基于用户的协同过滤推荐系统实战项目
文章目录
- 基于用户的协同过滤推荐系统实战项目
- 1. 推荐系统基础理论
- 1.1 协同过滤概述
- 1.2 基于用户的协同过滤原理
- 1.3 相似度计算方法
- 1.3.1 余弦相似度(Cosine Similarity)
- 1.3.2 皮尔逊相关系数(Pearson Correlation)
- 1.3.3 欧几里得距离(Euclidean Distance)
- 1.3.4 调整余弦相似度(Adjusted Cosine Similarity)
- 1.4 评分预测方法
- 1.4.1 简单加权平均
- 1.4.2 考虑用户评分偏置的加权平均
- 1.5 评估指标
- 1.5.1 均方根误差(RMSE)
- 1.5.2 平均绝对误差(MAE)
- 1.6 TopN推荐
- 1.6.1 精确率(Precision)和召回率(Recall)
- 1.6.2 F1分数
- 2. 项目介绍
- 2.1 数据集介绍
- 2.2 项目架构设计
- 2.2.1 模块化架构
- 3. 项目实施步骤
- 3.1 数据获取与探索
- 3.2 数据加载模块实现
- 3.3 构建评分矩阵和数据集拆分
- 3.4 日志系统设计
- 3.5 相似度计算模块
- 3.6 评分预测模块
- 3.7 推荐生成模块
- 3.8 评估模块
- 3.9 完整推荐系统模型
- 3.10 命令行接口设计
- 3.11 模型序列化与反序列化
- 3.12 Web应用开发
- 3.13 性能优化与错误处理
- 5. 模块化设计的优势
- 6. 结论与未来工作
- 7. 参考资料
基于用户的协同过滤推荐系统实战项目
1. 推荐系统基础理论
1.1 协同过滤概述
协同过滤(Collaborative Filtering, CF)是推荐系统中最经典、应用最广泛的技术之一。其核心思想是利用群体的智慧来进行推荐,基于"相似的用户喜欢相似的物品"或"喜欢某物品的用户也喜欢其他相似物品"的假设。
协同过滤主要分为两大类:
- 基于记忆的协同过滤(Memory-based CF):直接使用用户-物品交互数据进行推荐,包括基于用户的协同过滤(User-based CF)和基于物品的协同过滤(Item-based CF)。
- 基于模型的协同过滤(Model-based CF):通过机器学习算法从数据中学习模型,如矩阵分解(Matrix Factorization)、奇异值分解(SVD)等。
本项目主要聚焦于基于用户的协同过滤。
1.2 基于用户的协同过滤原理
基于用户的协同过滤的工作流程如下:
- 构建用户-物品评分矩阵:每行代表一个用户,每列代表一个物品,矩阵中的元素表示用户对物品的评分。
- 计算用户相似度:寻找与目标用户具有相似品味的用户群体。
- 预测评分:基于相似用户的评分,预测目标用户对未评分物品的可能评分。
- 生成推荐:为用户推荐评分最高的未接触物品。
1.3 相似度计算方法
在协同过滤中,常用的相似度计算方法包括:
1.3.1 余弦相似度(Cosine Similarity)
余弦相似度计算两个向量之间夹角的余弦值,范围从-1到1,值越大表示越相似。
对于用户 u u u和用户 v v v,其余弦相似度计算公式为:
s i m c o s ( u , v ) = ∑ i ∈ I u v r u i ⋅ r v i ∑ i ∈ I u r u i 2 ⋅ ∑ i ∈ I v r v i 2 sim_{cos}(u, v) = \frac{\sum_{i \in I_{uv}} r_{ui} \cdot r_{vi}}{\sqrt{\sum_{i \in I_{u}} r_{ui}^2} \cdot \sqrt{\sum_{i \in I_{v}} r_{vi}^2}} simcos(u,v)=∑i∈Iurui2⋅∑i∈Ivrvi2∑i∈Iuvrui⋅rvi
其中:
- I u v I_{uv} Iuv是用户 u u u和用户 v v v共同评分的物品集合
- r u i r_{ui} rui是用户 u u u对物品 i i i的评分
- r v i r_{vi} rvi是用户 v v v对物品 i i i的评分
- I u I_u Iu是用户 u u u评分的所有物品集合
- I v I_v Iv是用户 v v v评分的所有物品集合
在Python中,可以使用sklearn.metrics.pairwise中的cosine_similarity或1 - pairwise_distances(X, metric='cosine')计算余弦相似度。
1.3.2 皮尔逊相关系数(Pearson Correlation)
皮尔逊相关系数衡量两个变量之间的线性相关性,范围从-1到1,也称为"皮尔逊积矩相关系数"。
计算公式为:
s i m p e a r s o n ( u , v ) = ∑ i ∈ I u v ( r u i − r ˉ u ) ⋅ ( r v i − r ˉ v ) ∑ i ∈ I u v ( r u i − r ˉ u ) 2 ⋅ ∑ i ∈ I u v ( r v i − r ˉ v ) 2 sim_{pearson}(u, v) = \frac{\sum_{i \in I_{uv}} (r_{ui} - \bar{r}_u) \cdot (r_{vi} - \bar{r}_v)}{\sqrt{\sum_{i \in I_{uv}} (r_{ui} - \bar{r}_u)^2} \cdot \sqrt{\sum_{i \in I_{uv}} (r_{vi} - \bar{r}_v)^2}} simpearson(u,v)=∑i∈Iuv(rui−rˉu)2⋅∑i∈Iuv(rvi−rˉv)2∑i∈Iuv(rui−rˉu)⋅(rvi−rˉv)
其中:
- r ˉ u \bar{r}_u rˉu是用户 u u u的平均评分
- r ˉ v \bar{r}_v rˉv是用户 v v v的平均评分
皮尔逊相关系数考虑了用户评分的偏置(bias),能更好地处理用户评分标准不同的情况(有些用户倾向于给高分,有些用户倾向于给低分)。
在Python中,可以使用numpy.corrcoef()计算皮尔逊相关系数。
1.3.3 欧几里得距离(Euclidean Distance)
欧几里得距离直接计算两个向量在空间中的距离,距离越小表示越相似。
计算公式为:
d i s t a n c e e u c l i d e a n ( u , v ) = ∑ i ∈ I u v ( r u i − r v i ) 2 distance_{euclidean}(u, v) = \sqrt{\sum_{i \in I_{uv}} (r_{ui} - r_{vi})^2} distanceeuclidean(u,v)=∑i∈Iuv(rui−rvi)2
为了将距离转换为相似度,通常使用以下变换:
s i m e u c l i d e a n ( u , v ) = 1 1 + d i s t a n c e e u c l i d e a n ( u , v ) sim_{euclidean}(u, v) = \frac{1}{1 + distance_{euclidean}(u, v)} simeuclidean(u,v)=1+distanceeuclidean(u,v)1
在Python中,可以使用sklearn.metrics.pairwise中的euclidean_distances计算欧几里得距离。
1.3.4 调整余弦相似度(Adjusted Cosine Similarity)
调整余弦相似度在计算前先减去用户的平均评分,解决了用户评分标准不一致的问题:
s i m a d j _ c o s ( u , v ) = ∑ i ∈ I u v ( r u i − r ˉ u ) ⋅ ( r v i − r ˉ v ) ∑ i ∈ I u v ( r u i − r ˉ u ) 2 ⋅ ∑ i ∈ I u v ( r v i − r ˉ v ) 2 sim_{adj\_cos}(u, v) = \frac{\sum_{i \in I_{uv}} (r_{ui} - \bar{r}_u) \cdot (r_{vi} - \bar{r}_v)}{\sqrt{\sum_{i \in I_{uv}} (r_{ui} - \bar{r}_u)^2} \cdot \sqrt{\sum_{i \in I_{uv}} (r_{vi} - \bar{r}_v)^2}} simadj_cos(u,v)=∑i∈Iuv(rui−rˉu)2⋅∑i∈Iuv(rvi−rˉv)2∑i∈Iuv(rui−rˉu)⋅(rvi−rˉv)
1.4 评分预测方法
在确定用户相似度后,需要预测目标用户对未评分物品的可能评分。传统的基于用户的协同过滤通常采用加权平均的方式进行预测。
1.4.1 简单加权平均
r ^ u i = ∑ v ∈ N u ( i ) s i m ( u , v ) ⋅ r v i ∑ v ∈ N u ( i ) ∣ s i m ( u , v ) ∣ \hat{r}_{ui} = \frac{\sum_{v \in N_u(i)} sim(u, v) \cdot r_{vi}}{\sum_{v \in N_u(i)} |sim(u, v)|} r^ui=∑v∈Nu(i)∣sim(u,v)∣∑v∈Nu(i)sim(u,v)⋅rvi
其中:
- r ^ u i \hat{r}_{ui} r^ui是预测的用户 u u u对物品 i i i的评分
- N u ( i ) N_u(i) Nu(i)是与用户 u u u相似且评价过物品 i i i的用户集合
- s i m ( u , v ) sim(u, v) sim(u,v)是用户 u u u与用户 v v v的相似度
- r v i r_{vi} rvi是用户 v v v对物品 i i i的实际评分
1.4.2 考虑用户评分偏置的加权平均
为了解决不同用户评分标准不同的问题,可以使用考虑评分偏置的改进公式:
r ^ u i = r ˉ u + ∑ v ∈ N u ( i ) s i m ( u , v ) ⋅ ( r v i − r ˉ v ) ∑ v ∈ N u ( i ) ∣ s i m ( u , v ) ∣ \hat{r}_{ui} = \bar{r}_u + \frac{\sum_{v \in N_u(i)} sim(u, v) \cdot (r_{vi} - \bar{r}_v)}{\sum_{v \in N_u(i)} |sim(u, v)|} r^ui=rˉu+∑v∈Nu(i)∣sim(u,v)∣∑v∈Nu(i)sim(u,v)⋅(rvi−rˉv)
其中:
- r ˉ u \bar{r}_u rˉu是用户 u u u的平均评分
- r ˉ v \bar{r}_v rˉv是用户 v v v的平均评分
这种方法不直接使用原始评分,而是使用评分与用户平均评分的偏差,能够更好地处理用户评分偏好不同的情况。
1.5 评估指标
推荐系统的性能评估通常使用以下指标:
1.5.1 均方根误差(RMSE)
RMSE是预测评分与实际评分之间差异的平方平均的平方根,值越小表示预测越准确。
R M S E = 1 ∣ T ∣ ∑ ( u , i ) ∈ T ( r ^ u i − r u i ) 2 RMSE = \sqrt{\frac{1}{|T|} \sum_{(u,i) \in T} (\hat{r}_{ui} - r_{ui})^2} RMSE=∣T∣1∑(u,i)∈T(r^ui−rui)2
其中:
- T T T是测试集中的用户-物品对集合
- r ^ u i \hat{r}_{ui} r^ui是预测的评分
- r u i r_{ui} rui是实际评分
1.5.2 平均绝对误差(MAE)
MAE是预测评分与实际评分之间绝对差值的平均,同样值越小表示预测越准确。
M A E = 1 ∣ T ∣ ∑ ( u , i ) ∈ T ∣ r ^ u i − r u i ∣ MAE = \frac{1}{|T|} \sum_{(u,i) \in T} |\hat{r}_{ui} - r_{ui}| MAE=∣T∣1∑(u,i)∈T∣r^ui−rui∣
与RMSE相比,MAE对异常值的敏感度较低,因此两个指标通常一起使用,以全面评估推荐系统的性能。
1.6 TopN推荐
在实际应用中,我们通常不仅关注评分预测的准确度,还关注能否为用户推荐最适合的N个物品,称为TopN推荐。为此,可以使用额外的评估指标:
1.6.1 精确率(Precision)和召回率(Recall)
-
精确率:推荐的物品中实际相关的比例
P r e c i s i o n @ k = ∣ 推荐列表 ∩ 相关物品 ∣ ∣ 推荐列表 ∣ Precision@k = \frac{|推荐列表 \cap 相关物品|}{|推荐列表|} Precision@k=∣推荐列表∣∣推荐列表∩相关物品∣
-
召回率:实际相关物品中被成功推荐的比例
R e c a l l @ k = ∣ 推荐列表 ∩ 相关物品 ∣ ∣ 相关物品 ∣ Recall@k = \frac{|推荐列表 \cap 相关物品|}{|相关物品|} Recall@k=∣相关物品∣∣推荐列表∩相关物品∣
1.6.2 F1分数
F1分数是精确率和召回率的调和平均数,综合考虑两个指标。
F 1 = 2 ⋅ P r e c i s i o n ⋅ R e c a l l P r e c i s i o n + R e c a l l F1 = 2 \cdot \frac{Precision \cdot Recall}{Precision + Recall} F1=2⋅Precision+RecallPrecision⋅Recall
2. 项目介绍
协同过滤是推荐系统的核心算法之一,它基于用户行为数据来推荐物品。基于用户的协同过滤(User-Based Collaborative Filtering)算法通过寻找与目标用户相似的用户群体,然后推荐这些相似用户喜欢但目标用户尚未接触的物品。gitcode
本项目基于以下经典论文:
- Resnick P, Iacovou N, Suchak M, et al. Grouplens: An open architecture for collaborative filtering of netnews[C]//Proceedings of the 1994 ACM conference on Computer supported cooperative work. 1994: 175-186. https://doi.org/10.1145/192844.192905
- Breese J S, Heckerman D, Kadie C. Empirical analysis of predictive algorithms for collaborative filtering[J]. arXiv preprint arXiv:1301.7363, 2013. https://doi.org/10.48550/arXiv.1301.7363
2.1 数据集介绍
本项目使用经典的MovieLens 100K数据集,该数据集包含:
- 943个用户
- 1682部电影
- 10万条评分数据(1-5分)
- 用户的人口统计学特征
- 电影的类型信息
2.2 项目架构设计
为了构建一个可维护、可扩展的推荐系统,本项目采用模块化设计,将核心功能按照职责分散到不同模块中。
2.2.1 模块化架构
项目由以下核心模块组成:
- 数据加载模块(data_loader.py):负责数据读取、预处理和矩阵构建
- 相似度计算模块(similarity.py):实现多种相似度计算方法
- 评分预测模块(prediction.py):实现评分预测算法
- 推荐生成模块(recommendation.py):生成个性化推荐列表
- 评估模块(evaluation.py):实现多种评估指标计算
- 日志模块(logger.py):管理系统日志记录
- 主模型模块(model.py):集成各个组件,提供统一接口
- 命令行接口(main.py):提供命令行交互功能
- Web应用(app.py):提供Web界面
3. 项目实施步骤
3.1 数据获取与探索
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.metrics import mean_squared_error
from sklearn.metrics.pairwise import pairwise_distances
from scipy.spatial.distance import cosine
import warnings
warnings.filterwarnings('ignore')# 设置随机种子保证结果可重复
np.random.seed(42)# 加载数据集
# 从 https://grouplens.org/datasets/movielens/100k/ 下载
# 或使用以下代码自动下载
!wget -nc http://files.grouplens.org/datasets/movielens/ml-100k.zip
!unzip -n ml-100k.zip# 加载用户评分数据
column_names = ['user_id', 'item_id', 'rating', 'timestamp']
df = pd.read_csv('ml-100k/u.data', sep='\t', names=column_names)# 加载电影信息
movies_column_names = ['movie_id', 'movie_title', 'release_date', 'video_release_date','IMDb_URL', 'unknown', 'Action', 'Adventure', 'Animation','Children', 'Comedy', 'Crime', 'Documentary', 'Drama', 'Fantasy','Film-Noir', 'Horror', 'Musical', 'Mystery', 'Romance', 'Sci-Fi','Thriller', 'War', 'Western']
movies_df = pd.read_csv('ml-100k/u.item', sep='|', names=movies_column_names, encoding='latin-1')# 查看数据集基本信息
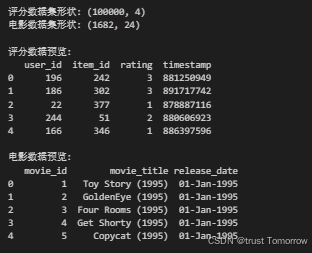
print(f"评分数据集形状: {df.shape}")
print(f"电影数据集形状: {movies_df.shape}")
print("\n评分数据预览:")
print(df.head())
print("\n电影数据预览:")
print(movies_df[['movie_id', 'movie_title', 'release_date']].head())
3.2 数据加载模块实现
我们将数据加载和处理功能封装在DataLoader类中,提供以下功能:
- 从文件加载数据
- 构建用户-物品评分矩阵
- 划分训练集和测试集
- 计算数据集统计信息
class DataLoader:"""负责加载和预处理MovieLens数据集的类"""def __init__(self, data_path="data/ml-100k"):"""初始化DataLoader并设置数据路径"""self.data_path = data_pathself.ratings_df = Noneself.movies_df = Noneself.n_users = Noneself.n_items = Noneself.ratings_matrix = Noneself.train_data = Noneself.test_data = Nonedef load_data(self):"""加载评分数据和电影数据"""# 检查数据路径if not os.path.exists(self.data_path):raise FileNotFoundError(f"数据目录 {self.data_path} 不存在")# 加载评分数据ratings_file = os.path.join(self.data_path, "u.data")if not os.path.exists(ratings_file):raise FileNotFoundError(f"评分文件 {ratings_file} 不存在")column_names = ["user_id", "item_id", "rating", "timestamp"]self.ratings_df = pd.read_csv(ratings_file, sep="\t", names=column_names)# 加载电影数据movies_file = os.path.join(self.data_path, "u.item")if not os.path.exists(movies_file):raise FileNotFoundError(f"电影文件 {movies_file} 不存在")movies_column_names = ["movie_id", "movie_title", "release_date", "video_release_date","IMDb_URL", "unknown", "Action", "Adventure", "Animation","Children", "Comedy", "Crime", "Documentary", "Drama", "Fantasy","Film-Noir", "Horror", "Musical", "Mystery", "Romance", "Sci-Fi","Thriller", "War", "Western"]self.movies_df = pd.read_csv(movies_file, sep="|", names=movies_column_names, encoding="latin-1")# 获取用户和电影数量self.n_users = self.ratings_df["user_id"].max()self.n_items = self.ratings_df["item_id"].max()return self.ratings_df, self.movies_df
3.3 构建评分矩阵和数据集拆分
def create_matrix(self):"""创建用户-物品评分矩阵"""if self.ratings_df is None:self.load_data()# 创建矩阵self.ratings_matrix = np.zeros((self.n_users, self.n_items))# 填充评分for row in self.ratings_df.itertuples():# 调整为0-based索引self.ratings_matrix[row.user_id-1, row.item_id-1] = row.ratingreturn self.ratings_matrixdef split_data(self, test_size=0.2, random_state=42):"""将数据划分为训练集和测试集"""if self.ratings_df is None:self.load_data()from sklearn.model_selection import train_test_split# 划分数据self.train_data, self.test_data = train_test_split(self.ratings_df, test_size=test_size, random_state=random_state)# 创建训练集矩阵self.train_matrix = np.zeros((self.n_users, self.n_items))for row in self.train_data.itertuples():self.train_matrix[row.user_id-1, row.item_id-1] = row.rating# 创建测试集矩阵self.test_matrix = np.zeros((self.n_users, self.n_items))for row in self.test_data.itertuples():self.test_matrix[row.user_id-1, row.item_id-1] = row.ratingreturn self.train_data, self.test_data, self.train_matrix, self.test_matrix
3.4 日志系统设计
为了跟踪系统运行状态、性能和错误,我们实现了一个灵活的日志模块:
import os
import logging
from logging.handlers import RotatingFileHandler
import timedef setup_logger(log_dir="results/logs", log_level=logging.INFO, silent=False):"""配置并返回推荐系统的日志记录器参数:log_dir: 日志文件存储目录log_level: 日志级别silent: 是否静默模式(不记录日志)返回:logger: 配置好的日志记录器"""# 创建日志记录器logger = logging.getLogger("recommendation_system")logger.setLevel(log_level)# 清除已有的处理器(避免重复日志)if logger.handlers:logger.handlers = []if silent:# 添加NullHandler以防止"找不到处理器"警告logger.addHandler(logging.NullHandler())else:# 创建日志目录os.makedirs(log_dir, exist_ok=True)# 使用时间戳创建唯一的日志文件名timestamp = time.strftime("%Y%m%d-%H%M%S")log_file = os.path.join(log_dir, f"recommender_{timestamp}.log")# 创建文件处理器(每文件最大10MB,保留5个备份)file_handler = RotatingFileHandler(log_file, maxBytes=10*1024*1024, backupCount=5, encoding="utf-8")file_handler.setLevel(log_level)# 创建控制台处理器console_handler = logging.StreamHandler()console_handler.setLevel(log_level)# 创建格式化器并添加到处理器formatter = logging.Formatter("%(asctime)s - %(name)s - %(levelname)s - %(message)s")file_handler.setFormatter(formatter)console_handler.setFormatter(formatter)# 将处理器添加到记录器logger.addHandler(file_handler)logger.addHandler(console_handler)return loggerdef get_logger():"""获取推荐系统日志记录器"""logger = logging.getLogger("recommendation_system")# 如果记录器没有处理器,设置一个默认的静默记录器if not logger.handlers:return setup_logger(silent=True)return logger
3.5 相似度计算模块
def calculate_similarity(ratings_matrix, method="cosine"):"""计算用户相似度矩阵参数:ratings_matrix: 用户-物品评分矩阵method: 相似度计算方法('cosine', 'pearson', 'euclidean', 'adjusted_cosine')返回:similarity: 用户相似度矩阵"""if method == "cosine":return cosine_similarity(ratings_matrix)elif method == "pearson":return pearson_similarity(ratings_matrix)elif method == "euclidean":return euclidean_similarity(ratings_matrix)elif method == "adjusted_cosine":return adjusted_cosine_similarity(ratings_matrix)else:raise ValueError(f"未知的相似度计算方法: {method}")
每种相似度计算方法的具体实现:
def cosine_similarity(ratings_matrix):"""计算余弦相似度"""similarity = 1 - pairwise_distances(ratings_matrix, metric="cosine", n_jobs=-1)similarity = np.nan_to_num(similarity) # 处理NaN值return similaritydef pearson_similarity(ratings_matrix):"""计算皮尔逊相关系数"""similarity = np.corrcoef(ratings_matrix)similarity = np.nan_to_num(similarity) # 处理NaN值return similaritydef euclidean_similarity(ratings_matrix):"""计算基于欧几里得距离的相似度"""distances = pairwise_distances(ratings_matrix, metric="euclidean", n_jobs=-1)similarity = 1 / (1 + distances) # 转换距离为相似度return similaritydef adjusted_cosine_similarity(ratings_matrix):"""计算调整后的余弦相似度"""# 获取非零元素以计算平均值rated_mask = ratings_matrix != 0# 计算用户平均评分(仅考虑已评分项目)user_means = np.sum(ratings_matrix, axis=1) / np.sum(rated_mask, axis=1)# 通过减去用户平均值归一化评分(仅对已评分项目)normalized_matrix = np.zeros_like(ratings_matrix)for i, (user_ratings, mask, mean) in enumerate(zip(ratings_matrix, rated_mask, user_means)):normalized_matrix[i, mask] = user_ratings[mask] - mean# 计算余弦相似度similarity = 1 - pairwise_distances(normalized_matrix, metric="cosine", n_jobs=-1)# 处理NaN值similarity = np.nan_to_num(similarity)return similarity
3.6 评分预测模块
def predict_ratings(ratings_matrix, similarity_matrix, method="bias_weighted", k=10):"""预测用户对物品的评分参数:ratings_matrix: 用户-物品评分矩阵similarity_matrix: 用户相似度矩阵method: 预测方法('simple_weighted', 'bias_weighted')k: 考虑的近邻数量返回:predicted_ratings: 预测评分矩阵"""if method == "simple_weighted":return simple_weighted_average(ratings_matrix, similarity_matrix, k)elif method == "bias_weighted":return bias_weighted_average(ratings_matrix, similarity_matrix, k)else:raise ValueError(f"未知的预测方法: {method}")def bias_weighted_average(ratings_matrix, similarity_matrix, k=10):"""使用考虑用户偏置的加权平均预测评分"""n_users, n_items = ratings_matrix.shapepredicted_ratings = np.zeros((n_users, n_items))# 计算用户平均评分user_rated_mask = ratings_matrix > 0user_ratings_count = np.sum(user_rated_mask, axis=1)user_ratings_sum = np.sum(ratings_matrix, axis=1)# 处理除零问题user_mean_ratings = np.where(user_ratings_count > 0, user_ratings_sum / user_ratings_count, 0)# 为每个用户预测评分for u in range(n_users):# 找到k个最相似用户(不包括自己)user_similarities = similarity_matrix[u]user_similarities[u] = -1 # 排除自己similar_users = np.argsort(user_similarities)[::-1][:k]# 用户的平均评分u_mean = user_mean_ratings[u]# 为每个物品预测评分for i in range(n_items):# 如果用户已经评分,保留原评分if ratings_matrix[u, i] > 0:predicted_ratings[u, i] = ratings_matrix[u, i]continue# 获取评价过该物品的相似用户sim_users_rated = [v for v in similar_users if ratings_matrix[v, i] > 0]# 如果没有相似用户评价过,使用用户平均评分if len(sim_users_rated) == 0:predicted_ratings[u, i] = u_mean if u_mean > 0 else np.mean(ratings_matrix[ratings_matrix > 0])continue# 计算考虑偏置的加权平均sim_sum = sum(abs(similarity_matrix[u, v]) for v in sim_users_rated)if sim_sum == 0:predicted_ratings[u, i] = u_meancontinueweighted_sum = sum(similarity_matrix[u, v] * (ratings_matrix[v, i] - user_mean_ratings[v])for v in sim_users_rated)predicted_rating = u_mean + weighted_sum / sim_sum# 将预测评分限制在有效范围[1,5]predicted_ratings[u, i] = max(1, min(5, predicted_rating))return predicted_ratings
3.7 推荐生成模块
def recommend_items(user_id, ratings_matrix, predicted_ratings, movies_df, top_n=10):"""为特定用户生成电影推荐参数:user_id: 用户ID(从1开始)ratings_matrix: 用户-物品评分矩阵predicted_ratings: 预测评分矩阵movies_df: 电影信息DataFrametop_n: 推荐数量返回:recommendations: 包含推荐电影的DataFrame"""# 调整为0-based索引user_idx = user_id - 1# 获取用户评分user_ratings = ratings_matrix[user_idx]user_predictions = predicted_ratings[user_idx]# 找出用户未评分的物品unrated_items = np.where(user_ratings == 0)[0]# 如果用户已评分所有物品,返回空DataFrameif len(unrated_items) == 0:return pd.DataFrame(columns=["movie_id", "movie_title", "predicted_rating"])# 获取未评分物品的预测评分unrated_predictions = user_predictions[unrated_items]# 按预测评分降序排序sorted_indices = np.argsort(-unrated_predictions)# 获取top_n推荐top_item_indices = sorted_indices[:top_n]top_items = unrated_items[top_item_indices]top_ratings = unrated_predictions[top_item_indices]# 转换为1-based电影IDmovie_ids = top_items + 1# 创建推荐DataFramerecommendations = pd.DataFrame({"movie_id": movie_ids,"predicted_rating": top_ratings})# 合并电影信息recommendations = recommendations.merge(movies_df[["movie_id", "movie_title"]], on="movie_id")# 按预测评分降序排序recommendations = recommendations.sort_values("predicted_rating", ascending=False)return recommendations

3.8 评估模块
def evaluate_recommendations(test_data, predicted_ratings, ratings_matrix=None, k_values=[5, 10], threshold=3.5):"""对推荐系统性能进行全面评估参数:test_data: 测试集DataFramepredicted_ratings: 预测评分矩阵ratings_matrix: 原始评分矩阵k_values: 评估的k值列表threshold: 判定物品相关性的评分阈值返回:results: 包含各项评估指标的字典"""# 评估评分预测rating_metrics = evaluate_rating_predictions(test_data, predicted_ratings)# 初始化结果字典results = rating_metrics.copy()# 评估top-k推荐for k in k_values:pr_metrics = calculate_precision_recall_at_k(test_data, predicted_ratings, ratings_matrix=ratings_matrix, k=k, threshold=threshold)precision_key = f"precision@{k}"recall_key = f"recall@{k}"results[precision_key] = pr_metrics[precision_key]results[recall_key] = pr_metrics[recall_key]# 计算F1分数precision = pr_metrics[precision_key]recall = pr_metrics[recall_key]f1 = calculate_f1_score(precision, recall)results[f"f1@{k}"] = f1return results
3.9 完整推荐系统模型
class UserBasedCF:"""基于用户的协同过滤推荐系统这个类实现了一个完整的推荐系统,使用基于用户的协同过滤算法。它通过识别具有相似评分模式的用户,并推荐这些相似用户喜欢但目标用户尚未体验的物品。"""def __init__(self, similarity_method="cosine", prediction_method="bias_weighted", k=30):"""初始化推荐系统模型参数:similarity_method: 计算用户相似度的方法prediction_method: 预测评分的方法k: 考虑的相似用户数量"""self.logger = get_logger()self.logger.info(f"初始化UserBasedCF模型,相似度方法={similarity_method},"f"预测方法={prediction_method},k={k}")self.similarity_method = similarity_methodself.prediction_method = prediction_methodself.k = k# 初始化数据属性self.ratings_df = Noneself.movies_df = Noneself.train_data = Noneself.test_data = Noneself.ratings_matrix = Noneself.user_similarity = Noneself.predicted_ratings = Noneself.n_users = Noneself.n_items = None# 跟踪模型是否已训练self.is_trained = Falsedef fit(self, ratings_df, movies_df=None, test_size=0.2, random_state=42):"""训练推荐模型参数:ratings_df: 包含评分数据的DataFramemovies_df: 包含电影信息的DataFrametest_size: 用于测试的数据比例random_state: 随机数种子返回:self: 训练后的模型实例"""from sklearn.model_selection import train_test_splitself.logger.info("开始模型训练")train_start = time.time()# 存储数据self.ratings_df = ratings_dfself.movies_df = movies_df# 获取维度self.n_users = ratings_df["user_id"].max()self.n_items = ratings_df["item_id"].max()self.logger.info(f"使用{self.n_users}个用户和{self.n_items}个物品训练模型")# 如果test_size>0,划分数据if test_size > 0:self.logger.info(f"划分数据,test_size={test_size},random_state={random_state}")split_start = time.time()self.train_data, self.test_data = train_test_split(ratings_df, test_size=test_size, random_state=random_state)split_time = time.time() - split_startself.logger.info(f"数据划分耗时{split_time:.2f}秒: {len(self.train_data)}训练样本,{len(self.test_data)}测试样本")else:self.train_data = ratings_dfself.test_data = Noneself.logger.info("使用所有数据进行训练(无测试集)")# 创建评分矩阵self.logger.info("从训练数据创建评分矩阵")matrix_start = time.time()self.ratings_matrix = np.zeros((self.n_users, self.n_items))for row in self.train_data.itertuples():# 调整为0-based索引user_idx = row.user_id - 1item_idx = row.item_id - 1self.ratings_matrix[user_idx, item_idx] = row.ratingmatrix_time = time.time() - matrix_startself.logger.info(f"评分矩阵创建耗时{matrix_time:.2f}秒")# 计算矩阵密度n_ratings = np.sum(self.ratings_matrix > 0)density = n_ratings / (self.n_users * self.n_items)self.logger.info(f"评分矩阵密度: {density:.6f} ({n_ratings}条评分)")# 计算用户相似度self.logger.info(f"使用{self.similarity_method}方法计算用户相似度")sim_start = time.time()self.user_similarity = calculate_similarity(self.ratings_matrix, method=self.similarity_method)sim_time = time.time() - sim_startself.logger.info(f"用户相似度计算耗时{sim_time:.2f}秒")# 预测评分self.logger.info(f"使用{self.prediction_method}方法预测评分,k={self.k}")pred_start = time.time()self.predicted_ratings = predict_ratings(self.ratings_matrix,self.user_similarity,method=self.prediction_method,k=self.k)pred_time = time.time() - pred_startself.logger.info(f"评分预测耗时{pred_time:.2f}秒")# 标记模型为已训练self.is_trained = Truetotal_time = time.time() - train_startself.logger.info(f"模型训练完成,总耗时{total_time:.2f}秒")return self
3.10 命令行接口设计
为了方便用户使用推荐系统,我们设计了一个功能丰富的命令行接口:
def parse_args():"""解析命令行参数"""parser = argparse.ArgumentParser(description="基于用户的协同过滤推荐系统")# 数据参数parser.add_argument("--data_path",type=str,default="data/ml-100k",help="MovieLens数据集目录路径")# 模型参数parser.add_argument("--similarity",type=str,default="cosine",choices=["cosine", "pearson", "euclidean", "adjusted_cosine"],help="使用的相似度度量")parser.add_argument("--prediction",type=str,default="bias_weighted",choices=["simple_weighted", "bias_weighted"],help="使用的预测方法")parser.add_argument("--k",type=int,default=30,help="考虑的相似用户数量")# 输出目录参数parser.add_argument("--output_dir",type=str,default="results",help="保存可视化输出的目录")parser.add_argument("--log_dir",type=str,default="results/logs",help="保存日志文件的目录")parser.add_argument("--log_level",type=str,default="INFO",choices=["DEBUG", "INFO", "WARNING", "ERROR", "CRITICAL"],help="日志级别")# 推荐参数parser.add_argument("--user_id",type=int,required=False,help="为其生成推荐的用户ID")parser.add_argument("--num_recommendations",type=int,default=10,help="生成的推荐数量")# 评估参数parser.add_argument("--test_size",type=float,default=0.2,help="用于测试的数据比例")parser.add_argument("--evaluate",action="store_true",help="评估模型")# 可视化参数parser.add_argument("--visualize",action="store_true",help="可视化用户相似度和推荐")# 模型保存/加载parser.add_argument("--save_model",type=str,default=None,help="保存训练模型的路径")parser.add_argument("--load_model",type=str,default=None,help="加载预训练模型的路径")# 参数调优parser.add_argument("--tune",action="store_true",help="执行参数调优")return parser.parse_args()
使用示例:
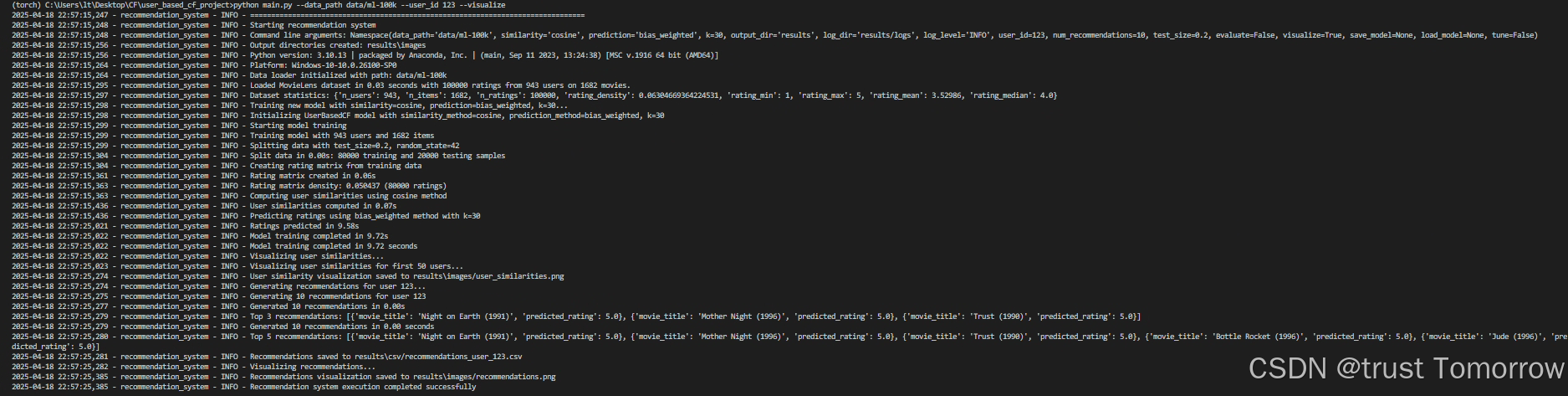
# 生成推荐
python main.py --user_id 123 --num_recommendations 10 --similarity cosine --k 30# 评估模型
python main.py --evaluate --test_size 0.2# 参数调优
python main.py --tune --output_dir results# 保存和加载模型
python main.py --similarity pearson --k 40 --save_model models/my_model.pkl
python main.py --load_model models/my_model.pkl --user_id 123
3.11 模型序列化与反序列化
对于训练好的模型,我们提供了保存和加载功能,以便在不同环境中复用:
def save_model(self, filepath):"""将训练好的模型保存到文件参数:filepath: 保存模型的路径"""if not self.is_trained:error_msg = "模型未训练。保存前请先调用fit()"self.logger.error(error_msg)raise ValueError(error_msg)self.logger.info(f"保存模型到{filepath}")# 如果目录不存在则创建os.makedirs(os.path.dirname(filepath), exist_ok=True)import picklemodel_data = {"similarity_method": self.similarity_method,"prediction_method": self.prediction_method,"k": self.k,"ratings_matrix": self.ratings_matrix,"user_similarity": self.user_similarity,"predicted_ratings": self.predicted_ratings,"n_users": self.n_users,"n_items": self.n_items,"is_trained": self.is_trained}save_start = time.time()with open(filepath, "wb") as f:pickle.dump(model_data, f)save_time = time.time() - save_start# 计算文件大小file_size = os.path.getsize(filepath) / (1024 * 1024) # MBself.logger.info(f"模型已保存到{filepath} ({file_size:.2f} MB),耗时{save_time:.2f}秒")@classmethod
def load_model(cls, filepath, movies_df=None):"""从文件加载训练好的模型参数:filepath: 模型文件路径movies_df: 电影信息DataFrame返回:model: 加载的模型实例"""logger = get_logger()logger.info(f"从{filepath}加载模型")if not os.path.exists(filepath):error_msg = f"模型文件{filepath}不存在"logger.error(error_msg)raise FileNotFoundError(error_msg)import pickleload_start = time.time()with open(filepath, "rb") as f:model_data = pickle.load(f)load_time = time.time() - load_start# 创建新实例model = cls(similarity_method=model_data["similarity_method"],prediction_method=model_data["prediction_method"],k=model_data["k"])# 恢复模型属性model.ratings_matrix = model_data["ratings_matrix"]model.user_similarity = model_data["user_similarity"]model.predicted_ratings = model_data["predicted_ratings"]model.n_users = model_data["n_users"]model.n_items = model_data["n_items"]model.is_trained = model_data["is_trained"]model.movies_df = movies_df# 计算文件大小file_size = os.path.getsize(filepath) / (1024 * 1024) # MBlogger.info(f"从{filepath}加载模型 ({file_size:.2f} MB),耗时{load_time:.2f}秒")logger.info(f"模型维度: {model.n_users}用户, {model.n_items}物品")return model
3.12 Web应用开发
为了提供友好的用户界面,我们使用Flask开发了一个Web应用:
from flask import Flask, render_template, request, redirect, url_for, flash, jsonify, send_fileapp = Flask(__name__)
app.secret_key = os.urandom(24)# 全局变量
data_loader = None
model = None
MODEL_PATH = "../models/user_based_cf.pkl"
DATA_PATH = "../data/ml-100k"
OUTPUT_DIR = "../results"# 创建目录
os.makedirs(os.path.dirname(MODEL_PATH), exist_ok=True)
os.makedirs(os.path.join(OUTPUT_DIR, "images"), exist_ok=True)def initialize_data_and_model():"""初始化数据加载器和模型"""global data_loader, modellogger.info("初始化数据和模型...")# 初始化数据加载器并加载数据if data_loader is None:try:data_loader = DataLoader(data_path=DATA_PATH)ratings_df, movies_df = data_loader.load_data()logger.info(f"数据加载完成: {len(ratings_df)}条评分, {len(movies_df)}部电影")except Exception as e:logger.error(f"加载数据出错: {str(e)}")logger.error(traceback.format_exc())return False# 初始化模型(如果未加载)if model is None:try:# 检查是否存在预训练模型if os.path.exists(MODEL_PATH):logger.info(f"从{MODEL_PATH}加载预训练模型")model = UserBasedCF.load_model(MODEL_PATH, movies_df=data_loader.movies_df)else:logger.info("使用默认参数训练新模型")model = UserBasedCF(similarity_method="cosine", prediction_method="bias_weighted", k=30)model.fit(data_loader.ratings_df, data_loader.movies_df, test_size=0)# 保存模型以供将来使用model.save_model(MODEL_PATH)logger.info(f"模型训练完成并保存到{MODEL_PATH}")except Exception as e:logger.error(f"初始化模型出错: {str(e)}")logger.error(traceback.format_exc())return Falsereturn True@app.route("/")
def index():"""渲染首页"""# 初始化数据和模型if not initialize_data_and_model():flash("初始化数据和模型出错,请检查日志", "danger")# 如果模型已初始化,获取模型参数model_params = {}if model and model.is_trained:model_params = {"similarity_method": model.similarity_method,"prediction_method": model.prediction_method,"k": model.k,"n_users": model.n_users,"n_items": model.n_items}# 获取可用的相似度和预测方法similarity_methods = ["cosine", "pearson", "euclidean", "adjusted_cosine"]prediction_methods = ["simple_weighted", "bias_weighted"]# 获取数据集统计信息dataset_stats = {}if data_loader:dataset_stats = data_loader.get_dataset_stats()return render_template("index.html",model_params=model_params,similarity_methods=similarity_methods,prediction_methods=prediction_methods,dataset_stats=dataset_stats)@app.route("/recommend", methods=["GET", "POST"])
def recommend():"""基于表单输入或URL参数生成推荐"""# 初始化数据和模型if not initialize_data_and_model():flash("初始化数据和模型出错,请检查日志", "danger")return redirect(url_for("index"))# 提取当前模型参数作为默认值current_similarity = model.similarity_method or "cosine"current_prediction = model.prediction_method or "bias_weighted"current_k = model.k or 30# 根据请求方法提取参数if request.method == "POST":# 获取表单数据user_id = int(request.form.get("user_id", 1))num_recommendations = int(request.form.get("num_recommendations", 10))similarity_method = request.form.get("similarity_method", current_similarity)prediction_method = request.form.get("prediction_method", current_prediction)k = int(request.form.get("k", current_k))else: # GET请求# 获取URL参数user_id = int(float(request.args.get("user_id", "1")))# 验证user_id在有效范围内if user_id < 1 or user_id > model.n_users:flash(f"无效的用户ID: {user_id}。必须在1到{model.n_users}之间", "danger")return redirect(url_for("index"))num_recommendations = int(request.args.get("num_recommendations", 10))similarity_method = request.args.get("similarity_method", current_similarity)prediction_method = request.args.get("prediction_method", current_prediction)k = int(request.args.get("k", current_k))# 确保参数不为Nonesimilarity_method = similarity_method or "cosine"prediction_method = prediction_method or "bias_weighted"k = k or 30logger.info(f"推荐参数: user_id={user_id}, similarity={similarity_method}, prediction={prediction_method}, k={k}")# 检查是否需要重新训练模型retrain = model.similarity_method != similarity_method or model.prediction_method != prediction_method or model.k != k# 如需要,重新训练if retrain:try:logger.info(f"使用参数重新训练模型: similarity={similarity_method}, prediction={prediction_method}, k={k}")model = UserBasedCF(similarity_method=similarity_method,prediction_method=prediction_method,k=k)model.fit(data_loader.ratings_df, data_loader.movies_df, test_size=0)# 保存重新训练的模型model.save_model(MODEL_PATH)logger.info("模型重新训练完成并保存")except Exception as e:logger.error(f"重新训练模型出错: {str(e)}")logger.error(traceback.format_exc())flash(f"重新训练模型出错: {str(e)}", "danger")return redirect(url_for("index"))# 生成推荐try:start_time = time.time()recommendations = model.recommend(user_id, top_n=num_recommendations)generation_time = time.time() - start_time# 可视化推荐img_path = Noneif not recommendations.empty:img_path = visualize_recommendations(user_id, recommendations)# 获取用户当前评分(如果有)user_ratings = Noneif data_loader:try:user_ratings = data_loader.get_user_ratings(user_id)# 按评分降序排序user_ratings = user_ratings.sort_values("rating", ascending=False)except:pass# 获取相似用户similar_users = Nonetry:similar_users = model.get_similar_users(user_id, top_n=5)except:passreturn render_template("recommendations.html",user_id=user_id,recommendations=recommendations,generation_time=generation_time,img_path=img_path,user_ratings=user_ratings,similar_users=similar_users,model_params={"similarity_method": model.similarity_method,"prediction_method": model.prediction_method,"k": model.k})except Exception as e:logger.error(f"生成推荐出错: {str(e)}")logger.error(traceback.format_exc())flash(f"生成推荐出错: {str(e)}", "danger")return redirect(url_for("index"))
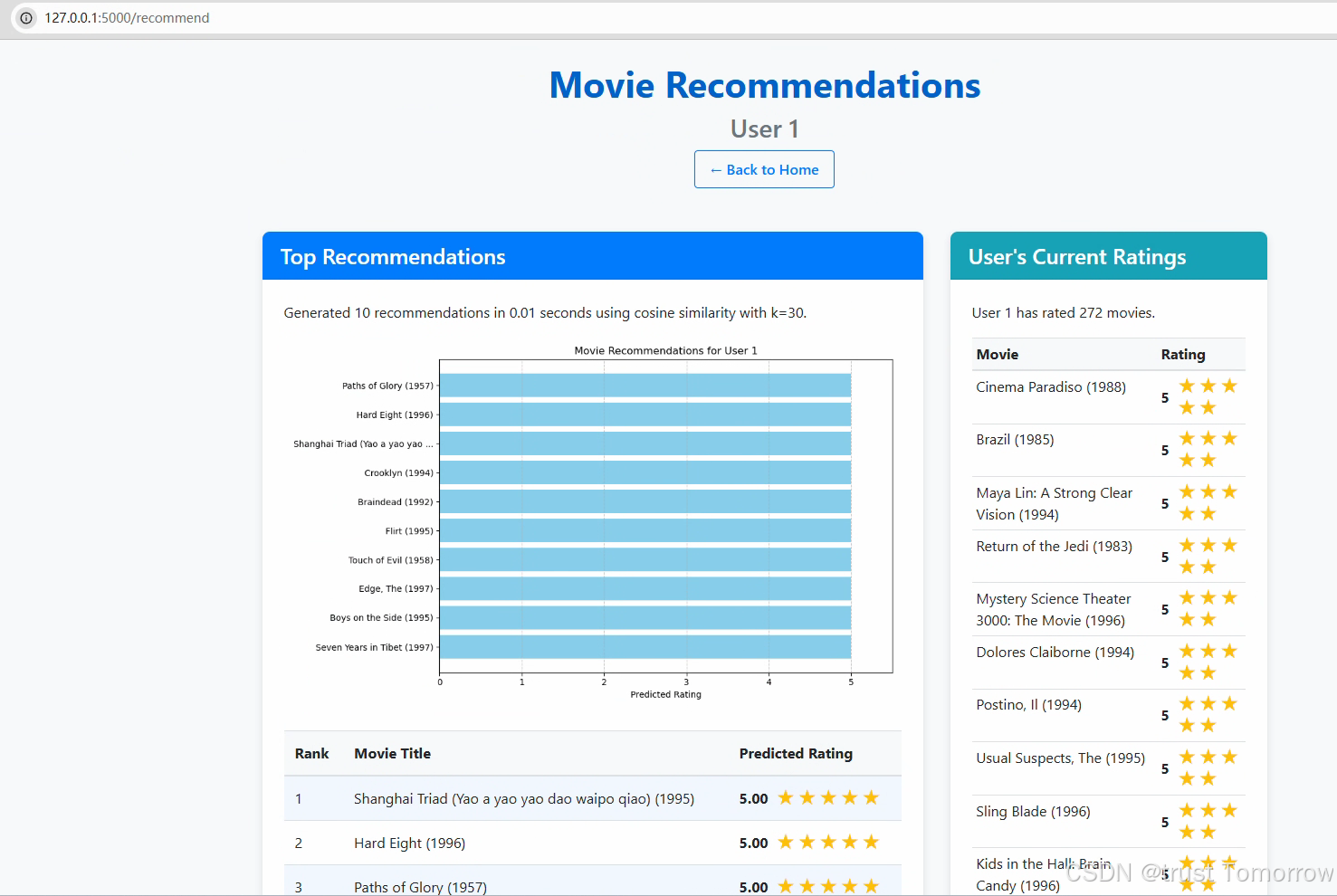
3.13 性能优化与错误处理
为了提高系统性能并增强鲁棒性,我们实现了以下优化与错误处理机制:
# 矩阵运算优化
# 使用向量化操作代替循环
def calculate_similarity_optimized(ratings_matrix, method="cosine"):"""优化的相似度计算函数"""# 利用多核加速计算return 1 - pairwise_distances(ratings_matrix, metric=method, n_jobs=-1)# 大规模数据处理:使用稀疏矩阵表示
def create_sparse_matrix(self):"""创建稀疏评分矩阵以节省内存"""from scipy.sparse import csr_matrixrows, cols, data = [], [], []for row in self.ratings_df.itertuples():rows.append(row.user_id - 1)cols.append(row.item_id - 1)data.append(row.rating)self.sparse_ratings_matrix = csr_matrix((data, (rows, cols)), shape=(self.n_users, self.n_items))return self.sparse_ratings_matrix# 异常处理与数据验证
def recommend(self, user_id, top_n=10):"""带异常处理的推荐函数"""# 验证模型状态if not self.is_trained:raise ValueError("模型未训练,请先调用fit()")# 验证用户IDif user_id < 1 or user_id > self.n_users:raise ValueError(f"无效的用户ID: {user_id}。必须在1到{self.n_users}之间")# 验证参数if top_n < 1:raise ValueError(f"无效的推荐数量: {top_n}。必须大于0")# 验证必要的数据是否可用if self.movies_df is None:raise ValueError("缺少电影信息。请在fit()中提供movies_df")# 生成推荐try:return recommend_items(user_id, self.ratings_matrix, self.predicted_ratings, self.movies_df, top_n)except Exception as e:self.logger.error(f"为用户{user_id}生成推荐时出错: {str(e)}")# 重新抛出异常,附加上下文信息raise RuntimeError(f"推荐生成失败: {str(e)}")
5. 模块化设计的优势
采用模块化设计使得我们的推荐系统具有以下优势:
- 代码可维护性:每个模块专注于单一功能,便于理解和修改
- 可扩展性:可以轻松添加新的相似度计算方法或评分预测算法
- 可重用性:各个组件可以在其他项目中重用
- 测试便利性:可以独立测试每个模块的功能
- 团队协作:不同团队成员可以同时开发不同模块
6. 结论与未来工作
本项目成功实现了一个基于用户的协同过滤推荐系统,并在MovieLens 100K数据集上进行了评估。系统具有以下特点:
- 模块化设计:清晰的代码结构,便于维护和扩展
- 多种算法支持:实现了多种相似度计算和评分预测方法
- 完整的评估体系:使用RMSE、MAE、精确率、召回率等指标全面评估性能
- 用户友好界面:提供命令行和Web两种交互方式
- 日志和错误处理:完善的日志系统和健壮的错误处理机制
7. 参考资料
- Resnick, P., Iacovou, N., Suchak, M., Bergstrom, P., & Riedl, J. (1994). GroupLens: An Open Architecture for Collaborative Filtering of Netnews. Proceedings of the 1994 ACM Conference on Computer Supported Cooperative Work.
- Breese, J. S., Heckerman, D., & Kadie, C. (1998). Empirical Analysis of Predictive Algorithms for Collaborative Filtering. Proceedings of the 14th Conference on Uncertainty in Artificial Intelligence.
- Sarwar, B., Karypis, G., Konstan, J., & Riedl, J. (2001). Item-based collaborative filtering recommendation algorithms. Proceedings of the 10th International Conference on World Wide Web.
- Harper, F. M., & Konstan, J. A. (2015). The MovieLens Datasets: History and Context. ACM Transactions on Interactive Intelligent Systems (TiiS).
- Koren, Y., Bell, R., & Volinsky, C. (2009). Matrix factorization techniques for recommender systems. Computer, 42(8), 30-37.
- Ning, X., Desrosiers, C., & Karypis, G. (2015). A comprehensive survey of neighborhood-based recommendation methods. Recommender systems handbook, 37-76.
相关文章:

基于用户的协同过滤推荐系统实战项目
文章目录 基于用户的协同过滤推荐系统实战项目1. 推荐系统基础理论1.1 协同过滤概述1.2 基于用户的协同过滤原理1.3 相似度计算方法1.3.1 余弦相似度(Cosine Similarity)1.3.2 皮尔逊相关系数(Pearson Correlation)1.3.3 欧几里得距离(Euclidean Distance)1.3.4 调整余弦相似度…...

浅析数据库面试问题
以下是关于数据库的一些常见面试问题: 一、基础问题 什么是数据库? 数据库是按照数据结构来组织、存储和管理数据的仓库。SQL 和 NoSQL 的区别是什么? SQL 是关系型数据库,使用表结构存储数据;NoSQL 是非关系型数据库,支持多种数据模型(如文档型、键值对型等)。什么是…...

【Python3】Django 学习之路
第一章:Django 简介 1.1 什么是 Django? Django 是一个高级的 Python Web 框架,旨在让 Web 开发变得更加快速和简便。它鼓励遵循“不要重复自己”(DRY,Don’t Repeat Yourself)的原则,并提供了…...
)
Java并发编程高频面试题(已整理Java面试宝典PDF完整版)
为什么要使用并发编程 提升多核CPU利用率:现代计算机通常配备多核CPU,通过创建多个线程,操作系统可以将不同线程分配到不同CPU核心上并行执行,从而充分利用硬件资源。若仅使用单线程,则只能利用一个CPU核心,…...

第 4 期:DDPM中的损失函数——为什么只预测噪声?
—— 从变分下界到噪声预测 回顾:我们到底在做什么? 在第 3 期中,我们介绍了扩散模型的逆过程建模。简而言之,目标是通过神经网络学习从噪声 x_t 中恢复图像 x_0,并且我们通过预测噪声 ϵ来完成这个任务。 今天&a…...

Docker使用、容器迁移
Docker 简介 Docker 是一个开源的容器化平台,用于打包、部署和运行应用程序及其依赖环境。Docker 容器是轻量级的虚拟化单元,运行在宿主机操作系统上,通过隔离机制(如命名空间和控制组)确保应用运行环境的一致性和可移…...
)
专业热度低,25西电光电工程学院(考研录取情况)
1、光电工程学院各个方向 2、光电工程学院近三年复试分数线对比 学长、学姐分析 由表可看出: 1、光学工程25年相较于24年下降20分, 2、光电信息与工程(专硕)25年相较于24年上升15分 3、25vs24推免/统招人数对比 学长、学姐分析…...

六、LangChain Agent 最佳实践
1. 架构设计与组件选择 (1) 核心组件分层设计 Model(LLM驱动层) 生产环境推荐:使用 gpt-4-1106-preview 或 Anthropic Claude 3 等高性能模型,结合 model.with_fallbacks() 实现故障转移(如备用模型或本地模型)。本地部署:选择 Llama3-70B 等开源模型,搭配 Docker 或 …...
之MapReduce编程)
ubantu18.04(Hadoop3.1.3)之MapReduce编程
说明:本文图片较多,耐心等待加载。(建议用电脑) 注意所有打开的文件都要记得保存。 第一步:准备工作 本文是在之前Hadoop搭建完集群环境后继续进行的,因此需要读者完成我之前教程的所有操作。 第二步&…...

PoCL环境搭建
PoCL环境搭建 **一.关键功能与优势****二.设计目的****三.测试步骤**1.创建容器2.安装依赖3.编译安装pocl4.运行OpenCL测试程序 Portable Computing Language (PoCL) 简介 Portable Computing Language (PoCL) 是一个开源的、符合标准的异构计算框架,旨在为 OpenCL…...

关于hadoop和yarn的问题
1.hadoop的三大结构及各自的作用? HDFS(Hadoop Distributed File System):分布式文件系统,负责海量数据的存储,具有高容错性和高吞吐量。 MapReduce:分布式计算框架,用于并行处理大…...

软件工程中数据一致性的探讨
软件工程中数据一致性的探讨 引言数据一致性:软件工程中的业务正确性与性能的权衡数据一致性为何重要业务正确性:事务的原子性与一致性ACID原则的基石分布式事务的挑战一致性级别:从强一致到最终一致 实践中的一致性权衡金融系统:…...

在服务器上安装redis
1.安装所需插件gcc 查看gcc版本 gcc -v 没有安装的话,安装命令如下 yum -y install gcc 2.安装 下载安装包 https://download.redis.io/releases/ 将安装包上传到/opt/software目录下 解压安装包 cd /opt/software tar -zxvf redis-6.2.6.tar.gz 编译并安装redis到指…...

如何选择适合您的过程控制器?
在现代工业中,过程控制器是确保生产效率、质量和安全性的关键设备。它们可以精准监测温度、湿度等变量,优化制造流程,减少人工干预,从而降低错误率和运营成本。但您是否清楚,哪种过程控制器更适合您的企业?…...
)
C#/.NET/.NET Core拾遗补漏合集(25年4月更新)
前言 在这个快速发展的技术世界中,时常会有一些重要的知识点、信息或细节被忽略或遗漏。《C#/.NET/.NET Core拾遗补漏》专栏我们将探讨一些可能被忽略或遗漏的重要知识点、信息或细节,以帮助大家更全面地了解这些技术栈的特性和发展方向。 ✍C#/.NET/.N…...

闲来无事,用HTML+CSS+JS打造一个84键机械键盘模拟器
今天闲来无聊,突发奇想要用前端技术模拟一个机械键盘。说干就干,花了点时间搞出来了这么一个有模有样的84键机械键盘模拟器。来看看效果吧! 升级版的模拟器 屏幕录制 2025-04-18 155308 是不是挺像那么回事的?哈哈! 它…...

极狐GitLab 项目导入导出设置介绍?
极狐GitLab 是 GitLab 在中国的发行版,关于中文参考文档和资料有: 极狐GitLab 中文文档极狐GitLab 中文论坛极狐GitLab 官网 导入导出设置 (BASIC SELF) 导入和导出相关功能的设置。 配置允许的导入源 在从其他系统导入项目之前,必须为该…...

极狐GitLab 项目 API 的速率限制如何设置?
极狐GitLab 是 GitLab 在中国的发行版,关于中文参考文档和资料有: 极狐GitLab 中文文档极狐GitLab 中文论坛极狐GitLab 官网 项目 API 的速率限制 (BASIC SELF) 引入于 15.10 版本,功能标志为rate_limit_for_unauthenticated_projects_api_…...

electron 渲染进程按钮创建新window,报BrowserWindow is not a constructor错误;
在 Electron 中,有主进程和渲染进程 主进程:在Node.js环境中运行—意味着能够使用require模块并使用所有Node.js API 渲染进程:每个electron应用都会为每个打开的BrowserWindow(与每个网页嵌入)生成一个单独的渲染器进…...

【前沿】成像“跨界”测量——扫焦光场成像
01 背景 眼睛是人类认识世界的重要“窗口”,而相机作为眼睛的“延伸”,已经成为生产生活中最常见的工具之一,广泛应用于工业检测、医疗诊断与影音娱乐等领域。传统相机通常以“所见即所得”的方式记录场景,传感器捕捉到的二维图像…...
图形编辑界面工具)
基于C++(MFC)图形编辑界面工具
MFC 图形编辑界面工具 一、背景 喔,五天的实训终于结束了,学校安排的这次实训课名称叫高级程序设计实训,但在我看来,主要是学习了 Visual C .NET 所提供的 MFC(Microsoft Foundation Class)库所提供的类及其功能函数…...

Linux网络通信核心机制解析与层级架构探秘
作为现代操作系统的神经网络,Linux网络通信系统通过多层协作架构实现高效的数据传输机制。本文将从模块化设计、报文处理路径、核心组件交互等多个维度,解析Linux网络通信系统的实现原理与优化策略,并结合内核源码示例与性能调优实践…...

Tensorflow实现用接口调用模型训练和停止训练功能
语言:Python 框架:Flask、Tensorflow 功能描述:存在两个接口,一个接口实现开始训练模型的功能,一个接口实现停止训练的功能。 实现:用一个全局变量存储在训练中的模型。 # 存储所有训练任务 training_task…...

HTTP测试智能化升级:动态变量管理实战与效能跃迁
在Web应用、API接口测试等领域,测试场景的动态性和复杂性对测试数据的灵活管理提出了极高要求。传统的静态测试数据难以满足多用户并发、参数化请求及响应内容验证等需求。例如,在电商系统性能测试中,若无法动态生成用户ID、订单号或实时提取…...

PyTorch 浮点数精度全景:从 float16/bfloat16 到 float64 及混合精度实战
PyTorch 在深度学习中提供了多种 IEEE 754 二进制浮点格式的支持,包括半精度(float16)、Brain‑float(bfloat16)、单精度(float32)和双精度(float64),并通过统…...
——统一建模语言UML、事务关系图)
《软件设计师》复习笔记(14.2)——统一建模语言UML、事务关系图
目录 1. UML概述 2. UML构造块 (1) 事物(Things) (2) 关系(Relationships) 真题示例: 3. UML图分类 (1) 结构图(静态) (2) 行为图(动态) 4. 核心UML图详解 5.…...
的细胞识别程序)
基于C++(MFC)的细胞识别程序
基于 mfc 的细胞识别程序 一、图像处理课程设计目标 1.1 课题与技术指标 课题:利用图像处理技术设计细胞识别程序。 技术指标: 实验 VS2019 MFC 开发平台待识别图像为 24bit 的真彩色细胞图像进行处理要求识别出细胞,并且保证准确度情况下…...

【前端HTML生成二维码——MQ】
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 前端HTML生成二维码——MQ 前言本文将介绍前端HTML如何更具用户输入的内容生成对应的二维码,附页面代码、实现函数、js脚本。一、自定义显示页面1、效果图二、使用步骤1、引入库2、实现函数3、页面及函数代…...

Spring Boot自动配置原理深度解析:从条件注解到spring.factories
大家好!今天我们来深入探讨Spring Boot最神奇的特性之一——自动配置(Auto-configuration)。这个功能让Spring Boot如此受欢迎,因为它大大简化了我们的开发工作。让我们一起来揭开它的神秘面纱吧!👀 🌟 什么是自动配置…...

【unity实战】Animator启用root motion根运动动画,实现完美的动画动作匹配
文章目录 前言1、动画分类2、如何使用根位移动画? 一、根位移动画的具体使用1、导入人形模型2、导入动画3、配置动画参数4、配置角色Animator动画状态机5、使用代码控制人物前进后退 二、问题分析三、Humanoid动画中的Root Motion机制及相关配置1、Humanoid动画中的…...
LCD显示数据存储(DS1302时钟模块教学)(LCD1602教程)(独立按键教程)(延时函数教程)(I2C总线认识)(AT24C02认识))
(51单片机)LCD显示数据存储(DS1302时钟模块教学)(LCD1602教程)(独立按键教程)(延时函数教程)(I2C总线认识)(AT24C02认识)
目录 演示视频: 源代码 main.c LCD1602.c LCD1602.h AT24C02.c AT24C02.h Key.c Key.h I2C.c I2C.h Delay.c Delay.h 代码解析与教程: Dealy模块 LCD1602模块 Key模块 I2C总线模块 AT24C02模块 /E2PROM模块 main模块 演示视频: &…...

2d深度预测
Depth anything v1 相对深度估计,要用绝对深度估计需要微调 概要: 1 使用大量的未标注图像信息 2 采用优化策略—数据增强工具(作用在未标注图像) 3 进行辅助监督—继承语义分割知识(作用在未标注图像) 数据层面: …...

Android12 ServiceManager::addService源码解读
源码 Status ServiceManager::addService(const std::string& name, const sp<IBinder>& binder, bool allowIsolated, int32_t dumpPriority) {auto ctx mAccess->getCallingContext();// apps cannot add servicesif (multiuser_get_app_id(ctx.uid) >…...

【HDFS入门】HDFS性能调优实战:从基准测试到优化策略
目录 引言 1 HDFS性能评估体系 1.1 性能评估体系架构 1.2 基准测试工具对比 2 TestDFSIO基准测试实战 2.1 TestDFSIO工作原理 2.2 测试执行步骤 2.3 结果分析指标 3 TeraSort基准测试实战 3.1 TeraSort测试流程 3.2 测试执行命令 3.3 关键性能指标 4 HDFS性能调优…...
)
Linux 内核开发/测试工具对比 Windows 驱动验证工具 (Driver Verifier)
Windows 的 Driver Verifier 是一个用于测试和验证驱动程序的强大工具。在 Linux 内核开发中,虽然没有一个完全等价的单一工具,但有多种工具和框架可以提供类似或更专业的功能。 Linux 内核开发和测试工具 1. KASAN (Kernel Address Sanitizer) 功能&…...

通信算法之269 : OFDM信号的循环自相关特性用于无人机图传信号识别
OFDM信号的循环自相关特性是其循环平稳性的核心体现,如下: [相关仿真代码,联系,提供] 一、循环自相关特性来源 循环前缀引入周期性 OFDM符号通过添加循环前缀(CP)形成符号周期结构,导致信号具有循环平稳性26。每个符号的CP与尾部数据重复,在时延等于FFT长度(N…...
 驱动电机,常见的电调协议,PWM协议,Oneshot协议,DShot协议)
【无人机】电子速度控制器 (ESC) 驱动电机,常见的电调协议,PWM协议,Oneshot协议,DShot协议
目录 1、ESCs & 电机 #1.1、ESC 协议 --ESC Protocols #1.1.1、PWM协议,需要校准 #1.1.2、One Shot 125协议,速率更快 #1.1.3、DShot ,减少延迟,无需校准 #1.1.4、无人机CAN 2、PWM 伺服系统和 ESC(电机控…...

LeadeRobot具身智能应用标杆:无人机X柔韧具身智能,空中精准作业游刃有余
当前,具身智能已成为全球科技领域的前沿焦点,更受到国家战略级重视,吸引科技产业巨头抢滩布局。但同时,具身智能的商业化路径、规模化应用场景、技术成本等难题也开始在资本界与产业圈引起广泛讨论。 目前,万勋科技基于Pliabot 柔韧技术已推出多款具身智能柔韧机器人产品,在柔…...

WebSocket:实现实时双向通信的技术
WebSocket是一种网络通信协议,它在单个TCP连接上提供全双工通信。WebSocket协议在2011年被IETF(互联网工程任务组)标准化为RFC 6455,并由W3C(万维网联盟)制定了WebSocket API标准,使得客户端&am…...

探索 HumanoidBench:类人机器人学习的新平台
在科技飞速发展的当下,类人机器人逐渐走进我们的视野,它们有着和人类相似的外形,看起来能像人类一样在各种环境里完成复杂任务,潜力巨大。但实际上,让类人机器人真正发挥出实力,还面临着重重挑战。 这篇文…...

「数据可视化 D3系列」入门第十一章:力导向图深度解析与实现
D3.js 力导向图深度解析与实现 力导向图核心概念 力导向图是一种通过物理模拟来展示复杂关系网络的图表类型,特别适合表现社交网络、知识图谱、系统拓扑等关系型数据。其核心原理是通过模拟粒子间的物理作用力(电荷斥力、弹簧引力等)自动计…...
)
「数据可视化 D3系列」入门第八章:动画效果详解(让图表动起来)
动画效果详解 一、D3.js动画核心API1. d3.transition()2. transition.duration()3. transition.delay()4. 其他重要API 二、动画实现原理三、完整动画示例解析1. 柱状图生长动画2. 文本跟随动画 四、动画效果优化技巧1. 缓动函数选择:2. 组合动画:3. 动画…...

index: 自动化浏览器智能体
GitHub:https://github.com/lmnr-ai/index 更多AI开源软件:https://www.aiinn.cn/ 在做浏览器自动化脚本时,我们常常需要编写大量代码来处理复杂的网页交互,不仅耗时耗力,还难以调试和优化,要是出错更是难以…...
)
网页端调用本地应用打开本地文件(PDF、Word、excel、PPT)
一、背景原因 根据浏览器的安全策略,在网页端无法直接打开本地文件,所以需要开发者曲线救国。 二、实现步骤 前期准备: 确保已安装好可以打开文件的应用软件,如,WPS; 把要打开的文件统一放在一个文件夹&am…...

如何批量在多个 Word 文档末尾添加广告页面
Word是我们日常使用非常频繁的文档编辑软件,凭借其强大的文本处理功能,如文字输入、格式设置、段落排版、图片插入等,可以帮助我们轻松创建专业且美观的文档。不过呢当我们需要将这些文档分享给他人时,往往需要在每个文档的末尾添…...

JavaScript原生实现简单虚拟列表
旧笔记,最近使用时做了点新优化,之前只发在了个人博客上 地址:JavaScript原生实现简单虚拟列表 背景 在公司项目中,需要给商品配置大量的属性值,可能其中一个属性的值数量就有成百上千条。 一个商品会有很多属性&…...

安心联车辆管理平台应用前景分析
安心联车辆管理平台凭借其技术创新与行业适配能力,展现出广阔的应用前景。以下从技术驱动、行业覆盖、实际效益、市场策略及未来潜力五个维度进行分析: 一、技术驱动的核心竞争力 高精度定位与多传感器融合 安心联采用北斗/GPS双模定位技术,实…...
)
力扣每日打卡 2176. 统计数组中相等且可以被整除的数对(简单)
力扣 2176. 统计数组中相等且可以被整除的数对 简单 前言一、题目内容二、解题方法1. 暴力解法2.官方题解官方也是暴力解法 前言 这是刷算法题的第十三天,用到的语言是JS 题目:力扣 2176. 统计数组中相等且可以被整除的数对(简单) 一、题目内容 给你一…...
Swift笔记20250418)
OpenStack Yoga版安装笔记(22)Swift笔记20250418
一、官方文档 https://docs.openstack.org/swift/yoga/admin/objectstorage-components.html#https://docs.openstack.org/swift/yoga/admin/objectstorage-components.html# 二、对象存储简介(Introduction to Object Storage) OpenStack 对象存储&a…...

Linux 线程互斥
目录 Linux线程互斥 进程线程间的互斥相关背景概念 互斥量的接口 初始化互斥量 互斥量加锁和解锁 锁的封装 编辑 互斥量加锁的非阻塞版本 互斥量实现原理探究 可重入VS线程安全 概念 常见的线程不安全的情况 常见的线程安全的情况 常见的不可重入的情况 常见的…...