仅追加KV数据库
仅追加KV数据库
6.1 我们将要做什么
在本章中,我们将创建一个基于文件的键值存储(KV Store),其核心是一个写时复制(Copy-on-Write, CoW)B+ 树。这种设计的目标是实现数据的持久性和原子性。
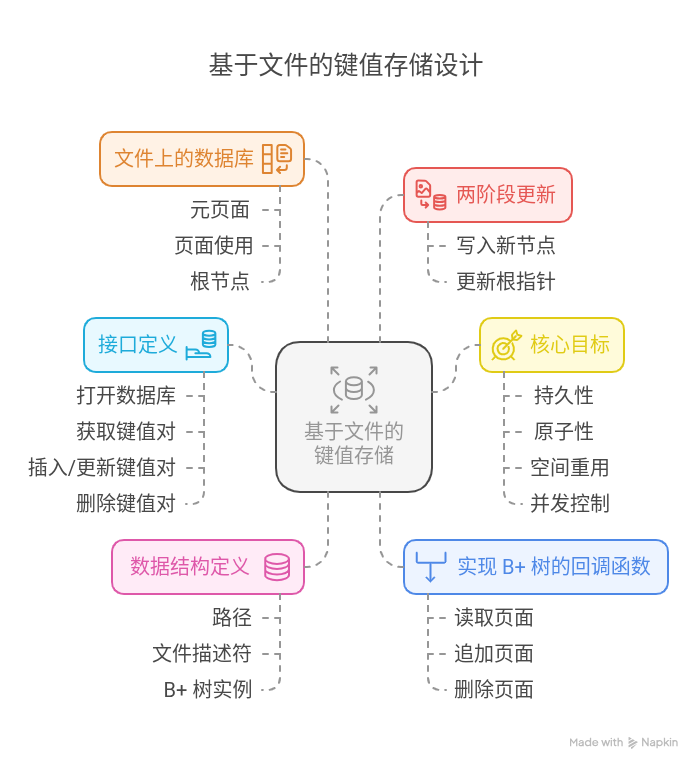
1. 设计概述
1.1 数据结构定义
type KV struct {Path string // 文件名// 内部字段fd int // 文件描述符tree BTree // B+ 树实例// 更多字段 ...
}
Path:存储文件的路径。fd:文件描述符,用于操作底层文件。tree:B+ 树实例,提供键值存储的核心功能。
1.2 接口定义
以下是 KV 提供的主要接口:
- 打开数据库:
func (db *KV) Open() error
- 打开或创建指定路径的文件,并初始化 B+ 树。
- 获取键值对:
func (db *KV) Get(key []byte) ([]byte, bool) {return db.tree.Get(key)
}
- 从 B+ 树中查找指定键,并返回对应的值和是否存在标志。
- 插入/更新键值对:
func (db *KV) Set(key []byte, val []byte) error {db.tree.Insert(key, val)return updateFile(db)
}
- 插入或更新键值对,并将更改写入文件。
- 删除键值对:
func (db *KV) Del(key []byte) (bool, error) {deleted := db.tree.Delete(key)return deleted, updateFile(db)
}
- 删除指定键值对,并将更改写入文件。
2. 核心目标
2.1 持久性
- 使用 追加写入(Append-Only) 的方式将数据写入文件。
- 每次修改都会生成新的页面,旧页面保持不变,确保数据不会因崩溃而丢失。
2.2 原子性
- 每次修改后,更新文件元信息以反映最新的树状态。
- 如果写入过程中发生崩溃,可以恢复到上次一致的状态。
2.3 空间重用
- 在本章中,我们忽略空间重用问题,所有数据都通过追加写入文件。
- 空间回收将在下一章中讨论。
2.4 并发控制
- 本章假设单进程顺序访问,忽略并发问题。
- 并发支持将在后续章节中实现。
3. 实现 B+ 树的回调函数
为了支持基于文件的 B+ 树,我们需要实现以下三个回调函数:
type BTree struct {root uint64get func(uint64) []byte // 读取页面new func([]byte) uint64 // 追加页面del func(uint64) // 删除页面(本章忽略)
}
6.2 两阶段更新
原子性 + 持久性
如第 3 章所述,对于写时复制树,根指针是被原子性更新的。然后使用 fsync 来请求并确认持久性。根指针本身的原子性是不够的;为了使整个树具有原子性,必须在根指针之前持久化新节点。由于缓存等因素,写入顺序并不是数据被持久化的顺序。因此,使用另一个 fsync 来确保顺序。
func updateFile(db *KV) error {// 1. 写入新节点。if err := writePages(db); err != nil {return err}// 2. 使用 `fsync` 强制执行步骤 1 和步骤 3 之间的顺序。if err := syscall.Fsync(db.fd); err != nil {return err}// 3. 原子性地更新根指针。if err := updateRoot(db); err != nil {return err}// 4. 使用 `fsync` 使所有内容持久化。return syscall.Fsync(db.fd)
}
替代方案:使用日志实现持久性
另一种双写方案也有两个包含 fsync 的阶段:
- 带校验和写入更新的页面。
- 使用
fsync使更新持久化(用于崩溃恢复)。 - 就地更新数据(应用双写)。
- 使用
fsync确保步骤 3 和步骤 1 的顺序(重用或删除双写)。
与写时复制的区别在于阶段的顺序:数据在第一次 fsync 后已持久化;数据库可以返回成功并将剩余操作放到后台完成。
双写类似于日志,日志每次更新也只需要一次 fsync。而且它可以是一个实际的日志,用来缓冲多个更新,从而提高性能。这是数据库中日志的另一个例子,除了 LSM 树之外。
我们不会使用日志,因为写时复制不需要它。但日志仍然提供了上述的好处;这也是日志在数据库中无处不在的原因之一。
内存数据的并发性
对于内存中的数据(关于并发性的原子性),可以通过互斥锁(mutex)或某些原子 CPU 指令来实现。存在一个类似的问题:由于乱序执行等因素,内存读/写可能不会按顺序出现。
对于内存中的写时复制树,在更新根指针之前,必须让新节点对并发读者可见。这称为内存屏障,类似于 fsync,尽管 fsync 不仅仅是强制顺序。
像互斥锁这样的同步原语,或者任何操作系统系统调用,将以一种可移植的方式强制内存顺序,因此你不必处理特定于 CPU 的原子操作或屏障(这些对于并发来说并不足够)。
6.3 文件上的数据库
文件布局
我们的数据库是一个单一文件,被划分为多个“页面”。每个页面都是一个 B+ 树节点,除了第一个页面;第一个页面包含指向最新根节点的指针和其他辅助数据,我们称这个页面为元页面(meta page)。
| 元页面 | 页面... | 根节点 | 页面... | (文件末尾)
| 根指针 | 页面使用 | | || | | |+----------|----------------+ || |+----------------------------+
新节点简单地像日志一样追加到文件中,但是我们不能使用文件大小来计算页面数量,因为在断电后,文件大小(元数据)可能与文件数据不一致。这取决于文件系统,我们可以通过在元页面中存储页面的数量来避免这个问题。
fsync 对目录的操作
正如第一章所述,在重命名之后必须对父目录使用 fsync。创建新文件时也是如此,因为有两件事情需要持久化:文件数据和引用该文件的目录。
我们将通过 O_CREATE 可能创建新文件后预执行 fsync。要同步一个目录,可以以只读模式 (O_RDONLY) 打开该目录。
func createFileSync(file string) (int, error) {// 获取目录文件描述符flags := os.O_RDONLY | syscall.O_DIRECTORYdirfd, err := syscall.Open(path.Dir(file), flags, 0o644)if err != nil {return -1, fmt.Errorf("open directory: %w", err)}defer syscall.Close(dirfd)// 打开或创建文件flags = os.O_RDWR | os.O_CREATEfd, err := syscall.Openat(dirfd, path.Base(file), flags, 0o644)if err != nil {return -1, fmt.Errorf("open file: %w", err)}// 同步目录if err = syscall.Fsync(dirfd); err != nil {_ = syscall.Close(fd) // 可能会留下空文件return -1, fmt.Errorf("fsync directory: %w", err)}return fd, nil
}
目录文件描述符可以由 openat 使用来打开目标文件,这保证了文件来自之前打开的同一个目录,以防目录路径在此期间被替换(竞态条件)。虽然这不是我们需要担心的问题,因为我们不期望有多进程操作。
mmap、页面缓存和 I/O
mmap 是一种将文件作为内存缓冲区进行读写的机制。使用 mmap 时,磁盘 I/O 是隐式的且自动完成的。
func Mmap(fd int, offset int64, length int, ...) (data []byte, err error)
为了理解 mmap,让我们回顾一些操作系统的基本概念。操作系统页面是虚拟地址和物理地址之间映射的最小单位。然而,进程的虚拟地址空间并不总是完全由物理内存支持;进程的一部分内存可以交换到磁盘上,当进程尝试访问它时:
- CPU 触发一个页面错误,将控制权交给操作系统。
- 操作系统然后:
- 将交换的数据读入物理内存。
- 重新映射虚拟地址到物理内存。
- 将控制权返回给进程。
- 进程继续运行,虚拟地址映射到实际的 RAM。
mmap 的工作原理与此类似,进程从 mmap 获得一个地址范围,当它访问其中的一个页面时,会发生页面错误,操作系统将数据读入缓存并重新映射页面到缓存。这就是只读场景下的自动 I/O。
当进程修改一个页面时,CPU 也会标记(称为脏位),以便操作系统稍后将页面写回磁盘。fsync 用于请求并等待 I/O 完成。这是通过 mmap 写入数据的方式,与 Linux 上的 write 并没有太大不同,因为 write 也进入相同的页面缓存。
你不必使用 mmap,但理解这些基础知识是很重要的。
6.4 管理磁盘页面
我们将使用 mmap 来实现这些页面管理回调,因为它非常方便。
func (db *KV) Open() error {db.tree.get = db.pageRead // 读取页面db.tree.new = db.pageAppend // 追加页面db.tree.del = func(uint64) {}// ...
}
调用 mmap
文件支持的 mmap 可以是只读(read-only)、读写(read-write)或写时复制(copy-on-write)。要创建一个只读的 mmap,可以使用 PROT_READ 和 MAP_SHARED 标志。
syscall.Mmap(fd, offset, size, syscall.PROT_READ, syscall.MAP_SHARED)
映射的范围可以大于当前文件大小,这是一个我们可以利用的事实,因为文件会增长。
mmap 处理增长的文件
mremap 重新映射到更大的范围,类似于 realloc。这是处理增长文件的一种方法。然而,地址可能会改变,这可能会影响后续章节中的并发读者。我们的解决方案是添加新的映射来覆盖扩展的文件。
type KV struct {// ...mmap struct {total int // mmap 大小,可以大于文件大小chunks [][]byte // 多个 mmap,可能是非连续的}
}
BTree.get:读取页面
func (db *KV) pageRead(ptr uint64) []byte {start := uint64(0)for _, chunk := range db.mmap.chunks {end := start + uint64(len(chunk))/BTREE_PAGE_SIZEif ptr < end {offset := BTREE_PAGE_SIZE * (ptr - start)return chunk[offset : offset+BTREE_PAGE_SIZE]}start = end}panic("bad ptr")
}
每次扩展文件时添加一个新的映射会导致大量映射,这对性能不利,因为操作系统需要跟踪它们。通过指数增长避免了这个问题,因为 mmap 可以超出文件大小。
func extendMmap(db *KV, size int) error {if size <= db.mmap.total {return nil // 足够的范围}alloc := max(db.mmap.total, 64<<20) // 将当前地址空间加倍for db.mmap.total + alloc < size {alloc *= 2 // 仍然不够?}chunk, err := syscall.Mmap(db.fd, int64(db.mmap.total), alloc,syscall.PROT_READ, syscall.MAP_SHARED, // 只读)if err != nil {return fmt.Errorf("mmap: %w", err)}db.mmap.total += allocdb.mmap.chunks = append(db.mmap.chunks, chunk)return nil
}
你可能会问,为什么不直接创建一个非常大的映射(比如 1TB),然后忘记文件的增长呢?毕竟未实现的虚拟地址不会产生任何成本。对于 64 位系统上的玩具数据库来说,这是可以接受的。
捕获页面更新
BTree.new 回调从 B+ 树更新中收集新页面,并从数据库末尾分配页面编号。
type KV struct {// ...page struct {flushed uint64 // 数据库大小(以页面数计)temp [][]byte // 新分配的页面}
}
pageAppend:追加页面
func (db *KV) pageAppend(node []byte) uint64 {ptr := db.page.flushed + uint64(len(db.page.temp)) // 直接追加db.page.temp = append(db.page.temp, node)return ptr
}
这些页面在 B+ 树更新后被写入(追加)到文件中。
写入页面
func writePages(db *KV) error {// 如果需要,扩展 mmapsize := (int(db.page.flushed) + len(db.page.temp)) * BTREE_PAGE_SIZEif err := extendMmap(db, size); err != nil {return err}// 将数据页面写入文件offset := int64(db.page.flushed * BTREE_PAGE_SIZE)if _, err := unix.Pwritev(db.fd, db.page.temp, offset); err != nil {return err}// 丢弃内存中的数据db.page.flushed += uint64(len(db.page.temp))db.page.temp = db.page.temp[:0]return nil
}
pwritev 是带偏移量和多个输入缓冲区的 write 的变体。
我们需要控制偏移量,因为我们稍后还需要写入元页面。多个输入缓冲区由内核合并。
6.5 元页面
读取元页面
我们将向元页面添加一些魔数(magic bytes)以识别文件类型。
const DB_SIG = "BuildYourOwnDB06" // 各章节之间不兼容// | sig | root_ptr | page_used |
// | 16B | 8B | 8B |func saveMeta(db *KV) []byte {var data [32]bytecopy(data[:16], []byte(DB_SIG))binary.LittleEndian.PutUint64(data[16:], db.tree.root)binary.LittleEndian.PutUint64(data[24:], db.page.flushed)return data[:]
}func loadMeta(db *KV, data []byte) {if string(data[:16]) != DB_SIG {panic("invalid database signature")}db.tree.root = binary.LittleEndian.Uint64(data[16:24])db.page.flushed = binary.LittleEndian.Uint64(data[24:32])
}
当文件为空时,会预留元页面。
func readRoot(db *KV, fileSize int64) error {if fileSize == 0 { // 空文件db.page.flushed = 1 // 在首次写入时初始化元页面return nil}// 读取页面data := db.mmap.chunks[0]loadMeta(db, data)// 验证页面// ...return nil
}
更新元页面
写少量页对齐的数据到实际磁盘上,只修改单个扇区,在硬件级别可能是掉电原子性的。一些真正的数据库依赖于此特性。这也是我们更新元页面的方式。
// 3. 更新元页面。它必须是原子的。
func updateRoot(db *KV) error {if _, err := syscall.Pwrite(db.fd, saveMeta(db), 0); err != nil {return fmt.Errorf("write meta page: %w", err)}return nil
}
然而,原子性在不同的层级意味着不同的事情,正如你所见,重命名也是如此。对于系统调用级别的并发读者而言,write 并不是原子性的。这可能是因为页面缓存的工作原理。
当我们添加并发事务时,将考虑读写的原子性,但我们已经看到了一种解决方案:在 LSM 树中,只有第一级会被更新,并且它作为 MemTable 被复制,从而将并发问题移到了内存中。我们可以保持元页面的内存副本,并使用互斥锁进行同步,从而避免并发的磁盘读/写。
即使硬件在掉电情况下不是原子性的,通过日志加校验和也可以实现原子性。我们可以在每次更新时切换两个带校验和的元页面,以确保掉电后至少有一个元页面是完好的。这被称为双缓冲(double buffering),是一个有两个条目的循环日志。
这种机制不仅提高了系统的可靠性,还确保了即使发生意外断电,数据库也能恢复到一个一致的状态。通过这种方式,可以有效地管理元数据的更新,并保证其一致性与持久性。
6.6 错误处理
IO 错误后的场景
错误处理的最低要求是通过 if err != nil 传播错误。接下来,考虑在发生 IO 错误(如 fsync 或 write)后继续使用数据库的可能性:
-
在更新失败后读取数据?
- 合理的选择是表现得像什么都没发生一样。
-
在失败后再次更新?
- 如果错误仍然存在,则预计会再次失败。
- 如果错误是暂时的,能否从之前的错误中恢复?
-
在问题解决后重新启动数据库?
- 这只是崩溃恢复;已在第 3 章讨论过。
回滚到之前的版本
有一项调查研究了 fsync 失败的处理方法。从中我们可以了解到,这个主题与文件系统相关。如果我们在 fsync 失败后读取数据,某些文件系统会返回失败的数据,因为页面缓存与磁盘不匹配。因此,回读失败的写入是有问题的。
但因为我们使用的是写时复制(copy-on-write),这并不是问题;我们可以回滚到旧的树根以避免问题数据。树根存储在元页面中,但我们从未在打开数据库后从磁盘读取元页面,因此只需回滚内存中的根指针即可。
func (db *KV) Set(key []byte, val []byte) error {meta := saveMeta(db) // 保存内存状态(树根)db.tree.Insert(key, val)return updateOrRevert(db, meta)
}func updateOrRevert(db *KV, meta []byte) error {// 两阶段更新err := updateFile(db)// 在错误时回滚if err != nil {// 内存状态可以立即回滚以允许读取loadMeta(db, meta)// 丢弃临时数据db.page.temp = db.page.temp[:0]}return err
}
因此,在写入失败后,仍然可以以只读模式使用数据库。读取也可能失败,但由于我们使用的是 mmap,在读取错误时进程会被 SIGBUS 杀死。这是 mmap 的缺点之一。
从临时写入错误中恢复
一些写入错误是暂时的,例如“磁盘空间不足”。如果一次更新失败,而下一次成功,则最终状态仍然是好的。问题在于中间状态:在两次更新之间,磁盘上的元页面内容是未知的!
如果 fsync 在元页面上失败,磁盘上的元页面可能是新版本或旧版本,而内存中的树根是旧版本。因此,第二次成功的更新会覆盖较新版本的数据页面,如果此时发生崩溃,可能会导致损坏的中间状态。
解决方案是在恢复时重写最后已知的元页面。
type KV struct {// ...failed bool // 上次更新是否失败?
}func updateOrRevert(db *KV, meta []byte) error {// 确保在错误后磁盘上的元页面与内存中的一致if db.failed {// 写入并同步之前的元页面// ...db.failed = false}err := updateFile(db)if err != nil {// 磁盘上的元页面处于未知状态;// 标记它以便在后续恢复时重写。db.failed = true// ...}return err
}
对文件系统的依赖性
我们依赖文件系统正确报告错误,但有证据[4]表明它们并不总是能做到这一点。因此,整个系统是否能够正确处理错误仍然是值得怀疑的。
总结
-
错误传播:
- 使用
if err != nil检查和传播错误是最基本的方式。
- 使用
-
回滚机制:
- 写时复制允许我们回滚到旧的树根,避免损坏的数据。
- 回滚通过内存中的元页面实现,无需从磁盘重新加载。
-
临时错误恢复:
- 对于临时错误(如磁盘空间不足),可以通过重写最后已知的元页面来确保一致性。
-
文件系统的不确定性:
- 文件系统可能无法正确报告错误,因此需要额外的措施来应对潜在的不可靠性。
通过这些机制,数据库能够在发生 IO 错误时保持一定程度的可用性和一致性,同时为未来的恢复提供保障。
相关文章:

仅追加KV数据库
仅追加KV数据库 6.1 我们将要做什么 在本章中,我们将创建一个基于文件的键值存储(KV Store),其核心是一个写时复制(Copy-on-Write, CoW)B 树。这种设计的目标是实现数据的持久性和原子性。 1. 设计概述 …...

【Java面试笔记:基础】8.对比Vector、ArrayList、LinkedList有何区别?
在Java中,Vector、ArrayList和LinkedList均实现了List接口,但它们在线程安全、数据结构、性能特性及应用场景上存在显著差异。 1. Vector、ArrayList 和 LinkedList 的区别 Vector: 线程安全:Vector 是线程安全的动态数组&#…...

Git分支管理方案
成都众望智慧有限公司Git分支管理方案 采用 轻量级Git Flow 敏捷版本控制策略,在保证稳定性的同时提升开发效率。以下是优化后的方案: 1. 精简分支模型(相比6-8人团队减少分支层级) 分支类型作用生命周期devops生产环境代码&am…...

SQL Tuning Advisor
什么是SQL Tuning Advisor STA可以用来优化那些已经被发现的高负载SQL. 默认情况下, Oracle数据库在自动维护窗口中自动认证那些有问题的SQL并且执行优化建议,找寻提升高负载SQL执行计划性能的方法. ** 如何查看自动优化维护窗口产生的报告? ** SQL> set ser…...

联易融出席深圳链主企业供应链金融座谈会,加速对接票交所系统
近日,深圳市委金融办组织召开全市链主企业供应链金融高质量发展座谈会。联易融作为供应链金融企业代表,与虾皮信息科技、电子元器件和集成电路国际交易中心等代表性机构以及行业协会、金融机构参加了会议。 发展供应链金融是破解中小微企业融资难、融资…...

【前端记事】关于electron的入门使用
electron入门使用 背景how to start第一步 创建一个vite-vue3项目第二步 装各种依赖第三步 配置vite.config.jspackage.jsonelectron入口 启动重写关闭、隐藏、最大化最小化 背景 最近对electron比较感兴趣,折腾一段时间后有了点眉目,记录一下 how to …...

Qt绘制可选择范围的日历
【日历控件设计】 #include <QApplication> #include <QWidget> #include <QVBoxLayout> #include <QCalendarWidget> #include <QHBoxLayout> #include <QSpinBox> #include <QPushButton> #include <QLabel> #include <Q…...
面向对象程序设计基础)
Pycharm(十五)面向对象程序设计基础
目录 一、定义类及使用类的成员 二、self关键字介绍 三、在类内部调用类中的函数 class 类名: 属性(类似于定义变量) 行为(类似于定义函数,只不过第一个形参要写self) 一、面向对象基本概述 属性&…...
——统计学解构材质与光影)
【C++游戏引擎开发】第21篇:基于物理渲染(PBR)——统计学解构材质与光影
引言 宏观现象:人眼观察到的材质表面特性(如金属的高光锐利、石膏的漫反射柔和),本质上是微观结构对光线的统计平均结果。 微观真相:任何看似平整的表面在放大后都呈现崎岖的微观几何。每个微表面(Microfacet)均为完美镜面,但大量微表面以不同朝向分布时,宏观上会表…...

flutter_slidable 插件使用
简介 flutter_slidable 是一个用于创建可滑动列表项的 Flutter 插件,它允许用户通过滑动来显示隐藏的操作按钮,比如删除、分享等功能。 安装 在 pubspec.yaml 中添加依赖(并运行 flutter pub get): dependencies:fl…...

[论文阅读]ConfusedPilot: Confused Deputy Risks in RAG-based LLMs
ConfusedPilot: Confused Deputy Risks in RAG-based LLMs [2408.04870] ConfusedPilot: Confused Deputy Risks in RAG-based LLMs DEFCON AI Village 2024 文章是针对Copilot这样一个RAG服务提供平台的攻击 在企业环境中整合人工智能工具(如 RAG)会…...

诠视科技MR眼镜如何使用头瞄点和UGUI交互
诠视科技MR眼镜如何使用头瞄点和UGUI交互 要实现头瞄点计算单元确认键操作UGUI,最快捷的方式,右键直接添加XvHeadGazeInputController。 添加以后会自动生成XvHeadGazeInputController到Head节点下面去。 重要的几个参数讲解: scaleFactor:…...
——原则与原理——原理方法)
数据赋能(204)——原则与原理——原理方法
原理更多地关注事物本身的客观规律,而原则侧重于指导人们的行为和决策。原则与原理是两个常常被提及,但有所区别的概念。原则和原理在各个领域中都发挥着重要的作用。 原理概念 原理,则通常指的是自然科学和社会科学中具有普遍意义的基本规…...

代码随想录算法训练营第五十六天 | 108.冗余连接 109.冗余连接II
108.冗余连接 题目链接:108. 冗余的边 文章讲解:代码随想录 思路: 题目说是无向图,返回一条可以删去的边,使得结果图是一个有着N个节点的树,如果有多个答案,则返回二维数组中最后出现的边。 …...

Git入门
一、Git 基础概念 1. 版本控制系统分类 本地版本控制:如RCS,仅在本机保存历史版本集中式版本控制:如SVN,单一中央服务器管理代码分布式版本控制:如Git,每个开发者都有完整的仓库副本 2. Git 核心概念 概…...

5G + 物联网:智能世界的催化剂,如何用Python打造下一代IoT应用?
5G 物联网:智能世界的催化剂,如何用Python打造下一代IoT应用? 在数字化时代,物联网(IoT) 已成为智能产业的关键技术。从智能家居到智慧城市,再到工业4.0,我们的世界正在变得越来越…...

从单点突破到链式攻击:XSS 的渗透全路径解析
在网络安全领域,跨站脚本攻击(Cross-Site Scripting,简称 XSS)早已不是新鲜话题。然而,随着网络技术的迭代与应用场景的复杂化,攻击者不再满足于单一的 XSS 漏洞利用,而是将 XSS 与其他安全漏洞…...

spark和hadoop的对比和联系
一、Apache Hadoop 简介 Hadoop是一个由Apache基金会开发的开源分布式计算平台。它主要由Hadoop分布式文件系统(HDFS)和MapReduce计算框架组成。HDFS是为大规模数据存储而设计的,它将文件分割成多个数据块(block)&…...

【Vue3 / TypeScript】 项目兼容低版本浏览器的全面指南
在当今前端开发领域,Vue3 和 TypeScript 已成为主流技术栈。然而,随着 JavaScript 语言的快速演进,许多现代特性在低版本浏览器中无法运行。本文将详细介绍如何使 Vue3 TypeScript 项目完美兼容 IE11 等低版本浏览器。 一、理解兼容性挑战 …...

从零开始搭建你的个人博客:使用 GitHub Pages 免费部署静态网站
🌐 从零开始搭建你的个人博客:使用 GitHub Pages 免费部署静态网站 在互联网时代,拥有一个属于自己的网站不仅是一种展示方式,更是一种技术能力的体现。今天我们将一步步学习如何通过 GitHub Pages 搭建一个免费的个人博客或简历…...

java 设计模式 原型模式
简介 原型模式(Prototype Pattern) 是一种创建型设计模式,它通过复制现有对象来生成新对象,而不是通过 new 关键字创建。核心思想是减少对象创建的开销,尤其是当对象初始化过程复杂或代价较高时。 原型模式的核心实现…...

分别配置Github,Gitee的SSH链接
文章目录 前言一、为第二个账号生成新的密钥对二、 配置 SSH config 文件1.引入库使用 Host 别名进行 clone/push/pull注意扩展 前言 之前已经在电脑配置过Github一个仓库ssh链接,今天想配一个Gitee仓库的ssh链接。运行 ssh-keygen -t rsa提示已经存在,…...

从零开始搭建Django博客②--Django的服务器内容搭建
本文主要在Ubuntu环境上搭建,为便于研究理解,采用SSH连接在虚拟机里的ubuntu-24.04.2-desktop系统搭建,当涉及一些文件操作部分便于通过桌面化进行理解,通过Nginx代理绑定域名,对外发布。 此为从零开始搭建Django博客…...

如何用python脚本读取本地excel表格Workbook.xlsx将里面B2:B8内容,发给本地ollama大模型改写内容后写入对应C2:C8?
环境: python3.10 Win10专业版 ollama 火山引擎 影刀 问题描述: 如何用python脚本读取本地excel表格Workbook.xlsx将里面B2:B8内容,发给本地ollama大模型改写内容后写入对应C2:C8? 解决方案: 1.制作一个python脚本如下: import openpyxl import requests import…...

webpack详细打包配置,包含性能优化、资源处理...
以下是一个详细的 Webpack 5 配置示例,包含常见资源处理和性能优化方案: const path require(path); const webpack require(webpack); const { BundleAnalyzerPlugin } require(webpack-bundle-analyzer); const TerserPlugin require(terser-webp…...

MYSQL的binlog
用于备份恢复和主从复制 binlog 有 3 种格式类型,分别是 STATEMENT(默认格式)、ROW、 MIXED: STATEMENT:每一条修改数据的 SQL 都会被记录到 binlog 中(相当于记录了逻辑操作,所以针对这种格式…...

Saliency Driven Perceptual Image Compression阅读
2021 WACV 创新点 常用的评估指标如MS-SSIM和PSNR不足以判断压缩技术的性能,它们与人类对相似性的感知不一致(2和3的MS-SSIM更高,但文字反而没那么清晰)。 考虑显著区域的压缩(a)将更多的比特分配给显著区域(b&#…...

【C++ 类和数据抽象】构造函数
目录 一、构造函数的基本概念 1.1 构造函数核心特性 1.2 构造函数的作用 1.3 构造函数类型体系 二、构造函数的类型 2.1 默认构造函数 2.2 带参数的构造函数 2.3 拷贝构造函数 2.4 移动构造函数(C11 及以后) 三、初始化关键技术 3.1 成员初始…...

kotlin的kmp编程中遇到Unresolved reference ‘java‘问题
解决办法 打开 File → Project Structure → Project 确保 Project SDK 是 与你的 jvmToolchain 保持一致 如果没有,点击右上角 Add SDK 添加 JDK 路径 同步Sync 然后就正常了。 package org.example.projectimport androidx.compose.animation.AnimatedVi…...

鸿蒙Flutter仓库停止更新?
停止更新 熟悉 Flutter 鸿蒙开发的小伙伴应该知道,Flutter 3.7.12 鸿蒙化 SDK 已经在开源鸿蒙社区发布快一年了, Flutter 3.22.x 的鸿蒙化适配一直由鸿蒙突击队仓库提供,最近有小伙伴反馈已经 2 个多月没有停止更新了,不少人以为停…...

【Ultralytics 使用yolo12 读取tiff 数据异常解决】
Ultralytics 使用yolo12 读取tiff 数据解决 Ultralytics 使用yolo12 读取tiff 数据异常解决 Ultralytics 使用yolo12 读取tiff 数据异常解决 Lib\site-packages\ultralytics\utils\patches.py def imread(filename: str, flags: int cv2.IMREAD_COLOR):"""Read…...

画布交互系统深度优化:从动态缩放、小地图到拖拽同步的全链路实现方案
画布交互系统深度优化:从动态缩放、小地图到拖拽同步的全链路实现方案 在可视化画布系统开发中,高效的交互体验与稳定的性能表现是核心挑战。本文针对复杂场景下的五大核心需求,提供完整的技术实现方案,涵盖鼠标中心缩放、节点尺寸…...
----修改限位开关触发电平)
GTS-400 系列运动控制器板(七)----修改限位开关触发电平
运动控制器函数库的使用 运动控制器驱动程序、dll 文件、例程、Demo 等相关文件请通过固高科技官网下载,网 址为:www.googoltech.com.cn/pro_view-3.html 1 Windows 系统下动态链接库的使用 在 Windows 系统下使用运动控制器,首先要安装驱动程序。在安装前需要提前下载…...
)
学习前端(前端技术更新较快,需持续关注技术更新)
目录 1. 基础三件套 1.1 HTML 1.2 CSS 1.3 JavaScript 2. 前端框架 2.1 React 2.2 Vue 2.3 Angular 3. 工程化工具 3.1 构建工具 3.2 代码质量 4. 网络和安全 4.1 HTTP/HTTPS 4.2 性能优化 5. 前沿技术 5.1 TypeScript 5.2 WebAssembly 5.3 微前端 5.4 可视…...

视频转换为MP4格式,小白工具批量转换,在线操作,简单快捷,超实用
小白工具https://www.xiaobaitool.net/videos/convert-to-mp4/ 是一款适合在线将视频转换为MP4格式的工具,尤其适合希望快速转换且无需下载安装软件的用户。以下是对该工具的详细推荐及使用建议: 一、工具特点 在线操作,无需下载 用户只需通…...

PDF处理控件Aspose.PDF指南:使用 Python 将 EPUB 转换为 PDF
EPUB是一种流行的电子书格式,用于可重排内容,而PDF则广泛用于固定版式文档,非常适合共享和打印。如果您想使用 Python 将 EPUB 转换为 PDF,Aspose.PDF for Python 提供了一个简单可靠的解决方案。在本教程中,我们将向您…...

超级扩音器手机版:随时随地,大声说话
在日常生活中,我们常常会遇到手机音量太小的问题,尤其是在嘈杂的环境中,如KTV、派对或户外活动时,手机自带的音量往往难以满足需求。今天,我们要介绍的 超级扩音器手机版,就是这样一款由上海聚告德业文化发…...

Jenkins的地位和作用
所处位置 Jenkins 是一款开源的自动化服务器,广泛应用于软件开发和测试流程中,主要用于实现持续集成(CI)和持续部署(CD)。它在开发和测试中的位置和作用可以从以下几个方面来理解: 1. 在开发和测…...

NumPy进阶:广播机制、高级索引与通用函数详解
目录 一、广播机制:不同形状数组间的运算 1. 概念 2. 广播规则 3. 实例 二、高级索引:布尔索引与花式索引 1. 布尔索引 (1)创建布尔索引 (2)布尔索引的应用 2. 花式索引 (1࿰…...

Trino分布式 SQL 查询引擎
Trino(以前称为 PrestoSQL)是一个开源的分布式 SQL 查询引擎,专为交互式分析查询设计,可对大规模数据集进行快速查询。以下从多个方面详细介绍 Trino: 主要特点 多数据源支持:Trino 能够连接多种不同类型…...

Oracle DBA 高效运维指南:高频实用 SQL 大全
大家好,这里是 DBA学习之路,专注于提升数据库运维效率。 目录 前言Top SQL表空间使用率RMAN 备份DataGuard等待事件行级锁在线日志切换用户信息ASM 磁盘组DBLink数据文件收缩AWR 写在最后 前言 作为一名 Oracle DBA,在日常数据库运维工作中&…...

SpringBoot原生实现分布式MapReduce计算
一、架构设计调整 核心组件替换方案: 1、注册中心 → 数据库注册表 2、任务队列 → 数据库任务表 3、分布式锁 → 数据库行级锁 4、节点通信 → HTTP REST接口 二、数据库表结构设计 节点注册表 CREATETABLE compute_nodes (node_id VARCHAR(36)PRIMARYKEY,last_…...

可吸收聚合物:医疗科技与绿色未来的交汇点
可吸收聚合物(Biodegradable Polymers)作为生物医学工程的核心材料,正引领一场从“金属/塑料植入物”到“智能降解材料”的范式转移。根据QYResearch(恒州博智)预测,2031年全球可吸收聚合物市场销售额将突破…...
之旅——抽象类和接口⑨)
Java从入门到“放弃”(精通)之旅——抽象类和接口⑨
Java从入门到“放弃”(精通)之旅🚀——抽象类和接口⑨ 引言 在Java面向对象编程中,抽象类和接口是两个非常重要的概念。它们为代码提供了更高层次的抽象能力,是设计灵活、可扩展系统的关键工具。 🟦一、抽…...

游戏引擎学习第239天:通过 OpenGL 渲染游戏
回顾并为今天的内容做准备 今天,我想继续完成这部分内容,因为实际上我们已经完成了大部分工作,剩下的部分并不复杂。我计划今天完成这部分实现,至少是那些不涉及纹理的部分。正如昨天所说,纹理部分才是唯一比较复杂的…...

基于Python的多光谱遥感数据处理与分类技术实践—以农作物分类与NDVI评估为例
多光谱遥感数据包含可见光至红外波段的光谱信息,Python凭借其丰富的科学计算库(如rasterio、scikit-learn、GDAL),已成为处理此类数据的核心工具。本文以Landsat-8数据为例,演示辐射校正→特征提取→监督分类→精度评…...

数字空间与VR有什么关系?什么是数字空间?
数字空间与VR的关系 数字空间与虚拟现实(VR)之间存在着紧密而复杂的关系,它们相互影响、共同促进发展。为了深入理解这一关系,我们需要明确数字空间的基本概念及其与VR技术的相互作用。 数字空间的概念 数字空间,通常…...

navicat导入sql文件 所有问题解决方法集合
问题一:mysql导入大批量数据出现MySQL server has gone away的解决方法 方法一: 查看mysql max_allowed_packet的值 show global variables like max_allowed_packet;可以看到是64M(67108864/1024/1024) 调整为所需大小 例如我们需要调整为1024M(102…...

3、有Bluetooth,LCD,USB,SD卡,PSRAM,FLASH、TP等软硬件驱动开发经验优先考虑
首先,Bluetooth驱动开发经验。蓝牙是一种无线通信技术,广泛应用于设备之间的数据传输,比如耳机、键盘、智能家居设备等。驱动开发可能涉及底层协议的实现、与硬件的交互,以及确保兼容性和稳定性。需要了解蓝牙协议栈,如…...

【k8s】PV,PVC的回收策略——return、recycle、delete
PV 和 PVC 的回收策略主要用于管理存储资源的生命周期,特别是当 PVC 被删除时,PV 的处理方式。回收策略决定了 PV 在 PVC 被删除后的行为。 回收策略的类型 Kubernetes 提供了三种主要的回收策略,用于管理 PV 的生命周期: Reta…...