MYSQL 全量,增量备份与恢复
目录
一 数据备份的重要性
1 数据备份的重要性
2 数据库备份类型
2.1 从物理与逻辑的角度分类
2.2. 从数据库的备份策略角度分类从数据库的备份策略角度,数据库的备份可分为完全备份、差异备份和增量备份。
3 常见的备份方法
3.1 物理冷备份 物理冷备份时需要在数据库处于关闭状态下,能够较好地保证数据库的完整性。物理冷备份一般用于非核心业务,这类业务一般都允许中断,物理冷备份的特点就是速度快,恢复时也是最为简单的。通常通过直接打包数据库文件夹(本章中的数据库文件夹位于/usr/local/mysq1/data)来实现备份
3.2 专用备份工具 mysqldump 或 mysqlhotcopy
3.3 通过启用二进制日志进行增量备份
3.4通过第三方工具备份
二. 数据库完全备份操作上面提到根据数据库备份策略分类,备份可分为完全备份、差异备份和增量备份。在本章中我们只介绍完全备份与增量备份,感兴趣的同学可以课下自学差异备份的方法。
1 物理冷备份与恢复
1.1 备份数据库
1.2 恢复数据库
2.mysqldump 备份与恢复
2.1备份数据库
2.2 查看备份文件
2.3 恢复数据库
3 MySQL 增量备份与恢复
3.1 MySQL 增量备份概述
(1)增量备份的特点
(2)MySQL二进制日志对备份的意义
3.2 MySQL 增量恢复
3.3 MYSQL 备份案例
1. 一般恢复
(1)添加数据库,表,录入信息
(2)先进性一次性完全备份
(3)继续录入新的数据并进行增量备份
(4)模拟错误操作删除user——info表
(5)恢复操作
2.基于位置恢复
3.基于时间恢复
三 备份策略思路
四 扩展:MYSQL的GTID 和XTRABACKUP
1.mysql的gtid
(1)配置my.cnf 开启gtid
(2)创建基本测试库,表,数据
(3)全量备份
(4)插入新数据
(5)模拟数据误删除
(6)导出增量备份
(7)恢复全量
(8)恢复增量
2.XtraBackup
(1)安装xtrabackup和qpress包
(2)完整备份与恢复备份
(3)增量备份与恢复备份
一 数据备份的重要性、、。
备份的主要目的是灾难恢复,备份还可以测试应用、回滚数据修改、查询历史数据、审计等。之前已经学习过如何安装 MySQL,本小节将从生产运维的角度了解备份恢复的分类与方法。
1 数据备份的重要性
在企业中数据的价值至关重要,数据保障了企业业务的正常运行。因此,数据的安全性及数据的可靠性是运维的重中之重,任何数据的丢失都可能对企业产生严重的后果。通常情况下造成数据丢失的原因有如下几种:
> 程序错误。 > 人为操作错误。 > 运算错误。 >磁盘故障。 >灾难(如火灾、地震)和盗窃
2 数据库备份类型
2.1 从物理与逻辑的角度分类
数据库备份可以分为物理备份和逻辑备份。
物理备份是对数据库操作系统物理文件(如数据文件、日志文件等)的备份。这种类型的备份适用于在出现问题时需要快速恢复的大型重要数据库。
物理备份又可以分为冷备份(脱机备份)、热备份(联机备份)和温备份。
> 冷备份: 在数据库关闭状态下进行备份操作。 > 热备份: 在数据库处于运行状态时进行备份操作,该备份方法依赖数据库的日志文件。 > 温备份: 数据库锁定表格(不可写入但可读)的状态下进行备份操作。
逻辑备份是:对数据库逻辑组件(如表等数据库对象)的备份,表示为逻辑数据库结构(CREATE DATABASE,CREATE TABLE 语句)和内容(INSERT 语句或分隔文本文件)的信息。这种类型的备份适用于可以编辑数据值或表结构较小的数据量,或者在不同的机器体系结构上重新创建数据。
2.2. 从数据库的备份策略角度分类
从数据库的备份策略角度,数据库的备份可分为完全备份、差异备份和增量备份。
完全备份 每次对数据进行完整的备份,即对整个数据库、数据库结构和文件结构的备份,保存的是备份完成时刻的数据库,是差异备份与增量备份基础。完全备份的备份与恢复操作都非常简单方便,但是数据存在大量的重复,且会占用大量的磁盘空间,备份的时间也很长。 差异备份 备份那些自从上次完全备份之后被修改过的所有文件,备份的时间节点是从上次完整备份起,备份数据量会越来越大。恢复数据时,只需复上次的完全备份与最近的一次差异备份。 增量备份 只有那些在上次完全备份或者增量备份后被修改的文件才会被备份。以上次完整备份或上次增量备份的时间为时间点,仅备份这之间的数据变化,因而备份的数据量小,占用空间小,备份速度快。但恢复时,需要从上一次的完整备份开始到最后一次增量备份之间的所有增量依次恢复,如中间某次的备份数据损坏,将导致数据的丢失。
3 常见的备份方法
MySQL 数据库的备份可以采用很多种方式,如直接打包数据库文件(物理冷备份)、专用备份工具(mysqldump)、二进制日志增量备份、第三方工具备份等。
3.1 物理冷备份
物理冷备份时需要在数据库处于关闭状态下,能够较好地保证数据库的完整性。物理冷备份一般用于非核心业务,这类业务一般都允许中断,物理冷备份的特点就是速度快,恢复时也是最为简单的。通常通过直接打包数据库文件夹(本章中的数据库文件夹位于/usr/local/mysq1/data)来实现备份
3.2 专用备份工具 mysqldump 或 mysqlhotcopy
mysqldump 程序和 mysqlhotcopy 都可以做备份。mysqldump 是客户端常用逻辑备份程序,能够产生一组被执行以后再现原始数据库对象定义和表数据的SQL 语句。它可以转储一个到多个MySQL数据库,对其进行备份或传输到远程SQL 服务器。mysqldump 更为通用,因为它可以备份各种表。mysqlhotcopy 仅适用于某些存储引擎。
mysqlhotcopy 是由 Tim Bunce 最初编写和贡献的Perl 脚本。mysqlhotcopy 仅用于备份MyISAM和ARCHIVE表。它只能运行在 UNIX或 Linux上。因为使用范围小,因此本文中不做详细介绍,如果同学们有兴趣可以在课下研究。
3.3 通过启用二进制日志进行增量备份
MySQL 支持增量备份,进行增量备份时必须启用二进制日志。二进制日志文件为用户 提供复制,对执行备份点后进行的数据库更改所需的信息进行恢复。如果进行增量备份(包含自上次完全备份或增量备份以来发生的数据修改),需要刷新二进制日志。
3.4通过第三方工具备份
Percona XtraBackup 是一个免费的MySQL 热备份软件,支持在线热备份Innodb 和 XtraDB,也可以支持 MySQL 表备份,不过 MyISAM 表的备份要在表锁的情况下进行。本节对于 Percona XtraBackupr 的叙述是基于 2.4 版本的。
Percona XtrBackup 有三个主要的工具:xtrabackup、innobackupex、xbstream.
xtrabackup: 是一个编译了的二进制文件,只能备份 Innodb/Xtradb 数据
文件。innodbackupex: 是一个封装了xtrabackup的Perl脚本,除了可以备份
Innodb/Xtradb 之外,还可以备份 MySIAM。xbstream: 是一个新组件,能够允许将文件格式转成 xbstream 格式或从xbstream格式转到文件格式。
xtrabackup 工具可以单独使用,但推荐使用 innobackupex 来进行备份,这是因为innobackupex本身就已经包含了xtrabackup 的所有功能。
xtrabackup 是基于 Innodb 的灾难恢复功能进行设计的,备份工具复制Innodb 的数据文件。但是,由于不锁表,这样复制出来的数据将不一致。Innodb维护了一个重做日志,包含 Innodb 数据的所有改动情况。在 xtrabackup 备份Innodb 数据的同时,xtrabackup 还有另外一个线程用来监控重做日志,一但日志发生变化,就把发生变化的日志数据复制走。这样就可以利用重做日志做灾难恢复了。
以上是备份过程,如果需要恢复数据,则在准备阶段,xtrabackup 就需要使用之前复制的重做日志对备份出来的 Innodb 数据文件进行灾难恢复,此阶段完成之后,数据库就可以进行重建还原了。
Percona XtraBackup 对 MySIAM 的复制,是按这样的一个顺序进行的:首先锁定表,然后复制,再解锁表。第三方工具备份操作本章中不做详细介绍,如果同学们有兴趣可以在课下研究
二. 数据库完全备份操作
上面提到根据数据库备份策略分类,备份可分为完全备份、差异备份和增量备份。在本章中我们只介绍完全备份与增量备份,感兴趣的同学可以课下自学差异备份的方法。
1 物理冷备份与恢复
物理冷备份一般用 tar 命令直接打包数据库文件夹,而在进行备份之前需要使用“systemct1 stop mysqld”命令关闭 mysqld 服务。
1.1 备份数据库
创建一个、backup 目录作为备份数据存储路径,使用tar创建备份文件,整个数据库文件夹备份属于完全备份的建立。
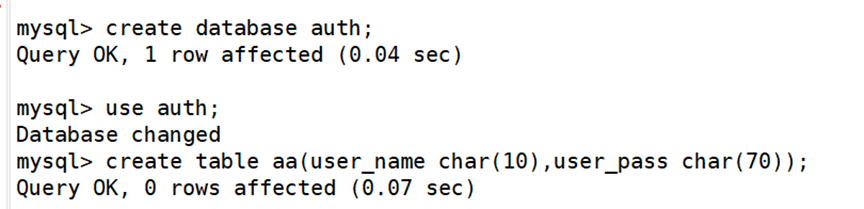

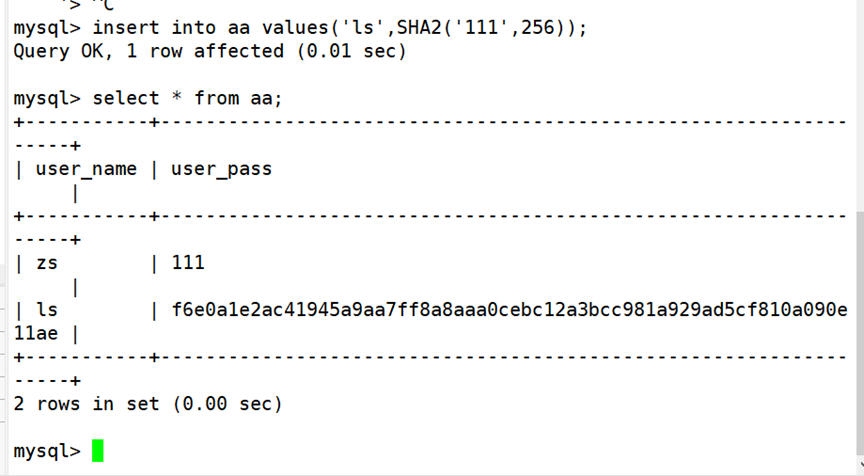
1.2 恢复数据库
执行下面操作将数据库文件、usr/local/mysql/data/转移至bak目录下,模拟故障。
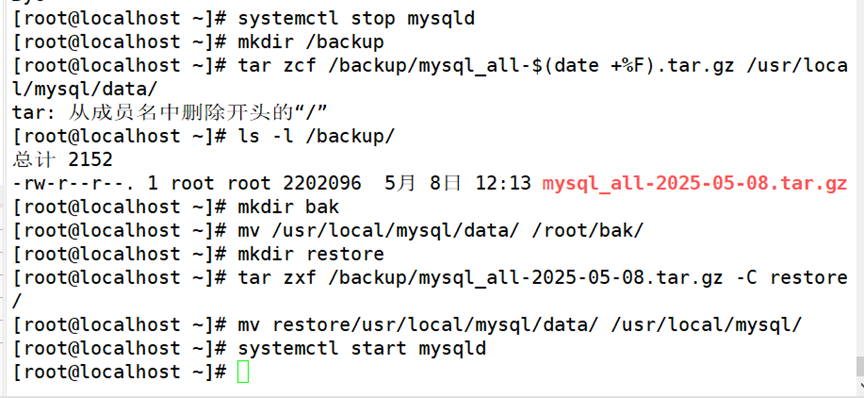
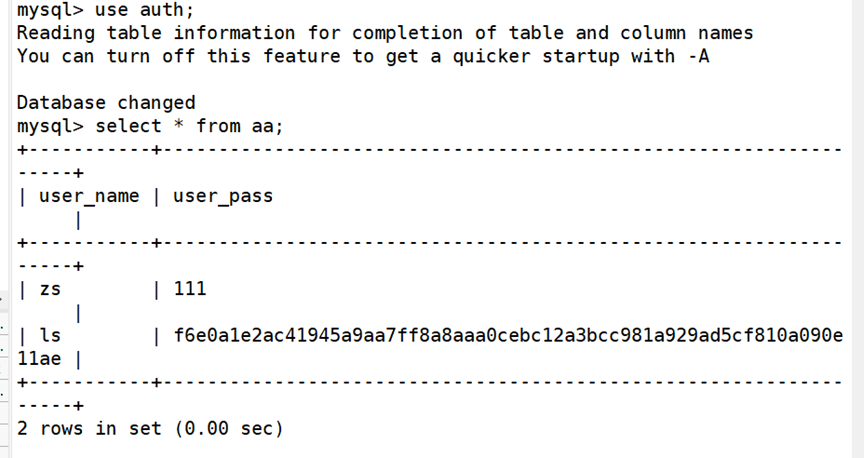
2.mysqldump 备份与恢复
通过 mysqldump 命令可以将指定的库、表或全部的库导出为SQL脚本,便于该命令在不同版本的 MySQL 服务器上使用。例如,当需要升级 MySQL 服务器时,可以先使用mysqldump 命令将原有库信息导出,然后直接在升级后的MySQL服务器中导入即可
2.1备份数据库
使用 mysqldump 命令导出数据时,默认会直接在终端显示,若要保存到文件,还需要结合 Shell的“>”重定向输出操作,命令格式如下所示。
格式 1:备份指定库中的部分表。
mysqldump[选项]库名[表名1][表名2]…>/备份路径/备份文件名
格式 2:备份一个或多个完整的库(包括其中所有的表)。
mysqldump[选项] -- databases 库名 1[库名 2]…>
格式 3:备份 MySQL 服务器中所有的库。
mysqldump[选项] -- all-databases>/备份路径/备份文件名
其中,常用的选项包括“-u”、“-p”,分别用于指定数据库用户名、密码。例如,以下操作分别使用格式 1、格式2,将 mysql 库中的 user 表导出为mysql-user.sql,将整个 test 库导出为 test.sql 文件,所有操作均以 root用户身份验证。
若需要备份整个 MySQL 服务器中的所有库,应使用格式3。当导出的数据量较大的时候,可以添加“ - opt”选项以优化执行速度。例如,执行以下操作将创建备份文件 all-data.sql,其中包括 MySQL 服务器中的所有库。
2.2 查看备份文件
通过 mysqldump 工具导出的 SQL 脚本是文本文件,其中“/ *…* /”部分或以“ -- ”开头的行表示注释信息。使用grep、less、cat 等文本工具可以查看脚本内容。例如,执行以下操作可以过滤出test.sql 脚本中的数据库操作语句。
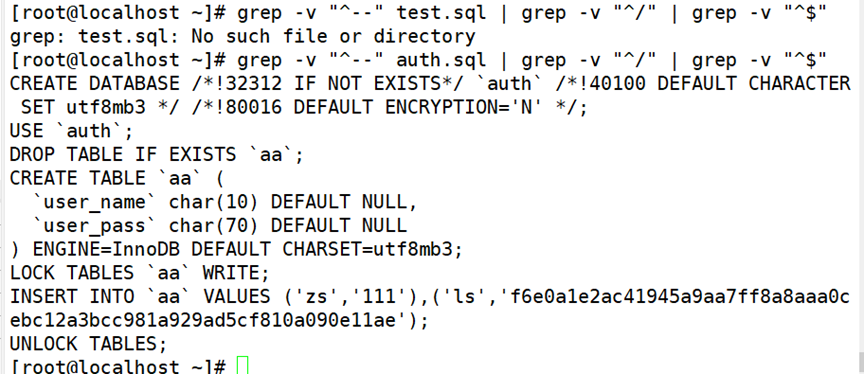
2.3 恢复数据库
使用 mysqldump 命令导出的 SQL 备份脚本,在需要恢复时可以通过 mysql命令对其进行导入操作,命令格式如下所示。
mysql[选项][库名][表名]</备份路径/备份文件名
当备份文件中只包含表的备份,而不包含创建的库的语句时,执行导入操作时必须指定库名,且目标库必须存在。
例如,执行以下操作可以从备份文件 mysql-user.sql 中将表导入test 库。其中“-e”选项是用于指定连接MySQL 后执行的命令,命令执行完后自动退出。

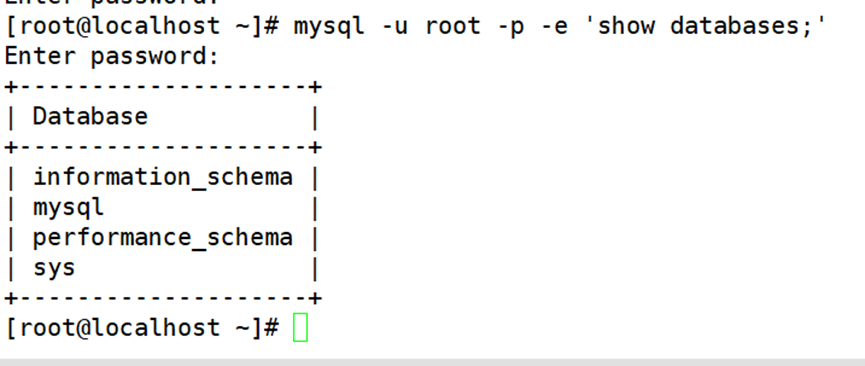
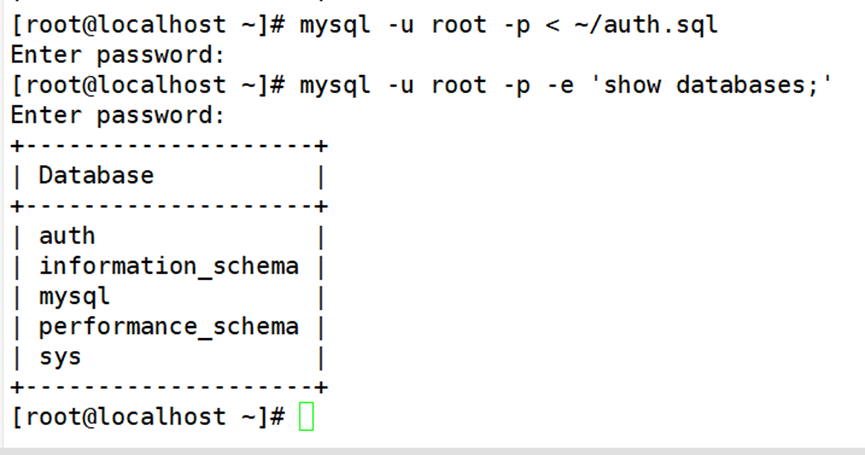
若备份文件中已经包括完整的库信息,则执行导入操作时无须指定库名。
例如 执行以下操作可以从备份文件 test.sql恢复test库
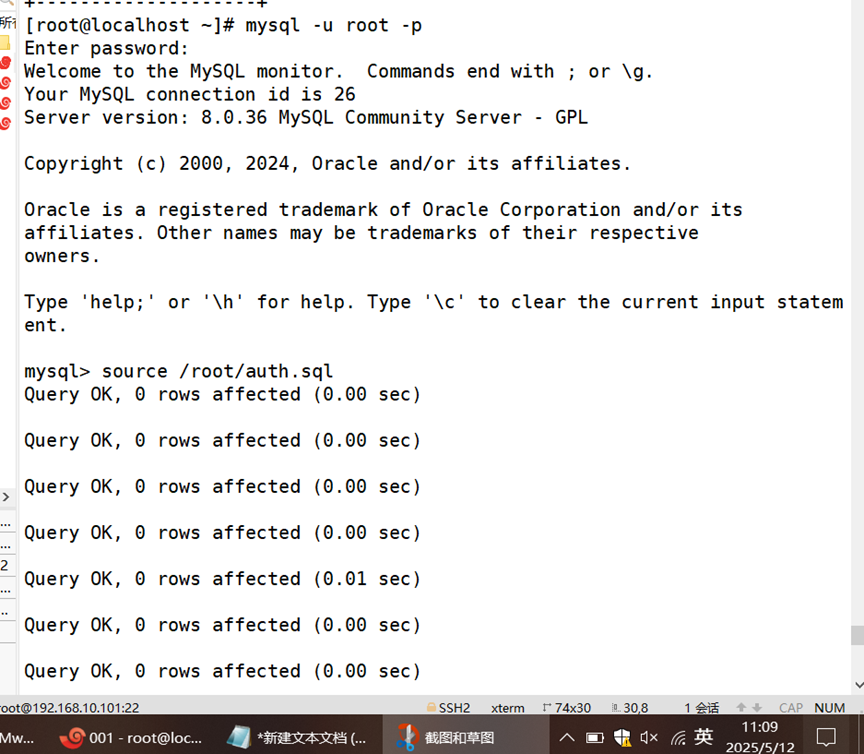
除了使用mysql命令结合“<”恢复数据外,还可以使用source命令恢复数据,具体如下
3 MySQL 增量备份与恢复
使用 mysqldump 进行完全备份,备份的数据中有重复数据,备份时间与恢复时间过长。而增量备份就是自上一次备份之后增加或改变的内容
3.1 MySQL 增量备份概述
(1)增量备份的特点
与完全备份不同,增量备份没有重复数据,备份量不大,时间短;但其恢复麻烦,需要上次完全备份及完全备份之后所有的增量备份才能恢复,而且要对所有增量备份进行逐个反推恢复。MySQL 没有提供直接的增量备份办法,可以通过MySQL 提供的二进制日志 (binary logs)间接实现增量备份
(2)MySQL二进制日志对备份的意义
二进制日志保存了所有更新数据库的操作。二进制日志在启动 MySQL 服务器后开始记录,并在文件达到二进制日志所设置的最大值或者接收到 flushlogs 命令后重新创建新的日志文件,生成二进制文件序列,并及时把这些日志保存到安全的存储位置,即可完成一个时间段的增量备份。使max_binlog_size配置项可以设置二进制日志文件的最大值,如果二进制文件的大小超过了max_binlog_size,它就会自动创建新的二进制文件。

![]()

要进行 MySQL 的增量备份,首先要开启二进制日志功能。开启 MySQL的进制日志功能的实现方法有很多种,最常用的是在 MySQL 配置文件的mysqld项下加入“log-bin=/文件路径/文件名”前缀,如log-bin=/usr/local/mysql/mysql-bin,然后重启 MySQL 服务就可 以在指定路径下查看二进制日志文件了。默认情况下,二进制日志文件的扩展名是一个六位的数字,如 mysq1-bin.000001。
Mysq18.0 默认已经开启binlog,无需显示配置binlog(默认binlog文件为:binlog.000001),如需自定义binlog配置,请添加如下配置项
3.2 MySQL 增量恢复
在维护数据库时,因为各种各样的原因可能会导致数据丢失,如:人为的 SQL语句破坏数据库、在进行下一次全备份之前发生系统故障导致数据库数据丢失、在数据库主从架构中主库的数据发生故障等。当出现以上场景时可以使用增量恢复来恢复数据。
常用的增量恢复的方法有三种:一般恢复、基于位置的恢复、基于时间点的恢复。
一般恢复:将所有备份的二进制日志内容全部恢复,命令格式如下所示。
mysqlbinlog [ -- no-defaults]增量备份文件|mysql-u用户名-p密码
基于位置的恢复:数据库管理员在操作数据库时可能在同一时间点既有错误的操作也有正确的操作,通过基于位置进行恢复可以更加精准,命令格式如下所示。
· 格式 1:恢复数据到指定位置。
mysqlbinlog -- stop-position='操作 id'二进制日志 |mysql-u用户名-p
密码·格式 2:从指定的位置开始恢复数据。
mysqlbinlog -- start-position='操作 id'二进制日志 |mysql-u 用户名 -p密码
基于时间点的恢复:跳过某个发生错误的时间点实现数据恢复,而基于时间点的恢复可以分成三种情况。
·格式 1:从日志开头截止到某个时间点的恢复。
mysqlbinlog [ -- no-defaults] -- stop-datetime='年-月-日 小时:分钟:秒’二进制日志 |mysql -u 用户名 -p 密码·格式 2:从某个时间点到日志结尾的恢复。
mysqlbinlog [ -- no-defaults] -- start-datetime='年-月-日 小时:分钟:秒’二进制日志|mysql-u 用户名 -p 密码·格式 3:从某个时间点到某个时间点的恢复。
mysqlbinlog [ -- no-defaults] -- start-datetime='年-月-日 小时:分钟:秒’-- stop-datetime='年-月-日小时:分钟:秒’二进制日志|mysql-u用户名 -p密码
3.3 MYSQL 备份案例
1. 一般恢复
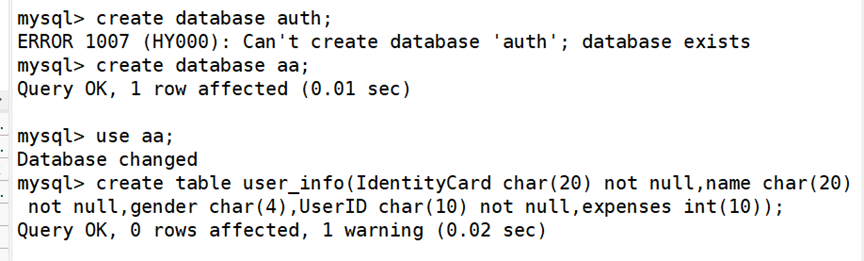
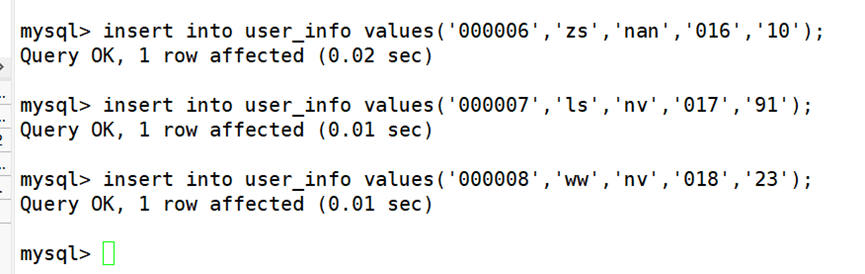
(1)添加数据库,表,录入信息
在进行备份之前,先根据给出的需求创建用户信息数据库 client、用户资费数据表user_info,并且根据需求描述中的表格插入前三条用户的数据。

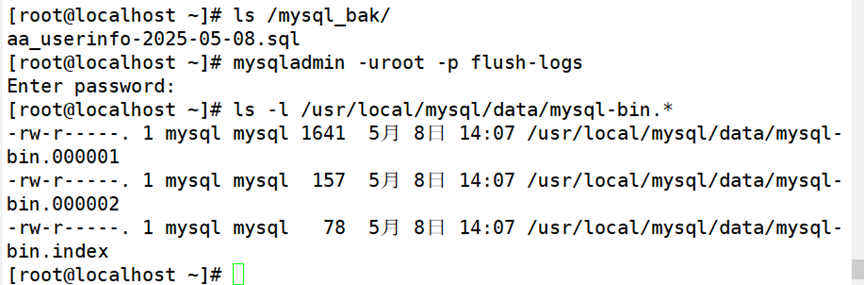
(2)先进性一次性完全备份
(3)继续录入新的数据并进行增量备份

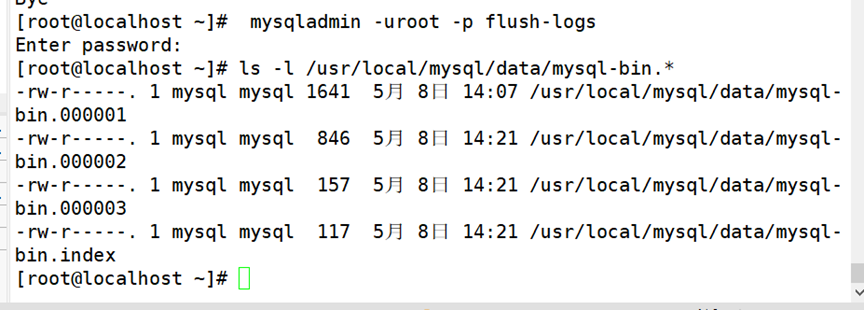
2.基于位置恢复
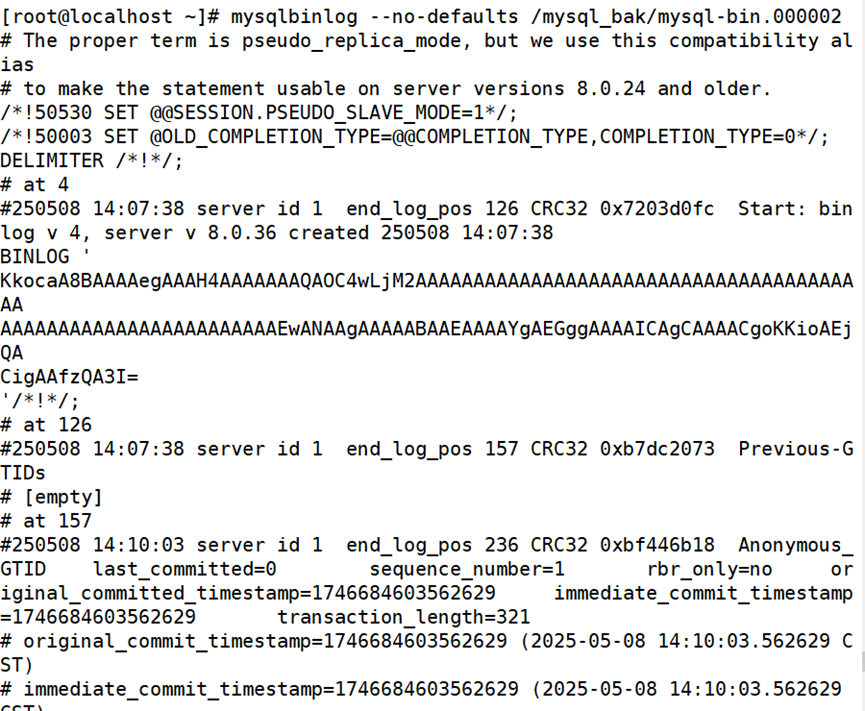
三 备份策略思路
在进行热备份时,备份操作和应用服务在同时运行,这样就十分消耗系统资原了,导致数据库服务性能下降,这就需要选择一个合适的时间(如在应用负担很小的时候)再来进行备份操作。
需要注意的是,不是备份完就万事大吉,最好确认备份是否可用,所以备份之后的恢复测试是非常有必要的。同时备份时间也要灵活调整,如:
数据更新频繁,则应该频繁地备份。 数据的重要性,在有适当更新时进行备份 在数据库压力小的时间段进行备份,如一周一次完全备份,每天进行增量备份。
中小公司,完全备份一般一天一次即可。 大公司可每周进行一次完全备份,每天进行一次增量备份。 尽量为企业实现主从复制架构,以增加数据的可用性。
四 扩展:MYSQL的GTID 和XTRABACKUP
1.mysql的gtid
GTID即全局事务 ID(globaltransaction identifier),其保证为每一个在主上提交的事务在复制集群中可以生成一个唯一的ID。GTID最初由google实现,官方MySQL在5.6才加入该功能
GTID 实际上是由UUID+TID(即transactionId)组成的。其中UUID(即server_uuid)产生于auto.conf文件(cat/data/mysql/data/auto.cnf),是一个MySQL实例的唯一标识。TID代表了该实例上已经提交的事务数量,并且随着事务提交单调递增,所以GTID能够保证每个MySQL实例事务的执行(不会重复执行同一个事务,并且会补全没有执行的事务)。GTID在一组复制中,全局唯
通过下面的实验,了解基于gtid的增量备份和恢复(Gtid的备份也是基于binlog的)
(1)配置my.cnf 开启gtid

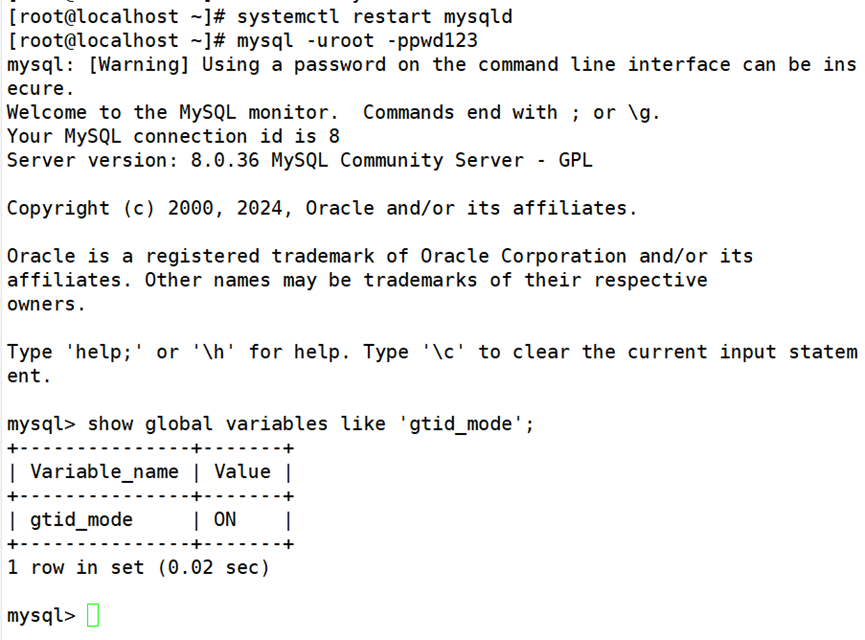
验证是否开启
(2)创建基本测试库,表,数据
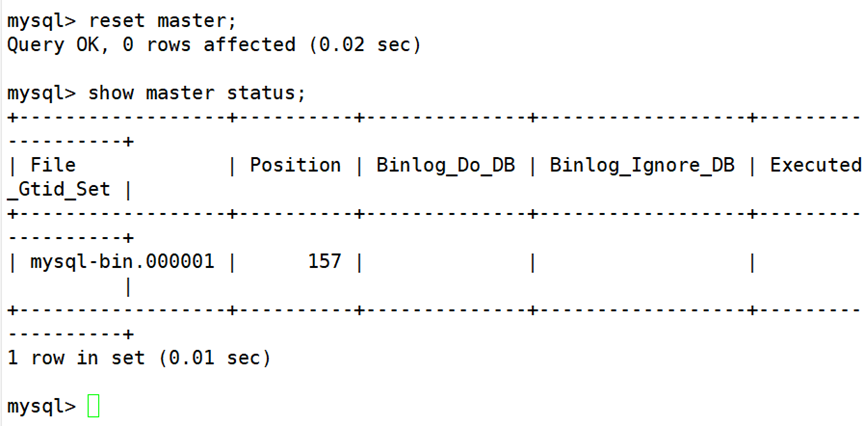

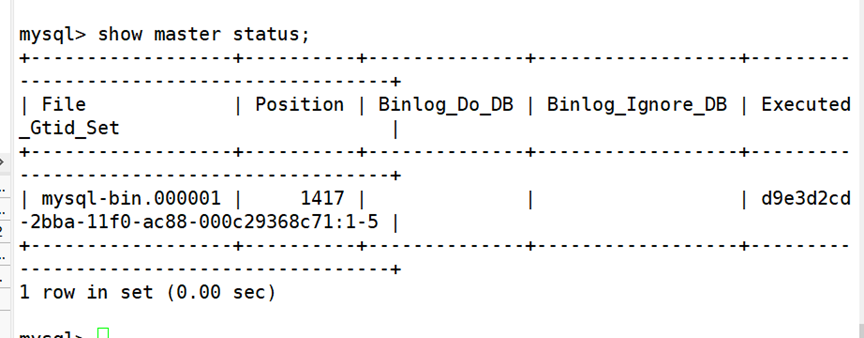
(3)全量备份
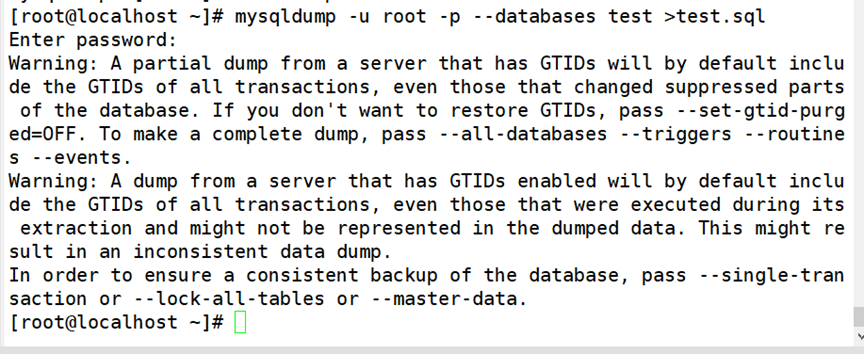

(4)插入新数据
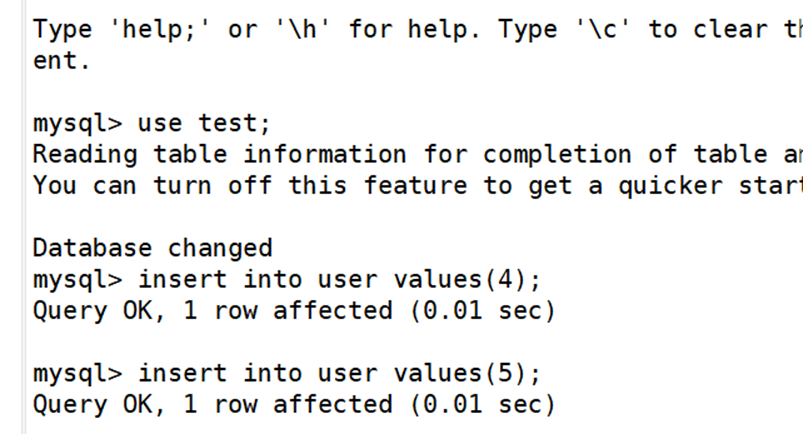
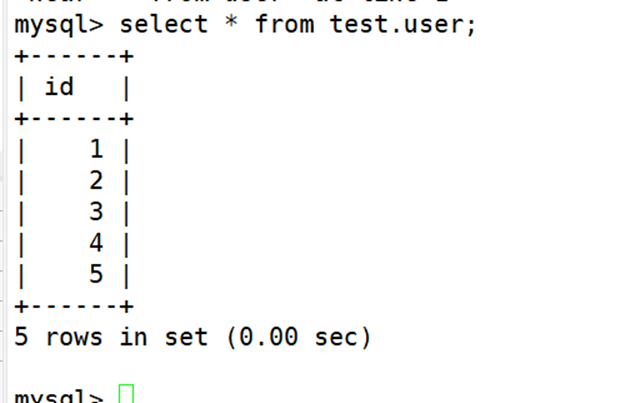
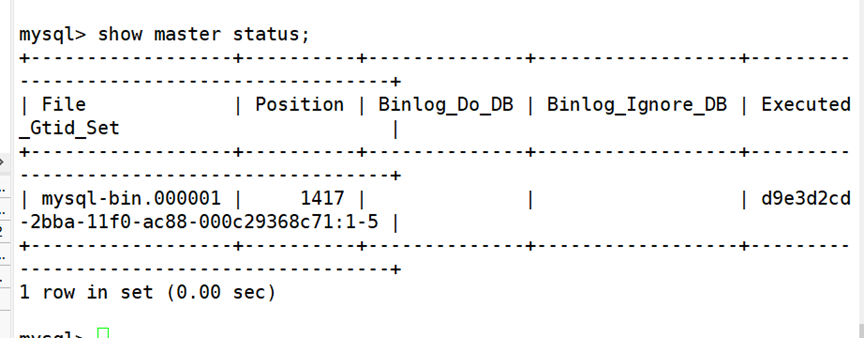
(5)模拟数据误删除
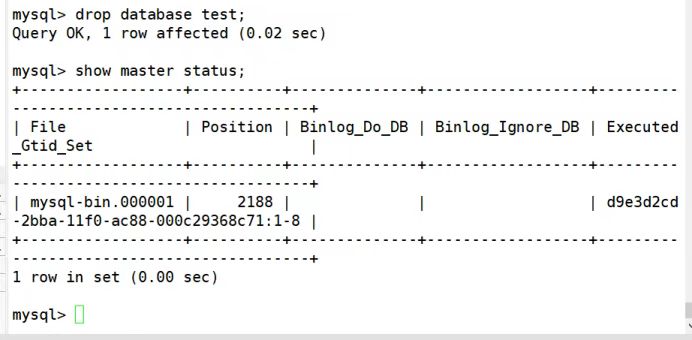
(6)导出增量备份

(7)恢复全量
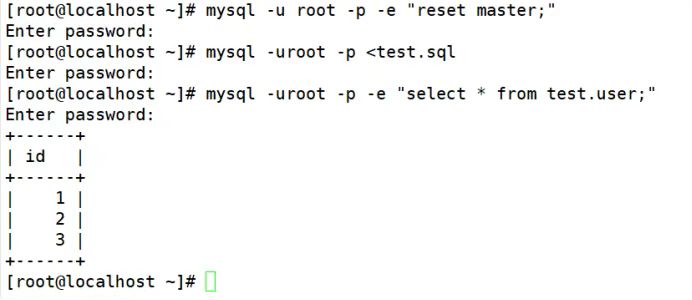
(8)恢复增量
2.XtraBackup
MySQL冷备、mysqldump、MySQL热拷贝都无法实现对数据库进行增量备份。在实际生产环境中增量备份是非常实用的,如果数据大于50G或100G,存储空间足够的情况下,可以每天进行完整备份,如果每天产生的数据量较大,需要定制数据备份策略。例如每周实用完整备份,周一到周六实用增量备份。而Percona-Xtrabackup 就是为了实现增量备份而出现的一款主流备份工具,xtrabakackup有2个工具,分别是xtrabakup、innobakupe。
Percona-xtrabackup是Percona公司开发的一个用于MySQL数据库物理热备的备份工具,支持MySQL、Percona server和MariaDB,开源免费,是目前较为受欢迎的主流备份工具。xtrabackup只能备份innoDB和xtraDB两种数据引擎的表,而不能备份MyISAM数据表。
相关文章:

MYSQL 全量,增量备份与恢复
目录 一 数据备份的重要性 1 数据备份的重要性 2 数据库备份类型 2.1 从物理与逻辑的角度分类 2.2. 从数据库的备份策略角度分类从数据库的备份策略角度,数据库的备份可分为完全备份、差异备份和增量备份。 3 常见的备份方法 3.1 物理冷备份 物理冷备份时需要在数据库处…...

10. Spring AI PromptTemplate:从模板到高级技巧
1、前言 如果学到了这里,相信大部分人对Prompt并不陌生了。 在 Spring AI 的世界里,与强大的语言模型进行交互的基石便是 Prompt(提示语)。它不仅仅是你输入给 AI 的一段文本,更是你与智能对话的桥梁,是你唤醒模型潜能的关键指令。理解 Prompt 的本质、构建原则以及在 …...

基于OpenCV的人脸识别:Haar级联分类器
文章目录 引言一、环境准备二、代码实现1. 图像加载与预处理2. 加载Haar级联分类器3. 人脸检测核心参数详解4. 结果显示与标注 三、效果优化建议四、完整代码五、总结 引言 本文将带你一步步实现一个简单但实用的人脸检测程序,使用Python和OpenCV库。 一、环境准备…...

Git安装教程及常用命令
1. 安装 Git Bash 下载 Git 安装包 首先,访问 Git 官方网站 下载适用于 Windows 的 Git 安装包。 安装步骤 启动安装程序:双击下载的 .exe 文件,启动安装程序。选择安装选项: 安装路径:可以选择默认路径࿰…...

【PmHub后端篇】Skywalking:性能监控与分布式追踪的利器
在微服务架构日益普及的当下,对系统的性能监控和分布式追踪显得尤为重要。本文将详细介绍在 PmHub 项目中,如何使用 Skywalking 实现对系统的性能监控和分布式追踪,以及在这过程中的一些关键技术点和实践经验。 1 分布式链路追踪概述 在微服…...

ChromeDriver 技术生态与应用场景深度解析
ChromeDriver 技术生态与应用场景深度解析 随着 Web 自动化测试、运维和数据采集需求的不断增长,ChromeDriver 及其相关技术栈在各行业中扮演着举足轻重的角色。本文将从技术选型、语言适配、典型场景、技术延伸等维度,结合最新行业趋势与实践经验&…...

链表面试题6之回文结构
经过前几道题的铺垫,那么我们也是来到了链表的第六关。这也是一道非常经典的题目。 目录 逆置法 数组法 那么对于这道题目,我们要判断回文结构,实际上就是判断链表对不对称。这种类型的题目我们好像在哪里见过,对了,…...

ASP.NET Core Identity框架使用指南
文章目录 前言一、核心功能二、核心组件三、使用1)创建项目2)安装必要 NuGet包3)配置数据库连接字符串4)用户与角色实体定义4)配置数据库上下文5) 注册服务6)数据库迁移与初始化7)用…...

Hugging Face推出了一款免费AI代理工具,它能像人类一样使用电脑
Hugging Face推出了一款免费AI代理工具,它能像人类一样使用电脑。 这款工具名为Open Computer Agent(开放计算机代理),可模拟真实的电脑操作。 无需安装,在浏览器中即可运行。 以下是一些信息: - Open C…...

一.Gitee基本操作
一.初始化 1.git init初始化仓库 git init 用于在当前目录下初始化一个本地 Git 仓库,让这个目录开始被 Git 跟踪和管理。 生成 .git 元数据目录,从而可以开始进行提交、回退、分支管理等操作。 2.git config user.name/user.email配置本地仓库 # 设置…...

24、DeepSeek-V3论文笔记
DeepSeek-V3论文笔记 **一、概述****二、核心架构与创新技术**0.汇总:1. **基础架构**2. **创新策略** 1.DeepSeekMoE无辅助损失负载均衡DeepSeekMoE基础架构无辅助损失负载均衡互补序列级辅助损失 2.多令牌预测(MTP)1.概念2、原理2.1BPD2.2M…...

神经网络初步学习——感知机
一、前言 神经网络,顾名思义,它与我们大脑生物学里面讲到的神经元有关联。前辈们在研究早期人工智能的时候,就开始过我们的“交叉融合”,他们思考能不能把我们的人工智能的学习模式改造成我们人脑中神经元之间的学习方式——于是乎…...

在Text-to-SQL任务中应用过程奖励模型
论文标题 Reward-SQL: Boosting Text-to-SQL via Stepwise Reasoning and Process-Supervised Rewards 论文地址 https://arxiv.org/pdf/2505.04671 代码地址 https://github.com/ruc-datalab/RewardSQL 作者背景 中国人民大学,香港科技大学广州,阿…...

Python的安装使用
一、下载Python安装包 下载python安装包,可以直接访问官网地址:https://www.python.org/downloads/ 通过页面咱们直接下载最新版本的python安装包即可,python3.13.3。在页面的下方也可下载安装之前的版本,目前咱们按最新版本安装…...

mapreduce-wordcount程序2
WordCount案例分析 给定一个路径,统计这个路径下所有的文件中的每一个单词的出现次数。 其中,需要我们去实现代码的部分是:map函数和reduce函数。它们各自的作用是: map函数的入参是kv结构,k是偏移量,v是一…...
与内存屏障:原理、实践与性能权衡)
Java 内存模型(JMM)与内存屏障:原理、实践与性能权衡
Java 内存模型(JMM)与内存屏障:原理、实践与性能权衡 在多线程高并发时代,Java 内存模型(JMM) 及其背后的内存屏障机制,是保障并发程序正确性与性能的基石。本文将系统梳理 JMM 的核心原理、内…...

1.6 偏导数
(铺垫)全导数与偏导数看似相似,实则对应不同维度的变化观察。理解它们的差异需要从"变量自由度"切入: (核心差异解剖) 维度偏导数全导数变量关系其他变量被强制锁定所有变量都通过中间变量关联…...

网络爬虫学习之正则表达式
开篇 本文整理自《python3 网络爬虫开发实战》的学习笔记。 笔记整理 match match是一种常用的匹配方法,向它传入要匹配的字符串以及正则表达式,就可以检测这个正则表达式是否和字符串相匹配。 match会尝试从字符串的起始位置开始匹配正则表达式&#x…...

Pytorch常用统计和矩阵运算
文章目录 常用统计函数torch.prod()求积torch.sum()求和torch.mean()求均值torch.max()求最值torch.var() 方差torch.std()标准差 常见矩阵运算矩阵乘法点积 (torch.dot)批量矩阵乘法 (torch.bmm)奇异值分解 (SVD)特征分解 (torch.eig)矩阵求逆 (torch.inverse)伪逆 (torch.pin…...

PyTorch Lightning实战 - 训练 MNIST 数据集
MNIST with PyTorch Lightning 利用 PyTorch Lightning 训练 MNIST 数据。验证梯度范数、学习率、优化器对训练的影响。 pip show lightning Version: 2.5.1.post0Fast dev run DATASET_DIR"/repos/datasets" python mnist_pl.py --output_grad_norm --fast_dev_run…...

内存泄漏系列专题分析之十一:高通相机CamX ION/dmabuf内存管理机制Camx ImageBuffer原理
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了:内存泄漏系列专题分析之八:高通相机CamX内存泄漏&内存占用分析--通用ION(dmabuf)内存拆解 这一篇我们开始讲: 内存泄漏系列专题分析之十一:高通相机CamX ION/dmabuf内存管理机制Camx ImageBuf…...

MySQL-逻辑架构
MySQL服务器逻辑架构图 主要分层结构 1.连接层 功能:处理连接、安全认证、线程管理等 核心模块:连接器:支持不同语言(JDBC)与MySQL交互;线程连接池:管理线程连接,减少线程频繁创建…...

架构思维:通用架构模式_系统监控的设计
文章目录 引言什么是监控三大常见监控类型1. 次数监控2. 性能监控3. 可用率监控 落地监控1. 服务入口2. 服务内部3. 服务依赖 监控时间间隔的取舍小结 引言 架构思维:通用架构模式_从设计到代码构建稳如磐石的系统 架构思维:通用架构模式_稳如老狗的SDK…...

架构、构架、结构、框架之间有什么区别?|系统设计|系统建模
在技术与知识中,我们总是频繁地遇到一些高度抽象、看似类似、却又各自承载着不同思想重量的词汇。“架构”、“构架”、“结构”、“框架”即是其中最为常见又最为令人困惑的一组术语。它们既是工程师们日常工作的核心语言,也是学者们在探索系统、组织、…...
:构件)
系统架构设计(五):构件
定义 构件(Component)是指一个具有明确边界和独立部署能力的模块化单元,能够封装实现细节,并通过接口与其他构件协作完成系统功能。 主要特性 特性说明可复用性构件可以在不同系统中被重复使用。可部署性构件可以独立部署&…...

【系统架构师】2025论文《基于架构的软件设计方法》【最新】
😊你好,我是小航,一个正在变秃、变强的文艺倾年。 🔔本文分享【系统架构师】2025论文《系统可靠性设计》,期待与你一同探索、学习、进步,一起卷起来叭! 目录 项目介绍背景介绍系统模块技术栈基于…...

MultiTTS 1.7.6 | 最强离线语音引擎,提供多音色无障碍朗读功能,附带语音包
MultiTTS是一款免费且支持离线使用的文本转语音(TTS)工具,旨在为用户提供丰富的语音包选项,实现多音色无障碍朗读功能。这款应用程序特别适合用于阅读软件中的离线听书体验,提供了多样化的语音选择,使得听书…...

Costmap代价地图
以下为ROS navigation导航工具包的move_base框架图。其中有两个关于代价地图的模块(红框所框),全局代价地图global_costmap和局部代价地图local_costmap,这两个代价地图实际上是调用的同一个功能包代码,通过配置不同的参数实例化为两个代价地…...

用生活例子通俗理解 Python OOP 四大特性
让我们用最生活化的方式,结合Python代码,来理解面向对象编程的四大特性。 1. 封装:像使用自动售货机 生活比喻: 你只需要投币、按按钮,就能拿到饮料 不需要知道机器内部如何计算找零、如何运送饮料 如果直接打开机…...

大规模容器集群怎么规划
规划大规模容器集群需要综合考虑多个方面,以下是一些关键的规划要点: 业务需求分析 应用类型和特点:明确容器集群上运行的应用类型,如 Web 应用、数据库、大数据处理等。不同类型的应用对资源的需求和性能要求各不相同。例如&am…...

机器学习第七讲:概率统计 → 预测可能性,下雨概率70%就是典型应用
机器学习第七讲:概率统计 → 预测可能性,下雨概率70%就是典型应用 资料取自《零基础学机器学习》。 查看总目录:学习大纲 关于DeepSeek本地部署指南可以看下我之前写的文章:DeepSeek R1本地与线上满血版部署:超详细手…...

蓝桥杯13届 卡牌
问题描述 这天, 小明在整理他的卡牌。 他一共有 n 种卡牌, 第 i 种卡牌上印有正整数数 i(i∈[1,n]), 且第 i 种卡牌 现有 ai 张。 而如果有 n 张卡牌, 其中每种卡牌各一张, 那么这 n 张卡牌可以被称为一 套牌。小明为了凑出尽可能多套牌, 拿出了 m 张空白牌, 他可以在上面…...

《Vue.js》阅读之响应式数据与副作用函数
Vue.js 《Vue.js设计与实现》(霍春阳) 适合:从零手写Vue3响应式系统,大厂面试源码题直接覆盖。重点章节:第4章(响应式)、第5章(渲染器)、第8章(编译器&…...

线下消费经济“举步维艰”,开源AI智能名片链动2+1+S2B2C小程序线上“狂飙突进”!
开源AI智能名片链动21模式S2B2C商城小程序:驱动消费经济迭代的数字化引擎 摘要:本文以中国消费经济四阶段演进为框架,分析开源AI智能名片链动21模式S2B2C商城小程序如何重构商业生态。研究显示,该系统通过AI算法驱动的精准需求匹…...

简述DNS域名服务器
DNS简述 在互联网中,识别一个主机通常有两种方式——主机名和IP地址。从人类角度来看,人类肯定更喜欢这些便于记忆的主机名标识方式,而对于路由器来说,路由器则更喜欢定长的,有结构层次的IP地址。所以DNS域名服务器就…...

小结: Port Security,DHCP Snooping,IPSG,DAI,
以下是华为和思科在 IP Source Guard、Dynamic ARP Inspection、DHCP Snooping、Port Security 四个安全功能的配置指令对比: 1. Port Security(端口安全) 思科(Cisco) # 进入接口模式 interface GigabitEthernet0/1…...
)
2025年阿里云ACP人工智能高级工程师认证模拟试题(附答案解析)
这篇文章的内容是阿里云ACP人工智能高级工程师认证考试的模拟试题。 所有模拟试题由AI自动生成,主要为了练习和巩固知识,并非所谓的 “题库”,考试中如果出现同样试题那真是纯属巧合。 1、在PAl-Studio实验运行完毕后,可以右键单…...

SwitchyOmega_Chromium 代理插件下载与配置
下载地址: 【免费】SwitchyOmega-Chromium.ran资源-CSDN文库 下载 SwitchyOmega_Chromium.ran 文件。 解压缩文件 解压第一层后,解压第二层代理插件SwitchyOmega_Chromium。 打开 Chromium 浏览器。 导入插件: 在浏览器地址栏输入 chrome://extensio…...
:按钮组组件的构建之旅)
【Nova UI】十四、打造组件库之按钮组件(下):按钮组组件的构建之旅
序言 在之前的探索中,我们成功雕琢出了功能完备且样式精美的 Vue 按钮组件,它在前端界面上绽放着独特的光彩✨。然而,前端开发的创新之路永无止境。如今,为了满足更丰富的交互需求,我们将目光聚焦在按钮组组件的实现上…...

SQL注入
sql注入核心语句 information_schema 虚拟数据库(物理上不存在),能提供方皓文数据库元数据的方式,元数据是关于数据的数据,如数据库名、表名、列的数据类型、访问权限等 只能访问 information_schema下面的表: schemata表…...

Java面试高阶篇:Spring Boot+Quarkus+Redis高并发架构设计与性能优化实战
Java面试高阶篇:Spring BootQuarkusRedis高并发架构设计与性能优化实战 面试官(严肃): Q1: 你项目中如何实现高并发下的缓存优化? 候选人(水货): 我们用了Redis做缓存,…...
 BCD)
【CF】Day57——Codeforces Round 955 (Div. 2, with prizes from NEAR!) BCD
B. Collatz Conjecture 题目: 思路: 简单模拟 很简单的模拟,我们只需要快速的找到下一个离 x 最近的 y 的倍数即可(要大于 x) 这里我们可以这样写 add y - (x % y),这样就知道如果 x 要变成 y 的倍数还要…...

Matlab 列车纵向滑模二阶自抗扰算法和PID对比
1、内容简介 Matlab 223-列车纵向滑模二阶自抗扰算法和PID对比 可以交流、咨询、答疑 2、内容说明 略 列车模型 在运行过程中,已知列车受到牵引力或者制动力,基本阻力和附加阻力的作用,规定与列车运行方向相同的力为正,与运行…...

Swift实战:如何优雅地从二叉搜索树中挑出最接近的K个值
文章目录 摘要描述题解答案题解代码分析示例测试及结果时间复杂度空间复杂度总结未来展望 摘要 在日常开发中,我们经常会遇到“在一堆数据中找出最接近某个值”的需求。尤其在搜索引擎、推荐系统或者地理坐标匹配中,这种“最近匹配”的问题非常常见。Le…...

深度策略梯度算法PPO
一、策略梯度核心思想和原理 从时序差分算法Q学习到深度Q网络,这些算法都侧重于学习和优化价值函数,属于基于价值的强化学习算法(Value-based)。 1. 基于策略方法的主要思想(Policy-based) 基于价值类方…...

QuickList
Redis在3.2版本引入数据结构,是一个双端链表,每个节点都是一个ZipList。 引入的原因:ZipList申请内存空间是连续的,如果内存占用较多,申请内存效率很低 思想:属于分片存储的思想 Redis配置项:…...

DVWA在线靶场-SQL注入部分
目录 1.SQL注入 1.1 low 1.2 Medium 1.3 high 1.4 impossible 1. SQL盲注 1.1 low 2.2 medium 2.3 high 2.4 impossible 1.SQL注入 显注:前端页面可以回显用户信息,比如 联合注入、报错注入。 盲注:前端页面不能回显用户信息,比…...

IDEA+git将分支合并到主分支、IDEA合并分支
文章目录 一、合并分支二、可能遇到的问题2.1、代码冲突 开发过程中我们可能在开发分支(dev)中进行开发,等上线后将代码合并到主分支(master)中,本文讲解如何在IDEA中将dev分支的代码合并到master分支中。 一、合并分支 功能说明:将dev分支的…...

【Linux笔记】——进程信号的产生
🔥个人主页🔥:孤寂大仙V 🌈收录专栏🌈:Linux 🌹往期回顾🌹:【Linux笔记】进程间通信——system v 共享内存 🔖流水不争,争的是滔滔不 一、进程信号…...
)
Java后端文件类型检测(防伪造)
在 Spring Boot 项目中,为了防止用户伪造 Content-Type(例如将 .txt 文件改为 image/jpeg 上传),可以通过检查文件的 Magic Number(文件头签名)来验证文件的真实类型。以下是 详细实现步骤 和 完整代码示例…...