计算机基础(下)
内存管理
内存管理主要做了什么?
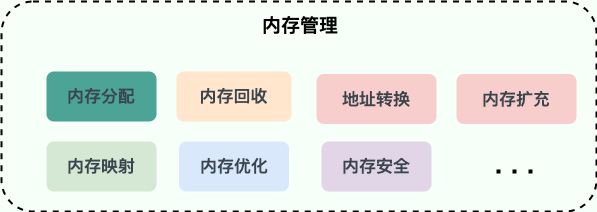
操作系统的内存管理非常重要,主要负责下面这些事情:
- 内存的分配与回收:对进程所需的内存进行分配和释放,malloc 函数:申请内存,free 函数:释放内存
- 地址转换:将程序中的虚拟地址转换成内存中的物理地址
- 内存扩充:当系统没有足够的内存时,利用虚拟内存技术或自动覆盖技术,从逻辑上扩充内存
- 内存映射:将一个文件直接映射到进程的进程空间中,这样可以通过内存指针用读写内存的办法直接存取文件内容,速度更快
- 内存优化:通过调整内存分配策略和回收算法来优化内存使用效率
- 内存安全:保证进程之间使用内存互不干扰,避免一些恶意程序通过修改内存来破坏系统的安全性
- ……
什么是内存碎片?
内存碎片是由内存的申请和释放产生的,通常分为下面两种:
- 内部内存碎片(Internal Memory Fragmentation,简称为内存碎片):已经分配给进程使用但未被使用的内存。导致内部内存碎片的主要原因是,当采用固定比例比如 2 的幂次方进行内存分配时,进程所分配的内存可能会比其实际所需要的大。举个例子,一个进程只需要 65 字节的内存,但为其分配了 128(2^7) 大小的内存,那 63 字节的内存就成为了内部内存碎片
- 外部内存碎片(External Memory Fragmentation,简称为外部碎片):由于未分配的连续内存区域太小,以至于不能满足任意进程所需要的内存分配请求,这些小片段且不连续的内存空间被称为外部碎片。也就是说,外部内存碎片指的是那些并未分配给进程但又不能使用的内存。我们后面介绍的分段机制就会导致外部内存碎片
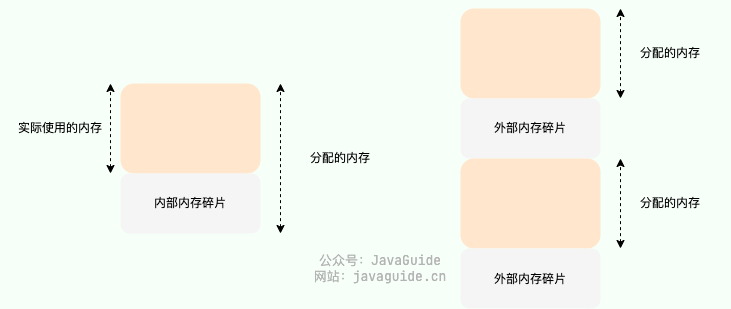
内存碎片会导致内存利用率下降,如何减少内存碎片是内存管理要非常重视的一件事情
常见的内存管理方式有哪些?
内存管理方式可以简单分为下面两种:
- 连续内存管理:为一个用户程序分配一个连续的内存空间,内存利用率一般不高
- 非连续内存管理:允许一个程序使用的内存分布在离散或者说不相邻的内存中,相对更加灵活一些
连续内存管理
块式管理 是早期计算机操作系统的一种连续内存管理方式,存在严重的内存碎片问题。块式管理会将内存分为几个固定大小的块,每个块中只包含一个进程。如果程序运行需要内存的话,操作系统就分配给它一块,如果程序运行只需要很小的空间的话,分配的这块内存很大一部分几乎被浪费了。这些在每个块中未被利用的空间,我们称之为内部内存碎片。除了内部内存碎片之外,由于两个内存块之间可能还会有外部内存碎片,这些不连续的外部内存碎片由于太小了无法再进行分配。
在 Linux 系统中,连续内存管理采用了 伙伴系统(Buddy System)算法 来实现,这是一种经典的连续内存分配算法,可以有效解决外部内存碎片的问题。伙伴系统的主要思想是将内存按 2 的幂次划分(每一块内存大小都是 2 的幂次比如 2^6=64 KB),并将相邻的内存块组合成一对伙伴(注意:必须是相邻的才是伙伴)
当进行内存分配时,伙伴系统会尝试找到大小最合适的内存块。如果找到的内存块过大,就将其一分为二,分成两个大小相等的伙伴块。如果还是大的话,就继续切分,直到到达合适的大小为止
假设两块相邻的内存块都被释放,系统会将这两个内存块合并,进而形成一个更大的内存块,以便后续的内存分配。这样就可以减少内存碎片的问题,提高内存利用率
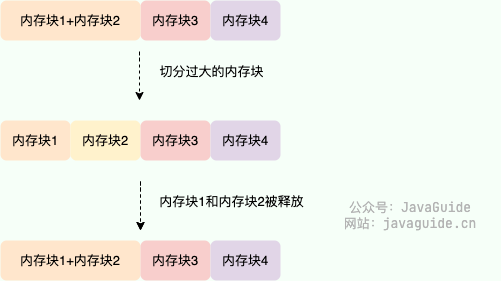
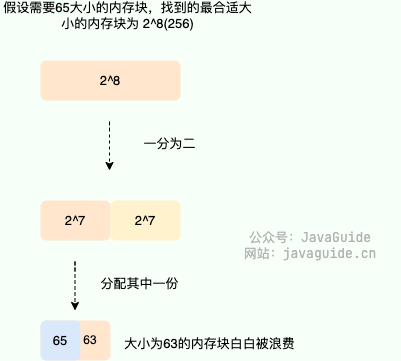
虽然解决了外部内存碎片的问题,但伙伴系统仍然存在内存利用率不高的问题(内部内存碎片)。这主要是因为伙伴系统只能分配大小为 2^n 的内存块,因此当需要分配的内存大小不是 2^n 的整数倍时,会浪费一定的内存空间。举个例子:如果要分配 65 大小的内存快,依然需要分配 2^7=128 大小的内存块
对于内部内存碎片的问题,Linux 采用 SLAB 进行解决。由于这部分内容不是本篇文章的重点,这里就不详细介绍了
非连续内存管理
非连续内存管理存在下面 3 种方式:
- 段式管理:以段(一段连续的物理内存)的形式管理/分配物理内存。应用程序的虚拟地址空间被分为大小不等的段,段是有实际意义的,每个段定义了一组逻辑信息,例如有主程序段 MAIN、子程序段 X、数据段 D 及栈段 S 等
- 页式管理:把物理内存分为连续等长的物理页,应用程序的虚拟地址空间也被划分为连续等长的虚拟页,是现代操作系统广泛使用的一种内存管理方式
- 段页式管理机制:结合了段式管理和页式管理的一种内存管理机制,把物理内存先分成若干段,每个段又继续分成若干大小相等的页
虚拟内存
什么是虚拟内存?有什么用?
虚拟内存(Virtual Memory) 是计算机系统内存管理非常重要的一个技术,本质上来说它只是逻辑存在的,是一个假想出来的内存空间,主要作用是作为进程访问主存(物理内存)的桥梁并简化内存管理
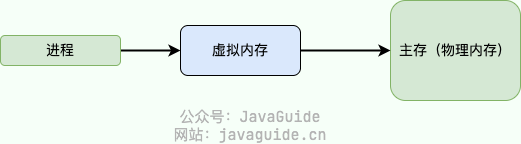
总结来说,虚拟内存主要提供了下面这些能力:
- 隔离进程:物理内存通过虚拟地址空间访问,虚拟地址空间与进程一一对应。每个进程都认为自己拥有了整个物理内存,进程之间彼此隔离,一个进程中的代码无法更改正在由另一进程或操作系统使用的物理内存
- 提升物理内存利用率:有了虚拟地址空间后,操作系统只需要将进程当前正在使用的部分数据或指令加载入物理内存
- 简化内存管理:进程都有一个一致且私有的虚拟地址空间,程序员不用和真正的物理内存打交道,而是借助虚拟地址空间访问物理内存,从而简化了内存管理
- 多个进程共享物理内存:进程在运行过程中,会加载许多操作系统的动态库。这些库对于每个进程而言都是公用的,它们在内存中实际只会加载一份,这部分称为共享内存
- 提高内存使用安全性:控制进程对物理内存的访问,隔离不同进程的访问权限,提高系统的安全性
- 提供更大的可使用内存空间:可以让程序拥有超过系统物理内存大小的可用内存空间。这是因为当物理内存不够用时,可以利用磁盘充当,将物理内存页(通常大小为 4 KB)保存到磁盘文件(会影响读写速度),数据或代码页会根据需要在物理内存与磁盘之间移动
没有虚拟内存有什么问题?
如果没有虚拟内存的话,程序直接访问和操作的都是物理内存,看似少了一层中介,但多了很多问题
具体有什么问题呢? 这里举几个例子说明(参考虚拟内存提供的能力回答这个问题):
- 用户程序可以访问任意物理内存,可能会不小心操作到系统运行必需的内存,进而造成操作系统崩溃,严重影响系统的安全
- 同时运行多个程序容易崩溃。比如你想同时运行一个微信和一个 QQ 音乐,微信在运行的时候给内存地址 1xxx 赋值后,QQ 音乐也同样给内存地址 1xxx 赋值,那么 QQ 音乐对内存的赋值就会覆盖微信之前所赋的值,这就可能会造成微信这个程序会崩溃
- 程序运行过程中使用的所有数据或指令都要载入物理内存,根据局部性原理,其中很大一部分可能都不会用到,白白占用了宝贵的物理内存资源
- ……
什么是虚拟地址和物理地址?
物理地址(Physical Address) 是真正的物理内存中地址,更具体点来说是内存地址寄存器中的地址。程序中访问的内存地址不是物理地址,而是 虚拟地址(Virtual Address)
也就是说,我们编程开发的时候实际就是在和虚拟地址打交道。比如在 C 语言中,指针里面存储的数值就可以理解成为内存里的一个地址,这个地址也就是我们说的虚拟地址
操作系统一般通过 CPU 芯片中的一个重要组件 MMU(Memory Management Unit,内存管理单元) 将虚拟地址转换为物理地址,这个过程被称为 地址翻译/地址转换(Address Translation)
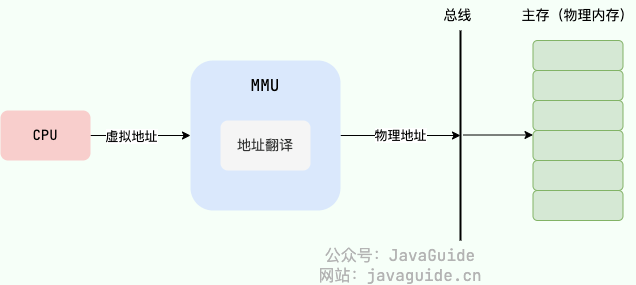
通过 MMU 将虚拟地址转换为物理地址后,再通过总线传到物理内存设备,进而完成相应的物理内存读写请求
MMU 将虚拟地址翻译为物理地址的主要机制有两种: 分段机制 和 分页机制
什么是虚拟地址空间和物理地址空间?
- 虚拟地址空间是虚拟地址的集合,是虚拟内存的范围。每一个进程都有一个一致且私有的虚拟地址空间
- 物理地址空间是物理地址的集合,是物理内存的范围
虚拟地址与物理内存地址是如何映射的?
MMU 将虚拟地址翻译为物理地址的主要机制有 3 种:
- 分段机制
- 分页机制
- 段页机制
其中,现代操作系统广泛采用分页机制,需要重点关注!
分段机制
分段机制(Segmentation) 以段(一段 连续 的物理内存)的形式管理/分配物理内存。应用程序的虚拟地址空间被分为大小不等的段,段是有实际意义的,每个段定义了一组逻辑信息,例如有主程序段 MAIN、子程序段 X、数据段 D 及栈段 S 等
段表有什么用?地址翻译过程是怎样的?
分段管理通过 段表(Segment Table) 映射虚拟地址和物理地址
分段机制下的虚拟地址由两部分组成:
- 段号:标识着该虚拟地址属于整个虚拟地址空间中的哪一个段
- 段内偏移量:相对于该段起始地址的偏移量
具体的地址翻译过程如下:
- MMU 首先解析得到虚拟地址中的段号;
- 通过段号去该应用程序的段表中取出对应的段信息(找到对应的段表项);
- 从段信息中取出该段的起始地址(物理地址)加上虚拟地址中的段内偏移量得到最终的物理地址
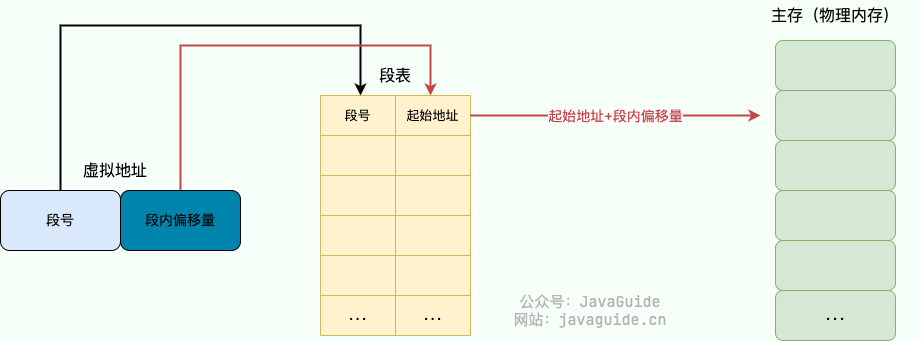
段表中还存有诸如段长(可用于检查虚拟地址是否超出合法范围)、段类型(该段的类型,例如代码段、数据段等)等信息
通过段号一定要找到对应的段表项吗?得到最终的物理地址后对应的物理内存一定存在吗?
不一定。段表项可能并不存在:
- 段表项被删除:软件错误、软件恶意行为等情况可能会导致段表项被删除
- 段表项还未创建:如果系统内存不足或者无法分配到连续的物理内存块就会导致段表项无法被创建
分段机制为什么会导致内存外部碎片?
分段机制容易出现外部内存碎片,即在段与段之间留下碎片空间(不足以映射给虚拟地址空间中的段)。从而造成物理内存资源利用率的降低
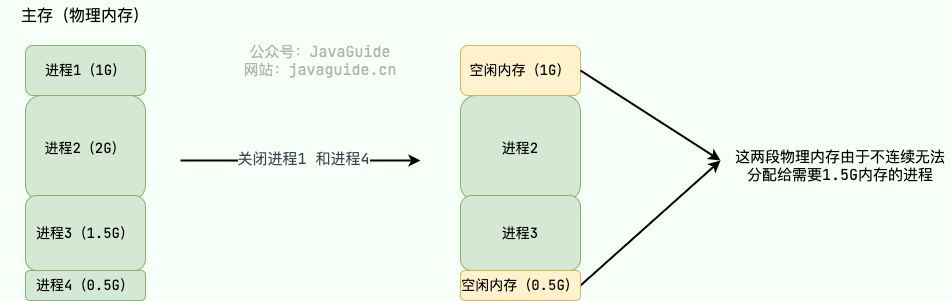
举个例子:假设可用物理内存为 5G 的系统使用分段机制分配内存。现在有 4 个进程,每个进程的内存占用情况如下:
- 进程 1:0~1G(第 1 段)
- 进程 2:1~3G(第 2 段)
- 进程 3:3~4.5G(第 3 段)
- 进程 4:4.5~5G(第 4 段)
此时,我们关闭了进程 1 和进程 4,则第 1 段和第 4 段的内存会被释放,空闲物理内存还有 1.5G。由于这 1.5G 物理内存并不是连续的,导致没办法将空闲的物理内存分配给一个需要 1.5G 物理内存的进程
分页机制
分页机制(Paging) 把主存(物理内存)分为连续等长的物理页,应用程序的虚拟地址空间划也被分为连续等长的虚拟页。现代操作系统广泛采用分页机制
注意:这里的页是连续等长的,不同于分段机制下不同长度的段
在分页机制下,应用程序虚拟地址空间中的任意虚拟页可以被映射到物理内存中的任意物理页上,因此可以实现物理内存资源的离散分配。分页机制按照固定页大小分配物理内存,使得物理内存资源易于管理,可有效避免分段机制中外部内存碎片的问题
页表有什么用?地址翻译过程是怎样的?
分页管理通过 页表(Page Table) 映射虚拟地址和物理地址。我这里画了一张基于单级页表进行地址翻译的示意图
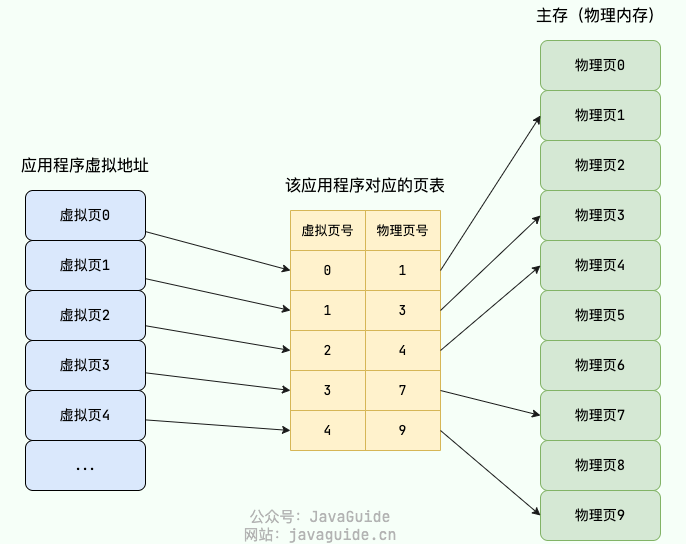
在分页机制下,每个应用程序都会有一个对应的页表
分页机制下的虚拟地址由两部分组成:
- 页号:通过虚拟页号可以从页表中取出对应的物理页号;
- 页内偏移量:物理页起始地址+页内偏移量=物理内存地址
具体的地址翻译过程如下:
- MMU 首先解析得到虚拟地址中的虚拟页号;
- 通过虚拟页号去该应用程序的页表中取出对应的物理页号(找到对应的页表项);
- 用该物理页号对应的物理页起始地址(物理地址)加上虚拟地址中的页内偏移量得到最终的物理地址。
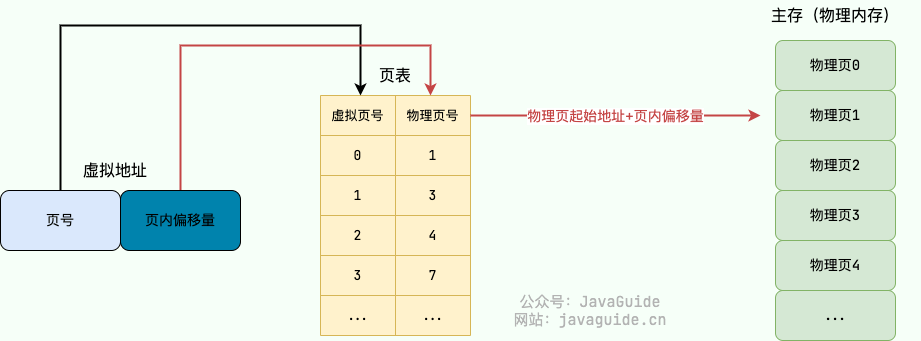
页表中还存有诸如访问标志(标识该页面有没有被访问过)、脏数据标识位等信息
通过虚拟页号一定要找到对应的物理页号吗?找到了物理页号得到最终的物理地址后对应的物理页一定存在吗?
不一定!可能会存在 页缺失 。也就是说,物理内存中没有对应的物理页或者物理内存中有对应的物理页但虚拟页还未和物理页建立映射(对应的页表项不存在)。关于页缺失的内容,后面会详细介绍到
单级页表有什么问题?为什么需要多级页表?
以 32 位的环境为例,虚拟地址空间范围共有 2^32(4G)。假设 一个页的大小是 2^12(4KB),那页表项共有 4G / 4K = 2^20 个。每个页表项为一个地址,占用 4 字节,2^20 * 2^2 / 1024 * 1024= 4MB。也就是说一个程序啥都不干,页表大小就得占用 4M
系统运行的应用程序多起来的话,页表的开销还是非常大的。而且,绝大部分应用程序可能只能用到页表中的几项,其他的白白浪费了
为了解决这个问题,操作系统引入了 多级页表 ,多级页表对应多个页表,每个页表与前一个页表相关联。32 位系统一般为二级页表,64 位系统一般为四级页表
这里以二级页表为例进行介绍:二级列表分为一级页表和二级页表。一级页表共有 1024 个页表项,一级页表又关联二级页表,二级页表同样共有 1024 个页表项。二级页表中的一级页表项是一对多的关系,二级页表按需加载(只会用到很少一部分二级页表),进而节省空间占用
假设只需要 2 个二级页表,那两级页表的内存占用情况为: 4KB(一级页表占用) + 4KB * 2(二级页表占用) = 12 KB
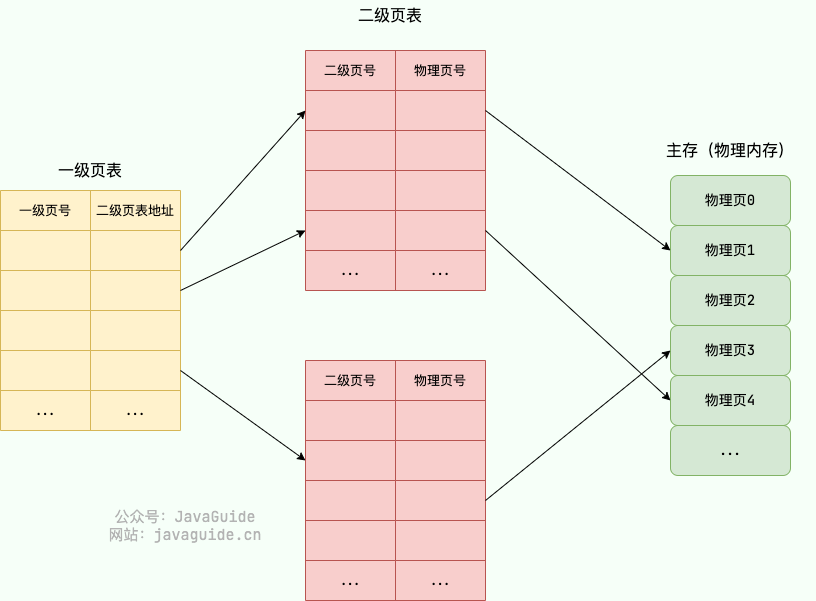
多级页表属于时间换空间的典型场景,利用增加页表查询的次数减少页表占用的空间
TLB 有什么用?使用 TLB 之后的地址翻译流程是怎样的?
为了提高虚拟地址到物理地址的转换速度,操作系统在 页表方案 基础之上引入了 转址旁路缓存(Translation Lookaside Buffer,TLB,也被称为快表)
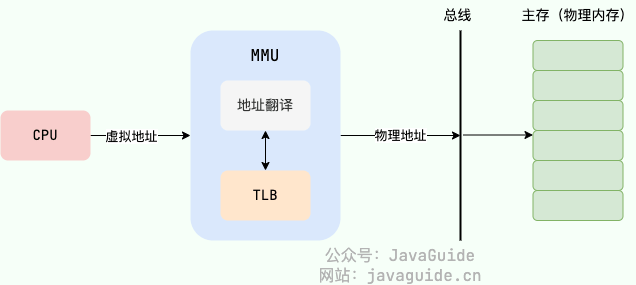
在主流的 AArch64 和 x86-64 体系结构下,TLB 属于 (Memory Management Unit,内存管理单元) 内部的单元,本质上就是一块高速缓存(Cache),缓存了虚拟页号到物理页号的映射关系,你可以将其简单看作是存储着键(虚拟页号)值(物理页号)对的哈希表
使用 TLB 之后的地址翻译流程是这样的:
- 用虚拟地址中的虚拟页号作为 key 去 TLB 中查询;
- 如果能查到对应的物理页的话,就不用再查询页表了,这种情况称为 TLB 命中(TLB hit)。
- 如果不能查到对应的物理页的话,还是需要去查询主存中的页表,同时将页表中的该映射表项添加到 TLB 中,这种情况称为 TLB 未命中(TLB miss)
- 当 TLB 填满后,又要登记新页时,就按照一定的淘汰策略淘汰掉快表中的一个页
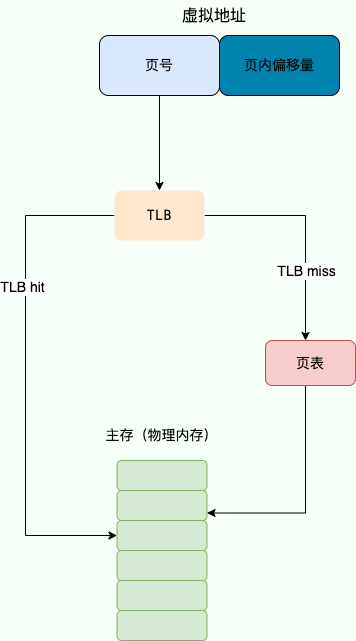
由于页表也在主存中,因此在没有 TLB 之前,每次读写内存数据时 CPU 要访问两次主存。有了 TLB 之后,对于存在于 TLB 中的页表数据只需要访问一次主存即可
TLB 的设计思想非常简单,但命中率往往非常高,效果很好。这就是因为被频繁访问的页就是其中的很小一部分
看完了之后你会发现快表和我们平时经常在开发系统中使用的缓存(比如 Redis)很像,的确是这样的,操作系统中的很多思想、很多经典的算法,你都可以在我们日常开发使用的各种工具或者框架中找到它们的影子
换页机制有什么用?
换页机制的思想是当物理内存不够用的时候,操作系统选择将一些物理页的内容放到磁盘上去,等要用到的时候再将它们读取到物理内存中。也就是说,换页机制利用磁盘这种较低廉的存储设备扩展的物理内存
这也就解释了一个日常使用电脑常见的问题:为什么操作系统中所有进程运行所需的物理内存即使比真实的物理内存要大一些,这些进程也是可以正常运行的,只是运行速度会变慢
这同样是一种时间换空间的策略,你用 CPU 的计算时间,页的调入调出花费的时间,换来了一个虚拟的更大的物理内存空间来支持程序的运行
什么是页缺失?
根据维基百科:
页缺失(Page Fault,又名硬错误、硬中断、分页错误、寻页缺失、缺页中断、页故障等)指的是当软件试图访问已映射在虚拟地址空间中,但是目前并未被加载在物理内存中的一个分页时,由 MMU 所发出的中断
常见的页缺失有下面这两种:
- 硬性页缺失(Hard Page Fault):物理内存中没有对应的物理页。于是,Page Fault Handler 会指示 CPU 从已经打开的磁盘文件中读取相应的内容到物理内存,而后交由 MMU 建立相应的虚拟页和物理页的映射关系
- 软性页缺失(Soft Page Fault):物理内存中有对应的物理页,但虚拟页还未和物理页建立映射。于是,Page Fault Handler 会指示 MMU 建立相应的虚拟页和物理页的映射关系
发生上面这两种缺页错误的时候,应用程序访问的是有效的物理内存,只是出现了物理页缺失或者虚拟页和物理页的映射关系未建立的问题。如果应用程序访问的是无效的物理内存的话,还会出现 无效缺页错误(Invalid Page Fault)
常见的页面置换算法有哪些?
当发生硬性页缺失时,如果物理内存中没有空闲的物理页面可用的话。操作系统就必须将物理内存中的一个物理页淘汰出去,这样就可以腾出空间来加载新的页面了
用来选择淘汰哪一个物理页的规则叫做 页面置换算法 ,我们可以把页面置换算法看成是淘汰物物理页的规则
页缺失太频繁的发生会非常影响性能,一个好的页面置换算法应该是可以减少页缺失出现的次数
常见的页面置换算法有下面这 5 种(其他还有很多页面置换算法都是基于这些算法改进得来的):
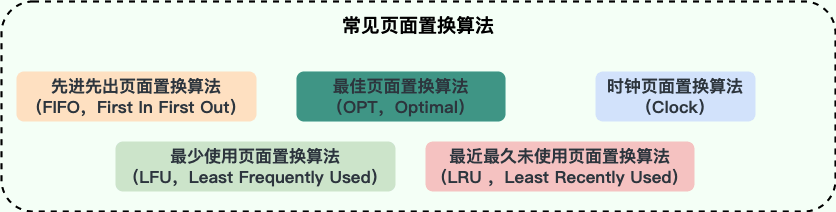
- 最佳页面置换算法(OPT,Optimal):优先选择淘汰的页面是以后永不使用的,或者是在最长时间内不再被访问的页面,这样可以保证获得最低的缺页率。但由于人们目前无法预知进程在内存下的若干页面中哪个是未来最长时间内不再被访问的,因而该算法无法实现,只是理论最优的页面置换算法,可以作为衡量其他置换算法优劣的标准
- 先进先出页面置换算法(FIFO,First In First Out) : 最简单的一种页面置换算法,总是淘汰最先进入内存的页面,即选择在内存中驻留时间最久的页面进行淘汰。该算法易于实现和理解,一般只需要通过一个 FIFO 队列即可满足需求。不过,它的性能并不是很好
- 最近最久未使用页面置换算法(LRU ,Least Recently Used):LRU 算法赋予每个页面一个访问字段,用来记录一个页面自上次被访问以来所经历的时间 T,当须淘汰一个页面时,选择现有页面中其 T 值最大的,即最近最久未使用的页面予以淘汰。LRU 算法是根据各页之前的访问情况来实现,因此是易于实现的。OPT 算法是根据各页未来的访问情况来实现,因此是不可实现的
- 最少使用页面置换算法(LFU,Least Frequently Used) : 和 LRU 算法比较像,不过该置换算法选择的是之前一段时间内使用最少的页面作为淘汰页
- 时钟页面置换算法(Clock):可以认为是一种最近未使用算法,即逐出的页面都是最近没有使用的那个
FIFO 页面置换算法性能为何不好?
主要原因主要有二:
- 经常访问或者需要长期存在的页面会被频繁调入调出:较早调入的页往往是经常被访问或者需要长期存在的页,这些页会被反复调入和调出
- 存在 Belady 现象:被置换的页面并不是进程不会访问的,有时就会出现分配的页面数增多但缺页率反而提高的异常现象。出现该异常的原因是因为 FIFO 算法只考虑了页面进入内存的顺序,而没有考虑页面访问的频率和紧迫性
哪一种页面置换算法实际用的比较多?
LRU 算法是实际使用中应用的比较多,也被认为是最接近 OPT 的页面置换算法
不过,需要注意的是,实际应用中这些算法会被做一些改进,就比如 InnoDB Buffer Pool( InnoDB 缓冲池,MySQL 数据库中用于管理缓存页面的机制)就改进了传统的 LRU 算法,使用了一种称为"Adaptive LRU"的算法(同时结合了 LRU 和 LFU 算法的思想)
分页机制和分段机制有哪些共同点和区别?
共同点:
- 都是非连续内存管理的方式
- 都采用了地址映射的方法,将虚拟地址映射到物理地址,以实现对内存的管理和保护
区别:
- 分页机制以页面为单位进行内存管理,而分段机制以段为单位进行内存管理。页的大小是固定的,由操作系统决定,通常为 2 的幂次方。而段的大小不固定,取决于我们当前运行的程序
- 页是物理单位,即操作系统将物理内存划分成固定大小的页面,每个页面的大小通常是 2 的幂次方,例如 4KB、8KB 等等。而段则是逻辑单位,是为了满足程序对内存空间的逻辑需求而设计的,通常根据程序中数据和代码的逻辑结构来划分
- 分段机制容易出现外部内存碎片,即在段与段之间留下碎片空间(不足以映射给虚拟地址空间中的段)。分页机制解决了外部内存碎片的问题,但仍然可能会出现内部内存碎片
- 分页机制采用了页表来完成虚拟地址到物理地址的映射,页表通过一级页表和二级页表来实现多级映射;而分段机制则采用了段表来完成虚拟地址到物理地址的映射,每个段表项中记录了该段的起始地址和长度信息
- 分页机制对程序没有任何要求,程序只需要按照虚拟地址进行访问即可;而分段机制需要程序员将程序分为多个段,并且显式地使用段寄存器来访问不同的段
段页机制
结合了段式管理和页式管理的一种内存管理机制,把物理内存先分成若干段,每个段又继续分成若干大小相等的页
在段页式机制下,地址翻译的过程分为两个步骤:
- 段式地址映射
- 页式地址映射
局部性原理
要想更好地理解虚拟内存技术,必须要知道计算机中著名的 局部性原理(Locality Principle)。另外,局部性原理既适用于程序结构,也适用于数据结构,是非常重要的一个概念
局部性原理是指在程序执行过程中,数据和指令的访问存在一定的空间和时间上的局部性特点。其中,时间局部性是指一个数据项或指令在一段时间内被反复使用的特点,空间局部性是指一个数据项或指令在一段时间内与其相邻的数据项或指令被反复使用的特点
在分页机制中,页表的作用是将虚拟地址转换为物理地址,从而完成内存访问。在这个过程中,局部性原理的作用体现在两个方面:
- 时间局部性:由于程序中存在一定的循环或者重复操作,因此会反复访问同一个页或一些特定的页,这就体现了时间局部性的特点。为了利用时间局部性,分页机制中通常采用缓存机制来提高页面的命中率,即将最近访问过的一些页放入缓存中,如果下一次访问的页已经在缓存中,就不需要再次访问内存,而是直接从缓存中读取
- 空间局部性:由于程序中数据和指令的访问通常是具有一定的空间连续性的,因此当访问某个页时,往往会顺带访问其相邻的一些页。为了利用空间局部性,分页机制中通常采用预取技术来预先将相邻的一些页读入内存缓存中,以便在未来访问时能够直接使用,从而提高访问速度
总之,局部性原理是计算机体系结构设计的重要原则之一,也是许多优化算法的基础。在分页机制中,利用时间局部性和空间局部性,采用缓存和预取技术,可以提高页面的命中率,从而提高内存访问效率
文件系统
文件系统主要做了什么?
文件系统主要负责管理和组织计算机存储设备上的文件和目录,其功能包括以下几个方面:
- 存储管理:将文件数据存储到物理存储介质中,并且管理空间分配,以确保每个文件都有足够的空间存储,并避免文件之间发生冲突
- 文件管理:文件的创建、删除、移动、重命名、压缩、加密、共享等等
- 目录管理:目录的创建、删除、移动、重命名等等
- 文件访问控制:管理不同用户或进程对文件的访问权限,以确保用户只能访问其被授权访问的文件,以保证文件的安全性和保密性
硬链接和软链接有什么区别?
在 Linux/类 Unix 系统上,文件链接(File Link)是一种特殊的文件类型,可以在文件系统中指向另一个文件。常见的文件链接类型有两种:
1、硬链接(Hard Link)
- 在 Linux/类 Unix 文件系统中,每个文件和目录都有一个唯一的索引节点(inode)号,用来标识该文件或目录。硬链接通过 inode 节点号建立连接,硬链接和源文件的 inode 节点号相同,两者对文件系统来说是完全平等的(可以看作是互为硬链接,源头是同一份文件),删除其中任何一个对另外一个没有影响,可以通过给文件设置硬链接文件来防止重要文件被误删
- 只有删除了源文件和所有对应的硬链接文件,该文件才会被真正删除
- 硬链接具有一些限制,不能对目录以及不存在的文件创建硬链接,并且,硬链接也不能跨越文件系统
ln命令用于创建硬链接
2、软链接(Symbolic Link 或 Symlink)
- 软链接和源文件的 inode 节点号不同,而是指向一个文件路径
- 源文件删除后,软链接依然存在,但是指向的是一个无效的文件路径
- 软连接类似于 Windows 系统中的快捷方式
- 不同于硬链接,可以对目录或者不存在的文件创建软链接,并且,软链接可以跨越文件系统。
ln -s命令用于创建软链接
硬链接为什么不能跨文件系统?
我们之前提到过,硬链接是通过 inode 节点号建立连接的,而硬链接和源文件共享相同的 inode 节点号
然而,每个文件系统都有自己的独立 inode 表,且每个 inode 表只维护该文件系统内的 inode。如果在不同的文件系统之间创建硬链接,可能会导致 inode 节点号冲突的问题,即目标文件的 inode 节点号已经在该文件系统中被使用
提高文件系统性能的方式有哪些?
- 优化硬件:使用高速硬件设备(如 SSD、NVMe)替代传统的机械硬盘,使用 RAID(Redundant Array of Inexpensive Disks)等技术提高磁盘性能
- 选择合适的文件系统选型:不同的文件系统具有不同的特性,对于不同的应用场景选择合适的文件系统可以提高系统性能
- 运用缓存:访问磁盘的效率比较低,可以运用缓存来减少磁盘的访问次数。不过,需要注意缓存命中率,缓存命中率过低的话,效果太差
- 避免磁盘过度使用:注意磁盘的使用率,避免将磁盘用满,尽量留一些剩余空间,以免对文件系统的性能产生负面影响
- 对磁盘进行合理的分区:合理的磁盘分区方案,能够使文件系统在不同的区域存储文件,从而减少文件碎片,提高文件读写性能
常见的磁盘调度算法有哪些?
磁盘调度算法是操作系统中对磁盘访问请求进行排序和调度的算法,其目的是提高磁盘的访问效率
一次磁盘读写操作的时间由磁盘寻道/寻找时间、延迟时间和传输时间决定。磁盘调度算法可以通过改变到达磁盘请求的处理顺序,减少磁盘寻道时间和延迟时间
常见的磁盘调度算法有下面这 6 种(其他还有很多磁盘调度算法都是基于这些算法改进得来的):
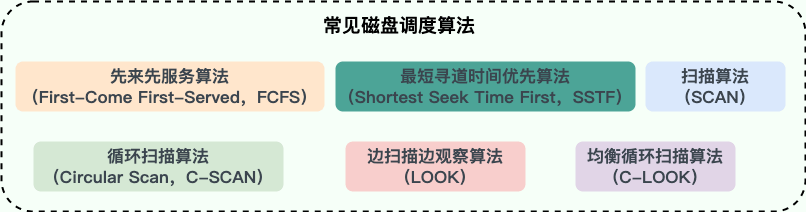
- 先来先服务算法(First-Come First-Served,FCFS):按照请求到达磁盘调度器的顺序进行处理,先到达的请求的先被服务。FCFS 算法实现起来比较简单,不存在算法开销。不过,由于没有考虑磁头移动的路径和方向,平均寻道时间较长。同时,该算法容易出现饥饿问题,即一些后到的磁盘请求可能需要等待很长时间才能得到服务
- 最短寻道时间优先算法(Shortest Seek Time First,SSTF):也被称为最佳服务优先(Shortest Service Time First,SSTF)算法,优先选择距离当前磁头位置最近的请求进行服务。SSTF 算法能够最小化磁头的寻道时间,但容易出现饥饿问题,即磁头附近的请求不断被服务,远离磁头的请求长时间得不到响应。实际应用中,需要优化一下该算法的实现,避免出现饥饿问题
- 扫描算法(SCAN):也被称为电梯(Elevator)算法,基本思想和电梯非常类似。磁头沿着一个方向扫描磁盘,如果经过的磁道有请求就处理,直到到达磁盘的边界,然后改变移动方向,依此往复。SCAN 算法能够保证所有的请求得到服务,解决了饥饿问题。但是,如果磁头从一个方向刚扫描完,请求才到的话。这个请求就需要等到磁头从相反方向过来之后才能得到处理
- 循环扫描算法(Circular Scan,C-SCAN):SCAN 算法的变体,只在磁盘的一侧进行扫描,并且只按照一个方向扫描,直到到达磁盘边界,然后回到磁盘起点,重新开始循环
- 边扫描边观察算法(LOOK):SCAN 算法中磁头到了磁盘的边界才改变移动方向,这样可能会做很多无用功,因为磁头移动方向上可能已经没有请求需要处理了。LOOK 算法对 SCAN 算法进行了改进,如果磁头移动方向上已经没有别的请求,就可以立即改变磁头移动方向,依此往复。也就是边扫描边观察指定方向上还有无请求,因此叫 LOOK
- 均衡循环扫描算法(C-LOOK):C-SCAN 只有到达磁盘边界时才能改变磁头移动方向,并且磁头返回时也需要返回到磁盘起点,这样可能会做很多无用功。C-LOOK 算法对 C-SCAN 算法进行了改进,如果磁头移动的方向上已经没有磁道访问请求了,就可以立即让磁头返回,并且磁头只需要返回到有磁道访问请求的位置即可
相关文章:
)
计算机基础(下)
内存管理 内存管理主要做了什么? 操作系统的内存管理非常重要,主要负责下面这些事情: 内存的分配与回收:对进程所需的内存进行分配和释放,malloc 函数:申请内存,free 函数:释放内存…...
——探索图像处理:自定义滤波与OpenCV卷积核)
OpenCV从入门到精通实战(七)——探索图像处理:自定义滤波与OpenCV卷积核
本文主要介绍如何使用Python和OpenCV库通过卷积操作来应用不同的图像滤波效果。主要分为几个步骤:图像的读取与处理、自定义卷积函数的实现、不同卷积核的应用,以及结果的展示。 卷积 在图像处理中,卷积是一种重要的操作,它通过…...
Java概述)
Java基础——(一)Java概述
Java特性 简单性:Java与C很相似,但剔除了C中许多比较复杂并且很少使用的功能,比如头文件、指针运算、结构、联合、操作符重载、虚基类等,从而使Java更易于上手、学习。面向对象:Java是一门面向对象语言,具…...

关于IDE的相关知识之三【插件安装、配置及推荐的意义】
成长路上不孤单😊😊😊😊😊😊 【14后😊///C爱好者😊///持续分享所学😊///如有需要欢迎收藏转发///😊】 今日分享关于ide插件安装、配置及推荐意义的相关内容…...

C++设计模式之组合模式的基本结构
组合模式的UML类图表示如下: ------------------ ------------------ | Component | <----- | Leaf | ------------------ ------------------ | operation() | | operation() | ------------------ --…...
)
Apache OFBiz xmlrpc XXE漏洞(CVE-2018-8033)
目录 1、漏洞描述 2、EXP下载地址 3、EXP利用 1、漏洞描述 Apache OFBiz是一套企业资源计划(ERP)系统。它提供了广泛的功能,包括销售、采购、库存、财务、CRM等。 Apache OFBiz还具有灵活的架构和可扩展性,允许用户根据业务需求…...

梯度——多元函数偏导数——梯度算子的理论基础
梯度是一个数学概念,在多维空间中表示函数在某一点处变化最快的方向和变化率。 对于一个多元函数 f ( x 1 , x 2 , ⋯ , x n ) f(x_1, x_2, \cdots, x_n) f(x1,x2,⋯,xn),其梯度是一个向量,记作 ∇ f \nabla f ∇f或者 grad f f f&…...

【GPT】力量训练的底层原理?
详细解读力量训练的每一个底层原理 力量训练之所以有效,是因为它利用了肌肉、神经系统和生物化学反应的基本机制。以下逐一详细解析,并解释相关概念。 1. 应力-恢复-适应理论 概念解析 应力(Stress):指训练带来的负…...

Django 路由层
1. 路由基础概念 URLconf (URL 配置):Django 的路由系统是基于 urls.py 文件定义的。路径匹配:通过模式匹配 URL,并将请求传递给对应的视图处理函数。命名路由:每个路由可以定义一个名称,用于反向解析。 2. 基本路由配…...

Unity项目性能优化列表
1、对象池 2、检查内存是否泄露。内存持续上升(闭包、委托造成泄露) 3、检查DrawCall数量,尽量减少SetPassCall 4、尽量多的利用四种合批 动态合批(Dynamic Batching)静态合批(Static Batching)GPUInstancingSRP Batcher 动态合批消耗内存把多个网格组合在一起合并…...

docker启动kafka、zookeeper、kafdrop
1、启动zookeeper docker run -d --name zookeeper -p 2181:2181 -t wurstmeister/zookeeper2、启动kafka docker run -d --name kafka --publish 9092:9092 --link zookeeper:zookeeper -e KAFKA_BROKER_ID1 -e HOST_IP127.0.0.1 -e KAFKA_ZOOKEEPER_CONNECTzookeeper:2181…...

Pytest使用Jpype调用jar包报错:Windows fatal exception: access violation
问题描述 之前我们有讲过如何使用Jpype调用jar包,在成功调用jar包后,接着在Pytest框架下编写自动测试用例。但是在Pytest下使用Jpype加载jar包,并调用其中的方法会以下提示信息: 虽然提示信息显示有Windows显示致命…...

【AI赋能 Python编程】第十一章 Python技能提升指南:借助AI加速学习
AI赋能 Python编程-系列文章目录 第十一章 Python技能提升指南:借助AI加速学习 文章目录 AI赋能 Python编程-系列文章目录第十一章 Python技能提升指南:借助AI加速学习 前言明确学习目标基础入门指导进阶学习指导学习过程互动综合学习提示模板 前言 在…...

️ 爬虫开发中常见的性能优化策略有哪些?
在爬虫开发中,性能优化是确保爬虫稳定、高效运行的关键。以下是一些常见的性能优化策略,结合了搜索结果中的信息: 异步编程: 使用 asyncio 和 aiohttp 实现高并发,提高爬取效率。异步请求允许在等待一个请求完成的同时…...

Ubuntu安装不同版本的opencv,并任意切换使用
参考: opencv笔记:ubuntu安装opencv以及多版本共存 | 高深远的博客 https://zhuanlan.zhihu.com/p/604658181 安装不同版本opencv及共存、切换并验证。_pkg-config opencv --modversion-CSDN博客 Ubuntu下多版本OpenCV共存和切换_ubuntu20如同时安装o…...

《操作系统 - 清华大学》5 -4:虚拟技术
文章目录 0. 虚拟存储的定义1. 目标2.局部性原理3. 虚拟存储的思路与规则4. 虚拟存储的基本特征5. 虚拟页式存储管理5.1 页表表项5.2 示例 0. 虚拟存储的定义 1. 目标 虚拟内存管理技术,简称虚存技术。那为什么要虚存技术?在于前面覆盖和交换技术&#…...

网安瞭望台第5期 :7zip出现严重漏洞、识别网络钓鱼诈骗的方法分享
国内外要闻 7 - Zip存在高危漏洞,请立刻更新 2024 年 11 月 24 日,do son 报道了 7 - Zip 中存在的一个高严重性漏洞 CVE - 2024 - 11477。7 - Zip 是一款广受欢迎的文件压缩软件,而这个漏洞可能会让攻击者在存在漏洞的系统中执行恶意代码。…...

【JS】面试八股文
类型 JavaScript 有哪些数据类型,它们的区别? 答:JavaScript 共有八种数据类型, 分别是 Undefined、 Null、 Boolean、Number、String、Object、Symbol、BigInt。 其中 Symbol是ES6中新增的,BigInt 是 ES2020 中新增的。 Symbol 代表创建后独一无二且不可变的数据类型,…...

1、正则表达式
grep匹配 grep用来过滤文本内容,以匹配要查询的结果。 grep root /etc/passwd:匹配包含root的行 -m 数字:匹配几次后停止 -v:取反-i:忽略字符的大小写,默认的,可以不加-n:…...

带有悬浮窗功能的Android应用
android api29 gradle 8.9 要求 布局文件 (floating_window_layout.xml): 增加、删除、关闭按钮默认隐藏。使用“开始”按钮来控制这些按钮的显示和隐藏。 服务类 (FloatingWindowService.kt): 实现“开始”按钮的功能,点击时切换增加、删除、关闭按钮的可见性。处…...

uniapp开发微信小程序笔记8-uniapp使用vant框架
前言:其实用uni-app开发微信小程序的首选不应该是vant,因为vant没有专门给uni-app设置专栏,可以看到目前Vant 官方提供了 Vue 2 版本、Vue 3 版本和微信小程序版本,并由社区团队维护 React 版本和支付宝小程序版本。 但是我之前维…...

C++软件设计模式之组合模式与其他模式的协作举例
组合模式(Composite Pattern)、装饰器模式(Decorator Pattern)、享元模式(Flyweight Pattern)、迭代器模式(Iterator Pattern)和访问者模式(Visitor Pattern)…...
关于广义线性回归工具的补充内容)
ArcGIS pro中的回归分析浅析(加更)关于广义线性回归工具的补充内容
在回归分析浅析中篇的文章中, 有人问了一个问题: 案例里的calls数据貌似离散,更符合泊松模型,为啥不采用泊松而采用高斯呢? 确实,在中篇中写道: 在这个例子中我们为了更好地解释变量&#x…...

mybatis-plus 实现分页查询步骤
MyBatis-Plus 是一个 MyBatis 的增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发、提高效率而生。它提供了代码生成器、条件构造器、分页插件等多种功能,其中分页查询是一个常用的功能。 以下是如何在 MyBatis-Plus 中实现分页查询…...

Vue开发中常见优化手段总结
Tree Shaking or Trunk 动态引入(Dynamic Imports) 动态引入是指在代码执行过程中,根据需要动态加载模块,而不是在应用启动时一次性加载所有模块。这可以通过JavaScript的import()函数实现,它返回一个Promise对象&…...

IDEA无法创建java8、11项目创建出的pom.xml为空
主要是由于Spring3.X版本不支持JDK8,JDK11,最低支持JDK17 解决的话要不就换成JDK17以上的版本,但是不太现实 另外可以参考以下方式解决 修改spring初始化服务器地址为阿里云的 https://start.aliyun.com/...
)
TCP/IP网络编程-C++(上)
TCP/IP网络编程-C (上) 一、基于TCP的服务端/客户端1、server端代码2、client端代码3、socket() 函数3.1、函数原型3.2、参数解析3.2.1、协议族(domain参数)3.2.2、套接字类型(type参数)3.2.3、最终使用的协…...

在线绘制Nature Communication同款双色、四色火山图,突出感兴趣的基因
导读:火山图通常使用三种颜色分别表示显著上调,显著下调和不显著。通过为特定的数据点添加另一种颜色,可以创建双色或四色火山图,从而更直观地突出感兴趣的数据点。 《Nature Communication》文章“Molecular and functional land…...

ctfshow pwn wp
文章目录 Test_your_ncpwn-0pwn1pwn2pwn3pwn4 前置基础pwn5pwn6pwn7pwn8pwn9pwn10pwn11pwn12pwn13:gcc编译执行C语言代码pwn14:gcc编译执行C语言代码pwn15:nasm编译asm,ld链接为可执行文件pwn16:gcc编译汇编文件.s为可…...

【数据结构实战篇】用C语言实现你的私有队列
🏝️专栏:【数据结构实战篇】 🌅主页:f狐o狸x 在前面的文章中我们用C语言实现了栈的数据结构,本期内容我们将实现队列的数据结构 一、队列的概念 队列:只允许在一端进行插入数据操作,在另一端…...
串的基本概念)
数据结构 (11)串的基本概念
一、串的定义 1.串是由一个或者多个字符组成的有限序列,一般记为:sa1a2…an(n≥0)。其中,s是串的名称,用单括号括起来的字符序列是串的值;ai(1≤i≤n)可以是字母、数字或…...
)
快速高效求素数|质数的方法—Java(模板)
判断素数|质数方法时间效率:线性筛法>埃氏筛法>试除法 在写算法题的时候,各种各样跟素数有关的题目非常常见,本文列出了三种常见的判断素数的方法 三种求素数方法的优缺点 一、试除法 试除法的基本思想是:判断一个数 x 是否为素数&…...

探秘嵌入式位运算:基础与高级技巧
目录 一、位运算基础知识 1.1. 位运算符 1.1.1. 与运算(&) 1.1.2. 或运算(|) 1.1.3. 异或运算(^) 1.1.4. 取反运算(~) 1.1.5. 双重按位取反运算符(~~…...

iOS 17.4 Not Installed
0x00 系统警告 没有安装 17.4 的模拟器,任何操作都无法进行! 点击 OK 去下载,完成之后,依旧是原样! 0x01 解决办法 1、先去官网下载对应的模拟器: https://developer.apple.com/download/all/?q17.4 …...

RestTemplate 使用教程
RestTemplate 是 Spring 框架提供的一种用于执行HTTP请求的同步客户端。它简化了与HTTP服务器的交互,并支持RESTful Web服务。 1. 添加依赖 首先,确保你的项目中包含了Spring Web的支持。如果你使用的是Maven,在pom.xml文件中添加如下依赖&…...

windows下安装wsl的ubuntu,同时配置深度学习环境
写在前面,本次文章只是个人学习记录,不具备教程的作用。个别信息是网上的,我会标注,个人是gpt生成的 安装wsl 直接看这个就行;可以不用备份软件源。 https://blog.csdn.net/weixin_44301630/article/details/1223900…...

【贪心算法第五弹——300.最长递增子序列】
目录 1.题目解析 题目来源 测试用例 2.算法原理 3.实战代码 代码解析 注意本题还有一种动态规划的解决方法,贪心的方法就是从动态规划的方法总结而来,各位可以移步博主的另一篇博客先了解一下:动态规划-子序列问题——300.长递增子序列…...

【数据分析】基于GEE解析2000-2020年武汉市FVC时空变化特征
武汉市FVC时空变化特征解析 1. 写在前面2. 2000~2020年武汉市FVC时空变化特征解析2.1. 数据获取与预处理2.2. 辐射定标和大气校正2.3. 云层和云影去除2.4. FVC计算2.5. 时空分析2.6. 代码1. 写在前面 🌍✨在应对全球气候变化和环境监测的挑战中,植被盖度(Fraction Vegetati…...
(条件分页查询、PageHelper、MYBATIS动态SQL、mapper映射配置文件、自定义类封装分页查询数据集))
springboot实战(19)(条件分页查询、PageHelper、MYBATIS动态SQL、mapper映射配置文件、自定义类封装分页查询数据集)
引言: 该类博客的学习是基于b站黑马视频springbootvue视频学习!具体围绕项目——"大事件"进行实战学习。 目录 一、功能介绍(需求)。 1、文章列表功能基本介绍。 2、条件分页查询功能与注意。 3、前端页面效果。&#x…...

Mongo数据库 --- Mongo Pipeline
Mongo数据库 --- Mongo Pipeline 什么是Mongo PipelineMongo Pipeline常用的几个StageExplanation with example:MongoDB $matchMongoDB $projectMongoDB $groupMongoDB $unwindMongoDB $countMongoDB $addFields Some Query Examples在C#中使用Aggreagtion Pipeline**方法一: …...

Docker部署mysql:8.0.31+dbsyncer
Docker部署mysql8.0.31 创建本地mysql配置文件 mkdir -p /opt/mysql/log mkdir -p /opt/mysql/data mkdir -p /opt/mysql/conf cd /opt/mysql/conf touch my.config [mysql] #设置mysql客户端默认字符集 default-character-setUTF8MB4 [mysqld] #设置3306端口 port33…...

银河麒麟桌面系统——桌面鼠标变成x,窗口无关闭按钮的解决办法
银河麒麟桌面系统——桌面鼠标变成x,窗口无关闭按钮的解决办法 1、支持环境2、详细操作说明步骤1:用root账户登录电脑步骤2:导航到kylin-wm-chooser目录步骤3:编辑default.conf文件步骤4:重启电脑 3、结语 Ὁ…...

【微服务】 Eureka和Ribbon
一、Eureka 服务调用出现的问题:在远程调用另一个服务时,我们采用的解决办法是发送一次http请求,每次环境的变更会产生新的地址,所以采用硬编码会出现很多麻烦,并且为了应对并发问题,采用分布式部署&#…...
)
C++设计模式(工厂模式)
一、介绍 1.动机 在软件系统中,经常面临着创建对象的工作,这些对象有可能是一系列相互依赖的对象;由于需求的变化,需要创建的对象的具体类型经常变化,同时也可能会有更多系列的对象需要被创建。 如何应对这种变化&a…...

nodejs第三方库sharp对图片的操作生成新图片、压缩、添加文字水印及图片水印等
Sharp是一个基于libvips的高性能Node.js图像处理库,它提供了广泛的功能,包括调整大小、裁剪、旋转、格式转换等。Sharp可以处理多种图像格式,并且能够高效地转换图像格式。 相关说明及用法看:https://sharp.nodejs.cn/ 安装&#…...

uniapp-vue2引用了vue-inset-loader插件编译小程序报错
报错信息 Error: Vue packages version mismatch: - vue3.2.45 (D:\qjy-myApp\admin-app\node_modules\vue\index.js) - vue-template-compiler2.7.16 (D:\qjy-myApp\admin-app\node_modules\vue-template-compiler\package.json) This may cause things to work incorrectly.…...
)
计算机的错误计算(一百六十七)
摘要 将计算机的错误计算(一百六十六)中算式的分母有理化,然后再在 MATLAB 讨论其计算精度。本节说明,MATLAB 的输出与(一百六十六)的输出几乎一致,有效数字的错误率也相同。 例1. 探讨 …...

交叉编译openSSH
升级原系统中的SSHd服务 由于原系统自带的SSH版本过低存在漏洞风险,所以需要升级新版本的SSH 交叉编译前准备 需要下面三个库,都是开源的,去对应的网站下载即可 openssh-9.6p1.tar.gz openssl-1.1.1w.tar.gz zlib-1.3.1.tar.gz 这里没有…...
添加支持arcgis切片功能)
从零开始学GeoServer源码(二)添加支持arcgis切片功能
文章目录 参考文章环境背景1、配置打包好的程序1.1、下载GeoServer的war包1.2、下载GeoWebCache1.3、拷贝jar包1.4、修改配置文件1.4.1、拷贝geowebcache-arcgiscache-context.xml1.4.2、修改geowebcache-core-context.xml1.4.3、修改geowebcache-servlet.xml 1.5、配置切片信息…...

Android OTA 更新面试题及参考答案
什么是 OTA 更新? OTA 更新即空中下载技术(Over-the-Air Technology)更新,是一种通过无线网络对移动设备的系统软件或应用程序进行远程更新的技术手段 。 其原理是设备通过移动网络或 Wi-Fi 连接到服务器,服务器检测设…...