【Pytorch 中的扩散模型】去噪扩散概率模型(DDPM)的实现

介绍
广义上讲,扩散模型是一种生成式深度学习模型,它通过学习到的去噪过程来创建数据。扩散模型有很多变体,其中最流行的通常是文本条件模型,它可以根据提示生成特定的图像。一些扩散模型(例如 Control-Net)甚至可以将图像与特定的艺术风格融合。以下是一个例子:

如果您不知道图像有什么特别之处,请尝试远离屏幕或眯起眼睛来查看图像中隐藏的秘密。
扩散模型的应用和类型多种多样,但在本教程中,我们将构建基础的非条件扩散模型 DDPM(去噪扩散概率模型)[1]。我们将首先直观地了解该算法的底层工作原理,然后在 PyTorch 中从头构建它。此外,本教程将主要关注该算法背后的直观概念和具体的实现细节。关于数学推导和背景知识,这本书 [2] 是很好的参考资料。
最后说明:此实现是为包含单个 GPU 且兼容 CUDA 的工作流构建的。此外,完整的代码库可在此处找到:

工作原理 -> 正向和反向过程
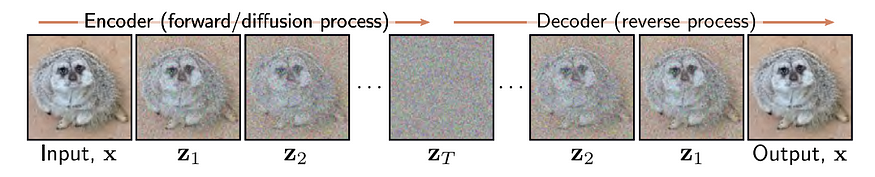
图片来自[2] 理解深度学习 作者:Simon JD Prince
扩散过程包括正向过程和逆向过程。正向过程是一个基于噪声表的预定马尔可夫链。噪声表是一组方差B1、B2、…BT,它们控制构成马尔可夫链的条件正态分布。
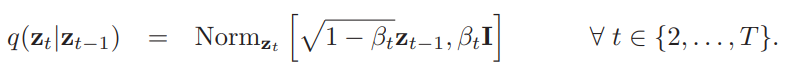
前向过程马尔可夫链 — 图片来自[2]
这个公式是前向过程的数学表示,但直观上我们可以将其理解为一个序列,我们逐渐将数据示例 X 映射到纯噪声。前向过程中的第一个项只是我们的初始数据示例。在中间时间步长 t,我们有一个带噪声的 X 版本,在最后的时间步长 T,我们得到纯噪声,它大致受标准正态分布的支配。在构建扩散模型时,我们会选择噪声计划。例如,在 DDPM 中,我们的噪声计划具有 1000 个时间步长,方差从 1e-4 线性增加到 0.02。还需要注意的是,我们的前向过程是静态的,这意味着我们选择噪声计划作为扩散模型的超参数,并且我们不会训练前向过程,因为它已经明确定义。还需要注意的是,我们的前向过程是静态的,这意味着我们选择噪声计划作为扩散模型的超参数,并且我们不训练前向过程,因为它已经被明确定义。
关于正向过程,我们必须了解的最后一个关键细节是:由于分布符合正态性,我们可以从数学上推导出一个称为“扩散核”的分布,它表示给定初始数据点,正向过程中任何中间值的分布。这使我们能够绕过在正向过程中迭代添加 t-1 级噪声的所有中间步骤,从而获得包含 t 个噪声的图像,这在以后训练模型时会派上用场。其数学表示为:
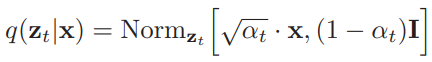
扩散核 — 图片来自[2]
其中时间 t 时的 alpha 定义为从初始时间步长到当前时间步长的累积乘积 (1-B)。
逆过程是扩散模型的关键。逆过程本质上是对正向过程的撤销,即逐步从纯噪声图像中去除一定量的噪声,从而生成新的图像。我们从纯噪声数据开始,在每个时间步 t 减去正向过程理论上在该时间步长上添加的噪声量。我们不断去除噪声,直到最终得到与原始数据分布相似的图像。我们的工作重点是训练一个模型,使其能够精确地逼近正向过程,从而估计能够生成新样本的逆向过程。
算法和训练目标
为了训练这样的模型来估计逆扩散过程,我们可以遵循下面定义的图像中的算法:
- 从我们的训练数据集中随机抽取一个数据点
- 在我们的噪声(方差)计划中选择一个随机时间步长
- 将该时间步的噪声添加到我们的数据中,通过“扩散核”模拟正向扩散过程
- 将我们的去噪图像传入模型,以预测我们添加的噪声
- 计算预测噪声和实际噪声之间的均方误差,并通过该目标函数优化模型参数
- 并重复!

DDPM 训练算法——图片来自[2]
从数学上讲,如果没有看到完整的推导,算法中的确切公式一开始可能看起来有点奇怪,但直观地说,它是基于我们的噪声计划的 alpha 值的扩散核的重新参数化,它只是预测噪声和我们添加到图像的实际噪声的平方差。
如果我们的模型能够根据前向过程的特定时间步长成功预测噪声量,我们可以从时间步长 T 的噪声开始迭代,并根据每个时间步长逐渐消除噪声,直到我们恢复类似于原始数据分布中生成的样本的数据。
采样算法总结如下:
- 从标准正态分布中生成随机噪声
对于从上一个时间步开始并向后移动的每个时间步:
2. 通过估计逆过程分布来更新 Z,其中平均值由上一步的 Z 参数化,方差由我们的模型在该时间步估计的噪声参数化
3. 添加少量噪音以增加稳定性(解释如下)
4. 重复此操作,直到到达时间步 0,即我们恢复的图像!

DDPM采样算法——图片来自[2]
随后采样并生成图像的算法在数学上可能看起来很复杂,但直观上可以归结为一个迭代过程:我们从纯噪声开始,估算在时间步 t 理论上添加的噪声,然后将其减去。如此反复,直到得到生成的样本。唯一需要注意的小细节是,在减去估算的噪声后,我们会再加回少量噪声,以保持过程稳定。例如,在迭代过程开始时一次性估算并减去总噪声会导致样本非常不连贯,因此实践证明,在每个时间步长上加回一点噪声并进行迭代可以生成更好的样本。
UNET
DDPM 论文的作者使用了最初为医学图像分割设计的 UNET 架构,构建了一个用于预测扩散逆过程噪声的模型。本教程中我们将使用的模型适用于 32x32 图像,非常适合 MNIST 等数据集,但该模型可以扩展以处理更高分辨率的数据。UNET 有很多变体,我们将要构建的模型架构概览如下图所示。
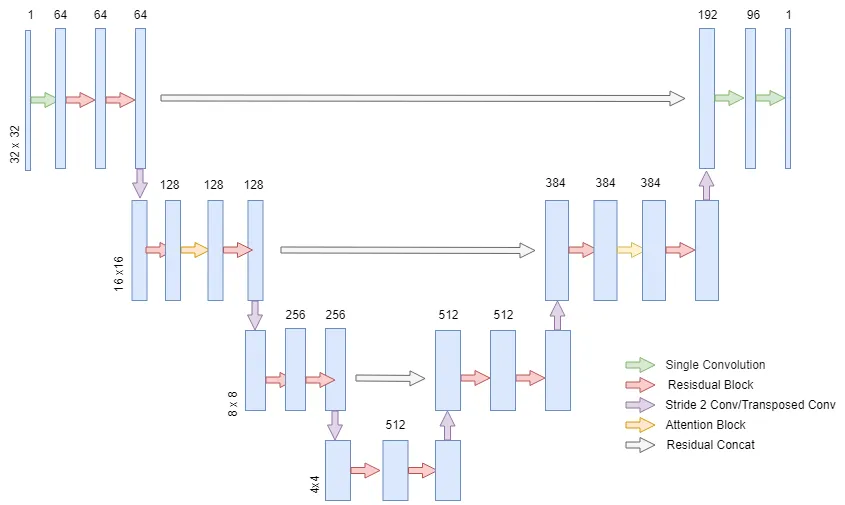
DDPM 的 UNET 与经典 UNET 类似,因为它包含下采样流和上采样流,从而减轻了网络的计算负担,同时在两个流之间具有跳过连接,以合并来自模型浅层和深层特征的信息。
DDPM UNET 与经典 UNET 的主要区别在于,DDPM UNET 在 16x16 维层中引入了注意力机制,并在每个残差块中嵌入了正弦 Transformer 嵌入。正弦嵌入背后的含义是告诉模型我们试图在哪个时间步预测噪声。这通过注入模型在噪声计划中所处位置的信息,帮助模型预测每个时间步的噪声。例如,如果我们有一个噪声计划,其中某些时间步包含大量噪声,那么模型了解它必须预测哪个时间步可以帮助模型预测相应时间步的噪声。对于那些还不熟悉 Transformer 架构的人来说,可以在这里 [3] 找到更多关于注意力机制和嵌入的一般信息。
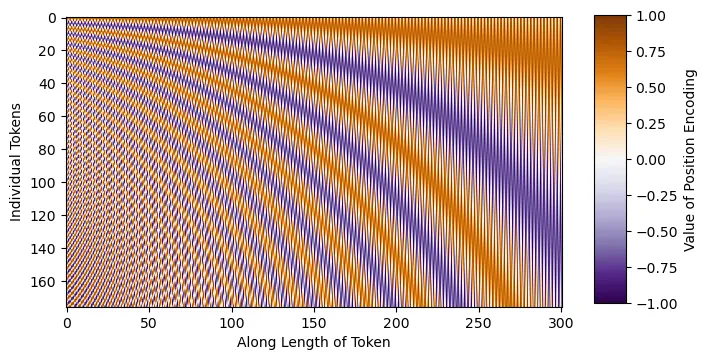
在模型实现中,我们将首先定义导入(pip install 命令已注释,仅供参考),并编写正弦时间步长的嵌入代码。直观地说,正弦嵌入是不同的正弦和余弦频率,可以直接添加到输入中,从而为模型提供额外的位置/顺序理解。如下图所示,每个正弦波都是独一无二的,这将使模型能够感知其在噪声表中的位置。
# 导入
import torch
import torch.nn as nn
import torch.nn . functional as F
from einops import rearrange #pip install einops
from Typing import List
import random
import math
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from timm.utils import ModelEmaV3 #pip install timm
from tqdm import tqdm #pip install tqdm
import matplotlib.pyplot as plt #pip install matplotlib
import torch.optim as optim
import numpy as np class SinusoidalEmbeddings (nn.Module): def __init__ ( self, time_steps: int , embed_dim: int ): super ().__init__() position = torch.arange(time_steps).unsqueeze( 1 ). float()div = torch.exp(torch.arange(0, embed_dim,2)。float()* -(math.log(10000.0)/ embed_dim))embeddings = torch.zeros(time_steps,embed_dim,requires_grad = False)embeddings[:,0 :: 2 ] = torch.sin(position * div)embeddings[:,1 :: 2 ] = torch.cos(position * div)self.embeddings = embeddings def forward(self,x,t):embeds = self.embeddings[t].to(x.device)返回embeds[:,:,None,None ]UNET 每一层的残差块将与原始 DDPM 论文中使用的残差块相同。每个残差块将包含一个组范数序列、ReLU 激活函数、一个 3x3 的“相同”卷积、dropout 和一个跳跃连接。
# 残差块
class ResBlock (nn.Module): def __init__ ( self, C: int , num_groups: int , dropout_prob: float ): super ().__init__() self.relu = nn.ReLU(inplace= True ) self.gnorm1 = nn.GroupNorm(num_groups=num_groups, num_channels=C) self.gnorm2 = nn.GroupNorm(num_groups=num_groups, num_channels=C) self.conv1 = nn.Conv2d(C, C, kernel_size= 3 , padding= 1 ) self.conv2 = nn.Conv2d(C, C, kernel_size= 3 , padding= 1 ) self.dropout = nn.Dropout(p=dropout_prob, inplace= True ) def forward ( self, x, embeddings ): x = x + embeddings[:, :x.shape[ 1 ], :, :] r = self.conv1(self.relu(self.gnorm1(x))) r = self.dropout(r) r = self.conv2(self.relu(self.gnorm2(r)))返回r + x在 DDPM 中,作者在 UNET 的每一层(分辨率尺度)使用了 2 个残差块;对于 16x16 维度的层,我们在两个残差块之间加入了经典的 Transformer 注意力机制。现在,我们将为 UNET 实现注意力机制:
<span style="background-color:#f9f9f9"><span style="color:#242424"> self.proj2 = nn.Linear(C,C)self.num_heads = num_heads self.dropout_prob = dropout_prob ( ) x = self.proj1(x) x = rearrange(x, , K= , H=self.num_heads) q,k,v = x[ ], x[ , h=h, w=w) x = self.proj2(x) <span style="color:#c41a16">'bhw C -> b C h w'</span> )</span></span>注意力机制的实现非常简单。我们重塑数据,将 h*w 维度组合成一个“序列”维度,类似于 Transformer 模型的经典输入,并将通道维度转换为嵌入特征维度。在此实现中,我们使用 torch.nn. functional.scaled_dot_product_attention,因为此实现包含 Flash 注意力机制,它是注意力机制的优化版本,在数学上仍然等同于经典 Transformer 注意力机制。有关 Flash 注意力机制的更多信息,请参阅以下论文:[4]、[5]。
最后,我们可以定义UNET的完整层:
类 UnetLayer(nn.Module):def __init__(self,upscale:bool,attention:bool,num_groups:int,dropout_prob:float,num_heads:int,C:int):super()。__init__()self.ResBlock1 = ResBlock(C = C,num_groups = num_groups,dropout_prob = dropout_prob)self.ResBlock2 = ResBlock(C = C,num_groups = num_groups,dropout_prob = dropout_prob)如果upscale:self.conv = nn.ConvTranspose2d(C,C// 2,kernel_size = 4,stride = 2,padding = 1)否则:self.conv = nn.Conv2d(C,C * 2,kernel_size = 3,stride = 2, padding= 1)如果注意:self.attention_layer = Attention(C,num_heads=num_heads,dropout_prob=dropout_prob)def forward(self,x,embeddings):x = self.ResBlock1(x,embeddings)如果 hasattr(self,'attention_layer'):x = self.attention_layer(x)x = self.ResBlock2(x,embeddings)返回self.conv(x),x如前所述,DDPM 中的每一层都有 2 个残差块,并且可能包含一个注意力机制,我们还会将嵌入传递到每个残差块中。此外,我们还会返回下采样或上采样值以及先验值,我们将存储该值并将其用于残差级联跳跃连接。
最后,我们可以完成 UNET 课程:
类 UNET(nn.Module):def __init__(self,Channels:List = [ 64 , 128 , 256 , 512 , 512 , 384 ],Attentions:List = [ False , True , False , False , False , True ],Upscales:List = [ False , False , False , True , True , True ],num_groups:int = 32,dropout_prob:float = 0.1,num_heads:int = 8,input_channels:int = 1,output_channels:int = 1,time_steps:int = 1000):super()。__init__()self.num_layers = len(Channels)self.shallow_conv = nn.Conv2d(input_channels,通道[ 0 ],内核大小= 3,填充= 1)out_channels =(通道[- 1 ]// 2)+通道[ 0 ] self.late_conv = nn.Conv2d(out_channels,out_channels// 2,内核大小= 3,填充= 1)self.output_conv = nn.Conv2d(out_channels// 2,output_channels,内核大小= 1)self.relu = nn.ReLU(inplace = True)self.embeddings = SinusoidalEmbeddings(time_steps = time_steps,embed_dim = max(通道))对于范围内的 i (self.num_layers): layer = UnetLayer( upscale = Upscales [i], attention = Attentions [i], num_groups = num_groups, dropout_prob=dropout_prob, C=Channels[i], num_heads=num_heads )setattr(self,f'Layer {i + 1 } ',layer)def forward(self,x,t):x = self.shallow_conv(x)residuals = [] for i in range(self.num_layers // 2):layer = getattr(self,f'Layer {i + 1 } ')embeddings = self.embeddings(x,t)x,r = layer(x,embeddings)residuals.append(r)for i in range(self.num_layers // 2,self.num_layers):layer = getattr(self,f'Layer {i + 1 } ')x = torch.concat((layer(x,embeddings)[ 0 ],residuals[self.num_layers-i- 1 ]),dim= 1)return self.output_conv(self.relu(self.late_conv(x)))基于我们已经创建的类,实现起来非常简单。此实现的唯一区别在于,我们的上游通道比 UNET 的典型通道略大。我发现,这种架构在配备 16GB VRAM 的单 GPU 上训练效率更高。
调度程序
为 DDPM 编写噪声/方差调度程序也非常简单。在 DDPM 中,我们的调度将从 1e-4 开始,如前所述,以 0.02 结束,并呈线性增长。
类 DDPM_Scheduler(nn.Module):def __init__(self,num_time_steps:int = 1000):super()。__init__()self.beta = torch.linspace(1e- 4,0.02 ,num_time_steps,requires_grad = False ) alpha = 1 -self.beta self.alpha = torch.cumprod(alpha,dim = 0).requires_grad_(False)def forward(self,t):返回self.beta [t],self.alpha [t]我们返回 beta(方差)值和 alpha 值,因为我们的训练和采样公式使用这两个值都是基于它们的数学推导。
def set_seed(种子:int = 42):torch.manual_seed(种子)torch.cuda.manual_seed_all(种子)torch.backends.cudnn.deterministic = Truetorch.backends.cudnn.benchmark = Falsenp.random.seed(种子)random.seed(种子)此外(非必需),此函数定义了一个训练种子。这意味着,如果您想重现特定的训练实例,可以使用一组种子,这样每次使用相同的种子时,随机权重和优化器初始化都是相同的。
训练
为了实现这一目标,我们将创建一个模型来生成 MNIST 数据(手写数字)。由于 PyTorch 默认这些图像的尺寸为 28x28,因此我们将图像填充到 32x32,以遵循原始论文中在 32x32 图像上训练的方法。
为了进行优化,我们使用 Adam,初始学习率为 2e-5。我们还使用 EMA(指数移动平均线)来辅助提高生成质量。EMA 是模型参数的加权平均值,在推理时间内可以创建更平滑、噪声更低的样本。对于此实现,我使用了 timm 库的 EMAV3 开箱即用实现,权重为 0.9999,与 DDPM 论文中使用的相同。
总结一下我们的训练过程,我们只需遵循上面的伪代码即可。我们为批次随机选取时间步长,并根据这些时间步长的计划对批次中的数据进行噪声处理,然后将该批次的噪声图像与时间步长本身一起输入到 UNET 中,以指导正弦嵌入。我们使用伪代码中基于“扩散核”的公式对图像进行噪声处理。然后,我们将模型对噪声添加量的预测与实际添加的噪声进行比较,并优化噪声的均方误差。我们还实现了基本的检查点,以便在不同的时期暂停和恢复训练。
def train(batch_size:int = 64,num_time_steps:int = 1000,num_epochs:int = 15,seed:int = - 1,ema_decay:float = 0.9999, lr = 2e-5,checkpoint_path:str = None):set_seed(random.randint(0,2 ** 32 - 1))如果seed == - 1 ,则设置seed(seed) train_dataset = datasets.MNIST(root = '。/ data ',train = True,download = False,transform = transforms.ToTensor()) train_loader = DataLoader(train_dataset,batch_size = batch_size,shuffle = True,drop_last = True,num_workers = 4) scheduler = DDPM_Scheduler(num_time_steps=num_time_steps) model = UNET()。cuda() 优化器 = optim.Adam(model.parameters(,lr=lr) ema = ModelEmaV3(model,decay=ema_decay)如果checkpoint_path不为None: checkpoint = torch.load(checkpoint_path) model.load_state_dict(checkpoint [ 'weights' ]) ema.load_state_dict(checkpoint [ 'ema' ]) optimizer.load_state_dict(checkpoint [ 'optimizer' ]) criterion = nn.MSELoss(reduction= 'mean')对于范围内的i (num_epochs): total_loss = 0 for bidx,(x,_)在枚举中(tqdm(train_loader,desc= f“Epoch {i + 1 } / {num_epochs} “)): x = x.cuda() x = F.pad(x, ( 2 , 2 , 2 , 2 )) t = torch.randint( 0 ,num_time_steps,(batch_size,)) e = torch.randn_like(x, require_grad= False ) a = Scheduler.alpha[t].view(batch_size, 1 , 1 , 1 ).cuda() x = (torch.sqrt(a)*x) + (torch.sqrt( 1 -a)*e)输出 = 模型(x,t)优化器.zero_grad()损失 = 标准(输出,e) total_loss += loss.item() 损失.backward()优化器.step() ema.update(模型)打印( f'Epoch {i + 1 } | 损失{total_loss / ( 60000 /batch_size): .5 f} ' )检查点 = { '权重':模型.state_dict(),'优化器':优化器.state_dict(),'ema':ema.state_dict() } torch.save(检查点,'检查点/ddpm_checkpoint' )对于推理,我们完全遵循伪代码的另一部分。直观地说,我们只是将正向过程反转。我们从纯噪声开始,现在训练好的模型可以预测每个时间步的估计噪声,然后可以迭代地生成全新的样本。对于每个不同的噪声起点,我们可以生成一个不同的独特样本,该样本与原始数据分布相似,但又独一无二。本文并未推导推理公式,但开头链接的参考文献可以为想要深入了解的读者提供指导。
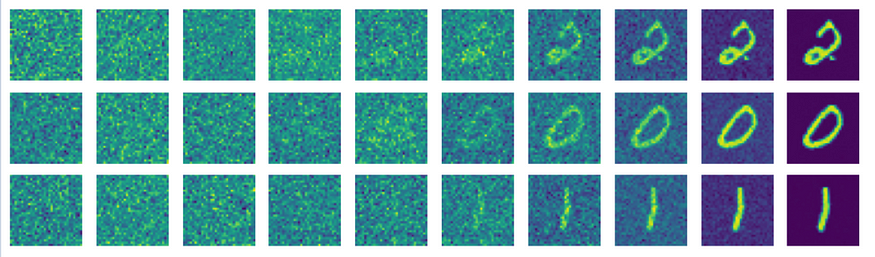
还要注意,我包含了一个辅助函数来查看漫射图像,以便您可以直观地看到模型学习逆向过程的程度。
def display_reverse(images:List):fig,axes = plt.subplots(1,10 , figsize = ( 10,1 ))对于i,ax in enumerate ( axes.flat): x = images[i].squeeze(0 ) x = rearrange(x,'chw -> hw c') x = x.numpy() ax.imshow(x) ax.axis('off') plt.show()def inference(checkpoint_path:str = None, num_time_steps:int = 1000, ema_decay:float = 0.9999,): checkpoint = torch.load(checkpoint_path) model = UNET()。cuda() model.load_state_dict(checkpoint [ 'weights') ema = ModelEmaV3(model,decay = ema_decay) ema.load_state_dict(checkpoint [ ' ema ' ])调度程序 = DDPM_Scheduler(num_time_steps = num_time_steps )时间= [ 0,15,50,100,200,300,400,550,700,999 ]图像 = [ ]与torch.no_grad ():模型= ema.module 。eval ()对于范围(10 )内的i : z = torch.randn( 1 , 1 , 32 , 32 )对于反转的t (范围(1,num_time_steps)): t = [t] temp = (scheduler.beta[t]/( (torch.sqrt( 1 -scheduler.alpha[t]))*(torch.sqrt( 1 -scheduler.beta[t])) )) z = ( 1 /(torch.sqrt( 1 -scheduler.beta[t])))*z - (temp*model(z.cuda(),t).cpu())如果t[ 0 ]在时间中: images.append(z) e = torch.randn( 1 , 1 , 32 ,32 ) z = z + (e*torch.sqrt(scheduler.beta[t])) temp = Scheduler.beta[ 0 ]/( (torch.sqrt( 1 -scheduler.alpha[ 0 ]))*(torch.sqrt( 1 -scheduler.beta[ 0 ])) ) x = ( 1 /(torch.sqrt( 1 -scheduler.beta[ 0 ])))*z - (temp*model(z.cuda(),[ 0 ]).cpu()) images.append(x) x = rearrange(x.squeeze( 0 ), 'chw -> hw c' ).detach() x = x.numpy() plt.imshow(x) plt.show() display_reverse(images) images = []def main():训练(checkpoint_path = 'checkpoints / ddpm_checkpoint',lr = 2e-5,num_epochs = 75)推理('checkpoints / ddpm_checkpoint')如果__name__ == '__main__':main()按照上面列出的实验细节进行 75 个 epoch 训练后,我们得到了以下结果:
此时,我们刚刚在 PyTorch 中从头开始编写了 DDPM 代码!
相关文章:
的实现)
【Pytorch 中的扩散模型】去噪扩散概率模型(DDPM)的实现
介绍 广义上讲,扩散模型是一种生成式深度学习模型,它通过学习到的去噪过程来创建数据。扩散模型有很多变体,其中最流行的通常是文本条件模型,它可以根据提示生成特定的图像。一些扩散模型(例如 Control-Net࿰…...

AR/VR衍射光波导性能提升遇阻?OAS光学软件有方法
衍射波导准直系统设计案例 简介 在现代光学显示技术中,衍射光波导系统因其独特的光学性能和紧凑的结构设计,在增强现实(AR)、虚拟现实(VR)等领域展现出巨大的应用潜力。本案例聚焦于衍射波导准直系统&…...

联易融受邀参加上海审计局金融审计处专题交流座谈
近日,联易融科技集团受邀出席了由上海市审计局金融审计处组织的专题交流座谈,凭借其在供应链金融领域的深厚积累和创新实践,联易融为与会人员带来了精彩的分享,进一步加深现场对供应链金融等金融发展前沿领域的理解。 在交流座谈…...

【中级软件设计师】程序设计语言基础成分
【中级软件设计师】程序设计语言基础成分 目录 【中级软件设计师】程序设计语言基础成分一、历年真题二、考点:程序设计语言基础成分1、基本成分2、数据成分3、控制成分 三、真题的答案与解析答案解析 复习技巧: 若已掌握【程序设计语言基础成分】相关知…...

高并发抢券系统设计与落地实现详解
📚 目录 一、业务背景与系统目标 二、架构设计总览 三、热点数据预热与缓存设计 四、抢券逻辑核心 —— Redis Lua 脚本 五、抢券接口实现要点 六、结果同步机制设计 七、性能优化策略 八、总结 在电商系统中,抢券作为一种典型的秒杀业务场景&a…...

外商在国内宣传 活动|发布会|参展 邀请媒体
传媒如春雨,润物细无声,大家好,我是51媒体胡老师。 外商在国内开展宣传活动、发布会或参展时,邀请媒体是扩大影响力、提升品牌知名度的关键环节。 一、活动筹备阶段:选择具有实力且更有性价比的媒体服务商(…...
 安全简介)
物联网 (IoT) 安全简介
什么是物联网安全? 物联网安全是网络安全的一个分支领域,专注于保护、监控和修复与物联网(IoT)相关的威胁。物联网是指由配备传感器、软件或其他技术的互联设备组成的网络,这些设备能够通过互联网收集、存储和共享数据…...
)
大模型面经 | 春招、秋招算法面试常考八股文附答案(四)
大家好,我是皮先生!! 今天给大家分享一些关于大模型面试常见的面试题,希望对大家的面试有所帮助。 往期回顾: 大模型面经 | 春招、秋招算法面试常考八股文附答案(RAG专题一) 大模型面经 | 春招、秋招算法面试常考八股文附答案(RAG专题二) 大模型面经 | 春招、秋招算法…...

从零开始学习MySQL的系统学习大纲
文章目录 前言第一阶段:数据库与 MySQL 基础认知数据库基础概念MySQL 简介 第二阶段:MySQL 安装与环境搭建安装前的准备MySQL 安装过程安装后的配置 第三阶段:SQL 基础语法SQL 概述数据库操作数据表操作数据操作 第四阶段:SQL 高级…...

ycsb性能测试的优缺点
YCSB(Yahoo Cloud Serving Benchmark)是一个开源的性能测试框架,用于评估分布式系统的读写性能。它具有以下优点和缺点: 优点: 简单易用:YCSB提供了简单的API和配置文件,使得性能测试非常容易…...

Linux:简单自定义shell
1.实现原理 考虑下⾯这个与shell典型的互动: [rootlocalhost epoll]# ls client.cpp readme.md server.cpp utility.h [rootlocalhost epoll]# ps PID TTY TIME CMD 3451 pts/0 00:00:00 bash 3514 pts/0 00:00:00 ps ⽤下图的时间轴来表⽰事件的发⽣次序。其中时…...

Android Studio开发 SharedPreferences 详解
文章目录 SharedPreferences 详解基本概念获取 SharedPreferences 实例1. Context.getSharedPreferences()2. Activity.getPreferences()3. PreferenceManager.getDefaultSharedPreferences() 存储模式写入数据apply() vs commit() 读取数据监听数据变化最佳实践高级用法存储字…...
)
Qt基础006(事件)
文章目录 消息对话框QMessageBox快捷键开发基础 事件事件处理过程事件过滤器 消息对话框QMessageBox QMessageBox 是 Qt 框架中用于显示消息框的一个类,它常用于向用户显示信息、询问问题或者报告错 误。以下是 QMessageBox 的一些主要用途: 显示信息…...

Mediatek Android13 设置Launcher
概述: 本章将围绕Launcher讲述两种修改默认Launcher的情况。 一:完全覆盖 第一种方法和预置apk类似,区别在于增加LOCAL_OVERRIDES_PACKAGES说明,该方法会完全覆盖系统默认的Launcher。 关于如何预置apk,可见另一篇文章: Mediatek Android13 预置APP-CSDN博客 修改A…...

【Linux网络】构建基于UDP的简单聊天室系统
📢博客主页:https://blog.csdn.net/2301_779549673 📢博客仓库:https://gitee.com/JohnKingW/linux_test/tree/master/lesson 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正! &…...

【微知】git reset --soft --hard以及不加的区别?
背景 在 Git 里,git reset 是用来将当前的 HEAD 复位到指定状态的命令。--soft、--hard 是它的两个常用选项,本文简单介绍他们的区别,以及不添加选项时的默认情况。 在 Git 里,HEAD 是一个重要的引用,它指向当前所在的…...

制作一个简单的操作系统7
实模式下到保护模式下并打印 运行效果: 完整代码: 【免费】制作一个简单的操作系统7的源代码资源-CSDN文库https://download.csdn.net/download/farsight_2098/90670296 从零开始写操作系统引导程序:实模式到保护模式的跨越 引言 操作系统的启动过程是计算机系统中最神…...

2025企微CRM系统功能对比:会话存档、客户画像与数据分析如何重构客户运营?
一、企微CRM管理系统:从“连接工具”到“智能中枢” 随着企业微信生态的成熟,企微CRM管理软件已从简单的客户沟通渠道,升级为融合数据、策略与服务的核心平台。2025年,企业对企微CRM系统的需求聚焦于三大能力:会话存档…...
(新手友好版~))
【JAVA】十三、基础知识“接口”精细讲解!(二)(新手友好版~)
哈喽大家好呀qvq,这里是乎里陈,接口这一知识点博主分为三篇博客为大家进行讲解,今天为大家讲解第二篇java中实现多个接口,接口间的继承,抽象类和接口的区别知识点,更适合新手宝宝们阅读~更多内容持续更新中…...

小白工具视频转MPG, 功能丰富齐全,无需下载软件,在线使用,超实用
在视频格式转换需求日益多样的今天,小白工具网的在线视频转 MPG 功能https://www.xiaobaitool.net/videos/convert-to-mpg/ )脱颖而出,凭借其出色特性,成为众多用户处理视频格式转换的优质选择。 从格式兼容性来看,它支…...
 for (ARR2IDX(arr) var=(arr).size(); var-->0; ))
#define RFOREACH(var, arr) for (ARR2IDX(arr) var=(arr).size(); var-->0; )
这个宏的定义: #define RFOREACH(var, arr) for (ARR2IDX(arr) var (arr).size(); var-- > 0; )是用来 反向遍历一个容器(比如 vector) 的,非常紧凑而且聪明的写法。 逐步解释一下: 假设你有一个容器,…...

MYSQL—两阶段提交
binlog 和 redo log: 有binlog了为什么还要有redo log: 历史原因,MyISAM不支持崩溃恢复,而InnoDB在加入MySQL前就已经支持崩溃恢复了InnoDB使用的是WAL技术,事务提交后,写完内存和日志,就算事…...

Qt之moveToThread
文章目录 前言一、基本概念1.1 什么是线程亲和性?1.2 moveToThread 的作用 二、使用场景三、使用方法四、使用示例五、注意事项六、常见问题总结 前言 moveToThread 是 Qt 中用于管理对象线程亲和性(Thread Affinity)的核心方法。它的作用是…...
)
Nacos 2.0.2 在 CentOS 7 上开启权限认证(含 Docker Compose 配置与接口示例)
介绍如何在 Nacos 2.0.2 CentOS 7 环境中开启权限认证,包括 解压部署 和 Docker Compose 部署 两种方式,提供客户端 Spring Boot 项目的接入配置和nacos接口验证示例。 环境说明 操作系统:CentOS 7Nacos 版本:2.0.2部署方式&…...

Oracle--SQL事务操作与管理流程
前言:本博客仅作记录学习使用,部分图片出自网络,如有侵犯您的权益,请联系删除 数据库系统的并发控制以事务为单位进行,通过内部锁定机制限制事务对共享资源的访问,确保数据并行性和一致性。事务是由一系列语…...

Qt -对象树
博客主页:【夜泉_ly】 本文专栏:【暂无】 欢迎点赞👍收藏⭐关注❤️ 目录 前言构造QObject::QObjectQObjectPrivate::setParent_helper 析构提醒 #mermaid-svg-FTUpJmKG24FY3dZY {font-family:"trebuchet ms",verdana,arial,sans-s…...

Unity 带碰撞的粒子效果
碰撞效果:粒子接触角色碰撞体弹起,粒子接触地面弹起。 粒子效果:粒子自行加速度下落,并且在接触碰撞体弹起时产生一个小的旋转。 *注意使用此效果时,自行判断是否需要调整碰撞层级。 以下为角色身高为1.7m时&#x…...
)
扩散模型(Diffusion Models)
扩散模型(Diffusion Models)是近年来在生成式人工智能领域崛起的一种重要方法,尤其在图像、音频和视频生成任务中表现突出。其核心思想是通过逐步添加和去除噪声的过程来学习数据分布,从而生成高质量样本。 核心原理 扩散…...

JSP服务器端表单验证
JSP服务器端表单验证 一、引言 在Web开发中,表单验证是保障数据合法性的重要环节。《Web编程技术》第五次实验要求,详细讲解如何基于JSP内置对象实现服务器端表单验证,包括表单设计、验证逻辑、交互反馈等核心功能。最终实现:输…...

Anaconda、conda和PyCharm在Python开发中各自扮演的角色
Anaconda、conda和PyCharm在Python开发中各自扮演不同角色,它们的核心用处、区别及相互关系如下: 一、Anaconda与conda的用处及区别 1. Anaconda - 定义:Anaconda是一个开源的Python和R语言发行版,专为数据科学、机器学习等场景…...

【数据结构 · 初阶】- 堆的实现
目录 一.初始化 二.插入 三.删除(堆顶、根) 四.整体代码 Heap.h Test.c Heap.c 我们使用顺序结构实现完全二叉树,也就是堆的实现 以前学的数据结构只是单纯的存储数据。堆除了存储数据,还有其他的价值——排序。是一个功能…...

Ubuntu与OpenHarmony OS 5.0显示系统架构比较
1. 总体架构对比 1.1 Ubuntu显示架构 Ubuntu采用传统Linux显示栈架构,自顶向下可分为: 应用层:GNOME桌面环境和应用程序显示服务器层:X11或Wayland图形栈中间层:Mesa, DRM/KMS硬件层:GPU驱动和硬件 1.2 …...

一键配置多用户VNC远程桌面:自动化脚本详解
在当今远程工作盛行的时代,高效且安全地管理多用户远程桌面访问变得至关重要。本文将介绍一个强大的自动化脚本,该脚本能够快速创建用户并配置VNC远程桌面环境,大大简化了系统管理员的工作。 一、背景介绍 在Linux系统中,手动配置VNC服务器通常需要执行多个步骤,包括创建…...

Qt进阶开发:鼠标及键盘事件
文章目录 一、Qt中事件的概念二、Qt中事件处理方式三、重新实现部件的事件处理函数3.1 常用事件处理函数3.2 自定义控件处理鼠标和绘图事件3.3 常用事件处理函数说明四、重写notify()函数五、QApplication对象上安装事件过滤器六、重写event()事件七、在对象上安装事件过滤器八…...

鸿蒙生态新利器:华为ArkUI-X混合开发框架深度解析
鸿蒙生态新利器:华为ArkUI-X混合开发框架深度解析 作者:王老汉 | 鸿蒙生态开发者 | 2025年4月 📢 前言:开发者们的新机遇 各位鸿蒙开发者朋友们,是否还在为多平台开发重复造轮子而苦恼?今天给大家介绍一位…...

VSCode 用于JAVA开发的环境配置,JDK为1.8版本时的配置
插件安装 JAVA开发在VSCode中,需要安装JAVA的必要开发。当前安装只需要安装 “Language Support for Java(TM) by Red Hat”插件即可 安装此插件后,会自动安装包含如下插件,不再需要单独安装 Project Manager for Java Test Runner for J…...

Git Flow分支模型
经典分支模型(Git Flow) 由 Vincent Driessen 提出的 Git Flow 模型,是管理 main(或 master)和 dev 分支的经典方案: main 用于生产发布,保持稳定; dev 用于日常开发,合并功能分支(feature/*); 功能开发在 feature 分支进行,完成后合并回 dev; 预发布分支(rele…...
傅里叶变换在图像处理中怎么用)
机器人进阶---视觉算法(六)傅里叶变换在图像处理中怎么用
傅里叶变换在图像处理中怎么用 傅里叶变换的基本原理应用场景Python代码示例逐行解释总结傅里叶变换在图像处理中是一种重要的工具,它将图像从空间域转换到频域,从而可以对图像的频率特性进行分析和处理。傅里叶变换在图像滤波、图像增强、图像压缩和图像分析等方面都有广泛应…...

Linux-skywalking部署步骤并且添加探针
skywalking部署步骤 上传skywalking安装包并解压将skywalking安装包apache-skywalking-apm-10.1.0.tar.gz上传到服务器/data目录下 用解压命令解压 cd /data tar -xvf apache-skywalking-apm-10.1.0.tar.gz 解压后重名目录 mv apache-skywalking-apm-bin skywalking 上传…...

开启报名!火山引擎 x PICO-全国大学生物联网设计竞赛赛题发布
全国大学生物联网设计竞赛(以下简称“竞赛”)是教育部高等学校计算机类专业教学指导委员会创办的物联网领域唯一的学科竞赛,是以学科竞赛推动专业建设、培养大学生创新能力为目标,面向高校大学生举办的全国性赛事。自 2014 年开始…...

【遥感科普】光谱分辨率是什么?
光谱分辨率是指传感器或光谱仪器在电磁波谱中区分相邻波长或频率的能力。它反映了设备对光谱细节的捕捉能力,通常用波长间隔(如纳米,nm)或波数(cm⁻)表示。例如,若光谱分辨率为10 nm,…...

Trae国内版怎么用?Trae IDE 内置 MCP 市场配置使用指南
近日,字节跳动旗下Trae IDE发布了全新版本,新版本中,Trae IDE 的自定义智能体能力让 AI 能够基于开发者需求灵活调度多维度的工具和资源,从而为任务提供全方位的支持,只需一下即可召唤智能体,这个过程中&am…...

Javase 基础入门 —— 02 基本数据类型
本系列为笔者学习Javase的课堂笔记,视频资源为B站黑马程序员出品的《黑马程序员JavaAI智能辅助编程全套视频教程,java零基础入门到大牛一套通关》,章节分布参考视频教程,为同样学习Javase系列课程的同学们提供参考。 01 注释 单…...

模型 螃蟹效应
系列文章分享模型,了解更多👉 模型_思维模型目录。个体互钳,团队难行。 1 螃蟹效应的应用 1.1 教育行业—优秀教师遭集体举报 行业背景:某市重点中学推行绩效改革,将班级升学率与教师奖金直接挂钩,打破原…...

597页PPT丨流程合集:流程梳理方法、流程现状分析,流程管理规范及应用,流程绩效的管理,流程实施与优化,流程责任人的角色认知等
流程梳理是通过系统化分析优化业务流程的管理方法,其核心包含四大步骤:①目标确认,明确业务痛点和改进方向;②现状分析,通过流程图、价值流图还原现有流程全貌,识别冗余环节和瓶颈节点;③优化设…...

Kotlin集合全解析:List和Map高频操作手册
Kotlin 中 Map 和 List 常用功能总结 List 常用功能 创建 List val immutableList listOf(1, 2, 3) // 不可变列表 val mutableList mutableListOf("a", "b", "c") // 可变列表 val emptyList emptyList<String>() // 空列表基本…...

【springsecurity oauth2授权中心】自定义登录页和授权确认页 P2
上一篇跑通了springsecurity oauth2的授权中心授权流程,这篇来将内置的登录页和授权确认页自定义一下 引入Thymeleaf 在模块authorization-server下的pom.xml里引入模板引擎 <dependency><groupId>org.springframework.boot</groupId><arti…...

Springboot整合MyBatisplus和快速入门
MyBatisPlus MyBatis-Plus (简称 MP)是一个 MyBatis的增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发、提高效率而生。 MyBatisPlus的官方网址: MyBatis-Plus 🚀 为简化开发而生 快速入门 导入起步依赖…...

Vue2-基础使用模板
data和el的第一种写法 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>VUE</title><script type"text/javascript" src"../js/vue.js"></script> </head&g…...

Vue2-指令语法
v-bind和v-model <a v-bind:href"url">笔记1</a> <a :href"url">笔记2</a><input type"text" v-model:value"name"/> <input type"text" v-model"name"/>data(){return {ur…...