【DeepSeek 学习推理】Llumnix: Dynamic Scheduling for Large Language Model Serving实验部分
6.1 实验设置
测试平台。我们使用阿里云上的16-GPU集群(包含4个GPU虚拟机,类型为ecs.gn7i-c32g1.32xlarge)。每台虚拟机配备4个NVIDIA A10(24 GB)GPU(通过PCI-e 4.0连接)、128个vCPU、752 GB内存和64 Gb/s网络带宽。
模型。我们以流行的LLaMA模型族[57]为实验对象。测试两种规格:LLaMA-7B(单GPU运行)和LLaMA-30B(通过张量并行在单机4个GPU上运行)。模型采用常见的16位精度。我们基于的vLLM版本仅支持原始LLaMA(最大序列长度2k),但近期已有支持更长序列长度(4k至256k)的LLaMA变体[3,7,58,65]。由于这些变体的模型架构和推理性能与LLaMA基本相似,我们认为从系统角度而言,我们的结果能代表更多模型类型和更长序列长度范围。
请求轨迹。与先前工作[34, 35, 67]类似,我们通过合成请求轨迹评估Llumnix的在线服务性能。
| 分布 | 平均值 | P50 | P80 | P95 | P99 |
|---|---|---|---|---|---|
| 真实 | |||||
| ShareGPT 输入 | 306 | 74 | 348 | 1484 | 3388 |
| 输出 | 500 | 487 | 781 | 988 | 1234 |
| BurstGPT 输入 | 830 | 582 | 1427 | 2345 | 3549 |
| 输出 | 271 | 243 | 434 | 669 | 964 |
| 生成 | |||||
| 短(S) | 128 | 38 | 113 | 413 | 1464 |
| 中(M) | 256 | 32 | 173 | 1288 | 4208 |
| 长(L) | 512 | 55 | 582 | 3113 | 5166 |
| 表1:评估中使用的序列长度(token数量)真实分布与生成分布。真实分布包含输入(“In”)和输出(“Out”)的长度。我们使用不同请求率(每秒请求数)的泊松分布和伽马分布生成请求到达时间。对于伽马分布,我们调整变异系数(CV)以控制请求的突发性。每个轨迹包含10,000个请求。我们选择合适的请求率或CV范围,使负载保持在合理区间:使用Llumnix时,P50请求几乎无排队延迟和抢占,P99请求的排队延迟在几十秒内。 |
对于请求的输入/输出长度,我们使用两个公开的ChatGPT-4对话数据集——ShareGPT (GPT4)[10]和BurstGPT (GPT4-Conversation)[62]——评估真实工作负载。考虑到Llumnix面向更多样化的应用场景,我们还使用生成的幂律长度分布模拟长尾工作负载,混合高频短序列(如聊天机器人、个人助手等交互式应用)和低频长序列(如摘要或文章生成)。我们生成多个不同长尾程度和平均长度(128、256、512)的分布,如表1中的短(S)、中(M)、长(L)分布。这些分布的最大长度为6k,因此请求的总序列长度(输入+输出)在运行LLaMA-7B时不会超过A10 GPU的容量(13,616 tokens)。为观察不同工作负载特征的性能,我们通过组合输入和输出的长度分布构建轨迹,包括S-S、M-M、L-L、S-L和L-S。
基线。我们将Llumnix与以下调度器对比。所有基线和Llumnix均使用vLLM作为底层推理引擎,以聚焦实例间请求调度的对比。
• 轮询调度:一种均衡分发请求的简单策略,是生产级服务系统的典型行为[4, 9, 47]。
• INFaaS++:优化版的INFaaS[53],一种先进的多实例服务调度器。我们评估其负载均衡调度和负载感知自动扩缩容策略。我们通过使其专注于LLM服务中的主导资源——GPU内存(包括排队请求占用的内存以反映队列压力)对其进行改进。
• Llumnix-base:Llumnix的基础版本,不区分优先级(所有请求视为同优先级),但启用迁移等其他功能。
关键指标。我们重点关注请求延迟,包括端到端延迟、预填充延迟(首个生成token的延迟)和解码延迟(自首个生成token至最后一个的平均延迟)。我们报告平均值和P99值。
6.2 迁移效率
我们首先评估Llumnix迁移机制的性能,包括对迁移请求引入的停机时间和对运行中请求的额外开销。我们测试了1-GPU的LLaMA-7B和4-GPU的LLaMA-30B模型。针对每种模型,我们在两台不同机器上部署两个实例。使用不同序列长度时,我们分别在两个实例上运行总长度为8k的同一批请求。随后将其中一个实例上的请求迁移至另一实例,并测量其停机时间及迁移期间两个实例上运行批次的解码速度。
我们比较了迁移期间的停机时间与两种简单方法:重新计算和使用Gloo阻塞式拷贝KV缓存(其他请求非阻塞)。如图10(左)所示,迁移的停机时间随序列长度增加几乎保持恒定(约20-30毫秒),甚至短于单次解码步骤。相比之下,基线方法的停机时间随序列长度增加而增长,最高达到迁移的111倍。例如,对LLaMA-30B重新计算8k序列需3.5秒,相当于54个解码步骤的服务停滞。我们还观察到,所有序列长度的迁移仅需两个阶段,这是最小值。这是因为数据拷贝速度足够快,且第一阶段生成的新token数量较少。
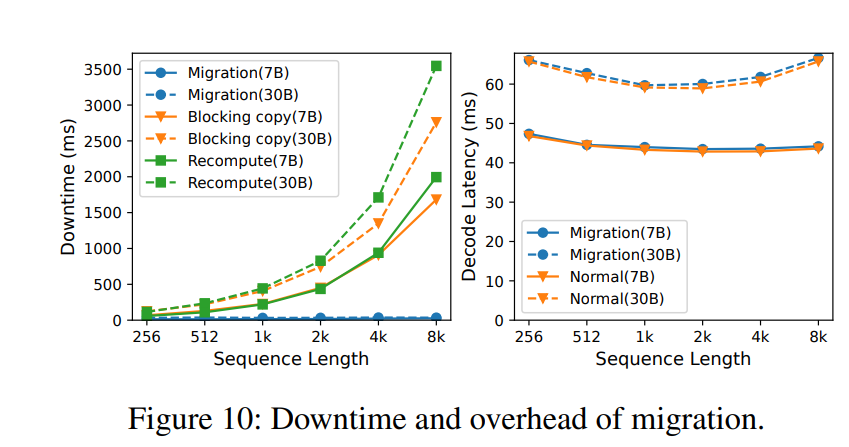
图10(右)进一步比较了源实例在迁移期间与正常执行时的单步解码时间(目标实例结果类似)。对于LLaMA-7B和LLaMA-30B,性能差异均不超过1%,表明迁移额外开销可忽略不计。此外,此类额外开销仅在实例上有请求被迁移(入或出)时存在。我们发现,在后续所有服务实验中,每个实例上正在进行迁移的时间跨度平均占比仅为约10%。这意味着实际额外开销更小,而迁移带来的调度收益显著,这一权衡是值得的。
6.3 服务性能
我们评估Llumnix在在线服务中的调度性能,使用16个LLaMA-7B实例(自动扩缩容功能仅在§6.5实验中启用)。
真实数据集。我们首先使用ShareGPT和BurstGPT轨迹(图11的前两行),
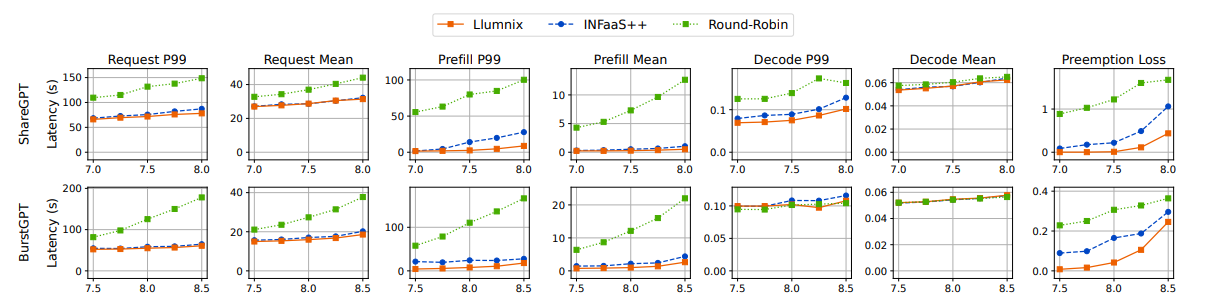
比较Llumnix与轮询及INFaaS++的性能。Llumnix在端到端请求延迟上显著优于基线方法,平均延迟最高提升2倍,P99延迟最高提升2.9倍。尤其值得注意的是,轮询策略的性能始终远低于INFaaS++和Llumnix:由于序列长度方差较大,单纯均匀分发请求仍会导致负载不均衡,从而影响预填充和解码延迟。
Llumnix在预填充延迟上相比轮询实现显著提升,平均延迟最高达26.6倍,P99延迟最高达34.4倍。这是由于轮询可能将新请求分发至过载实例,导致较长的排队延迟。通过负载均衡减少抢占,Llumnix将P99解码延迟最高降低2倍。由于抢占导致的延迟惩罚被所有生成token分摊,这一提升幅度看似较小。然而,每次抢占发生时,都会造成突发性服务停滞,影响用户体验。图11(最右侧列)报告了抢占损失(所有请求的额外排队和重计算时间均值)。Llumnix相比轮询平均减少84%的抢占损失。这些结果凸显了负载均衡在LLM服务中的重要性。在后续使用更高方差生成分布的实验中,轮询的延迟表现恶化至基线的两个数量级。因此,为保持图表清晰,后续实验将省略轮询,仅对比INFaaS++与Llumnix。
Llumnix在平均预填充延迟上超越INFaaS++最高达2.2倍,P99延迟最高达5.5倍,在P99解码延迟上最高提升1.3倍,证明迁移机制在调度时负载均衡之外的额外收益。接下来,我们通过更多不同特征的轨迹进一步评估两者的性能差异。
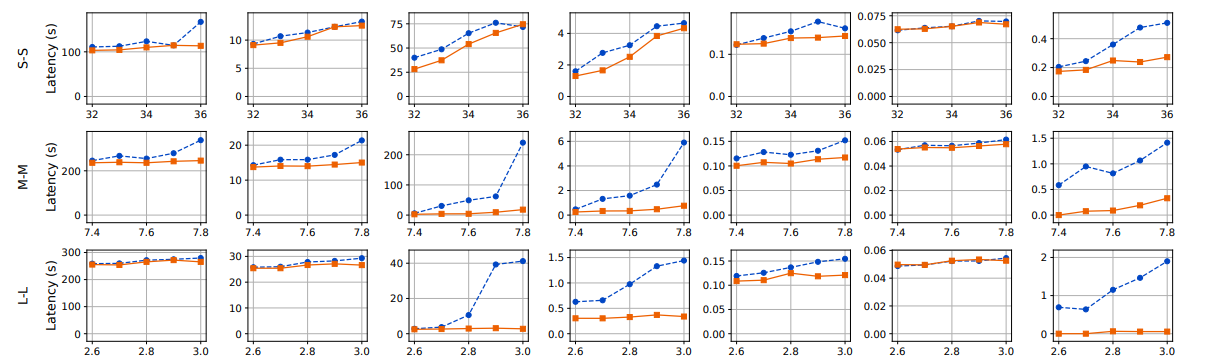
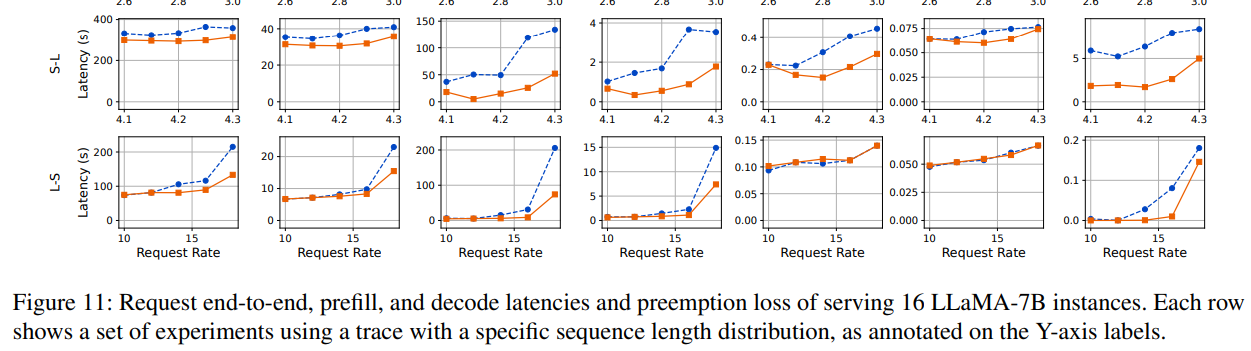
生成分布。我们使用多个生成分布(图11的底部五行)比较Llumnix与INFaaS++。Llumnix在所有轨迹的端到端请求延迟上均表现更优,平均延迟最高提升1.5倍,P99延迟最高提升1.6倍。预填充延迟的改进更为显著,平均延迟最高达7.7倍,P99延迟最高达14.8倍。尽管INFaaS++将请求分发至负载最低的实例,但由于碎片化问题(尤其是输入较长的长尾请求),仍会出现较长的排队延迟。Llumnix通过迁移实现碎片整理,从而减少此类排队延迟,在输入较长的轨迹中表现更优。
为了更深入地研究内存碎片化问题,我们进一步以请求速率为7.5的M-M跟踪实验为例进行案例研究。我们将每个时刻的碎片化内存定义为:在无碎片化情况下,集群空闲内存中能够满足所有实例队首阻塞请求需求的那部分内存。例如,若总空闲内存为8GB,存在三个各需3GB的队首阻塞请求,则碎片化内存计为6GB,即若无碎片化时这6GB内存可满足两个排队请求的需求。该指标反映了因碎片化导致的内存浪费程度。我们统计了碎片化内存在集群总内存中的占比。在上述示例中,若总内存为16GB,则占比为37.5%(6/16)。
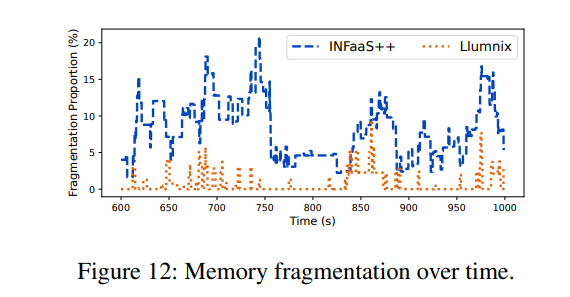
图12展示了实验期间繁忙时段的碎片化比例。我们观察到INFaaS++的碎片化比例经常超过10%,造成大量集群内存浪费。相比之下,Llumnix的碎片化比例通常为0。在该时段内,Llumnix和INFaaS++的平均碎片化比例分别为0.7%和7.9%(降低92%),突显了通过迁移进行碎片整理的效果。
通过减少抢占,Llumnix还将P99解码延迟最高提升了2倍。尽管INFaaS++已通过调度负载均衡来减少抢占,但迁移通过响应实际序列长度(请求到达时未知)对此进行了补充。如图11所示,Llumnix显著降低了抢占损失,在多数情况下接近零。所有实验的平均降幅为70.4%,相当于端到端请求延迟平均减少了1.3秒。
6.4 优先级支持
我们通过随机选取10%的请求并为其分配高调度优先级和执行优先级,评估了Llumnix对优先级的支持能力。实验采用短-短序列长度分布和Gamma到达分布的跟踪数据。通过调整变异系数(CV)参数,展示突发工作负载和负载峰值对高优先级请求的干扰程度。我们根据经验为高优先级请求设定1,600个token的目标内存负载,因为观察到该负载可维持接近理想的解码速度(参见图4)。Llumnix将此目标负载转换为高优先级请求对应的内存预留空间。我们将Llumnix与Llumnix-base进行对比,后者将所有请求视为相同优先级。
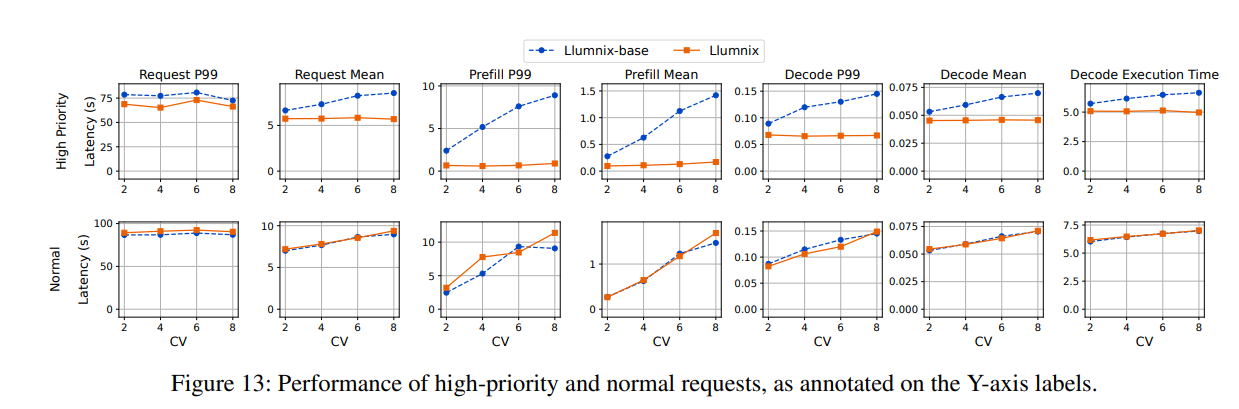
如图13第一行所示,随着CV值增加,Llumnix将高优先级请求的平均延迟改善了1.2倍至1.5倍。更高的CV值会导致更多高负载时段,若缺乏保护机制,高优先级请求可能遭受更严重的干扰。即使在更高CV值下,Llumnix仍能为高优先级请求提供稳定的延迟表现,体现了其对此类请求的隔离能力。这是因为Llumnix能通过动态为其腾出空间来应对变化的高优先级负载,而静态资源预留等方法难以实现这一点。对于预填充延迟,Llumnix的平均延迟改善达2.9倍至8.6倍,P99延迟改善达3.6倍至10倍。这通过高调度优先级减少排队延迟实现。Llumnix还将解码延迟的平均值改善了1.2倍至1.5倍,P99延迟改善了1.3倍至2.2倍。这种提升源于通过降低实例负载和干扰加速解码计算(最右侧列显示平均解码计算时间有类似提升)。我们还注意到Llumnix保持了普通请求的性能(图13第二行):Llumnix对普通请求的平均请求、预填充和解码延迟分别最多增加4.5%、13%和2%。
6.5 自动扩展
我们通过使用更大范围的请求速率和Gamma变异系数(CVs)来评估Llumnix的自动扩展能力,以展示其对负载变化的适应性。默认情况下,Llumnix使用[10, 60]的扩展阈值范围,即当平均空闲度(freeness)低于10或高于60时,Llumnix会扩展或缩减实例;需注意,该指标表示在当前批次下实例仍可运行的最大解码步数。我们让INFaaS++使用相同的扩展策略,因此Llumnix和INFaaS++的实例扩展激进程度一致。实验中最大实例数设为16,并采用长-长序列长度分布。
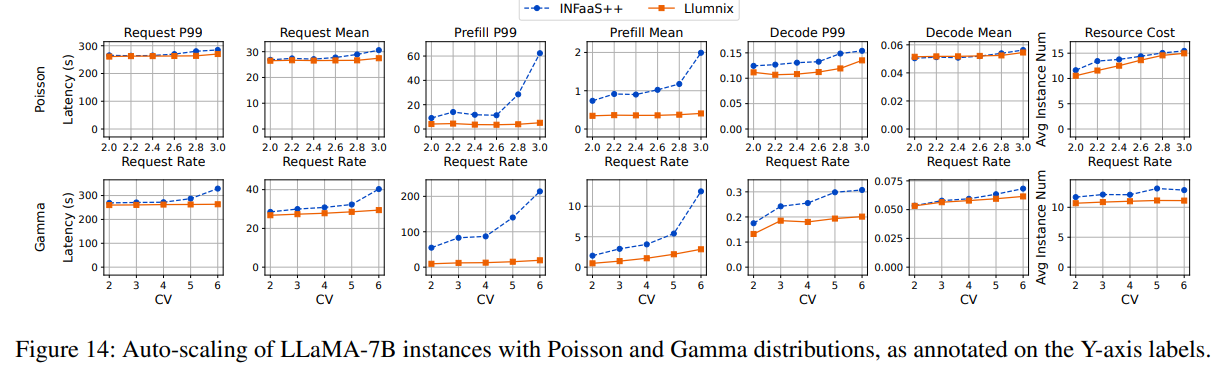
我们首先基于泊松分布调整请求速率。如图14第一行所示,Llumnix在所有请求速率下均实现了延迟改善,例如P99预填充延迟最高提升12.2倍。我们还以平均使用实例数衡量资源成本(见最右侧列)。Llumnix通过更快速地饱和或释放实例来提高自动扩展效率,从而节省高达16%的成本。此外,我们通过Gamma分布的不同变异系数测试了不同工作负载突发性(请求速率=2)。如第二行所示,Llumnix在延迟和成本方面表现类似改进,例如P99预填充延迟最高提升11倍,成本节省18%。
最后,我们通过分析Llumnix需要多激进地扩展实例以维持特定延迟目标(如给定的P99预填充延迟)来评估其成本效率。我们调整扩展阈值t,扩展范围设为[t, t+50]。t值越高,表示Llumnix倾向于使用更多实例。
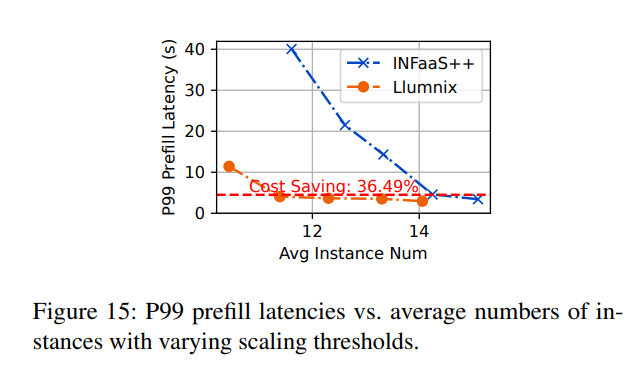
图15展示了不同扩展阈值下的P99预填充延迟和成本。观察发现,由于迁移减少排队延迟的能力与更高的自动扩展效率的结合,Llumnix在实现相似P99预填充延迟(约5秒,红色虚线)的同时,相比INFaaS++节省了36%的成本。
6.6 调度可扩展性
我们通过调度压力测试评估Llumnix在64个LLaMA-7B实例下的可扩展性,测试使用更高的请求速率。由于该集群规模超过我们的测试平台容量,我们通过离线测量A10 GPU在不同序列长度和批量大小下的表现,将vLLM中的真实GPU执行替换为简单的休眠命令(sleep command)。我们通过扩展vLLM调度器以集中管理所有实例的请求,构建了一个简单的集中式调度器作为基线。测试中,请求的输入和输出长度均为64个token,且请求速率逐步增加。
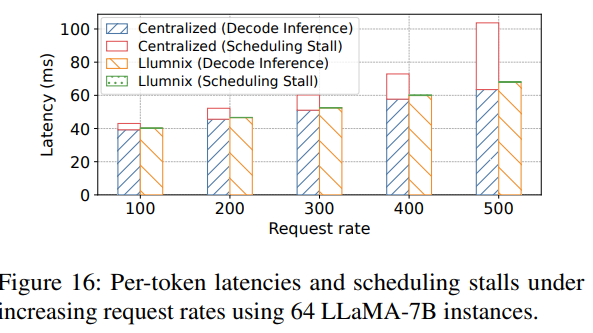
如图16所示,随着请求速率提升,基线方案在每次迭代的推理计算期间遭遇长达40毫秒的调度停滞,导致整体速度下降1.7倍。此类停滞源于实例与集中式调度器之间的通信——同步请求状态和调度决策的过程在高负载下成为瓶颈。相比之下,Llumnix即使在高请求速率下仍表现出接近零的调度停滞,展现了其分布式调度架构的可扩展性。Llumnix将实例内的调度逻辑卸载并分布到各个"llumlet"中,使其与全局调度并行且异步执行。此外,llumlet仅上报实例级指标,而非每个请求的精确状态,从而进一步提升了通信效率。
7 相关工作
LLM推理。随着Transformer模型在模型服务中的重要性日益凸显,近期工作如FasterTransformer[46]、TurboTransformer[25]、LightSeq[61]和FlashAttention[21, 22]通过优化GPU内核以提升推理性能。SpotServe[41]利用可抢占实例支持LLM推理,以提高成本效率。FastServe[63]采用抢占式时间切片方法优化请求完成时间。AlpaServe[35]通过流水线并行技术降低突发工作负载的服务延迟。为进一步提升GPU利用率和服务吞吐量,Orca[67]提出迭代级调度(在近期研究及本文中被称为连续批处理)和选择性批处理,而vLLM[34]则通过PageAttention优化内存使用。[55]提出在LLM实例上对请求进行公平调度。先前工作主要聚焦于单实例服务,因此与Llumnix形成互补。Llumnix探索了部署多实例LLM服务的挑战与机遇。KV缓存的关键追加-only特性被用于在推理引擎中实现请求迁移能力。该机制开辟了广阔的策略设计空间,以提供优先级和性能隔离、提升内存效率,并支持实例自动扩展。我们还计划探索跨实例全局调度与实例内本地调度技术(如抢占式[63]和公平[55]调度)之间的相互作用,作为未来工作。
请求调度。为支持深度学习模型部署,已提出多种系统(如Clipper[19]、Nexus[54]、DVABatch[20]和TritonServer[47])以优化DNN推理服务的请求调度。为满足DNN推理请求的服务等级目标(SLO),Clockwork[29]利用传统DNN的执行可预测性,而Reef[33]和Shepherd[68]通过抢占机制优先处理高优先级请求。AlpaServe[35]采用基于队列长度的简单负载均衡分发策略。这些工作主要针对传统DNN模型服务,其中单个请求仅需对模型进行一次性推理。然而,LLM推理服务需要对模型进行不可预测迭代次数的自回归计算,并引入中间状态(即KV缓存),展现出全新特性。DeepSpeed-MII[4]虽针对多实例LLM服务,但采用忽略LLM特性的简单轮询分发策略。Llumnix更进一步,通过整合请求迁移确保高吞吐量和低延迟,为优先级请求提供SLO,并通过统一的负载感知动态调度策略实现资源效率的实例自动扩展。
除多模型实例外,INFaaS[53]进一步支持跨多模型类型/变体的调度,综合考量不同应用场景的性能与精度需求。这也是LLM的典型场景:例如针对特定任务的微调模型(如代码生成[3, 13, 30]);或基座LLM不同规模或精度的变体([26,37,39])。我们计划在后续工作中扩展Llumnix以支持多模型类型,综合考量延迟/吞吐量与精度间的更大权衡空间。
隔离与碎片化。隔离与碎片化之间的权衡,或工作负载打包与分散之间的权衡,一直是经典的调度挑战。具体而言,工作负载打包可提升资源利用率,但可能引发共置工作负载间的干扰;而分散工作负载虽提供更好隔离性,却会增加资源碎片化。已有大量研究致力于在数据中心中更好地平衡大数椐作业和虚拟机的隔离与碎片化问题,通过识别工作负载的干扰敏感性并优化调度策略([16,18,23,24,27,31,32,40,60,66])。这一挑战在深度学习工作负载的GPU集群中同样存在。Amaral等提出了一种拓扑感知的放置算法,以解决多GPU服务器上深度学习训练作业打包与分散的权衡[12]。Gandiva[64]则通过内省式作业迁移,应对不同作业对打包/分散的异构敏感性。由于不可预测的自回归执行,LLM服务使这一挑战更为复杂。Llumnix通过运行时请求迁移响应工作负载动态,以更好地协调这两个目标。
迁移。Gandiva[64]在调度期间为深度学习训练作业启用内省式迁移。其利用深度学习固有的迭代特性,在最小工作集(即小批量边界)上执行检查点-恢复方法以迁移模型权重。尽管LLM推理同样具有迭代性,但直接迁移请求的完整状态不可接受,因为推理请求的延迟SLO至关重要。此外,每个请求的工作集与序列长度呈线性关系,而随着上下文长度增加趋势[49, 50],这一开销可能显著。Llumnix的迁移方法受虚拟机实时迁移[17]启发:通过在LLM请求持续解码时执行大部分迁移操作,Llumnix将迁移停机时间最小化,使成本不受序列长度影响而可忽略。
8 结论
Llumnix这一名称蕴含了我们的愿景——以类Unix方式服务LLM。这一愿景源于观察到LLM与现代操作系统具有共性,例如普适性、多租户特性和动态性,因而面临相似的需求与挑战。本文通过借鉴传统操作系统的经典设计理念,在LLM服务新场景中迈出重要一步:重新定义隔离性、优先级等经典抽象概念;通过推理请求迁移实现"上下文切换"这一核心方法;并利用迁移能力实现持续动态的请求重调度。这些设计的结合使Llumnix实现了更低的延迟、更高的成本效益以及差异化SLO支持,为LLM服务指明了新方向。
相关文章:

【DeepSeek 学习推理】Llumnix: Dynamic Scheduling for Large Language Model Serving实验部分
6.1 实验设置 测试平台。我们使用阿里云上的16-GPU集群(包含4个GPU虚拟机,类型为ecs.gn7i-c32g1.32xlarge)。每台虚拟机配备4个NVIDIA A10(24 GB)GPU(通过PCI-e 4.0连接)、128个vCPU、752 GB内…...

运行neo4j.bat console 报错无法识别为脚本,PowerShell 教程:查看语言模式并通过注册表修改受限模式
无法将“D:\neo4j-community-4.4.38-windows\bin\Neo4j-Management\Get-Args.ps1”项识别为cmdlet、函数、脚本文件或可运行程序的名称。请检查名称的拼写,如果包括路径,请确保路径正确,然后再试一次。 前提配置好环境变量之后依然报上面的错…...

AI写代码之GO+Python写个爬虫系统
下面我们我们来利用AI,来用GOPython写个爬虫系统。 帮我写一个Python语言爬取数据写入Mysql的案例,信息如下: 1、Mysql数据库地址是:192.168.1.20 ,mysql用户名是:root, Mysql密码是࿱…...

【FAQ】如何配置PCoIP零客户端AWI能访问
应用场景 在安全性要求较高的环境中,禁用 AWI 并使用 PCoIP 管理控制台配置端点,建议隐藏 OSD 以提高安全性。 通过OSD和AWI: 阻止 PCoIP 管理工具管理 PCoIP 零客户端。禁用对 Tera2 PCoIP Zero Client 的 AWI 的管理访问。下次访问 AWI 或 OSD 时强…...

RAGFlow:构建高效检索增强生成流程的技术解析
引言 在当今信息爆炸的时代,如何从海量数据中快速准确地获取所需信息并生成高质量内容已成为人工智能领域的重要挑战。检索增强生成(Retrieval-Augmented Generation, RAG)技术应运而生,它将信息检索与大型语言模型(L…...

go语言中defer使用指南
目录 1.使用场景 2.执行顺序 3.for循环中的defer及defer中的闭包陷阱 4.defer与返回值的关系 5.总结 1.使用场景 在编程的时候,经常需要打开一些资源,比如数据库连接、文件、锁等,这些资源需要在用完之后释放掉,否则会造成内…...

成熟软件项目解决方案:360°全景影像显控软件系统
若该文为原创文章,转载请注明原文出处 本文章博客地址:https://hpzwl.blog.csdn.net/article/details/147425300 长沙红胖子Qt(长沙创微智科)博文大全:开发技术集合(包含Qt实用技术、树莓派、三维、Open…...

域名解析体系中 IPv4/IPv6 地址切换的关键技术剖析
前言: 对接的一家学校业务,学校老师要求域名解析既能解析到ipv4地址又能解析到ipv6地址。听学校老师叙述(还是会考察v6开通率的),所以通过这个方法来实现的,域名解析到ipv6和ipv4都可以。 准备一台机器 机…...
)
PHP 爬虫如何获取 1688 商品详情(代码示例)
在电商领域,获取 1688 商品的详细信息对于市场分析、选品上架、库存管理和价格策略制定等方面至关重要。1688 作为国内领先的 B2B 电商平台,提供了丰富的商品数据。通过 PHP 爬虫技术,我们可以高效地获取 1688 商品的详细信息,包括…...

Mysql的redolog
保证事务持久性,用于崩溃恢复,崩溃恢复时,把redo上记载的页读到内存,对其修改,变为脏页,刷盘运用于WAL技术,将随机写改为顺序写 redo log有三种状态: 存在 redo log buffer 中&…...

C++ 哈希表
1. 哈希表的概念 在vector、list的顺序结构中,查找效率为 O ( N ) O(N) O(N),在set、map的树型结构中,查找效率为 O ( l o g 2 N ) O(log_2{N}) O(log2N),有没有更优的结构 —— 哈希表 如果让数据按照某种规则映射到某个值&a…...

【pytorch学习】土堆pytorch笔记1
学习参考 仓库 https://github.com/xiaotudui/pytorch-tutorialhttps://github.com/xiaotudui/pytorch-tutorial https://github.com/AccumulateMore/CV 参考博客 https://blog.csdn.net/weixin_44216612/article/details/124203730? https://www.morinha.cc/posts/cours…...

使用Python+OpenCV将多级嵌套文件夹下的视频文件抽帧
使用PythonOpenCV将多级嵌套文件夹下的视频文件抽帧 import os import cv2 import time# 存放视频文件的多层嵌套文件夹路径 videoPath D:\\videos\\ # 保存抽帧的图片的文件夹路径 savePath D:\\images\\if not os.path.exists(savePath):os.mkdir(savePath) video_num 0f…...

ASP.Net Web Api如何更改URL
1.找到appsettings.json 修改如下: 主要为urls的修改填本机私有地址即可 {"Logging": {"LogLevel": {"Default": "Information","Microsoft.AspNetCore": "Warning"}},"AllowedHosts": &q…...

毕业论文设计基本内容和要求:
毕业设计基本内容和要求: 研究内容 调查了解LAMP架构和PHP开发; 学习百度旅游调用的其他产品线服务并熟悉请求接口; 学习社区业务层规范; 设计并实现旅游主要模块; 技术指标 熟悉企业中流程运转的方式,…...

XML内容解析成实体类
XML解析成实体类 解析方法实体类测试 说明:直接上干货,不废话 解析方法 public static List<PlatJuMinBaoXian> parse(String xmlString) {List<PlatJuMinBaoXian> result new ArrayList<>();try {// 创建 DocumentBuilderDocumentB…...

推公式——耍杂技的牛
由图可知,只要存在一个逆序,把他们交换一下,最大风险值就会降低,答案更优,因此最优解是按照wisi从小到大升序排列,顺次计算每头牛的危险系数,最大值即是答案。 #include <iostream> #inc…...

Vue指令详解:从入门到精通
前言 Vue.js作为当下最流行的前端框架之一,其指令系统是Vue最核心的特性之一。指令是Vue模板中带有v-前缀的特殊属性,它们为HTML元素添加了特殊的响应式行为。本文将全面介绍Vue的各种指令及其用法。 一、Vue指令概述 Vue指令是带有v-前缀的特殊属性&…...

准确--CentOS 7 配置 Chrony 同步阿里云 NTP 时间服务器及手动同步指南
本文档介绍如何在 CentOS 7 系统上配置 chrony 服务,使其与阿里云 NTP 时间服务器保持时间同步,并说明如何在需要时手动触发一次立即同步。 前提条件: 拥有一台 CentOS 7 服务器。拥有 root 权限或可以使用 sudo 命令。服务器可以访问互联网 (使用公共…...
)
CLIP | 训练过程中图像特征和文本特征的在嵌入空间中的对齐(两个投影矩阵的学习)
在多模态学习(Multimodal Learning)中,投影矩阵 W i W_i Wi 和 W t W_t Wt 是通过训练过程学习得到的。它们的作用是将图像特征 I f I_f If 和文本特征 T f T_f Tf 映射到一个共享的嵌入空间(embedding space…...

Spring中配置 Bean 的两种方式:XML 配置 和 Java 配置类
在 Spring 框架中,配置 Bean 的方式主要有两种:XML 配置 和 Java 配置类。这两种方式都可以实现将对象注册到 Spring 容器中,并通过依赖注入进行管理。本文将详细介绍这两种配置方式的步骤,并提供相应的代码示例。 1. 使用 XML 配置的方式 步骤 创建 Spring 配置文件 创建…...

STM32 外部中断
引言:嵌入式系统中的中断革命 在嵌入式系统开发领域,中断机制堪称现代微控制器的"神经系统"。它通过高效的异步事件处理机制,彻底改变了传统轮询式系统资源利用率低下的局面。STM32作为业界领先的ARM Cortex-M系列微控制器&#x…...

4.22学习总结
开始写有关图的算法 图的一些基本概念,图的存储主要以 邻接矩阵,邻接表(数组链表的实现方式)的方式存储 邻接矩阵的优点: 表达方式简单,易于理解检查任意两个顶点间是否存在边的操作非常快适合稠密图&a…...

list底层原理
一.结构体的构建 这个用结构体更好,因为我们需要不断的访问节点,类中的成员函数一般都是私有的,需要还用友元函数什么的。 这个是我们来实现的类,我们实现的是双向带头循环链表,这个是实用性最高的一个链表的形式。 这…...

python+selenium+pytest自动化测试chrome driver版本下载
chrome浏览器chromedriver版本下载地址 https://googlechromelabs.github.io/chrome-for-testing/#stable...

发布一个npm包,更新包,删除包
发布一个npm包,更新包,删除包 如何将自己的项目 发布为一个 npm 包,并掌握 更新 和 删除 的操作流程。 🚀 一、发布一个 npm 包的完整流程 ✅ 1. 注册并登录 npm 账号 如果还没有账号,先注册: 官网注册&…...

代码随想录训练营38天 || 322. 零钱兑换 279. 完全平方数 139. 单词拆分
322. 零钱兑换 思路: 动规5部曲: 1.确定dp数组以及下标的含义: dp数组表示能凑出零钱的最少硬币数,下标表示要兑换的零钱 2.确定递推公式: j为背包容量,i为物品的下标 dp[ j ] min(dp[ j -coins[ i…...
华为 2026 届校招实习-硬件技术工程师-硬件通用/单板开发—机试题—(共14套)(每套四十题))
(最新)华为 2026 届校招实习-硬件技术工程师-硬件通用/单板开发—机试题—(共14套)(每套四十题)
(最新)华为 2026 届校招实习-硬件技术工程师-硬件通用/单板开发—机试题—(共14套)(每套四十题) 本套题目为硬件通用题目,适合多个岗位方向,如下 **岗位——硬件技术工程师 岗位意向…...

IOT项目——DIY Weather Station With ESP32
开源项目:ESP32 气象站 作者:GiovanniAggiustatutto 原文链接: ESP32 气象站 温度设备塔风向标风速计雨量计框架电子元件和压力传感器家庭助理配置及应用 气象站测量温度、湿度、气压、风速和风向以及降雨量。所有数据均由 ESP32收集…...

表格识别版面还原分析-GO语言集成-表格文字识别接口
数据驱动的时代,高效处理和分析各类文档中的信息变得尤为重要。无论是金融服务中的报表分析,制造与物流行业的库存管理,还是医疗卫生领域的病历记录,快速准确地将纸质或电子表格中的数据转换为可编辑、保存的电子数据成为提升工作…...

文件上传漏洞3
1. 例题:文件上传限制 1)上传漏洞靶场介绍 项目名称: upload-labs开发语言: 使用PHP语言编写功能定位: 专门收集渗透测试和CTF中遇到的各种上传漏洞的靶场关卡数量: 目前共21关,每关包含不同上传方式注意事项: 每关没有固定通关方法,不要自限…...

一洽智能硬件行业解决方案探索与实践
一、智能硬件行业发展现状剖析 在数字化浪潮推动下,智能硬件行业呈现蓬勃发展态势。软硬件一体化的深度融合,构建起智能化服务的核心架构,而移动应用作为连接用户与设备的重要桥梁,其作用愈发关键。深入研究该行业,可…...

什么是snmp协议?在优雅草星云智控AI物联网监控系统中如何添加设备进行监控【星云智控手册01】-优雅草卓伊凡
什么是snmp协议?在优雅草星云智控AI物联网监控系统中如何添加设备进行监控【星云智控手册01】-优雅草卓伊凡 优雅草星云智控物联网设备 本产品即将在5月15日在优雅草科技的承办下召开产品发布会,本产品需要报名参加可以通过活动行搜索星云智控进行报名…...
)
神经网络权重优化秘籍:梯度下降法全解析(五)
引言 在神经网络的训练过程中,权重更新是提升模型性能的关键环节,而梯度下降法及其优化算法则是实现这一关键环节的核心工具。理解并掌握这些方法,对于打造高效的神经网络模型至关重要。本文将深入剖析梯度下降法在神经网络权重更新中的应用…...

输入框仅支持英文、特殊符号、全角自动转半角 vue3
需求:封装一个输入框组件 1.只能输入英文。 2.输入的小写英文自动转大写。 3.输入的全角特殊符号自动转半角特殊字符 效果图 代码 <script setup> import { defineEmits, defineModel, defineProps } from "vue"; import { debounce } from "…...

Python简介与入门
目录 Python初始 Python的优势 Python 的特性 Linux下安装Python windows 系统安装python Python的语法基础 标识符 注释 语句与缩进 Python 常用的数据类型 数字 字符串 列表 列表的定义 列表的取值 重复列表 元组 元组的操作 字典 字典的创建 字典的取值操作 字典的添加、…...
——STL之排序算法)
C++学习笔记(三十六)——STL之排序算法
一、STL 算法 C的STL(Standard Template Library) 提供了一组高效、通用的算法,这些算法适用于各种容器(如 vector、list、set、map)。 这些算法主要位于 <algorithm> 和 <numeric> 头文件中。 通用性&a…...

G1 人形机器人软件系统架构与 Python SDK
如果说人形机器人的硬件是它的“身体”,那么软件系统就是它的“大脑”和“神经系统”,负责接收信息、进行决策并控制身体行动。理解 G1 机器人的软件架构,特别是如何通过编程接口与其交互,是进行机器人开发的核心。本节将剖析 G1 …...

Redis在SpringBoot中的使用
在SpringBoot项目中使用redis存储数据作为字典 本项目使用jdk1.8 一、添加依赖 <!-- spring boot redis缓存引入 --> <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId>…...
)
SuperMap GIS基础产品FAQ集锦(20250421)
一、SuperMap iDesktopX 问题1:iDesktopX怎么根据对数据集中的每条记录进行批量布局出图? 11.3.0 【解决办法】打开地图系列设置功能,勾选启用并设置索引地图,索引图层和索引字段等参数,打印地图册,设置输出路径&am…...

Linux学习笔记2
1.man man指令相当于一个在线手册 使用q可以退出指令运行 例如,使用 man ls 指令可以得到以下运行结果: 在查找的时候还可以使用数字,使用 man man 指令,对应每个数字所表示的内容: 在Linux下,一切皆是文件…...

电脑安装adb并且连接华为手机mate60pro后查看设备
1.下载adb工具 下载地址: https://developer.android.google.cn/tools/releases/platform-tools?hlzh-cn#downloads 根据需要下载自己系统需要的安装包 下载后解压 2.配置adb工具环境变量 添加ADB_HOME D:\softwares\platform-tools-latest-windows\platform-…...

EAL4+与等保2.0:解读中国网络安全双标准
EAL4与等保2.0:解读中国网络安全双标准 在当今数字化时代,网络安全已成为各个行业不可忽视的重要议题。特别是在金融、政府、医疗等领域,保护信息的安全性和隐私性显得尤为关键。在中国,EAL4和等级保护2.0(简称“等保…...

树莓派学习专题<8>:使用V4L2驱动获取摄像头数据--获取摄像头支持的分辨率
树莓派学习专题<8>:使用V4L2驱动获取摄像头数据--获取摄像头支持的分辨率 1. 获取摄像头支持的分辨率2. 代码分析3. 树莓派实测 1. 获取摄像头支持的分辨率 使用如下代码获取摄像头支持的输出分辨率。 struct v4l2_frmsizeenum stFrameSize …...

CSS预处理器对比:Sass、Less与Stylus如何选择
引言 CSS预处理器已成为现代前端开发的标准工具,它们通过添加编程特性来增强纯CSS的功能,使样式表更加模块化、可维护且高效。在众多预处理器中,Sass、Less和Stylus是三个最流行的选择,它们各自拥有独特的语法和功能特点。本文将深…...

Vue3集成sass
安装依赖 pnpm add -D sass-embedded配置全局变量 新建文件 src/styles/variables.scss配置Vite 修改 vite.config.ts variables.scss $base-color: bluevite.config.ts // https://vite.dev/config/ export default defineConfig({plugins: [vue(),],resolve: {alias: {:…...

超越Dify工作流:如何通过修改QwenAgent的Function Call及ReAct方法实现对日期时间的高效意图识别
在构建复杂的AI应用时,意图识别是一个至关重要的环节。传统上,许多开发者会使用Dify工作流来完成这一任务,但在处理复杂意图时,这种方法往往需要大模型进行多级反复识别,从而带来较高的时间成本。 本文将介绍如何通过修改QwenAgent框架中的FnCallAgent和ReActChat类,实现…...

Lua 第8部分 补充知识
8.1 局部变量和代码块 Lua 语言中的变量在默认情况下是全局变量 ,所有的局部变量在使用前必须声明 。 与全局变量不同,局部变量的生效范围仅限于声明它的代码块。一个代码块( block )是一个控制结构的主体,或是一个函…...

Lua 第7部分 输入输出
由于 Lua 语言强调可移植性和嵌入性 , 所以 Lua 语言本身并没有提供太多与外部交互的机制 。 在真实的 Lua 程序中,从图形、数据库到网络的访问等大多数 I/O 操作,要么由宿主程序实现,要么通过不包括在发行版中的外部库实现。 单就…...
 的区别)
Java 中 == 和 equals() 的区别
1. 运算符 是 Java 中的比较运算符,用于比较两个变量的值是否相等,但具体行为取决于变量的类型: 类型 比较的内容基本类型直接比较值是否相等(如 int a 5; int b 5; a b 返回 true)引用类型比较内存地址&#x…...