfjs库使用3
.App { text-align: center; height: 100vh; display: flex; flex-direction: column; background-color: #f5f5f5; } /* PDF 查看器容器样式 */ .pdf-viewer { flex: 1; padding: 20px; max-width: 100%; margin: 0 auto; box-sizing: border-box; background-color: white;…...
transformer-词嵌入和位置嵌入详解
文章目录 1、介绍一下位置嵌入Positional Encoding、什么是Positional Encoding呢?为什么Transformer需要Positional Enconding? Transformer 的 Positional Encoding 是如何表达相对位置关系的?2、我来简单举个例子2.1 词向量:每个token都会…...

大模型本地部署之ollama安装及deepseek、qwen等模型下载操作
大模型本地部署之----ollama安装指南 最新版--下载方式 Download Ollama on macOS 因github下载较慢,可以网上搜索github加速工具下载 ----download后加版本号 例如: https://github.com/ollama/ollama/releases/download/v0.6.5/OllamaSetup.exe 通过网盘分享…...

ffprobe 输出 HEVC 码流 Level:标准的 “错位” 与分析的 “归位”
问题描述 最近用ffprobe分析HEVC/H265的码流,发现了与理论知识不符合的现象,比如针对一个H265的码流,用ffprobe输入命令 ffprobe -show_streams 1.h265 时,输入如下;可以看到 H265 的码流 Level 显示等于 93,打印值与标准理论值不符合,用其他工具分析此时 Level 等于 3.…...

线程池七个参数的含义
Java中的线程池里七个参数的以及其各自的含义 面试题:说一下线程池七个参数的含义? 所谓的线程池的 7 大参数是指,在使用 ThreadPoolExecutor 创建线程池时所设置的 7 个参数,如以下源码所示: public ThreadPoolExe…...