大型视频学习平台项目问题解决笔记
一 数据库大量读操作导致数据库压力过大的解决方案
1. 优化SQL语句
2. 缓存
二 数据库大量写操作导致数据库压力过大的解决方案
1. 优化SQL语句
2. 改同步写为异步写——解决复杂事务的高并发写
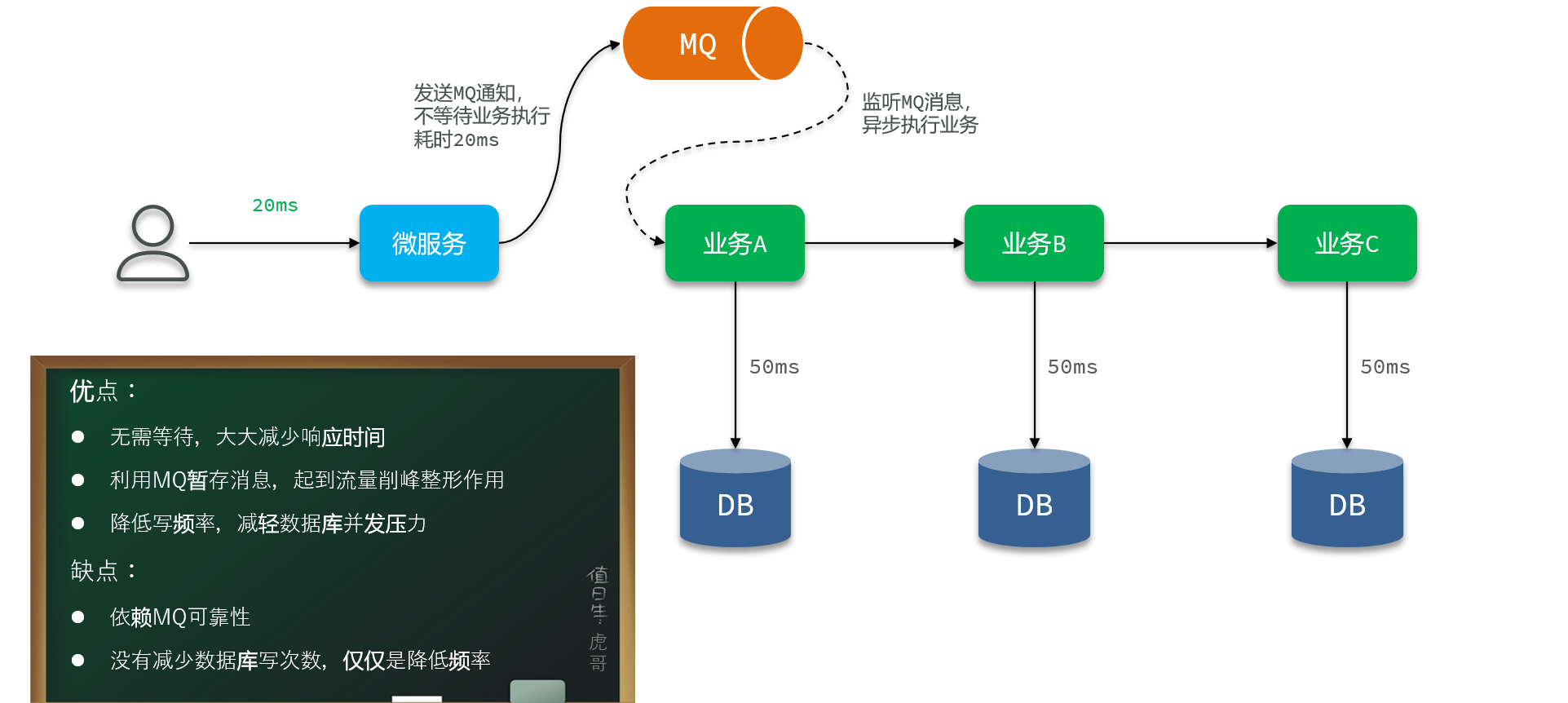
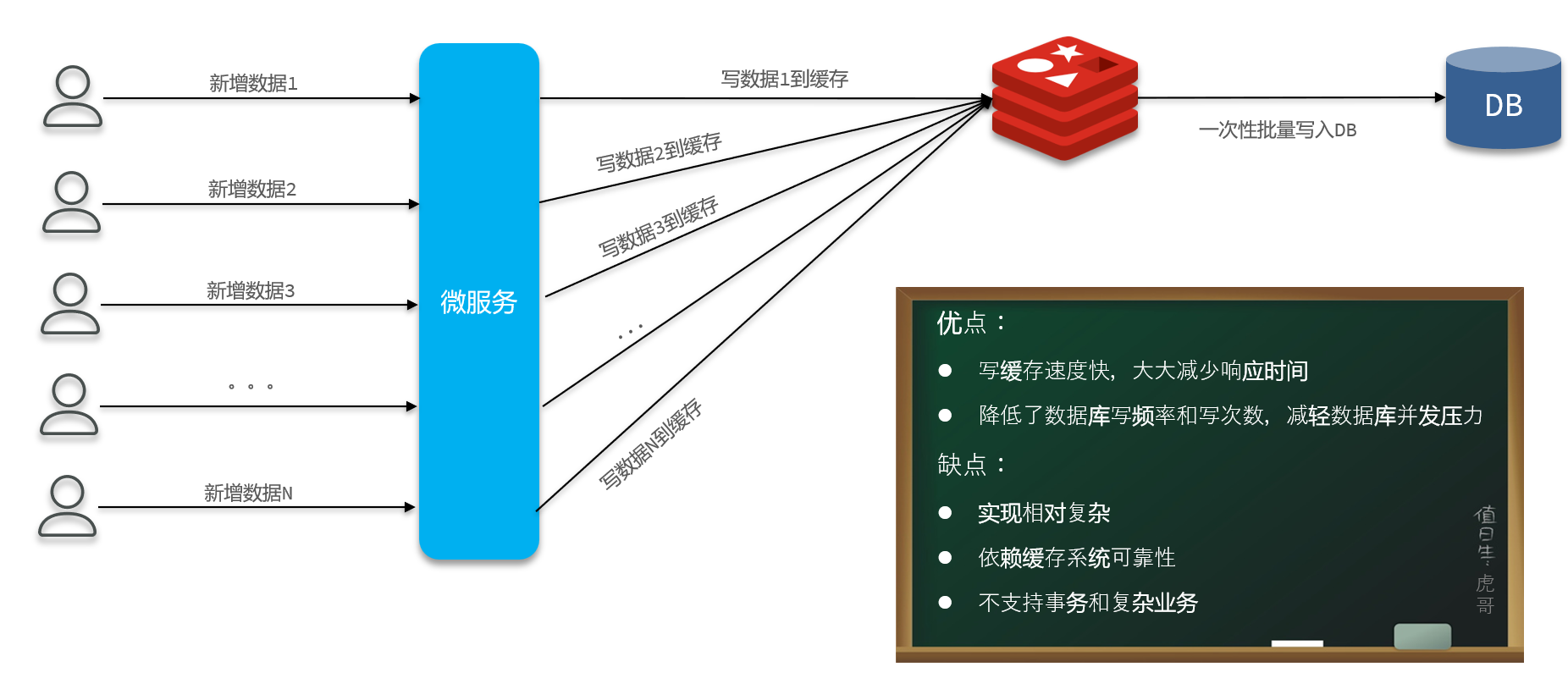
3. 合并写请求——解决简单事务的高并发写(额外实现一个异步操作来吧数据从缓存写到数据库)
1. 具体案例
遇到的问题:前端同学在播放视频的时候,前端每隔几秒钟就往后端发送当前视频的播放进度,以此来实时记录同学的学习进度。如果同学过多,那么这个请求并发量就会很大。
事务分析:这个请求有3个事务:同学第一次播放视频时插入数据,同学第一次学习完视频后将学习状态修改成已完成,以及实时更新视频数据的进度。前两个都是只在第一次才会发生,以此这个请求的第三个业务才是真正需要优化的高并发业务。
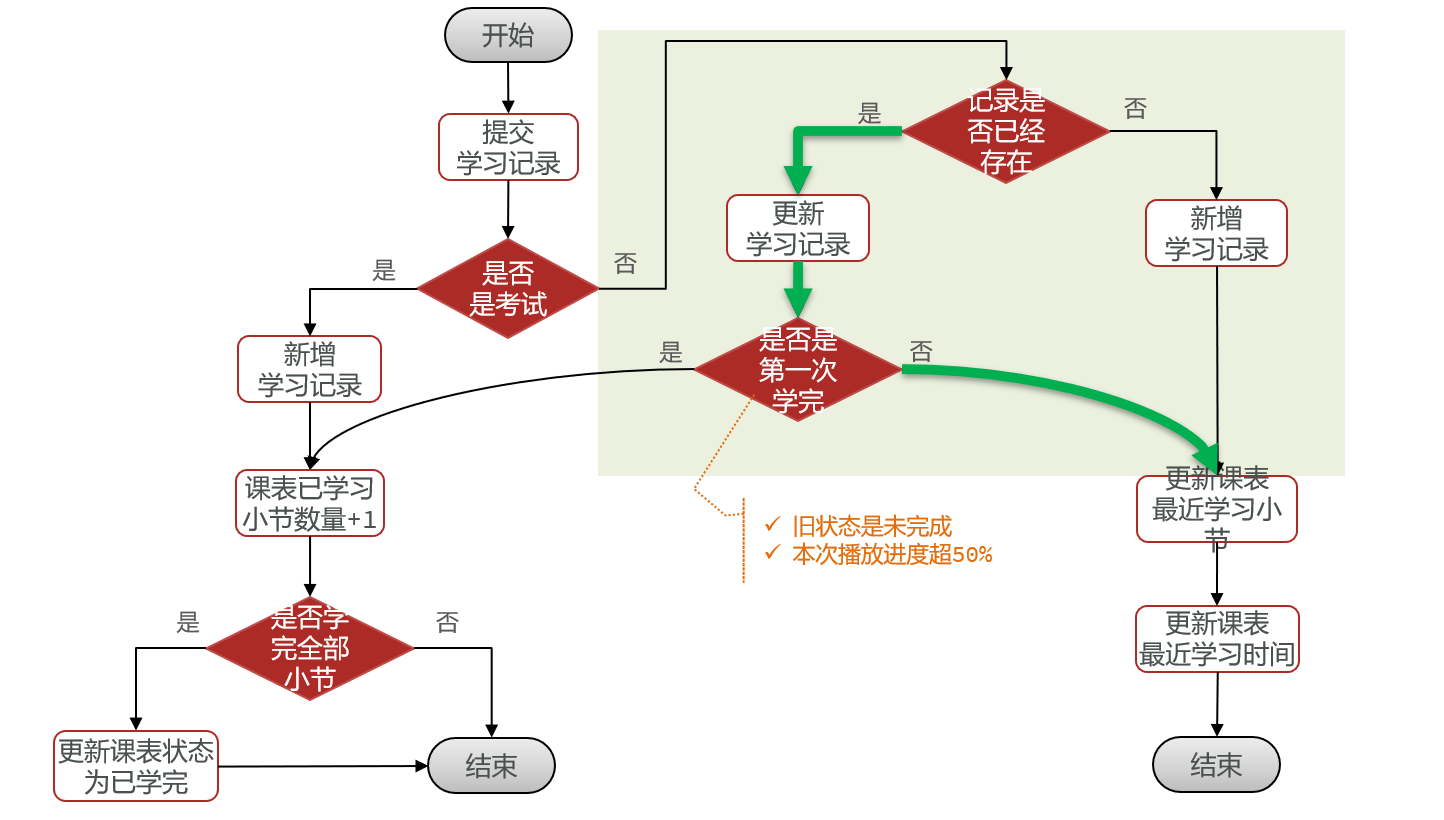
方法选择:由于更新视频学习进度只需要修改几个简单字段,没有其他事务掺和,也没什么判断逻辑,所以选择方案3,利用缓存合并写请求!
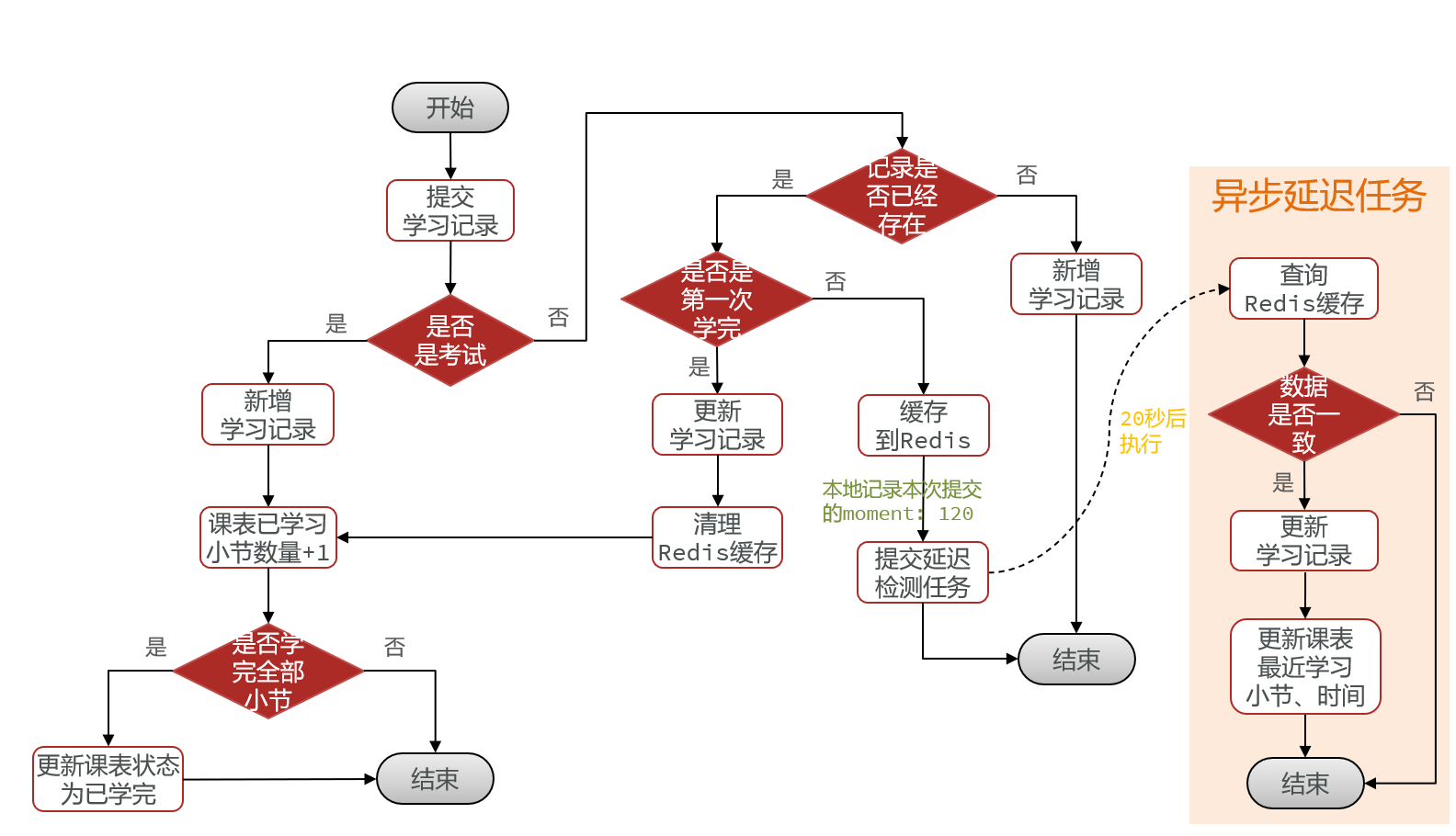
再进一步:由于每次判断完“是否是考试后”,都需要查询数据库判断记录是否存在,我们可以直接把记录存在redis里,到时候写操作也可以直接改redis的这个数据
再进一步:我们在什么时候把redis数据写到数据库里呢?第一个想法是用SpringTask,定时写回数据库,但是这有一个问题——定时的时间,太长或者太短都不行。还有假如一分钟写回数据库一次,那么如果用户观看了20分钟视频后退出,前19次的数据库更新是不是没有必要?只有第20次的记录,即用户离开页面时的记录才是重要的。所以我们可以采用延迟任务——比如前端每隔5秒钟传来一次记录,那么我们在更新完redis后发出一个延迟8秒的延迟请求,如果8秒后发现redis数据没变化,说明用户退出了页面,这时候就可以写回数据库;如果数据有变化,则直接扔掉请求。
延迟任务的工具选择:

(01性能好,但是耗内存;02,03不耗内存,但是过于依赖服务器自身和性能不太好;04性能好,但是实现起来比较复杂)
由于我们业务延迟短,数据量不高,因此使用方案一(后续数据量太大也可以转方案二,两种使用起来几乎一样)
delayQueue用法:DelayQueue中只能放实现了Delayed的对象,所以要先写一个任务对象:
package com.tianji.learning.utils;import lombok.Data;import java.time.Duration;
import java.util.concurrent.Delayed;
import java.util.concurrent.TimeUnit;@Data
public class DelayTask<D> implements Delayed {private D data;private long deadlineNanos;public DelayTask(D data, Duration delayTime) {this.data = data;this.deadlineNanos = System.nanoTime() + delayTime.toNanos();}@Overridepublic long getDelay(TimeUnit unit) {return unit.convert(Math.max(0, deadlineNanos - System.nanoTime()), TimeUnit.NANOSECONDS);}@Overridepublic int compareTo(Delayed o) {long delay = getDelay(TimeUnit.NANOSECONDS) - o.getDelay(TimeUnit.NANOSECONDS);return delay == 0 ? 0 : (delay > 0 ? 1 : -1);}
}具体使用:
package com.tianji.learning.utils;import lombok.extern.slf4j.Slf4j;
import org.junit.jupiter.api.Test;import java.time.Duration;
import java.util.concurrent.DelayQueue;@Slf4j
class DelayTaskTest {@Testvoid testDelayQueue() throws InterruptedException {// 1.初始化延迟队列DelayQueue<DelayTask<String>> queue = new DelayQueue<>();// 2.向队列中添加延迟执行的任务log.info("开始初始化延迟任务。。。。");queue.add(new DelayTask<>("延迟任务3", Duration.ofSeconds(3)));queue.add(new DelayTask<>("延迟任务1", Duration.ofSeconds(1)));queue.add(new DelayTask<>("延迟任务2", Duration.ofSeconds(2)));// 3.尝试执行任务while (true) {DelayTask<String> task = queue.take();log.info("开始执行延迟任务:{}", task.getData());}}
}三 点赞等计数系统
可以单独做成一个模块,对外提供接口让别的模板来调用——存下每一条用户点赞记录,业务的总点赞数放在业务模块的数据表里,然后每次有人点赞的时候就统计一下当前业务的总条数然后提醒一下业务服务器

业务:
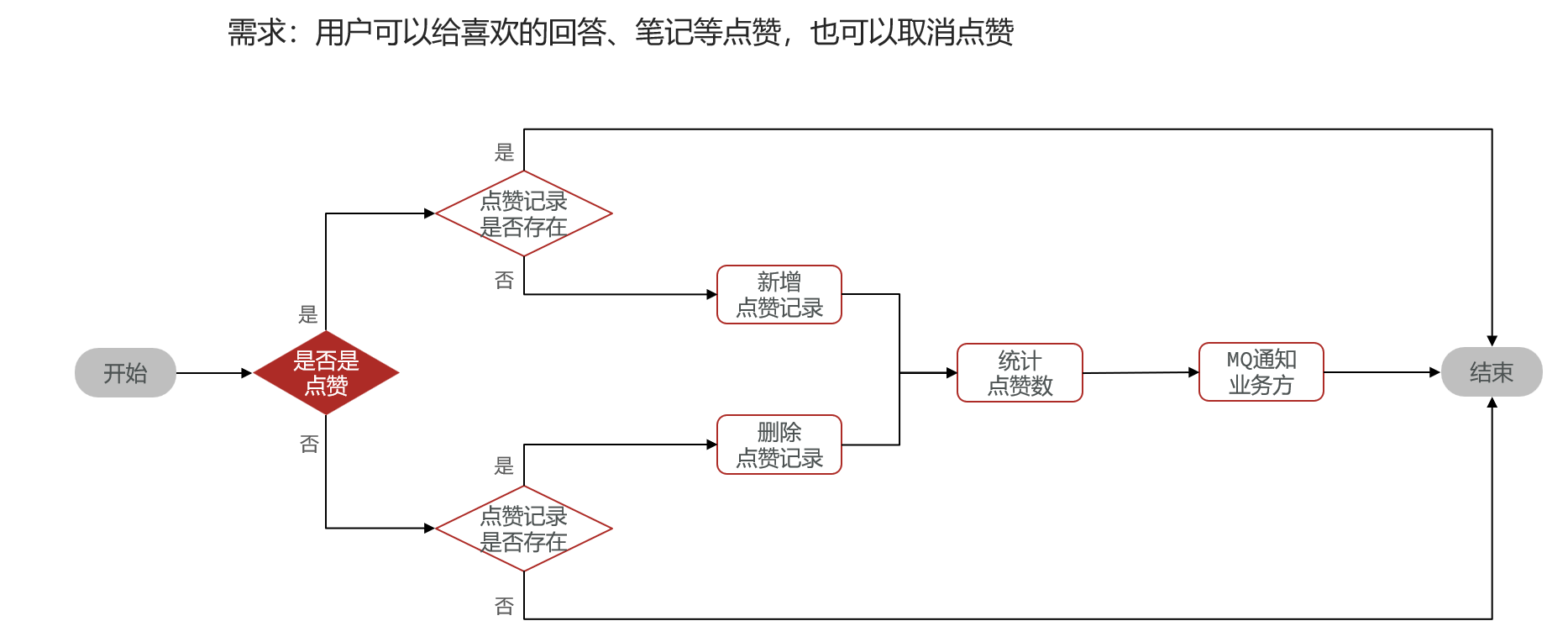
进阶:
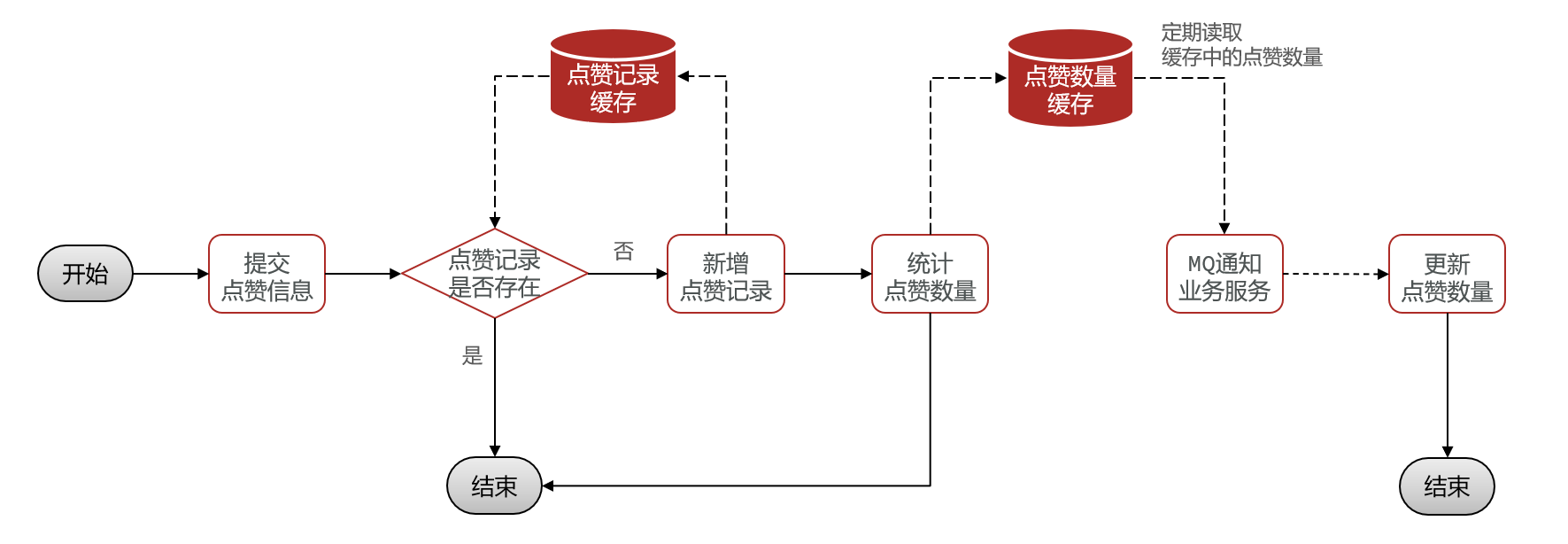
上面的业务进行了多次的数据库读写操作,性能比较差,其实我们可以用缓存来代替,然后使用SpringTask定期把总点赞数返回(注意,每次返回的数据都是一个集合,所以服务器修改要用批处理来提高效率)
有几个好处:
1. 新增点赞记录前不需要查询redis有没有数据了,因为我们使用Set数据结构来存储,插入是否成功会返回一个count条数。
2. 统计点赞数量不需要去使用count查数据库了,redis提供直接查询Set大小的方法,可以直接查到
/*** 点赞或者取消点赞* @param likeRecordFormDTO*/@Overridepublic void addOrDeleteLikes(LikeRecordFormDTO likeRecordFormDTO) {// 1. 判断是点赞还是取消点赞Long userId = UserContext.getUser();Boolean success = likeRecordFormDTO.getLiked() ? addLikes(userId, likeRecordFormDTO) : deleteLikes(userId, likeRecordFormDTO);// 2. 判断操作是否成功,失败则返回if(!success){return;}// 3. 如果成功,则把点赞数存到Redis中Long count = redisTemplate.opsForSet().size(RedisKeyTemplate.LIKED_RECORD_KEY + likeRecordFormDTO.getBizId());if(count == null){return;}redisTemplate.opsForZSet().add(RedisKeyTemplate.LIKED_COUNT_KEY + likeRecordFormDTO.getBizType(),likeRecordFormDTO.getBizId().toString(),count);}// 取消点赞private Boolean deleteLikes(Long userId, LikeRecordFormDTO likeRecordFormDTO) {// 1. 直接删除Long count = redisTemplate.opsForSet().remove(RedisKeyTemplate.LIKED_RECORD_KEY + likeRecordFormDTO.getBizId(),userId.toString());// 2. 存在是否删除成功return count != null && count > 0;}// 点赞private Boolean addLikes(Long userId, LikeRecordFormDTO likeRecordFormDTO) {// 1. 直接插入Long count = redisTemplate.opsForSet().add(RedisKeyTemplate.LIKED_RECORD_KEY + likeRecordFormDTO.getBizId(),userId.toString());// 2. 存在是否插入成功return count != null && count > 0;}拓展:
我们需要根据其他服务器发来的业务id列表,查询当前用户给列表里的哪些业务点赞:
这里使用了Redis的批处理,下面有注解
/*** 查询业务id列表中点赞的业务id* @param bizIdList* @return*/@Overridepublic Set<Long> getBizIsLike(List<Long> bizIdList) {// 1. 获取用户idLong userId = UserContext.getUser();// 2. 通过业务id列表查询已经点赞的业务列表List<Object> objects = redisTemplate.executePipelined(// new一个RedisCallback,重写批量操作方法new RedisCallback<Object>() {@Overridepublic Object doInRedis(RedisConnection connection) throws DataAccessException {// 由于我们使用的是StringRedisTemplate,所以这里的connection是StringRedisConnectionStringRedisConnection stringConnection = (StringRedisConnection) connection;// 这里就是批处理,这些命令会被一块打包过去,然后返回结果for (Long l : bizIdList) {String key = RedisKeyTemplate.LIKED_RECORD_KEY + l;// 查询当前业务下面是否有点赞记录stringConnection.sIsMember(key, userId.toString());}return null;}});Set<Long> result = new HashSet<>();for (int i = 0; i < objects.size(); i++) {Boolean isMember = (Boolean) objects.get(i);if(isMember){result.add(bizIdList.get(i));}}// 3. 返回数据return result;}四 积分系统
问题1:签到
需要记录每个用户每天的签到情况,如果用户一多,这张表的数据量可能达到一个难以想象的大小
解决方法:
我们按月来统计用户签到信息,签到记录为1,未签到则记录为0
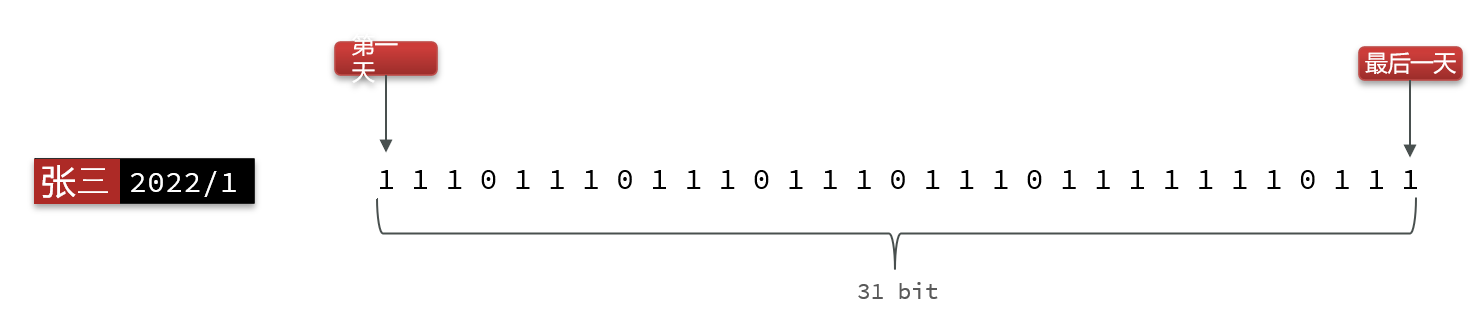
把每一个bit位对应当月的每一天,形成了映射关系。用0和1标示业务状态,这种思路就称为位图(BitMap)。
Redis中提供了BitMap数据结构,并且提供了很多操作bit的命令。(底层是使用String来实现的)
有些活动需要获取连续签到天数,可以参考getSignDays方法
/*** 添加签到记录* @return*/@Overridepublic SignResultVO addSignRecord() {// 1. 拼接密钥LocalDate now = LocalDate.now();String key = RedisConstant.SIGN_RECORD_KEY + UserContext.getUser()+ now.format(DateTimeFormatter.ofPattern(DateUtils.DEFAULT_MONTH_FORMAT_COMPACT));// 2. 插入签到记录Boolean exit = redisTemplate.opsForValue().setBit(key, now.getDayOfMonth() - 1, true);if(BooleanUtils.isTrue(exit)){throw new DbException("重复签到");}// 3. 获得连续签到天数Integer signDays = getSignDays(key, now.getDayOfMonth());// TODO 4. 获得签到积分Integer rewardPoints = 1;// 5. 返回SignResultVO result = new SignResultVO();result.setSignDays(signDays);result.setSignPoints(rewardPoints);return result;}private Integer getSignDays(String key, int dayOfMonth) {// 1. 获取当前用户签到数据List<Long> result = redisTemplate.opsForValue().bitField(key, BitFieldSubCommands.create().get(BitFieldSubCommands.BitFieldType.unsigned(dayOfMonth)).valueAt(0));if(CollUtils.isEmpty(result)){return 0;}long value = result.get(0);// 2. 获取连续签到天数int count = 0;while((value & 1) == 1){// 2.1 计数+1count ++;// 2.2 移除最右边的1位value >>>= 1;}return count;}问题2:实时排名系统
使用传统Mysql数据库,记录每个用户这个月的总分。每次查询排行榜都需要查询排序数据库,效率太低了。而Redis的SortedSet底层采用了跳表的数据结构,因此可以非常高效的实现排序功能,百万用户排序轻松搞定。而且每当用户积分发生变更时,我们可以实时更新Redis中的用户积分,而SortedSet也会实时更新排名。实现起来简单、高效,实时性也非常好。缺点就是需要一直占用Redis的内存,当用户量达到数千万万时,性能有一定的下降。
所以我们需要定期把redis数据放回Mysql中,这时候的排行榜就变成了历史排行榜,数据库字段多一个历史排名名词即可,之后查询就不需要排序了
/*** 获取积分榜单信息* @return*/@Overridepublic PointsBoardVO getPointsBoard(PointsBoardQuery query) {PointsBoardVO result = new PointsBoardVO();// 0. 校验查询的榜单是现在的还是历史的boolean isNow = query.getSeason() == null || query.getSeason() == 0;// 1. 获取自己的排名和积分Long userId = UserContext.getUser();LocalDate now = LocalDate.now();String key = RedisConstant.POINTS_BOARD_KEY + now.format(DateUtils.POINT_BOARD_SUFFIX_FORMATTER);PointsBoard sel = isNow ?getMyRankAndPoints(key, userId) : // 查询现在getMyRankAndPointsInHistory(query, userId); // TODO 查询历史if(sel != null){result.setPoints(sel.getPoints());result.setRank(sel.getRank());}// 2. 获取榜单信息List<PointsBoard> pointsBoardList = isNow ?getPointsBoardList(key, query) : // 查询现在榜单getPointsBoardListInHistory(query); // TODO 查询历史榜单if(CollUtils.isEmpty(pointsBoardList)){return result;}// 2.1 获取用户信息Set<Long> userIds = pointsBoardList.stream().map(PointsBoard::getUserId).collect(Collectors.toSet());List<UserDTO> userDTOS = userClient.queryUserByIds(userIds);if(CollUtils.isEmpty(userDTOS)){return result;}Map<Long, String> userMap = userDTOS.stream().collect(Collectors.toMap(UserDTO::getId, UserDTO::getName));// 3.封装返回List<PointsBoardItemVO> boards = new ArrayList<>(pointsBoardList.size());for (PointsBoard pointsBoard : pointsBoardList) {PointsBoardItemVO item = new PointsBoardItemVO();item.setName(userMap.get(pointsBoard.getUserId()));item.setPoints(pointsBoard.getPoints());item.setRank(pointsBoard.getRank());boards.add(item);}result.setBoardList(boards);return result;}private List<PointsBoard> getPointsBoardListInHistory(PointsBoardQuery query) {return null;}private List<PointsBoard> getPointsBoardList(String key, PointsBoardQuery query) {// 1. 查出榜单上分页要求的信息int startPageNo = (query.getPageNo() - 1) * query.getPageSize();Set<ZSetOperations.TypedTuple<String>> typedTuples = redisTemplate.opsForZSet().reverseRangeWithScores(key, startPageNo, startPageNo + query.getPageSize() + 1);if(CollUtils.isEmpty(typedTuples)){return CollUtils.emptyList();}// 2. 转换数据List<PointsBoard> pointsBoardList = new ArrayList<>(typedTuples.size());int rank = startPageNo + 1;for (ZSetOperations.TypedTuple<String> typedTuple : typedTuples) {String userId = typedTuple.getValue();Double points = typedTuple.getScore();if(userId == null || points == null){continue;}PointsBoard pBoard = new PointsBoard();pBoard.setUserId(Long.parseLong(userId));pBoard.setPoints(points.intValue());pBoard.setRank(rank ++);pointsBoardList.add(pBoard);}return pointsBoardList;}private PointsBoard getMyRankAndPointsInHistory(PointsBoardQuery query, Long userId) {return null;}private PointsBoard getMyRankAndPoints(String key, Long userId) {BoundZSetOperations<String, String> ops = redisTemplate.boundZSetOps(key);// 1. 查询我的积分Double score = ops.score(userId.toString());// 2. 查询我的排名Long rank = ops.reverseRank(userId.toString());PointsBoard pointsBoard = new PointsBoard();pointsBoard.setPoints(score == null ? 0 : score.intValue());pointsBoard.setRank(rank == null ? 0 : rank.intValue() + 1);return pointsBoard;}五 海量数据该怎么存储存储?
随着数据库存储的数据量越来越大,数据库的检索效率和压力也会越来越大,特别是对于需要高频读写的业务数据,这个问题亟待解决
常见的有4种方案:
1. 表分区
单表数据过多,就会导致文件体积非常大。文件就会跨越多个磁盘分区,数据检索时的速度就会非常慢。为了解决这个问题,MySQL在5.1版本引入表分区功能。简单来说,就是按照某种规则,把表数据对应的ibd文件拆分成多个文件来存储。从物理上来看,一张表的数据被拆到多个表文件存储了;从逻辑上来看,他们对外表现是一张表。
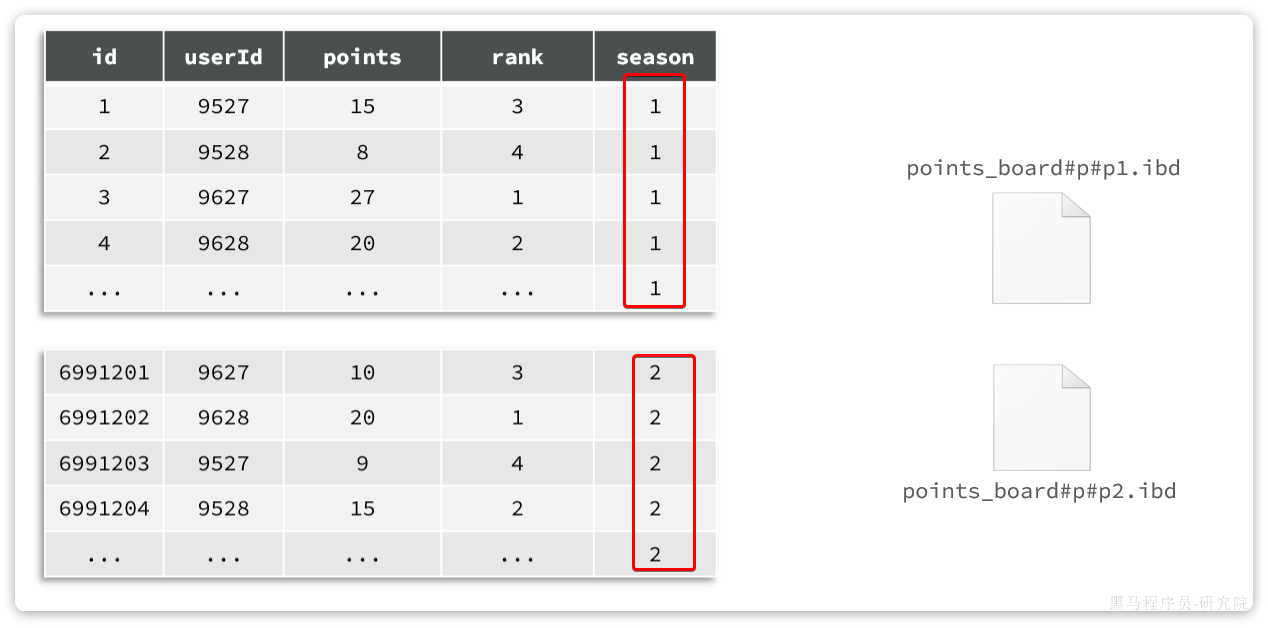

数据库支持的分区只有按照索引范围,枚举类型,某个字段的哈希等,不够灵活
2. 分表
分表是一种表设计方案,由开发者在创建表时按照自己的业务需求拆分表。也就是说这是开发者自己对表的处理,与数据库无关。而且,一旦做了分表,无论是逻辑上,还是物理上,就从一张表变成了多张表!增删改查的方式就发生了变化,必须自己考虑要去哪张表做数据处理。
水平分表:——如下分成board1和board2两张表
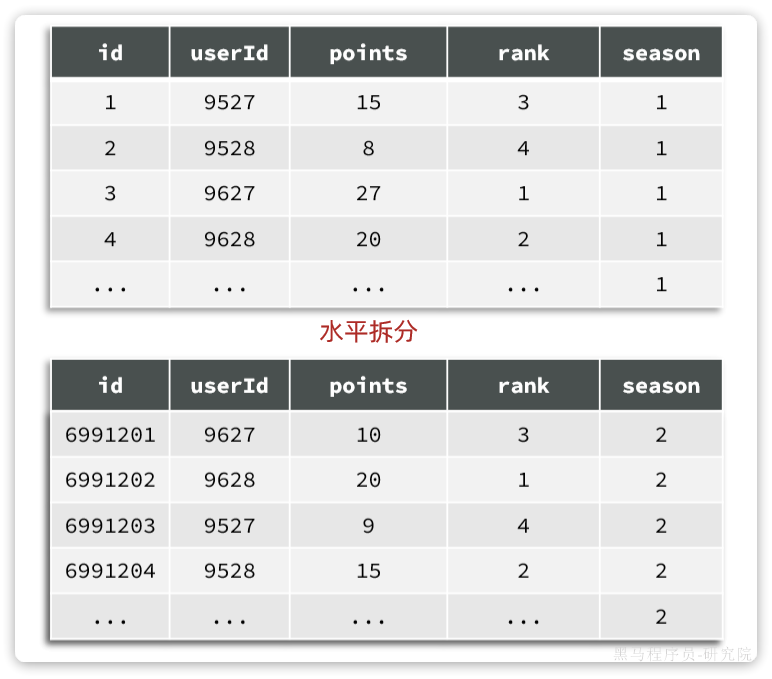
垂直分表:——如下把同一个id的4个字段拆成两张表,每张表2个字段


3. 分库和集群
无论是分区,还是分表,我们刚才的分析都是建立在单个数据库的基础上。但是单个数据库也存在一些问题:
-
单点故障问题:数据库发生故障,整个系统就会瘫痪
-
单库的性能瓶颈问题:单库受服务器限制,其网络带宽、CPU、连接数都有瓶颈
-
单库的存储瓶颈问题:单库的磁盘空间有上限,如果磁盘过大,数据检索的速度又会变慢
综上,在大型系统中,我们除了要做分表、还需要对数据做分库,建立综合集群。
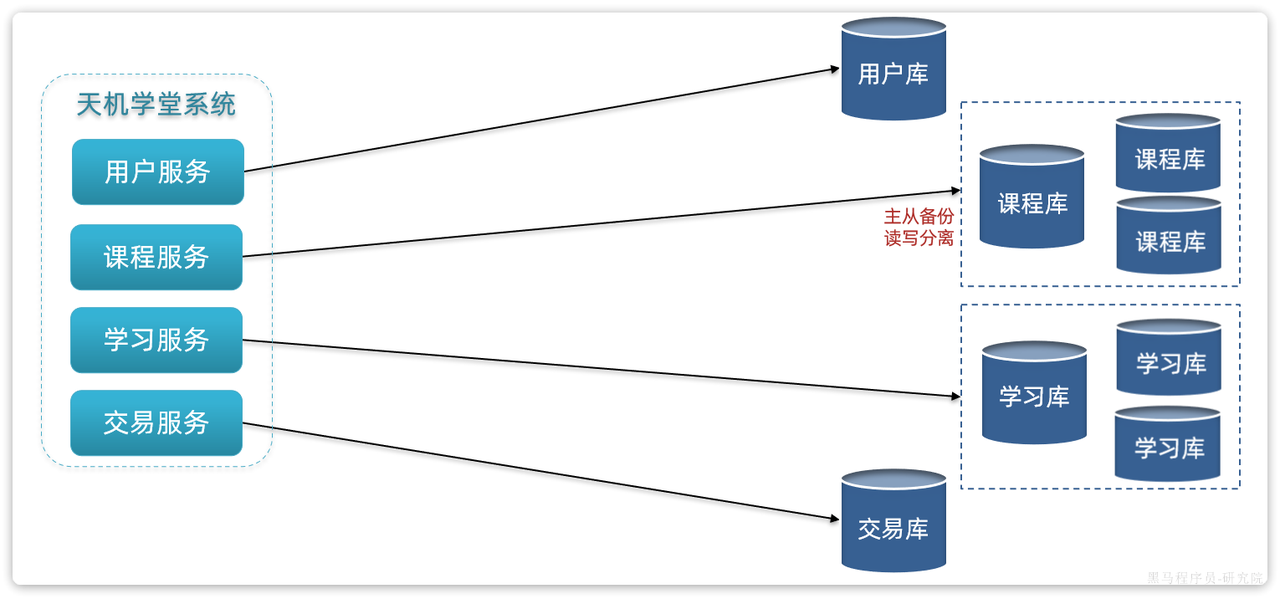
首先,在微服务项目中,我们会按照项目模块,每个微服务使用独立的数据库,因此每个库的表是不同的,这种分库模式成为垂直分库。
而为了保证单节点的高可用性,我们会给数据库建立主从集群,主节点向从节点同步数据。两者结构一样,可以看做是水平扩展。
可以是下面数据库这种,一个主库负责写,其他负责读(主库还会把变动写给从库),每个库数据最终一致;也可以是学习库这种,每个库各自存一些信息,要查的时候去不同库查

4. 结论
(1)解决单表数据量大的问题有哪些方案?
首先是库内表分区或者分表,可以解决大多数问题。如果单个库压力太大,再考虑分库。水平分库结合分表,实现数据分片。进一步提高数据存储规模。
(2)数据库的读写压力较大,并发较高该怎么办?
首先考虑垂直分表,看看能不能将写频繁的数据与其它数据分离,避免互相影响。如果不行则考虑搭建主从集群,实现读写分离。
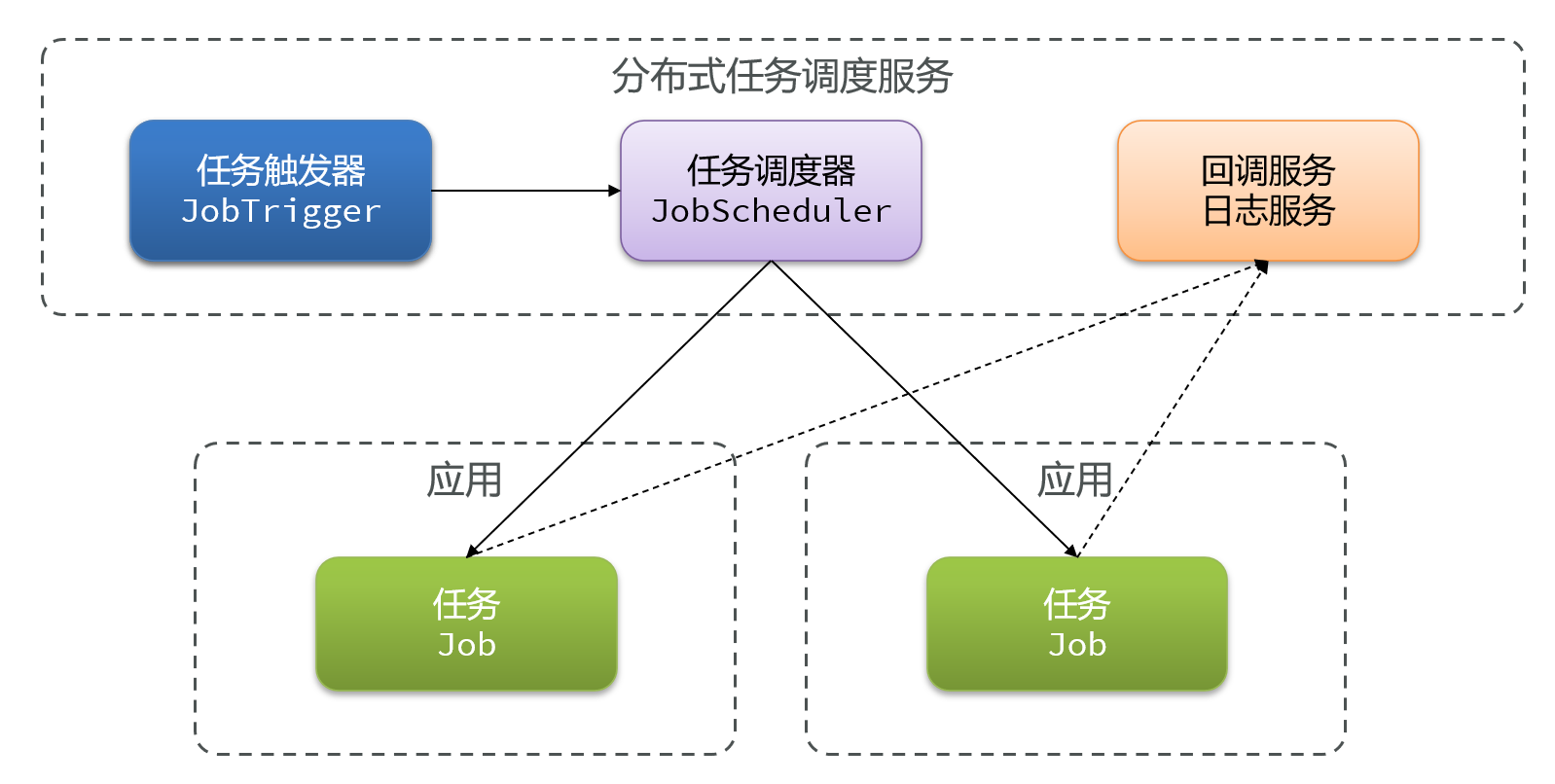
六 如何让定时任务可以调度?
我们希望能够有这么一个工具,可以让定时任务可以被调度,比如B任务只有在达到时间并且A任务做完后才能执行,还需要能够监控定时任务,SpringTask都不能实现
常规的SpringTask都有两个角色:任务触发器和任务,如果使用多实例部署,那么多个实例就会有多个任务触发器和任务各自工作
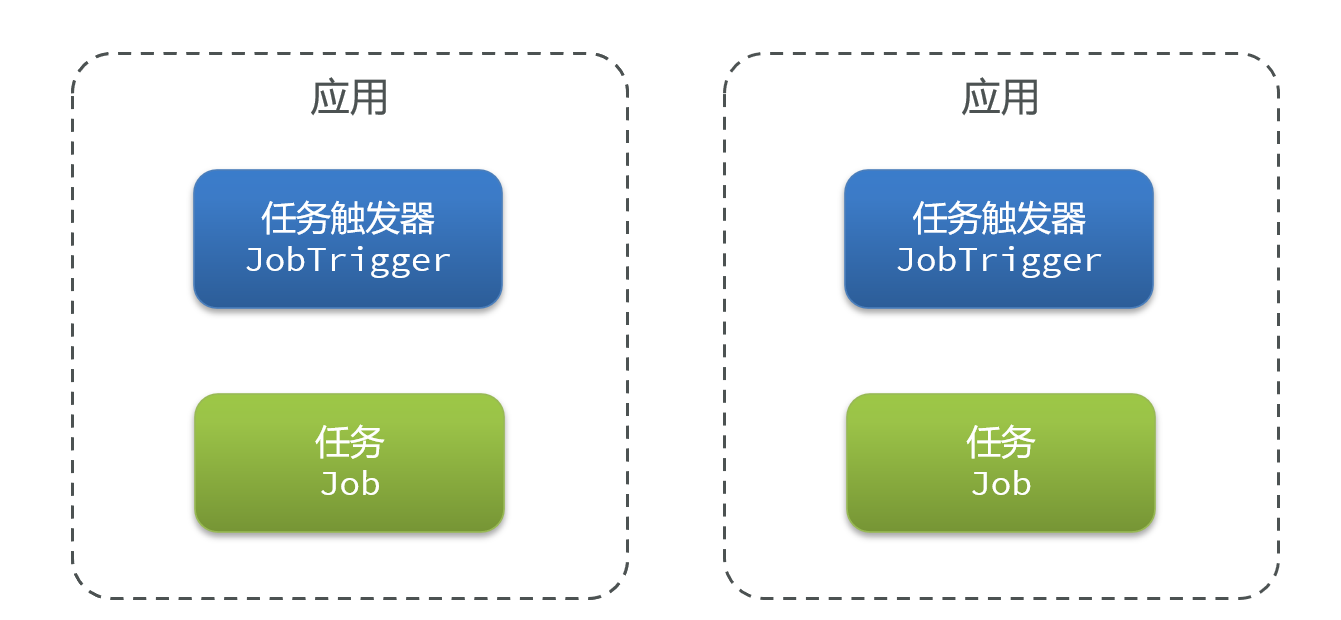
而我们希望这些任务只有一个执行就行,那么就必须采用分布式任务调度
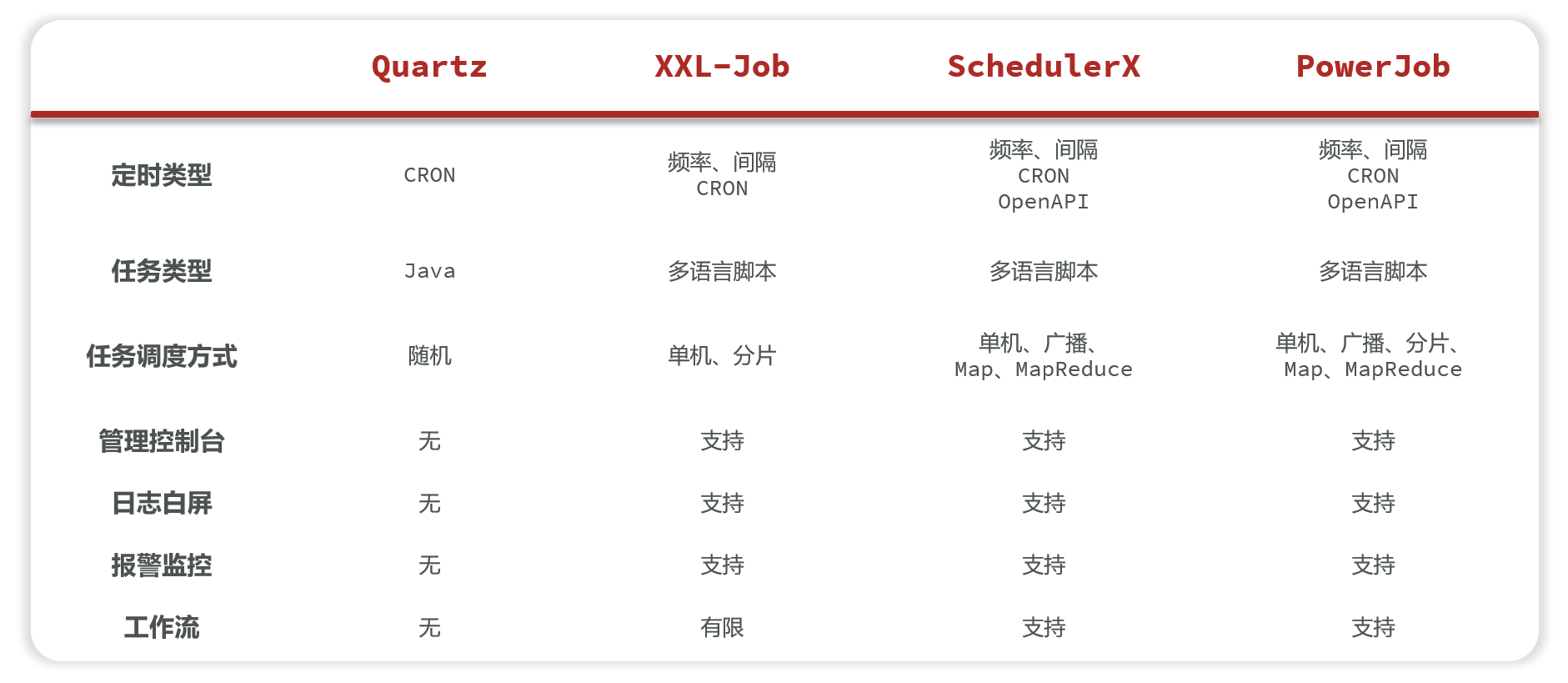
主流工具:
七 生成兑换码
1. 兑换码生成算法
要求:
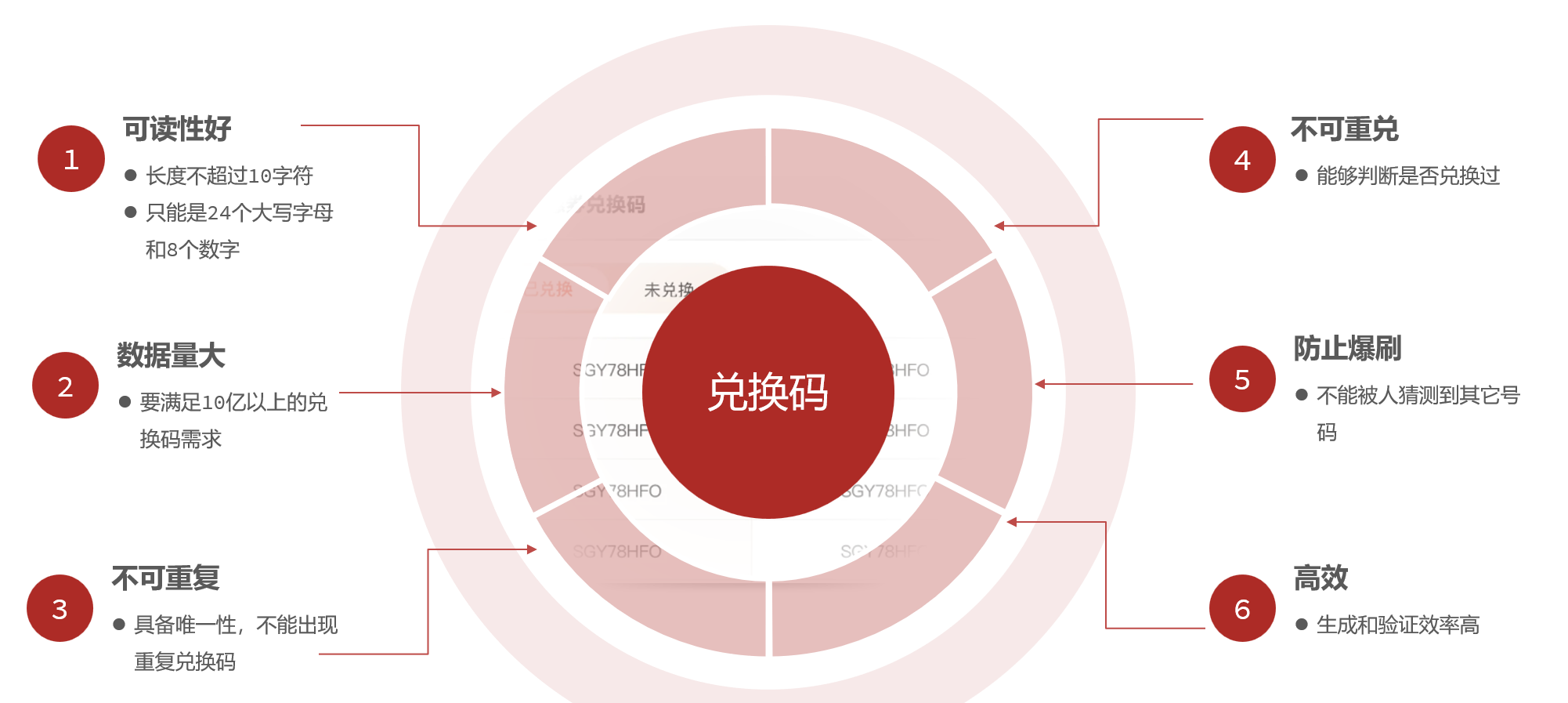
传统生成算法有3种:UUID,自增id,雪花算法,通过筛选,这里我选择自增id
但是如何能高效的生成和校验?这里就要使用BitMap位图,一个位代表一个兑换码(1表示已兑换,0表示未兑换),然后Redis底层的BitMap也是采用数组,我们可以直接根据id来查指定位的兑换码是否已经兑换,这样就可以提高效率。
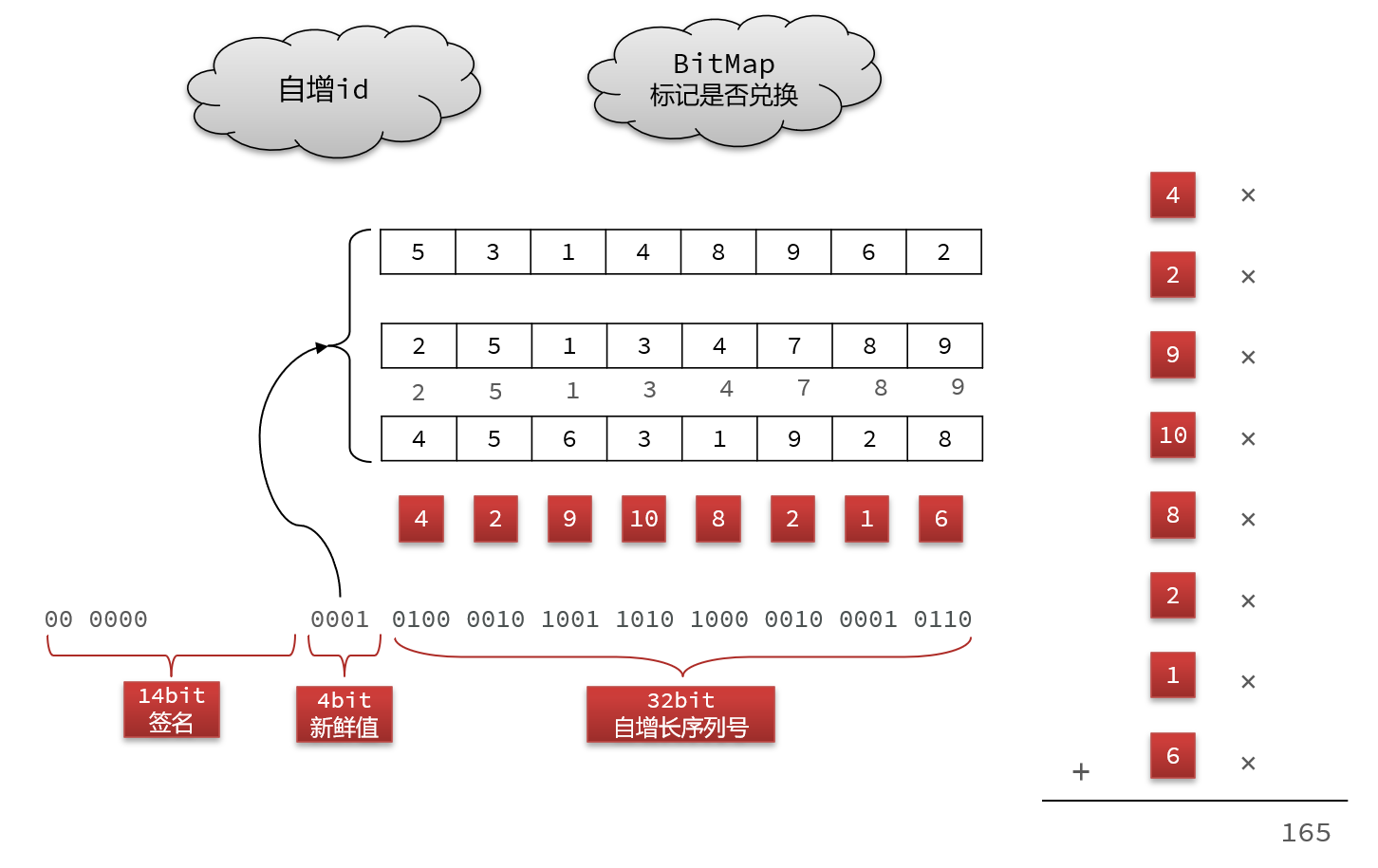
但是自增id还需要加密:

新鲜值:用来选择一组密钥
签名:逐位与密钥逐位相乘,最后相加得到签名,不足14bit前面补0就行
代码:
Base32加密算法
package com.tianji.promotion.utils;import cn.hutool.core.text.StrBuilder;/*** 将整数转为base32字符的工具,因为是32进制,所以每5个bit位转一次*/
public class Base32 {private final static String baseChars = "6CSB7H8DAKXZF3N95RTMVUQG2YE4JWPL";public static String encode(long raw) {StrBuilder sb = new StrBuilder();while (raw != 0) {int i = (int) (raw & 0b11111);sb.append(baseChars.charAt(i));raw = raw >>> 5;}return sb.toString();}public static long decode(String code) {long r = 0;char[] chars = code.toCharArray();for (int i = chars.length - 1; i >= 0; i--) {long n = baseChars.indexOf(chars[i]);r = r | (n << (5*i));}return r;}public static String encode(byte[] raw) {StrBuilder sb = new StrBuilder();int size = 0;int temp = 0;for (byte b : raw) {if (size == 0) {// 取5个bitint index = (b >>> 3) & 0b11111;sb.append(baseChars.charAt(index));// 还剩下3位size = 3;temp = b & 0b111;} else {int index = temp << (5 - size) | (b >>> (3 + size) & ((1 << 5 - size) - 1)) ;sb.append(baseChars.charAt(index));int left = 3 + size;size = 0;if(left >= 5){index = b >>> (left - 5) & ((1 << 5) - 1);sb.append(baseChars.charAt(index));left = left - 5;}if(left == 0){continue;}temp = b & ((1 << left) - 1);size = left;}}if(size > 0){sb.append(baseChars.charAt(temp));}return sb.toString();}public static byte[] decode2Byte(String code) {char[] chars = code.toCharArray();byte[] bytes = new byte[(code.length() * 5 )/ 8];byte tmp = 0;byte byteSize = 0;int index = 0;int i = 0;for (char c : chars) {byte n = (byte) baseChars.indexOf(c);i++;if (byteSize == 0) {tmp = n;byteSize = 5;} else {int left = Math.min(8 - byteSize, 5);if(i == chars.length){bytes[index] =(byte) (tmp << left | (n & ((1 << left) - 1)));break;}tmp = (byte) (tmp << left | (n >>> (5 - left)));byteSize += left;if (byteSize >= 8) {bytes[index++] = tmp;byteSize = (byte) (5 - left);if (byteSize == 0) {tmp = 0;} else {tmp = (byte) (n & ((1 << byteSize) - 1));}}}}return bytes;}
}
兑换码生成和解析
package com.tianji.promotion.utils;import com.tianji.common.constants.RegexConstants;
import com.tianji.common.exceptions.BadRequestException;/*** <h1 style='font-weight:500'>1.兑换码算法说明:</h1>* <p>兑换码分为明文和密文,明文是50位二进制数,密文是长度为10的Base32编码的字符串 </p>* <h1 style='font-weight:500'>2.兑换码的明文结构:</h1>* <p style='padding: 0 15px'>14(校验码) + 4 (新鲜值) + 32(序列号) </p>* <ul style='padding: 0 15px'>* <li>序列号:一个单调递增的数字,可以通过Redis来生成</li>* <li>新鲜值:可以是优惠券id的最后4位,同一张优惠券的兑换码就会有一个相同标记</li>* <li>载荷:将新鲜值(4位)拼接序列号(32位)得到载荷</li>* <li>校验码:将载荷4位一组,每组乘以加权数,最后累加求和,然后对2^14求余得到</li>* </ul>* <h1 style='font-weight:500'>3.兑换码的加密过程:</h1>* <ol type='a' style='padding: 0 15px'>* <li>首先利用优惠券id计算新鲜值 f</li>* <li>将f和序列号s拼接,得到载荷payload</li>* <li>然后以f为角标,从提前准备好的16组加权码表中选一组</li>* <li>对payload做加权计算,得到校验码 c </li>* <li>利用c的后4位做角标,从提前准备好的异或密钥表中选择一个密钥:key</li>* <li>将payload与key做异或,作为新payload2</li>* <li>然后拼接兑换码明文:f (4位) + payload2(36位)</li>* <li>利用Base32对密文转码,生成兑换码</li>* </ol>* <h1 style='font-weight:500'>4.兑换码的解密过程:</h1>* <ol type='a' style='padding: 0 15px'>* <li>首先利用Base32解码兑换码,得到明文数值num</li>* <li>取num的高14位得到c1,取num低36位得payload </li>* <li>利用c1的后4位做角标,从提前准备好的异或密钥表中选择一个密钥:key</li>* <li>将payload与key做异或,作为新payload2</li>* <li>利用加密时的算法,用payload2和s1计算出新校验码c2,把c1和c2比较,一致则通过 </li>* </ol>*/
public class CodeUtil {/*** 异或密钥表,用于最后的数据混淆*/private final static long[] XOR_TABLE = {61261925471L, 61261925523L, 58169127203L, 64169927267L,64169927199L, 61261925629L, 58169127227L, 64169927363L,59169127063L, 64169927359L, 58169127291L, 61261925739L,59169127133L, 55139281911L, 56169127077L, 59169127167L};/*** fresh值的偏移位数*/private final static int FRESH_BIT_OFFSET = 32;/*** 校验码的偏移位数*/private final static int CHECK_CODE_BIT_OFFSET = 36;/*** fresh值的掩码,4位*/private final static int FRESH_MASK = 0xF;/*** 验证码的掩码,14位*/private final static int CHECK_CODE_MASK = 0b11111111111111;/*** 载荷的掩码,36位*/private final static long PAYLOAD_MASK = 0xFFFFFFFFFL;/*** 序列号掩码,32位*/private final static long SERIAL_NUM_MASK = 0xFFFFFFFFL;/*** 序列号加权运算的秘钥表*/private final static int[][] PRIME_TABLE = {{23, 59, 241, 61, 607, 67, 977, 1217, 1289, 1601},{79, 83, 107, 439, 313, 619, 911, 1049, 1237},{173, 211, 499, 673, 823, 941, 1039, 1213, 1429, 1259},{31, 293, 311, 349, 431, 577, 757, 883, 1009, 1657},{353, 23, 367, 499, 599, 661, 719, 929, 1301, 1511},{103, 179, 353, 467, 577, 691, 811, 947, 1153, 1453},{213, 439, 257, 313, 571, 619, 743, 829, 983, 1103},{31, 151, 241, 349, 607, 677, 769, 823, 967, 1049},{61, 83, 109, 137, 151, 521, 701, 827, 1123},{23, 61, 199, 223, 479, 647, 739, 811, 947, 1019},{31, 109, 311, 467, 613, 743, 821, 881, 1031, 1171},{41, 173, 367, 401, 569, 683, 761, 883, 1009, 1181},{127, 283, 467, 577, 661, 773, 881, 967, 1097, 1289},{59, 137, 257, 347, 439, 547, 641, 839, 977, 1009},{61, 199, 313, 421, 613, 739, 827, 941, 1087, 1307},{19, 127, 241, 353, 499, 607, 811, 919, 1031, 1301}};/*** 生成兑换码:批量生成兑换码的时候,推荐使用自增序列作为serialNum,fresh是新鲜值(用来选择PRIME_TABLE取那一组作为密钥,随便传一个数字就行,它会自动取最后四位)** @param serialNum 递增序列号* @return 兑换码*/public static String generateCode(long serialNum, long fresh) {// 1.计算新鲜值fresh = fresh & FRESH_MASK;// 2.拼接payload,fresh(4位) + serialNum(32位)long payload = fresh << FRESH_BIT_OFFSET | serialNum;// 3.计算验证码long checkCode = calcCheckCode(payload, (int) fresh);System.out.println("checkCode = " + checkCode);// 4.payload做大质数异或运算,混淆数据payload ^= XOR_TABLE[(int) (checkCode & FRESH_MASK)];// 5.拼接兑换码明文: 校验码(14位) + payload(36位)long code = checkCode << CHECK_CODE_BIT_OFFSET | payload;// 6.转码return Base32.encode(code);}private static long calcCheckCode(long payload, int fresh) {// 1.获取码表int[] table = PRIME_TABLE[fresh];// 2.生成校验码,payload每4位乘加权数,求和,取最后13位结果long sum = 0;int index = 0;while (payload > 0) {sum += (payload & 0xf) * table[index++];payload >>>= 4;}return sum & CHECK_CODE_MASK;}public static long parseCode(String code) {if (code == null || !code.matches(RegexConstants.COUPON_CODE_PATTERN)) {// 兑换码格式错误throw new BadRequestException("无效兑换码");}// 1.Base32解码long num = Base32.decode(code);// 2.获取低36位,payloadlong payload = num & PAYLOAD_MASK;// 3.获取高14位,校验码int checkCode = (int) (num >>> CHECK_CODE_BIT_OFFSET);// 4.载荷异或大质数,解析出原来的payloadpayload ^= XOR_TABLE[(checkCode & FRESH_MASK)];// 5.获取高4位,freshint fresh = (int) (payload >>> FRESH_BIT_OFFSET & FRESH_MASK);// 6.验证格式:if (calcCheckCode(payload, fresh) != checkCode) {throw new BadRequestException("无效兑换码");}return payload & SERIAL_NUM_MASK;}
}
八 多线程安全问题——超卖
业务逻辑:先查询数据库数据,然后进行业务校验(判断库存是否充足),最后新增数据到数据库
问题:高并发情况下出现,发现新增过多数据到数据库里(实际新增数量大于库存,很明显有问题)
问题分析:——高并发情况下,可能出现多个线程同时查出数据,同时校验通过,再插入
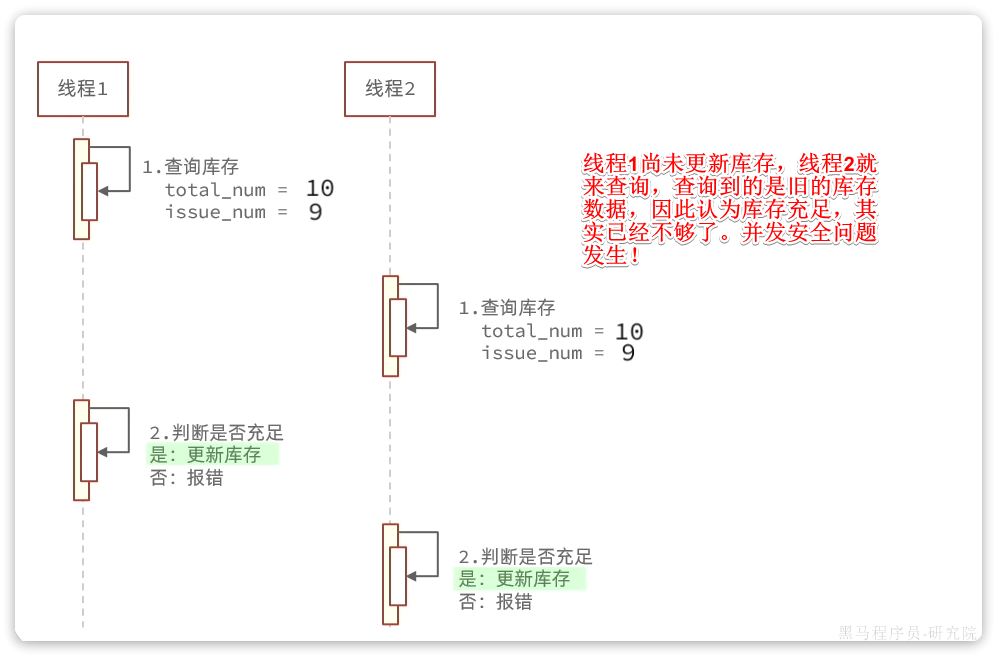
解决方法:
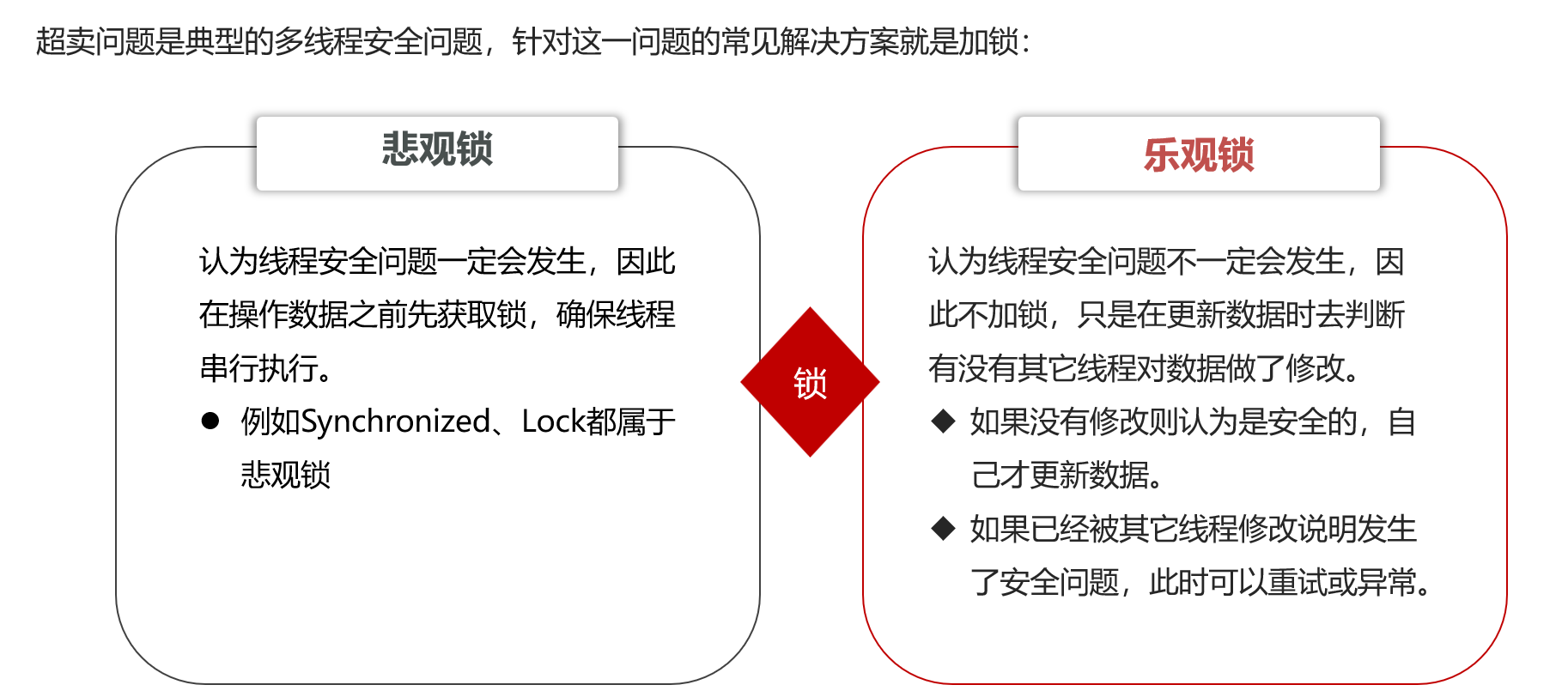
悲观锁:最终解决方法,性能低,但是能保证不出问题
乐观锁:性能高,但是成功率低(并行的N个线程只会有1个成功)
最先考虑如何加上乐观锁(一般是在数据库更新时加条件,根据返回结果(修改的条数)来判断执行是否成功)
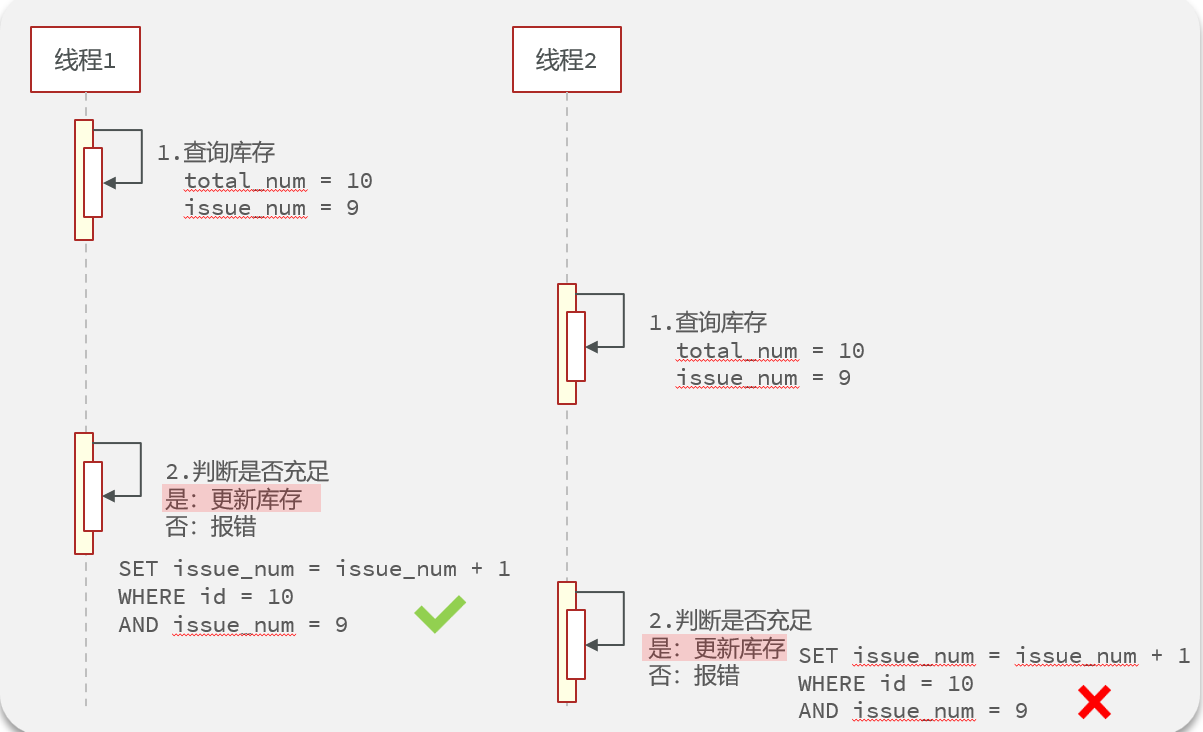
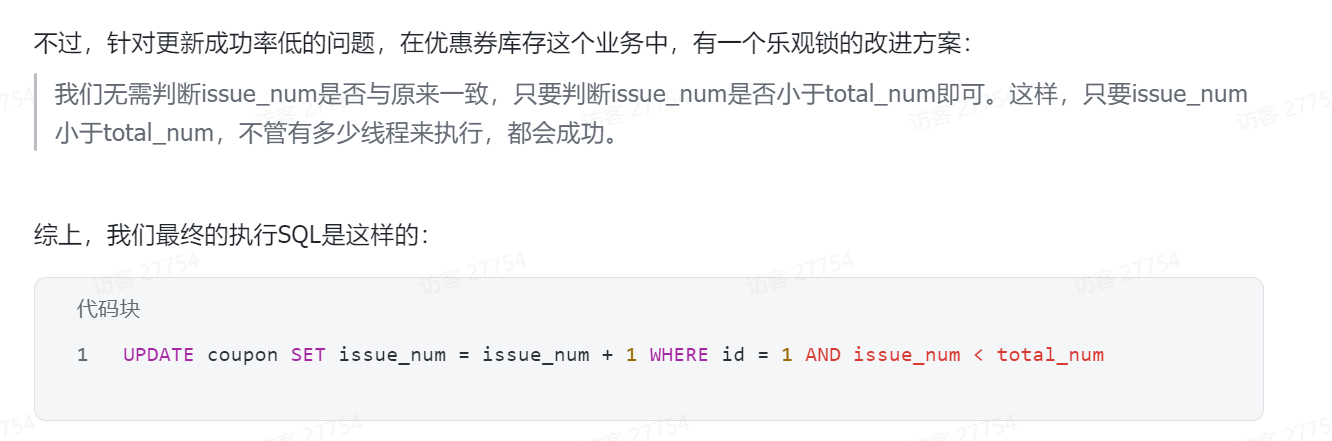
九 锁失效问题
1. 锁对象
(1)在业务中,我先是使用自定义类UserContext(上下文类,里面有ThreadLocal,存储用户id),调用get方法获取用户id,把这个id作为锁对象来隔离用户操作。但是失败了,因为ThreadLocal每gei一次就会创建一个新的Long对象返回,因此对于单个用户的多次操作,锁不唯一,失败。
(2)紧接着我使用id.toString(),但是还是不行。
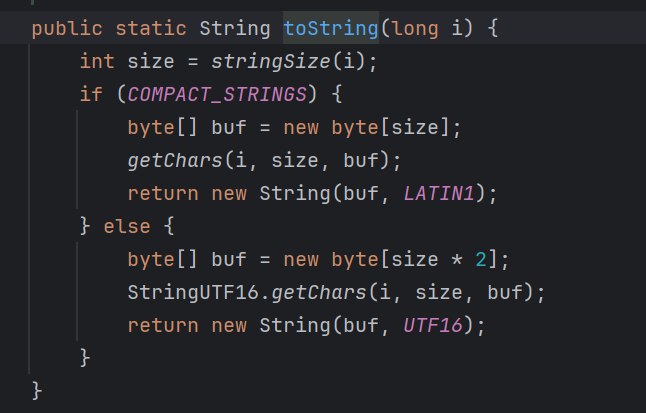
它本质上是new String返回,直接那它当锁也不行(因为地址不同)
(3)最后,我们发现,String类中提供了一个intern()方法:
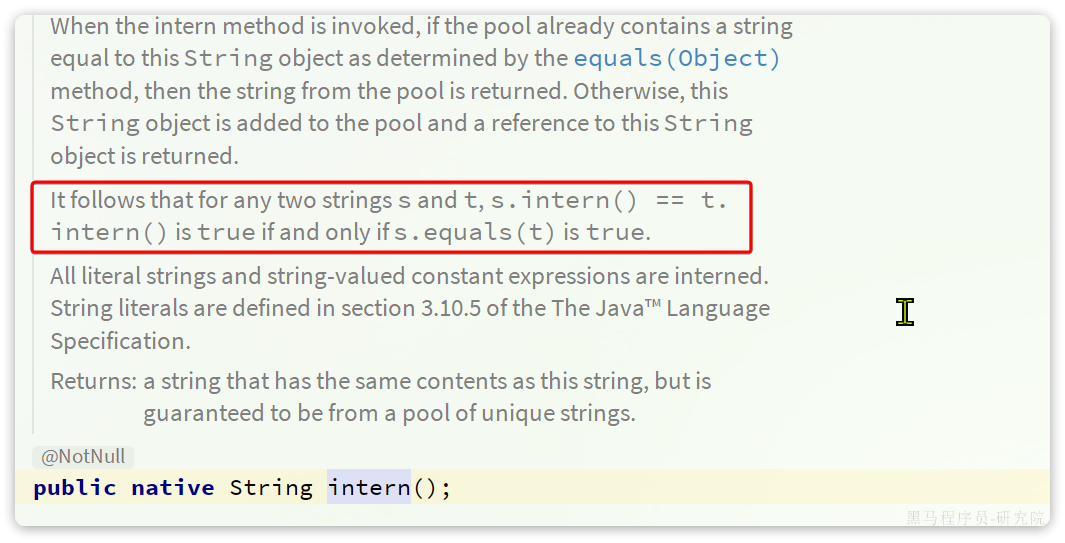
从描述中可以看出,只要两个字符串equals的结果为true,那么intern就能保证得到的结果用 ==判断也是true,其原理就是获取字符串字面值对应到常量池中的字符串常量。因此只要两个字符串一样,intern()返回的一定是同一个对象。因此最后,我们使用userId.toString().intern()作为锁。
2. 事务边界
在我们正确加了锁后,发现,锁依然失效了,下面是我们的代码:
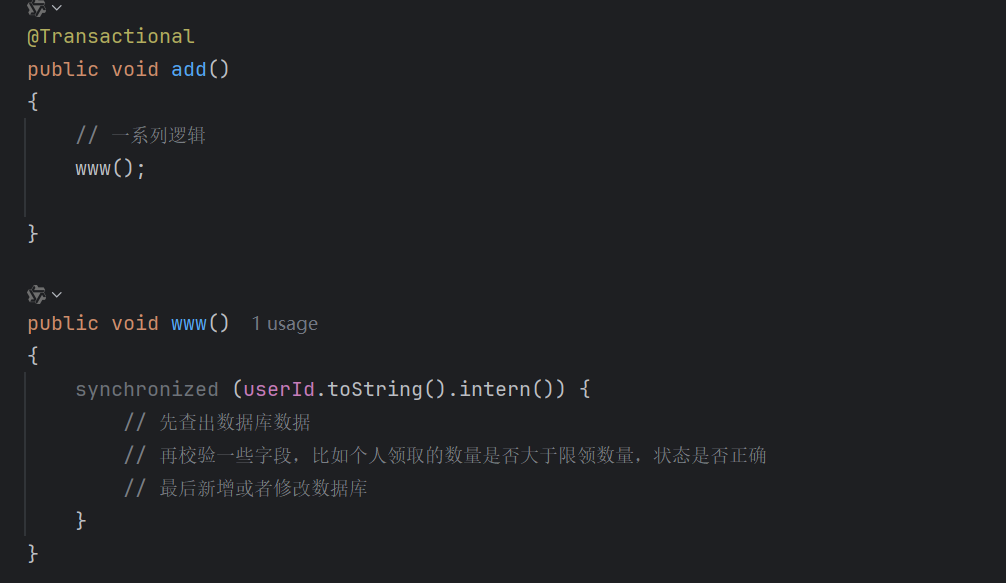
我们发现就算根据userId加了锁,www里的业务还是出现了个人领取的数量大于限领数量的情况,可是我们明明根据用户加了锁,按理来讲它不应该是:
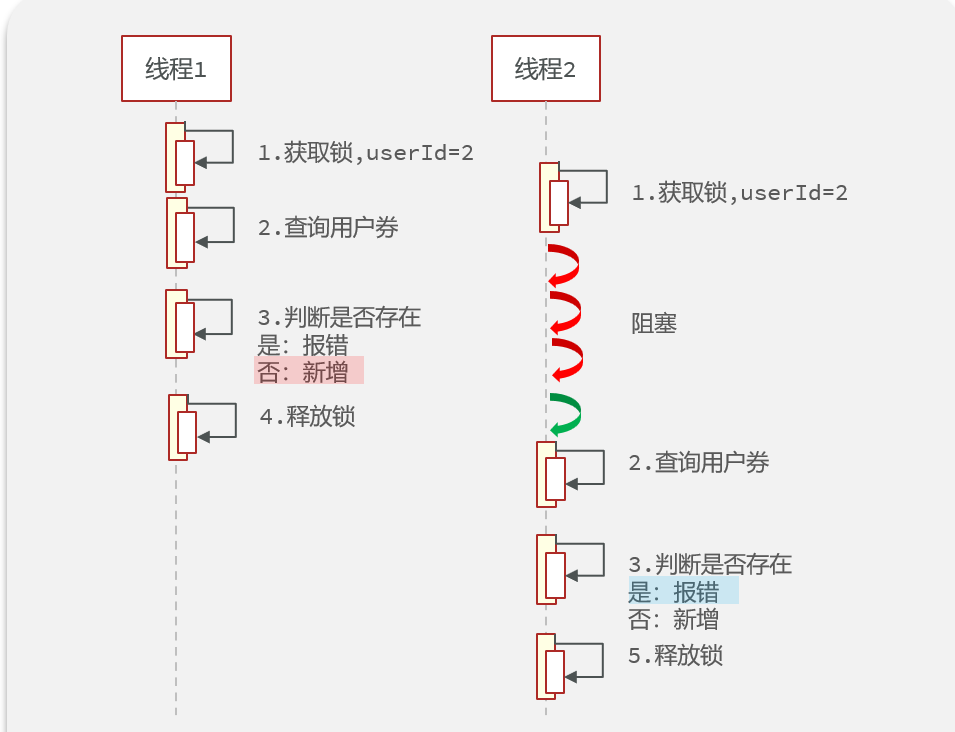
原因就是,我们aaa在调用www方法时,aaa上面有一个事务注解,那么就会出现下面的情况:
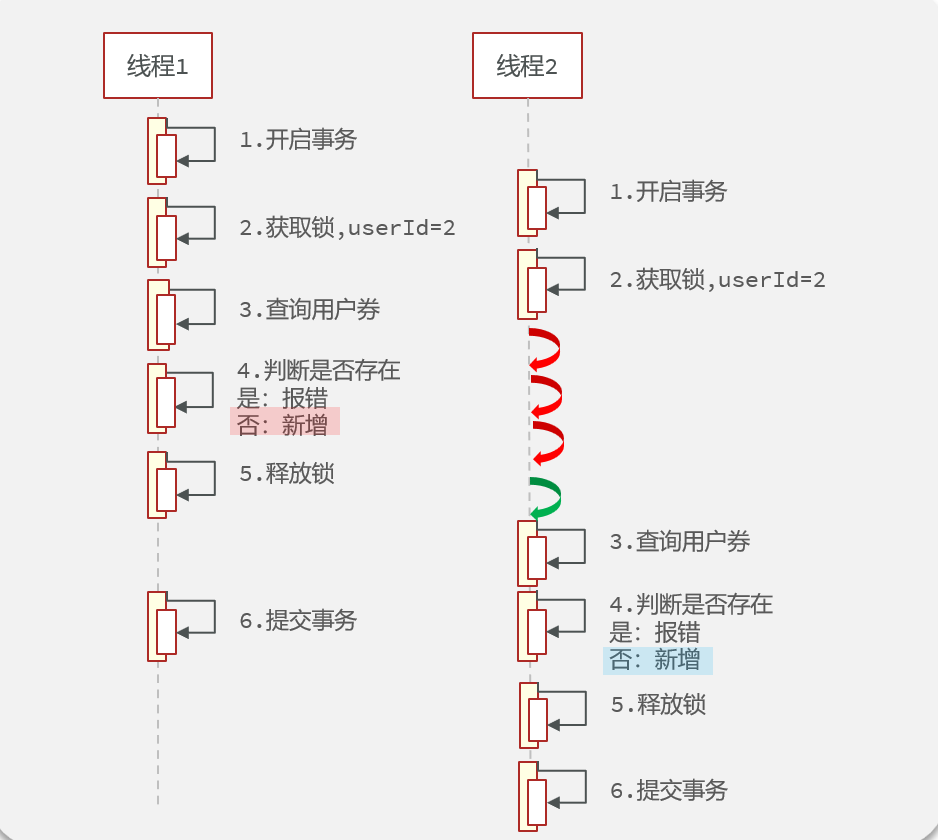
没错,事务在提交之前,数据库数据还没变化,先把userId锁给释放了,这时候别的线程抢先拿到锁,去查数据库,发现数据还没变化,于是出现线程安全问题
解决方法:跟换顺序,让事务在锁之前提交
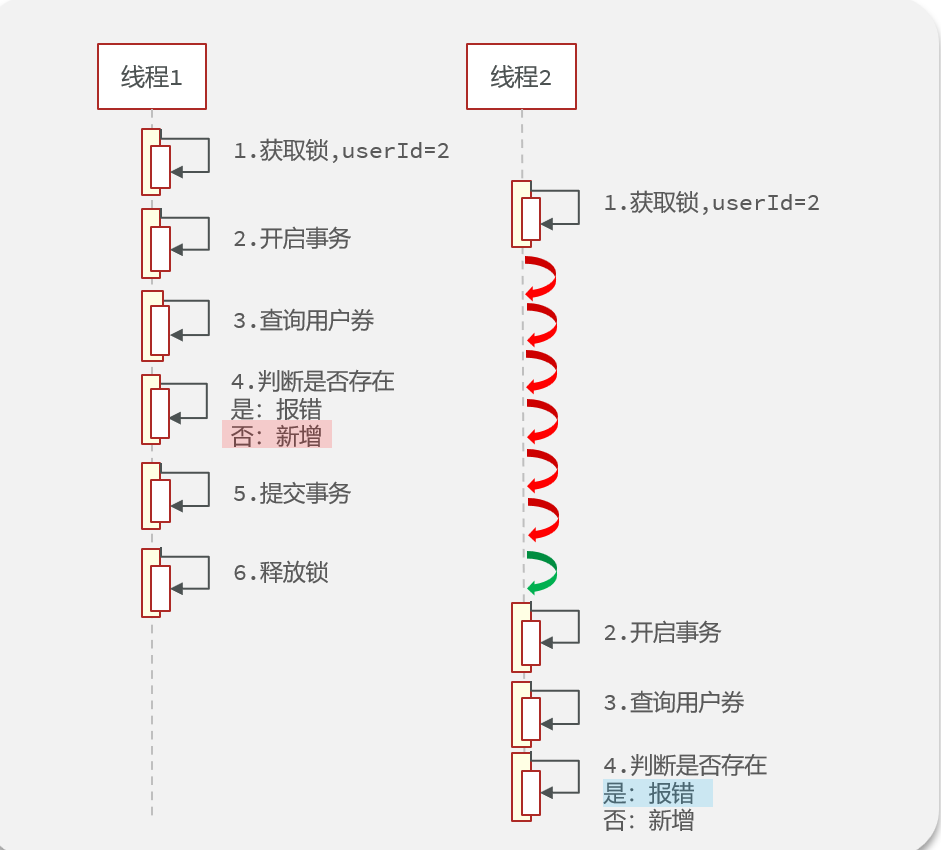
代码变动:aaa的锁放到www上,www内的锁放进aaa里,把事务包在里面即可(这样解决有问题,详见问题10事务失效)
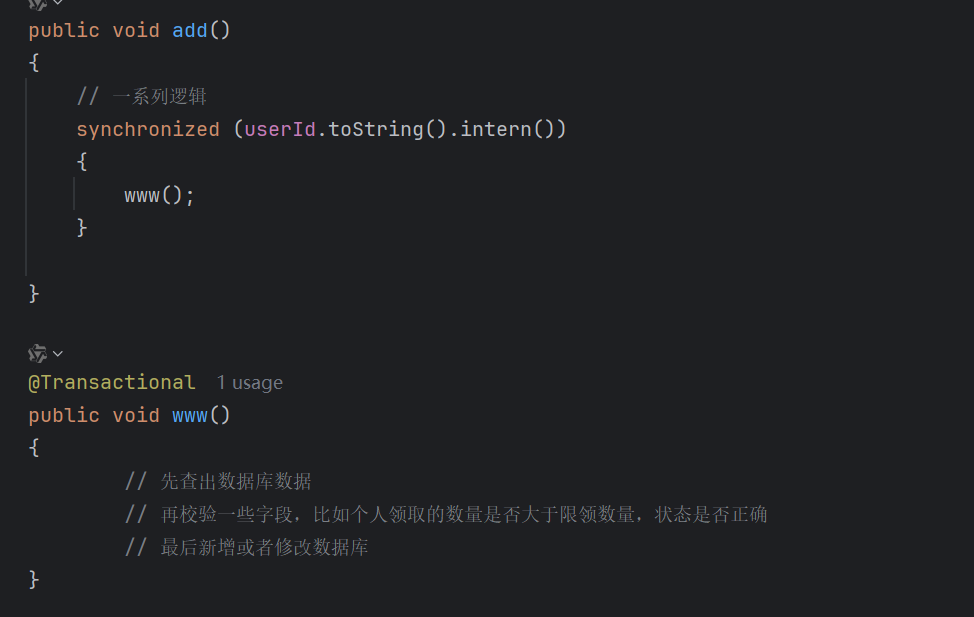
十 事务失效问题
在下面的代码里,我们在www里新增一行抛出错误的命令,发现抛出异常后事务没有回滚,这是就产生了事务失效问题?
1. 事务失效的原因
(1)事务方法非public修饰:由于Spring的事务是基于AOP的方式结合动态代理来实现的。因此事务方法一定要是public的,这样才能便于被Spring做事务的代理和增强。
(2)非事务方法调用事务方法(比如我们的代码):可以看到,www方法是一个事务方法,肯定会被Spring事务管理。Spring会给Service类生成一个动态代理对象,对www方法做增加,实现事务效果。但是现在aaa方法是一个非事务方法,在其中调用了www方法,这个调用其实隐含了一个this.的前缀。也就是说,这里相当于是直接调用原始的Service中的普通方法,而非被Spring代理对象的代理方法。那事务肯定就失效了!
(3)事务方法的异常被捕获了:

在这段代码中,reduceStock方法内部直接捕获了Exception类型的异常,也就是说方法执行过程中即便出现了异常也不会向外抛出。而Spring的事务管理就是要感知业务方法的异常,当捕获到异常后才会回滚事务。现在事务被捕获,就会导致Spring无法感知事务异常,自然不会回滚,事务就失效了。
(4)事务异常类型不对:
Spring的事务管理默认感知的异常类型是RuntimeException,当事务方法内部抛出了一个IOException时,不会被Spring捕获,因此就不会触发事务回滚,事务就失效了。因此,当我们的业务中会抛出RuntimeException以外的异常时,应该通过@Transactional注解中的rollbackFor属性来指定异常类型:

(5)事务传播行为不对:

当createOrder抛出异常时,insertOrder会回滚,但是reduceStock不会,因为它的行为是Propagation.REQUIRES_NEW
(6)没有被Spring管理:这个属于比较低级的错误,Service类没有添加@Service注解,因此就没有被Spring管理。你在方法上添加的@Transactional注解根本不会有人帮你动态代理,事务自然失效。
2. 解决方法
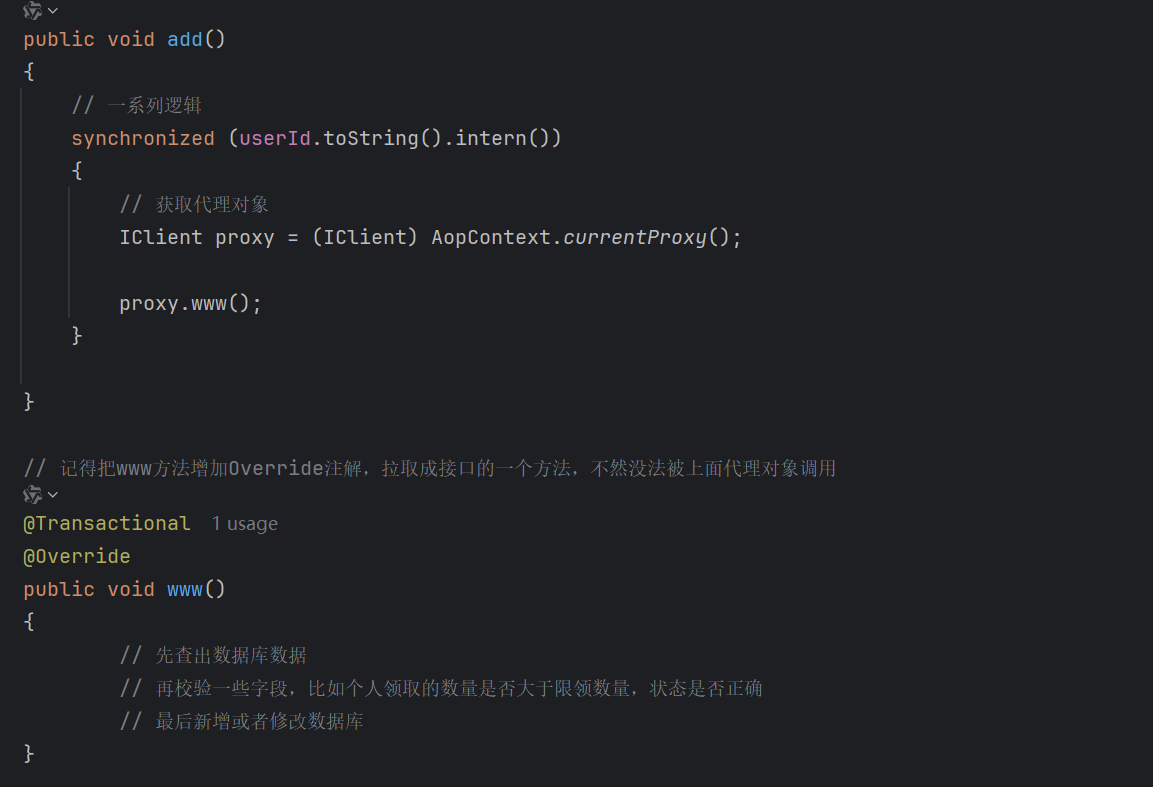
针对第二个原因,我们应该要让Spring代理对象来调用aaa方法,而不是this来调用,因此在调用前我们需要获取Service的代理对象
(1)引入依赖:
<!--aspecj-->
<dependency><groupId>org.aspectj</groupId><artifactId>aspectjweaver</artifactId>
</dependency>(2)在启动类头上加上这个注解:表示允许暴露代理对象
@EnableAspectJAutoProxy(exposeProxy = true)
(3)业务代码修改:
十一 集群下的锁失效
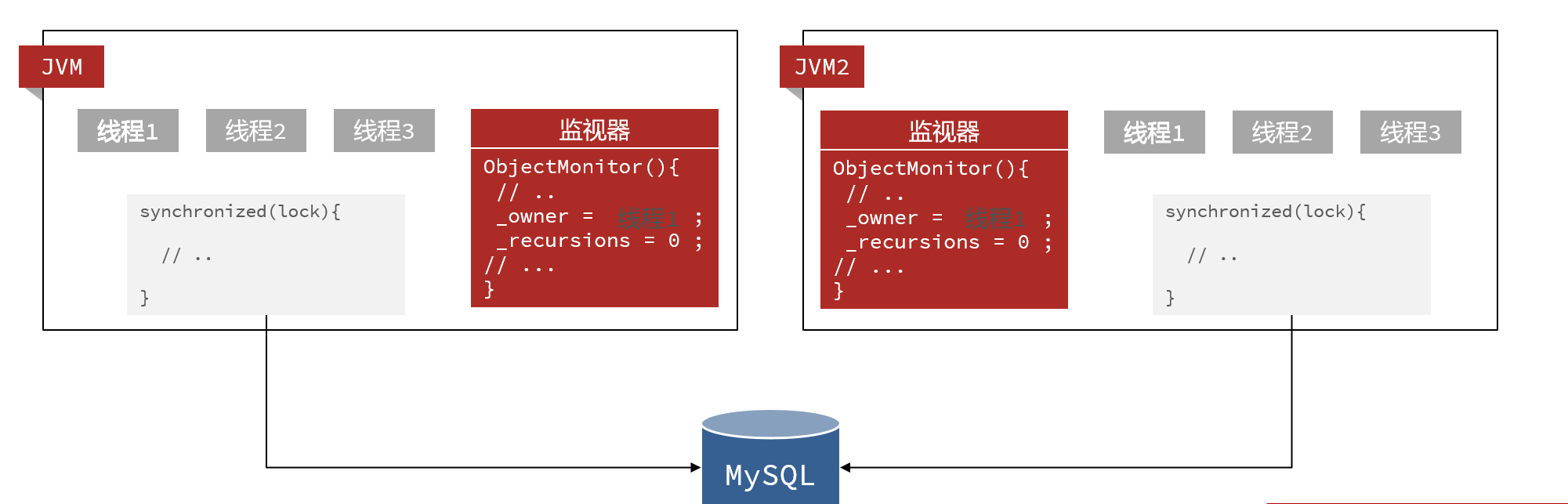
我们先了解一下常规的加锁过程:——每个实例都有自己的JVM,加锁之后锁会指向锁监视器,会去记录获取锁的线程信息,其他线程如果还要获取锁,监视器的owner已经有线程了,就不让它们获取锁了
1. redis实现分布式锁

多实例之后:——每个实例都有自己的JVM,自己的监视器,所以锁会失效
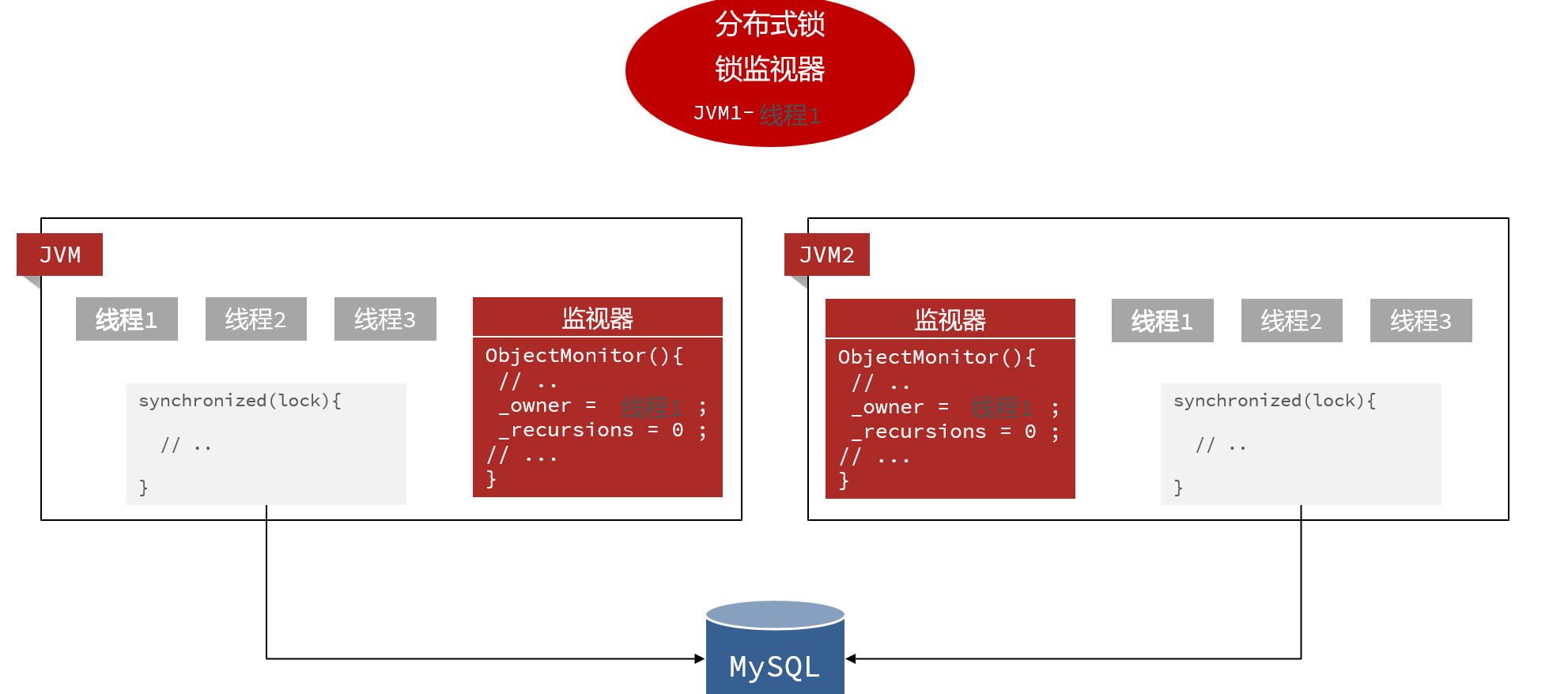
解决方法:
我们不能依赖于JVM的锁,必须使用JVM之外的工具来管理锁信息:
对这个工具只有几个要求:
-
多JVM实例都可以访问
-
互斥
能满足上述特征的组件有很多,因此实现分布式锁的方式也非常多,例如:
-
基于MySQL
-
基于Redis
-
基于Zookeeper
-
基于ETCD
但目前使用最广泛的还应该是基于Redis的分布式锁。
使用命令:

当前仅当key不存在的时候,setnx才能执行成功,并且返回1,其它情况都会执行失败,并且返回0.我们就可以认为返回值是1就是获取锁成功,返回值是0就是获取锁失败,实现互斥效果。
而当业务执行完成时,我们只需要删除这个key即可释放锁。这个时候其它线程又可以再次获取锁(执行setnx成功)了。

不过我们要考虑一种极端情况,比如我们获取锁成功,还未释放锁呢当前实例突然宕机了!那么释放锁的逻辑自然就永远不会被执行,这样lock就永远存在,再也不会有其它线程获取锁成功了!出现了死锁问题。
怎么办?
我们可以利用Redis的KEY过期时间机制,在获取锁时给锁添加一个超时时间:

锁的代码示例:
package com.tianji.promotion.utils;import com.tianji.common.utils.BooleanUtils;
import lombok.AllArgsConstructor;
import lombok.RequiredArgsConstructor;
import org.springframework.data.redis.core.StringRedisTemplate;import java.util.concurrent.TimeUnit;@RequiredArgsConstructor
@AllArgsConstructor
public class RedisLock {private String userGetCouponKey;private StringRedisTemplate stringRedisTemplate;public Boolean tryLock(Long timeout, TimeUnit unit){// 1. 获取线程名String value = Thread.currentThread().getName();// 2. 加锁Boolean absent = stringRedisTemplate.opsForValue().setIfAbsent(userGetCouponKey, value, timeout, unit);return BooleanUtils.isTrue(absent);}public void unlock(){//无论如何都要把锁释放了stringRedisTemplate.delete(userGetCouponKey);}}
使用锁的代码:
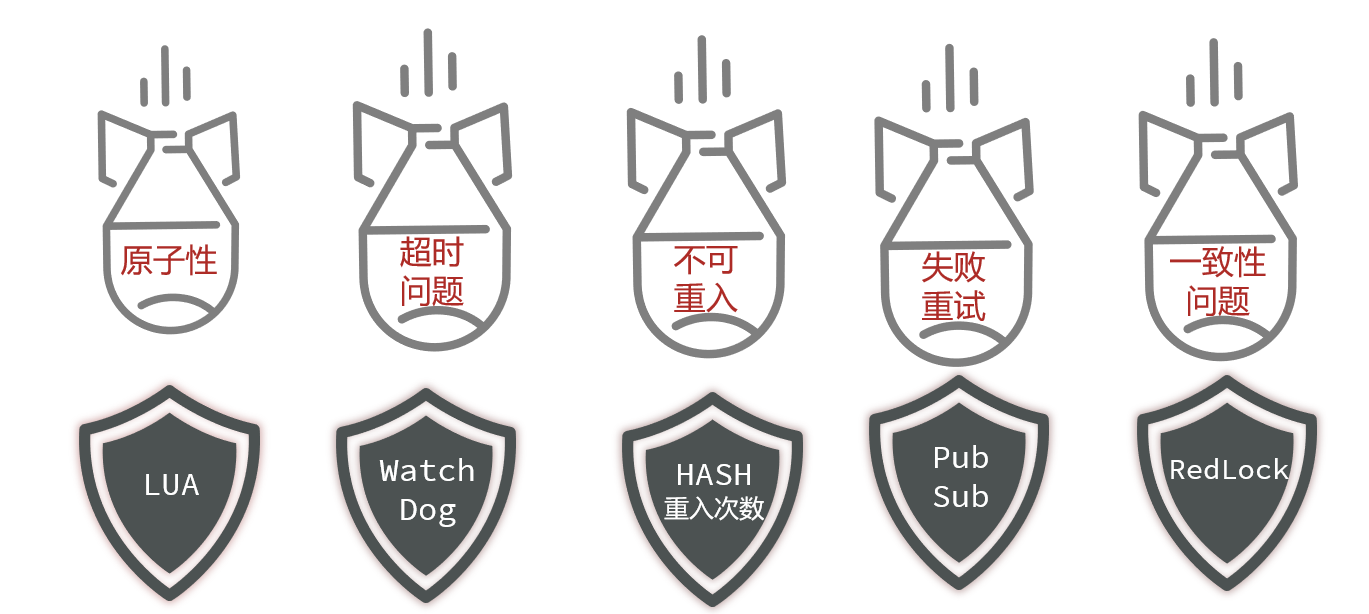
// 分布式锁String key = "lock:userId" + userId;RedisLock lock = new RedisLock(key, stringRedisTemplate);try {Boolean tryLock = lock.tryLock(5L, TimeUnit.SECONDS);if(!tryLock){throw new BizIllegalException("获取优惠券失败");}IUserCouponService proxy = (IUserCouponService) AopContext.currentProxy();proxy.CheckCouponUserLimitAndAddUserCoupon(coupon, now);} finally {lock.unlock();}但是这个方案有非常多缺陷:——当然,也有它的解决方法,但是非常麻烦
2. redisson
官网:https://redisson.org
详细看我的其他文章
相关文章:

大型视频学习平台项目问题解决笔记
一 数据库大量读操作导致数据库压力过大的解决方案 1. 优化SQL语句 2. 缓存 二 数据库大量写操作导致数据库压力过大的解决方案 1. 优化SQL语句 2. 改同步写为异步写——解决复杂事务的高并发写 3. 合并写请求——解决简单事务的高并发写(额外实现一个异步操作来…...

day18-数据结构引言
一、 概述 数据结构:相互之间存在一种或多种特定关系的数据元素的集合。 1.1 特定关系: 1. 逻辑结构 2.物理结构(在内存当中的存储关系) 逻辑结构物理结构集合,所有数据在同一个集合中,关系平等顺…...

Android音频解码中的时钟同步问题:原理、挑战与解决方案
一、为什么音频同步如此重要? 在多媒体播放系统中,音频同步问题直接影响用户体验。根据行业研究数据: • 15ms以上的同步偏差:53%的用户能感知到音画不同步 • 超过100ms的偏差:会导致明显的"口型对不上"现…...

深入浅出 iOS 对象模型:isa 指针 与 Swift Metadata
在 iOS 开发中,我们经常听到两个看似神秘的词:isa 指针 和 Metadata。这两个概念分别源自 Objective-C 和 Swift 的对象系统,是我们理解底层运行机制、优化性能乃至调试疑难问题的关键。今天我们就来聊一聊,它们到底是什么&#x…...

ARMV8 RK3399 u-boot TPL启动流程分析 --crt0.S
上一篇介绍到start.S 最后一个指令是跳转到_main, 接下来分析 __main 都做了什么 arch/arm/lib/crt0.S __main 注释写的很详细,主要分为5步 1. 准备board_init_f的运行环境 2. 跳转到board_init_f 3. 设置broad_init_f 申请的stack 和 GD 4. 完整u-boot 执行re…...

Lynx-字节跳动跨平台框架多端兼容Android, iOS, Web 原生渲染
介绍 字节跳动近期开源的跨平台框架Lynx被视为一项重要的技术创新。相较于市场上已有的解决方案如React Native (RN) 和Flutter,Lynx具有独特的特性。 首先,Lynx采用轻量级JavaScript逻辑设计,DOM节点构建完全置于Native层,确保U…...

手机换地方ip地址会变化吗?深入解析
在移动互联网时代,我们经常带着手机穿梭于不同地点,无论是出差旅行还是日常通勤。许多用户都好奇:当手机更换使用地点时,IP地址会随之改变吗?本文将深入解析手机IP地址的变化机制,帮助您全面了解这一常见但…...

Linux——数据库备份与恢复
一,Mysql数据库备份概述 1,数据库备份的重要性 数据灾难恢复:数据库可能会因为各种原因出现故障,如硬件故障、软件错误、误操作、病毒攻击、自然灾害等。这些情况都可能导致数据丢失或损坏。如果有定期的备份,就可以…...

矩阵键盘模块
目录 1.矩阵键盘介绍 2.扫描的概念 数码管扫描(输出扫描) 矩阵键盘扫描(输入扫描) 矩阵按键采用逐行扫描: 3.矩阵键盘代码 第一步: 第二步: 第三步: 第四步࿱…...

连接词化归律详解
1. 连接词化归律的基本概念 连接词化归律(也称为归结原理)是数理逻辑中用于简化逻辑表达式的重要方法,它允许我们将复杂的逻辑表达式转化为更简单的等价形式,特别是转化为合取范式(CNF)或析取范式(DNF)。 核心思想 连接词化归律基于一系列逻辑等价关系…...

Ubuntu 18.04 iso文件下载
参考:https://blog.csdn.net/Li060703/article/details/106075597 Rufus 官网: https://rufus.ie/zh/ 镜像下载地址 阿里云镜像站:https://mirrors.aliyun.com/ubuntu-releases/18.04/ 网易镜像:http://mirrors.163.com/ub…...

【C#】ToArray的使用
在 C# 中,ToArray 方法通常用于将实现了 IEnumerable<T> 接口的集合(如 List<T>)转换为数组。这个方法是 LINQ 提供的一个扩展方法,位于 System.Linq 命名空间中。因此,在使用 ToArray 方法之前࿰…...

学习日志03 java
最近有点懈怠了,多多实践,多敲代码,多多专注! 1 ArithmeticException ArithmeticException 是 Java 中的一个异常类,它继承自 RuntimeException,用于表示在算术运算中出现的错误。这个异常通常在以下情况…...

数据库故障排查指南
对于项目研发来讲,数据库是必不可少的一个重要环节,本文详细总结了项目研发中数据库故障问题排查指南,希望会对大家有所帮助。 数据库连接问题 检查数据库服务是否正常运行,确认网络连接是否畅通,验证数据库配置文件…...

洛谷 P1955 [NOI2015] 程序自动分析
【题目链接】 洛谷 P1955 [NOI2015] 程序自动分析 【题目考点】 1. 并查集 2. 离散化 【解题思路】 多组数据问题,对于每组数据,有多个 x i x j x_ix_j xixj或 x i ≠ x j x_i \neq x_j xixj的约束条件。 所有相等的变量构成一个集合&…...

音视频学习:使用NDK编译FFmpeg动态库
1. 环境 1.1 基础配置 NDK 22b (r22b)FFmpeg 4.4Ubuntu 22.04 1.2 下载ffmpeg 官网提供了 .tar.xz 包,可以直接下载解压: wget https://ffmpeg.org/releases/ffmpeg-4.4.tar.xz tar -xvf ffmpeg-4.4.tar.xz cd ffmpeg-4.41.3 安装基础工具链 sudo …...

OpenHarmony Linux内核本地管理
概述 写这篇文章的初衷,其实也是作者从事多年Android系统开发中,根深蒂固的目录情节导致的,再开发Harmony系统中,总是想模拟Android系统的开发思路。 对于OpenHarmony这个patch机制,其实我很讨厌它,虽然这样…...
)
2025最新出版 Microsoft Project由入门到精通(六)
目录 三种资源类型的分配方式 成本类资源的分配方式 第一步:切换视图为”任务分配状况“视图 第二步:选中任务→资源→分配资源,打开分配资源窗口选择资源单击”分配“ 资源成本的修改方式 编辑工时类资源的分配方式 工时类资源的…...

Tomcat服务部署
目录 一. Tomcat概述 1.1 什么是Tomcat 1.2 安装Tomcat 1.2.1 CentOS7 安装 1.2.2 ubuntu 安装 1.2.3 使用脚本快速安装 二. 配置文件及核心组件 2.1 配置文件 2.1.1 安装目录下文件介绍 2.1.2 conf子目录 2.2 组件 三. tomcat 处理请求过程 四. 常见配置详解 4.…...

Chrome更新到136以后selenium等自动化浏览器失效
Chrome更新到136以后,已经不再支持对默认浏览器数据文件夹进行自动化调试,从而导致selenium在指定user-data-dir为默认路径“C:\Users\{计算机名}\AppData\Local\Google\Chrome\User Data”会报错,相应地的selenium-wire,undetect…...

数据库原理期末考试速成--最后附带两套题
引言 为什么从3开始呢,毕竟是速成吗,总要放弃一些东西 前两章1.概论 2.关系数据库:这里面都是一些运算符什么的,我感觉都学这个:笛卡尔积之列的都会算 这两章比较重要的我就放在这里了 选择、投影、连接、除、并、交、差,其中选择、投影、并、差、笛卡尔积是5种基本关…...
)
网络基础1(应用层、传输层)
目录 一、应用层 1.1 序列化和反序列化 1.2 HTTP协议 1.2.1 URL 1.2.2 HTTP协议格式 1.2.3 HTTP服务器示例 二、传输层 2.1 端口号 2.1.1 netstat 2.1.2 pidof 2.2 UDP协议 2.2.1 UDP的特点 2.2.2 基于UDP的应用层…...

使用Spring Boot集成Nacos
Nacos是一个更易于构建云原生应用的动态服务发现、配置管理和服务管理平台。它集成了服务发现、服务配置和服务管理等功能,是微服务架构中一个非常重要的组件。以下是使用Spring Boot集成Nacos的详细步骤。 1. 环境准备 确保你已经安装和配置了以下环境࿱…...

破局智算瓶颈:400G光模块如何重构AI时代的网络神经脉络
一、技术演进与市场需求双重驱动 在数字化转型浪潮下,全球互联网流量正以每年30%的复合增长率持续攀升。根据Dell’Oro Group最新报告,2023年400G光模块市场规模已突破15亿美元,预计2026年将占据数据中心光模块市场60%以上份额。这种爆发式增…...

Vue:插值表达
Vue 的插值表达式是数据绑定的基础形式,它通过 {{ }} 将 JavaScript 数据动态渲染到模板中。下面通过代码示例,直观感受它的用法和限制。 基础用法 <template><div><!-- 直接显示数据 --><p>{{ messag…...

26考研|数学分析:函数列与函数项级数
前言 函数列与函数项级数这一章虽然课本安排章节较少,只要两小节,但是在具体学习过程中,确实会有一定的难度,首先难点便是在对于函数列与函数项级数的理解,其次关于一致收敛性质的理解与判断,也是难点所在…...

设置环境变量启动jar报
1. 环境变量设置 set PATHC:\Program Files\java17\jdk-17.0.9\bin;%PATH%2. 启动jar java -jar jar包名3. 记录原因 PATH路径前添加java执行文件路径才会管用。添加后可以试试以下命令 直接输入PATH 回车 PATH进行java版本测试 java -version...
)
项目售后服务承诺书,软件售后服务方案,软件安装文档,操作文档,维护文档(Word原件)
一、系统安全性保障 (一)设计原则 (二)应用安全 (三)数据安全 (四)用户安全 (五)管理安全 二、售后服务 (一)服务总体要…...

Arduino快速入门
Arduino快速入门指南 一、硬件准备 选择开发板: 推荐使用 Arduino UNO(兼容性强,适合初学者),其他常见型号包括NANO(体积小)、Mega(接口更多)。准备基础元件:…...

每日一题——樱桃分级优化问题:最小化标准差的动态规划与DFS解决方案
文章目录 一、问题描述输入格式输出格式 二、问题本质分析三、解题思路1. 前缀和预处理2. DFS 枚举与剪枝3. 剪枝策略4. 标准差计算 四、代码实现五、样例解析样例 1样例 2 六、一行行代码带你敲dfs 七、总结 一、问题描述 某大型樱桃加工厂使用自动化机械扫描了一批樱桃的尺寸…...
:六个默认构造函数(一))
C++类与对象(二):六个默认构造函数(一)
在学C语言时,实现栈和队列时容易忘记初始化和销毁,就会造成内存泄漏。而在C的类中我们忘记写初始化和销毁函数时,编译器会自动生成构造函数和析构函数,对应的初始化和在对象生命周期结束时清理资源。那是什么是默认构造函数呢&…...

荣耀手机,系统MagicOS 9.0 USB配置没有音频来源后无法被adb检测到,无法真机调试的解决办法
荣耀手机,系统MagicOS 9.0 USB配置没有音频来源后无法被adb检测到,无法真机调试的解决办法 前言环境说明操作方法 前言 一直在使用的uni-app真机运行荣耀手机方法,都是通过设置USB配置的音频来源才能成功。突然,因为我的手机的系…...

每日分享-Python哈希加盐加密实战分享
没事找事干,找到本地有个hashdemo.py,那就来分享一下代码吧,主要内容就是使用python实现哈希加盐加密方式。 1、导入所需库 不多BB,先打开我们的 pychram 然后导入所需要用到的库 import hashlib import random import strin…...

Webpack中Compiler详解以及自定义loader和plugin详解
Webpack Compiler 源码全面解析 Compiler 类图解析: 1. Tapable 基类 Webpack 插件系统的核心,提供钩子注册(plugin)和触发(applyPlugins)能力。Compiler 和 Compilation 均继承此类,支持插件…...

deepseek-coder-6.7b-instruct安装与体验-success
目录 步骤1:安装环境 步骤2:下载模型 步骤3:安装依赖 步骤4:运行模型 报错NameError: name torch is not defined 步骤5:运行结果 步骤1:安装环境 pip install modelscope 步骤2:下载模型 modelscope download --model deepseek-ai/deepseek-coder-6.7b-instruct --lo…...

对抗进行性核上性麻痹,健康护理筑牢生活防线
进行性核上性麻痹是一种复杂的神经退行性疾病,主要影响患者的运动、平衡及吞咽等功能,随着病情进展,患者生活质量会受到严重影响。除规范治疗外,科学的健康护理是提高患者生活质量、延缓病情发展的重要手段。 日常活动护理是基础。…...

科学养生,拥抱健康生活
在生活节奏日益加快的今天,养生不再是遥不可及的概念,而是可以融入日常的健康生活方式。即使抛开中医理念,通过科学的生活方式选择,也能为身体注入源源不断的活力。 从营养管理开始,构建科学的饮食体系。采用 “321 饮…...

基于若依框架的岗位名称查询模块实现
表名:sys_post(若依自带的一个表) 目标:获取post_name中所有的名字 模块结构说明 src/ ├── main/ │ ├── java/ │ │ └── com/ │ │ └── ruoyi/ │ │ └── nametraversal/ │ │…...
Python爬虫--requests)
(2)Python爬虫--requests
文章目录 前言一、 认识requests库1.1 前情回顾1.2 为什么要学习requests库1.3 requests库的基本使用1.4 响应的保存1.5 requests常用的方法1.6 用户代理1.7 requests库:构建ua池(可以先跳过去)1.8 requests库:带单个参数的get请求1.9 requests库&#x…...

springboot旅游小程序-计算机毕业设计源码76696
目 录 摘要 1 绪论 1.1研究背景与意义 1.2研究现状 1.3论文结构与章节安排 2 基于微信小程序旅游网站系统分析 2.1 可行性分析 2.1.1 技术可行性分析 2.1.2 经济可行性分析 2.1.3 法律可行性分析 2.2 系统功能分析 2.2.1 功能性分析 2.2.2 非功能性分析 2.3 系统…...

TCPIP详解 卷1协议 七 防火墙和网络地址转换
7.1——防火墙和网络地址转换 为防止终端系统不被攻击,需要一种方法来控制互联网中网络流量的流向。这项工作由防火墙来完成,它是一种能够限制所转发的流量类型的路由器。 随着部署防火墙来保护企业,另一个问题变得越来越重要:可…...

Golang 应用的 CI/CD 与 K8S 自动化部署全流程指南
一、CI/CD 流程设计与工具选择 1. 技术栈选择 版本控制:Git(推荐 GitHub/GitLab)CI 工具:Jenkins/GitLab CI/GitHub Actions(本文以 GitHub Actions 为例)容器化:Docker Docker Compose制品库…...

Jenkins:库博静态工具CI/CD 的卓越之选
在当今快节奏的软件开发领域,高效的持续集成(CI)和持续交付(CD)流程对于项目的成功至关重要。Jenkins 作为开源 CI/CD 软件的领导者,以其强大的功能、丰富的插件生态和高度的可扩展性,成为众多开…...

Maven私服搭建与登录全攻略
目录 1.背景2.简介3.安装4.启动总结参考文献 1.背景 回顾下maven的构建流程,如果没有私服,我们所需的所有jar包都需要通过maven的中央仓库或者第三方的maven仓库下载到本地,当一个公司或者一个团队所有人都重复的从maven仓库下载jar包&#…...

大模型数据分析破局之路20250512
大模型数据分析破局之路 本文面向 AI 初学者、数据分析从业者与企业技术负责人,围绕大模型如何为数据分析带来范式转变展开,从传统数据分析困境谈起,延伸到 LLM MCP 的协同突破,最终落脚在企业实践建议。 🌍 开篇导语…...
)
数据结构-树(1)
一、树的基本概念 二,树的抽象数据结构 三,树的存储结构 1.双亲表示法 数组存储结点,含数据域和双亲下标(根结点双亲为 - 1) 代码示例 include <stdio.h> #include <stdlib.h>#define MAX_TREE_SIZE 10…...

什么是ERP?ERP有哪些功能?小微企业ERP系统源码,SpringBoot+Vue+ElementUI+UniAPP
什么是ERP? ERP翻译过来叫企业资源计划,通俗的讲,应该叫企业的全面预算控制,其通常包括三个部分:工程预算、投资预算和经营预算(即产销存预算)。之所以做预算控制,是因为企业运作的…...
)
视觉-语言-动作模型:概念、进展、应用与挑战(上)
25年5月来自 Cornell 大学、香港科大和希腊 U Peloponnese 的论文“Vision-Language-Action Models: Concepts, Progress, Applications and Challenges”。 视觉-语言-动作 (VLA) 模型标志着人工智能的变革性进步,旨在将感知、自然语言理解和具体动作统一在一个计…...

C++ 与 Go、Rust、C#:基于实践场景的语言特性对比
目录 编辑 一、语法特性对比 1.1 变量声明与数据类型 1.2 函数与控制流 1.3 面向对象特性 二、性能表现对比编辑 2.1 基准测试数据 在计算密集型任务(如 10⁷ 次加法运算)中: 在内存分配测试(10⁵ 次对象创建…...

RDB和AOF的区别
Redis提供两种主要的持久化机制:RDB(Redis Database)和AOF(Append Only File),它们在数据持久化方式、性能影响及恢复策略上各有特点。以下是两者的对比分析及使用建议: RDB(快照持久…...