上下位关系自动检测方法
✨✨ 欢迎大家来访Srlua的博文(づ ̄3 ̄)づ╭❤~✨✨🌟🌟 欢迎各位亲爱的读者,感谢你们抽出宝贵的时间来阅读我的文章。
我是Srlua小谢,在这里我会分享我的知识和经验。🎥
希望在这里,我们能一起探索IT世界的奥妙,提升我们的技能。🔮
记得先点赞👍后阅读哦~ 👏👏
📘📚 所属专栏:人工智能、话题分享
欢迎访问我的主页:Srlua小谢 获取更多信息和资源。✨✨🌙🌙



目录
概述
算法原理
Hearst 模式
上下位关系得分
核心逻辑
效果演示
使用方式
参考文献
本文所有资源均可在该地址处获取。
概述
本文复现论文 Hearst patterns revisited: Automatic hypernym detection from large text corpora[1] 提出的文本中上位词检测方法。
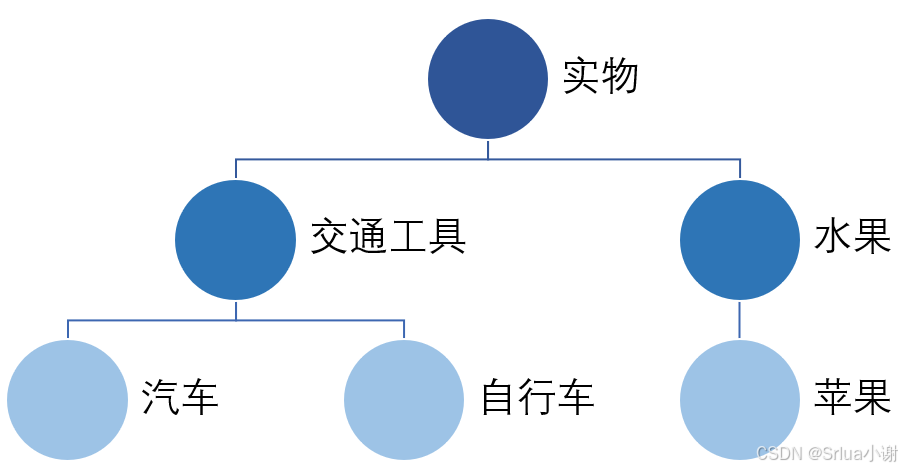
在自然语言处理中,上下位关系(Is-a Relationship)表示的是概念(又称术语)之间的语义包含关系。其中,上位词(Hypernym)表示的是下位词(Hyponym)的抽象化和一般化,而下位词则是对上位词的具象化和特殊化。举例来说:“水果”是“苹果”、“香蕉”、“橙子”等的上位词,“汽车”、“电动车”、“自行车”等则是“交通工具”的下位词。在自然语言处理任务中,理解概念之间的上下位关系对于诸如词义消歧、信息检索、自动问答、语义推理等任务都具有重要意义。
文本中上位词检测方法,即从文本中提取出互为上下位关系的概念。现有的无监督上位词检测方法大致可以分为两类——基于模式的方法和基于分布模型的方法:
(1)基于模式的方法:其主要思想是利用特定的词汇-句法模式来检测文本中的上下位关系。例如,我们可以通过检测文本中是否存在句式“【词汇1】是一种【词汇2】”或“【词汇1】,例如【词汇2】”来判断【词汇1】和【词汇2】间是否存在上下位关系。这些模式可以是预定义的,也可以是通过机器学习得到的。然而,基于模式的方法存在一个众所周知的问题——极端稀疏性,即词汇必须在有限的模式中共同出现,其上下位关系才能被检测到。
(2)基于分布模型的方法:基于大型文本语料库,词汇可以被学习并表示成向量的形式。利用特定的相似度度量,我们可以区分词汇间的不同关系。
在该论文中,作者研究了基于模式的方法和基于分布模型的方法在几个上下位关系检测任务中的表现,并发现简单的基于模式的方法在常见的数据集上始终优于基于分布模型的方法。作者认为这种差异产生的原因是:基于模式的方法提供了尚不能被分布模型准确捕捉到的重要上下文约束。
算法原理
Hearst 模式
作者使用如下模式来捕捉文本中的上下位关系:
| 模板 | 例子 |
|---|---|
| XX which is a (example|class|kind…) of YY | Coffee, which is a beverage, is enjoyed worldwide. |
| XX (and|or) (any|some) other YY | Coffee and some other hot beverages are popular in the morning. |
| XX which is called YY | Coffee, which is called “java”. |
| XX is JJS (most)? YY | Coffee is the most consumed beverage worldwide. |
| XX is a special case of YY | Espresso is a special case of coffee. |
| XX is an YY that | A latte is a coffee that includes steamed milk. |
| XX is a !(member|part|given) YY | A robot is a machine. |
| !(features|properties) YY such as X1X1, X2X2, … | Beverages such as coffee, tea, and soda have various properties such as caffeine content and flavor. |
| (Unlike|like) (most|all|any|other) YY, XX | Unlike most beverages, coffee is often consumed hot. |
| YY including X1X1, X2X2, … | Beverages including coffee, tea, and hot chocolate are served at the café. |
通过对大型语料库使用模式捕捉候选上下位词对并统计频次,可以计算任意两个词汇之间存在上下位关系的概率
上下位关系得分
设 p(x,y)p(x,y)是词汇 xx 和 yy 分别作为下位词和上位词出现在预定义模式集合 PP 中的频率,p−(x)p−(x)是 xx 作为任意词汇的下位词出现在预定义模式中的频率,p+(y)p+(y)是 yy 作为任意词汇的上位词出现在预定义模式中的频率。作者定义正逐点互信息(Positive Point-wise Mutual Information)作为词汇间上下位关系得分的依据:
ppmi(x,y)=max(0,logp(x,y)p−(x),p+(y))ppmi(x,y)=max(0,logp−(x),p+(y)p(x,y))
由于模式的稀疏性,部分存在上下位关系的词对并不会出现在特定的模式中。为了解决这一问题,作者利用PPMI得分矩阵的稀疏表示来预测任意未知词对的上下位关系得分。PPMI得分矩阵定义如下:
M∈Rm×m,Mij=ppmi(x,y)(1≤x,y≤m)M∈Rm×m,Mij=ppmi(x,y)(1≤x,y≤m)
,其中 m=|\{x|(x,y)\in P\or(y,x)\in P\}|。
对矩阵 MM 做奇异值分解可得 M=UΣVTM=UΣVT,然后我们可以通过下式计算出上下位关系 spmi 得分:
spmi(x,y)=uxTΣrvyspmi(x,y)=uxTΣrvy
其中 uxux 和 vyvy 分别是矩阵 UU 和 VV 的第 xx 行和第 yy 行,ΣrΣr是对 ΣΣ 的 rr 截断(即除了最大的 rr 个元素其余全部置零)。
核心逻辑
具体的核心逻辑如下所示:
import spacy
import json
from tqdm import tqdm
import re
from collections import Counter
import numpy as np
import mathnlp = spacy.load("en_core_web_sm")def clear_text(text):"""对文本进行清理"""# 这里可以添加自己的清理步骤# 删去交叉引用标识,例如"[1]"pattern = r'\[\d+\]'result = re.sub(pattern, '', text)return resultdef split_sentences(text):"""将文本划分为句子"""doc = nlp(text)sentences = [sent.text.strip() for sent in doc.sents]return sentencesdef extract_noun_phrases(text):"""从文本中抽取出术语"""doc = nlp(text)terms = []# 遍历句子中的名词性短语(例如a type of robot)for chunk in doc.noun_chunks:term_parts = []for token in list(chunk)[-1::]:# 以非名词且非形容词,或是代词的词语为界,保留右半部分(例如robot)if token.pos_ in ['NOUN', 'ADJ'] and token.dep_ != 'PRON':term_parts.append(token.text)else:breakif term_parts != []:term = ' '.join(term_parts)terms.append(term)return termsdef term_lemma(term):"""将术语中的名词还原为单数"""lemma = []doc = nlp(term)for token in doc:if token.pos_ == 'NOUN':lemma.append(token.lemma_)else:lemma.append(token.text)return ' '.join(lemma)def find_co_occurrence(sentence, terms, patterns):"""找出共现于模板的术语对"""pairs = []# 两两之间匹配for hyponym in terms:for hypernym in terms:if hyponym == hypernym:continuefor pattern in patterns:# 将模板中的占位符替换成候选上下位词pattern = pattern.replace('__HYPONYM__', re.escape(hyponym))pattern = pattern.replace('__HYPERNYM__', re.escape(hypernym))# 在句子中匹配if re.search(pattern, sentence) != None:# 将名词复数还原为单数pairs.append((term_lemma(hyponym), term_lemma(hypernym)))return pairsdef count_unique_tuple(tuple_list):"""统计列表中独特元组出现次数"""counter = Counter(tuple_list)result = [{"tuple": unique, "count": count} for unique, count in counter.items()]return resultdef find_rth_largest(arr, r):"""找到第r大的元素"""rth_largest_index = np.argpartition(arr, -r)[-r]return arr[rth_largest_index]def find_pairs(corpus_file, patterns, disable_tqdm=False):"""读取文件并找出共现于模板的上下位关系术语对"""pairs = []# 按行读取语料库lines = corpus_file.readlines()for line in tqdm(lines, desc="Finding pairs", ascii=" 123456789#", disable=disable_tqdm):# 删去首尾部分的空白字符line = line.strip()# 忽略空白行if line == '':continue# 清理文本line = clear_text(line)# 按句处理sentences = split_sentences(line)for sentence in sentences:# 抽取出句子中的名词性短语并分割成术语candidates_terms = extract_noun_phrases(sentence)# 找出共现于模板的术语对pairs = pairs + find_co_occurrence(sentence, candidates_terms, patterns)return pairsdef spmi_calculate(configs, unique_pairs):"""基于对共现频率的统计,计算任意两个术语间的spmi得分"""# 计算每个术语分别作为上下位词的出现频次terms = list(set([pair["tuple"][0] for pair in unique_pairs] + [pair["tuple"][1] for pair in unique_pairs]))term_count = {term: {'hyponym_count': 0, 'hypernym_count': 0} for term in terms}all_count = 0for pair in unique_pairs:term_count[pair["tuple"][0]]['hyponym_count'] += pair["count"]term_count[pair["tuple"][1]]['hypernym_count'] += pair["count"]all_count += pair["count"]# 计算PPMI矩阵 ppmi_matrix = np.zeros((len(terms), len(terms)), dtype=np.float32)for pair in unique_pairs:hyponym = pair["tuple"][0]hyponym_id = terms.index(hyponym)hypernym = pair["tuple"][1]hypernym_id = terms.index(hypernym)ppmi = (pair["count"] * all_count) / (term_count[hyponym]['hyponym_count'] * term_count[hypernym]['hypernym_count'])ppmi = max(0, math.log(ppmi))ppmi_matrix[hyponym_id, hypernym_id] = ppmi# 对PPMI进行奇异值分解并截断r = configs['clip']U, S, Vt = np.linalg.svd(ppmi_matrix)S[S < find_rth_largest(S, r)] = 0S_r = np.diag(S)# 计算任意两个术语间的spmiparis2spmi = []for hyponym_id in range(len(terms)):for hypernym_id in range(len(terms)):# 同一个术语间不计算得分if hyponym_id == hypernym_id:continuespmi = np.dot(np.dot(U[hyponym_id , :], S_r), Vt[:, hypernym_id]).item()# 保留得分大于阈值的术语对if spmi > configs["threshold"]:hyponym = terms[hyponym_id]hypernym = terms[hypernym_id]paris2spmi.append({"hyponym": hyponym, "hypernym": hypernym, "spmi": spmi})# 按spmi从大到小排序paris2spmi = sorted(paris2spmi, key=lambda x: x["spmi"], reverse=True)return paris2spmiif __name__ == "__main__":# 读取配置文件with open('config.json', 'r') as config_file:configs = json.load(config_file)# 读取模板with open(configs['patterns_path'], 'r') as patterns_file:patterns = json.load(patterns_file)# 语料库中共现于模板的术语对with open(configs['corpus_path'], 'r', encoding='utf-8') as corpus_file:pairs = find_pairs(corpus_file, patterns)# 统计上下位关系的出现频次unique_pairs = count_unique_tuple(pairs)with open(configs["pairs_path"], 'w') as pairs_file:json.dump(unique_pairs, pairs_file, indent=6, ensure_ascii=True)# 计算任意两个术语间的spmi得分paris2spmi = spmi_calculate(configs, unique_pairs)with open(configs['spmi_path'], 'w') as spmi_file:json.dump(paris2spmi, spmi_file, indent=6, ensure_ascii=True)
以上代码仅作展示,更详细的代码文件请参见附件。
效果演示
运行脚本main.py,程序会自动检测语料库中存在的上下位关系。运行结果如下所示:
使用方式
- 解压附件压缩包并进入工作目录。如果是Linux系统,请使用如下命令:
unzip Revisit-Hearst-Pattern.zip
cd Revisit-Hearst-Pattern
- 代码的运行环境可通过如下命令进行配置:
pip install -r requirements.txt
python -m spacy download en_core_web_sm
- 如果希望在本地运行程序,请运行如下命令:
python main.py
- 如果希望在线部署,请运行如下命令:
python main-flask.py
- 如果希望添加新的模板,请修改文件
data/patterns.json。- "_HYPONYM_"表示下位词占位符;
- "_HYPERNYM_"表示上位词占位符;
- 其余格式请遵照 python.re 模块的正则表达式要求。
- 如果希望使用自己的文件路径或改动其他实验设置,请在文件
config.json中修改对应参数。以下是参数含义对照表:
| 参数名 | 含义 |
|---|---|
| corpus_path | 文本语料库文件路径,默认为“data/corpus.txt”。 |
| patterns_path | 预定义模式库的路径。默认为“data/patterns.json”。 |
| pairs_path | 利用模式筛选出的上下位关系词对路径,默认为“data/pairs.json”。 |
| spmi_path | 上下位关系词对及其spmi得分路径,默认为“data/spmi.json”。 |
| clip | 用于对 ΣΣ 进行截断的参数 rr ,默认为10。 |
| threshold | spmi得分小于该值的词对将被舍去。默认为1。 |
| max_bytes | 输入文件大小上限(用于在线演示),默认为200kB。 |
(以上内容皆为原创,请勿转载)
参考文献
[1] Roller S, Kiela D, Nickel M. Hearst patterns revisited: Automatic hypernym detection from large text corpora[J]. arXiv preprint arXiv:1806.03191, 2018.

相关文章:

上下位关系自动检测方法
✨✨ 欢迎大家来访Srlua的博文(づ ̄3 ̄)づ╭❤~✨✨ 🌟🌟 欢迎各位亲爱的读者,感谢你们抽出宝贵的时间来阅读我的文章。 我是Srlua小谢,在这里我会分享我的知识和经验。&am…...
)
Linux入门攻坚——40、Linux集群系统入门-lvs(1)
Cluster,集群,为了解决某个特定问题将多台计算机组合起来形成的单个系统。 这个单个集群系统可以扩展,系统扩展的方式:scale up,向上扩展,更换更好的主机;scale out,向外扩展&…...

结构篇| 浅析LLaMA网络架构
01 前言 LLaMA(Large Language Model Meta AI)是由Meta AI 发布的一个开放且高效的大型基础语言模型。为什么突然讲这个模型,主要LLaMA 已经成为了最受欢迎的开源大语言模型之一,LLaMA 系列模型在学术界和工业界引起了广泛的 关注,对于推动大语言模型技术的开源发展做出了…...
)
CTF-PWN: 全保护下格式化字符串利用 [第一届“吾杯”网络安全技能大赛 如果能重来] 赛后学习(不会)
通过网盘分享的文件:如果能重来.zip 链接: https://pan.baidu.com/s/1XKIJx32nWVcSpKiWFQGpYA?pwd1111 提取码: 1111 --来自百度网盘超级会员v2的分享漏洞分析 格式化字符串漏洞,在printf(format); __int64 sub_13D7() {char format[56]; // [rsp10h] [rbp-40h]…...

openEuler卸载 rpm安装的 redis
停止 Redis 服务 sudo systemctl stop redis禁用 Redis 服务 sudo systemctl disable redis 卸载 Redis 软件包 sudo yum remove redis查找并删除 Redis 的残留文件 find / -name red*删除 Redis 配置文件 删除 Redis 数据文件 sudo rm -rf /var/lib/redis检查 Redis 是否…...

xxl-job分布式任务调度
XXL-JOB是一个轻量级分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。现已开放源代码并接入多家公司线上产品线,开箱即用。 GitHub:https://github.com/xuxueli/xxl-job 码云:https://gitee.com/xuxue…...

flutter_quill如何设置Editor中的文字为富文本
比如一个场景 在输入框中,某某某 是一个颜色,其他文本是一个颜色 这里要注意 const QuillEditor({required this.controller,required this.focusNode,required this.scrollController,required this.scrollable,required this.padding,required this…...
bash)
shell语法(1)bash
shell是我们通过命令行与操作系统沟通的语言,是一种解释型语言 shell脚本可以直接在命令行中执行,也可以将一套逻辑组织成一个文件,方便复用 Linux系统中一般默认使用bash为脚本解释器 在Linux中创建一个.sh文件,例如vim test.sh…...

AgGrid 组件封装设计笔记:自定义 icon 以及每个 icon 的点击事件处理
文章目录 问题目前解决效果 v1思路 目前解决效果 v0思路 代码V1 问题 自己封装的 AgGrid 如何自定义传递 icon ,以及点击事件的处理? 目前解决效果 v1 思路 目前解决效果 v0 思路 一张图片说明一下 代码 V1 父组件使用 <template><MyPageL…...

什么是TCP的三次握手
TCP(传输控制协议)的三次握手是一个用于在两个网络通信的计算机之间建立连接的过程。这个过程确保了双方都有能力接收和发送数据,并且初始化双方的序列号。以下是三次握手的详细步骤: 第一次握手(SYN)&…...

ElasticSearch学习记录
服务器操作系统版本:Ubuntu 24.04 Java版本:21 Spring Boot版本:3.3.5 如果打算用GUI,虚拟机安装Ubuntu 24.04,见 虚拟机安装Ubuntu 24.04及其常用软件(2024.7)_ubuntu24.04-CSDN博客文章浏览阅读6.6k次࿰…...
)
10.在 Vue 3 中使用 OpenLayers 加载引用 Stamen 地图(多种形式)
在 Web 地图开发中,OpenLayers 是一个非常强大且灵活的 JavaScript 库,它可以帮助我们加载各种地图层(如 OpenStreetMap、Google Maps、Bing Maps 等)。而 Stamen 地图是一个非常常见的地图样式,它提供了多种地图样式&…...

json与proto序列化,反序列化性能对比
1. 说proto快,必须知道他快多少?为什么快? 快多少? // 测试proto序列化和反序列化的性能func BenchmarkProtobufMarshal(b *testing.B) {// 创建一个 Request 对象req : &demo.Request{Ping: "ping",}// 测试序列化的性能b.ResetTimer()for i : 0; i < b…...

[Redis#14] 持久化 | RDB | bgsave | check-rdb | 灾备
目录 0.概述 持久化的策略 1 RDB 1.1 触发机制 1.2 流程说明 1.3 RDB 的优缺点 0.概述 在学习 MySQL 数据库时,我们了解到事务的四个核心特性:原子性、一致性、持久性和隔离性。这些特性确保了数据库操作的安全性和可靠性。当我们转向 Redis 时&a…...

ubuntu部署RocketMQ
Quick Start RocketMQ 下载 解压 把下载的文件解压重命名,放在想放的位置 需要提前配置JDK环境变量,或者直接在配置文件中指定JAVA_HOME 编辑 编辑 rocketmq/bin下的 runserver.sh 和runbroker.sh文件,把内存大小改小一点,因为…...

深入浅出:PHP中的变量与常量全解析
文章目录 引言理解变量普通变量赋值操作变量间赋值引用赋值取消引用 可变变量预定义变量 理解常量声明常量使用define()函数const关键字 使用常量预定义常量 扩展话题:作用域与生命周期实战案例总结与展望参考资料 引言 在编程的世界里,变量和常量是两种…...

概率论相关知识随记
作为基础知识的补充,随学随记,方便以后查阅。 概率论相关知识随记 期望(Expectation)期望的定义离散型随机变量的期望示例:掷骰子的期望 连续型随机变量的期望示例:均匀分布的期望 期望的性质线性性质期望的…...

gpt-computer-assistant - 极简的 GPT-4o 客户端
更多AI开源软件: AI开源 - 小众AIhttps://www.aiinn.cn/sources gpt-computer-assistant是一个将 ChatGPT MacOS 应用程序提供给 Windows 和 Linux 的替代工作。因此,这是一个全新且稳定的项目。此时,您可以轻松地将其作为 Python 库安装&am…...

【Java开发】Springboot集成mybatis-plus
1、引入 mybatis-plus 依赖 <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-boot-starter</artifactId> <version>3.5.0</version> </dependency> <!--mysql依赖--> <dependen…...

本地运行打包好的dist
首先输入打包命令 每个人设置不一样 一般人 是npm run build如果不知道可以去package.json里去看。 打包好文件如下 命令行输入 :npm i -g http-server 进入到dist目录下输入 命令cmd 输入 http-server 成功...

mac安装php和xdebug调试
要在Mac上安装PHP 7.4,你可以通过几种方式来完成,但鉴于PHP7.4官方已不再维护,并且Homebrew默认仓库中不再提供此版本,我们需要从第三方仓库或直接从源代码进行安装。本文以brew方式安装,如果安装的是8.0以上ÿ…...

使用Rufus制作Ubuntu需要注意
在使用Rufus制作Ubuntu启动盘并进行BIOS设置时,需要注意以下几点: 关闭RST(英特尔 快速存储技术):在BIOS设置中,如果电脑启用了RST功能,需要将其关闭。因为Ubuntu可能无法检测到硬盘&a…...

2024 阿里云Debian12.8安装apach2【图文讲解】
1. 更新系统,确保您的系统软件包是最新的 sudo apt update sudo apt upgrade -y 2. 安装 Apache Web 服务器 apt install apache2 -y 3. 安装 PHP 及常用的扩展 apt install php libapache2-mod-php -y apt install php-mysql php-xml php-mbstring php-curl php…...

iOS平台接入Facebook登录
1、FB开发者后台注册账户 2、完善App信息 3、git clone库文件代码接入 4、印尼手机卡开热点调试 备注: 可能遇到的问题: 1、Cocos2dx新建的项目要更改xcode的git设置,不然卡在clone,无法在线获取FBSDK 2、动态库链接 需要在…...

关于在ubuntu上无法运行EasyConnect的解决方法
需要这三个文件 libpangocairo-1.0-0_1.40.14-1_amd64.deb libpangoft2-1.0-0_1.40.14-1_amd64.deb libpango-1.0-0_1.40.14-1_amd64.deb然后执行 cp source /usr/share/sangfor/EasyConnect再重启EasyConnect即可 下载链接 http://kr.archive.ubuntu.com/ubuntu/pool/main/…...
)
常用 Linux 各资源指标监控示例(长期更新)
1、在 linux 中,查看指定进程下各线程运行情况 # ps 方式,查看 pid 为 776 的进程有哪些线程 ps -Tp 776 #> PID SPID TTY TIME CMD #> 776 776 ? 00:00:01 zebra #> 776 778 ? 00:00:00 RCU sweeper #&g…...

【目标跟踪】AntiUAV600数据集详细介绍
AntiUAV600数据集的提出是为了适应真实场景,即无人机可能会随时随地出现和消失。目前提出的Anti-UAV任务都只是将其看做与跟踪其他目标一样的任务,没有结合现实情况考虑。 论文链接:https://arxiv.org/pdf/2306.15767https://arxiv.org/pdf/…...
)
数学建模之RSR秩和比综合评价法(详细)
RSR秩和比综合评价法 一、概述 秩和比法(Rank-sum ratio,简称RSR法)是我国学者田凤调于1988年提出的,田教授是我国杰出的卫生统计学家,该方法最初提出时用于解决医学卫生领域的综合评价问题,后经各领域学者的补充和完善…...

【Vue3】【Naive UI】<NAutoComplete>标签
【Vue3】【Naive UI】标签 <NAutoComplete> 是 Naive UI 库中的一个组件,用于实现自动完成或联想输入功能。 它允许用户在输入时看到与当前输入匹配的建议列表,从而帮助用户更快地填写表单字段。 这个组件通常用于搜索框、地址输入等场景ÿ…...

SpringBoot自动装配原理
SpringBoot自动装配原理 在介绍SpringBoot自动装配原理之前我们需要先看一个注解 --> SpringBootApplication SpringBootApplication public class BackendApp {public static void main(String[] args) {SpringApplication.run(BackendApp.class, args);} }我们都知道Spr…...

Flask: flask框架是如何实现非阻塞并发的
写在前面:Flask框架是通过多线程/多进程+阻塞的socket实现非阻塞,其本质是基于python的源库socketserver实现的 前言 认识WSGI协议 认识Werkzeug flask是如何实现非阻塞的 本文使用的flask框架为最新的1.1.1版本,所有代码基于python3运行 一:前言 使用过flask或者其他web框…...

svg和canvas比较
SVG(Scalable Vector Graphics)和Canvas都是用于在网页上绘制图形的技术,但它们在工作原理、使用场景和特性上有所不同。以下是对SVG和Canvas的详细介绍及使用示例: 一、SVG 简介 SVG是一种基于XML的标记语言,用于描…...
)
【前端学习路线】(超详细版本)
先附上学习路线图:前端学习路线 第一阶段:前端入门(htmlcss) 前端最基本的知识,需要先将这些内容融汇贯通,学习后面内容才会不吃力。学习完可以做几个静态页练习一下。 推荐视频学习链接: 黑马程…...

VCU——matlab/simulink软件建模
一、认识MATLAB/Simulink 1. matlab主界面 2. simulink 二、Simulink 建模基础 1. Simulink模块 2. 模型的仿真 matlab 中比较两个浮点型,不要用,采取差值和Compare To Constant的方案 3. 自动代码生成...

ASP.NET Core SignalR 双工通信
01. 介绍 🎯 ASP.NET Core SignalR 是一个开放源代码库,它简化了向应用添加实时 Web 功能的过程。 实时 Web 功能使服务器端代码可以在服务器上激发事件时将事件推送到连接的客户端。 使用 SignalR,客户端也可以将消息发送到服务器ÿ…...

以数据驱动增长,火山引擎数智平台“数据找人”为双12营销提效
“双12”即将来临,众多商家最为关心的,莫过于如何借助对数据的充分利用实现降本增效,在竞争激烈的大环境中快人一步,为了达成这个目标,商家往往需要耗费人力、物力以及时间对海量数据进行寻找与分析。 那么,…...

VuePress学习
1.介绍 VuePress 由两部分组成:第一部分是一个极简静态网站生成器 (opens new window),它包含由 Vue 驱动的主题系统和插件 API,另一个部分是为书写技术文档而优化的默认主题,它的诞生初衷是为了支持 Vue 及其子项目的文档需求。…...

mysql cpu线上问题排查
查看当前的线程情况 show full processlist 查看当前的线程情况 SELECT * FROM performance_schema.threads WHERE PROCESSLIST_TIME > 0 查看当前数据库的连接数 SELECT * FROM performance_schema.threads WHERE PROCESSLIST_DB ‘db’ ; 查看当前mysql连接的数 SHOW GLO…...

QT6学习 第九天 QDialog
QT6学习第九天 QDialog 对话框 QDialog模态和非模态对话框标准对话框颜色对话框进度对话框 对话框 QDialog 模态和非模态对话框 QDialog 类是所有对话框类的基类。对话框是一个经常用来完成短小任务或和用户进行简单交互的顶层窗口。按照运行对话框时是否还可以和该程序的其…...

windows基础
系统目录 服务 端口 注册表 黑客常用DOS命令(在拿到shell时会用到) 一、 系统目录 Windows目录 系统的安装目录 System32configSAM文件 是用户密码的存储文件 System32etchost文件 记录本地解析(优先级大于DNS域名解析)可以自…...

《向量数据库指南》——OPPO分布式向量检索的实战与突破
OPPO对向量检索的探索:从单机到分布式的华丽转身 在当今这个数据爆炸的时代,如何高效地存储、检索和分析数据,成为了企业面临的一大挑战。特别是在人工智能领域,向量数据的处理更是占据了举足轻重的地位。OPPO,作为全球知名的智能手机制造商,自然也不会放过这个技术风口…...

golang语言机构和基础语法
语言结构和基础语法 1.包声明 2.引入包 3.函数 4.init函数 5.变量 6.标识符 7.行分隔符 8.语句&表达式 9.注释 10.公有成员与私有成员 11.关键字、保留字和预定义标志引用类型 1.切片 2.map 3.channel 4.interface 5.func 6.指针类型关键词 1.break 跳转语句,…...

在 MacOS 上为 LM Studio 更换镜像源
在 MacOS 之中使用 LM Studio 部署本地 LLM时,用户可能会遇到无法下载模型的问题。 一般的解决方法是在 huggingface.co 或者国内的镜像站 hf-mirror.com 的项目介绍卡页面下载模型后拖入 LM Studio 的模型文件夹。这样无法利用 LM Studio 本身的搜索功能。 本文将…...

python之Django连接数据库
文章目录 连接Mysql数据库安装Mysql驱动配置数据库信息明确连接驱动定义模型在模型下的models.py中定义表对象在settings.py 中找到INSTALLED_APPS添加创建的模型 测试testdb.py中写增删改查操作urls.py添加请求路径启动项目进行测试 连接Mysql数据库 安装Mysql驱动 pip inst…...
LangChain、LlamaIndex、LlamaIndex)
LLM学习笔记(15)LangChain、LlamaIndex、LlamaIndex
Transformer 和 PyTorch 是什么关系? Transformer和PyTorch可以很好地配合使用,但它们并不是同一层面的工具。具体来说: Transformer是一个神经网络的架构,最初用于自然语言处理,但也可以扩展到其他任务(…...

springai结合ollama
目录 ollama 介绍 使用 下载: 安装: 点击这个玩意next就行了。 运行 spring ai使用ollama调用本地部署的大模型 加依赖 配置yml 写代码 ollama 介绍 官网:Ollama Ollama是一个用于部署和运行各种开源大模型的工具; …...

扫描IP段内的使用的IP
扫描IP段内的使用的IP 方法一:命令行 命令行进入 for /L %i IN (1,1,254) DO ping -w 1 -n 1 192.168.3.%iarp -a方法二:python from scapy.all import ARP, Ether, srp import keyboarddef scan_network(ip_range):# 创建一个ARP请求包arp ARP(pds…...

ai即可一键生成ppt解决烦恼
在快节奏的职场环境中,制作PPT已经成为许多人日常工作的一部分。尽管PPT看似简单,却常常让人耗费大量时间。好在技术的进步为我们带来了全新的解决方案,比如智能生成PPT,让那些深夜加班的人看到了曙光。 从“手动排版”到“一键生…...

三、【docker】docker和docker-compose的常用命令
文章目录 一、docker常用命令1、镜像管理2、容器管理3、容器监控和调试4、网络管理5、数据卷管理6、系统维护7、实用组合命令8、常用技巧二、docker-compose常用命令1、基本命令2、构建相关3、运行维护4、常用组合命令5、实用参数 一、docker常用命令 1、镜像管理 # 查看本地…...

「Mac畅玩鸿蒙与硬件43」UI互动应用篇20 - 闪烁按钮效果
本篇将带你实现一个带有闪烁动画的按钮交互效果。通过动态改变按钮颜色,用户可以在视觉上感受到按钮的闪烁效果,提升界面互动体验。 关键词 UI互动应用闪烁动画动态按钮状态管理用户交互 一、功能说明 闪烁按钮效果应用实现了一个动态交互功能…...