【深度学习】目标检测算法大全
目录
一、R-CNN
1、R-CNN概述
2、R-CNN 模型总体流程
3、核心模块详解
(1)候选框生成(Selective Search)
(2)深度特征提取与微调
2.1 特征提取
2.2 网络微调(Fine-tuning)
(3)后端分类与边框回归
3.1 SVM 分类器
3.2 边框回归(BBox Regression)
4、训练与推理流程一览
5、模型性能与瓶颈
6、对后续模型的启示
二、SPPNet
1、模型动机
2、网络整体结构
3、数学原理与细节
4、训练与微调策略
5、性能评估
6、优缺点与局限
(1)优点
(2)缺点
7、对后续模型的启示
三、FastRCNN
1、Fast R-CNN 概述
2、网络结构
3、关键技术点
4、训练与推理流程
5、优缺点分析
6、后续演进
四、FasterRCNN
1、Faster R-CNN 概述
2、整体网络结构
3、关键技术点
(1)区域建议网络(RPN)
(2)多任务联合训练
(3)RoI Pooling 与后端 Head
4、训练与推理流程
(1)训练阶段
(2)推理阶段
5、优势与挑战
(1)优点
(2)缺点
6、后续演进
五、YOLO
1、YOLO 概述
2、基础网络结构(以 YOLOv1 为例)
3、关键技术点
4、训练与推理流程
5、优缺点分析
6、后续演进与分支
六、SSD
1、模型动机
2、网络整体结构
3、关键技术点
4、训练与推理流程
5、性能与优缺点
6、后续演进
七、DETR
1、动机背景
2、整体架构概览
3、核心组件详解
(1)Object Queries
(2)注意力机制
(3)位置编码(Positional Encoding)
(4)匈牙利匹配(Hungarian Matching)
(5)Set Prediction Loss
4、训练与推理流程
5、优缺点对比
6、后续改进与演进
一、R-CNN
1、R-CNN概述
R-CNN由Ross Girshick等人在2014年提出,是首批将深度卷积神经网络引入目标检测的经典方法。它将对象检测问题分解为“候选区域生成+分类+回归”三步走流程,有效地利用了深度特征,显著提升了检测精度,但也暴露出计算效率低的问题。
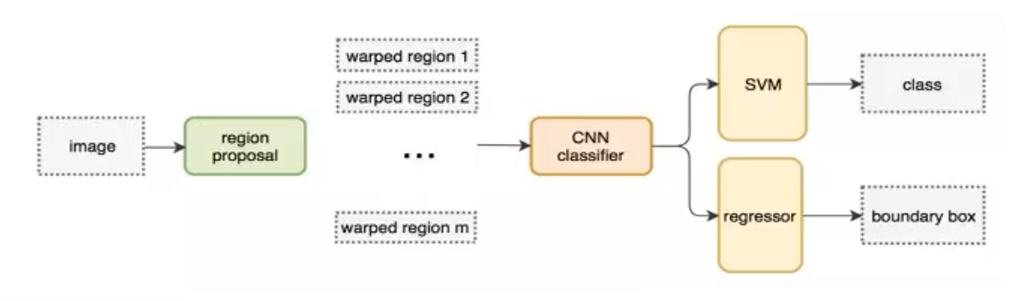
2、R-CNN 模型总体流程
R-CNN 将目标检测拆分为三大阶段:
-
候选框生成(Selective Search)
-
深度特征提取 & 微调(CNN + Fine-tune)
-
后端分类与回归(SVM + BBox Regression)
在推理时,依次执行以上三步,最终得到检测框与类别。
3、核心模块详解
(1)候选框生成(Selective Search)
-
原理:结合图像分割(Felzenszwalb 算法)和贪心区域合并,先基于颜色、纹理、尺寸、填充比等多种相似度逐层合并超像素;
-
输出:每幅图约 2,000 个高召回率的候选框,IoU 覆盖率可达 90% 以上。loU:交并比
-
复杂度:O(n log n),在 CPU 上每图耗时 ≈2 秒。

(2)深度特征提取与微调
2.1 特征提取
-
网络结构:采用 ImageNet 上预训练的 AlexNet 或 ZF-Net,去掉最后的分类层,仅保留到 fc7(4096 维特征)。
-
输入处理:对每个候选框执行:
-
裁剪:从原图裁剪出 bbox 区域;
-
Warp:双线性插值将裁剪区域缩放至固定的 227×227;
-
前向传播:单独将每个 patch 送入 CNN,提取 fc7 特征。
-
-
计算量:每个候选框一次完整的 227×227→conv→pool→fc 计算,推理时≈2,000次,导致极高的计算开销。
2.2 网络微调(Fine-tuning)
-
目标:使预训练分类网络更适应目标检测的特征分布;
-
流程:
-
用候选框 patch 及其对应的真实标签(正样本 IoU ≥0.5,负样本 IoU ≤0.3)构成训练集;
-
定义多分类交叉熵损失,微调网络最后两层(fc6、fc7)及分类层;
-
学习率较小(如原 lr 的 0.1–0.01),以防过拟合。
-
-
效果:特征在检测任务上表现更优,但训练时间仍需数小时至十数小时。
(3)后端分类与边框回归
3.1 SVM 分类器
-
训练:对每个类别训练一个 one-vs-all 线性 SVM,损失:
-
xi:CNN 提取的 4096 维特征;
-
:正负样本标签;
-
C:正则化权重。
-
-
样本:正样本 IoU ≥0.5,负样本 IoU ∈ [0.1, 0.5);对负样本进行难例挖掘(bootstrapping),过滤易分类样本。
3.2 边框回归(BBox Regression)
-
目标:将候选框
校正到更精确的 ground-truth 框
;
-
回归参数:
-
学习:对每个类别训练一个线性回归器,最小化平滑 L1 损失:
4、训练与推理流程一览
| 阶段 | 步骤 |
|---|---|
| 训练 | 1. 生成候选框; 2. 裁剪 Warp → CNN 微调; 3. 提取 fc7 特征 → 训练 SVM; 4. 用正样本训练边框回归器。 |
| 推理 | 1. 生成候选框; 2. 对每个框 Warp → CNN 前向 → 提取特征; 3. SVM 分类得分 + 回归偏移; 4. NMS 去重。 |
5、模型性能与瓶颈
-
检测精度
-
在 PASCAL VOC 2007 上,R-CNN mAP 可达 58.5%(AlexNet)、62.2%(ZF-Net);
-
-
速度与资源
-
训练:微调+特征提取+SVM 训练,整个流水线需数天;
-
推理:每张图约需 47s(CPU)或 10s(GPU);
-
存储:需缓存所有候选框的 4096D 特征(数 GB)。
-
-
瓶颈分析
-
重复卷积:2000 个候选框各自前向,卷积计算完全冗余;
-
多阶段训练:微调、特征提取、SVM、回归器四步不同目标,难以端到端优化;
-
候选框依赖:Selective Search 慢且无法并行 GPU 加速。
-
6、对后续模型的启示
-
共享特征计算:Fast R-CNN 引入 RoI Pooling,整图一次卷积后共享特征,解决了重复计算;
-
端到端训练:Fast R-CNN 及 Faster R-CNN 通过多任务损失实现单阶段训练;
-
候选框网络化:Faster R-CNN 的 RPN 将 region proposal 也集成到网络,进一步加速;
-
空间对齐精度:Mask R-CNN 用 RoIAlign 消除量化误差,提升小目标检测与分割精度。
二、SPPNet
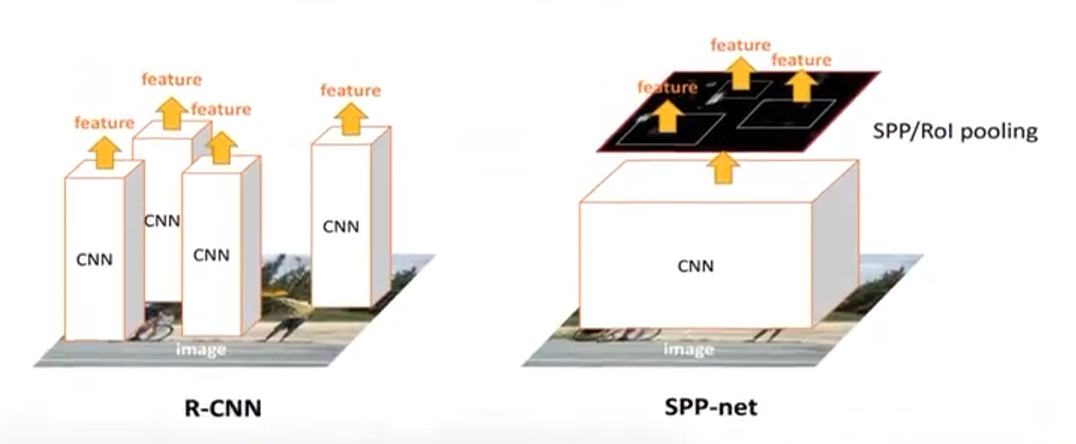
1、模型动机
传统 CNN(如 AlexNet、ZF-Net)在处理目标检测或图像检索时,需要将输入裁剪或变形到固定尺寸,才能接入全连接层。这带来两个主要问题:
-
形变失真:对长宽比差异大的图像或候选区域,Warp 变形会丢失部分几何信息;
-
重复计算:R-CNN 对每个候选框都要做一次完整的前向传播,极其低效。
SPPNet 的核心动机便是:
- 一张图片直接全部进行卷积,卷积后再考虑从特征图上裁剪2000个子特征图,比R-CNN计算2000次卷积计算量减少了很多。裁剪子特征图是依照原图的2000个候选框所在原图的位置,在总的特征图上进行裁剪作为某个候选框的特征图。这时候,不同候选框的特征图的大小是不相同的。多尺度池化统一特征图大小。
-
解除输入尺寸限制;
-
在 卷积特征图 上直接进行多尺度池化,实现对不同大小 ROI 的统一表征;
-
保留 CNN 的强大特征表达,同时大幅减少重复计算。
2、网络整体结构
输入:任意尺寸图像│
多层卷积 + 池化 → 特征图 F(尺寸为 H×W×C)│
┌──────────────────────────────────────────┐
│ 空间金字塔池化层 SPP(F) │
│ ┌── Level 1: 1×1 划分 → 每格 max-pool │
│ ├── Level 2: 2×2 划分 → 每格 max-pool │
│ ├── Level 3: 3×3 划分 → 每格 max-pool │
│ └── Level 4: 6×6 划分 → 每格 max-pool │
└──────────────────────────────────────────┘│
向量拼接 → 固定长度特征向量│
FC6 → FC7 → 分类 & 边框回归
-
卷积主干:通常使用与 R-CNN 相同的预训练网络(AlexNet、ZF-Net),只去掉最后的 FC 层。
-
SPP 层:在 F 上以多种网格尺寸(如 1×1、2×2、3×3、6×6)做 max-pooling,每个尺度产生
个区域的池化值,并将所有尺度结果串联。
-
输出维度:若 F 的通道数为 C,则各尺度输出通道总数为
该固定长度特征向量即可接入后续 FC。
3、数学原理与细节
-
SPP 池化区域计算
对于特征图大小为 (H,W),在第级金字塔(划分为
)中,第
个子网格的空间范围为
对此区域在通道维做 max-pooling,得到一个长度为 C 的向量。
-
梯度反向传播
SPP 层中每个子网格的 max-pooling 对应一个可微分的操作,最大值所在位置在反向时获得梯度,其他位置梯度为 0。这样上层的损失能正确传至主干网络。 -
与单尺度池化的比较
-
传统 RoI Pooling 仅做单个尺度(如 7×7)池化;
-
SPP 在多个尺度融合上下文信息,兼具全局与局部表征,有助于多尺寸目标的检测。
-
4、训练与微调策略
-
预训练
-
在 ImageNet 上训练主干卷积部分,得到基础权重。
-
-
候选框生成
-
使用 Selective Search 或 EdgeBoxes 等算法生成 Region Proposals。
-
-
共享卷积特征提取
-
整图一次前向卷积,得到特征图 F;
-
对每个 RoI 在 F 上进行 SPP 池化,避免了 R-CNN 对每个 RoI 重复前向。
-
-
FC 层微调
-
将 SPP 层输出送入 FC6、FC7,联合微调这些层及主干的后几层;
-
损失函数同 Fast R-CNN,包含分类交叉熵与回归平滑 L1,两者加权求和。
-
-
学习率与训练批次
-
通常先冻结 backbone,仅微调 FC;
-
再放开 backbone 后几层,使用较小学习率(如 0.001→0.0001)做细调;
-
每批采样若干图像和若干 RoI(例如 2 图 × 128 RoI)。
-
5、性能评估
| 方法 | PASCAL VOC07 mAP | GPU 推理速度 |
|---|---|---|
| R-CNN | 58.5% (AlexNet) | ≈0.5 FPS |
| SPPNet | 59.2% (ZF-Net) | ≈8 FPS |
| Fast R-CNN | 66.9% (ZF-Net) | ≈5 FPS |
-
SPPNet 相比 R-CNN,在 mAP 上持平或略增,同时速度提升约 16 倍。
-
与后来端到端的 Fast R-CNN 相比,SPPNet 在速度上仍有优势,但准确率略低,因为 RoI Pooling 的设计及训练流程更成熟。
6、优缺点与局限
(1)优点
-
任意尺寸支持:无需裁剪 Warp,图像及 RoI 保持原始比例;
-
多尺度上下文融合:不同金字塔层兼顾全局与细节;
-
高效共享计算:整图卷积一次完成,大幅降低重复量。
(2)缺点
-
外部候选框依赖:仍需 Selective Search,速度瓶颈未彻底解决;
-
金字塔固定模式:预设的层数和网格尺寸不够自适应;
-
内存与计算:SPP 输出维度大(如 C×50),可能导致 FC 计算量和内存占用增加。
7、对后续模型的启示
-
RoI Pooling:Fast R-CNN 将 SPP 简化为单尺度,使代码实现更直观;
-
RPN:Faster R-CNN 继承 SPPNet 的共享特征思想,把候选框生成也 “网络化”;
-
RoIAlign:Mask R-CNN 在 Pooling 对齐上更精细,解决量化误差;
-
自适应池化:后续工作(如 TridentNet)探索动态或可学习的多尺度池化方案。
三、FastRCNN
1、Fast R-CNN 概述
Fast R-CNN 由 Ross Girshick 于 2015 年提出,旨在在保持高精度的同时,进一步加速 R-CNN 系列模型的检测速度。它结合了 R-CNN 和 SPPNet 的思想,引入了 RoI Pooling 操作,使得所有候选区域共享整图一次卷积特征,并能在网络端到端地联合训练分类和回归分支。
改进点:提出一个Rol pooling,然后整合整个模型,把CNN、SPP变换层、分类器、bbox回归几个模块一起训练。
2、网络结构
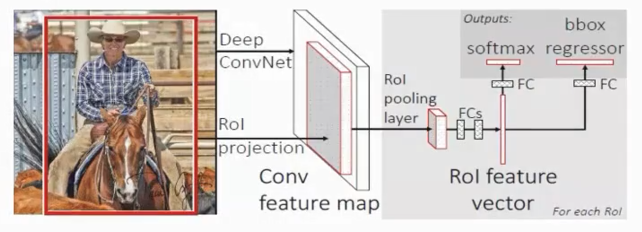
整体可分为以下几个模块(见下图示意):
输入图像─────────────────────────────────┐│ │
卷积 / 池化 层(backbone,如 VGG16)│ 候选框
特征图 ──────┐│ │RoI Pooling ───────────────────┴│全连接层(FC6→FC7)│┌────────┴────────┐│ │
分类分支 (Softmax) 边框回归分支 (BBox Regression)
-
Backbone(主干网络)
-
常用 VGG16、ZFNet 等预训练网络的前若干层(直到 conv5)
-
对整张图只做一次前向传播,输出高维特征图。
-
-
Region Proposals
-
输入:使用外部算法(如 Selective Search)生成约 2,000 个候选框。
-
这些候选框具有相对原图的坐标位置。
-
-
RoI Pooling 层
-
输入:主干网络产生的特征图 + 各 ROI 坐标
-
操作:将每个 ROI 在特征图上按照预定分辨率(如 7×7)划分网格,并在每个网格中进行最大池化。
-
输出:对于每个 ROI 都得到一个固定尺寸(7×7×C)的特征块。
-
-
全连接层 & Head
-
Flatten → FC6 → FC7:将每个 ROI 的池化特征扁平化,经两层全连接得到 4096 维向量。
-
双分支输出:
-
分类分支:Softmax 输出 K+1 类别(K 个目标类别 + 背景)。
-
回归分支:每个前景类别都有一组 4 维回归参数,用于微调 ROI 的坐标。
-
-
3、关键技术点
-
RoI Pooling
-
核心价值:使得来自不同大小 ROI 的特征都能被池化为相同尺寸,简化后续全连接处理;
-
高效共享:所有 ROI 共享同一次卷积特征,大幅减少重复计算,整体速度可提升到 5–10 FPS。
-
-
端到端多任务联合训练
-
损失函数
-
p:预测的类别概率分布;
-
u:真实类别标签;
-
t:预测的回归偏移;
-
v:真实偏移目标;
-
:交叉熵损失,
:平滑 L1 损失,只对前景 ROI 生效(u≥1指示函数)。
-
-
优势:分类和回归在同一网络中共同优化,特征能同时兼顾两者需求。
-
-
Mini-batch 设计
-
每次迭代从若干图像中采样固定数量的 RoI(如 2 图像、每图 128 个 RoI),保持训练稳定;
-
正负样本比通常设为 1:3,并使用 IoU 阈值(正样本 IoU ≥ 0.5,负样本 IoU ≤ 0.5)。
-
-
Backpropagation 流向
-
RoI Pooling 可视为可微分操作,其梯度能“准确地”分配回对应的特征图单元;
-
既更新全连接层,也更新 backbone 的卷积层,实现真正的端到端微调。
-
4、训练与推理流程
-
训练阶段
-
预训练:在 ImageNet 上训练 backbone 网络;
-
生成候选框:对训练集产生 RoI;
-
特征与 RoI Pooling:整图卷积 → RoI Pooling 得到固定特征;
-
前向+损失:过 FC → 计算分类与回归损失;
-
反向传播:梯度通过 FC、RoI Pooling 传至卷积层,联合更新所有参数。
-
-
推理阶段
-
对输入图像生成 RoI;
-
整图一次卷积 → 特征图;
-
对每个 RoI 做 Pooling → FC → 得到各类别得分和回归偏移;
-
对每个类别应用偏移校正并执行 NMS,输出最终检测结果。
-
5、优缺点分析
-
优点
-
速度大幅提高:共享卷积计算 + RoI Pooling,整体检测速度可达 5–10 FPS;
-
端到端训练:分类与回归任务在同一框架内联合优化,简化流程;
-
简单实用:只需替换 R-CNN 中的特征抽取与 SVM、回归器,结构清晰。
-
-
缺点
-
仍依赖外部候选框:Selective Search 速度瓶颈未解;
-
Pool 格网量化误差:RoI Pooling 的离散网格可能丢失对齐精度,尤其对细小目标不友好;
-
内存与计算:处理数千 RoI 时,后端 FC 计算仍然较重。
-
6、后续演进
-
Faster R-CNN(2015)
-
用 RPN 取代外部候选框,真正实现端到端、实时化的候选区域生成。
-
-
Mask R-CNN(2017)
-
引入 RoIAlign,消除量化误差;新增实例分割分支。
-
-
Cascade R-CNN、Libra R-CNN 等
-
针对不同 IoU 阈值的多级检测头设计;对样本分布进行均衡处理。
-
四、FasterRCNN
1、Faster R-CNN 概述
Faster R-CNN 由 Shaoqing Ren 等人在 2015 年提出,可看作 Fast R-CNN 与区域建议网络(RPN, Region Proposal Network)的有机结合。相比于依赖外部候选框生成(Selective Search)的 Fast R-CNN,Faster R-CNN 通过 RPN 在共享特征上实时生成高质量的候选区域,真正实现了端到端、近实时的目标检测。
2、整体网络结构
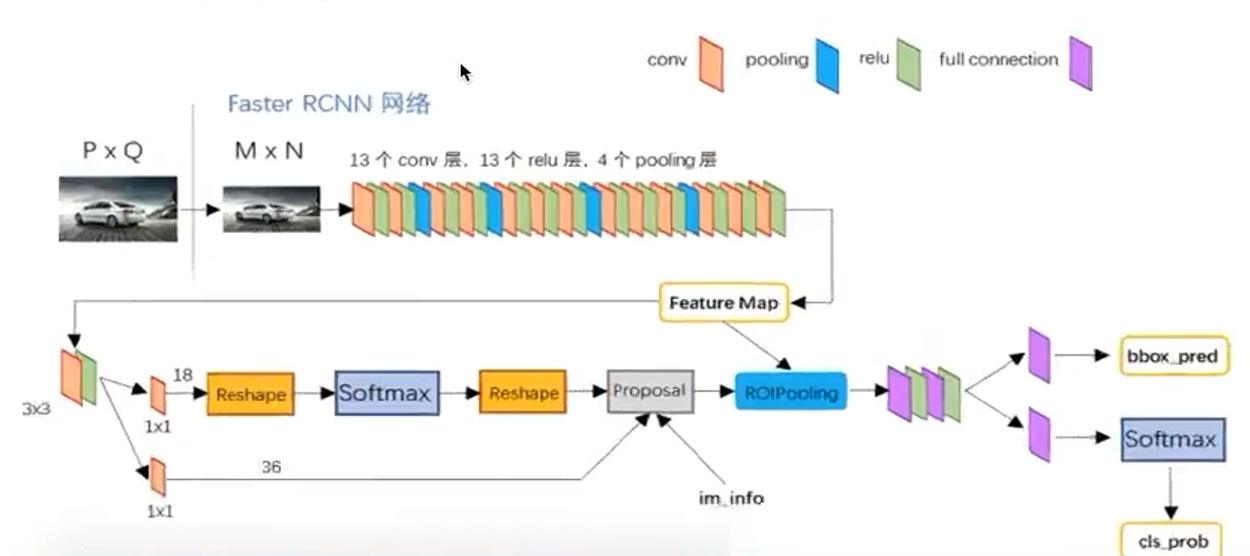
-
Backbone:常用 VGG16、ResNet-50/101 等,提取整图卷积特征。
-
RPN(Region Proposal Network):在特征图上滑动窗口,生成候选框及其前景概率和边框回归偏移。
-
RoI Pooling:对 RPN 输出的候选框,在共享特征图上做固定尺寸(如 7×7)的池化。
-
FC Head:对每个 RoI 池化特征经过两层全连接后,分别输出类别概率和更精细的边框回归。
3、关键技术点
(1)区域建议网络(RPN)
-
滑动窗口与 Anchor
-
在特征图的每个位置,用大小(如 128²、256²、512² 像素)和比例(1:1、1:2、2:1)预定义 9 个 anchor。
-
每个 anchor 对应两个任务:对象/背景分类、4 个坐标偏移的边框回归。
-
-
共享特征
-
RPN 与后续检测头共享 backbone 提取的特征,避免重复计算。
-
-
RPN 损失
-
:第 i 个 anchor 预测为前景的概率;
-
:真实标签(前景=1/背景=0);
-
vs.
:预测与真实的边框偏移;
-
只对前景 anchor 计算回归损失。
-
(2)多任务联合训练
-
端到端优化:RPN 与 Fast R-CNN 检测头可交替迭代训练,也可使用“近端微调”方式在一次网络中联合优化。
-
共享梯度:RPN 的梯度会反向传至 backbone,检测头的梯度同样更新 backbone,共享特征更加适应检测任务。
(3)RoI Pooling 与后端 Head
-
RoI Pooling:将任意尺寸的候选框映射到特征图后,以固定网格(一般为 7×7)做 max-pooling,输出尺寸一致的特征块。
-
FC Head:两层全连接后分出两个分支——分类分支(Softmax over K+1 类)与回归分支(每类 4 维偏移)。
4、训练与推理流程
(1)训练阶段
-
预训练 Backbone:在 ImageNet 分类数据集上预训练。
-
训练 RPN:在 detection 数据集上,仅微调 RPN 分支与 backbone,生成高质量 proposals。
-
训练检测头:用 RPN 提供的 proposals 训练 Fast R-CNN Head,微调 backbone & FC Head。
-
迭代优化:可交替重复上两步,使 RPN 与检测头协同进化,最终得到统一网络。
(2)推理阶段
-
整图卷积:输入一次图像,得到特征图。
-
RPN 预测:在特征图上滑窗,输出候选框及前景分数,经过 NMS 筛选前 300–600 个 proposals。
-
RoI Pooling + FC Head:对每个 proposal 池化并过 FC,输出最终类别分数与回归偏移,并再次做 NMS,输出最终检测结果。
5、优势与挑战
(1)优点
-
速度提升:RPN 轻量高效,可达 5–7 FPS(ResNet-50),极大优于前代。
-
端到端训练:检测网络完整一体,特征更具针对性;
-
高精度:基于 anchor 的多尺度、多长宽比设计,对各种尺寸目标均表现良好。
(2)缺点
-
Anchor 设计依赖:需要手动设定 anchor 尺度与比例,不同数据集需调参;
-
RoI Pooling 对齐误差:离散量化导致精度损失,尤其小物体,后续 Mask R-CNN 引入 RoIAlign 予以改进;
-
训练复杂度:RPN 与检测头的多阶段或交替训练流程较 Fast R-CNN 略繁琐。
6、后续演进
-
Mask R-CNN(2017)
-
用 RoIAlign 代替 RoI Pooling,消除量化误差;
-
在检测基础上增加实例分割分支。
-
-
RetinaNet(2017)
-
单阶段检测网络,引入 Focal Loss 处理正负样本极度不平衡问题。
-
-
Cascade R-CNN(2018)
-
多级检测头,逐级提高 IoU 阈值,增强高质量检测框性能。
-
-
DetectoRS、HTC、Sparse R-CNN…
-
持续在 backbone、proposal-free 设计、注意力机制等方面探索,推动检测性能与效率双提升。
-
五、YOLO
1、YOLO 概述
YOLO 系列模型由 Joseph Redmon 等人在 2016 年首次提出,其核心理念是将目标检测视为一个单一的回归问题——从整张图像直接回归出边界框坐标和类别概率,无需候选区域生成或后续分类器,因而具有极高的推理速度。自第一代 YOLO(YOLOv1)以来,YOLO 在速度与精度的权衡上持续改进,目前已发展到 YOLOv5、YOLOX、YOLOv7 乃至 Ultralytics 等多个分支。
2、基础网络结构(以 YOLOv1 为例)
YOLOv1 网络可分为三部分:
输入:整张 RGB 图像(例如 448×448)│
24 层卷积 + 若干池化 → 特征图(7×7×1024)│
卷积层降维(1×1 conv) → (7×7×B*(5+C))│
重塑 → → S × S × (B×5 + C) 输出张量
-
S×S 网格划分
将输入图像划分为 S×S(如 7×7)个网格,每个网格只预测 B(如 2)个边界框及对应置信度,以及 C(如 20)类的条件概率。 -
每个网格输出
-
边界框参数:4 个坐标 (x,y,w,h),相对于网格单元归一化;
-
置信度:
;
-
类别概率:
,通过 Softmax 输出。
-
3、关键技术点
-
单阶段回归检测
-
与两阶段(R-CNN 系列)不同,YOLO 仅一次网络前向就直接预测边框与类别,避免重复特征计算,极大提高速度。
-
-
统一损失函数
-
通过对坐标、置信度、类别三部分加权求和,实现回归与分类的联合优化。
-
采用
和
调节正负样本损失权重。
-
-
多尺度预测
-
后续版本(YOLOv2、YOLOv3)在不同尺度上预测特征图(如 13×13、26×26、52×52),更好地检测大、中、小目标。
-
引入 Feature Pyramid Network(FPN)思想,通过上采样与跳跃连接融合多层特征。
-
-
Anchor 机制(YOLOv2 及之后)
-
为每个网格预定义 K 个 anchor(典型为 5),每个 anchor 预测偏移量,增强对不同长宽比目标的适应性。
-
Anchor 尺度通过 k-means 聚类数据集标注框获得。
-
-
Darknet 主干网络
-
YOLOv2 引入 Darknet-19,YOLOv3 升级为 Darknet-53,均采用大量 3×3、1×1 卷积与残差连接,兼顾速度与表达能力。
-
4、训练与推理流程
-
训练阶段
-
数据增强:随机缩放、裁剪、翻转、色彩变换等,提升鲁棒性;
-
预训练:先在 ImageNet 上预训练主干网络;
-
微调:在 COCO 或 VOC 等检测数据集上微调全网权重;
-
学习率策略:采用阶梯衰减或余弦退火等动态调整。
-
-
推理阶段
-
输入预处理:统一缩放到固定尺寸(如 416×416)并归一化;
-
单次前向:网络输出多尺度或单尺度预测张量;
-
解码边框:根据网格、anchor 与网络预测偏移,恢复为原图坐标;
-
置信度过滤 & NMS:剔除低置信度(如 <0.5)预测,按类别进行非极大值抑制,输出最终检测结果。
-
5、优缺点分析
-
优点
-
极高速度:YOLOv3 在 GPU 上可达 45 FPS(416×416),适合实时应用;
-
端到端训练:无须外部候选框算法,框架简洁;
-
统一回归:检测与定位同框完成,模型紧凑。
-
-
缺点
-
定位精度较低:尤其小目标与重叠目标,因网格划分粗糙导致漏检或定位偏差;
-
类别不平衡:前背景样本差异大,YOLOX 等后续通过 Decoupled Head、SimOTA 策略改进;
-
尺度泛化:早期版本单尺度预测,对不同分辨率目标兼容性差。
-
6、后续演进与分支
-
YOLOv4 / YOLOv5(2020)
-
引入 CSPDarknet、Mosaic 数据增强、CIoU Loss、SPP 模块、PANet 等技术,进一步提升精度与速度平衡。
-
-
YOLOX(2021)
-
采用 anchor-free 设计,Decoupled Head、SimOTA 训练方案、EMA、SiLU 激活;
-
在 COCO 上取得 AP 50:50–95 达到 50+ 的水平。
-
-
YOLOv7 / YOLOv8(2022–2023)
-
发布多项结构与训练技巧创新,如 E-ELAN、Dynamic Head、自动混合精度;
-
Ultralytics YOLOv8 以 PyTorch 实现,接口友好并支持多任务(分类、检测、分割、分割跟踪)。
-
六、SSD
1、模型动机
SSD 于 2016 年由 Wei Liu 等人提出,旨在在保持较高检测精度的同时,实现真正的单阶段、单次前向检测。相比于两阶段方法(Faster R-CNN)和早期单阶段方法(YOLOv1/2):
-
两阶段:精度高但慢;
-
YOLOv1:速度快但对小目标、聚集目标精度不足;
-
SSD:引入多尺度特征图与多比例默认框(default boxes),在速度和精度间取得平衡。
2、网络整体结构
-
主干网络(Backbone)
-
通常选用 VGG16 (去掉最后的池化层和全连接层)作为基础特征提取器。
-
在 conv4_3、fc7(通过 1×1+3×3 conv 将原 fc6/fc7 转为卷积层)等多层均保留特征。
-
-
附加特征层(Extra Feature Layers)
-
在 backbone 之后,依次添加若干卷积层(例如 conv8_2、conv9_2、…conv11_2),每层特征图分辨率依次减半。
-
例如 SSD300 在输入 300×300 时,依次产生 38×38、19×19、10×10、5×5、3×3、1×1 的特征图。
-
-
多尺度预测(Multi-scale Prediction)
-
每个特征图位置生成若干个默认框(Default Boxes,也称 anchor):
-
不同宽高比(如 1:1、2:1、1:2、3:1、1:3);
-
不同尺度(结合当前层与下一层分辨率计算)。
-
-
并行预测:在每个位置,通过 3×3 卷积同时输出类别得分分支(K+1 个通道)和边框偏移分支(4 个通道 × default boxes 数量)。
-
-
输出张量
-
将所有尺度、所有位置、所有默认框的预测拼接,形成一个统一的输出向量,然后进行后处理(置信度过滤+NMS)。
-
3、关键技术点
-
Default Boxes 的设计
-
在第 m 个尺度特征图(大小
)上,定义 k 个默认框;每个默认框对应特定的尺度
和一组长宽比
。
-
默认框中心与特征图网格中心对齐,尺度按公式
线性计算。
-
-
多尺度、多比例覆盖
-
不同层的不同分辨率、不同框比例,联合覆盖各类大小和形状的目标。
-
conv4_3 层对小目标敏感;更深层对大目标更具语义。
-
-
端到端多任务损失
-
:平滑 L1 损失,对预测框偏移与对应 ground-truth 回归;
-
:分类交叉熵,对正负样本类别预测;
-
:指示默认框 i 与真实框 j 的匹配关系;
-
通过硬负例挖掘(Online Hard Example Mining)将负样本比例限制在正样本的 3 倍内,平衡训练。
-
-
硬负例挖掘
-
对所有未匹配正样本的默认框,按分类损失排序,挑选前
剩余框数
作为负样本,用于训练。
-
-
尺度归一化
-
对 conv4_3 层特征做 L2 正则化并乘以可学习缩放因子,以缓解浅层特征通道数较小、梯度传播不均的问题。
-
4、训练与推理流程
-
训练阶段
-
默认框与真实框匹配:IoU ≥ 0.5 的默认框标为正样本;后者随机补足。
-
计算损失:多任务损失按正负样本加权求和;
-
反向传播:同时优化 backbone、附加层、输出分支;
-
数据增强:随机裁剪、颜色抖动、翻转、缩放,提高模型鲁棒性。
-
-
推理阶段
-
单次前向:输入整图(如 300×300)→ 特征图 → 并行预测;
-
解码偏移:将网络学到的偏移还原到默认框,得到最终预测框坐标;
-
置信度过滤:丢弃低于阈值(如 0.5)的预测;
-
NMS:对每个类别执行非极大抑制,保留最高置信度的若干框。
-
5、性能与优缺点
| 模型 | 输入尺寸 | PASCAL VOC07 mAP | COCO AP@[.5:.95] | 推理速度(FPS@Titan X) |
|---|---|---|---|---|
| SSD300 | 300×300 | 77.5% | 23.2% | ~59 |
| SSD512 | 512×512 | 79.5% | 26.8% | ~22 |
-
优点
-
真正单阶段:无外部 proposal,速度快;
-
多尺度特征融合:对各大小目标均有较好覆盖;
-
端到端训练:简单统一的多任务优化。
-
-
缺点
-
小目标检测弱:300×300 分辨率下,对极小目标仍然不够敏感;
-
长尾样本不平衡:类别不均衡需额外策略;
-
依赖锚框设计:手工设定尺度与比例,需针对数据集调优。
-
6、后续演进
-
DSSD(2017)
-
在 SSD 基础上加入多尺度 deconvolution 和扩张卷积,提升小目标检测精度。
-
-
RefineDet(2018)
-
两段式单阶段:先粗略筛选,然后精细定位并分类,结合了两阶段与单阶段优点。
-
-
RetinaNet(2017)
-
引入 Focal Loss,解决极度正负样本不平衡,AP 表现超越 SSD。
-
-
YOLO 系列进化
-
后缀如 YOLOv4/5/6/7 在 anchor-free、解耦头、SimOTA 等方面不断优化,进一步推动单阶段检测性能。
-
七、DETR
1、动机背景
传统目标检测框架(R-CNN 系列、SSD、YOLO 等)大多依赖先验框(anchor)或候选区生成,并通过 NMS(非极大值抑制)来去重,实现复杂且多阶段的流水线训练。DETR(End-to-End Object Detection with Transformers)由 Facebook AI Research 于 2020 年提出,首创将 Transformer 架构直接应用于目标检测,实现端到端、无锚框、无 NMS 的统一检测框架。
2、整体架构概览
输入图片 → Backbone CNN → Flatten+Position Embedding → Transformer Encoder ↓ Transformer Decoder (object queries) ↓ 线性头:分类分支 + 边框回归分支 ↓ Hungarian Matcher + Set Prediction Loss → 端到端优化
-
Backbone CNN
-
通常使用 ResNet-50/101 等提取二维特征图(如 1/32 下采样尺寸的 C×H×W)。
-
-
位置编码与扁平化
-
将特征图扁平为长度为
的序列,并加上可学习的 2D 位置编码。
-
-
Transformer Encoder
-
多层自注意力(Multi-Head Self-Attention)+ 前馈网络,对图像特征进行全局上下文建模。
-
-
Transformer Decoder
-
预设 M 个object queries(可学习向量),每个 query 通过交叉注意力(Cross-Attention)“查询”编码器输出,生成对一个目标的预测。
-
-
输出 Head
-
对每个 query 输出一个 (C+1)-维分类分数(包含背景类“无目标”)和一个 4 维边框坐标(归一化到 [0,1])。
-
-
集匹配损失(Set Prediction Loss)
-
采用匈牙利算法(Hungarian Matching)将 M 个预测与真实目标进行一一匹配;
-
匹配后,对分类和回归损失进行加权求和,端到端反向传播,无需 NMS。
-
3、核心组件详解
(1)Object Queries
-
预定义 M 个长度为 d 的向量(如 M=100,d=256),并随训练学习;
-
每个 query 在 decoder 中与编码器特征做多轮交互,最终对应一个检测框或“空”(no object)。
(2)注意力机制
-
自注意力(Self-Attention):在 encoder/decoder 内部,建模各位置与各 query 之间的全局关系;
-
交叉注意力(Cross-Attention):decoder 中,query 对编码器所有位置的加权聚合,学习“在哪里有物体”。
(3)位置编码(Positional Encoding)
-
将二维网格位置映射为与特征同维度的向量,并与特征相加;
-
保持空间位置信息,使注意力机制区分不同区域。
(4)匈牙利匹配(Hungarian Matching)
-
对 M 个预测与 K 个 ground-truth 目标,构建 M×K 的匹配成本矩阵:
结合分类是否正确与边框回归误差,用匈牙利算法求最优一一匹配对;
-
未匹配的预测被视为背景(类别损失只计算为“无目标”)。
(5)Set Prediction Loss
-
匹配后,对每对 (i,j) 预测与真实目标计算:
-
分类损失:交叉熵;
-
回归损失:平滑
+ GIoU Loss(在 DETR 后续版本中引入)。
-
-
损失总和:
4、训练与推理流程
-
训练
-
将批量图像送入 backbone,提取特征并加位置编码;
-
编码器多层自注意力处理,得到全局特征表示;
-
decoder 交叉注意力将 object queries 转化为 M 条预测;
-
匈牙利匹配,计算 set prediction loss;
-
端到端反向传播,更新 backbone、Transformer、object queries。
-
-
推理
-
单次前向得到 M 个分类分数与边框;
-
选取分类分数最高的前 N′ 条(如 top-100)非背景预测;
-
直接输出,无需 NMS。
-
5、优缺点对比
| 方面 | 优势 | 局限 |
|---|---|---|
| 简洁性 | 端到端一体化,无需候选框、锚框、NMS 等繁琐步骤 | 训练收敛慢,需大批量数据和更长训练 |
| 全局交互 | Transformer 自注意力学习全局上下文,利于复杂场景下检测 | 计算与内存开销高,尤其大分辨率/大特征图尺寸时 |
| 可扩展性 | 容易结合多任务(如 Mask DETR、Deformable DETR、Conditional DETR 等) | 原始 DETR 在小目标检测、密集目标场景(人群、车流)效果欠佳 |
| 推理效率 | 无需 NMS,后处理简单 | Transformer decoder 层数和 query 数量直接影响推理速度 |
6、后续改进与演进
-
Deformable DETR
-
引入可学习的可变形 attention,仅在若干关键位置采样特征,大幅加速收敛和推理。
-
-
Conditional DETR
-
将位置信息条件化注入 decoder 查询,增强查询与特征的对齐,加速训练收敛。
-
-
DN-DETR (Denoising DETR)
-
在训练中加入带噪声的查询与目标标签对,用“去噪”任务辅助收敛。
-
-
Mask-DETR
-
在 DETR 基础上加上实例分割分支,实现端到端的检测+分割。
-
-
Sparse DETR / Efficient DETR
-
通过稀疏化多头注意力或采用更轻量设计,降低计算量,提升推理速度。
-
相关文章:

【深度学习】目标检测算法大全
目录 一、R-CNN 1、R-CNN概述 2、R-CNN 模型总体流程 3、核心模块详解 (1)候选框生成(Selective Search) (2)深度特征提取与微调 2.1 特征提取 2.2 网络微调(Fine-tuning) …...

【node】6 包与npm
前言 目标 1 了解什么是包 2 怎么使用npm下载包 #mermaid-svg-Ur0d2uCdQeAQOJjW {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-Ur0d2uCdQeAQOJjW .error-icon{fill:#552222;}#mermaid-svg-Ur0d2uCdQeAQOJjW .erro…...

【C++进阶篇】多态
深入探索C多态:静态与动态绑定的奥秘 一. 多态1.1 定义1.2 多态定义及实现1.2.1 多态构成条件1.2.1.1 实现多态两个必要条件1.2.1.2 虚函数1.2.1.3 虚函数的重写/覆盖1.2.1.4 协变1.2.1.5 析构函数重写1.2.1.6 override和final关键字1.2.1.7 重载/重写/隐藏的对⽐ 1…...

计算机网络|| 路由器和交换机的配置
一、实验目的 1. 了解路由器和交换机的工作模式和使用方法; 2. 熟悉 Cisco 网络设备的基本配置命令; 3. 掌握 Cisco 路由器的基本配置方式及配置命令; 4. 掌握路由器和交换机的基本配置与管理方法。 二、实验环境 1. 运行 Windows 操作…...

图形化编程如何从工具迭代到生态重构?
一、技术架构的范式突破 在图形化编程领域,技术架构的创新正在重塑行业格局。iVX 作为开源领域的领军者该平台通过图形化逻辑设计,将传统文本编程需 30 行 Python 代码实现的 "按钮点击→条件判断→调用接口→弹窗反馈" 流程,简化…...

歌曲《忘尘谷》基于C语言的歌曲调性检测技术解析
引言 在音乐分析与数字信号处理领域,自动检测歌曲调性是一项基础且关键的任务。本文以C语言为核心,结合音频处理库(libsndfile)和快速傅里叶变换库(FFTW),探讨如何实现调性检测,并通…...

Spring Boot 使用Itext绘制并导出PDF
最终效果 其实可以加分页,但是没有那么精细的需求,所以我最后就没有加,有兴趣的可以尝试下。 项目依赖 <!-- Spring Boot 版本有点老 --> <spring-boot.version>2.3.12.RELEASE</spring-boot.version><!-- 依…...

医学影像处理与可视化:从预处理到 3D 重建的技术实践
🧑 博主简介:CSDN博客专家、CSDN平台优质创作者,高级开发工程师,数学专业,10年以上C/C++, C#, Java等多种编程语言开发经验,拥有高级工程师证书;擅长C/C++、C#等开发语言,熟悉Java常用开发技术,能熟练应用常用数据库SQL server,Oracle,mysql,postgresql等进行开发应用…...

用 openssl 测试 tls 连接
以 baidu 为例,命令行为: openssl s_client -tlsextdebug -connect baidu.com:443 得到的输出为: CONNECTED(00000003) TLS server extension "renegotiation info" (id65281), len1 0000 - 00 …...

Matlab 汽车制动纵向动力学模型和PID控制
1、内容简介 Matlab 228-汽车制动纵向动力学模型和PID控制 可以交流、咨询、答疑 2、内容说明 略 3、仿真分析 略 4、参考论文 略...

重塑JavaScript原生功底=>【构造函数篇】
概念:用于创建对象的函数称之为构造函数 作用:构造函数在 JavaScript 中是用来创建对象的最根本操作。 语法:当一个函数通过 new 关键字 来调用的话,那么这个函数就是一个构造函数。 场景:构造函数是专门用来创建对象…...
)
从0到1:Python机器学习实战全攻略(8/10)
摘要:通过本文的学习,我们深入探索了 Python 机器学习从入门到实战的精彩世界。从 Python 在机器学习领域的独特优势,到机器学习的核心概念,再到各种强大工具库的应用,以及实战项目的完整演练,我们逐步揭开…...

[计算机网络]网络层
文章目录 408考研大纲IPV4数据报格式协议: IPv4 地址DHCP协议IP组播 408考研大纲 IPV4数据报格式 协议: 1:ICMP IPv4 地址 特殊IP 网络号全1又称直接广播地址,32位全1又称受限广播地址 因为255.255.255.255只能在本网络内广播,路由器不许通过它&…...

华为行业认证是什么?如何考取华为行业认证?
据IDC预测,2027年全球数字化转型市场规模将突破3.4万亿美元,而中国将成为增长最快的市场之一。然而,85%的企业在转型中面临核心人才短缺的困境,尤其缺乏兼具技术能力与行业洞察的复合型人才! 讯方技术作为华为授权培训…...

Kotlin与Qt跨平台框架深度解析:业务逻辑共享与多语言集成
简介 Kotlin Multiplatform和Qt作为两大主流跨平台开发框架,各自在技术生态和应用场景上展现出独特优势。Kotlin Multiplatform专注于业务逻辑的跨平台共享,通过Kotlin语言的统一特性实现高达80%的代码复用率,特别适合移动应用和Web服务的业务逻辑开发。而Qt则凭借其强大的…...

基于LNMP架构的个人博客系统部署
一、项目概述 本项目旨在通过两台服务器(Server-Web和Server-NFS-DNS)搭建一个基于LNMP(Linux、Nginx、MySQL、PHP)架构的个人博客系统。通过域名访问自建网站,同时实现资源文件的共享和DNS解析功能。 二、服务器配置…...

Python训练打卡Day21
常见的降维算法: # 先运行预处理阶段的代码 import pandas as pd import pandas as pd #用于数据处理和分析,可处理表格数据。 import numpy as np #用于数值计算,提供了高效的数组操作。 import matplotlib.pyplot as plt #用于绘…...
 与 Oracle 序列对比)
PostgreSQL 序列(Sequence) 与 Oracle 序列对比
PostgreSQL 序列(Sequence) 与 Oracle 序列对比 PostgreSQL 和 Oracle 都提供了序列(Sequence)功能,但在实现细节和使用方式上存在一些重要差异。以下是两者的详细对比: 一 基本语法对比 1.1 创建序列 PostgreSQL: CREATE [ { TEMPORARY | TEMP } |…...

直播:怎样用Agentic AI搭建企业AI应用?5.24日,拆解新一代“智能客服系统”案例
2025 DeepSeek掀起了中国企业的AI落地浪潮! 随着应用的深入,AI的落地技术正在快速演化。 3月,Manus一夜爆火,让AI Agent更加引人关注。 从生成式AI,到Agentic AI(代理式AI)。 AI正在从只能生…...

《Asp.net Mvc 网站开发》复习试题
一.选择题(注:每题2分,共 54分,只能在下列表格中,填写每个题目相应的正确字母选项) 01: 02: 03: 04: 05: 06: 07: 08: 09: 10: 11: 12: 13: 14: 15: 16: 17: 18: 19: 20: 21: 22: 23: 24: 25: 26: :27: 1. Mvc让软件…...
:货仓选址)
算法题(145):货仓选址
审题: 本题需要我们找出距离之和的最小值 思路: 方法一:贪心 贪心策略:将货仓建立在所有商店的中间可以达到距离之和最小 因为每家商店都需要接收一车商品,所以这里的距离之和指的是从货仓到每一家商店的路线的距离之和…...
)
✅ TensorRT Python 安装精简流程(适用于 Ubuntu 20.04+)
安装 TensorRT Python 轮子的步骤 确保 pip 和 wheel 模块已更新并安装: 参考链接 python3 -m pip install --upgrade pip python3 -m pip install wheel 1. 确认环境要求 Python:版本 3.8 - 3.13 OS:Ubuntu 20.04 或 Windows 10 CPU&a…...

MYSQL 全量,增量备份与恢复
目录 一 数据备份的重要性 1 数据备份的重要性 2 数据库备份类型 2.1 从物理与逻辑的角度分类 2.2. 从数据库的备份策略角度分类从数据库的备份策略角度,数据库的备份可分为完全备份、差异备份和增量备份。 3 常见的备份方法 3.1 物理冷备份 物理冷备份时需要在数据库处…...

10. Spring AI PromptTemplate:从模板到高级技巧
1、前言 如果学到了这里,相信大部分人对Prompt并不陌生了。 在 Spring AI 的世界里,与强大的语言模型进行交互的基石便是 Prompt(提示语)。它不仅仅是你输入给 AI 的一段文本,更是你与智能对话的桥梁,是你唤醒模型潜能的关键指令。理解 Prompt 的本质、构建原则以及在 …...

基于OpenCV的人脸识别:Haar级联分类器
文章目录 引言一、环境准备二、代码实现1. 图像加载与预处理2. 加载Haar级联分类器3. 人脸检测核心参数详解4. 结果显示与标注 三、效果优化建议四、完整代码五、总结 引言 本文将带你一步步实现一个简单但实用的人脸检测程序,使用Python和OpenCV库。 一、环境准备…...

Git安装教程及常用命令
1. 安装 Git Bash 下载 Git 安装包 首先,访问 Git 官方网站 下载适用于 Windows 的 Git 安装包。 安装步骤 启动安装程序:双击下载的 .exe 文件,启动安装程序。选择安装选项: 安装路径:可以选择默认路径࿰…...

【PmHub后端篇】Skywalking:性能监控与分布式追踪的利器
在微服务架构日益普及的当下,对系统的性能监控和分布式追踪显得尤为重要。本文将详细介绍在 PmHub 项目中,如何使用 Skywalking 实现对系统的性能监控和分布式追踪,以及在这过程中的一些关键技术点和实践经验。 1 分布式链路追踪概述 在微服…...

ChromeDriver 技术生态与应用场景深度解析
ChromeDriver 技术生态与应用场景深度解析 随着 Web 自动化测试、运维和数据采集需求的不断增长,ChromeDriver 及其相关技术栈在各行业中扮演着举足轻重的角色。本文将从技术选型、语言适配、典型场景、技术延伸等维度,结合最新行业趋势与实践经验&…...

链表面试题6之回文结构
经过前几道题的铺垫,那么我们也是来到了链表的第六关。这也是一道非常经典的题目。 目录 逆置法 数组法 那么对于这道题目,我们要判断回文结构,实际上就是判断链表对不对称。这种类型的题目我们好像在哪里见过,对了,…...

ASP.NET Core Identity框架使用指南
文章目录 前言一、核心功能二、核心组件三、使用1)创建项目2)安装必要 NuGet包3)配置数据库连接字符串4)用户与角色实体定义4)配置数据库上下文5) 注册服务6)数据库迁移与初始化7)用…...

Hugging Face推出了一款免费AI代理工具,它能像人类一样使用电脑
Hugging Face推出了一款免费AI代理工具,它能像人类一样使用电脑。 这款工具名为Open Computer Agent(开放计算机代理),可模拟真实的电脑操作。 无需安装,在浏览器中即可运行。 以下是一些信息: - Open C…...

一.Gitee基本操作
一.初始化 1.git init初始化仓库 git init 用于在当前目录下初始化一个本地 Git 仓库,让这个目录开始被 Git 跟踪和管理。 生成 .git 元数据目录,从而可以开始进行提交、回退、分支管理等操作。 2.git config user.name/user.email配置本地仓库 # 设置…...

24、DeepSeek-V3论文笔记
DeepSeek-V3论文笔记 **一、概述****二、核心架构与创新技术**0.汇总:1. **基础架构**2. **创新策略** 1.DeepSeekMoE无辅助损失负载均衡DeepSeekMoE基础架构无辅助损失负载均衡互补序列级辅助损失 2.多令牌预测(MTP)1.概念2、原理2.1BPD2.2M…...

神经网络初步学习——感知机
一、前言 神经网络,顾名思义,它与我们大脑生物学里面讲到的神经元有关联。前辈们在研究早期人工智能的时候,就开始过我们的“交叉融合”,他们思考能不能把我们的人工智能的学习模式改造成我们人脑中神经元之间的学习方式——于是乎…...

在Text-to-SQL任务中应用过程奖励模型
论文标题 Reward-SQL: Boosting Text-to-SQL via Stepwise Reasoning and Process-Supervised Rewards 论文地址 https://arxiv.org/pdf/2505.04671 代码地址 https://github.com/ruc-datalab/RewardSQL 作者背景 中国人民大学,香港科技大学广州,阿…...

Python的安装使用
一、下载Python安装包 下载python安装包,可以直接访问官网地址:https://www.python.org/downloads/ 通过页面咱们直接下载最新版本的python安装包即可,python3.13.3。在页面的下方也可下载安装之前的版本,目前咱们按最新版本安装…...

mapreduce-wordcount程序2
WordCount案例分析 给定一个路径,统计这个路径下所有的文件中的每一个单词的出现次数。 其中,需要我们去实现代码的部分是:map函数和reduce函数。它们各自的作用是: map函数的入参是kv结构,k是偏移量,v是一…...
与内存屏障:原理、实践与性能权衡)
Java 内存模型(JMM)与内存屏障:原理、实践与性能权衡
Java 内存模型(JMM)与内存屏障:原理、实践与性能权衡 在多线程高并发时代,Java 内存模型(JMM) 及其背后的内存屏障机制,是保障并发程序正确性与性能的基石。本文将系统梳理 JMM 的核心原理、内…...

1.6 偏导数
(铺垫)全导数与偏导数看似相似,实则对应不同维度的变化观察。理解它们的差异需要从"变量自由度"切入: (核心差异解剖) 维度偏导数全导数变量关系其他变量被强制锁定所有变量都通过中间变量关联…...

网络爬虫学习之正则表达式
开篇 本文整理自《python3 网络爬虫开发实战》的学习笔记。 笔记整理 match match是一种常用的匹配方法,向它传入要匹配的字符串以及正则表达式,就可以检测这个正则表达式是否和字符串相匹配。 match会尝试从字符串的起始位置开始匹配正则表达式&#x…...

Pytorch常用统计和矩阵运算
文章目录 常用统计函数torch.prod()求积torch.sum()求和torch.mean()求均值torch.max()求最值torch.var() 方差torch.std()标准差 常见矩阵运算矩阵乘法点积 (torch.dot)批量矩阵乘法 (torch.bmm)奇异值分解 (SVD)特征分解 (torch.eig)矩阵求逆 (torch.inverse)伪逆 (torch.pin…...

PyTorch Lightning实战 - 训练 MNIST 数据集
MNIST with PyTorch Lightning 利用 PyTorch Lightning 训练 MNIST 数据。验证梯度范数、学习率、优化器对训练的影响。 pip show lightning Version: 2.5.1.post0Fast dev run DATASET_DIR"/repos/datasets" python mnist_pl.py --output_grad_norm --fast_dev_run…...

内存泄漏系列专题分析之十一:高通相机CamX ION/dmabuf内存管理机制Camx ImageBuffer原理
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了:内存泄漏系列专题分析之八:高通相机CamX内存泄漏&内存占用分析--通用ION(dmabuf)内存拆解 这一篇我们开始讲: 内存泄漏系列专题分析之十一:高通相机CamX ION/dmabuf内存管理机制Camx ImageBuf…...

MySQL-逻辑架构
MySQL服务器逻辑架构图 主要分层结构 1.连接层 功能:处理连接、安全认证、线程管理等 核心模块:连接器:支持不同语言(JDBC)与MySQL交互;线程连接池:管理线程连接,减少线程频繁创建…...

架构思维:通用架构模式_系统监控的设计
文章目录 引言什么是监控三大常见监控类型1. 次数监控2. 性能监控3. 可用率监控 落地监控1. 服务入口2. 服务内部3. 服务依赖 监控时间间隔的取舍小结 引言 架构思维:通用架构模式_从设计到代码构建稳如磐石的系统 架构思维:通用架构模式_稳如老狗的SDK…...

架构、构架、结构、框架之间有什么区别?|系统设计|系统建模
在技术与知识中,我们总是频繁地遇到一些高度抽象、看似类似、却又各自承载着不同思想重量的词汇。“架构”、“构架”、“结构”、“框架”即是其中最为常见又最为令人困惑的一组术语。它们既是工程师们日常工作的核心语言,也是学者们在探索系统、组织、…...
:构件)
系统架构设计(五):构件
定义 构件(Component)是指一个具有明确边界和独立部署能力的模块化单元,能够封装实现细节,并通过接口与其他构件协作完成系统功能。 主要特性 特性说明可复用性构件可以在不同系统中被重复使用。可部署性构件可以独立部署&…...

【系统架构师】2025论文《基于架构的软件设计方法》【最新】
😊你好,我是小航,一个正在变秃、变强的文艺倾年。 🔔本文分享【系统架构师】2025论文《系统可靠性设计》,期待与你一同探索、学习、进步,一起卷起来叭! 目录 项目介绍背景介绍系统模块技术栈基于…...

MultiTTS 1.7.6 | 最强离线语音引擎,提供多音色无障碍朗读功能,附带语音包
MultiTTS是一款免费且支持离线使用的文本转语音(TTS)工具,旨在为用户提供丰富的语音包选项,实现多音色无障碍朗读功能。这款应用程序特别适合用于阅读软件中的离线听书体验,提供了多样化的语音选择,使得听书…...

Costmap代价地图
以下为ROS navigation导航工具包的move_base框架图。其中有两个关于代价地图的模块(红框所框),全局代价地图global_costmap和局部代价地图local_costmap,这两个代价地图实际上是调用的同一个功能包代码,通过配置不同的参数实例化为两个代价地…...