掌握MySQL:基本查询指令与技巧



目录
- `表的增删查改`
- `1 Create`
- `Insert`
- `1.1 单行数据 + 全列插入+指定列插入`
- `1.2 多行数据插入+ 指定列插入`
- `1.3 插入否则更新`
- `1.4 替换`
- `2 Retrieve`
- `2.1 SELECT 列`
- `2.1.1 全列查询`
- `2.1.2 指定列查询`
- `2.1.3 查询字段为表达式`
- `2.1.4 为查询结果指定别名`
- `2.1.5 结果去重`
- `2.2 WHERE 条件`
- `2.2.9 NULL 的查询`
- `2.3 结果排序 `
- 2.4 筛选分页结果
- `3 Update`
- `4 Delete`
- `4.1 删除数据`
- 4.2 截断表
- `5 插入查询结果`
- `6 聚合函数`
- `6.7 group by子句的使用`
表的增删查改
- CRUD : Create(创建), Retrieve(读取),Update(更新),Delete(删除)
1 Create
案例:
-- 创建一张学生表
mysql> create table student(-> id int unsigned primary key auto_increment,-> sn int not null unique key comment '学号',-> name varchar(20) not null comment '姓名',-> qq varchar(20) unique key-> );
Query OK, 0 rows affected (0.04 sec)mysql> desc student;
+-------+--------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+--------------+------+-----+---------+----------------+
| id | int unsigned | NO | PRI | NULL | auto_increment |
| sn | int | NO | UNI | NULL | |
| name | varchar(20) | NO | | NULL | |
| qq | varchar(20) | YES | UNI | NULL | |
+-------+--------------+------+-----+---------+----------------+
4 rows in set (0.00 sec)Insert
语法:
--values就像一个扁担一样,左边是列属性,右边是对应的内容--insert [into] table_name (列属性,逗号分隔) values (对应前面列的待插入内容,逗号分隔) --指定列插入insert [into] table_name values (插入内容); --全插入
--其中插入的内容是严格与你表格的列属性顺序是一致的
1.1 单行数据 + 全列插入+指定列插入
-- 插入两条记录,value_list 数量必须和定义表的列的数量及顺序一致
-- 注意,这里在插入的时候,也可以不用指定id(当然,那时候就需要明确插入数据到那些列了),
那么mysql会使用默认的值进行自增。
mysql> insert into student values (1,001,'孙悟空',null); --全插入
Query OK, 1 row affected (0.03 sec)mysql> insert into student (sn,name,qq) values (002,'唐三藏','12345'); --指定列插入
Query OK, 1 row affected (0.01 sec) --没有插入id,id自增到2-- 查看插入结果
mysql> select * from student;
+----+----+-----------+-------+
| id | sn | name | qq |
+----+----+-----------+-------+
| 1 | 1 | 孙悟空 | NULL |
| 2 | 2 | 唐三藏 | 12345 |
+----+----+-----------+-------+
2 rows in set (0.00 sec)1.2 多行数据插入+ 指定列插入
-- 插入两条记录,value_list 数量必须和指定列数量及顺序一致mysql> insert into student (id,sn,name) values -> (100,101,'曹孟德'),-> (101,111,'孙仲谋');
Query OK, 2 rows affected (0.01 sec)
Records: 2 Duplicates: 0 Warnings: 0-- 查看插入结果
mysql> select * from student;
+-----+-----+-----------+-------+
| id | sn | name | qq |
+-----+-----+-----------+-------+
| 1 | 1 | 孙悟空 | NULL |
| 2 | 2 | 唐三藏 | 12345 |
| 100 | 101 | 曹孟德 | NULL |
| 101 | 111 | 孙仲谋 | NULL |
+-----+-----+-----------+-------+
4 rows in set (0.00 sec)
1.3 插入否则更新
由于 主键 或者 唯一键 对应的值已经存在而导致插入失败
-- 主键冲突
mysql> insert into student (id,name,sn) values (101,'孙策','112');
ERROR 1062 (23000): Duplicate entry '101' for key 'student.PRIMARY'-- 唯一键冲突
mysql> insert into student (sn,name) values (111,'孙策');
ERROR 1062 (23000): Duplicate entry '111' for key 'student.sn'可以选择性的进行同步更新操作语法:
INSERT ... ON DUPLICATE KEY UPDATE
column = value [, column = value] ...
mysql> insert into student (id,name,sn) values (101,'孙策','112') -> on duplicate key updatee id=102,name='孙策',sn=112;
Query OK, 2 rows affected (0.01 sec)-- 0 row affected: 表中有冲突数据,但冲突数据的值和 update 的值相等
-- 1 row affected: 表中没有冲突数据,数据被插入
-- 2 row affected: 表中有冲突数据,并且数据已经被更新
-- 通过 MySQL 函数获取受到影响的数据行数
mysql> select row_count();
+-------------+
| ROW_COUNT() |
+-------------+
| 2 |
+-------------+
1 row in set (0.00 sec)
-- ON DUPLICATE KEY 当发生重复key的时候--插入成功
mysql> select * from student;
+-----+-----+-----------+-------+
| id | sn | name | qq |
+-----+-----+-----------+-------+
| 1 | 1 | 孙悟空 | NULL |
| 2 | 2 | 唐三藏 | 12345 |
| 100 | 101 | 曹孟德 | NULL |
| 102 | 112 | 孙策 | NULL |
+-----+-----+-----------+-------+
4 rows in set (0.00 sec)
1.4 替换
语法:
replace into table_name ( 列属性 ) values(列内容)
案例:
mysql> select * from student;
+-----+-----+-----------+-------+
| id | sn | name | qq |
+-----+-----+-----------+-------+
| 1 | 1 | 孙悟空 | NULL |
| 2 | 2 | 唐三藏 | 12345 |
| 100 | 101 | 曹孟德 | NULL |
| 102 | 112 | 孙策 | NULL |
+-----+-----+-----------+-------+
4 rows in set (0.00 sec)-- 主键 或者 唯一键 没有冲突,则直接插入;
-- 主键 或者 唯一键 如果冲突,则删除后再插入;mysql> replace into student (sn,name) values (101,'猪八戒');
Query OK, 2 rows affected (0.00 sec)
-- 1 row affected: 表中没有冲突数据,数据被插入
-- 2 row affected: 表中有冲突数据,删除后重新插入mysql> select * from student;
+-----+-----+-----------+-------+
| id | sn | name | qq |
+-----+-----+-----------+-------+
| 1 | 1 | 孙悟空 | NULL |
| 2 | 2 | 唐三藏 | 12345 |
| 102 | 112 | 孙策 | NULL |
| 103 | 101 | 猪八戒 | NULL |
+-----+-----+-----------+-------+
4 rows in set (0.00 sec)
2 Retrieve
准备测试表结构与数据
-- 创建表结构
mysql> create table exam_result(-> id int unsigned primary key auto_increment,-> name varchar(20) not null comment '姓名',-> chinese float default 0.0 comment '语文成绩',-> math float default 0.0 comment '数学成绩',-> english float default 0.0 comment '英语成绩'-> );
Query OK, 0 rows affected (0.03 sec)-- 插入测试数据
mysql> insert into exam_result (name,chinese,math,english) values-> ('刘备',67,98,56),-> ('孙权',87,78,77),-> ('曹超',88,98,90),-> ('诸葛亮',82,84,67),-> ('关羽',55,85,47),-> ('小乔',70,73,78),-> ('貂蝉',75,65,30)-> ;
Query OK, 7 rows affected (0.00 sec)
Records: 7 Duplicates: 0 Warnings: 02.1 SELECT 列
2.1.1 全列查询
-- 通常情况下不建议使用 * 进行全列查询
-- 1. 查询的列越多,意味着需要传输的数据量越大;
-- 2. 可能会影响到索引的使用。
mysql> select * from exam_result;
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 1 | 刘备 | 67 | 98 | 56 |
| 2 | 孙权 | 87 | 78 | 77 |
| 3 | 曹超 | 88 | 98 | 90 |
| 4 | 诸葛亮 | 82 | 84 | 67 |
| 5 | 关羽 | 55 | 85 | 47 |
| 6 | 小乔 | 70 | 73 | 78 |
| 7 | 貂蝉 | 75 | 65 | 30 |
+----+-----------+---------+------+---------+
7 rows in set (0.00 sec)2.1.2 指定列查询
-- 指定列的顺序不需要按定义表的顺序来
mysql> select name,chinese from exam_result;
+-----------+---------+
| name | chinese |
+-----------+---------+
| 刘备 | 67 |
| 孙权 | 87 |
| 曹超 | 88 |
| 诸葛亮 | 82 |
| 关羽 | 55 |
| 小乔 | 70 |
| 貂蝉 | 75 |
+-----------+---------+
7 rows in set (0.00 sec)2.1.3 查询字段为表达式
-- 表达式不包含字段
mysql> select id,name,chinese+10 from exam_result;
+----+-----------+------------+
| id | name | chinese+10 |
+----+-----------+------------+
| 1 | 刘备 | 77 |
| 2 | 孙权 | 97 |
| 3 | 曹超 | 98 |
| 4 | 诸葛亮 | 92 |
| 5 | 关羽 | 65 |
| 6 | 小乔 | 80 |
| 7 | 貂蝉 | 85 |
+----+-----------+------------+
7 rows in set (0.00 sec)
-- 表达式包含多个字段
mysql> select id,name,chinese+math+english from exam_result;
+----+-----------+----------------------+
| id | name | chinese+math+english |
+----+-----------+----------------------+
| 1 | 刘备 | 221 |
| 2 | 孙权 | 242 |
| 3 | 曹超 | 276 |
| 4 | 诸葛亮 | 233 |
| 5 | 关羽 | 187 |
| 6 | 小乔 | 221 |
| 7 | 貂蝉 | 170 |
+----+-----------+----------------------+
7 rows in set (0.00 sec)2.1.4 为查询结果指定别名
语法:
mysql> select id,name,chinese+math+english as total from exam_result;
+----+-----------+-------+
| id | name | total |
+----+-----------+-------+
| 1 | 刘备 | 221 |
| 2 | 孙权 | 242 |
| 3 | 曹超 | 276 |
| 4 | 诸葛亮 | 233 |
| 5 | 关羽 | 187 |
| 6 | 小乔 | 221 |
| 7 | 貂蝉 | 170 |
+----+-----------+-------+
7 rows in set (0.00 sec)--as可以省略
mysql> select id,name,chinese+math+english total from exam_result;
+----+-----------+-------+
| id | name | total |
+----+-----------+-------+
| 1 | 刘备 | 221 |
| 2 | 孙权 | 242 |
| 3 | 曹超 | 276 |
| 4 | 诸葛亮 | 233 |
| 5 | 关羽 | 187 |
| 6 | 小乔 | 221 |
| 7 | 貂蝉 | 170 |
+----+-----------+-------+
7 rows in set (0.00 sec)
2.1.5 结果去重
-- 98 分重复了
mysql> select math from exam_result;
+------+
| math |
+------+
| 98 |
| 78 |
| 98 |
| 84 |
| 85 |
| 73 |
| 65 |
+------+
7 rows in set (0.00 sec)-- 去重结果
mysql> select distinct math from exam_result;
+------+
| math |
+------+
| 98 |
| 78 |
| 84 |
| 85 |
| 73 |
| 65 |
+------+
6 rows in set (0.00 sec)2.2 WHERE 条件
比较运算符:
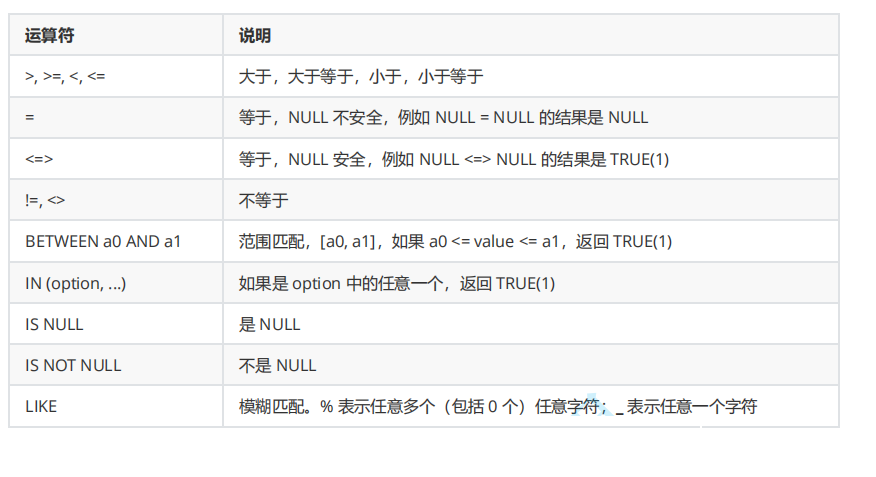
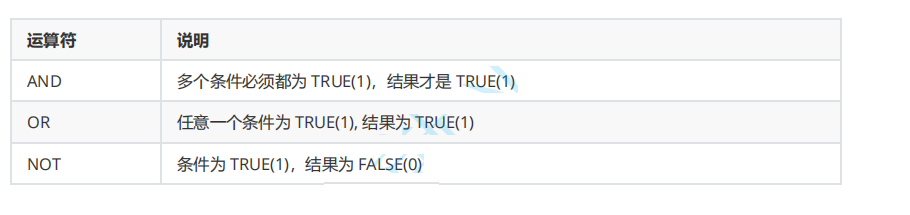
逻辑运算符:
2.2.1 英语不及格的同学及英语成绩 ( < 60 )
-- 基本比较
mysql> select name,chinese from exam_result where chinese<60;
+--------+---------+
| name | chinese |
+--------+---------+
| 关羽 | 55 |
+--------+---------+
1 row in set (0.00 sec)2.2.2 语文成绩在 [80, 90] 分的同学及语文成绩
-- 使用 and 进行条件连接
mysql> select id,name,chinese from exam_result where chinese>60 and chinese<90;
+----+-----------+---------+
| id | name | chinese |
+----+-----------+---------+
| 1 | 刘备 | 67 |
| 2 | 孙权 | 87 |
| 3 | 曹超 | 88 |
| 4 | 诸葛亮 | 82 |
| 6 | 小乔 | 70 |
| 7 | 貂蝉 | 75 |
+----+-----------+---------+
6 rows in set (0.00 sec)
-- 使用 BETWEEN ... and ... 条件
mysql> select id,name,chinese from exam_result where chinese between 60 and 90;
+----+-----------+---------+
| id | name | chinese |
+----+-----------+---------+
| 1 | 刘备 | 67 |
| 2 | 孙权 | 87 |
| 3 | 曹超 | 88 |
| 4 | 诸葛亮 | 82 |
| 6 | 小乔 | 70 |
| 7 | 貂蝉 | 75 |
+----+-----------+---------+
6 rows in set (0.00 sec)
2.2.3 数学成绩是 58 或者 59 或者 98 或者 99 分的同学及数学成绩
-- 使用 OR 进行条件连接
mysql> select id,name,math from exam_result -> where math=58 or -> math=59 or -> math=98 or -> math=99;
+----+--------+------+
| id | name | math |
+----+--------+------+
| 1 | 刘备 | 98 |
| 3 | 曹超 | 98 |
+----+--------+------+
2 rows in set (0.00 sec)-- 使用 IN 条件
mysql> select id,name,math from exam_result -> where math in (58,59,98,99);
+----+--------+------+
| id | name | math |
+----+--------+------+
| 1 | 刘备 | 98 |
| 3 | 曹超 | 98 |
+----+--------+------+
2 rows in set (0.00 sec)2.2.4 姓孙的同学 及 孙某同学
-- % 匹配任意多个(包括 0 个)任意字符
mysql> select id,name from exam_result where name like '孙%';
+----+-----------+
| id | name |
+----+-----------+
| 2 | 孙权 |
| 8 | 孙悟空 |
+----+-----------+
2 rows in set (0.00 sec)-- _ 匹配严格的一个任意字符
mysql> select id,name from exam_result where name like '孙_';
+----+--------+
| id | name |
+----+--------+
| 2 | 孙权 |
+----+--------+
1 row in set (0.00 sec)2.2.5 语文成绩好于英语成绩的同学
-- WHERE 条件中比较运算符两侧都是字段
mysql> select name,chinese,english from exam_result where chinese>english;
+-----------+---------+---------+
| name | chinese | english |
+-----------+---------+---------+
| 刘备 | 67 | 56 |
| 孙权 | 87 | 77 |
| 诸葛亮 | 82 | 67 |
| 关羽 | 55 | 47 |
| 貂蝉 | 75 | 30 |
| 孙悟空 | 99 | 77 |
+-----------+---------+---------+
6 rows in set (0.00 sec)2.2.6 总分在 200 分以下的同学
-- WHERE 条件中使用表达式
-- 别名不能用在 WHERE 条件中
mysql> select name,chinese+math+english total from exam_result where chinese+math+english>200;
+-----------+-------+
| name | total |
+-----------+-------+
| 刘备 | 221 |
| 孙权 | 242 |
| 曹超 | 276 |
| 诸葛亮 | 233 |
| 小乔 | 221 |
| 孙悟空 | 264 |
+-----------+-------+
6 rows in set (0.01 sec)-- 别名不能用在 WHERE 条件中
mysql> select name,chinese+math+english total from exam_result where total>200;
ERROR 1054 (42S22): Unknown column 'total' in 'where clause'
2.2.7 语文成绩 > 80 并且不姓孙的同学
-- AND 与 NOT 的使用
mysql> select name,chinese from exam_result -> where chinese>80 and -> name not like '孙%';
+-----------+---------+
| name | chinese |
+-----------+---------+
| 曹超 | 88 |
| 诸葛亮 | 82 |
+-----------+---------+
2 rows in set (0.00 sec)
2.2.8 孙某同学,否则要求总成绩 > 200 并且 语文成绩 < 数学成绩 并且 英语成绩 > 80
-- 综合性查询
mysql> select name,chinese,math,english,chinese+math+english total -> from exam_result where -> name like '孙_' or -> (chinese+math+english>200 and chinese<math and english>80);
+--------+---------+------+---------+-------+
| name | chinese | math | english | total |
+--------+---------+------+---------+-------+
| 孙权 | 87 | 78 | 77 | 242 |
| 曹超 | 88 | 98 | 90 | 276 |
+--------+---------+------+---------+-------+
2 rows in set (0.00 sec)
2.2.9 NULL 的查询
-- 查询 students 表
mysql> select * from student;
+-----+-----+-----------+-------+
| id | sn | name | qq |
+-----+-----+-----------+-------+
| 1 | 1 | 孙悟空 | NULL |
| 2 | 2 | 唐三藏 | 12345 |
| 102 | 112 | 孙策 | NULL |
| 103 | 101 | 猪八戒 | NULL |
+-----+-----+-----------+-------+
4 rows in set (0.00 sec)-- 查询 qq 号已知的同学姓名
mysql> select name,qq from student where qq is not null;
+-----------+-------+
| name | qq |
+-----------+-------+
| 唐三藏 | 12345 |
+-----------+-------+
1 row in set (0.00 sec)-- NULL 和 NULL 的比较,= 和 <=> 的区别
mysql> select null=null,null=1,null=0;
+-----------+--------+--------+
| null=null | null=1 | null=0 |
+-----------+--------+--------+
| NULL | NULL | NULL |
+-----------+--------+--------+
1 row in set (0.00 sec)mysql> select null<=>null,null<=>1,null<=>0;
+-------------+----------+----------+
| null<=>null | null<=>1 | null<=>0 |
+-------------+----------+----------+
| 1 | 0 | 0 |
+-------------+----------+----------+
1 row in set (0.00 sec)2.3 结果排序
语法:
-- ASC 为升序(从小到大)
-- DESC 为降序(从大到小)
-- 默认为 ASC
SELECT ... FROM table_name [WHERE ...]
order by column [ASC|DESC], [...];
注意:没有 ORDER BY 子句的查询,返回的顺序是未定义的,永远不要依赖这个顺序
案例:
2.3.1 同学及数学成绩,按数学成绩升序显示
mysql> select name,math from exam_result order by math asc;
+-----------+------+
| name | math |
+-----------+------+
| 貂蝉 | 65 |
| 小乔 | 73 |
| 孙权 | 78 |
| 诸葛亮 | 84 |
| 关羽 | 85 |
| 孙悟空 | 88 |
| 刘备 | 98 |
| 曹超 | 98 |
+-----------+------+
8 rows in set (0.00 sec)
2.3.2 同学及 qq 号,按 qq 号排序显示
-- NULL 视为比任何值都小,升序出现在最上面
mysql> select name,qq from student order by qq;
+-----------+-------+
| name | qq |
+-----------+-------+
| 孙悟空 | NULL |
| 孙策 | NULL |
| 猪八戒 | NULL |
| 唐三藏 | 12345 |
+-----------+-------+
4 rows in set (0.00 sec)2.3.3 查询同学各门成绩,依次按 数学降序,英语升序,语文升序的方式显示
-- 多字段排序,排序优先级随书写顺序
mysql> select name,math,english,chinese from exam_result -> order by math desc,-> english asc, -> chinese asc;
+-----------+------+---------+---------+
| name | math | english | chinese |
+-----------+------+---------+---------+
| 刘备 | 98 | 56 | 67 |
| 曹超 | 98 | 90 | 88 |
| 孙悟空 | 88 | 77 | 99 |
| 关羽 | 85 | 47 | 55 |
| 诸葛亮 | 84 | 67 | 82 |
| 孙权 | 78 | 77 | 87 |
| 小乔 | 73 | 78 | 70 |
| 貂蝉 | 65 | 30 | 75 |
+-----------+------+---------+---------+
8 rows in set (0.00 sec)
2.3.4 查询同学及总分,由高到低
-- ORDER BY 中可以使用表达式
mysql> select name,chinese+math+english total from exam_result -> order by chinese+math+english desc;
+-----------+-------+
| name | total |
+-----------+-------+
| 曹超 | 276 |
| 孙悟空 | 264 |
| 孙权 | 242 |
| 诸葛亮 | 233 |
| 刘备 | 221 |
| 小乔 | 221 |
| 关羽 | 187 |
| 貂蝉 | 170 |
+-----------+-------+
8 rows in set (0.00 sec)-- ORDER BY 子句中可以使用列别名
mysql> select name,chinese+math+english total from exam_result -> order by total desc;
+-----------+-------+
| name | total |
+-----------+-------+
| 曹超 | 276 |
| 孙悟空 | 264 |
| 孙权 | 242 |
| 诸葛亮 | 233 |
| 刘备 | 221 |
| 小乔 | 221 |
| 关羽 | 187 |
| 貂蝉 | 170 |
+-----------+-------+
8 rows in set (0.00 sec)-- 执行顺序
FROM 子句:访问 exam_result 表,获取所有行。
计算 SELECT 子句中的表达式:对每一行,计算 chinese + math + english 的值,并将其命名为 total。
ORDER BY 子句:根据 total 的值对结果进行降序排序。
返回结果:返回排序后的结果集,包括 name 和计算得到的 total。
--注意事项
别名使用:在 SELECT 子句中定义的别名(如 total)可以在 ORDER BY 子句中使用,
因为 ORDER BY 是在 SELECT 之后处理的(在逻辑上,尽管优化器可能会调整实际执行顺序)。
2.3.5 查询姓孙的同学或者姓曹的同学数学成绩,结果按数学成绩由高到低显示
-- 结合 WHERE 子句 和 ORDER BY 子句
mysql> select name,math from exam_result -> where (name like '孙%' or name like '曹%') -> order by math desc;
+-----------+------+
| name | math |
+-----------+------+
| 曹超 | 98 |
| 孙悟空 | 88 |
| 孙权 | 78 |
+-----------+------+
3 rows in set (0.00 sec)2.4 筛选分页结果
语法:
-- 起始下标为 0-- 从 s 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT s, n;-- 从 0 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n;-- 从 s 开始,筛选 n 条结果,比第二种用法更明确,建议使用
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n OFFSET s;
建议:对未知表进行查询时,最好加一条 LIMIT 1,避免因为表中数据过大,查询全表数据导致数据库卡死
按 id 进行分页,每页 3 条记录,分别显示 第 1、2、3 页
-- 第 1 页
mysql> select name,chinese from exam_result limit 0,3;
+--------+---------+
| name | chinese |
+--------+---------+
| 刘备 | 67 |
| 孙权 | 87 |
| 曹超 | 88 |
+--------+---------+
3 rows in set (0.00 sec)mysql> select name,chinese from exam_result limit 3,3;
+-----------+---------+
| name | chinese |
+-----------+---------+
| 诸葛亮 | 82 |
| 关羽 | 55 |
| 小乔 | 70 |
+-----------+---------+
3 rows in set (0.00 sec)mysql> select name,chinese from exam_result limit 3 offset 3;
+-----------+---------+
| name | chinese |
+-----------+---------+
| 诸葛亮 | 82 |
| 关羽 | 55 |
| 小乔 | 70 |
+-----------+---------+
3 rows in set (0.00 sec)-- 第 3 页,如果结果不足 3 个,不会有影响
mysql> select name,chinese from exam_result limit 6,3;
+-----------+---------+
| name | chinese |
+-----------+---------+
| 貂蝉 | 75 |
| 孙悟空 | 99 |
+-----------+---------+
2 rows in set (0.00 sec)mysql> select name,chinese from exam_result limit 3 offset 6;
+-----------+---------+
| name | chinese |
+-----------+---------+
| 貂蝉 | 75 |
| 孙悟空 | 99 |
+-----------+---------+
2 rows in set (0.00 sec)
3 Update
语法:
UPDATE table_name SET column = expr [, column = expr ...]
[WHERE ...] [ORDER BY ...] [LIMIT ...]
对查询到的结果进行列值更新
案例:
3.1 将孙悟空同学的数学成绩变更为 80 分
-- 更新值为具体值
-- 查看原数据
mysql> update exam_result set math=80 where name='孙悟空';
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0mysql> select name,math from exam_result where name='孙悟空';
+-----------+------+
| name | math |
+-----------+------+
| 孙悟空 | 80 |
+-----------+------+
1 row in set (0.00 sec)
3.2 将貂蝉同学的数学成绩变更为 60 分,语文成绩变更为 70 分
mysql> update exam_result set math=60,chinese=70 where name='貂蝉';
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0mysql> select name,chinese,math from exam_result where name='貂蝉';
+--------+---------+------+
| name | chinese | math |
+--------+---------+------+
| 貂蝉 | 70 | 60 |
+--------+---------+------+
1 row in set (0.00 sec)
3.3 将总成绩倒数前三的 3 位同学的数学成绩加上 30 分
-- 更新值为原值基础上变更
-- 查看原数据
-- 别名可以在ORDER BY中使用
mysql> select name,chinese+math+english total -> from exam_result order by total asc limit 0,3;
+--------+-------+
| name | total |
+--------+-------+
| 貂蝉 | 160 |
| 关羽 | 187 |
| 小乔 | 221 |
+--------+-------+
3 rows in set (0.00 sec)-- 数据更新,不支持 math += 30 这种语法
mysql> update exam_result set math = math + 30 -> order by chinese+math+english asc limit 3;
Query OK, 3 rows affected (0.00 sec)
Rows matched: 3 Changed: 3 Warnings: 0--注意:
在 UPDATE 语句中使用 LIMIT 时,MySQL不支持 LIMIT offset, row_count 这种带有偏移量的完整形式;
它只支持 LIMIT row_count。这是因为 UPDATE 语句的目的是修改数据,而不是像 SELECT 语句那样检索数据,
所以通常不需要跳过一定数量的行再开始更新。mysql> update exam_result set math = math + 30 -> order by chinese+math+english asc limit 0,3;
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for
the right syntax to use near ',3' at line 13.4 将所有同学的语文成绩更新为原来的 2 倍
注意:更新全表的语句慎用
-- 没有 WHERE 子句,则更新全表
-- 查看原数据
mysql> select * from exam_result;
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 1 | 刘备 | 67 | 128 | 56 |
| 2 | 孙权 | 87 | 48 | 77 |
| 3 | 曹超 | 88 | 98 | 90 |
| 4 | 诸葛亮 | 82 | 54 | 67 |
| 5 | 关羽 | 55 | 145 | 47 |
| 6 | 小乔 | 70 | 103 | 78 |
| 7 | 貂蝉 | 70 | 90 | 30 |
| 8 | 孙悟空 | 99 | 80 | 77 |
+----+-----------+---------+------+---------+
8 rows in set (0.00 sec)//更新数据
mysql> update exam_result set chinese=chinese*2;
Query OK, 8 rows affected (0.01 sec)
Rows matched: 8 Changed: 8 Warnings: 0//查看更新后的数据
mysql> select * from exam_result;
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 1 | 刘备 | 134 | 128 | 56 |
| 2 | 孙权 | 174 | 48 | 77 |
| 3 | 曹超 | 176 | 98 | 90 |
| 4 | 诸葛亮 | 164 | 54 | 67 |
| 5 | 关羽 | 110 | 145 | 47 |
| 6 | 小乔 | 140 | 103 | 78 |
| 7 | 貂蝉 | 140 | 90 | 30 |
| 8 | 孙悟空 | 198 | 80 | 77 |
+----+-----------+---------+------+---------+
8 rows in set (0.00 sec)
4 Delete
4.1 删除数据
语法:
delete from table_name [WHERE ...] [ORDER BY ...] [LIMIT ...]
案例:
4.1.1 删除孙悟空同学的考试成绩
-- 查看原数据
mysql> select * from exam_result;
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 1 | 刘备 | 134 | 128 | 56 |
| 2 | 孙权 | 174 | 48 | 77 |
| 3 | 曹超 | 176 | 98 | 90 |
| 4 | 诸葛亮 | 164 | 54 | 67 |
| 5 | 关羽 | 110 | 145 | 47 |
| 6 | 小乔 | 140 | 103 | 78 |
| 7 | 貂蝉 | 140 | 90 | 30 |
| 8 | 孙悟空 | 198 | 80 | 77 |
+----+-----------+---------+------+---------+
8 rows in set (0.00 sec)-- 删除数据
mysql> delete from exam_result where name='孙悟空';
Query OK, 1 row affected (0.01 sec)-- 查看删除结果
mysql> select * from exam_result;
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 1 | 刘备 | 134 | 128 | 56 |
| 2 | 孙权 | 174 | 48 | 77 |
| 3 | 曹超 | 176 | 98 | 90 |
| 4 | 诸葛亮 | 164 | 54 | 67 |
| 5 | 关羽 | 110 | 145 | 47 |
| 6 | 小乔 | 140 | 103 | 78 |
| 7 | 貂蝉 | 140 | 90 | 30 |
+----+-----------+---------+------+---------+
7 rows in set (0.00 sec)
4.1.2 删除整张表数据
注意:删除整表操作要慎用
-- 准备测试表
create table for_delete (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20)
);
Query OK, 0 rows affected (0.16 sec)-- 插入测试数据
insert into for_delete (name) VALUES ('A'), ('B'), ('C');
Query OK, 3 rows affected (1.05 sec)
Records: 3 Duplicates: 0 Warnings: 0-- 查看测试数据
select * from for_delete;
+----+------+
| id | name |
+----+------+
| 1 | A |
| 2 | B |
| 3 | C |
+----+------+
3 rows in set (0.00 sec)
-- 删除整表数据--注意:是删除整张表的数据,表的结构没有被删除
delete from for_delete;
Query OK, 3 rows affected (0.00 sec)-- 查看删除结果
SELECT * FROM for_delete;
Empty set (0.00 sec)
-- 再插入一条数据,自增 id 在原值上增长
insert into for_delete (name) VALUES ('D');
Query OK, 1 row affected (0.00 sec)-- 查看数据
select * from for_delete;
+----+------+
| id | name |
+----+------+
| 4 | D |
+----+------+
1 row in set (0.00 sec)-- 查看表结构,会有 AUTO_INCREMENT=n 项
show create table for_delete\G
*************************** 1. row ***************************
Table: for_delete
Create Table: CREATE TABLE `for_delete` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(20) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
4.2 截断表
语法:
truncate [table] table_name
注意:这个操作慎用
1. 只能对整表操作,不能像 DELETE 一样针对部分数据操作;
2. 实际上 truncate不对数据操作,所以比 DELETE 更快,但是 truncate在删除数据的时候,并不经过真正的事物,所以无法回滚
3. 会重置 AUTO_INCREMENT 项
-- 准备测试表
mysql> create table for_truncate( -> id int primary key auto_increment,-> name varchar(20) );
Query OK, 0 rows affected (0.04 sec)mysql> insert into for_truncate (name) values ('A'),('B'),('C');
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0mysql> select * from for_truncate;
+----+------+
| id | name |
+----+------+
| 1 | A |
| 2 | B |
| 3 | C |
+----+------+
3 rows in set (0.00 sec)-- 截断整表数据,注意影响行数是 0,所以实际上没有对数据真正操作
mysql> truncate for_truncate;
Query OK, 0 rows affected (0.04 sec)-- 查看删除结果
mysql> select * from for_truncate;
Empty set (0.00 sec)
-- 再插入一条数据,自增 id 在重新增长
mysql> insert into for_truncate (name) values ('D');
Query OK, 1 row affected (0.01 sec)mysql> select * from for_truncate;
+----+------+
| id | name |
+----+------+
| 1 | D |
+----+------+
1 row in set (0.00 sec)-- 查看表结构,会有 AUTO_INCREMENT=2 项
mysql> show create table for_truncate\G
*************************** 1. row ***************************Table: for_truncate
Create Table: CREATE TABLE `for_truncate` (`id` int NOT NULL AUTO_INCREMENT,`name` varchar(20) DEFAULT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
1 row in set (0.00 sec)5 插入查询结果
语法:
INSERT INTO table_name [(column [, column ...])] SELECT ...
案例:删除表中的的重复复记录,重复的数据只能有一份
-- 创建原数据表
mysql> create table duplicate_table (id int, name varchar(20));
Query OK, 0 rows affected (0.01 sec)
-- 插入测试数据
mysql> insert into duplicate_table VALUES-> (100, 'aaa'),-> (100, 'aaa'),-> (200, 'bbb'),-> (200, 'bbb'),-> (200, 'bbb'),-> (300, 'ccc');
Query OK, 6 rows affected (0.00 sec)
Records: 6 Duplicates: 0 Warnings: 0
思路:
-- 创建一张空表 no_duplicate_table,结构和 duplicate_table 一样
create table no_duplicate_table LIKE duplicate_table;
Query OK, 0 rows affected (0.00 sec)
-- 将 duplicate_table 的去重数据插入到 no_duplicate_table
insert into no_duplicate_table select distinct * from duplicate_table;
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0
-- 通过重命名表,实现原子的去重操作
rename table duplicate_table to old_duplicate_table,
no_duplicate_table TO duplicate_table;
Query OK, 0 rows affected (0.00 sec)
-- 查看最终结果
select * from duplicate_table;
+------+------+
| id | name |
+------+------+
| 100 | aaa |
| 200 | bbb |
| 300 | ccc |
+------+------+
3 rows in set (0.00 sec)
6 聚合函数
| 函数 | 说明 | |
|---|---|---|
| COUNT([DISTINCT] expr) | 返回查询到的数据的 数量 | |
| SUM([DISTINCT] expr) | 返回查询到的数据的 总和,不是数字没有意义 | |
| AVG([DISTINCT] expr) | 返回查询到的数据的 平均值,不是数字没有意义 | |
| MAX([DISTINCT] expr) | 返回查询到的数据的 最大值,不是数字没有意义 | |
| MIN([DISTINCT] expr) | 返回查询到的数据的 最小值,不是数字没有意义 |
案例:
6.1 统计班级共有多少同学
-- 使用 * 做统计,不受 NULL 影响
select count(*) from students;
+----------+
| count(*) |
+----------+
| 4 |
+----------+
1 row in set (0.00 sec)
-- 使用表达式做统计
select count(1) from students;
+----------+
| COUNT(1) |
+----------+
| 4 |
+----------+
1 row in set (0.00 sec)
6.2 统计班级收集的 qq 号有多少
-- NULL 不会计入结果
select cout(qq) FROM students;
+-----------+
| count(qq) |
+-----------+
| 1 |
+-----------+
1 row in set (0.00 sec)
6.3 统计本次考试的数学成绩分数个数
-- COUNT(math) 统计的是全部成绩
select count(math) from exam_result;
+---------------+
| count(math) |
+---------------+
| 6 |
+---------------+
1 row in set (0.00 sec)
-- count(distinct math) 统计的是去重成绩数量
select count(distinct math) FROM exam_result;
+------------------------+
| count(distinct math) |
+------------------------+
| 5 |
+------------------------+
1 row in set (0.00 sec)
6.4 统计数学成绩总分
SELECT SUM(math) FROM exam_result;
+-------------+
| SUM(math) |
+-------------+
| 569 |
+-------------+
1 row in set (0.00 sec)
-- 不及格 < 60 的总分,没有结果,返回 NULL
SELECT SUM(math) FROM exam_result WHERE math < 60;
+-------------+
| SUM(math) |
+-------------+
| NULL |
+-------------+
1 row in set (0.00 sec)
6.4 统计平均总分
SELECT AVG(chinese + math + english) 平均总分 FROM exam_result;
+--------------+
| 平均总分 |
+--------------+
| 297.5 |
+--------------+
6.5 返回英语最高分
SELECT MAX(english) FROM exam_result;
+-------------+
| MAX(english)|
+-------------+
| 90 |
+-------------+
1 row in set (0.00 sec)
6.6 返回 > 70 分以上的数学最低分
SELECT MIN(math) FROM exam_result WHERE math > 70;
+-------------+
| MIN(math) |
+-------------+
| 73 |
+-------------+
1 row in set (0.00 sec)
6.7 group by子句的使用
在select中使用group by 子句可以对指定列进行分组查询
select column1, column2, .. from table group by column;
如何显示每个部门的平均工资和最高工资
select deptno,avg(sal),max(sal) from EMP group by deptno;
显示每个部门的每种岗位的平均工资和最低工资
select avg(sal),min(sal),job, deptno from EMP group by deptno, job;
显示平均工资低于2000的部门和它的平均工资
- 统计各个部门的平均工资
select avg(sal) from EMP group by deptno
having和group by配合使用,对group by结果进行过滤
select avg(sal) as myavg from EMP group by deptno having myavg<2000;
--having经常和group by搭配使用,作用是对分组进行筛选,作用有些像where。
- 在 MySQL 中,HAVING 子句通常与 GROUP BY 子句一起使用,用于对分组后的结果进行过滤。与 WHERE 子句不同,WHERE 是在分组前对数据进行过滤,而 HAVING 是在分组和聚合计算后对数据进行过滤。
- 顺序:HAVING 子句在 GROUP BY 子句之后执行,因此它只能引用在 SELECT 列表或 GROUP BY 子句中定义的聚合函数或分组列。
相关文章:

掌握MySQL:基本查询指令与技巧
🍑个人主页:Jupiter. 🚀 所属专栏:MySQL初阶学习笔记 欢迎大家点赞收藏评论😊 目录 表的增删查改1 CreateInsert1.1 单行数据 全列插入指定列插入1.2 多行数据插入 指定列插入1.3 插入否则更新 1.4 替换 2 Retrieve …...

本地生活服务信息分类信息系统
最近在找分类信息系统,看了很多市面上常见的分类信息系统: 1,私集分类信息系统 2,火鸟分类信息系统 3,觅分类信息系统 4,框分类信息系统 5,蚂蚁分类信息系统 发现很多分类信息系统,…...

视频编解码种类/技术/区别/优缺点汇总
视频编解码种类/技术/区别/优缺点汇总 按国家/机构划分的全球主要视频编码标准 (含优缺点)视频编解码涉及到的主要技术及通俗解释主流视频编码标准的实现方式 按国家/机构划分的全球主要视频编码标准 (含优缺点) 组织/国家分类标准名称 (常用名/别名)推出年份 (约)主要制定组织…...
:最接近的三数之和,接雨水)
【专题刷题】双指针(四):最接近的三数之和,接雨水
📝前言说明: 本专栏主要记录本人的基础算法学习以及LeetCode刷题记录,按专题划分每题主要记录:(1)本人解法 本人屎山代码;(2)优质解法 优质代码;ÿ…...

星露谷物语 7000+ 大型MOD整合包
衣服美化、家具美化、地图美化、人物肖像美化 全地图装修存档、人物美化、扩展包、环境美化、家具、动植物、通用前置包、新增NPC、功能、服装发饰妆 帽子发型农场小镇美化大型玩法拓展实用功能mod 动漫人物形象MOD 地点/动物/地图/功能/机械/家具/建筑/界面美化/扩展/农场/食谱…...

Vue自定义指令-防抖节流
Vue2版本 // 防抖 // <el-button v-debounce"[reset,click,300]" ></el-button> // <el-button v-debounce"[reset]" ></el-button> Vue.directive(debounce, { inserted: function (el, binding) { let [fn, event "cl…...

几款开源C#插件框架
有几个优秀的开源C#插件框架可供选择,它们提供了更完善的功能和更好的扩展性。以下是几个主流的开源C#插件框架: 1. MEF (Managed Extensibility Framework) 官方库:System.ComponentModel.Composition 特点: .NET官方提供的插件系统 基于特性(Attribute)的声明式组件注册…...

PHP使用pandoc把markdown文件转为word
文章目录 首先安装pandocPHP处理 服务器操作系统是Linux,centos 首先安装pandoc yum install -y pandoc安装完成后输入如下代码,检查安装是否成功 pandoc --versionPHP处理 我把markdown内容存到了数据库里,所以要从数据库读取内容。对内容…...

Vmware esxi 查看硬盘健康状况
起因 硬盘掉盘 - - 使用自带的命令esxcli 列出所有硬盘 esxcli storage core device list[rootlocalhost:~] esxcli storage core device list t10.NVMe____INTEL_MEMPEK1W016GAL____________________PHBT83660BYP016D____00000001Display Name: Local NVMe Disk (t10.NVMe…...
)
vue3中ref创建的变量使用`.value`(可以使用volar插件自动添加`.value)
1.安装volar插件 2.打开>设置 >扩展...

Docker中镜像、容器、仓库三者之间的关系
镜像: 定义: 镜像只是一个静态的、只读的模板,包括了创建容器所需的文件系统、依赖库、和配置。类似于操作系统之中的安装光盘或虚拟机的磁盘镜像。 特点和作用 特点: 分层存储:镜像由多个只读层(Layer)叠加而成,每一层代表一…...
)
【刷题Day19】HTTP的各个版本(浅)
HTTP 1.0 和 2.0 有什么区别? HTTP/1.0 版本主要增加以下几点: 增加了HEAD、POST等新方法。增加了响应状态码。引入了头部,即请求头和响应头在请求中加入了HTTP版本号引入了Content-Type,使得传输的数据不再限于文本。 HTTP/1.…...

浅析StringBuilder和StringBuffer的区别和联系?
区别 1. 线程安全性 StringBuilder:是非线程安全的。这意味着在多线程环境下,如果多个线程同时访问并修改同一个 StringBuilder 对象,可能会导致数据不一致或其他并发问题。不过,由于不需要考虑线程安全的额外开销,它…...

【数据融合实战手册·实战篇】二维赋能三维的5种高阶玩法:手把手教你用Mapmost打造智慧城市标杆案例
在当今数字化时代,二三维数据融合技术的重要性不言而喻。二三维数据融合通过整合二维数据的结构化优势与三维数据的直观性,打破了传统数据在表达和分析上的局限,为各行业提供了更全面、精准的数据分析手段。从智慧城市建设到工业智能制造&…...

Linux 系统编程 day5 进程管道
进程间通信(IPC) Linux环境下,进程地址空间相互独立,任何一个进程的全局变量在另一个进程中都看不到,所以进程和进程之间不能互相访问,要交换数据必须通过内核,在内核中开辟一块缓冲区…...

【项目管理】第19章 配置与变更管理-- 知识点整理
项目管理-相关文档,希望互相学习,共同进步 风123456789~-CSDN博客 (一)知识总览 项目管理知识域 知识点: (项目管理概论、立项管理、十大知识域、配置与变更管理、绩效域) 对应:第6章-第19章 第6章 项目管理概论 4分第13章 项目资源管理 3-4分第7章 项目…...

C语言---FILE结构体
一、FILE 结构体的本质与定义 基本概念 FILE 是 C 语言标准库中用于封装文件操作的结构体类型,定义于 <stdio.h> 中。它代表一个“文件流”,可以是磁盘文件、标准输入输出(stdin/stdout/stderr)或其他输入输出设备。 实现特…...

C# 高级编程:Lambda 表达式
在 C# 的高级编程中,Lambda 表达式是一个强大而灵活的工具,广泛应用于 LINQ 查询、委托、事件处理以及函数式编程等多个领域。它不仅使代码更简洁、表达更直接,而且在某些场景中能极大提高代码的可读性与可维护性。本文将从 Lambda 表达式的基本语法入手,深入探讨其原理、常…...

【Python语言基础】22、异常处理
文章目录 1. 异常1.1 简介1.2 为什么需要异常处理 2. 基本语法2.1 各部分详解 3. 异常处理流程3.1 执行try代码块3.2 异常发生检查3.3 异常捕获与匹配3.4 执行匹配的 except 代码块3.5 执行 else 代码块(可选)3.6 执行 finally 代码块(可选&a…...

7、生命周期:魔法的呼吸节奏——React 19 新版钩子
一、魔法呼吸的本质 "每个组件都是活体魔法生物,呼吸节奏贯穿其生命始终,"邓布利多的冥想盆中浮现三维相位图,"React 19的呼吸式钩子,让组件能量流转如尼可勒梅的炼金术!" ——以霍格沃茨魔法生理…...

Echart 地图放大缩小
在 ECharts 中,可以通过设置地图的 roam 属性以及相关事件监听来实现地图的放大、缩小功能。以下是实现地图放大缩小的常用方法: 1. 开启 roam 属性 roam 是 ECharts 地图组件中的一个重要属性,用于控制地图是否支持平移和缩放操作。 roam:…...

Django ORM 定义模型
提示:定义模型字段的类型 文章目录 一、字段类型二、字段属性三、元信息 一、字段类型 常用字段 字段名描述备注AutoFieldint 自增必填参数 primary_keyTrue,无该字段时,django自动创建一个 BigAutoField,一个model不能有两个Au…...

Linux和Ubuntu的驱动适配情况
旧 一、Linux Yocto3.0 二、Ubuntu 1.驱动 1.rtc正常 2.led正常 3.加密芯片正常 4.硬件看门狗不行,驱动已经适配好,等硬件修复后,直接使用脚本就可以 5.千兆网口可以,两个百兆网口不行 6.USB上面和下面都可以(插u盘…...

JavaScript 性能优化实战
一、代码执行效率优化 1. 减少全局变量的使用 全局变量在 JavaScript 中会挂载在全局对象(浏览器环境下是window,Node.js 环境下是global)上,频繁访问全局变量会增加作用域链的查找时间。 // 反例:使用全局变量 var globalVar = example; function someFunction() {con…...

b站PC网页版视频播放页油猴小插件制作
文章目录 前言需求分析实施观察页面起始渲染编码效果展示 总结 前言 新手上路,欢迎指导 需求分析 想要一个简约干净的界面,需要去除推荐栏和广告部分. 想要自由调节视频播放速率,需要在视频控制栏加一个输入框控制视频倍速 实施 观察页面起始渲染 因为要使用MutationObse…...

C#获取当前方法的命名空间、类名称、方法名称以及方法的参数信息
C#获取当前方法的命名空间、类名称、方法名称以及方法的参数信息 输出示例模块示例 输出示例 获取信息:WindowsFormsApp1.Form1.button1_Click(System.Object sender,System.EventArgs e) 引发的异常:“System.IndexOutOfRangeException”(位于 WindowsFormsApp1.ex…...

git常用的命令
最近使用git进行团队开发遇到的一些分支的问题需要使用各种命令,整理一下方便日后使用 1.常用的Git命令 1.初始化仓库 git init //创建一个新的Git仓库2. 克隆仓库 git clone <repository-url> //克隆远程仓库到本地。3.查看当前的状态 git status …...

大语言模型的训练、微调及压缩技术
The rock can talk — not interesting. The rock can read — that’s interesting. (石头能说话,不稀奇。稀奇的是石头能读懂。) ----硅谷知名创业孵化器 YC 的总裁 Gar Tan 目录 1. 什么是大语言模型? 2. 语言建模ÿ…...

制作一个简单的操作系统2
Linux 一般都提供了需要的标准工具。使用nasm汇编器,gcc编写自己的os 开发环境截图: 创建一个文件,让 BIOS 将文件识别为一个可引导的磁盘 理论基础 计算机上电启动后,首先运行主板 BIOS 程序, BIOS 并不知道如何加载操作系统,所以 BIOS 把加载操作系统的任务交给引导…...

day31和day32图像处理OpenCV
文章目录 一、图像预处理10 图像添加水印11 图像噪点消除11.1 均值滤波11.2 方框滤波11.3 高斯滤波11.4 中值滤波11.5 双边滤波11.6 小结 12 图像梯度处理12.1 图像梯度12.2 垂直或水平边缘提取 一、图像预处理 10 图像添加水印 本实验中添加水印的概念其实可以理解为将一张图…...

火山引擎的生态怎么样
“火山引擎”是字节跳动旗下的**云计算服务平台**,主要为企业提供智能化的技术解决方案,涵盖云计算、大数据、人工智能、音视频处理等多个领域。其“生态”指的是火山引擎通过技术开放、合作伙伴计划、行业解决方案等构建的商业与技术协作网络。以下从多…...

AI 数字短视频系统AI数字人源码开发:开启短视频行业发展新维度
在短视频行业蓬勃发展的背后,创作效率瓶颈、内容同质化等问题逐渐凸显。AI 数字短视频数字人源码开发的出现,以创新性的解决方案,为行业发展带来了全新机遇与多元价值。 打破创作壁垒,释放全民创作潜力 对于普通创作者而言&…...

FreeFileSync:文件同步对比工具
FreeFileSync 是一款开源、跨平台的文件同步与备份工具,支持 Windows、Linux 和 macOS 系统。其核心功能是通过智能对比源文件夹与目标文件夹的内容差异,仅同步修改部分,提升效率并节省存储空间。软件体积小巧(约20MB…...

SimBody安装
SimBody安装 Simbody 是一个用于创建生物力学和机械系统仿真的多体动力学库。 SimBody安装 Windows安装: 下载地址:GitHub - simbody/simbody: High-performance C multibody dynamics/physics library for simulating articulated biomechanical and…...

刀片服务器的散热构造方式
刀片服务器的散热构造是其高密度、高性能设计的核心挑战之一。其散热系统需在有限空间内高效处理多个刀片模块产生的集中热量,同时兼顾能耗、噪音和可靠性。以下从模块化架构、核心散热技术、典型方案对比、厂商差异及未来趋势等方面展开分析: 一、模块化散热架构 刀片服务器…...

从数字化到智能化,百度 SRE 数智免疫系统的演进和实践
1. 为什么 SRE 需要数智免疫系统? 2022 年 10 月,在 Gartner 公布的 2023 年十大战略技术趋势中提到了「数字免疫系统」的概念,旨在通过结合数据驱动的一系列手段来提高系统的弹性和稳定性。 在过去 2 年的时间里,百度基于该…...

STM32F7安全库各版本发布内容的表格化中文总结
以下是STM32F7安全库各版本发布内容的中文总结: 英文原文: version V2.0.0 This document describes the STM32F7 Safety release V2.0.0 Main changes: Maintenance release with new STL lib Contents: the SW expansion package, delivery itse…...

使用dompurify修复XSS跨站脚本缺陷
1. 问题描述 漏洞扫描说有一个低危漏洞,容易被跨站脚本攻击XSS。 2. 使用dompurify修复 DOMPurify is a DOM-only, super-fast, uber-tolerant XSS sanitizer for HTML, MathML and SVG. 简单来说,我们可以使用 dompurify 处理xss跨站脚本攻击。 2.…...

下载electron 22.3.27 源码错误集锦
下载步骤同 electron源码下载及编译_electron源码编译-CSDN博客 问题1 从github 下载 dugite超时,原因没有找到 Validation failed. Expected 8ea2d0d3c9d9e4615069913207371ffe892dc10fb93975972f2f6e668f2e3b3a but got e3b0c44298fc1c149afbf4c8996fb92427ae41e…...

Java漏洞原理与实战
一、基本概念 1、序列化与反序列化 (1)序列化:将对象写入IO流中,ObjectOutputStream类的writeobject()方法可以实现序列化 (2)反序列化:从IO流中恢复对象,ObjectinputStream类的readObject()方法用于反序列化 (3)意义:序列化机制允许将实现序列化的J…...

查看matlab函数帮助文档的方法
方法一:在命令行窗口中使用help命令 方法二:在命令行窗口中使用doc命令 方法三:在帮助文档中搜索关键字...

string函数具体事例
输出所有字串出现的位置 输入两个字符串A和B,输出B在A中出现的位置 输入 两行 第一行是一个含有空格的字符串 第二行是要查询的字串 输出 字串的位置 样例输入 I love c c python 样例输出 -1 样例输入 I love c c c 样例输出 8 12 #include<iostream> #inclu…...

OpenCV 中的分水岭算法的原理及其应用---图像分割的利器
图像分割作为计算机视觉的基石领域,历经数十年的演进与革新,从传统的图像处理方法到如今蓬勃发展的深度学习技术,始终推动着计算机视觉应用的边界拓展。本系列文章将通过三篇深度技术博客,分别对三种极具代表性的图像分割技术展开…...

Python项目--基于机器学习的股票预测分析系统
1. 项目介绍 在当今数字化时代,金融市场的数据分析和预测已经成为投资决策的重要依据。本文将详细介绍一个基于Python的股票预测分析系统,该系统利用机器学习算法对历史股票数据进行分析,并预测未来股票价格走势,为投资者提供决策…...

第三阶段面试题
Nginx nginx常用模块以及其功能 proxy模块,进行代理功能 ssl模块,进行HTTPS协议的使用 gzip模块,进行传输数据的压缩 upstream模块,进行反向代理时使用 static模块,静态资源进行访问的模块 cache模块࿰…...

spring响应式编程系列:总体流程
目录 示例 程序流程 just subscribe new LambdaMonoSubscriber MonoJust.subscribe new Operators.ScalarSubscription onSubscribe request onNext 时序图 类图 数据发布者 MonoJust …...

基于PySide6与pyCATIA的圆柱体特征生成工具开发实战——NX建模之圆柱命令的参考与移植
引言 在机械设计领域,特征建模的自动化是提升设计效率的关键。本文基于PySide6与pycatia技术栈,深度解析圆柱特征自动化生成系统的开发实践,涵盖参数化建模、交互式元素选择、异常处理等核心模块,实现比传统手动操作提升3倍效率的…...

kafka jdbc connector适配kadb数据实时同步
测试结论 源端增量获取方式包括:bulk、incrementing、timestamp、incrementingtimestamp(混合),各种方式说明如下: bulk: 一次同步整个表的数据 incrementing: 使用严格的自增列标识增量数据。不支持对旧数据的更新…...

pgsql中使用jsonb的mybatis-plus和jps的配置
在pgsql中使用jsonb类型的数据时,实体对象要对其进行一些相关的配置,而mybatis和jpa中使用各不相同。 在项目中经常会结合 MyBatis-Plus 和 JPA 进行开发,MyBatis_plus对于操作数据更灵活,jpa可以自动建表,两者各取其…...

4.17-4.18学习总结 多线程
并发与并行: 并发和并行是有可能都在发生的。 多线程的实现方式: 第一种:创建子类对象,调用start方法启动线程。 第二种: 第三种: 第一种和第二种不可以获取到多线程结果,但第三章种可以。 多…...