w~视觉~3D~合集2
我自己的原文哦~ https://blog.51cto.com/whaosoft/13766161
#Sin3DGen
最近有点忙 可能给忘了,贴了我只是搬运工 发这些给自己看, 还有下面不是隐藏是发布出去 ~
北京大学xxx团队联合山东大学和xxx AI Lab的研究人员,提出了首个基于单样例场景无需训练便可生成多样高质量三维场景的方法。

多样高质的三维场景生成结果
- 论文地址:https://arxiv.org/abs/2304.12670
- 项目主页:http://weiyuli.xyz/Sin3DGen/
使用人工智能辅助内容生成(AIGC)在图像生成领域涌现出大量的工作,从早期的变分自编码器(VAE),到生成对抗网络(GAN),再到最近大红大紫的扩散模型(Diffusion Model),模型的生成能力飞速提升。以 Stable Diffusion,Midjourney 等为代表的模型在生成具有高真实感图像方面取得了前所未有的成果。同时,在视频生成领域,最近也涌现出很多优秀的工作,如 Runway 公司的生成模型能够生成充满想象力的视频片段。这些应用极大降低了内容创作门槛,使得每个人都可以轻易地将自己天马行空的想法变为现实。
但是随着承载内容的媒介越来越丰富,人们渐渐不满足于图文、视频这些二维的图形图像内容。随着交互式电子游戏技术的不断发展,特别是虚拟和增强现实等应用的逐步成熟,人们越来越希望能身临其境地从三维视角与场景和物体进行互动,这带来了对三维内容生成的更大诉求。
如何快速地生成高质量且具有精细几何结构和高度真实感外观的三维内容,一直以来是计算机图形学社区研究者们重点探索的问题。通过计算机智能地进行三维内容生成,在实际生产应用中可以辅助游戏、影视制作中重要数字资产的生产,极大地减少了美术制作人员的开发时间,大幅地降低资产获取成本,并缩短整体的制作周期,也为用户带来千人千面的个性化视觉体验提供了技术可能。而对于普通用户来说,快速便捷的三维内容创作工具的出现,结合如桌面级三维打印机等应用,未来将为普通消费者的文娱生活带来更加无限的想象空间。
目前,虽然普通用户可以通过便携式相机等设备轻松地创建图像和视频等二维内容,甚至可以对三维场景进行建模扫描,但总体来说,高质量三维内容的创作往往需要有经验的专业人员使用如 3ds Max、Maya、Blender 等软件手动建模和渲染,但这些有很高的学习成本和陡峭的成长曲线。
其中一大主要原因是,三维内容的表达十分复杂,如几何模型、纹理贴图或者角色骨骼动画等。即使就几何表达而言,就可以有点云、体素和网格等多种形式。三维表达的复杂性极大地限制了后续数据采集和算法设计。
另一方面,三维数据天然具有稀缺性,数据获取的成本高昂,往往需要昂贵的设备和复杂的采集流程,且难以大量收集某种统一格式的三维数据。这使得大多数数据驱动的深度生成模型难有用武之地。
在算法层面,如何将收集到的三维数据送入计算模型,也是难以解决的问题。三维数据处理的算力开销,要比二维数据有着指数级的增长。暴力地将二维生成算法拓展到三维,即使是最先进的并行计算处理器也难以在可接受的时间内进行处理。
上述原因导致了当前三维内容生成的工作大多只局限于某一特定类别或者只能生成较低分辨率的内容,难以应用于真实的生产流程中。
为了解决上述问题,提出了首个基于单样例场景无需训练便可生成多样高质量三维场景的方法。该算法具有如下优点:
1,无需大规模的同类训练数据和长时间的训练,仅使用单个样本便可快速生成高质量三维场景;
2,使用了基于神经辐射场的 Plenoxels 作为三维表达,场景具有高真实感外观,能渲染出照片般真实的多视角图片。生成的场景也完美的保留了样本中的所有特征,如水面的反光随视角变化的效果等;
3,支持多种应用制作场景,如三维场景的编辑、尺寸重定向、场景结构类比和更换场景外观等。
方法介绍
研究人员提出了一种多尺度的渐进式生成框架,如下图所示。算法核心思想是将样本场景拆散为多个块,通过引入高斯噪声,然后以类似拼积木的方式将其重新组合成类似的新场景。
作者使用坐标映射场这种和样本异构的表达来表示生成的场景,使得高质量的生成变得可行。为了让算法的优化过程更加鲁棒,该研究还提出了一种基于值和坐标混合的优化方法。同时,为了解决三维计算的大量资源消耗问题,该研究使用了精确到近似的优化策略,使得能在没有任何训练的情况下,在分钟级的时间生成高质量的新场景。更多的技术细节请参考原始论文。

随机场景生成

通过如左侧框内的单个三维样本场景,可以快速地生成具有复杂几何结构和真实外观的新场景。该方法可以处理具有复杂拓扑结构的物体,如仙人掌,拱门和石凳等,生成的场景完美地保留了样本场景的精细几何和高质量外观。当前没有任何基于神经网络的生成模型能做到相似的质量和多样性。
高分辨率大场景生成
视频发不了
该方法能高效地生成极高分辨率的三维内容。如上所示,我们可以通过输入单个左上角分辨率为 512 x 512 x 200 的三维 “千里江山图” 的一部分,生成 1328 x 512 x 200 分辨率的 “万里江山图”,并渲染出 4096 x 1024 分辨率的二维多视角图片。
真实世界无边界场景生成

作者在真实的自然场景上也验证了所提出的生成方法。通过采用与 NeRF++ 类似的处理方法,显式的将前景和天空等背景分开后,单独对前景内容进行生成,便可在真实世界的无边界场景中生成新场景。
其他应用场景
场景编辑

使用相同的生成算法框架,通过加入人为指定限制,可以对三维场景内的物体进行删除,复制和修改等编辑操作。如图中所示,可以移除场景中的山并自动补全孔洞,复制生成三座山峰或者使山变得更大。
尺寸重定向

该方法也可以对三维物体进行拉伸或者压缩的同时,保持其局部的形状。图中绿色框线内为原始的样本场景,将一列三维火车进行拉长的同时保持住窗户的局部尺寸。
结构类比生成

和图像风格迁移类似,给定两个场景 A 和 B,我们可以创建一个拥有 A 的外观和几何特征,但是结构与 B 相似的新场景。如我们可以参考一座雪山将另一座山变为三维雪山。
更换样本场景

由于该方法对生成场景采用了异构表达,通过简单地修改其映射的样本场景,便可生成更加多样的新场景。如使用同一个生成场景映射场 S,映射不同时间或季节的场景,得到了更加丰富的生成结果。
总结
这项工作面向三维内容生成领域,首次提出了一种基于单样本的三维自然场景生成模型,尝试解决当前三维生成方法中数据需求大、算力开销多、生成质量差等问题。该工作聚焦于更普遍的、语义信息较弱的自然场景,更多的关注生成内容的多样性和质量。算法主要受传统计算机图形学中纹理图像生成相关的技术,结合近期的神经辐射场,能快速地生成高质量三维场景,并展示了多种实际应用。
未来展望
该工作有较强的通用性,不仅能结合当前的神经表达,也适用于传统的渲染管线几何表达,如多边形网格 (Mesh)。我们在关注大型数据和模型的同时,也应该不时地回顾传统的图形学工具。研究人员相信,不久的未来,在 3D AIGC 领域,传统的图形学工具结合高质量的神经表达以及强力的生成模型,将会碰撞出更绚烂的火花,进一步推进三维内容生成的质量和速度,解放人们的创造力。
#OpenShape_code
三维点云的开放世界理解,分类、检索、字幕和图像生成样样行 , OpenShape 让三维形状的开放世界理解成为可能。
输入一把摇椅和一匹马的三维形状,能得到什么?

木马和坐在椅子上的牛仔!

木推车加马?得到马车和电动马;香蕉加帆船?得到香蕉帆船;鸡蛋加躺椅?得到鸡蛋椅。

来自UCSD、上海交大、高通团队的研究者提出最新三维表示模型OpenShape,让三维形状的开放世界理解成为可能。
- 论文地址:https://arxiv.org/pdf/2305.10764.pdf
- 项目主页:https://colin97.github.io/OpenShape/
- 交互demo: https://huggingface.co/spaces/OpenShape/openshape-demo
- 代码地址:https://github.com/Colin97/OpenShape_code
通过在多模态数据(点云 - 文本 - 图像)上学习三维点云的原生编码器,OpenShape 构建了一个三维形状的表示空间,并与 CLIP 的文本和图像空间进行了对齐。得益于大规模、多样的三维预训练,OpenShape 首次实现三维形状的开放世界理解,支持零样本三维形状分类、多模态三维形状检索(文本 / 图像 / 点云输入)、三维点云的字幕生成和基于三维点云的图像生成等跨模态任务。
三维形状零样本分类

OpenShape 支持零样本三维形状分类。无需额外训练或微调,OpenShape 在常用的 ModelNet40 基准(包含 40 个常见类别)上达到了 85.3% 的 top1 准确率,超过现有零样本方法 24 个百分点,并首次实现与部分全监督方法相当的性能。
OpenShape 在 ModelNet40 上的 top3 和 top5 准确率则分别达到了 96.5% 和 98.0%。

与现有方法主要局限于少数常见物体类别不同,OpenShape 能够对广泛的开放世界类别进行分类。在 Objaverse-LVIS 基准上(包含 1156 个物体类别),OpenShape 实现了 46.8% 的 top1 准确率,远超现有零样本方法最高只有 6.2% 的准确率。这些结果表明 OpenShape 具备有效识别开放世界三维形状的能力。
多模态三维形状检索
通过 OpenShape 的多模态表示,用户可以对图像、文本或点云输入进行三维形状检索。研究通过计算输入表示和三维形状表示之间的余弦相似度并查找 kNN,来从集成数据集中检索三维形状。

上图展示了输入图片和两个检索到的三维形状。

上图展示了输入文本和检索到的三维形状。OpenShape 学到了广泛的视觉和语义概念,从而支持细粒度的子类别(前两行)和属性控制(后两行,如颜色,形状,风格及其组合)。

上图展示了输入的三维点云和两个检索到的三维形状。

上图将两个三维形状作为输入,并使用它们的 OpenShape 表示来检索同时最接近两个输入的三维形状。检索到的形状巧妙地结合了来自两个输入形状的语义和几何元素。
基于三维形状的文本和图像生成
由于 OpenShape 的三维形状表示与 CLIP 的图像和文本表示空间进行了对齐,因此它们可以与很多基于 CLIP 的衍生模型进行结合,从而支持各种跨模态应用。

通过与现成的图像字幕模型(ClipCap)结合,OpenShape 实现了三维点云的字幕生成。

通过与现成的文本到图像的扩散模型(Stable unCLIP)结合,OpenShape 实现了基于三维点云的图像生成(支持可选的文本提示)。

训练细节
基于对比学习的多模态表示对齐:OpenShape 训练了一个三维原生编码器,它将三维点云作为输入,来提取三维形状的表示。继之前的工作,研究利用多模态对比学习来与 CLIP 的图像和文本表示空间进行对齐。与之前的工作不同,OpenShape 旨在学习更通用和可扩展的联合表示空间。研究的重点主要在于扩大三维表示学习的规模和应对相应的挑战,从而真正实现开放世界下的三维形状理解。

集成多个三维形状数据集:由于训练数据的规模和多样性在学习大规模三维形状表示中起着至关重要的作用,因此研究集成了四个当前最大的公开三维数据集进行训练。如下图所示,研究的训练数据包含了 87.6 万个训练形状。在这四个数据集中,ShapeNetCore、3D-FUTURE 和 ABO 包含经过人工验证的高质量三维形状,但仅涵盖有限数量的形状和数十个类别。Objaverse 数据集是最近发布的三维数据集,包含显著更多的三维形状并涵盖更多样的物体类别。然而 Objaverse 中的形状主要由网络用户上传,未经人工验证,因此质量参差不齐,分布极不平衡,需要进一步处理。

文本过滤和丰富:研究发现仅在三维形状和二维图像之间应用对比学习不足以推动三维形状和文本空间的对齐,即使在对大规模数据集进行训练时也是如此。研究推测这是由于 CLIP 的语言和图像表示空间中固有的领域差距引起的。因此,研究需要显式地将三维形状与文本进行对齐。然而来自原始三维数据集的文本标注通常面临着缺失、错误、或内容粗略单一等问题。为此,本文提出了三种策略来对文本进行过滤和丰富,从而提高文本标注的质量:使用 GPT-4 对文本进行过滤、对三维模型的二维渲染图进行字幕生成和图像检索。



在每个示例中,左侧部分展示了缩略图、原始形状名称和 GPT-4 的过滤结果。右上部分展示来来自两个字幕模型的图像字幕,而右下部分显示检索到的图像及其相应的文本。
扩大三维骨干网络。由于先前关于三维点云学习的工作主要针对像 ShapeNet 这样的小规模三维数据集, 这些骨干网络可能不能直接适用于我们的大规模的三维训练,需要相应地扩大骨干网络的规模。研究发现在不同大小的数据集上进行训练,不同的三维骨干网络表现出不同的行为和可扩展性。其中基于 Transformer 的 PointBERT 和基于三维卷积的 SparseConv 表现出更强大的性能和可扩展性,因而选择他们作为三维骨干网络。

困难负例挖掘:该研究的集成数据集表现出高度的类别不平衡。一些常见的类别,比如建筑,可能占据了数万个形状,而许多其他类别,比如海象和钱包,只有几十个甚至更少的形状,代表性不足。因此,当随机构建批次进行对比学习时,来自两个容易混淆的类别(例如苹果和樱桃)的形状不太可能出现在同一批次中被对比。为此,本文提出了一种离线的困难负例挖掘策略,以提高训练效率和性能。
#SPin-NeRF
神经辐射场(Neural Radiance Fields,简称 NeRF)已经成为一种流行的新视角合成方法。尽管 NeRF 迅速适应了更广泛的应用领域,但直观地编辑 NeRF 场景仍然是一个待解决的挑战。其中一个重要的编辑任务是从 3D 场景中移除不需要的对象,以使替换区域在视觉上是合理的,并与其上下文保持一致。本文提出了一种新颖的 3D 修复方法来解决这些挑战。
神经辐射场(NeRF)已经成为一种流行的新视图合成方法。虽然 NeRF 正在快速泛化到更广泛的应用以及数据集中,但直接编辑 NeRF 的建模场景仍然是一个巨大的挑战。一个重要的任务是从 3D 场景中删除不需要的对象,并与其周围场景保持一致性,这个任务称为 3D 图像修复。在 3D 中,解决方案必须在多个视图中保持一致,并且在几何上具有有效性。
本文来自三星、多伦多大学等机构的研究人员提出了一种新的三维修复方法来解决这些挑战,在单个输入图像中给定一小组姿态图像和稀疏注释,提出的模型框架首先快速获得目标对象的三维分割掩码并使用该掩码,然后引入一种基于感知优化的方法,该方法利用学习到的二维图像再进行修复,将他们的信息提取到三维空间,同时确保视图的一致性。
该研究还通过训练一个很有挑战性的现实场景的数据集,给评估三维场景内修复方法带来了新的基准测试。特别是,该数据集包含了有或没有目标对象的同一场景的视图,从而使三维空间内修复任务能够进行更有原则的基准测试。
- 论文地址:https://arxiv.org/pdf/2211.12254.pdf
- 论文主页:https://spinnerf3d.github.io/
下面为效果展示,在移除一些对象后,还能与其周围场景保持一致性:

本文方法和其他方法的比较,其他方法存在明显的伪影,而本文的方法不是很明显:

方法介绍
作者通过一种集成的方法来应对三维场景编辑任务中的各种挑战,该方法获取场景的多视图图像,以用户输入提取到的 3D 掩码,并用 NeRF 训练来拟合到掩码图像中,这样目标对象就被合理的三维外观和几何形状取代。现有的交互式二维分割方法没有考虑三维方面的问题,而且目前基于 NeRF 的方法不能使用稀疏注释得到好的结果,也没有达到足够的精度。虽然目前一些基于 NeRF 的算法允许去除物体,但它们并不试图提供新生成的空间部分。据目前的研究进展,这个工作是第一个在单一框架中同时处理交互式多视图分割和完整的三维图像修复的方法。
研究者利用现成的、无 3D 的模型进行分割和图像修复,并以视图一致性的方式将其输出转移到 3D 空间。建立在 2D 交互式分割工作的基础上,作者所提出的模型从一个目标对象上的少量用户用鼠标标定的图像点开始。由此,他们的算法用一个基于视频的模型初始化掩码,并通过拟合一个语义掩码的 NeRF ,将其训练成一个连贯的 3D 分割。然后,再应用预先训练的二维图像修复到多视图图像集上,NeRF 拟合过程用于重建三维图像场景,利用感知损失去约束 2 维画图像的不一致,以及画深度图像规范化掩码的几何区域。总的来说,研究者们提供了一个完整的方法,从对象选择到嵌入的场景的新视图合成,在一个统一的框架中对用户的负担最小,如下图所示。

综上所述,这篇工作的贡献如下:
- 一个完整的 3D 场景操作过程,从用户交互的对象选择开始,到 3D 修复的 NeRF 场景结束;
- 将二维的分割模型扩展到多视图情况,能够从稀疏注释中恢复出具有三维一致的掩码;
- 确保视图一致性和感知合理性,一种新的基于优化的三维修复公式,利用二维图像修复;
- 一个新的用于三维编辑任务评估的数据集,包括相应的操作后的 Groud Truth。

多视图分割模块获取输入的 RGB 图像、相应的相机内在和外部参数,以及初始掩码去训练一个语义 NeRF 。上图描述了语义 NeRF 中使用的网络;对于点 x 和视图目录 d,除了密度 σ 和颜色 c 外,它还返回一个 pre-sigmoid 型的对象 logit,s (x)。为了其快速收敛,研究者使用 instant-NGP 作为他们的 NeRF 架构。与光线 r 相关联的期望客观性是通过在等式中呈现 r 上的点的对数而不是它们相对于密度的颜色而得到的:

最后,采用两个阶段进行优化,进一步改进掩码;在获得初始三维掩码后,从训练视图呈现掩码,并用于监督二次多视图分割模型作为初始假设(而不是视频分割输出)。

上图显示了视图一致的修复方法概述。由于数据的缺乏妨碍了直接训练三维修改修复模型,该研究利用现有的二维修复模型来获得深度和外观先验,然后监督 NeRF 对完整场景的渲染拟合。这个嵌入的 NeRF 使用以下损失进行训练:

该研究提出具有视图一致性的修复方法,输入为 RGB。首先,该研究将图像和掩码对传输给图像修复器以获得 RGB 图像。由于每个视图都是独立修复的,因此直接使用修复完的视图监督 NeRF 的重建。本文中,研究者并没有使用均方误差(MSE)作为 loss 生成掩码,而是建议使用感知损失 LPIPS 来优化图像的掩码部分,同时仍然使用 MSE 来优化未掩码部分。该损失的计算方法如下:

即使有感知损失,修复视图之间的差异也会错误地引导模型收敛到低质量几何(例如,摄像机附近可能形成 “模糊” 几何测量,以解释每个视图的不同信息)。因此,研究员使用已生成的深度图作为 NeRF 模型的额外指导,并在计算感知损失时分离权值,使用感知损失只拟合场景的颜色。为此,研究者使用了一个对包含不需要的对象的图像进行了优化的 NeRF,并渲染了与训练视图对应的深度图。其计算方法是用到相机的距离而不是点的颜色代替的方法:


实验结果
多视图分割:首先评估 MVSeg 模型,没有任何编辑修复。在本实验中,假设稀疏图像点已经给出了一个现成的交互式分割模型,并且源掩码是可用的。因此,该任务是将源掩码传输到其他视图中。下表显示,新模型优于 2D(3D 不一致)和 3D 基线。此外研究者提出的两阶段优化有助于进一步改进所得到的掩码。

定性分析来说,下图将研究人员的分割模型的结果与 NVOS 和一些视频分割方法的输出进行了比较。与 3D 视频分割模型的粗边相比,他们的模型降低了噪声并提高了视图的一致性。虽然 NVOS 使用涂鸦(scribbles)不是研究者新模型中使用的稀疏点,但新模型的 MVSeg 在视觉上优于 NVOS。由于 NVOS 代码库不可用,研究人员复制了已发布的 NVOS 的定性结果(更多的例子请参见补充文档)。

下表显示了 MV 方法与基线的比较,总的来说,新提出的方法明显优于其他二维和三维修复方法。下表进一步显示,去除几何图形结构的引导会降低已修复的场景质量。

定性结果如图 6、图 7 所示。图 6 表明,本文方法可以重建具有详细纹理的视图一致场景,包括有光泽和无光泽表面的连贯视图。图 7 表明, 本文的感知方法减少了掩码区域的精确重建约束,从而在使用所有图像时防止了模糊的出现,同时也避免了单视图监督造成的伪影。


#FF3D~
3D 人像合成一直是备受关注的 AIGC 领域。随着 NeRF 和 3D-aware GAN 的日益进步,合成高质量的 3D 人像已经不能够满足大家的期待,能够通过简单的方式自定义 3D 人像的风格属性成为了更高的目标,例如直接使用文本描述指导合成想要的 3D 人像风格。
但是 3D 人像的风格化存在一个普遍的问题,当一个高质量的 3D 人像合成模型训练好后(例如训练一个 EG3D 模型),后续往往很难对其进行较大的风格化改变。基于模型隐空间编辑的方法会受限于预训练 3D 人像合成模型的数据分布;直接对 3D 人像不同视角进行风格化会破坏 3D 一致性;自己收集创建一个风格化的多视角人像数据集成本很高。以上这些问题使得大家难以简单的创建风格化 3D 人像。
中科院、阿里出品作者们提出一种简单高效的风格化 3D 人像合成方法,能够快速实现基于文本描述的自定义 3D 人像风格化。,创建自定义风格化3D人像只需三分钟
- 论文地址:https://arxiv.org/pdf/2306.15419.pdf
- 项目网站:https://tianxiangma.github.io/FF3D/
视频发不了 就别看了..
方法框架
该方法的核心步骤有两个:1. 小样本风格化人像数据集构建,2. Image-to-Triplane 模型微调。方法框架如下。

使用两种先验模型构建小样本风格化人像数据集
人工收集多视角风格化人像数据是困难的,但是研究团队可以利用已有的预训练模型来间接构建这种数据。本文采用两个预训练先验模型 EG3D 和 Instruct-pix2pix (IP2P) 来实现这一目标。

mage-to-Triplane 模型微调
构建出 Ds 后,需要学习一个符合该数据集人像风格的的 3D 模型。针对这个问题,研究团队提出一个 Image-to-Triplane (I2T) 网络,它可以建立人像图像到 Triplane 表征到映射。研究将预训练的 EG3D 模型的 Triplane 合成网络替换为本文提出的的 I2T 网络,并复用剩余的渲染网络。
因为 Ds 数据集的不同视角风格化肖像是 3D 不一致的,所以首先需要对 I2T 网络进行预训练,来预先建立人像到 Triplane 表征的准确映射关系。研究团队利用 EG3D 的合成数据来预训练 I2T 网络,训练损失函数如下:

该模型微调是十分高效的,可以在 3 分钟左右完成。至此,就能够得到一个自定义风格(使用文本提示 t 指定)的 3D 人像模型。
实验
在本文的首页所展示的就是一系列高质量的风格化 3D 人像合成结果。为了验证本文方法的可扩展性,研究团队构建了一个多风格多身份人像数据集。他们利用 ChatGPT 生成 100 种不同风格类型的问题提示,包含艺术风格、电影角色风格、游戏角色风格、以及基础属性编辑风格。对于每种风格使用本文的人像风格化 pipeline 合成 10*10 张不同视角的风格化人像,进而构建出包含 10,000 张图像的多风格单身份人像数据集(MSSI)。此外,在 MSSI 的基础上扩展每种风格的身份属性,即随机采样不同的 w 向量,得到多风格多身份人像数据集(MSMI)。该方法在这两个数据集上的微调模型的 3D 人像合成结果如下:


在 I2T 的 ws 隐空间进行插值即可实现 3D 人像的风格变化:

该方法与 baseline 方法的对比结果如下:

#PointGST
点云分析精度卷到99%了,还只用了2M训练参数
本文提出了一种全新的点云参数高效微调算法—PointGST,在极大地降低微调训练开销的同时,还展现出了优异的性能。仅凭 2M 可训练参数(仅为此前 SOTA 方法的 0.6%),PointGST 在多个点云分析数据集上均取得了 SOTA 结果,并首次在 ScanObjectNN OBJ_BG 数据集上实现了超过 99% 的准确率,几乎宣告了该数据集的性能达到了饱和。
近年来,点云分析技术在自动驾驶、虚拟现实、三维重建等领域得到了广泛应用。尽管点云预训练模型展现出了优越的性能,但随着模型参数量的急剧增加,对其进行微调的内存和存储开销也同步增加。为了缓解这一问题,本文提出了一种全新的点云参数高效微调算法——PointGST,在极大地降低微调训练开销的同时,还展现出了优异的性能。仅凭 2M 可训练参数(仅为此前 SOTA 方法的 0.6%),PointGST 在多个点云分析数据集上均取得了 SOTA 结果,并首次在 ScanObjectNN OBJ_BG 数据集上实现了超过 99% 的准确率,几乎宣告了该数据集的性能达到了饱和。

图1:近年来点云分析模型的训练参数大小和性能的发展趋势

论文地址:https://arxiv.org/abs/2410.08114
代码地址:https://github.com/jerryfeng2003/PointGST
单位:华中科技大学,百度
摘要
提出了一种全新的三维预训练模型微调算法:PointGST,它主要包含以下创新点:
1、构建了一套参数高效谱域微调方法,通过冻结预训练模型的参数并引入轻量级可训练模块,显著降低了模型在微调过程中的显存占用,同时实现了高性能。
2、通过图傅里叶变换,有效地消除了预训练模型内部点云tokens之间的混淆,并进一步引入点云几何结构信息,使得模型在不同数据集上的泛化能力显著增强。此外,PointGST采用了一种新的多层次点云图构建方法,能够更好地捕捉点云数据的内在特征。在实验中,PointGST在多个点云分析任务上展现出优异的准确性和鲁棒性,超越了目前所有同类方法。
动机
三维点云分析是计算机视觉的基础任务之一,广泛应用于自动驾驶、机器人和三维重建等领域。近年来,探索通过新的预训练方法提升点云分析模型性能已成为热门研究课题,这些方法通常通过对全部参数进行微调,然后将模型部署于下游任务中。
然而,由于需要更新全部参数,并且不同下游任务需要独立训练和存储,全微调带来了较高的GPU显存和存储开销,且随着现有模型参数量的逐渐增加而变得愈发显著。为了解决这一问题,一些研究者开始探索将参数高效微调(Parameter-Efficient Fine-Tuning)应用于点云分析领域,并取得了一定的成果。
但这些方法直接在空间域微调时缺乏下游任务的先验知识,难以消除预训练模型内部 token 的混淆;且这些方法未明确引入点云的固有内在结构,仅靠冻结参数的预训练模型来捕获结构信息存在缺陷。
针对上述问题,文章提出了一种基于谱域的三维预训练模型微调方法PointGST(Point Graph Spectral Tuning),用于进一步减轻预训练模型微调中的显存和存储开销问题,同时有效提升参数高效微调算法的性能。
方法
PointGST通过冻结预训练模型的参数,并向其中并行地插入轻量级的可训练模块,点云谱适配器(PCSA),在谱域内进行微调。通过图傅里叶变换(GFT),PointGST将点云tokens从空间域转换为谱域,使得各个token之间的相关性得以有效去除,缓解了预训练模型内部tokens的混淆。
与此同时,PointGST通过基于点云数据关键点构建多层次的点云图,再分别生成图傅里叶变换的基向量,由此引入点云数据的几何结构信息,使得在对下游任务进行微调时,能够通过谱域微调更好地捕捉到点云数据的固有信息。这使得PointGST在显著减少可学习参数量的同时,在多个点云数据集上实现了优异性能。模型整体的pipeline如下图所示:

图2:PointGST整体框架图
PointGST的核心在于将点云tokens从空间域转换到谱域进行处理。具体流程如下:
1、构建点云全局和局部图:通过Farthest Point Sampling (FPS)从原始点云中抽取n个关键点,作为全局图;利用空间填充曲线扫描,将点云中的关键点排序后划分出k组,作为k个点云局部图。通过文章提出的数据依赖放缩策略,由点云得到图的邻接矩阵W,并计算拉普拉斯矩阵L,对原始点云数据提取全局和局部点云的图结构,再加入模型由各个子层共用,在引入了全局和局部空间几何信息的同时,共用的基向量矩阵也显著减小了计算开销。
再对其进行特征值分解得到基向量U,传入各个Transformer子层中。具体过程如下图:

图3:全局和局部的图傅里叶变换基向量构建过程
2、图傅里叶变换(GFT):利用全局和局部图的基向量,对输入适配器并降维后的tokens做GFT,得到点云谱域tokens。此过程能够有效解耦点云数据的复杂空间关系,使得各个token在谱域内得到独立表示。图傅里叶变换即基向量矩阵乘输入图信号。其中,为了和局部图的点云分组对应,在对其进行图傅里叶变换前先由上一阶段关键点排序的索引对点云空间域tokens排序后分组,再对各组进行变换。
3、谱域微调:使用轻量级的点云谱适配器(PCSA)对谱域内的tokens进行微调。该适配器包括简单的线性层和残差连接,通过共享的线性层进行全局和局部谱域tokens的调整。
4、图傅里叶逆变换(iGFT):经过微调的谱域tokens通过逆傅里叶变换返回空间域,即乘以基向量矩阵的转置。随后将局部图点云tokens重排序后,各组tokens相加,升维并输出。为了使训练初始时不改变原有子层的输出,并维持图傅里叶正逆变换前后的一致性,对共享线性层和升维矩阵做零初始化,并加入残差连接结构。
通过这一完整的处理流程,PointGST在显著减少可训练参数的同时,实现了较高的微调性能。
实验结果
PointGST在真实世界点云分类数据集ScanObjectNN以及模拟数据集ModelNet40中取得了优异的性能。实验结果显示,相较于之前的点云参数高效微调方法,PointGST在显著减少了微调参数量和显存开销的同时,对于五种不同的baseline,在几乎所有任务上超过全微调并得到点云参数高效微调的SOTA结果。

表1:点云分类任务上参数高效微调方法对比
以PointGPT-L为baseline进行微调训练,超过以往的点云分析方法,实现了多个的SOTA结果,并首次在ScanObjectNN OBJ_BG数据集实现超过99%的准确率。

表2:点云分类任务上性能对比
下图展现了在NVIDIA 3090显卡上,不同批次大小下PointGST相比全微调和现有方法能极大地减小内存开销。与以往方法相比,PointGST采用了更加精简的网络结构,从而能够在保持性能的同时,显著降低显存需求,使得模型在实际应用中更加高效和灵活。

图4:微调训练中显存占用大小对比
与此同时,当只使用部分训练数据进行训练,PointGST在不同比例数据下得到了最优的结果,体现其在微调训练中能更好地收敛,并证明了其在鲁棒性上的优越性。

图5:部分数据进行微调训练性能对比
总结
PointGST作为一种全新的点云参数高效微调方法,通过引入谱域微调,有效缓解了传统全微调在显存开销和存储占用上的问题。其在多个数据集上的性能表现证明了该方法的优越性,特别是对大型点云预训练模型进行微调的潜力。PointGST为高效、精确和廉价的三维信息处理提供新的解决方案和可能思路。
#DensePose From WiFi
过去几年,在自动驾驶和 VR 等应用的推动下,使用 2D 和 3D 传感器(如 RGB 传感器、LiDARs 或雷达)进行人体姿态估计取得了很大进展。但是,这些传感器在技术上和实际使用中都存在一些限制。首先成本高,普通家庭或小企业往往承担不起 LiDAR 和雷达传感器的费用。其次,这些传感器对于日常和家用而言太过耗电。
用 WiFi 信号进行人体姿态估计并不新鲜,2018 年 MIT CSAIL 的研究者结合使用 WiFi 信号和深度学习,实现了隔墙人体姿态估计。近日,CMU 的研究者仅用 WiFi 信号搞定了遮挡、多人场景中的密集人体姿态估计。全身追踪、不怕遮挡
至于 RGB 相机,狭窄的视野和恶劣的照明条件会对基于相机的方法造成严重影响。遮挡成为阻碍基于相机的模型在图像中生成合理姿态预测的另一个障碍。室内场景尤其难搞,家具通常会挡住人。更重要的是,隐私问题阻碍了在非公共场所使用这些技术,很多人不愿意在家中安装摄像头记录自己的行为。但在医疗领域,出于安全、健康等原因,很多老年人有时不得不在摄像头和其他传感器的帮助下进行实时监控。
近日,CMU 的三位研究者在论文《DensePose From WiFi》中提出,在某些情况下,WiFi 信号可以作为 RGB 图像的替代来进行人体感知。照明和遮挡对用于室内监控的 WiFi 解决方案影响不大。WiFi 信号有助于保护个人隐私,所需的相关设备也能以合理的价格买到。关键的一点是,很多家庭都安装了 WiFi,因此这项技术有可能扩展到监控老年人的健康状况或者识别家中的可疑行为。
论文地址:https://arxiv.org/pdf/2301.00250.pdf
研究者想要解决的问题如下图 1 第一行所示。给定 3 个 WiFi 发射器和 3 个对应的接收器,能否在多人的杂乱环境中检测和复原密集人体姿态对应关系(图 1 第四行)?需要注意的是,很多 WiFi 路由器(如 TP-Link AC1750)都有 3 根天线,因此本文方法中只需要 2 个这样的路由器。每个路由器的价格大约是 30 美元,意味着整个设置依然比 LiDAR 和雷达系统便宜得多。
为了实现如图 1 第四行的效果,研究者从计算机视觉的深度学习架构中获得灵感,提出了一种可以基于 WiFi 执行密集姿态估计的神经网络架构,并实现了在有遮挡和多人的场景中仅利用 WiFi 信号来估计密集姿态。

下图左为基于图像的 DensePose,图右为基于 WiFi 的 DensePose。

另外,值得一提的是,论文一二作均为华人。论文一作 Jiaqi Geng 在去年 8 月取得了 CMU 机器人专业硕士学位,二作 Dong Huang 现为 CMU 高级项目科学家。
方法介绍
想要利用 WiFi 生成人体表面的 UV 坐标需要三个组件:首先通过振幅和相位步骤对原始 CSI( Channel-state-information,表示发射信号波与接收信号波之间的比值 )信号进行清理处理;然后,将处理过的 CSI 样本通过双分支编码器 - 解码器网络转换为 2D 特征图;接着将 2D 特征图馈送到一个叫做 DensePose-RCNN 架构中(主要是把 2D 图像转换为 3D 人体模型),以估计 UV 图。
原始 CSI 样本带有噪声(见图 3 (b)),不仅如此,大多数基于 WiFi 的解决方案都忽略了 CSI 信号相位,而专注于信号的幅度(见图 3 (a))。然而丢弃相位信息会对模型性能产生负面影响。因此,该研究执行清理(sanitization)处理以获得稳定的相位值,从而更好的利用 CSI 信息。

为了从一维 CSI 信号中估计出空间域中的 UV 映射,首先需要将网络输入从 CSI 域转换到空间域。本文采用 Modality Translation Network 完成(如图 4)。经过一番操作,就可以得到由 WiFi 信号生成的图像域中的 3×720×1280 场景表示。

在图像域中获得 3×720×1280 场景表示后,该研究采用类似于 DensePose-RCNN 的网络架构 WiFi-DensePose RCNN 来预测人体 UV 图。具体而言,在 WiFi-DensePose RCNN(图 5)中,该研究使用 ResNet-FPN 作为主干,并从获得的 3 × 720 × 1280 图像特征图中提取空间特征。然后将输出输送到区域提议网络。为了更好地利用不同来源的互补信息,WiFi-DensePose RCNN 还包含两个分支,DensePose head 和 Keypoint head,之后处理结果被合并输入到 refinement 单元。

然而从随机初始化训练 Modality Translation Network 和 WiFi-DensePose RCNN 网络需要大量时间(大约 80 小时)。为了提高训练效率,该研究将一个基于图像的 DensPose 网络迁移到基于 WiFi 的网络中(详见图 6)。

直接初始化基于 WiFi 的网络与基于图像的网络权重无法工作,因此,该研究首先训练了一个基于图像的 DensePose-RCNN 模型作为教师网络,学生网络由 modality translation 网络和 WiFi-DensePose RCNN 组成。这样做的目的是最小化学生模型与教师模型生成的多层特征图之间的差异。
实验
表 1 结果显示,基于 WiFi 的方法得到了很高的 AP@50 值,为 87.2,这表明该模型可以有效地检测出人体 bounding boxes 的大致位置。AP@75 相对较低,值为 35.6,这表明人体细节没有得到完美估计。

表 2 结果显示 dpAP・GPS@50 和 dpAP・GPSm@50 值较高,但 dpAP・GPS@75 和 dpAP・GPSm@75 值较低。这表明本文模型在估计人体躯干的姿势方面表现良好,但在检测四肢等细节方面仍然存在困难。

表 3 和表 4 的定量结果显示,基于图像的方法比基于 WiFi 的方法产生了非常高的 AP。基于 WiFi 的模型 AP-m 值与 AP-l 值的差异相对较小。该研究认为这是因为离相机远的人在图像中占据的空间更少,这导致关于这些对象的信息更少。相反,WiFi 信号包含了整个场景中的所有信息,而不管拍摄对象的位置。

#RODIN
微软亚洲研究院提出的RODIN模型,首次实现了利用生成扩散模型在 3D 训练数据上自动生成 3D 数字化身(Avatar)的功能。仅需一张图片甚至一句文字描述,RODIN 扩散模型就能秒级生成 3D 化身。
创建个性化的用户形象在如今的数字世界中非常普遍,很多 3D 游戏都设有这一功能。然而在创建个人形象的过程中,繁琐的细节调整常常让人又爱又恨,有时候大费周章地选了与自己相似的眼睛、鼻子、发型、眼镜等细节之后,却发现拼接起来与自己仍大相径庭。既然现在的 AI 技术已经可以生成惟妙惟肖的 2D 图像,那么在 3D 世界中,我们是否可以拥有一个“AI 雕塑家”,仅通过一张照片就可以帮我们量身定制自己的 3D 数字化身呢?
微软亚洲研究院新提出的 3D 生成扩散模型 Roll-out Diffusion Network (RODIN)可以轻松做到。让我们先来看看 RODIN 的实力吧!

(a) 给定的照片

(b) 生成的虚拟形象_图1:给定一张照片 ,RODIN 模型即可生成虚拟形象

(a)输入文字“留卷发和大胡子穿着黑色皮夹克的男性”

(b) 输入文字“红色衣着非洲发型的女性”_图2:给定文本描述,RODIN 模型可直接生成虚拟形象
与传统 3D 建模需要投入大量人力成本、制作过程繁琐不同的是,RODIN 以底层思路的创新突破与精巧的模型设计,突破了二次元到三次元的结界,实现了只输入一张图片或一句文字就能在几秒之内生成定制的 3D 数字化身的能力。 在此之前,AI 生成技术还仅仅围绕 2D 图像进行创作,RODIN 模型的出现也将极大地推动 AI 在 3D 生成领域的进步。相关论文“RODIN: A Generative Model for Sculpting 3D Digital Avatars Using Diffusion”已被 CVPR 2023 接收。
论文链接:https://arxiv.org/abs/2212.06135
项目页面:https://3d-avatar-diffusion.microsoft.com
RODIN模型首次将扩散模型应用于3D训练数据
在 3D 生成领域,尽管此前有不少研究利用 GAN(生成对抗网络)或 VAE(变分自动编码器)技术,从大量 2D 图像训练数据中生成 3D 图像,但结果却不尽如人意,“两面派”、“三头哪吒”等抽象派 3D 图像时有出现。科研人员们认为,造成这种现象的原因在于这些方法存在一个基础的欠定(ill posed)问题,也就是说由于单视角图片存在几何二义性,从仅仅通过大量的 2D 数据很难学到高质量 3D 化身的合理分布,所以才造成了各种不完美的生成结果。
对此,微软亚洲研究院的研究员们转变思路,首次提出 3D Diffusion Model,利用扩散模型的表达能力来建模 3D 内容。 这种方法通过多张视角图来训练 3D 模型,消除了歧义性、二义性所带来的“四不象”结果,从而得到一个正确解,创建出更逼真的 3D 形象。
然而,要实现这种方法,还需要克服三个难题:
- 首先,尽管扩散模型此前在 2D 内容生成上取得巨大成功,将其应用在 3D 数据上并没有可参考的实践方法和可遵循的前例。如何将扩散模型用于生成 3D 模型的多视角图,是研究员们找到的关键切入点;
- 其次,机器学习模型的训练需要海量的数据,但一个多视图、一致且多样、高质量和大规模的 3D 图像数据很难获取,还存在隐私和版权等方面的风险。网络公开的 3D 图像又无法保证多视图的一致性,且数据量也不足以支撑 3D 模型的训练;
- 第三,在机器上直接拓展 2D 扩散模型至 3D 生成,所需的内存存储与计算开销几乎无法承受。
多项技术创新让RODIN模型以低成本生成高质量的3D图像
为了解决上述难题,微软亚洲研究院的研究员们创新地提出了 RODIN 扩散模型,并在实验中取得了优异的效果,超越了现有模型的 SOTA 水平。
RODIN 模型采用神经辐射场(NeRF)方法,并借鉴英伟达的 EG3D 工作,将 3D 空间紧凑地表达为空间三个互相垂直的特征平面(Triplane),并将这些图展开至单个 2D 特征平面中,再执行 3D 感知扩散。具体而言,就是将 3D 空间在横、纵、垂三个正交平面视图上以二维特征展开,这样不仅可以让 RODIN 模型使用高效的 2D 架构进行 3D 感知扩散,将三维图像降维成二维图像也大幅降低了计算复杂度和计算成本。

图3:3D 感知卷积高效处理 3D 特征。(左图) 用三平面(triplane)表达 3D 空间,此时底部特征平面的特征点对应于另外两个特征平面的两条线。(右图)引入 3D 感知卷积处理展开的 2D 特征平面,同时考虑到三个平面的三维固有对应关系。
要实现 3D 图像的生成需要三个关键要素:
- 3D 感知卷积,确保降维后的三个平面的内在关联。 传统 2D 扩散中使用的 2D 卷积神经网络(CNN)并不能很好地处理 Triplane 特征图。而 3D 感知卷积并不是简单生成三个 2D 特征平面,而是在处理这样的 3D 表达时,考虑了其固有的三维特性,即三个视图平面中其中一个视图的 2D 特征本质上是 3D 空间中一条直线的投影,因此与其他两个平面中对应的直线投影特征存在关联性。为了实现跨平面通信,研究员们在卷积中考虑了这样的 3D 相关性,因此高效地用 2D 的方式合成 3D 细节。
- 隐空间协奏三平面 3D 表达生成。 研究员们通过隐向量来协调特征生成,使其在整个三维空间中具有全局一致性,从而获得更高质量的化身并实现语义编辑,同时,还通过使用训练数据集中的图像训练额外的图像编码器,该编码器可提取语义隐向量作为扩散模型的条件输入。这样,整体的生成网络可视为自动编码器,用扩散模型作为解码隐空间向量。对于语义可编辑性,研究员们采用了一个冻结的 CLIP 图像编码器,与文本提示共享隐空间。
- 层级式合成,生成高保真立体细节。 研究员们利用扩散模型先生成了一个低分辨率的三视图平面(64×64),然后再通过扩散上采样生成高分辨率的三平面(256×256)。这样,基础扩散模型集中于整体 3D 结构生成,而后续上采样模型专注于细节生成。

图4:RODIN 模型概述
此外,在训练数据集方面,研究员们借助开源的三维渲染软件 Blender,通过随机组合画师手动创建的虚拟 3D 人物图像,再加上从大量头发、衣服、表情和配饰中随机采样,进而创建了10万个合成个体,同时为每个个体渲染出了300个分辨率为256*256的多视图图像。在文本到 3D 头像的生成上,研究员们采用了 LAION-400M数据集的人像子集训练从输入模态到 3D 扩散模型隐空间的映射,最终让 RODIN 模型可以只使用一张 2D 图像或一句文字描述就能创建出逼真的 3D 头像。
图5:利用文字做 3D 肖像编辑

图6:更多随机生成的虚拟形象 (更多结果请点击阅读原文,移步项目网页)
微软亚洲研究院主管研究员张博表示,“此前,3D 领域的研究受限于技术或高成本,生成的 3D 结果主要是点云、体素、网格等形式的粗糙几何体,而 RODIN 模型可创建出前所未有的 3D 细节,为 3D 内容生成研究打开了新的思路。我们希望 RODIN 模型在未来可以成为 3D 内容生成领域的基础模型,为后续的学术研究和产业应用创造更多可能。”
让3D内容生成更个性、更普适
现如今,虚拟人、数字化身在电影、游戏、元宇宙、线上会议、电商等行业和场景中的需求日益增多,但其制作流程却相当复杂专业,每个高质量的化身都必须由专业的 3D 画师精心创作,尤其是在建模头发和面部毛发时,甚至需要逐根绘制,其中的艰辛历程外人难以想象。微软亚洲研究院 RODIN 模型的快速生成能力,可以协助 3D 画师减轻数字化身创作的工作量,提升效率,促进 3D 内容产业的发展。
“目前,3D 真人化身的创建耗时耗力,很多项目背后可能都有一个上百人的团队在做支持,实现方法更多的是借助虚幻引擎、游戏引擎,再加上画师的专业绘画能力,才能设计出高度逼真的真人定制 3D 化身,普通大众很难使用这些服务,通常只能得到一些现成的、与本人毫无关连的化身。而 RODIN 模型低成本和可定制化的 3D 建模技术,兼具普适性和个性化,让 3D 内容生成走向大众成为可能。” 微软亚洲研究院资深产品经理刘潏说
尽管当前 RODIN 模型生成结果主要为半身的 3D 头像,但是其技术能力并不仅限于 3D 头像的生成。随着包括花草树木、建筑、汽车家居等更多类别和更大规模训练数据的学习,RODIN 模型将能生成更多样的 3D 图像。下一步,微软亚洲研究院的研究员们将用 RODIN 模型探索更多 3D 场景创建的可能,向一个模型生成 3D 万物的终极目标不断努力。
#Point-NN
首次在3D领域中,提出了一个无参数无需训练的网络,Point-NN,并且在各个3D任务上都取得了良好的性能。
首次实现0参数量、0训练的3D点云分析:
Parameter is Not All You Need, Starting from Non-parametric Networks for 3D Point Cloud Analysis
不引入任何可学习参数或训练,我们是否可以直接实现3D点云的分类、分割和检测?
为此,本文提出了一个用于3D点云分析的非参数网络,Point-NN,它仅由纯不可学习的组件组成:最远点采样(FPS)、k近邻(k-NN)、三角函数(Trigonometric Functions)以及池化(Pooling)操作。不需要参数和训练,它能够在各种3D任务上都取得不错的准确率,甚至超过了一些现有的完全训练的模型。基于Point-NN的非参数框架,我们进一步提出两点Point-NN对于现今3D领域的贡献。
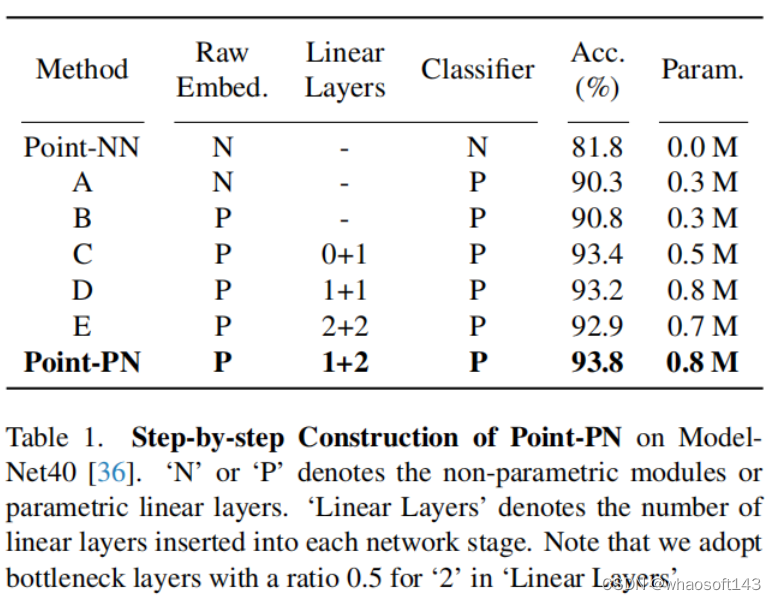
1、首先,我们可以通过插入简单的线性层,来构建Point-NN的参数化网络,Point-PN。由于Point-NN具有强大的非参数基础,所构建出的Point-PN仅需要少量可学习参数就可以表现出优秀的3D分类和分割性能。
2、其次,由于Point-NN不需要训练的属性,我们可以将其作为一个即插即用的增强模块,去增强现有已经训练好的3D模型。通过提供互补知识,Point-NN可以在各种3D任务上提升原本的SOTA性能。
作者:张仁瑞
文章链接:https://arxiv.org/abs/2303.08134
开源代码(已开源):https://github.com/ZrrSkywalker/Point-NN
3D点云的处理和分析是一项具有挑战性的任务,并且在学术界和工业界都取得了广泛的关注。自从PointNet++起,后续的3D模型为了提升性能,一方面设计了更加复杂的局部空间算子,一方面增大了网络的可学习参数量。然而,除了不断更新的可学习模块,他们基本都沿用了同一套潜在的多尺度网络框架,包括最远点采样(FPS)、k近邻(k-NN)和池化(Pooling)操作。目前,还几乎没有研究去探索这些非参数组件的潜力;因此,本文提出并探索了以下问题:这些非参数组件对于3D理解的贡献有多大?仅仅使用非参数组件,能否实现无需训练的3D点云分析?

为了解决以上问题,本文首次提出了一个非参数化(Non-Parametric)的3D网络,Point-NN,整体结构如上图所示。Point-NN由一个用于3D特征提取的非参数编码器(Non-Parametric Encoder)和一个用于特定任务识别的点云记忆库(Point-Memory Bank)组成。非参数编码器采用了多阶段的结构设计,使用了最远点采样(FPS)、k近邻(k-NN)、三角函数(Trigonometric Functions)和池化(Pooling)来逐步聚合局部几何图形,为点云生成一个高维度的全局特征。我们仅仅采用了简单的三角函数来捕捉局部空间几何信息,没有使用任何可学习算子。接下来,我们使用此编码器,去提取到所有训练集点云的特征,并缓存为点云记忆库。进行测试时,点云记忆库通过对测试点云和训练集点云的特征,进行相似度匹配,来输出特定任务的预测。
不需要任何训练,Point-NN可以在多种3D任务中实现优越的性能,例如3D分类、分割、检测,甚至可以超过一些现有的经过完全训练的模型。基于此,我们进一步提出了两点Point-NN对于现今3D领域的贡献,如下图(a)和(b)所示:
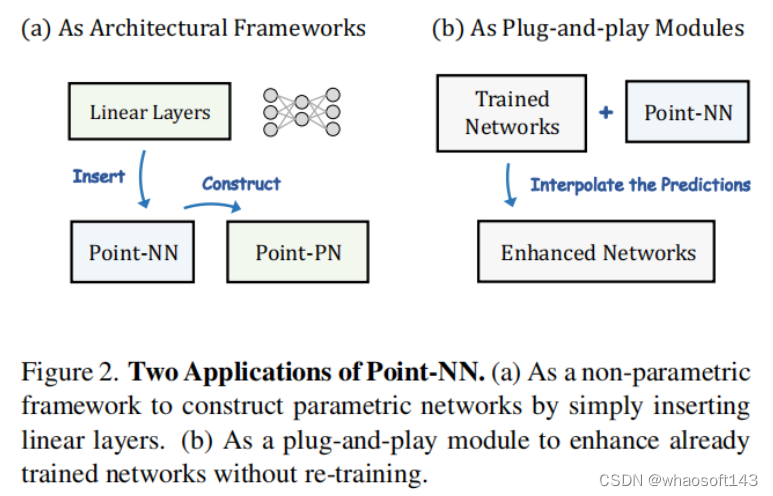
1、以Point-NN为基础框架,我们通过在Point-NN的每个阶段插入简单的线性层,引入了其parameter-efficient的变体Point-PN,如上图(a)所示。Point-PN不包含复杂的局部算子,仅仅包含线性层以及从Point-NN继承的三角函数算子,实现了效率和性能的双赢。
2、我们将Point-NN作为一个即插即用的模块,为各种3D任务中训练好的模型提供互补知识,并在推理过程中可以直接提升这些训练模型的性能,如上图(b)所示。
1. Point-NN
Point-NN由一个Non-Parametric Encoder (EncNP) 和一个Point-Memory Bank (PoM) 组成。对于输入的点云,我们使用EncNP提取其全局特征,并通过PoM的特征相似度匹配,来输出分类结果,公式如下图所示:
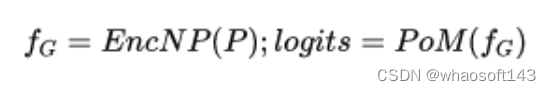
接下来,我们依次介绍Point-NN中的这两个模块。
(1)非参数编码器(Non-Parametric Encoder)
非参数编码器首先将输入点云进行Raw-point Embedding,将3维的原始点坐标转化为高维度特征,再经过4个阶段的Local Geometry Aggregation逐步聚合局部特征得到最终的点云全局特征,如下图所示。
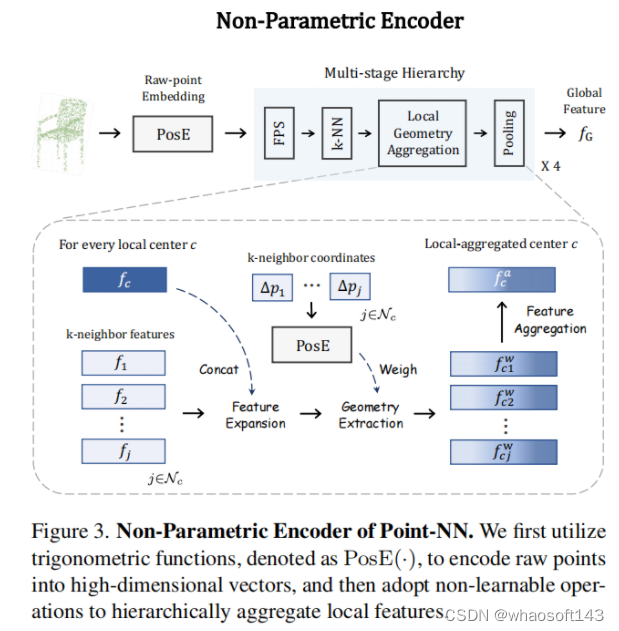
a. 原始点云映射(Raw-point Embedding)

b.局部几何特征的聚合(Local Geometry Aggregation)


(2)点云记忆库(Point-Memory Bank)
在经过非参数编码器(Non-Parametric Encoder)的特征提取后,由于Point-NN不含任何可学习参数,我们没有使用传统的可学习分类头,而是采用了无需训练的point-memory bank。首先,我们使用非参数编码器去构造关于训练集的bank,接着在推理过程通过相似度匹配输出预测,如下图所示。
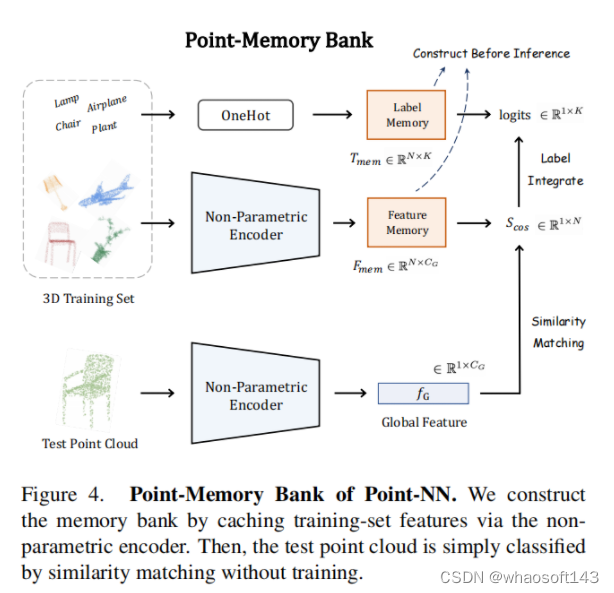
a. 记忆构建(Memory Construction)

b. 相似度预测 (Similarity-based Prediction)

2. Point–NN在其他3D任务的拓展
以上主要是对Point-NN在分类任务中的应用的介绍,Point-NN也可以被用于3D的部件分割和3D目标检测任务。
部件分割(3D Part Segmentation)

目标检测(3D Object Detection)
对于检测任务,我们将Point-NN作为一个3D检测器的分类头使用。当预训练好的检测器产生3D proposal后,Point-NN与分类任务相似,使用non-parametric encoder来获取被检测物体的全局特征。在构建point-memory bank时,我们在训练集中对在每个3D框标签内的点云进行采样,将采样后的每个物体的全局特征进行编码得到feature memory。特别的是,我们没有像其他任务一样对每个物体的点云坐标进行归一化,这是为了保留在原始空间中的3D位置信息,实现更好的检测性能。
3. 从Point-NN延伸( Starting from Point-NN)
(1)作为结构框架构建Point-PN(As Architectural Frameworks)
我们讲Point-NN视为一个良好的非参数化框架,在其中插入简单的可学习线性层,来构建参数化的3D网络,Point-PN。Point-PN相比于现有的3D网络,不含有复杂的局部算子,以极少的可学习参数量实现了优秀的3D性能。
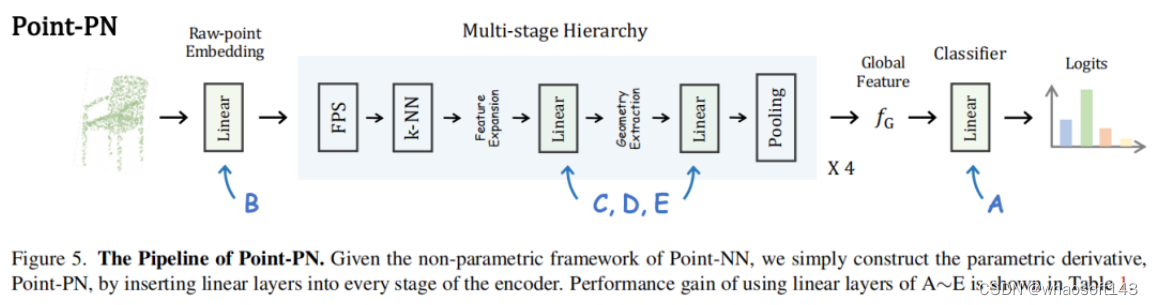
我们构建Point-PN的步骤如下:首先,将point-memory bank替换为传统的可学习的分类头,如上图(A)所示;在ModelNet40的分类任务上,这一步将分类性能从Point-NN的81.8%提高到了90.3%,且仅仅使用了0.3M的参数量。接着,我们将raw-point embedding替换为线性层(B),可以将分类性能进一步提高到90.8%。为了更好地提取多尺度层次特征,我们接着将线性层插入到每一阶段的non-parametric encoder中。具体来说,在每个阶段,两个线性层分别被插入到Geometry Extraction的前后来捕捉高层空间信息,如图中(C、D、E)所示。这样,最终的Point-PN可以仅仅使用0.8M的参数量达到93.8%的性能,且只包括三角函数和简单的线性层。这说明,与现有的高级的操作算子或者大参数两相比,我们可以从非参数框架出发,来获取一个简单高效的3D模型。
(2)作为即插即用模块(As Plug-and-play Modules)
Point-NN可以在不进行额外训练的情况下增强现有3D预训练模型的性能。以分类任务为例,我们直接将Point-NN与预训练模型预测的分类logits进行相加,来提供互补的3D知识提升性能。如下图对特征的可视化所示,Point-NN主要提取的是点云的低层次高频特征,在尖锐的三维结构周围产生了较高的响应值,例如飞机的翼尖、椅子的腿和灯杆;而经过训练的PointNet++更关注的是点云的高层次语义信息,通过对它们的logits相加可以得到互补的效果,例如,飞机的机身、椅子的主体和灯罩。

实验1.Point-NN和Point-PN
(1)3D物体分类(Shape Classification)
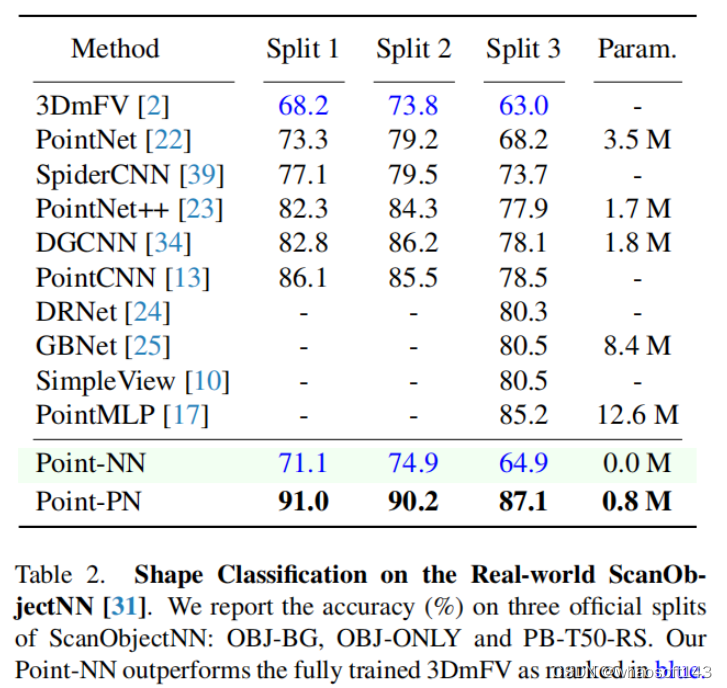
对于2个代表性的3D物体分类数据集,ModelNet40和ScanObjectNN,Point-NN都获得了良好的分类效果,甚至能够在ScanObjectNN上超过完全训练后的3DmFV模型。这充分说明了Point-NN在没有任何的参数或训练情况下的3D理解能力。
Point-PN在2个数据集上也都取得了有竞争力的结果。对于ScanObjectNN,与12.6M的PointMLP相比,Point-PN实现了参数量少16倍,推理速度快6倍,并且精度提升1.9%。在ModelNet40数据集上,Point-PN获得了与CurveNet相当的结果,但是少了2.5X的参数量,快了6X的推理速度。
(2)少样本3D分类(Few-shot Classification)
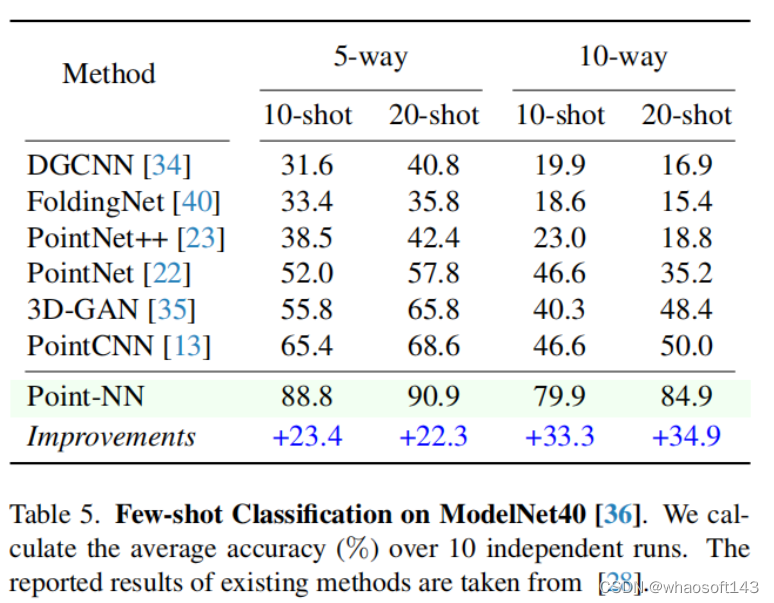
与现有的经过完全训练的3D模型相比,Point-NN的few shot性能显著超过了第二好的方法。这是因为训练样本有限,具有可学习参数的传统网络会存在严重的过拟合问题。
(3)3D部件分割(Part Segmentation)
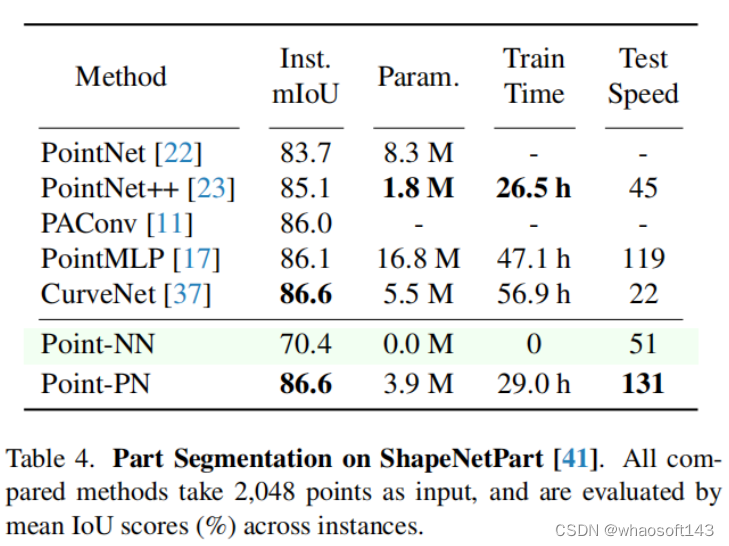
70.4%的mIoU表明由Point-NN在分割任务中也可以产生执行良好的单点级别的特征,并实现细粒度的3D空间理解。
Poinnt-PN能够取得86.6%的mIoU。与Curvenet相比,Point-PN可以节省28小时的训练时间,推理速度快6X。
(4)3D目标检测(3D Object Detection)
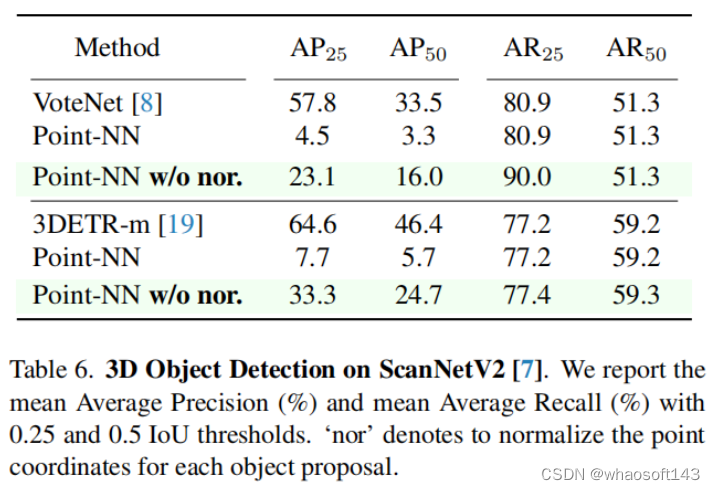
将Point-NN作为检测器的分类头,我们采用了两种流行的3D检测器VoteNet和3DETR-m来提取类别无关的3D region proposals。由于我们没有进行点云坐标的归一化处理(w/o nor.),这样可以保留原始场景中更多物体三维位置的信息,大大提升了Point-NN的AP分数。
2.Point-NN的即插即用(Plug-and-play)
(1)3D物体分类(Shape Classification)
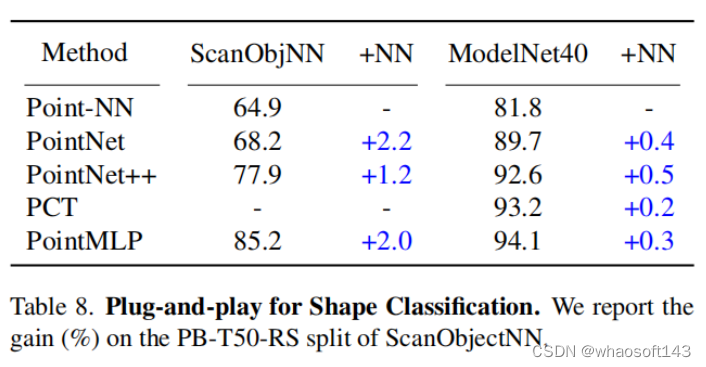
Point-NN可以有效提高现有方法的分类性能,在ScanObjectNN数据集上,Point-NN可以对PointNet和PoitMLP的分类准确率均提高2%。
(2)3D分割和检测(Segmentation and Detection)
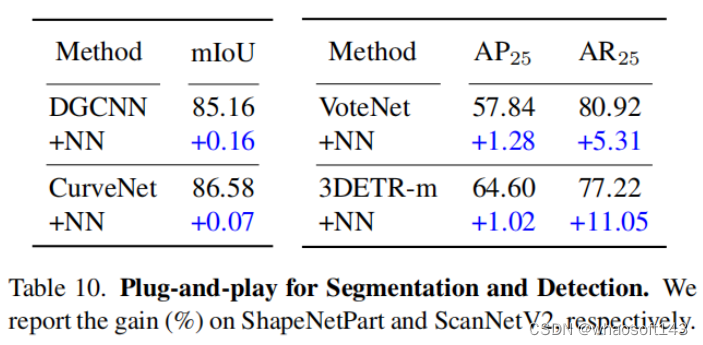

讨论
1.为什么Point-NN中的三角函数可以编码3D信息?
(1)捕获高频的3D结构信息
通过下图中Point-NN特征的可视化,以及我们分解出的点云低频和高频信息,可以观察到Point-NN主要捕获了点云的高频空间特征,例如边缘、拐角以及其它细粒度的细节。

(2)编码点云之间的相对位置信息

这个公式表示了x轴上两个点之间的相对位置。因此,三角函数可以得到点云之间的绝对和相对位置信息,这更有利于Point-NN对局部化点云的结构理解。
2.Point–NN可以即插即用的提升Point–PN的性能吗?

如上表所示,Point-NN对Point-PN的提升极其有限,从上图可视化的结果来看,Point-NN和Point-PN之间的互补性比Point-NN和PointNet++之间的互补性更弱。这是因为Point-PN的基础结构是继承自Point-NN,因此也会通过三角函数获取3D高频信息,和Point-PN拥有相似的特征捕获能力。
3.和其它无需训练的3D模型的比较
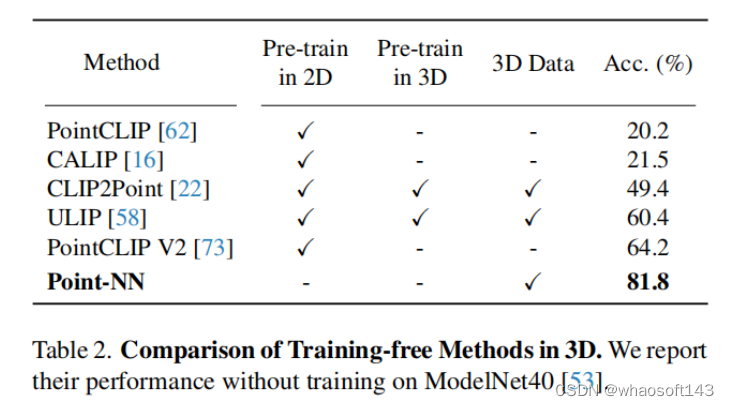
现有的3D模型中,有一类基于CLIP预训练模型的迁移学习方法,例如PointCLIP系列,它们也不需要进行3D领域中的训练过程。从上表的比较可以看出,Point-NN可以实现很优越的无需训练的分类性能。
4.Point–NN与PnP–3D的增强效果比较
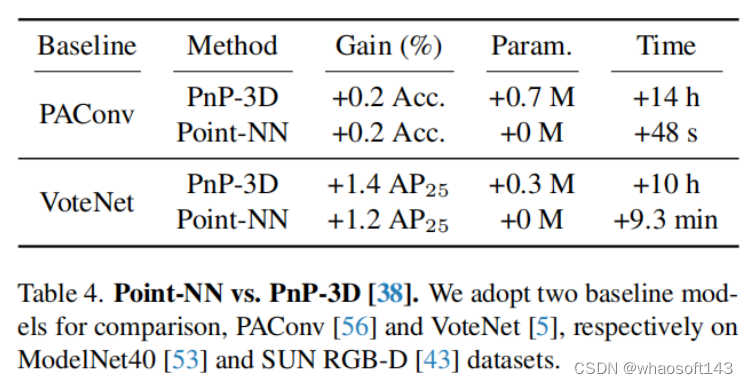
PnP-3D提出了一种对于3D模型的即插即用的可学习增强模块,但是它会引入额外的可学习参数,并且需要重新训练而消耗更多的计算资源。如上表所示,相比之下,Point-NN也能实现相似的增强性能,但是完全不需要额外参数或者训练。
总结和展望
本文首次在3D领域中,提出了一个无参数无需训练的网络,Point-NN,并且在各个3D任务上都取得了良好的性能。我们希望这篇工作可以启发更多的研究,来关注非参数化相关的3D研究,而不是一味的增加复杂的3D算子或者堆叠大量的网络参数。在未来的工作中,我们将探索更加先进的非参数3D模型,并推广到更广泛的3D应用场景中。
#OSX~~
本文提出了首个用于全身人体网格重建的一阶段算法OSX,通过模块感知的Transformer网络,高效、准确地重建出全身人体网格,并提出了一个大规模、关注真是应用场景的上半身人体重建数据集UBody。IDEA与清华提出首个一阶段3D全身人体网格重建算法
三维全身人体网格重建(3D Whole-Body Mesh Recovery)是三维人体重建领域的一个基础任务,是人类行为建模的一个重要环节,用于从单目图像中捕获出准确的全身人体姿态和形状,在人体重建、人机交互等许多下游任务中有着广泛的应用。来自粤港澳大湾区研究院(IDEA)与清华大学深研院的研究者们提出了首个用于全身人体网格重建的一阶段算法OSX,通过模块感知的Transformer网络,高效、准确地重建出全身人体网格,并提出了一个大规模、关注真是应用场景的上半身人体重建数据集UBody. 本文提出的算法从投稿至今(2022.11~2023.04),是AGORA榜单SMPL-X赛道的第一名。该工作已经被计算机视觉顶会CVPR2023接收,算法代码和预训练模型已经全部开源。
文章:https://arxiv.org/abs/2303.16160
代码:https://github.com/IDEA-Research/OSX
项目主页:https://osx-ubody.github.io/
单位:IDEA,清华大学深研院
三维全身人体网格重建(3D Whole-Body Mesh Recovery)是人类行为建模的一个重要环节,用于从单目图像中估计出人体姿态(Body Pose), 手势(Hand Gesture)和脸部表情(Facial Expressions),该任务在许多下游现实场景中有着广泛的应用,例如动作捕捉、人机交互等。得益于SMPLX等参数化模型的发展,全身人体网格重建精度得到了提升,该任务也得到越来越多的关注。
相比于身体姿态估计(Body-Only Mesh Recovery),全身人体网格重建需要额外估计手和脸部的参数,而手和脸部的分辨率往往较小,导致难以通过一个一阶段的网络,将全身参数估计出来。之前的方法大多采用多阶段的复制-粘贴(Copy-Paste)框架,提前检测出手和脸的包围框(Bounding Box),将其裁剪出来并放大,输入三个独立的网络,分别估计出身体(Body), 手(Hand), 和脸(Face)的参数,再进行融合。这种多阶段的做法可以解决手和脸分辨率过小的问题,然而,由于三部分的参数估计相对独立,容易导致最后的结果以及三部分之间的连接不够自然和真实,同时也会增加模型的复杂度。为了解决以上问题,我们提出了首个一阶段的算法OSX,我们使用一个模块感知的Transformer模型,同时估计出人体姿态, 手势和脸部表情。该算法在较小计算量和运行时间的情况下,在3个公开数据集(AGORA, EHF, 3DPW)上,超过了现有的全身人体网格重建算法.
我们注意到,目前的全身人体网格重建数据集,大部分是在实验室环境或者仿真环境下采集的,而这些数据集与现实场景有着较大的分布差异。这就容易导致训练出来的模型在应用于现实场景时,重建效果不佳。此外,现实中的许多场景,如直播、手语等,人往往只有上半身出现在画面中,而目前的数据集全部都是全身人体,手和脸的分辨率往往较低。为了弥补这方面数据集的缺陷,我们提出了一个大规模的上半身数据集UBody,该数据集涵盖了15个真实场景,包括100万帧图片和对应的全身关键点(2D Whole-Body Keypoint), 人体包围框(Person BBox)、人手包围框(Hand BBox)以及SMPLX标签。下图是UBody的部分数据可视化。

图1 UBody数据集展示
本工作的贡献点可以概括为:
- 我们提出了首个一阶段的全身人体网格重建算法OSX,能够用一个简单、高效的方式,估计出SMPLX参数。
- 我们的算法OSX在三个公开数据集上,超过了现有的全身人体网格重建算法。
- 我们提出了一个大规模的上半身数据集UBody,用以促进全身人体网格重建这个基础任务在现实场景中的应用。
一阶段重建算法介绍OSX整体框架
如下图所示,我们提出了一个模块感知(Component-Aware)的Transoformer模型,来同时估计全身人体参数,再将其输入SMPLX模型,得到全身人体网格。我们注意到,身体姿态(Body Pose)估计需要利用到全局的人体依赖信息,而手势(Hand Gesture)和脸部表情(Facial Expression)则更多的聚焦于局部的区域特征。因而,我们设计了一个全局编码器和一个局部解码器,编码器借助于全局自注意力机制(Global Self-attention),捕获人体的全身依赖关系,估计出身体姿态和形状(Body Pose and Shape),解码器则对特征图进行上采样,使用关键点引导的交叉注意力机制(Cross-Attention),用以估计手和脸部的参数。
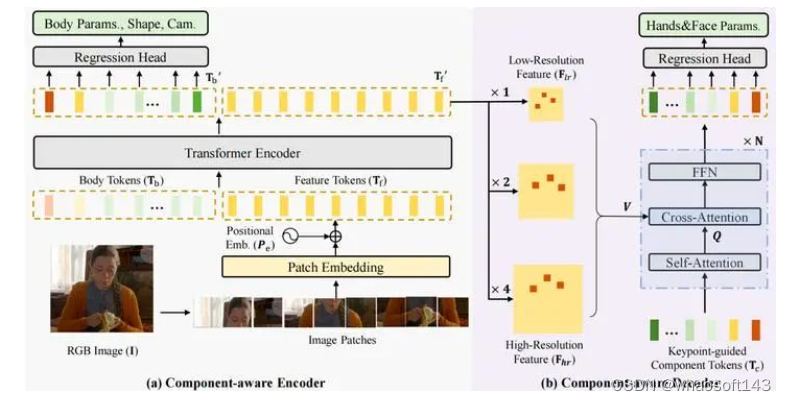
图2 OSX网络结构示意图
全局编码器

高分辨率局部解码器

最终,这些模块token通过全连接层,转换为手势和脸部表情,并于身体姿态和形状一起,输入SMPLX模型,转换为人体网格。
上半身数据集UBody介绍
数据集亮点
为了缩小全身人体网格重建这一基础任务与下游任务的差异,我们从15个现实场景,包括音乐演奏、脱口秀、手语、魔术表演等,收集了超过100万的图片,对其进行标注。这些场景与现有的数据集AGORA相比,由于只包含上半身,因而手和脸的分辨率更大,具有更加丰富的手部动作和人脸表情。同时,这些场景含有非常多样的遮挡、交互、切镜、背景和光照变化,因而更加具有挑战性,更加符合现实场景。此外,UBody是视频的形式,每个视频都包含了音频(Audio),因而未来也可以应用于多模态等任务。

图3 UBody 15个场景展示
IDEA自研高精度全身动捕标注框架
为了标注这些大规模的数据,我们提出了一个自动化标注方案,如下图所示,我们首先训练一个基于ViT的关键点估计网络,估计出高精度的全身人体关键点。接着,我们使用一个多阶段渐进拟合技术(Progreesive Fitting),将OSX输出的人体网格转换为三维关键点(3D Keypoints),并投影到图像平面,与估计的二维关键点(2D Keypoints)计算损失,用以优化OSX网络参数,直至估计出来的网格与2D关键点能够高度贴合。

图4 全身动捕标注框架图
以下是UBody数据集的几个场景及其标注结果的展示:

SignLanguage

Singing
实验结果
定量实验对比
OSX从投稿至今(2022.11~2023.04),是AGORA榜单上SMPLX赛道的榜首,在AGORA-test(https://agora-evaluation.is.tuebingen.mpg.de/)上的定量对比结果如下表所示:
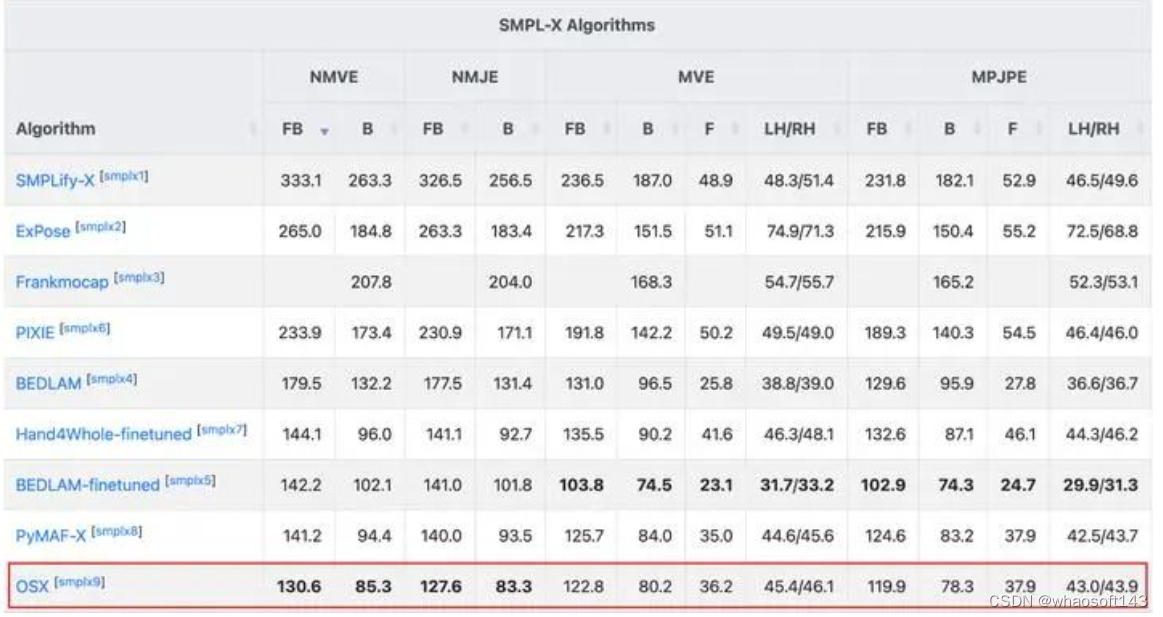
表1 OSX与SOTA算法在AGORA-test上的定量结果
在AGORA-val上的定量对比结果如下表所示:
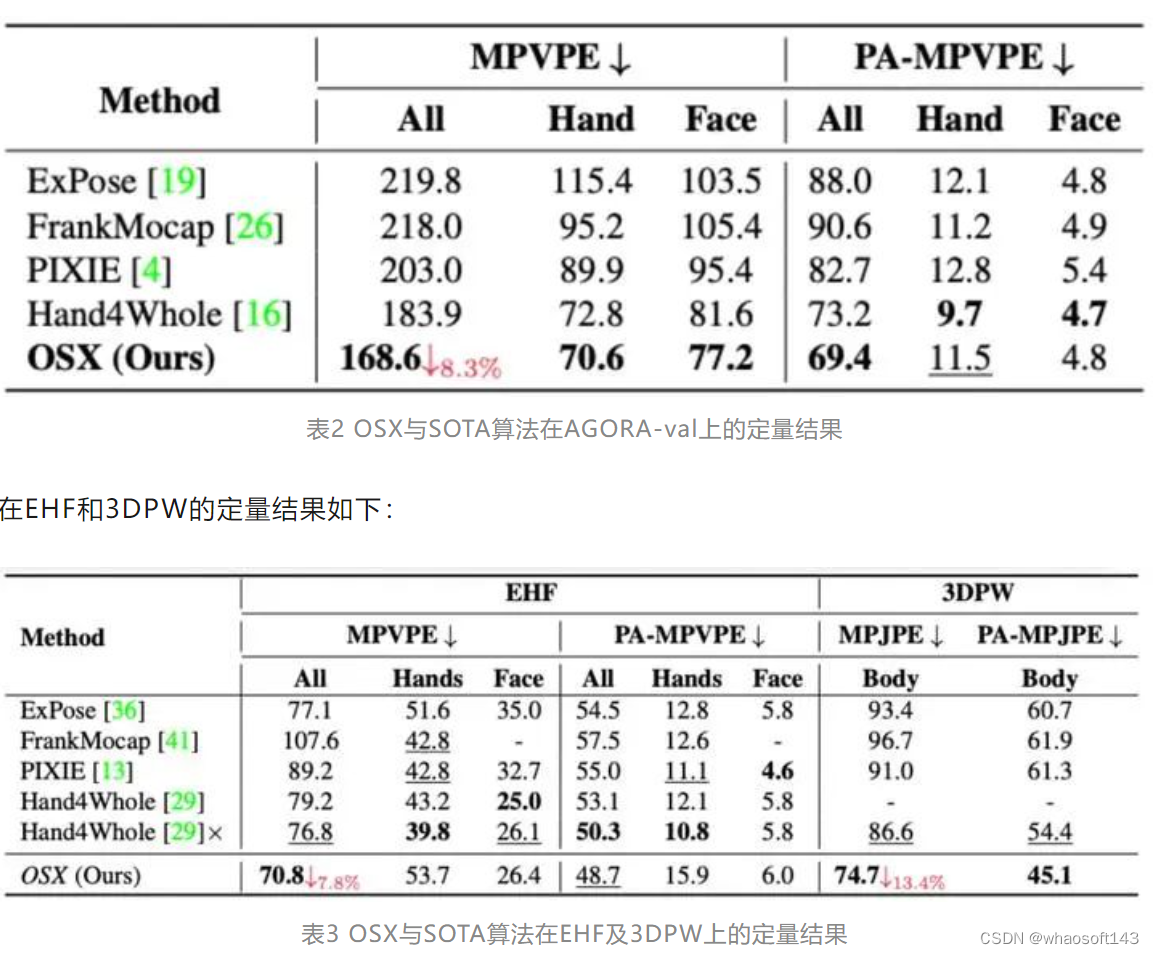
可以看出,OSX由于使用了模块感知的Transformer网络,能够同时保证全局依赖关系的建模和局部特征的捕获,在现有数据集,特别是AGORA这一较为困难的数据集上,显著超过了之前的方法。
定性实验对比
在AGORA上的定性对比结果如图所示:

从左到右依次为:输入图, ExPose, Hand4Whole, OSX(Ours)
可以看出,我们的算法OSX能够估计出更加准确的身体姿势,手部动作和脸部表情,重建出来的人体网格更加准确,与原图贴合的更好,更加鲁棒。
总结
OSX是首个一阶段全身人体网格重建的算法,通过一个模块感知的Transformer模型,同时估计了body pose, hand pose和facial experssion,在三个公开榜单上取得了目前最好whole-body mesh recovery最好的结果。此外,我们提出了一个大规模的上半身场景数据集UBody,用以促进人体网格重建任务在下游场景中的应用。我们的代码已经进行了开源,希望能够推动该领域的发展。
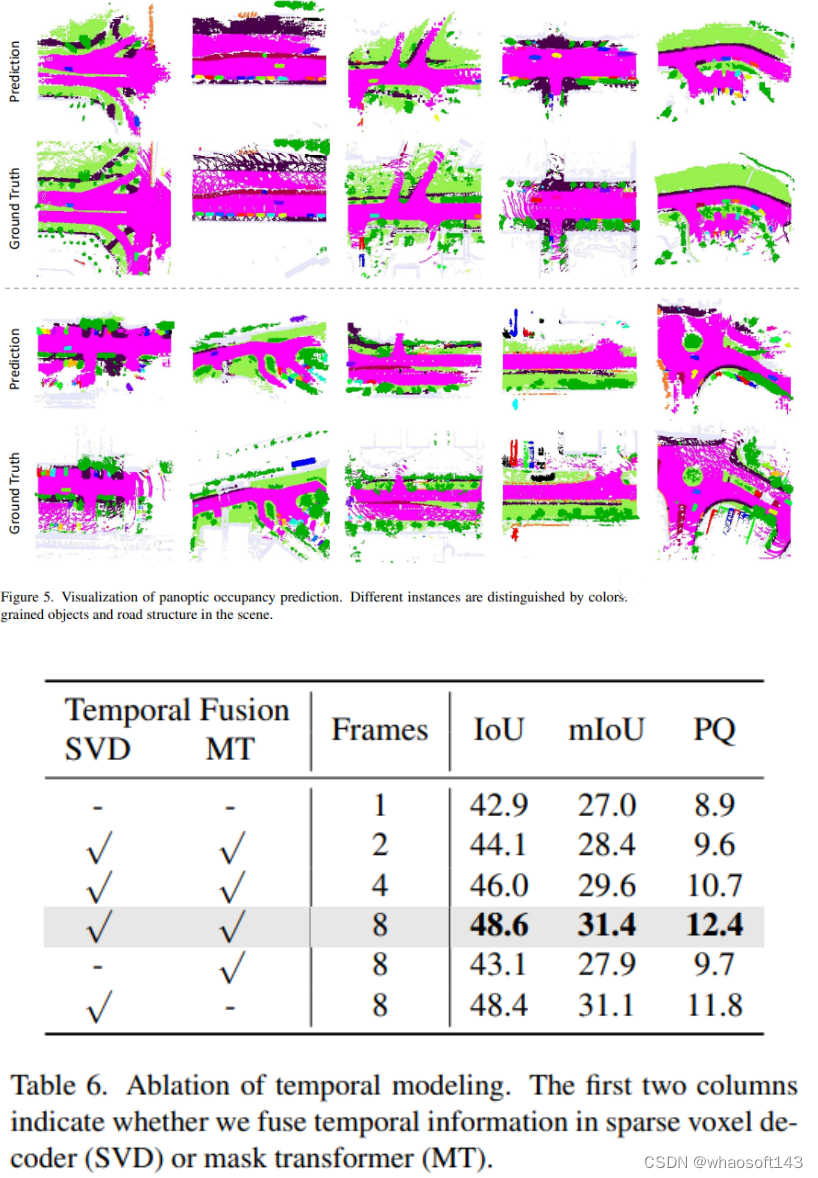
#SparseOcc
全稀疏3D全景占用预测
今天看到了arxiv版本更新到了V3,这应该是第一个做occupancy纯稀疏架构工作的paper,之前dense 的feature上做occupancy是比较容易的,大部分的方案也都是dense /semi-sparse(sparse-to-dense)的feature ,想做全稀疏的工作难度较高,作为第一篇值得精读,而且这个方案也算是重建了整个场景,目前看来感知和重建的方案在occ的发展上越来趋于一致
以前的OCC方法通常构建密集的3D体积,忽略了场景的固有稀疏性(大部分为空气),计算成本较高。为了弥合差距,我们引入了一种新的完全稀疏占用网络,称为SparseOcc。SparseOcc 最初从视觉输入重建稀疏的 3D 表示,然后通过稀疏查询从 3D 稀疏表示预测语义/实例占用。掩码引导的稀疏采样旨在使稀疏查询能够以完全稀疏的方式与 2D 特征交互,从而规避昂贵的密集特征或全局注意力。此外,我们设计了一个深思熟虑的基于光线的评估指标,即RayIoU,以解决传统体素级mIoU标准中沿深度的不一致惩罚。SparseOcc 通过实现 34.0 的 RayIoU 来证明其有效性,同时保持 17.3 FPS 的实时推理速度,具有 7 个历史帧输入。通过将前面的更多帧合并到 15 帧,SparseOcc 不断提高其性能到 35.1 RayIoU,没有花里胡哨的东西。
论文:Fully Sparse 3D Panoptic Occupancy Prediction
链接:https://arxiv.org/pdf/2312.17118.pdf
arxiv:https://arxiv.org/abs/2312.17118v3
code:GitHub - MCG-NJU/SparseOcc: Fully Sparse 3D Occupancy Prediction
现有的方法通常构造密集的3D特征,存在计算开销巨大(A100上的2∼3FPS)。然而,密集表示对于占用预测不是必需的。图1(a)中的统计揭示了几何稀疏性,超过90%的体素是空的。这通过利用稀疏性在入住率预测加速方面显示出巨大的潜力。voxformer、TPVformer探索了 3D 场景的稀疏性,但它们仍然依赖于sparse-to-dense的模块进行密集预测。这启发我们寻求一个完全稀疏的占用网络,不需要任何密集的设计
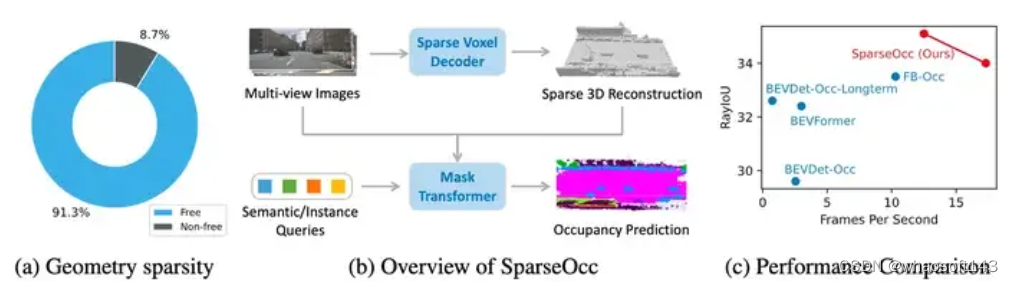
SparseOcc是第一个完全稀疏占用网络。如图1(b)所示,SparseOcc包括两个步骤。首先,它利用稀疏体素解码器以从粗到细的方式重建场景的稀疏几何形状。这仅对非自由区域进行建模,显着节省了计算成本。其次,我们设计了一个具有稀疏语义/实例查询的mask transformer来预测稀疏空间中片段的mask和label。mask transformer不仅提高了semantic occupancy的性能,而且为panoptic occupancy铺平了道路。设计了一种掩码引导的稀疏采样来实现mask transformer中的sparse cross-attention。
本文注意到常用的 mIoU指标的缺陷,并进一步设计 RayIoU 作为解决方案。考虑到未扫描体素的模糊标记,mIoU 标准是一个ill-posed公式(有些只是lidar点云稀疏没有扫描到,不代表真的没有占用)。以前的occ3d仅通过评估观察到的区域,也就是大家occ挑战赛常用的vismask来缓解这个问题,但会在深度的不一致惩罚中引发额外的问题。相反,RayIoU 同时解决了上述两个问题。它通过检索指定光线的深度和类别预测来评估预测的 3D 占用体积。具体来说,RayIoU 将查询光线(利用lidar线束生成的方法构造)投射到预测的 3D 体积中,并决定TP预测作为光线,其第一个被触及的占据体素网格的正确距离和类别。这制定了一个更加公平和合理的标准。
由于稀疏性设计,SparseOcc 在 Occ3D-nus [48] 上实现了 34.0 RayIoU,同时保持了 17.3 FPS(Tesla A100、PyTorch fp32 后端)的实时推理速度,具有 7 个历史帧输入。通过将更多的前一帧合并到 15 中,SparseOcc 不断提高其性能到 35.1 RayIoU。SparseOcc与以前的方法在性能和效率方面的比较如图1(c)所示。
不过flashocc的方法能在3090上达到200多FPS,sparseocc这个速度在A800上还是慢了一些,毕竟是第一篇,还会有优化空间
占用预测在自动驾驶领域发挥着关键作用。先前的方法通常构建密集的3D Volume,忽略了场景的固有稀疏性,这导致了高计算成本。此外,这些方法仅限于语义占用,无法区分不同的实例。为了利用稀疏性并确保实例感知,作者引入了一种新的完全稀疏全景占用网络,称为SparseOcc。SparseOcc最初从视觉输入重建稀疏的3D表示。随后,它使用稀疏实例查询来从稀疏3D表示预测每个目标实例。
此外,作者还建立了第一个以视觉为中心的全景占用基准。SparseOcc在Occ3D nus数据集,通过实现26.0的mIoU,同时保持25.4 FPS的实时推理速度。通过结合前8帧的时间建模,SparseOcc进一步提高了其性能,实现了30.9的mIoU,代码后面将开源。
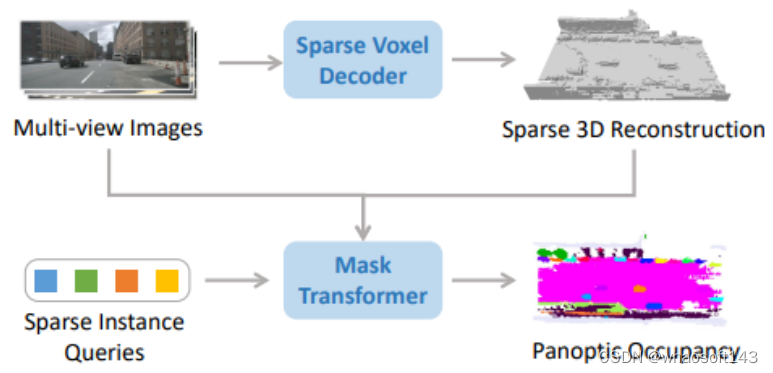
SparseOcc的结构和流程
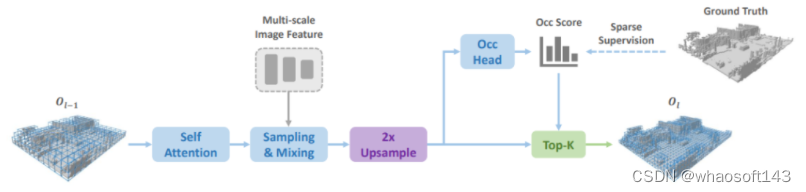
SparseOcc由两个步骤组成。首先,作者提出了一种稀疏体素解码器来重建场景的稀疏几何结构,它只对场景的非自由区域进行建模,从而显著节省了计算资源。其次,设计了一个mask transformer,它使用稀疏实例查询来预测稀疏空间中每个目标的mask和标签。
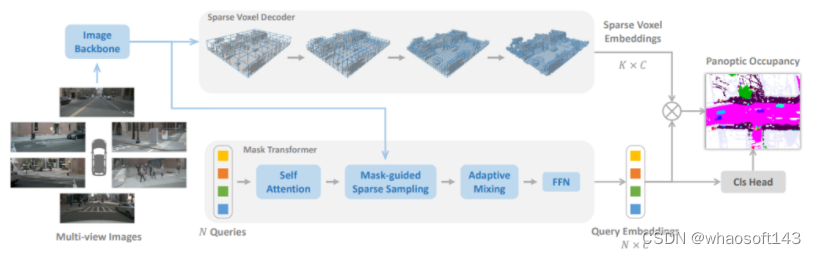
此外,作者还进一步提出了mask-guide的稀疏采样,以避免mask变换中的密集交叉注意。因此SparseOcc可以同时利用上述两种稀疏特性,形成完全稀疏的架构,因为它既不依赖于密集的3D特征,也不具有稀疏到密集的全局注意力操作。同时,SparseOcc可以区分场景中的不同实例,将语义占用和实例占用统一为全景占用!
由于3D OCC GT是形状为W×H×D的密集3D体积(例如200×200×16),现有方法通常构建形状为W×H×D×C的密集3D特征,但该类方法计算消耗大。
在本文中,我们认为这种密集表示对于occupancy预测不是必需的。与我们的统计数据一样,我们发现场景中超过 90% 的体素是空气。这促使我们探索一种稀疏 3D 表示,它只对场景的占据区域进行建模,从而节省计算资源。
Sparse Voxel Decoder如图3所示。它遵循coarse-to-fine的结构,但只对占据区域进行建模。Decoder从一组均匀分布在 3D 空间中的粗体素查询开始(例如 25×25)。在每一层中,我们首先将每个体素上采样 2 倍,例如大小为 d 的体素将被上采样到 8 个大小为 d2 的体素。接下来,我们估计每个体素的占用分数并进行修剪以去除无用的体素网格。在这里有两种修剪方法:一种是基于阈值(例如,只保留score > 0.5);另一种是 top-k 选择。在本文实现中,只需保留具有 top-k 个占用分数的体素,以提高训练效率。k 是一个与数据集相关的参数,通过计算每个样本中不同分辨率的非自由体素的最大数量来获得。修剪后的体素tokens将作为下一层的输入。
在每一层中,我们使用类似 Transformer 的架构来处理体素查询。具体架构的来自SparseBEV,这是一种使用稀疏方案的检测方法。具体来说,在第 l 层,具有由 3D 位置和 C-dim 内容向量描述的 Kl-1 体素查询,我们首先使用自注意力来聚合这些查询体素的局部和全局特征。然后,线性层用于从相关内容向量为每个体素查询生成 3D 采样偏移量 {(Δxi, Δyi, Δzi)}。这些采样偏移量用于变换体素查询以获得全局坐标中的参考点。最后,我们将这些采样的参考点投影到多视图图像空间,通过自适应混合来整合图像特征
时序建模:以前的dense occupancy方法通常将历史BEV/3D特征warp到当前时间戳,并使用deformable attention或3D卷积来融合时间信息。然而,由于本文 3D 特征的稀疏性质,这种方法在我们的案例中并不直接适用。为了解决这个问题,我们利用上述全局采样参考点的灵活性,将它们扭曲到先前的时间戳来对历史多视图图像特征进行采样。然后,通过自适应混合堆叠和聚合采样的多帧特征。
监督:计算每一层的稀疏体素的损失。我们使用二元交叉熵 (BCE) 损失作为监督,因为我们正在重建与类别无关的稀疏占用空间(这个时候真值标签只有0/1)。只有保留的稀疏体素被监督,而在早期阶段修剪期间丢弃的区域被忽略。
设计的稀疏体素解码器如图4所示。通常,它遵循从粗到细的结构,但采用一组稀疏的体素标记作为输入。在每个层的末尾,我们估计每个体素的占用分数,并基于预测的分数进行稀疏化。在这里,有两种稀疏化方法,一种是基于阈值(例如,仅保持分数>0.5),另一种是根据top-k。在这项工作中,作者选择top-k,因为阈值处理会导致样本长度不相等,影响训练效率。k是与数据集相关的参数,通过以不同分辨率对每个样本中非自由体素的最大数量进行计数而获得,稀疏化后的体素标记将用作下一层的输入!
时序建模。先前的密集占用方法通常将历史BEV/3D特征warp到当前时间戳,并使用可变形注意力或3D卷积来融合时间信息。然而,这种方法不适用于我们的情况,因为3D特征是稀疏的。为了处理这一问题,作者利用采样点的灵活性,将它们wrap到以前的时间戳来对图像特征进行采样。来自多个时间戳的采样特征通过自适应混合进行叠加和聚合。
loss设计:对每一层都进行监督。由于在这一步中重建了一个类不可知的占用,使用二进制交叉熵(BCE)损失来监督占用头。只监督一组稀疏的位置(根据预测的占用率),这意味着在早期阶段丢弃的区域将不会受到监督。
此外,由于严重的类别不平衡,模型很容易被比例较大的类别所支配,如地面,从而忽略场景中的其他重要元素,如汽车、人等。因此,属于不同类别的体素被分配不同的损失权重。例如,属于类c的体素分配有的损失权重为:
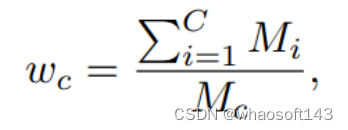
其中Mi是GT中属于第i类的体素的数量!
mask引导的稀疏采样。mask transformer的一个简单基线是使用Mask2Former中的mask交叉注意模块。然而,它涉及关键点的所有位置,这可能是非常繁重的计算。在这里,作者设计了一个简单的替代方案。给定前一个(l−1)Transformer解码器层的mask预测,通过随机选择掩码内的体素来生成一组3D采样点。这些采样点被投影到图像以对图像特征进行采样。此外,我们的稀疏采样机制通过简单地warp采样点(如在稀疏体素解码器中所做的那样)使时间建模更容易。

Mask Transformer
这里倒不算是sparseocc第一个使用这种方法,之前论文occformer也采用了类似模块思想,但细节不太一样。
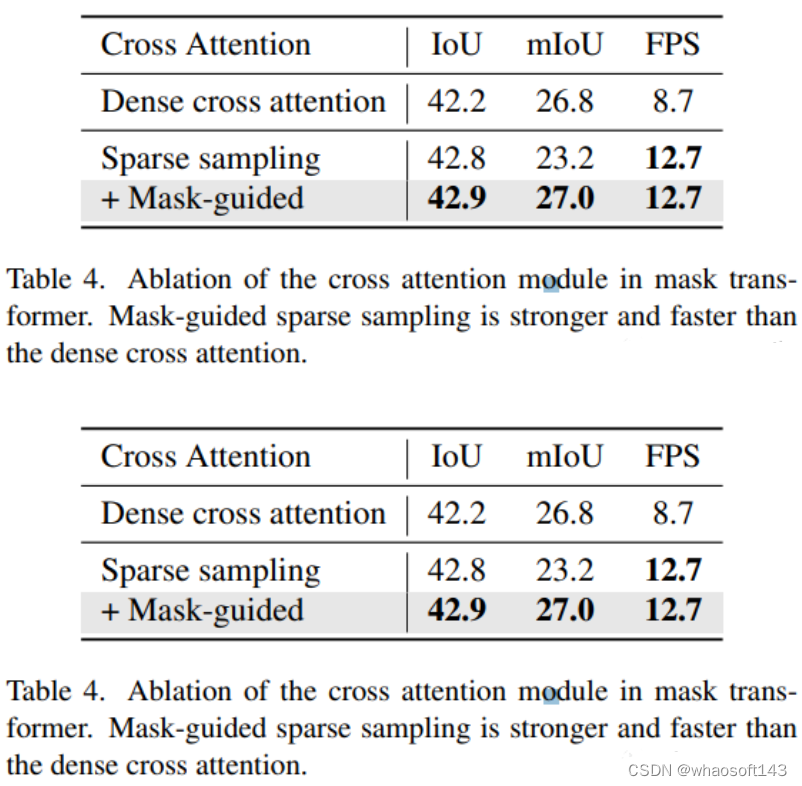
该部分源自Mask2Former,它使用 N 个稀疏语义/实例查询,由二进制mask query Qm ∈ [0, 1]N ×K 和content vector Qc ∈ RN ×C 解耦。掩码转换器包括三个步骤:多头自注意力(MHSA)、掩码引导的稀疏采样和自适应混合。MHSA 用于不同查询之间的交互作为常见的做法。Mask-guided稀疏采样和自适应混合负责查询和2D图像特征之间的交互。
Mask-guided sparse sampling:
一个简单基线是使用 Mask2Former 中的掩码交叉注意模块。但是,它关注key的所有位置,具有难以承受的计算。在这里,我们设计了一个简单的替代方案。我们首先在第 (l − 1) 个 Transformer 解码器层预测的掩码中随机选择一组 3D 点。然后,我们将这些 3D 点投影到多视图图像中,并通过双线性插值提取它们的特征。此外,稀疏采样机制通过简单地扭曲采样点(如稀疏体素解码器中所做的那样)来使时间建模更容易。
对于类别预测,应用了一个基于query embeddings Qc 的 sigmoid 激活的线性分类器。对于掩码预测,查询嵌入通过 MLP 转换为掩码嵌入。mask embeddings M ∈ R Q×C 具有与query embeddings Qc 相同的形状,并与稀疏体素嵌入 V ∈ R K×C 点积以产生掩码预测。因此,mask transformer的预测空间被限制在稀疏体素解码器的稀疏 3D 空间,而不是完整的 3D 场景(occformer是完整3D场景)。掩码预测将作为下一层的掩码查询 Qm。
Supervision:稀疏体素解码器的重建结果可能并不可靠,因为它可能会忽略或不准确检测某些元素(会漏一些前景voxel)。因此,监督mask transformer会带来一些挑战,因为它的预测被限制在这个不可靠的空间中。
在漏检占据区域的情况下,在预测的sparse occupancy不存在GT对应的预测,选择丢弃这些部分以防止混淆。
至于误检占据趋于,简单地将它们分类为一个额外的“"no object”类别。
遵循 MaskFormer,使用匈牙利匹配将基本事实与预测进行匹配。Focal loss Lf ocal 用于分类,而 DICE loss Ldice 和 BCE mask loss Lmask 的组合用于mask预测。Locc 是稀疏体素解码器的损失。因此,SparseOcc 的总损失由:
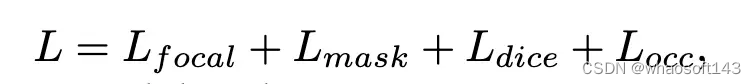
New metric:Ray-level mIoU
Occ3D 数据集及其提出的评估指标被广泛认可为该领域的基准。GT占用率由 LiDAR 测量重建,体素级别的平均 Intersection over Union (mIoU) 用于评估性能。然而,由于距离和遮挡等因素,累积的LiDAR点云不完善。LiDAR 未扫描的一些区域被标记为自由,导致实例碎片化(一些车的occ结果不全),如图 4(a) 所示。这引发了标签不一致的问题。以前解决评估问题的努力,例如 Occ3D,使用二进制vismask来指示在当前相机视图中是否观察到体素。然而,我们发现仅在观察到的体素位置计算 mIoU 仍然会造成歧义并且很容易被黑客攻击。如图 4 所示,RenderOcc [39] 生成了一个更厚的表面,射线状连续,这类方式是利用ray渲染,无法用于下游任务。然而,RenderOcc 的掩码 mIoU 远高于 BEVFormer 的预测,后者更稳定和干净。这表现了目前的评测指标还是不够合理

定性和定量结果之间的错位是由于vismask深度方向的不一致造成的。如图 5 所示,这个示例揭示了当前评估指标的几个问题:
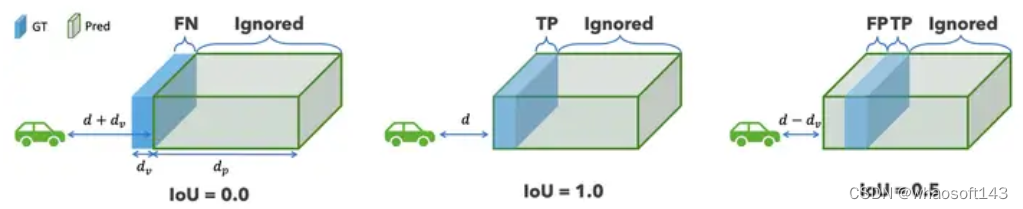
考虑一个场景,我们在前面有一个墙,地面真实距离为d,厚度为dv。当预测厚度为 dp >dv 时,如 RenderOcc 所示,mask mIoU 出现深度的不一致。如果我们预测的墙壁是 dv 比GT更远(总共 d + dv),那么它的 IoU 将为零,因为没有预测的体素与实际墙壁对齐。但是,如果我们预测的墙是 dv 更接近GT(总共 d - dv),我们仍然将达到 0.5 的 IoU,因为表面后面的所有体素都被填充。类似地,如果预测深度为 d − 2dv ,我们仍然有 1/3 的 IoU,依此类推。
考虑一个场景,我们在前面有一个墙,地面真实距离为d,厚度为dv。当预测厚度为 dp >dv 时,如 RenderOcc 所示,mask mIoU 出现深度的不一致。如果我们预测的墙壁是 dv 比GT更远(总共 d + dv),那么它的 IoU 将为零,因为没有预测的体素与实际墙壁对齐。但是,如果我们预测的墙是 dv 更接近
- 如果模型填充表面后面的所有区域,则不一致地惩罚深度预测。该模型可以通过填充表面后面的所有区域并预测更接近的深度来获得更高的 IoU。这种厚表面问题在使用可见掩码或 2D 监督的模型中很常见。
- 如果预测的占用是一个薄的表面,惩罚过于严格,因为一个体素的偏差将导致IoU为零。
- vismask只考虑当前时刻的可见区域,从而将占用减少到具有类别的深度估计任务,而忽略了在可见区域之外完成场景的关键能力。(从最新的趋势来看vismask的依赖变得逐渐减少了,毕竟推理的时候不使用会变很差)
Mean IoU by Ray Casting
为了解决上述问题,提出了一个新的评估指标:Ray-level mIoU(简称RayIoU)。在RayIoU中,集合的元素现在是查询射线,而不是体素。我们通过将查询光线投影到预测的 3D 占用体积来模拟 LiDAR射线。对于每个查询射线,计算它在相交任何表面并检索相应类标签之前传播的距离。然后,我们将相同的过程应用于GT,以获得GT深度和类别标签。如果光线与GT中存在的任何体素不相交,它将被排除在评估过程之外
如图6(a)所示,真实数据集中的原始激光雷达射线往往从近到远不平衡。因此,我们对 LiDAR 射线重新采样以平衡不同距离的分布,如图 6(b) 所示。对于近距离,我们修改了LiDAR射线通道,以在投影到地平面时实现等距离间距。在远距离,我们增加了角分辨率通道,以确保在不同范围内更均匀的数据密度。此外,查询射线可以起源于ego路径当前、过去或未来时刻的激光雷达位置。如图6所示,时序堆叠更好地评估场景完成性能,同时确保任务保持良好。
RayIoU的覆盖区域。(a)不同距离的原始激光雷达射线样本不平衡。(b)对射线重新采样,以平衡RayIoU中距离的权重。(c)为了研究场景完成的性能,我们建议通过在访问的路点上投射光线来评估可见区域在宽时间跨度内的占用率
如果类标签重合,并且地面真实深度和预测深度之间的L1误差小于某个阈值(例如,2m),则查询射线被分类为真阳性(TP)。设C是类的数量
RayIoU解决了上述三个问题:
- 由于查询射线只计算它接触第一个体素的距离,因此模型不能通过填充表面后面的区域来获得更高的IoU。
- RayIoU通过距离阈值确定TP,减轻体素级mIoU过于苛刻的性质
- 查询射线可以起源于场景中的任何位置,从而考虑模型的场景补全能力和防止occupancy衰减成深度估计。
在Occ3D-nus上进行,使用提出的RayIoU来评估语义分割性能。查询光线来自ego路径的 8 个 LiDAR 位置。计算三个距离阈值下的RayIoU: 1,2和4米。最终的排名指标在这些距离阈值上取平均值
FPS 是在 Tesla A100 GPU 上使用 PyTorch fp32 (1个batch size)测量的。
实验结果
Occ3D nuScenes数据集上的3D占用预测性能。“8f”意味着融合来自7+1帧的时间信息。本文的方法在较弱的设置下实现了与以前的方法相同甚至更高的性能!
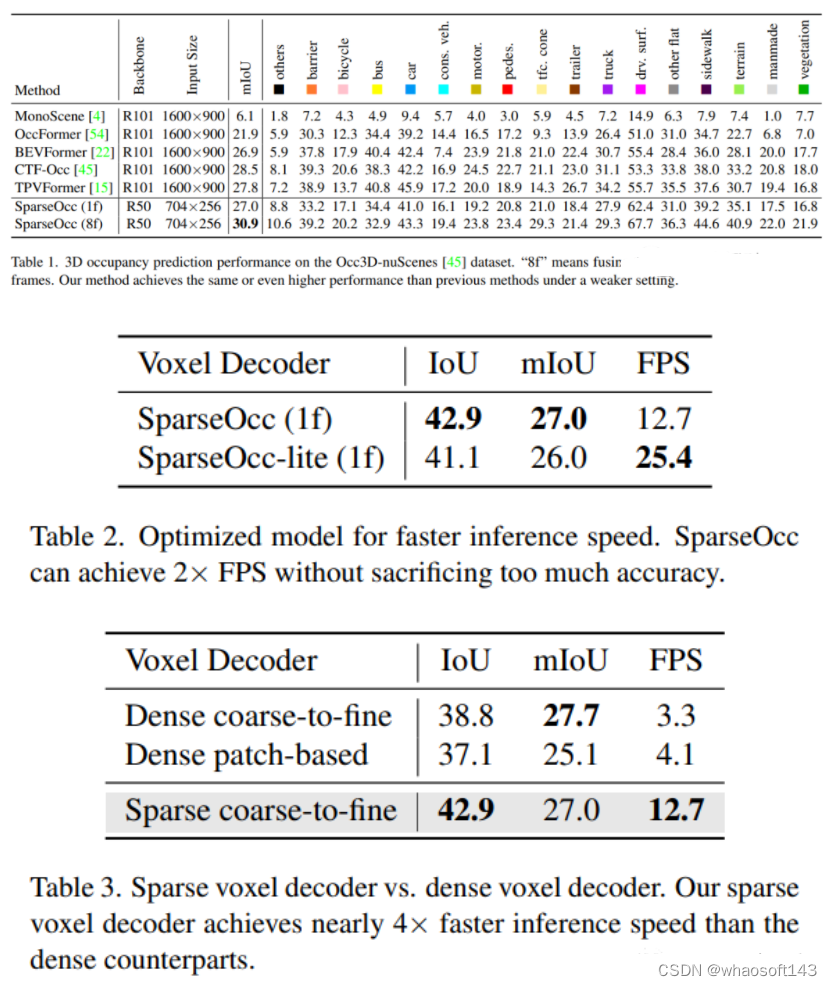
稀疏体素够预测整个场景吗?
在这项研究中,我们深入研究了体素稀疏性对最终性能的影响。为了研究这一点,我们系统地消融了图 8 (a) 中 k 的值。
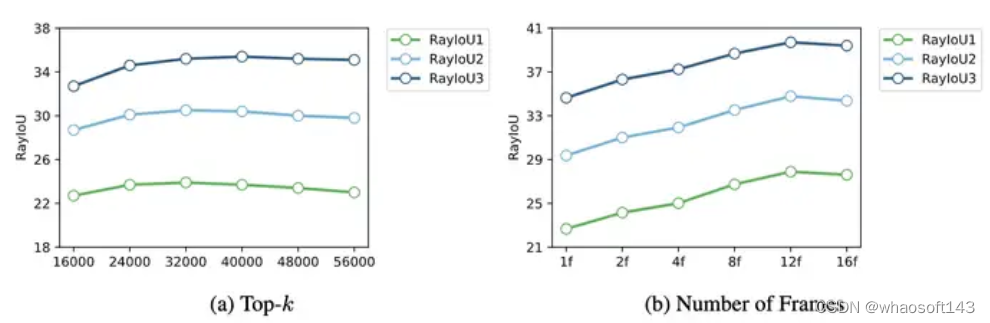
k只是密集体素总数的 5%(200×200×16 = 640000)。进一步增加 k 不会产生任何性能改进;相反,它会引入噪声。因此,我们的研究结果表明 5% 的稀疏级别就足够了,额外的稀疏性将适得其反。这个应该是rayiou指标造成的现象,感觉miou的话,应该会涨。时序上12帧就饱和了
Panoptic occupancy。展示了SparseOcc可以很容易地扩展到泛视占用预测,这是一个从全景分割派生的任务,它不仅将图像分割成语义上有意义的区域,而且可以检测和区分单个实例。与全景分割相比,全景占用预测要求模型是几何感知来构建用于分割的 3D 场景。通过在掩码转换器中引入实例查询。在图9中,可视化了SparseOcc的全景占用结果。
通过去除路面来增强稀疏性。大多数无非占用数据与背景几何有关。实际应用时,占用率可以有效地替换为高清地图(HD Map)或online mapping。这种替换不仅简化了稀疏性,而且丰富了道路的语义和结构理解。我们构建了实验来研究在 SparseOcc 中去除路面的效果。表7可以看出去除背景query数量降低了,对比原来性能也没有变化,但是这里对比原来的FPS没有变化,比较意外,感觉不正常。不过纯稀疏的架构确实可以通过这种操作减少计算量
Miou对比
之前大家一直都是miou的指标对比,其实也可以发现整体场景的miou而言,sparseocc性能也能达到30,这个是16帧的结果,对比没有使用vismask比fb-occ性能(作者自己实现的fb-occ变体)还强,虽然速度确实还不够理想,

在训练期间使用可见掩码可以提高大多数前景类的性能,例如公共汽车、自行车和卡车。然而,它对可驾驶表面、地形和人行道等背景类产生负面影响。
这一观察引发了进一步的问题:为什么背景类的性能下降。为了解决这个问题,我们在图 10 中提供了 FB-Occ 中预测可驾驶表面的深度误差和高度图的可视化比较,无论是否在训练期间使用可见掩码。该图表明,使用可见掩码进行训练会导致更厚、更高的地面表示,从而导致远处区域的深度误差很大。相反,没有可见掩码训练的模型以更高的精度预测深度

“FB w/mask”倾向于预测更高和更厚的路面,导致沿射线的深度误差显著。相比之下,“FB wo/mask”预测一个既准确又一致的路面
vismask结论:在训练期间使用vismask通过解决未扫描体素的模糊标记问题有利于前景类occ预测。然而,它损害了深度估计的准确性,因为模型倾向于预测更厚和更紧密的表面。
总结
这是第一个纯稀疏占用网络,不依赖于密集的 3D 特征,也不依赖于稀疏到密集和全局的注意力操作。
还创建了RayIoU,这是一种用于occupancy评估的射线级度量,消除了先前度量miou的一些问题。
#UniMODE
目前,在自动驾驶的视觉感知任务当中,基于单目相机的3D目标检测方案因其在相机的成本效益和综合语义特征表达方面的优势,吸引众多研究者们的广泛关注,并且各种新颖的解决方案不断地涌现出来。但是,如何在同时包括室内和室外场景的前提下,实现基于单目相机的统一3D目标检测依旧是非常具有挑战性的研究课题。一般而言,自动驾驶任务中设计的各类视觉感知算法通常只应用在某一类环境场景下:
- 常见的室外城市道路下的自动驾驶:设计的3D视觉感知算法主要与室外的开放场景进行交互,得出待检测目标对应的空间位置信息和语义类别结果
- 常见的室内地库场景下的自动泊车:设计的感知算法主要与室内的封闭场景进行交互,得到相应的停车位角点,感知停车场立柱、泊车牌子等环境元素
但如果想要设计的检测算法需要同时实现对室外和室内场景整体检测的鲁棒性,这其中最重要的就是解决室内和室外场景各自包含的独特特征。具体而言,两者场景包含的关键区别如下:
- 室内场景中所包含的目标主要集中在一个较为狭小的密闭空间。通常来说,这类目标的几何形状结构一般比较小,并且在狭小密闭的空间上排列也相对比较密集,物体与物体之间的缝隙比较小。
- 室外场景中所包含的目标相比于室内场景而言,通常来说分布在一个更加广阔的3D空间当中,并且其中的目标距离采集相机的深度距离也更加的广泛,远距离的目标甚至可以达到100米以上的距离。
实现统一的单目3D目标检测,包括室内和室外场景,在机器人导航等领域具有重大意义。然而,由于数据场景的显著不同特性,如图形属性的多样性和异质领域分布,将各种数据场景融入模型训练中提出了挑战。为了应对这些挑战,作者基于鸟瞰图(BEV)检测范式构建了一个检测器,其中明确的特征投影有助于在采用多种场景数据训练检测器时解决几何学习的不确定性。接着,作者将经典的BEV检测架构分为两个阶段,并提出了一个不均匀的BEV网格设计来处理由上述挑战引起的收敛不稳定性。此外,作者开发了一种稀疏BEV特征投影策略以减少计算成本,以及一种统一的领域对齐方法来处理异质领域。结合这些技术,作者得到了一个统一的检测器UniMODE,它超越了之前在具有挑战性的Omni3D数据集(一个包括室内外场景的大规模数据集)上的最佳性能,提高了4.9% ,这是BEV检测器首次在统一3D目标检测上的成功泛化。
1 Introduction
单目3D目标检测旨在仅使用相机捕获的单张图像准确确定目标的确切3D边界框[13, 16]。与其他基于模态(如激光雷达点云)的3D目标检测相比,基于单目的解决方案在成本效益和全面的语义特征方面具有优势[17, 19]。此外,由于其在自动驾驶[8]等广泛应用领域的潜力,单目3D目标检测最近受到了很多关注。
得益于研究界的努力,已经开发出了众多检测器。有些是针对户外场景[9, 38],如城市驾驶设计的,而其他则专注于室内检测[28]。尽管这些检测器的共同目标是单目3D目标检测,但它们在网络架构上存在显著差异[5]。这种分歧阻碍了研究行人将各种场景的数据结合起来,训练一个在多样化场景中表现良好的统一模型,这是许多重要应用(如机器人导航[30])所需求的。
统一3D目标检测中最关键的挑战在于解决不同场景的独特特性。例如,室内物体通常较小且相互之间距离较近,而室外检测需要覆盖广阔的感知范围。最近,Cube RCNN [5] 成为研究这一问题的先驱。它直接在相机视图中生成3D框预测,并采用深度解耦策略来克服场景之间的领域差距。然而,作者观察到它存在严重的收敛困难,并且在训练过程中容易崩溃。
为了克服Cube RCNN不稳定收敛的问题,作者采用了近期流行的鸟瞰图(BEV)检测范式来开发一个统一的3D目标检测器。这是因为BEV范式中的特征投影将图像空间与3D现实空间明确对齐[15],这缓解了单目3D目标检测中的学习歧义。然而,经过大量探索后,作者发现简单地采用现有的BEV检测架构[15, 18]并不能取得令人满意的效果,这主要归咎于以下障碍。
首先,如图1(a)和(b)所示,室内外场景之间的几何属性(例如,感知范围,目标位置)差异很大。具体来说,室内物体通常距离摄像头几米远,而室外目标可能超过100米远。由于需要一个统一的鸟瞰图(BEV)检测器来识别所有场景中的物体,BEV特征必须覆盖最大可能的感知范围。同时,由于室内物体通常较小,室内检测所需的BEV网格分辨率需要非常精确。所有这些特性可能导致收敛不稳定和计算负担加重。为了应对这些挑战,作者开发了一个两阶段的检测架构。在这个架构中,第一阶段产生初始目标位置估计,第二阶段利用这个估计作为先验信息来定位目标,这有助于稳定收敛过程。此外,作者引入了一种创新的非均匀BEV网格分割策略,在保持可管理的BEV网格大小的同时扩展了BEV空间范围。此外,还开发了一种稀疏BEV特征投影策略,将投影计算成本降低了82.6%。

另一个障碍源于不同场景中的异构领域分布(例如,图像风格,标签定义)。例如,如图1(a)、(b)和(c)所示,数据可以在真实场景中收集或虚拟合成。此外,比较图1(c)和(d),一类目标可能在某个场景中被标注,但在另一个场景中未被打标签,这会导致网络收敛时的混淆。为了处理这些冲突,作者提出了一个由两部分组成的统一领域对齐技术,包括领域自适应层归一化以对齐特征,以及用于缓解标签定义冲突的类别对齐损失。

2 Related Work
单目3D目标检测。 由于其经济和灵活的优势,单目3D目标检测吸引了大量研究关注[22]。现有的检测器大致可以分为两类:相机视角检测器和鸟瞰图(BEV)检测器。其中,相机视角检测器在将结果转换为3D真实空间之前,在2D图像平面上生成结果[10, 25]。这一组通常更容易实现。然而,从2D相机平面到3D物理空间的转换可能会引入额外的误差[32],这会对通常在3D空间进行的下游规划任务产生负面影响[7]。
另一方面,BEV检测器先将2D相机平面上的图像特征转换到3D物理空间,然后在3D空间生成结果[12]。这种方法有利于下游任务,因为规划也是在3D空间进行的[18]。然而,BEV检测器面临的挑战是,特征转换过程依赖于准确的深度估计,仅凭相机图像很难实现这一点[23]。因此,在处理不同的数据场景时,收敛变得不稳定[5]。
统一目标检测。 为了提高检测器的泛化能力,一些研究探索了在模型训练过程中整合多个数据源[14, 34]。例如,在2D目标检测领域,SMD [40] 通过学习一个统一的标签空间来提高检测器的性能。在3D目标检测领域,PPT [36] 研究了如何利用来自不同数据集的广泛的3D点云数据进行检测器的预训练。此外,Uni3DETR [35] 展示了如何设计一个统一的基于点的3D目标检测器,该检测器在不同的领域表现良好。对于基于相机的检测任务,Cube RCNN [5] 是统一单目3D目标检测研究的唯一先驱。然而,Cube RCNN 面临着收敛不稳定的问题,这需要在此领域进行进一步的深入研究。
3 Method
Overall Framework
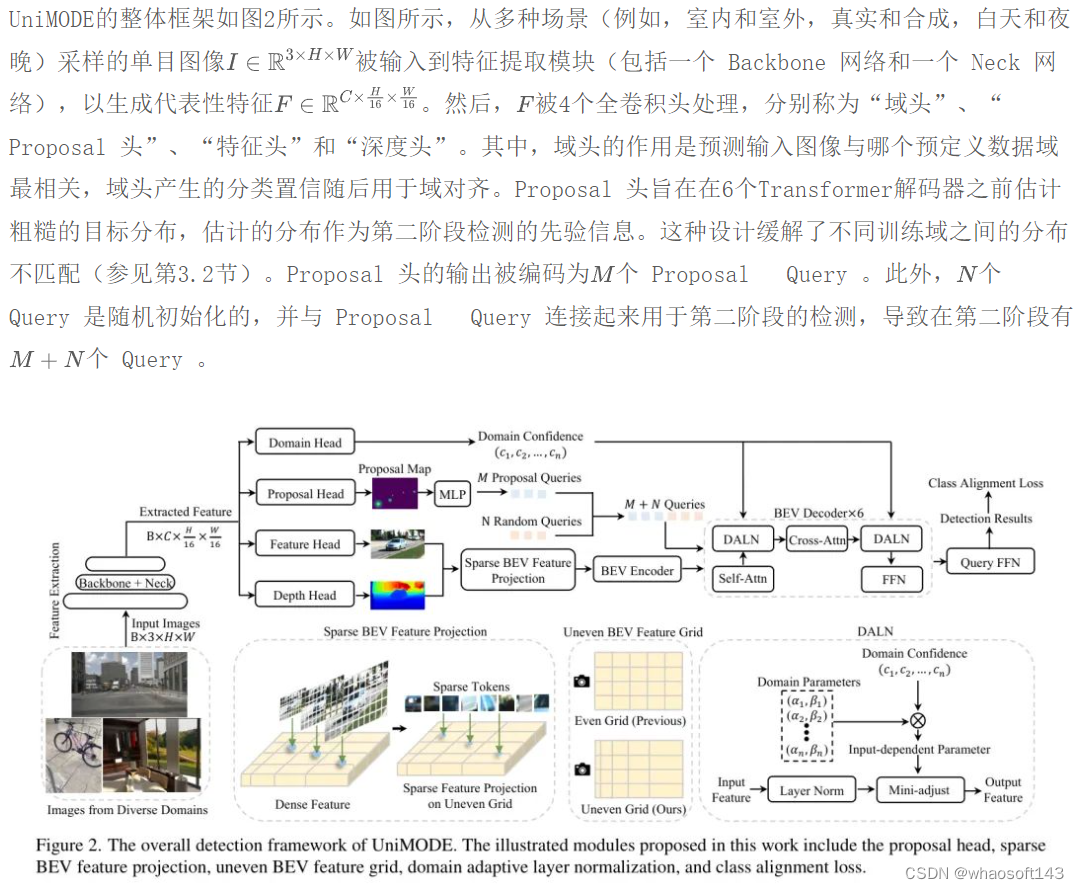
特征头和深度头负责将图像特征投影到BEV平面并获得BEV特征。在这个投影过程中,作者开发了一种技术来去除不必要的投影点,这大约减少了82.6%的计算负担(参见第3.4节)。此外,作者提出了不均匀的BEV特征(参见第3.3节),这意味着距离摄像机更近的BEV网格拥有更精确的分辨率,而距离摄像机更远的网格覆盖更广的感知区域。这种设计很好地平衡了室内检测和室外检测之间网格大小的矛盾,而且不增加额外的内存负担。

Two-Stage Detection Architecture
室内外三维目标检测的整合颇具挑战性,这主要是因为不同的几何特性(例如,感知范围、目标位置)。室内检测通常涉及近距离目标,而室外检测则关注在更广阔的三维空间中分散的目标。如图3所示,室内外检测场景中的感知范围和目标位置存在显著差异,这对于传统的鸟瞰图(BEV)三维目标检测器来说是一项挑战,因为它们具有固定的BEV特征分辨率。
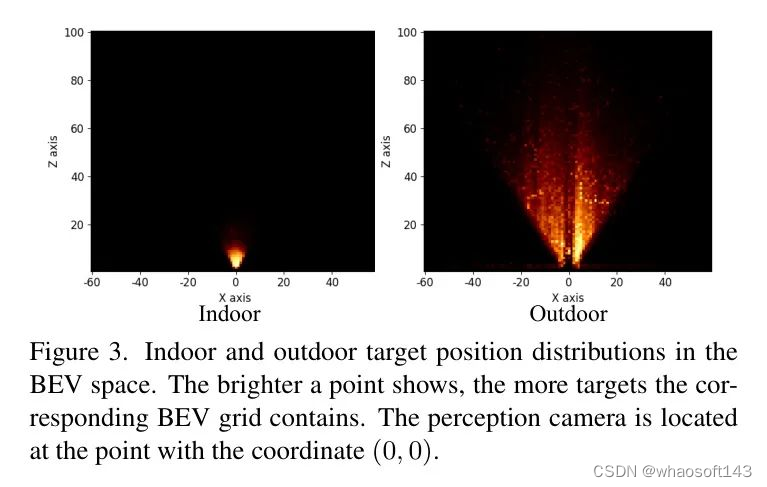
几何属性差异被识别为导致BEV检测器不稳定收敛的一个重要原因[15]。例如,目标位置分布差异使得基于Transformer的检测器难以学习如何逐渐将 Query 参考点更新到关注目标。实际上,通过可视化作者发现,在6个Transformer解码器中的参考点更新是混乱的。因此,如果作者采用经典的可变形DETR架构[41]来构建一个3D目标检测器,由于学习到的参考点位置不准确,训练很容易崩溃,导致梯度突然消失或爆炸。

此外,由于 Query 参考点的位置并非随机初始化,因此放弃了在deformable DETR [41]中提出的迭代边界框细化策略,因为它可能导致参考点质量的下降。实际上,作者观察到这种迭代边界框细化策略可能导致收敛崩溃。
Uneven BEV Grid
室内与室外3D目标检测的一个显著区别在于数据收集过程中,物体到相机的几何信息(例如,尺度、接近度)。室内环境通常具有更小的物体,且这些物体位于离相机更近的位置,而室外环境则涉及更大的物体,且这些物体位于更远的位置。此外,室外3D目标检测器必须考虑到更宽的环境感知范围。因此,现有的室内3D目标检测器通常使用较小的 Voxel 或柱子尺寸。例如,CAGroup3D [31],一个最先进的室内3D目标检测器,其 Voxel 尺寸为0.04米,而经典室内数据集SUN-RGBD [29]中的最大目标深度大约为8米。相比之下,室外数据集展现出更大的感知范围。例如,常用的室外检测数据集KITTI [8]的最大深度范围为100米。由于这种巨大的感知范围和有限的计算资源,室外检测器采用更大的鸟瞰图(BEV)网格尺寸,例如,在BEVDepth [11],一个最先进的室外3D目标检测器中,BEV网格尺寸为0.8米。
因此,当前户外检测器的鸟瞰图(BEV)网格尺寸通常较大,以适应广阔的感知范围,而室内检测器的尺寸较小,这是由于复杂的室内场景所致。然而,由于UniMODE旨在使用统一的模型结构和网络权重来解决室内和室外三维目标检测,其BEV特征必须覆盖一个大感知区域,同时仍然使用小的BEV网格,这在有限的GPU内存条件下提出了一个巨大的挑战。

值得注意的是,方程式1的数学形式与CaDDN [26]中深度的线性递增离散化相似,但其本质上有根本的不同。在CaDDN中,特征投影分布被调整以分配更多特征给靠近相机的网格。在实验中,作者观察到这种调整导致BEV特征更加不平衡,即靠近的网格特征更密集,而远处的网格更多为空。由于所有网格的特征都是由同一个网络提取的,这种不平衡降低了性能。相比之下,作者的非均匀BEV网格方法通过使特征密度更加平衡,提高了检测精度。
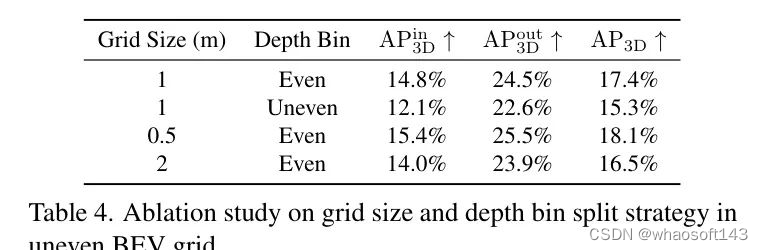
Sparse BEV Feature Projection

Unified Domain Alignment
异构领域分布存在于各种场景中,作者通过特征和损失的角度来应对这一挑战。
领域自适应层归一化。 对于特征视图,作者初始化特定于领域的可学习参数以应对在多种训练数据领域中观察到的变化。然而,这一策略必须遵循两个关键要求。首先,即使在训练过程中未遇到图像域时,检测器在推理过程中也应表现出稳健的性能。其次,引入这些特定于领域的参数应尽可能减少计算开销。

尽管存在一些与自适应标准化相关的先前技术,但几乎所有的技术都是直接回归依赖于输入的参数[36]。因此,它们需要为每个标准化层构建一个特殊的回归头。相比之下,DALN使所有层能够共享同一个域头,因此计算负担要小得多。此外,DALN引入了特定于域的参数,这些参数在训练时更加稳定。
类别对齐损失。 在损失方面,作者旨在解决结合多个数据源时遇到的异质标签冲突问题。具体来说,在Omni3D中有6个独立标记的子数据集,它们的标签空间是不同的。例如,如图4所示,虽然_ARKitScenes_中标注了_Window_类别,但在Hypersim中却没有被标记。由于Omni3D的标签空间是所有子集中所有类别的并集,因此在图4(a)中 未标注 的窗户变成了一个缺失的目标,这损害了收敛稳定性。


4 Experiment
实施细节。 相机坐标系中X轴、Y轴和Z轴的感知范围是。

Performance Comparison
在这一部分,作者比较了所提出检测器与先前方法的性能。其中,Cube RCNN是唯一一个也探索统一检测的检测器。BEVFormer [15] 和 PETR [18] 是两种流行的BEV检测器,作者在Omni3D基准上重新实现了它们以获得检测得分。其他比较的检测器的性能来自[5]。所有结果均在表1中给出。此外,作者还展示了UniMODE在Omni3D中各个子数据集上的详细检测得分,如表2所示。
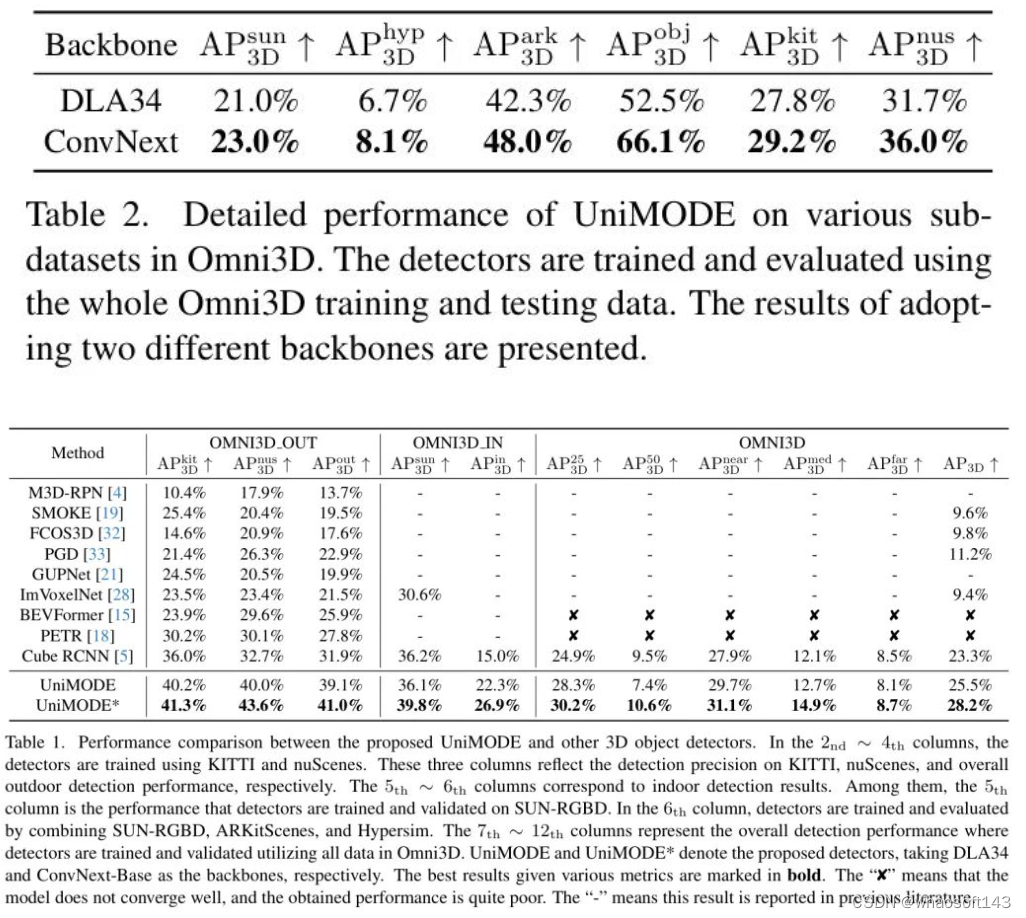

此外,从表1可以观察到,在统一检测设定下,BEVFormer和PETR并未很好地收敛,而在使用户外数据集训练时表现出了希望。这一现象暗示了统一室内和户外3D目标检测的难度。通过分析,作者发现,当BEVFormer使用所有领域的数据时,结果较差,因为其收敛性相当不稳定,且在训练期间损失曲线常常跃升到高值。PETR表现不佳是因为它隐式地学习了2D像素与3D Voxel 之间的对应关系。当在一个数据集中,如nuScenes [6],所有样本的摄像头参数保持相似时,PETR能够平滑地收敛。然而,在像Omni3D这样摄像头参数变化剧烈的数据集上训练时,PETR的训练变得更为困难。
Ablation Studies
关键组件设计。 作者在UniMODE中消融了所提出策略的有效性,包括 Proposal 头、不均匀的鸟瞰图(BEV)网格、稀疏的BEV特征投影以及统一的领域对齐。实验结果展示在表3中。值得注意的是,如前所述,由于计算资源有限,这一部分的实验是在低计算资源环境下进行的。
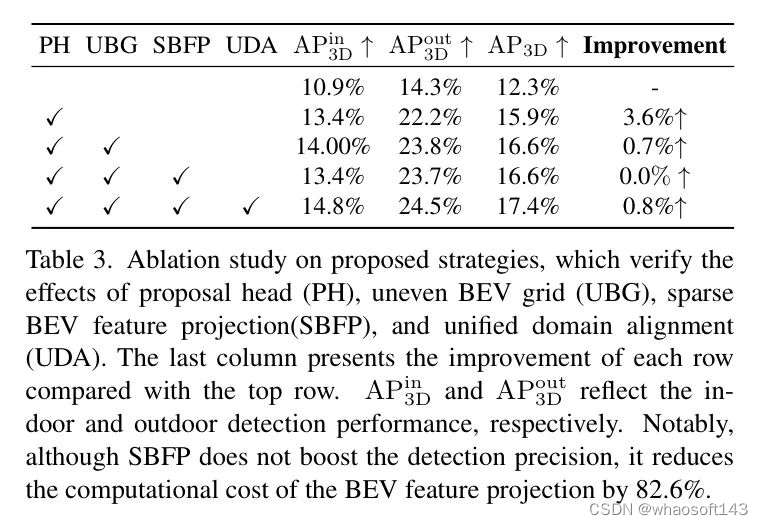

不均匀的BEV网格。 作者研究了在不均匀BEV网格设计中BEV特征网格大小和深度划分策略的影响,结果如表4所示。当深度划分不均匀时,作者按照方程式1划分深度区间。
比较表4中的第1行和第2行结果,作者可以发现不均匀的深度区间会恶化检测性能。作者推测这是因为这种策略在较近的鸟瞰图(BEV)网格中投射了更多的点,而在较远的网格中投射的点较少,这进一步增加了投影特征的不平衡分布。此外,通过比较表4中的第1行、第3行和第4行结果,作者观察到较小的BEV网格会导致更好的性能。由于计算资源有限以及Omni3D大量的训练数据,作者在所有其他实验中将BEV网格大小设置为1米,而不是0.5米,即如果作者减小BEV网格的大小,UniMODE的性能相比于当前性能可以得到进一步的提升。
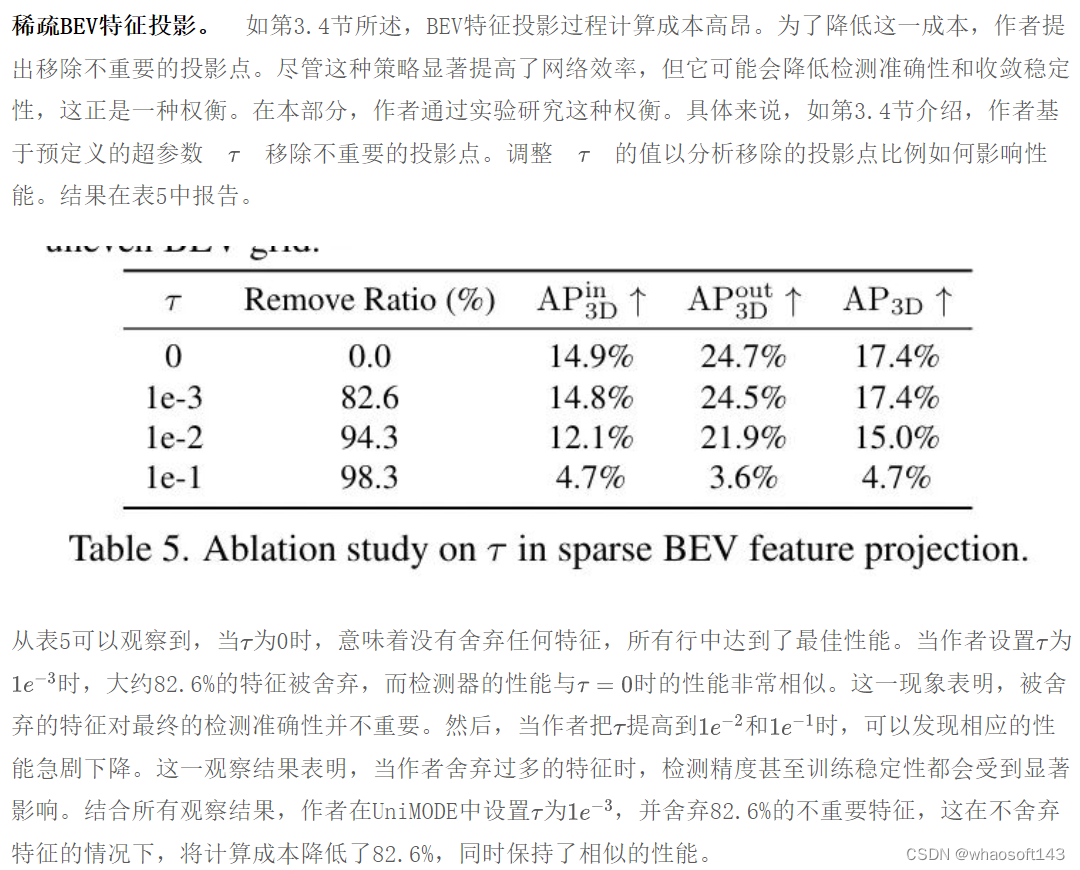
DALN的有效性。 在这项实验中,作者通过比较没有任何领域自适应策略的朴素 Baseline 、使用直接回归(DR)[24]预测动态参数的 Baseline ,以及带有DALN(作者提出的)的 Baseline ,来验证DALN的有效性。所有这些模型仅使用ARKitScenes进行训练,并分别使用ARKitScenes(域内)和SUN-RGBD(域外)进行评估。结果如表6所示。可以观察到,DR可能会降低检测精度,而DALN则显著提升了性能,这揭示了DALN的零样本域外有效性。
Cross-domain Evaluation
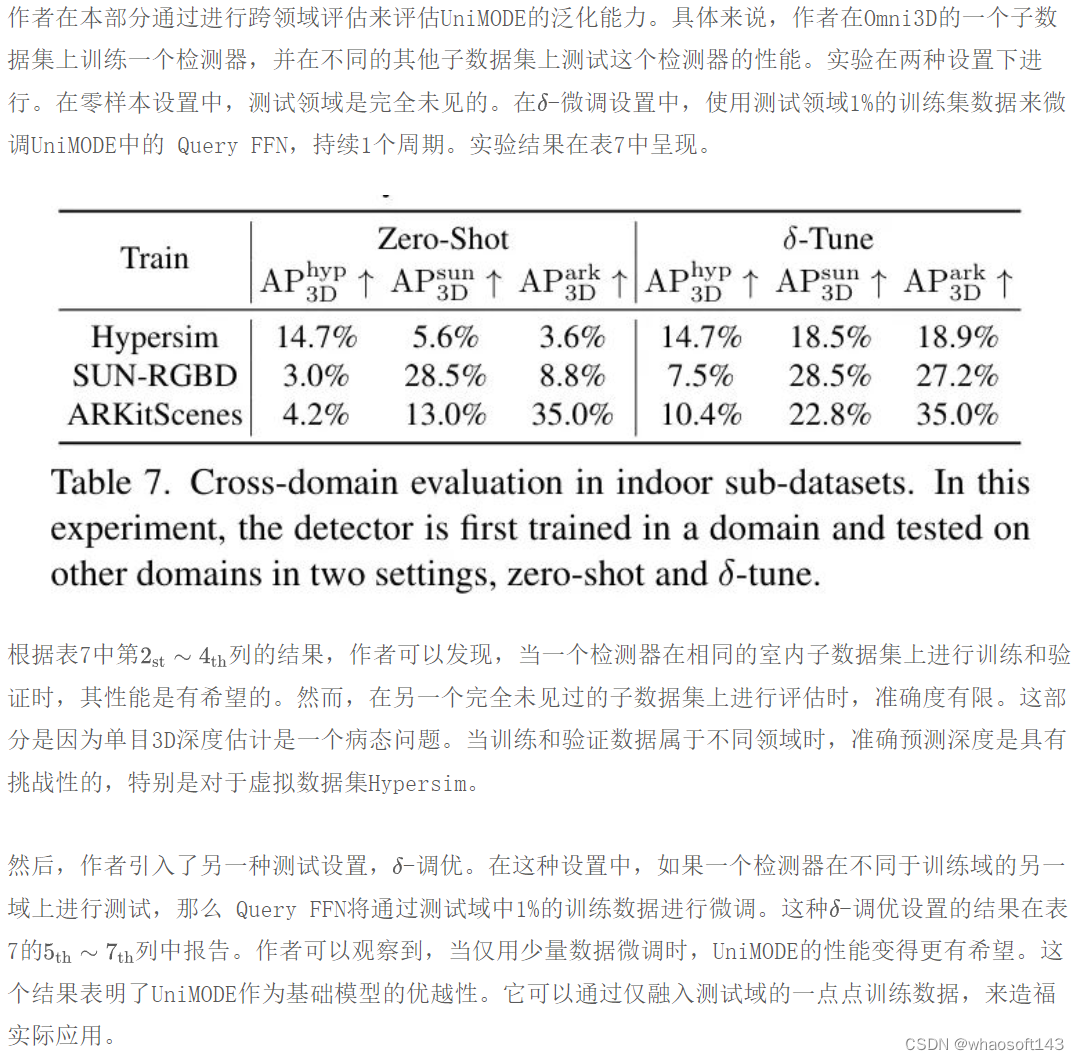
Visualization
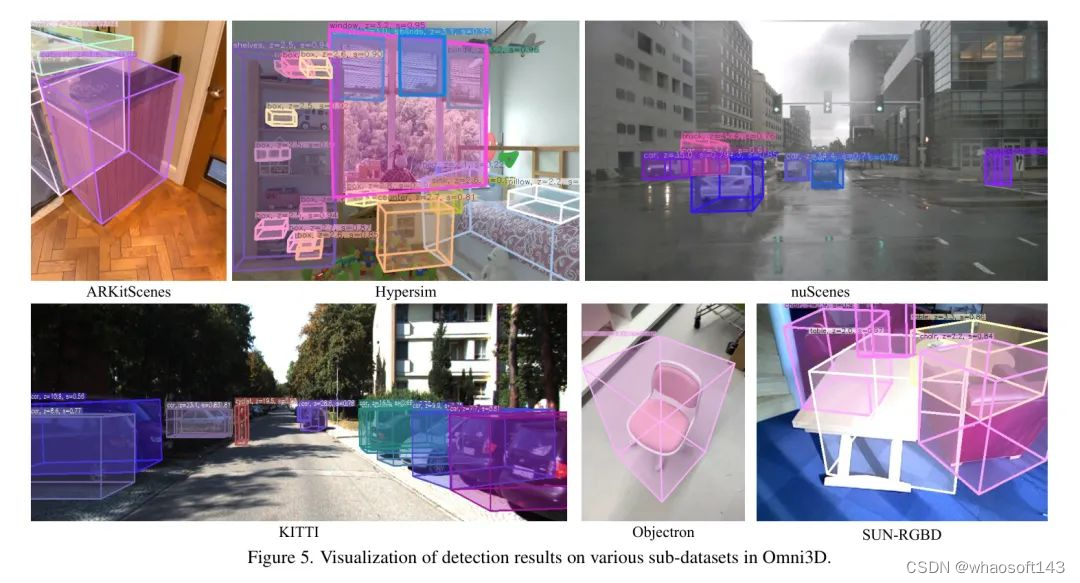
作者展示了UniMODE在Omni3D各个子数据集上的检测结果。展示的结果如图5所示,其中UniMODE在所有数据样本上的表现都相当出色,并且准确捕捉了复杂室内外场景下的三维物体边界框。
此外,正如先前所提及的,训练不稳定是统一不同训练领域的主要挑战。为了更清楚地解释训练不稳定的含义,作者在图6中展示了UniMODE的损失曲线和一个PETR的不稳定情况。可以观察到,在PETR的训练过程中存在突然的损失增加和持续的梯度消失,而UniMODE则能平滑地收敛。
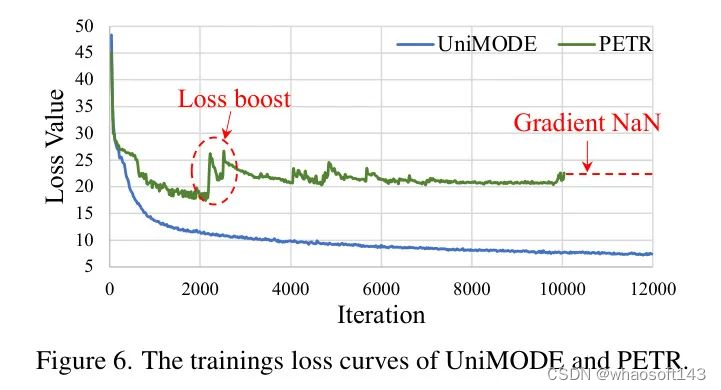
5 Conclusion and Limitation
在这项工作中,作者提出了一种名为UniMODE的统一单目3D目标检测器,其中包含了几项精心设计的技术,以解决在统一3D目标检测中观察到的许多挑战。所提出的检测器在Omni3D基准测试上达到了SOTA性能,并展示了高效率。进行了大量实验来验证所提出技术的高效性。检测器的局限性在于其对未见数据场景的零样本泛化能力仍然有限。未来,作者将继续研究如何通过诸如扩大训练数据等策略来提升UniMODE的零样本泛化能力。
#xxx
#xxx
相关文章:

w~视觉~3D~合集2
我自己的原文哦~ https://blog.51cto.com/whaosoft/13766161 #Sin3DGen 最近有点忙 可能给忘了,贴了我只是搬运工 发这些给自己看, 还有下面不是隐藏是发布出去 ~ 北京大学xxx团队联合山东大学和xxx AI Lab的研究人员,提出了首个基于单样例场景无需训练便可生…...

SAS宏核心知识与实战应用
1. SAS宏基础 1.1 核心概念 1.1.1 宏处理器 宏处理器在SAS程序运行前执行,用于生成动态代码,可实现代码的灵活定制。 通过宏处理器,可基于输入参数动态生成不同的SAS代码,提高代码复用性。 1.1.2 宏变量 宏变量是存储文本值的容器,用&符号引用,如&var,用于存储…...

windows使用openssl生成IIS自签证书全流程
使用 OpenSSL 生成适用于 IIS 的证书,通常需要经过以下步骤:生成私钥、生成证书签名请求(CSR)、生成自签名证书或通过 CA 签名,最后将证书转换为 IIS 所需的 PFX 格式。以下是详细步骤: 1. 安装 OpenSSL …...

笔记本电脑研发笔记:BIOS,Driver,Preloader详记
在笔记本电脑的研发过程中,Driver(驱动程序)、BIOS(基本输入输出系统)和 Preloader(预加载程序)之间存在着密切的相互关系和影响,具体如下: 相互关系 BIOS 与 Preload…...

鸿蒙生态:鸿蒙生态校园行心得
(个人观点,仅供参考) 兄弟们,今天来浅浅聊一聊这次的设立在长沙的鸿蒙生态行活动。 老样子,我们先来了解一下这个活动: Harmon&#x…...

云原生周刊:KubeSphere 平滑升级
开源项目推荐 Kagent Kagent 是一个开源的 K8s 原生框架,旨在帮助 DevOps 和平台工程师在 K8s 环境中构建和运行 AI 代理(Agentic AI)。与传统的生成式 AI 工具不同,Kagent 强调自主推理和多步骤任务的自动化执行,适…...
)
Uniapp:swiper(滑块视图容器)
目录 一、基本概述二、属性说明三、基本使用 一、基本概述 一般用于左右滑动或上下滑动,比如banner轮播图 二、属性说明 属性名类型默认值说明平台差异说明indicator-dotsBooleanfalse是否显示面板指示点indicator-colorColorrgba(0, 0, 0, .3)指示点颜色indicat…...

开源的自动驾驶模拟器
以下是目前主流的 开源自动驾驶模拟器,适用于算法开发、测试和研究: 1. CARLA 官网/GitHub: carla.org | GitHub许可证: MIT特点: 基于虚幻引擎(Unreal Engine),提供高保真城市场景(支…...
)
Uniapp:scroll-view(区域滑动视图)
目录 一、基本概述二、属性说明三、基本使用3.1 纵向滚动3.2 横向滚动 一、基本概述 scroll-view,可滚动视图区域。用于区域滚动。 二、属性说明 属性名类型默认值说明平台差异说明scroll-xBooleanfalse允许横向滚动scroll-yBooleanfalse允许纵向滚动 三、基本使…...

【漏洞复现】Struts2系列
【漏洞复现】Struts2系列 1. 了解Struts21. Struts2 S2-061 RCE (CVE-2020-17530)1. 漏洞描述2. 影响版本3. 复现过程 1. 了解Struts2 Apache Struts2是一个基于MVC设计模式的Web应用框架,会对某些标签属性(比如 id)的…...

洗车小程序系统前端uniapp 后台thinkphp
洗车小程序系统 前端uniapp 后台thinkphp 支持多门店 分销 在线预约 套餐卡等...

【RuleUtil】适用于全业务场景的规则匹配快速开发工具
一、RuleUtil 开发背景 1.1 越来越多,越来越复杂的业务规则 1、规则的应用场景多 2、规则配置的参数类型多(ID、数值、文本、日期等等) 3、规则的参数条件多(大于、小于、等于、包含、不包含、区间等等) 4、规则的结…...

多表查询之嵌套查询
目录 引言 一、标量嵌套查询 二、列嵌套查询 三、行嵌套查询 四、表嵌套查询 引言 1、概念 SQL语句中嵌套 select 语句,称为嵌套查询,又称子查询。嵌套查询外部的语句可以是 insert / update / delete / select 的任何一个。 嵌套…...

js原型链prototype解释
function Person(){} var personnew Person() console.log(啊啊,Person instanceof Function);//true console.log(,Person.__proto__Function.prototype);//true console.log(,Person.prototype.__proto__ Object.prototype);//true console.log(,Function.prototype.__prot…...

RK3588 ubuntu20禁用自带的TF卡挂载,并设置udev自动挂载
禁用系统的自动挂载(udisks2) sudo vim /etc/udev/rules.d/80-disable-automount.rules添加 ACTION"add", KERNEL"mmcblk1p1", ENV{UDISKS_IGNORE}"1"KERNEL“mmcblk1p1”:匹配设备名(TF卡通常是…...
的实现)
【Pytorch 中的扩散模型】去噪扩散概率模型(DDPM)的实现
介绍 广义上讲,扩散模型是一种生成式深度学习模型,它通过学习到的去噪过程来创建数据。扩散模型有很多变体,其中最流行的通常是文本条件模型,它可以根据提示生成特定的图像。一些扩散模型(例如 Control-Net࿰…...

AR/VR衍射光波导性能提升遇阻?OAS光学软件有方法
衍射波导准直系统设计案例 简介 在现代光学显示技术中,衍射光波导系统因其独特的光学性能和紧凑的结构设计,在增强现实(AR)、虚拟现实(VR)等领域展现出巨大的应用潜力。本案例聚焦于衍射波导准直系统&…...

联易融受邀参加上海审计局金融审计处专题交流座谈
近日,联易融科技集团受邀出席了由上海市审计局金融审计处组织的专题交流座谈,凭借其在供应链金融领域的深厚积累和创新实践,联易融为与会人员带来了精彩的分享,进一步加深现场对供应链金融等金融发展前沿领域的理解。 在交流座谈…...

【中级软件设计师】程序设计语言基础成分
【中级软件设计师】程序设计语言基础成分 目录 【中级软件设计师】程序设计语言基础成分一、历年真题二、考点:程序设计语言基础成分1、基本成分2、数据成分3、控制成分 三、真题的答案与解析答案解析 复习技巧: 若已掌握【程序设计语言基础成分】相关知…...

高并发抢券系统设计与落地实现详解
📚 目录 一、业务背景与系统目标 二、架构设计总览 三、热点数据预热与缓存设计 四、抢券逻辑核心 —— Redis Lua 脚本 五、抢券接口实现要点 六、结果同步机制设计 七、性能优化策略 八、总结 在电商系统中,抢券作为一种典型的秒杀业务场景&a…...

外商在国内宣传 活动|发布会|参展 邀请媒体
传媒如春雨,润物细无声,大家好,我是51媒体胡老师。 外商在国内开展宣传活动、发布会或参展时,邀请媒体是扩大影响力、提升品牌知名度的关键环节。 一、活动筹备阶段:选择具有实力且更有性价比的媒体服务商(…...
 安全简介)
物联网 (IoT) 安全简介
什么是物联网安全? 物联网安全是网络安全的一个分支领域,专注于保护、监控和修复与物联网(IoT)相关的威胁。物联网是指由配备传感器、软件或其他技术的互联设备组成的网络,这些设备能够通过互联网收集、存储和共享数据…...
)
大模型面经 | 春招、秋招算法面试常考八股文附答案(四)
大家好,我是皮先生!! 今天给大家分享一些关于大模型面试常见的面试题,希望对大家的面试有所帮助。 往期回顾: 大模型面经 | 春招、秋招算法面试常考八股文附答案(RAG专题一) 大模型面经 | 春招、秋招算法面试常考八股文附答案(RAG专题二) 大模型面经 | 春招、秋招算法…...

从零开始学习MySQL的系统学习大纲
文章目录 前言第一阶段:数据库与 MySQL 基础认知数据库基础概念MySQL 简介 第二阶段:MySQL 安装与环境搭建安装前的准备MySQL 安装过程安装后的配置 第三阶段:SQL 基础语法SQL 概述数据库操作数据表操作数据操作 第四阶段:SQL 高级…...

ycsb性能测试的优缺点
YCSB(Yahoo Cloud Serving Benchmark)是一个开源的性能测试框架,用于评估分布式系统的读写性能。它具有以下优点和缺点: 优点: 简单易用:YCSB提供了简单的API和配置文件,使得性能测试非常容易…...

Linux:简单自定义shell
1.实现原理 考虑下⾯这个与shell典型的互动: [rootlocalhost epoll]# ls client.cpp readme.md server.cpp utility.h [rootlocalhost epoll]# ps PID TTY TIME CMD 3451 pts/0 00:00:00 bash 3514 pts/0 00:00:00 ps ⽤下图的时间轴来表⽰事件的发⽣次序。其中时…...

Android Studio开发 SharedPreferences 详解
文章目录 SharedPreferences 详解基本概念获取 SharedPreferences 实例1. Context.getSharedPreferences()2. Activity.getPreferences()3. PreferenceManager.getDefaultSharedPreferences() 存储模式写入数据apply() vs commit() 读取数据监听数据变化最佳实践高级用法存储字…...
)
Qt基础006(事件)
文章目录 消息对话框QMessageBox快捷键开发基础 事件事件处理过程事件过滤器 消息对话框QMessageBox QMessageBox 是 Qt 框架中用于显示消息框的一个类,它常用于向用户显示信息、询问问题或者报告错 误。以下是 QMessageBox 的一些主要用途: 显示信息…...

Mediatek Android13 设置Launcher
概述: 本章将围绕Launcher讲述两种修改默认Launcher的情况。 一:完全覆盖 第一种方法和预置apk类似,区别在于增加LOCAL_OVERRIDES_PACKAGES说明,该方法会完全覆盖系统默认的Launcher。 关于如何预置apk,可见另一篇文章: Mediatek Android13 预置APP-CSDN博客 修改A…...

【Linux网络】构建基于UDP的简单聊天室系统
📢博客主页:https://blog.csdn.net/2301_779549673 📢博客仓库:https://gitee.com/JohnKingW/linux_test/tree/master/lesson 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正! &…...

【微知】git reset --soft --hard以及不加的区别?
背景 在 Git 里,git reset 是用来将当前的 HEAD 复位到指定状态的命令。--soft、--hard 是它的两个常用选项,本文简单介绍他们的区别,以及不添加选项时的默认情况。 在 Git 里,HEAD 是一个重要的引用,它指向当前所在的…...

制作一个简单的操作系统7
实模式下到保护模式下并打印 运行效果: 完整代码: 【免费】制作一个简单的操作系统7的源代码资源-CSDN文库https://download.csdn.net/download/farsight_2098/90670296 从零开始写操作系统引导程序:实模式到保护模式的跨越 引言 操作系统的启动过程是计算机系统中最神…...

2025企微CRM系统功能对比:会话存档、客户画像与数据分析如何重构客户运营?
一、企微CRM管理系统:从“连接工具”到“智能中枢” 随着企业微信生态的成熟,企微CRM管理软件已从简单的客户沟通渠道,升级为融合数据、策略与服务的核心平台。2025年,企业对企微CRM系统的需求聚焦于三大能力:会话存档…...
(新手友好版~))
【JAVA】十三、基础知识“接口”精细讲解!(二)(新手友好版~)
哈喽大家好呀qvq,这里是乎里陈,接口这一知识点博主分为三篇博客为大家进行讲解,今天为大家讲解第二篇java中实现多个接口,接口间的继承,抽象类和接口的区别知识点,更适合新手宝宝们阅读~更多内容持续更新中…...

小白工具视频转MPG, 功能丰富齐全,无需下载软件,在线使用,超实用
在视频格式转换需求日益多样的今天,小白工具网的在线视频转 MPG 功能https://www.xiaobaitool.net/videos/convert-to-mpg/ )脱颖而出,凭借其出色特性,成为众多用户处理视频格式转换的优质选择。 从格式兼容性来看,它支…...
 for (ARR2IDX(arr) var=(arr).size(); var-->0; ))
#define RFOREACH(var, arr) for (ARR2IDX(arr) var=(arr).size(); var-->0; )
这个宏的定义: #define RFOREACH(var, arr) for (ARR2IDX(arr) var (arr).size(); var-- > 0; )是用来 反向遍历一个容器(比如 vector) 的,非常紧凑而且聪明的写法。 逐步解释一下: 假设你有一个容器,…...

MYSQL—两阶段提交
binlog 和 redo log: 有binlog了为什么还要有redo log: 历史原因,MyISAM不支持崩溃恢复,而InnoDB在加入MySQL前就已经支持崩溃恢复了InnoDB使用的是WAL技术,事务提交后,写完内存和日志,就算事…...

Qt之moveToThread
文章目录 前言一、基本概念1.1 什么是线程亲和性?1.2 moveToThread 的作用 二、使用场景三、使用方法四、使用示例五、注意事项六、常见问题总结 前言 moveToThread 是 Qt 中用于管理对象线程亲和性(Thread Affinity)的核心方法。它的作用是…...
)
Nacos 2.0.2 在 CentOS 7 上开启权限认证(含 Docker Compose 配置与接口示例)
介绍如何在 Nacos 2.0.2 CentOS 7 环境中开启权限认证,包括 解压部署 和 Docker Compose 部署 两种方式,提供客户端 Spring Boot 项目的接入配置和nacos接口验证示例。 环境说明 操作系统:CentOS 7Nacos 版本:2.0.2部署方式&…...

Oracle--SQL事务操作与管理流程
前言:本博客仅作记录学习使用,部分图片出自网络,如有侵犯您的权益,请联系删除 数据库系统的并发控制以事务为单位进行,通过内部锁定机制限制事务对共享资源的访问,确保数据并行性和一致性。事务是由一系列语…...

Qt -对象树
博客主页:【夜泉_ly】 本文专栏:【暂无】 欢迎点赞👍收藏⭐关注❤️ 目录 前言构造QObject::QObjectQObjectPrivate::setParent_helper 析构提醒 #mermaid-svg-FTUpJmKG24FY3dZY {font-family:"trebuchet ms",verdana,arial,sans-s…...

Unity 带碰撞的粒子效果
碰撞效果:粒子接触角色碰撞体弹起,粒子接触地面弹起。 粒子效果:粒子自行加速度下落,并且在接触碰撞体弹起时产生一个小的旋转。 *注意使用此效果时,自行判断是否需要调整碰撞层级。 以下为角色身高为1.7m时&#x…...
)
扩散模型(Diffusion Models)
扩散模型(Diffusion Models)是近年来在生成式人工智能领域崛起的一种重要方法,尤其在图像、音频和视频生成任务中表现突出。其核心思想是通过逐步添加和去除噪声的过程来学习数据分布,从而生成高质量样本。 核心原理 扩散…...

JSP服务器端表单验证
JSP服务器端表单验证 一、引言 在Web开发中,表单验证是保障数据合法性的重要环节。《Web编程技术》第五次实验要求,详细讲解如何基于JSP内置对象实现服务器端表单验证,包括表单设计、验证逻辑、交互反馈等核心功能。最终实现:输…...

Anaconda、conda和PyCharm在Python开发中各自扮演的角色
Anaconda、conda和PyCharm在Python开发中各自扮演不同角色,它们的核心用处、区别及相互关系如下: 一、Anaconda与conda的用处及区别 1. Anaconda - 定义:Anaconda是一个开源的Python和R语言发行版,专为数据科学、机器学习等场景…...

【数据结构 · 初阶】- 堆的实现
目录 一.初始化 二.插入 三.删除(堆顶、根) 四.整体代码 Heap.h Test.c Heap.c 我们使用顺序结构实现完全二叉树,也就是堆的实现 以前学的数据结构只是单纯的存储数据。堆除了存储数据,还有其他的价值——排序。是一个功能…...

Ubuntu与OpenHarmony OS 5.0显示系统架构比较
1. 总体架构对比 1.1 Ubuntu显示架构 Ubuntu采用传统Linux显示栈架构,自顶向下可分为: 应用层:GNOME桌面环境和应用程序显示服务器层:X11或Wayland图形栈中间层:Mesa, DRM/KMS硬件层:GPU驱动和硬件 1.2 …...

一键配置多用户VNC远程桌面:自动化脚本详解
在当今远程工作盛行的时代,高效且安全地管理多用户远程桌面访问变得至关重要。本文将介绍一个强大的自动化脚本,该脚本能够快速创建用户并配置VNC远程桌面环境,大大简化了系统管理员的工作。 一、背景介绍 在Linux系统中,手动配置VNC服务器通常需要执行多个步骤,包括创建…...

Qt进阶开发:鼠标及键盘事件
文章目录 一、Qt中事件的概念二、Qt中事件处理方式三、重新实现部件的事件处理函数3.1 常用事件处理函数3.2 自定义控件处理鼠标和绘图事件3.3 常用事件处理函数说明四、重写notify()函数五、QApplication对象上安装事件过滤器六、重写event()事件七、在对象上安装事件过滤器八…...

鸿蒙生态新利器:华为ArkUI-X混合开发框架深度解析
鸿蒙生态新利器:华为ArkUI-X混合开发框架深度解析 作者:王老汉 | 鸿蒙生态开发者 | 2025年4月 📢 前言:开发者们的新机遇 各位鸿蒙开发者朋友们,是否还在为多平台开发重复造轮子而苦恼?今天给大家介绍一位…...