数据治理域——数据治理体系建设
摘要
本文主要介绍了数据治理系统的建设。数据治理对企业至关重要,其动因包括应对数据爆炸增长、提升内部管理效率、支撑复杂业务需求、加强风险防控与合规管理以及实现数字化转型战略。其核心目的是提升数据质量、统一数据标准、优化数据资产管理、支撑业务发展和提升系统效率与稳定性。数据治理的终极目标是实现数据资产化、数据驱动决策、数据价值变现和形成企业级数据中台。一个完整的数据治理方案通常包含组织与职责建设、数据标准体系建设等关键组成部分。
1. 数据治理背景
1.1. 数据治理背景
企业开展数据治理的动因包括:
- 应对数据爆炸增长的挑战:海量数据如果不治理,将变成负担;
- 提升内部管理效率:减少重复开发、提升协同效率;
- 支撑复杂业务需求:高质量、稳定、可复用的数据是现代业务创新的基础;
- 加强风险防控与合规管理:满足数据安全、隐私保护和行业监管要求;
- 实现数字化转型战略:数据治理是企业从“人治”走向“数治”的基础工程。
数据治理的核心目的在于:
- 提升数据质量:保证数据的准确性、一致性、完整性与可用性。
- 统一数据标准:规范命名、格式、分类、接口,消除“数据孤岛”。
- 优化数据资产管理:梳理数据资产目录,明确数据责任归属,实现可追溯、可共享。
- 支撑业务发展:通过治理构建高效数据服务体系,提升数据支撑决策与运营的能力。
- 提升系统效率与稳定性:降低重复建设、减少资源浪费、提高系统健壮性。
1.2. 数据治理终极目标
数据治理的终极目标是实现:
- 数据资产化:让数据像资产一样被管理、评估与使用;
- 数据驱动决策:增强数据对业务决策、运营优化与战略制定的支持;
- 数据价值变现:释放数据潜能,提升企业运营效率与创新能力;
- 形成企业级数据中台:支撑多业务系统数据共享与复用,提升系统整体灵活性与可扩展性。
1.3. 数据治理方案设计
一个完整的数据治理方案通常包含以下关键组成部分:
| 方案 | 措施 | 备注 |
| 组织与职责建设 | 建立数据治理委员会 | |
| 明确数据拥有者、管理员、使用者的职责边界 | ||
| 数据标准体系建设 | 定义元数据、主数据、参考数据等标准 | |
| 制定数据质量标准与指标体系 | ||
| 数据质量管理机制 | 建立数据质量监控、评估、预警与修复机制 | |
| 数据全生命周期管理 | 包括数据采集、处理、存储、使用、归档与销毁等环节 | |
| 数据资产目录与血缘分析 | 建立统一数据资产目录 | |
| 支持数据的溯源、依赖关系跟踪与影响分析 | ||
| 数据服务与共享平台 | 构建数据服务平台,实现数据可查、可管、可用、可控 |
2. 数据治理体系架构
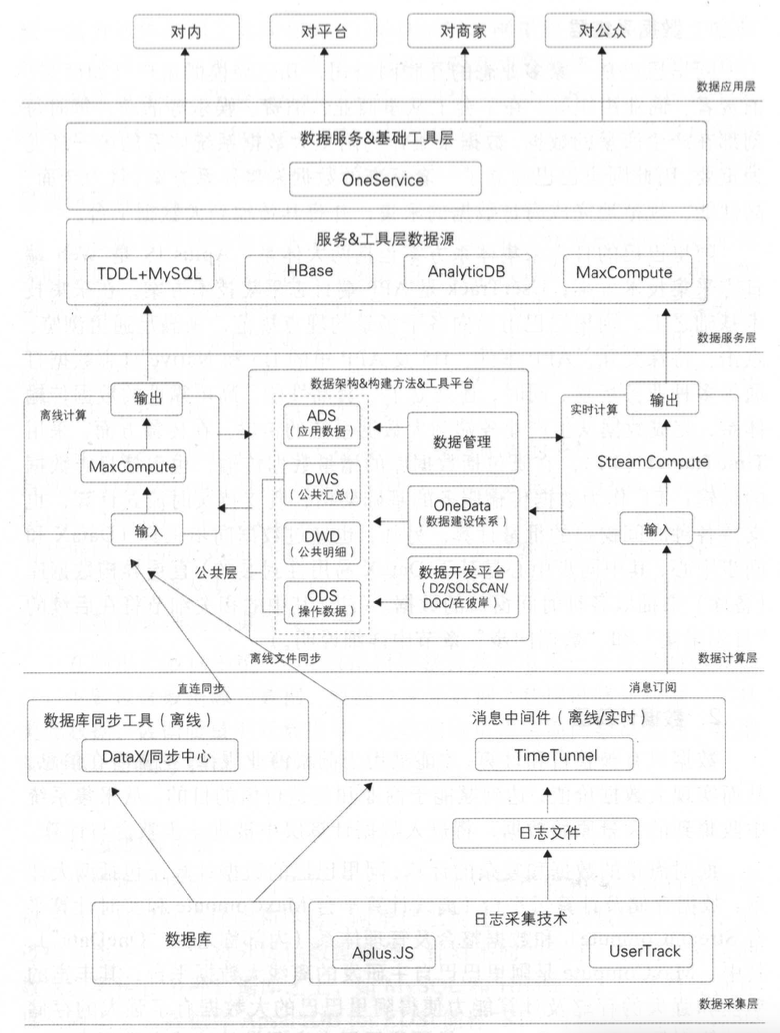
3. 数据治理体系设计
3.1. 数据采集层
在大数据体系中,数据采集层是数据治理的起点和基础。阿里作为一家业务多元、用户规模庞大的互联网企业,每时每刻都在处理来自电商、金融、内容、物流等多业务场景下的海量数据。为保障数据的全面性、及时性与准确性,阿里构建了一套高性能、标准化、覆盖全端的数据采集体系,以支持大数据平台的上层计算与治理需求。
3.1.1. 数据采集定义与作用
定位:位于系统架构的最底层,是数据流入系统的入口。
核心目标:将分散、异构的数据源(如传感器、日志、数据库、API等)中的原始数据,转换为标准化格式并输送到数据处理层。
重要性:直接影响数据质量、实时性及后续分析的准确性。
3.1.2. 数据源类型
结构化数据:关系型数据库(MySQL、Oracle)、ERP/CRM系统。
半结构化数据:日志文件(Nginx日志)、JSON/XML格式数据(API响应)。
非结构化数据:文本文件、图片、音视频、IoT传感器数据。
实时流数据:Kafka消息队列、MQTT协议设备数据。
第三方数据:公开API、合作伙伴数据接口。
3.1.3. 数据采集核心功能
数据抽取:通过主动查询(轮询)、事件驱动(推送)或日志监听(如Filebeat)获取数据。
数据标准化:清洗脏数据(去重、补全)、格式转换(时间戳统一、编码转换)。
数据传输:支持批量(如每日同步)或实时(如Kafka)传输,确保低延迟与高吞吐。
容错与重试:断点续传、失败任务重试机制,保障数据完整性。
3.1.4. 数据采集常用技术与工具
| 场景 | 工具示例 |
| 日志采集 | Filebeat、Flume、Logstash |
| 数据库同步 | Sqoop、Debezium(CDC)、Maxwell |
| IoT设备 | MQTT Broker、Apache NiFi |
| API/流数据 | Kafka Connect、Telegraf |
| 分布式采集 | Apache NiFi、Airbyte |
3.1.5. 数据采集关键挑战与解决方案
| 挑战 | 应对策略 |
| 高并发数据流 | 分布式采集架构(如Kafka分区分片) |
| 数据质量参差不齐 | 实时清洗(如Spark Streaming去噪) |
| 异构协议适配 | 开发多协议连接器(HTTP/SFTP/Modbus等) |
| 资源消耗优化 | 压缩传输(Snappy)、增量更新(CDC) |
3.1.6. 6. 数据采集典型应用场景
- 物联网(IoT):采集传感器数据(温度、GPS),用于智慧城市监控。
- 业务系统:同步订单数据(从MySQL到数据仓库)支持BI分析。
- 日志分析:实时收集Web服务器日志,用于异常检测(如ELK Stack)。
- 广告技术:聚合用户点击流数据,优化广告投放策略。
3.2. 数据计算层
数据计算层是数据处理架构中的核心组成部分,负责对原始数据进行加工、分析和计算,最终输出可用结果。以下从多个维度详细解析这一概念:
3.2.1. 数据计算定义与定位
位置:位于数据架构中层,连接数据存储层(如数据湖、数据仓库)与上层应用(如BI工具、业务系统)。
核心目标:将原始数据转化为业务价值,支撑实时分析、机器学习、报表生成等场景。
3.2.2. 数据计算核心功能
数据加工:清洗(去重、补全)、转换(格式标准化)、聚合(统计指标计算)。
复杂计算:机器学习模型训练、图计算、实时流处理。
资源调度:合理分配CPU、内存、GPU等资源,优化任务执行效率。
3.2.3. 数据计算技术方案
计算引擎
- 批处理:Apache Spark(内存计算)、Hadoop MapReduce(离线高吞吐)。
- 流处理:Apache Flink(低延迟)、Kafka Streams(实时管道)。
- 混合计算:Apache Beam(统一编程模型,支持批/流)。
任务调度
- 分布式调度:Airflow(DAG工作流)、DolphinScheduler(可视化编排)。
- 资源管理:YARN(Hadoop生态)、Kubernetes(容器化计算)。
数据接口
- SQL/API:支持标准SQL查询(Presto、ClickHouse),或通过REST API暴露计算结果。
3.2.4. 数据计算技术选型策略
| 场景 | 推荐技术 | 示例 |
| 离线批处理 | Spark、Flink(批模式) | 用户行为日志聚合分析 |
| 实时流处理 | Flink、Kafka + Flink CEP | 金融交易风控实时监测 |
| 机器学习训练 | TensorFlow、PyTorch + Horovod | 图像识别模型分布式训练 |
| Serverless轻量级计算 | AWS Lambda、Google Cloud Functions | 突发性小规模数据处理 |
3.2.5. 数据计算设计原则
扩展性:采用分布式架构(如K8s自动扩缩容),支持横向扩展。
容错性:检查点机制(Flink Savepoint)、任务重试策略。
性能优化:内存计算(Spark RDD)、向量化执行(Apache Arrow)。
成本控制:Spot实例(AWS)、存算分离(Snowflake架构)。
3.2.6. 数据计算典型应用场景
实时推荐系统:Flink实时处理用户点击流,更新推荐模型。
IoT数据分析:边缘节点预处理传感器数据,云端聚合分析。
基因测序:Spark分布式处理TB级基因序列数据。
3.2.7. 数据计算挑战与解决方案
数据倾斜:自定义分区策略、局部聚合(加盐处理)。
状态管理:使用RocksDB(Flink状态后端)处理超大状态。
延迟敏感场景:Flink窗口优化(增量聚合+会话窗口)。
3.3. 数据服务层
数据服务层是大数据系统架构中的核心环节,负责将底层存储与计算的数据资源转化为可被业务直接调用的标准化服务,同时解决数据易用性、稳定性、安全性等问题。以下是结合阿里巴巴实践的数据服务层核心要点:
3.3.1. 数据服务层核心目标
高效赋能业务:为内部员工、外部客户及合作伙伴提供统一、标准化的数据服务接口,降低数据使用门槛。
保障服务质量:确保数据服务的实时性、准确性、稳定性,支撑高并发业务场景(如双11实时数据披露)。
实现数据资产化:通过服务化将数据转化为可量化、可运营的资产,提升数据复用价值。
3.3.2. 数据服务架构设计要点
数据接入与整合
- 统一接入规范:制定标准化的数据接入协议,支持多源异构数据(日志、数据库、IoT设备等)的统一采集。
- 多源数据融合:整合离线(批处理)与实时(流处理)数据,构建全域数据视图。
数据处理与建模
- 分层数据模型:构建ODS(原始数据层)、DWD(明细数据层)、DWS(汇总数据层)、ADS(应用数据层)等分层体系,提升数据复用性。
- 实时与离线协同:通过Lambda或Kappa架构平衡实时计算(如Flink)与离线计算(如Hadoop)的协同效率。
服务化能力
- API网关管理:提供标准化API接口,支持SQL、RESTful等多种调用方式,实现数据服务的统一入口。
- 动态资源调度:基于容器化技术(如Kubernetes)弹性分配计算资源,应对突发流量(如双11支付峰值)。
安全与权限管控
- 精细化权限控制:基于RBAC(角色访问控制)模型,实现数据分级分类授权(如商家仅能访问自身数据)。
- 数据脱敏与加密:对敏感字段(如用户身份信息)进行动态脱敏,保障数据安全合规。
3.3.3. 数据服务关键技术挑战与解决方案
| 挑战 | 解决方案 |
| 高并发实时响应 | 使用内存计算技术(如Redis)、预计算(Cube)优化,实现PB级数据毫秒级响应。 |
| 数据一致性保障 | 通过分布式事务框架(如Seata)、数据校验规则引擎确保跨系统数据一致性。 |
| 服务性能瓶颈 | 引入缓存机制(如CDN、本地缓存)、异步处理(消息队列)提升吞吐量。 |
| 资源成本控制 | 动态资源调度(如弹性伸缩)、存储分层(热数据/冷数据分离)降低资源消耗。 |
3.3.4. 数据服务典型应用场景
内部赋能:
- 数据中台:为业务部门提供统一数据看板、BI工具,支持实时决策(如供应链优化)。
- 数据产品:开放“生意参谋”等数据产品,赋能商家运营分析。
外部开放:
- 数据市场:通过API或数据沙箱向合作伙伴提供脱敏数据,驱动生态协作(如广告投放优化)。
3.4. 数据应用层
数据应用层是大数据系统架构的“最后一公里”,直接面向业务场景和终端用户,将经过治理的数据转化为可感知、可操作的业务价值。其核心目标是通过数据驱动业务决策、优化运营效率、创新产品体验,是数据从“资源”转化为“生产力”的关键环节。以下是结合阿里巴巴实践的数据应用层核心内容:
3.4.1. 数据应用核心目标
业务赋能:将数据能力嵌入业务流程,支撑实时决策、精准营销、用户运营等场景。
体验升级:通过数据驱动产品智能化(如个性化推荐、智能客服),提升用户体验。
价值变现:对外输出数据服务(如数据市场、行业解决方案),实现数据商业化。
3.4.2. 数据应用主要功能与场景
业务决策支持
- 实时BI与可视化:通过数据看板(如阿里“数据大屏”)实时监控业务指标(如双11支付峰值、GMV)。支持多维度下钻分析,辅助管理层快速决策(如库存调配、流量分配)。
- 预测与预警:基于机器学习模型预测业务趋势(如销量预测、用户流失预警)。
用户端应用
- 个性化推荐:利用用户画像、协同过滤算法(如“猜你喜欢”)提升点击率与转化率。结合实时行为数据动态调整推荐策略(如淘宝“千人千面”)。
- 智能客服:基于NLP(自然语言处理)的智能问答(如阿里“小蜜”),降低人工客服成本。
商家端赋能
- 数据产品工具:提供“生意参谋”等数据产品,帮助商家分析市场趋势、优化商品运营。开放API接口,支持商家自主获取经营数据(如流量来源、转化漏斗)。
- 广告投放优化:基于RTB(实时竞价)模型,通过数据匹配实现精准广告投放(如阿里妈妈)。
生态协同应用
- 供应链优化:通过数据预测需求波动,优化库存与物流链路(如菜鸟网络智能分仓)。
- 智慧城市:城市交通流量预测、公共资源调度(如杭州“城市大脑”)。
3.4.3. 数据应用技术挑战与解决方案
| 挑战 | 解决方案 |
| 实时性要求高 | 流批一体架构(如Flink+Iceberg),实现秒级延迟的数据应用。 |
| 多源数据一致性 | 通过数据湖(Data Lake)统一存储,结合数据血缘追踪确保数据可信。 |
| 个性化与规模化矛盾 | 构建通用推荐框架(如X-DeepFM模型),支持大规模用户个性化需求。 |
| 隐私与合规风险 | 联邦学习(Federated Learning)实现数据“可用不可见”,满足GDPR等法规要求。 |
3.4.4. 数据应用典型应用案例
- 阿里巴巴内部:
-
- 双11大促:实时数据看板监控全球交易动态,动态调整服务器资源与营销策略。
- 聚划算:基于商品热度预测与用户兴趣匹配,实现活动商品的精准推荐。
- 外部合作:
-
- 数据市场:向企业提供脱敏后的行业趋势数据,辅助其战略规划。
- 金融风控:输出信用评估模型,助力金融机构降低坏账率。
4. 数据治理体系难点和重点
数据治理体系是企业在DT时代实现数据资产化、价值化的核心基础,但其建设面临复杂挑战,需平衡技术、管理与业务需求。以下是关键难点、重点及技术应用方向:
4.1. 数据治理体系的核心难点
数据规模与复杂性
- 挑战:EB级数据存储、千亿级实时记录、多源异构数据(日志、IoT、业务系统等)整合困难。
- 典型场景:阿里双11期间单日数据量超百亿级,需支持实时分析与历史回溯。
多源异构数据融合
- 挑战:数据来源分散(数据库、日志、第三方API),格式多样(结构化、半结构化、非结构化),语义不一致。
- 典型问题:同一实体(如用户)在不同系统中标识不一致,导致数据冗余与冲突。
实时性与一致性要求
- 挑战:高并发场景(如支付峰值)需毫秒级响应,同时保证跨系统数据一致性(如订单与库存同步)。
- 矛盾点:实时计算(流处理)与离线批处理的协同效率问题。
安全与隐私合规
- 挑战:数据泄露风险(如用户敏感信息)、GDPR/《数据安全法》等法规合规压力。
- 难点:如何在数据共享与隐私保护间平衡(如多方数据联合建模)。
技术与组织协同
- 挑战:技术架构复杂(分布式存储、微服务化),跨部门协作低效(如数据需求响应慢)。
- 典型矛盾:业务部门需求快速迭代 vs. 数据治理流程僵化。
4.2. 数据治理体系的核心重点
标准化与规范化
- 目标:建立统一数据模型、命名规范、质量标准,消除歧义。
- 实践:阿里数据中台的“OneData”体系,通过分层建模(ODS→DWD→DWS→ADS)实现全域数据标准化。
数据质量管控
- 目标:确保准确性、完整性、一致性、时效性。
- 方法:
-
- 规则引擎:定义数据质量规则(如字段非空、值域校验);
- 自动化检测:实时监控异常数据(如订单金额负值);
- 根因分析:通过血缘追踪定位问题源头(如上游ETL任务失败)。
安全与隐私保护
- 目标:实现数据“可用不可见”与合规使用。
- 技术:
-
- 动态脱敏:对敏感字段(如手机号)按角色动态掩码;
- 联邦学习:跨机构联合建模,避免原始数据出域;
- 区块链存证:记录数据操作日志,确保审计可追溯。
高效架构设计
- 目标:支持弹性扩展、高并发与低成本运维。
- 技术选型:
-
- 云原生架构:容器化(Kubernetes)+ 弹性伸缩(Auto Scaling)应对流量洪峰;
- 数据湖与湖仓一体:统一存储(如Hudi/Iceberg)支持批流一体,降低存储成本。
工具链与自动化
- 目标:降低人工干预,提升治理效率。
- 工具:
-
- 元数据管理平台:自动采集数据血缘、Schema变更;
- 数据开发IDE:一站式完成ETL开发、调试与部署;
- AI辅助治理:NLP自动生成数据字典,机器学习识别数据异常模式。
4.3. 数据治理技术上需重点
| 技术方向 | 核心作用 | 典型应用场景 |
| 实时计算引擎 | 支持低延迟、高吞吐的实时数据处理 | Flink处理双11支付峰值每秒12万笔交易实时统计 |
| 数据湖与湖仓一体 | 统一存储多源数据,支持批流协同分析 | 阿里云Data Lake Analytics实现PB级数据低成本存储与分析 |
| 数据血缘与图谱 | 追踪数据全生命周期,支持影响分析 | 阿里“数据血缘平台”自动解析表级/字段级依赖关系 |
| 自动化质量治理 | 减少人工巡检,提升数据可靠性 | 阿里“数据质量管家”自动拦截脏数据并触发告警 |
| 隐私计算技术 | 解决跨域数据协作中的隐私问题 | 蚂蚁链摩斯平台支持多方安全计算(MPC)建模 |
| AI驱动的智能运维 | 预测资源需求,优化集群性能 | 阿里云MaxCompute基于时序预测动态扩缩容 |
4.4. 数据治理技术落地的关键原则
- 业务驱动:治理目标需与业务场景强关联(如双11保障优先级高于日常治理)。
- 分层推进:从核心业务(如交易数据)切入,逐步扩展至全域数据。
- 技术组合:混合架构(如OLAP+OLTP)适配不同场景需求。
- 持续迭代:通过A/B测试验证治理效果,动态优化策略。
阿里巴巴实践启示:
- 数据中台:通过“OneEntity, OneID, OneService”实现数据资产化;
- 数据血缘平台:支持分钟级定位数据问题,降低运维成本30%+;
- 隐私计算:在金融风控领域实现数据“可用不可见”,坏账率下降15%。
核心结论:数据治理是技术、管理与业务的系统性工程,需以标准化为基础、智能化为手段、安全合规为底线,最终实现数据从“成本”到“资产”的跃迁。
博文参考
《阿里巴巴大数据实践》
相关文章:

数据治理域——数据治理体系建设
摘要 本文主要介绍了数据治理系统的建设。数据治理对企业至关重要,其动因包括应对数据爆炸增长、提升内部管理效率、支撑复杂业务需求、加强风险防控与合规管理以及实现数字化转型战略。其核心目的是提升数据质量、统一数据标准、优化数据资产管理、支撑业务发展和…...

数据库实验报告 SQL SERVER 2008的基本操作 1
实验报告(第 1 次) 实验名称 SQL SERVER 2008的基本操作 实验时间 9月14日1-2节 一、实验内容 数据库的基本操作:包括创建、修改、附加、分离和删除数据库等。 二、源程序及主要算法说明 本次实验不涉及程序和算法。 三、测…...

基于STM32、HAL库的ICP-20100气压传感器 驱动程序设计
一、简介: ICP-20100 是 InvenSense(TDK 集团旗下公司)生产的一款高精度数字气压传感器,专为需要精确测量气压和海拔高度的应用场景设计。它具有低功耗、高精度、快速响应等特点,非常适合物联网、可穿戴设备和无人机等应用。 二、硬件接口: ICP-20100 引脚STM32L4XX 引脚…...

提示工程实战指南:Google白皮书关键内容一文讲清
You don’t need to be a data scientist or a machine learning engineer – everyone can writea prompt. 一、概述 Google于2025年2月发布的《Prompt Engineering》白皮书系统阐述了提示工程的核心技术、实践方法及挑战应对策略。该文档由Lee Boonstra主编,多位…...

国产大模型「五强争霸」:决战AGI,谁主沉浮?
引言 中国AI大模型市场正经历一场史无前例的洗牌!曾经“百模混战”的局面已落幕,字节、阿里、阶跃星辰、智谱和DeepSeek五大巨头强势崛起,形成“基模五强”新格局。这场竞争不仅是技术实力的较量,更是资源、人才与生态的全面博弈。…...
、设置阻塞/非阻塞)
Linux进程10-有名管道概述、创建、读写操作、两个管道进程间通信、读写规律(只读、只写、读写区别)、设置阻塞/非阻塞
目录 1.有名管道 1.1概述 1.2与无名管道的差异 2.有名管道的创建 2.1 直接用shell命令创建有名管道 2.2使用mkfifo函数创建有名管道 3.有名管道读写操作 3.1单次读写 3.2多次读写 4.有名管道进程间通信 4.1回合制通信 4.2父子进程通信 5.有名管道读写规律ÿ…...

高吞吐与低延迟的博弈:Kafka与RabbitMQ数据管道实战指南
摘要 本文全面对比Apache Kafka与RabbitMQ在数据管道中的设计哲学、核心差异及协同方案。结合性能指标、应用场景和企业级实战案例,揭示Kafka在高吞吐流式处理中的优势与RabbitMQ在复杂路由和低延迟传输方面的独特特点;介绍了使用Java生态成熟第三方库&…...
 深入解析)
C++23 views::slide (P2442R1) 深入解析
文章目录 引言C20 Ranges库回顾什么是Rangesstd::views的作用 views::slide 概述基本概念原型定义辅助概念工作原理代码示例输出结果 views::slide 的应用场景计算移动平均值查找连续的子序列 总结 引言 在C的发展历程中,每一个新版本都会带来一系列令人期待的新特…...

SpringDataRedis的入门案例,以及RedisTemplate序列化实现
目录 SpringDataRedis 简单介绍 入门案例 RedisTemplate序列化方案 方案一: 方案二: SpringDataRedis 简单介绍 提供了对不同Redis客户端的整合(Lettuce和Jedis) 提供了RedisTemplate统一API来操作Redis 支持Redis的发布订阅模型 支持Redis哨兵和Redis集群 支持基于…...

鸿蒙HarmonyOS list优化一: list 结合 lazyforeach用法
list列表是开发中不可获取的,非常常用的组件,使用过程中会需要不断的优化,接下来我会用几篇文章进行list在纯原生的纯血鸿蒙的不断优化。我想进大厂,希望某位大厂的看到后能给次机会。 首先了解一下lazyforeach: Laz…...

【Jenkins简单自动化部署案例:基于Docker和Harbor的自动化部署流程记录】
摘要 本文记录了作者使用Jenkins时搭建的一个简单自动化部署案例,涵盖Jenkins的Docker化安装、Harbor私有仓库配置、Ansible远程部署等核心步骤。通过一个SpringBoot项目 (RuoYi) 的完整流程演示,从代码提交到镜像构建、推送、滚动更新,逐步实…...

【愚公系列】《Manus极简入门》034-跨文化交流顾问:“文化桥梁使者”
🌟【技术大咖愚公搬代码:全栈专家的成长之路,你关注的宝藏博主在这里!】🌟 📣开发者圈持续输出高质量干货的"愚公精神"践行者——全网百万开发者都在追更的顶级技术博主! …...

数字滤波器应用介绍
此示例说明如何设计、分析数字过滤器并将其应用于数据。它将帮助您回答以下问题: 如何补偿滤波器引入的延迟?如何避免使信号失真?如何从信号中删除不需要的内容?如何微分信号?以及积分信号文章目录 补偿筛选引入的延迟补偿恒定滤波器延迟 如FIR引起的消除方法,末尾添零补…...

木马查杀篇—Opcode提取
【前言】 介绍Opcode的提取方法,并探讨多种机器学习算法在Webshell检测中的应用,理解如何在实际项目中应用Opcode进行高效的Webshell检测。 Ⅰ 基本概念 Opcode:计算机指令的一部分,也叫字节码,一个php文件可以抽取出…...
)
栈和队列复习(C语言版)
目录 一.栈的概念 二.栈的实现 三.队列的概念 四.队列的实现 五.循环队列的实现 一.栈的概念 可以将栈抽象地理解成羽毛球桶,或者理解成坐直升电梯;最后一个进去的,出来时第一个出来,并且只有一个出入口。这边需要注意的是&am…...

SDK does not contain ‘libarclite‘ at the path
Xcode16以上版本更新SDK之后就报错了。是因为缺少libarclite_iphoneos.a文件。所以需要在网上找一下该文件根据路径添加进去,arc文件可能需要新建一下。 clang: error: SDK does not contain ‘libarclite’ at the path ‘/Applications/Xcode.app/Contents/Develo…...

Kotlin跨平台Compose Multiplatform实战指南
Kotlin Multiplatform(KMP)结合 Compose Multiplatform 正在成为跨平台开发的热门选择,它允许开发者用一套代码构建 Android、iOS、桌面(Windows/macOS/Linux)和 Web 应用。以下是一个实战指南,涵盖核心概念…...

Oracle数据库全局性HANG的处理过程
如果Oracle数据库全局性HANG,首先要做的就是收集数据库HANG时的状态,只有收集到了相应状态,抓住故障现场,才可以进一步分析故障产生的可能原因。 出现此故障,一般情况下可以如此处理: 如果数据库是单节点&a…...
英文题库(21-30))
MySQL 8.0 OCP(1Z0-908)英文题库(21-30)
目录 第21题题目分析正确答案 第22题题目分析正确答案 第23题题目分析正确答案 第24题题目分析正确答案 第25题题目分析正确答案 第26题题目分析正确答案 第27题题目分析正确答案 第28题题目分析正确答案 第29题题目分析正确答案 第30题题目解析正确答案 第21题 Choose three.…...
)
beyond compare 免密钥进入使用(删除注册表)
beyond compare 免密钥进入,免费使用(删除注册表) 温馨提醒:建议仅个人使用,公司使用小心律师函警告! 1.winr 输入regedit 打开注册表 2.删除计算机 \HKEY_CURRENT_USER\Software\Scooter Software\Beyo…...

前端项目2-01:个人简介页面
目录 一.代码显示 二.效果图 三.代码分析 1. 文档声明和 HTML 基本结构 2. CSS 样式部分 全局样式 body 样式 页面主要容器 box 样式 左侧区域 l 样式 右侧区域 r 样式 左侧区域中头像容器 to 样式 头像图片样式及悬停效果 左侧区域中个人信息容器 tit 样式 个人…...

.NET 8 API 实现websocket,并在前端angular实现调用
.NET 8 API 实现websocket,并在前端angular实现调用。 后端:.NET 8 WebSocket API 实现 在 .NET 8 中,可以通过 Microsoft.AspNetCore.WebSockets 提供的支持来实现 WebSocket 功能。以下是创建一个简单的 WebSocket 控制器的步骤。 安装必…...

P2P架构
P2P 是 Peer-to-Peer(点对点) 的缩写,是一种 去中心化 的网络架构,其中每个节点(称为 “对等节点”,Peer)既是 “客户端”,也是 “服务器”,可以直接与其他节点通信、共享…...

菊厂0510面试手撕题目解答
题目 输入一个整数数组,返回该数组中最小差出现的次数。 示例1:输入:[1,3,7,5,9,12],输出:4,最小差为2,共出现4次; 示例2:输入:[90,98,90,90,1,1]…...
VPN虚拟专用网 L2TP、PPTP、PPP认证方式;IPSec、GRE)
【25软考网工】第六章(4)VPN虚拟专用网 L2TP、PPTP、PPP认证方式;IPSec、GRE
博客主页:christine-rr-CSDN博客 专栏主页:软考中级网络工程师笔记 大家好,我是christine-rr !目前《软考中级网络工程师》专栏已经更新二十多篇文章了,每篇笔记都包含详细的知识点,希望能帮助到你!…...
)
C语言:深入理解指针(3)
目录 一、数组名的理解 二、用指针访问数组 三、一维数组传参的本质 四、冒泡排序 五、二级指针 六、指针数组 七、指针数组模拟二维数组 八、结语 一、数组名的理解 数组名其实就是首元素的地址 int arr[3] {1,2,3}; printf("arr :%p\n" ,arr); printf(…...
)
R语言实战第5章(1)
第一部分:数学、统计和字符处理函数 数学和统计函数:R提供了丰富的数学和统计函数,用于执行各种计算和分析。这些函数可以帮助用户快速完成复杂的数学运算、统计分析等任务,例如计算均值、方差、相关系数、进行假设检验等。字符处…...

Lodash isEqual 方法源码实现分析
Lodash isEqual 方法源码实现分析 Lodash 的 isEqual 方法用于执行两个值的深度比较,以确定它们是否相等。这个方法能够处理各种 JavaScript 数据类型,包括基本类型、对象、数组、正则表达式、日期对象等,并且能够正确处理循环引用。 1. is…...

探索边缘计算:赋能物联网的未来
摘要 随着物联网(IoT)技术的飞速发展,越来越多的设备接入网络,产生了海量的数据。传统的云计算模式在处理这些数据时面临着延迟高、带宽不足等问题,而边缘计算的出现为解决这些问题提供了新的思路。本文将深入探讨边缘…...

Ubuntu中配置【Rust 镜像源】
本篇主要记录Ubuntu中配置Rust编程环境时,所需要做的镜像源相关的配置 无法下载 Rust 工具链 通过环境变量指定 Rust 的国内镜像源(如中科大或清华源)。 方法一:临时设置镜像 export RUSTUP_DIST_SERVERhttps://mirrors.ustc.e…...

netty 客户端发送消息服务端收到消息无法打印,springBoot配合 lombok使用@Slf4j
netty 客户端发送消息服务端收到消息无法打印,springBoot配合 lombok使用Slf4j 服务端代码 Slf4j public class EventLoopServer {public static void main(String[] args) throws InterruptedException {new ServerBootstrap().group(new NioEventLoopGroup()).c…...
)
学习笔记:黑马程序员JavaWeb开发教程(2025.4.3)
12.1 基础登录功能 EmpService中的login方法,是根据接收到的用户名和密码,查询时emp数据库中的员工信息,会返回一个员工对象。使用了三元运算符来写返回 Login是登录,是一个业务方法,mapper接口是持久层,是…...
)
Spark SQL 运行架构详解(专业解释+番茄炒蛋例子解读)
1. 整体架构概览 Spark SQL的运行过程可以想象成一个"SQL查询的加工流水线",从原始SQL语句开始,经过多个阶段的处理和优化,最终变成分布式计算任务执行。主要流程如下: SQL Query → 解析 → 逻辑计划 → 优化 → 物理…...
字符数组的输入输出)
【时时三省】(C语言基础)字符数组的输入输出
山不在高,有仙则名。水不在深,有龙则灵。 ----CSDN 时时三省 字符数组的输入输出可以有两种方法。 ( 1 )逐个字符输入输出。用格式符“% c”输入或输出一个字符. ( 2 )将整个字符串一次输入或输出。用“% s”格式符,意思是对字符串( strin…...

Hive HA配置高可用
Hive的高可用性(HA)通过消除关键组件的单点故障来实现,确保系统在部分故障时仍能正常运行。其基本原理涉及以下核心组件和策略: 1. Hive Metastore 的高可用 多实例部署:部署多个Metastore服务实例,每个实例连接到共享的后端数据库(如MySQL、PostgreSQ…...

Python爬虫第20节-使用 Selenium 爬取小米商城空调商品
目录 前言 一、 本文目标 二、环境准备 2.1 安装依赖 2.2 配置 ChromeDriver 三、小米商城页面结构分析 3.1 商品列表结构 3.2 分页结构 四、Selenium 自动化爬虫实现 4.1 脚本整体结构 4.2 代码实现 五、关键技术详解 5.1 Selenium 启动与配置 5.2 页面等待与异…...

重构金融数智化产业版图:中电金信“链主”之道
近日,《商学院》杂志独家专访了中电金信常务副总经理(主持经营工作)冯明刚,围绕“金融科技”“数字底座”“架构转型”“AI驱动”等议题,展开了一场关于未来架构、技术变革与系统创新的深入对话。 当下,数字…...

笔记本电脑升级实战手册【扩展篇1】:flash id查询硬盘颗粒
文章目录 前言:一、硬盘颗粒介绍1、MLC(Multi-Level Cell)2、TLC(Triple-Level Cell)3、QLC(Quad-Level Cell) 二、硬盘与主控1、主控介绍2、主流主控厂家 三 、硬盘颗粒查询使用flash id工具查…...

文档外发安全:企业数据防护的最后一道防线
在当今数字化时代,数据已成为企业最宝贵的资产之一。随着网络安全威胁日益增多,企业安装专业加密软件已从"可选"变为"必选"。本文将全面分析企业部署华途加密解决方案后获得的各项战略优势。 一、数据安全防护升级 核心数据全面保护…...

springboot集成langchain4j实现票务助手实战
前言 看此篇的前置知识为langchain4j整合springboot,以及springboot集成langchain4j记忆对话。 Function-Calls介绍 langchain4j 中的 Function Calls(函数调用)是一种让大语言模型(LLM)与外部工具(如 A…...
: VDMA HDMI 彩条显示)
ZYNQ笔记(二十一): VDMA HDMI 彩条显示
版本:Vivado2020.2(Vitis) 任务:实现驱动 HDMI 显示彩条图像,同时支持输出给 HDMI 的图像分辨率可调。 目录 一、介绍 二、硬件设计 (1)DVI_Transmitter (2)Clockin…...

常用的maven插件及其使用指南
目录 1.maven官方插件列表2.两种方式调用maven插件3.常用的maven插件总结参考文献 1.maven官方插件列表 groupId为org.apache.maven.pluginshttp://maven.apache.org/plugins/index.html 2.两种方式调用maven插件 将插件目标与生命周期阶段绑定,例如maven默认将m…...

Meilisearch 安装
1.环境 rockey linux 9.2 meilisearch-linux-amd64 2.下载 访问:https://github.com/meilisearch/meilisearch/releases 下载适合自己系统版本的。 注意:我下载的不是最新版本的,因为最新版本的需要GLIBC2.35,我本地系统的是…...

用postman的时候如何区分服务器还是自己的问题?
作为测试人员,在使用Postman进行接口测试时,准确判断问题是出在服务器端还是本地环境非常重要。以下是一些实用的区分方法: 1. 基础检查方法 本地问题排查清单: ✅ 检查网络连接是否正常 ✅ 确认Postman版本是否为最新 ✅ 验证请求URL是否正确(特别是环境变量是否被正确…...

【Python算法】最长递增子序列
题目链接 方法1: 记忆化搜索 class Solution:def lengthOfLIS(self, nums: List[int]) -> int:cachedef dfs(i):res0 for j in range(i):if nums[j]<nums[i]:res max(res,dfs(j))return res1 # 返回res表示以nums[i]结尾的LIS长度return max(dfs(i) for i…...

springboot-web基础
21.web spring MVC 基于浏览器的 B/S 结构应用十分流行。Spring Boot 非常适合 Web 应用开发。可以使用嵌入式 Tomcat、Jetty、 Undertow 或 Netty 创建一个自包含的 HTTP 服务器。一个 Spring Boot 的 Web 应用能够自己独立运行,不依赖需 要安装的 Tomcat&#x…...

解构赋值
【系统学习ES6】 本专题旨在对ES6的常用技术点进行系统性梳理,帮助大家对其有更好的掌握,希望大家有所收获。 ES6允许按照一定模式,从数组和对象中提取值,对变量进行赋值,这被称为解构。解构是一种打破数据结构&#x…...

Leetcode-BFS问题
LeetCode-BFS问题 1.Floodfill问题 1.图像渲染问题 [https://leetcode.cn/problems/flood-fill/description/](https://leetcode.cn/problems/flood-fill/description/) class Solution {public int[][] floodFill(int[][] image, int sr, int sc, int color) {//可以借助另一…...

AI 时代 UI 设计的未来范式
在人工智能技术持续突破的浪潮下,UI 设计领域正经历着前所未有的变革。AI 的深度介入不仅重塑了设计流程,更催生了全新的设计范式,为用户带来颠覆式的交互体验。探索 AI 时代 UI 设计的未来范式,是把握行业发展趋势的关键所在。…...

键盘输出希腊字符方法
在不同操作系统中,输出希腊字母的方法有所不同。以下是针对 Windows 和 macOS 系统的详细方法,以及一些通用技巧: 1.Windows 系统 1.1 使用字符映射表 字符映射表是一个内置工具,可以方便地找到并插入希腊字母。 • 步骤…...