Python复习
第一章 Python概述
python特点
优点:
- 简单易学;
- 开发效率高;
- 典型的工具语言;
- 强大丰富的模块库;
- 优秀的跨平台;
缺点:
- 执行效率不高;
- 代码不能加密;
- 用缩进区分语句关系;
行和缩进
python最具特色的是:用缩进来写模块;
缩进体现的是代码的逻辑关系和层次关系,缩进的空白数量可变,但所有代码块语句必须包含相同的缩进空白数量;
由于行缩进导致编码执行报错,经常有两种情况:
1.IndentationError: unexpected indent :文件格式不对,可能是tab和空格没对齐的问题;
2.IndentationError: unindent does not match any outer indentation level :使用的缩进方式不一致,有的是tab键缩进,有的是空格缩进;
在 Python 的代码块中必须使用相同数目的行首缩进空格数;建议每个缩进层次使用单个制表符或两个空格或四个空格,但不能混用;
编码多行显示
python一般以新行作为语句的结束符,但一行代码太长,可以用反斜杠 \ 将一行语句分为多行显示;
num1 = 10
num2 = num1 + \5 + \6
语句中包含[],{},()不需要多行连接符,直接换行即可;
引号
Python 可以使用单引号( ’ )、双引号( " )、三引号( ‘’’ 或 “”" ) 来表示字符串
其中三引号可以由多行组成,编写多行文本的快捷语法,常用于文档字符串,在文件的特定地点,被当做注释。
注释
单行注释
不能换行,只能在1行内应用;
多行注释 (三个单引号)‘’’ 或(三个双引号)“”"
用于大段文字说明,可以换行使用;
输入
input(‘输入提示内容’)该函数用来接收屏幕输入数据并返回字符类型
input函数接受数据都被定义为字符类型,如果输入整数或小数,使用int或float强制转换;
第二章 Python基本语法
常量
通常用全部大写的变量名,但实际定义的常量还是一个变量,可以改变其值;
数据类型
- 数字类型
整型、浮点型、复数类型、布尔类型;
数字类型用于存储数值,不可改变的数据类型,改变数字数据类型会分配给一个新的对象
id()函数返回对象标识,输出的是一个整数,对于给定的对象是唯一的,并且输出数值保持不变;
type()函数可以查看变量的类型
- 组合类型
字符串、列表、元组、字典、集合;
字符串:不可改变数据类型,有单行字符串(包含在一对单引号或双引号中)、多行字符串(一对三单引号或三双引号中)
输出
print输出
print("ts的值是:")
print(t3)
格式化输出
f 默认小数点之后6位
pi = 3.1415926535
print("%f" %pi) #3.141593
f(‘表达式’)
print(f'我的名字是{name},我的学号是:{sno},我今年{age}岁。')
列表、元组、集合、字典
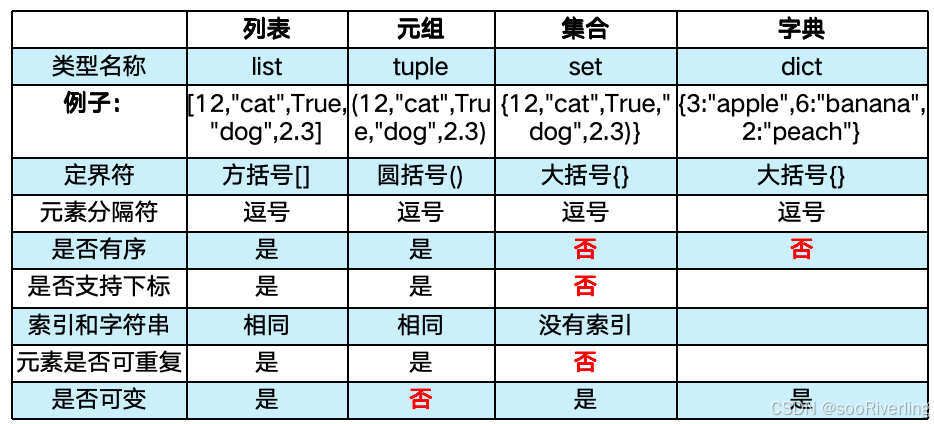
数学函数math
- ceil(x) 向上取整,返回不小于x的最小整数;
- fabs(x) 返回x的绝对值;
- factorial(x) 返回x阶乘,x必须为正整数或0,否则会报错;
- floor(x) 向下取整,返回不大于x的最大整数;
- pow(x, y) 返回x的y次幂;
运算符
- 逻辑运算符
or 连接两个操作数,若左操作数布尔值为True,则返回左操作数;否则返回右操作数或其计算结果;
and 连接两个操作数,若左操作数布尔值为False,则返回左操作数或其计算结果;否则返回右操作数的执行结果;
not 若操作数的布尔值为False,则返回True,否则返回False
- 身份运算符
is 测试两个对象的内存地址是否相同,相同返回True,否则返回False
== 比较操作符:用来比较两个对象值是否相等。
is 同一性运算符:比较两个对象的id值是否相等,即是否是同一对象,是否指向同一个内存地址。
第三章 字符串
字符串常见操作
- find():查找某个子串是否包含在该字符串中,如果在返回这个子串开始的位置下标,否则返回-1。
- index():检索某个子串是否包含在该字符串中,如果在返回这个子串开始的位置下标,否则则报异常。
- count():返回某个子串在字符串中出现的次数。
- replace(): 把字符串中的old字符串替换成new字符串,最终返回替换后的新字符串。
- split():按照指定的分隔符对字符串进行切割,返回由切割结果组成的列表。
- join():将序列中的元素以指定的字符连接成一个新的字符串。
- str.capitalize() #将字符串的第一个字母大写,其他字母都小写
str.title() #将字符串中每个单词首字母大写
str.lower() #将字符串中所有字母都小写
str.upper() #将字符串中所有字母都大写
str.swapcase() #将字符串中所有小写字母变成大写,所有大写字母变成小写 - ljust():返回一个将原字符串左对齐,并使用指定字符将字符串填充至对应长度的新字符串。
rjust(width[,fillchar):返回一个将原字符串右对齐,并使用指定字符将字符串填充至对应长度的新字符串。
center(width[,fillchar):返回一个用fillchar填充,宽度为width,原字符串居中的新字符串。 - str.strip():删除str头部和尾部的空格
- startswith() 用于检查字符串在[start,end]范围内是否以指定子字符串开头。如果是返回True,否则返回False。
字符串格式化
使用字符串中的format方法也可以进行字符串的格式化操作。它的基本语法是通过 {} 和 : 来代替以前的 %.
format方法返回的是格式化字符串副本,并不会改变原字符串内容;
{}和%作用相同,用来控制修改字符串中插入值位置;
#1. 通过位置参数
str1 = '{0}的学号是{1},{0}的年龄是{2}。'
print(str1.format('李四', 1002, 22))#2. 通过关键字参数名称
str2 = '{name}的学号是{sno},{name}的年龄是{age}。'
print(str2.format(name = '张三', sno = 1001, age = 20))#format方法返回的是格式化的字符串副本,并不会改变原字符串内容。
print(str1) #{0}的学号是{1},{0}的年龄是{2}。
print(str2) #{name}的学号是{sno},{name}的年龄是{age}。#3. 通过对象属性
class Student:def __init__(self, name, sno, age):self.name = nameself.sno = snoself.age = ages = Student('小明', 2001, 20)
my_str = '{stu.name}的学号是{stu.sno},{stu.name}的年龄是{stu.age}。'
print(my_str.format(stu = s)) #小明的学号是2001,小明的年龄是20。
正则表达式
正则表达式是一个特殊的字符序列,能检查一个字符串是否与某种模式匹配;
[0-9]:匹配任一数字,0~9
[a-z]: 匹配任一小写字符
[A-Z]:匹配任一大写字符
[0-9A-Za-z]:匹配任一数字和字母
[0-9A-Za-z_]:匹配任一数字、字母和下划线
.(点):匹配除了换行的任一单个字符。
^(插入符):匹配行头;$:匹配行尾;
?:匹配前面的字符0次或1次;
* :匹配前面字符0或多次;
+ :匹配前面字符1或多次;
\d:匹配任一数字,等价于[0-9];
\D:匹配任一非数字的字符;
\w:匹配数字,下划线和任意字母,等价于[0-9A-Za-z_]
.(点星):其中.(点)可以匹配任意字符(除换行符),(星)代表匹配前面的字符无限次,所以它们组合在一起就可以匹配任意字符了。
.*?(点星问):尽可能少的匹配任意字符。
re模块
re模块提供了正则表达式,提供文本匹配查找、文本替换、文本分隔等功能;
常见函数
- compile(pattern,flags=0):将一个字符串形式的正则表达式编译成一个正则表达式Pattern对象。以便于重复使用正则表达式,减少系统开销。pattern是一个正则表达式,flags指定匹配模式,忽略大小写,多行模式等。
import re
content = 'I like Python , I am in Python class'
comRegex = re.compile(r'Pytho\w', re.I) # 不区分大小写
print(type(comRegex)) #pattern类型
alist = comRegex.findall(content)
print(alist) #['Python', 'Python']
- re.match(pattern, string, flags=0):尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。
- re. search(pattern, string, flags=0): 与match 函数只匹配文本开始字符串不同,search函数可以匹配文本任意位置的字符串。只要找到第一个匹配则返回一个匹配对象,否则返回为None。
- group([num]):获取匹配的字符串,或者获取第num个子组的匹配结果;
- groups():返回一个由所有分组的匹配结果字符串组成的元组
- re.findall(pattern,string,flags=0): match函数只能匹配文本开始,search函数也只能返回第一个匹配项,如果对文本需要进行全文匹配,则需要使用findall和finditer函数。re模块中的findall函数用于在字符串中找到所有与正则表达式匹配的子串,返回一个列表;finditer以迭代器形式返回结果;
- re.split(pattern,string,maxsplit=0,flags=0):split函数会将字符串按照正则表达式匹配的子串进行分隔。
- sub函数:用于替换字符串中与正则表达式匹配的子串;subn函数会以元组形式返回替换后的新字符串和替换次数。
第四章 函数
函数定义
函数语法:
def 函数名 (参数列表):
函数体
return 返回值
__MAIN__ :
if __name__ == '__main__':Statements
可以让该python文件既可以独立运行,也可以当作模块导入其他文件中;
参数
参数类型
默认参数:
1)所有默认参数必须放在非默认参数之后;
2)在定义时给默认参数指定了值,但函数调用时仍可以为它传入其它的值;
不定长参数:
用户可以给函数提供可变长度的参数,这就是不定长参数,可以通过在形参前面使用*来实现。
如果一个函数所需要的参数存储在列表、元组或字典中,可以直接从列表、元组或字典中拆分出函数所需要的参数;
其中,列表、元组拆分出来的结果作为位置参数,而字典拆分出来的结果作为关键字参数;
参数的传递
- 按位置传递:avgScore(90,85,79)依次对应a,b,c;
- 按名称传递:avgScore(c=79,a=90,b=85);
- 传对象引用
函数收到的是一个可变对象的引用(如字典或列表),就能修改对象的原始值,相当于传地址;如果收到的是一个不可变对象(如数字、字符、元组),就不能直接修改原始对象,相当于传值;
传值的参数类型:数字,字符串,元组;
传址的参数类型:列表,字典;
变量
全局变量
在所有函数外部定义的变量都是全局变量,如果需要在函数内部给一个全局变量赋值,则需要用global关键字来声明;
nonlocal关键字
在函数的嵌套中,如果想在被嵌套的函数中修改外部函数变量的值,可以使用nonlocal关键字;
模块
- 内置标准模块(标准库)——python自带模块;
- 自定义模块——用户自己编写的模块;
- 第三方模块——其他人已经编写好的模块;
import语句
当要使用一个模块中的某些功能时,我们可以通过import方式将该模块导入。
若只想导入模块中的某个对象,则可以使用from导入模块中的指定对象,其语法格式如下:
1.from 模块名 import 导入对象名 #导入模块中某个对象
2.from 模块名 import 导入对象名as别名 #给导入的对象指定别名
如果想导入模块中所有对象 ,可以定义为: from 模块名 import *
注意:使用from导入的对象可以直接使用,不需要使用模块名作为限定符。
包和库
一个“包”里面会有多个模块,每个库都有好多个包;
在该目录中放一个__init__.py文件。 __init__.py是一个空文件,将它放在某个目录中,就可以将该目录中的其他.py文件作为模块被引用。
猴子补丁
在运行时动态替换已有的代码,而不需要修改原始代码;主要用于在不修改已有代码情况下修改其功能或增加新功能的支持。
常用的内置标准模块
-
random模块:
用于生成随机数,返回一个0到1之间的随机浮点数n(0<=n<1); -
time模块:
用于获取并处理时间,有两种时间表达方式:时间戳——time模块中的time()函数可以获取当前的时间戳;时间元组——localtime()函数可以将一个时间戳转换为一个当前时区的时间元组; -
sys模块:
sys.argv 是变量,专门用来向python解释器传递参数,称为命令行参数;
sys.exit() 这个方法的意思是退出当前程序。
高阶函数
把函数作为参数的一种函数
def FunAdd(f,x,y): #定义函数FunAddreturn f(x)+f(y) #用传给f的函数先对x和y分别处理后,再求和并返回 def Square(x): #定义函数Squarereturn x**2 #返回x的平方def Cube(x): #定义函数Cubereturn x**3 #返回x的立方print(FunAdd(Square,3,-5)) #调用函数FunAdd,计算32+(-5)2print(FunAdd(Cube,3,-5)) #调用函数FunAdd,计算33+(-5)3
函数不仅可以赋给形参,也可以赋给普通变量。赋值完后,可以用变量名替代函数名完成函数调用;
lambda函数
lambda函数也称为匿名函数,是一种不使用def定义函数的形式,其作用是能快速定义一个简短的函数。lambda函数的函数体只是一个表达式;
lambda [参数1[, 参数2, …, 参数n]]: 表达式
闭包函数
内层函数使用了外层函数定义的局部变量,并且外层函数的返回值是内层函数的引用,就构成了闭包;
定义在外层函数中但由内层函数使用的变量被称为自由变量。
def avg():scores=[]def inner(score):nonlocal scoresscores.append(score)if not scores:return Noneavg = sum(scores)/len(scores)return avgreturn inneravg_score = avg()if __name__=='__main__':print(avg_score)print(avg_score(80))print(avg_score(90))
闭包的主要作用在于可以封存函数执行的上下文环境。
装饰器
利用装饰器,可以在不修改已有函数的情况下向已有函数中注入代码,使其具备新的功能。一个装饰器可以为多个函数注入代码,一个函数也可以注入多个装饰器的代码。利用装饰器可以将日志处理、执行时间计算等较为通用的代码注入到不同的函数中,从而使得代码更加简洁。
例:给每个函数写一个记录日志的功能,要求:每调用一次函数之前,都要将函数名称、时间节点输出;
import datetimedef decorator(fn):def wrapper(*args,**kwargs):timestamp = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')print(f"{timestamp}-Calling:{fn.__name__}")return fn(*args,**kwargs)return wrapper@decorator
def avg():scores=[]def inner(score):nonlocal scoresscores.append(score)avg = sum(scores)/len(scores)return avgreturn inneravg_score = avg()if __name__=='__main__':print(avg_score(80))print(avg_score(90))
装饰器能修饰的函数,如果装饰器内部wrapper函数参数只有两个,那么它只能用于装饰带两个参数的函数,如果没有参数,只能修饰没有参数的函数;
第五章 面向对象
构造方法
构造方法是类成员方法中特殊的方法,在类实例化对象的过程中自动调用;
类的名称必须为:
__init__(两个下划线)
方法的第一个参数为self
作用:为对象创建内存空间;类中属性的初始化;
访问权限
_xxx:一个下划线,受保护成员,只有类对象和子类对象能访问这些变量;__xxx__:前后均有下划线,系统定义的特殊成员;__xxx:私有成员,只有类对象自己能访问,子类对象不能直接访问到这个成员。
类的成员
类属性:类属性是类本身的属性,无论根据该类创建了多少的对象,类属性依然只有一个,所以对象与对象之间可以共享类属性。
所有实例方法都必须至少有一个名为self的参数,并且必须是方法的第一个形参(如果有多个形参的话),self参数代表当前对象。在实例方法中访问实例成员时需要以self为前缀。
静态方法和类方法
类方法和静态方法不属于任何实例,不会绑定到任何实例,当然也不依赖于任何实例的状态,与实例方法相比能够减少很多开销。
类方法和静态方法都可以通过类名和对象名调用。
类方法和静态方法不能直接访问属于对象的成员,只能访问属于类的成员。
类方法一般以cls作为类方法的第一个参数表示该类自身,在调用类方法时不需要为该参数传递值,静态方法则可以不接收任何参数。
在 Python 中,实例对象可以访问和修改类属性,但行为会有所不同,具体取决于你是直接通过实例对象还是通过类名来访问和修改类属性。
1. 直接通过实例对象访问类属性
当你通过实例对象访问类属性时,Python 会首先在实例字典中查找该属性。如果实例字典中不存在该属性,Python 会查找类字典中的属性。
2. 通过实例对象修改类属性
当你通过实例对象修改类属性时,Python 会在实例字典中创建一个新的属性,而不是修改类字典中的属性。这会导致类属性和实例属性看起来不同。
示例
假设我们有一个类 MyClass,它有一个类属性 class_attr:
class MyClass:class_attr = 0# 创建实例
obj1 = MyClass()
obj2 = MyClass()# 通过类名访问类属性
print(MyClass.class_attr) # 输出: 0# 通过实例对象访问类属性
print(obj1.class_attr) # 输出: 0
print(obj2.class_attr) # 输出: 0# 通过类名修改类属性
MyClass.class_attr = 1
print(MyClass.class_attr) # 输出: 1
print(obj1.class_attr) # 输出: 1
print(obj2.class_attr) # 输出: 1# 通过实例对象修改类属性
obj1.class_attr = 2
print(MyClass.class_attr) # 输出: 1
print(obj1.class_attr) # 输出: 2
print(obj2.class_attr) # 输出: 1
解释
-
通过类名访问类属性:
print(MyClass.class_attr) # 输出: 0直接通过类名访问类属性,输出
0。 -
通过实例对象访问类属性:
print(obj1.class_attr) # 输出: 0 print(obj2.class_attr) # 输出: 0通过实例对象访问类属性,因为实例字典中没有
class_attr,所以会查找类字典中的class_attr,输出0。 -
通过类名修改类属性:
MyClass.class_attr = 1 print(MyClass.class_attr) # 输出: 1 print(obj1.class_attr) # 输出: 1 print(obj2.class_attr) # 输出: 1通过类名修改类属性,类字典中的
class_attr被修改为1,所有实例对象访问class_attr时都会输出1。 -
通过实例对象修改类属性:
obj1.class_attr = 2 print(MyClass.class_attr) # 输出: 1 print(obj1.class_attr) # 输出: 2 print(obj2.class_attr) # 输出: 1通过实例对象
obj1修改class_attr,实际上在obj1的实例字典中创建了一个新的属性class_attr,值为2。类字典中的class_attr仍然是1,因此obj2访问class_attr时输出1。
总结
- 通过类名访问和修改类属性:直接修改类字典中的属性,影响所有实例。
- 通过实例对象访问类属性:如果实例字典中没有该属性,会查找类字典中的属性。
- 通过实例对象修改类属性:在实例字典中创建一个新的属性,不会影响类字典中的属性。
类方法
使用@classmethod装饰器,类对象或实例对象都可以调用;第一个参数必须是当前类对象,该参数名一般约定为“cls”,通过cls传递类的属性和方法;
静态方法
使用@staticmethod装饰器,参数随意,没有self和cls参数,但是方法体中不能使用类或实例的任何属性和方法;
静态方法是个独立的、单纯的函数,它仅仅托管于某个类的名称空间中,便于使用和维护。
继承
class InsurancePolicy:def __init__(self, price_of_item):self.price_of_insured_item = price_of_itemclass VehicleInsurance(InsurancePolicy):def __init__(self,price_of_item,vehicle_name):super().__init__(price_of_item)self.vehicle_name = vehicle_namedef get_rate(self):return self.price_of_insured_item * 0.001如果子类重写了父类的方法,就会把父类的同名方法覆盖,如果被重写的子类同名的方法里面没有引入父类同名的方法,实例化对象要调用父类的同名方法相关的属性时,程序就会报错。
在子类里面重写父类同名方法的时候,先引入父类的同名方法:调用未绑定的父类方法或使用super函数
类中常见其他方法
__init__():构造方法;__del__():析构方法,用于销毁Python对象——在任何Python对象将被系统回收的时候,系统都会自动调用这个方法。__new__():真正的类构造方法,用于确定是否产生对象;__str__():使用print语句时被调用;__repr__():控制台输出;__cmp__(self, x):当前对象与x进行比较;
内置函数
isinstance函数:判断一个对象所属的类是否是指定类或指定类的子类;
issubclass函数:判断一个类是否是另一个类的子类;
type函数:用于获取一个对象所属的类;
动态扩展类与实例
python作为一种动态语言,除了可以在定义类时定义属性和方法外,还可以动态地为已经创建的对象绑定新的属性和方法;它支持类的动态扩展,可以动态给类对象或实例添加属性或者方法。
from types import MethodType
class Student: #定义学生类pass
def SetName(self,name):#定义SetName函数self.name=name
def SetSno(self,sno):#定义SetSno函数self.sno=sno
if __name__=='__main__':stu1=Student() #定义Student类对象stu1stu2=Student() #定义Student类对象stu2stu1.SetName=MethodType(SetName, stu1) #为stu1对象绑定SetName方法Student.SetSno=SetSno #为学生类绑定SetSno方法stu1.SetName('张三')stu1.SetSno('2020200')__slots__
python可以在运行过程中修改代码,比如给对象增加属性、给类增加方法等操作;
实际开发中,给实例添加属性进行约束,Python允许在定义class的时候,定义一个特殊的__slots__变量,来限制该class实例能添加的属性。
__slots__ = ("name", "age")只允许增加属性name、age,添加属性sex会出错;
父类设置约束,对子类没有约束力;
元类与单例模式
python一切都是对象,是对象就有对应的类,可以用type得到对象的类;
元类
类的类型都是type,type的类型还是type;
对象的类型叫做类,类的类型称作元类meta-class;元类可以看成是创建类时所使用的模板,也可以理解为创建类的类。
class Student(metaclass=type):pass
stu = Student()
print("stu所属的类是:",stu.__class__) #__class__属性可以获取所属的类
print("Student所属的类是:",Student.__class__)

单例模式
保证只有一个对象实例的模式,也就是无论创建多少个实例,他们的id值相同,只指向一个地址;
单例模式使用场景:python的logger就是一个单例模式,用以日志记录;
什么情况下需要单例模式?
1.当每个实例都会占用资源,而且实例初始化会影响性能,可以考虑单例模式,好处是只有一个实例占用资源,并且只需初始化一次;
2.当有同步需要时,可以通过一个实例来进行同步控制,比如对某个共享文件的控制,对计数器的同步控制等;这种情况下只有一个实例,不用担心同步问题;
class Singleton(Object):__instance = Nonedef __new__(cls, *args, **kwargs): #这里不能使用__init__,因为__init__是在instance生成之后才去调用的if cls.__instance is None:cls.__instance = super(Singleton,cls).__new__(cls,*args,*kwargs)return cls.__instances1 = Singleton()
s2 = Singleton()
print(s1)
print(s2)

在Python中,
super()是一个内置函数,它返回一个代理对象,这个代理对象可以用来调用最近的父类(超类)的方法。使用super()可以避免直接使用父类名称,并且可以在多继承的情况下正确解析方法。
以下是 super() 的一些关键点:
-
单继承中的使用:
当你有一个子类从一个父类继承时,你可以使用super()来调用父类的方法。这有助于维护代码和防止硬编码父类名,从而提高了代码的可维护性。class Parent:def __init__(self):print("Parent init")class Child(Parent):def __init__(self):super().__init__() # 调用父类的构造函数print("Child init") -
多继承中的使用:
在多继承场景下,super()遵循方法解析顺序(Method Resolution Order, MRO),这是一个确定哪个父类的方法应该被优先调用的顺序。MRO 是根据 C3 线性化算法计算出来的,可以通过ClassName.__mro__或help(ClassName)查看。class A:def method(self):print("A.method")class B(A):def method(self):super().method()print("B.method")class C(A):def method(self):super().method()print("C.method")class D(B, C):def method(self):super().method()print("D.method")d = D() d.method() # 输出: # A.method # C.method # B.method # D.method # D.mro: D B C A object 按照这个顺序进行调用
现在我们可以更清晰地看到为什么输出顺序是这样的:
D.method:首先执行 D.method,其中调用了 super().method(),根据 MRO,这将转向 B.method。
B.method:在 B.method 中,再次调用 super().method(),根据 MRO,接下来应该是 C.method,因为 C 排在 A 之前。
C.method:在 C.method 中,调用 super().method(),这时才真正到达 A.method,因为 C 后面紧接着是 A。
A.method:在 A.method 中,没有更多的 super().method() 调用,因此它执行完后返回。
回溯执行:
当 A.method 执行完毕后,程序控制返回到 C.method,然后输出 “C.method”。
接着控制返回到 B.method,输出 “B.method”。
最后回到 D.method,输出 “D.method”。
-
传递参数给super():
在Python 3中,super()可以不带参数使用。但是在Python 2中或者当你想要明确指定要引用的类和实例时,你可以传递两个参数给super():第一个是子类,第二个是 self。super(CurrentClass, self).__init__() -
不仅仅是初始化:
super()不仅限于用于__init__方法;它可以用于任何需要调用父类方法的地方。
鸭子类型
鸭子类型是动态类型的一种风格,一个对象有效的语义,由当前方法和属性的集合决定;
第六章 组合数据类型
组合数据类型概述
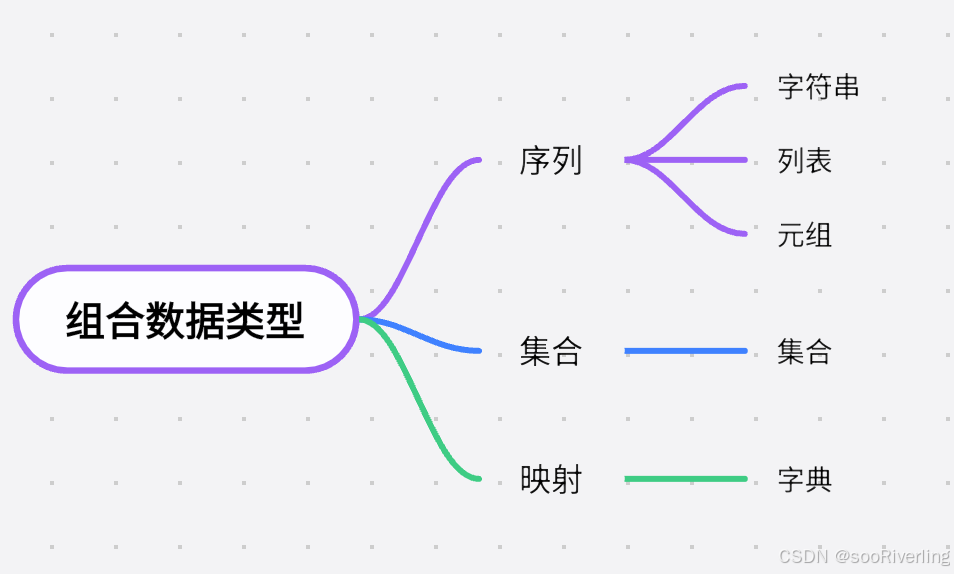
序列类型是指元素按照一定顺序排成一列的一组数,支持双向索引;元组和字符串属于不可变类型,列表属于可变类型;
Python中对象类型分为:可变类型和不可变类型;
可变类型:可以对该类型对象中保存的元素值做修改:列表、字典、集合;
不可变类型:该类型对象中保存的元素值不允许修改,只能通过给对象整体赋值来修改对象所保存的值,本质是创建一个新的不可变类型的对象,而不是改变原对象的值:数字、字符串、元组;
序列类型
序列指的是一块可存放多个值的连续内存空间,这些值具有一定的先后顺序。序列是一维元素向量,元素类型可以不同,元素间由索引引导;
列表类型
- 列表创建:
- 只需要把将逗号分割的数据项使用[]括起来即可创建列表,列表能够保存任意数目的Python对象,而且列表还可以保存不同类型的对象
- 使用标准类型内置函数list()也可以创建列表,需要注意的是该函数接受的参数必须是可迭代类型;
- 更新列表:
- 可以使用del语句来删除列表中的某个元素
del list[2]
可以使用isinstance函数判断一个对象是否是可迭代对象;
对于列表来说,比较规则如下:
1)如果比较的元素是同类型的,则比较其值;
2)如果比较的元素不是同类型的,则视情况而定;
如果都是数值类型,则执行数值的强制类型转换,然后比较;如果一方元素是数字,则另一方大(“数字最小”);否则按照类型名字的字母顺序进行比较;
3)如果有一个列表首先到达末尾,则另一方值大;
4)如果两个列表元素和个数都相等,则两个列表相等,返回0
列表操作函数
sum(iterable[, start]):求列表所有元素之和;
sorted(iterable, key=None, reverse=False) :该函数对所有可迭代的对象进行排序操作。key接受一个函数,这个函数只接受一个元素,默认为None,reverse是一个布尔值。如果设置为True,列表元素将被倒序排列,默认为False。
price1_true = sorted(price1)price1_false = sorted(price1, reverse=True)
sorted函数使用后,返回的是一个新对象,sort是对price1自身进行排序,不创建新对象返回;sort的方法和标准类型内置函数sorted不同,sorted函数不会改变原来列表的内容,而是返回一个新的列表对象,list.sort方法会改变原列表内容。
sorted_studentsList = sorted(studentsList, key=lambda x:float(x["score"]),reverse=True)
zip() 函数用于将任意多个可迭代对象作为参数,将对象中对应的元素打包成元组,然后返回由这些元组组成的可迭代的zip对象,可以使用 list() 转换来输出列表。
alist = [1,2,3]
blist = [4,5,6]
clist = ["a","b","c","d"]
zipped = zip(alist,blist) #返回一个对象
print(list(zipped)) #list转换为列表 结果为:[(1, 4), (2, 5), (3, 6)]
print(list(zip(alist,clist))) #元素个数与最短的列表一致 [(1, 'a'), (2, 'b'), (3, 'c')]a1,a2 = zip(*(zip(alist,blist))) #与zip相反,zip(*)可理解为解压,返回二维矩阵式
print(list(a1)) #[1, 2, 3]
print(list(a2)) #[4, 5, 6]


浅拷贝和深拷贝
浅拷贝:为新对象开辟存储空间,但对象中的元素仍和原对象属于同一引用;如果改变原对象中的不可变类型元素,本质上产生了一个新的不可变元素,拷贝对象中的元素仍指向原来的不可变元素,所以不发生改变;如果改变原对象中可变类型元素,拷贝对象也会改变;
import copy
original_list = [5,[1, 2], [3, 4]]
shallow_copied_list = copy.copy(original_list)#修改浅拷贝后的不可变数据类型
shallow_copied_list[0] = 1print(original_list) # 输出: [5, [1, 2], [3, 4]]
print(shallow_copied_list) # 输出: [1, [1, 2], [3, 4]]# 修改浅拷贝后的内部列表
shallow_copied_list[1][0] = 'changed'print(original_list) # 输出: [5, ['changed', 2], [3, 4]]
print(shallow_copied_list) # 输出: [1, ['changed', 2], [3, 4]]
深拷贝
使用copy模块的deep方法可以实现深拷贝,deepcopy方法的语法格式如下:copy.deepcopy(d)
深拷贝不仅使原对象和生成对象对应不同的内存空间,而且使得两个对象中
的元素对应不同的内存空间,从而使得两个对象完全独立;
import copyoriginal_list = [[1, 2], [3, 4]]
deep_copied_list = copy.deepcopy(original_list)# 修改深拷贝后的内部列表
deep_copied_list[0][0] = 'changed'print(original_list) # 输出: [[1, 2], [3, 4]]
print(deep_copied_list) # 输出: [['changed', 2], [3, 4]]
列表生成表达式
可以使用列表生成表达式来产生列表:
new_lst = [表达式 for 变量 in 范围 if 条件 ]
元组
元组是不可变的序列类型,可以把元组看做只读元素列表,不能进行增加、修改和删除元素的操作;
元组中只包含一个元素时,需要在元素后面添加逗号,否则括号会被当作运算符使用。
tup4 = (50) print(type(tup4)) #输出结果为:<class 'int'> tup5=(50,) print(type(tup5)) #输出结果为:<class 'tuple'>
集合
集合对象是一组无序排列的不可重复的哈希值;集合对象支持交集、并集、差集等操作;
可以使用大括号 { } 或者 set() 函数创建集合,注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典
一个对象能被称为可哈希的 ,它必须有个哈希值,这个值在整个生命周期都不会变化,而且必须可以进行相等比较。对于 Python 的内建类型来说,不可变类型都是 可哈希的, 如字符串,可变类型:列表、字典、集合,他们在改变值的同时却没有改变id,无法由地址定位值的唯一性,因而无法哈希
集合中的元素必须是可哈希的,集合是一组哈希值的集合,这些哈希值不可重复;
集合运算符
- in 和 not in :检查某项元素是否是集合中的成员;
- == 和 != :两个集合相等当且仅当其中一个集合中的每个成员同时也是另一个集合中的成员。集合是否等价于集合中的成员的顺序无关,只与集合的元素有关。
-
、<和>=、<= : <和<=判断是否是子集,>和>=判断是否为超集。
- |(union):并集,集合A和集合B元素合并到一起组成的集合,然后返回一个新集合;
- &(intersection):交集,属于A同时属于B的元素组成的集合,返回一个新集合;
- -(difference):差集,A-B——
- ^(symmetric_difference):补集,属于集合A和集合B但不同时属于两者的元素集合,返回一个新集合;
- |= ,等同于update():并集,并更新原有集合;
- -=, 等同于difference_update():差集,并更新原有集合
集合常见操作
len(),max(),min(),sum(),sorted()都适用于集合类型,作用和前面作用到组合类型中的作用相似。
frozenset(val):参数接受一个可迭代的对象,比如列表、字典、元组、字符串等;返回新的frozenset对象,如果不提供任何参数,默认生成空集合;
frozenset 对象是冻结的集合,它是不可变的,存在哈希值,好处是它可以作为字典的key,也可以作为其它集合的元素。缺点是一旦创建便不能更改,没有add,remove等方法。


字典
字典是python语言中唯一的映射类型,用于存储具有关联关系的数据;可以容纳任意个数的Python对象;字典类型和序列类型的区别是存储和访问数据的方式不同。
字典的创建、初始化
可以直接用{},或者dict()创建字典
使用fromkeys方法进行字典初始化
D2=dict().fromkeys([‘sno’,’name’,’major’],’Unknown’)
字典值可以是任何python对象,既可以是标准的对象,也可以是用户定义的,但键不行;不允许同一个键出现两次,键必须不可变,不能使用列表、集合、字典;
字典常用操作函数
- get(key, default=None):返回指定键的值,如果不存在则返回default设置的默认值;
- update(dict2):使用dict2的key-value更新字典;
- items():获取字典中的所有 key-value 对,其结果最好不要直接使用,可通过list函数转换为列表
- keys():获取字典中的所有key,结果也需要list函数转换为列表
- values():获取字典中的所有value,结果也需要list函数转换为列表
- pop(key[,default]):获取指定 key 对应的 value,并删除这个 key-value 对;
- popitem():随机弹出字典一个键值对;
- setdefault(key, default=None):和get类似,但如果键不存在于字典中,将会添加键并将值设为default;
- fromkeys():
迭代器和生成器
迭代是可以通过遍历的方式依次把某个对象中的元素取出的方法,在python中,迭代是通过使用for…in…语句完成的。
可迭代对象(iterable):可以被直接作用于for语句的对象都可以被称为可迭代对象;
可以直接作用于for语句的数据类型有以下两种:
1)组合数据类型:str,list,tuple,dict,set…
2)生成器(generator),包括生成器和带yield的生成器函数
对于某个数据是否属于某种数据类型,可以用isinstance函数来判断迭代器(iterator):可以被next函数调用并不断返回下一个值的对象;通过isinstance函数对其进行判断;
生成器(generator):用在迭代器操作中,是一个特殊的迭代器,具有和迭代器一样的特性,但实现方式不一样,可以用两种方式创建生成器:生成器表达式、生成器函数;
迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退。迭代器有两个基本的方法:iter() 和 next()。字符串,列表或元组对象都可用于创建迭代器。
字符串,列表或元组对象都属于可迭代对象,但不是迭代器,可以使用isinstance方法判断一个对象是否是可迭代对象。
from collections.abc import Iterator,Iterable
numList = [1,2,3]
print(isinstance(numList,Iterable)) #属于可迭代对象 True
print(isinstance(numList,Iterator)) #不属于迭代器 False
list1 = [1,2,3,4]
it = iter(list1) #创建迭代器对象
print(isinstance(it,Iterator)) #True
生成器表达式
g=(x*x for x in range(6))
for i in g:print(i)
使用yield关键字函数可以实现生成器功能;调用一个生成器函数,返回的是一个迭代器对象;在调用生成器运行的过程中,每次遇到 yield 时函数会暂停并保存当前所有的运行信息,返回 yield 的值, 并在下一次执行时从当前位置继续运行。
第七章 文件及异常
文件概述
文件是一个存储在磁盘上的数据序列,可以包含任何数据内容;文件是数据存储的一种形式,所有文件均以二进制方式存储;
根据数据的组织形式不同,分为文本文件和二进制文件;
文本文件:文件是数据序列的集合,如果这些数据是由单一特定的字符编码组成的,就是文本文件;
二进制文件:数据存储时直接使用0/1存储;
- open():内置函数,打开文件,创建file对象;
- close():文件关闭;
- with语句:对资源进行访问的场合,保证with语句执行完毕后关闭打开的文件;
- with open(<文件> [, <打开模式>] ) as <文件对象>
- read():从文件中读取字节数,如果未指定则读取文件全部信息;返回值为文件中读取的字符串;
- readline():从文件中读取整行,返回指定大小的字符串数据;
- readlines():用于读取文件中所有行,并返回列表;
- write():将字符串写入一个打开的文件;
- writelines():将字符串列表写入文本文件;
- f.tell():返回一个整数,表示当前文件指针的位置(就是到文件头的字节数)。
CSV模块
常用函数:
- csv.reader():返回一个读取器对象,它将迭代给定csv文件中的行;
- csv.writer():返回一个编写器对象,负责将用户数据转换为给定文件对象上的分隔字符串;
常用类:
- csv.DictReader()
- csv.DictWriter()
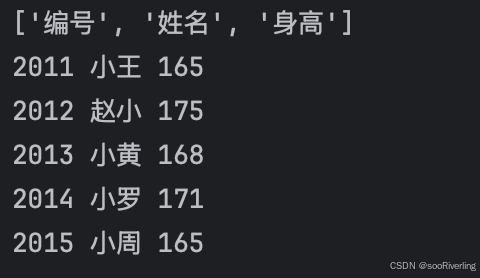
import csvwith open("classInfo.csv") as f1:reader = csv.DictReader(f1)print(reader.fieldnames) # ['编号', '姓名', '身高']for row in reader:print(row['编号'],row['姓名'],row['身高'])
异常
异常是一个事件,python无法正常处理程序时,就会发生一个异常;
自定义异常:应通过直接或间接的方式继承Exception类 class 自定义异常类名(Exception):
抛出异常:python使用关键字raise抛出自定义的异常;
一般,raise语句出现在try语句块内部,否则程序会中断;raise MyException(defineexceptname);
class InvalidInputError(Exception):def __init__(self, message):self.message = messagedef check_input(self, input_value):if input_value < 0 or input_value > 100:raise InvalidInputError("Input value should be between 0 and 100")
try:input_value = int(input("Enter a number between 0 and 100: "))InvalidInputError("").check_input(input_value)
except InvalidInputError as e:print(e.message)
第八章 数据可视化
数据表示与获取
导入numpy库import numpy as np
Ndarray数组与List区别
- Ndarray数据存储在连续地址空间,处理速度快;
- Ndarray具有丰富的广播功能函数
ndarray数组基本概念
- 维度:又称为轴(axis),轴的个数称为秩(rank);
- 常用属性: ndim(秩)、shape(维度)、size(元素总个数)、dtype(元素类型)
数组定义方法:
array():创建数组;
arr = np.array([2,3,4])
arange():创建ndarray数组array:将输入数据转换为numpy数组;输入可以是任何序列型对象或嵌套序列,只要其结构能够被解释为一个多维数组;可以用dtype强制转换数组元素的数据类型;
np.array([[1, 2], [3, 4]]) 将创建一个二维数组,形状为 (2, 2);
arange:类似于内置函数range函数,返回一个ndarray数组;
arr1 = np.arange(1,100,2)表示1-100(不包括100)每隔2的数组;random:创建随机数数组
arr2 = np.random.randint(1,100,[5,5]) # 生成一个五行五列的矩阵,值为1-100中的随机数
从CSV文件等读取创建ndarray数组:
arr3 = np.loadtxt("classInfo.csv",dtype=str,delimiter=",",skiprows=1,encoding="utf-8")
读取classinfo文件,返回数组的数据类型时是str,字段之间的分隔符为逗号,跳过第一行;结果返回一个二维数组;
- 其他常用数组定义方法
- np.ones(shape):根据shape生成一个全1数组,shape是元组、列表类型;
- np.zeros(shape):根据shape生成一个全0数组,shape是元组、列表类型;
- np.full(shape,val):根据shape生成一个数组,每个元素都是val;
- np.eye(n):创建一个n*n单位矩阵,对角线为1,其余为0;
- np.linspace():生成等间隔的数字序列;
import numpy as np# 创建从0到1,包含5个元素的数组
arr = np.linspace(0, 1, num=5)
print(arr) # 输出: [0. 0.25 0.5 0.75 1. ]# 创建从0到1,不包括1,包含4个元素的数组
arr_without_endpoint = np.linspace(0, 1, num=4, endpoint=False)
print(arr_without_endpoint) # 输出: [0. 0.2 0.4 0.6]# 获取间距
arr_with_step, step = np.linspace(0, 1, num=5, retstep=True)
print(step) # 输出: 0.25# 指定数据类型
arr_dtype = np.linspace(0, 1, num=5, dtype=float)
print(arr_dtype) # 输出: [0. 0.25 0.5 0.75 1. ]
- np.concatenate():将两个或多个数组合并成一个新的数组,输入必须是数组形式;
ndarray数组操作
- 数组的索引:获取数组中特定位置元素,索引值从0开始;
- arr[3,2]:表示二维数组第4行第3列元素
- 数组的切片:获取数组元素子集;
- arr[0:3,1:4]:获取二维数组的第0,1,2行及第1,2,3列中元素
- 数组类型转换: np.astype(dtype) , dtype可以是str, int, float等
数值计算

创建一个简单的直方图
data = [1, 2, 1, 3, 4, 5, 6, 7, 8, 9]
hist, bin_edges = np.histogram(data, bins=5)print("Histogram:", hist) # 输出: Histogram: [2 1 2 3 2]
print("Bin edges:", bin_edges) # 输出: Bin edges: [1. 3.2 5.4 7.6 9.8]
使用自定义范围和密度计算
hist_density, bin_edges_density = np.histogram(data, bins=5, range=[0, 10], density=True)print("Density histogram:", hist_density) # 输出: Density histogram: [0.04 0.02 0.04 0.06 0.04]
print("Bin edges for density:", bin_edges_density) # 输出: Bin edges for density: [ 0. 2. 4. 6. 8. 10.]
绘制图表
导入matplotlib
通常导入matplotlib.pyplot基础模块,绘制各种图形;
import matplotlib.pyplot as pltplt.show() #显示图表
plt.savefig(filename,dpi) #保存图表
点线图
import matplotlib.pyplot as plt
import numpy as np
x = np.arange(0,11,0.2) # x坐标采样点生成
y = np.sin(x) # 计算对应x的正弦值
plt.plot(x,y, 'bs--') # 控制图形格式为蓝色方形的虚线
# 添加图表标题和坐标轴名称
plt.title("正弦曲线图") #设置图表标题
plt.xlabel("time") #设置x坐标轴标签
plt.ylabel("voltage") #设置y坐标轴标签
# 中文显示和负号问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['font.serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.savefig("test",dpi=300) #保存图表
plt.show()
成绩分布柱状图
# 引入模块及基本设置
import matplotlib.pyplot as plt
import numpy as np
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['font.serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 构建数据
x = bins[0:-1] #bins:[0 60 70 80 90 100]
y = hist #hist:[2 14 27 17 3]
# 绘制柱状图
plt.bar(x,y,width=5,color='steelblue')
# 设置标题及坐标轴名称
plt.title("成绩分布图")
plt.xlabel("分数段")
plt.ylabel("人数")
# x轴刻度间隔显示异常,刻度显示位置也异常,修改后
bins[0] = 50 # 50代表60分以下成绩,个数与hist数组相同
x = bins[0:-1]
#修改坐标轴刻度值
plt.axis([40,100,0,40]) # 设置坐标值范围, x轴范围[40,100],y轴范围[0,40]
plt.xticks(x,['60分以下','60-70分','70-80分','80-90分','90-100分']) # ticks:设置x轴刻度间隔,labels:设置每个间隔的显示标签
# 调整x轴刻度对齐方式
plt.bar(x, y, width=5, color='steelblue', align='center')
#每个柱状块上没有具体数据,修改后
for x,y in zip(x,hist): # 将可迭代对象打包成一个元组plt.text(x, y+0.05, str(y), ha='center', va= 'bottom')
#添加背景网络
plt.grid(True)
# 显示图表
plt.show()
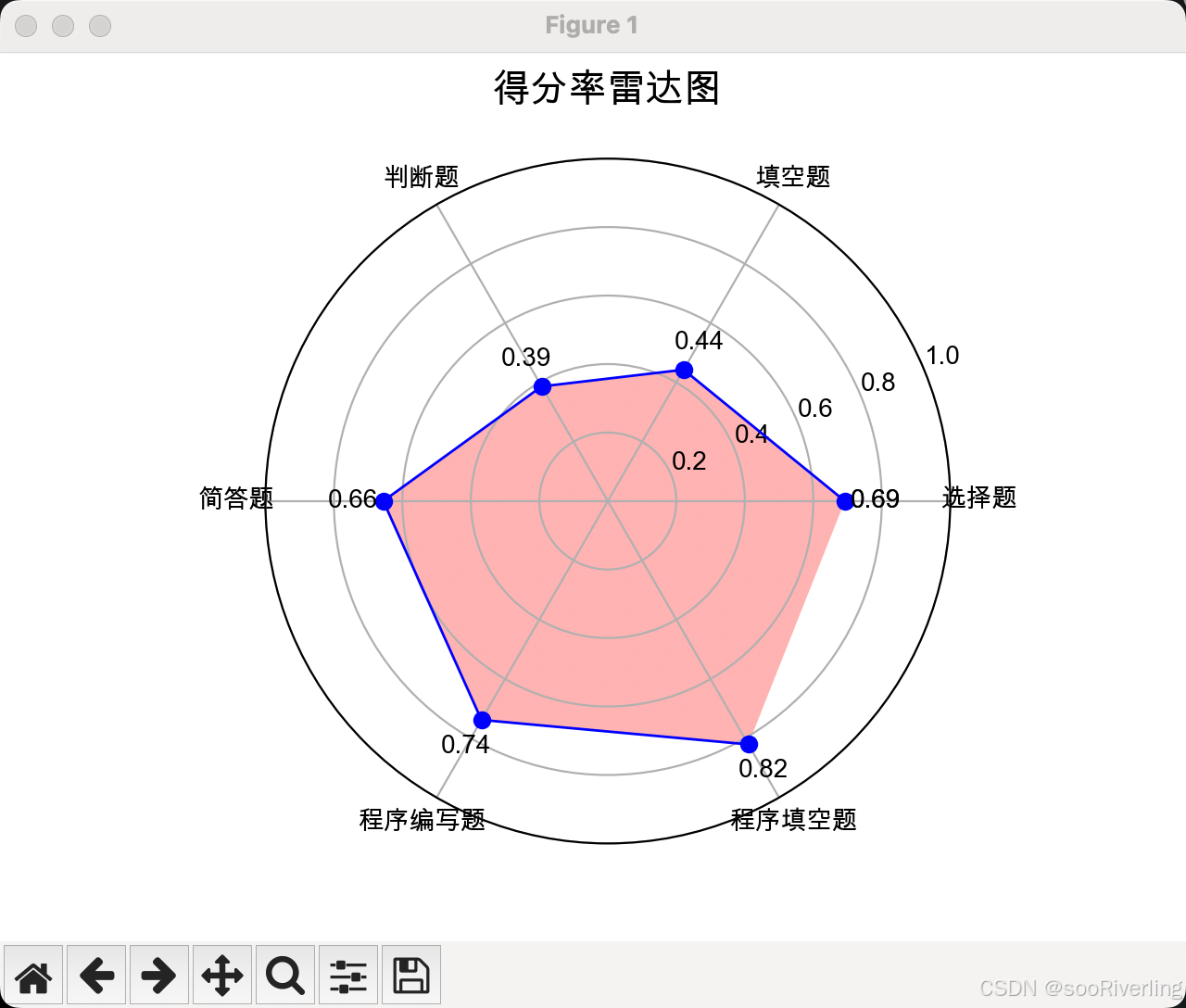
得分率雷达图
用matplotlib画雷达图需要使用极坐标体系(ploar)
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from numpy.ma.core import angle# 使用numpy的mean方法得出题目得分率:
# tdfl,结果为[ 0.69206349 0.44285714 0.38650794 0.65555556 0.73809524 0.82063492]
tdfl = np.array([0.69206349,0.44285714,0.38650794,0.65555556,0.73809524,0.82063492])plt.rcParams['font.family'] = ['Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
# 构建数据
angles = np.linspace(0,2*np.pi,6,endpoint=False) #将整个圆平均分为6份,endpoint=False 表示不包括停止值 2*np.pi
data = tdfl
labels = ['选择题','填空题','判断题','简答题','程序编写题','程序填空题']
# 绘制极坐标图
plt.polar(angles,data,"bo-",lw=1) # lw=1 设置了线条宽度为1
# 设置标题及坐标轴名称
plt.title("得分率雷达图")
plt.thetagrids(angles * 180/np.pi,labels,y=0.02) # 设置极坐标标签
# 闭合数据连线
angles = np.concatenate((angles,[angles[0]])) # 角度数据首尾相接,曲线闭合
data = np.concatenate((data,[data[0]]))
# 填充闭合连线区域
plt.fill(angles,data,"r",alpha=0.3)
# 标题太低,极坐标范围不正确
plt.title("得分率雷达图",y=1.06,fontsize=15)
#修改极坐标范围
plt.ylim(0,1) #设置极坐标轴范围为0到1
# 添加数据点数据显示
for x,y in zip(angles,data):plt.text(x,y+0.09,round(y,2),ha='center',va='center')
# 显示图表
plt.show()
绘图区域问题
- figure:画布;一个图像只能有一个figure对象
- subplot:区域;画布上的一个子图:figure对象下创建一个或多个subplot对象(即axes)用于绘制图像
- axis:坐标轴;子图上的坐标系
plt.subplot(nrows, ncols, plot_number):nrows为子图的行数, ncols为子图列数; plot_number是指子区域中的第几幅图
修改定位雷达图子绘图区:plt.subplot(122,polar=True) #添加极坐标标记参数,并设置为True
import matplotlib.pyplot as plt
import numpy as np# 创建数据点
x = np.linspace(0, 10, 100)
y = np.sin(x)# 在4x4网格的第7个位置绘制子图
plt.subplot(4, 4, 7)
plt.plot(x, y)
plt.title('Sine Wave')plt.show()
第九章 数据分析
Pandas
概述
- 主要两个数据结构Series(一维)和DataFrame(二维)
- 与sql或excel表类似的数据;
- 带行标签的矩阵数据;
解决数据输出时,列名不对齐的问题
pd.set_option('display.unicode.east_asian_width', True)
Series对象
Series是Pandas库中一种数据结构,类似于一维数组;
索引使用
s=pd.Series(data, index=index)
- data:表示数据,支持列表、字典、numpy数组等;
- index:表示行标签;
import pandas as pd#解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width',True)# 默认索引
s1 = pd.Series({"xm":90,"xh":80,"xg":62})
s2 = pd.Series([1,2,3,4,5])
# 手动设置索引
# 字典中没有索引,用键表示索引,否则返回NaN
s3 = pd.Series({"xm":90,"xh":80,"xg":62},index=["xm", "xh", "xg"])
s4 = pd.Series([1,2,3,4,5],index=['a','c','d','f','g'])print(s1)
print(s2)
print(s3)
print(s4)# 位置索引
print(s2[1]) # 输出为2
# 标签索引
print(s4['c']) # 输出为2
# 切片索引
print(s2[:4])
print(s4['a':'c'])
# 位置切片不会包含结束边界,而标签切片会包含结束边界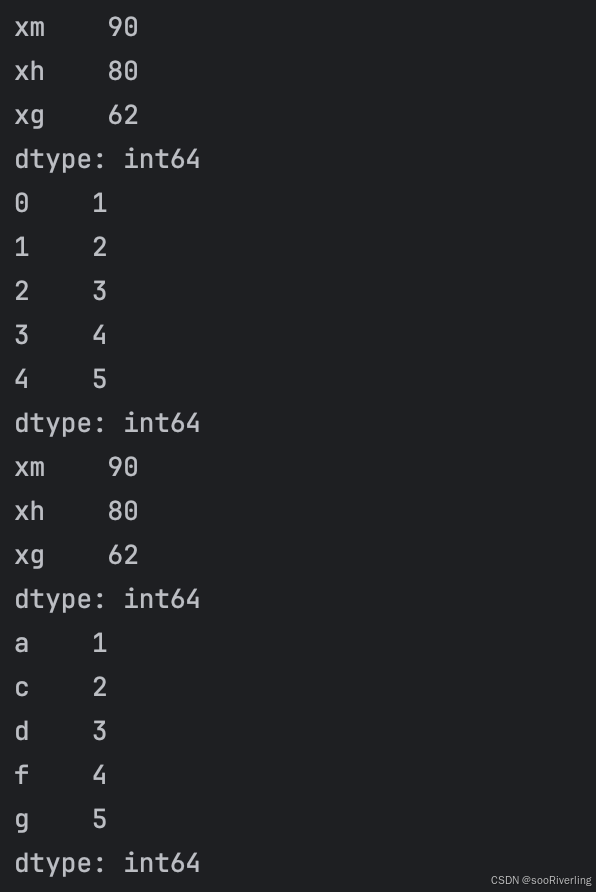
切片索引

获取索引和值
import pandas as pd
s1 = pd.Series([1,2,3,4,5],index=['a','c','d','f','g'])
print(s1.index)
print(s1.values)
DataFrame对象
概述
DataFrame是一个二维数据结构,由行列数据组成的表格,既有行索引也有列索引;
pandas.DataFrame(data,index,columns,dtype,copy)
- index:表示行标签;
- columns:表示列标签;
- dtype:每一列数据的数据类型,与Python的数据类型有区别;
- copy:用于复制数据;
dtype区别:(Pandas——Python数据类型)
object——str、int64——int、float64——float、bool——bool、datetime64——datetime64[ns]、timedelta[ns]——NA、category——NA
import pandas as pd#解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width',True)data = [[1,2,3],[4,5,6],[7,8,9]]
index=[1,2,3]
columns=['a','b','c']
df = pd.DataFrame(data=data,index=index,columns=columns)
print(df)
重要属性
- head:查看前n条数据,默认为5条;
- tail:查看后n条数据,默认5条;
- shape:查看行数和列数;
print(df.shape[0],df.shape[1]) # 3 3 行数是3,列数是3 - describe:查看每列统计汇总信息;
print(df.describe())
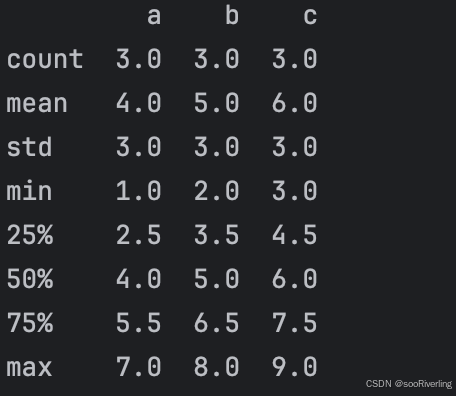
- count:返回每一列中的非空值个数
- sum:返回每一列的和,无法计算返回空;
- max(min):返回每一列最大(小)值;
- argmax(argmin):返回某一列最大(小)值所在的自动索引位置
print(df) print(df.max()) print(df['a'].argmax())
- idxmax(idxmin):返回最大(小)值所在的自定义索引位置;
- mean:返回每一列的平均值;
- median:返回每一列的中位数;
- var:返回每一列方差;
- std:返回每一列标准差;
- isnull:检查df中的空值,空值为True,非空返回False;
- notnull:检查df中的空值,非空为True,空值为False,返回布尔类型数组
导入数据
导入excel数据(.xls或.xlsx)
pandas.read_excel(io,sheet_name,header)
- io:文件路径或文件对象;
- sheet_name:工作表,值可以是None、字符串、整数或列表,默认为0;
- header:指定作为列名的行,默认为0;
导入csv数据或txt文件
pandas.read_csv(filepath,sep,header)
- filepath:文件路径;
- sep:分隔符;
- header:指定作为列名的行;
导入网页
pandas.read_html(io,match,header,encoding)
- io:文件路径或URL;
- match:正则表达式,返回与正则表达式匹配的表格;
- header:指定作为列名的行;
数据抽取
对DataFrame抽取数据主要使用loc和iloc。
loc:以列名和行名作为参数,当只有一个参数时,默认是行名,df.loc[‘A’];
iloc:以行和列位置的索引作为参数,0表示第一行,当只有一个参数时,默认是行索引,即抽取整行数据,df.iloc[1];
import pandas as pd#解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width',True)data=[[88,75,99],[95,78,85],[89,82,83],[82,65,72]]
name=['A','B','C','D']
columns=['数学','英语','数据结构']
df=pd.DataFrame(data=data,index=name,columns=columns)
print(df)# 抽取单行数据
print(f"抽取单行数据")
print(df.loc['D'])
# 抽取多行数据
print(f"抽取多行数据")
print(df.iloc[[0,2]]) # 如果是df.iloc([0,2]) 输出的是对应位置的数字,此式子是一个参数,默认行名,返回行
print(df.iloc[0:2])
# 抽取指定列数据
print(f"抽取指定列数据")
print(df.loc[:,['数学','英语']])
print(df.loc[:,'英语':])
print(df.iloc[:,[1,2]])
# 抽取指定行列
print(f"抽取指定行列")
print(df.loc['A','数学'])
print(df.iloc[1:3,[0,2]])
# 按指定条件抽取数据
print(f"按指定条件抽取数据")
print((df['数学']>85) & (df['英语']>70))
print(df.loc[(df['数学']>85) & (df['英语']>70)])
数据增加
# 增加列
df['操作系统']=[90,78,81,86]#增加末尾一列
df.insert(1,‘操作系统’,‘os’)#增加指定位置列# 增加行
df.loc['E']=[90,80,70]#一行数据修改
- 修改列标题
df.columns=['数学','C语言','数据结构']
df.rename(columns={‘数学’:‘数学’,‘英语’:‘C语言’,‘数据结构':'操作系统'},inplace=True)
- 修改行标题
df.index=['AA','BB','CC','DD']
df.rename({'A':'AA','B':'BB','C':'CC','D':'DD'},inplace=True)
- 修改数据
df.loc['A']=[90,80,70]#整行修改
df.iloc[0,:]=[90,80,70]#整行修改
df.loc[:,'数学']=[90,80,70,60]#整列修改
df.iloc[:,0]=[90,80,70,60]#整列修改
df.loc['A','数学']=95#单值修改
df.iloc[0,0]=95#单值修改
数据删除
DataFrame.drop(labels,axis,index,columns,level,inplace,errors)
- labels:表示行或列标签;
- axis:0表示按行删除,1表示按列删除;
- index:删除行;
- columns:删除列;
- level:针对有两级索引的数据;
- inplace:对原数组作出修改并返回一个新数组,默认False,True表示直接替换原数组;
- errors:默认raise,ignore取消错误
删除指定数据
df.drop(['数学'],axis=1,inplace=True)#删除某列
df.drop(labels='数学',axis=1,inplace=True)#删除数学列
df.drop(['A'],inplace=True)#删除某行
df.drop(labels='A',axis=0,inplace=True)#删除A行
删除特定条件数据
df.drop(df[df['数学'].isin([88])].index,inplace=True)#删除数学分数88的行
df.drop(df[df['英语']<80].index,inplace=True)#删除英语小于80的行
数据清洗
- 查看缺失值:缺失值是指由于某种原因导致数据为空,这种情况一般有四种处理方式:不处理、删除、填充或替换、插值;
- 判断是否存在缺失值:df.isnull()、df.notnull()
- 缺失值删除:df.dropna(inplace=True)
df1=df[df[‘column'].notnull()] - 缺失值填充处理:对于缺失值比例高于某个值,可以选择放弃该指标,进行删除处理
df['总数量']=df['总数量'].fillna(0)#用0填充缺失值
- 重复值处理:对于数据中存在的重复数据,包括重复的行或者某几行中的某几列的值重复(视具体数据来定),一般做删除处理,主要使用drop_duplicates方法;
- df.duplicated:判断每一行数据是否重复;
- df.drop_duplicates:删除所有重复数据;
- df.drop_duplicates(‘数学’):去除指定列的重复数据,删除一行
- df.drop_duplicates([‘A’],keep=‘last’):保留重复行中的最后一行
import pandas as pd# 构建测试数据框
df = pd.DataFrame({'brand': ['Yum Yum', 'Yum Yum', 'Indomie', 'Indomie', 'Indomie'],'style': ['cup', 'cup', 'cup', 'pack', 'pack'],'rating': [4, 4, 3.5, 15, 5]
})# 默认按所有列去重
print(df.drop_duplicates())# 指定列去重
print(df.drop_duplicates(subset=['brand']))# 保留最后一个重复值
print(df.drop_duplicates(subset=['brand', 'style'], keep='last'))# 删除所有重复项不保留
print(df.drop_duplicates(subset=['brand', 'style'], keep=False))
- 异常值的检测:异常值指超出或低于正常范围的值;
异常值处理:
删除;
将异常值作为缺失值处理;
将异常值作为特殊情况进行分析,研究异常出现的原因;
索引设置
设置索引
使用reindex可以创建一个适应新索引的新对象;
DataFrame.reindex(labels,index,columns,axis, method, copy,level,fill_value,limit,tolerance)
- labels:标签;index:行索引;columns:列索引;
- method:重新设置索引时,选择插值方法,bfill/backfill(向后填充)、ffill/pad(向前扩充);
- fill_value:缺失值要填充的数据,如fill_value=0,用0填充;
import pandas as pdpd.set_option('display.unicode.east_asian_width',True)
s1 = pd.Series([88,60,75],index=[1,2,3])
print(s1)
print(s1.reindex([1,2,3,4,5])) # 重新设置索引
print(s1.reindex([1,2,3,4,5],method='ffill')) # 向前填充
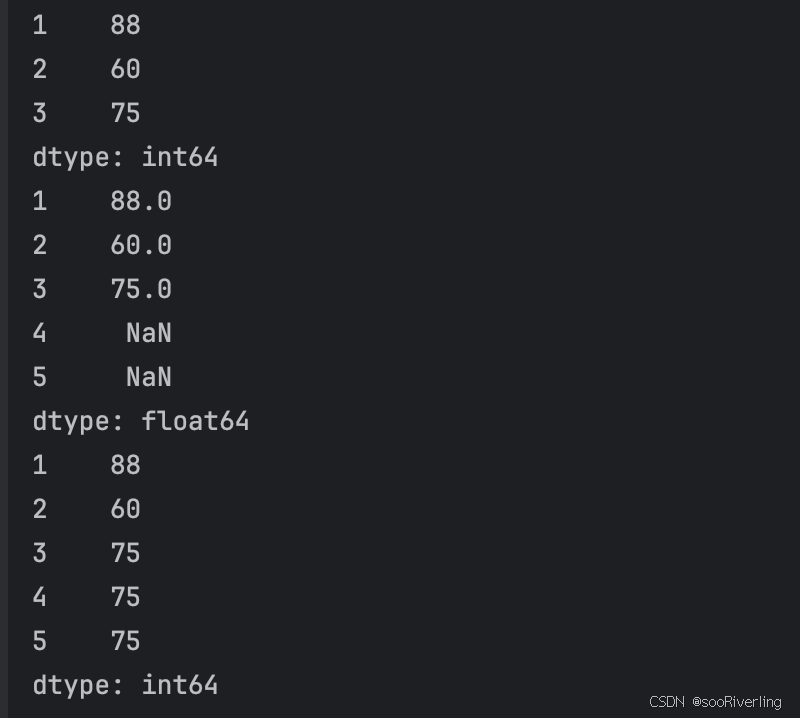
- 设置某列为索引:df=df.set_index([‘列名’])
- 数据清洗后重新设置连续的行索引:df=df.dropna().reset_index(drop=True)
数据排序
DataFrame.sort_values(by,axis,ascending,inplace,kind,na_position,ignore_index)
- by:排序的列名或列名的列表。指定一个或多个列来根据这些列进行排序;
- axis:0表示行,1表示列,默认按行排序;
- ascending:默认为 True,表示升序排序。如果是 False,则表示降序排序;
- inplace:默认为 False,表示返回排序后的新 DataFrame。如果设置为 True,则在原地修改 DataFrame,并返回 None;
- kind: 排序算法;
- na_position: 控制缺失值的排序位置。默认为 ‘last’,表示缺失值放在排序的最后。如果设置为 ‘first’,缺失值会排在前面;
- ignore_index: 默认为 False,表示不重置索引。如果设置为 True,排序后将重新生成索引;
按统计结果排序;
df1 = df.groupby(['数学'])['英语'].sum()
print(type(df1)) #Series
print(df1)
df2 = df.groupby(['数学'])['英语'].sum().reset_index()
print(df2)

按行排序
df.sort_values(by=0,ascending=True,axis=1)
数据排名
DataFrame.rank(axis,method,numeric_only,na_option,ascending,pct)
- method:表示具有相同值的情况下所使用的排序方法
- pct:布尔值,是否以百分比形式返回排名,默认值为False
import pandas as pd# 创建示例 DataFrame
data = {'Student': ['Alice', 'Bob', 'Charlie', 'David', 'Eva'],'Score': [95, 80, 85, 90, 95]}
df = pd.DataFrame(data)print("原始数据:")
print(df)df['Rank'] = df['Score'].rank(ascending=True)
print("按分数升序排名:")
print(df)df['Rank'] = df['Score'].rank(ascending=False)
print("按分数降序排名:")
print(df)# 处理重复排名:使用不同的 method 参数
df['Rank_avg'] = df['Score'].rank(method='average')
print("使用 'average' 方法排名:")
print(df)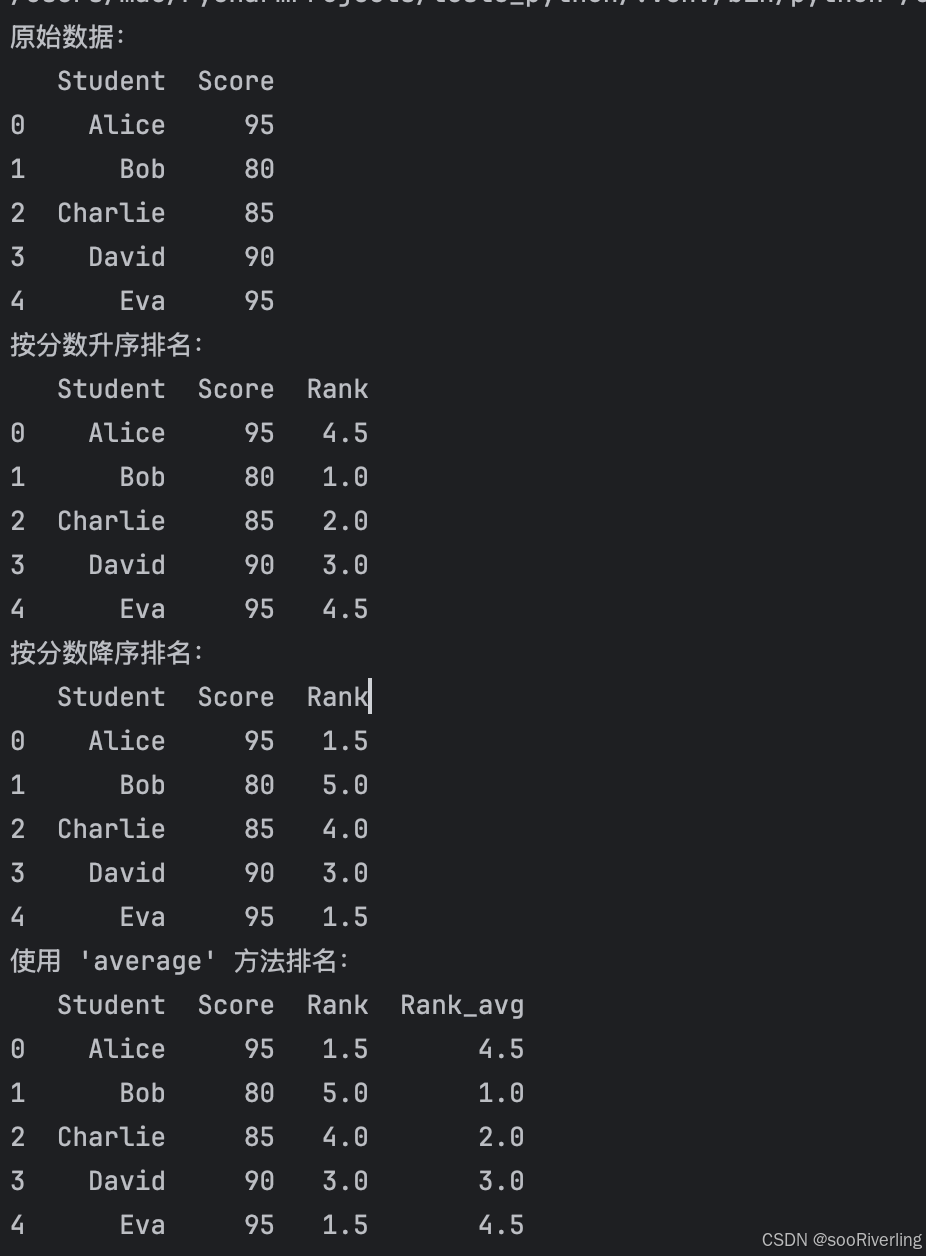
第十章 网络爬虫
网络爬虫概述
- 网络爬虫又称为网页蜘蛛、网络机器人,是一种按照一定规则自动地爬取万维网信息的程序或脚本;
网络爬虫分类: - 通用爬虫:又称全网爬虫,通用爬虫只能爬取文字相关爬虫,不提供多问题文件;且爬虫内容千篇一律,不能针对不同背景人提供特定结果;
- 聚焦爬虫:又称主题网络爬虫,聚焦爬虫针对某种内容的爬虫,也可以被称为面向主题/需求爬虫,针对某个特定的内容进行爬虫,会保证需求和爬取内容息息相关;
通用爬虫
- 将爬取对象从一些种子URL扩充到整个Web上的网站;
- 为门户站点搜索引擎和大型Web服务提供商采集数据;
- 爬取范围和数量巨大,要求高速、高存储空间、对爬取顺序要求较低;
- 通常采用并行工作方式
聚焦爬虫
- 选择性爬取与预先定义好的主题相关的页面;
- 相对节省硬件和网络资源;
- 涉及数量小、更新快;
- 可很好满足一些特定人群对特定领域信息的需求;
爬虫爬取网页
- 选取一些网页地址作为种子URL;
- 将种子URL放入待抓取URL队列中;
- 爬虫从待爬取URL队列中依次读取URL,并通过DNS解析URL,把链接地址转换为网站服务器所对应的IP地址;
- 将生成的IP地址和网页相对路径名称交给网页下载器;
- 网页下载器将相应网页的内容下载到本地;
- 将下载的网页存储到页面模块中,等待建立索引以及后续处理;同时,将已下载的网页URL放入已抓取URL队列中,以避免重复抓取网页;
- 从(6)中下载的网页中抽取出所有链接信息,检查其是否已被抓取,若未被抓取,将这个URL放入待抓取URL队列中;
- 重复步骤(2)~(7),直到待抓取URL队列为空。
抓取网页数据
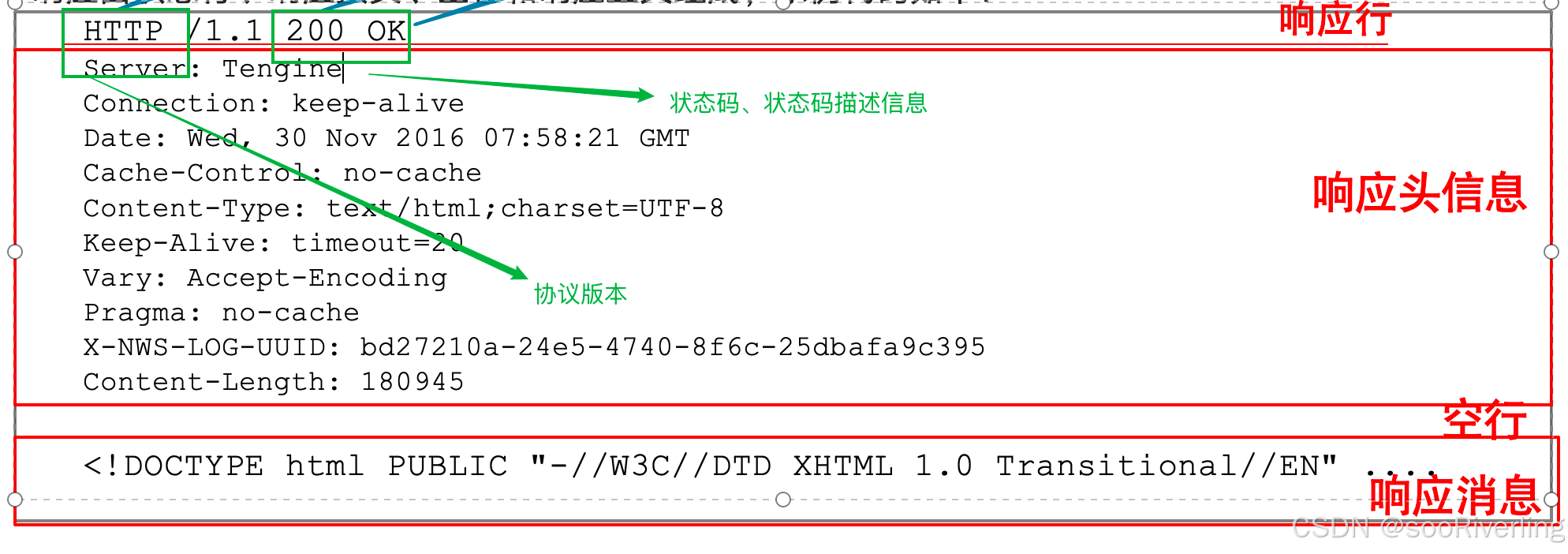
HTTP消息格式
浏览网页的过程中,浏览器会向服务器发起HTTP请求,也会接收服务器返回的HTTP响应。
HTTP是网络中用于传输HTML等超文本的应用层协议,它规定了HTTP请求消息与HTTP响应消息的格式。
请求消息
请求消息由请求行、请求头、空行和请求参数四部分组成

响应信息
响应由状态行、响应报头、空行和响应正文组成
使用requests模块抓取网页
Python中的第三方模块requests是专为人类设计的HTTP模块,该模块支持发送请求,也支持获取响应
发送请求
-requests.request(method, url, **kwargs):构造一个请求,支撑以下各方法的基础方法;method:请求方式,url:待获取页面的 URL 链接,kwargs:控制访问的参数;
- requests.get():获取HTML网页的主要方法,对应于HTTP的GET请求方式;
- requests.post():向HTML网页提交POST请求的方法,对应于HTTP的POST请求方式;
GET和POST区别
1.get请求一般是去取获取数据;post请求一般是去提交数据。
2.get因为参数会放在url中,所以隐私性,安全性较差,请求的数据长度是有限制的;post请求是没有的长度限制,请求数据是放在body中;
3.get请求刷新服务器或者回退没有影响,post请求回退时会重新提交数据请求。
4.get请求可以被缓存,post请求不会被缓存。
5.get请求会被保存在浏览器历史记录当中,post不会。get请求可以被收藏为书签,因为参数就是url中,但post不能。它的参数不在url中。
深入理解:
1.GET 和 POST都是http请求方式, 底层都是 TCP/IP协议;通常GET 产生一个 TCP 数据包;POST 产生两个 TCP 数据包(但firefox是发送一个数据包),
2.对于 GET 方式的请求,浏览器会把 http header 和 data 一并发送出去,服务器响应 200(返回数据)表示成功;而对于 POST,浏览器先发送 header,服务器响应 100, 浏览器再继续发送 data,服务器响应 200 (返回数据)。
获取响应
Requests模块提供的Response类对象用于:
- 动态响应客户端请求;
- 控制发送给用户的信息;
- 动态地生成响应,包括状态码、网页的内容;
属性:
- status_code:Http请求返回状态,200表示连接成功,404表示失败;
- text:http响应内容的字符串形式,即URL对应的页面内容;
- encoding:从HTTP请求头中猜测的响应内容编码方式
import requests
base_url = 'http://www.baidu.com'
res = requests.get(base_url) # 发送GET请求
# 获取响应状态码
print("响应状态码:{}".format(res.status_code))
# 获取响应内容的编码方式
print("编码方式:{}".format(res.encoding))
# 更新响应内容的编码方式为utf-8
res.encoding = 'utf-8'
# 获取响应内容
print("网页源代码:\n{}".format(res.text))
解析网页数据
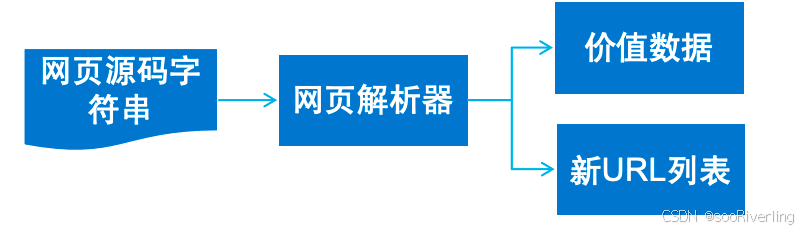
解析网页技术
- 正则表达式:可以处理任何格式的字符串文档;
- XPath和BeautifulSoup:适合处理层级比较明显的数据;
- JSONPath:用于JSON文档的数据解析
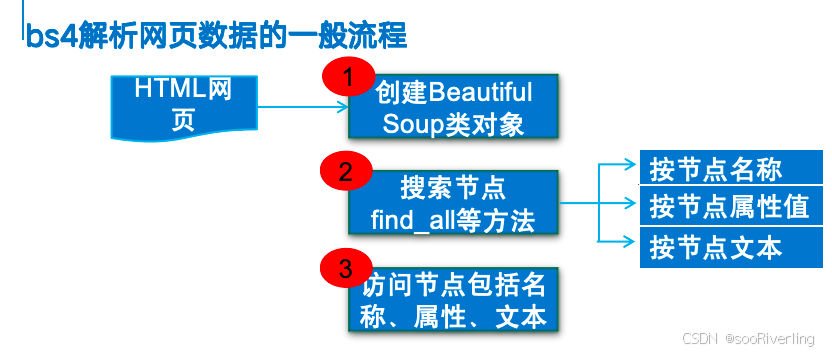
bs4
bs4会将复杂的HTML文档换成树结构,每个结点都是一个对象,这些对象可以归纳为四种:
- bs4.element.Tag类:HTML中的标签,最基本的信息组织单元;表示标签名字的name属性,表示标签属性的attrs属性;
- bs4.element.NavigableString类:表示HTML中标签的文本(非属性字符串);
- bs4.BeautifulSoup类:表示HTML DOM中的全部内容;
- bs4.element.Comment类:表示标签内字符串的注释部分,是一种特殊的NavigableString对象;
添加
issubstance
class Person: # 定义Person类passclass Student(Person): # 以Person作为父类定义子类Studentpassclass Flower: # 定义Flower类passif __name__ =='__main__':stu = Student() # 创建Student类对象stuf = Flower() # 创建Flower对象fprint(isinstance(stu, Person)) # Trueprint(isinstance(f, Person)) # Falseprint(issubclass(Student, Person)) # Trueprint(type(f))
isinstance用于检查对象是否是指定类或其子类的实例;
issubclass用于检查一个类是否是另一个类的子类;
元类
class Student(metaclass=type): #定义Student类pass
stu=Student() #定义Student类的对象stu
print('stu所属的类是',stu.__class__) #使用__class__属性获取所属的类
print('Student所属的类是',Student.__class__)
输出:
stu所属的类是 <class ‘main.Student’>
Student所属的类是 <class ‘type’>
动态扩展类
from types import MethodType
class Student: #定义学生类passdef SetName(self,name): #定义SetName函数self.name=name
def SetSno(self,sno): #定义SetSno函数self.sno=sno
if __name__=='__main__':stu1=Student() #定义Student类对象stu1stu2=Student() #定义Student类对象stu2stu1.SetName=MethodType(SetName, stu1) #为stu1对象绑定SetName方法Student.SetSno=SetSno #为学生类绑定SetSno方法stu1.SetName('张三')stu1.SetSno('2020200')
单例模式
class Singleton(object):__instance = Nonedef __new__(cls, *args, **kwargs): # 这里不能使用__init__,因为__init__是在instance已经生成以后才去调用的if cls.__instance is None:cls.__instance = object.__new__(cls)return cls.__instancedef __init__(self,name,age):self.name = nameself.age = ageprint("ninhao")
# s1 = Singleton()
# s2 = Singleton()
s1 = Singleton("zhangsan",12) # 输出:ninhao
s2 = Singleton("wangwu",15) # 输出:ninhao
# print(s1)
# print(s2)
print(s1.__dict__) # {'name': 'wangwu', 'age': 15}
slots
class Person(object):def __init__(self, name, age):self.name = nameself.age = age# 注意这里__slots__函数中的参数用“”包裹__slots__ = ("name", "age","sex")
class Student(Person):def __init__(self, name, sex, age):super().__init__(name, age)self.sex = sex
p1 = Person("tom", 18)
p1.sex = "male"
stu1 = Student("jack", "male", 22)
print(stu1.name, stu1.sex, stu1.age)
stu1.country = "china"
print(stu1.country) # 虽然父类设置__slots__属性约束,但是对子类没有约束力。slots 来限制实例可以拥有的属性,slots 被设置为一个元组 (“name”, “age”, “sex”),这意味着 Person 类的实例只能有 name、age 和 sex 三个属性;
鸭子类型
class duck():def walk(self):print('I walk like a duck')def swim(self):print('i swim like a duck')
class person():def walk(self):print('this one walk like a person')def swim(self):print('this man swim like a person')
def watch_duck(animal):animal.walk()animal.swim()
small_duck = duck()
watch_duck(small_duck)
duck_like_man = person()
watch_duck(duck_like_man)
输出:
I walk like a duck
i swim like a duck
this one walk like a person
this man swim like a person
鸭子类型(Duck Typing),即在 Python 中,函数和方法不依赖于对象的类型,而是依赖于对象是否具备所需的方法和行为
列表生成表达式
#new_lst = [表达式 for 变量 in 范围 if 条件 ]
a = [x**2 for x in range(0,11) if x%2==0]
print(a)#另外列表生产表达式中也支持多层循环的形式,这里只给出两层循环的例子:
classList=['数学','语文']
nameList=['张轩','李岚','王晨','周明']
ls=['课程:'+cls+',姓名:'+name for cls in classList for name in nameList]
print(ls)
for stu in ls:print(stu)
学生成绩排序
import random# 类定义
class Student:def __init__(self, name, age, score):self.name = nameself.age = ageself.score = scoredef info(self):print(f"{self.name}, {self.age} 岁, 成绩:{self.score:.2f}.")# 创建学生列表
students = []
for i in range(5):age = random.randint(18, 21)score = random.uniform(0, 100) # 随机生成浮动成绩students.append(Student(f'张三{i}', age, score))# 输出学生信息
print("所有学生信息:")
for student in students:student.info()# 按成绩降序排序
print("\n按成绩排序后的学生信息:")
students.sort(key=lambda stu: stu.score, reverse=True)
for student in students:student.info()# 去掉最高分和最低分
print("\n去掉最高分和最低分后的学生信息:")
highest = students.pop(0)
lowest = students.pop(-1)
highest.info()
lowest.info()
for student in students:student.info()# 拷贝学生信息并逆序排序
print("\n逆序排序后的学生信息:")
stuList = students.copy()
stuList.reverse()
for student in stuList:student.info()frozenset
set2 = {2, 5, 1, 4, 2, 5} # 创建集合,重复的元素会被自动去重
set1 = set2 # set1 和 set2 指向同一个集合对象
print(id(set2), id(set1)) # 打印 set2 和 set1 的内存地址,应该相同set1.add(4) # 尝试添加 4,集合中已经有 4,所以集合内容不变
print(set2) # 打印 set2# 由于集合无序,pop() 会随机删除并返回一个元素
removed_element = set2.pop() # pop() 删除一个随机元素
print(f"Removed element: {removed_element}")
print(set2) # 打印删除元素后的 set2 内容
print(set1) # set1 和 set2 是同一个对象,所以它们内容是一样的set3 = frozenset([1,2,3,4]) # 不可变集合
print(set3)
使用yield关键字函数可以实现生成器
def fibonacci(n): # 生成器函数 - 斐波那契a, b, counter = 0, 1, 0while True:if (counter >= n):return #结束函数的执行yield aa, b = b, a + bcounter += 1
f = fibonacci(10) # f 是一个迭代器,由生成器返回生成
while True:try:print (next(f), end=" ")except StopIteration:exit()
yield:用于定义生成器函数,它返回一个生成器对象,可以通过 next() 获取值;会暂停函数的执行并保持当前状态;可以节省内存;
斐波那契数列迭代器
#定义一个生成斐波那契数列的迭代器:
from collections.abc import Iterable,Iterator
from doctest import testmodclass Fibonacci:def __init__(self):self.a=0self.b=1def __next__(self):tmp=self.aself.a=self.bself.b=tmp+self.breturn tmpdef __iter__(self):return self # 迭代器的 __iter__ 返回对象本身
fibs=Fibonacci()
print(isinstance(fibs,Iterator))
for i in range(6):print(next(fibs))交、差、补、并
stuList={'张轩','李岚','王晨','刘峰','赵钢','周明','孙柯','韩函'}
mathSet=stuList.copy()
pythonStu=stuList.copy()
#随机分班
mathClass1=set()
pythonClass2=set()
for i in range(4):mathClass1.add(mathSet.pop())# 随机删除学生,这里得到的mathClass1学生:{'王晨', '刘峰', '李岚', '周明'}
for i in range(5):pythonClass2.add(pythonStu.pop())#随机删除学生,这里得到的pythonClass2学生:{'周明', '王晨', '李岚', '刘峰', '张轩'}
#既在数学班又在python班的学生(交集)
mathAndPython=mathClass1.intersection(pythonClass2) #结果为:{'王晨', '周明', '李岚', '刘峰'}
#在python班但是不在math班的学生(差集)
pythonNotMatn=pythonClass2.difference(mathClass1) #结果为:{'张轩'}
#在数学班或者python班,但是没有同时才加两个班级的学生(补集)
notMath=pythonClass2.symmetric_difference(mathClass1) #结果为:{'张轩'}
#返回进入数学班或者python班的学生(并集)
pythonOrMath=mathClass1.union(pythonClass2)
得分率雷达图
import matplotlib.pyplot as plt
import numpy as npplt.rcParams['font.family'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False # 显示负号(-)时使用 Unicode 字符(−)而不是普通的 ASCII 字符(-)arr=np.loadtxt("a.csv",dtype=int,delimiter=',',skiprows=1).astype(int)
tarr = arr[ : , 1 : 6]#计算每道题目的平均分:
tmean = tarr.mean(axis=0)#计算得分率:平均分/总分值
ts = np.array([20, 20, 20, 20, 20])
tdfl = tmean / ts#构建数据
angles = np.linspace(0,2*np.pi,5,endpoint=False)
# endpoint=False 避免在最后一个角度2pi被包含,确保图形是闭合的
print(angles)#将整圆2π平均分成5份,参数endpoint必须设置为False
data= tdfl #使用numpy计算出的得分率数组
labels= ['选择题','填空题','判断题','简答题','程序编写题']
#绘制极坐标图
plt.polar(angles,data, "bo-",lw=1) #极坐标绘图, bo-表示格式字符串
#设置标题及坐标轴名称
plt.title("得分率雷达图")
plt.thetagrids(angles * 180/np.pi, labels,y=0.005) #设置极角标签
#显示图表#闭合数据连线:使用concatenate()连接制作闭合数据
angles=np.concatenate((angles,[angles[0]])) #角度数据首尾相接,曲线闭合
data= np.concatenate((data,[data[0]])) #得分率数据首尾相接,曲线闭合
#填充闭合连线区域
plt.fill(angles,data, "r",alpha=0.3)
plt.polar(angles,data, "bo-",lw=1)#修改标题位置
plt.title("得分率雷达图",y=1.06,fontsize=15) #调整标题显示位置及文字大小
#修改极坐标范围
plt.ylim(0,1) #设置极坐标轴范围为0到1
#添加数据点数据显示
for x,y in zip(angles,data):plt.text(x, y+0.1, round(y,2), ha='center', va= 'bottom')plt.show()成绩分布柱状图
import matplotlib.pyplot as plt
import numpy as npplt.rcParams['font.family'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = Falsearr=np.loadtxt("a.csv",dtype=int,delimiter=',',skiprows=1).astype(int)
# print(arr)sarr = arr[:, 6: 7]
hist, bins = np.histogram(sarr, bins=[0, 60, 70, 80, 90, 100], range=(0, 100))
# histogram计算直方图的Numpy函数,将数据数组分割成多个区间(bins),并返回每个区间元素数量
# range 考虑的值的范围
# histogram返回两个值:hist:每个区间内的元素个数;bins:包含所有区间的边界值,与bins相同#构建数据
x = bins[0:-1] #bins:[ 0 60 70 80 90 100]
y = hist #hist: [2 3 6 1 2]#修改bins值
bins[0]=50 #50代表60分以下成绩,个数与hist数组相同
# x = bins[0:-1]
#修改坐标轴刻度值
plt.axis([40,100,0,20]) #设置坐标值范围, x轴范围[40,100],y轴范围[0,40]
plt.xticks(x,['60分以下','60-70分','70-80分','80-90分','90-100分'])#ticks:设置X轴刻度间隔#labels: 设置每个间隔的显示标签
#调整x轴刻度对齐方式
plt.bar(x, y, width=8, color='steelblue', align='center')#绘制柱状图
# plt.bar(x, y, width=5, color='steelblue')
#设置标题及坐标轴名称
plt.title("成绩分布图")
plt.xlabel("分数段")
plt.ylabel("人数")#在任意位置增加文本
# plt.text(x横坐标,y纵坐标,显示数据,水平对齐,垂直对齐)
for x,y in zip(x,hist): # 将可迭代对象打包成一个元组plt.text(x, y+0.15, str(y), ha='center', va= 'bottom')
#添加背景网络
plt.grid(True)#显示图表
plt.show()
点线图
import matplotlib.pyplot as plt
import numpy as npx = np.arange(0, 11, 0.2) # x坐标采样点生成
y = np.sin(x) # 计算对应x的正弦值
plt.plot(x, y, 'bs--') # 控制图形格式为蓝色方形的虚线plt.title("正弦曲线图") #设置图表标题
plt.xlabel("time") #设置x坐标轴标签
plt.ylabel("voltage") #设置y坐标轴标签
# #
plt.rcParams['font.sans-serif'] = 'SimHei' # 用来正常显示中文(黑体)
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.show()
plt.savefig("test", dpi=300) # 保存图表
pandas画图
pd.set_option('display.unicode.east_asian_width', True)
data=[[1,2,3],[4,5,6],[7,8,9]]
index=[1,2,3]
columns=['a','b','c']
df=pd.DataFrame(data=data,index=index,columns=columns)
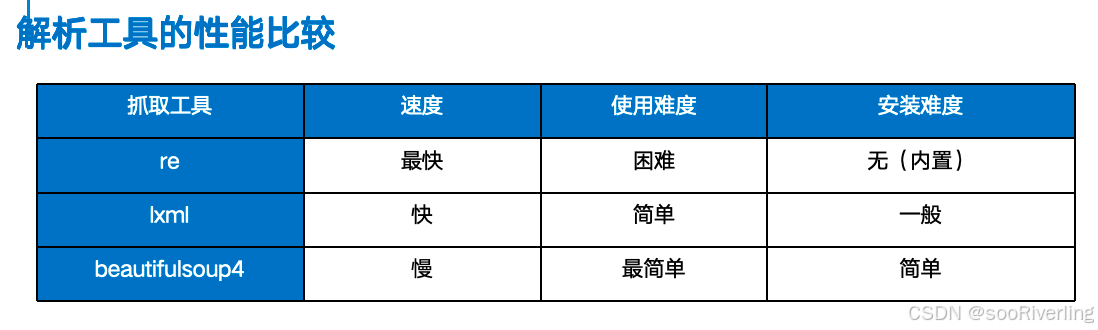
df.plot()
plt.show()
#折线图
s1 = pd.Series(np.random.randn(5))
print(np.random.randn(5))
s1.plot()
生成五个随机正态分布的数
网络爬虫
from bs4 import BeautifulSoup
import requests
import csv
# 服务器地址
url = "https://movie.douban.com/top250"
# 伪装成浏览器
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36'}
all_movie = []
# 发送请求
resp = requests.get(url, headers=headers)
html_code = resp.text
# 得到 BeautifulSoup 对象。万里长征的第一步。
bs = BeautifulSoup(html_code, "html.parser")
# div_tag = bs.find("div",class_='info')
div_tags = bs.find_all("div",class_='info')
# print(div_tags)
# # print(type(div_tags[0]))
for div_tag in div_tags:div_tag_name = div_tag.find("span",class_='title').contents# print(div_tag_name)div_tag_link = div_tag.find("a").attrs['href'] # attrs是获得属性div_tag_judge = div_tag.find("span", attrs={"class":"rating_num" ,"property":"v:average"}).contentsmovie_name = div_tag_name[0]movie_link = div_tag_linkmovie_judge = div_tag_judge[0]all_movie.append([movie_name,movie_link,movie_judge])print(all_movie)with open("movieT250.csv",'w',newline='') as f:csv_movieT250 = csv.writer(f)csv_movieT250.writerow(["电影名称","电影链接","电影评分"])csv_movieT250.writerows(all_movie)相关文章:

Python复习
第一章 Python概述 python特点 优点: 简单易学;开发效率高;典型的工具语言;强大丰富的模块库;优秀的跨平台; 缺点: 执行效率不高;代码不能加密;用缩进区分语句关系&…...

通信系统中物理层与网络层联系与区别
在通信系统中,物理层和网络层是OSI(开放系统互连)模型中的两个重要层次,分别位于协议栈的最底层和第三层。它们在功能、职责和实现方式上有显著的区别,但同时也在某些方面存在联系。以下是物理层与网络层的联系与区别的…...

go 错误处理 error
普通错误处理 // 包路径 package mainimport ("errors""fmt" )func sqrt(f1, f2 float64) (float64, error) {if f2 < 0 {return 0, errors.New("error: f2 < 0")}return f1 / f2, nil }func sqrt1(f1, f2 float64) {if re, err : sqrt(f…...

Redis 缓存穿透、击穿、雪崩:问题与解决方案
在使用 Redis 作为缓存中间件时,系统可能会面临一些常见的问题,如 缓存穿透、缓存击穿 和 缓存雪崩。这些问题如果不加以解决,可能会导致数据库压力过大、系统响应变慢甚至崩溃。本文将详细分析这三种问题的起因,并提供有效的解决…...

Spring容器初始化扩展点:ApplicationContextInitializer
目录 一、什么是ApplicationContextInitializer? 1、核心作用2、适用场景 二、ApplicationContextInitializer的使用方式 1、实现ApplicationContextInitializer接口2、注册初始化器 三、ApplicationContextInitializer的执行时机四、实际应用案例 1、动态设置环境…...

冯·诺依曼体系结构、理解操作系统管理
在谈操作系统概念之前,先简单讲解一下冯诺伊曼体系结构,理解了在硬件层面上数据流的走向,这对后续的理解有很大的帮助。 文章目录 一.冯诺依曼结构冯诺依曼体系结构内存存在的意义 二.理解操作系统管理操作系统的作用管理的本质系统调用 一.…...

Linux初体验:从零开始掌握操作系统的发展与多样性
Linux初体验:从零开始掌握操作系统的发展与多样性 前言一、什么是Linux?1. Linux的定义2. Linux的组成 二、Linux的发展历史1. Unix的诞生2. Linux的诞生3. Linux的普及 三、Linux的发行版1. **Ubuntu**2. **CentOS**3. **Debian**4. **Fedora**5. **Arc…...

文心一言大模型的“三级跳”:从收费到免费再到开源,一场AI生态的重构实验
2025年2月,百度文心大模型接连抛出两枚“重磅炸弹”:4月1日起全面免费,6月30日正式开源文心大模型4.5系列。这一系列动作不仅颠覆了李彦宏此前坚持的“闭源优势论”13,更标志着中国AI大模型竞争进入了一个全新的阶段——从技术壁垒…...
)
技术教程 | 如何实现1v1音视频通话(含源码)
今天,给大家讲一下怎么实现1v1音视频通话,以下是教程内容: 开发环境 开发环境要求如下: 环境要求说明JDK 版本1.8.0 及以上版本Android API 版本API 21、Android Studio 5.0 及以上版本CPU架构ARM 64、ARMV7IDEAndroid Studio其…...

mysql实时同步到es
测试了多个方案同步,最终选择oceanu产品,底层基于Flink cdc 1、实时性能够保证,binlog量很大时也不产生延迟 2、配置SQL即可完成,操作上简单 下面示例mysql的100张分表实时同步到es,优化备注等文本字段的like查询 创…...

Linux-ubuntu系统移植之Uboot启动流程
Linux-ubuntu系统移植之Uboot启动流程 一,Uboot启动流程1.Uboot的两阶段1.1.第一阶段1.11.硬件初始化1.12.复制 U-Boot 到 RAM1.13.跳转到第二阶段 1.2.第二阶段1.21.C 语言环境初始化1.22. 硬件设备初始化1.23. 加载环境变量1.24. 显示启动信息1.25. 等待用户输入&…...

《Operating System Concepts》阅读笔记:p62-p75
《Operating System Concepts》学习第 10 天,p62-p75 总结,总计 14 页。 一、技术总结 1. system call (1) 定义 The primary interface between processes and the operating system, providing a means to invoke services made available by th…...

【Java场景题】MySQL死锁排查
大家好,今天XiXi给大家分享一个MySQL死锁排查的实验,文章主要有: 通过show engine innodb status,查看最近一次死锁信息开启innodb_print_all_deadlocks,在错误日志中能够记录所有死锁信息通过解析binlog日志定位死锁…...
)
JSON格式,C语言自己实现,以及直接调用库函数(一)
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,易于人阅读和编写,同时也易于机器解析和生成。以下为你提供不同场景下常见的 JSON 格式示例。 1. 简单对象 JSON 对象是由键值对组成,用花括号 {} 包裹&…...

leetcode刷题第十三天——二叉树Ⅲ
本次刷题顺序是按照卡尔的代码随想录中给出的顺序 翻转二叉树 226. 翻转二叉树 /*** Definition for a binary tree node.* struct TreeNode {* int val;* struct TreeNode *left;* struct TreeNode *right;* };*//*总体思路就是,对于每一个结点&…...

spring boot知识点5
1.如何你有俩套配置环境,运行时如何选择 如果有俩套配置环境,则需要三个yml application.yml 用于配置你用那个配置环境 application-dev.yml 用于开发配置环境 application-prod.yml 用于发布配置环境 spring:profiles:active: prod # 指定当前激…...

bboss v7.3.5来袭!新增异地灾备机制和Kerberos认证机制,助力企业数据安全
ETL & 流批一体化框架 bboss v7.3.5 发布,多源输出插件增加为特定输出插件设置记录过滤功能;Elasticsearch 客户端新增异地双中心灾备机制,提升框架高可用性;Elasticsearch client 和 http 微服务框架增加对 Kerberos 认证支持…...

Android自带的省电模式主要做什么呢?
Android自带的省电模式主要做什么呢? 省电模式支持的策略 LOCATION 灭屏后开启GPS待机省电模式 VIBRATION 关闭触摸震动和来电震动 ANIMATION 关闭动画 FULL_BACKUP 全备份 KEYVALUE_BACKUP 键值备份 NETWORK_FIREWALL 网络防火墙,限制 Doze …...

tp6上传文件大小超过了最大值+验证文件上传大小和格式函数
问题: 最近用tp6的文件上传方法上传文件时报文件过大错误。如下所示: $file $this->request->file(file);{"code": 1,"msg": "上传文件大小超过了最大值!","data": {"code": 1,&q…...

将RocketMQ集成到了Spring Boot项目中,实现站内信功能
1. 添加依赖 首先,在pom.xml中添加RocketMQ的依赖: <dependencies><!-- Spring Boot Starter Web --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifac…...

Spring Boot文件上传
5.3.1文件上传 开发Web应用时,文件上传是很常见的一个需求浏览器通过表单形式将文件以流的形式传递给服务器,服务器再对上传的数据解析处理。下面我们通过一个案例讲解如何使用SpringBoot实现文件上传,具体步骤如下。 1.编写文件上传的表单…...

动态规划算法
动态规划算法模板 public class DynamicProgramming {public int solve(int n, int[] nums) {// Step 1: 初始化 dp 数组,dp[i] 表示从0到i的最优解int[] dp new int[n 1]; // Step 2: 设置初始条件,通常是dp数组的第一个元素dp[0] 0; // 假设从第0个…...

Python中常见库 PyTorch和Pydantic 讲解
PyTorch 简介 PyTorch 是一个开源的深度学习框架,由 Facebook 的 AI 研究团队开发。它提供了丰富的工具和库,用于构建和训练各种深度学习模型,如卷积神经网络(CNN)、循环神经网络(RNN)及其变体&…...
)
74. 搜索二维矩阵(LeetCode 热题 100)
题目来源; 74. 搜索二维矩阵 - 力扣(LeetCode) 题目内容: 给你一个满足下述两条属性的 m x n 整数矩阵: 每行中的整数从左到右按非严格递增顺序排列。 每行的第一个整数大于前一行的最后一个整数。 给你一个整数 target &am…...

高防服务器的适用场景有哪些?
高防服务器作为具有着较高防御能力的网络设备,可以抵御DDOS和CC等常见的网络攻击类型,保障企业服务的连续性和稳定性,那高防服务器的适用场景有哪些呢? 对于大型的网站和电商平台来说,高流量的用户访问和数据信息让它们…...

HTTP与网络安全
一、HTTPS和HTTP有怎样的区别呢?HTTPS HTTP SSL/TLS(SSL或者TLS) HTTP:应用层 SSL/TLS:协议中间层 TCP:传输层 IP:网络层 HTTPS 是安全的HTTP,他的安全是由SSL或者TLS来决定的&a…...

UE地编材质世界对齐纹理旋转
帖子地址 https://forums.unrealengine.com/t/how-to-rotate-a-world-aligned-texture/32532/4世界对齐纹理本身不能改 自己创建了个函数 把世界对齐纹理的内容赋值粘贴 在纹理偏移里给值 不要局限0-1 给值给大一点...

SpringBoot使用Nacos进行application.yml配置管理
Nacos是阿里巴巴开源的一个微服务配置管理和服务发现的解决方案。它提供了动态服务发现、配置管理和 服务管理平台。Nacos的核心功能包括服务发现、配置管理和动态服务管理,使得微服务架构下的服务治理 变得简单高效。 Nacos的设计基于服务注册与发现、配置管理、动…...

JavaScript中的symbol类型的意义和使用
JavaScript 中的Symbol类型是 ES6(ECMAScript 2015)引入的一种原始数据类型,它表示独一无二的值。下面详细介绍 Symbol 的意义和使用方法。 意义 1. 避免属性名冲突 在 JavaScript 中,对象的属性名通常是字符串。当多个模块或者…...

C++ 设计模式-状态模式
火箭状态模式,涵盖发射、多级分离、入轨、返航、紧急状态等流程,以及状态间的转换逻辑: 状态设计 状态列表: IdleState(待机)PreparingState(准备)LaunchingState(发射中)FirstStageSeparatingState(一级分离)SecondStageSeparatingState(二级分离)ThirdStageSep…...

verilog基础知识
一,Verilog和VHDL区别 全世界高层次数字系统设计领域中,应用Verilog和VHDL的比率是80%和20%;这两种语言都是用于数字电路系统设计的硬件描述语言, 而且都已经是 IEEE 的标准。 VHDL 是美国军方组织开发的,VHDL1987年成为标准;Verilog 是由一个公司的私有财产转化而来,…...

14.8 Auto-GPT 自主智能体设计解密:构建具备长期记忆的智能决策系统
Auto-GPT 自主智能体设计解密:构建具备长期记忆的智能决策系统 关键词:Auto-GPT 架构设计、自主智能体开发、LangChain Agents、长期记忆系统、工具链编排 1. 自主智能体的核心架构设计 Auto-GPT 系统架构图解: #mermaid-svg-NuDU1eo6sXqhA6Ve {font-family:"trebuch…...

ubuntu安装docker docker/DockerHub 国内镜像源/加速列表【持续更新】
ubuntu安装docker & docker镜像代理【持续更新】 在Ubuntu上安装Docker,你可以选择两种主要方法:从Ubuntu的仓库安装,或者使用Docker的官方仓库安装。下面我会详细解释这两种方法。 方法一:从Ubuntu的仓库安装Docker 这种方…...

模拟实现分布式文件存储
Q1:如何解决海量数据存的下的问题 传统做法是在单机存储。但是随着数据变多,会遇到存储瓶颈。 单机纵向扩展:内存不够加内存,磁盘不够加磁盘。有上限限制,不能无限制加下去。 多机横向扩展:采用多台机器存储&#x…...

HW面试经验分享 | 北京蓝中研判岗
目录: 所面试的公司介绍 面试官的问题: 1、面试官先就是很常态化的让我做了一个自我介绍 2、自我介绍不错,听你讲熟悉TOP10漏洞,可以讲下自己熟悉哪些方面吗? 3、sql注入原理可以讲下吗? 4、sql注入绕WAF有…...

HarmonyOS学习第3天: 环境搭建开启鸿蒙开发新世界
一、引言 在数字化时代,操作系统作为连接用户与硬件设备的桥梁,其重要性不言而喻。HarmonyOS 作为华为公司推出的面向全场景的分布式操作系统,以其创新的理念和卓越的性能,正逐渐在全球范围内崭露头角。它打破了设备之间的界限&a…...

基于STM32与BD623x的电机控制实战——从零搭建无人机/机器人驱动系统
系列文章目录 1.元件基础 2.电路设计 3.PCB设计 4.元件焊接 5.板子调试 6.程序设计 7.算法学习 8.编写exe 9.检测标准 10.项目举例 11.职业规划 文章目录 一、为什么选择这两个芯片?1.1 STM32微控制器1.2 ROHM BD623x电机驱动 二、核心控制原理详解2.1 H桥驱动奥…...

【react18】如何使用useReducer和useContext来实现一个todoList功能
重点知识点就是使用useReducer来攻坚小型的公共状态管理,useImmerReducer来实现数据的不可变 实现效果 实现代码 项目工程结构 App.js文件 import logo from "./logo.svg"; import "./App.css"; import TodoLists from "./comps/TodoLi…...

Java多线程三:补充知识
精心整理了最新的面试资料,有需要的可以自行获取 点击前往百度网盘获取 点击前往夸克网盘获取 Lambda表达式 简介: 希腊字母表中排序第十一位的字母,英语名称为Lambda避免匿名内部类定义过多其实质属于函数式编程的概念 为什么要使用lam…...

go WEB框架
推荐选型 https://chat.deepseek.com/a/chat/s/e6061607-8f33-4768-a5f0-8970cb1ffefd echo github:https://github.com/labstack/echo wiki:https://echo.labstack.com/docs/quick-start block:https://blog.csdn.net/qq_38105536/artic…...
】探索数据可视化的魔法世界)
【Python爬虫(27)】探索数据可视化的魔法世界
【Python爬虫】专栏简介:本专栏是 Python 爬虫领域的集大成之作,共 100 章节。从 Python 基础语法、爬虫入门知识讲起,深入探讨反爬虫、多线程、分布式等进阶技术。以大量实例为支撑,覆盖网页、图片、音频等各类数据爬取ÿ…...

渲染 101 支持 3ds Max 的渲染器及其优势
在 3ds Max 创作流程里,渲染环节对最终成果的呈现效果起着决定性作用,渲染 101 云渲染平台则为 3ds Max 用户提供了全面且高效的渲染解决方案。 支持的渲染器 V-Ray 渲染器 在 3ds Max 中应用广泛,具备全局光照、光线追踪技术,…...

在 Java 中使用 `if` 语句实现双重判定
关于在 Java 中使用 if 语句实现双重判定,并使用 Eclipse 和 JUnit4 进行单元测试的详细介绍: --- ### 一、双重判定的实现 **双重判定**指在 if 语句中通过逻辑运算符组合两个条件。常用方式: - **逻辑与 &&**:两个条件…...

Ollama 安装
Ollama 支持多种操作系统,包括 macOS、Windows、Linux 以及通过 Docker 容器运行。 Ollama 对硬件要求不高,旨在让用户能够轻松地在本地运行、管理和与大型语言模型进行交互。 CPU:多核处理器(推荐 4 核或以上)。GPU…...

Docker Swarm 内置的集群编排
在现代容器化应用中,容器编排(Container Orchestration)是至关重要的,它负责自动化容器的部署、扩展、负载均衡和管理。Docker Swarm 是 Docker 提供的原生集群管理和容器编排工具,允许用户通过 Docker CLI 在多个 Doc…...

AF3 _build_query_to_hit_index_mapping函数解读
AlphaFold3 中templates模块的_build_query_to_hit_index_mapping函数是将原始查询序列(original_query_sequence)中的索引与hit 序列(hit_sequence)中的索引进行映射。 在蛋白质序列比对(如 HHsearch)中,hit 是与查询序列部分匹配的区域。由于存在缺口(-)和部分比对…...

Windows 中的启动项如何打开?管理电脑启动程序的三种方法
在日常使用电脑时,我们经常会发现一些应用程序在开机时自动启动,这不仅会拖慢系统的启动速度,还可能占用不必要的系统资源。幸运的是,通过几个简单的步骤,你可以轻松管理这些开机自启的应用程序。接下来,我…...

科普:“git“与“github“
Git与GitHub的关系可以理解为:Git是一种软件工具,而GitHub则是一个在线平台,它们是“一家子”。二者的关联最直接体现在你通过Git在GitHub仓库中clone软件包到你的机器中来。 具体来说: 一、Git 定义:Git是一个开源的…...

module ‘cv2.dnn‘ has no attribute ‘DictValue‘解决办法
module ‘cv2.dnn‘ has no attribute ‘DictValue‘解决办法 pip install opencv-python4.7.0.72 -i https://pypi.tuna.tsinghua.edu.cn/simple 测试: python -c"import cv2"...

国产编辑器EverEdit - 语法着色及嵌入式多语言着色
1 文档-着色及语法相关 1.1 应用场景 在编辑代码文件或脚本文件过程中,如果对语法着色、模式等文件进行了修改,需要立即生效时,可以通过文档-高级功能下的重新加载功能,立即生效相关配置。 1.2 使用方法 1.2.1 重新加载着色 着…...