JVM之垃圾回收器
部分内容来源:JavaGuide,二哥Java
垃圾回收器快速复习
JDK 8: Parallel Scavenge(新生代)+ Parallel Old(老年代)
JDK8: Serial +Serial Old
JDK 9 ~ JDK22: G1
新生代:标记-复制算法
老年代:标记-整理算法
Serial:单线程,Stop The World
ParNew:Serial的多线程版本
Paralled:ParNew的多功能版,提供了很多参数供用户找到最合适的停顿时间或最大吞吐量(这也是为什么用Paralled而不是ParNew)
CSM:JDK1.4引入,老年代回收器,标记清除法,关注GC停顿时间(Stop The World),并发执行,三色标记法解决Stop The Wrold
标记流程:初始标记,并发标记,重新标记,并发清除
优点:并发+几乎没有Stop The World(几乎不用暂停用户线程)
缺点:CPU资源敏感,标记清除法的内存碎片问题,并行时无法处理用户线程产生的浮动垃圾(垃圾过多会强制回退成Serial回收器进行收集)
三色标记法:可达性分析法的改进,实现垃圾回收线程和用户线程的并发执行,减少STW
白色->灰色->黑色,最后回收白色对象(不可达对象)
优点:并发,高效,减少STW
缺点:漏标问题,标记阶段需扫描大量对象耗时过长
漏标问题的解决方案:增量更新法(添加引用时将引用对象染成灰色),删除插入法(提前将删除前的白色对象染成灰色)
G1:并行,分代收集(物理Region分区,逻辑上分代),可预测的停顿
标记流程:初始标记,并发标记,重新标记,筛选回收
G1 收集器在后台维护了一个优先列表,每次根据允许的收集时间,优先选择回收价值最大的 Region(这也就是它的名字 Garbage-First 的由来)
使用 Region 划分内存空间以及有优先级的区域回收方式
G1的五个属性:
分代收集思想+多个相同大小的Region分配内存
Humongous区专门分配大对象(超过Region的50%)
并行
标记-复制法(避免全堆整理,维护可预测的停顿时间模型)
可预测的停顿模型,G1 在停顿时间上添加了预测机制,用户可以指定期望停顿时间
转移阶段要处理所有存活的对象,耗时会较长
因此,G1 停顿时间的瓶颈主要是标记 - 复制中的转移阶段 STW
ZGC:低延迟垃圾收集器:
三色标记法
并发标记 - 清除 - 整理过程中结合复制算法(优化标记整理算法),ZGC 在标记、转移和重定位阶段几乎都是并发的
跨代引用:
目的-避免全堆扫描,同时确保引用关系的正确性
记忆集:每个年轻代区域都有一个对应的记忆集,用来记录老年代对象中指向该区域的引用
写屏障:在老年代对象产生新引用(或删除引用)时,通过写屏障将这些引用变化记录到记忆集中
根植扫描:根集扫描是在GC启动时(标记初始阶段),扫描根集(GC Roots)以识别老年代引用年轻代对象的情况
CMS 适用场景:
- 低延迟需求:适用于对停顿时间要求敏感的应用程序。
- 老生代收集:主要针对老年代的垃圾回收。
- 碎片化管理:容易出现内存碎片,可能需要定期进行 Full GC 来压缩内存空间。
G1 适用场景:
- 大堆内存:适用于需要管理大内存堆的场景,能够有效处理数 GB 以上的堆内存。
- 对内存碎片敏感:G1 通过紧凑整理来减少内存碎片,降低了碎片化对性能的影响。
- 比较平衡的性能:G1 在提供较低停顿时间的同时,也保持了相对较高的吞吐量
知道JVM的垃圾收集算法吗?说一下
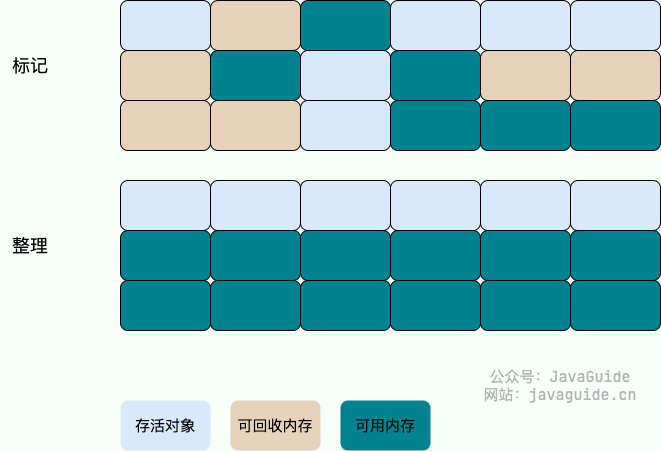
标记-清除算法
标记-清除(Mark-and-Sweep)算法分为“标记(Mark)”和“清除(Sweep)”阶段:首先标记出所有不需要回收的对象,在标记完成后统一回收掉所有没有被标记的对象。
它是最基础的收集算法,后续的算法都是对其不足进行改进得到。这种垃圾收集算法会带来两个明显的问题:
1效率问题:标记和清除两个过程效率都不高。
2空间问题:标记清除后会产生大量不连续的内存碎片。
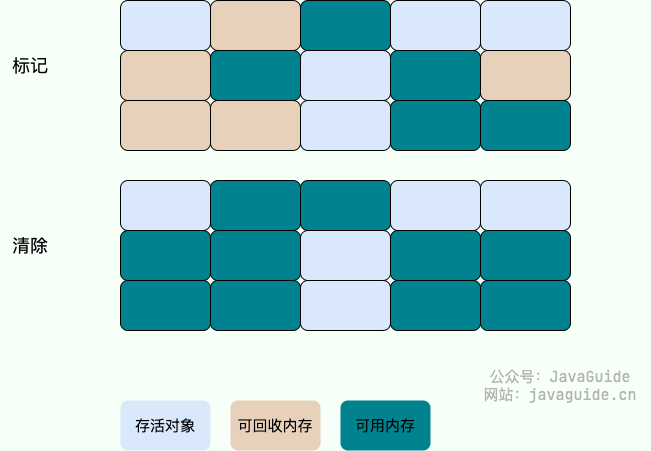

标记-复制算法(分成一半)
为了解决标记-清除算法的效率和内存碎片问题,复制(Copying)收集算法出现了。
它可以将内存分为大小相同的两块,每次使用其中的一块。
当这一块的内存使用完后,就将还存活的对象复制到另一块去,然后再把使用的空间一次清理掉。这样就使每次的内存回收都是对内存区间的一半进行回收。
虽然改进了标记-清除算法,但依然存在下面这些问题:
●可用内存变小:可用内存缩小为原来的一半。
●不适合老年代:如果存活对象数量比较大,复制性能会变得很差
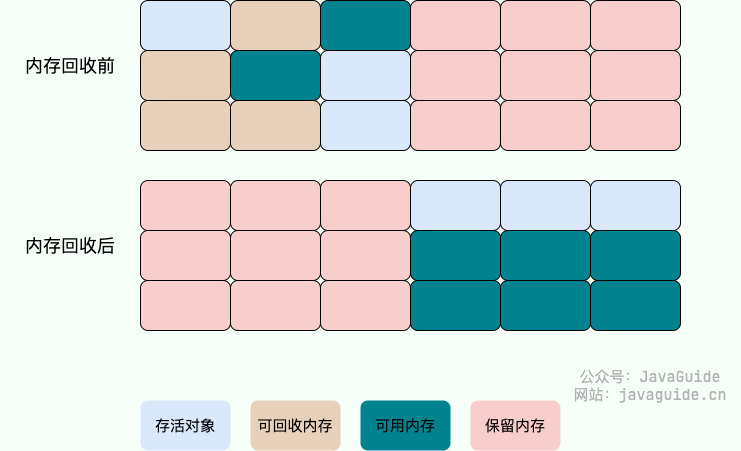
标记-整理算法
标记-整理(Mark-and-Compact)算法是根据老年代的特点提出的一种标记算法,标记过程仍然与“标记-清除”算法一样
但后续步骤不是直接对可回收对象回收,而是让所有存活的对象向一端移动,然后直接清理掉端边界以外的内存
由于多了整理这一步,因此效率也不高,适合老年代这种垃圾回收频率不是很高的场景
分代收集算法
当前虚拟机的垃圾收集都采用分代收集算法,这种算法没有什么新的思想,只是根据对象存活周期的不同将内存分为几块。一般将 Java 堆分为新生代和老年代,这样我们就可以根据各个年代的特点选择合适的垃圾收集算法。
比如在新生代中,每次收集都会有大量对象死去,所以可以选择”标记-复制“算法,只需要付出少量对象的复制成本就可以完成每次垃圾收集。而老年代的对象存活几率是比较高的,而且没有额外的空间对它进行分配担保,所以我们必须选择“标记-清除”或“标记-整理”算法进行垃圾收集
什么是垃圾回收器
如果说收集算法是内存回收的方法论,那么垃圾收集器就是内存回收的具体实现。
虽然我们对各个收集器进行比较,但并非要挑选出一个最好的收集器。因为直到现在为止还没有最好的垃圾收集器出现,更加没有万能的垃圾收集器,我们能做的就是根据具体应用场景选择适合自己的垃圾收集器。试想一下:如果有一种四海之内、任何场景下都适用的完美收集器存在,那么我们的 HotSpot 虚拟机就不会实现那么多不同的垃圾收集器了
说一下JDK默认垃圾回收器
- JDK 8: Parallel Scavenge(新生代)+ Parallel Old(老年代)
- JDK8: Serial +Serial Old
- JDK 9 ~ JDK22: G1
新生代和老年代的垃圾回收算法
新生代:标记-复制算法
老年代:标记-整理算法
Serial收集器
Serial(串行)收集器是最基本、历史最悠久的垃圾收集器了。
大家看名字就知道这个收集器是一个单线程收集器了。
它的 “单线程” 的意义不仅仅意味着它只会使用一条垃圾收集线程去完成垃圾收集工作,更重要的是它在进行垃圾收集工作的时候必须暂停其他所有的工作线程( "Stop The World" ),直到它收集结束。
新生代采用标记-复制算法,老年代采用标记-整理算法。
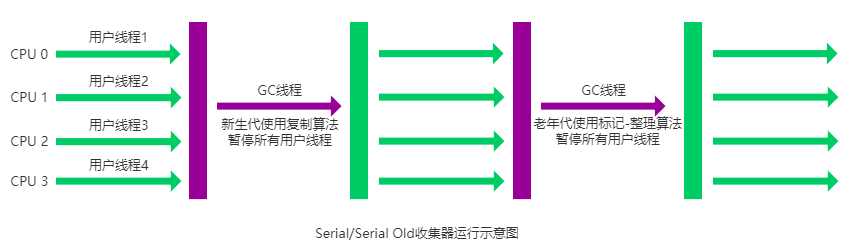
Serial 收集器
虚拟机的设计者们当然知道 Stop The World 带来的不良用户体验,所以在后续的垃圾收集器设计中停顿时间在不断缩短(仍然还有停顿,寻找最优秀的垃圾收集器的过程仍然在继续)。
但是 Serial 收集器有没有优于其他垃圾收集器的地方呢?当然有,它简单而高效(与其他收集器的单线程相比)。
Serial 收集器由于没有线程交互的开销,自然可以获得很高的单线程收集效率。
Serial 收集器对于运行在 Client 模式下的虚拟机来说是个不错的选择
ParNew收集器
ParNew 收集器其实就是 Serial 收集器的多线程版本,除了使用多线程进行垃圾收集外,其余行为(控制参数、收集算法、回收策略等等)和 Serial 收集器完全一样。
新生代采用标记-复制算法,老年代采用标记-整理算法。
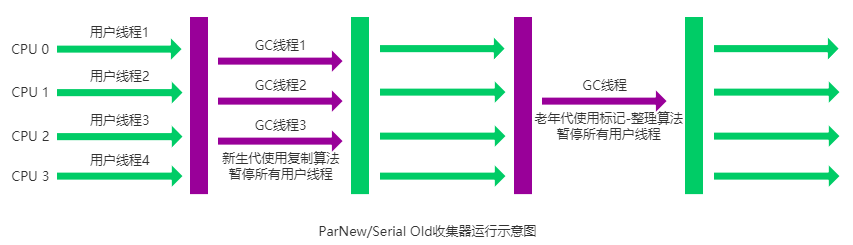
ParNew 收集器
它是许多运行在 Server 模式下的虚拟机的首要选择,除了 Serial 收集器外,只有它能与 CMS 收集器(真正意义上的并发收集器,后面会介绍到)配合工作。
并行和并发概念补充:
- 并行(Parallel):指多条垃圾收集线程并行工作,但此时用户线程仍然处于等待状态。
- 并发(Concurrent):指用户线程与垃圾收集线程同时执行(但不一定是并行,可能会交替执行),用户程序在继续运行,而垃圾收集器运行在另一个 CPU 上
Parallel Scavenge收集器
Parallel Scavenge 收集器也是使用标记-复制算法的多线程收集器,它看上去几乎和 ParNew 都一样
那么它有什么特别之处呢?
Parallel Scavenge 收集器关注点是吞吐量(高效率的利用 CPU)。
CMS 等垃圾收集器的关注点更多的是用户线程的停顿时间(提高用户体验)。
所谓吞吐量就是 CPU 中用于运行用户代码的时间与 CPU 总消耗时间的比值。
Parallel Scavenge 收集器提供了很多参数供用户找到最合适的停顿时间或最大吞吐量,如果对于收集器运作不太了解,手工优化存在困难的时候,使用 Parallel Scavenge 收集器配合自适应调节策略,把内存管理优化交给虚拟机去完成也是一个不错的选择。
新生代采用标记-复制算法,老年代采用标记-整理算法。
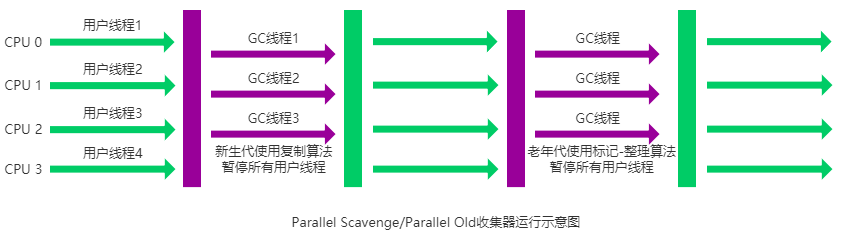
Parallel Old收集器运行示意图
这是 JDK1.8 默认收集器
Serial Old收集器
Serial 收集器的老年代版本,它同样是一个单线程收集器。
它主要有两大用途:一种用途是在 JDK1.5 以及以前的版本中与 Parallel Scavenge 收集器搭配使用,另一种用途是作为 CMS 收集器的后备方案。
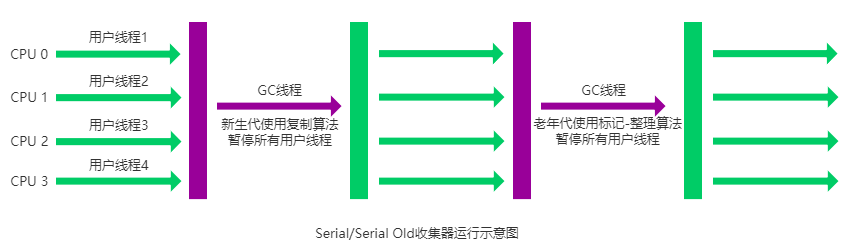
Parallel Old收集器
Parallel Scavenge 收集器的老年代版本。使用多线程和“标记-整理”算法。在注重吞吐量以及 CPU 资源的场合,都可以优先考虑 Parallel Scavenge 收集器和 Parallel Old 收集器。
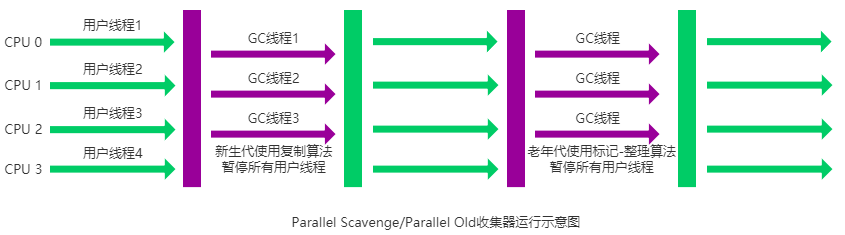
CMS收集器
是JDK1.4引入的
CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器。它非常符合在注重用户体验的应用上使用。
CMS(Concurrent Mark Sweep)收集器是 HotSpot 虚拟机第一款真正意义上的并发收集器
它第一次实现了让垃圾收集线程与用户线程(基本上)同时工作。
从名字中的Mark Sweep这两个词可以看出,CMS 收集器是一种 “标记-清除”算法实现的,它的运作过程相比于前面几种垃圾收集器来说更加复杂一些。整个过程分为四个步骤:
- 初始标记: 暂停所有的其他线程,并记录下直接与 root 相连的对象,速度很快 ;
- 并发标记: 同时开启 GC 和用户线程,用一个闭包结构去记录可达对象。但在这个阶段结束,这个闭包结构并不能保证包含当前所有的可达对象。因为用户线程可能会不断的更新引用域,所以 GC 线程无法保证可达性分析的实时性。所以这个算法里会跟踪记录这些发生引用更新的地方。
- 重新标记: 重新标记阶段就是为了修正并发标记期间因为用户程序继续运行而导致标记产生变动的那一部分对象的标记记录,这个阶段的停顿时间一般会比初始标记阶段的时间稍长,远远比并发标记阶段时间短
- 并发清除: 开启用户线程,同时 GC 线程开始对未标记的区域做清扫
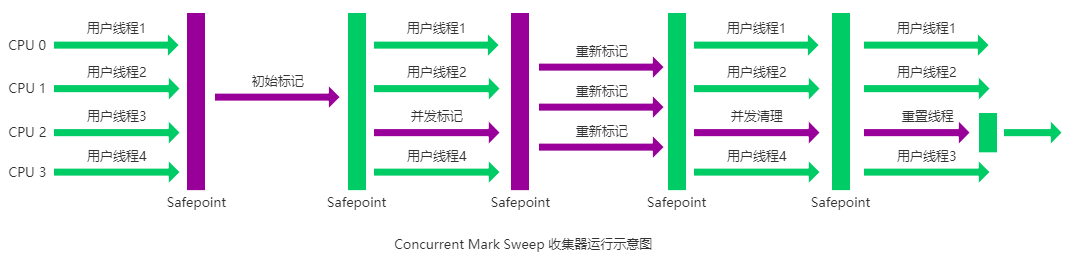
CMS 收集器
从它的名字就可以看出它是一款优秀的垃圾收集器,主要优点:并发收集、低停顿。但是它有下面三个明显的缺点:
- 对 CPU 资源敏感;
- 无法处理浮动垃圾;
- 它使用的回收算法-“标记-清除”算法会导致收集结束时会有大量空间碎片产生。
CMS 垃圾回收器在 Java 9 中已经被标记为过时(deprecated),并在 Java 14 中被移除
说一下分代收集器CMS
什么是CMS收集器
以获取最短回收停顿时间为目标,采用“标记-清除”算法,分 4 大步进行垃圾收集,其中初始标记和重新标记会 STW,JDK 1.5 时引入,JDK9 被标记弃用,JDK14 被移除,详情可见 JEP 363。
CMS(Concurrent Mark Sweep)垃圾收集器是第一个关注 GC 停顿时间(STW 的时间)的垃圾收集器
之前的垃圾收集器,要么是串行的垃圾回收方式,要么只关注系统吞吐量
为什么CMS能够实现对 GC 停顿时间的控制
CMS 垃圾收集器之所以能够实现对 GC 停顿时间的控制,其本质来源于对「可达性分析算法」的改进,即三色标记算法
在 CMS 出现之前,无论是 Serious 垃圾收集器,还是 ParNew 垃圾收集器,以及 Parallel Scavenge 垃圾收集器,它们在进行垃圾回收期间都需要 Stop the World,无法实现垃圾回收线程与用户线程的并发执行。
(也就是我们的CMS垃圾回收器进行垃圾回收并不是整个过程就是STW,而是部分过程STW,减少了我们的GC的停顿的时间)
也就是我们的CMS实现了并行通过通过三色标记法解决了Stop The World
CMS的四个步骤
CMS 垃圾收集器通过三色标记算法,实现了垃圾回收线程与用户线程的并发执行,从而极大地降低了系统响应时间,提高了强交互应用程序的体验。它的运行过程分为 4 个步骤,包括:
- 初始标记
- 并发标记
- 重新标记
- 并发清除
初始标记
指的是寻找所有被 GCRoots 引用的对象,该阶段需要「Stop the World」
这个步骤仅仅只是标记一下 GC Roots 能直接关联到的对象,并不需要做整个引用的扫描,因此速度很快。
并发标记
指的是对「初始标记阶段」标记的对象进行整个引用链的扫描,该阶段不需要「Stop the World」。 对整个引用链做扫描需要花费非常多的时间,因此通过垃圾回收线程与用户线程并发执行,可以降低垃圾回收的时间。
这也是 CMS 能极大降低 GC 停顿时间的核心原因,但这也带来了一些问题
即:并发标记的时候,引用可能发生变化,因此可能发生漏标(本应该回收的垃圾没有被回收)和多标(本不应该回收的垃圾被回收)了。
重新标记
指的是对「并发标记」阶段出现的问题进行校正,该阶段需要「Stop the World」
正如并发标记阶段说到的,由于垃圾回收算法和用户线程并发执行,虽然能降低响应时间
但是会发生漏标和多标的问题
所以对于 CMS 来说,它需要在这个阶段做一些校验,解决并发标记阶段发生的问题。
并发清除
指的是将标记为垃圾的对象进行清除,该阶段不需要「Stop the World」。 在这个阶段,垃圾回收线程与用户线程可以并发执行,因此并不影响用户的响应时间。
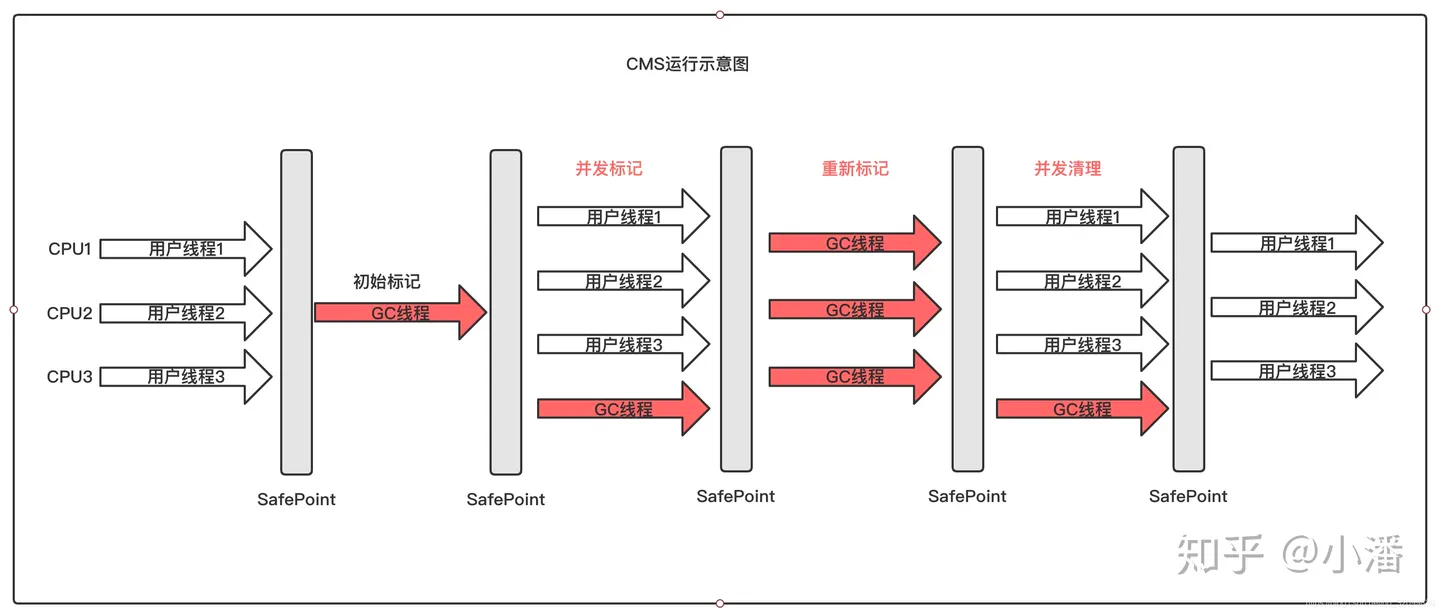
说一下CMS垃圾回收的四大步骤
初始标记
并发标记
重新标记(检验错误)
并发清除
说一下分代收集器CMS的优缺点
优点
并发收集
低停顿(减少了Stop The World)
缺点
①对 CPU 资源非常敏感
因此在 CPU 资源紧张的情况下,CMS 的性能会大打折扣。
默认情况下,CMS 启用的垃圾回收线程数是(CPU数量 + 3)/4,当 CPU 数量很大时,启用的垃圾回收线程数占比就越小。但如果 CPU 数量很小,例如只有 2 个 CPU,垃圾回收线程占用就达到了 50%,这极大地降低系统的吞吐量,无法接受。
②CMS 采用的是「标记-清除」算法
会产生大量的内存碎片,导致空间不连续,当出现大对象无法找到连续的内存空间时,就会触发一次 Full GC,这会导致系统的停顿时间变长
③CMS 无法处理浮动垃圾
当 CMS 在进行垃圾回收的时候,应用程序还在不断地产生垃圾,这些垃圾会在 CMS 垃圾回收结束之后产生,这些垃圾就是浮动垃圾,CMS 无法处理这些浮动垃圾,只能在下一次 GC 时清理掉
CMS采用的是什么算法?
CMS是老年代回收器
标记清除法
CMS怎么处理浮动垃圾
CMS处理不了浮动垃圾
而且我们的CMS没有stop the world,所以用户线程和垃圾回收线程并行执行的时候,仍然会生成浮动垃圾
所以当我们浮动垃圾过多的时候,我们会退化Serial垃圾回收器,然后我们Stop The World进行垃圾回收
说一下什么是三色标记法
三色标记法解决了什么
三色标记算法其本质是对「可达性分析算法」的改进
在 CMS 出现之前,无论是 Serious 垃圾收集器,还是 ParNew 垃圾收集器,以及 Parallel Scavenge 垃圾收集器,它们在进行垃圾回收期间都需要 Stop the World,无法实现垃圾回收线程与用户线程的并发执行
CMS 垃圾收集器通过三色标记算法,实现了垃圾回收线程与用户线程的并发执行,从而极大地降低了系统响应时间,提高了强交互应用程序的体验
三色标记法简介
三色标记法是一种常用于垃圾回收器(GC)中的标记清除算法的实现方式,用于追踪对象的可达性
通过对对象染色(白、灰、黑)分类,算法能够高效地标记活动对象并清理不可达对象。
三色标记的定义
- 白色:表示对象尚未被访问。初始时,所有对象都是白色。垃圾回收结束时,白色对象即为不可达对象,需被回收。
- 灰色:表示对象已被访问,但其引用的对象未被完全扫描。灰色对象需要进一步扫描。
- 黑色:表示对象已被访问,且其引用的对象已全部扫描完成。黑色对象不会再被重新扫描,也不会被回收。
工作流程
- 初始化阶段:将所有对象染成白色,将根对象(GC Roots)染成灰色
- 扫描阶段:从灰色对象开始扫描:
- 将灰色对象的引用对象染成灰色;
- 将灰色对象自身染成黑色。
- 清理阶段:当没有灰色对象时,白色对象即为不可达对象,回收它们
三色标记法的优点
三色标记法的优点
- 高效处理可达性:三色标记法通过颜色分类避免重复扫描已经处理的对象,提升效率。
- 并发性:三色标记法适合并发垃圾回收,GC线程与用户线程可以同时工作。
- 清晰性:标记过程逻辑清晰,容易实现分阶段操作。
- 让我们不用整个垃圾回收期间都Stop The World
三色标记法的缺点
1. 漂移问题(漏标问题)
- 如果在并发过程中,用户线程修改了灰色对象的引用(删除了对白色对象的引用),导致某些白色对象仍然可达,但被错误地回收。
- 人话:漏标导致了可达对象被错误回收
漏标的详细过程
以下是一个具体的“漏标问题”的场景:
- 初始状态:
- 假设有一个灰色对象
A,它引用了一个白色对象B。 - 白色对象
B暂时还未被扫描,因此仍然是“待回收”的候选。
- 用户线程修改引用:
- 在GC线程对灰色对象
A进行扫描之前,用户线程删除了A指向B的引用。 - 删除后,从
A不再能够访问到B。
- GC线程扫描:
- GC线程扫描到
A时,发现A的引用列表中已经没有B,因此不会将B标记为灰色。 - 此时,
B依然是白色。
- 错误回收:
- 如果
B还有其他途径可达(例如另一个对象C引用了B),但是GC线程没有标记到B,就会将B视为不可达,最终将其回收。 - 这种情况导致了错误回收,因为
B实际上仍然是可达的。
2. 暂停时间不确定
- 在单线程实现中,标记阶段可能需要扫描大量对象,可能导致GC暂停时间较长。
三色标记法漂移问题的解决方法
漂移问题的解决方法
其实也就是引用或删除时多做几步处理
写屏障:在用户线程修改引用时,通知GC线程,使得GC能够追踪这些引用的变化
- 增量更新法:当从黑色对象添加引用时,将被引用对象染成灰色,保证新对象能被正确标记
- 删除插入法:当删除灰色对象指向白色对象的引用时,提前将删除前的白色对象染成灰色,避免错误回收
读屏障:在用户线程访问引用时进行干预,确保GC线程的对象状态不受影响。
- 更适合实时GC,但实现复杂且开销较大
三色标记法的目的是什么?
三色标记法的主要目的是通过有效地标记节点状态来实现图的遍历、环路检测、依赖关系处理等功能
从而提高算法的效率和可靠性
G1收集器
什么是G1收集器
G1 (Garbage-First) 是一款面向服务器的垃圾收集器,主要针对配备多颗处理器及大容量内存的机器. 以极高概率满足 GC 停顿时间要求的同时,还具备高吞吐量性能特征.
被视为 JDK1.7 中 HotSpot 虚拟机的一个重要进化特征。它具备以下特点:
- 并行与并发:G1 能充分利用 CPU、多核环境下的硬件优势,使用多个 CPU(CPU 或者 CPU 核心)来缩短 Stop-The-World 停顿时间。部分其他收集器原本需要停顿 Java 线程执行的 GC 动作,G1 收集器仍然可以通过并发的方式让 java 程序继续执行。
- 分代收集:虽然 G1 可以不需要其他收集器配合就能独立管理整个 GC 堆,但是还是保留了分代的概念。
- 空间整合:与 CMS 的“标记-清除”算法不同,G1 从整体来看是基于“标记-整理”算法实现的收集器;从局部上来看是基于“标记-复制”算法实现的。
- 可预测的停顿:这是 G1 相对于 CMS 的另一个大优势,降低停顿时间是 G1 和 CMS 共同的关注点,但 G1 除了追求低停顿外,还能建立可预测的停顿时间模型,能让使用者明确指定在一个长度为 M 毫秒的时间片段内,消耗在垃圾收集上的时间不得超过 N 毫秒
并发+分代收集思想+可预测的停顿
G1 收集器运作的步骤
- 初始标记
- 并发标记
- 最终标记
- 筛选回收
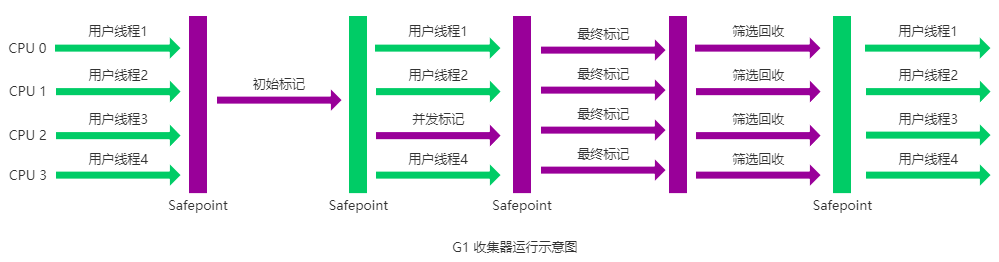
额外知识
G1 收集器在后台维护了一个优先列表,每次根据允许的收集时间,优先选择回收价值最大的 Region(这也就是它的名字 Garbage-First 的由来)
这种使用 Region 划分内存空间以及有优先级的区域回收方式,保证了 G1 收集器在有限时间内可以尽可能高的收集效率(把内存化整为零)。
从 JDK9 开始,G1 垃圾收集器成为了默认的垃圾收集器
说一下G1垃圾收集器
Region的意思是区域
G1(Garbage-First Garbage Collector)在 JDK 1.7 时引入
在 JDK 9 时成为了默认的垃圾收集器
Young GC、Mixed GC 用标记-复制算法
Full GC用标记-整理法
说一下G1的五个属性
G1 有五个属性:分代、增量、并行、标记整理、STW
①、分代
相信大家还记得我们上一讲中的年轻代和老年代,G1 也是基于这个思想进行设计的。
它将堆内存分为多个大小相等的区域(Region)
每个区域都可以是 Eden 区、Survivor 区或者 Old 区。
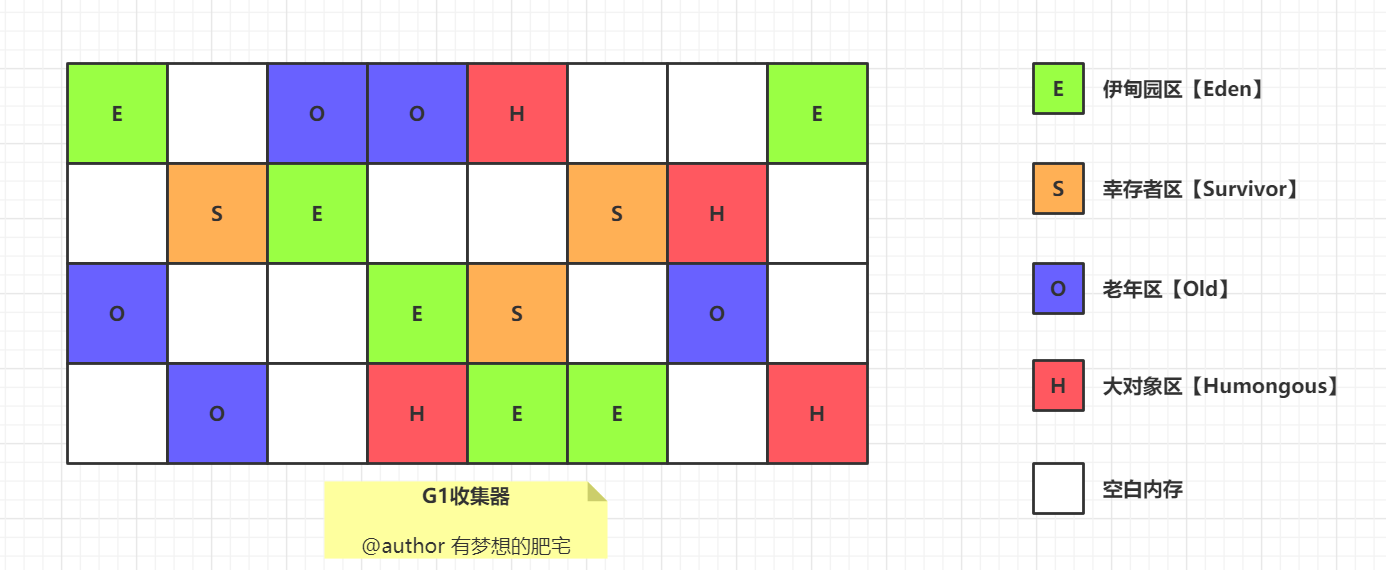
可以通过 -XX:G1HeapRegionSize=n 来设置 Region 的大小,可以设定为 1M、2M、4M、8M、16M、32M(不能超过)。
Humongous区专门分配大对象
G1 有专门分配大对象的 Region 叫 Humongous 区,而不是让大对象直接进入老年代的 Region 中。
在 G1 中,大对象的判定规则就是一个大对象超过了一个 Region 大小的 50%,比如每个 Region 是 2M,只要一个对象超过了 1M,就会被放入 Humongous 中
而且一个大对象如果太大,可能会横跨多个 Region 来存放。
G1 会根据各个区域的垃圾回收情况来决定下一次垃圾回收的区域,这样就避免了对整个堆内存进行垃圾回收,从而降低了垃圾回收的时间。
②、增量方式回收垃圾
G1 可以以增量方式执行垃圾回收 这意味着它不需要一次性回收整个堆空间,而是可以逐步、增量地清理。 有助于控制停顿时间,尤其是在处理大型堆时。
③、并行
G1 垃圾回收器可以并行回收垃圾,这意味着它可以利用多个 CPU 来加速垃圾回收的速度,这一特性在年轻代的垃圾回收(Minor GC)中特别明显,因为年轻代的回收通常涉及较多的对象和较高的回收速率。
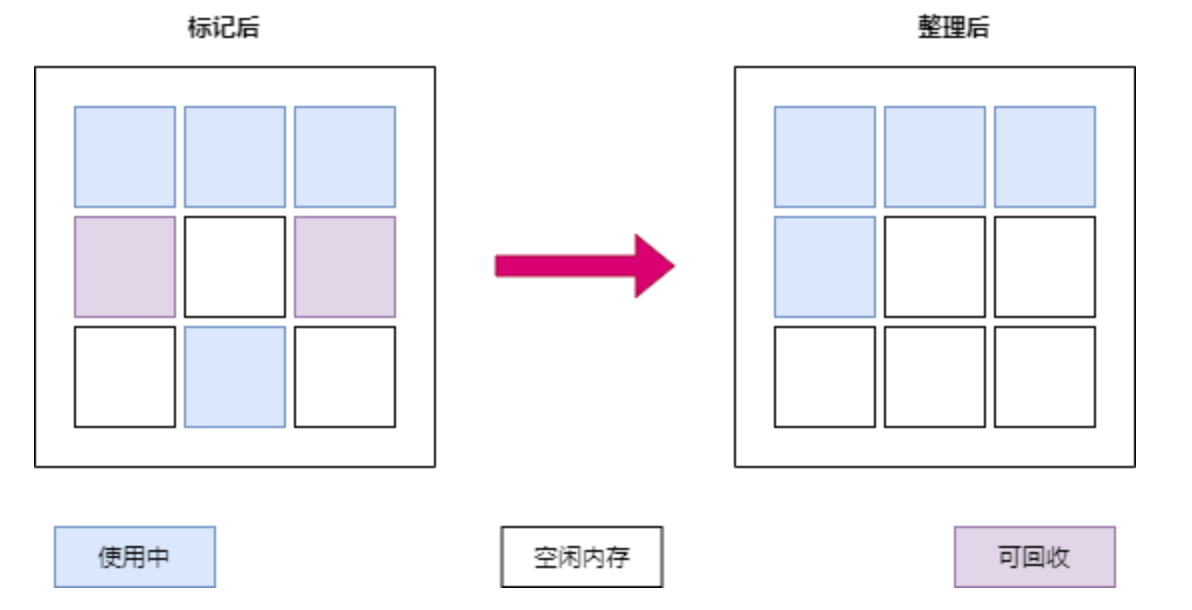
④、标记整理
在进行老年代的垃圾回收时,G1 使用标记-整理算法。这个过程分为两个阶段:标记存活的对象和整理(压缩)堆空间。通过整理,G1 能够避免内存碎片化,提高内存利用率。
年轻代的垃圾回收(Minor GC)使用 标记-复制算法 ,因为年轻代的对象通常是朝生夕死的。
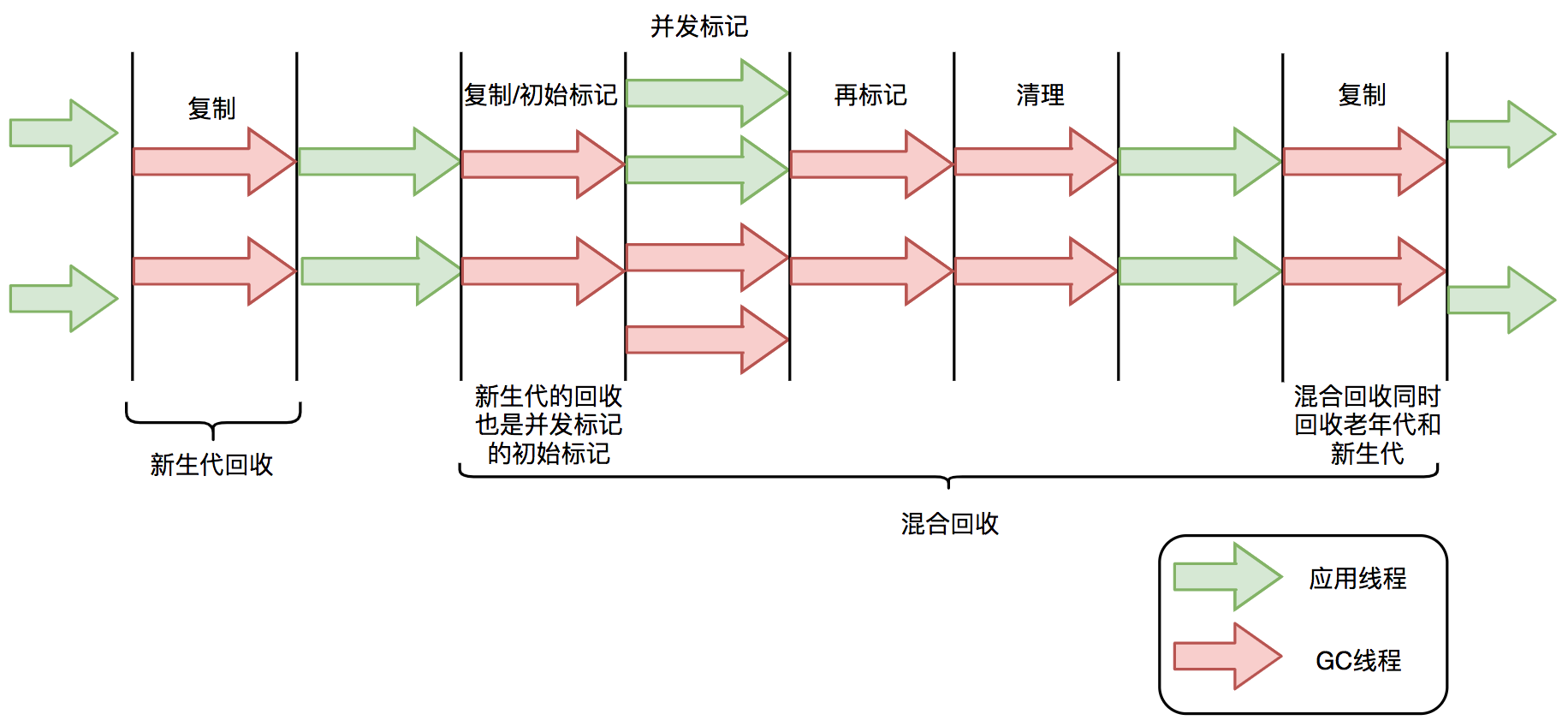
⑤、STW(Stop The World)
G1 也是基于「标记-清除」算法,因此在进行垃圾回收的时候,仍然需要「Stop the World」。不过,G1 在停顿时间上添加了预测机制,用户可以指定期望停顿时间。
说一下GC中存在的三种模式
G1 中存在三种 GC 模式,分别是 Young GC、Mixed GC 和 Full GC
简单来说:
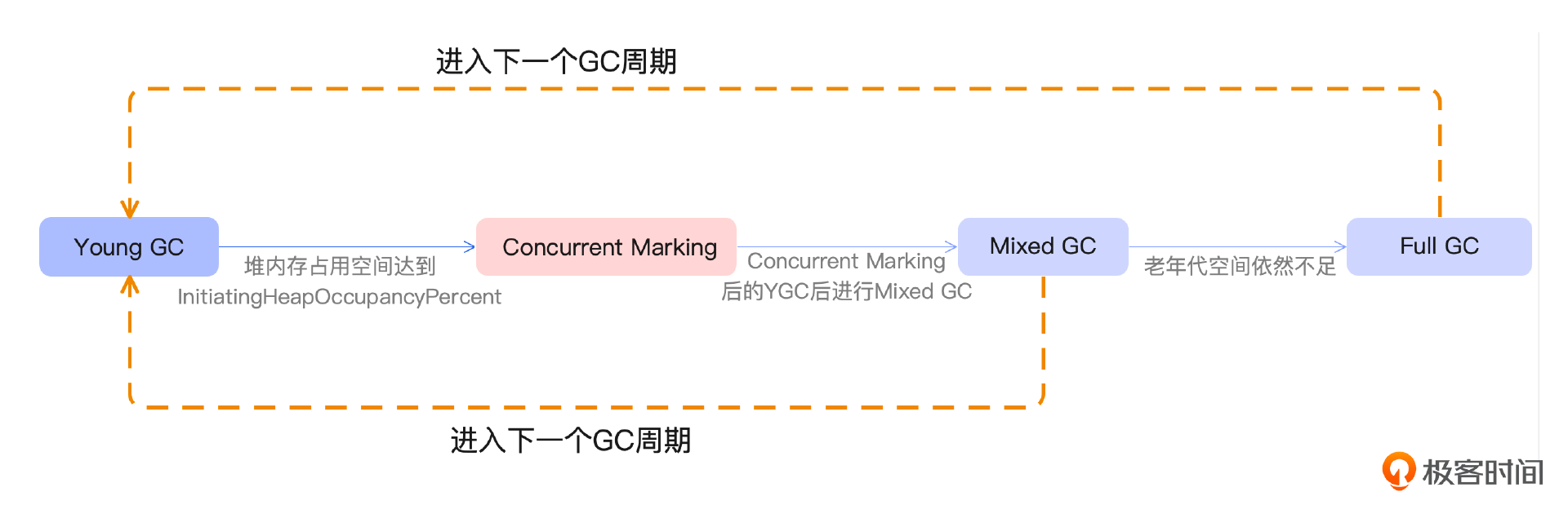
Young GC
当 Eden 区的内存空间无法支持新对象的内存分配时,G1 会触发 Young GC。
当需要分配对象到 Humongous 区域或者堆内存的空间
(我们指的是当前这个区域的对象总和对总的空间占比,而不是单个空间对这个区域的占比)
占比超过 -XX:G1HeapWastePercent 设置的 InitiatingHeapOccupancyPercent 值时,G1 会触发一次 concurrent marking
它的作用就是计算老年代中有多少空间需要被回收,当发现垃圾的占比达到 -XX:G1HeapWastePercent 中所设置的 G1HeapWastePercent 比例时,在下次 Young GC 后会触发一次 Mixed GC。
Mixed GC
Mixed GC 是指回收年轻代的 Region 以及一部分老年代中的 Region。Mixed GC 和 Young GC 一样,采用的也是复制算法。
在 Mixed GC 过程中,如果发现老年代空间还是不足,此时如果 G1HeapWastePercent 设定过低,可能引发 Full GC。-XX:G1HeapWastePercent 默认是 5,意味着只有 5% 的堆是“浪费”的。
Full GC
如果浪费的堆的百分比大于 G1HeapWastePercent,则运行 Full GC。
G1垃圾收集器的停顿预测模型
在以 Region 为最小管理单元以及所采用的 GC 模式的基础上,G1 建立了停顿预测模型,即 Pause Prediction Model 。这也是 G1 非常被人所称道的特性。
我们可以借助 -XX:MaxGCPauseMillis 来设置期望的停顿时间(默认 200ms)
G1 会根据这个值来计算出一个合理的 Young GC 的回收时间,然后根据这个时间来制定 Young GC 的回收计划
你了解G1垃圾回收器吗?说一下
G1垃圾回收器的属性+特点+基本知识
JDK9
G1垃圾回收器在JDK9的时候取代了我们的CMS垃圾回收器,成为了我们的默认的垃圾回收器
存储空间部分不分代,回收思想分代
G1回收器我们的存储空间不是分代的,也就是我们的Region不是分为新生代,老年代这样的,
而是分为多个大小相等的Region,每个Region都可以是我们的Eden,Surivor,Old区域。
虽然我们的存储空间不是分代的,但是我们的回收思想是分代的
分配大对象的特点:Humongous区
之前我们的分代收集法,我们是大对象放不进新生代我们就直接进入老年代
但我们的G1 有专门分配大对象的 Region 叫 Humongous 区
在 G1 中,大对象的判定规则就是一个大对象超过了一个 Region 大小的 50%,比如每个 Region 是 2M,只要一个对象超过了 1M,就会被放入 Humongous 中
逐步回收+并行回收
G1垃圾回收器 会根据各个区域的垃圾回收情况来决定下一次垃圾回收的区域,这样就避免了对整个堆内存进行垃圾回收,从而降低了垃圾回收的时间。
(因为我们是分成多个相等大小的Region,所以我们上次回收后,我们回收器可以根据回收情况自我决定下次回收的区域,这样避免某些区域重复回收,提高了我们的垃圾回收的效率)
G1垃圾回收器可以并行地进行垃圾回收
用到的垃圾回收算法
Young GC Mixed GC用标记复制法
Full GC用标记整理法
其实标记整理法和标记复制法本质上是一个东西,不过标记整理多了整理这一个步骤导致效率降低,适用于老年代,因为老年代不经常回收效率低一点无所谓,而且标记复制会让使用空间砍半,本来老年代就是要放大部分对象的,所以不使用,效率低一点没事,我们存的东西也多了
新生代的话我们经常进行垃圾回收,所以我们要效率高一点的标记复制法
Stop The World
G1垃圾回收器仍然需要Stop The World,但我们的G1垃圾回收器有停顿预测模型
我们G1有个停顿时间预测机制,我们可以手动指定一个期望停顿的时间,然后我们的G1垃圾回收器会根据这个时间来指定合理的垃圾回收计划
G1进行垃圾回收的三种模式
Young GC
当Eden区域无法存放新对象的时候,我们就进行Young GC
当我们的当前对象+准备放入的区域里对象的占用空间总和 > 设置的XX值,G1就会触发一次Concurrent Marking
Concurrent Marking的作用就是计算老年代中有多少空间需要被回收
Mixed GC
当发现垃圾的占比达到 -XX:G1HeapWastePercent 中所设置的 G1HeapWastePercent 比例时,在下次 Young GC 后会触发一次 Mixed GC
Mixed GC 是指回收年轻代的 Region 以及一部分老年代中的 Region
Mixed GC 和 Young GC 一样,采用的也是复制算法
在 Mixed GC 过程中,如果发现老年代空间还是不足,此时如果 G1HeapWastePercent 设定过低,可能引发 Full GC。-XX:G1HeapWastePercent 默认是 5,意味着只有 5% 的堆是“浪费”的
Full GC
如果浪费的堆的百分比大于 G1HeapWastePercent,则运行 Full GC。
ZGC收集器
与 CMS 中的 ParNew 和 G1 类似,ZGC 也采用标记-复制算法,不过 ZGC 对该算法做了重大改进。
ZGC 可以将暂停时间控制在几毫秒以内,且暂停时间不受堆内存大小的影响
出现 Stop The World 的情况会更少,但代价是牺牲了一些吞吐量。
ZGC 最大支持 16TB 的堆内存。
ZGC 在 Java11 中引入,处于试验阶段。经过多个版本的迭代,不断的完善和修复问题,ZGC 在 Java15 已经可以正式使用了
说一下ZGC垃圾回收器
什么是ZGC
ZGC(The Z Garbage Collector)是 JDK11 推出的一款低延迟垃圾收集器,适用于大内存低延迟服务的内存管理和回收,SPEC jbb 2015 基准测试,在 128G 的大堆下,最大停顿时间才 1.68 ms,停顿时间远胜于 G1 和 CMS。
ZGC 的设计目标是:在不超过 10ms 的停顿时间下,支持 TB 级的内存容量和几乎所有的 GC 功能,这也是 ZGC 名字的由来,Z 代表着 Zettabyte,也就是 1024EB,也就是 1TB 的 1024 倍。
不过,我需要告诉大家的是,上面这段是我胡编的(😂),JDK 官方并没有明确给出 Z 的定义,就像小米汽车 su7,7 也是个魔数,没有明确的定义。
总之就是,ZGC 很牛逼,它的目标是:
- 停顿时间不超过 10ms;
- 停顿时间不会随着堆的大小,或者活跃对象的大小而增加;
- 支持 8MB~4TB 级别的堆,未来支持 16TB。
复制算法
前面讲 G1 垃圾收集器的时候提到过,Young GC 和 Mixed GC 均采用的是复制算法
复制算法主要包括以下 3 个阶段:
①、标记阶段,从 GC Roots 开始,分析对象可达性,标记出活跃对象。
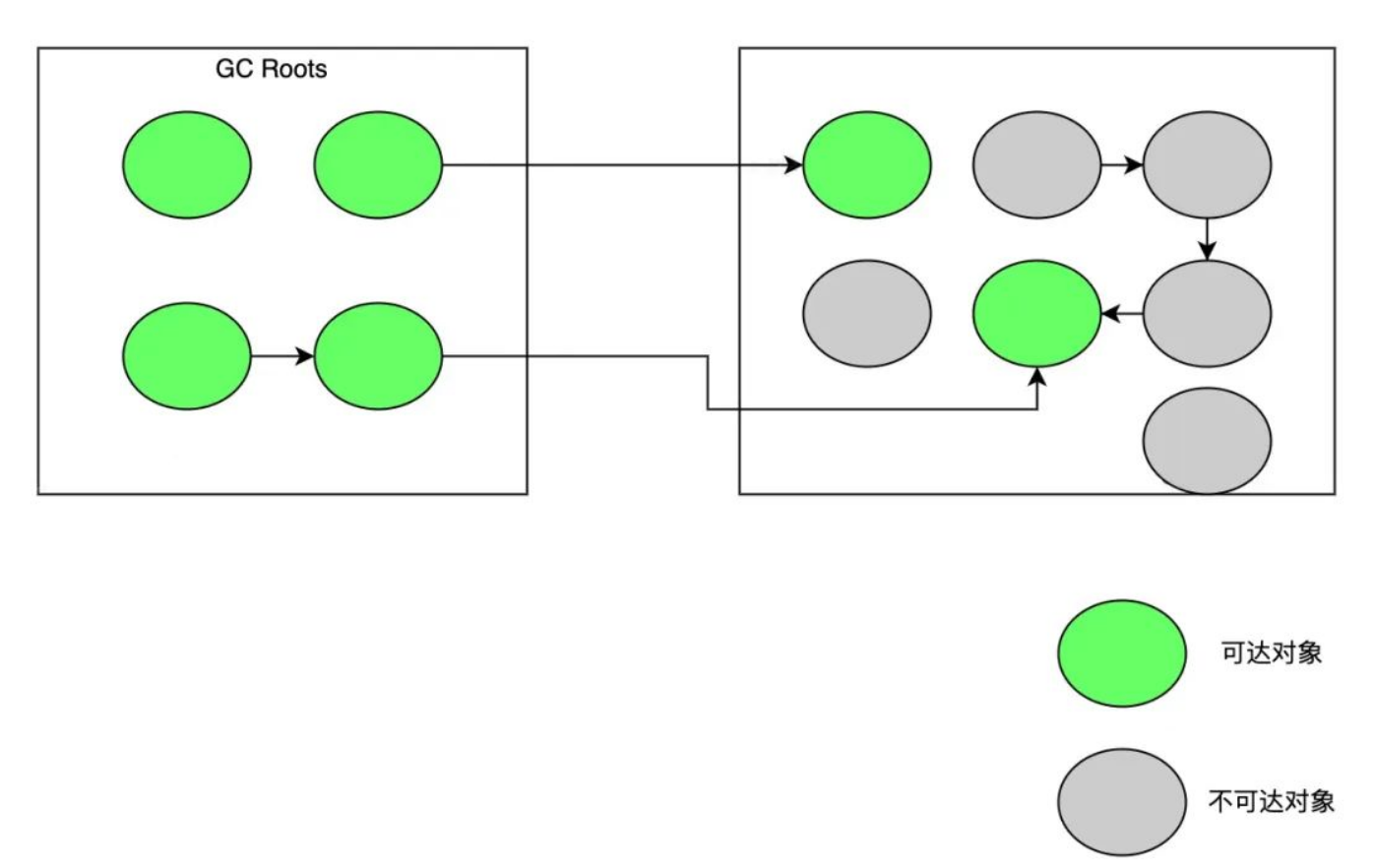
②、对象转移阶段,把活跃对象复制到新的内存地址上。
③、重定位阶段,因为转移导致对象地址发生了变化,在重定位阶段,所有指向对象旧地址的引用都要调整到对象新的地址上。
标记阶段因为只标记 GC Roots,耗时较短。但转移阶段和重定位阶段需要处理所有存活的对象,耗时较长,并且转移阶段是 STW 的
因此,G1 的性能瓶颈就主要卡在转移阶段。
与 G1 和 CMS 类似,ZGC 也采用了复制算法,只不过做了重大优化
ZGC 在标记、转移和重定位阶段几乎都是并发的
这是 ZGC 实现停顿时间小于 10ms 的关键所在。
ZGC是怎么做到的
指针染色+读屏障提高速度,保证对象访问的正确性
ZGC 是怎么做到的呢?
- 指针染色(Colored Pointer):一种用于标记对象状态的技术
- 读屏障(Load Barrier):一种在程序运行时插入到对象访问操作中的特殊检查,用于确保对象访问的正确性
这两种技术可以让所有线程在并发的条件下就指针的颜色 (状态) 达成一致,而不是对象地址
因此,ZGC 可以并发的复制对象,这大大的降低了 GC 的停顿时间
指针染色
在一个指针中,除了存储对象的实际地址外,还有额外的位被用来存储关于该对象的元数据信息
这些信息可能包括:
- 对象是否被移动了(即它是否在回收过程中被移动到了新的位置)
- 对象的存活状态
- 对象是否被锁定或有其他特殊状态
通过在指针中嵌入这些信息,ZGC 在标记和转移阶段会更快
因为通过指针上的颜色就能区分出对象状态,不用额外做内存访问
ZGC仅支持64位系统,它把64位虚拟地址空间划分为多个子空间,如下图所示:
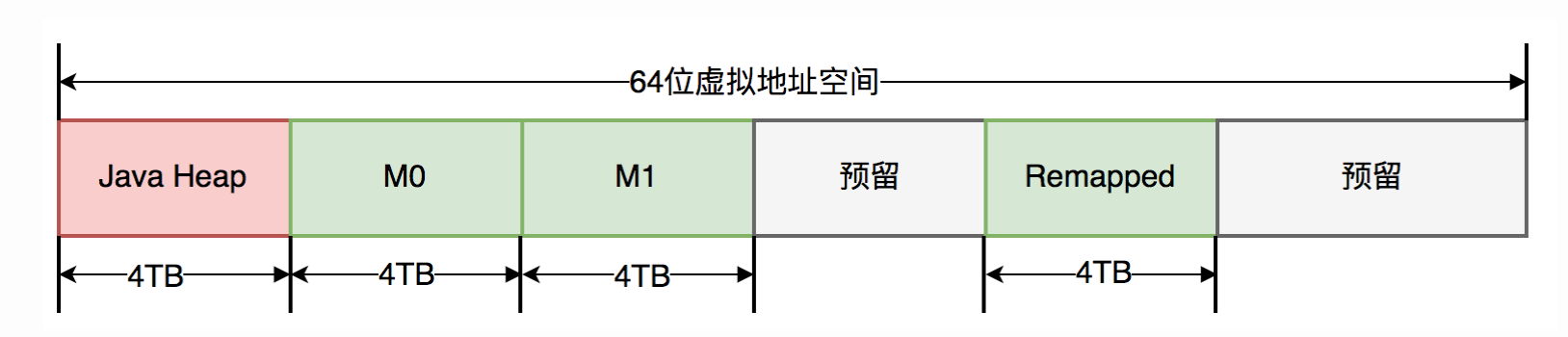
其中,0-4TB 对应 Java 堆,4TB-8TB 被称为 M0 地址空间,8TB-12TB 被称为 M1 地址空间,12TB-16TB 预留未使用,16TB-20TB 被称为 Remapped 空间
当创建对象时,首先在堆空间申请一个虚拟地址,该虚拟地址并不会映射到真正的物理地址
同时,ZGC 会在 M0、M1、Remapped 空间中为该对象分别申请一个虚拟地址,且三个虚拟地址都映射到同一个物理地址
读屏障
当程序尝试读取一个对象时,读屏障会触发以下操作:
- 检查指针染色:读屏障首先检查指向对象的指针的颜色信息
- 处理移动的对象:如果指针表示对象已经被移动(例如,在垃圾回收过程中),读屏障将确保返回对象的新位置
- 确保一致性:通过这种方式,ZGC 能够在并发移动对象时保持内存访问的一致性,从而减少对应用程序停顿的需要
ZGC读屏障如何实现呢?
来看下面这段伪代码,涉及 JVM 的底层 C++ 代码:
// 伪代码示例,展示读屏障的概念性实现
Object* read_barrier(Object* ref) {if (is_forwarded(ref)) {return get_forwarded_address(ref); // 获取对象的新地址}return ref; // 对象未移动,返回原始引用
}- read_barrier 代表读屏障
- 如果对象已被移动(is_forwarded(ref)),方法返回对象的新地址(get_forwarded_address(ref))
- 如果对象未被移动,方法返回原始的对象引用
读屏障可能被GC线程和业务线程触发,并且只会在访问堆内对象时触发
访问的对象位于GC Roots时不会触发,这也是扫描GC Roots时需要STW的原因
下面是一个简化的示例代码,展示了读屏障的触发时机
Object o = obj.FieldA // 从堆中读取引用,需要加入屏障
<Load barrier>
Object p = o // 无需加入屏障,因为不是从堆中读取引用
o.dosomething() // 无需加入屏障,因为不是从堆中读取引用
int i = obj.FieldB //无需加入屏障,因为不是对象引用下图是虚拟地址的空间划分:
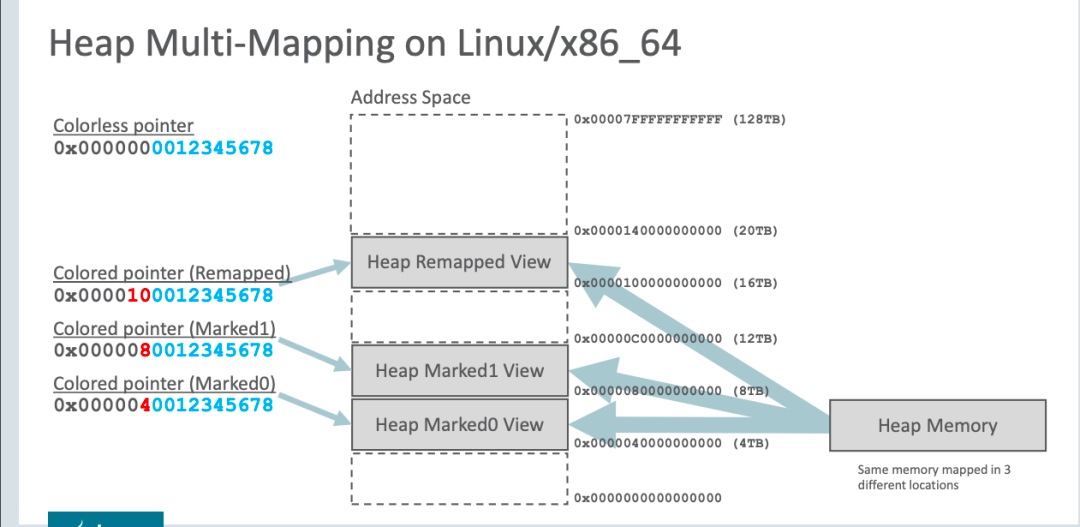
不过,三个空间在同一时间只有一个空间有效。ZGC 之所以设置这三个虚拟地址,是因为 ZGC 采用的是“空间换时间”的思想,去降低 GC 的停顿时间
与上述地址空间划分相对应,ZGC实际仅使用64位地址空间的第0-41位,而第42-45位存储元数据,第47-63位固定为0
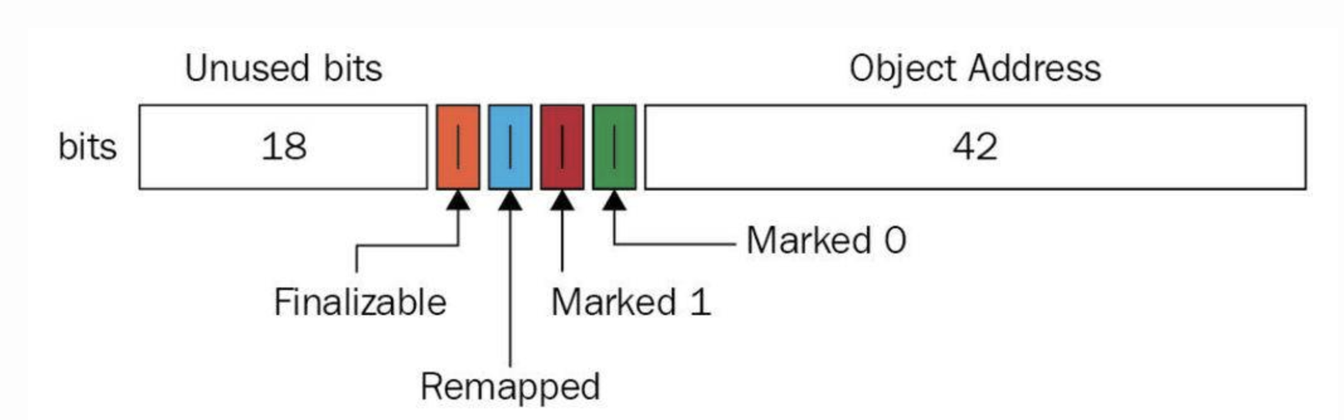
由于仅用了第 0~43 位存储对象地址,$2^{44}$ = 16TB,所以 ZGC 最大支持 16TB 的堆
至于对象的存活信息,则存储在42-45位中,这与传统的垃圾回收并将对象存活信息放在对象头中完全不同
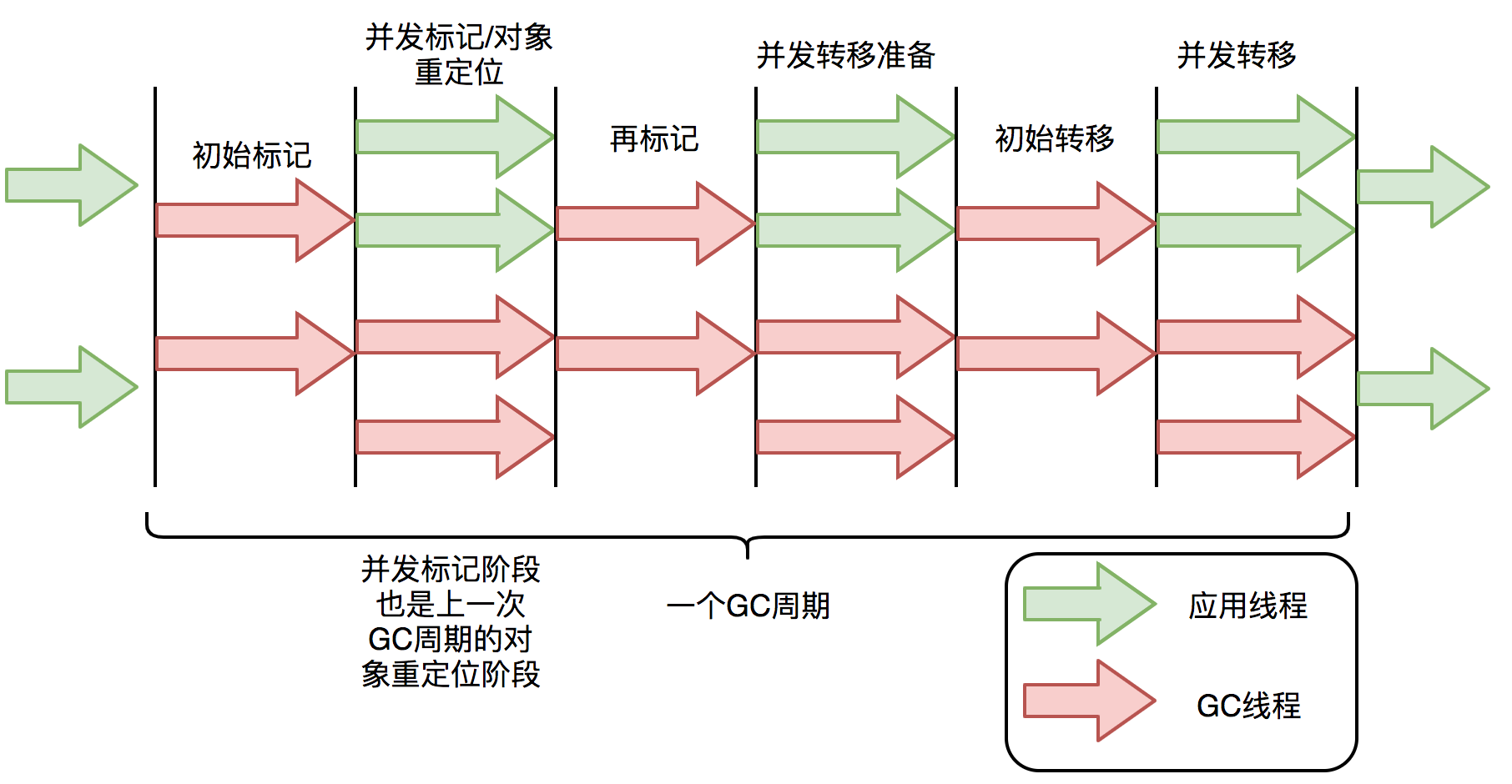
说一下ZGC的工作过程
ZGC 周期由
三个 STW 暂停:
标记开始
重新映射开始
暂停结束
和四个并发阶段组成:
标记/重新映射
并发引用处理
并发转移准备
并发转移
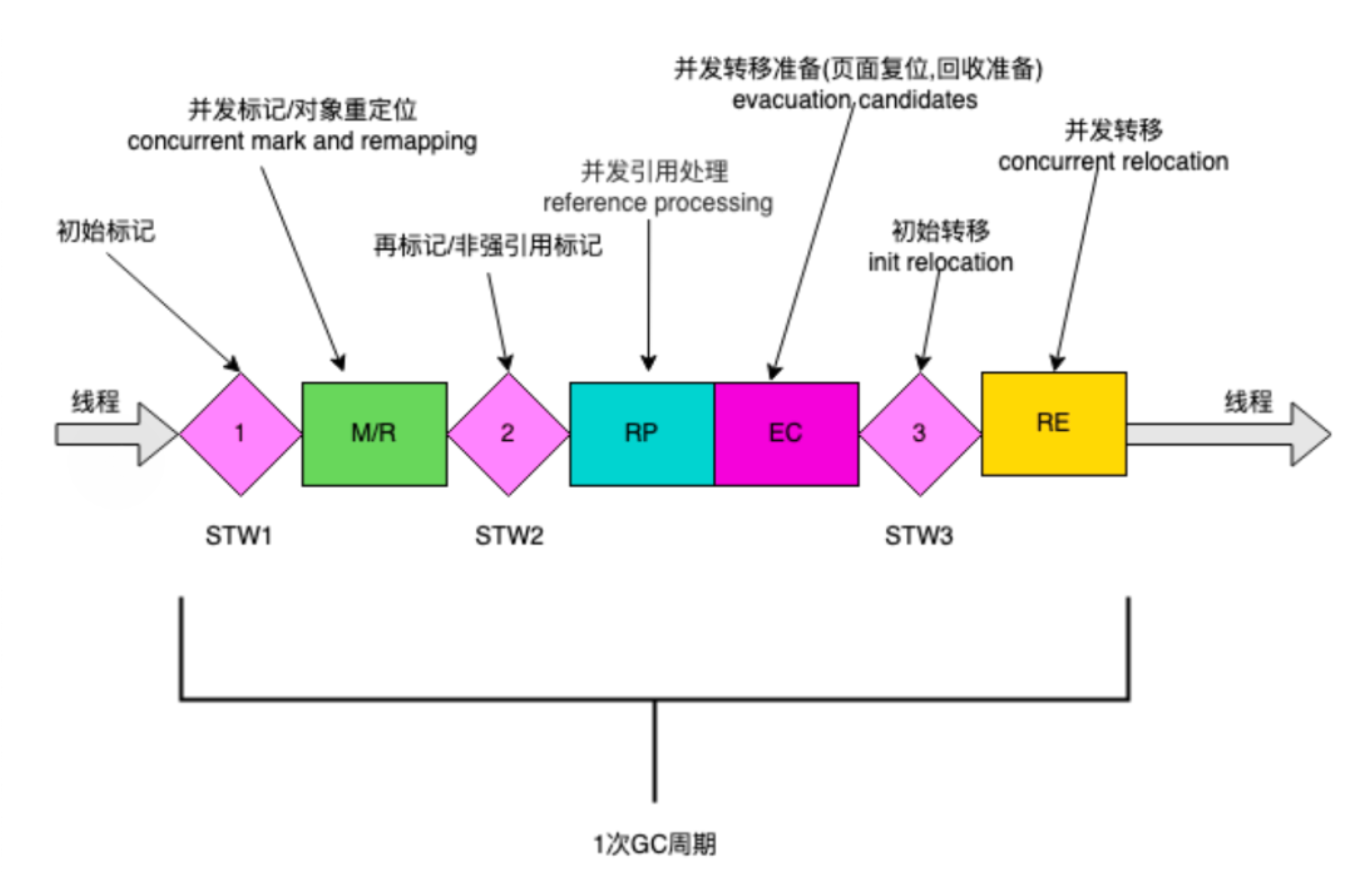
Stop-The-World 暂停阶段
- 标记开始(Mark Start)STW 暂停:这是 ZGC 的开始,进行 GC Roots 的初始标记。在这个短暂的停顿期间,ZGC 标记所有从 GC Root 直接可达的对象。
- 重新映射开始(Relocation Start)STW 暂停:在并发阶段之后,这个 STW 暂停是为了准备对象的重定位。在这个阶段,ZGC 选择将要清理的内存区域,并建立必要的数据结构以进行对象移动。
- 暂停结束(Pause End)STW 暂停:ZGC 结束。在这个短暂的停顿中,完成所有与该 GC 周期相关的最终清理工作。
并发阶段
- 并发标记/重新映射 (M/R) :这个阶段包括并发标记和并发重新映射。在并发标记中,ZGC 遍历对象图,标记所有可达的对象。然后,在并发重新映射中,ZGC 更新指向移动对象的所有引用。
- 并发引用处理 (RP) :在这个阶段,ZGC 处理各种引用类型(如软引用、弱引用、虚引用和幽灵引用)。这些引用的处理通常需要特殊的考虑,因为它们与对象的可达性和生命周期密切相关。
- 并发转移准备 (EC) :这是为对象转移做准备的阶段。ZGC 确定哪些内存区域将被清理,并准备相关的数据结构。
- 并发转移 (RE) :在这个阶段,ZGC 将存活的对象从旧位置移动到新位置。由于这一过程是并发执行的,因此应用程序可以在大多数垃圾回收工作进行时继续运行。
ZGC 的两个关键技术:指针染色和读屏障,不仅应用在并发转移阶段,还应用在并发标记阶段:
将对象设置为已标记,传统的垃圾回收器需要进行一次内存访问,并将对象存活信息放在对象头中;
而在ZGC中,只需要设置指针地址的第42-45位即可,并且因为是寄存器访问,所以速度比访问内存更快。
你就简单介绍一下垃圾回收器吧
介绍一下默认的垃圾回收器的转变吧
JDK1.8之前
对于64位系统,我们默认是Parallel Scavenge收集器+Parallel Old收集器
对于32位系统,我们默认是Serial收集器+Serial Old收集器
在JDK9以及之后
不管64位还是32位系统,我们默认的垃圾收集器都是G1收集器
其实除了默认的垃圾收集器我们还有一些其他的垃圾收集器
例如我们的ParNew收集器(Serial串行收集器的并发版本)
CMS收集器,ZGC收集器
为什么我们JDK1.8之前用Parallel Scavenge收集器呢
是因为我们的Parallel Scavenge收集器比Serial和ParNew收集器的吞吐量更大
然后你可能会问为什么不用CMS作为默认垃圾回收器?
1.因为CMS是在JDK5被引入的,JDK9被弃用,JDK14被移除
2.因为吞吐量的区别,以及垃圾回收器设计目标的区别
Paralled组合更注重吞吐量,本来Paralled吞吐量就高
而CMS的关注点是用户线程的停顿时间(提高用户体验)
为什么要用G1回收器来代替我们的Parallel回收器
G1垃圾回收器是在JDK7被引入,然后JDK9被当成了默认的垃圾回收器
首先我们就要说一下G1的特点和优点了
1.它有一个停顿预测模型,CMS可以根据设置的预测停顿时间来合理规划GC回收
2.我们之前是存储空间划分成新生代和老年代的。
但是我们的G1是划分为多个相等大小的Region,而我们的垃圾回收思想才是分代回收。
也就是物理上不分代逻辑上分代回收
3.因为我们分为多个Region,所以我们的G1垃圾回收器还有个逐步回收功能
G1垃圾回收器 会根据各个区域的垃圾回收情况来决定下一次垃圾回收的区域,这样就避免了对整个堆内存进行垃圾回收,从而降低了垃圾回收的时间
不同回收器的垃圾回收算法
Serial:新生代采用标记-复制算法,老年代采用标记-整理算法
ParNew(Serial的多线程版本):新生代采用标记-复制算法,老年代采用标记-整理算法
Parallel Scavenge:新生代采用标记-复制算法,老年代采用标记-整理算法
CMS:标记-清除算法之三色标记法
G1:Young GC、Mixed GC 用标记-复制算法、Full GC用标记-整理法
ZGC:标记-清除算法之三色标记法,并发标记 - 清除 - 整理过程中结合复制算法
什么是跨代引用
在现代垃圾回收算法中,跨代引用(Cross-Generational References)是指不同代的对象之间的引用关系
垃圾回收器通常将堆内存划分为年轻代(Young Generation)、老年代(Old Generation),甚至还有永久代(PermGen)或元空间(Metaspace),以优化内存管理和回收效率
然而,当一个代的对象引用另一个代的对象时,这种跨代引用可能会带来问题
尤其是在回收年轻代时,如何快速识别被老年代引用的对象是一个关键问题
跨代引用的问题
- 年轻代GC的高效性依赖于对象分代:
- 年轻代通常回收频率高,但扫描范围小(只扫描年轻代)。
- 如果老年代的对象引用年轻代的对象,GC需要特别处理以避免误判为垃圾。
- 全堆扫描的开销:
- 如果垃圾回收器为了追踪跨代引用,需要扫描整个老年代寻找对年轻代的引用,会导致性能大幅下降。
跨代引用该如何解决(记忆集,写屏障,根集扫描)
解决方法
解决跨代引用问题的关键在于避免全堆扫描,同时确保引用关系的正确性。
以下是常见的技术:
1. 记忆集(Remembered Set, RSet)
记忆集是一种记录跨代引用的机制,主要用于跟踪哪些老年代的对象引用了年轻代的对象。
- 定义:
-
- 每个年轻代区域都有一个对应的记忆集,用来记录老年代对象中指向该区域的引用。
- 实现方式:
-
- 通常使用卡表(Card Table)来实现。内存被划分成固定大小的“卡页”(Card Page),每个卡页对应一个字节的卡表条目。
- 当老年代对象对年轻代对象产生引用时,标记对应的卡表条目为“脏”(Dirty)。
- 优点:
-
- 垃圾回收时,GC只需要扫描记忆集中记录的卡页,而不需要扫描整个老年代,显著提高效率。
2. 写屏障(Write Barrier)
写屏障是垃圾回收器用于捕获引用关系变化的一种机制,通常在跨代引用的维护中起到核心作用。
作用:
- 在老年代对象产生新引用(或删除引用)时,通过写屏障将这些引用变化记录到记忆集中。
常见策略:
- 增量更新:当一个老年代对象引用了一个年轻代对象时,立即将老年代对象所在的卡页标记为“脏”。
- 删除插入:当老年代对象的引用被移除时,将其之前指向的年轻代对象重新标记为可能可达。
优点:
- 写屏障的开销较小,能够快速捕获跨代引用的变化
3. 根集扫描(GC Roots)
根集扫描是在GC启动时,扫描根集(GC Roots)以识别老年代引用年轻代对象的情况。
适用场景:
- 主要用于初始标记阶段。
- 当跨代引用较少时,根集扫描可以简化处理。
说一下跨代引用处理的具体流程
跨代引用处理的具体流程(以HotSpot为例)
- 分代内存模型:
-
- 堆内存分为年轻代和老年代。
- 垃圾回收器在回收年轻代(Minor GC)时需要考虑哪些对象被老年代引用。
- 写屏障捕获引用变化:
-
- 当老年代对象的字段被赋值为年轻代对象时,写屏障会将这一变化记录到记忆集中。
- GC触发时扫描记忆集:
-
- 当触发Minor GC时,GC线程会扫描记忆集,只处理被标记的“脏”卡页,而非整个老年代。
- 标记和清理:
-
- GC会通过记忆集找到被老年代引用的年轻代对象,标记这些对象为存活。
- 剩余未标记的年轻代对象将被清理回收。
优缺点分析
优点:
- 避免全堆扫描:记忆集和写屏障减少了GC扫描范围,大幅提升性能。
- 分代模型效率高:年轻代GC更加快速,老年代GC的频率更低。
- 灵活适配:记忆集的设计可根据实际需求调整大小和精度。
缺点:
- 写屏障的开销:虽然小,但在写操作频繁的场景中,写屏障仍然会引入一定的性能成本。
- 记忆集维护复杂:需要额外的内存空间存储记忆集,并对其进行维护。
- 误报问题:卡表可能记录一些不相关的“脏”卡页,需要GC进一步验证。
垃圾回收算法的那些阶段会stop the world
我们拿我们的G1垃圾回收器来举例子
标记 - 复制算法应用在 CMS 新生代(ParNew 是 CMS 默认的新生代垃圾回收器)和 G1 垃圾回收器中。标记 - 复制算法可以分为三个阶段:
- 标记阶段,即从 GC Roots 集合开始,标记活跃对象;
- 转移阶段,即把活跃对象复制到新的内存地址上;
- 重定位阶段,因为转移导致对象的地址发生了变化,在重定位阶段,所有指向对象旧地址的指针都要调整到对象新的地址上。
下面以 G1 为例,通过 G1 中标记 - 复制算法过程(G1 的 Young GC 和 Mixed GC 均采用该算法),分析 G1 停顿耗时的主要瓶颈。G1 垃圾回收周期如下图所示:
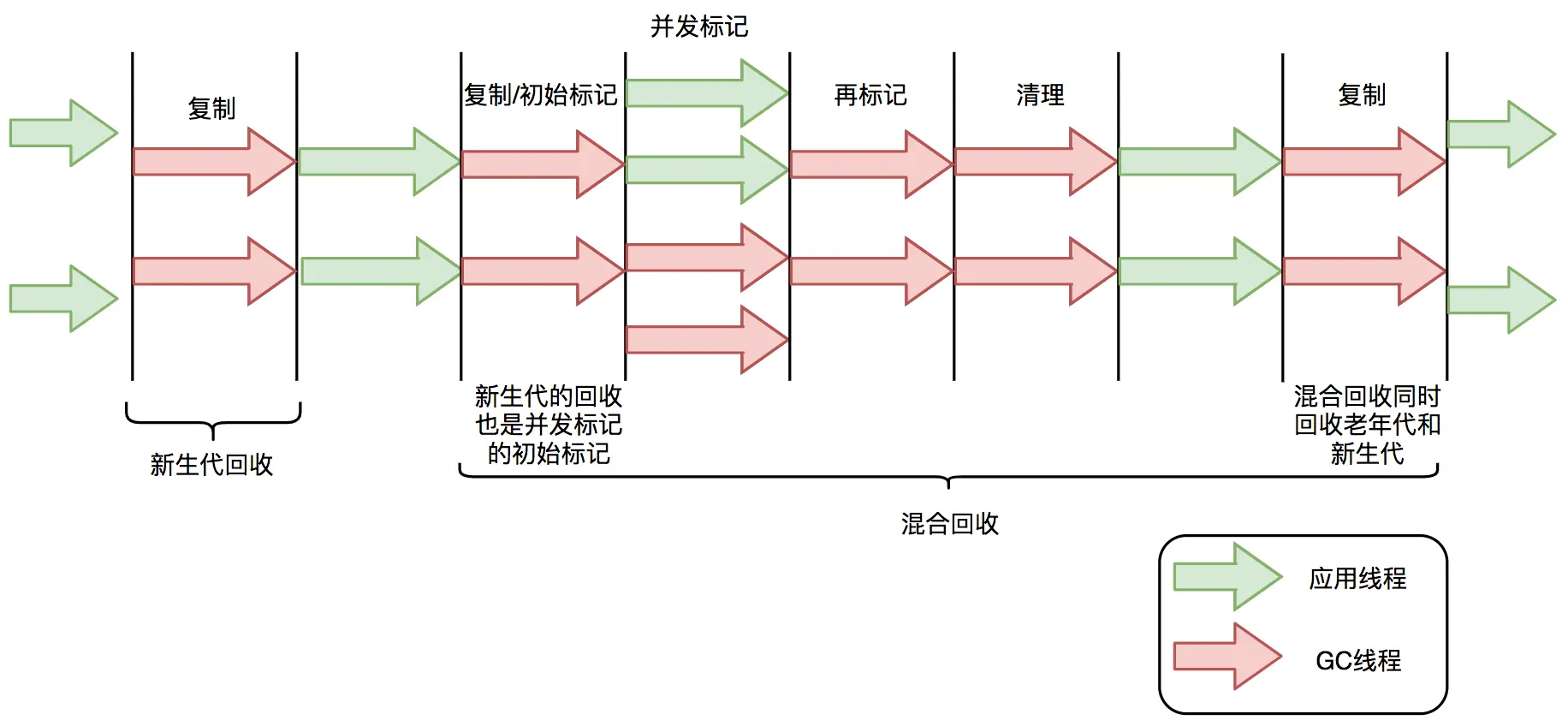
G1 的混合回收过程可以分为标记阶段、清理阶段和复制阶段。
标记阶段停顿分析
- 初始标记阶段:初始标记阶段是指从 GC Roots 出发标记全部直接子节点的过程,该阶段是 STW 的。由于 GC Roots 数量不多,通常该阶段耗时非常短。
- 并发标记阶段:并发标记阶段是指从 GC Roots 开始对堆中对象进行可达性分析,找出存活对象。该阶段是并发的,即应用线程和 GC 线程可以同时活动。并发标记耗时相对长很多,但因为不是 STW,所以我们不太关心该阶段耗时的长短。
- 再标记阶段:重新标记那些在并发标记阶段发生变化的对象。该阶段是 STW 的
清理阶段停顿分析
- 清理阶段清点出有存活对象的分区和没有存活对象的分区,该阶段不会清理垃圾对象,也不会执行存活对象的复制。该阶段是 STW 的
复制阶段停顿分析
- 复制算法中的转移阶段需要分配新内存和复制对象的成员变量。转移阶段是 STW 的,其中内存分配通常耗时非常短,但对象成员变量的复制耗时有可能较长,这是因为复制耗时与存活对象数量与对象复杂度成正比。对象越复杂,复制耗时越长。
四个 STW 过程中,初始标记因为只标记 GC Roots,耗时较短。
再标记因为对象数少,耗时也较短。清
理阶段因为内存分区数量少,耗时也较短。
转移阶段要处理所有存活的对象,耗时会较长。
因此,G1 停顿时间的瓶颈主要是标记 - 复制中的转移阶段 STW
垃圾回收器CMS和G1的区别
区别一:使用的范围不一样:
CMS 收集器是老年代的收集器,可以配合新生代的 Serial 和 ParNew 收集器一起使用
G1 收集器收集范围是老年代和新生代。不需要结合其他收集器使用
区别二:STW 的时间:
CMS 收集器以最小的停顿时间为目标的收集器。
G1 收集器可预测垃圾回收的停顿时间(建立可预测的停顿时间模型)
区别三: 垃圾碎片
CMS 收集器是使用 “标记 - 清除” 算法进行的垃圾回收,容易产生内存碎片
G1 收集器使用的是 “标记 - 整理” 算法,进行了空间整合,没有内存空间碎片
区别四:垃圾回收过程不同

区别五: CMS 会产生浮动垃圾
CMS 产生浮动垃圾过多时会退化为 serial old,效率低,因为在上图的第四阶段,CMS 清除垃圾时是并发清除的,这个时候,垃圾回收线程和用户线程同时工作会产生浮动垃圾,也就意味着 CMS 垃圾回收器必须预留一部分内存空间用于存放浮动垃圾
而 G1 没有浮动垃圾,G1 的筛选回收是多个垃圾回收线程并行 gc 的,没有浮动垃圾的回收,在执行‘并发清理’步骤时,用户线程也会同时产生一部分可回收对象,但是这部分可回收对象只能在下次执行清理时才会被回收。如果在清理过程中预留给用户线程的内存不足就会出现‘Concurrent Mode Failure’, 一旦出现此错误时便会切换到 SerialOld 收集方式
什么情况下使用CMS?什么情况下使用G1?
CMS 适用场景:
- 低延迟需求:适用于对停顿时间要求敏感的应用程序。
- 老生代收集:主要针对老年代的垃圾回收。
- 碎片化管理:容易出现内存碎片,可能需要定期进行 Full GC 来压缩内存空间。
G1 适用场景:
- 大堆内存:适用于需要管理大内存堆的场景,能够有效处理数 GB 以上的堆内存。
- 对内存碎片敏感:G1 通过紧凑整理来减少内存碎片,降低了碎片化对性能的影响。
- 比较平衡的性能:G1 在提供较低停顿时间的同时,也保持了相对较高的吞吐量
G1回收器的特色是什么?
G1 的特点:
G1 最大的特点是引入分区的思路,弱化了分代的概念
合理利用垃圾收集各个周期的资源,解决了其他收集器、甚至 CMS 的众多缺陷。
G1 相比较 CMS 的改进:
算法:G1 基于标记 -- 整理算法,不会产生空间碎片,在标记 - 清除算法执行后,被回收对象的内存会分散留下许多不连续小块内存,即内存碎片。而 G1 的标记 - 整理算法通过移动存活对象,让内存连续,所以不会产生碎片,所以在分配大对象时,不会因无法得到连续的空间,而提前触发一次 FULL GC (内存碎片过多,就会导致我们没有足够的连续内存分配大对象)
停顿时间可控:G1 可以通过设置预期停顿时间(Pause Time)来控制垃圾收集时间避免应用雪崩现象
并行与并发:G1 能更充分的利用 CPU 多核环境下的硬件优势,来缩短 stop the world 的停顿时间
GC只会对堆进行回收吗
JVM 的垃圾回收器不仅仅会对堆进行垃圾回收,它还会对方法区进行垃圾回收
- 堆(Heap):堆是用于存储对象实例的内存区域。大部分的垃圾回收工作都发生在堆上,因为大多数对象都会被分配在堆上,而垃圾回收的重点通常也是回收堆中不再被引用的对象,以释放内存空间
- 方法区(Method Area):方法区是用于存储类信息、常量、静态变量等数据的区域。虽然方法区中的垃圾回收与堆有所不同,但是同样存在对不再需要的常量、无用的类信息等进行清理的过程
相关文章:

JVM之垃圾回收器
部分内容来源:JavaGuide,二哥Java 垃圾回收器快速复习 JDK 8: Parallel Scavenge(新生代) Parallel Old(老年代) JDK8: Serial Serial Old JDK 9 ~ JDK22: G1 新生代:标记-复制算法 老年代&…...

【K8S学习之生命周期钩子】详细了解 postStart 和 preStop 生命周期钩子
0. 参考 Kubernetes容器生命周期 —— 钩子函数详解(postStart、preStop) - 人艰不拆_zmc - 博客园详解Kubernetes Pod优雅退出 - 人艰不拆_zmc - 博客园 1. Kubernetes 生命周期钩子概述 在 Kubernetes 中,生命周期钩子(Lifec…...

深度强化学习有什么学习建议吗?
什么是强化学习? 广泛地讲,强化学习是机器通过与环境交互来实现目标的一种计算方法。机器和环境的一 轮交互是指,机器在环境的一个状态下做一个动作决策,把这个动作作用到环境当中,这个环 境发生相应的改变并且将相应…...

Flutter - UIKit开发相关指南 - 控制器,主题,表单
环境 Flutter 3.29 macOS Sequoia 15.4.1 Xcode 16.3 控制器(ViewControllers) 在UIKit中,通过ViewController控制数据在视图上展现,多个ViewController组合在一起构建复杂的用户界面。在Flutter中,因为所有都是Widget,所以ViewController相关的功能也由Widget来承担。 生命周…...

嵌入式软件开发常见warning之 warning: implicit declaration of function
文章目录 🧩 1. C 编译流程回顾(背景)📍 2. 出现 warning 的具体阶段:**编译阶段(Compilation)**🧬 2.1 词法分析(Lexical Analysis)🌲 2.2 语法分…...

AI赋能安全生产,推进数智化转型的智慧油站开源了。
AI视频监控平台简介 AI视频监控平台是一款功能强大且简单易用的实时算法视频监控系统。它的愿景是最底层打通各大芯片厂商相互间的壁垒,省去繁琐重复的适配流程,实现芯片、算法、应用的全流程组合,从而大大减少企业级应用约95%的开发成本。用…...
毛子整洁架构(测试))
(六)毛子整洁架构(测试)
文章目录 项目地址一、 项目地址 教程作者:教程地址: 代码仓库地址: 所用到的框架和插件: dbt airflow一、...
实现讲解附带源码)
Vue3 Echarts 3D饼图(3D环形图)实现讲解附带源码
文章目录 前言一、准备工作1. 所需工具2. 引入依赖方式一:CDN 快速引入方式二:npm 本地安装(推荐) 二、实现原理解析三、echarts-gl 3D插件 使用回顾grid3D 常用通用属性:series 常用通用属性:surface&…...

Java大师成长计划之第20天:Spring Framework基础
📢 友情提示: 本文由银河易创AI(https://ai.eaigx.com)平台gpt-4o-mini模型辅助创作完成,旨在提供灵感参考与技术分享,文中关键数据、代码与结论建议通过官方渠道验证。 在Java开发领域,Spring …...

WebSocket集成方案对比
WebSocket集成方案对比与实战 架构选型全景图 #mermaid-svg-BEuyOkkoP6cFygI0 {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-BEuyOkkoP6cFygI0 .error-icon{fill:#552222;}#mermaid-svg-BEuyOkkoP6cFygI0 .er…...

新能源汽车电池加热技术:传统膜加热 vs. 脉冲自加热
在新能源汽车的普及过程中,低温环境下的电池性能一直是影响用户体验的关键问题。当温度低于0C时,锂电池的内阻增大,充放电效率下降,续航缩短,甚至可能因低温充电导致电池损坏。 引言:电池低温性能衰减机理 …...

C++ 状态模式详解
状态模式(State Pattern)是一种行为设计模式,它允许一个对象在内部状态改变时改变其行为,使对象看起来像是改变了其类。 核心概念 设计原则 状态模式遵循以下设计原则: 单一职责原则:将状态相关行为分离…...

1. 使用 IntelliJ IDEA 创建 React 项目:创建 React 项目界面详解;配置 Yarn 为包管理器
1. 使用 IntelliJ IDEA 创建 React 项目:创建 React 项目界面详解;配置 Yarn 为包管理器 🧩 使用 IntelliJ IDEA 创建 React 项目(附 Yarn 配置与 Vite 建议)📷 创建 React 项目界面详解1️⃣ Name…...

【深度学习】目标检测算法大全
目录 一、R-CNN 1、R-CNN概述 2、R-CNN 模型总体流程 3、核心模块详解 (1)候选框生成(Selective Search) (2)深度特征提取与微调 2.1 特征提取 2.2 网络微调(Fine-tuning) …...

【node】6 包与npm
前言 目标 1 了解什么是包 2 怎么使用npm下载包 #mermaid-svg-Ur0d2uCdQeAQOJjW {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-Ur0d2uCdQeAQOJjW .error-icon{fill:#552222;}#mermaid-svg-Ur0d2uCdQeAQOJjW .erro…...

【C++进阶篇】多态
深入探索C多态:静态与动态绑定的奥秘 一. 多态1.1 定义1.2 多态定义及实现1.2.1 多态构成条件1.2.1.1 实现多态两个必要条件1.2.1.2 虚函数1.2.1.3 虚函数的重写/覆盖1.2.1.4 协变1.2.1.5 析构函数重写1.2.1.6 override和final关键字1.2.1.7 重载/重写/隐藏的对⽐ 1…...

计算机网络|| 路由器和交换机的配置
一、实验目的 1. 了解路由器和交换机的工作模式和使用方法; 2. 熟悉 Cisco 网络设备的基本配置命令; 3. 掌握 Cisco 路由器的基本配置方式及配置命令; 4. 掌握路由器和交换机的基本配置与管理方法。 二、实验环境 1. 运行 Windows 操作…...

图形化编程如何从工具迭代到生态重构?
一、技术架构的范式突破 在图形化编程领域,技术架构的创新正在重塑行业格局。iVX 作为开源领域的领军者该平台通过图形化逻辑设计,将传统文本编程需 30 行 Python 代码实现的 "按钮点击→条件判断→调用接口→弹窗反馈" 流程,简化…...

歌曲《忘尘谷》基于C语言的歌曲调性检测技术解析
引言 在音乐分析与数字信号处理领域,自动检测歌曲调性是一项基础且关键的任务。本文以C语言为核心,结合音频处理库(libsndfile)和快速傅里叶变换库(FFTW),探讨如何实现调性检测,并通…...

Spring Boot 使用Itext绘制并导出PDF
最终效果 其实可以加分页,但是没有那么精细的需求,所以我最后就没有加,有兴趣的可以尝试下。 项目依赖 <!-- Spring Boot 版本有点老 --> <spring-boot.version>2.3.12.RELEASE</spring-boot.version><!-- 依…...

医学影像处理与可视化:从预处理到 3D 重建的技术实践
🧑 博主简介:CSDN博客专家、CSDN平台优质创作者,高级开发工程师,数学专业,10年以上C/C++, C#, Java等多种编程语言开发经验,拥有高级工程师证书;擅长C/C++、C#等开发语言,熟悉Java常用开发技术,能熟练应用常用数据库SQL server,Oracle,mysql,postgresql等进行开发应用…...

用 openssl 测试 tls 连接
以 baidu 为例,命令行为: openssl s_client -tlsextdebug -connect baidu.com:443 得到的输出为: CONNECTED(00000003) TLS server extension "renegotiation info" (id65281), len1 0000 - 00 …...

Matlab 汽车制动纵向动力学模型和PID控制
1、内容简介 Matlab 228-汽车制动纵向动力学模型和PID控制 可以交流、咨询、答疑 2、内容说明 略 3、仿真分析 略 4、参考论文 略...

重塑JavaScript原生功底=>【构造函数篇】
概念:用于创建对象的函数称之为构造函数 作用:构造函数在 JavaScript 中是用来创建对象的最根本操作。 语法:当一个函数通过 new 关键字 来调用的话,那么这个函数就是一个构造函数。 场景:构造函数是专门用来创建对象…...
)
从0到1:Python机器学习实战全攻略(8/10)
摘要:通过本文的学习,我们深入探索了 Python 机器学习从入门到实战的精彩世界。从 Python 在机器学习领域的独特优势,到机器学习的核心概念,再到各种强大工具库的应用,以及实战项目的完整演练,我们逐步揭开…...

[计算机网络]网络层
文章目录 408考研大纲IPV4数据报格式协议: IPv4 地址DHCP协议IP组播 408考研大纲 IPV4数据报格式 协议: 1:ICMP IPv4 地址 特殊IP 网络号全1又称直接广播地址,32位全1又称受限广播地址 因为255.255.255.255只能在本网络内广播,路由器不许通过它&…...

华为行业认证是什么?如何考取华为行业认证?
据IDC预测,2027年全球数字化转型市场规模将突破3.4万亿美元,而中国将成为增长最快的市场之一。然而,85%的企业在转型中面临核心人才短缺的困境,尤其缺乏兼具技术能力与行业洞察的复合型人才! 讯方技术作为华为授权培训…...

Kotlin与Qt跨平台框架深度解析:业务逻辑共享与多语言集成
简介 Kotlin Multiplatform和Qt作为两大主流跨平台开发框架,各自在技术生态和应用场景上展现出独特优势。Kotlin Multiplatform专注于业务逻辑的跨平台共享,通过Kotlin语言的统一特性实现高达80%的代码复用率,特别适合移动应用和Web服务的业务逻辑开发。而Qt则凭借其强大的…...

基于LNMP架构的个人博客系统部署
一、项目概述 本项目旨在通过两台服务器(Server-Web和Server-NFS-DNS)搭建一个基于LNMP(Linux、Nginx、MySQL、PHP)架构的个人博客系统。通过域名访问自建网站,同时实现资源文件的共享和DNS解析功能。 二、服务器配置…...

Python训练打卡Day21
常见的降维算法: # 先运行预处理阶段的代码 import pandas as pd import pandas as pd #用于数据处理和分析,可处理表格数据。 import numpy as np #用于数值计算,提供了高效的数组操作。 import matplotlib.pyplot as plt #用于绘…...
 与 Oracle 序列对比)
PostgreSQL 序列(Sequence) 与 Oracle 序列对比
PostgreSQL 序列(Sequence) 与 Oracle 序列对比 PostgreSQL 和 Oracle 都提供了序列(Sequence)功能,但在实现细节和使用方式上存在一些重要差异。以下是两者的详细对比: 一 基本语法对比 1.1 创建序列 PostgreSQL: CREATE [ { TEMPORARY | TEMP } |…...

直播:怎样用Agentic AI搭建企业AI应用?5.24日,拆解新一代“智能客服系统”案例
2025 DeepSeek掀起了中国企业的AI落地浪潮! 随着应用的深入,AI的落地技术正在快速演化。 3月,Manus一夜爆火,让AI Agent更加引人关注。 从生成式AI,到Agentic AI(代理式AI)。 AI正在从只能生…...

《Asp.net Mvc 网站开发》复习试题
一.选择题(注:每题2分,共 54分,只能在下列表格中,填写每个题目相应的正确字母选项) 01: 02: 03: 04: 05: 06: 07: 08: 09: 10: 11: 12: 13: 14: 15: 16: 17: 18: 19: 20: 21: 22: 23: 24: 25: 26: :27: 1. Mvc让软件…...
:货仓选址)
算法题(145):货仓选址
审题: 本题需要我们找出距离之和的最小值 思路: 方法一:贪心 贪心策略:将货仓建立在所有商店的中间可以达到距离之和最小 因为每家商店都需要接收一车商品,所以这里的距离之和指的是从货仓到每一家商店的路线的距离之和…...
)
✅ TensorRT Python 安装精简流程(适用于 Ubuntu 20.04+)
安装 TensorRT Python 轮子的步骤 确保 pip 和 wheel 模块已更新并安装: 参考链接 python3 -m pip install --upgrade pip python3 -m pip install wheel 1. 确认环境要求 Python:版本 3.8 - 3.13 OS:Ubuntu 20.04 或 Windows 10 CPU&a…...

MYSQL 全量,增量备份与恢复
目录 一 数据备份的重要性 1 数据备份的重要性 2 数据库备份类型 2.1 从物理与逻辑的角度分类 2.2. 从数据库的备份策略角度分类从数据库的备份策略角度,数据库的备份可分为完全备份、差异备份和增量备份。 3 常见的备份方法 3.1 物理冷备份 物理冷备份时需要在数据库处…...

10. Spring AI PromptTemplate:从模板到高级技巧
1、前言 如果学到了这里,相信大部分人对Prompt并不陌生了。 在 Spring AI 的世界里,与强大的语言模型进行交互的基石便是 Prompt(提示语)。它不仅仅是你输入给 AI 的一段文本,更是你与智能对话的桥梁,是你唤醒模型潜能的关键指令。理解 Prompt 的本质、构建原则以及在 …...

基于OpenCV的人脸识别:Haar级联分类器
文章目录 引言一、环境准备二、代码实现1. 图像加载与预处理2. 加载Haar级联分类器3. 人脸检测核心参数详解4. 结果显示与标注 三、效果优化建议四、完整代码五、总结 引言 本文将带你一步步实现一个简单但实用的人脸检测程序,使用Python和OpenCV库。 一、环境准备…...

Git安装教程及常用命令
1. 安装 Git Bash 下载 Git 安装包 首先,访问 Git 官方网站 下载适用于 Windows 的 Git 安装包。 安装步骤 启动安装程序:双击下载的 .exe 文件,启动安装程序。选择安装选项: 安装路径:可以选择默认路径࿰…...

【PmHub后端篇】Skywalking:性能监控与分布式追踪的利器
在微服务架构日益普及的当下,对系统的性能监控和分布式追踪显得尤为重要。本文将详细介绍在 PmHub 项目中,如何使用 Skywalking 实现对系统的性能监控和分布式追踪,以及在这过程中的一些关键技术点和实践经验。 1 分布式链路追踪概述 在微服…...

ChromeDriver 技术生态与应用场景深度解析
ChromeDriver 技术生态与应用场景深度解析 随着 Web 自动化测试、运维和数据采集需求的不断增长,ChromeDriver 及其相关技术栈在各行业中扮演着举足轻重的角色。本文将从技术选型、语言适配、典型场景、技术延伸等维度,结合最新行业趋势与实践经验&…...

链表面试题6之回文结构
经过前几道题的铺垫,那么我们也是来到了链表的第六关。这也是一道非常经典的题目。 目录 逆置法 数组法 那么对于这道题目,我们要判断回文结构,实际上就是判断链表对不对称。这种类型的题目我们好像在哪里见过,对了,…...

ASP.NET Core Identity框架使用指南
文章目录 前言一、核心功能二、核心组件三、使用1)创建项目2)安装必要 NuGet包3)配置数据库连接字符串4)用户与角色实体定义4)配置数据库上下文5) 注册服务6)数据库迁移与初始化7)用…...

Hugging Face推出了一款免费AI代理工具,它能像人类一样使用电脑
Hugging Face推出了一款免费AI代理工具,它能像人类一样使用电脑。 这款工具名为Open Computer Agent(开放计算机代理),可模拟真实的电脑操作。 无需安装,在浏览器中即可运行。 以下是一些信息: - Open C…...

一.Gitee基本操作
一.初始化 1.git init初始化仓库 git init 用于在当前目录下初始化一个本地 Git 仓库,让这个目录开始被 Git 跟踪和管理。 生成 .git 元数据目录,从而可以开始进行提交、回退、分支管理等操作。 2.git config user.name/user.email配置本地仓库 # 设置…...

24、DeepSeek-V3论文笔记
DeepSeek-V3论文笔记 **一、概述****二、核心架构与创新技术**0.汇总:1. **基础架构**2. **创新策略** 1.DeepSeekMoE无辅助损失负载均衡DeepSeekMoE基础架构无辅助损失负载均衡互补序列级辅助损失 2.多令牌预测(MTP)1.概念2、原理2.1BPD2.2M…...

神经网络初步学习——感知机
一、前言 神经网络,顾名思义,它与我们大脑生物学里面讲到的神经元有关联。前辈们在研究早期人工智能的时候,就开始过我们的“交叉融合”,他们思考能不能把我们的人工智能的学习模式改造成我们人脑中神经元之间的学习方式——于是乎…...

在Text-to-SQL任务中应用过程奖励模型
论文标题 Reward-SQL: Boosting Text-to-SQL via Stepwise Reasoning and Process-Supervised Rewards 论文地址 https://arxiv.org/pdf/2505.04671 代码地址 https://github.com/ruc-datalab/RewardSQL 作者背景 中国人民大学,香港科技大学广州,阿…...

Python的安装使用
一、下载Python安装包 下载python安装包,可以直接访问官网地址:https://www.python.org/downloads/ 通过页面咱们直接下载最新版本的python安装包即可,python3.13.3。在页面的下方也可下载安装之前的版本,目前咱们按最新版本安装…...

mapreduce-wordcount程序2
WordCount案例分析 给定一个路径,统计这个路径下所有的文件中的每一个单词的出现次数。 其中,需要我们去实现代码的部分是:map函数和reduce函数。它们各自的作用是: map函数的入参是kv结构,k是偏移量,v是一…...