24、DeepSeek-V3论文笔记
DeepSeek-V3论文笔记
- **一、概述**
- **二、核心架构与创新技术**
- 0.汇总:
- 1. **基础架构**
- 2. **创新策略**
- 1.DeepSeekMoE无辅助损失负载均衡
- DeepSeekMoE基础架构
- 无辅助损失负载均衡
- 互补序列级辅助损失
- 2.多令牌预测(MTP)
- 1.概念
- 2、原理
- 2.1BPD
- 2.2Meta改进版
- 单次训练(示意图)
- batch批量训练(示意图)
- 2.3DeepSeek改进版MTP
- 原理
- Teacher forcing和free-running模式
- 训练的输入系列预测对应位置
- 单次训练(示意图)
- batch批量训练(示意图)
- 推理
- 2.4 对比(训练推理)
- 3、DeepSeek MTP实例说明
- 一、核心设计逻辑:从单令牌到多令牌预测
- 二、MTP模块实现:以D=2为例(预测未来2个令牌)
- 1. **k=1深度:预测第i+1个令牌(下一个令牌)**
- 2. **k=2深度:预测第i+2个令牌(下下个令牌)**
- 3. **因果链保持**:
- 三、训练目标:多深度损失计算实例
- 四、推理阶段:推测解码加速实例
- 五、关键优势与对比
- 总结:MTP如何提升模型性能?
- 4、Multi-Token Prediction(原文解释)
- MTP模块
- MTP训练目标
- MTP在推理中的应用
- 3.多头潜在注意力(MLA)
- **三、训练基础设施与优化**
- 1. **硬件与混合精度训练**
- 2. **训练框架优化**
- **四、预训练与后训练流程**
- 1. **预训练阶段**
- 2. **后训练阶段**
- **五、性能评估与基准测试**
- 1. **核心基准表现**
- 2. **闭源模型对比**
- **六、训练成本与效率**
- **七、局限性与未来方向**
- 1. **当前局限**
- 2. **未来方向**
- **八、核心贡献**
- 总结
一、概述

DeepSeek-V3是深度求索(DeepSeek-AI)开发的混合专家(MoE)语言模型,总参数671B,每个令牌激活37B参数。其核心目标是在高效推理、低成本训练与高性能之间取得平衡,通过架构创新、训练优化和大规模数据预训练,成为当前最强开源模型之一,性能接近GPT-4o、Claude-3.5等闭源模型。


二、核心架构与创新技术
0.汇总:
1. 基础架构
- Multi-head Latent Attention (MLA):
- 通过低秩压缩键值对(KV)和查询向量,减少推理时的缓存占用(仅缓存压缩后的潜在向量),在保持性能的同时,将KV缓存量显著降低,提升推理效率。
- DeepSeekMoE: (DeepSeek-V2中的结构)
- 采用细粒度专家设计(1个共享专家+256个路由专家),每个令牌激活8个专家,通过节点限制路由(最多4节点)控制跨节点通信成本,提升训练效率。
2. 创新策略
- 无辅助损失负载均衡的DeepSeekMoE:
- 动态调整专家偏置(bias term)以平衡负载,避免传统辅助损失对模型性能的负面影响。通过监控批次级负载,动态增减偏置,确保专家负载均衡,同时保留专家专业化能力。
- 多令牌预测(MTP):
- 训练时预测未来2个令牌,密集训练信号,提升数据效率;推理时可用于推测解码,解码速度提升1.8倍。
1.DeepSeekMoE无辅助损失负载均衡
辅助无损负载均衡。对于 MoE 模型,不平衡的专家负载将导致路由崩溃(Shazeer et al., 2017),并在具有专家并行性的场景中降低计算效率。常规解决方案通常依赖于辅助损失(Fedus et al., 2021;Lepikhin et al., 2021)以避免负载不平衡。然而,过大的辅助损耗会损害模型性能(Wang et al., 2024a)。为了在负载均衡和模型性能之间实现更好的权衡,我们开创了一种辅助无损负载均衡策略(Wang et al., 2024a)来确保负载均衡。具体来说,我们为每个专家引入了一个偏差术语 b i b_{i} bi,并将其添加到对应的亲和度分数sᵢ,ₜ中,以确定Top-K路由,动态调整专家偏置(bias term)以平衡负载,避免传统辅助损失对模型性能的负面影响。
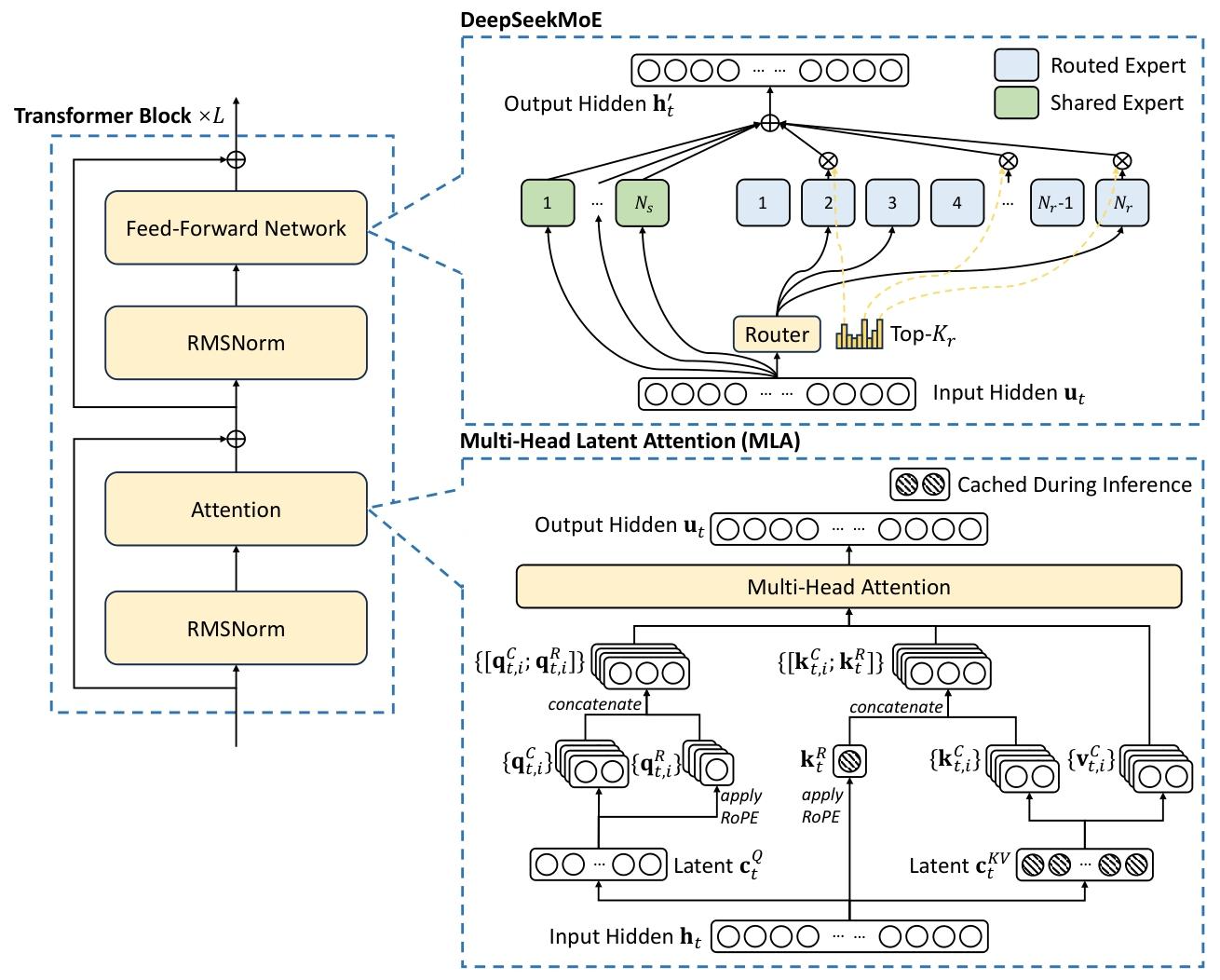
图 2 |DeepSeek-V3 的基本架构图示。在 DeepSeek-V2 之后,我们采用 MLA 和 DeepSeekMoE 进行高效推理和经济训练。
无辅助损失负载均衡的DeepSeekMoE
DeepSeekMoE基础架构
具体原理参考:DeepSeekMoE论文笔记链接 ,MOE汇总链接
在前馈网络(FFNs)方面,DeepSeek-V3采用DeepSeekMoE架构(Dai等人,2024)。与GShard(Lepikhin等人,2021)等传统MoE架构相比,DeepSeekMoE使用更细粒度的专家,并将部分专家隔离为共享专家。令uₜ表示第t个令牌的FFN输入,FFN输出h’ₜ计算如下:
h t ′ = u t + ∑ i = 1 N s FFN i ( s ) ( u t ) + ∑ i = 1 N r g i , t FFN i ( r ) ( u t ) , ( 12 ) h'_t = u_t + \sum_{i=1}^{N_s} \text{FFN}_i^{(s)}(u_t) + \sum_{i=1}^{N_r} g_{i,t} \text{FFN}_i^{(r)}(u_t), \quad (12) ht′=ut+i=1∑NsFFNi(s)(ut)+i=1∑Nrgi,tFFNi(r)(ut),(12)
g i , t = g i , t ′ ∑ j = 1 N r g j , t ′ , ( 13 ) g_{i,t} = \frac{g'_{i,t}}{\sum_{j=1}^{N_r} g'_{j,t}}, \quad (13) gi,t=∑j=1Nrgj,t′gi,t′,(13)
g i , t ′ = { s i , t , s i , t ∈ Topk ( { s j , t ∣ 1 ≤ j ≤ N r } , K r ) , 0 , otherwise , ( 14 ) g'_{i,t} = \begin{cases} s_{i,t}, & s_{i,t} \in \text{Topk}(\{s_{j,t} \mid 1 \leq j \leq N_r\}, K_r), \\ 0, & \text{otherwise}, \end{cases} \quad (14) gi,t′={si,t,0,si,t∈Topk({sj,t∣1≤j≤Nr},Kr),otherwise,(14)
s i , t = Sigmoid ( u t T e i ) , ( 15 ) s_{i,t} = \text{Sigmoid}(u_t^T e_i), \quad (15) si,t=Sigmoid(utTei),(15)
其中,Nₛ和Nᵣ分别表示共享专家和路由专家的数量;FFNᵢ⁽ˢ⁾(·)和FFNᵢ⁽ʳ⁾(·)分别表示第i个共享专家和第i个路由专家;Kᵣ表示激活的路由专家数量;gᵢ,ₜ是第i个专家的门控值;sᵢ,ₜ是令牌与专家的亲和度分数;eᵢ是第i个路由专家的质心向量;Topk(·, K)表示为第t个令牌与所有路由专家计算的亲和度分数中前K个最高分的集合。与DeepSeek-V2略有不同,DeepSeek-V3使用Sigmoid函数计算亲和度分数,并对所有选中的亲和度分数进行归一化以生成门控值。
无辅助损失负载均衡
对于MoE模型,专家负载不平衡会导致路由崩溃(Shazeer等人,2017),并降低专家并行场景下的计算效率。传统解决方案通常依赖辅助损失(Fedus等人,2021;Lepikhin等人,2021)来避免负载不平衡,但过大的辅助损失会损害模型性能(Wang等人,2024a)。为了在负载均衡和模型性能之间实现更好的权衡,我们首创了无辅助损失负载均衡策略(Wang等人,2024a)以确保负载均衡。具体来说,我们为每个专家引入偏置项bᵢ,并将其添加到对应的亲和度分数sᵢ,ₜ中,以确定Top-K路由:
g i , t ′ = { s i , t , s i , t + b i ∈ Topk ( { s j , t + b j ∣ 1 ≤ j ≤ N r } , K r ) , 0 , otherwise . ( 16 ) g'_{i,t} = \begin{cases} s_{i,t}, & s_{i,t} + b_i \in \text{Topk}(\{s_{j,t} + b_j \mid 1 \leq j \leq N_r\}, K_r), \\ 0, & \text{otherwise}. \end{cases} \quad (16) gi,t′={si,t,0,si,t+bi∈Topk({sj,t+bj∣1≤j≤Nr},Kr),otherwise.(16)
注意,偏置项仅用于路由,与FFN输出相乘的门控值仍由原始亲和度分数sᵢ,ₜ推导而来。训练过程中,我们持续监控每个训练步骤整个批次的专家负载。每一步结束时,若对应专家过载则将偏置项减少γ,欠载则增加γ,其中γ是称为偏置更新速度的超参数。通过动态调整,DeepSeek-V3在训练期间保持专家负载平衡,性能优于仅通过辅助损失实现负载均衡的模型。
互补序列级辅助损失
尽管DeepSeek-V3主要依赖无辅助损失策略实现负载均衡,但为防止单个序列内出现极端不平衡,我们还采用了互补的序列级平衡损失:
L Bal = α ∑ i = 1 N r f i P i , ( 17 ) L_{\text{Bal}} = \alpha \sum_{i=1}^{N_r} f_i P_i, \quad (17) LBal=αi=1∑NrfiPi,(17)
f i = N r K r T ∑ t = 1 T 1 ( s i , t ∈ Topk ( { s j , t ∣ 1 ≤ j ≤ N r } , K r ) ) , ( 18 ) f_i = \frac{N_r}{K_r T} \sum_{t=1}^T \mathbb{1}(s_{i,t} \in \text{Topk}(\{s_{j,t} \mid 1 \leq j \leq N_r\}, K_r)), \quad (18) fi=KrTNrt=1∑T1(si,t∈Topk({sj,t∣1≤j≤Nr},Kr)),(18)
s i , t ′ = s i , t ∑ j = 1 N r s j , t , ( 19 ) s'_{i,t} = \frac{s_{i,t}}{\sum_{j=1}^{N_r} s_{j,t}}, \quad (19) si,t′=∑j=1Nrsj,tsi,t,(19)
P i = 1 T ∑ t = 1 T s i , t ′ , ( 20 ) P_i = \frac{1}{T} \sum_{t=1}^T s'_{i,t}, \quad (20) Pi=T1t=1∑Tsi,t′,(20)
其中平衡因子α是超参数(DeepSeek-V3中取值极小);𝟙(·)表示指示函数;T为序列中的令牌数。序列级平衡损失促使每个序列内的专家负载趋于均衡。
2.多令牌预测(MTP)
1.概念
什么是MTP(what)
MTP(Multi-Token Prediction)实际上就是将大模型原始的1-token的生成,转变成multi-token的生成,从而提升训练和推理的性能。具体来说,在训练阶段,一次生成多个后续token,可以一次学习多个后续位置上的label,进而有效提升样本的利用效率,提升训练速度;在推理阶段通过一次生成多个后续token,实现成倍的推理加速来提升推理性能。
当前主流的大模型(LLMs)都是decoder-base的模型结构,也就是无论在模型训练还是在推理阶段,对于一个序列的生成过程,都是token-by-token的。每次在生成一个token的时候,都要频繁跟访存交互,加载KV-Cache,再通过多层网络做完整的前向计算。对于这样的访存密集型的任务,通常会因为访存效率形成训练或推理的瓶颈。针对token-by-token生成效率的瓶颈,业界很多方法来优化,包括减少存储的空间和减少访存次数等,进而提升训练和推理性能。
2、原理
2.1BPD
Blockwise Parallel Decoding
首先我们来看一篇Google的工作,这是Google在18年发表在NIPS上的工作(18年是Transformer诞生的元年)。
paper:Blockwise Parallel Decoding for Deep Autoregressive Models
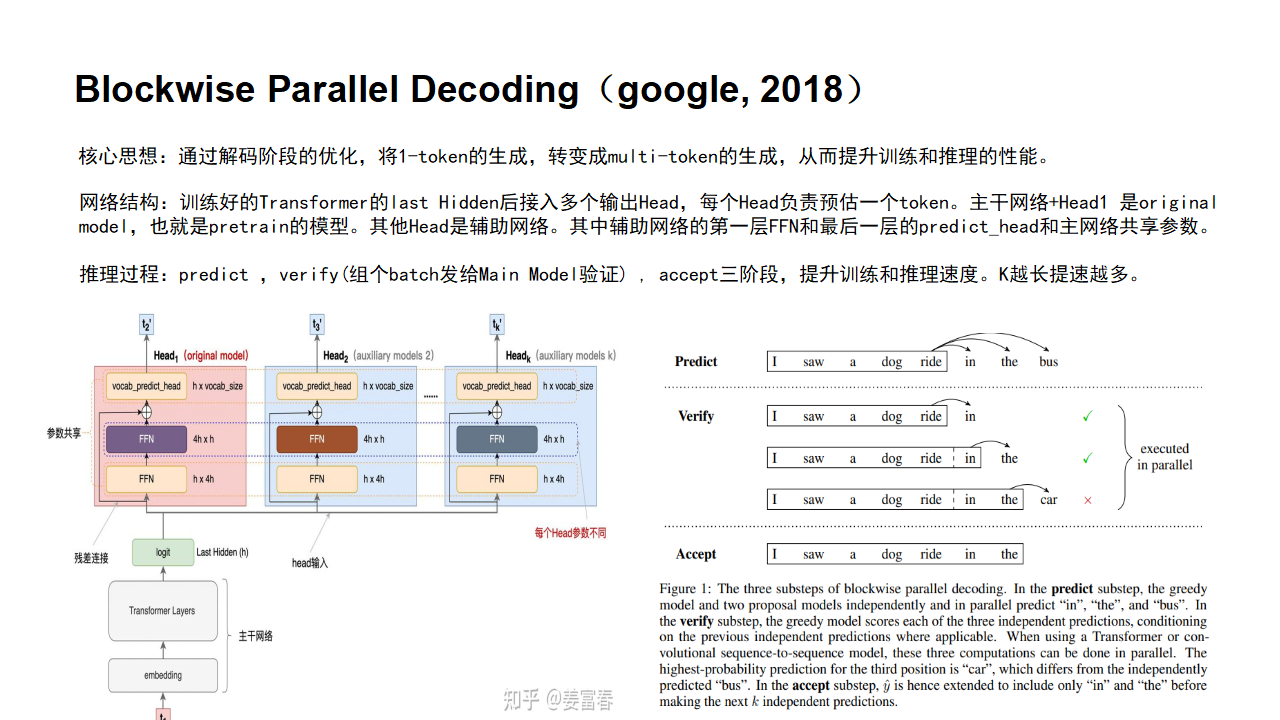


Blockwise Parallel Decoding 的核心内容,该方法主要是为了做推理阶段的并行加速而设计的。虽然命名上没有遵循MPT类,但后面一些演进的方法比如Speculative Sample和下面要介绍的Meta’s MTP等,都有该方法设计的影子。
参考:https://zhuanlan.zhihu.com/p/18056041194
2.2Meta改进版
原始版MTP有个什么问题呢?因为那时候当前LLM的decoder架构还不受到重视,因此meta结合当前LLM的架构,重新设计了更符合大模型的MTP。
这是meta 于2024年4月发表的一篇工作。
paper : Better & Faster Large Language Models via Multi-token Prediction
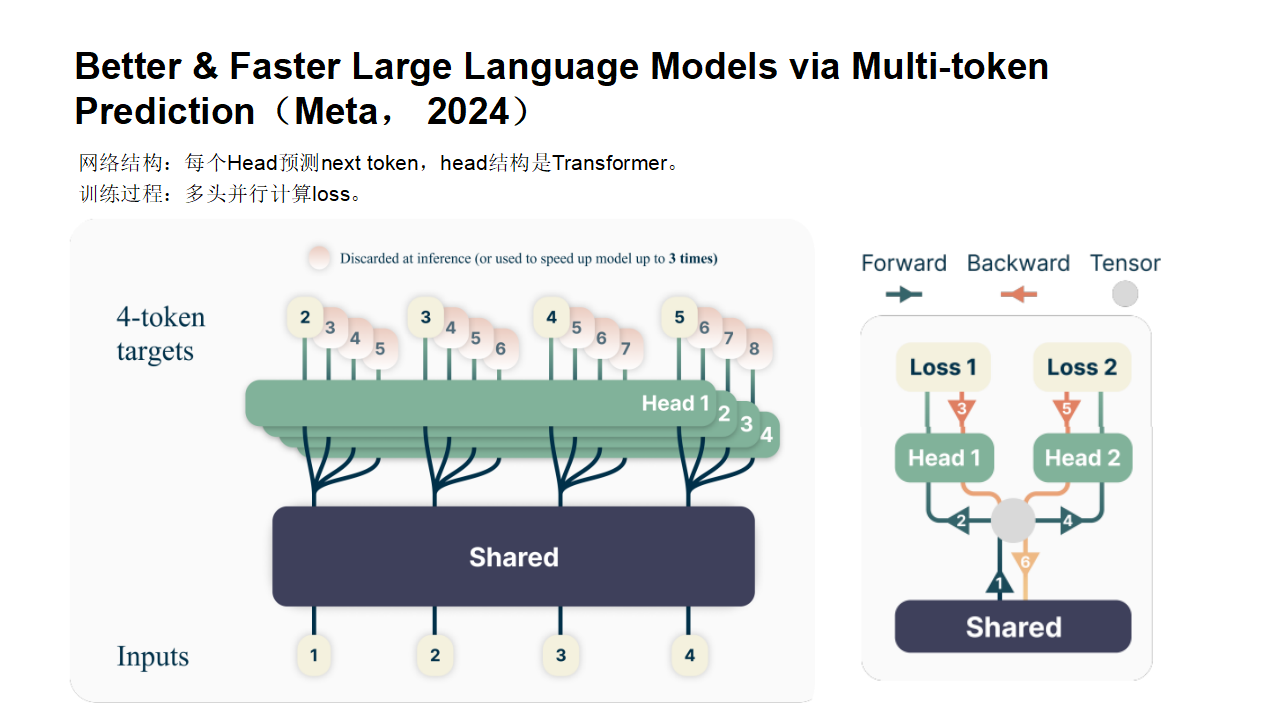


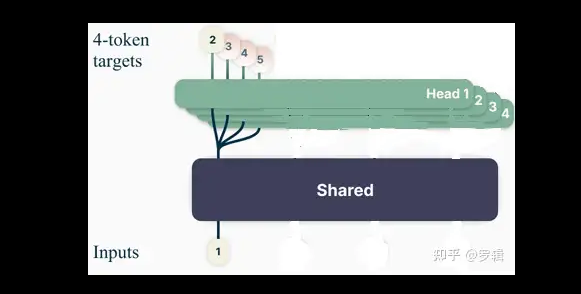
单次训练(示意图)

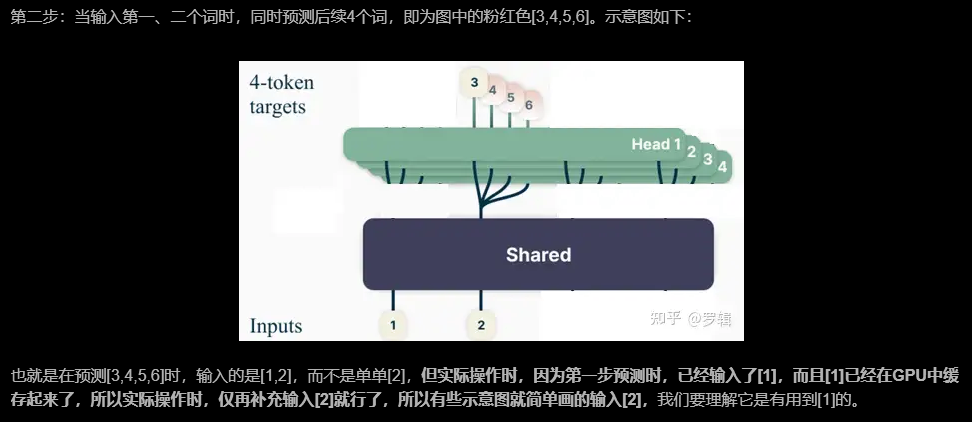
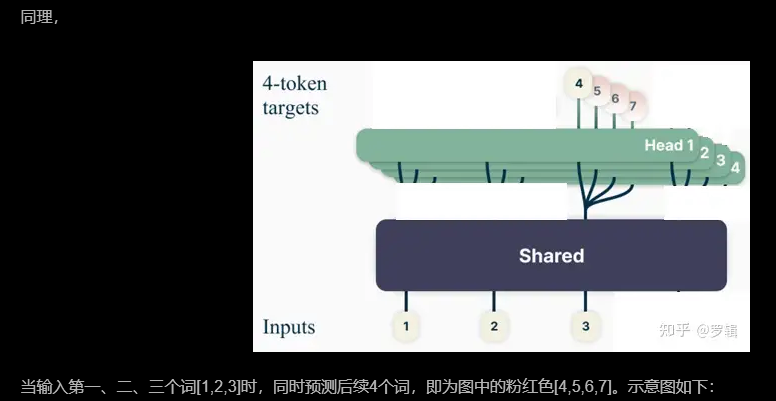
batch批量训练(示意图)
Meta GPU批次并行预测(batch)
因为GPU在训练时,是支持批量同时训练的,多条数据组成一个batch批次,同时并行计算,因此,可以把上面几个训练画在一张图里,就变成了如下原始论文形式:
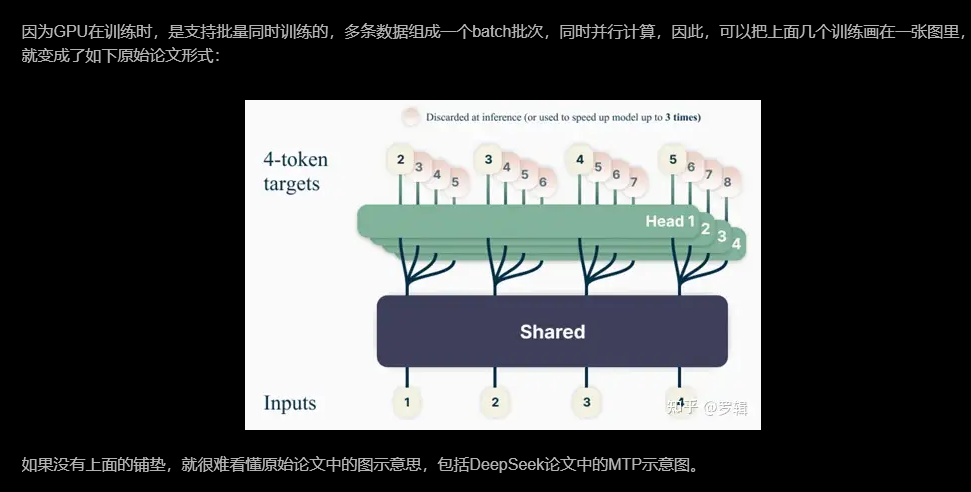
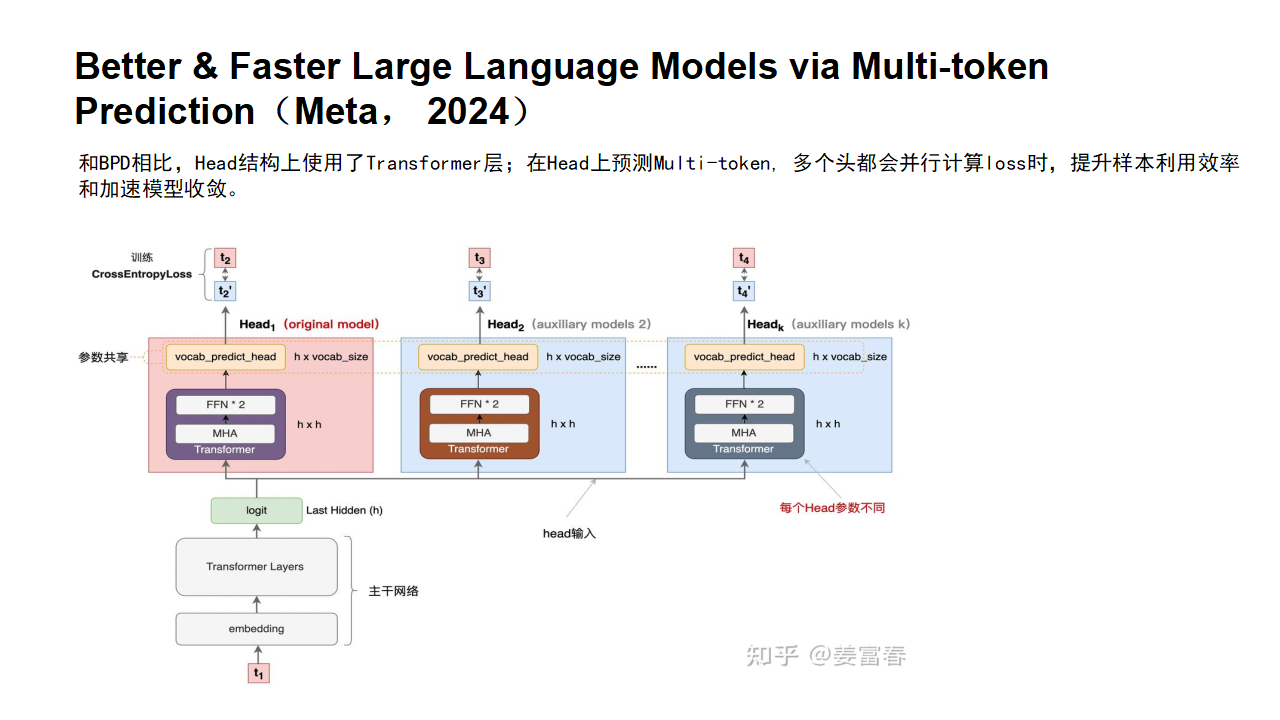
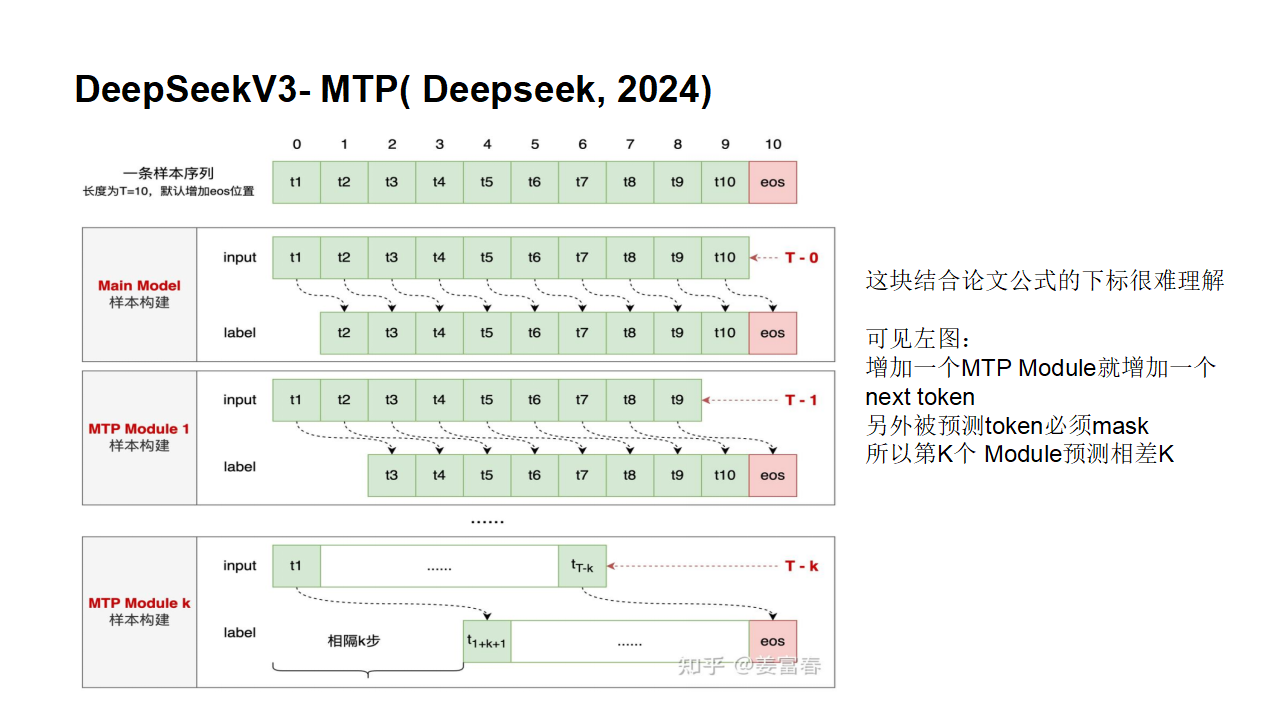
2.3DeepSeek改进版MTP
原理
DeepSeek-V3/R1与Meta的多令牌预测存在两个关键差异:“与Gloeckle等人(2024)[Meta Research]不同,他们使用独立的输出头并行预测D个额外的令牌,而我们则按顺序预测额外的令牌,并在每个预测深度保持完整的因果链。”——DeepSeek-V3
Meta的模型预测4个令牌,而DeepSeek-V3预测2个令牌。Meta模型的预测头相互独立,而DeepSeek-V3的预测头则是顺序连接的。
多 Token 预测(MTP):
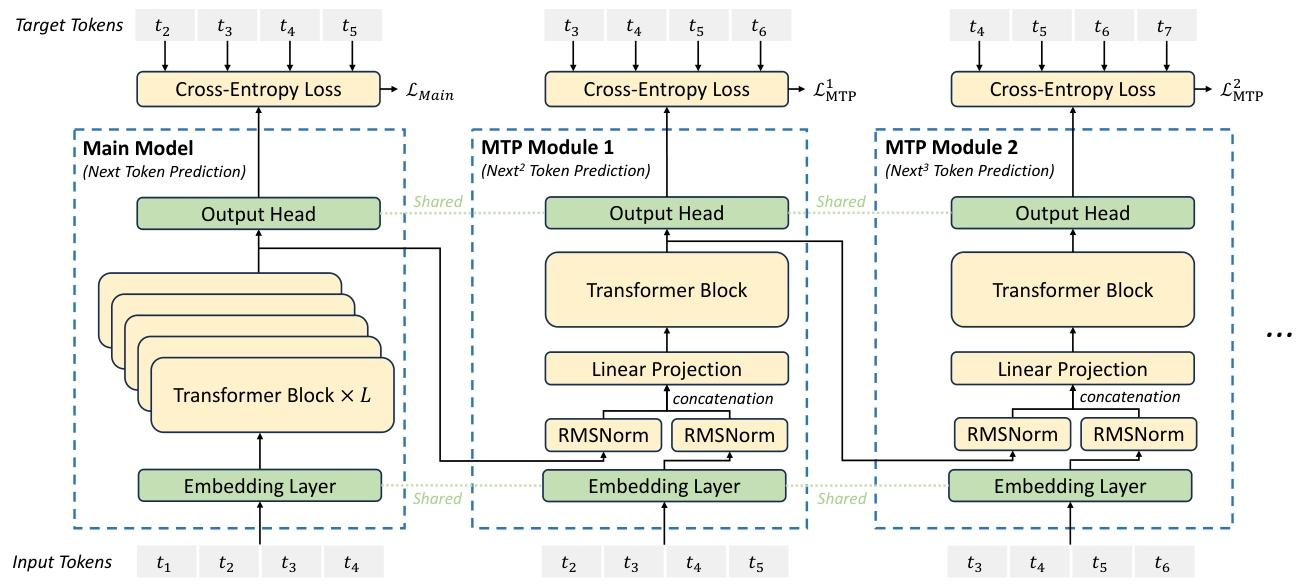
图 3 |我们的多令牌预测 (MTP) 实施图示。我们保留了完整的因果链,用于预测每个深度的每个代币。
MTP在DeepSeek-R1中是如何工作的呢?让我们逐步解析相关图表: 在训练过程中,输入令牌(位于左下角)先经过嵌入层,然后传播通过所有的Transformer块/层。



Teacher forcing和free-running模式
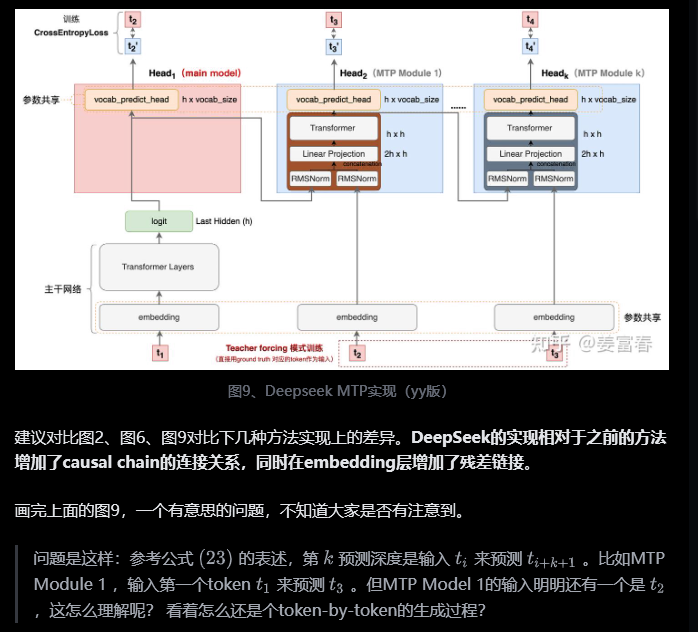

训练的输入系列预测对应位置


单次训练(示意图)
batch批量训练(示意图)
DeepSeek GPU批次并行预测(batch)
参照3.2.1中meta MTP的并行“因果关系”训练的具体过程,可以把一个batch中的多条记录,画在一张图上,就成了如下所示:美化一下,调整一下排版,就成了DeepSeek论文中的样子。
推理
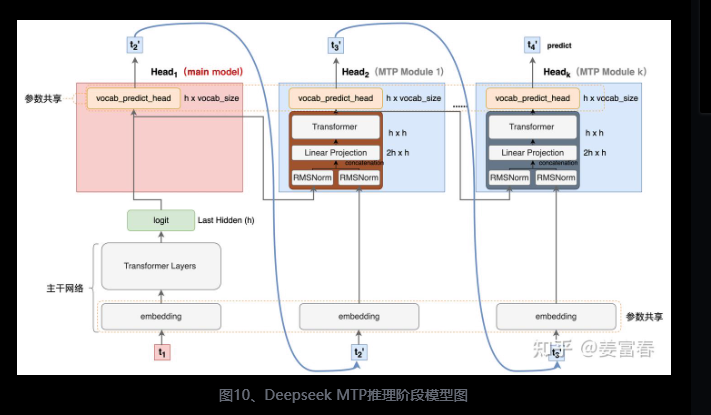

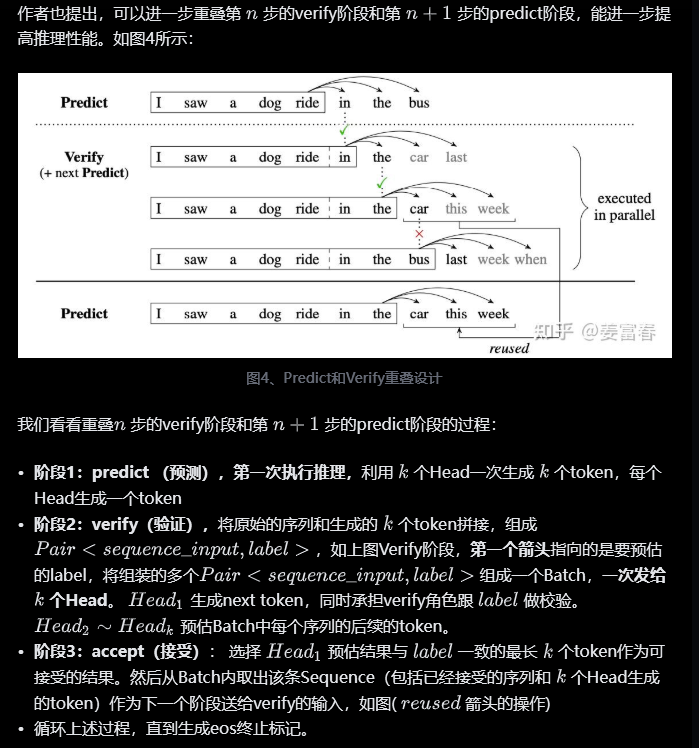
2.4 对比(训练推理)
传统方法的问题(预测下一个token):
- 训练阶段:token-by-token生成,是一种感知局部的训练方法,难以学习长距离的依赖关系。
- 推理阶段:逐个token生成,推理速度较慢
MTP方法(一次预测多个token):
- 训练阶段:通过预测多步token,迫使模型学到更长的token依赖关系,从而更好理解上下文,避免陷入局部决策的学习模式。同时一次预测多个token,可大大提高样本的利用效率,相当于一次预估可生成多个<predict, label>样本,来更新模型,有助于模型加速收敛。
- 推理阶段:并行预估多个token,可提升推理速度
DeepSeek MTP与Meta方案的对比
| 特性 | Meta的MTP | DeepSeek的MTP |
|---|---|---|
| 预测方式 | 并行独立预测多个令牌(4个独立头) | 级联顺序预测(2-3个模块) |
| 因果性 | 可能破坏因果链 | 严格保持因果链 |
| 参数共享 | 独立输出头 | 共享嵌入、输出头和部分Transformer层 |
| 适用场景 | 短文本快速生成 | 长文本连贯性要求高的任务 |
训练推理
| 维度 | 训练阶段(Training) | 推理阶段(Inference) |
|---|---|---|
| 输入数据 | 使用完整的目标序列(真实标签),通过掩码或分组强制模型并行预测多令牌。 | 仅依赖已生成的令牌(初始为<s>),逐步扩展生成序列。 |
| 目标函数 | 计算多令牌的联合概率损失(如交叉熵),优化模型对全局依赖的建模能力。 | 通过解码策略(如波束搜索)生成高概率序列,无需反向传播。 |
| 生成逻辑 | 教师强制(Teacher Forcing):直接输入真实令牌,无需模型自回归生成。 | 自回归或半自回归:依赖前序生成结果,逐步预测后续多令牌。 |
| 并行性 | 高度并行:一次处理多个目标位置的真实令牌,批量计算损失。 | 部分并行:每次生成一批令牌(如k个),但需按步骤迭代生成。 |
参考:
https://zhuanlan.zhihu.com/p/18056041194
https://blog.csdn.net/weixin_43290383/article/details/146245802
https://zhuanlan.zhihu.com/p/24226643215
https://cloud.tencent.com/developer/article/2505000
备份:链接
3、DeepSeek MTP实例说明
DeepSeek-V3的多令牌预测(MTP)通过预测未来多个令牌优化训练,提升模型对序列生成的规划能力。以下结合具体示例,从设计逻辑、实现步骤、训练目标及推理应用展开说明:
一、核心设计逻辑:从单令牌到多令牌预测
传统单令牌预测:
- 输入序列:
[我, 吃, 苹, 果] - 预测目标:每个位置仅预测下一个令牌(如“我”→预测“吃”,“吃”→预测“苹”)。
- 缺点:训练信号稀疏,模型需多次迭代才能学习长距离依赖。
MTP多令牌预测:
- 目标:每个位置预测未来D个令牌(如D=2时,“我”→预测“吃”和“苹”,“吃”→预测“苹”和“果”)。
- 优势:密集训练信号,强制模型提前规划多步生成,提升长序列生成效率。
二、MTP模块实现:以D=2为例(预测未来2个令牌)
假设输入序列为 [t₁=我, t₂=吃, t₃=苹, t₄=果],序列长度T=4,MTP模块按深度k=1和k=2顺序预测:
1. k=1深度:预测第i+1个令牌(下一个令牌)
-
输入处理:
- 对于第i=1个令牌“我”,k=1时,前一层表示h⁰₁为主模型输出的“我”的表示。
- 结合未来第i+1=2个令牌“吃”的嵌入:
h 1 ′ 1 = M 1 [ RMSNorm ( h 1 0 ) ; RMSNorm ( Emb ( t 2 = 吃 ) ) ] h'^1_1 = M_1 \left[ \text{RMSNorm}(h^0_1) ; \text{RMSNorm}(\text{Emb}(t₂=吃)) \right] h1′1=M1[RMSNorm(h10);RMSNorm(Emb(t2=吃))]
(拼接并投影为2d维度,d为隐藏层维度)
-
Transformer处理:
- 将h’^1_1输入TRM₁,生成当前深度表示h¹₁,用于预测第i+1+1=2+1=3个令牌“苹”(实际应为i+k+1=1+1+1=3,即t₃)。
-
输出预测:
- 共享输出头计算概率分布:
P 3 1 = OutHead ( h 1 1 ) (预测t₃=苹的概率) P^1_3 = \text{OutHead}(h^1_1) \quad \text{(预测t₃=苹的概率)} P31=OutHead(h11)(预测t₃=苹的概率)
- 共享输出头计算概率分布:
2. k=2深度:预测第i+2个令牌(下下个令牌)
-
输入处理:
- 对于i=1,k=2时,前一层表示h¹₁(k=1的输出)。
- 结合未来第i+2=3个令牌“苹”的嵌入:
h 1 ′ 2 = M 2 [ RMSNorm ( h 1 1 ) ; RMSNorm ( Emb ( t 3 = 苹 ) ) ] h'^2_1 = M_2 \left[ \text{RMSNorm}(h^1_1) ; \text{RMSNorm}(\text{Emb}(t₃=苹)) \right] h1′2=M2[RMSNorm(h11);RMSNorm(Emb(t3=苹))]
-
Transformer处理:
- 输入TRM₂生成h²₁,用于预测第i+2+1=4个令牌“果”(t₄)。
-
输出预测:
P 4 2 = OutHead ( h 1 2 ) (预测t₄=果的概率) P^2_4 = \text{OutHead}(h^2_1) \quad \text{(预测t₄=果的概率)} P42=OutHead(h12)(预测t₄=果的概率)
3. 因果链保持:
- 预测t₃时,仅依赖t₁和t₂的信息;预测t₄时,依赖t₁、t₂、t₃的信息,确保每个预测步骤符合因果关系(即不依赖未来未生成的令牌)。
三、训练目标:多深度损失计算实例
假设T=4,D=2,λ=0.3,计算MTP损失:
- k=1深度损失:
- 预测范围:i=2+1=3到T+1=5(实际序列长度为4,故有效范围i=3到4)。
- 真实令牌:t₃=苹,t₄=果。
- 损失:
L 1 MTP = − 1 4 ( log P 3 1 [ 苹 ] + log P 4 1 [ 果 ] ) \mathcal{L}^{\text{MTP}}_1 = -\frac{1}{4} \left( \log P^1_3[苹] + \log P^1_4[果] \right) L1MTP=−41(logP31[苹]+logP41[果])
- k=2深度损失:
- 预测范围:i=2+2=4到T+1=5(仅i=4)。
- 真实令牌:t₄=果。
- 损失:
L 2 MTP = − 1 4 log P 4 2 [ 果 ] \mathcal{L}^{\text{MTP}}_2 = -\frac{1}{4} \log P^2_4[果] L2MTP=−41logP42[果]
- 整体MTP损失:
L MTP = 0.3 × 1 2 ( L 1 MTP + L 2 MTP ) \mathcal{L}^{\text{MTP}} = 0.3 \times \frac{1}{2} \left( \mathcal{L}^{\text{MTP}}_1 + \mathcal{L}^{\text{MTP}}_2 \right) LMTP=0.3×21(L1MTP+L2MTP)
该损失与主模型的单令牌预测损失共同优化模型,强化多步生成能力。
四、推理阶段:推测解码加速实例
- 传统解码:逐令牌生成,生成“我吃苹果”需4次迭代(每次生成1个令牌)。
- MTP推测解码:
- 通过MTP模块提前预测下2个令牌候选(如“吃”“苹”)。
- 验证候选令牌正确性,若正确则一次性生成,减少迭代次数(如2次迭代生成4个令牌)。
- 效果:解码速度提升1.8倍,尤其适合长文本生成(如代码、数学证明)。
五、关键优势与对比
| 特性 | DeepSeek-V3 MTP | Gloeckle et al. (2024) |
|---|---|---|
| 预测方式 | 顺序预测(保持因果链) | 并行独立预测(多输出头) |
| 参数共享 | 共享主模型嵌入层和输出头 | 独立输出头(参数更多) |
| 核心目标 | 训练阶段增强模型能力 | 推理阶段加速(推测解码) |
| 典型应用 | 提升数学、代码长序列生成质量 | 单纯加速生成速度 |
总结:MTP如何提升模型性能?
通过顺序预测未来多个令牌,MTP在训练阶段为模型提供更密集的监督信号,迫使模型学习序列生成的长期依赖(如语法、逻辑连贯)。例如,生成数学证明时,预测下一步公式推导步骤;生成代码时,提前规划函数调用顺序。这种预规划能力在推理阶段通过推测解码进一步加速,实现“训练提效+推理加速”的双重优势,是DeepSeek-V3在复杂任务上表现突出的关键技术之一。
4、Multi-Token Prediction(原文解释)
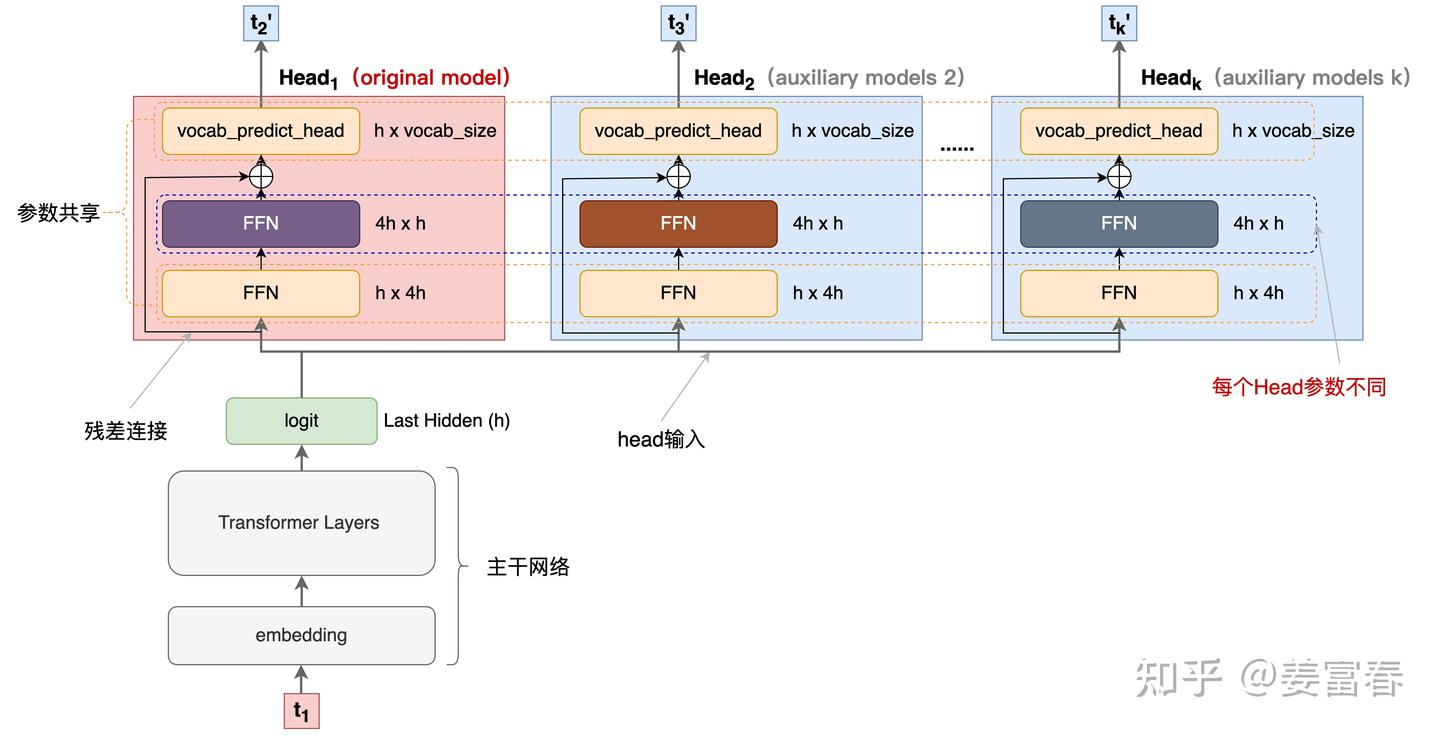
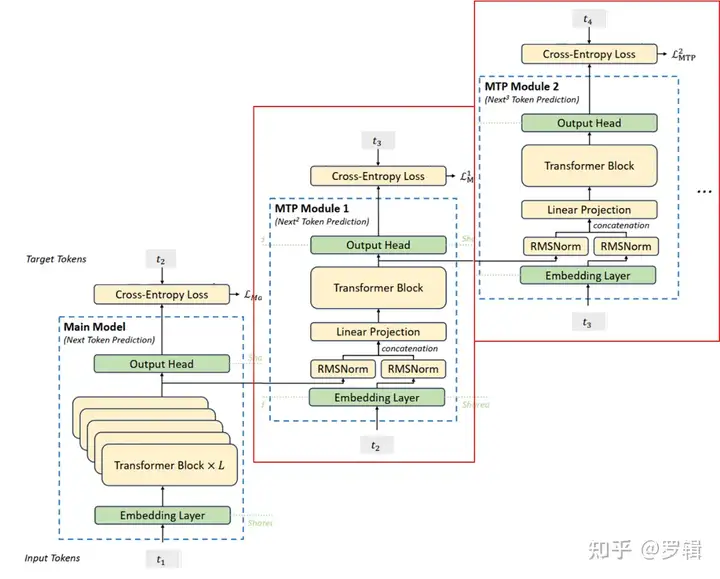
受格洛克勒(Gloeckle)等人(2024年)启发,我们为DeepSeek-V3设计了**多令牌预测(Multi-Token Prediction, MTP)**目标,将每个位置的预测范围扩展到多个未来令牌。一方面,MTP目标通过密集化训练信号提升数据效率;另一方面,它使模型能够预规划表示,从而更好地预测未来令牌。图3展示了我们的MTP实现方式。不同于格洛克勒等人(2024年)使用独立输出头并行预测D个额外令牌的方法,我们采用顺序预测额外令牌的方式,并在每个预测深度保持完整的因果链。本节将详细介绍MTP的实现细节。
MTP模块
具体而言,我们的MTP实现通过D个顺序模块预测D个额外令牌。第k个MTP模块包含一个共享嵌入层Emb(·)、一个共享输出头OutHead(·)、一个Transformer块TRMₖ(·)和一个投影矩阵𝑀ₖ∈Rᵈײᵈ。对于第i个输入令牌𝑡ᵢ,在第k个预测深度,我们首先将第(i)个令牌在(k−1)深度的表示h⁽ᵏ⁻¹⁾ᵢ∈Rᵈ与第(i+k)个令牌的嵌入Emb(𝑡ᵢ₊ₖ)∈Rᵈ通过线性投影结合:
h i ( k ) = 𝑀 k [ RMSNorm ( h i ( k − 1 ) ) ; RMSNorm ( Emb ( 𝑡 i + k ) ) ] ( 21 ) h'⁽ᵏ⁾ᵢ = 𝑀ₖ \left[ \text{RMSNorm}(h⁽ᵏ⁻¹⁾ᵢ) ; \text{RMSNorm}(\text{Emb}(𝑡ᵢ₊ₖ)) \right] \quad (21) hi(k)=Mk[RMSNorm(hi(k−1));RMSNorm(Emb(ti+k))](21)
其中[·; ·]表示拼接操作。特别地,当k=1时,h⁽ᵏ⁻¹⁾ᵢ为主模型输出的令牌表示。注意,每个MTP模块的嵌入层与主模型共享。拼接后的h’⁽ᵏ⁾ᵢ作为第k深度Transformer块的输入,生成当前深度的输出表示h⁽ᵏ⁾ᵢ:
h 1 : 𝑇 − k ( k ) = TRMₖ ( h 1 : 𝑇 − k ( k ) ) ( 22 ) h⁽ᵏ⁾_{1:𝑇−ᵏ} = \text{TRMₖ}(h'⁽ᵏ⁾_{1:𝑇−ᵏ}) \quad (22) h1:T−k(k)=TRMₖ(h1:T−k(k))(22)
其中T为输入序列长度,i:j表示包含左右边界的切片操作。最后,共享输出头以h⁽ᵏ⁾ᵢ为输入,计算第k个额外预测令牌的概率分布𝑃⁽ᵏ⁾_{𝑖+𝑘+1}∈Rᵛ(V为词汇表大小):
𝑃 𝑖 + 𝑘 + 1 ( k ) = OutHead ( h i ( k ) ) ( 23 ) 𝑃⁽ᵏ⁾_{𝑖+𝑘+1} = \text{OutHead}(h⁽ᵏ⁾ᵢ) \quad (23) Pi+k+1(k)=OutHead(hi(k))(23)
输出头OutHead(·)将表示线性映射为对数概率(logits),并通过Softmax函数计算第k个额外令牌的预测概率。每个MTP模块的输出头同样与主模型共享。我们保持预测因果链的原则与EAGLE(Li等人,2024b)类似,但其主要目标是推测解码(Leviathan等人,2023;Xia等人,2023),而我们利用MTP优化训练过程。
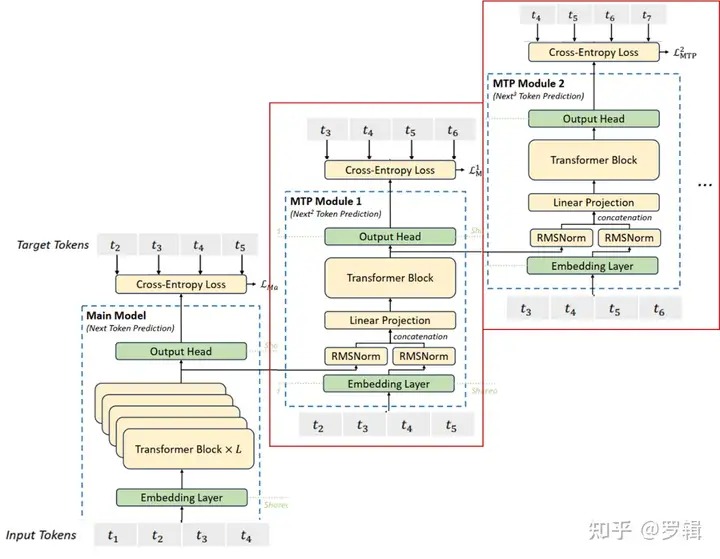
MTP训练目标
对于每个预测深度,计算交叉熵损失𝐿⁽ᵏ⁾_MTP:
𝐿 MTP ( k ) = CrossEntropy ( 𝑃 2 + 𝑘 : 𝑇 + 1 ( k ) , 𝑡 2 + 𝑘 : 𝑇 + 1 ) = − 1 𝑇 ∑ 𝑖 = 2 + 𝑘 𝑇 + 1 log 𝑃 𝑖 ( k ) [ 𝑡 i ] ( 24 ) 𝐿⁽ᵏ⁾_{\text{MTP}} = \text{CrossEntropy}(𝑃⁽ᵏ⁾_{2+𝑘:𝑇+1}, 𝑡_{2+𝑘:𝑇+1}) = -\frac{1}{𝑇} \sum_{𝑖=2+𝑘}^{𝑇+1} \log 𝑃⁽ᵏ⁾_𝑖[𝑡ᵢ] \quad (24) LMTP(k)=CrossEntropy(P2+k:T+1(k),t2+k:T+1)=−T1i=2+k∑T+1logPi(k)[ti](24)
其中T为序列长度,𝑡ᵢ为第i位置的真实令牌,𝑃⁽ᵏ⁾_𝑖[𝑡ᵢ]为第k个MTP模块对𝑡ᵢ的预测概率。最终,将所有深度的MTP损失取平均并乘以权重因子λ,得到整体MTP损失𝐿_MTP,作为DeepSeek-V3的额外训练目标:
𝐿 MTP = λ 𝐷 ∑ 𝑘 = 1 𝐷 𝐿 MTP ( k ) ( 25 ) 𝐿_{\text{MTP}} = \frac{\lambda}{𝐷} \sum_{𝑘=1}^{𝐷} 𝐿⁽ᵏ⁾_{\text{MTP}} \quad (25) LMTP=Dλk=1∑DLMTP(k)(25)
MTP在推理中的应用
MTP策略主要用于提升主模型性能,因此推理时可直接丢弃MTP模块,主模型独立正常运行。此外,我们还可将MTP模块用于推测解码,进一步降低生成延迟。
3.多头潜在注意力(MLA)
具体原理参考:DeepSeek-V2论文笔记链接 ,MLA汇总链接
在注意力机制方面,DeepSeek-V3采用了MLA(多头潜在注意力)架构。设𝑑为嵌入维度,𝑛ₕ为注意力头数,𝑑ₕ为每个头的维度,且hₜ∈Rᵈ表示给定注意力层中第t个令牌的注意力输入。MLA的核心是对注意力键和值进行低秩联合压缩,以减少推理时的键值(KV)缓存:
c t K V = W D K V h t , ( 1 ) c_{t}^{KV} = W^{DKV} h_t, \quad (1) ctKV=WDKVht,(1)
[ k t , 1 C ; k t , 2 C ; … ; k t , n h C ] = k t C = W U K c t K V , ( 2 ) \left[k_{t,1}^{C}; k_{t,2}^{C}; \dots; k_{t,n_h}^{C}\right] = k_t^C = W^{UK} c_t^{KV}, \quad (2) [kt,1C;kt,2C;…;kt,nhC]=ktC=WUKctKV,(2)
k t R = RoPE ( W K R h t ) , ( 3 ) k_t^R = \text{RoPE}(W^{KR} h_t), \quad (3) ktR=RoPE(WKRht),(3)
k t , i = [ k t , i C ; k t R ] , ( 4 ) k_{t,i} = \left[k_{t,i}^{C}; k_t^R\right], \quad (4) kt,i=[kt,iC;ktR],(4)
[ v t , 1 C ; v t , 2 C ; … ; v t , n h C ] = v t C = W U V c t K V , ( 5 ) \left[v_{t,1}^{C}; v_{t,2}^{C}; \dots; v_{t,n_h}^{C}\right] = v_t^C = W^{UV} c_t^{KV}, \quad (5) [vt,1C;vt,2C;…;vt,nhC]=vtC=WUVctKV,(5)
其中,c𝐾𝑉𝑡∈Rᵈᶜ是键和值的压缩潜在向量;𝑑ᶜ(≪𝑑ₕ𝑛ₕ)表示KV压缩维度;𝑊𝐷𝐾𝑉∈Rᵈᶜ×ᵈ为下投影矩阵;𝑊𝑈𝐾、𝑊𝑈𝑉∈Rᵈₕ𝑛ₕ×ᵈᶜ分别为键和值的上投影矩阵;𝑊𝐾𝑅∈R𝑑ᴿₕ×ᵈ是用于生成携带旋转位置嵌入(RoPE)的解耦键的矩阵(Su等人,2024);RoPE(·)表示应用RoPE矩阵的操作;[·; ·]表示拼接。注意,对于MLA,生成过程中仅需缓存蓝色框向量(即c𝐾𝑉𝑡和k𝑅𝑡),这在保持与标准多头注意力(MHA,Vaswani等人,2017)相当性能的同时,显著减少了KV缓存。
对于注意力查询,我们也进行低秩压缩以减少训练时的激活内存:
c t Q = W D Q h t , ( 6 ) c_t^Q = W^{DQ} h_t, \quad (6) ctQ=WDQht,(6)
[ q t , 1 C ; q t , 2 C ; … ; q t , n h C ] = q t C = W U Q c t Q , ( 7 ) \left[q_{t,1}^{C}; q_{t,2}^{C}; \dots; q_{t,n_h}^{C}\right] = q_t^C = W^{UQ} c_t^Q, \quad (7) [qt,1C;qt,2C;…;qt,nhC]=qtC=WUQctQ,(7)
[ q t , 1 R ; q t , 2 R ; … ; q t , n h R ] = q t R = RoPE ( W Q R c t Q ) , ( 8 ) \left[q_{t,1}^{R}; q_{t,2}^{R}; \dots; q_{t,n_h}^{R}\right] = q_t^R = \text{RoPE}(W^{QR} c_t^Q), \quad (8) [qt,1R;qt,2R;…;qt,nhR]=qtR=RoPE(WQRctQ),(8)
q t , i = [ q t , i C ; q t , i R ] , ( 9 ) q_{t,i} = \left[q_{t,i}^{C}; q_{t,i}^{R}\right], \quad (9) qt,i=[qt,iC;qt,iR],(9)
其中,c𝑄𝑡∈R𝑑′ᶜ是查询的压缩潜在向量;𝑑′ᶜ(≪𝑑ₕ𝑛ₕ)表示查询压缩维度;𝑊𝐷𝑄∈R𝑑′ᶜ×ᵈ、𝑊𝑈𝑄∈Rᵈₕ𝑛ₕ×𝑑′ᶜ分别为查询的下投影和上投影矩阵;𝑊𝑄𝑅∈R𝑑ᴿₕ𝑛ₕ×𝑑′ᶜ是用于生成携带RoPE的解耦查询的矩阵。
最终,注意力查询(q𝑡,𝑖)、键(k𝑗,𝑖)和值(v𝐶𝑗,𝑖)结合生成最终注意力输出u𝑡:
o t , i = ∑ j = 1 t Softmax j ( q t , i T k j , i d h + d h R ) v j , i C , ( 10 ) o_{t,i} = \sum_{j=1}^t \text{Softmax}_j \left( \frac{q_{t,i}^T k_{j,i}}{\sqrt{d_h + d_h^R}} \right) v_{j,i}^C, \quad (10) ot,i=j=1∑tSoftmaxj dh+dhRqt,iTkj,i vj,iC,(10)
u t = W O [ o t , 1 ; o t , 2 ; … ; o t , n h ] , ( 11 ) u_t = W^O \left[ o_{t,1}; o_{t,2}; \dots; o_{t,n_h} \right], \quad (11) ut=WO[ot,1;ot,2;…;ot,nh],(11)
其中,𝑊𝑂∈Rᵈ×ᵈₕ𝑛ₕ为输出投影矩阵。
三、训练基础设施与优化
1. 硬件与混合精度训练
- 计算集群:
- 使用2048张NVIDIA H800 GPU,节点内通过NVLink互联,节点间通过InfiniBand通信,支持高效分布式训练。
- FP8混合精度框架:
- 首次在超大规模模型中验证FP8可行性,通过细粒度量化(1x128激活块、128x128权重块)和高精度累加(CUDA核心FP32累加),将相对损失误差控制在0.25%以内,训练速度提升2倍,显存占用减少。
2. 训练框架优化
- DualPipe算法:
- 优化流水线并行,减少气泡并重叠计算与通信,使跨节点专家并行的通信开销接近零,支持模型高效扩展。
- 内存效率优化:
- 重计算RMSNorm和MLA上投影,CPU异步更新指数移动平均(EMA),避免显存冗余,无需昂贵的张量并行(Tensor Parallelism)。
四、预训练与后训练流程
1. 预训练阶段
- 数据构建:
- 14.8万亿高质量令牌,包含数学、编程、多语言数据,采用文档打包和Fill-in-Middle(FIM)策略增强数据多样性。
- 超参数与扩展:
- 61层Transformer,隐藏维度7168,激活参数37B/令牌;通过两阶段扩展上下文至128K(YaRN技术),NIAH测试验证长上下文稳定性。
- 训练稳定性:
- 全程无不可恢复的损失骤增或回滚,优化后的负载均衡策略确保训练稳定。
2. 后训练阶段
- 监督微调(SFT):
- 150万实例,融合DeepSeek-R1生成的推理数据(数学、代码等),平衡准确性与响应长度。
- 强化学习(RL):
- 采用Group Relative Policy Optimization(GRPO),结合规则奖励(如数学答案格式验证)和模型奖励,提升复杂任务表现。
五、性能评估与基准测试
1. 核心基准表现
| 领域 | 基准 | DeepSeek-V3成绩 | 对比模型表现 | 优势 |
|---|---|---|---|---|
| 知识推理 | MMLU (5-shot EM) | 88.5 | LLaMA-3.1-405B (88.6), GPT-4o (87.2) | 开源领先,接近闭源模型 |
| 数学推理 | MATH-500 (EM) | 90.2 | Qwen2.5-72B (80.0), Claude-3.5 (73.8) | 非长CoT模型中最高,超越多数闭源 |
| 代码生成 | LiveCodeBench | 37.6 (Pass@1) | HumanEval-Mul (82.6 Pass@1) | 代码竞赛任务领先,工程能力突出 |
| 中文任务 | C-SimpleQA | 64.8 (Correct) | GPT-4o (59.3), Qwen2.5 (48.4) | 中文事实性知识超越闭源模型 |
| 长上下文 | NIAH (128K tokens) | 稳定高分 | - | 支持128K上下文,性能无显著下降 |
2. 闭源模型对比
- 在MMLU-Pro、GPQA-Diamond等专业知识基准,以及Codeforces编程竞赛任务中,DeepSeek-V3性能接近GPT-4o和Claude-3.5,部分中文任务(如C-Eval)超越闭源模型。
六、训练成本与效率
- 总GPU小时:278.8万(预训练266.4万+上下文扩展11.9万+后训练0.5万),假设H800租金$2/小时,总成本约**$557.6万**,仅为同类模型的1/3~1/2。
- 效率优势:每万亿令牌训练仅需18万H800 GPU小时,通过FP8训练和通信优化,无需张量并行,硬件利用率提升30%。
七、局限性与未来方向
1. 当前局限
- 部署门槛:推荐部署单元较大(如解码阶段需320 GPU),对中小团队不友好;生成速度仍有提升空间(依赖硬件优化)。
- 模型能力:复杂逻辑推理(如长链CoT)仍需依赖蒸馏技术,原生推理能力待增强。
2. 未来方向
- 架构创新:探索无限上下文支持、非Transformer架构(如MoE优化),提升长文本处理效率。
- 数据与训练:多维度数据增强(如跨模态)、引入动态训练目标,避免基准过拟合。
- 评估体系:开发更全面的多维度评估方法,覆盖真实场景任务(如实时推理、多轮对话)。
八、核心贡献
- 架构层面:开创无辅助损失负载均衡和多令牌预测,提升MoE模型效率与性能。
- 工程层面:首次验证FP8在超大规模模型的可行性,设计高效训练框架降低成本。
- 开源生态:提供高性能开源模型(Checkpoint可用),缩小开源与闭源模型差距,推动AGI研究普惠化。
总结
DeepSeek-V3通过架构创新、训练优化与大规模数据的结合,在性能、效率和成本之间实现突破,成为当前最强开源MoE模型。其核心技术(如无辅助损失负载均衡、FP8训练)为后续大模型研发提供了可复用的工程范式,尤其在数学、代码等复杂任务上的表现,彰显了开源模型在特定领域超越闭源的潜力。未来通过硬件协同设计和架构升级,DeepSeek-V3有望进一步推动通用人工智能的落地。
相关文章:

24、DeepSeek-V3论文笔记
DeepSeek-V3论文笔记 **一、概述****二、核心架构与创新技术**0.汇总:1. **基础架构**2. **创新策略** 1.DeepSeekMoE无辅助损失负载均衡DeepSeekMoE基础架构无辅助损失负载均衡互补序列级辅助损失 2.多令牌预测(MTP)1.概念2、原理2.1BPD2.2M…...

神经网络初步学习——感知机
一、前言 神经网络,顾名思义,它与我们大脑生物学里面讲到的神经元有关联。前辈们在研究早期人工智能的时候,就开始过我们的“交叉融合”,他们思考能不能把我们的人工智能的学习模式改造成我们人脑中神经元之间的学习方式——于是乎…...

在Text-to-SQL任务中应用过程奖励模型
论文标题 Reward-SQL: Boosting Text-to-SQL via Stepwise Reasoning and Process-Supervised Rewards 论文地址 https://arxiv.org/pdf/2505.04671 代码地址 https://github.com/ruc-datalab/RewardSQL 作者背景 中国人民大学,香港科技大学广州,阿…...

Python的安装使用
一、下载Python安装包 下载python安装包,可以直接访问官网地址:https://www.python.org/downloads/ 通过页面咱们直接下载最新版本的python安装包即可,python3.13.3。在页面的下方也可下载安装之前的版本,目前咱们按最新版本安装…...

mapreduce-wordcount程序2
WordCount案例分析 给定一个路径,统计这个路径下所有的文件中的每一个单词的出现次数。 其中,需要我们去实现代码的部分是:map函数和reduce函数。它们各自的作用是: map函数的入参是kv结构,k是偏移量,v是一…...
与内存屏障:原理、实践与性能权衡)
Java 内存模型(JMM)与内存屏障:原理、实践与性能权衡
Java 内存模型(JMM)与内存屏障:原理、实践与性能权衡 在多线程高并发时代,Java 内存模型(JMM) 及其背后的内存屏障机制,是保障并发程序正确性与性能的基石。本文将系统梳理 JMM 的核心原理、内…...

1.6 偏导数
(铺垫)全导数与偏导数看似相似,实则对应不同维度的变化观察。理解它们的差异需要从"变量自由度"切入: (核心差异解剖) 维度偏导数全导数变量关系其他变量被强制锁定所有变量都通过中间变量关联…...

网络爬虫学习之正则表达式
开篇 本文整理自《python3 网络爬虫开发实战》的学习笔记。 笔记整理 match match是一种常用的匹配方法,向它传入要匹配的字符串以及正则表达式,就可以检测这个正则表达式是否和字符串相匹配。 match会尝试从字符串的起始位置开始匹配正则表达式&#x…...

Pytorch常用统计和矩阵运算
文章目录 常用统计函数torch.prod()求积torch.sum()求和torch.mean()求均值torch.max()求最值torch.var() 方差torch.std()标准差 常见矩阵运算矩阵乘法点积 (torch.dot)批量矩阵乘法 (torch.bmm)奇异值分解 (SVD)特征分解 (torch.eig)矩阵求逆 (torch.inverse)伪逆 (torch.pin…...

PyTorch Lightning实战 - 训练 MNIST 数据集
MNIST with PyTorch Lightning 利用 PyTorch Lightning 训练 MNIST 数据。验证梯度范数、学习率、优化器对训练的影响。 pip show lightning Version: 2.5.1.post0Fast dev run DATASET_DIR"/repos/datasets" python mnist_pl.py --output_grad_norm --fast_dev_run…...

内存泄漏系列专题分析之十一:高通相机CamX ION/dmabuf内存管理机制Camx ImageBuffer原理
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了:内存泄漏系列专题分析之八:高通相机CamX内存泄漏&内存占用分析--通用ION(dmabuf)内存拆解 这一篇我们开始讲: 内存泄漏系列专题分析之十一:高通相机CamX ION/dmabuf内存管理机制Camx ImageBuf…...

MySQL-逻辑架构
MySQL服务器逻辑架构图 主要分层结构 1.连接层 功能:处理连接、安全认证、线程管理等 核心模块:连接器:支持不同语言(JDBC)与MySQL交互;线程连接池:管理线程连接,减少线程频繁创建…...

架构思维:通用架构模式_系统监控的设计
文章目录 引言什么是监控三大常见监控类型1. 次数监控2. 性能监控3. 可用率监控 落地监控1. 服务入口2. 服务内部3. 服务依赖 监控时间间隔的取舍小结 引言 架构思维:通用架构模式_从设计到代码构建稳如磐石的系统 架构思维:通用架构模式_稳如老狗的SDK…...

架构、构架、结构、框架之间有什么区别?|系统设计|系统建模
在技术与知识中,我们总是频繁地遇到一些高度抽象、看似类似、却又各自承载着不同思想重量的词汇。“架构”、“构架”、“结构”、“框架”即是其中最为常见又最为令人困惑的一组术语。它们既是工程师们日常工作的核心语言,也是学者们在探索系统、组织、…...
:构件)
系统架构设计(五):构件
定义 构件(Component)是指一个具有明确边界和独立部署能力的模块化单元,能够封装实现细节,并通过接口与其他构件协作完成系统功能。 主要特性 特性说明可复用性构件可以在不同系统中被重复使用。可部署性构件可以独立部署&…...

【系统架构师】2025论文《基于架构的软件设计方法》【最新】
😊你好,我是小航,一个正在变秃、变强的文艺倾年。 🔔本文分享【系统架构师】2025论文《系统可靠性设计》,期待与你一同探索、学习、进步,一起卷起来叭! 目录 项目介绍背景介绍系统模块技术栈基于…...

MultiTTS 1.7.6 | 最强离线语音引擎,提供多音色无障碍朗读功能,附带语音包
MultiTTS是一款免费且支持离线使用的文本转语音(TTS)工具,旨在为用户提供丰富的语音包选项,实现多音色无障碍朗读功能。这款应用程序特别适合用于阅读软件中的离线听书体验,提供了多样化的语音选择,使得听书…...

Costmap代价地图
以下为ROS navigation导航工具包的move_base框架图。其中有两个关于代价地图的模块(红框所框),全局代价地图global_costmap和局部代价地图local_costmap,这两个代价地图实际上是调用的同一个功能包代码,通过配置不同的参数实例化为两个代价地…...

用生活例子通俗理解 Python OOP 四大特性
让我们用最生活化的方式,结合Python代码,来理解面向对象编程的四大特性。 1. 封装:像使用自动售货机 生活比喻: 你只需要投币、按按钮,就能拿到饮料 不需要知道机器内部如何计算找零、如何运送饮料 如果直接打开机…...

大规模容器集群怎么规划
规划大规模容器集群需要综合考虑多个方面,以下是一些关键的规划要点: 业务需求分析 应用类型和特点:明确容器集群上运行的应用类型,如 Web 应用、数据库、大数据处理等。不同类型的应用对资源的需求和性能要求各不相同。例如&am…...

机器学习第七讲:概率统计 → 预测可能性,下雨概率70%就是典型应用
机器学习第七讲:概率统计 → 预测可能性,下雨概率70%就是典型应用 资料取自《零基础学机器学习》。 查看总目录:学习大纲 关于DeepSeek本地部署指南可以看下我之前写的文章:DeepSeek R1本地与线上满血版部署:超详细手…...

蓝桥杯13届 卡牌
问题描述 这天, 小明在整理他的卡牌。 他一共有 n 种卡牌, 第 i 种卡牌上印有正整数数 i(i∈[1,n]), 且第 i 种卡牌 现有 ai 张。 而如果有 n 张卡牌, 其中每种卡牌各一张, 那么这 n 张卡牌可以被称为一 套牌。小明为了凑出尽可能多套牌, 拿出了 m 张空白牌, 他可以在上面…...

《Vue.js》阅读之响应式数据与副作用函数
Vue.js 《Vue.js设计与实现》(霍春阳) 适合:从零手写Vue3响应式系统,大厂面试源码题直接覆盖。重点章节:第4章(响应式)、第5章(渲染器)、第8章(编译器&…...

线下消费经济“举步维艰”,开源AI智能名片链动2+1+S2B2C小程序线上“狂飙突进”!
开源AI智能名片链动21模式S2B2C商城小程序:驱动消费经济迭代的数字化引擎 摘要:本文以中国消费经济四阶段演进为框架,分析开源AI智能名片链动21模式S2B2C商城小程序如何重构商业生态。研究显示,该系统通过AI算法驱动的精准需求匹…...

简述DNS域名服务器
DNS简述 在互联网中,识别一个主机通常有两种方式——主机名和IP地址。从人类角度来看,人类肯定更喜欢这些便于记忆的主机名标识方式,而对于路由器来说,路由器则更喜欢定长的,有结构层次的IP地址。所以DNS域名服务器就…...

小结: Port Security,DHCP Snooping,IPSG,DAI,
以下是华为和思科在 IP Source Guard、Dynamic ARP Inspection、DHCP Snooping、Port Security 四个安全功能的配置指令对比: 1. Port Security(端口安全) 思科(Cisco) # 进入接口模式 interface GigabitEthernet0/1…...
)
2025年阿里云ACP人工智能高级工程师认证模拟试题(附答案解析)
这篇文章的内容是阿里云ACP人工智能高级工程师认证考试的模拟试题。 所有模拟试题由AI自动生成,主要为了练习和巩固知识,并非所谓的 “题库”,考试中如果出现同样试题那真是纯属巧合。 1、在PAl-Studio实验运行完毕后,可以右键单…...

SwitchyOmega_Chromium 代理插件下载与配置
下载地址: 【免费】SwitchyOmega-Chromium.ran资源-CSDN文库 下载 SwitchyOmega_Chromium.ran 文件。 解压缩文件 解压第一层后,解压第二层代理插件SwitchyOmega_Chromium。 打开 Chromium 浏览器。 导入插件: 在浏览器地址栏输入 chrome://extensio…...
:按钮组组件的构建之旅)
【Nova UI】十四、打造组件库之按钮组件(下):按钮组组件的构建之旅
序言 在之前的探索中,我们成功雕琢出了功能完备且样式精美的 Vue 按钮组件,它在前端界面上绽放着独特的光彩✨。然而,前端开发的创新之路永无止境。如今,为了满足更丰富的交互需求,我们将目光聚焦在按钮组组件的实现上…...

SQL注入
sql注入核心语句 information_schema 虚拟数据库(物理上不存在),能提供方皓文数据库元数据的方式,元数据是关于数据的数据,如数据库名、表名、列的数据类型、访问权限等 只能访问 information_schema下面的表: schemata表…...

Java面试高阶篇:Spring Boot+Quarkus+Redis高并发架构设计与性能优化实战
Java面试高阶篇:Spring BootQuarkusRedis高并发架构设计与性能优化实战 面试官(严肃): Q1: 你项目中如何实现高并发下的缓存优化? 候选人(水货): 我们用了Redis做缓存,…...
 BCD)
【CF】Day57——Codeforces Round 955 (Div. 2, with prizes from NEAR!) BCD
B. Collatz Conjecture 题目: 思路: 简单模拟 很简单的模拟,我们只需要快速的找到下一个离 x 最近的 y 的倍数即可(要大于 x) 这里我们可以这样写 add y - (x % y),这样就知道如果 x 要变成 y 的倍数还要…...

Matlab 列车纵向滑模二阶自抗扰算法和PID对比
1、内容简介 Matlab 223-列车纵向滑模二阶自抗扰算法和PID对比 可以交流、咨询、答疑 2、内容说明 略 列车模型 在运行过程中,已知列车受到牵引力或者制动力,基本阻力和附加阻力的作用,规定与列车运行方向相同的力为正,与运行…...

Swift实战:如何优雅地从二叉搜索树中挑出最接近的K个值
文章目录 摘要描述题解答案题解代码分析示例测试及结果时间复杂度空间复杂度总结未来展望 摘要 在日常开发中,我们经常会遇到“在一堆数据中找出最接近某个值”的需求。尤其在搜索引擎、推荐系统或者地理坐标匹配中,这种“最近匹配”的问题非常常见。Le…...

深度策略梯度算法PPO
一、策略梯度核心思想和原理 从时序差分算法Q学习到深度Q网络,这些算法都侧重于学习和优化价值函数,属于基于价值的强化学习算法(Value-based)。 1. 基于策略方法的主要思想(Policy-based) 基于价值类方…...

QuickList
Redis在3.2版本引入数据结构,是一个双端链表,每个节点都是一个ZipList。 引入的原因:ZipList申请内存空间是连续的,如果内存占用较多,申请内存效率很低 思想:属于分片存储的思想 Redis配置项:…...

DVWA在线靶场-SQL注入部分
目录 1.SQL注入 1.1 low 1.2 Medium 1.3 high 1.4 impossible 1. SQL盲注 1.1 low 2.2 medium 2.3 high 2.4 impossible 1.SQL注入 显注:前端页面可以回显用户信息,比如 联合注入、报错注入。 盲注:前端页面不能回显用户信息,比…...

IDEA+git将分支合并到主分支、IDEA合并分支
文章目录 一、合并分支二、可能遇到的问题2.1、代码冲突 开发过程中我们可能在开发分支(dev)中进行开发,等上线后将代码合并到主分支(master)中,本文讲解如何在IDEA中将dev分支的代码合并到master分支中。 一、合并分支 功能说明:将dev分支的…...

【Linux笔记】——进程信号的产生
🔥个人主页🔥:孤寂大仙V 🌈收录专栏🌈:Linux 🌹往期回顾🌹:【Linux笔记】进程间通信——system v 共享内存 🔖流水不争,争的是滔滔不 一、进程信号…...
)
Java后端文件类型检测(防伪造)
在 Spring Boot 项目中,为了防止用户伪造 Content-Type(例如将 .txt 文件改为 image/jpeg 上传),可以通过检查文件的 Magic Number(文件头签名)来验证文件的真实类型。以下是 详细实现步骤 和 完整代码示例…...

知名人工智能AI培训公开课内训课程培训师培训老师专家咨询顾问唐兴通AI在金融零售制造业医药服务业创新实践应用
AI赋能未来工作:引爆效率与价值创造的实战营 AI驱动的工作革命:从效率提升到价值共创 培训时长: 本课程不仅是AI工具的操作指南,更是面向未来的工作方式升级罗盘。旨在帮助学员系统掌握AI(特别是生成式AI/大语言模型…...

VUE3基础样式调整学习经验
首先创建一个vue项目最好要把不属于自己的样式都删除掉,以面出现css难以调整的情况: 1.assets目录下的main.css、base.css等样式全部删除 2.app.vue下的样式也全部删除 3.使用element plus一定要加入样式包: import element-plus/dist/in…...

AI与IoT携手,精准农业未来已来
AIoT:农业领域的变革先锋 在科技飞速发展的当下,人工智能(AI)与物联网(IoT)的融合 ——AIoT,正逐渐成为推动各行业变革的关键力量,农业领域也不例外。AIoT 技术通过将 AI 的智能分析能力与 IoT 的设备互联能力相结合,为农业生产带来了前所未有的精准度和智能化水平。 …...

物联网驱动的共享充电站系统:智能充电的实现原理与技术解析!
随着新能源汽车的快速普及,共享充电站系统作为其核心基础设施,正通过物联网技术的深度赋能,实现从“传统充电”到“智能充电”的跨越式升级。本文将从系统架构、核心技术、优化策略及实际案例等角度,解析物联网如何驱动共享充电站…...

MCP 入门实战:用 C# 开启 AI 新篇章
MCP 入门实战:用 C# 开启 AI 新篇章 一、什么是 MCP? MCP,全称为 Model Context Protocol(模型上下文协议),是一个开放的协议,它为应用程序向大型语言模型(LLM)提供上下…...

ES常识7:ES8.X集群允许4个 master 节点吗
在 Elasticsearch(ES)中,4 个 Master 节点的集群可以运行,但存在稳定性风险,且不符合官方推荐的最佳实践。以下从选举机制、故障容错、资源消耗三个维度详细分析: 一、4 个 Master 节点的可行性࿱…...

WebRTC:去中心化网络P2P框架解析
在互联网的世界里,数据的传输就像一场永不停歇的 “信息快递”。当我们使用 WebRTC 实现视频通话时,背后支撑的网络框架至关重要。今天,我们将深入探索 WebRTC 开发中视频通话的前置基础 ——P2P(点对点)框架ÿ…...

Linux 上安装RabbitMQ
🐇 安装 Erlang/OTP 27.3.4(最新稳定版) 1. 下载 Erlang 源码 cd /usr/local/src wget https://erlang.org/download/otp_src_27.3.4.tar.gz2. 解压源码 tar -zxvf otp_src_27.3.4.tar.gz cd otp_src_27.3.43. 安装依赖 sudo apt update …...

Service Mesh实战之Istio
Service Mesh(服务网格)是一种专为微服务架构设计的网络代理层,用于处理服务间的通信、管理和监控。Istio 是一个流行的开源 Service Mesh 实现,通过提供流量管理、观测性和安全性等功能,帮助开发者应对分布式系统的复…...

BGP练习
一、要求拓扑图 二、要求 完成上图内容,要求五台路由器的环回地址均可以相互访问 三、需求分析 1. 网络连通性目标 - 需求明确要求五台路由器(AR1 - AR5 )的环回地址能够相互访问。环回地址是路由器上用于测试、管理及作为BGP等协议中Ro…...