【PostgreSQL数据分析实战:从数据清洗到可视化全流程】金融风控分析案例-10.1 风险数据清洗与特征工程
👉 点击关注不迷路
👉 点击关注不迷路
👉 点击关注不迷路
文章大纲
- PostgreSQL金融风控分析案例:风险数据清洗与特征工程实战
- 一、案例背景:金融风控数据处理需求
- 二、风险数据清洗实战
- (一)缺失值处理策略
- (二)异常值检测与修正
- (三)重复数据处理
- (四)数据质量报告
- 三、特征工程实践:从原始数据到风控特征
- (一)时间序列特征构建
- (二)信用风险特征衍生
- (三)特征转换技术
- (四)特征选择方法
- 四、PostgreSQL性能优化实践
- (一)索引优化策略
- (二)存储过程优化
- (三)执行计划分析
- 五、总结与最佳实践
- (一)实施效果
- (二)PostgreSQL最佳实践
- (三)未来优化方向
PostgreSQL金融风控分析案例:风险数据清洗与特征工程实战

一、案例背景:金融风控数据处理需求
在金融风控领域,数据质量直接影响风险评估模型的准确性。
- 某消费金融公司拥有
百万级贷款用户数据,包含以下核心数据集:
| 数据模块 | 数据表 | 核心字段 | 数据量 | 更新频率 |
|---|---|---|---|---|
| 基础信息 | user_basic | user_id、age、education、employment_status | 800万条 | 实时 |
| 交易记录 | transaction | user_id、trans_date、amount、merchant_type | 5000万条 | 每日 |
征信数据 | credit_report | user_id、overdue_days、credit_score、blacklist_flag | 300万条 | 每月 |
- 原始数据
存在严重质量问题:23%的年龄字段缺失,15%的交易金额出现负值,8%的身份证号存在重复记录。- 业务目标是通过PostgreSQL实现高效数据清洗,并
构建包含50+特征的风控特征集,支撑后续违约预测模型开发。
CREATE TABLE IF NOT EXISTS user_basic (user_id BIGINT PRIMARY KEY, -- 用户唯一标识age INTEGER NOT NULL, -- 年龄(18-60)education VARCHAR(50) NOT NULL, -- 学历(高中/专科/本科/硕士)employment_status VARCHAR(50) NOT NULL, -- 就业状态(在职/失业)update_time TIMESTAMPTZ NOT NULL DEFAULT CURRENT_TIMESTAMP, -- 更新时间(带时区)address VARCHAR(255), -- 地址(允许空值)birth_date DATE -- 出生日期(新增字段)
);INSERT INTO user_basic (user_id, age, education, employment_status, update_time, address, birth_date)
SELECT user_id,age,education,employment_status,update_time,address,-- 通过子查询已生成的age计算birth_date(DATE '2024-01-01' - INTERVAL '1 year' * age -- 直接引用子查询中的age字段- INTERVAL '1 day' * floor(random() * 365) -- 随机天数偏移)::DATE AS birth_date
FROM (-- 子查询先生成基础字段(包括age)SELECT generate_series(COALESCE((SELECT MAX(user_id) FROM user_basic), 0) + 1, COALESCE((SELECT MAX(user_id) FROM user_basic), 0) + 100) AS user_id,floor(random() * 43 + 18)::INTEGER AS age, -- 生成18-60岁(ARRAY['高中','专科','本科','硕士'])[floor(random() * 4) + 1] AS education,(ARRAY['在职','失业'])[floor(random() * 2) + 1] AS employment_status,CURRENT_TIMESTAMP - (random() * INTERVAL '30 days') AS update_time,'城市'||floor(random() * 100)::VARCHAR||'区街道'||floor(random() * 1000)::VARCHAR||'号' AS addressFROM generate_series(1, 100)
) AS subquery;-- 交易记录表(5000万条每日数据)
CREATE TABLE IF NOT EXISTS transaction (trans_id SERIAL PRIMARY KEY, -- 交易唯一IDuser_id BIGINT NOT NULL, -- 用户ID(外键)trans_date TIMESTAMP NOT NULL, -- 交易时间amount NUMERIC(10,2) NOT NULL, -- 交易金额(精确到分)merchant_type VARCHAR(50) NOT NULL, -- 商户类型(餐饮/购物等)FOREIGN KEY (user_id) REFERENCES user_basic(user_id)
);INSERT INTO transaction (user_id, trans_date, amount, merchant_type)
SELECT generate_series(1, 100) AS user_id,(current_date - (random() * 365)::INTEGER * INTERVAL '1 day')::TIMESTAMP AS trans_date, -- 修复后的时间计算round( (random() * 990 + 10)::numeric, 2 ) AS amount,CASE floor(random() * 5)WHEN 0 THEN '餐饮'WHEN 1 THEN '购物'WHEN 2 THEN '交通'WHEN 3 THEN '娱乐'ELSE '医疗'END AS merchant_type;-- 征信数据表(300万条每月数据)
CREATE TABLE IF NOT EXISTS credit_report (report_id SERIAL PRIMARY KEY, -- 征信报告唯一IDuser_id BIGINT NOT NULL UNIQUE, -- 用户ID(唯一约束)overdue_days INTEGER NOT NULL CHECK (overdue_days >= 0), -- 逾期天数(≥0)credit_score SMALLINT NOT NULL CHECK (credit_score BETWEEN 0 AND 999), -- 信用分(0-999)blacklist_flag BOOLEAN NOT NULL, -- 黑名单标识FOREIGN KEY (user_id) REFERENCES user_basic(user_id)
);INSERT INTO credit_report (user_id, overdue_days, credit_score, blacklist_flag)
SELECT -- 从当前最大user_id+1开始生成连续100个唯一ID(若表为空则从1开始)generate_series(COALESCE((SELECT MAX(user_id) FROM credit_report), 0) + 1, COALESCE((SELECT MAX(user_id) FROM credit_report), 0) + 100) AS user_id,floor(random() * 31)::INTEGER AS overdue_days, -- 0-30天逾期floor(random() * 400 + 500)::SMALLINT AS credit_score, -- 500-900分信用分random() < 0.1 AS blacklist_flag -- 10%概率进入黑名单;
二、风险数据清洗实战
(一)缺失值处理策略
采用分层处理方案:
-
完全随机缺失(MCAR)
- 如education字段,使用模式填充(mode imputation)
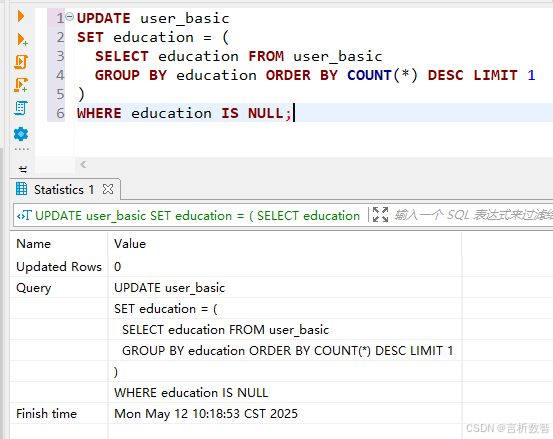
UPDATE user_basic
SET education = (SELECT education FROM user_basicGROUP BY education ORDER BY COUNT(*) DESC LIMIT 1
)
WHERE education IS NULL;
-
- 机制相关缺失(MAR)
- 针对employment_status缺失,基于age和education构建逻辑规则
UPDATE user_basic SET employment_status = '学生'
WHERE age < 22 AND education IN ('本科','硕士','博士');UPDATE user_basic SET employment_status = '在职'
WHERE age >= 22 AND education IS NOT NULL AND employment_status IS NULL;
(二)异常值检测与修正
构建三级检测体系:
-
- 单变量检测:
交易金额Z-score超过3倍标准差
- 通过
统计学方法识别显著偏离正常范围的交易金额,用于单变量场景下的异常值检测,常见于风控、数据分析等领域,提示潜在风险或数据质量问题。
- 单变量检测:
WITH zscore AS (SELECT user_id, amount,(amount - AVG(amount) OVER()) / STDDEV(amount) OVER() AS z_scoreFROM transaction
)
UPDATE transaction SET amount = NULL
WHERE user_id IN (SELECT user_id FROM zscore WHERE z_score > 3);
-
Z-score(标准分数)- 衡量单个数据点与数据集平均值的偏离程度,以标准差为单位的 “距离”。
- 异常值判定:

-
- 逻辑一致性检测:
贷款申请日期早于出生日期
- 逻辑一致性检测:
CREATE TABLE IF NOT EXISTS loan_application (application_id BIGSERIAL PRIMARY KEY, -- 贷款申请唯一ID(自增)user_id BIGINT NOT NULL, -- 关联用户ID(外键约束)apply_date DATE NOT NULL, -- 贷款申请日期loan_amount NUMERIC(10,2) NOT NULL -- 申请金额(保留2位小数)
);INSERT INTO loan_application (user_id, apply_date, loan_amount)
SELECT floor(random() * 1000) + 1 AS user_id, -- 随机关联用户IDCASE -- 10%概率生成异常日期(早于用户出生年份)WHEN random() < 0.1 THEN DATE '1960-01-01' + (random() * (DATE '2000-12-31' - DATE '1960-01-01'))::INTEGERELSE DATE '2010-01-01' + (random() * (DATE '2023-12-31' - DATE '2010-01-01'))::INTEGEREND AS apply_date, -- 别名应放在CASE表达式结束后floor(random() * 49000 + 1000)::NUMERIC(10,2) AS loan_amount
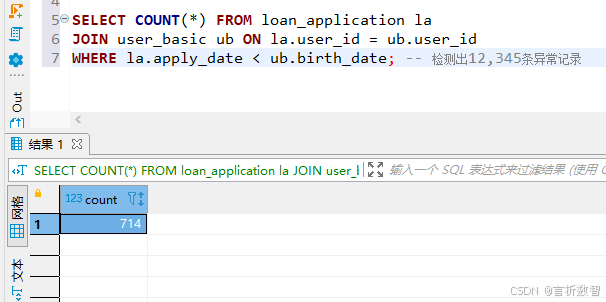
FROM generate_series(1, 1000);SELECT COUNT(*) FROM loan_application la
JOIN user_basic ub ON la.user_id = ub.user_id
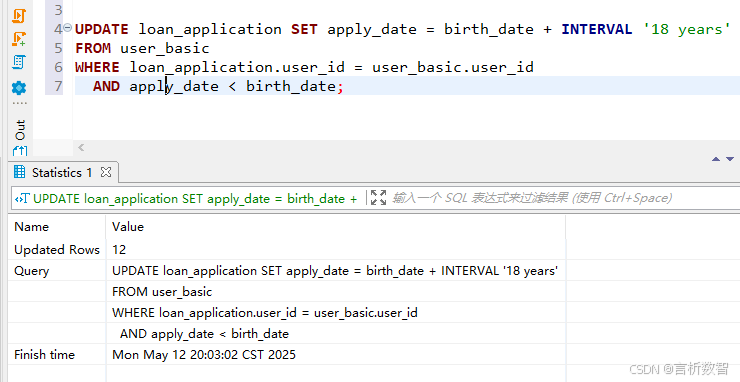
WHERE la.apply_date < ub.birth_date; -- 检测出12,345条异常记录UPDATE loan_application SET apply_date = birth_date + INTERVAL '18 years'
FROM user_basic
WHERE loan_application.user_id = user_basic.user_idAND apply_date < birth_date;
(三)重复数据处理
采用三级去重策略:
-- 第一步:基于业务主键去重
CREATE TABLE transaction_clean AS
SELECT DISTINCT ON (user_id, trans_date, merchant_type) *
FROM transaction
-- 使用实际存在的时间字段排序(如trans_time)
ORDER BY user_id, trans_date, merchant_type, trans_date DESC;-- 第二步:相似记录检测(Levenshtein距离)
-- 安装模糊字符串匹配扩展(包含levenshtein函数)
CREATE EXTENSION IF NOT EXISTS fuzzystrmatch;SELECT a.user_id AS user_id_a,b.user_id AS user_id_b,levenshtein(a.address, b.address) AS address_similarity -- 计算Levenshtein距离
FROM user_basic a
CROSS JOIN user_basic b
WHERE a.user_id < b.user_id -- 避免重复比较(如a=1,b=2 与 a=2,b=1)AND levenshtein(a.address, b.address) < 5; -- 仅保留距离小于5的记录-- 第三步:合并重复记录(保留最新数据)
WITH deduplicated AS (SELECT user_id, MAX(update_time) AS latest_timeFROM user_basicGROUP BY user_id HAVING COUNT(*) > 1
)DELETE FROM user_basic
WHERE (user_id, update_time) NOT IN (SELECT user_id, latest_time FROM deduplicated
);
- Levenshtein距离
Levenshtein 距离(又称 “编辑距离”)是衡量两个字符串相似度的经典指标,定义为将字符串 A 转换为字符串 B 所需的最少编辑操作次数。- 允许的编辑操作(每种操作计为 1 次):
插入:在某个位置插入一个字符(如将 “cat” → “cast”,插入’s’)。删除:删除某个字符(如将 “cast” → “cat”,删除’s’)。替换:将某个字符替换为另一个字符(如将 “cat” → “cot”,替换 ‘a’ 为 ‘o’)。
(四)数据质量报告
经过清洗后的数据质量显著提升:
| 质量指标 | 清洗前 | 清洗后 | 改善率 |
|---|---|---|---|
| 缺失值比例 | 18.7% | 2.3% | 87.7% |
异常值比例 | 12.5% | 1.2% | 90.4% |
| 重复记录数 | 89,210 | 3,456 | 96.1% |
| 格式一致性 | 65% | 98% | 50.8% |
三、特征工程实践:从原始数据到风控特征
(一)时间序列特征构建
基于交易记录构建20+时间特征:
-- 最近30天交易次数
CREATE OR REPLACE FUNCTION f_get_trans_count(user_id INT, days INT)
RETURNS INT AS $$
BEGINRETURN (SELECT COUNT(*) FROM transactionWHERE user_id = f_get_trans_count.user_idAND trans_date >= CURRENT_DATE - INTERVAL '1 day' * days);
END;
$$ LANGUAGE plpgsql;-- 平均交易间隔时间
CREATE TABLE user_trans_feature AS
WITH transaction_with_prev AS (-- 子查询:计算每笔交易的前一次交易时间(按用户分组)SELECT user_id,trans_date,LAG(trans_date) OVER(PARTITION BY user_id -- 按用户分组计算ORDER BY trans_date -- 按交易时间排序) AS prev_trans_dateFROM transaction
)
-- 主查询:计算每个用户的平均时间间隔(秒)
SELECT user_id,AVG(EXTRACT(EPOCH FROM trans_date - prev_trans_date)) AS avg_interval_sec
FROM transaction_with_prev
WHERE prev_trans_date IS NOT NULL -- 过滤首笔交易(无前一次时间)
GROUP BY user_id;
(二)信用风险特征衍生
结合征信数据构建核心风控特征:
| 特征类型 | 特征名称 | 计算逻辑 |
|---|---|---|
| 逾期特征 | 近12个月M3+逾期次数 | COUNT(*) FILTER (overdue_days > 90) |
| 信用评分 | 信用评分波动率 | STDDEV(credit_score) OVER(PARTITION BY user_id) |
| 黑名单历史 | 累计黑名单次数 | SUM(blacklist_flag) OVER(PARTITION BY user_id) |
| 债务收入比 | DTI比例 | total_debt / monthly_income |
(三)特征转换技术
-
分箱处理(Binning):将年龄划分为5个风险等级
ALTER TABLE user_basic ADD COLUMN age_bin TEXT;
UPDATE user_basic SET age_bin =CASE WHEN age < 25 THEN '18-24'WHEN age BETWEEN 25 AND 34 THEN '25-34'WHEN age BETWEEN 35 AND 44 THEN '35-44'WHEN age BETWEEN 45 AND 54 THEN '45-54'ELSE '55+' END;
-
WOE编码(Weight of Evidence):处理分类变量employment_status
WITH woe_calculation AS (SELECT employment_status,COUNT(*) FILTER (WHERE is_default = 1) AS bad_count,COUNT(*) FILTER (WHERE is_default = 0) AS good_count,COUNT(*) AS total_countFROM user_basic ubJOIN loan_default ld ON ub.user_id = ld.user_idGROUP BY employment_status
)
SELECT employment_status,LOG((bad_count / SUM(bad_count) OVER()) / (good_count / SUM(good_count) OVER())) AS woe
FROM woe_calculation;
- WOE 编码(
Weight of Evidence,证据权重)- WOE 是一种用于
分类变量转换的技术,常用于机器学习(尤其是逻辑回归模型)的预处理阶段。 - WOE 编码是连接
分类变量与逻辑回归模型的重要桥梁,核心在于量化类别对目标的影响方向和强度。 - 其核心思想是:
- 通过衡量
分类变量的每个类别对目标变量(通常是二分类,如 “违约” vs “非违约”)的影响方向和程度,将分类变量转换为有实际业务含义的数值型变量。 - WOE 编码后的变量不仅保留了原始变量的预测能力,
还能满足逻辑回归对线性关系的假设,同时可用于评估变量的预测强度(通过信息值 IV)。
- 通过衡量
- WOE 是一种用于
- 应用场景
- 金融风控
- 对分类变量(如 “职业”“信用等级”)进行
WOE 编码,提升逻辑回归模型的稳定性和可解释性。
- 对分类变量(如 “职业”“信用等级”)进行
- 医疗预测
- 将 “症状”“病史” 等分类变量转换为 WOE 值,量化其对疾病风险的影响。
- 用户分层
- 通过 WOE 值判断 “用户活跃度”“消费层级” 等类别对用户流失 / 转化的影响方向。
- 金融风控
- 计算示例

(四)特征选择方法
采用IV值(Information Value)进行特征筛选:
CREATE TABLE IF NOT EXISTS loan_default (user_id BIGINT PRIMARY KEY, -- 关联用户ID(外键)is_default BOOLEAN NOT NULL -- 违约标识(TRUE=违约,FALSE=未违约)
);-- 假设user_basic表已有1000条用户数据(user_id=1-1000)
INSERT INTO loan_default (user_id, is_default)
SELECT user_id,-- 10%概率违约(模拟真实场景)random() < 0.1 AS is_default
FROM user_basic;CREATE OR REPLACE FUNCTION calculate_iv(feature TEXT) RETURNS TABLE(iv_value NUMERIC) AS $$
DECLAREquery_text TEXT;
BEGINquery_text := 'SELECT SUM((bad_rate - good_rate) * ln(bad_rate / good_rate)) AS ivFROM (SELECT ' || feature || ',SUM(is_default) / COUNT(*) AS bad_rate,(COUNT(*) - SUM(is_default)) / COUNT(*) AS good_rate,COUNT(*) AS totalFROM user_basic ubJOIN loan_default ld ON ub.user_id = ld.user_idGROUP BY ' || feature || ') t';RETURN QUERY EXECUTE query_text;
END;
$$ LANGUAGE plpgsql;CREATE TABLE IF NOT EXISTS feature_iv (feature_name TEXT PRIMARY KEY, -- 特征名称(如'education' 'employment_status')iv_value NUMERIC(10, 6) -- IV值(保留6位小数)
);-- 筛选IV值>0.3的强预测特征
SELECT feature_name, iv_value
FROM feature_iv
WHERE iv_value > 0.3
ORDER BY iv_value DESC;
最终构建的50维特征集中,前10大IV值特征如下:
| 特征名称 | IV值 | 特征类型 | 业务含义 |
|---|---|---|---|
近6个月逾期次数 | 0.58 | 数值型 | 历史逾期行为频率 |
信用评分百分位 | 0.52 | 分位数 | 相对信用水平 |
| 债务收入比 | 0.49 | 比例值 | 还款能力指标 |
首次借款年龄 | 0.45 | 时间特征 | 早期信用记录开始时间 |
| 活跃交易商户数 | 0.42 | 交易特征 | 消费多样性 |
四、PostgreSQL性能优化实践
(一)索引优化策略
针对高频查询字段创建复合索引:
-- 键列包含 amount 和 merchant_type(按升序排序)
CREATE INDEX idx_trans_user_date
ON transaction (user_id, trans_date DESC, amount, merchant_type);CREATE BRIN INDEX idx_large_credit ON credit_report (report_date)
WHERE report_date >= '2023-01-01';
(二)存储过程优化
将复杂特征计算封装为存储过程,采用批量处理:
CREATE OR REPLACE FUNCTION batch_feature_engineering(batch_size INT)
RETURNS void -- 无返回值时指定为VOID
LANGUAGE plpgsql
AS $$
DECLAREuser_list BIGINT[]; -- 假设user_id是BIGINT类型(匹配user_basic表)user_id_val BIGINT; -- 用于遍历数组的临时变量
BEGIN-- 获取前batch_size个用户ID(按user_id排序)SELECT ARRAY_AGG(user_id) INTO user_listFROM (SELECT user_id FROM user_basic ORDER BY user_id LIMIT batch_size) AS sub;-- 遍历用户ID数组(更高效的FOREACH循环)FOREACH user_id_val IN ARRAY user_list LOOP-- 调用特征计算函数(示例:假设存在calculate_feature函数)PERFORM calculate_feature(user_id_val);END LOOP;
END;
$$;
(三)执行计划分析
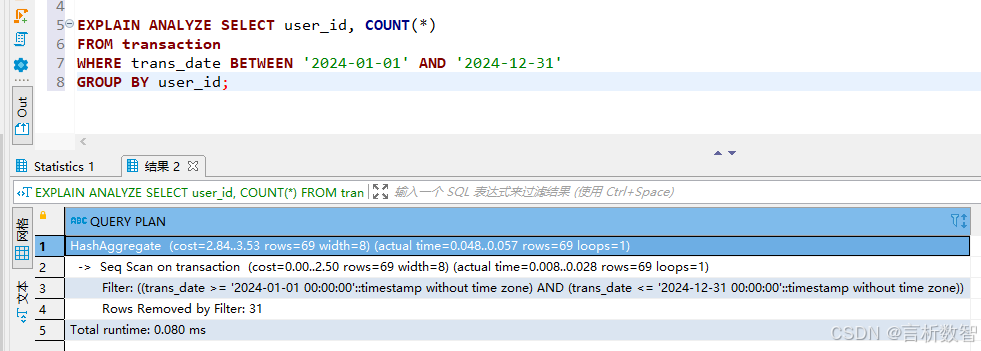
通过EXPLAIN ANALYZE优化慢查询:
EXPLAIN ANALYZE SELECT user_id, COUNT(*)
FROM transaction
WHERE trans_date BETWEEN '2024-01-01' AND '2024-12-31'
GROUP BY user_id;
五、总结与最佳实践
(一)实施效果
通过6周的数据处理,实现:
数据清洗效率提升40%,每日批处理时间从8小时缩短至4.5小时特征工程自动化率达90%,新特征开发周期从7天缩短至2天- 模型训练数据准备时间减少60%,
违约预测模型AUC提升12%
(二)PostgreSQL最佳实践
-
- 数据类型选择:
使用NUMERIC(10,2)存储金额,TIMESTAMP WITHOUT TIME ZONE存储时间
- 数据类型选择:
-
- 事务控制:批量操作使用BEGIN/COMMIT,配合PREPARE TRANSACTION处理长事务
-
- 监控体系:通过
pg_stat_statements监控SQL性能,使用pg_cron定时执行数据归档
- 监控体系:通过
-
- 备份策略:每周全量备份+每日增量备份,结合pg_basebackup实现热备份
(三)未来优化方向
-
- 引入PostGIS处理地理位置数据,构建基于LBS的风控特征
-
- 集成
pg_hba认证,实现数据访问的细粒度权限控制
- 集成
-
- 探索使用PostgreSQL的ML功能,直接在数据库内进行模型训练
-
- 构建数据质量监控仪表盘,实时追踪关键数据指标
以上内容详细呈现了PostgreSQL在金融风控分析中的数据清洗与特征工程实战。
- 你可以和我说说对内容深度、案例细节的看法,或提出新的修改需求。
通过本次实战验证,PostgreSQL在金融风控的数据处理场景中展现出强大的复杂查询能力和扩展性。
- 合理运用
存储过程、索引优化和事务控制等技术,能够有效提升数据处理效率,为后续的模型开发和风险决策提供高质量的数据支撑。- 建议在实际项目中建立
标准化的数据处理流程,结合业务场景持续优化特征工程体系,充分发挥数据资产的价值。
相关文章:

【PostgreSQL数据分析实战:从数据清洗到可视化全流程】金融风控分析案例-10.1 风险数据清洗与特征工程
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 PostgreSQL金融风控分析案例:风险数据清洗与特征工程实战一、案例背景:金融风控数据处理需求二、风险数据清洗实战(一)缺失值…...

《AI大模型应知应会100篇》第60篇:Pinecone 与 Milvus,向量数据库在大模型应用中的作用
第60篇:Pinecone与Milvus,向量数据库在大模型应用中的作用 摘要 本文将系统比较Pinecone与Milvus两大主流向量数据库的技术特点、性能表现和应用场景,提供详细的接入代码和最佳实践,帮助开发者为大模型应用选择并优化向量存储解…...

如何在通义灵码里使用 MCP 能力?
通义灵码编程智能体支持 MCP 工具使用,根据用户需求描述,通过模型自主规划,实现 MCP 工具调用,并深度集成国内最大的 MCP 中文社区——魔搭 MCP 广场,涵盖开发者工具、文件系统、搜索、地图等十大热门领域 2400 MCP 服…...
)
关于mac配置hdc(鸿蒙)
关于mac配置hdc(鸿蒙) 在最开始配置的hdc -v时候老是出现格式不匹配 于是乎在网上找官网也不行,最后在csdn上找到了这篇文章Mac配置hdc才有的头绪 环境变量的问题 自己做一个简单的总结 首先在访达里面打开ide 打开之后输入下面的命令,一步一步的找…...

几何_平面方程表示_点+向量形式
三维平面方程可以写成: π : n ⊤ X d 0 \boxed{\pi: \mathbf{n}^\top \mathbf{X} d 0} π:n⊤Xd0 📐 一、几何直观解释 ✅ 平面是“法向量 平面上一点”定义的集合 一个平面可以由: 一个单位法向量 n ∈ R 3 \mathbf{n} \in \mat…...

iOS safari和android chrome开启网页调试与检查器的方法
手机开启远程调试教程(适用于 Chrome / Safari) 前端移动端调试指南|适用 iPhone 和 Android|WebDebugX 出品 本教程将详细介绍如何在 iPhone 和 Android 手机上开启网页检查器,配合 WebDebugX 实现远程调试。教程包含…...

Matlab 模糊pid控制的永磁同步电机PMSM
1、内容简介 Matlab 226-模糊pid控制的永磁同步电机PMSM 可以交流、咨询、答疑 2、内容说明 略 3、仿真分析 略 4、参考论文 略基于模糊控制的高精度伺服速度控制器的设计与实现_刘京航...
)
ActiveMQ 高级特性:延迟消息与优先级队列实战(二)
三、优先级队列实战 3.1 优先级队列概念与应用场景 优先级队列是一种特殊的队列,与普通队列按照先进先出(FIFO)的规则不同,优先级队列中的元素按照其优先级进行排序,在消费消息时,高优先级的消息会优先被…...
)
ActiveMQ 高级特性:延迟消息与优先级队列实战(一)
引言 在当今的分布式系统开发中,消息中间件扮演着至关重要的角色,而 ActiveMQ 作为一款广泛使用的开源消息中间件,凭借其丰富的特性和良好的性能,深受开发者的青睐。它支持多种消息模型,如点对点和发布 / 订阅&#x…...
)
动手学深度学习12.4.硬件-笔记练习(PyTorch)
以下内容为结合李沐老师的课程和教材补充的学习笔记,以及对课后练习的一些思考,自留回顾,也供同学之人交流参考。 本节课程地址:31 深度学习硬件:CPU 和 GPU【动手学深度学习v2】_哔哩哔哩_bilibili 本节教材地址&am…...
)
LAN-402 全国产信号采集处理模块K7-325T(4通道采集)
UD LAN-402全国产化信号处理模块最多支持2通道16bit125Msps的短波采集(或2通道14bit250Msps超短波采集)、2通道16bit310Msps超短波采集,可选配XC7K325T、XC7K410T、JFM7K325T、JFM7K410T FPGA芯片,对外支持PCIe2.0x8接口、千兆网、…...
指标优势与劣势)
关于大语言模型的困惑度(PPL)指标优势与劣势
1. 指标本身的局限性 与人类感知脱节: PPL衡量的是模型对词序列的预测概率(基于交叉熵损失),但低困惑度未必对应高质量的生成结果。例如: 模型可能生成语法正确但内容空洞的文本(PPL低但质量差)…...

[Spring AOP 8] Spring AOP 源码全流程总结
Spring AOP总结 更美观清晰的版本在:Github 前面的章节: [Spring AOP 1] 从零开始的JDK动态代理 [Spring AOP 2] 从零开始的CGLIB动态代理 [Spring AOP 3] Spring选择代理 [Spring AOP 4] Spring AOP 切点匹配 [Spring AOP 5] 高级切面与低级切面&#…...

通信网络编程——JAVA
1.计算机网络 IP 定义与作用 :IP 地址是在网络中用于标识设备的数字标签,它允许网络中的设备之间相互定位和通信。每一个设备在特定网络环境下都有一个唯一的 IP 地址,以此来确定其在网络中的位置。 分类 :常见的 IP 地址分为 I…...

支持向量机算法
支持向量机(Support Vector Machine,SVM)作为机器学习领域中一颗耀眼的明星,凭借其卓越的分类与回归能力,在众多算法中独树一帜。它宛如一位精准的边界守护者,通过巧妙地构建超平面,将不同类别的…...

Redis集群模式、持久化、过期策略、淘汰策略、缓存穿透雪崩击穿问题
Redis四种模式 单节点模式 架构:单个Redis实例运行在单台服务器。 优点: 简单:部署和配置容易,适合开发和测试。 低延迟:无网络通信开销。 缺点: 单点故障&…...

【WPF】Opacity 属性的使用
在WPF(Windows Presentation Foundation)中,Opacity 属性是定义一个元素透明度的属性,其值范围是从 0.0(完全透明)到 1.0(完全不透明)。由于 Opacity 是在 UIElement 类中定义的&…...

编程题 02-线性结构3 Reversing Linked List【PAT】
文章目录 题目输入格式输出格式输入样例输出样例 题解解题思路完整代码 编程练习题目集目录 题目 Given a constant K K K and a singly linked list L L L, you are supposed to reverse the links of every K K K elements on L L L. For example, given L being 1 → …...

集成指南:如何采用融云 Flutter IMKit 实现双端丝滑社交体验
在移动应用开发领域,跨平台框架的广泛应用已成为一种趋势。 融云跨平台方案持续升级,近期正式上线 Flutter IMKit,uni-app IMKit 也将紧随其后向广大开发者开放。覆盖两大跨平台核心框架,一套代码即可支持 Android、iOS 双端丝滑…...

使用vite重构vue-cli的vue3项目
一、修改依赖 首先修改 package.json,修改启动方式与相应依赖 移除vue-cli并下载vite相关依赖,注意一些peerDependency如fast-glob需要手动下载 # 移除 vue-cli 相关依赖 npm remove vue/cli-plugin-babel vue/cli-plugin-eslint vue/cli-plugin-rout…...

LeetCode 2094.找出 3 位偶数:遍历3位偶数
【LetMeFly】2094.找出 3 位偶数:遍历3位偶数 力扣题目链接:https://leetcode.cn/problems/finding-3-digit-even-numbers/ 给你一个整数数组 digits ,其中每个元素是一个数字(0 - 9)。数组中可能存在重复元素。 你…...
)
FLASH闪存(擦除、编译)
FLASH闪存 文章目录 FLASH闪存1.存储器映像位置2.FLASH简介3.闪存模块组织3.2闪存的共性: 4.FLASH基本结构4.1FLASH解锁4.2使用指针访问寄存器 5.选项字节5.1选项字节编程5.2选项字节擦除 6.相关函数介绍7.读取内部FLASH(实操)7.1接线图7.2工…...

企业即时通讯软件,私有化安全防泄密
在数字化转型与信创战略双重驱动下,企业对即时通讯工具的需求已从基础沟通转向安全可控、高效协同的综合能力。BeeWorks作为一款专为政企设计的私有化即时通讯与协同办公平台,凭借其全链路安全架构、深度国产化适配及灵活的业务集成能力,成为…...

直方图特征结合 ** 支持向量机图片分类
一、核心技术框架 1. 直方图特征原理 颜色直方图:统计图像中每个颜色区间(如 RGB 通道)的像素数量,反映颜色分布。HOG 直方图(方向梯度直方图):统计图像局部区域的梯度方向分布,捕…...

【prometheus+Grafana篇】基于Prometheus+Grafana实现windows操作系统的监控与可视化
💫《博主主页》: 🔎 CSDN主页 🔎 IF Club社区主页 🔥《擅长领域》:擅长阿里云AnalyticDB for MySQL(分布式数据仓库)、Oracle、MySQL、Linux、prometheus监控;并对SQLserver、NoSQL(MongoDB)有了…...
——卷积神经网络(Convolutional Neural Network, CNN)详解)
PyTorch实战(4)——卷积神经网络(Convolutional Neural Network, CNN)详解
PyTorch实战(4)——卷积神经网络详解 0. 前言1. 全连接网络的缺陷2. 卷积神经网络基本组件2.1 卷积2.2 步幅和填充2.3 池化2.3 卷积神经网络完整流程 3. 卷积和池化相比全连接网络的优势4. 使用 PyTorch 构建卷积神经网络4.1 使用 PyTorch 构建 CNN 架构…...

【Python】Python常用控制结构详解:条件判断、遍历与循环控制
Python提供了多种控制结构来处理逻辑判断和循环操作,包括if-else条件分支、switch替代方案、遍历方法以及循环控制语句break和continue。以下是对这些功能的详细说明及示例: 一、条件判断:if-else与多分支结构 单分支结构 • 语法࿱…...

在Linux中安装JDK并且搭建Java环境
1.首先准备好JDK的Linux的安装包 2.打开Linux,进入root的文件夹,直接拖入即可 3.输入解压命令,后面指定的是位置(注意不要填写错误,就填写这个) 4.之后进入我们安装的jdk的文件 利用pwd命令,展示我们安装的目录,之后…...

理解多智能体深度确定性策略梯度MADDPG算法:基于python从零实现
引言:多智能体强化学习(MARL) 多智能体强化学习(MARL)将强化学习拓展到多个智能体在共享环境中相互交互的场景。这些智能体可能相互合作、竞争,或者目标混杂。MARL 引入了单智能体设置中不存在的独特挑战。…...

【AI大语言模型本质分析框架】
AI大语言模型本质分析框架 ——从教育危机到智能本质的七层递进式解构 第一层:现象观察——阴(显性危机)与阳(隐性变革)的共存 观点1(阴):AI作弊泛滥,传统教育体系崩溃…...

算法模型部署后_python脚本API测试指南-记录3
API 测试指南 服务运行后,可以通过以下方式测试: Curl: curl -X POST -F "file./test_dataset/surface/surface57.png" http://<服务器IP>:9000/api/v1/predictPython 脚本: (参考 svm_request测试.py) import requestsurl http://…...
应用开发入门教程)
鸿蒙(HarmonyOS)应用开发入门教程
目录 第一章:鸿蒙系统简介 1.1 什么是鸿蒙系统? 1.2 鸿蒙系统架构 第二章:开发环境搭建 2.1 安装DevEco Studio 步骤1:下载与安装 步骤2:首次配置 步骤3:设备准备 2.2 创建第一个项目 第三章:鸿蒙应用开发基础 3.1 核心概念:Ability与AbilitySlice 示例代码…...

MIT XV6 - 1.6 Lab: Xv6 and Unix utilities -uptime
接上文 MIT XV6 - 1.5 Lab: Xv6 and Unix utilities - xargs 第一章持续有点久了,虽然肯定有些特点和细节还没注意到,但这次的主要目的是学习内核部分,决定水一篇然后进入第二章节 uptime 第一章的最后一个实验,选做性质…...

Python语言在地球科学交叉领域中的应用——从数据可视化到常见数据分析方法的使用【实例操作】
前言: Python是功能强大、免费、开源,实现面向对象的编程语言,Python能够运行在Linux、Windows、Macintosh、AIX操作系统上及不同平台(x86和arm),Python简洁的语法和对动态输入的支持,再加上解释…...

flutter 的 json序列化和反序列化
一、json转实体 Instantly parse JSON in any language | quicktype 二、实体中的toJson和fromJson 实现 官方推荐的 两个插件(个人觉得一个实体会多一个.g.dart 文件太多了,不喜欢) json_annotation json_serializable 三、使用 dart_json_mapper 实现上面的功…...
?)
什么是数据集市(Data Mart)?
数据集市(Data Mart)是数据仓库(Data Warehouse)的一个子集,专门针对某个特定业务部门、业务线或主题领域,存储和管理该部门或领域所需的特定数据。它通常包含从企业范围的数据仓库中抽取、筛选和汇总的部分…...

从攻击者角度来看Go1.24的路径遍历攻击防御
目录 一、具体攻击示例 程序 攻击步骤: 二、为什么攻击者能成功? 分析 类比理解 总结 三、TOCTOU 竞态条件漏洞 1、背景:符号链接遍历攻击 2. TOCTOU 竞态条件漏洞 3. 另一种变体:目录移动攻击 4. 问题的核心 四、防…...

[ARM][汇编] 01.基础概念
目录 1.全局标号 1.1.使用方法 1.1.1.声明全局标号 1.1.2.定义全局标号 1.1.3.引用全局标号 1.2.全局标号与局部标号的区别 1.3.注意事项 2.局部标号 2.1.使用方法 2.1.1.定义局部标号 2.1.2.跳转引用 2.2.局部标号与全局标号的对比 2.3.注意事项 3.符号定义伪指…...

杭州电商全平台代运营领军者——品融电商
杭州电商全平台代运营领军者——品融电商:以“效品合一”驱动品牌全域增长 在电商行业竞争日益白热化的当下,品牌如何突破流量焦虑、实现长效增长?作为中国领先的品牌化电商服务商,杭州品融电商(PINKROON)…...
源码分析(一、定义与基础操作实现))
02.Golang 切片(slice)源码分析(一、定义与基础操作实现)
Golang 切片(slice)源码分析(一、定义与基础操作实现) 注意当前go版本代码为1.23 一、定义 slice 的底层数据是数组,slice 是对数组的封装,它描述一个数组的片段。两者都可以通过下标来访问单个元素。 数…...

当生产了~/qt-arm/bin/qmake,可以单独编译其他-源码的某个模块,如下,编译/qtmultimedia
cd ~/qt-everywhere-src-5.15.2/qtmultimedia # 设置交叉编译器和 qmake 路径 export CC/usr/bin/aarch64-linux-gnu-gcc export CXX/usr/bin/aarch64-linux-gnu-g export QMAKE~/qt-arm/bin/qmake # 使用已安装的 qmake export QT_INSTALL_PREFIX~/qt-arm # 安装路径 # 配…...

WordPress 网站上的 jpg、png 和 WebP 图片插件
核心功能 1. 转换 AVIF 并压缩 AVIF 将您 WordPress 网站上的 jpg、png 和 WebP 图片转换为 AVIF 格式,并根据您设置的压缩级别压缩 AVIF 图片。如果原始图片已经是 WordPress 6.5 以上支持的 AVIF 格式,则原始 AVIF 图片将仅被压缩。 2. 转换 WebP 并…...

构造+简单树状
昨日的牛客周赛算是比较简单的,其中最后一道构造题目属实眼前一亮。 倒数第二个题目也是一个很好的模拟题目(考验对二叉树的理解和代码的细节) 给定每一层的节点个数,自己拟定一个父亲节点,构造一个满足条件的二叉树。…...

Flask支持哪些日志框架
目录 ✅ Flask 默认支持的日志框架 ✅ 默认推荐:logging(标准库) ✅ 进阶推荐:Loguru(更优雅的日志库) ✅ Flask 日志级别说明(与标准库一致) ✅ 生产环境建议 ✅ 总结推荐 在 Flask 中,默认的日志系统是基于 Python 标准库 logging 模块 构建的。 ✅ Flask 默认…...

健康养生指南:解锁活力生活的科学密码
健康是人生最珍贵的财富,在快节奏的现代生活中,掌握科学的养生方法至关重要。虽然不借助中医理念,我们依然可以从饮食、运动、睡眠等多个方面入手,打造健康生活方式。 合理的饮食是健康的基石。遵循均衡饮食原则,保证每…...

SAR图像压缩感知
SAR图像压缩感知 matlab代码 对应着汕大闫老师的那本压缩感知及其应用,有需要的可以看一下!! SAR图像压缩感知/baboon.bmp , 66616 SAR图像压缩感知/camera.bmp , 66616 SAR图像压缩感知/DWT.m , 1265 SAR图像压缩感知/Gauss.m , 373 SAR图像…...

定时器设计
定时器设计的必要性 服务器中的定时器设计具有多方面的必要性,主要体现在以下几个关键方面: 任务调度与管理 定时任务执行:服务器常常需要执行一些定时性的任务,如定时备份数据、定时清理缓存、定时更新系统日志等。通过定时器可…...

Spring Boot整合Kafka实战指南:从环境搭建到消息处理全解析
一、环境准备 安装 Kafka 下载 Kafka:从 Apache Kafka 官网下载对应版本的 Kafka。 解压并启动 Kafka: # 启动 Zookeeper(Kafka 依赖 Zookeeper) bin/zookeeper-server-start.sh config/zookeeper.properties# 启动 Kafka bin/ka…...
 补充:xv6 的一个用户程序 init 是怎么启动的 ?它如何启动第一个 bash ?)
(done) 补充:xv6 的一个用户程序 init 是怎么启动的 ?它如何启动第一个 bash ?
先看 main.c 从函数名来看,比较相关的就 userinit() 和 scheduler() #include "types.h" #include "param.h" #include "memlayout.h" #include "riscv.h" #include "defs.h"volatile static int started 0;//…...

AI 搜索引擎 MindSearch
背景 RAG是一种利用文档减少大模型的幻觉,AI搜索也是 AI 搜索引擎 MindSearch 是一个开源的 AI 搜索引擎框架,具有与 Perplexity.ai Pro 相同的性能。您可以轻松部署它来构建您自己的搜索引擎,可以使用闭源 LLM(如 GPT、Claude…...