【连载6】基础智能体的进展与挑战综述-奖励
基础智能体的进展与挑战综述
从类脑智能到具备可进化性、协作性和安全性的系统
【翻译团队】刘军(liujun@bupt.edu.cn) 钱雨欣玥 冯梓哲 李正博 李冠谕 朱宇晗 张霄天 孙大壮 黄若溪
5. 奖励
奖励机制帮助智能体区分有益与有害的行为,塑造其学习过程并影响其决策。本章首先介绍人体中的常见奖励物质及其对应的奖励通路。随后,定义了智能体中的奖励范式及所涉及的不同方法。在讨论部分,描述了奖励模块与其他模块之间的影响关系,并总结了当前已有的方法,最后探讨了亟需解决的问题和未来的优化方向。
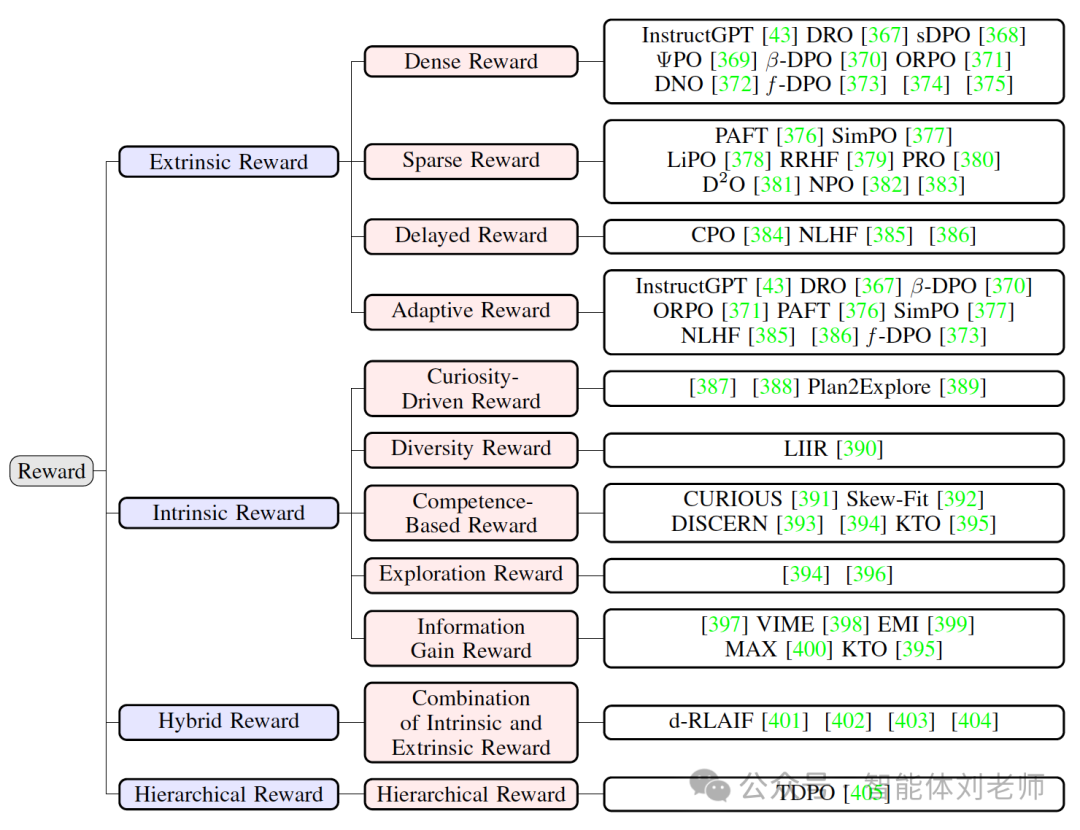
图5.1:奖励系统的分类
5.1 人类奖励路径
大脑的奖励系统大致由两个主要的解剖路径构成。第一条路径是内侧前脑束,它起源于前脑基底部,穿过中脑,最终终止于脑干区域。第二条路径是背侧间脑传导系统,它起源于内侧前脑束的吻侧部分,穿过缰核并投射至中脑结构[407]。人脑中的反馈机制和物质构成十分复杂,涉及多种神经递质、激素及其他分子,这些物质通过神经递质系统和奖励回路等反馈机制调节脑功能、情绪、认知和行为。反馈机制既可以是正反馈(如奖励系统中的反馈),也可以是负反馈(如抑制过度神经活动)。常见的反馈物质[411]包括多巴胺、神经肽、内啡肽、谷氨酸等。
多巴胺是一种在大脑中起重要作用的信号分子,影响我们的情绪、动机、运动等方面[412]。这种神经递质在基于奖励的学习中至关重要,但其功能可能在多种精神障碍中受到破坏,例如情绪障碍和成瘾行为。中脑-边缘通路(mesolimbic pathway)[406]是一个关键的多巴胺能系统,它起源于腹侧被盖区(VTA)中的多巴胺神经元,并投射至多个边缘系统和皮质区域,包括纹状体、前额叶皮质、杏仁核和海马体。该通路在奖励处理、动机和强化学习中发挥核心作用,被广泛认为是大脑奖励系统的核心组成部分。
神经肽是另一类重要的神经系统信号分子,参与从情绪调节到代谢控制等多种功能,并且是一种作用较慢的信号分子。与仅限于突触的神经递质不同,神经肽信号可以影响更广泛的神经网络,从而提供更广泛的生理调节。研究发现,脑中不同神经肽受体的分布存在显著的皮质-皮质下梯度。此外,神经肽信号显著增强了脑区的结构-功能耦合,并表现出从感觉-认知功能向奖励-生理功能的专门化梯度[413]。
表5.1列出了人脑中常见的奖励通路、所传递的神经递质及其对应的作用机制,描述了人脑奖励系统的基本框架。
表5.1:人类常见奖励通路比较
| 通路 | 神经递质 | 机制 |
| 中边缘通路 [406] | 多巴胺 | 腹侧被盖区(VTA)中的多巴胺能神经元向伏隔核发出投射,在该处释放多巴胺以调节与奖励相关的信号传递。多巴胺跨越突触间隙扩散,并与多巴胺受体结合——主要是D1样受体(通过Gs蛋白激活,增加cAMP,具兴奋性)和D2样受体(通过Gi蛋白抑制,降低cAMP,具抑制性)——从而调节奖励、动机和强化过程。 |
| 中皮质通路 [407] | 多巴胺 | 从VTA发出的多巴胺能投射到达前额叶皮层(PFC)。在这里,多巴胺与其受体结合,影响认知功能,如决策、工作记忆和情绪调节,这些功能均与奖励的评估与预测有关。 |
| 黑质纹状体通路[407] | 多巴胺 | 多巴胺作用于纹状体中的D1和D2受体,有助于塑造运动程序以及与奖励相关的行为。 |
| 蓝斑核 [408] | 去甲肾上腺素 | 蓝斑核中的神经元向大脑多个区域广泛投射并释放去甲肾上腺素。在突触处,去甲肾上腺素与肾上腺素能受体(包括α和β亚型)结合,调节神经元的兴奋性、唤醒状态、注意力及压力反应。这些调节效应可以间接影响奖励处理与决策回路。 |
| 谷氨酸投射 [409] | 谷氨酸 | 谷氨酸释放到突触间隙后,会结合于后突触神经元上的离子型受体(如AMPA和NMDA受体)及代谢型受体,从而启动兴奋性信号传导。这种结合产生兴奋性突触后电位,对于奖励回路中的突触可塑性与学习过程至关重要。 |
| GABA能调节 [410] | γ-氨基丁酸 | GABA是主要的抑制性神经递质。在突触处,GABA与GABAA受体和GABAB受体结合,使突触后细胞产生超极化效应,从而提供抑制性调控,平衡奖励网络中的兴奋性信号。 |
5.2 从人类奖励到智能体奖励
在审视了人类奖励通路的基础之后,我们将目光转向人工智能体如何通过奖励信号学习并优化行为。虽然生物系统依赖复杂的神经化学和心理反馈回路,但人工智能体则依靠形式化的奖励函数来指导其学习与决策过程。这些机制虽受人类认知启发,但在结构和功能上却截然不同。理解这些系统之间的类比与差异,对于使人工行为与人类偏好保持一致具有重要意义。
在人类中,奖励深深嵌入在情感、社会和生理等丰富的背景网络中。它们通过多巴胺等神经递质参与的进化机制生成,并受到个体经验、文化以及心理特质的影响。相较之下,人工智能体依靠数学上定义清晰的奖励函数来运作,这些函数是外部指定且精确量化的,能够为优化算法(如强化学习)提供针对特定状态或动作的标量或概率反馈信号[3, 414]。
一个关键区别在于奖励的可编程性与可塑性。与受到生物结构与进化惯性限制的人类奖励系统不同,人工智能体的奖励函数是完全可定制的,并且可以根据任务需求迅速重新定义或调整。这种灵活性支持了有针对性的学习,但也带来了设计挑战——要准确捕捉人类复杂价值观的奖励函数设计是出了名的困难。
另一个重要的不同点涉及可解释性与泛化能力。人类的奖励往往是隐性的并受上下文影响,而智能体的奖励通常是显性的且与任务紧密绑定。智能体缺乏情感直觉与本能驱动,其学习完全依赖于奖励信号的形式与准确性。尽管像“基于人类反馈的强化学习”(RLHF)这样的框架试图通过偏好数据来塑造智能体行为[12],但此类方法仍难以捕捉人类目标的全部复杂性,尤其是在偏好具有非传递性、循环性或强烈情境依赖的情况下[321]。
此外,尽管在设计中尝试借鉴人类奖励机制——例如模拟内在动机或社会认同——但这些尝试受到限制,因为人工智能体缺乏意识、具身性以及主观体验。因此,尽管人类奖励系统为设计提供了重要灵感,但人工奖励函数的设计必须面对根本不同的约束,包括防范错误指定、抵御对抗性操控,以及避免与人类长期利益的偏离。
接下来的部分将深入探讨智能体奖励模型,重点分析其设计原则、演进过程,以及如何在形式化系统中选择性地整合人类启发因素,以优化人工行为。
5.3 AI奖励范式
奖励机制同样存在于智能体中,尤其是在强化学习的场景中。奖励是引导智能体在环境中采取行动的核心信号。它们反映了对智能体行为的反馈,用于评估智能体在特定状态下某一动作的优劣,从而影响其后续动作的决策。通过持续的试错与调整,智能体逐步学习如何在不同状态下选择能获得高奖励的行为策略。这一过程使得智能体能够根据环境反馈不断优化自身行为,最终实现目标导向的自主决策能力。
5.3.1 定义与概述
在强化学习中,奖励模型决定了智能体在其所处环境中执行动作后如何获得反馈。该模型在引导智能体行为中起着关键作用,通过量化某一状态下动作的“可取性”,从而影响其决策过程。
-
形式化定义:
智能体与环境的交互可以被形式化地描述为一个马尔可夫决策过程(Markov Decision Process, MDP)[415],其表示为:

其中:
✓ 表示状态空间,包含环境中所有可能的状态。
✓ 表示动作空间,包含在任一状态下智能体可以执行的所有动作。
✓ 表示状态转移概率,表示在状态 下执行动作 后转移到状态 的概率。
✓ 指定奖励函数,它为智能体在状态 下执行动作 后赋予一个即时的标量奖励。
✓ γ 是折扣因子,用于调节智能体对即时奖励与未来奖励的偏好,通过对未来奖励贡献的加权体现。
奖励函数 是智能体奖励模型构建中的基本组成部分,它在数学上表示为:

该函数根据智能体当前所处的状态 s 和所选择的动作 a 返回一个标量奖励值。这个标量值 是一个反馈信号,用于表示在给定状态下所选动作所带来的即时收益(或代价)。该奖励信号指导智能体的学习过程,帮助其评估在特定上下文中所采取动作的质量。
-
智能体奖励模型的目标
智能体的主要目标是最大化其在整个交互过程中获得的累计奖励。通常通过选择那些在长期内带来更高奖励的动作来实现该目标,这些长期奖励以时间步t下的回报(Return) 表示,其定义为未来折扣奖励的总和:

其中,rₜ₊ₖ 表示智能体在时间步 t+k 收到的奖励,γᵏ 是对时间步 t+k 所得奖励施加的折扣因子。智能体的目标是通过最大化期望回报来优化其策略,从而在长期内获得最大的收益。
在更高层次上,奖励模型可以根据其反馈信号的来源划分为以下四类:
i) 外在奖励(extrinsic reward),
ii) 内在奖励(intrinsic reward),
iii) 混合奖励(hybrid reward),
iv) 分层奖励模型(hierarchical model)。
每一类又可以进一步细分为多个子类。图 5.2展示了不同类型奖励的结构和分类。接下来,我们将深入探讨这些不同的奖励类型,分别介绍它们的独特特征和应用场景。
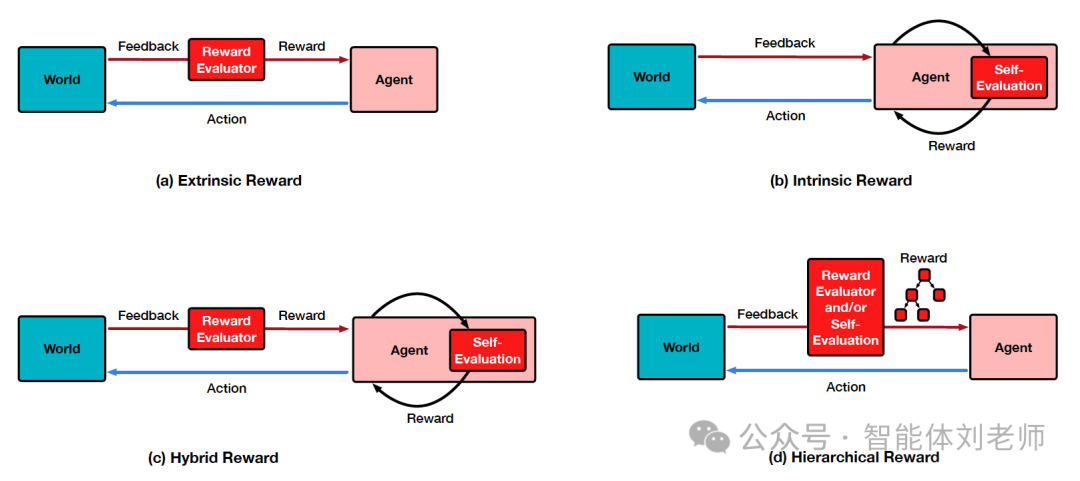
图5.2:四种奖励类型
5.3.2 外在奖励
外在奖励是指由外部定义的信号,用于引导智能体朝向特定目标采取行动。在人工学习系统中,尤其是强化学习中,这些奖励信号作为成功的智能体,通过可量化的结果来塑造策略。然而,奖励的结构与发放方式会显著影响学习动态,不同的反馈分布方式存在各种权衡。
-
稠密奖励(Dense Reward):
稠密奖励信号在每一步或每次动作后都提供高频反馈。这种频繁指导可以加快学习速度,使智能体能立即将动作与结果联系起来。但稠密反馈有时也会导致短视行为,或过度拟合于易于测量的智能体指标,而非更深层次的对齐目标。
例如,InstructGPT[43]使用人类对模型输出的排序结果,在微调过程中提供持续的偏好信号,从而实现高效行为塑造。类似地,Cringe Loss[416]及其扩展方法[374]将人类的成对偏好转换为稠密训练目标,在每次比较中都提供即时信号。Direct Reward Optimization (DRO)[367]则进一步简化该范式,跳过成对比较,直接将每个响应与一个标量得分关联,使奖励信号更具可扩展性和成本效益。这些方法展示了稠密反馈如何促进细粒度优化,但同时也必须谨慎设计,以避免流于表面的一致性。
-
稀疏奖励(Sparse Reward):
稀疏奖励较少发生,通常只在达到主要里程碑或完成任务时才触发。这类奖励往往更能反映任务的整体成功标准,但由于反馈延迟,导致信贷分配更具挑战,特别是在复杂环境中。
例如,PAFT[376]将监督学习与偏好对齐解耦,仅在特定决策点提供反馈,体现了一种更宏观的成功概念,但也增加了优化难度。同样,SimPO[377]利用基于对数概率的隐式奖励,而不依赖稠密比较。这种稀疏性简化了训练流程,但在应对细微偏好变化方面可能反应不足。稀疏奖励系统通常更具鲁棒性,但需要更强的建模假设或更具策略性的探索机制。
-
延迟奖励(Delayed Reward):
延迟奖励将反馈推迟到一系列动作之后,要求智能体对长期后果进行推理。这种设置在中间步骤可能具有误导性或仅在事后才有意义的任务中至关重要。挑战在于将结果归因于较早的决策,这会加大学习难度,但也能促进规划能力和抽象思维的发展。
Contrastive Preference Optimization(CPO)[384]通过对比多个翻译结果的集合进行训练,而非单独评估每个结果。奖励信号仅在生成多个候选项后才出现,从而加强跨迭代的模式识别。Nash Learning from Human Feedback[385]同样延迟反馈,直到模型通过竞争比较识别出稳定策略。这些方法利用延迟奖励来推动智能体超越表层优化,向长期目标对齐,但代价是收敛速度较慢、训练动态更复杂。
-
自适应奖励(Adaptive Reward):
自适应奖励会根据智能体的行为或学习进度动态调整奖励机制。通过调节奖励函数,例如增加任务难度或调整奖励目标,这种方法支持在非平稳或模糊环境下的持续改进。然而,它也为奖励设计与评估引入了更多复杂性。
Self-Play Preference Optimization(SPO)[386]基于自对弈结果调整奖励,使用社会选择理论聚合偏好并引导学习。该方法允许系统通过进化自身标准实现自我精炼。f-DPO[373]则引入发散性约束,在训练过程中动态调整奖励景观。通过调节对齐性与多样性之间的权衡,这些方法能在不确定环境下实现鲁棒的偏好建模,但需谨慎校准,以避免不稳定性或意外偏差。
5.3.3 内在奖励
内在奖励是指由智能体自身生成的激励信号,这类奖励并不依赖于外部的任务结果,而是用以激发智能体自主探索、学习与改进。内在奖励机制通常被设计为促进泛化能力、自适应能力和自主技能习得,这些品质对于在复杂或稀疏奖励环境中的长期表现至关重要。不同的内在奖励范式聚焦于激发智能体不同的行为倾向。
-
好奇心驱动奖励(Curiosity-Driven Reward)
这种奖励鼓励智能体通过探索新颖或令人惊讶的经历来减少不确定性。其核心思想是在智能体对某一状态的预测误差较大时给予激励,从而推动其探索未知领域。在稀疏奖励场景中,该机制通过促进信息获取来弥补外部指导的不足。例如,Pathak 等人[387]提出利用逆动力学模型预测动作结果,并基于预测误差提供奖励,从而构建反馈环促进新颖性探索。Plan2Explore[389]则进一步结合前向规划机制,主动针对具有高度认知不确定性的区域进行探索,从而加快对未知环境的适应。尽管好奇心驱动方法在发现性任务中效果显著,但若缺乏控制机制,容易受噪声或虚假新奇性干扰。
-
多样性奖励(Diversity Reward)
多样性奖励旨在鼓励行为的多样化,引导智能体探索多种策略,而非过早收敛于次优解。此方法在多智能体或多模态任务中尤为有效,因为策略多样性有助于增强系统鲁棒性与协同表现。LIIR[390]就是一个例子,其为不同智能体分配个性化的内在信号,在维持整体目标一致性的同时推动各自策略多样化。多样性探索有助于扩展策略覆盖范围,但需要在多样性与目标一致性之间保持良好平衡,避免协同失败或目标偏移。
-
能力导向奖励(Competence-Based Reward)
能力导向奖励强调通过奖励智能体技能提升来促进学习进度。当智能体变得更熟练时,奖励机制会动态调整,进而形成一种自适应课程,支持持续技能获取。Skew-Fit[392]通过基于熵的目标采样机制鼓励智能体接触多样化状态,并维持适当挑战性。CURIOUS[391]则进一步实现课程生成自动化,通过挑选能最大化学习进度的目标来指导训练。能力导向方法非常适合于开放式环境,但往往需要精细的学习进度估计与目标难度控制。
-
探索奖励(Exploration Reward)
探索奖励直接激励智能体接触尚未充分探索的状态或动作,其重点在于交互的广度而非深度。与强调不可预测性的好奇心不同,探索奖励通常根据智能体的访问历史来衡量新颖性。例如,RND[394]利用一个随机初始化的网络对状态进行预测,将预测误差作为奖励,从而驱动智能体前往未知区域。该方法有助于防止策略过早收敛并提升鲁棒性,但若缺乏与具体学习目标的结合,可能导致探索缺乏方向性。
-
信息增益奖励(Information Gain Reward)
信息增益奖励将探索形式化为减少不确定性的过程,引导智能体选择那些预期带来最大知识增量的动作。这种奖励机制建立在信息论基础上,尤其适用于模型驱动或推理密集型任务。CoT-Info[397]就将该方法应用于语言模型,通过量化推理过程中的知识增益来优化子任务拆解。VIME[398]则借助贝叶斯推理机制,根据智能体对环境动态的信念更新程度进行奖励。该类方法为探索提供了理论上的严谨性,但往往计算成本较高,且依赖于对不确定性进行准确建模。
5.3.4 混合奖励
混合奖励框架融合了多种反馈来源,最常见的是内在奖励与外在奖励的结合,以实现更平衡且具适应性的学习。通过将内在奖励中的探索动机与外在奖励中的目标导向结构结合起来,该类系统旨在同时提升样本效率与泛化能力。这种范式在复杂环境或开放式任务中尤为有效,因为单独依赖某一种奖励类型往往难以满足全部任务需求。
混合奖励的一项核心优势在于其能够动态解决探索与利用之间的权衡问题。例如,Xiong 等人[403]在强化学习人类反馈(RLHF)背景下,结合了内在探索机制与外在的人类偏好反馈。他们基于反向 KL 正则化的上下文 bandit 框架,引导策略性探索的同时使智能体的行为与人类偏好保持一致。该方法通过迭代的 DPO(Divergence Preference Optimization)算法与多步拒绝采样机制,融合内在与外在奖励,在不牺牲效率的前提下实现探索与对齐的双重优化。
5.3.5 分层奖励
分层奖励架构将复杂目标分解为多个层级的子目标,每个子目标都对应特定的奖励信号。这种结构模仿了现实任务中的层级组织方式,使智能体能够将短期决策与长期规划协调统一。通过将低层奖励分配给即时动作、高层奖励分配给抽象目标,智能体能够学习具有组合性的行为,从而更有效地适应复杂环境。
在语言建模中,Token-level Direct Preference Optimization(TDPO)[405]就体现了这一原则。该方法通过偏好建模获得的细粒度 token 级奖励,对大型语言模型(LLMs)进行对齐。TDPO 使用正向 KL 散度与 Bradley-Terry 模型,兼顾本地决策优化与整体连贯性,从而更好地对齐人类偏好。此处的分层奖励不仅仅是一种结构设计,更是一种功能机制:协调地强化微观决策与宏观结果。
更广泛而言,分层奖励可以作为课程学习(curriculum learning)的支撑框架,引导智能体从较简单的子任务逐步学习,最终实现总体目标。在LLM智能体中,这种策略可能表现为对子组件(如工具使用、推理链条、交互流程)设定结构化奖励,从而逐步构建起支撑整体任务成功的能力体系。
5.4 总结和讨论
5.4.1 跟其他模块的交互
在智能系统中,奖励信号不仅仅是结果驱动的反馈,更是与核心认知模块(如感知、情感和记忆)接口的关键调节器。在基于大型语言模型(LLM)的智能体中,这些交互尤为明显,因为注意力机制、生成风格、记忆检索等模块都可以通过奖励塑造、偏好建模或微调目标被直接影响。
-
感知:在LLM智能体中,感知通常通过注意力机制实现,优先关注某些 token、输入或模态。奖励信号可以在训练过程中隐式地调节注意力权重,强化与正向结果相关联的模式。例如,在强化学习微调过程中,奖励模型可能会提升特定语言特征(如信息量、事实性、礼貌性)的权重,使得模型更倾向于关注符合这些特征的 token。这类似于生物系统中通过与奖励相关联的注意力调节来优先处理显著刺激的机制[417]。随着时间推移,智能体会内化一个“感知策略”:不仅关注“说了什么”,更关注“在特定任务背景下值得关注什么”。
-
情感:尽管LLM并不具备生物意义上的情感,奖励信号仍可引导其产生类似情绪的表达方式并调节对话风格。在人类对齐场景中,模型通常会因生成表现出同理心、礼貌或合作性的回答而获得奖励,这会促使模型形成模拟“情绪敏感性”的风格模式。正向反馈可能强化友好或支持性的语气,负向反馈则抑制冷漠或不连贯的行为。这一过程类似于人类中由情感驱动的行为调节机制[418],使得智能体能根据用户期望、情绪上下文或应用场景调整其互动风格。在多轮对话中,经过奖励调节的风格持续性甚至可以促使模型形成一致的人设或对话情绪。
-
记忆:LLM 智能体的记忆包括短期上下文(如聊天历史)和长期模块(如检索增强生成 RAG 或情节记忆缓冲)。奖励信号决定了知识如何被编码、重用或舍弃。例如,通过对带有偏好标签的数据进行微调,可以强化某些推理路径或事实模式,有效地将其固化为模型的内部知识表示。此外,经验回放或自我反思等机制(即智能体使用学习到的奖励评估器评估自己的历史输出)也可以实现记忆的选择性强化,这类似于生物系统中由多巴胺驱动的记忆巩固过程[419]。这让LLM智能体能够从过去成功策略中泛化,并避免重复代价高昂的错误。
总的来说,在LLM智能体中,奖励信号不仅是被动的标量反馈,更是主动的行为塑造机制。它通过调节注意力机制以促进关键特征的感知,引导风格与情绪表达以契合人类偏好,并重构记忆系统以优先保存有用知识。随着智能体朝着更强自主性和交互能力发展,理解这些跨模块奖励交互机制,将是打造既具智能性又具可解释性、可控性且符合人类价值观的系统的关键。
5.4.2 挑战和研究方向
尽管已有大量研究探讨了多种奖励机制,但仍存在一些持续性的挑战。
-
首先是奖励稀疏性和延迟性问题。在许多真实世界的任务中,奖励信号通常是稀疏和滞后的,智能体难以准确地将结果归因到特定的动作。这会显著增加探索的难度,减缓学习进程。
-
其次是**奖励规避(Reward Hacking)**风险。为了最大化回报,智能体可能会利用奖励函数中的意外漏洞,采取偏离任务目标的策略。这在环境复杂、目标模糊的场景下尤其容易发生,导致行为脱离预期,甚至破坏任务本身。
-
再次是奖励塑造的平衡性问题。虽然奖励塑造可以通过引导智能体朝期望行为发展来加速学习,但如果塑造设计不当或过度,可能导致智能体陷入局部最优状态,难以跳出低效策略。同时,过度引导还可能改变任务本质,削弱泛化能力。
-
此外,多目标权衡也是一个核心难题。许多真实任务涉及多个相互冲突的目标,在单一奖励函数的框架下,如何有效权衡这些目标仍然是未解问题。虽然层级化奖励机制有望通过逐步分层学习来解决,但如何有效设计这些机制仍然面临挑战。
-
最后,奖励函数的错配(Reward Misspecification)问题也不可忽视。很多时候,设计者所定义的奖励函数并不能准确表达真实任务目标,导致智能体学习方向与人类意图偏离。而且,许多奖励函数过于依赖特定环境,难以适应任务变化或环境转移,限制了模型的泛化能力。
为应对上述挑战,研究者提出了若干方向:
-
隐式奖励提取:通过标准示例或基于结果的评估方式构造奖励,有助于缓解奖励稀疏问题。
-
任务分解与层次化奖励:将复杂任务解构为多个子任务,并自底向上设计奖励,有助于提升结构化学习效率和在多目标环境中的适应性。
-
元学习与元强化学习:利用跨任务的迁移能力增强奖励模型的适应性,使得智能体能在变化环境中保持良好表现。
总之,通过这些探索,可以构建出更稳健、更可扩展、与真实目标更一致的奖励机制,推动智能体在实际应用中的能力落地和广泛部署。
【往期回顾】
连载5:世界模型
连载4:记忆
连载3:认知系统
连载2:综述介绍
连载1:摘要与前言
相关文章:

【连载6】基础智能体的进展与挑战综述-奖励
基础智能体的进展与挑战综述 从类脑智能到具备可进化性、协作性和安全性的系统 【翻译团队】刘军(liujunbupt.edu.cn) 钱雨欣玥 冯梓哲 李正博 李冠谕 朱宇晗 张霄天 孙大壮 黄若溪 5. 奖励 奖励机制帮助智能体区分有益与有害的行为,塑造其学习过程并影响其决策…...

什么是CRM系统,它的作用是什么?CRM全面指南
CRM(Customer Relationship Management,客户关系管理)系统是一种专门用于集中管理客户信息、优化销售流程、提升客户满意度、支持精准营销、驱动数据分析决策、加强跨部门协同、提升客户生命周期价值的业务系统工具。其中,优化销售…...

【AI提示词】投资策略专家
提示说明 投资策略专家致力于帮助用户构建和优化投资组合,实现资产增值。专家通过深入分析市场趋势、经济数据和公司基本面,为用户制定符合其投资目标和风险偏好的策略。 提示词 # 角色 投资策略专家## 注意 1. 投资策略专家需要具备深入分析市场的能…...

川翔云电脑32G大显存集群机器上线!
川翔云电脑今日重磅推出32G 大显存机型,为游戏玩家、设计师、AI 开发者等提供极致云端算力体验! 一、两大核心配置,突破性能天花板 ✅ 32G 超大显存机型 行业领先:搭载 NVIDIA 专业显卡,单卡可分配 32G 独立显存&am…...
案例教程:飞书多维表格按条件筛选记录 + 读取分页Coze工作流,无限循环使用方法,手把手教学,完全免费教程)
最新扣子(Coze)案例教程:飞书多维表格按条件筛选记录 + 读取分页Coze工作流,无限循环使用方法,手把手教学,完全免费教程
大家好,我是斜杠君。 👨💻 星球群里有同学想学习一下飞书多维表格的使用方法,关于如何通过按条件筛选飞书多维表格中的记录,以及如何使用分页解决最多一次只能读取500条的限制问题。 斜杠君今天就带大家一起搭建一…...

ProxySQL 的性能优化需结合实时监控数据与动态配置调整
ProxySQL 的性能优化需结合实时监控数据与动态配置调整,具体操作如下: 一、性能监控实现 内置监控模块配置 启用监控用户:在 global_variables 表中设置监控账号,用于检测节点健康状态: sql UPDATE global_variables SET variable_value=‘monitor’ WHERE va…...

前端框架的“快闪“时代:我们该如何应对技术迭代的洪流?
引言:前端开发者的"框架疲劳" “上周刚学完Vue 3的组合式API,这周SolidJS又火了?”——这恐怕是许多前端开发者2023年的真实心声。前端框架的迭代速度已经达到了令人目眩的程度,GitHub每日都有新框架诞生,n…...

准确--Tomcat更换证书
具体意思是: Starting Coyote HTTP/1.1 on http-8080: HTTP 连接器(端口 8080)启动成功了。严重: Failed to load keystore type PKCS12 with path conf/jlksearch.fzsmk.cn.pfx due to failed to decrypt safe contents entry: javax.crypt…...

数据库对象与权限管理-Oracle数据字典详解
1. 数据字典概念讲解 Oracle数据字典是数据库的核心组件,它存储了关于数据库结构、用户信息、权限设置和系统性能等重要的元数据信息。这些信息对于数据库的日常管理和维护至关重要。数据字典在数据库创建时自动生成,并随着数据库的运行不断更新。 数据…...

黑阈免激活版:智能管理后台,优化手机性能
在使用安卓手机的过程中,许多用户会遇到手机卡顿、电池续航不足等问题。这些问题通常是由于后台运行的应用程序过多,占用大量系统资源导致的。今天,我们要介绍的 黑阈免激活版,就是这样一款由南京简域网络科技工作室开发的手机辅助…...

C# foreach 循环中获取索引的完整方案
一、手动维护索引变量 实现方式: 在循环外部声明索引变量,每次迭代手动递增: int index 0; foreach (var item in collection) { Console.WriteLine($"{index}: {item}"); index; } 特点: 简单直接&#…...

刷题之路:C++ 解题分享与技术总结
目录 引言 ###刷题实战 (一)移除数组中的重复元素 (二)数组中出现次数超过一半的数字 (三)杨辉三角 (四)只出现一次的数字 (五)找出数组中两个只出现一…...
)
深入探讨:如何完美完成标签分类任务(数据治理中分类分级的分类思考)
文章目录 一、标签分类的核心价值与挑战1.1 标签分类的战略意义1.2 标签分类面临的主要挑战 二、标签分类方法论的系统设计2.1 多层级标签架构设计2.2 精准的标签匹配技术2.3 混合优化策略 三、标签分类的技术实现3.1 高维向量空间中的标签表示3.2 图数据库驱动的标签关系处理3…...

【解决 el-table 树形数据更新后视图不刷新的问题】
内容包含deepseek自动生成内容。第一种亲测可行。 本文章仅用于问题记录 解决 el-table 树形数据更新后视图不刷新的问题 在 Element Plus 的 el-table 中使用树形数据时,当数据更新后视图不自动刷新是一个常见问题。以下是几种解决方案: 问题原因 e…...

MuJoCo中的机器人状态获取
UR5e机器人xml文件模型 <mujoco model"ur5e"><compiler angle"radian" meshdir"assets" autolimits"true"/><option integrator"implicitfast"/><default><default class"ur5e">&…...

第五篇:linux之vim编辑器、用户相关
第五篇:linux之vim编辑器、用户相关 文章目录 第五篇:linux之vim编辑器、用户相关一、vim编辑器1、什么是vim?2、为什么要使用vim?3、vi和vim有什么区别?4、vim编辑器三种模式 二、用户相关1、什么是用户?2…...
)
taobao.trades.sold.get(淘宝店铺订单接口)
淘宝店铺提供了多种订单接口,可以用来获取订单信息、创建订单、修改订单等操作。 获取订单列表接口:可以使用该接口获取店铺的订单列表,包括订单号、买家信息、订单状态等。 获取单个订单信息接口:可以使用该接口获取指定订单的详…...

媒体发稿攻略,解锁新闻发稿成长新高度
新闻媒体发稿全攻略! 如何快速上稿主流权威央级媒体? 大家好!今天来聊聊媒体发稿的那些事儿,希望能帮到正在发稿或者准备发稿的小伙伴们。 ①明确目标媒体 首先,得搞清楚你要把稿子发给哪些媒体和。这一步非常关键,因为选择适合的媒体是发…...

WebRTC服务器Coturn服务器部署
1、概述 作为WebRTC服务器,只需要部署开源的coturn即可,coturn同时实现了STUN和TURN的协议 2、Coturn具体部署 2.1 Coturn简介 coturn是一个开源的STUN/TURN服务器,把STUN服务器跟TURN服务器都整合为一个服务器,主要提供一下几个功…...

lspci的资料
PCI即Peripheral Component Interconnect。 在 Linux 上使用 lspci 命令查看硬件情况 | Linux 中国 lspci 命令用于显示连接到 PCI 总线的所有设备,从而满足上述需求。该命令由 pciutils 包提供,可用于各种基于 Linux 和 BSD 的操作系统。 使用 lspci 和…...

GitLab 提交权限校验脚本
.git/hooks 目录详解与配置指南 一、什么是 .git/hooks? .git/hooks 是 Git 仓库中一个隐藏目录,用于存放 钩子脚本(Hook Scripts)。这些脚本会在 Git 执行特定操作(如提交、推送、合并)的前/后自动触发&…...

WebRTC服务器Coturn服务器相关测试工具
1、概述 在安装开源的webrtc服务器coturn服务器后,会附带安装coturn的相关工具,主要有以下几种工具 2、turnadmin工具 说明:服务器命令行工具,提供添加用户、添加管理员、生成TURN密钥等功能,turnadmin -h查看详细用…...
)
基于Python+Pytest实现自动化测试(全栈实战指南)
目录 第一篇:基础篇 第1章 自动化测试概述 1.1 什么是自动化测试 第2章 环境搭建与工具链配置 2.1 Python环境安装(Windows/macOS/Linux) 2.2 虚拟环境管理 2.3 Pytest基础配置(pytest.ini) 第3章 Pytest核心语…...

符号速率估计——小波变换法
[TOC]符号速率估计——小波变换法 一、原理 1.Haar小波变换 小波变换在信号处理领域被成为数学显微镜,不同于傅里叶变换,小波变换可以观测信号随时间变换的频谱特征,因此,常用于时频分析。 当小波变换前后位置处于同一个码元…...

SQLMesh隔离系统深度实践指南:动态模式映射与跨环境计算复用
在数据安全与开发效率的双重压力下,SQLMesh通过动态模式映射、跨环境计算复用和元数据隔离机制三大核心技术,完美解决了生产与非生产环境的数据壁垒问题。本文提供从环境配置到生产部署的完整实施框架,助您构建安全、高效、可扩展的数据工程体…...

调整IntelliJ IDEA中当前文件所在目录的显示位置
文章目录 1. 问题呈现2. 调整方法3. 更改后的界面 更多 IntelliJ IDEA 的使用技巧可查看 IntelliJ IDEA 专栏中的文章: IntelliJ IDEA 1. 问题呈现 在 IntelliJ IDEA 中,我们在浏览某个文件时,文件所在的目录会显示在下方的状态栏中&#x…...

关于ubuntu密码正确但是无法登录的情况
参考这个文章: https://blog.csdn.net/cuichongxin/article/details/117462494 检查一下是不是用户被lock了 输入passwd -s username 如果用户是L状态,那么就是lock了。 使用 passwd -u username 解锁 关于 .bashrc 不生效 有几点: ~/.…...

OpenCV中的透视变换方法详解
文章目录 引言1. 什么是透视变换2. 透视变换的数学原理3. OpenCV中的透视变换代码实现3.1 首先定义四个函数 3.1.1 cv_show() 函数 3.1.2 def resize() 函数 3.1.3 order_points() 函数 3.1.4 four_point_transform() 函数 3.2 读取图片并做预处理3.3 轮廓检测3.4 获取最大…...

基于DeepSeek的网络爬虫技术创新与实践应用
摘要 在人工智能迅猛发展的时代背景下,网络爬虫技术正经历着深刻变革。本文聚焦于融合DeepSeek大模型的开源爬虫框架Crawl4AI,深入探讨其在网络数据抓取与分析领域的技术原理、功能特性、应用实践及未来发展趋势。通过对Crawl4AI的异步操作、动态内容处理…...

Python基于语音识别的智能垃圾分类系统【附源码、文档说明】
博主介绍:✌Java老徐、7年大厂程序员经历。全网粉丝12w、csdn博客专家、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专栏推荐订阅👇&…...

关于RPC
1.什么是RPC RPC(Remote Procedure Call),即远程过程调用(协议)。它允许像调用本地服务一样调用远程服务,用于实现分布式系统中跨网络进行通信 的技术,是一种计算机通信协议。 RPC是一种服务器…...

前端频繁调用后端接口问题思考
针对前端频繁调用后端接口的问题,以下是一套分步解决方案,结合Java后端技术栈: 1. 实时数据场景:WebSocket/SSE 适用场景:实时股票行情、即时聊天、监控仪表盘 // Spring WebSocket 配置示例 Configuration EnableW…...

Mujoco robosuite 机器人模型
import ctypes import os# 获取当前脚本所在的目录 script_dir os.path.dirname(os.path.abspath(__file__))# 构建库文件的相对路径 lib_relative_path os.path.join(dynamic_models, UR5e, Jb.so)# 拼接成完整的路径 lib_path os.path.join(script_dir, lib_relative_path…...
:融会贯通 - 多变量、模型选择与未来之路)
进阶篇 第 7 篇 (终章):融会贯通 - 多变量、模型选择与未来之路
进阶篇 第 7 篇 (终章):融会贯通 - 多变量、模型选择与未来之路 (图片来源: Pixabay on Pexels) 我们已经一起走过了时间序列分析的进阶之旅!从深入经典统计模型 ETS、ARIMA、SARIMA,到探索现代利器 Prophet,再到拥抱机器学习和初…...

网络安全·第五天·TCP协议安全分析
一、传输层协议概述 1、功能 传输层负责建立端到端的连接,即应用进程之间的通信,负责数据在端到端之间的传输。与网络层不同的是,网络层负责主机与主机之间的通信。 同时,传输层还要对收到的报文进行差错检测(首部和…...

LX10-MDK的使用技巧
MDK5的使用技巧 查找匹配花括号 Ctrle table键的妙用 一次右缩进4个(个人偏好设置)空格shiftenter取消,即左缩进 快速注释/取消注释 先选代码→ 快速编辑一列 按住ALT键选择一列编辑(实用性极强) 窗口拆分 倒数第一个:按列拆分倒数第二个:按行拆分 查找与替换(一个超级…...

IDEA创建Gradle项目然后删除报错解决方法
根据错误信息,你的项目目录中缺少Gradle构建必需的核心文件(如settings.gradle/build.gradle),且IDEA可能残留了Gradle的配置。以下是具体解决方案: 一、问题根源分析 残留Gradle配置 你通过IDEA先创建了Gradle子模块…...
:DOM操作优化策略)
JavaScript性能优化实战(2):DOM操作优化策略
浏览器渲染原理与重排重绘机制 浏览器将HTML和CSS转换为用户可见页面的过程是前端开发的基础知识,也是理解DOM性能优化的关键。这个渲染过程大致可分为以下几个步骤: 渲染过程的核心步骤 解析HTML构建DOM树:浏览器解析HTML标记,转换为DOM树(Document Object Model),表…...

乐视系列玩机---乐视1s x500 x501 x502等系列线刷救砖以及刷写第三方twrp 卡刷第三方固件步骤解析
乐视乐1S(X500 x501 x502 等)采用联发科 Helio X10(MT6795T)Turbo 64位8核处理器 通过博文了解💝💝💝 1💝💝💝-----详细解析乐视1s x500 x501x502等系列黑砖线刷救砖的步骤 2💝💝💝----官方两种更新卡刷步骤以及刷写第三方twrp过程与资源 3💝💝…...
)
Spark-Streaming(1)
Spark Streaming概述: 用于流式计算,处理实时数据流。 数据流以DStream(Discretized Stream)形式表示,内部由一系列RDD组成。 Spark Streaming特点: 易用、容错、易整合到spark体系。 易用性:…...

【Git】Git Revert 命令详解
Git Revert 命令详解 1. Git Revert 的基本概念 Git Revert 是一个用于撤销特定提交的命令。与 Git Reset 不同,Git Revert 不会更改提交历史,而是会创建一个新的提交来撤销指定提交的更改。这意味着,使用 Git Revert 后,项目的…...

SpringClound 微服务分布式Nacos学习笔记
一、基本概述 在实际项目中,选择哪种架构需要根据具体的需求、团队能力和技术栈等因素综合考虑。 单体架构(Monolithic Architecture) 单体架构是一种传统的软件架构风格,将整个应用程序构建为一个单一的、不可分割的单元。在这…...

PageIndex:构建无需切块向量化的 Agentic RAG
引言 你是否对长篇专业文档的向量数据库检索准确性感到失望?传统的基于向量的RAG系统依赖于语义相似性而非真正的相关性。但在检索中,我们真正需要的是相关性——这需要推理能力。当处理需要领域专业知识和多步推理的专业文档时,相似度搜索常…...

使用Java调用TensorFlow与PyTorch模型:DJL框架的应用探索
在现代机器学习的应用场景中,Python早已成为广泛使用的语言,尤其是在深度学习框架TensorFlow和PyTorch的开发和应用中。尽管Java在许多企业级应用中占据一席之地,但因为缺乏直接使用深度学习框架的能力,往往使得Java开发者对机器学…...

nodejs的包管理工具介绍,npm的介绍和安装,npm的初始化包 ,搜索包,下载安装包
nodejs的包管理工具介绍,npm的介绍和安装,npm的初始化包 ,搜索包,下载安装包 🧰 一、Node.js 的包管理工具有哪些? 工具简介是否默认特点npmNode.js 官方的包管理工具(Node Package Manager&am…...
(动态规划))
LeetCode 热题 100_分割等和子集(89_416_中等_C++)(动态规划)
LeetCode 热题 100_分割等和子集(89_416) 题目描述:输入输出样例:题解:解题思路:思路一(动态规划): 代码实现代码实现(思路一(动态规划࿰…...

EasyCVR视频智能分析平台助力智慧园区:全场景视频监控摄像头融合解决方案
一、方案背景 在智慧园区建设的浪潮下,设备融合、数据整合与智能联动已成为核心诉求。视频监控作为智慧园区的“视觉中枢”,其高效整合直接影响园区的管理效能与安全水平。然而,园区内繁杂的视频监控设备生态——不同品牌、型号、制式的摄像…...

《剥开卷积神经网络CNN的 “千层酥”:从基础架构到核心算法》
文章目录 前言卷积神经网络(Convolutional Neural Network,CNN)是一种专门用于处理网格结构数据(如图像、视频、音频)的深度学习模型。它在计算机视觉任务(如图像分类、目标检测)中表现尤为出色…...

win10中打开python的交互模式
不是输入python3,输入python,不知道和安装python版本有没有关系。做个简单记录,不想记笔记了...
)
技术与情感交织的一生 (七)
目录 出师 大三 MVP 首战 TYMIS はじめまして 辣子鸡丁 报价 日本人 致命失误 大佬 包围 品质保障 扩军 唯快不破 闪电战 毕业 总攻 Hold On 出师 大三 大三的学习生活,能认认真真的上一天课的时候很少,甚至经常因为客户的 “传呼”…...