Redis集群模式、持久化、过期策略、淘汰策略、缓存穿透雪崩击穿问题
Redis四种模式
单节点模式
架构:单个Redis实例运行在单台服务器。
优点:
简单:部署和配置容易,适合开发和测试。
低延迟:无网络通信开销。
缺点:
单点故障:节点故障会导致服务不可用。
容量受限:数据量受限于单机内存。
性能瓶颈:读写压力集中在单节点,无法扩展。
适用场景:
本地开发、测试环境。
数据量小且对可用性要求不高的场景。
主从模式(Replication)
主从模式的核心原理
- 角色划分:
主节点(Master):唯一处理写操作(SET, DEL等),数据变更后异步复制到从节点。
从节点(Slave/Replica):通过复制主节点数据保持与主节点一致,仅处理读操作(GET等)。 - 数据复制流程:
建立连接:从节点启动后向主节点发送 SYNC 或 PSYNC 命令,请求同步数据。
全量复制(RDB快照):主节点生成当前数据的 RDB 快照发送给从节点,从节点加载快照完成初始同步。
增量复制(Replication Buffer):主节点将后续的写命令缓存在 repl_backlog_buffer 中,从节点持续接收并执行这些命令以保持数据一致。
心跳检测:主从节点通过定期发送 PING 和 REPLCONF ACK 维持连接,检测网络和节点状态。 - 复制模式:
全量复制:首次连接或复制中断后无法增量恢复时触发(资源消耗大)。
增量复制(Redis 2.8+):基于 PSYNC 命令,通过偏移量(offset)和复制积压缓冲区(repl_backlog)实现断点续传。
主从模式拓扑结构:
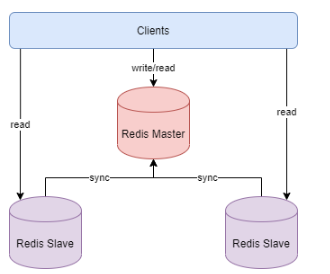
一主多从:单个主节点挂载多个从节点,适合读请求量大的场景。
树状结构:从节点可以作为其他从节点的主节点(级联复制),减轻主节点压力。
Master → Slave1 → Slave2
↘ Slave3
主从模式的优缺点
- 优点:
读写分离:
主节点处理写请求,从节点分担读请求,提升读并发能力。
数据冗余:
从节点是主节点的完整副本,提供数据备份,防止单点数据丢失。
灾备恢复:
主节点故障时,可手动将从节点提升为新主节点(需配合哨兵实现自动化)。 - 缺点:
主节点单点故障:
主节点宕机后需手动切换从节点,服务会短暂不可用。
复制延迟:
异步复制可能导致从节点数据短暂不一致(写入主节点后,从节点未及时同步)。
写能力受限:
所有写操作仍由主节点处理,无法横向扩展写性能。
主从数据同步详解
Redis 主从模式通过异步复制实现数据同步,核心目标是让从节点(Slave/Replica)与主节点(Master)保持数据一致。其同步过程分为 全量同步(Full Sync) 和 增量同步(Partial Sync) 两种机制,具体流程如下:
全量同步(Full Sync)
- 触发条件:
从节点首次连接主节点。
主从节点复制偏移量(offset)差距过大,超出主节点repl_backlog缓冲区范围。
主节点重启或切换导致 run_id 变更,从节点无法识别新主节点。 - 全量同步流程:
a 建立连接
从节点发送 PSYNC ? -1 命令请求同步(若 Redis 版本 < 2.8,使用 SYNC 命令)。
b 主节点生成 RDB 快照
主节点调用 bgsave 后台生成当前数据的 RDB 快照文件。
生成期间的新写命令会存入 复制缓冲区(Replication Buffer)。
c 传输 RDB 文件
RDB 文件生成完成后,主节点将其发送给从节点。
传输期间主节点继续处理写命令,并缓存到复制缓冲区。
d 从节点加载 RDB
从节点清空旧数据,加载 RDB 文件完成初始数据同步。
加载完成后,主节点将复制缓冲区中的写命令发送给从节点执行。
e 进入增量同步
全量同步完成后,主从进入增量同步阶段,主节点持续推送新写命令。 - 全量同步资源消耗:
主节点:生成 RDB 消耗 CPU/内存,传输 RDB 占用网络带宽。
从节点:加载 RDB 时可能阻塞其他操作(取决于配置)。
增量同步(Partial Sync)
- 触发条件:
主从节点断开后重连,且从节点的复制偏移量(offset)仍在主节点的 repl_backlog 缓冲区内。 - 增量同步流程:
a 从节点发送 PSYNC 命令
携带主节点 run_id 和自身记录的复制偏移量(offset)。
b 主节点校验偏移量
若从节点的 offset 在 repl_backlog 缓冲区内,则发送缺失的写命令。
否则触发全量同步(例如缓冲区已被覆盖)。
c 同步缺失数据
主节点发送从 offset 之后的所有写命令,从节点执行这些命令更新数据。 - 核心组件:
复制偏移量(offset)
主从节点各自维护一个偏移量,表示已复制的数据字节数。
主节点每次接收写命令,offset 增加;从节点复制后更新自身 offset。
复制积压缓冲区(repl_backlog)
主节点维护的环形内存缓冲区,默认大小 1MB(可配置)。
记录最近一段时间(由缓冲区大小决定)的写命令,用于增量同步。
主节点运行 ID(run_id)
每个主节点启动时生成唯一 run_id,从节点记录该 ID。
主节点重启或切换时,run_id 变更,从节点需重新全量同步。
哨兵模式(Sentinel)
Redis 哨兵模式是 Redis 高可用性(HA)的核心解决方案,用于自动化监控主从节点、故障检测与转移,保障服务持续可用。(哨兵模式基于主从复制模式,只是引入了哨兵来监控与自动处理故障。)
哨兵模式的核心功能
- 监控(Monitoring)
哨兵持续检查主节点和从节点的健康状态(是否在线、响应延迟等)。
2. 自动故障转移(Automatic Failover)
主节点故障时,自动选举新主节点,并更新从节点和客户端的配置。 - 配置中心(Configuration Provider)
客户端通过哨兵获取当前主节点地址,无需硬编码。 - 通知(Notification)
支持通过 API 或脚本通知管理员集群状态变化。
哨兵模式架构
- 哨兵节点(Sentinel):
独立运行的 Redis 进程,不存储业务数据,仅负责监控和决策。 - 主从节点(Master/Slave):
与普通主从模式相同,哨兵依赖主从结构实现数据冗余。
哨兵的工作流程
- 监控阶段
a 周期性检查主节点状态:
每个哨兵每隔 sentinel down-after-milliseconds (默认30秒)向主节点发送 PING 命令。
b 主观下线(SDOWN):
若主节点在指定时间内未响应,哨兵将其标记为 主观下线。
c 客观下线(ODOWN):
当超过半数哨兵(由 quorum 参数控制)确认主节点主观下线,主节点被标记为 客观下线,触发故障转移。 - 故障转移(Failover)
a 选举领导者哨兵:
所有哨兵通过 Raft算法 选举一个领导者哨兵(Leader Sentinel)来执行故障转移。
Raft:
发现master下线的哨兵节点(我们称他为A)向每个哨兵发送命令,要求对方选自己为领头哨兵
如果目标哨兵节点没有选过其他人,则会同意选举A为领头哨兵
如果有超过一半的哨兵同意选举A为领头,则A当选
如果有多个哨兵节点同时参选领头,此时有可能存在一轮投票无竞选者胜出,此时每个参选的节点等待一个随机时间后再次发起参选请求,进行下一轮投票竞选,直至选举出领头哨兵
b 选择新主节点:
领导者哨兵根据规则从从节点中选举新主节点,优先级规则:
从节点与主节点断开时间(slave_repl_offset 差异小者优先)。
数据最新的从节点(复制偏移量最大者优先)。
若配置了 slave-priority,优先级高者优先。
c 切换主从角色:
新主节点执行 REPLICAOF NO ONE 脱离从属角色。
其他从节点通过 REPLICAOF 命令指向新主节点。
d 客户端更新:
哨兵通知客户端(通过发布/订阅机制)新主节点地址。 - 旧主节点恢复
旧主节点恢复后,哨兵将其降级为从节点,并指向新主节点。
哨兵模式的优缺点
- 优点:
高可用性:自动故障转移,减少人工干预。
透明切换:客户端自动感知主节点变化。
扩展性:支持多哨兵节点,防止哨兵单点故障。 - 缺点:
配置复杂:需部署多个哨兵节点并维护配置一致性。
写扩展不足:写操作仍由单一主节点处理,无法水平扩展。
网络分区风险:极端情况下可能出现脑裂(需合理配置 quorum 和 majority)。
集群模式(Cluster)
Redis 集群(Cluster)是 Redis 官方提供的分布式解决方案,旨在解决大规模数据存储、高并发访问和高可用性需求。
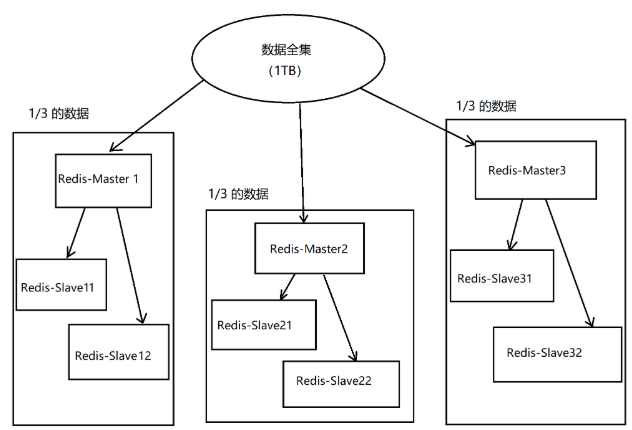
Redis 集群的核心特性
- 数据分片(Sharding)
数据被自动分片到多个节点,突破单机内存限制。 - 高可用性
每个分片(主节点)至少有一个从节点,支持故障自动切换。 - 横向扩展
可动态添加节点,提升集群容量和性能。 - 去中心化架构
节点间通过 Gossip 协议 直接通信,无需依赖外部协调服务(如 ZooKeeper)。
集群架构核心概念
- 数据分片机制
哈希槽(Hash Slot)
Redis 将数据划分为 16384 个槽,每个键通过 CRC16 算法 计算哈希值后,映射到其中一个槽:
slot = CRC16(key) % 16384
槽分配
每个主节点负责一部分槽。例如,3主节点集群可能的槽分配:
节点A:0-5460
节点B:5461-10922
节点C:10923-16383 - 节点角色
主节点(Master)
负责处理读写请求,并管理分配的槽。
从节点(Slave)
复制主节点数据,主节点故障时通过选举成为新主节点。
最小集群要求
至少3个主节点:确保故障转移时能达成多数派共识。
每个主节点至少1个从节点:保证高可用性,推荐3主3从架构。
数据分片算法
哈希求余
设有N个分⽚,使⽤[0,N-1]这样序号进⾏编号.
针对某个给定的key,先计算hash值,再把得到的结果%N,得到的结果即为分⽚编号.
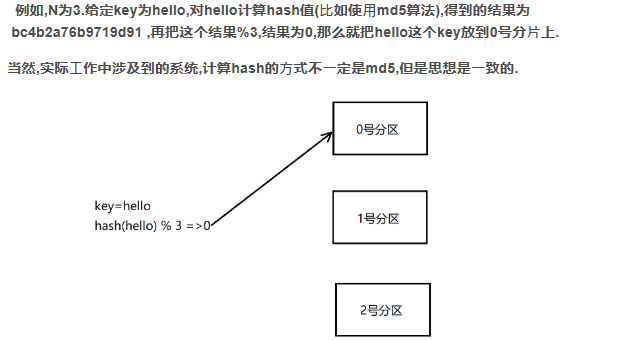
优点: 简单⾼效,数据分配均匀.
缺点: ⼀旦需要进⾏扩容,N改变了,原有的映射规则被破坏,就需要让节点之间的数据相互传输,重新排列,以满⾜新的映射规则.此时需要搬运的数据量是⽐较多的,开销较⼤.
N为3的时候,[100,120]这21个hash值的分布(此处假定计算出的hash值是⼀个简单的整数,⽅便 ⾁眼观察)
当引⼊⼀个新的分⽚,N从3=>4时,⼤量的key都需要重新映射.(某个key%3和%4的结果不⼀样, 就映射到不同机器上了).
⼀致性哈希算法
为了降低上述的搬运开销,能够更⾼效扩容,业界提出了"⼀致性哈希算法".
key 映射到分⽚序号的过程不再是简单求余了,⽽是改成以下过程:
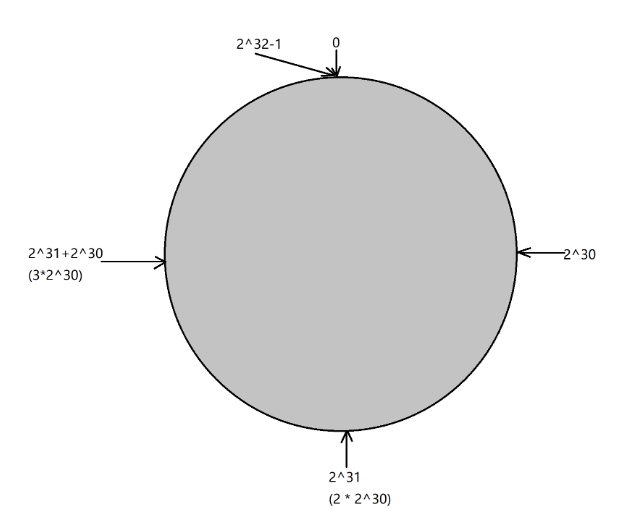
第⼀步:把0->2^32-1这个数据空间,映射到⼀个圆环上.数据按照顺时针⽅向增⻓.
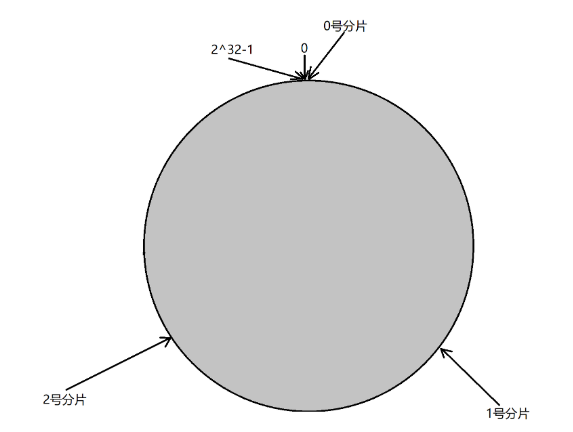
第⼆步:假设当前存在三个分⽚,就把分⽚放到圆环的某个位置上.
第三步:假定有⼀个key,计算得到hash值H,那么这个key映射到哪个分⽚呢?规则很简单,就是从H 所在位置,顺时针往下找,找到的第⼀个分⽚,即为该key所从属的分⽚.
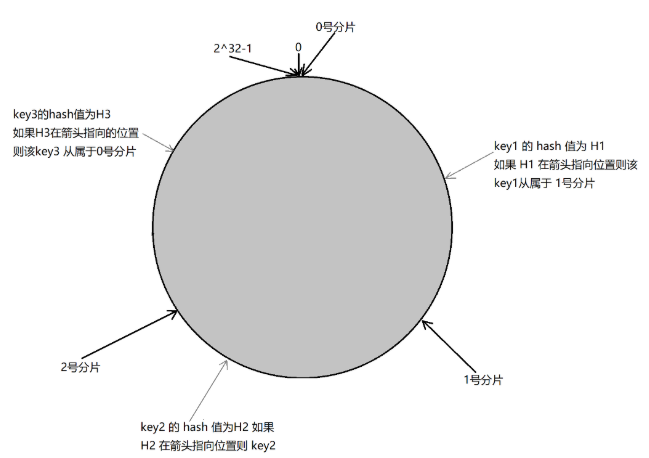
这就相当于,N个分⽚的位置,把整个圆环分成了N个管辖区间.Key的hash值落在某个区间内,就归对应区间管理.
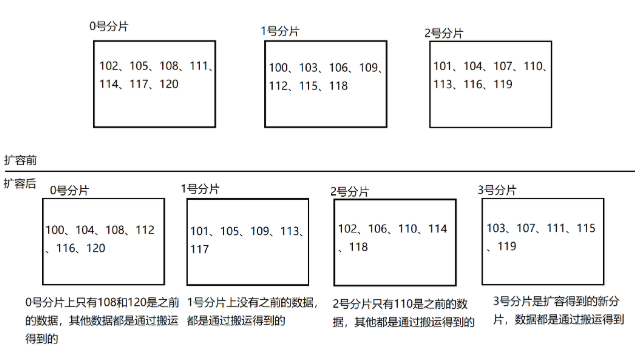
在这个情况下,如果扩容⼀个分⽚,如何处理呢? 原有分⽚在环上的位置不动,只要在环上新安排⼀个分⽚位置即可.
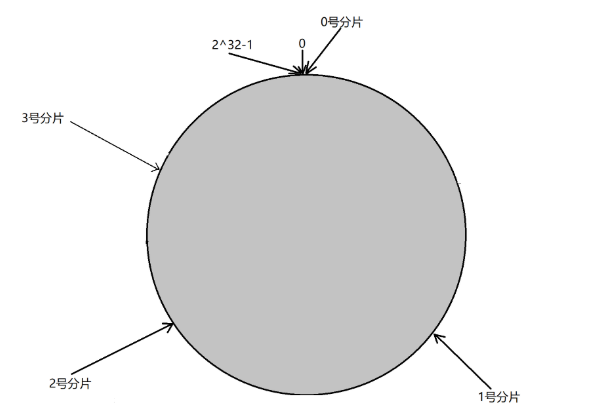
此时,只需要把0号分⽚上的部分数据,搬运给3号分⽚即可.1号分⽚和2号分⽚管理的区间都是不变的.
优点: ⼤⼤降低了扩容时数据搬运的规模,提⾼了扩容操作的效率.
缺点: 数据分配不均匀(有的多有的少,数据倾斜).
哈希槽分区算法(Redis使⽤)
为了解决上述问题(搬运成本⾼和数据分配不均匀),Rediscluster引⼊了哈希槽(hashslots)算法
hash_slot = crc16(key) % 16384
其中crc16也是⼀种hash算法.
16384 其实是16*1024,也就是2^14.
相当于是把整个哈希值,映射到16384个槽位上,也就是[0,16383]。
然后再把这些槽位⽐较均匀的分配给每个分⽚.每个分⽚的节点都需要记录⾃⼰持有哪些分⽚.
假设当前有三个分⽚,⼀种可能的分配⽅式:
- 0号分⽚:[0,5461],共5462个槽位
- 1号分⽚:[5462,10923],共5462个槽位
- 2号分⽚:[10924,16383],共5460个槽位
这⾥的分⽚规则是很灵活的.每个分⽚持有的槽位也不⼀定连续. 每个分⽚的节点使⽤位图来表⽰⾃⼰持有哪些槽位.对于16384个槽位来说,需要2048个字 节(2KB)⼤⼩的内存空间表⽰.
如果需要进⾏扩容,⽐如新增⼀个3号分⽚,就可以针对原有的槽位进⾏重新分配.
⽐如可以把之前每个分⽚持有的槽位,各拿出⼀点,分给新分⽚.
⼀种可能的分配⽅式:
- 0号分⽚:[0,4095],共4096个槽位
- 1号分⽚:[5462,9557],共4096个槽位
- 2号分⽚:[10924,15019],共4096个槽位
- 3号分⽚:[4096,5461]+[9558,10923]+[15019,16383],共4096个槽位
集群的高可用机制
在 Redis 集群模式中,当主节点宕机时,从节点(Replica)会自动触发故障转移(Failover)流程,选举出新的主节点。
故障转移触发条件
- 主观下线(PFAIL)
集群中其他节点通过心跳检测(Gossip协议)发现主节点无响应,会将其标记为 PFAIL(Possible Failure)。 - 客观下线(FAIL)
当超过半数的主节点(至少 N/2+1,N为集群主节点总数)确认该主节点不可达,则标记为 FAIL,触发故障转移。
从节点选举流程
- 资格检查
从节点必须满足以下条件才能参与选举:
数据同步正常:slave_repl_offset 与旧主节点的 master_repl_offset 差距在合理范围内(由 cluster-replica-validity-factor 控制,默认10秒)。
旧主节点已被标记为 FAIL 状态。 - 发起选举
从节点向集群中所有主节点发送 FAILOVER_AUTH_REQUEST 请求投票。 - 投票机制
每个主节点只能投一票,且需满足以下条件:
主节点当前未参与其他故障转移。
主节点确认旧主节点确实处于 FAIL 状态。
从节点获得 超过半数主节点(N/2+1)的投票 后,成为新主节点。 - 切换主节点角色
当选的从节点执行 REPLICAOF NO ONE,脱离从属角色,接管旧主节点的哈希槽(Hash Slots)。
其他从节点重新指向新主节点,开始同步数据。
对比总结
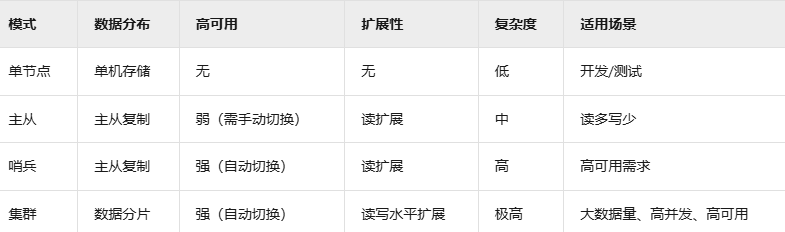
Redis持久化
Redis 提供两种核心持久化机制:RDB(Redis Database) 和 AOF(Append Only File),用于将内存数据持久化到磁盘,确保数据在服务重启或故障后不丢失。
RDB(快照持久化)
工作原理
定时快照:根据配置规则,将内存数据生成二进制压缩的 RDB文件(默认 dump.rdb)。
全量备份:每次持久化保存整个数据库状态。
触发条件
自动触发:
配置 save 规则(默认:save 900 1、save 300 10、save 60 10000)。
执行 SHUTDOWN 或 FLUSHALL 命令时自动生成 RDB。
手动触发:
# 同步生成RDB(阻塞主线程,生产环境慎用)
SAVE
# 异步生成RDB(后台执行)
BGSAVE
优点
高性能:二进制压缩文件体积小,恢复速度快。
容灾友好:适合备份全量数据到远程存储(如 AWS S3)。
资源消耗低:异步 BGSAVE 通过 fork 子进程处理,主进程无阻塞。
缺点
数据丢失风险:两次快照之间的数据可能丢失(依赖配置频率)。
大内存场景 fork 延迟:BGSAVE 在数据量较大时,fork 子进程可能引发短暂阻塞。
配置示例(Redis默认开启RDB)
# redis.conf
save 900 1 # 900秒内至少1次修改触发保存
save 300 10 # 300秒内至少10次修改触发保存
save 60 10000 # 60秒内至少10000次修改触发保存
rdbcompression yes # 启用压缩
dbfilename dump.rdb # RDB文件名
dir ./ # 保存路径
RDB对过期key的处理
过期key对RDB没有任何影响,
- 从内存数据库持久化数据到RDB文件,持久化key之前,会检查是否过期,过期的key不进入RDB文件。
- 从RDB文件恢复数据到内存数据库,数据载入数据库之前,会对key先进行过期检查,如果过期,不导入数据库(主库情况)。
AOF(日志追加持久化)
工作原理
日志记录:将每个写操作以协议文本格式追加到 appendonly.aof 文件。
重写机制(Rewrite):定期压缩AOF文件,消除冗余命令(如多次SET同一键)。
同步策略
appendfsync 配置:
always:每次写操作都同步到磁盘(最安全,性能最低)。
everysec(默认):每秒同步一次(平衡安全与性能)。
no:由操作系统决定同步时机(最快,数据丢失风险最高)。
优点
高数据安全:appendfsync always 可确保零数据丢失。
可读性强:AOF文件为文本格式,便于人工审计或修复。
缺点
文件体积大:未压缩的日志文件可能远大于RDB。
恢复速度慢:重放AOF日志比加载RDB慢。
长期写入压力:频繁同步可能影响性能(尤其是 always 模式)。
配置示例
# redis.conf
appendonly yes # 启用AOF
appendfilename "appendonly.aof" # AOF文件名
appendfsync everysec # 同步策略
auto-aof-rewrite-percentage 100 # 文件体积比上次重写后增长100%时触发重写
auto-aof-rewrite-min-size 64mb # 文件体积至少64MB才触发重写
aof-load-truncated yes # 加载截断的AOF文件(避免启动失败)
AOF对过期key的处理
过期key对AOF没有任何影响
从内存数据库持久化数据到AOF文件: 当key过期后,还没有被删除,此时进行执行持久化操作(该key是不会进入aof文件的,因为没有发生修改命令) 当key过期后,在发生删除操作时,程序会向aof文件追加一条del命令(在将来的以aof文件恢复数据的时候该过期的键就会被删掉) AOF重写 重写时,会先判断key是否过期,已过期的key不会重写到aof文件
混合持久化(Redis 4.0+)
工作原理
RDB + AOF:在AOF重写时,将当前数据状态以RDB格式写入AOF文件头部,后续增量操作仍以AOF格式追加。
文件格式:.aof 文件前半部分为RDB二进制数据,后半部分为AOF日志。
优点
快速恢复:利用RDB快速加载全量数据,再重放增量AOF日志。
数据安全:保留AOF的细粒度操作记录。
配置启用
# redis.conf
aof-use-rdb-preamble yes # 启用混合持久化(需同时开启AOF)
持久化策略对比
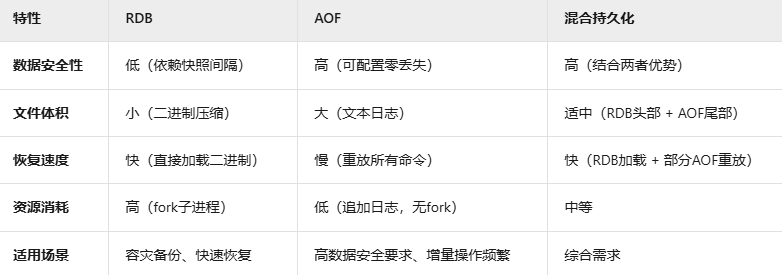
Redis主从数据不一致的解决方案
- 强制全量同步(Full Resync)
通过重启从节点或手动触发全量复制,使从节点重新同步主节点数据:
# 在从节点执行
redis-cli -h <slave-ip> -p <slave-port> REPLICAOF NO ONE # 解除从属关系
redis-cli -h <slave-ip> -p <slave-port> FLUSHALL # 清空数据(可选)
redis-cli -h <slave-ip> -p <slave-port> REPLICAOF <master-ip> <master-port> # 重新同步
- 使用 WAIT 命令(折中一致性)
原理:主节点写入后阻塞客户端,直到数据同步到指定数量的从节点。
import org.springframework.data.redis.core.RedisCallback;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Service;@Service
public class RedisWaitService {private final RedisTemplate<String, String> redisTemplate;public RedisWaitService(RedisTemplate<String, String> redisTemplate) {this.redisTemplate = redisTemplate;}/*** 写入数据并等待同步到指定数量的从节点* @param key 键* @param value 值* @param numReplicas 需要等待的从节点数* @param timeoutMillis 超时时间(毫秒)* @return 实际同步成功的从节点数*/public Long writeAndWait(String key, String value, int numReplicas, long timeoutMillis) {// 执行写操作redisTemplate.opsForValue().set(key, value);// 执行 WAIT 命令return redisTemplate.execute((RedisCallback<Long>) connection -> {Object result = connection.execute("WAIT".getBytes(),String.valueOf(numReplicas).getBytes(),String.valueOf(timeoutMillis).getBytes());return (result != null) ? Long.parseLong(result.toString()) : 0L;});}
}
注意:WAIT 会降低写入性能,需权衡一致性与吞吐量。
- 强制读主节点(强一致性)
适用场景:对数据一致性要求极高的关键操作(如支付成功页)。
实现方式:
业务逻辑区分:对需要强一致性的读请求,直接访问主节点。
# 伪代码示例:写操作后,后续读操作强制走主节点
def set_key(key, value):master_conn.set(key, value)# 标记后续读操作需走主节点cache.set(f"force_master:{user_id}", True, timeout=2) # 设置短期标记def get_key(key, user_id):if cache.get(f"force_master:{user_id}"):return master_conn.get(key)else:return slave_conn.get(key)
优点:数据强一致。
缺点:主节点压力增大,失去读写分离优势。
- 客户端降级重试(最终一致性)
适用场景:可容忍短暂不一致的非关键业务(如商品详情页)。
实现方式:
def get_key_with_retry(key, retries=3):for _ in range(retries):value = slave_conn.get(key)if value is not None:return valuetime.sleep(0.1) # 等待短暂延迟后重试# 降级策略:最终从主节点读取return master_conn.get(key)
优点:减少主节点压力,保持读写分离。
缺点:增加业务逻辑复杂度,可能需多次重试。
Redis过期策略
Redis的过期键删除策略结合了惰性删除和定期删除两种机制,以平衡内存利用和性能消耗。
- 惰性删除(Lazy Expiration)
原理:当客户端访问某个键时,Redis会先检查该键是否过期。如果过期,则立即删除并返回空值;否则正常返回数据。
优点:仅在访问时触发,节省CPU资源。
缺点:若大量键长期未被访问,会导致内存浪费。 - 定期删除(Active Expiration)
原理:Redis周期性随机抽取部分键检查过期状态,删除已过期的键。
实现细节:
频率控制:由配置参数hz(默认10)决定,即每秒运行10次,每100ms执行一次。
扫描过程:
每次从每个数据库中随机选取一定数量的键(默认20个,由ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP定义)。
删除其中已过期的键。
若过期的键比例超过25%,则重复该过程,直到比例低于25%或超时。
时间限制:每次定期删除的总时间不超过25ms(避免阻塞主线程)。
对于定期删除,在程序中有一个全局变量current_db来记录下一个将要遍历的库,假设有16个库,我们这一次定期删除遍历了10个,那此时的current_db就是11,下一次定期删除就从第11个库开始遍历,假设current_db等于15了,那么之后遍历就再从0号库开始(此时current_db==0)
Redis缓存淘汰策略
Redis的缓存淘汰策略(Eviction Policy)用于在内存达到上限(maxmemory)时决定删除哪些键以释放空间。
| 策略名称 | 行为描述 | 适用场景 |
|---|---|---|
| noeviction | 拒绝所有写入操作(默认策略) | 数据不可丢失,且内存不足时需人工干预的场景 |
| volatile-lru | 从设置了过期时间的键中,淘汰最近最少使用(LRU)的键 | 区分缓存和数据,仅淘汰缓存 |
| allkeys-lru | 从所有键中淘汰最近最少使用(LRU)的键 | 全部数据为缓存,需全局优化 |
| volatile-lfu | 从设置了过期时间的键中,淘汰最不经常使用(LFU)的键(Redis 4.0+) | 高频访问缓存场景,优先保留常用数据 |
| allkeys-lfu | 从所有键中淘汰最不经常使用(LFU)的键(Redis 4.0+) | 全局高频访问场景 |
| volatile-random | 从设置了过期时间的键中随机淘汰 | 缓存淘汰无需考虑访问模式 |
| allkeys-random | 从所有键中随机淘汰 | 数据重要性相同,淘汰随机键 |
| volatile-ttl | 从设置了过期时间的键中,淘汰剩余存活时间最短的键(TTL) | 优先清理即将过期的缓存 |
LRU与LFU的区别

Redis的LRU机制
传统 LRU:
维护一个链表,每次访问键时将其移动到链表头部,淘汰时直接删除链表尾部(需要精确维护顺序,内存和 CPU 开销大)。
Redis 的 LRU:
为了节省内存和性能,Redis 采用近似 LRU:
- 每个键会记录一个 lru 字段(24 bits),存储最后一次访问的时间戳(精度为秒级,但实际是逻辑时钟计数)。
- 当需要淘汰键时,Redis 随机抽取 N 个键(默认 N=5,由 maxmemory-samples 配置),比较它们的 lru 字段值,淘汰其中最久未被访问的键。
- 若淘汰后内存仍不足,重复此过程。
Redis的LFU机制
LFU(Least Frequently Used),表示最近最少使用,它和key的使用次数有关,其思想是:根据key最近被访问的频率进行淘汰,比较少访问的key优先淘汰,反之则保留。
LRU的原理是使用计数器来对key进行排序,每次key被访问时,计数器会增大,当计数器越大,意味着当前key的访问越频繁,也就是意味着它是热点数据。 它很好的解决了LRU算法的缺陷:一个很久没有被访问的key,偶尔被访问一次,导致被误认为是热点数据的问题。
LFU维护了两个链表,横向组成的链表用来存储访问频率,每个访问频率的节点下存储另外一个具有相同访问频率的缓存数据。具体的工作原理是:
- 当添加元素时,找到相同访问频次的节点,然后添加到该节点的数据链表的头部。如果该数据链表满了,则移除链表尾部的节点。当获取元素或者修改元素时,都会增加对应key的访问频次,并把当前节点移动到下一个频次节点。
- 添加元素时,访问频率默认为1,随着访问次数的增加,频率不断递增。而当前被访问的元素也会随着频率增加进行移动。
频率计数与衰减
传统 LFU 需要精确记录每个键的访问次数,但会带来两个问题:
内存开销大:每个键需存储一个较大的计数器(如 64 位整数),对海量键的场景不友好。
对突发访问敏感:短期大量访问的键可能迅速成为“高频”键,挤占长期稳定访问的键。
Redis 的 LFU 采用 8 位(0~255)对数计数器 + 概率递增 机制,既能压缩存储空间,又能抑制短期突发访问对频率的影响。
- 计数器递增规则
每次访问键时,计数器的递增不是固定加 1,而是按概率决定是否增加。
概率公式为:

fu_log_factor 是配置参数(默认 10),控制计数器的增长速度。
当前计数器值 是键的当前频率估算值(0~255)。
例如当前值=1,lfu_log_factor=10,访问 11 次,大约有 1 次(1/11≈9.09%)会触发计数器值+1。 - 频率衰减
为避免旧数据长期占用内存,Redis会定期减少计数器的值:
每经过 lfu_decay_time 分钟(默认1),计数器值减半(若值大于0)。
LFU关键配置参数:
| 参数 | 默认值 | 说明 |
|---|---|---|
| lfu-log-factor | 10 | 控制计数器增长速率。值越大,低频访问的计数器增长越慢,区分度越高。 |
| lfu-decay-time | 1 | 计数器衰减时间(单位:分钟)。值越大,频率衰减越慢。 |
| maxmemory-samples | 5 | 每次淘汰时随机采样的键数量。值越大,淘汰精度越高,但CPU消耗增加。 |
淘汰策略配置方式
# 设置最大内存(例如1GB)
maxmemory 1gb
# 选择淘汰策略(例如allkeys-lru)
maxmemory-policy allkeys-lru
主从节点的淘汰行为
- 主节点:主动执行淘汰策略并同步DEL命令到从节点。
- 从节点:默认不执行淘汰策略,依赖主节点同步删除指令(可通过replica-lazy-eviction no强制从节点自行淘汰)。
Redis中的缓存穿透、雪崩、击穿的原因以及解决方案
三者出现的根本原因:Redis命中率下降,请求直接打在DB上,导致DB的压力瞬间变大而卡死或者宕机。
缓存穿透
缓存穿透产生的原因:请求根本不存在的资源(DB本身就不存在,Redis更是不存在)
解决方式:
- 对空值进行缓存
- 实时监控:
对redis进行实时监控,当发现redis中的命中率下降的时候进行原因的排查,配合运维人员对访问对象和访问数据进行分析查询,从而进行黑名单的设置限制服务(拒绝黑客攻击) - 使用布隆过滤器
使用BitMap作为布隆过滤器,将目前所有可以访问到的资源通过简单的映射关系放入到布隆过滤器中(哈希计算),当一个请求来临的时候先进行布隆过滤器的判断,如果有那么才进行放行,否则就直接拦截 - 接口校验
类似于用户权限的拦截,对于id=-3872这些无效访问就直接拦截,不允许这些请求到达Redis、DB上。
缓存雪崩
缓存雪崩产生的原因:redis中大量的key集体过期
解决方式:
- 将失效时间分散开
通过使用自动生成随机数使得key的过期时间是随机的,防止集体过期 - 使用多级架构
使用nginx缓存+redis缓存+其他缓存,不同层使用不同的缓存,可靠性更强 - 设置缓存标记
记录缓存数据是否过期,如果过期会触发通知另外的线程在后台去跟新实际的key - 使用锁或者队列的方式
如果查不到就加上排它锁,其他请求只能进行等待
缓存击穿
产生缓存雪崩的原因:redis中的某个热点key过期,但是此时有大量的用户访问该过期key
解决方案:
- 提前对热点数据进行设置
类似于新闻、某博等软件都需要对热点数据进行预先设置在redis中 - 监控数据,适时调整
监控哪些数据是热门数据,实时的调整key的过期时长 - 使用锁机制
只有一个请求可以获取到互斥锁,然后到DB中将数据查询并返回到Redis,之后所有请求就可以从Redis中得到响应
相关文章:

Redis集群模式、持久化、过期策略、淘汰策略、缓存穿透雪崩击穿问题
Redis四种模式 单节点模式 架构:单个Redis实例运行在单台服务器。 优点: 简单:部署和配置容易,适合开发和测试。 低延迟:无网络通信开销。 缺点: 单点故障&…...

【WPF】Opacity 属性的使用
在WPF(Windows Presentation Foundation)中,Opacity 属性是定义一个元素透明度的属性,其值范围是从 0.0(完全透明)到 1.0(完全不透明)。由于 Opacity 是在 UIElement 类中定义的&…...

编程题 02-线性结构3 Reversing Linked List【PAT】
文章目录 题目输入格式输出格式输入样例输出样例 题解解题思路完整代码 编程练习题目集目录 题目 Given a constant K K K and a singly linked list L L L, you are supposed to reverse the links of every K K K elements on L L L. For example, given L being 1 → …...

集成指南:如何采用融云 Flutter IMKit 实现双端丝滑社交体验
在移动应用开发领域,跨平台框架的广泛应用已成为一种趋势。 融云跨平台方案持续升级,近期正式上线 Flutter IMKit,uni-app IMKit 也将紧随其后向广大开发者开放。覆盖两大跨平台核心框架,一套代码即可支持 Android、iOS 双端丝滑…...

使用vite重构vue-cli的vue3项目
一、修改依赖 首先修改 package.json,修改启动方式与相应依赖 移除vue-cli并下载vite相关依赖,注意一些peerDependency如fast-glob需要手动下载 # 移除 vue-cli 相关依赖 npm remove vue/cli-plugin-babel vue/cli-plugin-eslint vue/cli-plugin-rout…...

LeetCode 2094.找出 3 位偶数:遍历3位偶数
【LetMeFly】2094.找出 3 位偶数:遍历3位偶数 力扣题目链接:https://leetcode.cn/problems/finding-3-digit-even-numbers/ 给你一个整数数组 digits ,其中每个元素是一个数字(0 - 9)。数组中可能存在重复元素。 你…...
)
FLASH闪存(擦除、编译)
FLASH闪存 文章目录 FLASH闪存1.存储器映像位置2.FLASH简介3.闪存模块组织3.2闪存的共性: 4.FLASH基本结构4.1FLASH解锁4.2使用指针访问寄存器 5.选项字节5.1选项字节编程5.2选项字节擦除 6.相关函数介绍7.读取内部FLASH(实操)7.1接线图7.2工…...

企业即时通讯软件,私有化安全防泄密
在数字化转型与信创战略双重驱动下,企业对即时通讯工具的需求已从基础沟通转向安全可控、高效协同的综合能力。BeeWorks作为一款专为政企设计的私有化即时通讯与协同办公平台,凭借其全链路安全架构、深度国产化适配及灵活的业务集成能力,成为…...

直方图特征结合 ** 支持向量机图片分类
一、核心技术框架 1. 直方图特征原理 颜色直方图:统计图像中每个颜色区间(如 RGB 通道)的像素数量,反映颜色分布。HOG 直方图(方向梯度直方图):统计图像局部区域的梯度方向分布,捕…...

【prometheus+Grafana篇】基于Prometheus+Grafana实现windows操作系统的监控与可视化
💫《博主主页》: 🔎 CSDN主页 🔎 IF Club社区主页 🔥《擅长领域》:擅长阿里云AnalyticDB for MySQL(分布式数据仓库)、Oracle、MySQL、Linux、prometheus监控;并对SQLserver、NoSQL(MongoDB)有了…...
——卷积神经网络(Convolutional Neural Network, CNN)详解)
PyTorch实战(4)——卷积神经网络(Convolutional Neural Network, CNN)详解
PyTorch实战(4)——卷积神经网络详解 0. 前言1. 全连接网络的缺陷2. 卷积神经网络基本组件2.1 卷积2.2 步幅和填充2.3 池化2.3 卷积神经网络完整流程 3. 卷积和池化相比全连接网络的优势4. 使用 PyTorch 构建卷积神经网络4.1 使用 PyTorch 构建 CNN 架构…...

【Python】Python常用控制结构详解:条件判断、遍历与循环控制
Python提供了多种控制结构来处理逻辑判断和循环操作,包括if-else条件分支、switch替代方案、遍历方法以及循环控制语句break和continue。以下是对这些功能的详细说明及示例: 一、条件判断:if-else与多分支结构 单分支结构 • 语法࿱…...

在Linux中安装JDK并且搭建Java环境
1.首先准备好JDK的Linux的安装包 2.打开Linux,进入root的文件夹,直接拖入即可 3.输入解压命令,后面指定的是位置(注意不要填写错误,就填写这个) 4.之后进入我们安装的jdk的文件 利用pwd命令,展示我们安装的目录,之后…...

理解多智能体深度确定性策略梯度MADDPG算法:基于python从零实现
引言:多智能体强化学习(MARL) 多智能体强化学习(MARL)将强化学习拓展到多个智能体在共享环境中相互交互的场景。这些智能体可能相互合作、竞争,或者目标混杂。MARL 引入了单智能体设置中不存在的独特挑战。…...

【AI大语言模型本质分析框架】
AI大语言模型本质分析框架 ——从教育危机到智能本质的七层递进式解构 第一层:现象观察——阴(显性危机)与阳(隐性变革)的共存 观点1(阴):AI作弊泛滥,传统教育体系崩溃…...

算法模型部署后_python脚本API测试指南-记录3
API 测试指南 服务运行后,可以通过以下方式测试: Curl: curl -X POST -F "file./test_dataset/surface/surface57.png" http://<服务器IP>:9000/api/v1/predictPython 脚本: (参考 svm_request测试.py) import requestsurl http://…...
应用开发入门教程)
鸿蒙(HarmonyOS)应用开发入门教程
目录 第一章:鸿蒙系统简介 1.1 什么是鸿蒙系统? 1.2 鸿蒙系统架构 第二章:开发环境搭建 2.1 安装DevEco Studio 步骤1:下载与安装 步骤2:首次配置 步骤3:设备准备 2.2 创建第一个项目 第三章:鸿蒙应用开发基础 3.1 核心概念:Ability与AbilitySlice 示例代码…...

MIT XV6 - 1.6 Lab: Xv6 and Unix utilities -uptime
接上文 MIT XV6 - 1.5 Lab: Xv6 and Unix utilities - xargs 第一章持续有点久了,虽然肯定有些特点和细节还没注意到,但这次的主要目的是学习内核部分,决定水一篇然后进入第二章节 uptime 第一章的最后一个实验,选做性质…...

Python语言在地球科学交叉领域中的应用——从数据可视化到常见数据分析方法的使用【实例操作】
前言: Python是功能强大、免费、开源,实现面向对象的编程语言,Python能够运行在Linux、Windows、Macintosh、AIX操作系统上及不同平台(x86和arm),Python简洁的语法和对动态输入的支持,再加上解释…...

flutter 的 json序列化和反序列化
一、json转实体 Instantly parse JSON in any language | quicktype 二、实体中的toJson和fromJson 实现 官方推荐的 两个插件(个人觉得一个实体会多一个.g.dart 文件太多了,不喜欢) json_annotation json_serializable 三、使用 dart_json_mapper 实现上面的功…...
?)
什么是数据集市(Data Mart)?
数据集市(Data Mart)是数据仓库(Data Warehouse)的一个子集,专门针对某个特定业务部门、业务线或主题领域,存储和管理该部门或领域所需的特定数据。它通常包含从企业范围的数据仓库中抽取、筛选和汇总的部分…...

从攻击者角度来看Go1.24的路径遍历攻击防御
目录 一、具体攻击示例 程序 攻击步骤: 二、为什么攻击者能成功? 分析 类比理解 总结 三、TOCTOU 竞态条件漏洞 1、背景:符号链接遍历攻击 2. TOCTOU 竞态条件漏洞 3. 另一种变体:目录移动攻击 4. 问题的核心 四、防…...

[ARM][汇编] 01.基础概念
目录 1.全局标号 1.1.使用方法 1.1.1.声明全局标号 1.1.2.定义全局标号 1.1.3.引用全局标号 1.2.全局标号与局部标号的区别 1.3.注意事项 2.局部标号 2.1.使用方法 2.1.1.定义局部标号 2.1.2.跳转引用 2.2.局部标号与全局标号的对比 2.3.注意事项 3.符号定义伪指…...

杭州电商全平台代运营领军者——品融电商
杭州电商全平台代运营领军者——品融电商:以“效品合一”驱动品牌全域增长 在电商行业竞争日益白热化的当下,品牌如何突破流量焦虑、实现长效增长?作为中国领先的品牌化电商服务商,杭州品融电商(PINKROON)…...
源码分析(一、定义与基础操作实现))
02.Golang 切片(slice)源码分析(一、定义与基础操作实现)
Golang 切片(slice)源码分析(一、定义与基础操作实现) 注意当前go版本代码为1.23 一、定义 slice 的底层数据是数组,slice 是对数组的封装,它描述一个数组的片段。两者都可以通过下标来访问单个元素。 数…...

当生产了~/qt-arm/bin/qmake,可以单独编译其他-源码的某个模块,如下,编译/qtmultimedia
cd ~/qt-everywhere-src-5.15.2/qtmultimedia # 设置交叉编译器和 qmake 路径 export CC/usr/bin/aarch64-linux-gnu-gcc export CXX/usr/bin/aarch64-linux-gnu-g export QMAKE~/qt-arm/bin/qmake # 使用已安装的 qmake export QT_INSTALL_PREFIX~/qt-arm # 安装路径 # 配…...

WordPress 网站上的 jpg、png 和 WebP 图片插件
核心功能 1. 转换 AVIF 并压缩 AVIF 将您 WordPress 网站上的 jpg、png 和 WebP 图片转换为 AVIF 格式,并根据您设置的压缩级别压缩 AVIF 图片。如果原始图片已经是 WordPress 6.5 以上支持的 AVIF 格式,则原始 AVIF 图片将仅被压缩。 2. 转换 WebP 并…...

构造+简单树状
昨日的牛客周赛算是比较简单的,其中最后一道构造题目属实眼前一亮。 倒数第二个题目也是一个很好的模拟题目(考验对二叉树的理解和代码的细节) 给定每一层的节点个数,自己拟定一个父亲节点,构造一个满足条件的二叉树。…...

Flask支持哪些日志框架
目录 ✅ Flask 默认支持的日志框架 ✅ 默认推荐:logging(标准库) ✅ 进阶推荐:Loguru(更优雅的日志库) ✅ Flask 日志级别说明(与标准库一致) ✅ 生产环境建议 ✅ 总结推荐 在 Flask 中,默认的日志系统是基于 Python 标准库 logging 模块 构建的。 ✅ Flask 默认…...

健康养生指南:解锁活力生活的科学密码
健康是人生最珍贵的财富,在快节奏的现代生活中,掌握科学的养生方法至关重要。虽然不借助中医理念,我们依然可以从饮食、运动、睡眠等多个方面入手,打造健康生活方式。 合理的饮食是健康的基石。遵循均衡饮食原则,保证每…...

SAR图像压缩感知
SAR图像压缩感知 matlab代码 对应着汕大闫老师的那本压缩感知及其应用,有需要的可以看一下!! SAR图像压缩感知/baboon.bmp , 66616 SAR图像压缩感知/camera.bmp , 66616 SAR图像压缩感知/DWT.m , 1265 SAR图像压缩感知/Gauss.m , 373 SAR图像…...

定时器设计
定时器设计的必要性 服务器中的定时器设计具有多方面的必要性,主要体现在以下几个关键方面: 任务调度与管理 定时任务执行:服务器常常需要执行一些定时性的任务,如定时备份数据、定时清理缓存、定时更新系统日志等。通过定时器可…...

Spring Boot整合Kafka实战指南:从环境搭建到消息处理全解析
一、环境准备 安装 Kafka 下载 Kafka:从 Apache Kafka 官网下载对应版本的 Kafka。 解压并启动 Kafka: # 启动 Zookeeper(Kafka 依赖 Zookeeper) bin/zookeeper-server-start.sh config/zookeeper.properties# 启动 Kafka bin/ka…...
 补充:xv6 的一个用户程序 init 是怎么启动的 ?它如何启动第一个 bash ?)
(done) 补充:xv6 的一个用户程序 init 是怎么启动的 ?它如何启动第一个 bash ?
先看 main.c 从函数名来看,比较相关的就 userinit() 和 scheduler() #include "types.h" #include "param.h" #include "memlayout.h" #include "riscv.h" #include "defs.h"volatile static int started 0;//…...

AI 搜索引擎 MindSearch
背景 RAG是一种利用文档减少大模型的幻觉,AI搜索也是 AI 搜索引擎 MindSearch 是一个开源的 AI 搜索引擎框架,具有与 Perplexity.ai Pro 相同的性能。您可以轻松部署它来构建您自己的搜索引擎,可以使用闭源 LLM(如 GPT、Claude…...
)
HTML简单语法标签(后续实操:云备份项目)
以下是一些 HTML 的简单语法标签及其功能介绍: 基本结构标签 <!DOCTYPE html>:声明文档类型为 HTML5<html>:HTML 文档的根标签<head>:包含文档元数据(如标题、字符编码等)<title>…...

CentOS 和 RHEL
CentOS 和 RHEL(Red Hat Enterprise Linux)关系非常紧密,简而言之: CentOS 最初是 RHEL 的免费、开源克隆版,几乎与 RHEL 二进制兼容。 CentOS 原是 RHEL 的“免费双胞胎”,但已被放弃,现在推荐…...

java----------->代理模式
目录 什么是代理模式? 为什么会有代理模式? 怎么写代理模式? 实现代理模式总共需要三步: 什么是代理模式? 代理模式:给目标对象提供一个代理对象,并且由代理对象控制目标对象的引用 代理就是…...

Wpf学习片段
IRegionManager 和IContainerExtension IRegionManager 是 Prism 框架中用于管理 UI 区域(Regions)的核心接口,它实现了模块化应用中视图(Views)的动态加载、导航和生命周期管理。 IContainerExtension 是依赖注入&…...

智能手表测试用例文档
智能手表测试用例文档 产品名称:智能手表 A1 版本号:FW v1.0.0 测试负责人:[填写] 编写时间:2025-xx-xx 文档状态:初次版本 📁 测试用例结构说明 字段描述用例编号测试用例唯一编号,如 TC-FUN…...

密码学--希尔密码
一、实验目的 1、通过实现简单的古典密码算法,理解密码学的相关概念 2、理解明文、密文、加密密钥、解密密钥、加密算法、解密算法、流密码与分组密码等。 二、实验内容 1、题目内容描述 ①定义分组字符长度 ②随机生成加密密钥,并验证密钥的可行性 …...

配置Hadoop集群-集群配置
以下是 Hadoop 集群的核心配置步骤,基于之前的免密登录和文件同步基础,完成 Hadoop 分布式环境的搭建: 1. 集群规划 假设集群包含 3 个节点: master:NameNode、ResourceManagerslave1:DataNode、NodeMana…...

第三方软件测评中心分享:软件功能测试类型和测试工具
在数字化时代,软件测试已成为确保产品质量的重要环节。功能测试作为软件测试中的核心部分,关注于软件产品是否按预期功能正常运作。 软件功能测试可以按不同的方式进行分类,主要包括以下几种类型: 1.正功能测试:验…...

Profibus DP主站与Modbus RTU/TCP网关与海仕达变频器轻松实现数据交互
Profibus DP主站与Modbus RTU/TCP网关与海仕达变频器轻松实现数据交互 Profibus DP主站转Modbus RTU/TCP(XD-MDPBm20)网关在Profibus总线侧实现主站功能,在Modbus串口侧实现从站功能。可将ProfibusDP协议的设备(如:海…...

多视角系统,视角之间的切换,输入操作。无人机Pawn视角的实现
一.创建自己的PlayerController。它相当于是灵魂,穿梭在不同Pawn之间。也即是切换视角。不同输入的响应也写在这里。这样即使,都有鼠标操作,也能区分。避免了代码的重复耦合。也可以叫做视角系统。 class LZJGAMEMODE_API ALZJPlayerControl…...

[学习]RTKLib详解:ionex.c、options.c与preceph.c
RTKLib详解:ionex.c、options.c与preceph.c 本文是 RTKLlib详解 系列文章的一篇,目前该系列文章还在持续总结写作中,以发表的如下,有兴趣的可以翻阅。 [学习] RTKlib详解:功能、工具与源码结构解析 [学习]RTKLib详解&…...

【Linux笔记】——进程信号的保存
🔥个人主页🔥:孤寂大仙V 🌈收录专栏🌈:Linux 🌹往期回顾🌹:【Linux笔记】——进程信号的产生 🔖流水不争,争的是滔滔不 一、信号的相关概念二、信…...

教育机构教务管理系统哪个好?
在当今教育培训行业快速发展的背景下,一个高效、专业的教务管理系统已成为教育机构提升运营效率、优化教学质量的关键工具。本文将深入分析爱耕云教务管理系统的核心优势,通过具体功能解析和代码示例展示其技术实现方式,并对比市场上其他主流…...
:Clocking Wizard 动态配置)
ZYNQ笔记(二十):Clocking Wizard 动态配置
版本:Vivado2020.2(Vitis) 任务:ZYNQ PS端 通过 AXI4Lite 接口配置 Clocking Wizard IP核输出时钟频率 目录 一、介绍 二、寄存器定义 三、配置 四、PS端代码 一、介绍 Xilinx 的 Clock Wizard IP核 用于在 FPGA 中生成和管理…...

电商平台一站式网络安全架构设计指南
摘要:据 Gartner 统计,采用一体化安全方案的电商企业数据泄露成本降低 67%。本文从攻击链分析到防御体系构建,详解如何实现网络层、应用层、数据层的协同防护。 一、电商安全威胁全景图(2024 攻击态势) 1.1 攻击者完…...