小白爬虫——selenium入门超详细教程
目录
一、selenium简介
二、环境安装
2.1、安装Selenium
2.2、浏览器驱动安装
三、基本操作
3.1、对页面进行操作
3.1.1、初始化webdriver
3.1.2、打开网页
3.1.3、页面操作
3.1.4、页面数据提取
3.1.5、关闭页面
3.1.6、综合小案例
3.2、对页面元素进行操作
3.2.1、获取页面链接元素
3.2.2、模拟鼠标的基本操作
3.2.3、页面加载策略和延时等待
3.2.4、切换窗口
3.2.5、切换表单
3.2.6、动作链
四、高级操作
4.1、反检测
4.1.1、使用stealth.min.js文件
4.1.2、使用debugging模式
4.1.3、使用undetected_edgedriver
4.2、图片验证码
五、结语
一、selenium简介
Selenium是一个用于自动化测试的工具,它可以模拟用户在浏览器中的各种操作。除了用于爬虫,Selenium还可以用于测试,尤其是在处理动态加载页面时非常有用。本文将提供一个超级详细的Selenium教程,以帮助您快速入门并了解其各种功能和用法。
二、环境安装
2.1、安装Selenium
在终端通过pip安装:
1|pip install selenium2.2、浏览器驱动安装
针对不同的浏览器,安装不同的驱动:(本文以Edge浏览器为例)
2.2.1、查看浏览器的版本


2.2.2、下载对应版本的驱动程序
下载网址链接:Microsoft Edge WebDriver |Microsoft Edge 开发人员

2.2.3、解压获取exe文件地址

三、基本操作
3.1、对页面进行操作
3.1.1、初始化webdriver
在使用Selenium之前,我们需要初始化WebDriver。WebDriver是一个控制浏览器的工具,它可以模拟用户在浏览器中的各种操作。Selenium支持多种浏览器,如Chrome、Firefox、Safari等。下面是一些示例代码,展示如何初始化Edge、Chrome和Firefox浏览器的WebDriver:
from selenium import webdriver# 初始化Edge浏览器
driver = webdriver.Edge()
# 初始化Chrome浏览器
driver = webdriver.Chrome()
# 初始化Firefox浏览器
driver = webdriver.Firefox()3.1.2、打开网页
一旦我们初始化好了WebDriver,接下来我们就可以使用它来打开网页。下面是一些示例代码,展示如何使用WebDriver打开网页:
from selenium import webdriver# 初始化Edge浏览器
driver = webdriver.Edge()
driver.get("https://www.baidu.com/")
driver.get("https://www.jd.com/")3.1.3、页面操作
一旦我们打开了网页,我们就可以使用WebDriver来模拟各种用户操作,如设置窗口最大化、设置窗口位置、设置窗口大小等。下面是一些示例代码,展示如何在网页中进行一些常见的操作:
import timefrom selenium import webdriver# 初始化Edge浏览器
driver = webdriver.Edge()
driver.get("https://www.baidu.com/")
# 调用maximize_window方法,使浏览器窗口最大化显示
driver.maximize_window()
# 设置浏览器的窗口位置
driver.set_window_position(1100, 20)
# 设置浏览器的窗口大小
driver.set_window_size(900, 900)
time.sleep(5)3.1.4、页面数据提取
除了操作页面,Selenium还可以用于提取页面的源代码。我们可以使用WebDriver的page_source来获取页面源代码,下面是示例代码,展示如何提取页面中的数据:
import time
from selenium import webdriver# 初始化Edge浏览器
driver = webdriver.Edge()
driver.get("https://www.baidu.com/")
# 调用maximize_window方法,使浏览器窗口最大化显示
driver.maximize_window()
# 设置浏览器的窗口位置
driver.set_window_position(1100, 20)
# 设置浏览器的窗口大小
driver.set_window_size(900, 900)
time.sleep(5)
# 获取页面源代码
page_content = driver.page_source
# 打印获取内容
print(page_content)3.1.5、关闭页面
当我们完成了对网页的操作和数据提取后,最后不要忘记关闭WebDriver。关闭WebDriver将会关闭浏览器窗口,并释放相关的资源。下面是示例代码,展示如何关闭WebDriver:
import time
from selenium import webdriver# 初始化Edge浏览器
driver = webdriver.Edge()
driver.get("https://www.baidu.com/")
# 调用maximize_window方法,使浏览器窗口最大化显示
driver.maximize_window()
time.sleep(2)
# 获取页面数据
page_content = driver.page_source
# 打印页面数据内容
print(page_content)
# 关闭一个页面
driver.close()
# 关闭全部页面
driver.quit()3.1.6、综合小案例
"""
@Author :江上挽风&sty
@Blog(个人博客地址):https://blog.csdn.net/weixin_56097064
@File :Selenium爬虫
@Time :2024/12/5 11:19
@Motto:一直努力,一直奋进,保持平常心"""
import timefrom selenium import webdriver
from selenium.webdriver.edge.service import Service
from selenium.webdriver.edge.options import Optionsurl = "https://www.baidu.com/"
url1 = "https://www.jd.com/"
# Service类用于设置WebDriver服务,这里指定了Edge浏览器驱动程序的路径
service = Service(executable_path='D:\ApplicationsSoftware\EdgeDriver\edgedriver_win32\msedgedriver.exe')
opt = Options()
opt.add_argument("--disable-blink-features=AutomationControlled")
# 使用上面定义的服务对象来创建一个Edge浏览器的WebDriver对象,这个对象可以模拟浏览器操作
browser = webdriver.Edge(service=service,options=opt)
# 调用maximize_window方法,使浏览器窗口最大化显示
browser.maximize_window()
# 设置浏览器的窗口位置
# browser.set_window_position(1100, 20)
# 设置浏览器的窗口大小
# browser.set_window_size(900, 900)
# 使用get方法通过url打开指定的网页
browser.get(url)
# time模块的sleep函数用于暂停程序执行,这里暂停5秒,以便有足够的时间观察网页加载情况
time.sleep(2)
# 通过url访问另一个网页
browser.get(url1)
time.sleep(2)
# 调用back返回上一个网页
browser.back()
time.sleep(2)
# 调用forward()函数前往下一个网页
browser.forward()
time.sleep(1)
# 刷新页面
browser.refresh()
time.sleep(1)
# 调用page_source获取网页内容
page_content = browser.page_source
print(page_content)
# 最后,调用close方法关闭浏览器窗口
browser.close()
3.2、对页面元素进行操作
3.2.1、获取页面链接元素
鼠标右键然后选择检查(或者按F12),获取页面的全部元素,然后选中元素,进行复制。
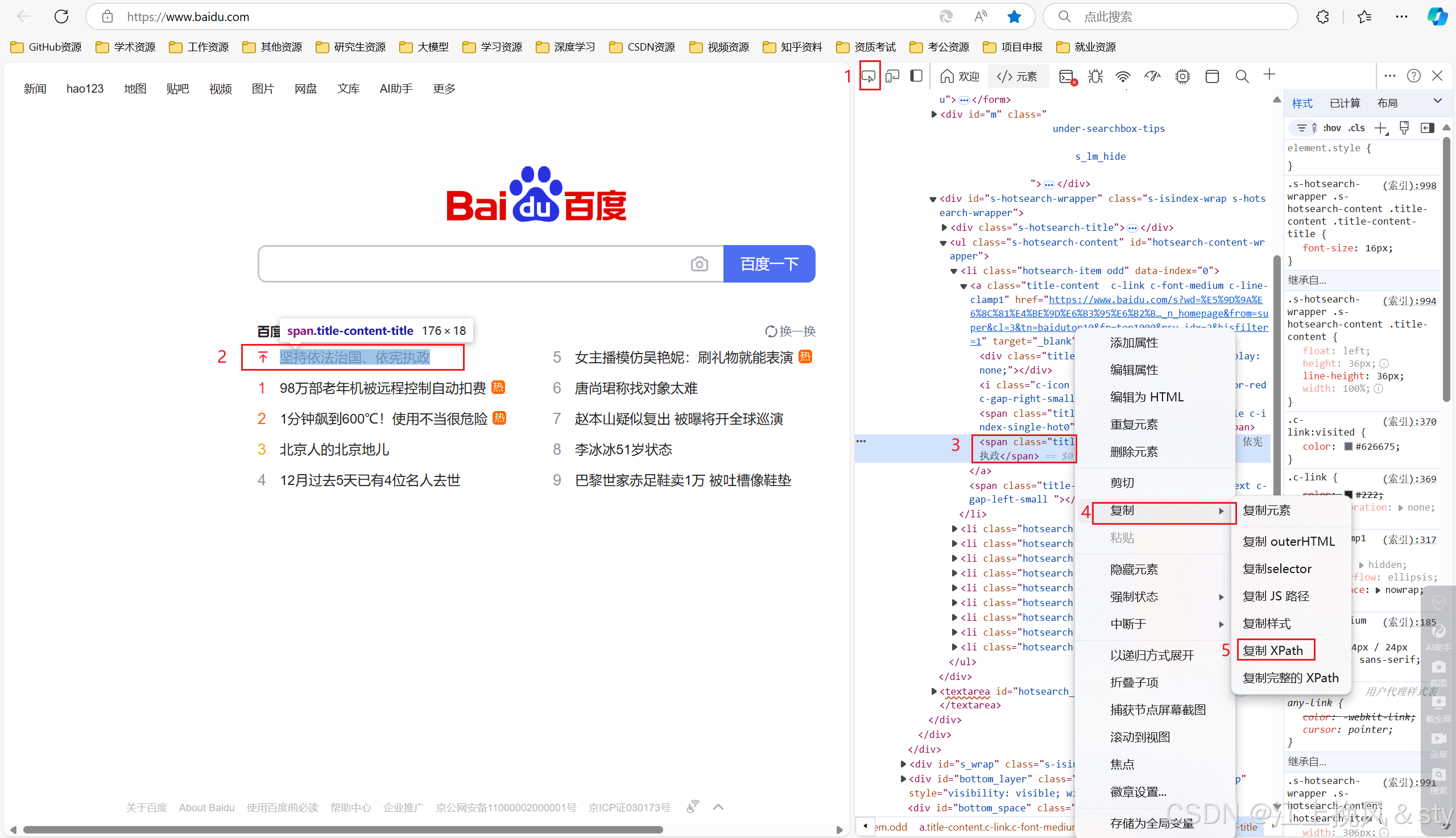
from selenium import webdriver
from selenium.webdriver.common.by import By# 初始化Edge浏览器
driver = webdriver.Edge()
driver.get("https://www.baidu.com/")
# 调用maximize_window方法,使浏览器窗口最大化显示
driver.maximize_window()
# 模拟点击百度页面链接进行跳转
# 获取页面元素
link = driver.find_element(by=By.XPATH,value="//*[@id='hotsearch-content-wrapper']/li[1]/a/span[2]")
# 链接跳转
link.click()我们在实际使用浏览器的时候,很重要的操作有输入文本、点击确定等等。对此,Selenium提供了一系列的方法来方便我们实现以上操作。通过webdriver对象的 find_element(by=“属性名”, value=“属性值”),主要包括以下这八种:
| 属性 | 函数 |
| CLASS | find_element(by=By.CLASS_NAME, value=‘’) |
| XPATH | find_element(by=By.XPATH, value=‘’) |
| LINK_TEXT | find_element(by=By.LINK_TEXT, value=‘’) |
| CSS | find_element(by=By.CSS_SELECTOR, value=‘’) |
| ID | find_element(by=By.ID, value=‘’) |
| TAG | find_element(by=By.TAG_NAME, value=‘’) |
| PARTIAL_LINK_TEXT | find_element(by=By.PARTIAL_LINK_TEXT, value=‘’) |
3.2.2、模拟鼠标的基本操作
首先,我们需要引入Keys类。
from selenium.webdriver.common.keys import Keys其次,模型通过百度搜索python爬虫。
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
# 初始化Edge浏览器
driver = webdriver.Edge()
driver.get("https://www.baidu.com/")
# 调用maximize_window方法,使浏览器窗口最大化显示
driver.maximize_window()# 模拟点击百度页面链接进行跳转
# 获取页面元素
search_element = driver.find_element(by=By.XPATH,value="//*[@id='kw']")
# 模拟向输入框中输入python爬虫并回车
search_element.send_keys('python爬虫', Keys.ENTER)
time.sleep(10)
基本操作:
| 具体操作 | 函数 |
| 删除键 | send_keys(Keys.BACK_SPACE) |
| 空格键 | send_keys(Keys.SPACE) |
| 制表键 | send_keys(Keys.TAB) |
| 回退键 | send_keys(Keys.ESCAPE) |
| 回车 | send_keys(Keys.ENTER) |
| 全选 | send_keys(Keys.CONTRL,‘a’) |
| 复制 | send_keys(Keys.CONTRL,‘c’) |
| 剪切 | send_keys(Keys.CONTRL,‘x’) |
| 粘贴 | send_keys(Keys.CONTRL,‘x’) |
| 键盘F1 | send_keys(Keys.F1) |
3.2.3、页面加载策略和延时等待
页面加载策略是指在浏览器中加载网页时,Selenium WebDriver等待页面加载完成的行为。这些策略可以帮助我们控制WebDriver在页面加载时的行为,以适应不同的测试需求和性能优化。选择合适的页面加载策略可以显著影响测试的执行时间和稳定性。例如,在单页应用中,由于页面内容是动态加载的,使用eager或none策略可能更合适,因为它们可以更快地响应页面的变化。而在需要完全加载所有资源以确保页面功能正常的测试中,使用normal策略可能更合适以下是Selenium支持的页面加载策略:
| 页面加载策略 | 特点 |
| normal | 这是默认的页面加载策略。在这种策略下,WebDriver会等待整个页面包括所有子资源(如图像、CSS、JavaScript等)都加载完成,直到触发load事件后才会继续执行后续的操作。这意味着WebDriver会等待页面完全加载,包括所有的外部资源加载完成 |
| eager | 在eager策略下,WebDriver会等待文档被完全加载和解析完成,但不会等待样式表、图像和iframe等子资源加载完成。这通常意味着WebDriver会等待DOMContentLoaded事件触发后继续执行,这比load事件更早 |
| none | 使用none策略时,WebDriver不会等待页面加载完成,它仅等待初始的HTML被部分下载后就会停止等待,允许脚本继续执行。这意味着WebDriver不会等待任何额外的资源加载,如CSS、JavaScript或图像 |
在Selenium中,设置WebDriver等待是一种重要的技术,用于确保在执行某些操作之前,页面上的元素已经加载完成或者某个条件已经满足。Selenium提供了两种主要的等待机制:显式等待(Explicit Wait)和隐式等待(Implicit Wait)。
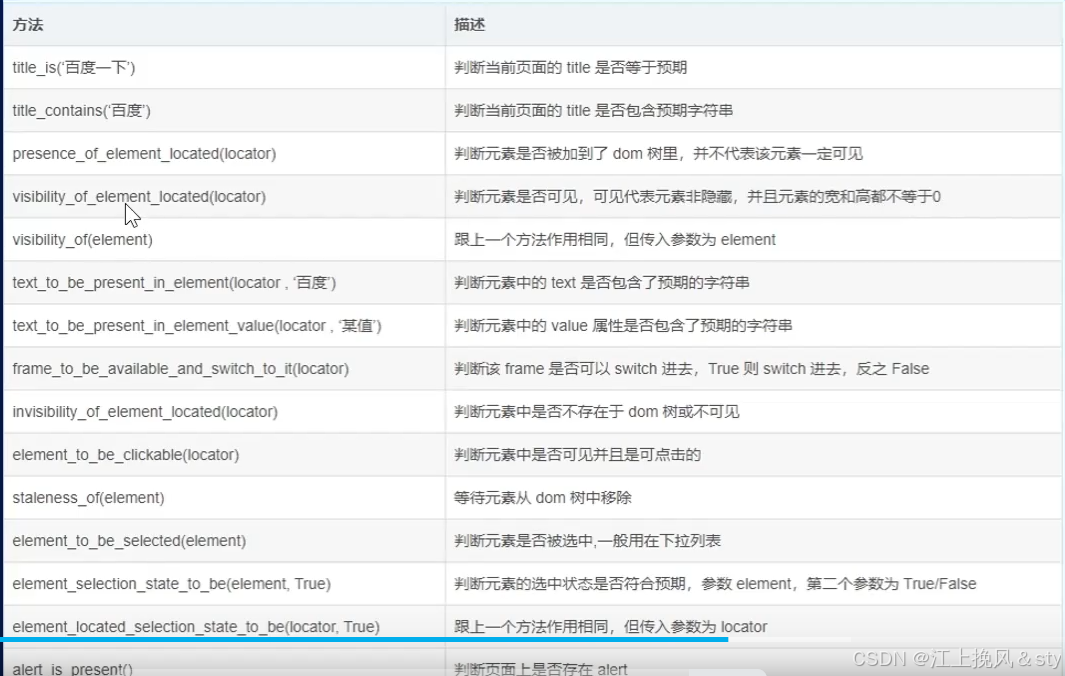
显式等待:显式等待允许你等待某个条件成立,而不是盲目地等待一个固定的时间。它提供了更灵活的控制,可以等待特定的元素出现、元素变得可点击、元素的可见性等。下面包含常用的显式等待方法:
"""
@Author :江上挽风&sty
@Blog(个人博客地址):https://blog.csdn.net/weixin_56097064
@File :练习
@Time :2024/12/5 13:57
@Motto:一直努力,一直奋进,保持平常心"""
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
# 导入显式等待库
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC# 初始化Edge浏览器
driver = webdriver.Edge()
driver.get("https://www.baidu.com/")
# 调用maximize_window方法,使浏览器窗口最大化显示
driver.maximize_window()
# 设置显式等待,最多等待10秒
wait = WebDriverWait(driver, 10)
try:# 等待直到某个元素出现element = wait.until(EC.presence_of_element_located((By.XPATH, "//*[@id='kw']")))
except:print("未找到元素")driver.close()exit()
# 获取页面元素
search_element = driver.find_element(by=By.XPATH,value="//*[@id='kw']")
# 模拟向输入框中输入python爬虫并回车
search_element.send_keys('python爬虫', Keys.ENTER)
time.sleep(10)
driver.close() 隐式等待:隐式等待设置了一个全局等待时间,在这个时间内,WebDriver会等待某个元素出现。如果在设置的时间内找到了元素,WebDriver会继续执行;如果超时,则抛出NoSuchElementException异常。
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
# 初始化Edge浏览器
driver = webdriver.Edge()
# 设置隐式等待5秒钟
driver.implicitly_wait(5)
driver.get("https://www.baidu.com/")
# 调用maximize_window方法,使浏览器窗口最大化显示
driver.maximize_window()# 模拟点击百度页面链接进行跳转
# 获取页面元素
search_element = driver.find_element(by=By.XPATH,value="//*[@id='kw']")
# 模拟向输入框中输入python爬虫并回车
search_element.send_keys('python爬虫', Keys.ENTER)
time.sleep(10)
driver.close()3.2.4、切换窗口
在 selenium 操作页面的时候,可能会因为点击某个链接而跳转到一个新的页面(打开了一个新标签页),这时候 selenium 实际还是处于上一个页面的,需要我们进行切换才能够定位最新页面上的元素。
- 打开一个新的页面并切换到新页面:switch_to.new_window('tab')
- 打开一个新的窗口并切换到新窗口:switch_to.new_window('window')
"""
@Author :江上挽风&sty
@Blog(个人博客地址):https://blog.csdn.net/weixin_56097064
@File :练习
@Time :2024/12/5 13:57
@Motto:一直努力,一直奋进,保持平常心"""
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.edge.service import Service
from selenium.webdriver.edge.options import Options
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC# Service类用于设置WebDriver服务,这里指定了Edge浏览器驱动程序的路径
service = Service(executable_path='D:\ApplicationsSoftware\EdgeDriver\edgedriver_win32\msedgedriver.exe')
opt = Options()
opt.add_argument("--disable-blink-features=AutomationControlled")
opt.page_load_strategy = 'eager'
# 初始化Edge浏览器
driver = webdriver.Edge()
driver.get("https://www.readnovel.com/book/22312481000716402#Catalog")
# 调用maximize_window方法,使浏览器窗口最大化显示
driver.maximize_window()
time.sleep(3)
locator = (By.XPATH, '//*[@id="j-catalogWrap"]/div[2]/div[2]/ul/li/a')
WebDriverWait(driver, 5).until(EC.presence_of_all_elements_located(locator))
# //*[@id="j-catalogWrap"]/div[2]/div[2]/ul/li[1]/a
# //*[@id="j-catalogWrap"]/div[2]/div[2]/ul/li[14]/a
# //*[@id="j-catalogWrap"]/div[2]/div[2]/ul/li[15]/a
next_page = driver.find_elements(by=By.XPATH, value="//*[@id='j-catalogWrap']/div[2]/div[2]/ul/li/a")for next in next_page:next.click()a = str(next.get_attribute('href').split("/")[-1])print(a)time.sleep(2)driver.execute_script('$(".lbf-panel-head").css("display","none")')driver.execute_script('$(".lbf-panel-body").css("display","none")')# link = driver.find_element(by=By.ID, value='//*[@id="j_closeGuide"]')# link.click()# locator1 = (By.XPATH, '//*[@id="chapter-95831384777767481"]/div/div[1]/h1')# locator1 = (By.XPATH, '//*[@id="chapter-95831384777833017"]/div/div[1]/h1')95831384777833017driver.switch_to.window(driver.window_handles[-1])# WebDriverWait(driver,20).until(EC.presence_of_element_located(locator1))time.sleep(5)# filename = driver.find_element(by=By.XPATH,value='//*[@id="chapter-id}]/div/div[1]/h1').textfilename = driver.find_element(by=By.XPATH, value=f'//*[@id="chapter-{a}"]/div/div[1]/h1').textcontent = driver.find_element(by=By.XPATH,value=f'//*[@id="chapter-{a}"]/div/div[2]/div').textwith open(f'D:\ProjectCode\Spider\StudySpider07\\{filename}.txt', 'w', encoding='utf-8') as f:f.write(content)print(f'已下载{filename}')driver.switch_to.window(driver.window_handles[0])3.2.5、切换表单
在Selenium中,处理表单切换是一个常见的任务,尤其是在涉及到frame或iframe元素时。以下是Selenium中切换表单的一些关键点:
- Selenium提供了
switch_to.frame()方法来切换到frame或iframe。这个方法可以接受几种类型的参数,包括id、name、index以及页面元素对象。 - 完成
frame/iframe内的操作后,可以通过switch_to.default_content()切换回主文档,或者使用switch_to.parent_frame()切换到父级frame。 - 如果页面中有多层嵌套的
frame/iframe,你可能需要多次调用switch_to.frame()方法来逐层深入,或者使用switch_to.parent_frame()来逐层返回。
"""
@Author :江上挽风&sty
@Blog(个人博客地址):https://blog.csdn.net/weixin_56097064
@File :切换表单
@Time :2024/12/6 13:41
@Motto:一直努力,一直奋进,保持平常心"""
import timefrom selenium import webdriver
from selenium.webdriver.edge.service import Service
from selenium.webdriver.edge.options import Options
from selenium.webdriver.common.by import Byurl = "https://www.qidian.com/all/"
# Service类用于设置WebDriver服务,这里指定了Edge浏览器驱动程序的路径
service = Service(executable_path='D:\ApplicationsSoftware\EdgeDriver\edgedriver_win32\msedgedriver.exe')
opt = Options()
opt.add_argument("--disable-blink-features=AutomationControlled")
# 使用上面定义的服务对象来创建一个Edge浏览器的WebDriver对象,这个对象可以模拟浏览器操作
browser = webdriver.Edge(service=service, options=opt)
# 调用maximize_window方法,使浏览器窗口最大化显示
browser.maximize_window()
browser.get(url)
# 显式等待五秒,加载页面
browser.implicitly_wait(5)time.sleep(3)
login_button = browser.find_element(by=By.XPATH, value='//*[@id="login-btn"]')
login_button.click()
time.sleep(3)
# 先获取表单所在的iframe元素
iframe = browser.find_element(by=By.XPATH, value='//*[@id="loginIfr"]')
# 进入这个表单
browser.switch_to.frame(iframe)
time.sleep(3)
browser.find_element(by=By.XPATH, value='//*[@id="username"]').send_keys('17369961234')
time.sleep(3)
browser.find_element(by=By.XPATH, value='//*[@id="password"]').send_keys('skjhg')
time.sleep(3)
browser.find_element(by=By.XPATH, value='//*[@id="j-inputMode"]/div[2]/div/label[2]').click()
time.sleep(2)
browser.find_element(by=By.XPATH, value='//*[@id="j-loginInputMode"]/div[3]/div[1]/p[2]/label').click()
time.sleep(2)
browser.find_element(by=By.XPATH, value='//*[@id="j-inputMode"]/div[2]/a').click()
time.sleep(2)
browser.switch_to.default_content()
time.sleep(2)3.2.6、动作链
在Selenium中,动作链(ActionChains)是一种用于执行复杂用户交互的方法,比如鼠标移动、点击、拖放和键盘输入等。以下是Selenium中动作链的一些基本介绍和常用方法。动作链允许你将多个操作按顺序存放在一个队列里,当你调用perform()方法时,这些操作会依次执行。
常用方法:
| 方法 | 解释 |
| click(on_element=None) | 单击鼠标左键 |
| click_and_hold(on_element=None) | 点击鼠标左键并保持按下状态 |
| context_click(on_element=None) | 执行鼠标右键点击(上下文菜单) |
| double_click(on_element=None) | 双击鼠标左键 |
| drag_and_drop(source, target) | 将一个元素拖拽到另一个元素上释放 |
| drag_and_drop_by_offset(source, xoffset, yoffset) | 将源元素拖动到指定的偏移位置上释放 |
| key_down(value, element=None) | 按下键盘上的某个键,不释放 |
| key_up(value, element=None) | 释放键盘上的某个键 |
| move_by_offset(xoffset, yoffset) | 鼠标从当前位置移动到某个坐标 |
| move_to_element(to_element) | 鼠标移动到某个元素 |
| move_to_element_with_offset(to_element, xoffset, yoffset) | 移动到距某个元素多少距离的位置 |
| perform() | 执行链中的所有动作 |
| release(on_element=None) | 在某个元素位置松开鼠标左键 |
| send_keys(*keys_to_send) | 发送某个键到当前焦点的元素 |
| send_keys_to_element(element, *keys_to_send) | 发送某个键到指定元素 |
"""
@Author :江上挽风&sty
@Blog(个人博客地址):https://blog.csdn.net/weixin_56097064
@File :动作链
@Time :2024/12/6 14:11
@Motto:一直努力,一直奋进,保持平常心"""
import timefrom selenium import webdriver
from selenium.webdriver.edge.service import Service
from selenium.webdriver.edge.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.select import Selecturl = "https://www.12306.cn/index/index.html"
# Service类用于设置WebDriver服务,这里指定了Edge浏览器驱动程序的路径
service = Service(executable_path='D:\ApplicationsSoftware\EdgeDriver\edgedriver_win32\msedgedriver.exe')
opt = Options()
# 防止Edge在自动化测试过程中弹出一些对话框
opt.add_argument("--disable-blink-features=AutomationControlled")
# 使用add_experimental_option方法可以添加一些实验性的Edge选项
opt.add_experimental_option('excludeSwitches', ['enable-automation'])
# 的作用是让浏览器在WebDriver会话结束后保持开启状态
opt.add_experimental_option("detach", True)
# 使用上面定义的服务对象来创建一个Edge浏览器的WebDriver对象,这个对象可以模拟浏览器操作
browser = webdriver.Edge(service=service, options=opt)
# 显式等待五秒,加载页面
browser.implicitly_wait(5)
# 调用maximize_window方法,使浏览器窗口最大化显示
browser.maximize_window()
browser.get(url)time.sleep(1)
# 将鼠标悬停在车票上
ticket_element = browser.find_element(by=By.XPATH, value='//*[@id="J-chepiao"]/a')
ActionChains(browser).move_to_element(ticket_element).perform()
time.sleep(2)
# 点击单程进入下一个页面
one_way_element = browser.find_element(by=By.XPATH, value='//*[@id="megamenu-3"]/div[1]/ul/li[1]/a')
ActionChains(browser).click(one_way_element).perform()
# 输入出发地
time.sleep(2)
from_station = browser.find_element(by=By.XPATH, value='//*[@id="fromStationText"]')
ActionChains(browser).click(from_station).pause(1).send_keys('重庆').pause(1).send_keys(Keys.ARROW_DOWN).pause(1).send_keys(Keys.ENTER).perform()
time.sleep(2)
# 输入目的地
to_station = browser.find_element(by=By.XPATH, value='//*[@id="toStationText"]')
ActionChains(browser).click(to_station).pause(1).send_keys('长沙').pause(1).send_keys(Keys.ENTER).perform()
time.sleep(2)
# 输入出发日期
date = browser.find_element(by=By.XPATH, value='//*[@id="place_area"]/ul/li[4]/span')
ActionChains(browser).click(date).pause(1).send_keys(Keys.CLEAR).pause(1).send_keys("2024-12-06").pause(1).send_keys(Keys.ARROW_DOWN).pause(1).send_keys(Keys.ENTER).perform()
time.sleep(2)
# 选择学生
browser.find_element(by=By.XPATH, value='//*[@id="sf2_label"]').click()
time.sleep(2)
# 勾线高铁
browser.find_element(by=By.XPATH, value='//*[@id="_ul_station_train_code"]/li[1]/label').click()
time.sleep(1)
# 选择发车时间
start_time_element = browser.find_element(by=By.XPATH, value='//*[@id="cc_start_time"]')
Select(start_time_element).select_by_visible_text('12:00--18:00')
# 单击查询
browser.find_element(by=By.XPATH, value='//*[@id="query_ticket"]').click()
time.sleep(3)四、高级操作
4.1、反检测
在使用Selenium进行自动化测试或爬虫时,网站可能会通过各种方式检测到自动化工具的使用。以下是一些常用的Selenium反检测方法。
4.1.1、使用stealth.min.js文件
stealth.min.js 是一个JavaScript文件,它包含了一系列的代码,用于隐藏Selenium WebDriver的自动化特征,使得使用Selenium进行自动化测试时,浏览器的行为更接近于真实用户的浏览器行为,从而降低被网站检测为自动化工具的风险。在使用Selenium WebDriver时,可以在启动浏览器之前,通过执行stealth.min.js中的JavaScript代码来实现隐藏特征。这通常是通过Selenium的execute_cdp_cmd方法实现的,该方法允许执行Chrome DevTools Protocol命令。
下载安装stealth.min.js文件:

4.1.2、使用debugging模式
在Selenium中使用调试模式来防止检测,主要是指通过开启Chrome的远程调试端口来接管已经打开的浏览器会话,从而避免被网站检测到自动化工具的使用。
步骤:
1、找到Edge浏览器的安装路径:
C:\Program Files (x86)\Microsoft\Edge\Application
2、在命令提示符下输入命令创建配置浏览器:
msedge.exe --remote-debugging-port=9222 --user-data-dir="你的用户数据目录路径"
3、复制在Edge的快捷方式,并在其上右击,选择属性,在目标栏后面加上空格加上下面命令
"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe" --remote-debugging-port=9222 --user-data-dir="你的用户数据目录路径"
from selenium import webdriver
from selenium.webdriver.chrome.options import Optionsoptions = Options()
options.add_experimental_option("debuggerAddress", "127.0.0.1:9222")
driver = webdriver.Edge(options=options)4.1.3、使用undetected_edgedriver
undetected_edgedriver是一个基于undetected_chromedriver进行一些调整以支持Edge浏览器的Selenium库。它旨在帮助自动化脚本更难被网站检测到,从而提高自动化任务的成功率。
安装 undetected_edgedriver:
pip3 install undetected-edgedriver使用方法:
import undetected_edgedriver as uc
# 创建Edge浏览器实例
browser = uc.Edge(use_subprocess=True)
# 打开网页
browser.get(url="https://your-target-website.com/")
# 执行其他操作,例如查找元素、点击按钮等
# ...
# 关闭浏览器
browser.quit()4.2、图片验证码
使用超级鹰打码平台识别验证码图片中的数据,用于模拟登陆操作。
- 查询该用户是否还有剩余的题分

- 创建一个软件:用户中心>软件ID>生成一个软件ID>录入软件名称>提交(软件id和秘钥)

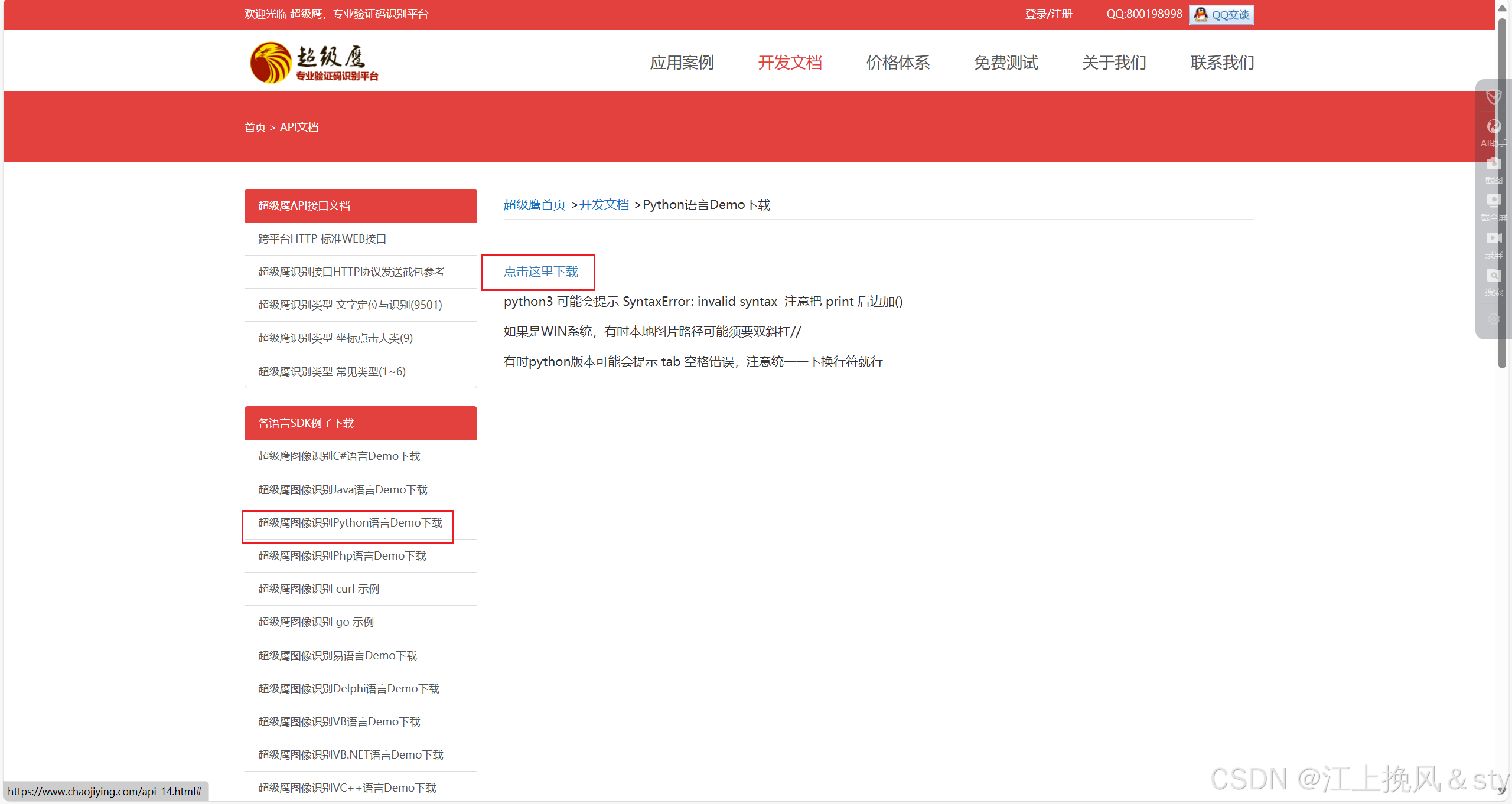
- 下载示例代码:开发文档>点此下载python示例
- 示例代码:
#!/usr/bin/env python
# coding:utf-8
import jsonimport requests
from hashlib import md5class Chaojiying_Client(object):def __init__(self, username, password, soft_id):self.username = usernamepassword = password.encode('utf8')self.password = md5(password).hexdigest()self.soft_id = soft_idself.base_params = {'user': self.username,'pass2': self.password,'softid': self.soft_id,}self.headers = {'Connection': 'Keep-Alive','User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)',}def PostPic(self, im, codetype):"""im: 图片字节codetype: 题目类型 参考 http://www.chaojiying.com/price.html"""params = {'codetype': codetype,}params.update(self.base_params)files = {'userfile': ('ccc.jpg', im)}r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files, headers=self.headers)return r.json()def PostPic_base64(self, base64_str, codetype):"""im: 图片字节codetype: 题目类型 参考 http://www.chaojiying.com/price.html"""params = {'codetype': codetype,'file_base64':base64_str}params.update(self.base_params)r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, headers=self.headers)return r.json()def ReportError(self, im_id):"""im_id:报错题目的图片ID"""params = {'id': im_id,}params.update(self.base_params)r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers)return r.json()if __name__ == '__main__':with open('password.json','r',encoding='utf-8') as f:info = json.loads(f.read())password = info['password']username = info['username']soft_id = info['soft_id']print(username)chaojiying = Chaojiying_Client(username, password, soft_id) #用户中心>>软件ID 生成一个替换 96001im = open('a.jpg', 'rb').read()code = chaojiying.PostPic(im,1902)print(code)#本地图片文件路径 来替换 a.jpg 有时WIN系统须要//# print chaojiying.PostPic(im, 1902)# #1902 验证码类型 官方网站>>价格体系 3.4+版 print 后要加()#print chaojiying.PostPic(base64_str, 1902) #此处为传入 base64代码只需要password.jsonw文件中替换自己的用户名、密码和ID即可。
selenium模拟验证码登入超级鹰专业验证码识别平台案例:
"""
@Author :江上挽风&sty
@Blog(个人博客地址):https://blog.csdn.net/weixin_56097064
@File :验证码
@Time :2024/12/6 16:13
@Motto:一直努力,一直奋进,保持平常心"""
import json
import timefrom selenium import webdriver
from selenium.webdriver.edge.service import Service
from selenium.webdriver.common.by import Byfrom chaojiying_Python import chaojiying
from chaojiying_Python.chaojiying import Chaojiying_Clientservice = Service(executable_path='D:\ApplicationsSoftware\EdgeDriver\edgedriver_win32\msedgedriver.exe')
def login(url,password,username,soft_id):browser = webdriver.Edge(service=service)browser.get(url)# 输入用户名browser.find_element(by=By.XPATH, value='/html/body/div[3]/div/div[3]/div[1]/form/p[1]/input').send_keys(username)# 输入密码time.sleep(2)browser.find_element(by=By.XPATH, value='/html/body/div[3]/div/div[3]/div[1]/form/p[2]/input').send_keys(password)# 获取验证码img = browser.find_element(by=By.XPATH, value='/html/body/div[3]/div/div[3]/div[1]/form/div/img').screenshot_as_pngtime.sleep(2)Chaojiying_Client(username,password,soft_id)code = chaojiying.chaojiying.PostPic(img,1902)['pic_str']# 输入验证码browser.find_element(by=By.XPATH, value='/html/body/div[3]/div/div[3]/div[1]/form/p[3]/input').send_keys(code)time.sleep(2)# 点击登入browser.find_element(by=By.XPATH, value='/html/body/div[3]/div/div[3]/div[1]/form/p[4]/input').click()if __name__ == '__main__':url = "https://www.chaojiying.com/user/login/"with open('chaojiying_Python/password.json','r',encoding='utf-8') as f:info = json.loads(f.read())password = info['password']username = info['username']soft_id = info['soft_id']login(url, password, username, soft_id)五、结语
本博客为自学python爬虫的过程贴,内容上可能存在些许错误,希望大家批评指正,后续我将努力完善修改,散花!
相关文章:

小白爬虫——selenium入门超详细教程
目录 一、selenium简介 二、环境安装 2.1、安装Selenium 2.2、浏览器驱动安装 三、基本操作 3.1、对页面进行操作 3.1.1、初始化webdriver 3.1.2、打开网页 3.1.3、页面操作 3.1.4、页面数据提取 3.1.5、关闭页面 3.1.6、综合小案例 3.2、对页面元素进行操作 3.2.…...

斯坦福李飞飞《AI Agent:多模态交互前沿调查》论文
多模态AI系统很可能会在我们的日常生活中无处不在。将这些系统具身化为物理和虚拟环境中的代理是一种有前途的方式,以使其更加互动化。目前,这些系统利用现有的基础模型作为构建具身代理的基本构件。将代理嵌入这样的环境中,有助于模型处理和…...
)
Wordpress ElementorPageBuilder插件存在文件读取漏洞(CVE-2024-9935)
免责声明: 本文旨在提供有关特定漏洞的深入信息,帮助用户充分了解潜在的安全风险。发布此信息的目的在于提升网络安全意识和推动技术进步,未经授权访问系统、网络或应用程序,可能会导致法律责任或严重后果。因此,作者不对读者基于本文内容所采取的任何行为承担责任。读者在…...

多模态视频大模型Aria在Docker部署
多模态视频大模型Aria在Docker部署 契机 ⚙ 闲逛HuggingFace的时候发现一个25.3B的多模态大模型,支持图片和视频。刚好我有H20的GPU所以部署来看看效果,因为我的宿主机是cuda-12.1所以为了防止环境污染采用docker部署,通过一系列的披荆斩棘…...

【网盘系统】递归删除批量文件
为何需要用到递归? 在网盘系统中,文件的类型分为文件和文件夹两种类型。当我们想要批量删除文件时,不乏其中会包含文件夹,而想要删除这个文件夹,自然其中所包含的文件都要删除,而其中所包含的文件也有可能…...

产品转后端?2
产品经理的视角能让你成为更好的后端工程师: 理解业务需求转换为技术方案的过程知道为什么要这样设计API明白数据结构的选择如何影响用户体验了解性能指标对业务的实际影响 在实习过程中可以有意识地向后端倾斜: 常规产品经理工作: "…...

电子商务人工智能指南 2/6 - 需求预测和库存管理
介绍 81% 的零售业高管表示, AI 至少在其组织中发挥了中等至完全的作用。然而,78% 的受访零售业高管表示,很难跟上不断发展的 AI 格局。 近年来,电子商务团队加快了适应新客户偏好和创造卓越数字购物体验的需求。采用 AI 不再是一…...

CSS中要注意的样式效果
1. 应用过渡效果 transition: var(--aa); 2.告诉浏览器元素可能会发生变换,从而优化性能。 will-change: transform; 3.使元素不响应鼠标事件。 pointer-events: none; 4.隐藏水平方向上的溢出内容 overflow-x: hidden; 5.定义一个元素的宽度和高度之间的比…...

CTFshowPHP特性
目录 web89 代码分析 playload web90 代码分析 playload web91 代码分析 playload web92 代码分析 playload web93 代码分析 playload web94 代码分析 playload web95 web96 代码分析 playload web97 代码分析 playload web98 代码分析 playload w…...

基于Springboot+Vue的电子博物馆系统
基于SpringbootVue的电子博物馆系统 前言:随着信息技术的不断发展,传统博物馆的参观方式逐渐向数字化、在线化转型。电子博物馆作为这一转型的重要组成部分,能够通过信息化手段为用户提供更丰富、更便捷的博物馆参观体验。本文基于Spring Boo…...

HarmonyOS:使用HTTP访问网络
HTTP 一、导入http模块 module.json5里添加网络权限 导入http模块 二、创建http请求 创建http请求 import { http } from kit.NetworkKitfunction getNetData() {// 创建数据请求对象let httpRequest http.createHttp() }三、发起请求 请求方法 四、请求示例 GET请求 PO…...
)
sqlmap --os-shell的原理(MySQL,MSSQL,PostgreSQL,Oracle,SQLite)
1. MySQL 条件 数据库用户需要具备高权限(如 FILE 权限)。数据库服务运行用户需要对目标目录有写权限。Web 服务器有可写目录,且支持执行上传的脚本(如 PHP、JSP 等)。 原理 利用 MySQL 的 SELECT ... INTO OUTFIL…...

浅谈网络安全态势感知
一、基本概念 前美国空军首席科学家Endsley博士给出的动态环境中态势感知的通用定义是: 态势感知是感知大量的时间和空间中的环境要素,理解它们的意义,并预测它们在不久将来的状态。 在这个定义中,我们可以提炼出态势感知的三个要素…...

【大模型】ChatGPT 提示词优化进阶操作实战详解
目录 一、前言 二、ChatGPT 提示词几个基本的优化原则 2.1 明确的提示词 2.1.1 提示词具体而清晰 2.1.1.1操作案例演示 2.2 确定焦点 2.2.1 操作案例演示 2.3 保持提示词的相关性 2.3.1 什么是相关性 2.3.2 提示词相关性操作案例一 2.3.2 提示词相关性操作案例二 三…...

【计算机网络】实验11:边界网关协议BGP
实验11 边界网关协议BGP 一、实验目的 本次实验旨在验证边界网关协议(BGP)的实际作用,并深入学习在路由器上配置和使用BGP协议的方法。通过实验,我将探索BGP在不同自治系统之间的路由选择和信息交换的功能,理解其在互…...

【Linux系统】System V 的 IPC 机制在 Linux 系统中的实现
System V 的 IPC(Inter-Process Communication,进程间通信) 机制是 UNIX 系统中的一大特色,用于在不同进程之间共享数据或同步操作。Linux 系统完整实现了 System V 的 IPC 机制,并在其基础上进行了优化和扩展。这些机…...

计算机网络安全
从广义来说,凡是涉及到网络上信息的机密性、报文完整性、端点鉴别等技术和理论都是网络安全的研究领域。 机密性指仅有发送方和接收方能理解传输报文的内容,而其他未授权用户不能解密(理解)该报文报文完整性指报文在传输过程中不…...
)
30.100ASK_T113-PRO 用QT编写视频播放器(一)
1.再buildroot中添加视频解码库 X264, 执行 make menuconfig Target packages -->Libraries --> Multimedia --> X264 CLI 还需要添加 FFmpeg 2. 保存,重新编译 make all 3.将镜像下载开发板...

攻防世界 ctf刷题 新手区1-10
unserialize3 因为我上个笔记写了 php返序列化 所以先趁热打铁 看这个题目名字 我们就知道是 反序列化呀 因为flag有值所以 我们先输个 111 看看有没有线索 没线索但是这边 有个发现就是他是使用get方式传参的 可能他会把我们的输入 进行传入后台有可能进行反…...

DAY35|动态规划Part03|LeetCode:01背包问题 二维、01背包问题 一维、416. 分割等和子集
目录 01背包理论基础(一) 基本思路 C代码 01背包理论基础(二) 基本思路 C代码 LeetCode:416. 分割等和子集 基本思路 C代码 01背包理论基础(一) 题目链接:卡码网46. 携带研究材料 文字…...

三款电容麦的对比
纸面参数 第一款麦克风 灵敏度: -36 dB 2 dB(0 dB1V/Pa at 1 kHz) 灵敏度较低,需要更高的增益来拾取同样的音量。频率响应: 40 Hz - 18 kHz 响应范围较窄,尤其在高频区域。等效噪音级: ≤18 dB(A计权) 噪…...

【实战攻略】如何从零开始快速实现深度学习新想法?——四步走战略
标题 【实战攻略】如何从零开始快速实现深度学习新想法?——四步走战略 【核心结论】 通过四步走战略,即找到baseline论文、深入baseline代码、搭建自己的pipeline、融入核心算法,新手也能快速实现深度学习新想法。 【通俗解释࿰…...

Python+OpenCV系列:入门环境搭建、图像读写、像素操作、色彩空间和通道、
入门环境搭建、图像读写、像素操作、色彩空间和通道 **Python与OpenCV环境搭建、图像处理与色彩空间介绍****引言****1. Python和OpenCV的环境搭建****1.1 安装Python和OpenCV****1.2 配置开发环境** **2. 图像的读取、显示与保存****2.1 图像的读取****2.2 图像的显示****2.3 …...

如何在鸿蒙API9和x86模拟器中使用MQTT
目录 引言 安装MQTT软件包 避免MQTT软件包自动升级 程序的编写 运行测试 结语 引言 虽然我的课主要是OpenHarmony南向开发的,但是结课时有个同学说他在写鸿蒙APP时无法将MQTT库加入到设备中,希望我帮忙看看。由于他没有鸿蒙的真机,只能…...

http multipart/form-data 数据如何分块传输是一次传输还是多次
multipart/form-data 是一种用于 HTTP 协议中传输数据的格式,它用于传输数据量较大的数据,如文件等。在 multipart/form-data 中,数据可以被分成多个部分(chunk),这些部分之间通过特定的分隔符进行分隔。 …...

️️耗时一周,肝了一个超丝滑的卡盒小程序
前言 先看看成品效果: 在上个月,我出于提升自己的英语造句能力的目的,想要找一个阅读或者练习造句类的英语学习 APP,但是最终找了几个 APP 不是不太好用就是要付费。于是我转换思路,找到了一本书,叫《36…...

ubuntu的matlab使用心得
1.读取视频 v VideoReader(2222.mp4);出问题,报错: matlab 错误使用 VideoReader/initReader (第 734 行) 由于出现意外错误而无法读取文件。原因: Unable to initialize the video properties 出错 audiovideo.internal.IVideoReader (第 136 行) init…...

vscode插件 live-server配置https
背景:前端有时候需要在本地搭建https环境测试某些内容(如https下访问http资源,下载) 步骤: 1.vscode集成开发软件(应该所有前端开发同学都安装了,我用webstorm,vscode备用) 2.vscode安装live…...

腾讯最新图标点选验证码
注意,本文只提供学习的思路,严禁违反法律以及破坏信息系统等行为,本文只提供思路 如有侵犯,请联系作者下架 本文识别已同步上线至OCR识别网站: http://yxlocr.nat300.top/ocr/iconclick/9 注意:后续点选验证码内容我不会再讲那么详细,毕竟点选验证训练很多读者都会,而…...

安防视频监控平台Liveweb视频汇聚管理系统管理方案
智慧安防监控Liveweb视频管理平台能在复杂的网络环境中,将前端设备统一集中接入与汇聚管理。国标GB28181协议视频监控/视频汇聚Liveweb平台可以提供实时远程视频监控、视频录像、录像回放与存储、告警、语音对讲、云台控制、平台级联、磁盘阵列存储、视频集中存储、…...

VBA信息获取与处理第四个专题第二节:将工作表数据写入VBA数组
《VBA信息获取与处理》教程(版权10178984)是我推出第六套教程,目前已经是第一版修订了。这套教程定位于最高级,是学完初级,中级后的教程。这部教程给大家讲解的内容有:跨应用程序信息获得、随机信息的利用、电子邮件的发送、VBA互…...
PyTorch 中的实用工具 SummaryWriter 和 TensorBoard 的说明)
神经网络入门实战:(六)PyTorch 中的实用工具 SummaryWriter 和 TensorBoard 的说明
(一) SummaryWriter 这里先讲解 SummaryWriter ,TensorBoard 会在第二大点进行说明。 SummaryWriter 是 PyTorch 中的一个非常实用的工具,它主要用于将深度学习模型训练过程中的各种日志和统计数据记录下来,并可以与 TensorBoard 配合使用&am…...

SpringBoot的validation参数校验
文章目录 前言一、引入validation 依赖二、validation中的注解说明 (1)Validated(2)Valid(3)NotNull(4)NotBlank(5)NotEmpty(6)Patte…...

RPC与HTTP调用模式的架构差异
RPC(Remote Procedure Call,远程过程调用)和 HTTP 调用是两种常见的通信模式,它们在架构上有以下一些主要差异: 协议层面 RPC:通常使用自定义的二进制协议,对数据进行高效的序列化和反序列化&am…...
:总结)
R语言机器学习论文(六):总结
文章目录 介绍参考文献介绍 本文采用R语言对来自进行数据描述、数据预处理、特征筛选和模型构建。 最后我们获得了一个能有效区分乳腺组织的随机森林预测模型,它的性能非常好,这意味着它可能拥有非常好的临床价值。 在本文中,我们利用R语言对来自美国加州大学欧文分校的B…...

工业—使用Flink处理Kafka中的数据_ProduceRecord2
使用 Flink 消费 Kafka 中 ProduceRecord 主题的数据,统计在已经检验的产品中,各设备每 5 分钟 生产产品总数,将结果存入HBase 中的 gyflinkresult:Produce5minAgg 表, rowkey“...

【嵌套查询】.NET开源 ORM 框架 SqlSugar 系列
.NET开源 ORM 框架 SqlSugar 系列 【开篇】.NET开源 ORM 框架 SqlSugar 系列【入门必看】.NET开源 ORM 框架 SqlSugar 系列【实体配置】.NET开源 ORM 框架 SqlSugar 系列【Db First】.NET开源 ORM 框架 SqlSugar 系列【Code First】.NET开源 ORM 框架 SqlSugar 系列【数据事务…...

SpringBoot整合JWT
一. JWT简介 1. 什么是JWT? JWT(JSON Web Token)是为了在网络应用环境间传递声明而执行的一种基于JSON的开放标准。 它将用户信息加密到token里,服务器不保存任何用户信息。服务器通过使用保存的密钥验证token的正确性,只要正确即通过验证&…...

使用docker创建cloudstack虚拟主机
文章目录 概要 环境准备: 1.使用rockyLinux:8镜像 2.配置yum源 3.添加vim cloudstack.repo为以下内容 4.前期我们已经搭好了cloudstack平台,这里需要映射几个目录到容器里面, 5.创建Dockerfile 6.构建镜像 7.使用命令创建…...

mybatis-xml映射文件及mybatis动态sql
规范 XML映射文件的名称与Mapper接口名称一致,并且将XML映射文件和Mapper接口放置在相同包下(同包同名)。 XML映射文件的namespace属性为Mapper接口全限定名一致。 XML映射文件中sql语句的id与Mapper接口中的方法名一致,并保持返回类型一致…...

Qt | TCP服务器实现QTcpServer,使用线程管理客户端套接字
点击上方"蓝字"关注我们 01、QTcpServer >>> QTcpServer 是 Qt 网络模块中的一个类,用于实现TCP服务器。它允许创建一个服务器,可以接受来自客户端的连接。QTcpServer 是事件驱动的,这意味着它将通过信号和槽机制处理网络事件。 常用函数 构造函数: QT…...

rustdesk远程桌面使用
文章目录 简介1.客户端rustdesk使用2.基于 S6-overlay 的镜像 服务端部署3.声明 简介 为什么使用rustdesk,因为向日葵,todesk,免费版本的有各种各样的坑,比如限制你的登录,需要你重新登录使用,画面模糊&am…...

C#中图片的Base64编码与解码转换详解
在C#中,我们可以使用Base64编码将图片转换为字符串,也可以将Base64编码的字符串转换回图片。这通常用于在需要文本表示图像数据的场合(例如在Web开发中传输图像数据)。 将图片转换为Base64字符串 要将图片文件转换为Base64字符串…...

瑞芯微方案主板Linux修改系统串口波特率教程,触觉智能RK3562开发板演示
遇到部分串口工具不支持1500000波特率,这时候就需要进行修改,本文以触觉智能RK3562开发板修改系统波特率为115200为例,介绍瑞芯微方案主板Linux修改系统串口波特率教程。 温馨提示:瑞芯微方案主板/开发板串口波特率只支持115200或…...
)
阿里云整理(二)
阿里云整理 1. 访问网站2. 专业名词2.1 域名2.2 域名备案2.3 云解析DNS2.4 CDN2.5 WAF 1. 访问网站 用户使用浏览器访问网站大体分为几个过程: 用户在浏览器输入域名URL,例如www.baidu.com。 不过,浏览器并不知道为该域名提供服务的服务器具…...

python实现一个简单的不断发送dns查询的功能
the code below: import socket import struct import time import randomdef create_dns_query(domain"example123.com"):# DNS HeaderID random.randint(0, 65535) # 随机查询IDFLAGS 0x0100 # Standard queryQDCOUNT 1 # One questionANCOUNT 0 # …...

鲲鹏麒麟使用Docker部署Redis5
本次部署采用Docker方式进行部署,服务器为鲲鹏服务器,CPU架构为ARM64,操作系统版本信息为 # cat /etc/kylin-release Kylin Linux Advanced Server release V10 (Tercel)镜像 下载镜像鲲鹏麒麟Redis5镜像包 部署 1、上传镜像到服务器 2、…...

MySQL悲观锁和乐观锁
MySQL悲观锁和乐观锁 在数据库中,锁是用来管理并发控制的一种机制,确保数据的一致性和完整性。MySQL中的悲观锁和乐观锁是两种不同的并发控制策略,它们在处理并发事务时采用不同的方法。 悲观锁(Pessimistic Locking)…...

【AI模型对比】Kimi与ChatGPT的差距:真实对比它们在六大题型中的全面表现!
文章目录 Moss前沿AI语义理解文学知识数学计算天文学知识物理学知识英语阅读理解详细对比列表总结与建议 Moss前沿AI 【OpenAI】获取OpenAI API Key的多种方式全攻略:从入门到精通,再到详解教程!! 【VScode】VSCode中的智能AI-G…...

一根网线如何用软路由给手机、电脑分配设置不同IP
众所周知,在同一个网络下,我们的互联网IP是一样的,即外网只有一个IP。很多互联网公司、游戏工作室、营利工作室都需要利用它们来实现同一网络下多台设备IP地址不同的效果。对此我们该怎么办?下面给大家简单分享一下! 在…...