【落羽的落羽 C++】stack和queue、deque、priority_queue、仿函数
文章目录
- 一、stack和queue
- 1. 概述
- 2. 使用
- 3. 模拟实现
- 二、deque
- 三、priority_queue
- 1. 概述和使用
- 2. 模拟实现
- 四、仿函数
一、stack和queue
1. 概述
我们之前学习的vector和list,以及下面要认识的deque,都属于STL的容器(containers)组件。而stack和queue,属于STL的配置器(或称为配接器)(adapters)组件,或者归类为容器配置器(container adapters),它们可以修饰容器的接口而呈现出全新的容器性质,即stack的“先进后出”和queue的“先进先出”特点。
2. 使用
stack的所有元素的进出都必须符合“先进后出”的条件,queue的所有元素的进出都必须符合“先进先出”的条件。换句话说,只有stack的栈顶元素和queue的队头元素才有机会被移除,因此stack和queue不提供遍历的功能,也不提供迭代器。
除此之外,stack和queue的功能和使用也都很好理解了,之前我们已经学过栈和队列。
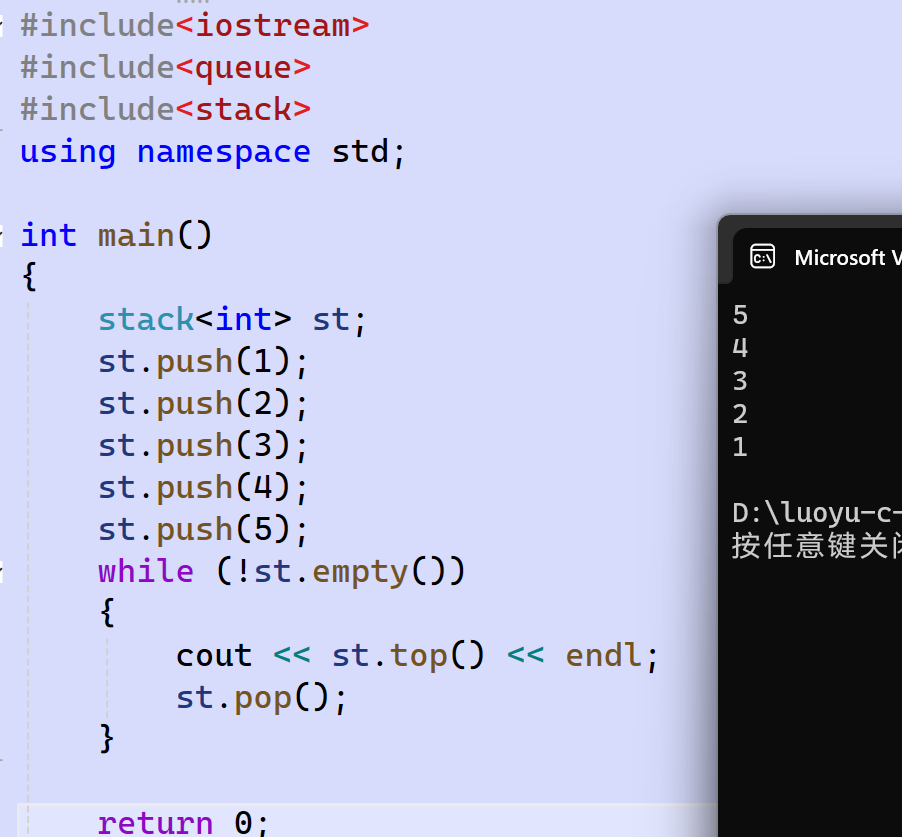
- stack:
| 函数声明 | 接口说明 |
|---|---|
| stack() | 构造空的栈 |
| empty() | 检测栈是否为空 |
| size() | 返回栈中元素个数 |
| top() | 返回栈顶元素的引用 |
| push() | 在栈顶入栈 |
| pop() | 将栈顶元素出栈 |
使用演示:
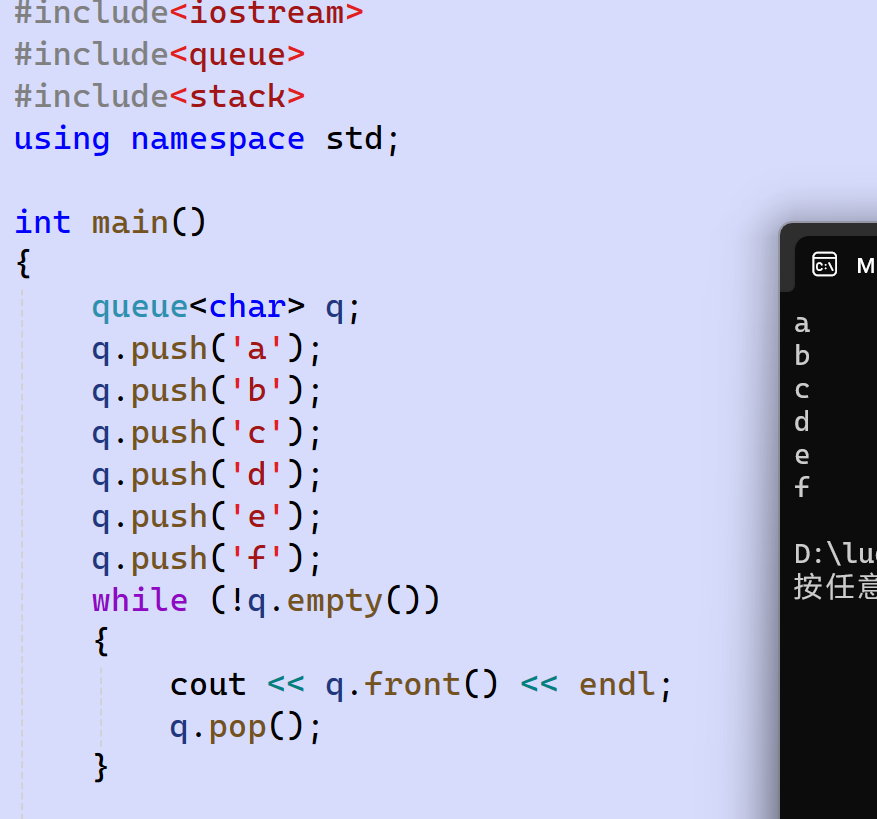
- queue:
| 函数声明 | 接口说明 |
|---|---|
| queue() | 构造空的队列 |
| empty() | 检测队列是否为空 |
| size() | 返回队列中元素个数 |
| front() | 返回队头元素的引用 |
| back() | 返回队尾元素的引用 |
| push() | 在队尾入队列 |
| pop() | 将队头元素出队列 |
使用演示:
3. 模拟实现
STL库中的stack和queue的模板实际上有两个模板类型:


第一个就是要存储的数据类型了。第二个代表它们所修饰的容器类型,前面说过,它们不是独立的容器,而是容器配置器,要依靠别的容器才能实现它们,这就是第二个模板参数的意义。我们可以用vector或list来实现出stack和queue,如stack<int, vector<int>>或queue<char, list<char>>,我们在上层使用stack和queue时是感受不到vector或list的区别的。不论是哪种容器,都有push、pop、front、back、empty等相关操作,得以再封装成stack和queue的功能。
模板参数也是可以有缺省值的,我们能看到STL标准库中的stack和queue的Container模板类型默认给了deque,deque也是一种容器,我们一会再介绍它。
除了这一点,stack和queue的模拟实现就很简单了,遵循它们的特性就好:
namespace lydly
{template<class T, class Container = deque<T>>class queue{private:Container _con;public:void push(const T& x){_con.push_back(x);}void pop(){_con.pop_front();}T& front(){return _con.front();}const T& front() const{return _con.front();}T& back(){return _con.back();}const T& back() const{return _con.back();}bool empty() const{return _con.empty();}size_t size() const{return _con.size();}};template<class T, class Container = deque<T>>class stack{private:Container _con;public:void push(const T& x){_con.push_back(x);}void pop(){_con.pop_back();}T& top(){return _con.back();}const T& top() const{return _con.back();}bool empty() const{return _con.empty();}size_t size() const{return _con.size();}};
}
二、deque
关于deque,简单了解就好。
对比一下vector和list的优缺点:
| 容器 | 优点 | 缺点 |
|---|---|---|
| vector | 支持下标随机访问、CPU高速缓存命中率高 | 头部或中部插入删除数据效率低、扩容有一定成本,存在一定浪费 |
| list | 任意位置插入删除数据效率高、不用扩容,按需申请空间,不存在浪费 | 不支持下标随机访问、CPU高速缓存命中率低 |
可见,vector和queue都有各自的优缺点,deque包含了两种容器的优点,是一种双向开口的线性连续空间
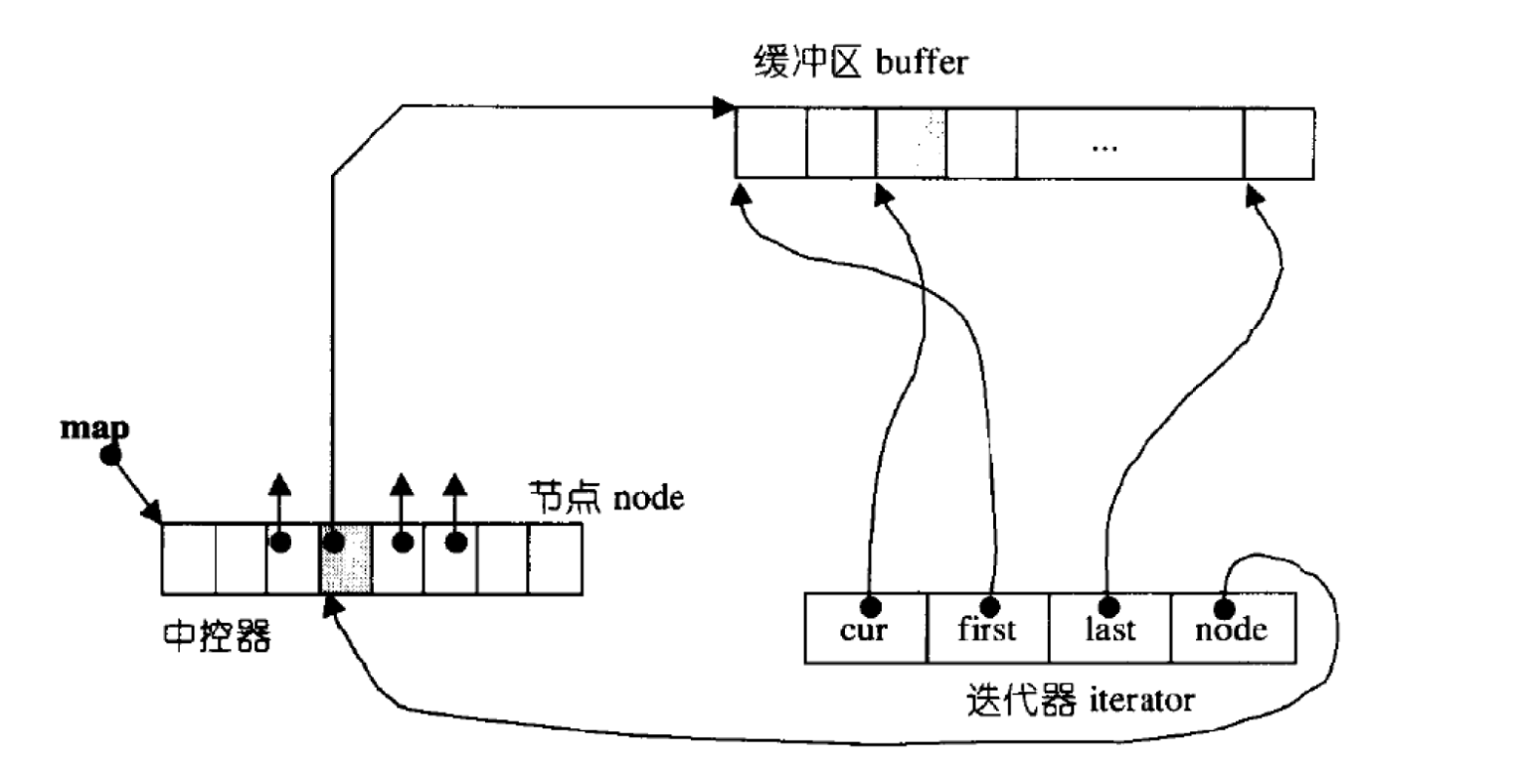
deque有一个中控器,存放着指向不同节点的指针,每一个节点是一个缓冲区buffer,是一个数组用于存放数据。执行尾插时,就在当前buffer的尾部插入数据,若当前buffer已满,就去中控器的下一个节点指向的buffer的第一个位置存放;执行头插时,要倒着看,当前buffer头部没有空间,就去中控器的上一个节点指向的buffer的最后一个位置存放,再头插一次就存放到倒数第二个位置,以此类推。头删和尾删也是一样的道理。
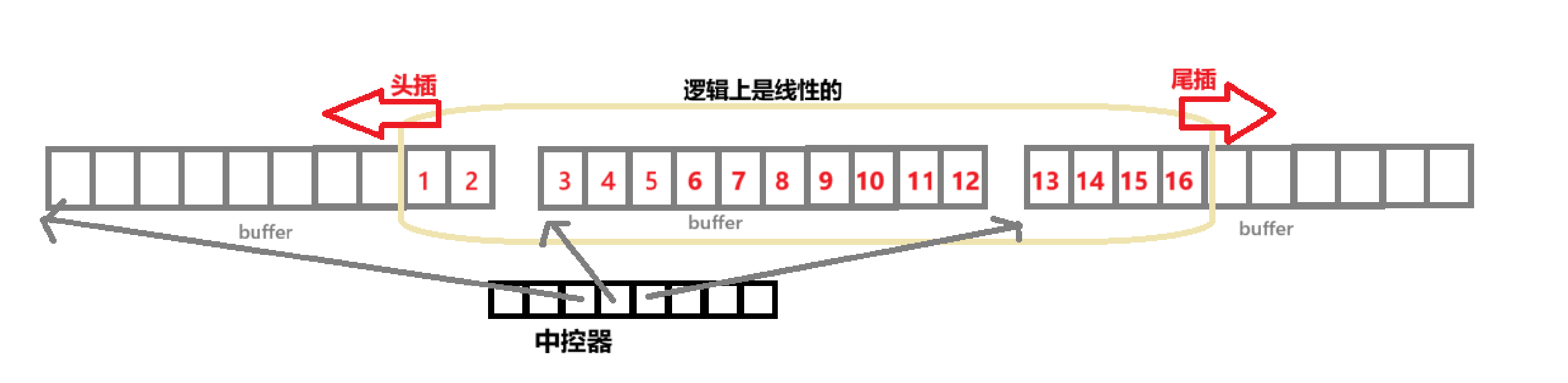
deque并不是真正完全连续的空间,而是由一段段连续的小空间拼接而成的,实际deque类似一个动态的二维数组,deque的迭代器的结构就更为复杂了。
所以,deque与vector相比,头部插入效率更高,不需要挪动元素;与list相比,空间利用率更高。但是,deque不适合遍历,因为在遍历时迭代器需要频繁检测每一个buffer是否到达边界,导致效率低下。而在序列式场景中,可能经常需要遍历,所以实际需要线性数据结构时,大多数情况下优先考虑vector和list,deque的应用并不多,目前能看到的一个应用就是STL用它作为stack和queue的底层数据结构。
而STL选择deque作为stack和queue的底层,主要原因也是stack和queue不需要遍历,只在固定的一端或两端进行操作,以及deque结合vector和list的优点了。
三、priority_queue
1. 概述和使用
priority_queue,意为优先级队列,是queue的一种,带有权值观念,其内的元素并非按照入队列的顺序排列,而是按照元素的权值排列,默认权值较高的元素排在前面。
举个栗子:
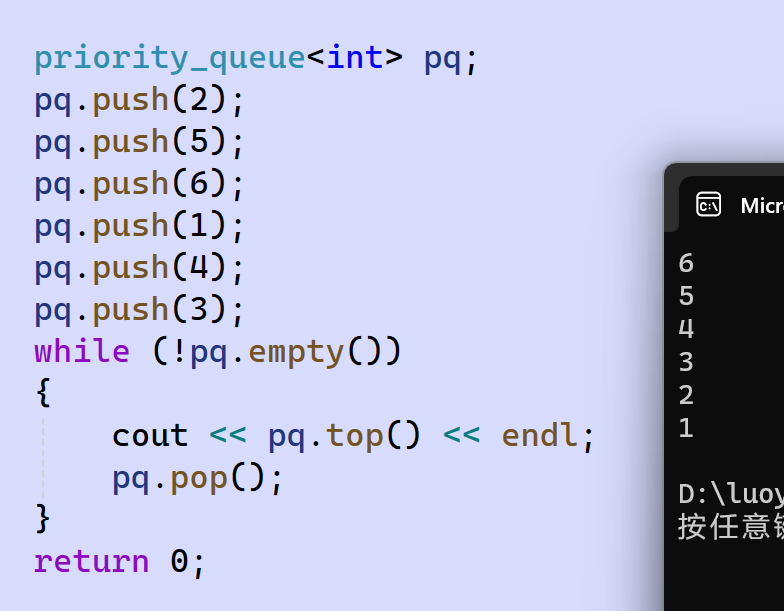
有没有发现,优先级队列其实就是我们之前学过的堆。

优先级队列默认使用vector作为其底层存储数据的容器,在vector上又使用了堆算法将vector中元素构造成堆的结构,因此priority_queue就是堆,所有需要用到堆的场景,都可以考虑使用优先级队列。默认情况下,优先级队列是大堆。
| 函数声明 | 接口说明 |
|---|---|
| priority_queue() | 构造空的优先级队列 |
| empty() | 检测优先级队列是否为空 |
| size() | 返回优先级队列中元素个数 |
| top() | 返回优先级队列中的最大(最小)元素,即堆顶元素 |
| push() | 在优先级队列中插入元素 |
| pop() | 删除优先级队列中的最大(最小)元素,即堆顶元素 |
2. 模拟实现
既然优先级队列就是堆,那么实现优先级队列也就和实现堆道理类似了:
传送门:https://blog.csdn.net/2402_86681376/article/details/145808942?spm=1011.2415.3001.5331(堆的讲解
要用到的向上调整算法、向下调整算法,我们都学习过了。
namespace lydly
{template<class T, class Container = vector<T>>class priority_queue{private:Container _con;public:priority_queue(){}void push(const T& x){_con.push_back(x);adjustup(_con.size() - 1);}void pop(){swap(_con[0], _con[_con.size() - 1]);_con.pop_back();adjustdown(0);}const T& top() const{return _con[0];}bool empty() const{return _con.empty();}size_t size() const{return _con.size();}private:void adjustup(int child){int parent = (child - 1) / 2;while (child > 0){if (_con[parent] < _con[child]){swap(_con[child], _con[parent]);child = parent;parent = (child - 1) / 2;}else{break;}}}void adjustdown(size_t parent){size_t child = parent * 2 + 1;while (child < _con.size()){if (child + 1 < _con.size() && _con[child] < _con[child + 1]){++child;}if (_con[parent] < _con[child]){swap(_con[child], _con[parent]);parent = child;child = parent * 2 + 1;}else{break;}}}};
}
问题来了,我们想让优先级队列降序排列元素,再重载一次·未必太麻烦了,怎么办呢?这里就需要用到仿函数。
四、仿函数
在STL标准库中,我们看到优先级队列的模板参数中还有一个Compare,这个就是仿函数。

仿函数是一种类对象,顾名思义,它可以“模仿函数”,允许用户“以模板参数来指定所要采取的策略”。在priority_queue中,它的第三个模板类型参数就是仿函数,默认给了一个less,less其实是这样的:
template<class T>
class less
{
public:bool operator()(const T& x, const T& y){return x < y;}
};
less是一个类,less<typename Container::value_type>就是一个匿名对象,它的里面重载了(),这样一来,倘若有less<T> Com;那我们就可以写出Com(a, b),(a,b是T类型的)这个表达式的意思就是a < b!
举一反三,STL中还有greater的仿函数:
template<class T>
class greater
{
public:bool operator()(const T& x, const T& y){return x > y;}
};
倘若有greater<T> Com;那我们就可以写出Com(a, b),这个表达式的意思就是a > b!
大堆和小堆的区别在于AdjustUp和AdjustDown中几处<或>的不同,有了上面的两种仿函数,我们就能在创建优先级队列时根据需要,模板参数传less或greater,区分大堆和小堆。具体是<还是>,就可以依靠传的是less还是greater来分别。STL的仿函数中的less和greater,就可以传给priority_queue的模板:
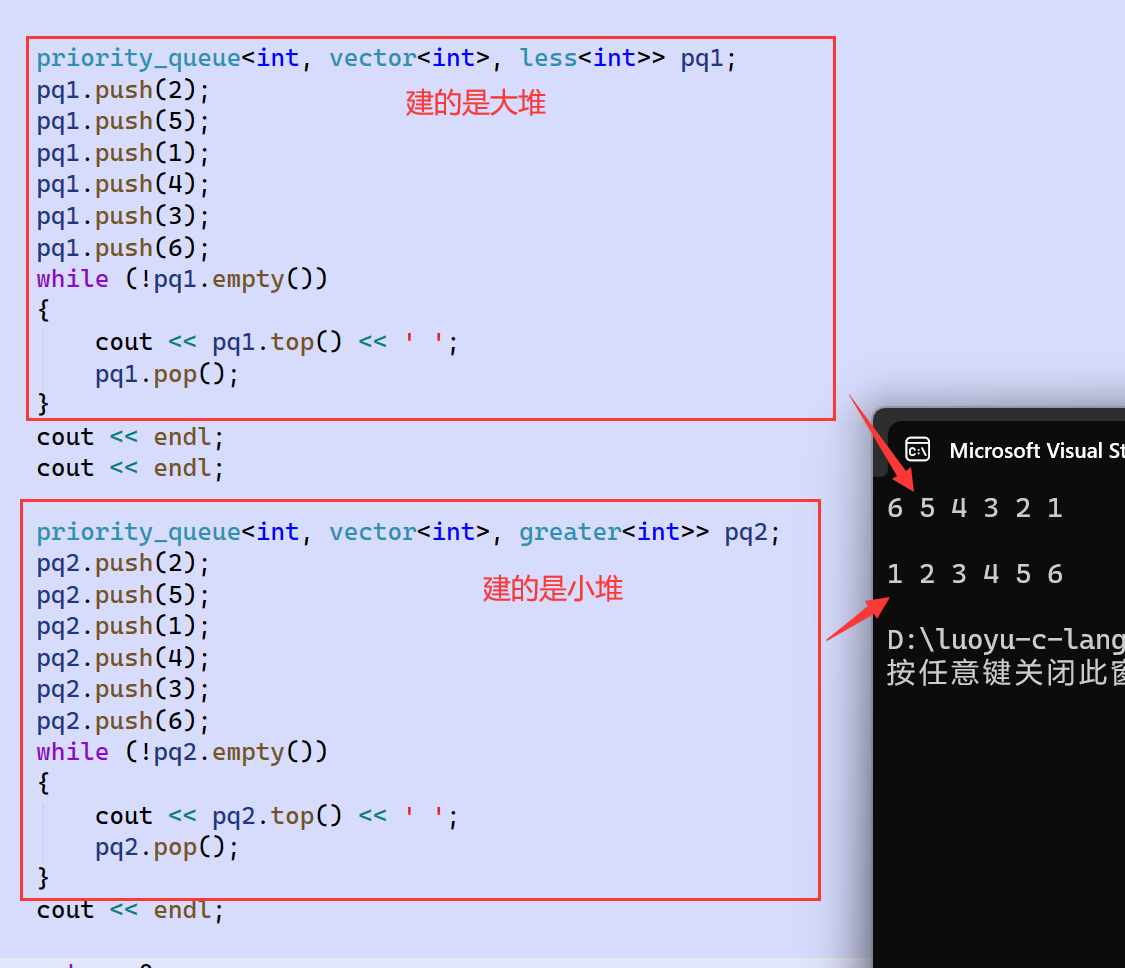
我们的模拟实现也按照这个思路来完成:
namespace lydly
{template<class T>class less{public:bool operator()(const T& x, const T& y){return x < y;}};template<class T>class greater{public:bool operator()(const T& x, const T& y){return x > y;}};template<class T, class Container = vector<T>, class Compare = less<T>>class priority_queue{private:Container _con;public:priority_queue(){}void push(const T& x){_con.push_back(x);adjustup(_con.size() - 1);}void pop(){swap(_con[0], _con[_con.size() - 1]);_con.pop_back();adjustdown(0);}const T& top() const{return _con[0];}bool empty() const{return _con.empty();}size_t size() const{return _con.size();}private:void adjustup(int child){//构造一个less或greater的对象Compare com;int parent = (child - 1) / 2;while (child > 0){if (com(_con[parent], _con[child])){swap(_con[child], _con[parent]);// child = parent;parent = (child - 1) / 2;}else{break;}}}void adjustdown(size_t parent){//构造一个less或greater的对象Compare com;size_t child = parent * 2 + 1;while (child < _con.size()){if (child + 1 < _con.size() && com(_con[child], _con[child + 1])){++child;}if (com(_con[parent], _con[child])){swap(_con[child], _con[parent]);parent = child;child = parent * 2 + 1;}else{break;}}}};
}
关于less,我们还可能会遇到其他情况:
- 当想要比较的是自定义类型时,就需要这个自定义类型中重载<和>运算符,这一点很好理解。
- 当传入指针时,一般我们应该是想要比较的是指向的内容,但如果只把less写成刚才那样,会被解析成直接比较两个地址的值。这时,需要写成这样:
template<class T>
class less<T*>
{
public:bool operator()(const T* const & x, const T* const & y){return *x < *y;}
};
相关文章:

【落羽的落羽 C++】stack和queue、deque、priority_queue、仿函数
文章目录 一、stack和queue1. 概述2. 使用3. 模拟实现 二、deque三、priority_queue1. 概述和使用2. 模拟实现 四、仿函数 一、stack和queue 1. 概述 我们之前学习的vector和list,以及下面要认识的deque,都属于STL的容器(containers&#x…...

Golang 空结构体特性与用法
文章目录 1.简介2.核心特性2.1 零内存占用2.2 值比较语义2.3 类型隔离2.4 值地址 3.作用3.1 实现集合(Set)3.2 不发送数据的信道3.3 无状态方法接收者3.4 作为 context 的 value 的 key 4.小结参考文献 1.简介 在 Go 语言中,空结构体是一个不…...

企业对数据集成工具的需求及 ETL 工具工作原理详解
当下,数据已然成为企业运营发展过程中的关键生产要素,其重要性不言而喻。 海量的数据分散在企业的各类系统、平台以及不同的业务部门之中,企业要充分挖掘这些数据背后所蕴含的巨大价值,实现数据驱动的精准决策,数据集…...

基于HTTP头部字段的SQL注入:SQLi-labs第17-20关
前置知识:HTTP头部介绍 HTTP(超文本传输协议)头部(Headers)是客户端和服务器在通信时传递的元数据,用于控制请求和响应的行为、传递附加信息或定义内容类型等。它们分为请求头(Request Headers&…...

Megatron系列——流水线并行
内容总结自:bilibili zomi 视频大模型流水线并行 注:这里PipeDream 1F1B对应时PP,Interleaved 1F1B对应的是VPP 1、朴素流水线并行 备注: (1)红色三个圈都为空泡时间,GPU没有做任何计算 &am…...
)
Android HttpAPI通信问题(待解决)
使用ClearTextTraffic是Android中一项重要的网络设置,它控制了应用程序是否允许在不使用HTTPS加密的情况下访问网络。在默认情况下,usescleartexttraffic的值为true,这意味着应用程序可以通过普通的HTTP协议进行网络通信。然而,这…...

WebFlux vs WebMVC vs Servlet 对比
WebFlux vs WebMVC vs Servlet 技术对比 WebFlux、WebMVC 和 Servlet 是 Java Web 开发中三种不同的技术架构,它们在编程模型、并发模型和适用场景上有显著区别。以下是它们的核心对比: 核心区别总览 特性ServletSpring WebMVCSpring WebFlux编程模型…...

Spring MVC参数传递
本内容采用最新SpringBoot3框架版本,视频观看地址:B站视频播放 1. Postman基础 Postman是一个接口测试工具,Postman相当于一个客户端,可以模拟用户发起的各类HTTP请求,将请求数据发送至服务端,获取对应的响应结果。 2. Spring MVC相关注解 3. Spring MVC参数传递 Spri…...

Spring MVC 和 Spring Boot 是如何访问静态资源的?
Spring MVC 和 Spring Boot 在配置静态资源访问方面有所不同,Spring Boot 提供了更便捷的自动配置。 一、Spring Boot 如何配置静态资源访问 (推荐方式) Spring Boot 遵循“约定优于配置”的原则,对静态资源的访问提供了非常方便的自动配置。 默认静态…...

如何应对网站被爬虫和采集?综合防护策略与实用方案
在互联网时代,网站内容被恶意爬虫或采集工具窃取已成为常见问题。这不仅侵犯原创权益,还可能影响网站性能和SEO排名。以下是结合技术、策略与法律的综合解决方案,帮助网站构建有效防护体系。 一、技术防护:阻断爬虫的“技术防线”…...

MySQL 分页查询优化
目录 前言1. LIMIT offset, count 的性能陷阱:为什么它慢?😩2. 优化策略一:基于排序字段的“跳跃式”查询 (Seek Method) 🚀3. 优化策略二:利用子查询优化 OFFSET 扫描 (ID Subquery)4. 基础优化࿱…...

我用Deepseek + 亮数据爬虫神器 1小时做出輿情分析器
我用Deepseek 亮数据爬虫神器 1小时做出輿情分析器 一、前言二、Web Scraper API 实战(1)选择对应的URL(2)点击进入对应url界面(3)API结果实例和爬取结果展示(4)用户直接使用post请…...

langchain4j中使用milvus向量数据库做RAG增加索引
安装milvus向量数据库 官方网址 https://milvus.io/zh 使用docker安装milvus mkdir -p /data/docker/milvus cd /data/docker/milvus wget https://raw.githubusercontent.com/milvus-io/milvus/master/scripts/standalone_embed.sh#在docker中启动milvus sh standalone_emb…...

【开源工具】深度解析:基于PyQt6的Windows时间校时同步工具开发全攻略
🕒 【开源工具】深度解析:基于PyQt6的Windows时间校时同步工具开发全攻略 🌈 个人主页:创客白泽 - CSDN博客 🔥 系列专栏:🐍《Python开源项目实战》 💡 热爱不止于代码,热…...

开源 RPA 工具深度解析与官网指引
开源 RPA 工具深度解析与官网指引 摘要 :本文深入解析了多款开源 RPA 工具,涵盖 TagUI、Aibote、Taskt 等,分别介绍了它们的核心功能,并提供了各工具的官网链接,方便读者进一步了解与使用,同时给出了基于不…...
VS设置)
【免杀】C2免杀技术(一)VS设置
一、概述 编译器生成的二进制文件特征(代码结构、元数据、指纹)可能被杀软的静态或动态检测规则匹配。Visual Studio 的构建设置(特别是运行库、编译器优化、链接方式等)会直接影响最终生成的二进制文件的结构、行为特征和依赖关…...

OpenHarmony 开源鸿蒙南向开发——linux下使用make交叉编译第三方库——nettle库
准备工作 请依照这篇文章搭建环境 OpenHarmony 开源鸿蒙南向开发——linux下使用make交叉编译第三方库——环境配置_openharmony交叉编译-CSDN博客 编译依赖 相关依赖有 gmp-6.3.0 请依照这篇文章编译 OpenHarmony 开源鸿蒙南向开发——linux下使用make交叉编译第三方库…...

Kotlin与Ktor构建Android后端API
以下是一个使用 Kotlin 和 Ktor 构建 Android 后端 API 的详细示例,包含常见功能实现: 1. 项目搭建 (build.gradle.kts) plugins {applicationkotlin("jvm") version "1.9.0"id("io.ktor.plugin") version "2.3.4"id("org.je…...

网页jupyter如何显示jpipvenv虚拟环境
今天使用社区版pycharm编辑.ipynb文件时,发现pycharm编辑.ipynb文件需要订阅。但是发现pipvenv虚拟环境解释器在jupyter中只有一个Python3:ipykernel版本,没有venv和conda的虚拟环境。因此在网上搜寻资料,作为备份记录。 以windows为例 假设目…...

学习黑客5 分钟深入浅出理解Windows System Configuration
5 分钟深入浅出理解Windows System Configuration ⚙️ 大家好!今天我们将探索Windows系统配置——这是Windows操作系统的核心控制中心,决定了系统如何启动、运行和管理各种功能。无论你是计算机初学者,还是在TryHackMe等平台上学习网络安全…...

Spyglass:跨时钟域同步方案
相关阅读 Spyglasshttps://blog.csdn.net/weixin_45791458/category_12828934.html?spm1001.2014.3001.5482 Spyglass可以用于检测设计中的跨时钟域相关问题,确保电路中添加了适当的同步机制,以避免此类问题的发生,例如: 与亚稳…...

Ubuntu虚拟机文件系统扩容
1. 删除所有的虚拟机快照。 2. 选择扩展 将最大大小调整为你所需的大小 3. 进入虚拟机,输入命令: sudo apt install gparted sudo gparted 4. 选择磁盘,右键根分区,选择Resize/Move,调整大小。 5. 调整所需分区大…...

Window、CentOs、Ubuntu 安装 docker
Window 版本 网址:https://www.docker.com/ 下载 下载完成后,双击安装就可以了 Centos 版本 卸载 Docker (可选) yum remove docker \docker-client \docker-client-latest \docker-common \docker-latest \docker-latest-log…...

mac M2下虚拟机CentOS 8 安装上安装 Berkeley DB
问题:直接在centos8 yum安装db4-devel失败,只能手工安装 进入home目录,下载 wget http://download.oracle.com/berkeley-db/db-4.6.21.tar.gz 解压 tar -zxvf db-4.6.21.tar.gz 切到cd db-4.6.21的build_unix下 cd db-4.6.21 cd build_…...
)
Python文字转语音TTS库示例(edge-tts)
1. 安装 pip install edge-tts2. 命令行使用 # 生成语音文件 # -f:要转换语音的文本文件,例如一个txt文件 # --text:指明要保存的mp3的文本 # --write-media:指明保存的mp3文件路径 # --write-subtitles:指定输出字幕…...

lua入门语法,包含安装,注释,变量,循环等
文章目录 LUA入门什么是lualua安装入门lua的使用方式注释定义变量lua中的数据类型流程控制ifelsewhile语法:for 函数表模块 LUA入门 什么是lua 一种脚本语言,设计的目的是为了能够在一些应用程序提供灵活的扩展功能和定制功能。 lua安装 有linux版本…...

【文心智能体】使用文心一言来给智能体设计一段稳定调用工作流的提示词
🌹欢迎来到《小5讲堂》🌹 🌹这是《文心智能体》系列文章,每篇文章将以博主理解的角度展开讲解。🌹 🌹温馨提示:博主能力有限,理解水平有限,若有不对之处望指正࿰…...
)
TWASandGWAS中GBS filtering and GWAS(1)
F:\文章代码\TWASandGWAS\GBS filtering and GWAS README.TXT 请检查幻灯片“Vitamaize_update_Gorelab_Ames_GBS_filtering_20191122.pptx”中关于阿姆斯(Ames)ID处理流程的详细信息。 文件夹“Ames_ID_processing”包含了用于处理阿姆斯ID的文件和R…...
,发热管理(thermal),温度控制)
Linux电源管理(五),发热管理(thermal),温度控制
更多linux系统电源管理相关的内容请看:Linux电源管理、功耗管理 和 发热管理 (CPUFreq、CPUIdle、RPM、thermal、睡眠 和 唤醒)-CSDN博客 本文主要基于linux-5.4.18版本的内核代码进行分析。 1 简介 1.1 硬件知识 CPU等芯片在工作时会产生大量热量,…...

【C++11】异常
前言 上文我们学习到了C11中类的新功能【C11】类的新功能-CSDN博客 本文我们来学习C下一个新语法:异常 1.异常的概念 异常的处理机制允许程序在运行时就出现的问题进行相应的处理。异常可以使得我们将问题的发现和问题的解决分开,程序的一部分负…...

C#WPF里不能出现滚动条的原因
使用下面这段代码,就不能出现滚动条: <mdix:DrawerHost.LeftDrawerContent><Grid Width="260" Background="{StaticResource MaterialDesign.Brush.Primary}"><Grid.RowDefinitions><RowDefinition Height="auto"/>&l…...

安装Hadoop并运行WordCount程序
一、安装 Java Hadoop 依赖 Java,首先需要安装 Java 开发工具包(JDK)。以 Ubuntu 为例: bash sudo apt update sudo apt install openjdk-8-jdk安装后,设置环境变量: bash echo export JAVA_HOME/usr/li…...

从零搭建AI工作站:Gemma3大模型本地部署+WebUI配置全套方案
文章目录 前言1. 安装Ollama2.Gemma3模型安装与运行3. 安装Open WebUI图形化界面3.1 Open WebUI安装运行3.2 添加模型3.3 多模态测试 4. 安装内网穿透工具5. 配置固定公网地址总结 前言 如今各家的AI大模型厮杀得如火如荼,每天都有新的突破。今天我要给大家安利一款…...

《数字人技术实现路径深度剖析与研究报告》
《数字人技术实现路径深度剖析与研究报告》 一、引言 1.1 研究背景与意义 近年来,随着人工智能、虚拟现实、计算机图形学等技术的飞速发展,数字人技术应运而生并取得了显著进展。数字人作为一种新兴的技术应用,正逐步渗透到各个领域,成为推动行业创新发展的重要力量。从最…...

《棒球百科》MLB棒球公益课·棒球1号位
MLB(美国职业棒球大联盟)的棒球公益课通过推广棒球运动、普及体育教育,对全球多个地区产生了多层次的影响: 1. 体育文化推广 非传统棒球地区的普及:在棒球基础较弱的地区(如中国、欧洲部分国家)…...
内存泄漏问题及解决方案)
Android 中 Handler (创建时)内存泄漏问题及解决方案
一、Handler 内存泄漏核心原理 真题 1:分析 Handler 内存泄漏场景 题目描述: 在 Activity 中使用非静态内部类 Handler 发送延迟消息,旋转屏幕后 Activity 无法释放,分析原因并给出解决方案。 内存泄漏链路分析: 引…...
)
linux-驱动开发之设备树详解(RK平台为例)
前言 Linux3.x以后的版本才引入了设备树,设备树用于描述一个硬件平台的板级细节。 在早些的linux内核,这些“硬件平台的板级细节”保存在linux内核目录“/arch”, 以ARM为例“硬件平台的板级细节”保存在“/arch/arm/plat-xxx”和“/arch/ar…...

【现代深度学习技术】注意力机制05:多头注意力
【作者主页】Francek Chen 【专栏介绍】 ⌈ ⌈ ⌈PyTorch深度学习 ⌋ ⌋ ⌋ 深度学习 (DL, Deep Learning) 特指基于深层神经网络模型和方法的机器学习。它是在统计机器学习、人工神经网络等算法模型基础上,结合当代大数据和大算力的发展而发展出来的。深度学习最重…...

RDD的五大特征
1. 由多个分区(Partitions)组成 特性:RDD 是分区的集合,每个分区在集群的不同节点上存储。分区是数据并行处理的基本单位。作用:分区使 RDD 能够在集群中并行计算,提高处理效率。 2. 有一个计算每个分区的…...
)
键盘RGB矩阵与LED指示灯(理论部分)
键盘RGB矩阵与LED指示灯(理论部分) 一、LED指示灯基础 在键盘世界里,LED指示灯不仅仅是装饰,它们还能提供丰富的状态信息。QMK固件提供了读取HID规范中定义的5种LED状态的方法: Num Lock(数字锁定)Caps Lock(大写锁定)Scroll Lock(滚动锁定)Compose(组合键)Desp…...
)
HTTP方法和状态码(Status Code)
HTTP方法 HTTP方法(也称HTTP动词)主要用于定义对资源的操作类型。根据HTTP/1.1规范(RFC 7231)以及后续扩展,常用的HTTP方法有以下几种: GET:请求获取指定资源的表示形式。POST:向指…...

【sqlmap需要掌握的参数】
sqlmap需要掌握的参数 目标-u 指定URL 用于get请求-l 用于post请求- r 用于post请求指定数据库/表/字段 -D/-T/-C 脱库获得数据库获取用户获取表获取列获取字段获取字段类型获取值 其他 目标 -u 指定URL 用于get请求 -u URL, --urlURL 目标URL 只使用于get命令中 -l 用于pos…...

用 AltSnap 解锁 Windows 窗口管理的“魔法”
你有没有遇到过这样的场景:电脑屏幕上堆满了窗口,想快速调整它们的大小和位置,却只能拖来拖去,费时又费力?或者你是个多任务狂魔,喜欢一边写代码、一边看文档、一边刷视频,却发现 Windows 自带的…...
:TLS无锁访问以及Central Cache结构设计)
高并发内存池(三):TLS无锁访问以及Central Cache结构设计
目录 前言: 一,thread cache线程局部存储的实现 问题引入 概念说明 基本使用 thread cache TLS的实现 二,Central Cache整体的结构框架 大致结构 span结构 span结构的实现 三,Central Cache大致结构的实现 单例模式 thr…...

数据治理域——数据治理体系建设
摘要 本文主要介绍了数据治理系统的建设。数据治理对企业至关重要,其动因包括应对数据爆炸增长、提升内部管理效率、支撑复杂业务需求、加强风险防控与合规管理以及实现数字化转型战略。其核心目的是提升数据质量、统一数据标准、优化数据资产管理、支撑业务发展和…...

数据库实验报告 SQL SERVER 2008的基本操作 1
实验报告(第 1 次) 实验名称 SQL SERVER 2008的基本操作 实验时间 9月14日1-2节 一、实验内容 数据库的基本操作:包括创建、修改、附加、分离和删除数据库等。 二、源程序及主要算法说明 本次实验不涉及程序和算法。 三、测…...

基于STM32、HAL库的ICP-20100气压传感器 驱动程序设计
一、简介: ICP-20100 是 InvenSense(TDK 集团旗下公司)生产的一款高精度数字气压传感器,专为需要精确测量气压和海拔高度的应用场景设计。它具有低功耗、高精度、快速响应等特点,非常适合物联网、可穿戴设备和无人机等应用。 二、硬件接口: ICP-20100 引脚STM32L4XX 引脚…...

提示工程实战指南:Google白皮书关键内容一文讲清
You don’t need to be a data scientist or a machine learning engineer – everyone can writea prompt. 一、概述 Google于2025年2月发布的《Prompt Engineering》白皮书系统阐述了提示工程的核心技术、实践方法及挑战应对策略。该文档由Lee Boonstra主编,多位…...

国产大模型「五强争霸」:决战AGI,谁主沉浮?
引言 中国AI大模型市场正经历一场史无前例的洗牌!曾经“百模混战”的局面已落幕,字节、阿里、阶跃星辰、智谱和DeepSeek五大巨头强势崛起,形成“基模五强”新格局。这场竞争不仅是技术实力的较量,更是资源、人才与生态的全面博弈。…...
、设置阻塞/非阻塞)
Linux进程10-有名管道概述、创建、读写操作、两个管道进程间通信、读写规律(只读、只写、读写区别)、设置阻塞/非阻塞
目录 1.有名管道 1.1概述 1.2与无名管道的差异 2.有名管道的创建 2.1 直接用shell命令创建有名管道 2.2使用mkfifo函数创建有名管道 3.有名管道读写操作 3.1单次读写 3.2多次读写 4.有名管道进程间通信 4.1回合制通信 4.2父子进程通信 5.有名管道读写规律ÿ…...